Non-parametric Causal Discovery for EU Allowances Returns Through the Information Imbalance
Abstract
We propose to use a recently introduced non-parametric tool named Differentiable Information Imbalance (DII) to identify variables that are causally related – potentially through non-linear relationships – to the financial returns of the European Union Allowances (EUAs) within the EU Emissions Trading System (EU ETS). We examine data from January 2013 to April 2024 and compare the DII approach with multivariate Granger causality, a well-known linear approach based on VAR models. We find significant overlap among the causal variables identified by linear and non-linear methods, such as the coal futures prices and the IBEX35 index. We also find important differences between the two causal sets identified. On two synthetic datasets, we show how these differences could originate from limitations of the linear methodology.
Keywords: Causality, Differentiable Information Imbalance, EU ETS, Financial Returns, Non-Linear Analysis
1 Introduction
The European Union Emission Trading System (EU ETS) is a key element in the EU’s strategy to address climate change and reduce greenhouse gas (GHG) emissions. Based on the cap-and-trade principle, this system establishes a gradual limit on GHG emissions across important sectors of the economy, primarily targeting energy, aviation, and energy-intensive industry. Under the EU ETS, participating companies receive emission permits, known as European Union Allowances (EUA), each granting the release of one tonne of carbon dioxide or its equivalent into the atmosphere.
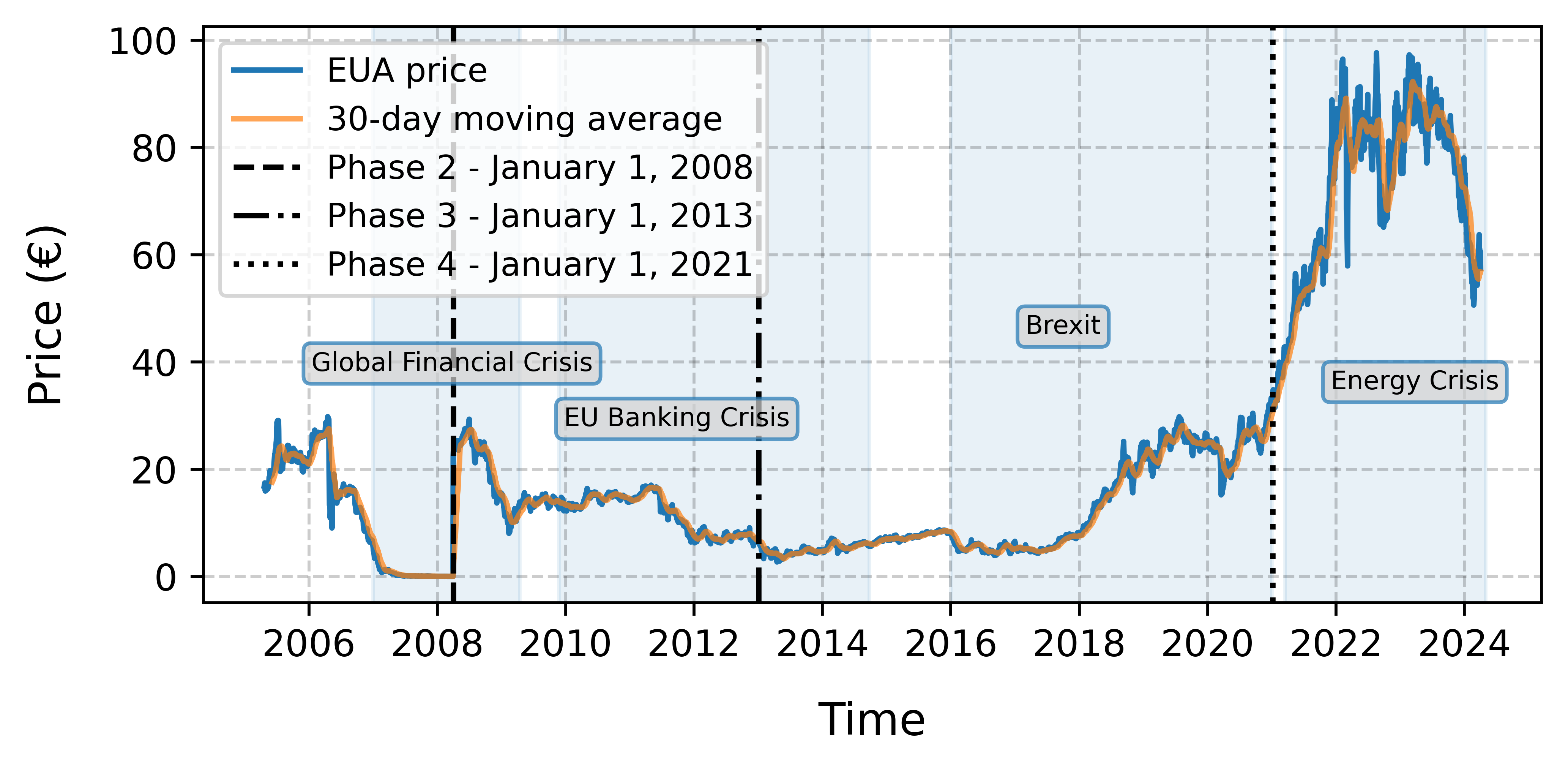
Companies participating in the market have the flexibility to trade these emission allowances on the ETS market. If a company exceeds its allocated allowances it must purchase additional permits to cover excess emissions, otherwise heavy fines, €100 per tonne of GHG emissions, are faced [39]. This market-driven approach provides an economic instrument for addressing GHG emissions efficiently. Companies are encouraged to invest in emission reduction initiatives and technology to lower their emissions below their allocated allowances, enabling them to sell surplus permits for profit. Furthermore, the EU ETS undergoes regular reviews and adjustments to emission limits, with a key mechanism being the Linear Reduction Factor (LRF). The LRF annually reduces the cap, ensuring that emission reduction targets remain consistently aligned with the EU’s broader climate goals and evolving environmental priorities. Through the LRF, the market can be driven towards progressively more ambitious emission reduction targets while encouraging innovation and investment in cleaner technologies. In essence, the EU ETS is a sophisticated market-based mechanism that leverages economic incentives to drive emissions reductions. Its alignment with international agreements, such as the Kyoto Protocol (2005) and the Paris Agreement (2016), further highlights its importance as a critical tool in the global effort to combat climate change. The historical evolution of EUA futures prices and the phases of the EU ETS are illustrated in Figure 1.
1.1 Literature review
Understanding causal relationships in financial time series is essential for interpreting market behaviour, forecasting asset dynamics, and measuring volatility effects. In the context of increasingly complex and interconnected financial systems, particularly those involving energy and commodity markets, accurate identification of causality goes beyond mere correlation and requires robust analytical tools.
Over the years, a wide range of methods have been developed for this purpose, beginning with linear models such as Granger causality and Vector Autoregressions (VARs), which remain influential due to their simplicity and interpretability. However, the limitations of these traditional approaches in capturing non-linear dependencies have prompted the emergence of alternative techniques, including non-parametric measures like Transfer Entropy (TE) and recent advances in information-theoretic metrics. This literature review provides an overview of these methodologies, highlighting their respective strengths and weaknesses, and positioning the Differentiable Information Imbalance (DII) metric within this evolving landscape of causal discovery tools.
The study of causality in financial time series has long been dominated by linear econometric models, particularly the Granger causality framework and Vector Autoregressive (VAR) models. Granger causality, introduced by [29], defines a variable as a cause of another variable if the inclusion of past values of improves the prediction of , beyond what is possible using only past values of . This notion is implemented through VAR models, which represent each variable in a multivariate system as a linear function of its own lags and the lags of other variables in the system [44]. However, the reliability of Granger causality and VAR inference critically depends on the assumption of linearity, which is a clear oversimplification in financial time series. In this scenario, linear models can produce misleading conclusions about causal relationships or fail to detect them altogether [6, 24].
Recent research has increasingly turned to non-linear and non-parametric methods to analyse causality in financial systems. Among these, Transfer Entropy (TE), introduced by [43], stands out as a powerful and model-free measure that detects directional and non-linear causal influences between time series. Unlike Granger causality, which is based on linear predictability, TE quantifies the amount of information flow from the past of one variable to the future of another using an information-theoretic measure. Early applications of [4] revealed patterns of sectoral influence in the US stock market, particularly highlighting the role of the energy sector. More recent work, such as [36], applied TE to the Chinese stock market to construct speculative influence networks, demonstrating that sectors exerting stronger influence were more vulnerable during market crashes. In bond markets, [14] used the TE to reveal the leadership of sovereign bonds over credit default swaps in pricing sovereign credit risk during periods of financial distress. Despite its theoretical appeal, computing TE in high-dimensional settings is challenging [20], as it relies on estimating probability densities of the dynamic variables.
Complementing these approaches, Convergent Cross Mapping (CCM), introduced by [45], offers a model-free, state-space reconstruction method to infer directional causality by assessing whether one time series can reliably reconstruct the states of another. CCM has been applied to financial markets, including the work of [37], who identified non-linear causal links between major stock indices during periods of market turbulence.
In the context of financial time series, especially under conditions of non-linearity and high dimensionality, approaches that do not rely on the estimation of probability densities offer a powerful alternative to classical tools. A recent and promising framework in this class is Information Imbalance (II), which quantifies the directional predictive power one variable (or set of variables) has over another, using a non-parametric, rank-based comparison of distances [28]. In [21], the II was employed to detect asymmetric causal relationships between high-dimensional dynamical systems with non-linear dynamics.
The Differentiable Information Imbalance (DII) extends this approach by introducing a gradient-based formulation that allows for automated feature selection and weighting, facilitating the application of causal discovery in large and complex datasets [49, 21]. This differentiable variant enhances scalability while preserving the method’s non-parametric and model-agnostic nature. Compared to other non-linear methods such as TE, the II and DII frameworks offer unique advantages: they do not assume any generative model, can be computed without any explicit estimate of probability densities, and provide directional insights into variable relationships. These properties make them well-suited for causal inference in complex systems, including financial markets.
The European Union Emissions Trading System (EU ETS) has attracted considerable attention from researchers applying both traditional and modern methods to analyse causality, and risk transmission across energy and financial markets. Numerous studies have employed tools such as Granger causality, spillover indices, and machine learning to uncover the dynamics linking EUA prices with external shocks, compliance cycles, and interconnected markets like energy and equities.
For instance, Granger causality and volatility models such as EGARCH have been widely used to characterise the temporal dynamics and risk profiles of EUA prices. [17], and [16], demonstrate the relevance of conditional volatility and implied option-based measures in capturing regime shifts around compliance events and post-Kyoto uncertainty. High-frequency volatility modelling further reveals asymmetric responses and long-memory features, underscoring the complexity of EUA dynamics [48]. Similarly, [18] highlight how institutional events and policy milestones affect the stability and predictability of EUA price behaviour.
More recent work focuses on the role of external shocks and market spillovers. [38] show that geopolitical crises, such as the Russia–Ukraine conflict and the broader energy crisis, substantially amplify volatility in the carbon market through industrial output, emissions demand, and stock-energy linkages. These findings are supported by [12] and [3], who emphasise the structural co-movement between energy prices and EUA volatility due to rising marginal abatement costs and uncertainty. Moreover, the inclusion of sustainability and transition risk proxies, such as energy indices, reflects the growing recognition of systemic risks in low-carbon financial markets [40].
Against this backdrop, [42] offer a novel methodological advance by applying a non-parametric feature selection approach, based on the II, to uncover the variables that are more related to the EUA price formation. The present study builds upon and extends their methodology by incorporating Differentiable Information Imbalance (DII) into a broader causal framework, showcasing its applicability to high-dimensional market settings.
1.2 Motivation and goals
Despite extensive research on causality in financial and energy markets, existing methods often fall short in capturing the non-linear and directional dynamics of complex high-dimensional systems like the EU ETS. This study aims to improve the understanding of energy and commodity market dynamics by proposing a novel approach to identify non-linear causal relationships in financial time series data.
The approach leverages a non-parametric and non-linear metric called II [28], in its differentiable version DII [49, 1]. The II metric used in this work provides a general and robust quantification of the predictive power that one set of variables has on another [28]. To evaluate the effectiveness of the DII, we apply it in conjunction with standard linear methods on a dataset of financial returns, which includes a heterogeneous set of assets and indices related to energy markets.
A specific objective of this research is to investigate the causal relationships influencing the European Union Allowances market and to examine how external factors affect the financial return dynamics of EUA. The impact of each variable is determined by the improvement it brings to the prediction of EUA, compared to a prediction where the same variable is excluded. This is quantified using the F-statistic in multivariate Granger causality, and the Imbalance Gain (IG) in the DII approach.
In our analysis, we assume a condition known as causal sufficiency [41], namely that the employed data do not exclude any variable, financial or not, that is a common driver (or confounder) of EUA and the other predictors in the dataset. This is an important assumption for both the DII approach and the standard Granger causality analysis. The assumption is most likely not satisfied in practice as unobservable variables such as risk aversion, liquidity needs, expectations about future emissions, economic activity, environmental policies, etc., which contribute to determining prices and returns, are by definition (being unobservable) not included in the dataset. Although the estimated causal relationships may not fully account for all confounding influences, they can still reveal dominant interactions and offer interpretable hypotheses for further investigation.
The current work is closely related to [42], where the authors introduced the II to identify key determinants of EUA prices. That initial investigation inspired the current study, in which we extend the II methodology for causal discovery on EUA returns. The key contribution lies in using DII on a multivariate dataset of financial, energy, and carbon variables, offering new insights into EUA price formation and inter-market dependencies amid uncertainty and transition.
1.3 Organisation of the work
The rest of this work is structured as follows. Section 2 provides details on the dataset used along with descriptive statistics. Section 3 offers an introduction to the fundamental theoretical background on linear causal discovery (based on VAR models and the Granger test), and on the non-linear causal discovery method we put forward (based on the DII and the IG). The section also explains how the two approaches are related and how they can be applied to our objectives. Section 4 presents the empirical results obtained by applying multivariate Granger causality and the DII approach to EUA and the variables considered. The discussion of the findings is presented in Section 5, while the concluding remarks are provided in Section 6.
2 Data
The daily dataset we consider includes a range of market categories such as environmental markets, commodities, exchange rates, energy indices, and country-specific indices. The financial returns dataset spans January 2013 to April 2024, totalling 2902 observations. In this work, we collect and use the closing prices and hence do not consider any temporal effect that might arise from differences in recording times. As we focus on the long-term relationships between variables rather than on intraday fluctuations, we believe that the absence of precisely aligned recording times does not significantly affect our results.
Table 1 presents the dataset, highlighting variables related to uncertainty indicators and commodity prices, notably the VSTOXX volatility index and futures for ICE Brent oil and LME Copper.
| ID | Category | Variables | Abbreviations | Database |
|---|---|---|---|---|
| 0 | T | EUA (ICEENDEX) | EUA | Bloomberg® |
| 1 | UNC | GPR | GPR | GPR website |
| 2 | UNC | VSTOXX (V2X) | VSTOXX | Bloomberg® |
| 3 | UNC | Unc. EUR/USD (CAFZUUEU) | UncEURUSD | Bloomberg® |
| 4 | UNC | Unc. EUR/JPY (CAFZUEJP) | UncEURJPY | Bloomberg® |
| 5 | UNC | Unc. EUR/GBP (CAFZUEGB) | UncEURGBP | Bloomberg® |
| 6 | UNC | Unc. EUR/CHF (CAFZUECH) | UncEURCHF | Bloomberg® |
| 7 | COM | ICE Dutch TTF Natural Gas (TTF0NXHR) | NatGas | Bloomberg® |
| 8 | COM | Electricity Prices Spain (OMLPDAHD) | ElecES | Bloomberg® |
| 9 | COM | Electricity Prices Germany (EXAPBDHD) | ElecDE | Bloomberg® |
| 10 | COM | Electricity Prices France (PWNXFRAV) | ElecFR | Bloomberg® |
| 11 | COM | ICE Coal Rotterdam futures (TMA Comdty) | CoalFut | Bloomberg® |
| 12 | COM | LME Copper futures (LMCADS03 Comdty) | CuFut | Bloomberg® |
| 13 | COM | ICE Brent oil futures (CO1 Comdty) | Brent | Bloomberg® |
| 14 | COM | Silver (XAG Comdty) | AgFut | Bloomberg® |
| 15 | COM | Gold (GCZ3 Comdty) | Gold | Bloomberg® |
| 16 | ER | EUR/USD spot (EUR/USD) | EURUSD | Eikon Refinitiv® |
| 17 | ER | EUR/JPY spot (EUR/JPY) | EURJPY | Eikon Refinitiv® |
| 18 | ER | EUR/GBP spot (EUR/GBP) | EURGBP | Eikon Refinitiv® |
| 19 | ER | EUR/CHF spot (EUR/CHF) | EURCHF | Eikon Refinitiv® |
| 20 | ENR | WilderHill New Energy Global Innovation index (Nex) | WHNewEnergy | Bloomberg® |
| 21 | ENR | Bloomberg Energy TR index (BCOMENTR) | BbgEnergy | Bloomberg® |
| 22 | ENR | Solactive CEA Future index (SOLAFCEA) | SolCEA | Bloomberg® |
| 23 | ENR | EUROSTOXX Electricity index (SXEELC) | ESTXElect | Bloomberg® |
| 24 | ENR | Solactive ESG Fossil EU 50 index | SEF EU50 | Bloomberg® |
| 25 | ENR | Low Carbon 100 index (LC100) | LC100EU | Bloomberg® |
| 26 | ENR | MSCI Europe Energy Sector index (MXEU0EN) | MSCIEnrg | Bloomberg® |
| 27 | ENR | ERIX index | ERIX | Bloomberg® |
| 28 | CTRY | Euronext100 (N100) | Euronext100 | Bloomberg® |
| 29 | CTRY | IBEX35 | IBEX35 | Eikon Refinitiv® |
| 30 | CTRY | DAX | DAX | Eikon Refinitiv® |
| 31 | CTRY | CAC | CAC | Eikon Refinitiv® |
| 32 | CTRY | FTSEmib | FTSEmib | Eikon Refinitiv® |
| 33 | CTRY | Bund 10y EU (BN10) | Bund10y | Bloomberg® |
| 34 | CTRY | Bond 3m EU (BN03) | Bond3m | Bloomberg® |
| T: Target; UNC: Uncertainty variables; COM: Commodity-related variables; | ||||
| ER: Exchange rates; ENR: Energy-related indexes/variables; CTRY: Country indexes. | ||||
Previous research has demonstrated the importance of emissions trading schemes in influencing market dynamics and price formation [34]. Furthermore, uncertainty indices such as the GPR and VSTOXX have shown strong correlations with market volatility and investment decisions [5]. This dataset also includes spot rates for major currency pairs such as EUR/USD, EUR/JPY, EUR/GBP, EUR/CHF, as well as energy indices, such as the WilderHill New Energy Global Innovation Index. The dataset is sourced from Bloomberg and Eikon Refinitiv. Standardised returns are used in the following analyses since the variances of the 35 original dataset variables differ by up to 3 orders of magnitude. This standardisation ensures comparability and numerical stability. Standardisation is also needed to remove any scale dependence for the weights recovered by both linear and non-linear methodologies, that are not scale-invariant. The Imbalance Gain measure, as we will comment in Section 3.2, satisfies scale-invariance and is not affected by this choice.
2.1 Computation and analysis of financial returns
The financial returns at time , , are calculated as
| (1) |
where is the asset’s price at time .
Financial returns are commonly used as a proxy for volatility because they reflect price fluctuations, with larger returns typically corresponding to higher volatility. This relationship is central to models namely the ARCH model, where past returns help estimate current volatility [25]. The interest rate variables we consider in our dataset also present negative values. Although for time series with negative values, financial returns are often substituted with other transformations [46, 22], we prefer to use financial returns for all variables for coherence, as done elsewhere [47, 2]. Furthermore, the mentioned time series change signs very rarely, hence the choice of financial returns does not pose substantial sign problems for this study.
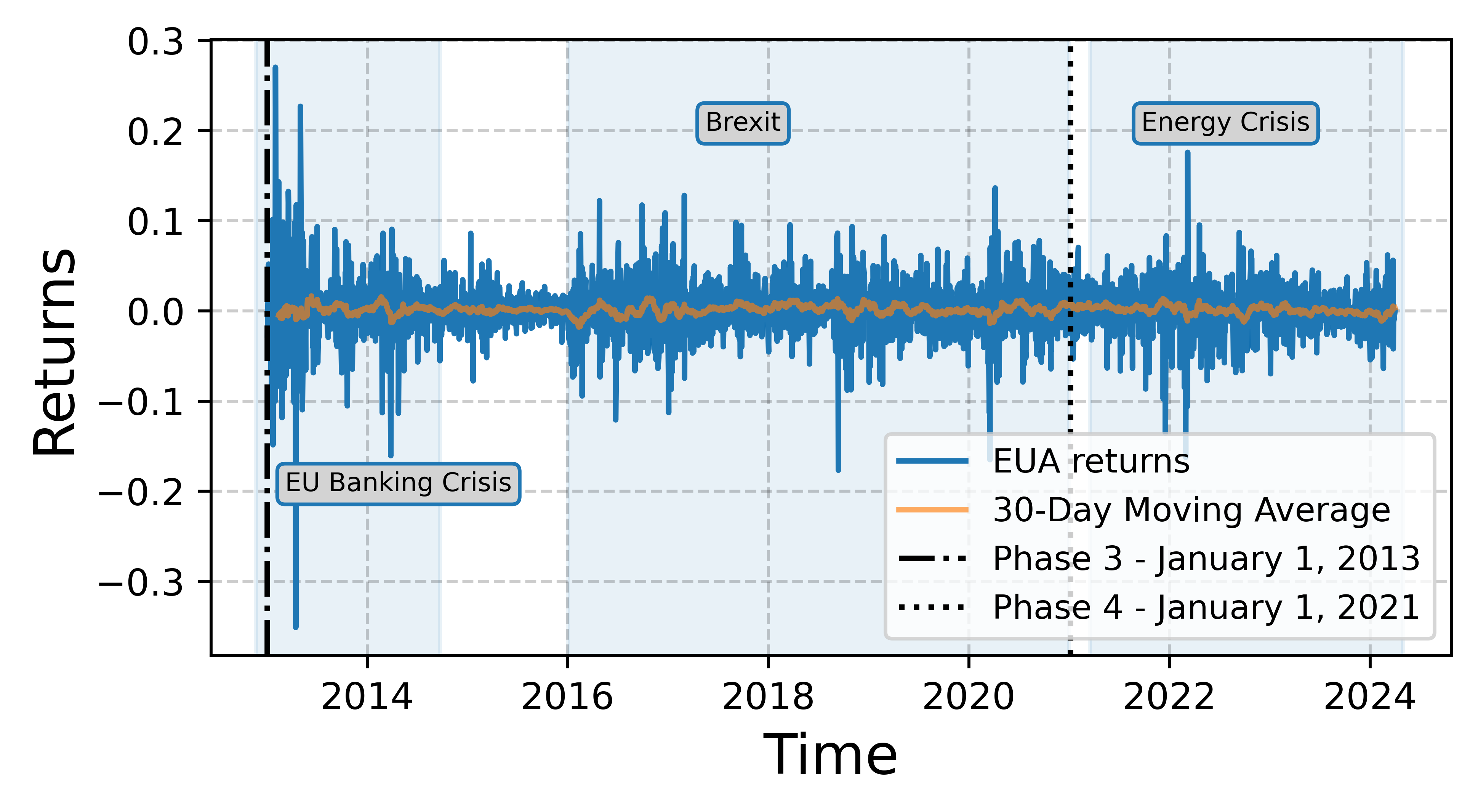
Figure 2 shows EUA futures returns along with notable economic and geopolitical events that might have affected them. For example, during the EU Banking Crisis (2009–2014), financial instability might have led to reduced liquidity and market confidence, causing firms to reevaluate their emissions and compliance costs. This period was marked by elevated volatility in carbon markets [26].
| ID | Variables | Mean | STD | Min | Max | 25% | 50% | 75% | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | EUA | 0.0013 | 0.0316 | -0.3511 | -0.0143 | 0.0010 | 0.0177 | 0.2703 | -0.2903 | 10.5662 |
| 1 | GPR | 0.0999 | 0.5408 | -0.9500 | -0.2355 | -0.0018 | 0.3031 | 9.4341 | 3.5417 | 37.5951 |
| 2 | VSTOXX | 0.0024 | 0.0725 | -0.3526 | -0.0398 | -0.0049 | 0.0332 | 0.6256 | 1.3944 | 7.1025 |
| 3 | UncEURUSD | 0.0001 | 0.0207 | -0.1033 | -0.0078 | 0.0000 | 0.0054 | 0.1850 | 0.9916 | 8.9573 |
| 4 | UncEURJPY | 0.0002 | 0.0291 | -0.3153 | -0.0076 | 0.0000 | 0.0064 | 0.4380 | 1.6756 | 44.7733 |
| 5 | UncEURGBP | 0.0003 | 0.0294 | -0.4078 | -0.0081 | 0.0000 | 0.0065 | 0.6793 | 5.7195 | 145.6690 |
| 6 | UncEURCHF | 0.0011 | 0.0638 | -0.3430 | -0.0065 | 0.0000 | 0.0057 | 3.0505 | 38.3296 | 1814.1401 |
| 7 | NatGas | 0.0009 | 0.0437 | -0.2970 | -0.0155 | -0.0004 | 0.0147 | 0.5110 | 1.4312 | 16.1099 |
| 8 | ElecES | 0.1398 | 2.1517 | -0.9918 | -0.0755 | -0.0028 | 0.0723 | 70.6610 | 26.3826 | 776.1512 |
| 9 | ElecDE | 0.0674 | 3.2588 | -72.7895 | -0.1358 | -0.0198 | 0.1348 | 150.2692 | 29.4670 | 1648.0117 |
| 10 | ElecFR | 0.0467 | 0.7004 | -0.8609 | -0.1047 | -0.0126 | 0.0970 | 32.3447 | 35.1401 | 1574.0379 |
| 11 | CoalFut | 0.0005 | 0.0259 | -0.3103 | -0.0093 | 0.0001 | 0.0097 | 0.3746 | 0.9355 | 36.1277 |
| 12 | CuFut | 0.0001 | 0.0120 | -0.0776 | -0.0065 | 0.0000 | 0.0067 | 0.0712 | -0.0431 | 2.2281 |
| 13 | Brent | 0.0334 | 0.6771 | -0.8609 | -0.0386 | -0.0022 | 0.0249 | 32.3447 | 38.8817 | 1805.5031 |
| 14 | AgFut | 0.0001 | 0.0176 | -0.1161 | -0.0080 | 0.0000 | 0.0081 | 0.0930 | -0.2531 | 5.5203 |
| 15 | Gold | 0.0001 | 0.0092 | -0.0907 | -0.0046 | 0.0003 | 0.0050 | 0.0509 | -0.4578 | 6.2462 |
| 16 | EURUSD | -0.0001 | 0.0050 | -0.0278 | -0.0030 | 0.0000 | 0.0026 | 0.0318 | 0.0964 | 2.9530 |
| 17 | EURJPY | 0.0001 | 0.0060 | -0.0510 | -0.0030 | 0.0001 | 0.0034 | 0.0445 | -0.1842 | 5.4367 |
| 18 | EURGBP | 0.0001 | 0.0057 | -0.1046 | -0.0026 | -0.0001 | 0.0025 | 0.1164 | 1.2510 | 101.7974 |
| 19 | EURCHF | -0.0001 | 0.0045 | -0.1689 | -0.0016 | -0.0001 | 0.0016 | 0.0290 | -18.0536 | 688.2632 |
| 20 | WHNewEnergy | 0.0004 | 0.0134 | -0.1023 | -0.0063 | 0.0007 | 0.0071 | 0.0948 | -0.2600 | 5.5705 |
| 21 | BbgEnergy | -0.0001 | 0.0189 | -0.1353 | -0.0095 | 0.0001 | 0.0097 | 0.1055 | -0.3188 | 4.7386 |
| 22 | SolCEA | 0.0012 | 0.0314 | -0.3508 | -0.0141 | 0.0005 | 0.0174 | 0.2690 | -0.3441 | 10.8382 |
| 23 | ESTXElect | 0.0003 | 0.0115 | -0.1594 | -0.0056 | 0.0003 | 0.0066 | 0.0593 | -1.2169 | 15.6282 |
| 24 | SEF EU50 | 0.0002 | 0.0114 | -0.1321 | -0.0049 | 0.0003 | 0.0059 | 0.0881 | -0.7391 | 11.3356 |
| 25 | LC100EU | 0.0003 | 0.0010 | -0.1100 | -0.0041 | 0.0006 | 0.0052 | 0.0768 | -0.7697 | 9.9159 |
| 26 | MSCIEnrg | 0.0002 | 0.0164 | -0.1808 | -0.0071 | 0.0004 | 0.0076 | 0.1938 | -0.1182 | 17.7366 |
| 27 | ERIX | 0.0007 | 0.0163 | -0.1217 | -0.0076 | 0.0010 | 0.0092 | 0.1055 | -0.1282 | 3.8237 |
| 28 | Euronext100 | 0.0003 | 0.0108 | -0.1197 | -0.0045 | 0.0006 | 0.0058 | 0.0818 | -0.7453 | 10.1859 |
| 29 | IBEX35 | 0.0002 | 0.0123 | -0.1406 | -0.0060 | 0.0004 | 0.0066 | 0.0857 | -0.9574 | 12.7946 |
| 30 | DAX | 0.0004 | 0.0118 | -0.1224 | -0.0047 | 0.0006 | 0.0063 | 0.1098 | -0.3781 | 9.6570 |
| 31 | CAC | 0.0003 | 0.0117 | -0.1228 | -0.0049 | 0.0006 | 0.0061 | 0.0839 | -0.6053 | 9.6292 |
| 32 | FTSEmib | 0.0003 | 0.0140 | -0.1692 | -0.0062 | 0.0007 | 0.0077 | 0.0892 | -1.1029 | 13.0261 |
| 33 | Bund10y | -0.0080 | 0.7693 | -32.6667 | -0.0348 | 0.0000 | 0.0353 | 13.0000 | -25.8877 | 1165.6719 |
| 34 | Bond3m | 0.0002 | 0.7113 | -27.0000 | -0.0125 | 0.0000 | 0.0155 | 8.2857 | -18.4459 | 742.9117 |
Table 2 provides summary statistics for the 35 time series of returns considered. These highlight key features across diverse markets. For instance, EUA futures exhibit a slightly positive mean return (0.0013) with relatively high volatility (0.0316) and negative skewness (-0.2903), indicating a tendency for extreme negative returns. Energy commodities, such as natural gas and Brent oil, show pronounced volatility, driven by geopolitical tensions and supply constraints during the ongoing energy crisis. The Spanish electricity market reveals an even higher dispersion (STD 0.3836), reflecting uncertainty in regional energy markets. Financial indices such as EUROSTOXX and DAX exhibit lower volatility.
These differences underscore the diversity in return behaviours across asset classes. High volatility in energy commodities, extreme kurtosis in currency markets, and asymmetric distributions in financial indices highlight the importance of these characteristics for risk assessment and portfolio management. These patterns emphasise the sensitivity of markets to geopolitical shocks, creating both challenges and opportunities for investors [8].
Finally, the post-Brexit increase in the volatility of currency pairs, particularly EUR / USD and EUR / GBP, underscores the economic instability resulting from new trade agreements and regulatory changes [11]. Such insights can be important for understanding market dynamics and guiding investment strategies. In our analysis, following the causal sufficiency hypothesis, we assume that all economic and geopolitical influences on EUA returns are either directly captured by the variables listed in Table 2 or indirectly mediated through one or more variables in our dataset.
3 Methods
In this section, we first review multivariate GC [7, 10], a standard linear method for detecting causal variables and the strengths of their effects, based on VAR. We then describe a recently introduced alternative method based on the concept of II, which can be seen as a non-linear generalisation of multivariate GC [1]. Finally, we illustrate the differences and similarities of the two approaches by applying them to two different synthetic datasets.
3.1 Linear causal discovery: VAR models and Granger’s F-statistic
3.1.1 VAR models
VAR models are often used in conjunction with the GC test to estimate causal weights on financial datasets. The VAR model is used to capture the interdependencies between the target and predictor variables over time. Consider a VAR() model, where represents the number of lags, and the system of equations is given by
| (2) |
where is a vector of variables at time , is the weight matrix for the -th lag, and is a white Gaussian random vector. The key idea behind such a VAR is that each variable in is modelled as a linear function of its past values and the past values of all other variables [30].
The vector of variables is typically assumed to contain both a target variable and potential predictors . Hence, without loss of generality, we can write .
The causal weight associated with the predictor at lag can be simply computed as the absolute value of the (1,)-component of matrix . We recall that in our notation the first row of matrix contains the weights which determine the impact of all predictors at lag on the target . The optimal lag for the VAR model can be selected using the Akaike Information Criterion (AIC), which minimises the trade-off between model fit and complexity. The lag with the lowest AIC value is chosen as the optimal one.
Granger’s F-statistic
For each time lag, the Granger causality test is used to assess whether the past values of a specific predictor () help predict the target variable [29]. The null hypothesis of absence of causality is tested by fitting and comparing two models: a first VAR that includes the lagged values of in the potential predictors , and a second VAR that does not include , while keeping all other predictors untouched. If the test rejects the null hypothesis, it suggests a causal relationship between the predictor and the target variable .
The statistical test relies on the construction of an F-statistic that evaluates the joint significance of the weights associated with the predictor variable, within the VAR model that includes this variable. Specifically, for each predictor variable , the F-statistic tests whether the weights associated with the lagged values of across all lags are jointly different from zero. A high F-statistic value indicates that the past values of the predictor have significant explanatory power for the target variable, suggesting the presence of a causal relationship [29].
The F-statistic is calculated as
| (3) |
In the above equation, denotes the restricted residual sum of squares, which is obtained from the model where causality restrictions are imposed (i.e., some weights are set to zero). The term represents the unrestricted residual sum of squares, calculated from the full model, where all weights are estimated without restrictions. The letter indicates the number of restrictions, which corresponds to the number of weights set to zero in the restricted model. In standard implementations, the restricted VAR is constructed by setting to zero all lagged values of a single putative causal variable, so . Finally, denotes the number of observations, and the number of parameters estimated in the unrestricted model.
Beyond determining whether to accept or reject the null hypothesis at a chosen significance level, the F-statistic in Eq. (3) can naturally be used to compare the causal impacts of different variables on the same target.
3.2 Non-linear causal discovery: Differentiable Information Imbalance and Imbalance Gain
3.2.1 Information Imbalance
The methodology employed in this work is a generalisation of the II measure, introduced in [28] and reviewed in the following. Given a dataset of points, the II allows to quantify how much a set of variables can predict a given target variable . We here assume to be multi-dimensional and to be one-dimensional as this setting is the most relevant for our application, but it is important to stress that the method can be applied regardless of the dimensionality of the two sets. The II measure is based on the idea that is predictive with respect to when data points that are close in remain close in . In practice, we use Euclidean distance functions and , such that the distances between two points and can be written as and as , where () denotes the representation of point in terms of space (). Then, for each point , we sort distances between and all the other points from the smallest to the largest. We define the distance rank () as the position of () in the list of sorted distances. For example, if is the closest point to according to the distance , and if is the fifth nearest neighbour of according to . We write the II from to as
| (4) |
where denotes the Kronecker delta function, which restricts the sum to pairs of points satisfying .
As Eq. (4) shows, is directly proportional to the average distance rank in space , conditioned over pairs of points that are nearest neighbours in . The prefactor allows an asymptotic normalisation of the II to 1, as a function of , in the case of minimum predictivity, namely when carries no information about . Indeed, in this case , as the conditional distance ranks in space will be uniformly distributed between 1 and .
In the opposite regime, namely when is maximally predictive of , , as all nearest neighbour points in will also be nearest neighbours in . In this second limit case, , which approaches 0 in the limit of large . Therefore, suggests that variables are highly informative in predicting variable , while indicates that variables provide little to no predictive information about variable .
Differentiable Information Imbalance
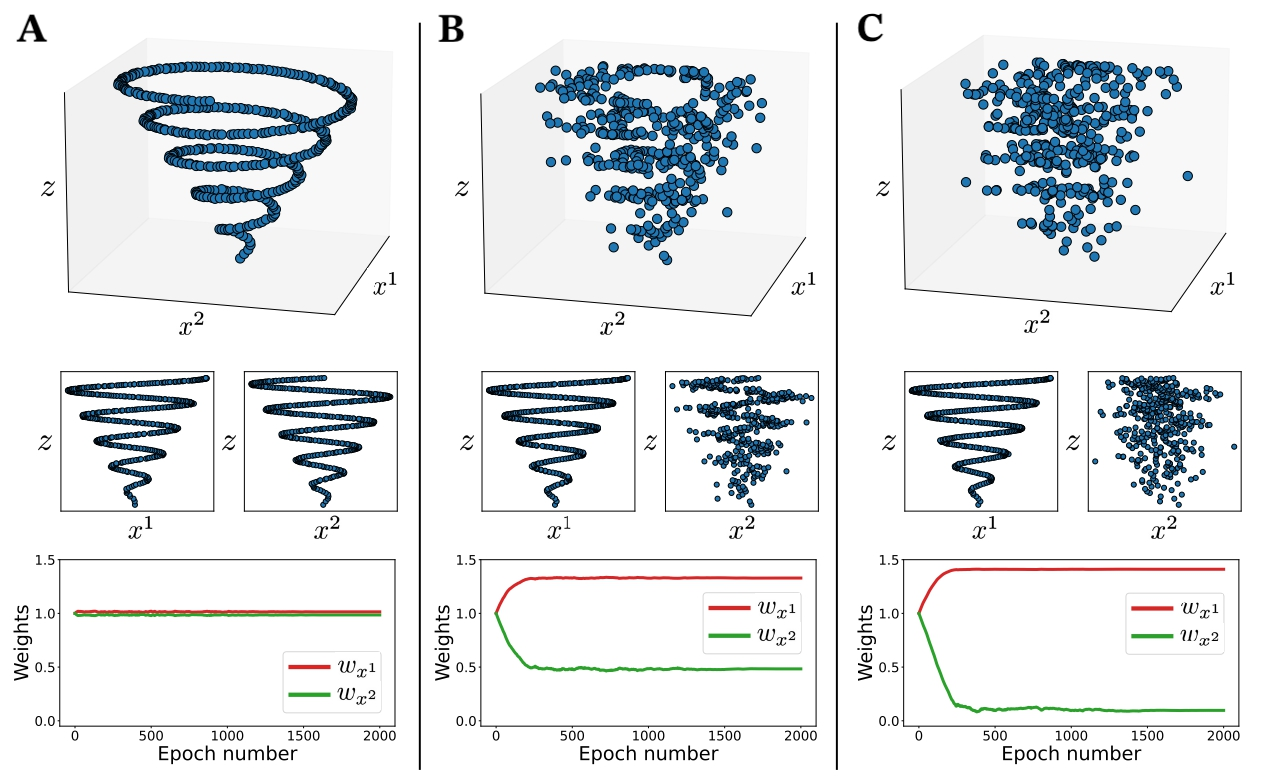
Given a target distance , the ability of a set of variables to reproduce the neighbourhood relationships defined by depends on the functional form of . Although the use of the Euclidean distance appears reasonable, as for sufficiently small distances the data manifold can be approximated as locally flat, the relative scale of the different variables entering this distance is to some extent arbitrary. This problem was accounted for in [49] by formulating a differentiable version of the II, the DII. To introduce it, we define the weighted space with denoting the element-wise product between a vector of arbitrary weights and the space of predictor variables. Each variable in is scaled by one component of the weight vector . Finally, we define the distance as the Euclidean distance in this weighted space. The DII from to reads
| (5) |
where the weights are defined as
| (6) |
Here, is a small and positive parameter that defines the size of neighbourhoods in space . Specifically, in the limit the softmax weights in Eq. (6) tend to the Kronecker delta of Eq. (5), recovering the standard II, where only the nearest neighbour is selected. The advantage of the formulation in Eq. (5) is that derivatives of the DII with respect to weights can be explicitly computed. This allows minimising DII via gradient descent, namely following an update rule of the form
| (7) |
until reaching convergence. Here, denotes a hyperparameter known as the learning rate and is the gradient of the DII with respect to the weight vector. As a result, the optimisation of the DII via gradient descent automatically identifies, among the candidate variables, the weighted combination that optimally predicts the target space . An illustrative example is depicted in Figure 3. Further details on the DII optimisation are reported in Appendix A.
Imbalance Gain
In [21] the standard II was employed to detect the presence of causal relationships between high-dimensional dynamical systems, generalising in a non-linear framework the predictability criterion of Granger causality.
Given two one-dimensional time series and , one can say that at time improves the prediction of at a future time if a distance measure built with both and is more informative of than a distance where only appears. This is satisfied when there exists a value of such that the following inequality holds [21]
| (8) |
where is a two dimensional space composed of the scaled variable and the target variable . Here, the weight allows increasing the expressivity of the space containing both and , and the minimisation over is carried out to select the most informative space with respect to . Distances are computed between independent realisations of the dynamics, which can be extracted from a single stationary time series by sampling time frames that are taken as independent initial conditions. For processes exhibiting long memory effects, considering time lags can enhance the detection of dynamical couplings, as the impact of a causal link may become more pronounced after a specific time span following the interaction [21, 1].
The inequality above can be written in terms of a relative difference called Imbalance Gain (IG):
| (9) |
which can be expressed as a percentage variation. In particular, Eq. (8) is equivalent to the condition IG. Both equations can be generalised to a multivariate setting, in the same fashion of multivariate GC [21].
However, this generalisation comes with additional optimisation parameters, making the minimisation on the right-hand side of Eq. (8) computationally demanding. In [1], this problem was solved using the automatic optimisation of the DII. Using the same notation employed in Sec. 3.1 for GC, the generalisation of Eq. (8) in a multivariate setting reads
| (10) |
where , and are vectors of and optimisation parameters, respectively, and denotes vector without variable . Equivalently, the multivariate version of the IG can be written as
| (11) |
such that a causal effect of on is detected when for some .
Importantly, while the optimal weights minimising the DII depend on the variances of the (unscaled) input variables, the minimum value of the DII, and consequently the IG measure, are independent of such original scales. Therefore, choosing whether to standardise or not the input variables results in different optimal weights, but does not affect the final estimate of the IG, if equivalent global minima are reached.
3.3 Two illustrative applications on synthetic data
We here compare the linear approach described in Sec. 3.1 with the novel non-linear methodology described in Sec. 3.2 on two synthetic datasets with a known data-generating process. Both datasets were constructed by generating time series for and , initialising the state of the system with three Gaussian random numbers of unit variance and discarding the initial 5000 steps to avoid equilibration artefacts. Then, we selected time steps after equilibration to match the number of observations used in the empirical analysis of the returns with the DII (see Appendix A). We considered VAR models of order and DII models with time-lag .
3.3.1 False negatives from linear causal discovery
The first synthetic dataset is intended to illustrate how the linear causal discovery method can miss important causal predictors that are non-linearly related to a target variable. The dataset is constructed by simulating the following stochastic process, with one target variable and two causal predictors and
| (12a) | ||||
| (12b) | ||||
| (12c) | ||||
Here, , and are independent Gaussian white noise terms, sampled from . According to Eq. (12c), variable is driven by both and , as the state of at time is determined by both variables at the previous step. Importantly, the causal relationship is linear, while the link involves a non-linear (quadratic) coupling.
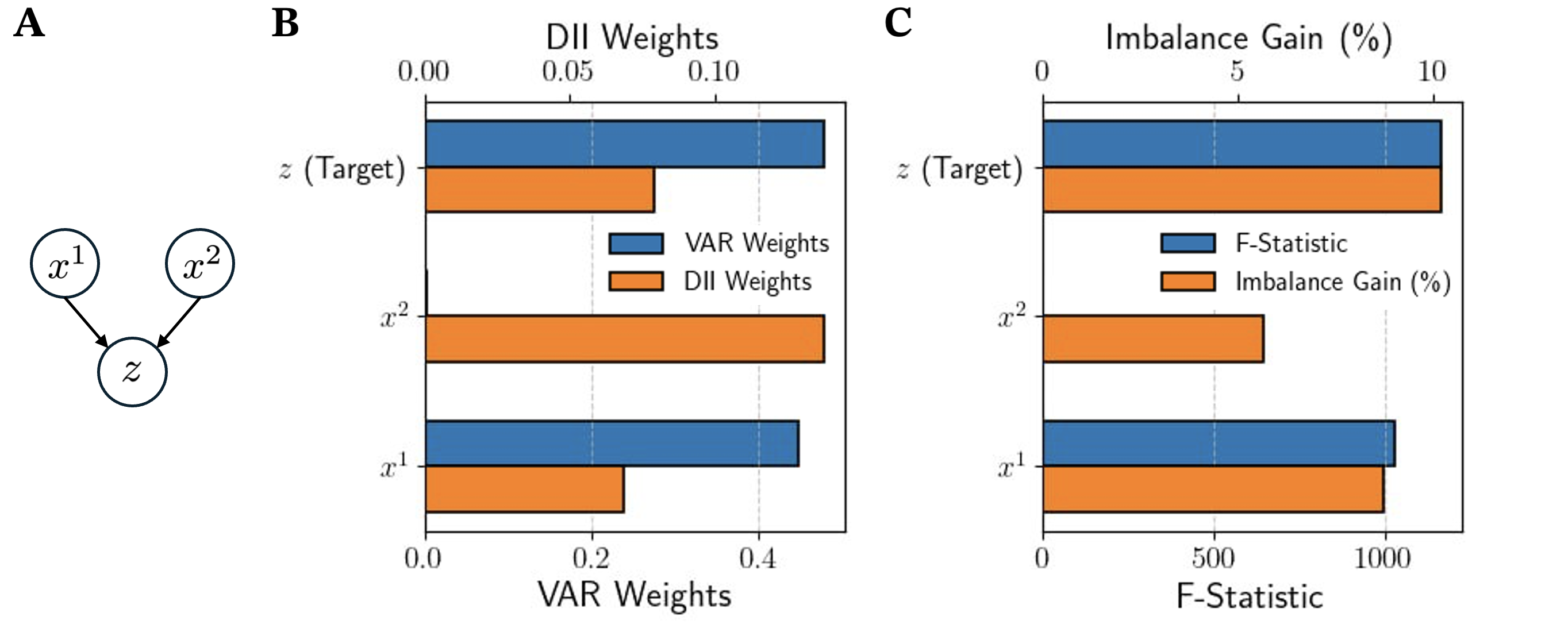
The results of the two methods on this simple stochastic process are reported in Figure 4. As expected, the linear causal relationship is detected by both methodologies, as can be seen by looking both at the variable weights (left panel) and at the F-statistic and IG measures (right panels). On the other hand, the non-linear relationship is missing according to both the VAR weights and the F-statistic, while it is correctly detected by the DII methodology. This simple example shows that standard multivariate GC is prone to false negatives in the presence of non-linear relationships.
3.3.2 False positives from linear causal discovery
The second synthetic dataset is intended to illustrate how the linearity assumption of VAR models and multivariate GC can lead to the incorrect detection of false causal relationships. The dataset is constructed by simulating the stochastic process
| (13a) | ||||
| (13b) | ||||
| (13c) | ||||
Here, , , and are independent Gaussian white noise terms with standard deviations of 0.2, 0.5 and 1.0 respectively. In the system described by Eqs. (13), is a common driver of and , and causes both variables through a non-linear quadratic relationship.
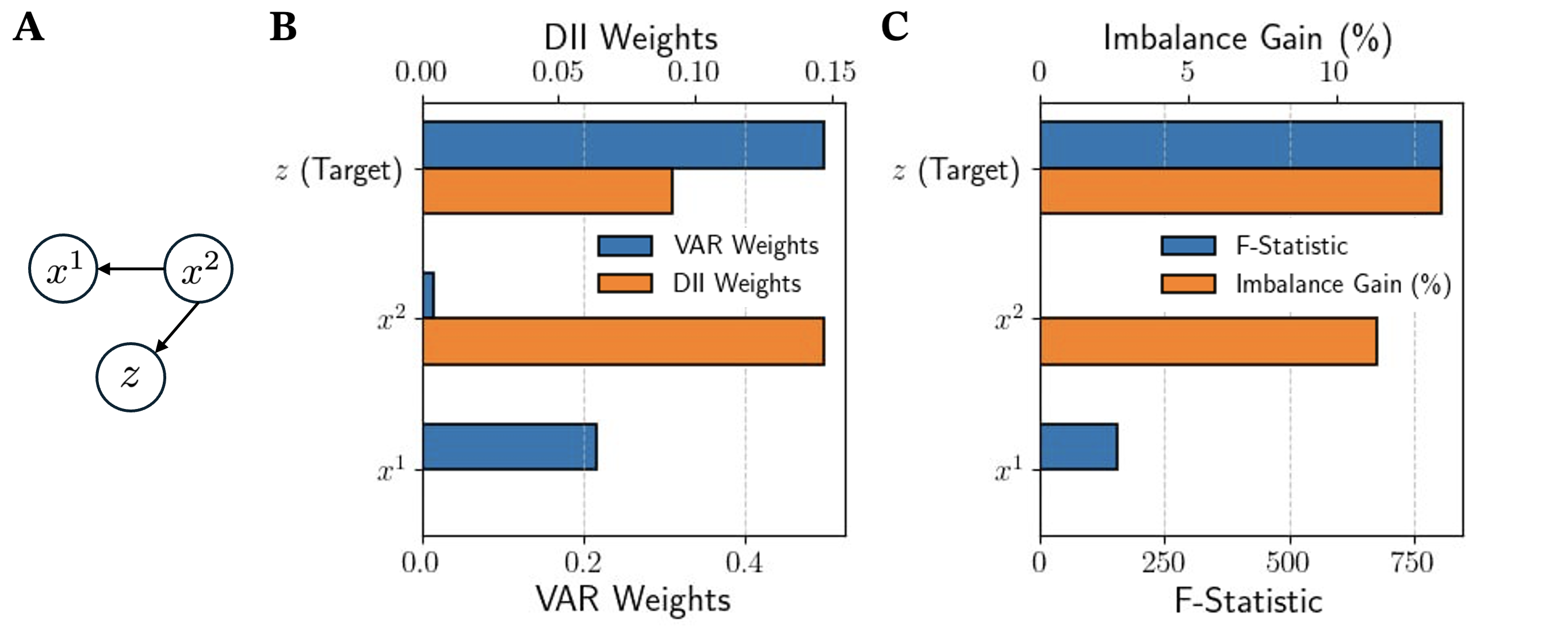
Figure 5 presents the results of applying multivariate GC (blue bars) and the DII approach (orange bars) to the system under consideration, selecting as the target variable. As in the previous example, we observe that the linear methodology is not able to detect the non-linear coupling , while both the optimal weight from the DII optimisation and the IG measure associated with are significantly non-zero. Furthermore, the linear methodology detects a spurious causal link , as one can see from the magnitudes of both the VAR weight associated to and its F-statistic from the GC test. On the other hand, both the DII weights and the IG in direction allows us to conclude that the impact of on the dynamics of is actually irrelevant. Our second example illustrates that linear methodologies can suffer from false positive detections in the presence of common drivers and non-linear relationships, while the DII approach appears robust against this drawback.
The two examples illustrated above motivate the introduction of non-linear generalisations, such as the DII, for analysing real-world time series in which the assumption of linear relationship may be, to different extents, violated.
4 Empirical analysis
In our analysis of EUA returns, we use the optimal VAR model with lag , selected based on the AIC criterion. For the DII analysis, we compare the two methods using a single-day time lag , consistent with the VAR model. These choices are supported by the ACF and PACF findings (see Tables 3, 4, and Figures 8, 9). Details regarding DII optimisation are provided in Appendix A.
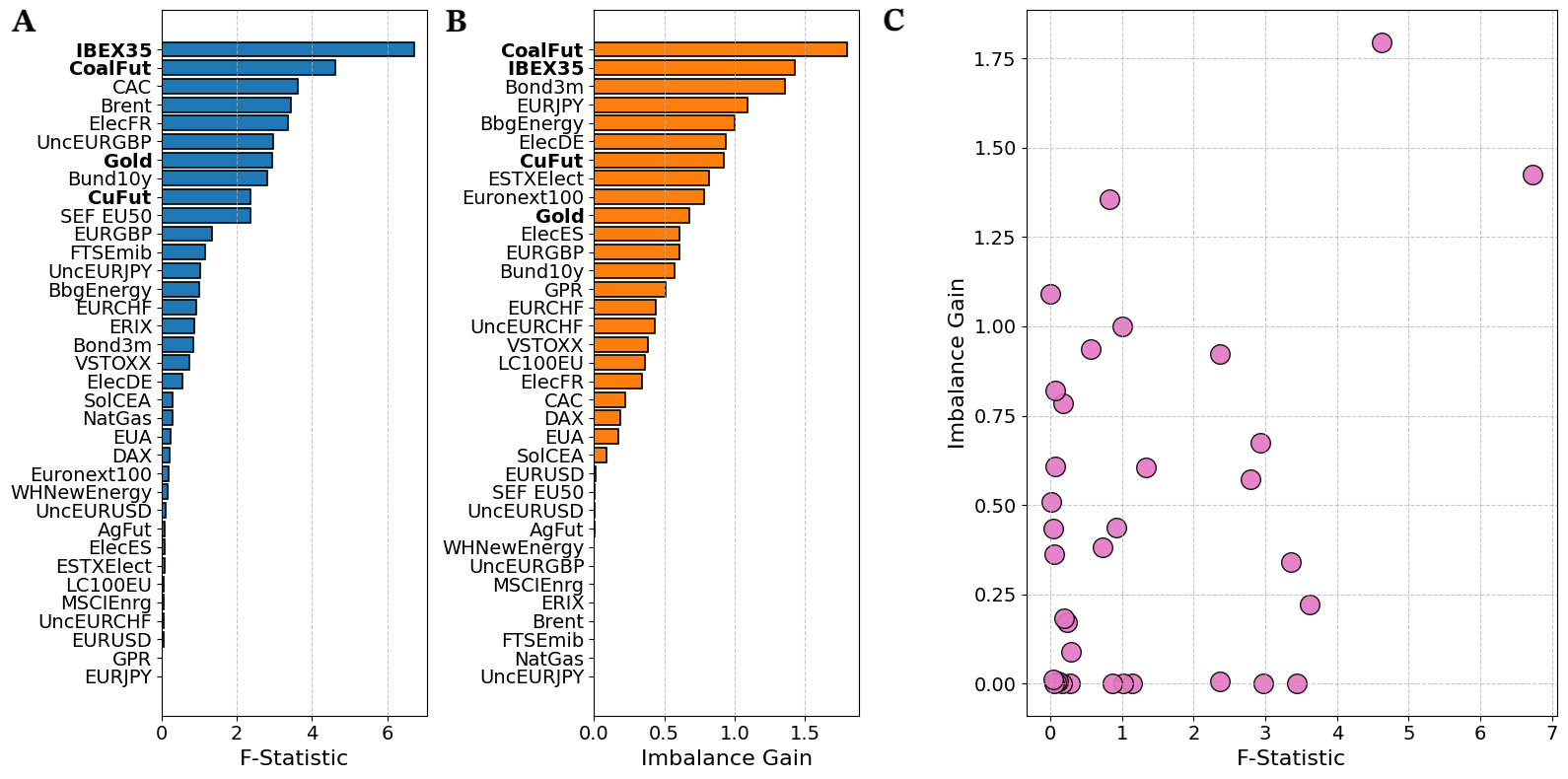
Figure 6 compares the IGs and the Granger’s F-statistics, computed for all predictors with respect to the EUA returns. In the first panel, the IG highlights IBEX35 index and ICE Coal Rotterdam futures as the variables with the most substantial causal contributions. Interestingly, the IG metric aligns with the Granger’s F-statistic in attributing similar importance to these variables. However, a deeper inspection reveals differences in the ranking of causal impacts between the two approaches. Among the next eight most important variables, only Gold and LME Copper futures appear as causally relevant for both the linear and the non-linear methods.
In particular, in the scatter plot of Figure 6 we observe that several variables that display a non-zero IG are also assigned a negligible F-statistic. Following the findings of the first example of Sec. 3.3, we argue that the causal impact of such variables may be underestimated by multivariate GC as a consequence of non-linear relationships with respect to EUA.
Indeed, we recall that a key distinction between the two metrics lies in the nature of the couplings they can detect. The F-statistic is sensitive to linear relationships between the target variable and each predictor, which are inherently constrained by the linear structure of the VAR model. In contrast, the IG metric captures non-linear and model-free contributions. On the other hand, fewer variables display null IG estimates but non-zero F-statistic.
As illustrated in the second example of Sec. 3.3, this may occur in the presence of a common driver of EUA and the candidate causal variable identified by GC, featuring similar non-linear relationships that are not directly detectable by linear approaches.
If non-linear relationships play a relevant role in the complex dynamics of financial returns, and in particular in the relationships that affect EUA’s evolution, the IG may be a valuable tool to avoid false negatives and false positives produced by standard non-linear techniques. While the IG and the F-statistic are similar in their goal of identifying causal relationships, a key difference is that the F-statistic provides a measure of statistical significance, allowing for hypothesis testing regarding the presence of causality. In contrast, IG does not directly offer such a test of significance, as it is based on an unsupervised approach. This difference stems from the fact that the IG methodology does not rely on assumptions of statistical models, making it more flexible but also less suited for significance testing compared to the F-statistic. However, IG provides additional insights by capturing non-linear relationships, which may not be detected using traditional methods like VAR and the F-statistic. To validate the robustness of our findings, we apply both IG and the F-statistic together, ensuring consistency and confirming that IG contributes valuable complementary information.
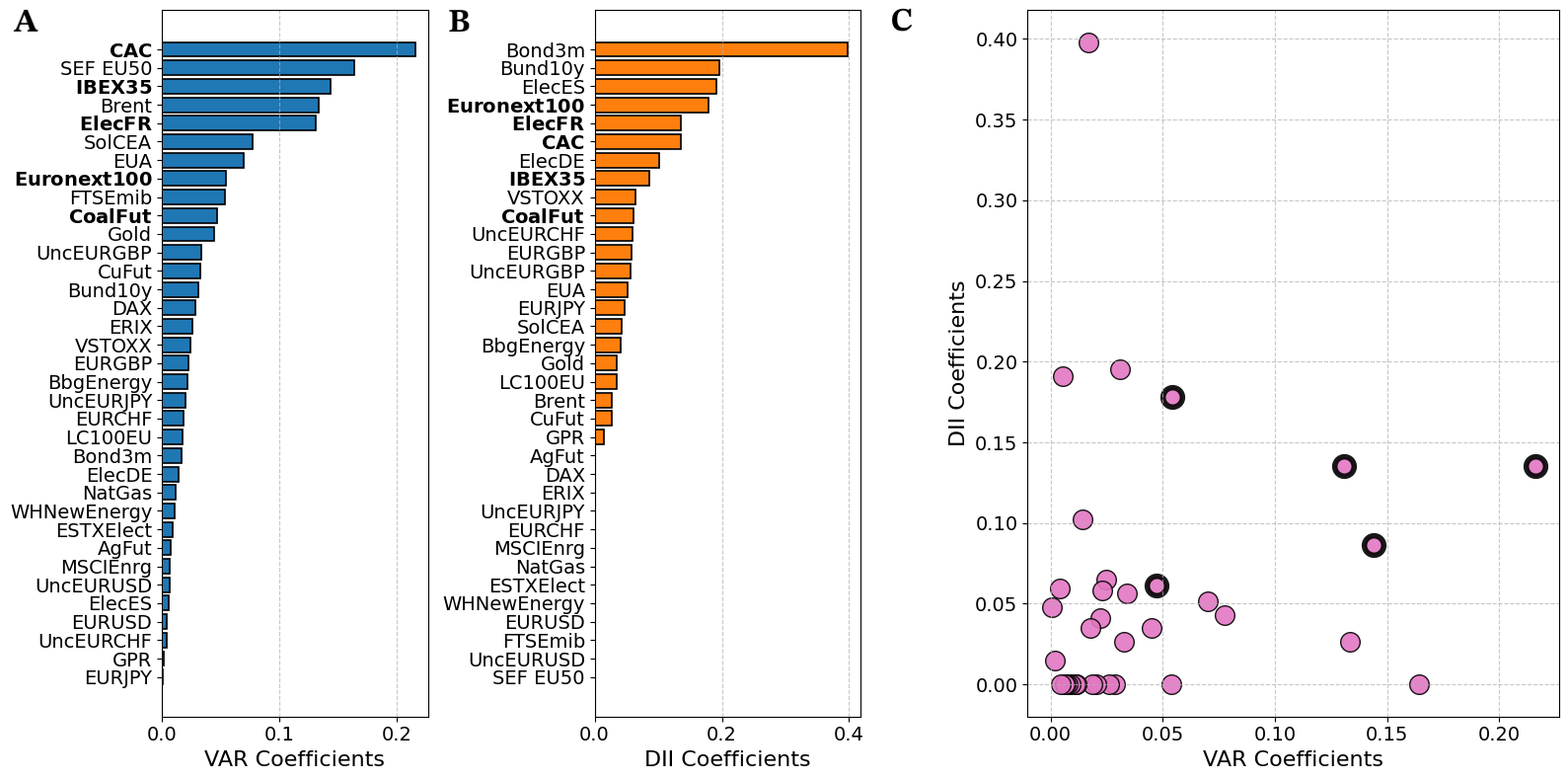
To complement the analysis, we report in Figure 7 a comparison of weight estimates derived from the VAR(1) model and the DII model. Variables highlighted in bold represent the top five weights (out of the ten largest) that are common to the two estimation approaches, showcasing a degree of consistency between the two methods also according to the weight estimates. As shown in the applications to synthetic data (Sec. 3.3), the optimal weights can provide valuable insights but their estimate in noisy time series could be slightly biased towards non-zero values even in absence of causal links, requiring the use of an appropriate threshold to avoid false positive detections [1]. In this work, we present the optimal DII weights solely for comparison with their linear counterparts.
5 Discussion on the variables identified
The EU ETS market operates within a highly interconnected network of European markets, where various economic and energy-related drivers influence the prices of the European carbon Allowances (EUA).
Our study employs the novel DII measure, along with a Granger VAR(1) model, to identify causal relationships. As demonstrated in Sec. 4, both approaches consistently highlight two key drivers: the influence of the IBEX35 Spanish stock index and European coal futures on EUA financial returns.
The evidence showed a Granger-causal link between the Spanish stock market and EUA financial returns that indicates that fluctuations in IBEX35 index can predict changes in carbon allowance prices. Following [33], this relationship was especially pronounced during Phase II of the EU ETS, which coincided with the Global Financial Crisis (2007-2008). During this period, the financial crisis led to reduced economic activity, lower industrial production, and a contraction in energy demand. As a result, firms were more likely to sell their EUAs to increase liquidity, which in turn had significant effects on carbon prices [9]. In general, the causal relationship between stock market movements and EUA price changes can be explained by broader economic shocks, where equity markets often reflect investor sentiment regarding future economic conditions, which in turn affects demand for carbon allowances [13].
Consistently with our findings, [15] identified strong volatility links between coal futures and EUA, highlighting the close interrelationship between commodities and EU ETS. These results suggest that fluctuations in coal prices, as a major energy source with significant carbon emissions, exert a direct influence on carbon allowance prices. The interconnectedness arises from the fact that coal is often a key input in industries that must comply with carbon emission regulations, suggesting that changes in coal prices can affect the cost of carbon allowances [32]. Consequently, shifts in energy prices, particularly those driven by the cost of fossil fuels such as coal, tend to ripple through carbon markets, influencing EUA pricing dynamics. This mutual influence on prices reflects the broader economic mechanisms at play, where energy market shocks often drive changes in emissions-related costs and vice versa [50].
6 Conclusions
In this work, we introduced a novel approach for identifying non-linear causal relationships within energy and commodity markets, specifically focussing on the European Union Allowances market. The method we proposed is based on the Information Imbalance, a non-parametric and model-free measure to quantify the non-linear predictive power that one space possesses on another. More specifically, we leveraged its differentiable version, the Differentiable Information Imbalance, as an alternative to traditional linear models such as VARs for detecting causal relationships. As in VAR models, the DII approach assigns a single weight to each variable in the dataset, allowing for a one-to-one comparison of the results from the two methodologies. In addition, we proposed the Imbalance Gain measure as an alternative to the Granger’s F-statistic for evaluating causal contributions. Based on the DII model, the Imbalance Gain can capture both linear and non-linear relationships in a model-free context.
Using simple stochastic processes with known underlying equations, we demonstrated that the DII approach can accurately detect the underlying couplings, even when VAR and multivariate GC fail due to the presence of non-linear relationships. The Imbalance Gain measure, in particular, proved valuable in identifying non-linear causal links that the F-statistic fails to capture, potentially offering a more precise representation of the variable impacts. Furthermore, we showed that linear methodologies may result in spurious causal detections due to the presence of common drivers and non-linear relationships, while the Imbalance Gain can reliably distinguish real from spurious links in the same scenario.
We then analysed a heterogeneous dataset of financial returns from January 2013 to April 2024. Here, our empirical analysis revealed that the DII approach and the VAR approach show some overlap in identifying key variables influencing EUA returns. Specifically, both methodologies detect significant causal effects on the EUA returns from IBEX35 and Coal Futures.
By introducing the Imbalance Gain as an analogous alternative to the F-statistic, and the DII model as an analogous alternative to the VAR model, we have extended the tools available for causal discovery, with a non-linear and model-free technique. This is beneficial for two reasons. First, the DII methodology can be used to validate results coming from standard VAR-based approaches. Indeed, the agreement of DII-based and VAR-based causality detection on a few variables, such as IBEX35 and Coal Futures in our study, can be taken as strong evidence that such variables are causally relevant. Second, as demonstrated on synthetic data, the DII methodology is more robust and effective than standard linear methods when significant non-linear relationships come into play [19, 31].
In this respect, we foresee different complementary lines of future investigation. To start with, it would be important to further investigate the empirical discrepancies found between the results of VAR and DII methodologies. While we demonstrated on two synthetic datasets that the differences might be due to the intrinsic limitations of the VAR model, these differences require further exploration to better understand how linear methods, like VAR, might miss or misrepresent certain causal relationships that could be better captured by non-parametric methods such as DII. On the other hand, systematic studies on the robustness of the DII approach against different levels of noise and sampling times may be beneficial for assessing its reliability in challenging real-world scenarios. An important limitation of the DII approach is the lack of a simple way to estimate the statistical significance or the confidence intervals for its prediction. This is not a limitation of the linear methods considered, since VAR weights and F-statistics can easily be assigned to a given statistical significance. Future research should focus in this direction to develop an efficient methodology to compute the statistical significance of the predictions coming from DII approach using, e.g., efficiently implemented resampling techniques. Another line of future research could involve leveraging the DII model to extend the Spillover methodology [23] with a non-linear analogue, and comparing the causal networks derived from the VAR Spillover, with those generated by the DII approach [1]. While the VAR Spillover model offers a solid framework for analysing linear relationships and dynamic interactions, the DII approach could provide a more flexible tool that can better adapt to non-linear dependencies. This comparison will help clarify the advantages of non-parametric causal inference methods and could provide a more robust framework for understanding causal interactions in financial and economic data.
Finally, although we applied the DII methodology to financial data related to EUA market, the technique we proposed is general and could be applied seamlessly to other financial markets. This could provide further evidence of the value of the DII methodology, proving it as a valuable new tool for robust causal discovery.
Acknowledgments
We sincerely thank Matteo Allione (Politecnico di Torino, Italy) for his valuable collaboration on the project. His support and contributions have been greatly appreciated throughout the development and application of the methodology. We thank Luigi Bellomarini, Marco Benedetti, Claudia Biancotti, Ivan Faiella and Marco Taboga (Banca d’Italia, Italy) for their useful feedback on this work.
Funding
The work by M. E. De Giuli has been supported by the Italian Minister of University and Research (MUR) project: A geo-localized data framework for managing climate risks and designing policies to support sustainable investments (No. 20229CWYXC) within the PRIN 2022 program. Her research was also supported by the Centre for the Analysis and Measurement of Global Risks (CAM-Risk) Project Financial Oversight and Risk-Tailored Understanding for New Evaluation.
The work by A. Mira has been supported by Swiss National Science Foundation Grant 200021_208249.
CRediT authorship contribution statement
Cristiano Salvagnin: Conceptualisation, Software, Validation, Formal analysis, Investigation, Data Curation, Visualisation, Writing - Original draft, Writing - Review and Editing. Vittorio Del Tatto: Methodology, Software, Formal analysis, Validation, Visualisation, Writing - Review and Editing. Maria Elena De Giuli: Writing - Review and Editing, Supervision, Funding acquisition. Antonietta Mira: Conceptualisation, Writing - Review and Editing, Supervision, Funding acquisition. Aldo Glielmo: Conceptualisation, Methodology, Software, Writing - Review and Editing, Supervision, Project Administration.
Disclaimer
The views and opinions expressed in this paper are those of the authors and do not necessarily reflect the official policy or position of Banca d’Italia.
Disclosure statement
The authors report there are no competing interests to declare.
Replicating and Supplementary Materials
All replication materials, supplementary information, and datasets are available in a dedicated GitHub repository titled EUA Causal Discovery DII, accessible at:
https://github.com/SaveChris/EUACausalDiscoveryDII
The implementation of Differentiable Information Imbalance is based on the DADApy software package [27].
References
- [1] Matteo Allione, Vittorio Del Tatto, and Alessandro Laio. Linear scaling causal discovery from high-dimensional time series by dynamical community detection. Phys. Rev. Lett., pages –, Jun 2025.
- [2] Martin M Andreasen, Tom Engsted, Stig V Møller, and Magnus Sander. The yield spread and bond return predictability in expansions and recessions. The Review of Financial Studies, 34(6):2773–2812, 09 2020.
- [3] Aydin Aslan and Peter N. Posch. Does carbon price volatility affect european stock market sectors? a connectedness network analysis. Finance Research Letters, 50, 2022.
- [4] Seung Ki Baek, Beom Jun Kim, and Hawoong Lee. Transfer entropy analysis of the stock market. arXiv preprint physics/0509014, 2005.
- [5] Scott R. Baker, Nicholas Bloom, and Steven J. Davis. Measuring Economic Policy Uncertainty*. The Quarterly Journal of Economics, 131(4):1593–1636, 07 2016.
- [6] Lionel Barnett, Adam B Barrett, and Anil K Seth. Granger causality and transfer entropy are equivalent for gaussian variables. Physical Review Letters, 103(23):238701, 2009.
- [7] Adam B. Barrett, Lionel Barnett, and Anil K. Seth. Multivariate granger causality and generalized variance. Phys. Rev. E, 81:041907, Apr 2010.
- [8] Christiane Baumeister and Lutz Kilian. Forty years of oil price fluctuations: Why the price of oil may still surprise us. Journal of Economic Perspectives, 30(1):139–60, February 2016.
- [9] Germà Bel and Stephan Joseph. Emission abatement: Untangling the impacts of the eu ets and the economic crisis. Energy Economics, 49:531–539, 2015.
- [10] Katarzyna J. Blinowska, Rafał Kuś, and Maciej Kamiński. Granger causality and information flow in multivariate processes. Phys. Rev. E, 70:050902, Nov 2004.
- [11] Simone Borghesi and Andrea Flori. With or without u(k): A pre-brexit network analysis of the eu ets. PLOS ONE, 14(9), 09 2019.
- [12] Don Bredin and Cal Muckley. An emerging equilibrium in the eu emissions trading scheme. Energy Economics, 33(2):353 – 362, 2011.
- [13] Raphael Calel and Antoine Dechezleprêtre. Environmental policy and directed technological change: Evidence from the european carbon market. Review of Economics and Statistics, 94(4):918–938, 2012.
- [14] Alice Caserini and Paolo Pagnottoni. Effective transfer entropy in credit markets. Statistical Methods & Applications, 31:1103–1131, 2022.
- [15] Chia-Lin Chang, Michael McAleer, and Guangdong Zuo. Volatility spillovers and causality of carbon emissions, oil and coal spot and futures for the eu and usa. Sustainability, 9(10), 2017.
- [16] Julien Chevallier. Detecting instability in the volatility of carbon prices. Energy Economics, 33(1):99 – 110, 2011.
- [17] Julien Chevallier and Benoît Sévi. On the realized volatility of the ecx co2 emissions 2008 futures contract: Distribution, dynamics and forecasting. Annals of Finance, 7(1):1 – 29, 2011.
- [18] Christian Conrad, Daniel Rittler, and Waldemar Rotfuß. Modeling and explaining the dynamics of european union allowance prices at high-frequency. Energy Economics, 34(1):316 – 326, 2012.
- [19] Rama Cont. Empirical properties of asset returns: stylized facts and statistical issues. Quantitative Finance, 1(2):223, mar 2001.
- [20] Vittorio Del Tatto, Debarshi Banerjee, Ali Hassanali, and Alessandro Laio. Towards a robust approach to infer causality in molecular systems satisfying detailed balance, 2025.
- [21] Vittorio Del Tatto, Gianfranco Fortunato, Domenica Bueti, and Alessandro Laio. Robust inference of causality in high-dimensional dynamical processes from the information imbalance of distance ranks. Proceedings of the National Academy of Sciences, 121(19):e2317256121, 2024.
- [22] Francis X. Diebold and Canlin Li. Forecasting the term structure of government bond yields. Journal of Econometrics, 130(2):337–364, 2006.
- [23] Francis X. Diebold and Kamil Yilmaz. Better to give than to receive: Predictive directional measurement of volatility spillovers. International Journal of Forecasting, 28(1):57–66, 2012.
- [24] Cees Diks and Valentyn Panchenko. A new statistic and practical guidelines for nonparametric granger causality testing. Journal of Economic Dynamics and Control, 30(9-10):1647–1669, 2006.
- [25] Robert F. Engle. Autoregressive conditional heteroskedasticity with estimates of the variance of united kingdom inflation. Econometrica, 50(4):987–1007, 1982.
- [26] European Central Bank. Impact of economic crises on emissions and eu allowances, 2022. Accessed: 2024-11-28.
- [27] Aldo Glielmo, Iuri Macocco, Diego Doimo, Matteo Carli, Claudio Zeni, Romina Wild, Maria d’Errico, Alex Rodriguez, and Alessandro Laio. Dadapy: Distance-based analysis of data-manifolds in python. Patterns, 3(10), 2022.
- [28] Aldo Glielmo, Claudio Zeni, Bingqing Cheng, Gábor Csányi, and Alessandro Laio. Ranking the information content of distance measures. PNAS nexus, 1(2):pgac039, 2022.
- [29] C. W. J. Granger. Investigating causal relations by econometric models and cross-spectral methods. Econometrica, 37(3):424–438, 1969.
- [30] James Douglas Hamilton. Time Series Analysis. Princeton University Press, 1994.
- [31] David A. Hsieh. Chaos and nonlinear dynamics: Application to financial markets. The Journal of Finance, 46(5):1839–1877, 1991.
- [32] Qiang Ji, Dayong Zhang, and Jiang-bo Geng. Information linkage, dynamic spillovers in prices and volatility between the carbon and energy markets. Journal of Cleaner Production, 198:972 – 978, 2018.
- [33] Rebeca Jiménez-Rodríguez. What happens to the relationship between eu allowances prices and stock market indices in europe? Energy Economics, 81:13–24, 2019.
- [34] Andreas Karpf, Antoine Mandel, and Stefano Battiston. Price and network dynamics in the european carbon market. Journal of Economic Behavior & Organization, 153:103–122, 2018.
- [35] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017.
- [36] Lin Li and Didier Sornette. Speculative influence network during financial bubbles: application to chinese stock markets. Journal of Economic Interaction and Coordination, 13(2):385–431, 2018.
- [37] Haochun Ma, Davide Prosperino, Alexander Haluszczynski, and Christoph Räth. Linear and nonlinear causality in financial markets. Chaos, 34(11):113125, 2024.
- [38] Junlong Mi, Xing Yang, Feifei Huang, and Yufa Xu. Geopolitical, economic risk and the time-varying structure of extreme risk in the carbon emissions trading market. Frontiers in Environmental Science, 12, 2024.
- [39] European Parliament and the Council of the European Union. Directive 2003/87/ec of the european parliament and of the council establishing a scheme for greenhouse gas emission allowance trading within the community and amending council directive 96/61/ec, 2003. Accessed: 2024-11-17.
- [40] Lixin Qiu, Lijun Chu, Ran Zhou, Haitao Xu, and Sai Yuan. How do carbon, stock, and renewable energy markets interact: Evidence from europe. Journal of Cleaner Production, 407:137106, 2023.
- [41] J. Runge. Causal network reconstruction from time series: From theoretical assumptions to practical estimation. Chaos: An Interdisciplinary Journal of Nonlinear Science, 28(7):075310, 07 2018.
- [42] Cristiano Salvagnin, Aldo Glielmo, Maria Elena De Giuli, and Antonietta Mira. Investigating the price determinants of the european emission trading system: a non-parametric approach. Quantitative Finance, 24(10):1529–1544, 2024.
- [43] Thomas Schreiber. Measuring information transfer. Phys. Rev. Lett., 85:461–464, Jul 2000.
- [44] Christopher A Sims. Macroeconomics and reality. Econometrica: journal of the Econometric Society, pages 1–48, 1980.
- [45] George Sugihara, Robert May, Hao Ye, Chih-hao Hsieh, Ethan Deyle, Michael Fogarty, and Stephan Munch. Detecting causality in complex ecosystems. Science, 338(6106):496–500, 2012.
- [46] Francis E.H. Tay and L.J. Cao. Modified support vector machines in financial time series forecasting. Neurocomputing, 48(1):847–861, 2002.
- [47] Luis M. Viceira. Bond risk, bond return volatility, and the term structure of interest rates. International Journal of Forecasting, 28(1):97–117, 2012. Special Section 1: The Predictability of Financial Markets Special Section 2: Credit Risk Modelling and Forecasting.
- [48] Elena Villar-Rubio, María-Dolores Huete-Morales, and Federico Galán-Valdivieso. Using egarch models to predict volatility in unconsolidated financial markets: the case of european carbon allowances. Journal of Environmental Studies and Sciences, 13(3):500 – 509, 2023.
- [49] Romina Wild, Felix Wodaczek, Vittorio Del Tatto, Bingqing Cheng, and Alessandro Laio. Automatic feature selection and weighting in molecular systems using differentiable information imbalance. Nature Communications, 16, 01 2025.
- [50] Yue-Jun Zhang and Ya-Fang Sun. The dynamic volatility spillover between european carbon trading market and fossil energy market. Journal of Cleaner Production, 112:2654–2663, 2016.
Appendix A Details on the DII optimisation
We report in this section technical details about the DII optimisation. A relevant hyperparameter of the method is appearing in the softmax coefficients of Eq. (6), which defines the size of the neighbourhoods in the first distance space. Although the classical II is recovered in the limit , too small values of make the DII optimization inefficient, as decreasing also decreases the magnitude of the DII derivatives employed in the gradient descent updates [49]. In this work, we compute with a point-adaptive scheme. Namely, we use a distinct value for each set of coefficients . This approach allows handling data sets where points are not homogenously distributed, and where a single distance scale would result in different numbers of neighbours for points in different regions of the data manifold. Specifically, we computed each as
| (14) |
where 0.1 is an empirical prefactor and is the -th nearest neighbour of according to distance . In all the optimisations carried out in this work, was fixed to 5% of the points entering the calculation of the DII (i.e., ). To keep into account the variation of during the DII optimisation, the set of is recomputed at each gradient descent update.
Other relevant aspects that may affect the convergence of the DII to its global minimum are the choice of the optimiser and the use of mini-batches. The use of mini-batches, namely the computation of the gradient on random subsets of points at each gradient descent update, is a well-known strategy that can improve convergence speed and stability of training in optimisation algorithms, especially when the loss function features several local minima. In this work, all the optimisations were carried out by selecting distinct frames from the original time series, and randomly splitting the data set into 28 mini-batches with points in each training epoch. Using this approach, the value of defining the set of was fixed to 5 in each mini-batch. Beyond improving the convergence properties, in our application the use of small mini-batches allows to sample time frames which are likely to be uncorrelated, satisfying one of the requirements of our approach (see Sec. 3.2.1). In contrast, computing the DII without mini-batches would require an undersampling of the original time series to fulfil this requirement, reducing the statistical significance of the results when dealing with short time series. Rather than using the vanilla gradient descent approach provided in Eq. (7), in this work we used the Adam optimiser [35], which is widely employed by the machine learning community and well-known for its good convergence properties.
All optimisations were carried out for 2000 training epochs, setting the initial learning rate to , and progressively decreasing it to zero according to a cosine decay schedule. After learning the optimal weights, the DII terms appearing in the IG expression of Eq. (11) were computed over all the time frames originally extracted. In the analysis of the financial returns, in order to satisfy the requirement of independent initial conditions in the DII calculation, the final DII estimates were carried out by discarding, for each frame , distances with points within a time window . Similarly, in both systems of Sec. 3.3 the final IGs were computed by discarding distances between each frame and points within .
Appendix B Stationarity and Optimal VAR Lag Order
| Asset | ADF Statistic | p-value | Stationary | 1% | 5% | 10% |
|---|---|---|---|---|---|---|
| EUA | -15.038364 | True | -3.432621 | -2.862543 | -2.567304 | |
| GPR | -39.378217 | True | -3.432621 | -2.862543 | -2.567304 | |
| VSTOXX | -12.997073 | True | -3.432621 | -2.862543 | -2.567304 | |
| UncEURUSD | -9.957579 | True | -3.432621 | -2.862543 | -2.567304 | |
| UncEURJPY | -25.692109 | True | -3.432621 | -2.862543 | -2.567304 | |
| UncEURGBP | -28.913692 | True | -3.432621 | -2.862543 | -2.567304 | |
| UncEURCHF | -45.237371 | True | -3.432621 | -2.862543 | -2.567304 | |
| NatGas | -9.492228 | True | -3.432621 | -2.862543 | -2.567304 | |
| ElecES | -20.773602 | True | -3.432621 | -2.862543 | -2.567304 | |
| ElecDE | -54.043368 | True | -3.432621 | -2.862543 | -2.567304 | |
| ElecFR | -16.706846 | True | -3.432621 | -2.862543 | -2.567304 | |
| CoalFut | -9.772322 | True | -3.432621 | -2.862543 | -2.567304 | |
| CuFut | -19.373083 | True | -3.432621 | -2.862543 | -2.567304 | |
| Brent | -16.711492 | True | -3.432621 | -2.862543 | -2.567304 | |
| AgFut | -10.018897 | True | -3.432621 | -2.862543 | -2.567304 | |
| Gold | -30.521431 | True | -3.432621 | -2.862543 | -2.567304 | |
| EURUSD | -18.132932 | True | -3.432621 | -2.862543 | -2.567304 | |
| EURJPY | -56.465380 | True | -3.432621 | -2.862543 | -2.567304 | |
| EURGBP | -29.500339 | True | -3.432621 | -2.862543 | -2.567304 | |
| EURCHF | -17.840216 | True | -3.432621 | -2.862543 | -2.567304 | |
| WHNewEnergy | -12.735846 | True | -3.432621 | -2.862543 | -2.567304 | |
| BbgEnergy | -55.477960 | True | -3.432621 | -2.862543 | -2.567304 | |
| SolCEA | -15.054414 | True | -3.432621 | -2.862543 | -2.567304 | |
| ESTXElect | -16.622364 | True | -3.432621 | -2.862543 | -2.567304 | |
| SEF EU50 | -13.901380 | True | -3.432621 | -2.862543 | -2.567304 | |
| LC100EU | -11.741741 | True | -3.432621 | -2.862543 | -2.567304 | |
| MSCIEnrg | -15.784380 | True | -3.432621 | -2.862543 | -2.567304 | |
| ERIX | -17.304976 | True | -3.432621 | -2.862543 | -2.567304 | |
| Euronext100 | -11.347695 | True | -3.432621 | -2.862543 | -2.567304 | |
| IBEX35 | -36.352004 | True | -3.432621 | -2.862543 | -2.567304 | |
| DAX | -17.000522 | True | -3.432621 | -2.862543 | -2.567304 | |
| CAC | -11.317838 | True | -3.432621 | -2.862543 | -2.567304 | |
| FTSEmib | -37.865048 | True | -3.432621 | -2.862543 | -2.567304 | |
| Bund10y | -13.497101 | True | -3.432621 | -2.862543 | -2.567304 | |
| Bond3m | -12.556939 | True | -3.432621 | -2.862543 | -2.567304 |
| Lag | AIC | BIC | FPE | HQIC |
|---|---|---|---|---|
| 1 | -30.11* | -27.51* | 8.377e-14* | -29.17* |
| 2 | -29.97 | -24.84 | 9.680e-14 | -28.12 |
| 3 | -29.71 | -22.05 | 1.250e-13 | -26.95 |
| 4 | -29.56 | -19.37 | 1.462e-13 | -25.89 |
| 5 | -29.55 | -16.83 | 1.482e-13 | -24.96 |
| 6 | -29.21 | -13.96 | 2.091e-13 | -23.71 |
| 7 | -28.89 | -11.12 | 2.870e-13 | -22.49 |
| 8 | -28.58 | -8.277 | 3.960e-13 | -21.26 |
| 9 | -28.38 | -5.550 | 4.875e-13 | -20.15 |
| 10 | -28.35 | -2.989 | 5.091e-13 | -19.21 |