Nonlinear ensemble filtering with diffusion models:
Application to the surface quasi-geostrophic dynamics
Abstract
The intersection between classical data assimilation methods and novel machine learning techniques has attracted significant interest in recent years. Here we explore another promising solution in which diffusion models are used to formulate a robust nonlinear ensemble filter for sequential data assimilation. Unlike standard machine learning methods, the proposed Ensemble Score Filter (EnSF) is completely training-free and can efficiently generate a set of analysis ensemble members. In this study, we apply the EnSF to a surface quasi-geostrophic model and compare its performance against the popular Local Ensemble Transform Kalman Filter (LETKF), which makes Gaussian assumptions on the posterior distribution. Numerical tests demonstrate that EnSF maintains stable performance in the absence of localization and for a variety of experimental settings. We find that EnSF achieves competitive performance relative to LETKF in the case of linear observations, but leads to significant advantages when the state is nonlinearly observed and the numerical model is subject to unexpected shocks. A spectral decomposition of the analysis results shows that the largest improvements over LETKF occur at large scales (small wavenumbers) where LETKF lacks sufficient ensemble spread. Overall, this initial application of EnSF to a geophysical model of intermediate complexity is very encouraging, and motivates further developments of the algorithm for more realistic problems.
Keywords:
diffusion models ensemble data assimilation surface quasi-geostrophic turbulence1 Introduction
Since its introduction by Evensen (1994), the ensemble Kalman filter (EnKF) has been utilized extensively for the initialization of geophysical models and has inspired the rapidly developing subfield of ensemble data assimilation (DA). In numerical weather prediction (NWP), the ensemble approach has been highly successful either on its own or in conjunction with variational methods such as 4D-Var (e.g., Isaksen et al. 2010). This success largely stems from the ability of a forecast ensemble to capture the “errors of the day”, replacing the assumptions of static forecast covariances used in earlier DA methods (e.g., optimal interpolation) and purely variational approaches.
In meteorological applications, EnKF algorithms have been particularly beneficial at the convective scales due to their ability to handle complex numerical models and observing systems (e.g., Aksoy et al. 2009, 2010; Jones et al. 2010; Chipilski et al. 2020, 2022; Hu et al. 2023). One of the practical advantages of ensemble DA methods is their ability to incorporate highly nonlinear models and observations without the need to explicitly compute any tangent linear and adjoint operators. This is an extra overhead for any variational DA method in operational contexts as one needs to continuously recompute these operators once a new version of the model is released. Nevertheless, standard EnKFs still approximate the Kalman filter’s analysis equations, which are derived from restrictive Gaussian assumptions. These Gaussian assumptions manifest themselves in the linear nature of the EnKF’s update, which limits the ability to represent more complex analysis (posterior) distributions (Spantini et al. 2022). Recent studies have shown that the analysis biases introduced by methods leveraging the Kalman filter equations, such as the EnKF, can have a detrimental impact on the ability to forecast high-impact weather events like hurricanes (Poterjoy 2022).
Particle filters (PFs; Gordon et al. 1993; van Leeuwen 2009; van Leeuwen et al. 2019) represent a natural replacement for standard EnKFs due to their provable convergence to the correct posterior distribution (Crisan and Doucet 2002). Although they were introduced around the same time as EnKFs, they have taken a long time to reach operational potential. The underlying reasons have practical dimensions – in order to avoid the curse of dimensionality, PFs require a prohibitively large number of particles. There has been visible progress in this direction, with several great examples of successful PF implementations in large systems (Tödter et al. 2016; Poterjoy et al. 2017; Rojahn et al. 2023). PFs have also stimulated the development of many complementary non-Gaussian DA approaches, including lognormal and bi-Gaussian extensions of standard DA methods (Fletcher 2010; Fletcher et al. 2023; Chan et al. 2020) and the recently developed two-step quantile-conserving ensemble filtering framework (QCEFF) of Anderson (2022, 2023).
It is clear that research into nonlinear/non-Gaussian ensemble DA methods will continue to attract more interest in view of the increasing complexity of numerical models and observing systems. One promising way to address these challenges is to exploit the ongoing revolution in generative artificial intelligence (GenAI; see Luo and Hu 2021; Song et al. 2021; Baranchuk et al. 2022). Up to now, two GenAI approaches have been adopted in the ensemble DA context. Chipilski (2023) showed how the appealing mathematical properties of invertible neural networks (normalizing flows) can help generalize the Kalman Filter to arbitrarily non-Gaussian distributions. The resulting Conjugate Transform Filter (CTF) is amenable to ensemble approximations which can take advantage of existing EnKF solvers. The second GenAI framework is associated with the score-based filter of Bao et al. (2023b) which harnesses the expressive power of diffusion models to approximate complex posterior distributions. The use of a pseudo time to gradually transform samples to the desired distribution makes this approach somewhat similar to the Particle Flow Filter (PFF; Pulido and van Leeuwen 2019; Hu and van Leeuwen 2021), but its ability to incorporate non-Gaussian priors is an important distinction. Following its original formulation, a more efficient ensemble version of the score-based filter, henceforth referred to as the Ensemble Score Filter (EnSF), has been developed. Owing to its training-free nature, EnSF has been shown to estimate the states of a high-dimensional Lorenz-96 system with up to variables (Bao et al. 2023a). More recently, the EnSF framework has been also extended to conduct joint state-parameter estimation (Bao et al. 2023c).
In this study, we focus on the further development of the EnSF algorithm and aim to introduce its capabilities to the geophysical community. Motivated by its scalable performance in high-dimensional and nonlinear settings, we implement EnSF in a surface quasi-geostrophic (SQG) model which provides a realistic description of geophysical turbulence (Smith et al. 2023). Our main objective is to demonstrate that (i) EnSF maintains stable performance in high dimensions while (ii) offering advantages compared to standard EnKF methods. This is achieved by performing a hierarchy of SQG experiments in which we gradually increase the complexity of the DA task toward more nonlinear settings.
The rest of this paper is organized as follows. In Section 2, we introduce basic theory from diffusion models and discuss how the associated backward (reverse-time) stochastic differential equations (SDEs) can be used to sample from the Baysian posterior. After describing important experimental design choices in Section 3, we present our DA results with the SQG model in Section 4. In Section 5, we conclude with a summary of all main findings and outline several interesting research directions.
2 Methodology
We first introduce the diffusion model as a general framework to sample from a user-specified target distribution. Then, we explain how score-based diffusion models fit the standard forecast-analysis procedure of sequential DA methods. Finally, we discuss numerical schemes for solving the DA problem under the score-based filtering framework, and provide details on how to build ensemble approximations.
2.1 Introduction to diffusion models
In a diffusion model, there is a forward -valued stochastic differential equation (SDE) defined as
| (1) |
where is a standard -valued Brownian motion (Wiener process) corresponding to an Itô type stochastic integral , while and are two explicitly given functions referred to as the drift and diffusion coefficients, respectively. The initial condition of the SDE in Eq. (1) follows some target distribution with its probability density function (pdf) denoted by . One can show that with properly chosen and , the diffusion process can transform any target pdf to a standard Gaussian, i.e. , where is often referred to as the pseudo-time interval.
Generating samples of the target random variable pertains to simulating the following reverse-time SDE:
| (2) |
where is a backward Itô stochastic integral (Kloeden and Platen 1992; Bao et al. 2016), and is the so-called score function given by
| (3) |
where denotes the pdf of . Note that the reverse-time SDE in Eq. (2) is also a diffusion process except that the propagation direction is backwards in time from to with initial condition given at time . An important result from the literature is that the solution of the reverse-time SDE follows the target distribution (Bao et al. 2023b). The practical implications are that we can generate samples from a standard Gaussian distribution (which can be done efficiently) and use the reverse-time SDE to transform them to samples of the target distribution. The score function has an important role in this mapping process as it stores information about the distribution of the samples, which in turn helps guide their transformation over the pseudo-time interval as . In particular, having the score function associated with the target pdf and the predefined forward SDE allows us to generate an unlimited number of target samples by running the reverse-time SDE in Eq. (2).
In both the forward SDE and the reverse-time SDE, one needs to carefully choose the drift and diffusion coefficients and . While there are multiple options for and , in this work we let
| (4) | ||||
with and for , which is consistent with the choice made in Song et al. (2021). Nevertheless, in future work we plan to explore the sensitivity of EnSF to different options for the drift and diffusion coefficients.
The traditional use of diffusion models in the machine learning (ML) literature is to generate highly realistic images and videos (Song et al. 2021). Later in our exposition, we will discuss how this powerful approach can be also used in the context of data assimilation (DA).
2.2 The general filtering solution
The formulation of every DA method requires two main ingredients – (stochastic) dynamic and observation models. Let be a time index. A general representation of the discretized system evolution is given by
| (5) |
where stands for the (true) state vector we wish to estimate and represents the error-prone numerical model. The model errors arise due to (i) discretization of the governing equations and (ii) imperfect knowledge about the simulated process. In this study, we assume the model errors are known and we only need to infer the unknown true state from the noisy observations
| (6) |
where is an observation operator and are the associated observation errors. Note that while the formulation of Eq. (6) follows the standard additive-Gaussian observation error model, it is possible to introduce more general statistical assumptions (Chipilski 2023).
Given the model and observation equations, a rather general formulation of the DA problem is to seek the filtering (posterior) pdf 111The notation is shorthand for the set of integers from to ., which can be done recursively by iterating through a prediction and an update step:
Prediction:
Given the filtering pdf at the previous time level , we can first compute the prior pdf using the Chapman-Kolmogorov equation
| (7) |
where is the transition pdf determined from the dynamic model in Eq. (5).
Update:
After receiving the new set of observations , we can adjust the forecast state towards the observations by applying Bayes’ theorem,
| (8) |
where the likelihood function is determined from the observation model in Eq. (6). In view of our Gaussian assumptions, the likelihood can be written as
| (9) |
2.3 Score-based filtering for data assimilation
The central idea in score-based filtering is to create score models which represent the filtering pdfs at different times and then generate analysis ensemble members according to the reverse-time SDE in Eq. (2). To this end, we introduce the score functions and corresponding to the prior pdf and the posterior pdf :
-
•
Prior filtering score such that ; i.e., .
-
•
Posterior filtering score such that ; i.e., .
Next, we describe a recursive procedure to implement the score-based filter for DA. To proceed, it is assumed that the posterior score associated with the posterior (filtering) pdf at time level is given. This is analogous to how the initial state distribution is assumed to be known in sequential DA. An Euler scheme can be used to discretize the reverse-time SDE in Eq. (2) (Kloeden and Platen 1992) as follows
| (10) | ||||
where is a set of iid samples, , , and the above scheme uses the following time discretization
over the diffusion model’s pseudo-time interval . The Euler scheme is one of the two most popular schemes for solving SDEs numerically. The second one is based on the Milstein method (Milstein 1975), but for the standard SDE formulation used here (in which the diffusion coefficient is state independent), the two schemes give identical results.
Following the standard workflow of diffusion models, the reverse-time SDE is initialized with samples drawn from a standard Gaussian distribution; that is, . Leveraging the Euler scheme in Eq. (10), these initial samples are mapped to the analysis ensemble which follows the filtering pdf by construction.
The generative nature of the diffusion process needed to obtain the analysis ensemble is worth elaborating on. With an appropriately estimated score function , we can generate unlimited samples from the posterior pdf , which can be seen as a non-Gaussian extension of the class of resampling EnKFs discussed by Anderson (2001). In addition, the sample size can be an arbitrary number depending on the specific application and computing resources.
Prediction step:
The prediction step in the score filter is analogous to all ensemble DA methods. In particular, the dynamic model in Eq. (5) is used to advance each analysis ensemble member to the next observation time level . In doing so, we obtain the forecast ensemble which approximates the prior pdf and will be used to estimate the prior score function .
Update step:
The posterior score function implicitly encodes the posterior pdf , which is why its estimation is an essential part of the update step in the score filter. Since combines information from both the prior and the likelihood, the derivation of will focus on how to effectively adjust the prior score based on the assimilated observations. Indeed, this is a general challenge for all DA methods. Calculating the gradient of the logarithm of Eq. (8), we see that
| (11) |
where the gradient is taken with respect to the state variable .
The posterior pdf is the target distribution for the update step of the score filter, implying that is the desired posterior score function at pseudo-time (recall the score function definition in Eq. 3). Further notice that is the prior pdf, hence is equivalent to the prior score function at pseudo time . This suggests that should be the likelihood portion of the posterior filtering score at pseudo time . Taking advantage of this link, we propose the following posterior score function
| (12) |
The prior score is already estimated from the forecast ensemble, and we will refer to as the likelihood score associated with the observational data . The coefficient multiplying the likelihood score is a damping function satisfying the following property:
is monotonically decreasing in with and .
We use for the SQG experiments reported in this paper. However, it should be emphasized there are multiple choices to define , and the question of which one is mathematically optimal remains open.
Having the posterior score , we can now use the discretized scheme in Eq. (10) to transport a set of samples from to the desired analysis ensemble from .
2.4 The Ensemble Score Filter (EnSF)
The estimation of score functions is a central topic in the score-based filtering approach discussed so far. The standard technique to estimate scores is via deep learning (Song et al. 2021; Bao et al. 2023b). Here, we introduce an ensemble approximation referred to as the Ensemble Score Filter (EnSF) which does not require the training of neural networks.
Since the likelihood score appearing in Eq. (12) can be computed explicitly in the Gaussian case considered here, the major computational effort in EnSF lies in evaluating the prior score . The latter can be achieved by setting to the forecast ensemble . From the definition of score functions and the choice of and in Eq. (4), we have that the conditional density needed in the forward SDE is given by
| (13) |
With this, marginalizing over yields the following score function
| (14) | ||||
where the weight function is defined by
| (15) |
and satisfies the condition .
Then, we can apply a Monte Carlo approximation for based on Eq. (14) at a given and :
| (16) |
where is a mini-batch of samples from the forecast ensemble , and is a Monte Carlo approximation of Eq. (15) such that
| (17) |
Having the estimated prior score , we can use Eq. (12) to write the approximate posterior score as
| (18) |
With these approximations in mind, we are finally in a position to summarize the EnSF algorithm:
Algorithm: Ensemble Score Filter (EnSF)
1: Input: The forecast model and initial state pdf ;
2: Generate samples from the initial pdf ;
3: for : % physical time loop
4: Run the forecast model to get the forecast ensemble ;
5: for : % pseudo-time loop for the backward SDE
6: Compute the weight using Eq. (17);
7: Compute using Eq. (16);
8: Compute and store using Eq. (18);
9: end
10: Compute using Eq. (10) and set ;
11: end
3 Experimental design
Before presenting our results, we outline some details on the numerical model and reference EnKF method used in this study.
3.1 Surface quasi-geostrophic (SQG) model
The SQG model belongs to a special class of quasi-geostrophic models in which a fluid of constant potential vorticity (PV) is bounded between two flat, rigid surfaces (Tulloch and Smith 2009b). Despite its idealized nature, the system is capable of simulating turbulent motions similar to those occurring in real geophysical flows (Smith et al. 2023). It is also suitable for DA studies because the SQG flow is inherently chaotic and sensitive to initial condition errors (Rotunno and Snyder 2008; Durran and Gingrich 2014).
In this study, we adopt the SQG formulation proposed by Tulloch and Smith (2009a) in which the dynamics reduce to the nonlinear Eady model with an f-plane approximation as well as uniform stratification and shear. For this case, the governing equations simplify to the advection of potential temperature on the bounding surfaces. Those equations are solved numerically by first applying a fast Fourier transform (FFT) to map model variables to spectral space. They are integrated forward with a 4-order Runge Kutta scheme that uses a dealiasing rule and implicit treatment of hyperdiffusion. Further numerical details and open-source code can be found on the GitHub page shared at the end of the paper.
3.2 Observing system simulation experiments
The EnSF performance is assessed with ensemble members using a standard observing system simulation experiment (OSSE) framework where synthetic observations are generated by corrupting the true (nature) run with random noise. The construction of the nature run mostly follows the details of Wang et al. (2021). Two notable exceptions are that we perform additional experiments with a higher resolution version of the model (96 96 points) and further carry out imperfect model experiments where the nature run is contaminated with unpredictable model errors.
More significant differences appear in the generation of synthetic observations. First, we utilize a 12-hour assimilation window. Compared to the 3-hour window of Wang et al. (2021), this constitutes a more challenging scenario as it creates larger differences with the true state and likely causes more significant departures from Gaussianity in the forecast ensemble. Moreover, we test a wider range of observing networks, starting with the simpler case of a fully observed state with linear observations and finishing with a partially and nonlinearly observed state (50 coverage) that is additionally subject to unexpected model errors. More specific details about the different observing networks are deferred to Section 4.
3.3 Reference LETKF method
While there is a vast array of available EnKF methods we could compare EnSF’s performance against, here we opt for the Local Ensemble Transform Kalman Filter (LETKF; Hunt et al. 2007). LETKF is a popular EnKF variant that is currently implemented in several major operational centers (e.g., Schraff et al. 2016; Frolov et al. 2024). One of the most appealing features of this method is its efficiency – the model state is decomposed into overlapping subdomains which are updated separately (and in parallel) using the analysis equations of the Ensemble Transform Kalman Filter (ETKF; Bishop et al. 2001). Our numerical implementation considers local regions surrounding single grid points defined by a cutoff radius. The cut-off radius is determined by standard Gaspari-Cohn (GC) taper functions (Gaspari and Cohn 1999), and we also apply the original -localization strategy of Hunt et al. (2007)222With R-localization, the local observation error variances are multiplied by the inverse GC function. to smoothly decrease the impact of observation away from each model grid point. Analogous to Wang et al. (2021), the vertical and horizontal localization scales are coupled dynamically through the Rossby radius of deformation. We also apply the relaxation to prior spread (RTPS) inflation discussed in Whitaker and Hamill (2012) in order to prevent underdispersive analysis ensembles as a result of the finite ensemble size. In most experiments, the inflation factor is optimally tuned for LETKF while EnSF currently sets RTPS to 1.
While the simultaneous use of localization and inflation can greatly improve LETKF’s performance, achieving optimal analysis results necessitates careful parameter tuning, which is computationally demanding in operational contexts. Moreover, sensitivity tests are required each time one makes changes to the NWP system (model resolution, type of assimilated observations, etc). Our initial results in Section 4 emphasize how LETKF’s skill is highly sensitive to suboptimal choices of localization and inflation even in the conceivably simpler case of a fully and linearly observed state. This will be contrasted with EnSF’s performance which leads to stable performance across all experiments and without any further ensemble regularization strategies (although additional experiments not presented in the paper suggest that optimal tuning of RTPS can further improve EnSF’s performance).
4 Results
The analysis skill of EnSF and LETKF is examined in the context of 4 different experimental settings with increasing complexity. Table 1 separates them according to the type of observations (linear vs. nonlinear) as this accounts for the largest filtering differences.
| Linear observations | Nonlinear observations |
| EXP_L1: fully observed state | EXP_NL1: fully observed state |
| EXP_L2: fully observed state subject to unknown model errors | EXP_NL2: partially observed state subject to unknown model errors |
4.1 Linear observations
In EXP_L1, we compare the performance of EnSF and LETKF in the case where the state of the SQG model is fully and linearly observed. Measurements are corrupted by additive Gaussian errors such that
| (19) |
with (i.e., the observation error variance is K). While this represents a fairly straightforward test for most conventional DA methods, the combination of a small ensemble size () and large number of independent observations will likely cause weight collapse in the traditional (bootstrap) particle filter. This compels us to first explore the stability properties of the new EnSF method.
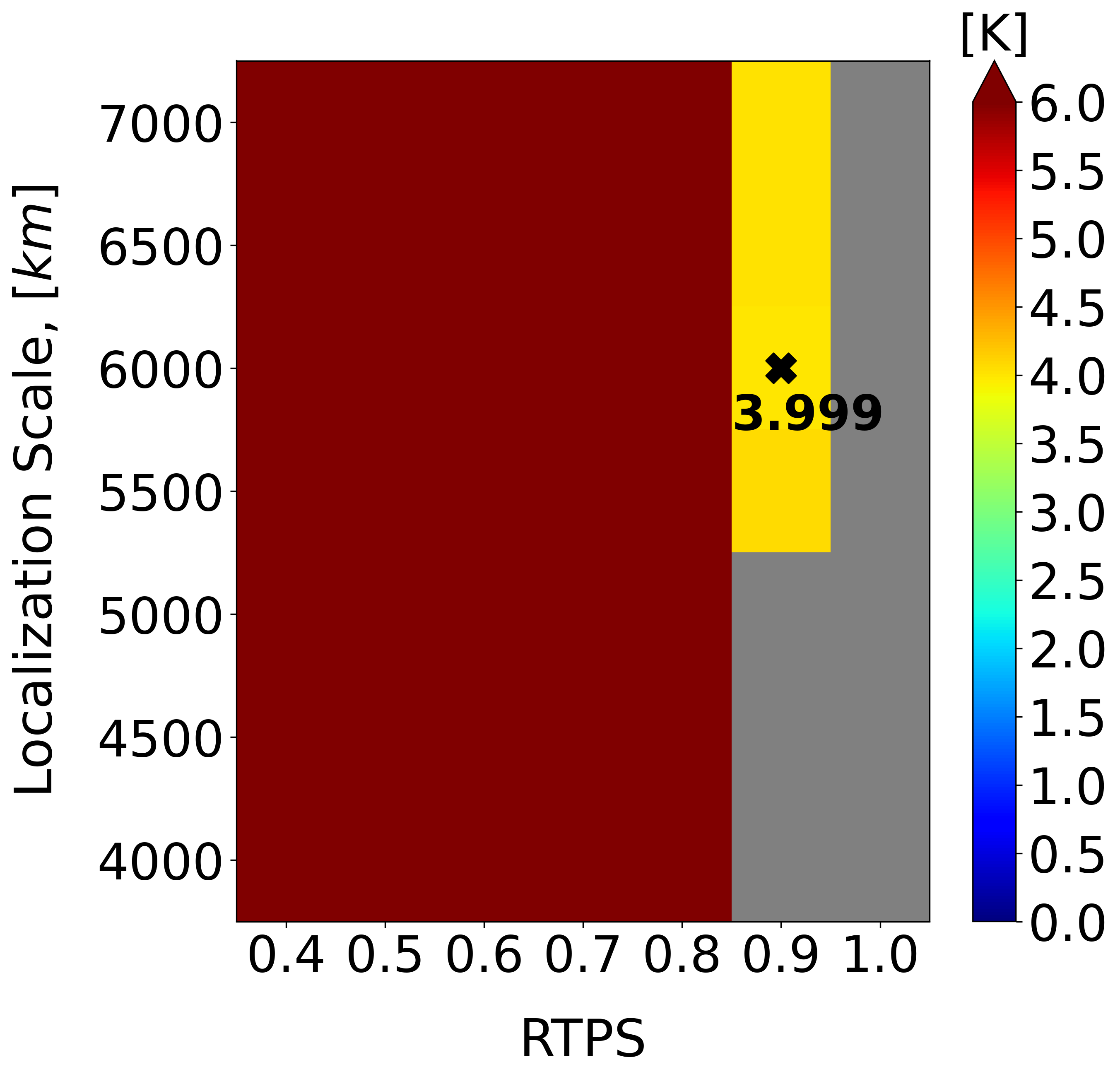
It was already discussed in Section 33.3 that one of the major obstacles with EnKFs is the need for a careful parameter tuning. The impact of suboptimal choices for these parameters is illustrated in Figure 1 where LETKF uses the same localization and inflation parameters as Fig. 11a of Wang et al. (2021) [horizontal localization scale of km and RTPS ]. Despite the physical realism of these parameter choices, we see that the LETKF experiment quickly diverges due to changes in the model resolution ( vs. grid points in the horizontal), assimilation period (12h vs. 3h) and number of observations (fully vs. partially observed state). By contrast, EnSF demonstrates stable performance throughout all 300 assimilation cycles without requiring any additional parameter tuning.
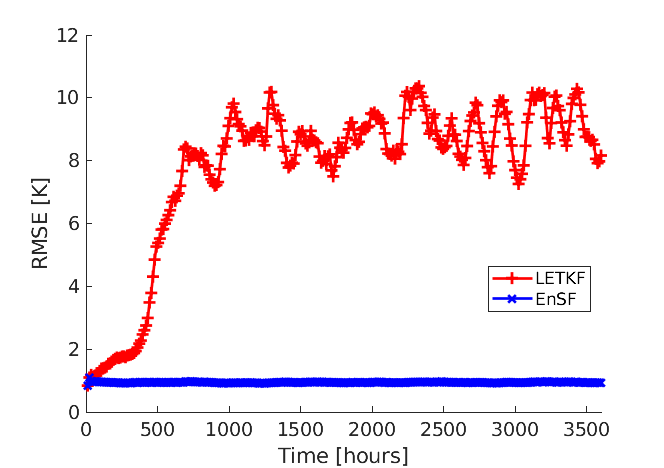
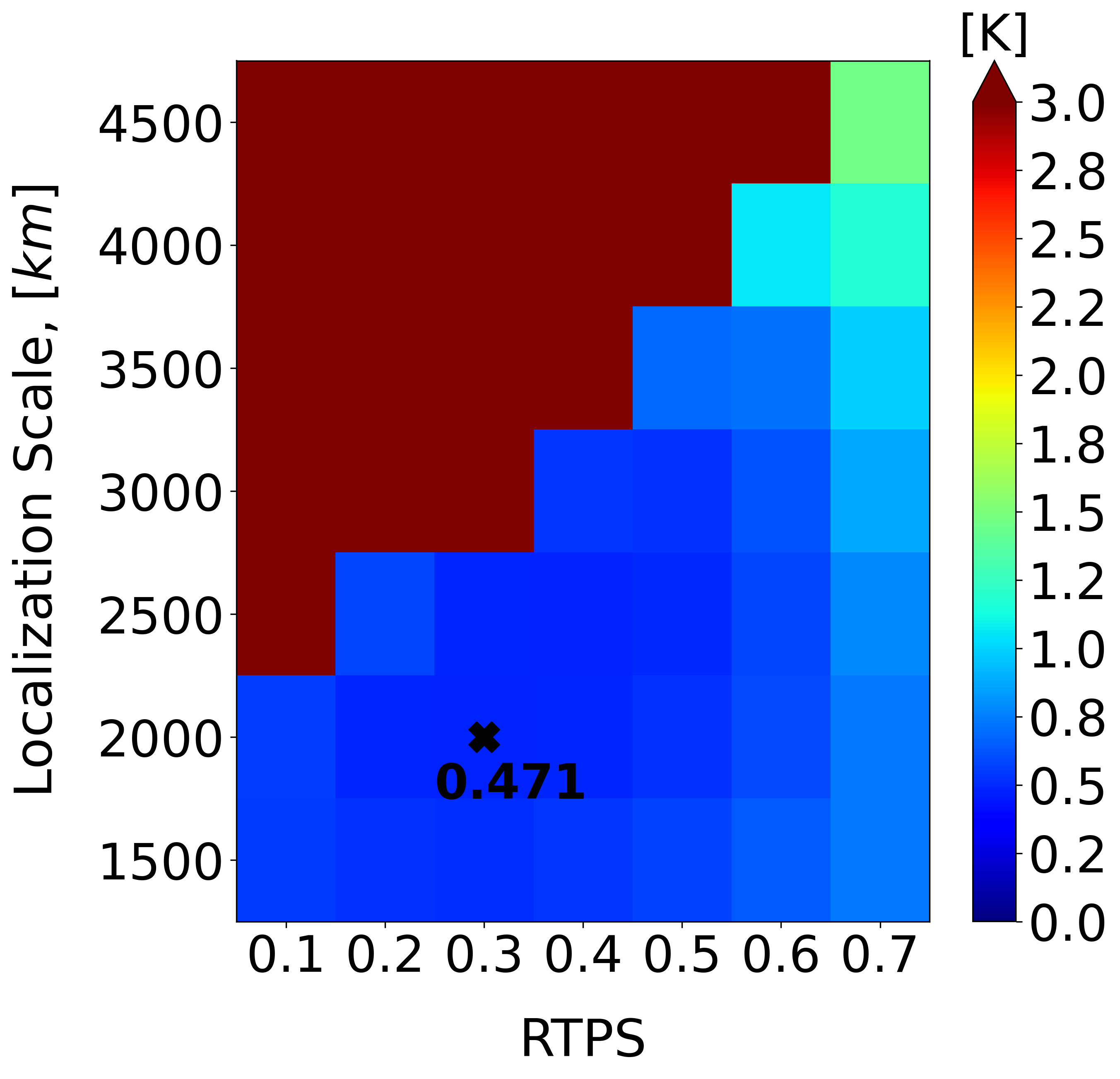
To achieve a fair comparison between the two DA methods in this linear observation regime, our next step is to optimize LETKF’s localization and inflation parameters. We revert back to the coarser model resolution of horizontal grid points and see from Figure 2a that the best LETKF performance is achieved with km and RTPS = . Evidently, LETKF performs slightly better in this case. However, it is worth noting that EnSF continues to maintain stable performance despite the change in model resolution and lack of additional parameter tuning. EnSF’s sensitivity to different parameter settings will be the subject of future work and is expected to further reduce the gap between the two filtering techniques in this linear regime (EXP_L1).
In the next experimental setting EXP_L2, we address the more challenging but realistic scenario involving an imperfect model. While still assuming direct measurements of all state variables, we add an a-priori unknown stochastic noise to the SQG state evolution. Assuming the noise is Gaussian, the modified stochastic-dynamic model can be written as
| (20) |
The covariance matrix is taken to be diagonal as we want to impose spatially uncorrelated model noise. We also assume that the unknown model errors are white in time (i.e., no temporal correlations). More specifically, in EXP_L2 is defined as the composition of four distinct state-dependent error processes: (1) chance of occurrence (in time) with model noise, (2) chance of occurrence with model noise, (3) chance of occurrence with model noise, and (4) chance of occurrence with model noise. The purpose of introducing this variety of model errors is to simulate the effects of flow-dependent model uncertainties. For example, the rare occurrence of high-amplitude model errors in the 4 process might be associated with the rapid development of dynamical instabilities in the field. The study of Held et al. (1995) shows examples of such instabilities and discusses how they tend to form along temperature filaments (see their Fig. 2).
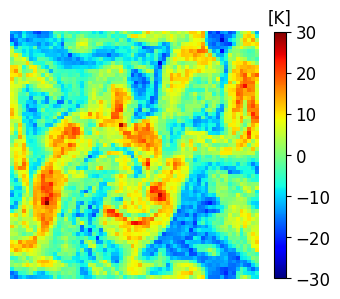
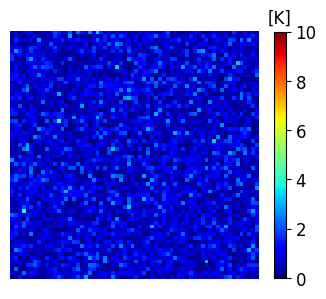
It is crucial to highlight that although we specified a particular structure for the time-dependent error process , obtaining an explicit expression for is impractical in reality. Consequently, adjusting the LETKF inflation and localization parameters to account for the unknown model errors is not feasible. In Figure 3, we visually illustrate the impact of adding model errors of various amplitude to the true state at the final time.
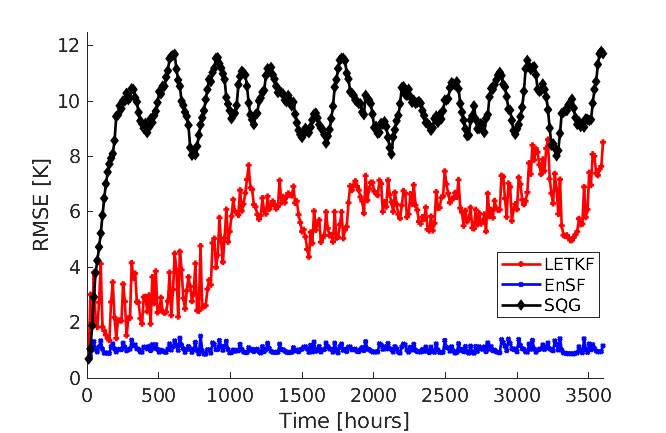
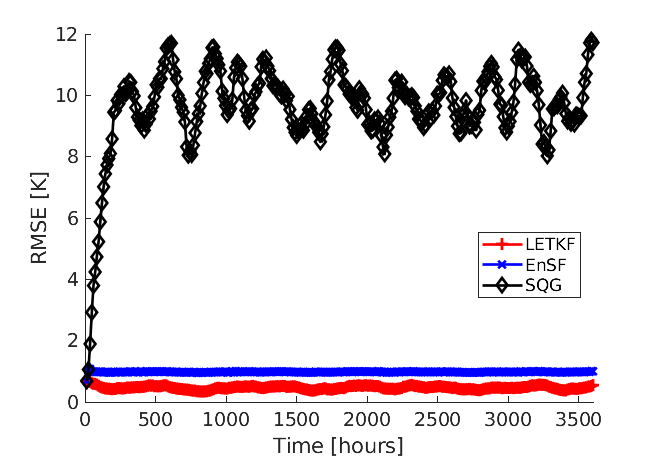
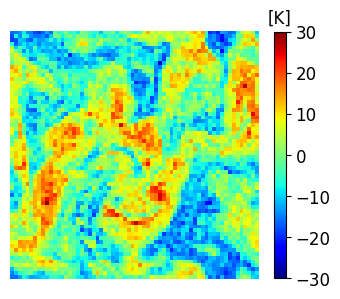
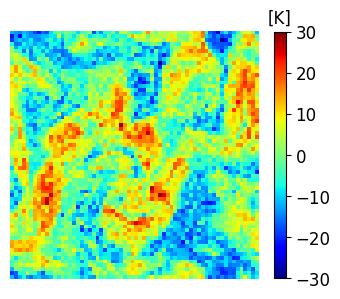
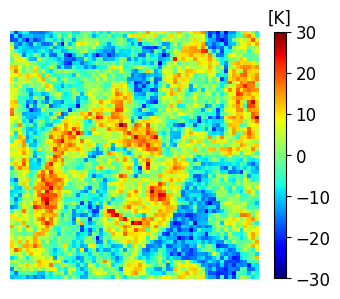
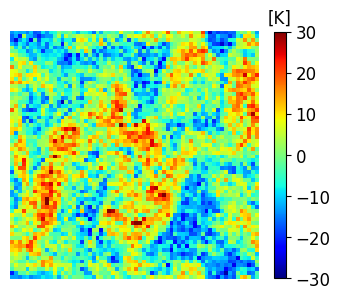
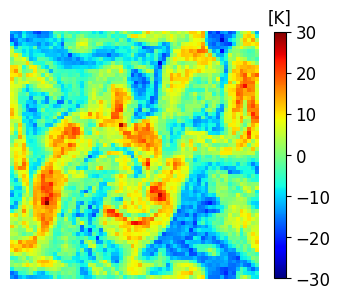
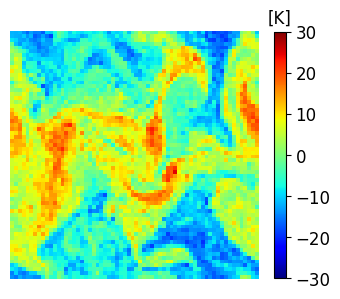
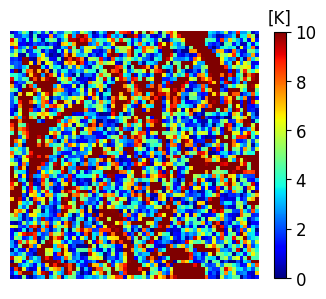
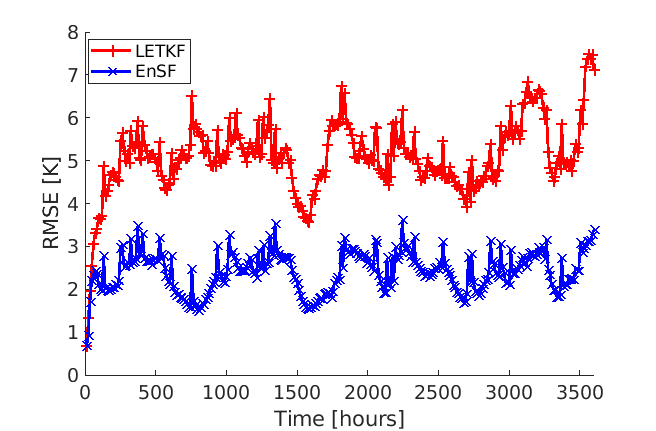
A comparison between the analysis RMSE errors of EnSF and LETKF in EXP_L2 is presented in Figure 4. Unlike our previous experiment, LETKF diverges from the true state as model errors accumulate in time, with analysis RMSEs now comparable to the free forecast run where no observations are assimilated. This finding offers additional evidence for the enhanced sensitivity of LETKF to model imperfections – without the implementation of more advanced regularization techniques (e.g., adaptive inflation), LETKF will be susceptible to analysis errors even when nearly optimal parameters have been used and the system is fully and linearly observed. This is to be contrasted with EnSF’s performance where we achieve stable performance throughout all analysis cycles despite the lack of any further tuning. A snapshot of these differences at the last analysis time is shown in Figure 5. The top 3 figures offer a visual confirmation that EnSF’s analysis mean (panel b) is much closer to the truth (panel a). While LETKF (panel c) does well at representing large-scale patterns, it struggles to capture some of the small-scale features and extreme values in the potential temperature field. The larger error magnitude in LETKF is also confirmed by the two error plots in the second row.
4.2 Nonlinear observations
In the second round of experiments, the synthetically generated observations are nonlinear functions of the SQG state. Specifically, we consider an arctangent nonlinearity and additive Gaussian observation errors. The observation model relevant to EXP_NL1 from Table 1 can be written as
Notice that the observation error variance is scaled relative to the linear observation experiments in order to reflect the narrower range of the arctangent function. In this case, we choose . Moreover, EXP_NL1 tests are carried out in the absence of unpredictable model shocks.
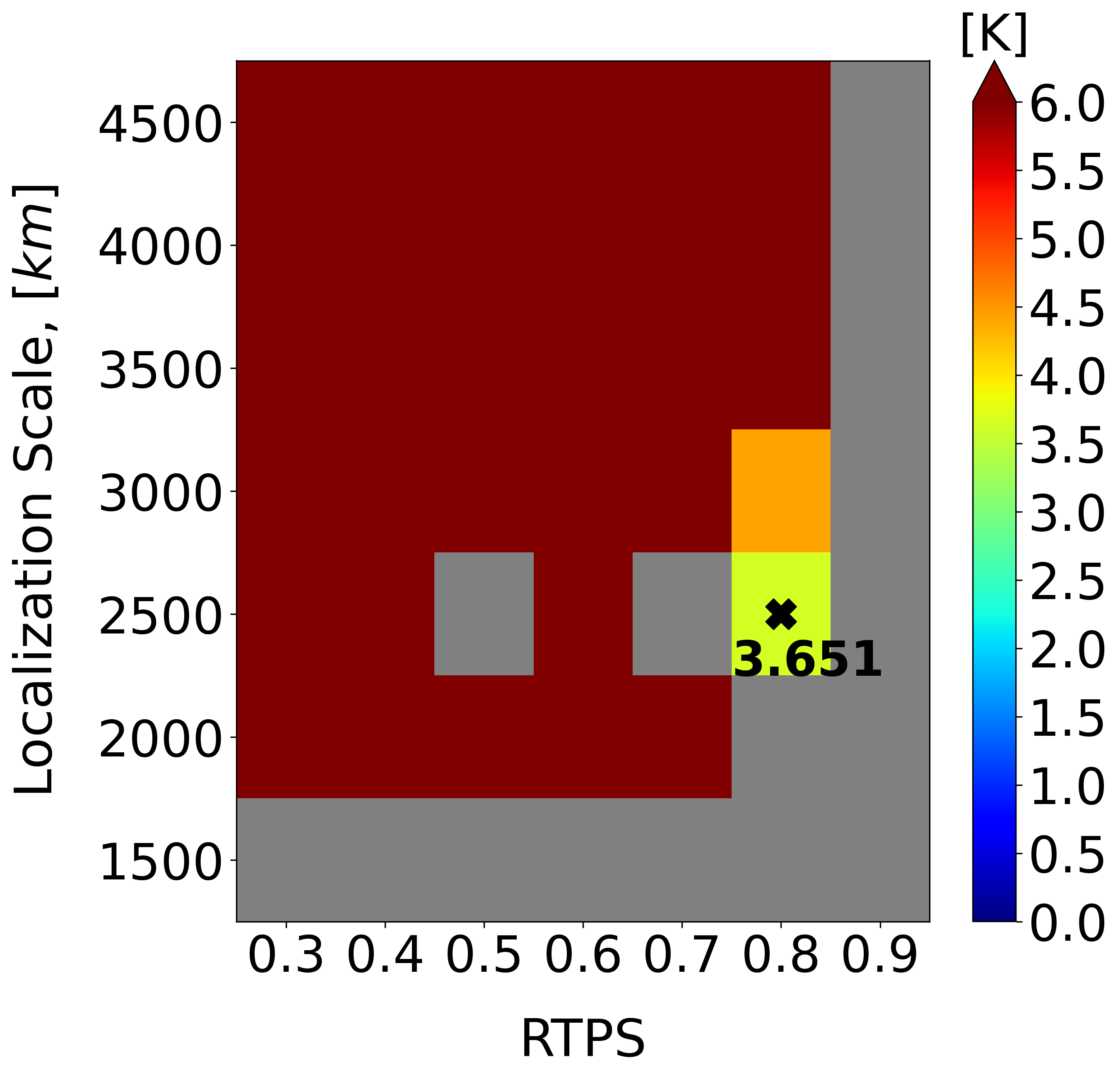
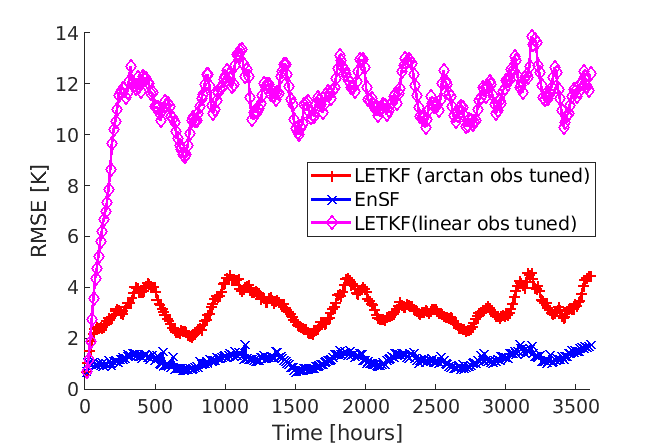
Analogous to the linear observation setting, stabilizing LETKF’s performance requires extensive parameter tuning. Figure 6a indicates the existence of a very narrow range of optimal localization and inflation parameters for which LETKF does not diverge – a manifestation of the strong deviations from non-Gaussianity in the posterior distribution. The red curve in Figure 6b confirms that this best tuned LETKF maintains stability during the entire experiment. On the other hand, a naive substitution of the optimal LETKF parameters from the linear observation setting results in a rapidly diverging filter (magenta curve in Figure 6b). While this comparison admittedly constitutes an extreme modification of the observing system, it reaffirms our earlier point that any changes in operational NWP systems require costly calibrations of the underlying EnKF algorithm. By contrast, EnSF systematically outperforms the best LETKF configuration without further application of ensemble regularization strategies.
Our last experimental setting EXP_NL2 considers the most complex DA scenario – only half of the SQG state is observed nonlinearly such that
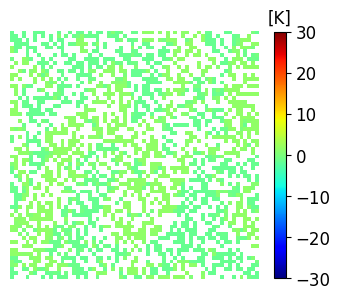
where is a selection matrix determining which state variables are observed at a given time level . Similar to Wang et al. (2021), we implement a procedure which randomly selects the observed model grid points for each . An example realization of the nonlinear observations is presented in Figure 7b. Comparison with the true field in Figure 7a serves as a good illustration for the squashing effect of the arctangent nonlinearity, and the general difficulty of extracting useful information from observations with a severely limited numerical range.
We also work under the imperfect model assumption described by Eq. (20), but choose a simpler definition for the unknown model errors . In particular, a single stochastic noise is added 10% of the time with a magnitude that equals 30% of the nature run’s values.
Under the challenging DA setting of EXP_NL2, we find that EnSF’s analysis RMSEs remain nearly intact (compare blue curves in Figures 6b and 8b), while LETKF (Figure 8a) exhibits a visible skill deterioration (compare red curves in Figures 6b and 8b) despite our efforts to fine tune its performance for this case.
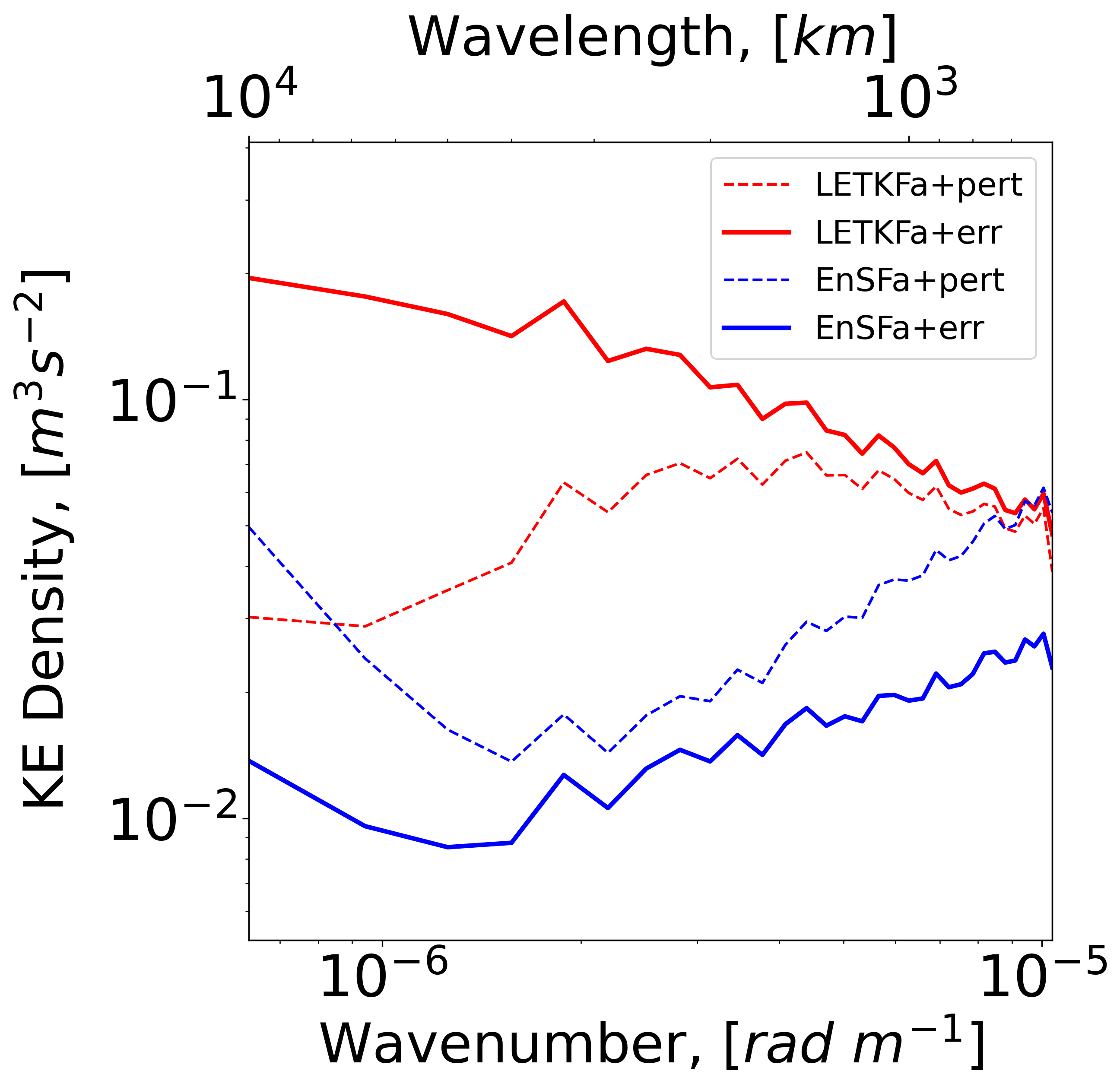
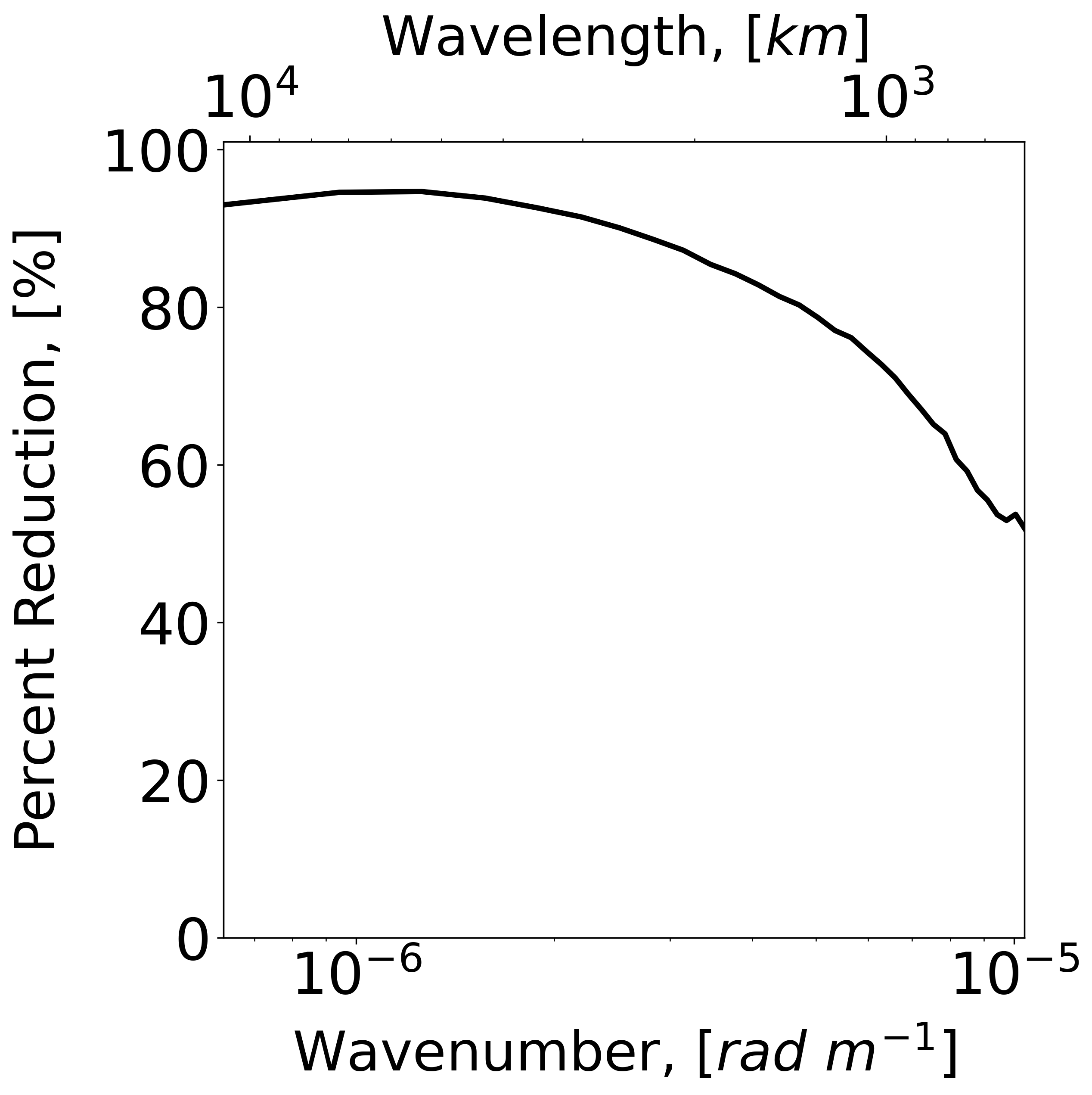
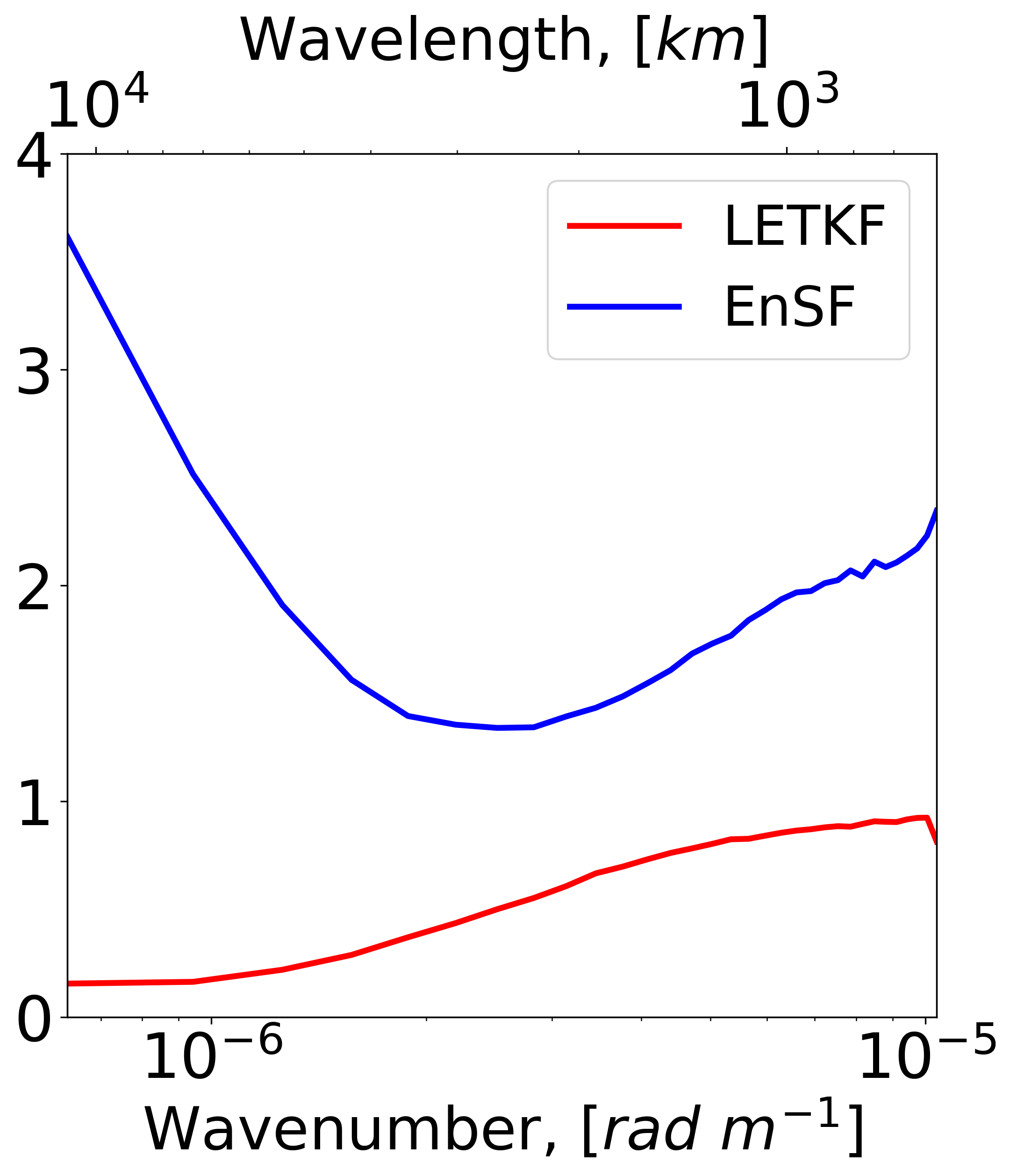
Given the multiscale characteristics of the SQG model, we conclude this section by presenting a spectral comparison of the EnSF and LETKF results in Figure 9. The plotted diagnostics still refer to the EXP_NL2 setting (partially and nonlinearly observed state corrupted by unpredictable model errors) but are now averaged in time. Examination of the solid red and blue curves in panel (a) indicates that EnSF has consistently lower analysis errors for all wavenumbers, but the most significant improvements occur at large scales (also refer to panel b). Focusing our attention on the LETKF results (red cuferves), we notice a systematic underdispersion of the analysis ensemble, which is most pronounced at large scales (panel c). This is perhaps one of the important reasons why a large number of LETKF experiments diverge in EXP_NL2. A different situation emerges for EnSF (blue curves) which tends to be overdispersive on average (panel c). This behavior is connected to the specific inflation settings used in EnSF (RTPS ) but is likely also influenced by our choice of SDE and score parameters such as and . We hypothesize that an optimal selection of these parameters will further improve EnSF’s performance and lead to a better spread-error consistency. Nevertheless, it is clear that even this “vanilla” implementation of EnSF offers significant performance benefits over LETKF.
5 Conclusions
In this study, we introduced a stable and highly efficient implementation of the Ensemble Score Filter (EnSF) for sequential data assimilation with geophysical systems. The theoretical basis for EnSF comes from diffusion models – an extremely popular class of generative AI (GenAI) methods which have the ability to produce highly realistic images and videos. Like other diffusion-based techniques, EnSF uses score functions (the gradient of the log probability) to store complex information about the underlying filtering (posterior) distribution. However, sampling from the posterior utilizes a training-free, Monte Carlo procedure which only requires access to the forecast ensemble members.
The resulting algorithm is applied to the surface quasi-geostrophic (SQG) model and compared against a benchmark Local Ensemble Transform Kalman Filter (LETKF). The analysis performance of both methods is explored in a hierarchy of experiments with increasing complexity. While they demonstrate comparable skill in the case of a fully and linearly observed state, EnSF performs significantly better when observations are partial and nonlinear, as well as when the model is subject to unexpected errors. We report stable EnSF performance in all experiments despite the lack of localization and additional parameter tuning. Even though we only use 20 ensemble members in our experiments, the results suggest that EnSF can reliably capture the non-Gaussian characteristics of a high-dimensional state with components. Although LETKF is competitive or even slightly more skillful in the linear observation case, the results are highly sensitive to the choice of inflation and localization parameters; this effect is even more pronounced with nonlinear observations when slight changes in the LETKF settings often lead to rapid filter divergence.
The EnSF findings outlined in this study are very encouraging and suggest a few possible avenues for further development. An immediate extension of this work will be to explore the sensitivity of EnSF to different types of observing networks. Moreover, we believe the algorithm will benefit from additional theoretical refinements. One ongoing line of research from the authors is to derive an optimal damping function . Given the important role of in determining how observations are incorporated in the diffusion-based filtering procedure (cf. Eq. 12), we expect to see further improvements in EnSF’s analysis performance. Although localization was not required to prevent filter divergence in the SQG context, more work is still needed to understand how sampling errors affect EnSF in higher dimensions. Together with a suitable choice for , an optimally designed localization scheme is expected to make EnSF comparable to a fine-tuned LETKF in linear-Gaussian regimes.
5.0.1 Acknowledgements.
This material is based upon work supported by the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research, Applied Mathematics program under the contract ERKJ387 at the Oak Ridge National Laboratory, which is operated by UT-Battelle, LLC, for the U.S. Department of Energy under Contract DE-AC05-00OR22725. The first author (FB) would also like to acknowledge support from the U.S. National Science Foundation through project DMS-2142672 and the support from the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research, Applied Mathematics program under Grant DE-SC0022297. The computing for this project was performed on the high performance computing (HPC) cluster at the Florida State University Research Computing Center.
5.0.2 Data availability statement.
All code written as part of this study will be made available on GitHub upon completing the peer-review process for this article. An open-source version of the SQG model used in our experiments can be found at https://github.com/jswhit/sqgturb.
References
- Aksoy et al. (2009) Aksoy, A., D. Dowell, and C. Snyder, 2009: A multicase comparative assessment of the ensemble Kalman filter for assimilation of radar observations. Part I: Storm-scale analyses. Mon. Wea. Rev., 137, 1805–1824, doi:10.1175/2008MWR2691.1.
- Aksoy et al. (2010) Aksoy, A., D. Dowell, and C. Snyder, 2010: A multicase comparative assessment of the ensemble Kalman filter for assimilation of radar observations. Part II: Short-range ensemble forecasts. Mon. Wea. Rev., 138, 1273–1292, doi:10.1175/2009MWR3086.1.
- Anderson (2001) Anderson, J. L., 2001: An ensemble adjustment Kalman filter for data assimilation. Mon. Wea. Rev., 129, 2884–2903, doi:10.1175/1520-0493(2001)129<2884:AEAKFF>2.0.CO;2.
- Anderson (2022) Anderson, J. L., 2022: A quantile-conserving ensemble filter framework. Part I: Updating an observed variable. Mon. Wea. Rev., 150, 1061–1074, doi:10.1175/MWR-D-21-0229.1.
- Anderson (2023) Anderson, J. L., 2023: A quantile-conserving ensemble filter framework. Part II: Regression of observation increments in a probit and probability integral transformed space. Mon. Wea. Rev., 151, 2759–2777, doi:10.1175/MWR-D-23-0065.1.
- Bao et al. (2016) Bao, F., Y. Cao, A. Meir, and W. Zhao, 2016: A first order scheme for backward doubly stochastic differential equations. SIAM/ASA J. Uncertain. Quantif., 4 (1), 413–445.
- Bao et al. (2023a) Bao, F., Z. Zhang, and G. Zhang, 2023a: An ensemble score filter for tracking high-dimensional nonlinear dynamical systems. arXiv, 1–17, doi:arXiv:2309.00983.
- Bao et al. (2023b) Bao, F., Z. Zhang, and G. Zhang, 2023b: A score-based nonlinear filter for data assimilation. arXiv, 1–20, doi:arXiv:2306.09282.
- Bao et al. (2023c) Bao, F., Z. Zhang, and G. Zhang, 2023c: A unified filter method for jointly estimating state and parameters of stochastic dynamical systems via the ensemble score filter. arXiv, 1–24, doi:arXiv:2312.10503.
- Baranchuk et al. (2022) Baranchuk, D., A. Voynov, I. Rubachev, V. Khrulkov, and A. Babenko, 2022: Label-efficient semantic segmentation with diffusion models. International Conference on Learning Representations, URL https://openreview.net/forum?id=SlxSY2UZQT.
- Bishop et al. (2001) Bishop, C. H., B. J. Etherton, and S. J. Majumdar, 2001: Adaptive sampling with the ensemble transform Kalman filter. Part I: Theoretical aspects. Mon. Wea. Rev., 129, 420–436, doi:10.1175/1520-0493(2001)129<0420:ASWTET>2.0.CO;2.
- Chan et al. (2020) Chan, M.-Y., J. Anderson, and X. Chen, 2020: An efficient bi-Gaussian ensemble Kalman filter for satellite infrared radiance data assimilation. Mon. Wea. Rev., 148, 5087–5104, doi:10.1175/MWR-D-20-0142.1.
- Chipilski (2023) Chipilski, H. G., 2023: Exact nonlinear state estimation. arXiv, 1–31, doi:10.48550/arXiv.2310.10976.
- Chipilski et al. (2020) Chipilski, H. G., X. Wang, and D. B. Parsons, 2020: Impact of assimilating PECAN profilers on the prediction of bore-driven nocturnal convection: A multiscale forecast evaluation for the 6 july 2015 case study. Mon. Wea. Rev., 148, 1147–1175, doi:10.1175/MWR-D-19-0171.1.
- Chipilski et al. (2022) Chipilski, H. G., X. Wang, D. B. Parsons, A. Johnson, and S. K. Degelia, 2022: The value of assimilating different ground-based profiling networks on the forecasts of bore-generating nocturnal convection. Mon. Wea. Rev., 150, 1273–1292, doi:10.1175/MWR-D-21-0193.1.
- Crisan and Doucet (2002) Crisan, D., and A. Doucet, 2002: A survey of convergence results on particle filtering methods for practitioners. IEEE Transactions on Signal Processing, 50, 736–746, doi:10.1109/78.984773.
- Durran and Gingrich (2014) Durran, D. R., and M. Gingrich, 2014: Atmospheric predictability: why butterflies are not of practical importance. Journal of the Atmospheric Sciences, 71, 2476–2488, doi:10.1175/JAS-D-14-0007.1.
- Evensen (1994) Evensen, G., 1994: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J. Geophys. Res., 99, 10 143–10 162, doi:10.1029/94JC00572.
- Fletcher (2010) Fletcher, S. J., 2010: Mixed Gaussian-lognormal four-dimensional data assimilation. Tellus A: Dynamic Meteorology and Oceanography, 62, 266–287, doi:10.1111/j.1600-0870.2009.00439.x.
- Fletcher et al. (2023) Fletcher, S. J., and Coauthors, 2023: Lognormal and mixed Gaussian-lognormal Kalman filters. Mon. Wea. Rev., 151, 761–774, doi:0.1175/MWR-D-22-0072.1.
- Frolov et al. (2024) Frolov, S., and Coauthors, 2024: Local volume solvers for Earth system data assimilation: Implementation in the framework for Joint Effort for Data Assimilation Integration. Journal of Advances in Modeling Earth Systems, 16, e2023MS003 692, doi:10.1029/2023MS003692.
- Gaspari and Cohn (1999) Gaspari, G., and S. Cohn, 1999: Construction of correlation functions in two and three dimensions. Quart. J. Roy. Meteor. Soc., 125, 723–757, doi:10.1002/qj.49712555417.
- Gordon et al. (1993) Gordon, N. J., D. J. Salmond, and A. F. M. Smith, 1993: Novel approach to nonlinear/non-Gaussian Bayesian state estimation. Proc. Inst. Elect. Eng. F, 1400, 107–113.
- Held et al. (1995) Held, I. M., R. T. Pierrehumbert, S. T. Garner, and K. L. Swanson, 1995: Surface quasi-geostrophic dynamics. J. Fluid Mech., 282, 1–20, doi:10.1017/S0022112095000012.
- Hu and van Leeuwen (2021) Hu, C.-C., and P. J. van Leeuwen, 2021: A particle flow filter for high-dimensional system applications. Quart. J. Roy. Meteor. Soc., 147, 2352–2374, doi:10.1002/qj.4028.
- Hu et al. (2023) Hu, G., S. L. Dance, R. N. Bannister, H. G. Chipilski, O. Guillet, B. Macpherson, M. Weissmann, and N. Yussouf, 2023: Progress, challenges, and future steps in data assimilation for convection-permitting numerical weather prediction: Report on the virtual meeting held on 10 and 12 november 2021. Atmos. Sci. Let., 24, e1130, doi:10.1002/asl.1130.
- Hunt et al. (2007) Hunt, B. R., E. J. Kostelich, and I. Szunyogh, 2007: Efficient data assimilation for spatiotemporal chaos: A local ensemble transform Kalman filter. Physica D, 230, 112–126, doi:10.1016/j.physd.2006.11.008.
- Isaksen et al. (2010) Isaksen, L., M. Bonaita, R. Buizza, M. Fisher, J. Haseler, M. Leutbecher, and L. Raynaud, 2010: Ensemble of data assimilations at ECMWF. ECMWF Technical Memoranda, 636, 1–41.
- Jones et al. (2010) Jones, T. A., K. Knopfmeier, D. Wheatley, G. Creager, P. Minnis, and R. Palikonda, 2010: Storm-scale data assimilation and ensemble forecasting with the NSSL experimental Warn-on-Forecast system. Part II: Combined radar and satellite data experiments. Wea. Forecasting, 30, 1795–1817, doi:10.1175/WAF-D-15-0043.1.
- Kloeden and Platen (1992) Kloeden, P. E., and E. Platen, 1992: Numerical solution of stochastic differential equations, Applications of Mathematics (New York), Vol. 23. Springer-Verlag, Berlin, xxxvi+632 pp.
- Luo and Hu (2021) Luo, S., and W. Hu, 2021: Score-based point cloud denoising. 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, IEEE, 4563–4572, doi:10.1109/ICCV48922.2021.00454, URL https://doi.org/10.1109/ICCV48922.2021.00454.
- Milstein (1975) Milstein, G. N., 1975: Approximate integration of stochastic differential equations. Theory of probability & its applications, 19, 557–562, doi:10.1137/1119062.
- Poterjoy (2022) Poterjoy, J., 2022: Implications of multivariate non-Gaussian data assimilation for multi-scale weather prediction. Mon. Wea. Rev., 150, 1475–1493, doi:10.1175/MWR-D-21-0228.1.
- Poterjoy et al. (2017) Poterjoy, J., R. A. Sobash, and J. L. Anderson, 2017: Convective-scale data assimilation for the Weather Research and Forecasting model using the local particle filter. Mon. Wea. Rev., 145, 1897–1918, doi:10.1175/MWR-D-16-0298.1.
- Pulido and van Leeuwen (2019) Pulido, M., and P. J. van Leeuwen, 2019: Sequential Monte Carlo with kernel embedded mappings: The mapping particle filter. J. Comp. Phys., 396, 400–415, doi:10.1016/j.jcp.2019.06.060.
- Rojahn et al. (2023) Rojahn, A., N. Schenk, P. J. van Leeuwen, and R. Potthast, 2023: Particle filtering and Gaussian mixtures - on a localized mixture coefficients particle filter (LMCPF) for global NWP. J. Meteor. Soc. Japan, 101, 233–253, doi:10.2151/jmsj.2023-015.
- Rotunno and Snyder (2008) Rotunno, R., and C. Snyder, 2008: A generalization of Lorenz’s model for the predictability of flows with many sclaes of motion. J. Atmos. Sci., 65, 1063–1076, doi:10.1175/2007JAS2449.1.
- Schraff et al. (2016) Schraff, C., H. Reich, A. Rhodin, A. Schomburg, K. Stephan, A. Periáñez, and R. Potthast, 2016: Kilometre-scale ensemble data assimilation for the COSMO model (KENDA). Quart. J. Roy. Meteor. Soc., 142, 1453–1472, doi:10.1002/qj.2748.
- Smith et al. (2023) Smith, T. A., S. G. Penny, J. A. Platt, and T.-C. Chen, 2023: Temporal subsampling diminishes small spatial scales in recurrent neural network emulators of geophysical turbulence. Journal of Advances in Modeling Earth Systems, 15, e2023MS003 792, doi:10.1029/2023MS003792.
- Song et al. (2021) Song, Y., J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, 2021: Score-based generative modeling through stochastic differential equations. International Conference on Learning Representations, URL https://openreview.net/forum?id=PxTIG12RRHS.
- Spantini et al. (2022) Spantini, A., R. Baptista, and Y. Marzouk, 2022: Coupling techniques for nonlinear ensemble filtering. SIAM Review, 144, 921–953, doi:10.1137/20M1312204.
- Tödter et al. (2016) Tödter, J., P. Kirchgessner, L. Nerger, and B. Ahrens, 2016: Assessment of a nonlinear ensemble transform filter for high-dimensional data assimilation. Mon. Wea. Rev., 144, 409–427, doi:10.1175/MWR-D-15-0073.1.
- Tulloch and Smith (2009a) Tulloch, R., and K. S. Smith, 2009a: A note on the numerical presentation of surface dynamics in quasigeostrophic turbulence. J. Atmos. Sci., 66, 1063–1068, doi:10.1175/2008JAS2921.1.
- Tulloch and Smith (2009b) Tulloch, R., and K. S. Smith, 2009b: Quasigeostrophic turbulence with explicit surface dynamics: Application to the atmospheric energy spectrum. J. Atmos. Sci., 66, 450–467, doi:10.1175/2008JAS2653.1.
- van Leeuwen (2009) van Leeuwen, P. J., 2009: Particle filtering in geophysical systems. Mon. Wea. Rev., 137, 4089–4114, doi:10.1175/2009MWR2835.1.
- van Leeuwen et al. (2019) van Leeuwen, P. J., H. R. Künsch, L. Nerger, R. Potthast, and S. Reich, 2019: Particle filters for high-dimensional geoscience applications: a review. Quart. J. Roy. Meteor. Soc., 145, 2335–2365, doi:10.1002/qj.3551.
- Wang et al. (2021) Wang, X., H. G. Chipilski, C. H. Bishop, E. Satterfield, N. Baker, and J. S. Whitaker, 2021: A multiscale local gain form ensemble transform kalman filter (MLGETKF). Mon. Wea. Rev., 149, 605–622, doi:10.1175/MWR-D-20-0290.1.
- Whitaker and Hamill (2012) Whitaker, J. S., and T. Hamill, 2012: Evaluating methods to account for system rrrors in ensemble data assimilation. Mon. Wea. Rev., 140, 3078–3089, doi:10.1175/MWR-D-11-00276.1.