Non-target Divergence Hypothesis: Toward Understanding Domain Gaps in Cross-Modal Knowledge Distillation
Abstract
Compared to single-modal knowledge distillation, cross-modal knowledge distillation faces more severe challenges due to domain gaps between modalities. Although various methods have proposed various solutions to overcome these challenges, there is still limited research on how domain gaps affect cross-modal knowledge distillation. This paper provides an in-depth analysis and evaluation of this issue. We first introduce the Non-Target Divergence Hypothesis (NTDH) to reveal the impact of domain gaps on cross-modal knowledge distillation. Our key finding is that domain gaps between modalities lead to distribution differences in non-target classes, and the smaller these differences, the better the performance of cross-modal knowledge distillation. Subsequently, based on Vapnik-Chervonenkis (VC) theory, we derive the upper and lower bounds of the approximation error for cross-modal knowledge distillation, thereby theoretically validating the NTDH. Finally, experiments on five cross-modal datasets further confirm the validity, generalisability, and applicability of the NTDH.
Index Terms:
Cross-Modal Knowledge Distillation, Domain Gaps, Multimodal Fusion.I Introduction
In recent years, cross-modal knowledge distillation (KD) has expanded the traditional KD approach to encompass multimodal learning, achieving notable success in various applications [1, 2, 3, 4]. However, when there are considerable domain gaps in cross-modal KD, even a more accurate teacher model may not effectively instruct the student model. To overcome these challenges, many researchers have sought to enhance the effectiveness of cross-modal KD by designing efficient fusion strategies [5, 6, 7, 8] or developing novel loss functions [9, 10, 11, 12, 13, 14]. However, most of these methods focus on complex technical designs with less emphasis on exploring their theoretical foundations, which is the focus of this paper.
Xue et al. [15] are the first to theoretically focus on KD under modality differences, proposing the Modality Focus Hypothesis (MFH). This hypothesis posits that the performance of cross-modal KD hinges on the modality-general decisive features preserved in the teacher network. These features indicate the degree of alignment between different modalities, with greater alignment leading to improved KD outcomes. Fig. 1(a) shows an example of a multimodal dataset with both audio and images, where the image data includes not only the scene of guitar music but also background information, leading to incomplete modality alignment; according to the MFH, improved feature alignment is expected to enhance cross-modal KD effectiveness. However, the above hypothesis has two shortcomings: (1) It cannot explain why cross-modal KD might still fail even when there is modality alignment, as shown in situations like those in Fig. 1(b)-(d). (2) It lacks a mathematical definition of modality-general key features, making it difficult to identify these features in practical applications.

To address these deficiencies, we first pre-register or align the modalities involved in our study to eliminate the effects caused by unregistered modalities, thereby focusing our research on domain gaps. We adopt this approach because we believe that misalignment is merely an external manifestation, while the actual domain gaps between modalities are the core distinction between cross-modal and single-modal KD.
Secondly, we clearly define the key factors affecting cross-modal KD. Specifically, inspired by [16], we divide classification predictions into two levels: (1) Target class prediction distribution: a binary prediction distribution for the target category and all non-target categories; (2) Non-target class prediction distribution: a multi-category prediction distribution for each non-target category. We find that for cross-modal KD, the distribution divergence in non-target categories is the decisive factor. The smaller the divergences, the better the effect of cross-modal KD, which we refer to as the Non-target Divergence Hypothesis. Since the distance of non-target distributions can be easily measured using existing distance functions, they can be explicitly defined and calculated. For example, in multimodal point cloud semantic segmentation, both point clouds and images classify road areas. These predictions can be divided into road class prediction distribution and non-road class prediction distribution. If the distribution difference of the non-road class predictions is large, the effectiveness of cross-modal KD is significantly affected and may even fail, as shown in Fig. 2. The purpose of this work is to prove the validity of the hypothesis from a theoretical analysis perspective. Our major contributions are the following:
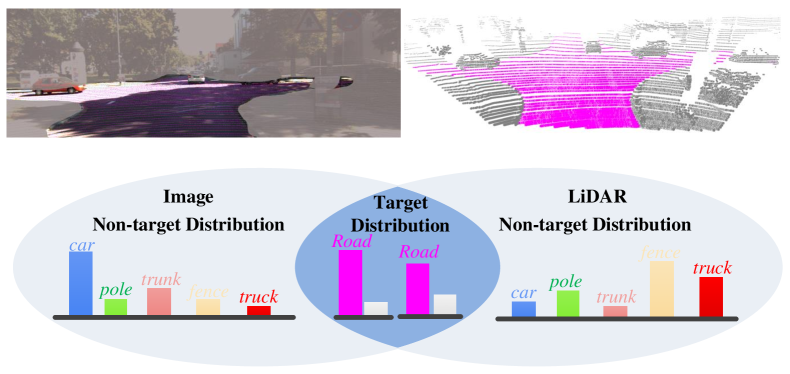
-
1)
We propose the Non-target Divergence Hypothesis (NTDH), which posits that the divergence of non-target distributions between modalities is a key factor determining the effectiveness of cross-modal KD.
-
2)
We theoretically prove the upper and lower bounds of the cross-modal KD approximation error, thereby validating the rationality of NTDH.
-
3)
We design a weight regulation method and a masking method to experimentally verify the hypothesis. Experimental results on five multimodal datasets support the proposed NTDH.
II Related Work
II-A Unimodal KD
KD is a general technique for transferring knowledge from a teacher network to a student network, widely applied in various vision tasks [1, 2, 3, 4]. Although progress has been made in improving distillation techniques and exploring new application areas, research on the mechanisms underlying KD remains limited [17, 18, 19, 20]. For example, Cho et al. [18] and Mirzadeh et al. [21] investigate KD in the context of model compression, focusing on the performance of student and teacher networks when their model sizes differ. They point out that a mismatch in capacity between the student and teacher networks can lead to KD failure. Ren et al. [20] analyze KD in vision transformers and find that the inductive bias of the teacher model is more important than its accuracy in improving the performance of the student model. However, the aforementioned methods mainly focus on the factors affecting unimodal KD, while research on cross-modal KD remains limited.
II-B Crossmodal KD
With the widespread use of the internet and the increasing application of multimodal sensors, there is a surge of interest in multimodal learning [22]. In line with this trend, KD extends to cross-modal KD, which commonly applies in three scenarios. First, Knowledge Expansion: Cross-modal KD compensates for insufficient data in a single modality. For instance, Ahmad et al. [23] use multimodal MRI data to overcome clinical data scarcity, while Li et al. [24] transfer RGB-trained models to infrared data, addressing its data limitations. Similar approaches include using Galvanic Skin Response signals to offset Electroencephalogram data collection challenges [25], supplementing Synthetic Aperture Radar images with RGB data [26], and transferring English-trained models to other languages [27]. Second, Multimodal Knowledge Fusion: Cross-modal KD fuses complementary information from different modalities into a unimodal network, requiring multimodal data only during training and simplifying deployment [28], such as using Lidar for RGB images [29], RGB for point clouds [30], facial images for voice data [31], and RGB to enhance thermal imaging [32]. Large language models also aid in cross-modal retrieval [33]. Third, Additional Constraints: In some cases, significant differences in network structures for different modalities make feature layer fusion highly challenging. The loss function of cross-modal knowledge distillation then acts as a regularization term, enforcing consistency constraints on outputs to enhance the performance of individual modalities. For instance, Sarkar et al. [34] use KL divergences to align audio and video outputs, while another method, MCKD [35], applies multimodal contrastive KD for video-text retrieval. Although these methods show potential in cross-modal KD, most widely used approaches still rely on single-modal techniques, raising questions about their effectiveness and limitations. This paper, therefore, analyzes key factors influencing cross-modal KD to enhance its application.
II-C Domain Gaps in Cross-modal KD
In cross-modal KD, domain gaps critically impact performance. To reduce these gaps, modality alignment methods are often employed to unify different modalities from various domains into a common [36, 37, 31, 34, 38, 16] or intermediate modality [39]. However, this approach may result in the loss of modality-specific characteristics. To address this, some methods incorporate decoupling strategies to preserve these characteristics, such as using independent detection heads [40] for KD or employing feature partitioning to effectively transfer knowledge from the teacher modality while preserving unique features of the student modality [41]. Additionally, other approaches focus on minimizing domain gaps by filtering out features with significant discrepancies. For example, Zhuang et al. [42] and Wang et al. [43] focus on evaluating and filtering significant domain discrepancies, while Huo et al. [44] selectively filter out misaligned samples to avoid modality imbalance. Although these methods have made some progress, they primarily address multimodal feature fusion and are not directly applicable to dual-branch networks in cross-modal KD. To address this issue, this paper proposes a mask-based approach to mitigate the impact of domain shifts on cross-modal KD.
III The Proposed Hypothesis
In this section, we first define the symbols and present the necessary assumptions for subsequent proofs. Next, we introduce the Non-target Divergence Hypothesis and provide a detailed explanation of this hypothesis based on experimental results on Scikit-learn dataset [45]. Finally, we prove the hypothesis using Vapnik-Chervonenkis (VC) theory [46].
III-A Symbol Definitions And Conditional Assumptions
We provide a comprehensive overview of the fundamentals of KD and introduce the symbols used in this study. Although our focus is primarily on C-class classification problems, the concepts discussed are also applicable to regression tasks. To maintain the generality of the framework, we consider a two-modal setting, where the data is represented as and , corresponding to the data from modalities ‘A’ and ‘B’, respectively, as shown in Eq. (1).
| (1) |
where and respectively represent the feature-label pair of modality ‘A’ and modality ‘B’, and represents the set of c-dimensional probability vectors.
Suppose that our goal is to train a student network that takes as input. In the case of cross-modal KD, the teacher network takes the training data as input and minimizes the training objective as follows:
| (2) |
where is a class of functions from to , the function : is the softmax operation
| (3) |
For all , the function is Kullback-Leibler(KL) Divergence [47], and is an increasing function which serves as a regularizer.
After training the teacher model using the data from modality ‘A’, our goal is to transfer the knowledge acquired by the teacher network to the student network operating in modality ‘B’. Therefore, in addition to minimizing the KL loss between the student output and one-hot label, it is also required to minimize the KL loss between the teacher and student outputs. The objective of optimizing the student network is as follows:
| (4) | ||||
where represents the soft predictions obtained from about the training on modality ‘A’. The temperature parameter () controls the level of softening or smoothing of the class-probability predictions from and the imitation parameter determines the balance between imitating the soft predictions and predicting the true hard labels .
Given that the primary focus of this paper is the impact of domain gaps in cross-modal KD, we have listed the following assumptions conditions to control variables and exclude the interference of model capacity and modality strength. These assumptions form the foundational conditions for the discussion in this paper and the basis for the theoretical reasoning in Sec. III-C.
-
•
Assumption 1: and have the same model capacity, meaning they have the same ability to fit or learn complexity or accommodate information.
-
•
Assumption 2: and have the same modality strength, meaning that when the same model is trained using and as data separately, the difference in model prediction accuracy is not significant.
III-B Non-target Divergence Hypothesis
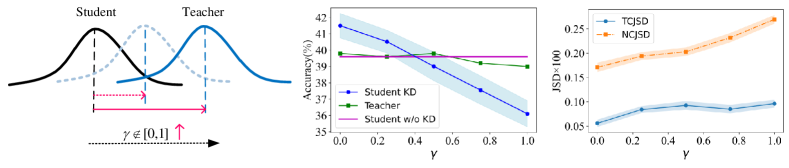
Under the assumption in Sec. III-A and based on VC theory [46], the upper and lower bounds of the cross-modal KD approximation error have been derived (see Sec. III-C for the omitted proof). According to this conclusion, it can be inferred that the divergence in non-target class prediction distributions between the teacher and student networks is a key factor affecting the effectiveness of cross-modal KD. This divergence stems from inherent domain discrepancies between modalities, which hinder effective guidance from the teacher to the student. This leads to the non-target divergence hypothesis.
Non-target Divergence Hypothesis (NTDH): For cross-modal KD, the performance of KD is determined by the distribution divergence of non-target classes. The smaller this divergence, the better the student network performs.
This hypothesis posits that cross-modal KD benefits from the consistency in the distribution of non-target classes. Furthermore, it explains the observation that, in certain circumstances, the performance of the teacher network is not directly correlated with the performance of the student network.
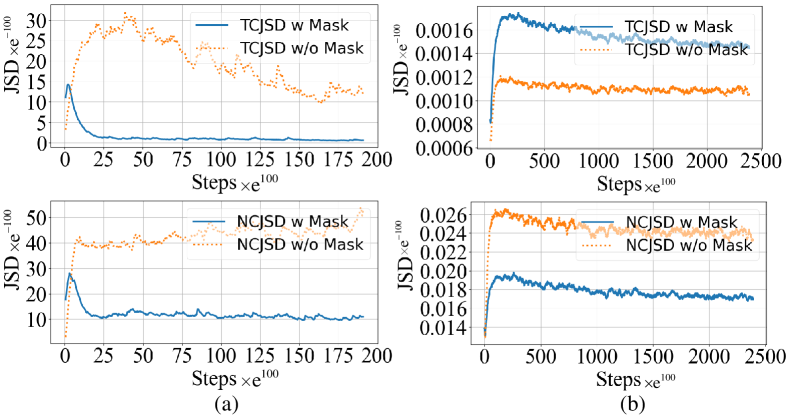
To intuitively understand our hypothesis, we use the Scikit-learn toolkit to simulate six sets of multimodal data, where represents the degree of domain discrepancy between modalities, with higher values indicating greater domain differences, as shown in Fig. 3. To satisfy Assumptions 1 and 2, both the teacher and student networks use the same architecture and maintain consistency in data intensity (see Sec. III-C for details). We conduct experiments on these six datasets and record the Jensen-Shannon Divergence between the teacher and student networks in both target and non-target distributions during stable training, denoted as TCJSD and NCJSD, respectively:
| (5) |
| (6) |
where ,
,
The experimental results indicate that as the domain discrepancy between modalities increases (i.e., as increases from 0 to 1), the accuracy of the teacher network remains stable, while the performance of the student network declines significantly. Concurrently, there is a significant increase in the distance of the non-target distribution, whereas the distance of the target distribution remains almost unchanged, as illustrated in Fig. 3. These findings suggest that in cross-modal KD, the greater the distribution divergence of non-target classes, the lower the effectiveness of KD. In contrast, a smaller discrepancy leads to better distillation outcomes. This is a qualitative observation; further validation of these conclusions will be provided through theoretical derivations in Sec. III-C.
III-C Prove the Non-target Divergence Hypothesis
Recall our three actors: the student function (trained on ), the teacher function (trained on or ), and the real target function of interest to both the student and the teacher, . For simplicity, consider pure distillation, where the imitation parameter is set to .
According to VC theory [46], the classification error of the classifier, can be expressed as:
| (7) |
where the and terms are the estimation and approximation error, respectively. The former refers to the performance gap between a model on training data and its theoretical best performance. The latter refers to the difference between a model output and the true target function. It reflects whether the model representational capacity is sufficiently powerful to accurately approximate the true target function. If the hypothesis space of a model cannot capture the complexity of the target function, the approximation error will be large. Here, represents the error, denotes a measure of the capacity of some function class, and represents the number of data points.
Let and be the teacher function trained on and , then:
| (8) |
| (9) |
Then, we can transfer the knowledge of the teacher separately from data ‘A’ or ‘B’ to the student. Let serve as the teacher function in cross-modal KD, and in Unimodal KD, then:
Cross modal KD
| (10) |
where is the approximation error of the teacher function class with respect to , and .
Unimodal KD
| (11) |
where is the approximation error of the teacher function class with respect to .
Then, if we employ cross-modal KD, combining Eqs. (8) and (10), we can obtain an alternative expression for the student learning the real function , as follows:
Alternative Expression Through Cross-Modal KD
| (12) | ||||
Similarly, by employing unimodal KD and combining Eqs. (9) and (11), we can obtain an alternative expression for the student’s learning of the real function , as follows:
Alternative Expression Through Unimodal KD
| (13) | ||||
Combining Eqs. (12) and (13), it is necessary to satisfy Eq. (14); otherwise, cross-modal KD would not outperform Unimodal KD.
| (14) |
Observing Eq. (14), we can see that it consists of two components: estimation and approximation error. Next, we will analyze these two parts separately.
Regarding estimation error, it is primarily determined by model capacity and data pattern strength. According to the assumptions in Sec. III-A, when the model capacity and data strength are the same, and are equivalent. Therefore, we can eliminate and from both sides of Eq. (14) without altering its outcome.
Regarding the approximation error term, it reflects the difference between the output of the neural network or the KD model and the target. In a neural network model, the model has only one objective: to minimize the difference between the network’s predictions and the one-hot encoded target. Here, and represent the approximation errors when training the neural network model under the modality and the modality , respectively. Under the conditions of Assumption 2, when the intensities of the data modalities are the same, the error between the prediction results trained under modality a and modality b and the ground truth are the same. Therefore, we can further eliminate and on both sides of Eq. (14). In the KD model, the model has two objectives: first, to minimize the discrepancy between the student output and the one-hot target; second, to reduce the difference between teacher and student outputs. represents the unimodal KD model, while represents the multimodal KD model. For the error generated by the first objective, regardless of whether the prediction results come from the unimodal or multimodal model, they are compared with the ground truth. When both Assumption 1 and Assumption 2 are satisfied, the approximation errors of the models is the same and can therefore be offset against each other. For the error generated by the second objective, due to the different targets of the unimodal and multimodal models (the unimodal model aims to approximate the prediction results under modality , while the multimodal model aims to approximate the prediction results under modality ), they cannot be offset against each other. For the unimodal model, if the training time is sufficient and Assumption 1 is met, the error will approach zero because the input modalities of the teacher and student networks are the same. In contrast, due to the modality differences in the multimodal model, the error is larger and cannot be ignored.
Based on the above analysis, we simplify Eq. (14) by canceling with and with on both sides, ignoring , and retaining , ultimately reducing Eq. (14) to:
| (15) |
Since uses the KL divergence for optimization in cross-modal KD, and according to Gibbs’ inequality, the KL divergence is nonnegative, must also satisfy the following:
| (16) |
By comparing Eq. (15) with Eq. (16), we arrive at a contradictory conclusion, indicating that the condition for cross-modal KD to outperform unimodal KD cannot hold. In other words, when both Assumption 1 and Assumption 2 are satisfied, the performance of cross-modal KD cannot exceed that of unimodal KD. Thus, we obtain the lower bound for the approximation error in cross-modal KD, which corresponds to unimodal KD. In this case, unimodal KD can be regarded as a special case of cross-modal KD, where there are no modality differences.
Next, we will further derive the upper bound of the approximation error in cross-modal KD. According to [14], KL divergence can be decomposed into a part related to the target class distribution and a part related to the non-target class distribution, denoted by and respectively. The decomposed result is represented as:
| (17) |
where
Based on Eq. (17), the upper bound of the approximation error in cross-modal KD can be obtained as follows:
| (18) | ||||
According to Eq. (18), the upper bound of the approximation error in cross-modal KD is composed of two parts: one part is determined by the distribution error of the target classes, referred to as TCKL; the other part is determined by the distribution error of the non-target classes, referred to as NCKL. Compared to TCKL, NCKL involves the probability distributions of more classes, thereby increasing its complexity and uncertainty. It can be proven that when the number of non-target classes exceeds two, NCKL becomes significantly larger than TCKL. To demonstrate this, consider the expressions for TCKL and NCKL:
| (19) |
| (20) |
| (21) |
To estimate , we perform a Taylor series expansion and approximate by neglecting higher-order infinitesimal terms. Let and , where and are small quantities. After the Taylor series expansion, the result of is as follows:
| (22) |
Therefore, NCKL and TCKL can be approximated by:
| NCKL | ||||
| (23) |
| (24) |
| (25) |
Based on Assumptions 1 and 2, the prediction errors of the teacher and student networks on the target class are comparable, so is much smaller than . When is sufficiently large, will be much greater than 1. In summary, we have proven that in cross-modal KD, when the number of classes is greater than 2, NCKL is significantly larger than TCKL. Therefore, the distribution differences among the non-target classes are the key factors that influence the effectiveness of cross-modal KD. When the distribution differences among non-target classes decrease, the upper bound of the approximation error will correspondingly reduce, thereby enhancing the effectiveness of cross-modal KD.
IV Experiments

In this section, we validate the hypothesis through experiments conducted on five multimodal datasets. First, we introduce the datasets and network models used in the experiments. Next, we elaborate on the experimental design and methodology. Finally, we assess the validity of the hypothesis in the context of traditional KD [49]. Additionally, we demonstrate the broad applicability and practical value of NTDH.
IV-A Datasets
The five multimodal datasets encompass three types: a simulated dataset (Scikit-learn), a synthetic dataset (MNIST/MNIST-M), and three real-world datasets (RAVDESS, SemanticKITTI, and NYU Depth V2). To ensure that the experimental datasets adhere to the assumptions outlined in Section III-A and to mitigate the effects of data modality strength and model capacity on the results, we perform preprocessing. The adjustments to model capacity and modality strength are summarized in Table I.
| Dataset | Model Capacity | Modality Strength |
| RAVDESS | Image: 13.07M Audio: 13.24M | Image: 71.4% Audio: 74.6% |
| Scikit-learn Data | 0.0014M | 39.6% |
| semanticKITTI | 21.42M | Lidar: 60.5% |
| Image: 58.4% | ||
| MNIST/MNIST-M | 0.53M | 69.1% |
| NYU-Depth V2 | 0.17M | Depth: 24.7% |
| Image: 24.4% |
IV-A1 Scikit-learn
The Scikit-learn dataset is generated using the Scikit-learn toolkit, which allows us to precisely control the differences and strengths between modalities, ensuring that the data fully meets Assumptions 1 and 2. Specifically, we use the make_classification function from the toolkit to generate multi-class data, where the labels are determined by the feature , and the length of the feature is . Next, let , , and constitute the multimodal data . Each modality is formed by a portion of the decisive features of combined with noise . Specifically, , , and . We define a ratio , which characterizes the ratio of domain difference between modalities. As increases, the domain difference between data modalities also increases. In the experiment, is fixed, and is set to , constructing data with varying modality domain differences, as shown in Fig. 4(a).
IV-A2 MNIST/MNIST-M
MNIST [50] is a widely used dataset for handwritten digit recognition, containing grayscale images of digits from 0 to 9, each paired with a corresponding label. Each image has a resolution of 28x28 pixels, with the dataset comprising 60,000 training images and 10,000 test images. MNIST-M [51] is derived from the MNIST digits by randomly mixing colored patches from the BSDS500 [52], creating a different modality of the same handwritten digits. Since the accuracy performance of MNIST and MNIST-M varies under the same model, to satisfy Assumption 2, which requires that the data strengths of both modalities be the same, we add noise of varying intensities into MNIST and MNIST-M, as shown in Fig. 4(b).
IV-A3 RAVDESS
The RAVDESS [53] is a dataset used for multimodal emotion recognition, containing data in both audio and video modalities. The dataset consists of speech and song recordings by 24 actors (12 male and 12 female), covering emotional categories such as neutral, happy, angry, fearful, disgusted, surprised, and sad. RAVDESS includes a total of 1,440 files and is widely used in research on emotion recognition, multi-modal learning, and human-computer interaction systems. In our study, we use the video modality as the input for the student network, while the audio modality serves as the input for the teacher network.
IV-A4 SemanticKITTI
SemanticKITTI [54] is a large-scale dataset based on the KITTI odometry benchmark, providing 43,000 scans with point-wise semantic annotations, of which 21,000 scans (sequences 00-10) are available for training and validation. The dataset includes 19 semantic categories and is used for the evaluation of point cloud semantic segmentation benchmarks. To enable different modalities to be processed by the same network, we follow [42] and project the original 3D point cloud data into the camera coordinate system, resulting in 2D point cloud features, as shown on the left side of Fig. 4(c).
Additionally, in point cloud semantic segmentation, the image modality lacks dense semantic labels, leading to significantly higher segmentation accuracy for the point cloud modality compared to the image modality. To equalize the data strength, we obtain dense semantic labels for the image modality following the method described in [48], as shown on the right side of Fig. 4(c).
IV-A5 NYU Depth V2
The NYU Depth V2 dataset, introduced by Silberman et al. in 2012, is collected using Microsoft Kinect’s RGB and depth cameras from commercial and residential buildings across three cities in the United States. The dataset consists of 1,449 densely annotated pairs of RGB and depth images, covering 464 distinct indoor scenes across 26 scene categories. In this study, the RGB data serve as the input for the teacher network, while the depth images are used as input for the student network, and experiments are conducted in the context of the semantic scene completion task.
IV-B Network Model
We fine-tune the existing network models to serve as the teacher and student models for our experiments. Specifically, for the Scikit-learn, both the teacher and student networks use a 2-layer fully connected network; for the MNIST/MNIST-M, both employ a 3-layer fully connected network; for the RAVDESS, due to the differing shapes of audio and image data, both the teacher and student networks utilize a 2D convolutional network with the same number of layers, and the kernel sizes are adjusted to accommodate the different data modalities. In the SemanticKITTI, the overall network architecture proposed by [42] is adopted, with the intermediate fusion layer removed; similarly, in the NYU Depth V2, the network architecture proposed by [55] is used, and the fusion layer is also removed.
IV-C Experiment Plan
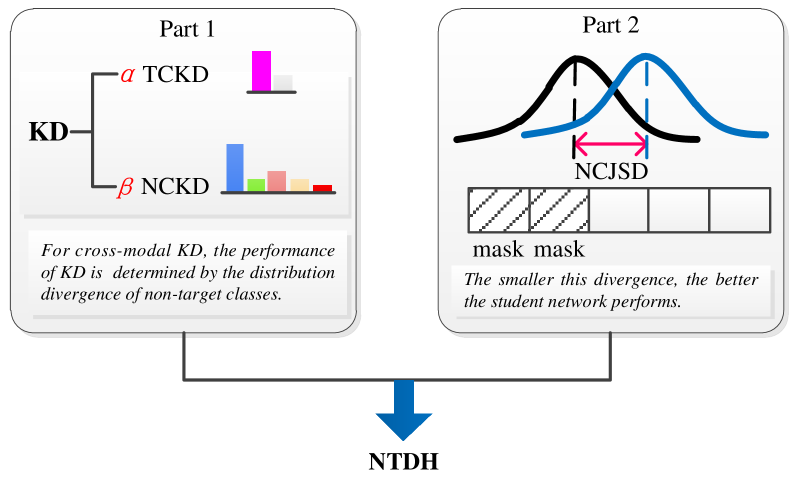
To verify the validity of our hypothesis, we design a detailed experimental plan. We employ a divide-and-conquer approach by splitting the hypothesis into two parts and validating each separately. For the first part, we use a weight adjustment method to verify that the distribution differences among non-target classes are the primary factors affecting the effectiveness of KD. This is done by adjusting the weight coefficients in the loss function that account for the distribution differences between target and non-target classes. For the second part, we apply a masking method to remove features or samples that have a significant impact on the distribution differences among non-target classes, observing whether this can improve the performance of cross-modal KD. The experimental plan is illustrated in Fig. 5, with the detailed steps as follows:
IV-C1 The First Part
We observe whether the distribution differences among non-target classes are the primary factors affecting KD by altering the weights in the loss function that optimize the distribution differences between target and non-target classes. We refer to this method as the weight adjustment method. Specifically, we first decompose the KL divergence-based KD loss function into TCKL and NCKL according to Eqs. (19) and (20). TCKL aims to reduce the distribution gap between the teacher and student for target classes, while NCKL focuses on reducing the distribution gap for non-target classes. Next, we assign weight coefficients and to TCKL and NCKL, respectively. Finally, by adjusting these weight coefficients, we either increase or decrease the influence of the distribution divergence of non-target classes.
IV-C2 The Second Part
In the first part of the study, we confirm that the distribution differences among non-target classes are a key factor affecting the effectiveness of cross-modal KD. To further explore the relationship between non-target distribution differences and KD performance, we propose a mask-based method. This method ranks the features or samples based on the non-target distribution differences. After ranking, we only use the top-ranked features or samples during the distillation process to reduce the non-target distribution differences. If this method improves the performance of KD, it validates our hypothesis. For smaller datasets, such as the Scikit-learn dataset, MNIST/MNIST-M, and RAVDESS, we apply the feature mask, while for larger datasets, such as SemanticKITTI and NYU Depth V2, we use the sample mask. The specific algorithm is as follows:
| (26) | ||||
Feature Mask: The main steps of the feature mask method are shown in Algorithm 1. The inputs are , , and , representing pairs of features from modalities and , as well as the corresponding labels for these targets. The output is a saliency vector , which represents the difference in non-target class distribution between the teacher and student networks, where the -th entry reflects the saliency of the corresponding feature dimension. A larger saliency value indicates a greater difference in non-target class distribution for that feature channel.
Algorithm 1 is designed based on a backtracking approach starting from the output layer. Specifically, in Step 4, we jointly train two unimodal networks, and , which take unimodal data and as inputs, respectively. The first term in Eq. (26) aims to align the feature spaces learned by the two networks, while the remaining terms ensure that the learned features accurately predict the labels. In Step 5, we utilize the idea of feature importance ranking [56] to trace the saliency of input features with respect to non-target class distribution differences. For the -th dimension in , we randomly permute the values along that dimension and obtain the permuted result in Step 8. Next, in Step 10, we quantify the difference in non-target class distribution for each input feature channel by calculating the NCJSD, where a larger distance indicates a more significant difference between the teacher and student networks. Therefore, we can quantify the magnitude of the non-target class distribution difference in each input feature channel using the saliency vector .
We repeat the permutation process multiple times and average the distance values to improve stability. Finally, in Step 13, is normalized to . Once the feature channels are ranked, we can reduce the non-target class distribution differences during distillation by applying a mask to the top of the feature channels.
Sample Mask: The main steps of the feature masking method are illustrated in Algorithm 2. The inputs to Algorithm 2 are and , representing the predicted probability distributions of the teacher and student networks, respectively. The output is a saliency vector , which indicates the difference in non-target class distribution between the teacher and student networks, where the -th entry reflects the saliency of the corresponding sample. A larger saliency value indicates that the sample exhibits a greater difference in non-target class distribution. Here, represents the number of samples, such as the number of points in each batch for the SemanticKITTI or the number of pixels in each batch for the NYU Depth V2.
In Step 6, we calculate the NCJSD for all samples in each batch. In Step 8, we sort these distances, where larger distances indicate more significant differences in non-target class distribution between the teacher and student networks. Therefore, we can quantify the magnitude of the non-target class distribution difference for each sample using the saliency vector . Finally, in Step 12, is normalized to . Once the sorting of all samples in the batch is completed, we can reduce the distribution differences between the non-target classes during distillation by applying a mask to the top of the samples.
IV-D The Results of the First Part
IV-D1 Scikit-learn
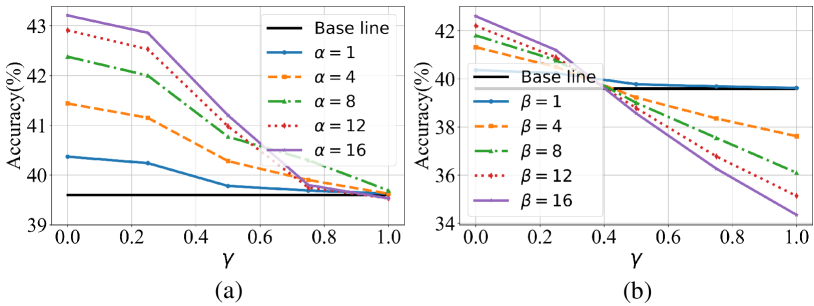
The results of the Scikit-learn dataset are shown in Fig. 6. The horizontal axis represents the modality difference , where indicates no difference and indicates the maximum difference. The experiment sets six levels of modality divergence. By adjusting the weights and , we study the impact of distribution divergence between target and non-target classes on the effectiveness of KD.
In Fig. 6(a), we fix and increase to give more weight to the target class under the six different modality differences. Correspondingly, in Fig. 6(b), we fix the and increase the to give more weight to the distribution divergence of non-target classes. By comparing the experimental results, it can be observed that when , indicating a large modality difference, increasing significantly improves the effectiveness of KD, whereas increasing significantly reduces the effectiveness. This indicates that, in cases of large modality differences, the distribution divergence of non-target classes play a crucial role in the effectiveness of KD.
IV-D2 Other dataset
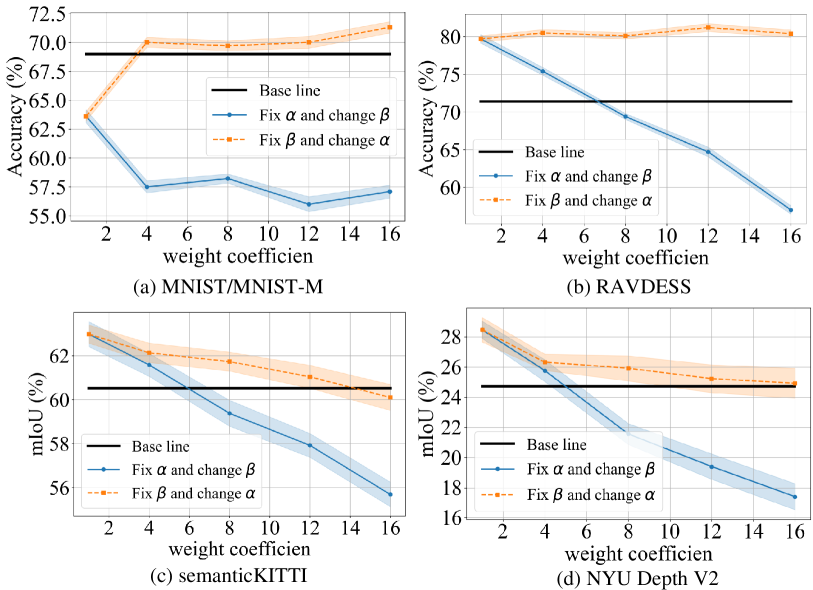
On the MNIST/MNIST-M datasets, we employ the feature mask, fixing the parameter while gradually increasing the to amplify the weight of the distribution divergence of non-target classes. We then fix the and increase the to enhance the weight of target class distribution differences. The results show that when the weight of non-target class distribution divergence increases, accuracy significantly decreases, while increasing the weight of target class distribution divergence results in almost no noticeable change. This indicates that the distribution divergence of non-target classes is a crucial factor influencing the effectiveness of cross-modal KD. To further validate this phenomenon, similar experiments are conducted on the RAVDESS, SemanticKITTI, and NYU Depth V2 datasets, and consistent results are obtained, as shown in Figs. 7(b)-(d), respectively. These consistent results across different datasets further confirm our hypothesis.
IV-E The Results of the Second Part
IV-E1 Scikit-learn
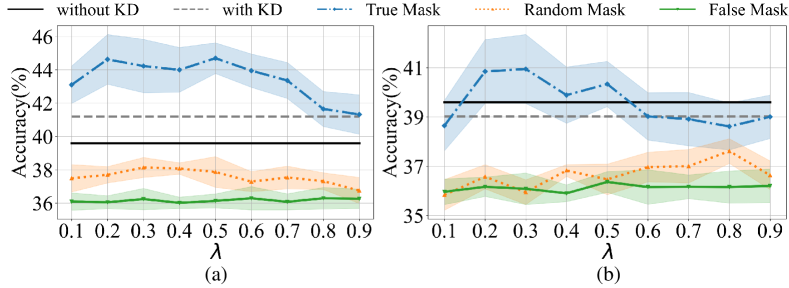
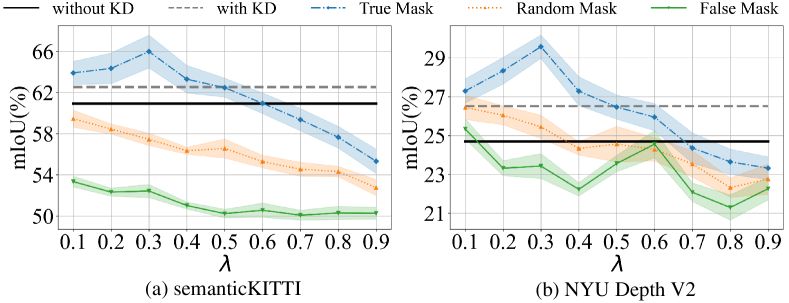
By applying Algorithm 1 to deactivate the top of features with the highest NCJSD, we reduce the non-target distribution divergence between the teacher and student networks, which is referred to as the True Mask. For control purposes, we establish two additional groups: one that deactivates the top of features with the lowest NCJSD, thereby increasing the non-target distribution divergence between the teacher and student networks, is known as the False Mask; the other randomly deactivates of features, referred to as the Random Mask.
Fig. 8 shows the results for and on the Scikit-learn dataset. The 0-th layer features of the teacher network (i.e., the input data) are selected as the masking object, with nine different masking ratios ranging from 10% to 90%. For the True Mask, a higher removal ratio indicates that more features with greater non-target distribution divergence are removed from the teacher network. Conversely, for the False Mask, the situation is reversed. The results show that for the True Mask, the performance of the student network initially improves with increasing . This improvement suggests that features with significant non-target distribution divergence between the teacher and student networks are being progressively discarded, thereby enhancing the performance of the student network. However, as the deactivation process starts to affect features with smaller non-target distribution divergence, performance begins to decline. In contrast, the False Mask performs the worst, while the Random Mask results fall between the two. This observation is consistent with our expectations.
IV-E2 MNIST/MNIST-M and RAVDESS
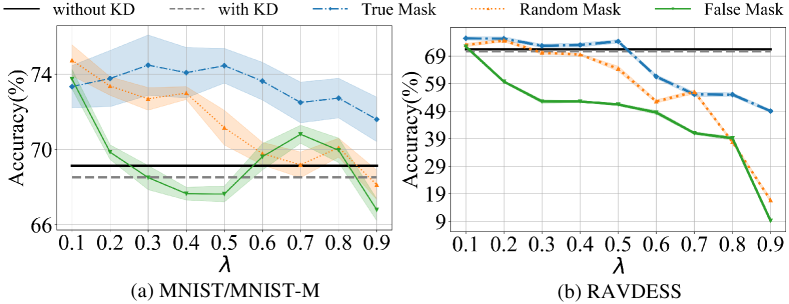
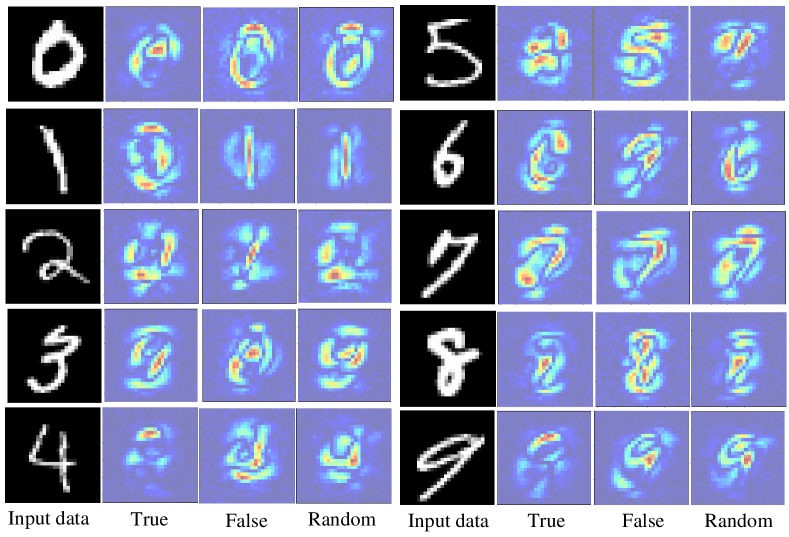
Similarly, we also conduct experiments on the MNIST/MNIST-M and RAVDESS datasets using Algorithm 1, and reach similar conclusions, as shown in Figs. 9(a) and (b). Additionally, we use heatmaps to visualize the masked areas on the MNIST/MNIST-M datasets, as shown in Fig. 10. For the False Mask, the highlighted regions are mainly concentrated in the non-target areas, with fewer in the target areas; for the True Mask, the situation is the opposite, with the highlighted regions primarily focused on the target areas and fewer in the non-target areas. From these results, it is observed that the target areas are mainly concentrated in the foreground, while the non-target areas are concentrated in the background, which aligns with our previous analysis.
IV-E3 SemanticKITTI and NYU Depth V2
We use Algorithm 2 on the SemanticKITTI and NYU Depth V2 datasets, as shown in Figs. 11(a) and (b). The results indicate that the effectiveness of KD initially improves and then declines as samples with large non-target class distribution divergence are removed. Initially, removing these samples enhances KD because their significant distribution differences hinder the process. However, as the removal proportion increases, samples with smaller distribution divergences are also eliminated, leading to a decrease in KD effectiveness in later stages.
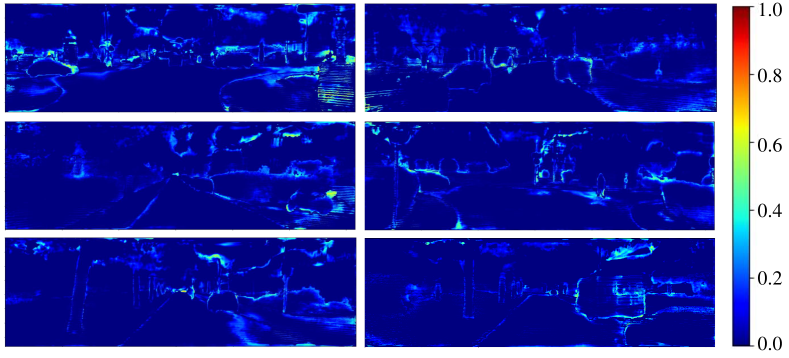
Furthermore, we visualize the samples with significant distribution divergence in non-target classes on the SemanticKITTI dataset, as shown in Fig. 12. The highlighted areas, primarily concentrated along object edges, indicate that distribution divergence is greatest in these regions. The reason for this is that in segmentation tasks, the edges are typically the most challenging to distinguish, leading to the most pronounced divergence in non-target class distributions between different modalities.
IV-F Generalization
Beyond traditional KD [49], various improved algorithms have been proposed. To evaluate the generalization ability of NTDH, we apply the feature masking method to several of these improved KD algorithms, including FitNet [9], Contrastive Representation Distillation (CRD) [10], Relational Knowledge Distillation (RKD) [11], Probabilistic Knowledge Transfer for deep representation learning (PKT) [12] , Similarity-Preserving KD (SP) [13] and Decoupled Knowledge Distillation (DKD) [14].
Table II presents the experimental results on the MNIST/MNIST-M dataset. The results show that none of the methods improve student performance, indicating that KD methods designed for unimodal scenarios are not suitable for cross-modal applications. However, when we use Algorithm 1 to remove portions with significant non-target class distribution divergence, especially at smaller removal proportions (e.g., 25% and 50%), all algorithms show significant performance improvements. In contrast, random and false masking lead to substantial performance declines, highlighting the critical role of non-target class differences in cross-modal KD.
Table III presents the experimental results on the RAVDESS dataset. The results show that cross-modal KD fails to improve student performance, highlighting the limitations of these methods in cross-modal applications. However, using Algorithm 1 to remove portions with significant modal differences, particularly at lower removal proportions (e.g., 25% and 50%), leads to performance improvements in most algorithms. In contrast, control experiments with Random and False masking result in significant performance declines, underscoring the decisive role of non-target class distribution divergence in cross-modal KD.
| FitNet | CRD | RKD | PKT | SP | DKD | ||
| w/o KD | 69.1 | 69.1 | 69.1 | 69.1 | 69.1 | 69.1 | |
| w/o mask | 68.5 | 68.5 | 68.5 | 68.5 | 68.5 | 68.5 | |
| w mask () | T | 70.3 | 71.3 | 70.1 | 59.85 | 72.4 | 75.8 |
| R | 50.1 | 72.1 | 70.9 | 60.8 | 70.2 | 75.4 | |
| F | 48.2 | 68.2 | 68.3 | 54.8 | 64.7 | 69.9 | |
| w mask () | T | 61.6 | 75.6 | 70.9 | 60.4 | 69.8 | 76.4 |
| R | 50.1 | 70.1 | 71.4 | 56.3 | 68.5 | 73.2 | |
| F | 43.6 | 63.6 | 69.3 | 53.5 | 62.7 | 69.6 | |
| w mask () | T | 59.3 | 70.3 | 70.1 | 57.1 | 65.6 | 72.7 |
| R | 52.9 | 65.9 | 69.83 | 53.5 | 63.8 | 70.1 | |
| F | 47.8 | 57.8 | 67.9 | 55.1 | 64.1 | 67.9 | |
| FitNet | CRD | RKD | PKT | SP | DKD | ||
| w/o KD | 71.4 | 71.4 | 71.4 | 71.4 | 71.4 | 71.4 | |
| w/o mask | 70.8 | 70.8 | 70.8 | 70.8 | 70.8 | 70.8 | |
| w mask () | T | 81.7 | 75.3 | 69.8 | 80.3 | 79.6 | 77.8 |
| R | 81.2 | 55.1 | 70.8 | 78.8 | 77.1 | 75.8 | |
| F | 56.3 | 53.2 | 64.8 | 55.2 | 55.9 | 53.6 | |
| w mask () | T | 83.0 | 66.6 | 70.4 | 78.0 | 78.0 | 77.1 |
| R | 77.7 | 55.1 | 66.3 | 78.0 | 76.8 | 78.2 | |
| F | 57.5 | 48.6 | 63.5 | 55.4 | 57.1 | 54.8 | |
| w mask () | T | 63.5 | 64.3 | 67.1 | 62.9 | 63.6 | 72.3 |
| R | 40.1 | 63.9 | 63.5 | 63.3 | 65.7 | 62.6 | |
| F | 53.6 | 57.7 | 65.1 | 53.1 | 54.7 | 53.0 | |
IV-G Applications
This section further explores the practical application of NTDH. According to this hypothesis, in cross-modal KD, if the non-target class distribution difference between Teacher (a) and the student is smaller than that between Teacher (b) and the student, then we expect the student guided by Teacher (a) to outperform the student guided by Teacher (b). To reduce the non-target class distribution difference between the teacher and student networks, the method in Algorithm 2 can be applied. To validate the effectiveness of this method, we apply it to existing cross-modal KD algorithms, such as 2DPASS [57] and PMF [42], and conduct tests on the SemanticKITTI dataset.
Table IV shows the experimental results, indicating that appropriately masking samples with significant non-target distribution divergence (e.g., 25% and 50%) can improve performance. For 2DPASS, the maximum improvement reached 2.0%. By comparing the change curves of NCJSD and TCJSD distances before and after masking, as shown in Fig. 13(a), it is evident that the non-target distribution divergence significantly decreases, while the target distribution divergence changes only slightly. This confirms that the performance improvement is due to the reduction of non-target distribution differences. In contrast, the improvement in PMF is smaller because the Perception-Aware Loss in the original paper has already removed samples with large modality differences, leading to insignificant changes in NCJSD and TCJSD distances before and after masking, as shown in Fig. 13(b).
| Base Line | w mask () | w mask () | w mask () | |||||||
| T | F | R | T | F | R | T | F | R | ||
| 2DPASS | 64.2 | 65.2 | 61.2 | 64.6 | 66.2 | 59.2 | 63.2 | 63.2 | 63.2 | 60.2 |
| PMF | 63.2 | 64.2 | 60.2 | 57.2 | 65.2 | 58.2 | 62.2 | 62.2 | 60.2 | 63.2 |
V Conclusion
In this work, we delve into cross-modal KD and introduce the NTDH method, which analyzes the impact of domain gaps in multimodal data on KD performance, highlighting the importance of non-target class distribution divergence. Through theoretical analysis and carefully designed experiments, we validate the rationale, generalization capability, and potential applications of NTDH. We aim for NTDH to provide valuable insights for the practical use of cross-modal KD and to foster interest in understanding domain discrepancies in multimodal learning. However, as this paper focuses on the effects of domain discrepancies on cross-modal KD, the exploration of theoretical applications is limited.
References
- [1] L. Wang and K.-J. Yoon, “Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks,” IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 6, pp. 3048–3068, 2021.
- [2] Y. Liu, J. Chen, and Y. Liu, “Dccd: Reducing neural network redundancy via distillation,” IEEE Transactions on Neural Networks and Learning Systems, 2023.
- [3] K. Liu, Z. Huang, C.-D. Wang, B. Gao, and Y. Chen, “Fine-grained learning behavior-oriented knowledge distillation for graph neural networks,” IEEE Transactions on Neural Networks and Learning Systems, 2024.
- [4] J. Singh, S. Murala, and G. S. R. Kosuru, “Kl-dnas: Knowledge distillation-based latency aware-differentiable architecture search for video motion magnification,” IEEE Transactions on Neural Networks and Learning Systems, 2024.
- [5] T. Sun, Z. Zhang, X. Tan, Y. Peng, Y. Qu, and Y. Xie, “Uni-to-multi modal knowledge distillation for bidirectional lidar-camera semantic segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
- [6] H. Liu, M. Ye, Y. Wang, S. Zhao, P. Li, and J. Shen, “A new framework of collaborative learning for adaptive metric distillation,” IEEE Transactions on Neural Networks and Learning Systems, 2023.
- [7] C. Tan and J. Liu, “Improving knowledge distillation with a customized teacher,” IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 2, pp. 2290–2299, 2022.
- [8] F. Ding, Y. Yang, H. Hu, V. Krovi, and F. Luo, “Dual-level knowledge distillation via knowledge alignment and correlation,” IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 2, pp. 2425–2435, 2022.
- [9] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio, “Fitnets: Hints for thin deep nets,” arXiv preprint arXiv:1412.6550, 2014.
- [10] Y. Tian, D. Krishnan, and P. Isola, “Contrastive representation distillation,” arXiv preprint arXiv:1910.10699, 2019.
- [11] W. Park, D. Kim, Y. Lu, and M. Cho, “Relational knowledge distillation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3967–3976.
- [12] N. Passalis and A. Tefas, “Probabilistic knowledge transfer for deep representation learning,” CoRR, abs/1803.10837, vol. 1, no. 2, p. 5, 2018.
- [13] F. Tung and G. Mori, “Similarity-preserving knowledge distillation,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1365–1374.
- [14] B. Zhao, Q. Cui, R. Song, Y. Qiu, and J. Liang, “Decoupled knowledge distillation,” in Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 2022, pp. 11 953–11 962.
- [15] Z. Xue, Z. Gao, S. Ren, and H. Zhao, “The modality focusing hypothesis: Towards understanding crossmodal knowledge distillation,” in ICLR, 2023.
- [16] Y. Li, Y. Wang, and Z. Cui, “Decoupled multimodal distilling for emotion recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6631–6640.
- [17] M. Phuong and C. Lampert, “Towards understanding knowledge distillation,” in International conference on machine learning. PMLR, 2019, pp. 5142–5151.
- [18] J. H. Cho and B. Hariharan, “On the efficacy of knowledge distillation,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4794–4802.
- [19] J. Tang, R. Shivanna, Z. Zhao, D. Lin, A. Singh, E. H. Chi, and S. Jain, “Understanding and improving knowledge distillation,” arXiv preprint arXiv:2002.03532, 2020.
- [20] S. Ren, Z. Gao, T. Hua, Z. Xue, Y. Tian, S. He, and H. Zhao, “Co-advise: Cross inductive bias distillation,” in Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 2022, pp. 16 773–16 782.
- [21] S. I. Mirzadeh, M. Farajtabar, A. Li, N. Levine, A. Matsukawa, and H. Ghasemzadeh, “Improved knowledge distillation via teacher assistant,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 04, 2020, pp. 5191–5198.
- [22] J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,” International Journal of Computer Vision, vol. 129, pp. 1789–1819, 2021.
- [23] S. Ahmad, Z. Ullah, and J. Gwak, “Multi-teacher cross-modal distillation with cooperative deep supervision fusion learning for unimodal segmentation,” Knowledge-Based Systems, vol. 297, p. 111854, 2024.
- [24] H. Li, Y. Zha, H. Li, P. Zhang, and W. Huang, “Efficient thermal infrared tracking with cross-modal compress distillation,” Engineering Applications of Artificial Intelligence, vol. 123, p. 106360, 2023.
- [25] Y. Liu, Z. Jia, and H. Wang, “Emotionkd: a cross-modal knowledge distillation framework for emotion recognition based on physiological signals,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 6122–6131.
- [26] R. N. Nair and R. Hänsch, “Let me show you how it’s done-cross-modal knowledge distillation as pretext task for semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 595–603.
- [27] Y. Weng, J. Dong, W. He, X. Liu, Z. Liu, H. Gao et al., “Zero-shot cross-lingual knowledge transfer in vqa via multimodal distillation,” IEEE Transactions on Computational Social Systems, 2024.
- [28] W. Wang, F. Liu, W. Liao, and L. Xiao, “Cross-modal graph knowledge representation and distillation learning for land cover classification,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [29] R. Dai, S. Das, and F. Bremond, “Learning an augmented rgb representation with cross-modal knowledge distillation for action detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 13 053–13 064.
- [30] Z. Chen, Z. Li, S. Zhang, L. Fang, Q. Jiang, and F. Zhao, “Bevdistill: Cross-modal bev distillation for multi-view 3d object detection,” arXiv preprint arXiv:2211.09386, 2022.
- [31] Y. Jin, G. Hu, H. Chen, D. Miao, L. Hu, and C. Zhao, “Cross-modal distillation for speaker recognition,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 11, 2023, pp. 12 977–12 985.
- [32] Z. Feng, Y. Guo, and Y. Sun, “Cekd: Cross-modal edge-privileged knowledge distillation for semantic scene understanding using only thermal images,” IEEE Robotics and Automation Letters, vol. 8, no. 4, pp. 2205–2212, 2023.
- [33] J. Li, W. K. Wong, L. Jiang, X. Fang, S. Xie, and Y. Xu, “Ckdh: Clip-based knowledge distillation hashing for cross-modal retrieval,” IEEE Transactions on Circuits and Systems for Video Technology, 2024.
- [34] P. Sarkar and A. Etemad, “Xkd: Cross-modal knowledge distillation with domain alignment for video representation learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 13, 2024, pp. 14 875–14 885.
- [35] W. Ma, Q. Chen, T. Zhou, S. Zhao, and Z. Cai, “Using multimodal contrastive knowledge distillation for video-text retrieval,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 10, pp. 5486–5497, 2023.
- [36] P. Liu, H. Guo, T. Dai, N. Li, J. Bao, X. Ren, Y. Jiang, and S.-T. Xia, “Taming pre-trained llms for generalised time series forecasting via cross-modal knowledge distillation,” arXiv preprint arXiv:2403.07300, 2024.
- [37] Y. Chen, T. He, J. Fu, L. Wang, J. Guo, and H. Cheng, “Vision-language meets the skeleton: Progressively distillation with cross-modal knowledge for 3d action representation learning,” arXiv preprint arXiv:2405.20606, 2024.
- [38] H. Yun, J. Na, and G. Kim, “Dense 2d-3d indoor prediction with sound via aligned cross-modal distillation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 7863–7872.
- [39] M. Chen, L. Xing, Y. Wang, and Y. Zhang, “Enhanced multimodal representation learning with cross-modal kd,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 11 766–11 775.
- [40] P. Lee, T. Kim, M. Shim, D. Wee, and H. Byun, “Decomposed cross-modal distillation for rgb-based temporal action detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2373–2383.
- [41] S. Kim, Y. Kim, S. Hwang, H. Jeong, and D. Kum, “Labeldistill: Label-guided cross-modal knowledge distillation for camera-based 3d object detection,” arXiv preprint arXiv:2407.10164, 2024.
- [42] Z. Zhuang, R. Li, K. Jia, Q. Wang, Y. Li, and M. Tan, “Perception-aware multi-sensor fusion for 3d lidar semantic segmentation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 16 280–16 290.
- [43] H. Wang, C. Ma, J. Zhang, Y. Zhang, J. Avery, L. Hull, and G. Carneiro, “Learnable cross-modal knowledge distillation for multi-modal learning with missing modality,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2023, pp. 216–226.
- [44] F. Huo, W. Xu, J. Guo, H. Wang, and S. Guo, “C2kd: Bridging the modality gap for cross-modal knowledge distillation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 006–16 015.
- [45] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg et al., “Scikit-learn: Machine learning in python,” the Journal of machine Learning research, vol. 12, pp. 2825–2830, 2011.
- [46] V. N. Vapnik, “An overview of statistical learning theory,” IEEE transactions on neural networks, vol. 10, no. 5, pp. 988–999, 1999.
- [47] S. Kullback and R. A. Leibler, “On information and sufficiency,” The annals of mathematical statistics, vol. 22, no. 1, pp. 79–86, 1951.
- [48] Y. Chen, Z. Xu, R. Zhang, X. Jiang, X. Gao et al., “Foundation model assisted weakly supervised lidar semantic segmentation,” arXiv preprint arXiv:2404.12861, 2024.
- [49] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
- [50] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- [51] Y. Ganin and V. Lempitsky, “Unsupervised domain adaptation by backpropagation,” in International conference on machine learning. PMLR, 2015, pp. 1180–1189.
- [52] D. Martin, C. Fowlkes, D. Tal, and J. Malik, “A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics,” in Proceedings eighth IEEE international conference on computer vision. ICCV 2001, vol. 2. IEEE, 2001, pp. 416–423.
- [53] S. R. Livingstone and F. A. Russo, “The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english,” PloS one, vol. 13, no. 5, p. e0196391, 2018.
- [54] J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “Semantickitti: A dataset for semantic scene understanding of lidar sequences,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9297–9307.
- [55] J. Li, K. Han, P. Wang, Y. Liu, and X. Yuan, “Anisotropic convolutional networks for 3d semantic scene completion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3351–3359.
- [56] M. Wojtas and K. Chen, “Feature importance ranking for deep learning,” Advances in neural information processing systems, vol. 33, pp. 5105–5114, 2020.
- [57] X. Yan, J. Gao, C. Zheng, C. Zheng, R. Zhang, S. Cui, and Z. Li, “2dpass: 2d priors assisted semantic segmentation on lidar point clouds,” in European Conference on Computer Vision. Springer, 2022, pp. 677–695.