Non-intrusive optimal experimental design for large-scale nonlinear Bayesian inverse problems using a Bayesian approximation error approach
Abstract
We consider optimal experimental design (OED) for nonlinear inverse problems within the Bayesian framework. Optimizing the data acquisition process for large-scale nonlinear Bayesian inverse problems is a computationally challenging task since the posterior is typically intractable and commonly-encountered optimality criteria depend on the observed data. Since these challenges are not present in OED for linear Bayesian inverse problems, we propose an approach based on first linearizing the associated forward problem and then optimizing the experimental design. Replacing an accurate but costly model with some linear surrogate, while justified for certain problems, can lead to incorrect posteriors and sub-optimal designs if model discrepancy is ignored. To avoid this, we use the Bayesian approximation error (BAE) approach to formulate an A-optimal design objective for sensor selection that is aware of the model error. In line with recent developments, we prove that this uncertainty-aware objective is independent of the exact choice of linearization. This key observation facilitates the formulation of an uncertainty-aware OED objective function using a completely trivial linear map, the zero map, as a surrogate to the forward dynamics. The base methodology is also extended to marginalized OED problems, accommodating uncertainties arising from both linear approximations and unknown auxiliary parameters. Our approach only requires parameter and data sample pairs, hence it is particularly well-suited for black box forward models. We demonstrate the effectiveness of our method for finding optimal designs in an idealized subsurface flow inverse problem and for tsunami detection.
keywords:
optimal experimental design, Bayesian inverse problems, Bayesian approximation error, linearization62F15, 65K05, 62-08, 62E17
1 Introduction
Many problems of interest in engineering and the natural sciences can be described by mathematical models involving partial differential equations (PDEs) or systems of ordinary differential equations. In various settings, however, it is parameters of the models, such as coefficients or boundary/initial conditions, which are of importance. These parameters often cannot be observed directly, and are instead estimated using observations of a related quantity as well as the governing mathematical equations. In typical applications, the observations are noisy and informative about a small subset of the unknown parameters, making parameter estimation an ill-posed problem. The Bayesian approach to parameter estimation (or inverse problems) is commonly used to deal with the ill-posedness of the problem. In the Bayesian approach, the solution to the inverse problem is a conditional distribution that enables quantifying the probability that the observed data originated from any candidate parameter choice.
The quality and quantity of the measurement data has a significant effect on the quality of the solution to the Bayesian inverse problem. Thus, it is crucial to guide data acquisition and choose experimental conditions that lead to informative observations. This requires solving an optimal experimental design (OED) problem [1, 13]. While the OED framework encompasses various different problem-specific design types, the subclass we focus on is that of sensor placement. Specifically, assuming measurements can be acquired at some set of sensors, the OED problem consists of choosing the most informative sensor subset from some candidate set.
Finding the optimal sensor placement is a particularly challenging problem if the parameter-to-observable (PTO) map is nonlinear. For nonlinear Bayesian inverse problems, the most informative design can be formulated as the optimizer of an expected utility function that evaluates the effectiveness of solving the inverse problem with data collected at any design choice. However, finding the analytic optimizer is generally impossible, and numerical approximation presents further difficulties. These stem from various factors — many utility functions (including the classical A- and D-optimality) are functions of the intractable posterior distribution, the expectation is taken with respect to the (typically unknown) conditional density for the data given the design (i.e., the evidence), and even approximate evaluation of the utility function requires a large number of costly forward (and potentially adjoint) PDE solves.
A commonly employed approximation to the expected utility function is obtained via linearization of the PTO map or through a Gaussian approximation to the posterior [4, 2, 56]. This is also the approach we take in this present work, however, we employ a global linearization (as opposed to local linearizations as in the aforementioned works) and incorporate the resulting model error into the Bayesian inverse problem using the Bayesian approximation error (BAE) approach [34, 36]. Focusing on the A-optimal criterion, we expand on the work of [49] and show that the optimal designs obtained using the global linear map are independent of the choice of linearization when model error is incorporated with the BAE approach. As a consequence, we present a scalable, derivative-free linearization approach for finding A-optimal sensor placements for nonlinear Bayesian inverse problems. We also extend our approach to OED under uncertainty, i.e., finding designs that are optimal for estimating some primary parameter(s) of interest while incorporating uncertainty in auxiliary nuisance parameters.
Related work
There has been a recent surge of interest in optimal experimental design for parameter estimation problems governed by uncertain mathematical models. Many of these references assume exact knowledge of the governing dynamics and focus on uncertainty due to unknown nuisance/auxiliary inputs to the model [5, 2, 23, 38], or misspecification of the statistical model [7]. However, in certain situations, the accurate forward model is unknown or prohibitively expensive to use in an optimization procedure, hence an approximate or surrogate model is used instead. The importance of accounting for model error in the context of Bayesian inversion has been well-established in the literature (see, e.g., [35, 37]). This importance naturally extends to the OED problem, and in [18], the authors explore OED under uncertainty from the perspective of designing observation operators that mitigate model error. In contrast, we focus on the classical OED problem of choosing experimental conditions that lead to optimal parameter inference and formulate an uncertainty-aware optimality criterion.
Model error-informed approximations to posterior distributions can be obtained in various ways, e.g., by employing Gaussian processes [37, 29], via error-corrected delayed acceptance Markov chain Monte Carlo (MCMC) [17], and through the Bayesian approximation error approach [36]. Here, we follow the latter technique for incorporating model error into the OED problem. The BAE approach is also used for sensor placement design problems in [2] to account for model error stemming from unknown nuisance parameters, however our formulation differs in the following key ways: (i) we use a global linear approximation to the parameter-to-observable map, rather than many local Gaussian approximations, (ii) our approach accommodates model error due to the use of a linear surrogate as well as auxiliary input parameters, and (iii) we employ the full BAE error approach, rather than the so-called enhanced error model. The latter point facilitates a derivative-free approach to linearized OED. An alternative derivative-free approach to OED under model uncertainty is presented in [20], where D-optimal designs are obtained using an ensemble-based approximation to the posterior covariance matrix. In their approach, which is based on a calibrate-emulate-sample algorithm, a cheap-to-evaluate emulator and the corresponding model error correction term are learned using Gaussian processes.
Contributions
The main contributes of this article are: (i) We propose a tractable, uncertainty-aware approach for optimal sensor placement in infinite-dimensional Bayesian inverse problems by substituting the costly accurate forward model with an inexpensive linear surrogate and incorporating the corresponding model error using the BAE approach. (ii) Expanding on the work of [49], we show that the resulting approximate uncertainty-aware OED objective is asymptotically independent of the specific choice of linear surrogate. This result is key in formulating a black-box OED algorithm that only requires sample parameter and data pairs. (iii) The base methodology and theorems are also extended to marginalized OED, where the unknowns include some primary parameters of interest as well as some unimportant (or uninteresting) auxiliary inputs. (iv) With two model problems, we present comprehensive computational studies that illustrate the effectiveness of our approach for both standard and marginalized OED. In particular, we showcase the necessity of incorporating model error into the design problem, and the effectiveness of the optimal designs computed using our non-intrusive approach in solving the original high-fidelity inverse problem.
Limitations
Of course, the approach presented also has some limitations, which include: (i) Similar to any sort of linearization-based approximation procedure, our approach may not be well-suited for Bayesian inverse problems involving highly nonlinear PTO maps or non-Gaussian priors. While our approach does not place explicit restrictions on the prior, there is no guarantee that the resulting designs are effective in solving the original problem. However, if a the problem is not well-approximated by a Gaussian, the uncertainty-informed approximate posterior can still be used in more accurate (hence more costly) OED schemes as, e.g., a proposal density for MCMC-based methods, or as a reference density for transport-based approaches. (ii) Independence of the approximate posterior to the choice of linear surrogate is only guaranteed asymptotically, thus sufficient approximation to the second-order statistics may require a potentially large number of expensive PDE solves, particularly if the linear surrogate is a poor approximation to the true dynamics (as is the case when using the zero operator). This challenge is not exclusive to our methodology, since many OED algorithms rely on expensive offline PDE solves. However, if the number of samples required is prohibitively expensive and the PTO map is differentiable, using the derivative as a control variate could speed up convergence to the true error statistics. A theoretical study of the surrogate-dependent statistical convergence could help develop a better understanding of the suitability and limitations of our approach. (iii) In the current paper the methods used are based on explicit formulation of the associated covariance operators/matrices, and as such could be become infeasible for large problems. However, low-rank and other matrix representations, or potentially matrix-free variants, could avoid this potential bottleneck.
Outline of the paper
In Section 2 we introduce notation used throughout the paper and outline relevant background material on infinite-dimensional Bayesian inverse problems, and the Bayesian approximation error approach. In Section 3, we outline our uncertainty-aware linearize-then-optimize approach to optimal experimental design and show that the resulting objective is independent of the choice of linear surrogate. As shown in Section 3.2, this independence also extends to marginalized OED under model error, i.e., in this section, we consider OED for Bayesian inverse problems where the model error stems from the use of a linear surrogate and the presence of auxiliary unknown inputs to the forward model. The effectiveness of our proposed method is illustrated in Section 4 and Section 5, where OED is considered for an idealized subsurface flow geometric inverse problem and a tsunami source detection problem, respectively.
2 Background
In this section, we motivate our approach for carrying out derivative-free linearized OED for large-scale PDE-constrained problems. We begin by introducing the required notation and preliminaries in Section 2.1. We then briefly recall the Bayesian approach to inverse problems and the Bayesian approximation error approach.
2.1 Preliminaries
In this article we are interested in parameters which take values in possibly infinite-dimensional Hilbert spaces. For a Hilbert space , the corresponding inner product is denoted by and the associated norm by . For and Hilbert spaces, we let denote the space of bounded linear operators from to .
In this article we are particularly interested in Gaussian measures on Hilbert spaces. To this end, throughout the article we use to denote a Gaussian measure with mean and covariance operator . In the infinite dimensional case, the covariance operator is required to satisfy certain regularity assumptions to ensure the Bayesian inverse problem is well-defined [53]. As such, we assume is a strictly positive self-adjoint trace-class operator. We recall the Gaussian measure on induces the Cameron-Martin space , which is endowed with the inner product for all .
For and real Hilbert spaces, and for a linear operator , we denote by the adjoint. Moreover, for and , we define the (outer product) operator by , for any . The (cross-)covariance operator (between and ) is then defined
| (1) |
2.2 Bayesian inverse problems
The discussion presented here is carried out in the possibly infinite-dimensional Hilbert space setting [53]. We consider the problem of inferring an unknown parameter given observations that are related to as
| (2) |
where denotes measurement noise. In our target applications, the (potentially) nonlinear parameter-to-observable map can be decomposed into the composition of two operators, , where the parameter-to-state map (for some suitably-chosen function space ) requires solving a partial differential equation (PDE), and denotes a linear spatio-temporal observation operator.
In the Bayesian approach for parameter estimation, is treated as a random variable and is endowed with a prior probability law () that encompasses any knowledge we have about prior to data collection. Here we use a Gaussian prior with prior mean and a trace-class covariance operator . In practice it is often assumed that the data is corrupted by Gaussian noise which is independent of the parameter, i.e., , where is a symmetric-positive-definite (SPD) covariance matrix and .
Within the Bayesian framework, the solution to the inverse problem is the (data-informed) posterior law of , which we denote by . The posterior law is established as a Radon-Nikodym derivative via Bayes’ law and takes the following form under our additive Gaussian noise model,
| (3) |
Fully characterizing the posterior in the case of PDE-constrained inverse problems is generally infeasible. As a computationally practical alternative it is common to compute a Gaussian approximation to the posterior measure. A commonly utilized approximation is the so-called Laplace approximation [55], which approximates as a Gaussian, , centered around the maximum a posteriori (MAP) estimate [27],
| (4) |
The approximate posterior covariance operator of the Laplace approximation is given by , where denotes the Hessian of evaluated at the MAP estimate.
Construction of the Laplace approximation presents many challenges. While the MAP estimator is guaranteed to exist under relatively mild assumptions on the PTO map and data misfit, uniqueness of the estimator can not be guaranteed in general for nonlinear Bayesian inverse problems (see [19] for details). Additional theoretical difficulties arise if the map is not differentiable since the Laplace approximation requires access to derivatives of the PTO map. Constructing the Laplace approximation is also computationally costly. Finding the MAP estimator via minimization of (4) can involve many applications of the PTO map and its adjoint. Additionally, the inverse Hessian defining the posterior covariance operators typically not available in explicit form and needs to be estimated with additional forward and adjoint solves using, e.g., optimal low-rank approximations as described in [52]. This computational cost is exacerbated when one seeks optimal designs for nonlinear Bayesian inverse problems. As discussed in Section 3, OED in the nonlinear setting typically requires solving many Bayesian inverse problems. Thus, typical approaches (e.g., [4]) involve building many Gaussian approximations.
An alternative approach to obtaining a Gaussian approximation to the posterior distribution that circumvents some of the aforementioned challenges is to employ a linear surrogate to the PTO map. We leave the precise form of the linear (affine) surrogate arbitrary for now, and denote the linear map with . Naturally, replacing the nonlinear map with some linear approximation leads to errors that need to be accounted for to avoid erroneous overconfidence and bias in the resulting Gaussian posterior. These model approximation errors can be incorporated using the Bayesian approximation error (BAE) approach [34, 36].
Before outlining the BAE approach to account for the resulting approximation errors, we recall the explicit results of the linear Gaussian case.
The linear Gaussian case
In the case of a linear PTO map, i.e.,
for , under Gaussian prior and additive Gaussian noise, the posterior measure is Gaussian, with conditional mean and conditional covariance given, respectively, by (see [53, Example 6.23])
| (5) |
2.3 The Bayesian approximation error approach
Neglecting the model errors and uncertainties induced by the use of a surrogate to the PTO map in general leads to overconfidence in biased estimates [36, 34]. To avoid this, we employ the BAE approach, which has been used for incorporating various types of model uncertainties into the Bayesian inverse problem as well as the OED problem (see, e.g., [6, 48, 26, 2, 2]). Here we outline the BAE approach as it pertains to our method.
As alluded to in the preceding section, the typical approach to OED within the Bayesian framework requires repeatedly solving the optimization problem (4) and constructing the (local) Laplace approximation***An alternative (approximate) approach is proposed in [56] (see Section 3.4) where the Laplace approximation is carried out at samples from the prior, thus negating the need to compute any MAP estimates. However, this approximate approach is not well-suited for highly ill-posed inverse problems.. While using a surrogate (or reduced order model approximation) to the PTO map can reduce the computational costs associated with computing the MAP estimate, the cost for accurate Monte Carlo (MC) approximation of the optimality criterion can still be significant since it requires approximating the MAP estimate for many data samples.
In what follows, we let denote a surrogate model. The starting point for the BAE approach is to rewrite the accurate relationship between the data and parameters (2) as
| (6) |
where is the approximation error, and is the total error. At this point, a conditional Gaussian approximation for the approximation error is made, i.e.,
| (7) |
with (where we denote )
where and defined as in (1). As a direct consequence of (7) we have
| (8) |
and we approximate Bayes’ law (3) by
| (9) |
In some applications of the BAE the further approximation is employed, which is often referred to as the enhanced error model [6, 34].
A particularly straight-forward choice of surrogate model is a (affine) linear model, i.e., take . The standard choice for such a surrogate model is the (generalized) derivative of evaluated at some nominal point , i.e., . However, as long as the approximation error is taken into account using the BAE approach, the resulting (approximate) posterior is independent of the particular choice of linear surrogate, as stated in the following theorem from [49].
Theorem 1.
Let be a Hilbert space with and assume has prior measure with mean and (trace-class) covariance operator given by and , respectively. Suppose further that
where is the bounded PTO map, and has mean and covariance matrix . Then the approximate likelihood model parameterized by ,
where , and
is independent of the choice of .
As an immediate consequence, using (5), we have the following corollary.
Corollary 1.
The resulting (approximate) posterior is Gaussian and independent of the choice of linear model, with conditional mean and covariance given by
| (10) | ||||
| (11) |
respectively, with .
Remark 1.
The independence of the approximate posterior to the choice of linearization is a consequence of employing a linear surrogate map and accounting for model uncertainty using the (full) BAE approach. Specifically, employing the BAE approach introduces an affine (in ) correction to the approximate forward model, namely . As such, any change in the linear surrogate map is canceled out/offset by the correction term. However, as seen in the proof of [49, Theorem 1], the cross-covariance term is crucial for the result. If the cross-covariance is neglected (e.g., using the enhanced error model) the result would not follow.
In various inverse problems there are additional uncertain model parameters which are not estimated [34]. This is usually because ) these parameters are not of interest, or ) estimation of these parameters is too costly (or impossible). We will refer to these additional (to the primary parameters of interest) parameters as auxiliary parameters, though in the literature the terms nuisance parameters, secondary parameters, and latent parameters are also common. Neglecting the uncertainty in the auxiliary parameters while inferring the primary parameters typically results in misleading estimates and significantly underestimated uncertainty. The same can also be said for the OED process; neglecting the uncertainty in the auxiliary parameters while carrying out OED generally yields sub-optimal designs [2].
The BAE approach can be applied as a means to account for uncertainty in auxiliary parameters during both the inference and OED stages. Specifically, let , with the primary parameter the auxiliary parameter. Then assuming the accurate PTO model is , we can rewrite the relationship between the data and the primary parameters as (cf. (6))
| (12) |
In keeping with the theme of the paper, we will be particularly interested in cases where the surrogate model is linear, i.e., . For such cases the following corollary, outlining the independence of the approximate posterior to the choice of linear(-ized) model can be useful.
Corollary 2.
Let and be Hilbert spaces with and . Assume has (joint) prior measure with mean and (trace-class) covariance operator given by and , respectively. Suppose further that
where is the bounded PTO map, and has mean and covariance matrix . Then the approximate Gaussian marginal posterior measure parameterized by , with mean and covariance given by
respectively, with , is independent of the choice of .
Computing the approximation error statistics
In general the (second order) statistics of the approximation error are not known a priori. As such, these are computed using Monte Carlo simulations. More specifically, an ensemble of samples for are drawn from the joint prior and the associated approximation error is computed, i.e.,
| (13) |
From this ensemble of samples the sample means and (cross-)covariances can be computed:
| (14) | ||||
| (15) | ||||
| (16) |
3 A data-driven approach to optimal experimental designs
Here we present our tractable approach to approximating optimal designs for nonlinear Bayesian inverse problems. In Section 3.1 we outline relevant material on sensor placement design problems and their associated computational challenges. Our black-box approach that overcomes these challenges for OED and marginalized OED is presented in Section 3.2. In Section 3.3 we discuss an efficient numerical implementation of our method.
3.1 Optimal sensor placement for Bayesian inverse problems
Here we focus on inverse problems where data is collected at a set of sensors. In this setting, the OED goal is finding an optimal set of locations for sensor deployment in some prescribed measurement domain . To this end, we fix a candidate set of locations (with each ) and define the design problem as that of finding an optimal subset of locations from this set†††This discrete approach to sensor placement is common in OED literature [1], however a continuous formulation is also possible [47].. To distinguish between different designs or sensor arrangements, a binary weight is assigned to each sensor location . If , then data is collected using the sensor at location , whereas a weight of implies no measurement is conducted at . For general Bayesian inverse problems, the optimal arrangement of sensors is then defined through the optimal weight vector , which minimizes an expected utility function, i.e.,
| (17) |
The utility function assesses the effectiveness of using any sensor combination (defined via the weight vector ) in solving the Bayesian inverse problem with measurement data . Since the posterior measure depends on the data, minimizing the expectation of the utility function ensures that the chosen sensor placement works well on average for all possible realizations of the data. The utility function is typically problem-specific and some common choices for infinite-dimensional Bayesian OED are described in [1]. For illustrative purposes, we focus on the A-optimality criterion, though our approach could be extended to other utility functions. The -sensor A-optimal design minimizes the expected value of the average posterior pointwise variance. Letting denote the posterior covariance operator at a fixed design and measurement data , the A-optimal design can be obtained by solving the minimization problem (17) with .
For Bayesian inverse problems governed by nonlinear PTO maps or involving non-Gaussian prior measures, there is no closed-form expression for the data-dependent posterior covariance operator. Thus efficient techniques for approximating the expected utility are required. In the infinite-dimensional setting, the approximation is often carried out by combining a Gaussian approximation to the posterior measure with a sample average approximation (SAA) to the expectation, e.g., using a Laplace or Gauss-Newton approximation (see [4, 43]). As mentioned in Section 2.2, employing these techniques to approximate the SAA to the expected utility requires computing the MAP estimator for many data samples.
The linear Gaussian case
For linear Bayesian inverse problems with Gaussian priors and additive Gaussian noise, the A-optimality criterion simplifies, and an explicit formula is available. For notational convenience, we introduce a weight matrix . In our target applications, we assume measurements can be obtained at each sensor for different times, so (where denotes the number of selected sensors) and . The matrix is thus a block-diagonal matrix with each diagonal block defined as a sub-matrix of where the rows corresponding to zero weights have been removed (as described in [2]).
With this notation and the assumptions and , the design-dependent relationship between the data and parameters,
induces a design-dependent Gaussian posterior with conditional mean and covariance
| (18) |
where . For linear Bayesian inverse problems, the posterior covariance operator is independent of the observed data, i.e., the expectation in (17) is extraneous. Hence the A-optimal design can be found by minimizing the simplified criterion:
| (19) |
3.2 Invariance of the uncertainty-aware optimal design to linearization choice
In this section, we outline our approach to optimal sensor placement for Bayesian inverse problems where the accurate (but computationally costly) PTO map has been replaced with some linear surrogate. As in Section 2.3, with we denote the surrogate map that approximates the accurate nonlinear operator .
To incorporate model error into the design-dependent Bayesian inverse problem, we follow the BAE approach outlined in Section 2.3. The data measured at any subset of the candidate locations can be modeled by
where , and the random variable is used to approximate the total error at the chosen sensor locations. The total error mean and covariance are defined in (2.3) and (7) and can be estimated using Monte Carlo sampling as described in the end of Section 2.3. Since the design matrix enters linearly into the model, the design-dependent approximate posterior is also independent of the particular choice of linearization. That is, we can extend the results of 1 and 1 to design-dependent Bayesian inverse problems. This is done in the following corollary.
Corollary 3.
Let be a Hilbert space and assume has prior measure with mean and trace-class covariance operator . Assume that
where is a bounded PTO map, the matrix is defined as described in Section 3.1 for any , and .
Then for any , the approximate posterior parameterized by some linear map ,
where
is independent of the choice of . In particular, for any , we have:
Proof.
Note that as a consequence of 1, , and are independent of the choice of , and the result thus follows.
An immediate consequence of the invariance of the A-optimality criterion to the specific linearization is that the uncertainty-aware A-optimal designs are also independent of the specific choice of surrogate map . Thus the trivial map, the zero operator , leads to the same optimal sensor placements as a more complicated tailored surrogate when model error is incorporated using the BAE approach. This is the key insight that facilitates our greedy, derivative-free approach to optimal experimental design, which we describe in Section 3.3.
Remark 2.
As mentioned previously, in practice, the results in 1 and thus 3 only hold asymptotically as the number of samples used in the MC approximation of the model error statistics go to infinity. In particular, in [49], it was shown that the use of the zero map led to posteriors with underestimated pointwise variance when a small number of samples (typically ) was used. Thus, if the cost of evaluating significantly limits , it is advisable to use a surrogate that is highly correlated with .
Uncertainty-aware marginalized OED
As alluded to in Section 2.3, in many inverse problems there may be uncertain auxiliary parameters which are not estimated. In such settings, designs are chosen to minimize uncertainty in the marginal posterior for the primary parameters-of-interest. It is straightforward to extend our uncertainty-aware approach to approximate optimal sensor placements for such marginalized design problems. Decompose into a primary parameter-of-interest and an auxiliary parameter , and let denote linear a projection operator onto . The approximate marginal posterior measure, parameterized by some linear surrogate , is and the optimal sensor placements for the marginalized design problem thus satisfy
| (20) |
Since and are independent of the choice of (using 3), as is the projection operator , it is straightforward to see that the (approximate) optimal design for the marginalized problem is independent of the linear surrogate . As a consequence, the zero operator is also a valid surrogate for the marginalized OED problem.
3.3 Efficient computation of the greedy A-optimal designs
In this section, we outline a greedy procedure for computing A-optimal sensor placements for both design problems (19) and (20). Although we emphasize that our approach could be used with the zero map surrogate (and this is what we will use for the numerical examples in Section 4 and Section 5), for generality we present the procedure using an arbitrary linear surrogate map .
For the remainder of this section, let , , and denote the discretized parameter , accurate PTO map , and linear surrogate PTO map , respectively. The discretized uncertainty-aware model is thus
where , with and . Here, the discretized statistics , and are computed via Monte Carlo (as in (14)) using the discretized operators and . Letting , the corresponding discretized posterior covariance operator is then
| (21) | ||||
| (22) |
where denotes the adjoint of , and the last equation follows from the Woodbury matrix identity and .
Using the last equality and the cyclic property of the trace operator, we have
Thus, letting the A-optimal design satisfies
| (23) |
This reformulation of the A-optimality criterion is computationally advantageous if , which is often the case for inverse problems, particularly when dealing with discretizations of infinite-dimensional parameters .
Discrete marginalized A-optimal design problem
In the case where , and we are interested in finding designs that optimize the marginalized A-optimality criterion (20), we again let , with and (with ) denoting the discretized primary and auxiliary parameters, respectively. Additionally, we decompose , , and . Using (22), it is straightforward to see that
Denoting , the marginal A-optimal design thus satisfies
| (24) |
Note that (23) and (24) define NP-hard optimization problems. Approaches to solving this challenging problem often involve relaxation techniques [3, 28, 57], although relaxation-free approaches are also available (see, e.g., [8]). However, here we take a greedy approach to finding the placement of sensors that approximately solves the optimization problem (23). In the greedy approach to sensor placement, sensors that lead to the largest decrease in the A-optimality criterion are chosen one at a time from the (diminishing) candidate set. The procedure is outlined in Algorithm 1. The greedy approach to sensor placement generally yields sub-optimal designs. However, it has been shown to produce reasonable designs in practice [5, 2, 33]. Additionally, the greedy approach to sensor placement is completely hands-off (since no derivative information of the objective is required). Thus, when combined with the zero map surrogate, , our proposed approach is a black box that only requires sample parameter and data pairs.
At each step , the objective function defined in (23) (resp. (24) in the marginal OED case) needs to be evaluated times. Once the matrices and (resp. ) are precomputed, each evaluation of the objective only requires solving a system with a matrix of dimension (where denotes the number of times measurements are collected at each sensor) and summing up the diagonal entries. The computational bottleneck for most problems with PDE-dependent PTO maps will be the computation of the statistics ((14)-(16)) required for modeling the error using the BAE approach, since this requires solving PDEs with the accurate (costly) PTO map. We note that for our proposed zero map surrogate, precomputing the matrices in question is straightforward. In particular, and the equations for and simplify:
However, if is defined via a discretized (linear) PDE, then some approximation to may be required. There are various ways of constructing such approximations efficiently, e.g., using randomized matrix algorithms [25].
Input Target number of sensors , prior distribution , mean and covariance of the observational noise, accurate and (linear) surrogate parameter-to-observable maps ,
Output Optimal weight vector
In the next two sections we illustrate the application of our proposed linearize-then-optimize approach for computing optimal designs for two inverse problems. Specifically, for an idealized subsurface flow problem and for a tsunami detection problem.
4 Numerical example 1: Idealized subsurface flow
The first numerical example we consider is an idealized subsurface flow problem. Specifically, we consider the inverse problem of estimating the the (log-)boundary flux and the (log-)permeability field in a two dimensional subsurface aquifer from noisy (point-wise) measurements of the (head) pressure . The boundary flux and permeability field are related to the pressure by the steady state Darcy flow equation within the aquifer:
| (25) | ||||||
with denoting the outward normal vector. For a more in-depth discussion on the physical interpretation of the problem, we refer to [11, 10, 12]. Similar problems are commonly considered as benchmark tests [42, 31, 4].
In the current work we employ a level set approach[21, 32] for the parametrization of the permeability . Specifically, we take
| (26) |
where is the indicator function, , and for are the discrete (-)permeability values. Thus maps the so-called level set field to the permeability . We make explicit that although the permeability is the parameter of interest, inference and the associated optimal experimental design problem are carried out for the the level set field .
4.1 Problem set up
We consider the problem in the unit square; , and set , , and as the top, bottom and left and right boundaries, respectively, i.e., , , , and . A Galerkin finite element method is used to solve the forward problem (25). More specifically, the domain is discretized into 3042 triangular elements and 1600 continuous piece-wise linear basis functions. Thus the pressure as well as the permeability have dimension 1600. On the other hand, the unknown log-boundary flux is 40 dimensions. We impose a single level set threshold at on the level set field, with the permeability values (see (26)) when , and when . Finally, we take a total of 1600 candidate sensor locations which are distributed in an equally spaced 40 by 40 grid-like array (see Figure 5). In Figure 1 we show the true underlying level set field , the resulting true permeability , the true boundary flux , and the resulting true pressure .
Prior models
We assume the parameters and are a priori independent, i.e., . Furthermore, the (marginal) prior measure for the permeability is the push-forward of the prior measure of the level set field [21, 22, 32], i.e., . As such, the joint prior used here is of the form .
We postulate Gaussian prior measures for both the top boundary flux and the underlying level set field of the permeability, i.e., and . The covariance operators are defined by
| (27) | ||||
| (28) |
with and the domain of being . The parameter controls the characteristic length scale of samples of , while and control correlation length and variance of the samples of . Such covariance operators are fairly standard for subsurface flow Bayesian inverse problems [32, 30, 4]. In the current example we set , , and . In Figure 2 we show several prior samples , samples pf along with the corresponding samples of the permeability .
Optimal experimental design
We consider several cases of OED for this numerical example, each carried out using the proposed linearize-then-optimize procedure. In particular, we consider joint OED (of both and ), and then marginal OED for . For the marginal OED case we also compare the results found when neglecting the uncertainty in . Thus, for the idealized subsurface flow example, we consider the following three OED problems:
-
1.
Joint OED for and ,
-
2.
Marginal OED for while accounting for the uncertainty in , and
-
3.
Marginal OED for while ignoring the uncertainty in .
Linearization
In all cases we use the zero operator defined by for all as the approximate linear forward model. The zero model is particularly straight-forward to implement, completely non-invasive (i.e., well-suited in the case of black-box models), computationally cheap, and avoids the differentiability issues associated with the level set parameterization. More specifically, we generate samples from the joint prior, i.e., for , and compute the corresponding (noiseless) model predictions, . Subsequently, all required quantities are computed using Equations (14)-(16).
4.2 Reference case
Before considering the OED problem we solve the Bayesian inverse problem based on measurements collected at all candidate sensor locations. Specifically, we compute the approximate joint posterior for and based on the linear(-ized) BAE approach outlined in Section 2.3 and the “true” joint posterior with the full nonlinear PTO map using Markov chain Monte Carlo (MCMC) with the preconditioned Crank–Nicolson (pCN) algorithm [14, 16]. This reference task serves to provide a best case scenario in terms of uncertainty reduction, while also giving some insights into the accuracy of the approximate conditional mean and covariance (see (10) and (11) respectively) relative to those computed using MCMC. For the MCMC approach, we use a single chain of four million samples and discard the first four hundred thousand as burn-in. The results of the reference case, including those found using the linear BAE-based approach, are shown in Figure 3 for and in Figure 4 for (and ).
We generally observe that the (approximate) posterior computed using the linear BAE approach has higher levels of uncertainty (in , and ) compared to respective posteriors computing using MCMC. This is expected however, as a fundamental feature of the BAE framework is the incorporation of model errors/uncertainties (induced here by the use of the linear(-ized) surrogate model), which generally increases posterior uncertainty in the parameters. To investigate the posterior uncertainty of we compute the (sample-based) posterior covariance based on 10,000 posterior samples of (one batch from the MCMC-based posterior, and one batch for the linear BAE-based posterior) and computing . It is worth noting that due to the nature of the relationship between and , namely via , the posterior uncertainty of found using the linear BAE-approach is dependent on the data. This is evident by the increased uncertainty towards the interfaces of the conditional mean of in Figure 4.
Our main focus in this work is concerned with reductions and measures of posterior uncertainty rather than posterior estimates themselves. However, as expected, the conditional mean estimates found MCMC-based approach do more closely resemble the true parameters compared to those found using the linear BAE-based approach (see Figure 4 and Figure 3).
4.3 Optimal experimental design results
We now consider carrying out the problem of optimal sensor selection using the proposed linearize-then-optimize OED procedure. Specifically, we consider the problem of computing the optimal 20 sensor locations to measure the pressure for each of the three problems listed above.
To illustrate the effectiveness of the proposed approach to OED, we compare the optimal design found to randomly chosen designs. Specifically, for a given number of sensors we sample (without replacement) 100 random sensor configurations. The design criterion (trace of the relevant joint or marginal (approximate) posterior covariance operator) is then evaluated for each of the random sensor configurations. It should be noted that the optimal designs computed using the linear surrogate may not be optimal for the true posterior, even if uncertainty is accounted for. To this end, for the joint OED problem (Problem 1) we also investigate the effectiveness of our computed designs in minimizing , where is the “true” posterior covariance operator obtained using the model (2) with the accurate PTO map .
The results for Problem 1 are shown in Figure 5. The optimal design found using the proposed linearize-then-optimize approach as well a comparison of this optimal design to randomly selected designs is presented. We see that the design found using our proposed approach outperforms the random designs. This becomes more pronounced as the number of sensors increases up to 20‡‡‡If the number of sensors were to grow toward the total possible number of sensors the difference would diminish.. This appears to demonstrate the usefulness of the proposed method for OED. As alluded to above, to further investigate the applicability of our approach, for Problem 1 we also compare the performance of the designs found using the linearized approach to random designs using a SAA to . Specifically, for comparison, 10 different samples of from the joint prior are used to generate 10 sets of data at all measurement locations. For each sample we then evaluate the trace of the accurate posterior covariance operator with a subset of data collected at: the optimal design computed using the linearize-then-optimize approach, as well as for 10 (randomly selected) different designs, all consisting of 20 sensors. Each of the (110 in total) accurate posterior covariances are computed using the pCN MCMC algorithm using a single chain of four hundred thousand samples with the first one hundred thousand discarded as burn in. Note in this case the optimal design significantly outperforms the randomly chosen designs.
We next investigate the performance of the proposed approach on the marginal OED problem, i.e., carrying out OED for while treating as an auxiliary parameter. As a comparison, we also consider carrying out the uncertainty-unaware formulation of the marginal OED problem, i.e., ignoring the additional uncertainty due to unknown auxiliary parameter. The results for the marginal OED problem are shown in Figure 6. There is a significant difference in the optimal designs found using the uncertainty-aware approach and the uncertainty-unaware approach. This can most likely be attributed to large uncertainty in the approximation errors resulting from marginalizing over (which has significantly larger uncertainty than ). While the optimal design found using the proposed uncertainty-aware approach are reasonably distributed throughout the domain, the optimal design found using the uncertainty-unaware approach are localized near the top boundary. This is to be expected: the boundary flux is defined over the top boundary only, thus when ignoring the additional uncertainty induced by it is natural to measure near or on to reduce the uncertainty in . When comparing to random designs, we see that both the uncertainty-aware and uncertainty-unaware designs perform well (using the uncertainty-aware formulation of the posterior), however the uncertainty-aware design outperforms the corresponding uncertainty-unaware design for all cases considered.
5 Numerical example 2: tsunami detection problem
In our second example, we aim to find optimal designs for tsunami source reconstruction in the deep ocean. Propagation of earthquake-induced tsunami waves in a two-dimensional spatial domain is commonly modeled using the shallow water equations (SWE) [40, 54]. The SWEs are a nonlinear hyperbolic system of depth-averaged conservation laws used to model gravity waves and are well-suited for simulating tsunami waves due to their characteristically long wavelengths relative to water depth. For tsunamis arising from an instantaneous change to the ocean floor, i.e., a bathymetry change, the shallow water equations describing the changing water depth (defined as the height of the water above the ocean floor) and fluid flows in the and directions ( and respectively) at any point , are
where is the post-earthquake bathymetry and is the gravitational acceleration. It is assumed that the ocean is initially at rest, i.e., and where is the pre-earthquake bathymetry.
5.1 Modeling the bathymetry change using the Okada model
Our target example are tsunamis caused by suboceanic earthquakes. The Okada model [50] is commonly utilized to model the relationship between slips at fault plates beneath the ocean floor and seafloor deformations or bathymetry changes. Given a discretization of the fault region into a finite number of patches, the Okada model assumes the Earth behaves like a linear elastic material and provides a closed-form expression for evaluating the instantaneous bathymetry change induced by slips at these fault patches in a prescribed rake or direction.
Given a vector of slip magnitudes and rakes at fault patches, the post-earthquake bathymetry can be defined as
| (29) |
where the linear operator is defined by
| (30) |
with the functions defining the seafloor deformation induced by a slip at patch .
The Okada model makes various simplifications about the physical properties of the Earth as well as the mechanisms of the deformation (e.g., it assumes the Earth is a homogeneous isotropic elastic material and that the rupture occurs instantaneously) and thus only provides an approximation to the true bathymetry change induced by a slip at a fault. However, it is assumed to provide adequate approximations for the purposes of tsunami modeling and is often used in literature. Additionally, the scarcity of the observed data (due to financial constraints limiting the quantity of deployed deep-ocean pressure sensors) makes detailed reconstruction of the infinite-dimensional ocean deformations difficult, particularly without the use of a physically relevant prior. Parametrization of the seafloor deformation through the Okada model facilitates the use of a prior on the slip patches that results in physically realistic seafloor deformations, as will be discussed in Section 5.2.
5.2 Bayesian inversion using a linearization of the SWEs
The typical goal for tsunami hazard assessment and tsunami warning systems is to estimate the tsunami-causing seafloor rupture and use the estimate for predictions and threat assessment. Time is crucial for these predictions, and using the nonlinear shallow water equations can be costly. However, away from shore in the deep ocean, the linearized SWEs (centered around the ocean at rest) provide a reasonably accurate approximation to the dynamics of propagating tsunami waves [40]. This motivates the use of an affine surrogate to the PTO map obtained through a first-order Taylor expansion centered around the bathymetry of the ocean at rest, i.e.,
| (31) |
with , and , denoting the derivative of (with respect to m and , respectively) evaluated at the fixed parameters and . The linearized PTO map mapping the slip magnitude perturbations and rake vectors to incremental ocean-depth observations is obtained through: solution of the hyperbolic system
| (32) |
with zero initial conditions for and and application of an observation operator mapping the incremental state to the spatio-temporal observations of the water depth. We note here that the linearization, when centered at the rest bathymetry, is invariant to changes in the rake vector, i.e., . This means that simultaneous inversion for both the magnitude and rake is not possible using this linear model alone.
Our primary focus is on tsunamis caused by large magnitude earthquakes. In particular, we focus on earthquakes with a magnitude class between . To ensure our designs perform well for detecting such earthquakes we choose a Gaussian prior on the slip magnitudes () following the procedure outlined in [41, Sections 2 and 5]. Regardless of the earthquake magnitude, the direction of the slip for thrust earthquakes is typically around , therefore we assume a priori that for each slip patch . Some sample slip magnitudes (as well as the corresponding bathymetry changes) obtained from this tailored prior are visualized in Figure 7.
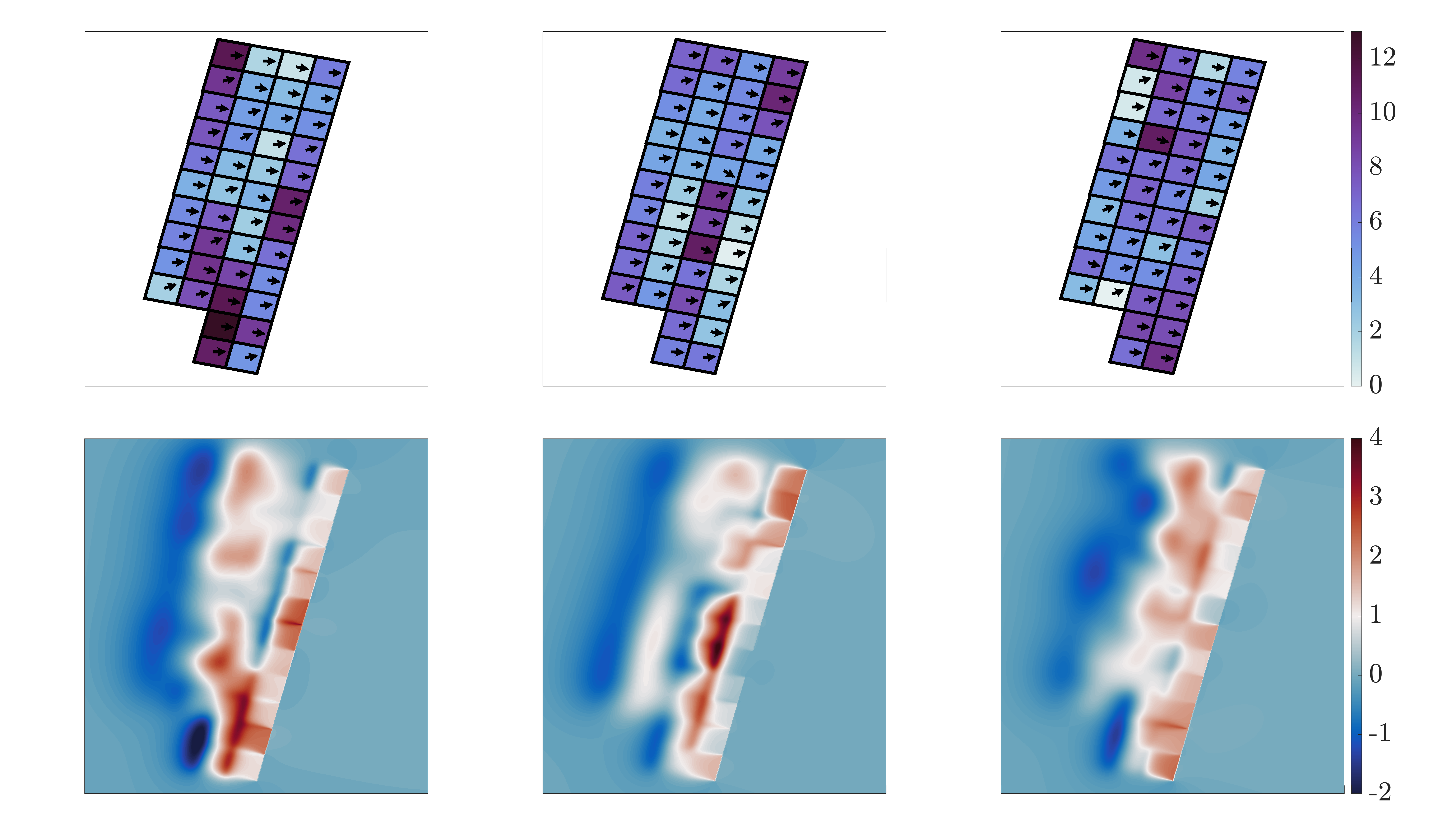
5.3 Computational setup
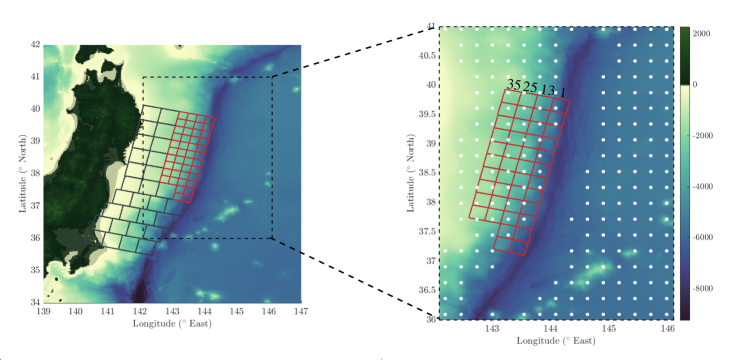
The bathymetry data used for the simulations, visualized in Figure 8, is from [44] and can be found in the corresponding repository [39]. Since the linear approximation to the shallow water equations degrades in accuracy near shore, we limit our computational domain to a rectangular region offshore as can be seen in the right image in Figure 8. We assume the tsunami originates from a vertical deformation of the seafloor in this region. To simulate the bathymetry change, a potential fault region is discretized into slip patches km in length and width, each with a dip of and strike of (see Figure 8). The slip patches chosen for these numerical experiments are a slightly modified subset of of the patches used in [24]. Specifically, to suit our needs, each original patch was split into four equally-sized patches and the depths were adjusted accordingly.
We model our ocean-floor sensors on a simplified Deep-ocean Assessment and Reporting of Tsunamis (DART) II system, which consists of a pressure sensor tethered to the ocean floor and a seasurface companion buoy equipped with satellite telecommunications capability [46]. For simplicity, we assume the sensors can measure the height of the water column above them directly. We specify locations for possible data collection, assuming the sensors can only be placed in depths between kilometers. A visualization of these possible locations is shown on the right in Figure 8. Since the water amplitude can be resolved with higher accuracy away from the region of maximum deformation (see, e.g., [46]) we impose uncorrelated Gaussian measurement noise with zero mean and standard deviation meters for data collected at sensors situated away from the fault and meters for sensors close to the fault.
To simulate “event mode” of the DART sensors, we assume each sensor produces measurements at second intervals for the first four minutes (starting at seconds after the seafloor rupture) resulting in depth readings for each sensor. For simplicity, we assume the -second depth interval readings are average readings over a two second interval, i.e., for , , which we approximate with the trapezoidal rule.
5.4 Results
In this section, we compare the optimal placement of sensors using the uncertainty-aware and uncertainty-unaware formulation of the OED problem. The uncertainty-aware designs are obtained treating both the magnitudes m and directions at each fault patch as parameters-of-interest and accounting for uncertainty due to the use of the linear surrogate map. All the forward simulations in this section were performed using the Conservation Laws Package (Clawpack [15, 45]) and the GeoClaw toolbox [9].
As in Section 4, we again choose the zero operator for obtaining the uncertainty-aware designs. For the uncertainty-unaware designs, the linearized SWEs (32) are used to approximate the propagating tsunami and model error is ignored. For both uncertainty-aware and uncertainty-unaware designs, we compute the optimal placement of the sensors using the greedy approach outlined in Section 3.1 with samples used to approximate the BAE statistics for the uncertainty-aware model. The uncertainty-aware and uncertainty-unaware optimal placements of sensors are visualized in Figure 9.
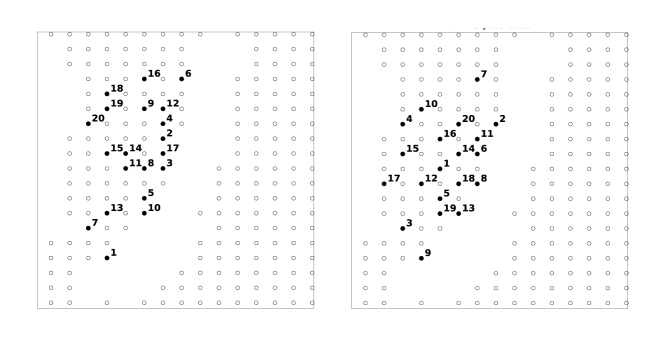
To illustrate the effectiveness of uncertainty-aware designs compared to uncertainty-unaware designs, in Figure 10 we compare the posterior mean and standard deviation obtained using both designs with 13 sensors and the uncertainty-aware formulation of the Bayesian inverse problem. In all cases, noisy data was simulated with a randomly chosen “true” parameter vector and the full nonlinear SWEs. The designs optimized using the linearized SWE without accounting for uncertainty lead to lower posterior uncertainty in the slip magnitudes than the uncertainty-aware designs. This is not surprising — uncertainty in the rakes can not be reduced using (32), therefore sensor placements are chosen to optimally infer the slip magnitudes. Thus, the uncertainty is higher in the slip rakes, and the overall reconstruction of the fault (and resulting bathymetry change) is worse when using the uncertainty-unaware designs. This observation is strengthened by the relative distance (measured using the Euclidean norm) from the truth to the posterior means, which is approximately: 0.44 and 0.26 for the relative error in the slip magnitude estimates using the uncertainty-unaware and uncertainty-aware designs, respectively, and 0.17 and 0.13 for the relative error in the slip rake estimates using the uncertainty-unaware and uncertainty-aware designs, respectively. Note that without accounting for model error in the Bayesian inverse problem, the optimal uncertainty-unaware design performs rather poorly in reconstructing the true parameter vector (see Figure 11).
We further evaluate the quality of the optimal uncertainty-aware designs compared to the optimal uncertainty-unaware designs and randomly chosen configurations in Figure 12. For each design configuration involving sensors, we evaluate: the trace of the resulting uncertainty-aware posterior covariance matrix, and the expected relative error of the posterior mean. To obtain the latter, we fix sample parameters from the prior distribution (different than those used for computing the covariance statistics required for the BAE approach) and synthesize noisy data using the nonlinear SWEs, i.e., . The expected error in the posterior mean is then approximated using a sample average approach, , where denotes the posterior mean corresponding to data . The uncertainty-aware designs outperform the uncertainty-unaware and random designs in reducing the posterior trace as well as the average approximation error in the posterior mean. Additionally, while the uncertainty-aware designs in comparisons in Fig. 9 and Fig. 10 were obtained using error statistics computed with samples, for Figure 12 we computed optimal uncertainty-aware designs using samples. While using more samples does produce more effective designs, we emphasize that reasonable designs could be obtained using as few as samples, i.e., using only runs of the costly forward model.
6 Discussion and Conclusion
We have presented a scalable approach for approximating optimal sensor placements for nonlinear Bayesian inverse problems. Our method involves replacing a nonlinear parameter-to-observable map with a linear surrogate while incorporating model error into the inverse problem with the Bayesian approximation error approach. Notably, we demonstrated that this formulation yields an approximation to the A-optimality criterion that is asymptotically independent of the specific linearization choice. This result enables a derivative-free approach to linearized OED. Through two numerical examples, we illustrated the efficacy of sensor placements obtained with our method using the zero map as a surrogate to the accurate forward dynamics.
The results in this article point to several possibilities for future work. Firstly, we reiterate that equivalence of the A-optimal designs under different linearizations can only be guaranteed asymptotically. While the design comparisons in Sections Section 4 and Section 5 indicate that the number of samples used in our examples were sufficient in yielding effective designs, simulating tens-of-thousands of data samples using the accurate model may be prohibitively expensive for certain problems. To accommodate such cases, exploring the use of well-chosen control variates to expedite convergence will be crucial to reduce the number of samples needed.
Additionally, a key aspect of our approach is that it relies solely on sample parameter and data pairs. While the “accurate” data used in our examples was synthetic, this suggests the potential of applying our method for model-free OED. That is, in situations where the accurate forward model is unknown, our approach could be utilized using experimental data for fixed parameter choices. Lastly, another intriguing direction is a study of how well our designs perform in minimizing the uncertainty in the “true” posterior. We provide a heuristic comparison for the subsurface flow example in Section 4, however a more rigorous study would provide insight into the limitations of linearization-based approximations to optimal designs.
Acknowledgments
The work of KK has been partially funded by Carl-Zeiss-Stiftung through the project “Model-Based AI: Physical Models and Deep Learning for Imaging and Cancer Treatment”. The authors thank Alen Alexanderian, Alex de Beer, Oliver Maclaren, and Georg Stadler for helpful discussions and their valuable comments about this manuscript.
References
- [1] A. Alexanderian, Optimal experimental design for infinite-dimensional Bayesian inverse problems governed by PDEs: A review, Inverse Problems, (2021).
- [2] A. Alexanderian, R. Nicholson, and N. Petra, Optimal design of large-scale nonlinear Bayesian inverse problems under model uncertainty, arXiv preprint arXiv:2211.03952, (2022).
- [3] A. Alexanderian, N. Petra, G. Stadler, and O. Ghattas, A-optimal design of experiments for infinite-dimensional Bayesian linear inverse problems with regularized -sparsification, SIAM Journal on Scientific Computing, 36 (2014), pp. A2122–A2148.
- [4] A. Alexanderian, N. Petra, G. Stadler, and O. Ghattas, A fast and scalable method for A-optimal design of experiments for infinite-dimensional Bayesian nonlinear inverse problems, SIAM Journal on Scientific Computing, 38 (2016), pp. A243–A272.
- [5] A. Alexanderian, N. Petra, G. Stadler, and I. Sunseri, Optimal design of large-scale Bayesian linear inverse problems under reducible model uncertainty: good to know what you don’t know, SIAM/ASA Journal on Uncertainty Quantification, 9 (2021), pp. 163–184.
- [6] S. R. Arridge, J. P. Kaipio, V. Kolehmainen, M. Schweiger, E. Somersalo, T. Tarvainen, and M. Vauhkonen, Approximation errors and model reduction with an application in optical diffusion tomography, Inverse problems, 22 (2006), p. 175.
- [7] A. Attia, S. Leyffer, and T. Munson, Robust A-optimal experimental design for Bayesian inverse problems, arXiv preprint arXiv:2305.03855, (2023).
- [8] A. Attia, S. Leyffer, and T. S. Munson, Stochastic learning approach for binary optimization: Application to Bayesian optimal design of experiments, SIAM Journal on Scientific Computing, 44 (2022), pp. B395–B427.
- [9] M. J. Berger, D. L. George, R. J. LeVeque, and K. T. Mandli, The GeoClaw software for depth-averaged flows with adaptive refinement, Advances in Water Resources, 34 (2011), pp. 1195–1206.
- [10] J. Carrera and S. P. Neuman, Estimation of aquifer parameters under transient and steady state conditions: 1. Maximum likelihood method incorporating prior information, Water Resources Research, 22 (1986), pp. 199–210.
- [11] , Estimation of aquifer parameters under transient and steady state conditions: 2. Uniqueness, stability, and solution algorithms, Water Resources Research, 22 (1986), pp. 211–227.
- [12] , Estimation of aquifer parameters under transient and steady state conditions: 3. Application to synthetic and field data, Water Resources Research, 22 (1986), pp. 228–242.
- [13] K. Chaloner and I. Verdinelli, Bayesian experimental design: A review, Statistical Science, (1995), pp. 273–304.
- [14] V. Chen, M. M. Dunlop, O. Papaspiliopoulos, and A. M. Stuart, Dimension-robust MCMC in Bayesian inverse problems, arXiv preprint arXiv:1803.03344, (2018).
- [15] Clawpack Development Team, Clawpack software. https://doi.org/10.5281/zenodo.4025432, 2020. Version 5.8.0.
- [16] S. L. Cotter, G. O. Roberts, A. M. Stuart, and D. White, MCMC methods for functions: Modifying old algorithms to make them faster, (2013).
- [17] T. Cui, C. Fox, and M. J. O’Sullivan, A posteriori stochastic correction of reduced models in delayed-acceptance MCMC, with application to multiphase subsurface inverse problems, International Journal for Numerical Methods in Engineering, 118 (2019), pp. 578–605.
- [18] N. Cvetković, H. C. Lie, H. Bansal, and K. Veroy, Choosing observation operators to mitigate model error in Bayesian inverse problems, arXiv preprint arXiv:2301.04863, (2023).
- [19] M. Dashti, K. J. Law, A. M. Stuart, and J. Voss, MAP estimators and their consistency in Bayesian nonparametric inverse problems, Inverse Problems, 29 (2013), p. 095017.
- [20] O. R. Dunbar, M. F. Howland, T. Schneider, and A. M. Stuart, Ensemble-based experimental design for targeting data acquisition to inform climate models, Journal of Advances in Modeling Earth Systems, 14 (2022), p. e2022MS002997.
- [21] M. M. Dunlop, M. A. Iglesias, and A. M. Stuart, Hierarchical Bayesian level set inversion, Statistics and Computing, 27 (2017), pp. 1555–1584.
- [22] M. M. Dunlop and Y. Yang, Stability of Gibbs posteriors from the Wasserstein loss for Bayesian full waveform inversion, SIAM/ASA Journal on Uncertainty Quantification, 9 (2021), pp. 1499–1526.
- [23] C. Feng and Y. M. Marzouk, A layered multiple importance sampling scheme for focused optimal Bayesian experimental design, arXiv preprint arXiv:1903.11187, (2019).
- [24] Y. Fujii, K. Satake, S. Sakai, M. Shinohara, and T. Kanazawa, Tsunami source of the 2011 off the pacific coast of Tohoku earthquake, Earth, planets and space, 63 (2011), pp. 815–820.
- [25] N. Halko, P. G. Martinsson, and J. A. Tropp, Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions, SIAM Review, 53 (2011), pp. 217–288.
- [26] N. Hänninen, A. Pulkkinen, A. Leino, and T. Tarvainen, Application of diffusion approximation in quantitative photoacoustic tomography in the presence of low-scattering regions, Journal of Quantitative Spectroscopy and Radiative Transfer, 250 (2020), p. 107065.
- [27] T. Helin and M. Burger, Maximum a posteriori probability estimates in infinite-dimensional Bayesian inverse problems, Inverse Problems, 31 (2015), p. 085009.
- [28] E. Herman, A. Alexanderian, and A. K. Saibaba, Randomization and reweighted -minimization for A-optimal design of linear inverse problems, SIAM Journal on Scientific Computing, 42 (2020), pp. A1714–A1740.
- [29] D. Higdon, M. Kennedy, J. C. Cavendish, J. A. Cafeo, and R. D. Ryne, Combining field data and computer simulations for calibration and prediction, SIAM Journal on Scientific Computing, 26 (2004), pp. 448–466.
- [30] L. Holbach, M. Gurnis, and G. Stadler, A Bayesian level set method for identifying subsurface geometries and rheological properties in Stokes flow, Geophysical Journal International, 235 (2023), pp. 260–272.
- [31] M. A. Iglesias, K. J. Law, and A. M. Stuart, Ensemble Kalman methods for inverse problems, Inverse Problems, 29 (2013), p. 045001.
- [32] M. A. Iglesias, Y. Lu, and A. M. Stuart, A Bayesian level set method for geometric inverse problems, Interfaces and free boundaries, 18 (2016), pp. 181–217.
- [33] J. Jagalur-Mohan and Y. Marzouk, Batch greedy maximization of non-submodular functions: Guarantees and applications to experimental design, The Journal of Machine Learning Research, 22 (2021), pp. 11397–11458.
- [34] J. Kaipio and V. Kolehmainen, Approximate marginalization over modeling errors and uncertainties in inverse problems, Bayesian theory and applications, (2013), pp. 644–672.
- [35] J. Kaipio and E. Somersalo, Statistical and computational inverse problems, Springer, Dordrecht, 2005.
- [36] , Statistical inverse problems: Discretization, model reduction and inverse crimes, Journal of computational and applied mathematics, 198 (2007), pp. 493–504.
- [37] M. C. Kennedy and A. O’Hagan, Bayesian calibration of computer models, Journal of the Royal Statistical Society: Series B (Statistical Methodology), 63 (2001), pp. 425–464.
- [38] K. Koval, A. Alexanderian, and G. Stadler, Optimal experimental design under irreducible uncertainty for linear inverse problems governed by PDEs, Inverse Problems, 36 (2020), p. 075007.
- [39] R. LeVeque. https://github.com/rjleveque/tohoku2011-paper1, 2014.
- [40] R. J. LeVeque, D. L. George, and M. J. Berger, Tsunami modelling with adaptively refined finite volume methods, Acta Numerica, 20 (2011), p. 211.
- [41] R. J. LeVeque, K. Waagan, F. I. González, D. Rim, and G. Lin, Generating random earthquake events for probabilistic tsunami hazard assessment, in Global Tsunami Science: Past and Future, Volume I, Springer, 2016, pp. 3671–3692.
- [42] Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, and A. Anandkumar, Neural operator: Learning maps between function spaces with applications to PDEs., J. Mach. Learn. Res., 24 (2023), pp. 1–97.
- [43] Q. Long, M. Scavino, R. Tempone, and S. Wang, Fast estimation of expected information gains for Bayesian experimental designs based on Laplace approximations, Computer Methods in Applied Mechanics and Engineering, 259 (2013), pp. 24–39.
- [44] B. T. MacInnes, A. R. Gusman, R. J. LeVeque, and Y. Tanioka, Comparison of earthquake source models for the 2011 Tohoku event using tsunami simulations and near-field observations, Bulletin of the Seismological Society of America, 103 (2013), pp. 1256–1274.
- [45] K. T. Mandli, A. J. Ahmadia, M. Berger, D. Calhoun, D. L. George, Y. Hadjimichael, D. I. Ketcheson, G. I. Lemoine, and R. J. LeVeque, Clawpack: Building an open source ecosystem for solving hyperbolic PDEs, PeerJ Computer Science, 2 (2016), p. e68.
- [46] C. Meinig, S. E. Stalin, A. I. Nakamura, and H. B. Milburn, Real-time deep-ocean tsunami measuring, monitoring, and reporting system: The NOAA DART II description and disclosure, NOAA, Pacific Marine Environmental Laboratory (PMEL), (2005), pp. 1–15.
- [47] I. Neitzel, K. Pieper, B. Vexler, and D. Walter, A sparse control approach to optimal sensor placement in PDE-constrained parameter estimation problems, Numerische Mathematik, 143 (2019), pp. 943–984.
- [48] R. Nicholson, N. Petra, and J. P. Kaipio, Estimation of the Robin coefficient field in a Poisson problem with uncertain conductivity field, Inverse Problems, 34 (2018), p. 115005.
- [49] R. Nicholson, N. Petra, U. Villa, and J. P. Kaipio, On global normal linear approximations for nonlinear Bayesian inverse problems, Inverse Problems, 39 (2023), p. 054001.
- [50] Y. Okada, Surface deformation due to shear and tensile faults in a half-space, Bulletin of the seismological society of America, 75 (1985), pp. 1135–1154.
- [51] C. P. Robert, G. Casella, and G. Casella, Monte Carlo statistical methods, vol. 2, Springer, 1999.
- [52] A. Spantini, A. Solonen, T. Cui, J. Martin, L. Tenorio, and Y. Marzouk, Optimal low-rank approximations of Bayesian linear inverse problems, SIAM Journal on Scientific Computing, 37 (2015), pp. A2451–A2487.
- [53] A. M. Stuart, Inverse problems: A Bayesian perspective, Acta numerica, 19 (2010), pp. 451–559.
- [54] S. Tong, E. Vanden-Eijnden, and G. Stadler, Extreme event probability estimation using PDE-constrained optimization and large deviation theory, with application to tsunamis, Communications in Applied Mathematics and Computational Science, 16 (2021), pp. 181–225.
- [55] R. Wong, Asymptotic approximations of integrals, SIAM, 2001.
- [56] K. Wu, P. Chen, and O. Ghattas, A fast and scalable computational framework for large-scale and high-dimensional Bayesian optimal experimental design, arXiv preprint arXiv:2010.15196, (2020).
- [57] J. Yu and M. Anitescu, Multidimensional sum-up rounding for integer programming in optimal experimental design, Mathematical Programming, (2017), pp. 1–40.