Tuhin Sarkar \Emailtsarkar@mit.edu
\addr77 Massachusetts Ave, Cambridge, MA 02139
and \NameAlexander Rakhlin \Emailrakhlin@mit.edu
\addr77 Massachusetts Ave, Cambridge, MA 02139
and \NameMunther A. Dahleh \Emaildahleh@mit.edu
\addr77 Massachusetts Ave, Cambridge, MA 02139
Nonparametric Finite Time LTI System Identification
Abstract
We address the problem of learning the parameters of a stable linear time invariant (LTI) system or linear dynamical system (LDS) with unknown latent space dimension, or order, from a single time–series of noisy input-output data. We focus on learning the best lower order approximation allowed by finite data. Motivated by subspace algorithms in systems theory, where the doubly infinite system Hankel matrix captures both order and good lower order approximations, we construct a Hankel-like matrix from noisy finite data using ordinary least squares. This circumvents the non-convexities that arise in system identification, and allows accurate estimation of the underlying LTI system. Our results rely on careful analysis of self-normalized martingale difference terms that helps bound identification error up to logarithmic factors of the lower bound. We provide a data-dependent scheme for order selection and find an accurate realization of system parameters, corresponding to that order, by an approach that is closely related to the Ho-Kalman subspace algorithm. We demonstrate that the proposed model order selection procedure is not overly conservative, i.e., for the given data length it is not possible to estimate higher order models or find higher order approximations with reasonable accuracy.
keywords:
Linear Dynamical Systems, System Identification, Non–parametric statistics, control theory, Statistical Learning theory1 Introduction
Finite-time system identification—the problem of estimating the system parameters given a finite single time series of its output—is an important problem in the context of control theory, time series analysis, robotics, and economics, among many others. In this work, we focus on parameter estimation and model approximation of linear time invariant (LTI) systems or linear dynamical system (LDS), which are described by
| (1) |
Here ; are process and output noise, is an external control input, is the latent state variable and is the observed output. The goal here is parameter estimation, i.e., learning from a single finite time series of when the order, , is unknown. Since typically , it becomes challenging to find suitable parametrizations of LTI systems for provably efficient learning. When are observed (or, is known to be the identity matrix), identification of in Eq. (1) is significantly easier, and ordinary least squares (OLS) is a statistically optimal estimator. It is, in general, unclear how (or if) OLS can be employed in the case when ’s are not observed.
To motivate the study of a lower-order approximation of a high-order system, consider the following example:
Example 1.1.
Consider with
| (2) |
where and . Here the order of is . However, it can be approximated well by which is of a much lower order and given by
| (3) |
For the same input , if be the output generated by and respectively then a simple computation shows that
This suggests that the actual value of is not important; rather there exists an effective order, (which is in this case). This lower order model captures “most” of the LTI system.
Since the true model order is not known in many cases, we emphasize a nonparametric approach to identification: one which adaptively selects the best model order for the given data and approximates the underlying LTI system better as (length of data) grows. The key to this approach will be designing an estimator from which we obtain a realization of the selected order.
1.1 Related Work
Linear time invariant systems are an extensively studied class of models in control and systems theory. These models are used in feedback control systems (for example in planetary soft landing systems for rockets (Açıkmeşe et al., 2013)) and as linear approximations to many non–linear systems that nevertheless work well in practice. In the absence of process and output noise, subspace-based system identification methods are known to learn (up to similarity transformation)(Ljung, 1987; Van Overschee and De Moor, 2012). These typically involve constructing a Hankel matrix from the input–output pairs and then obtaining system parameters by a singular value decomposition. Such methods are inspired by the celebrated Ho-Kalman realization algorithm (Ho and Kalman, 1966). The correctness of these methods is predicated on the knowledge of or presence of infinite data. Other approaches include rank minimization-based methods for system identification (Fazel et al., 2013; Grussler et al., 2018), further relaxing the rank constraint to a suitable convex formulation. However, there is a lack of statistical guarantees for these algorithms, and it is unclear how much data is required to obtain accurate estimates of system parameters from finite noisy data. Empirical methods such as the EM algorithm (Dempster et al., 1977) are also used in practice; however, these suffer from non-convexity in problem formulation and can get trapped in local minima. Learning simpler approximations to complex models in the presence of finite noisy data was studied in Venkatesh and Dahleh (2001) where identification error is decomposed into error due to approximation and error due to noise; however the analysis assumes the knowledge of a “good” parametrization and does not provide statistical guarantees for learning the system parameters of such an approximation.
More recently, there has been a resurgence in the study of statistical identification of LTI systems from a single time series in the machine learning community. In cases when , i.e., is observed directly, sharp finite time error bounds for identification of from a single time series are provided in Faradonbeh et al. (2017); Simchowitz et al. (2018); Sarkar and Rakhlin (2018). The approach to finding is based on a standard ordinary least squares (OLS) given by
Another closely related area is that of online prediction in time series Hazan et al. (2018); Agarwal et al. (2018). Finite time regret guarantees for prediction in linear time series are provided in Hazan et al. (2018). The approach there circumvents the need for system identification and instead uses a filtering technique that convolves the time series with eigenvectors of a specific Hankel matrix.
Closest to our work is that of Oymak and Ozay (2018). Their algorithm, which takes inspiration from the Kalman–Ho algorithm, assumes the knowledge of model order . This limits the applicability of the algorithm in two ways: first, it is unclear how the techniques can be extended to the case when is unknown—as is usually the case—and, second, in many cases is very large and a much lower order LTI system can be a very good approximation of the original system. In such cases, constructing the order estimate might be unnecessarily conservative (See Example 1.1). Consequently, the error bounds do not reflect accurate dependence on the system parameters.
When is unknown, it is unclear when a singular value decomposition should be performed to obtain the parameter estimates via Ho-Kalman algorithm. This leads to the question of model order selection from data. For subspace based methods, such problems have been addressed in Shibata (1976) and Bauer (2000). These papers address the question of estimating order in the context of subspace methods. Specifically, order estimation is achieved by analyzing the information contained in the estimated singular values and/or estimated innovation variance. Furthermore, they provide guarantees for asymptotic consistency of the methods described. Another line of literature studied in Ljung et al. (2015) for example, approaches the identification of systems with unknown order by first learning the largest possible model that fits the data and then performing model reduction to obtain the final system. Although one can show that asymptotically this method outputs the true model, we show that such a two step procedure may underperform in a finite time setting. A possible explanation for this could be that learning the largest possible model with finite data over-fits on the exogenous noise and therefore gives poor model estimates.
Other related work on identifying finite impulse response approximations include Goldenshluger (1998); Tu et al. (2017); but they do not discuss parameter estimation or reduced order modeling. Several authors Campi and Weyer (2002); Shah et al. (2012); Hardt et al. (2016) and references therein have studied the problem of system identification in different contexts. However, they fail to capture the correct dependence of system parameters on error rates. More importantly, they suffer from the same limitation as Oymak and Ozay (2018) that they require the knowledge of .
2 Mathematical Preliminaries
Throughout the paper, we will refer to an LTI system with dynamics as Eq. (1) by . For a matrix , let be the singular value of with . Further, . Similarly, we define , where is an eigenvalue of with . Again, .
Definition 2.1.
A matrix is Schur stable if .
We will only be interested in the class of LTI systems that are Schur stable. Fix (and possibly much greater than ). The model class of LTI systems parametrized by is defined as
| (4) |
Definition 2.2.
The –dimensional Hankel matrix for as
and its associated Toeplitz matrix as
We will slightly abuse notation by referring to . Similarly for the Toeplitz matrices . The matrix is known as the system Hankel matrix corresponding to , and its rank is known as the model order (or simply order) of . The system Hankel matrix has two well-known properties that make it useful for system identification. First, the rank of has an upper bound . Second, it maps the “past” inputs to “future” outputs. These properties are discussed in detail in appendix as Section 9.2. For infinite matrices , , i.e., the operator norm.
Definition 2.3.
The transfer function of is given by where .
The transfer function plays a critical role in control theory as it relates the input to the output. Succinctly, the transfer function of an LTI system is the Z–transform of the output in response to a unit impulse input. Since for any invertible the LTI systems have identical transfer functions, identification may not be unique, but equivalent up to a transformation , i.e., . Next, we define a system norm that will be important from the perspective of model identification and approximation.
Definition 2.4.
The –system norm of a Schur stable LTI system is given by
Here, is the transfer function of . The –truncation of the transfer function is defined as
| (5) |
For a stable LTI system we have
Proposition 1 (Lemma 2.2 Glover (1987)).
Let be a LTI system then
where are the singular values of .
For any matrix , define as the submatrix including row to and column to . Further, is the submatrix including row to and all columns and a similar notion exists for . Finally, we define balanced truncated models which will play an important role in our algorithm.
Definition 2.5 (Kung and Lin (1981)).
Let where ( is the model order). Then for any , the –order balanced truncated model parameters are given by
For , the –order balanced truncated model parameters are the –order truncated model parameters.
Definition 2.6.
We say a random vector is subgaussian with variance proxy if
and . We denote this by .
A fundamental result in model reduction from systems theory is the following
Theorem 2 (Theorem 21.26 Zhou et al. (1996)).
Let be the true model of order and be its balance truncated model of order . Assume that . Then
where are the Hankel singular values of .
Critical to obtaining refined error rates, will be a result from the theory of self–normalized martingales, an application of the pseudo-maximization technique in (Peña et al., 2008, Theorem 14.7):
Theorem 3.
Let be a filtration. Let be stochastic processes such that are measurable and is -conditionally for some . For any , define . Then for any and all we have with probability at least
The proof of this result can be found as Theorem 7.
We denote by universal constants which can change from line to line. For numbers , we define and .
Finally, for two matrices with , where .
Proposition 4 (System Reduction).
Let and the singular values of be arranged as follows:
Furthermore, let be such that
| (6) |
Define , then
and .
The proof is provided in Proposition 4 in the appendix. This is an extension of Wedin’s result that allows us to scale the recovery error of the singular vector by only condition number of that singular vector. This is useful to represent the error of identifying a -order approximation as a function of the -singular value only.
We briefly summarize our contributions below.
3 Contributions
In this paper we provide a purely data-driven approach to system identification from a single time–series of finite noisy data. Drawing from tools in systems theory and the theory of self–normalized martingales, we offer a nearly optimal OLS-based algorithm to learn the system parameters. We summarize our contributions below:
-
•
The central theme of our approach is to estimate the infinite system Hankel matrix (to be defined below) with increasing accuracy as the length of data grows. By utilizing a specific reformulation of the input–output relation in Eq. (1) we reduce the problem of Hankel matrix identification to that of regression between appropriately transformed versions of output and input. The OLS solution is a matrix of size . More precisely, we show that with probability at least ,
for above a certain threshold, where is the principal submatrix of the system Hankel. Here is the –system norm.
-
•
We show that by growing with in a specific fashion, becomes the minimax optimal estimator of the system Hankel matrix. The choice of for a fixed is purely data-dependent and does not depend on spectral radius of or .
-
•
It is well known in systems theory that SVD of the doubly infinite system Hankel matrix gives us . However, the presence of finite noisy data prevents learning these parameters accurately. We show that it is always possible to learn the parameters of a lower-order approximation of the underlying system. This is achieved by selecting the top singular vectors of . The estimation guarantee corresponds to model selection in Statistics. More precisely, for every if are the parameters of a -order balanced approximation of the original LTI system and are the estimates of our algorithm then for above a certain threshold we have
with probability at least where is the largest singular value of .
4 Problem Formulation and Discussion
4.1 Data Generation
Assume there exists an unknown for some unknown . Let the transfer function of be . Suppose we observe the noisy output time series in response to user chosen input series, . We refer to this data generated by as . We enforce the following assumptions on .
Assumption 1
The noise process in the dynamics of given by Eq. (1) are i.i.d. and are isotropic with subGaussian parameter . Furthermore, almost surely. We will only select inputs, , that are isotropic subGaussian with subGaussian parameter .
The input–output map of Eq. (1) can be represented in multiple alternate ways. One commonly used reformulation of the input–output map in systems and control theory is the following
where is defined as the Toeplitz matrix corresponding to process noise (similar to Definition 2.2):
denote observed amplifications of the control input and process noise respectively. Note that stability of ensures . Suppose both in Eq. (1). Then it is a well-known fact that
| (7) |
Assumption 2
There exist universal constants such that
Remark 4.1 (-norm estimation).
Assumption 2 implies that an upper bound to the –norm of the system. It is possible to estimate from data (See Tu et al. (2018a) and references therein). It is reasonable to expect that error rates for identification of the parameters depend on the noise-to-signal ratio , i.e., identification is much harder when the ratio is large.
Remark 4.2 ( estimation).
The noise to signal ratio hyperparameter can also be estimated from data, by allowing the system to run with and taking the average norm of the output , i.e., . For the purpose of the results of the paper we simply assume an upper bound on . If was instead of , the noise-to-signal ratio is modified to instead.
| : Input dimension, : Output dimension |
|---|
| : Known upper bound on |
| : Error probability |
| : Known absolute constants |
| : Known noise to signal ratio, or, |
| : Known upper bound on -norm of LTI system |
| , |
| , |
5 Algorithmic Details
We will now represent the input–output relationship in terms of the Hankel and Toeplitz matrices defined before. Fix a , then for any we have
| (8) |
or, succinctly,
| (9) |
Here
Furthermore, are defined similar to and are similar to . The and signs indicate moving forward and backward in time respectively. This representation will be at the center of our analysis.
There are three key steps in our algorithm which we describe in the following sections:
-
(a)
Hankel submatrix estimation: Estimating for every . We refer to the estimators as .
-
(b)
Model Selection: From the estimators select in a data dependent way such that it “best” estimates .
-
(c)
Parameter Recovery: For every , we do a singular value decomposition of to obtain parameter estimates for a “good” -order approximation of the true model.
5.1 Hankel Submatrix Estimation
The goal of our systems identification is to estimate either or . Since we only have finite data and no apriori knowledge of it is not possible to directly estimate the unknown matrices. The first step then is to estimate all possible Hankel submatrices that are “allowed” by data, i.e., for . For a fixed , Algorithm 1 estimates the principal submatrix .
Input
Output System Parameters:
It can be shown that
| (10) |
and by running the algorithm times, we obtain . A key step in showing that is a good estimator for is to prove the finite time isometry of , i.e., the sample covariance matrix.
Lemma 1.
Define
where is some universal constant. Define the sample covariance matrix . We have with probability and for
| (11) |
Lemma 1 allows us to write Eq. (10) as with high probability and upper bound estimation error for principal submatrix.
Theorem 2.
Fix and let be the output of Algorithm 1. Then for any and , we have with probability at least
Here , is a universal constant and from Table 1.
Proof 5.1.
We outline the proof here. Recall Eq. (8), (9). Then for a fixed
Then the identification error is
| (12) |
with
By Lemma 1 we have, whenever , with probability at least
| (13) |
This ensures that, with high probability, that exists and decays as . The next step involves showing that grows at most as with high probability. This is reminiscent of Theorem 3 and the theory of self–normalized martingales. However, unlike that cases the conditional sub-Gaussianity requirements do not hold here. For example, let then for all since is not an independent sequence. As a result it is not immediately obvious on how to apply Theorem 3 to our case. Under the event when Eq. (13) holds (which happens with high probability), a careful analysis of the normalized cross terms, i.e., shows that with high probability. This is summarized in Propositions 1-3. The idea is to decompose into a linear combination of independent subgaussians and reduce it to a form where we can apply Theorem 3. This comes at the cost of additional scaling in the form of system dependent constants – such as the –norm. Then we can conclude with high probability that . The full proof has been deferred to Section 11.1 in Appendix 11.
Remark 5.2.
We next present bounds on in Theorem 2. From the perspective of model selection in later sections, we require that be known. In the next proposition we present two bounds on , the first one depends on unknown parameters and recovers the precise dependence on . The second bound is an apriori known upper bound and incurs an additional factor of .
Proposition 3.
upper bound independent of :
where depends only on .
Proof 5.3.
By Gelfand’s formula, since where and is a constant that only depends on , it implies that
and
Then
Similarly, there exists a finite upper bound on by replacing and with and respectively. For the independent upper bound, we have
Since , then
For the we get an extra because .
The key feature of the data dependent upper bound is that it only depends on and which are known apriori.
Recall that , i.e., the -order FIR truncation of . Since the rows of the matrix corresponds to we can obtain estimators for any -order FIR.
Corollary 4.
Let denote the first -rows of . Then for any and , we have with probability at least ,
Proof 5.4.
Proof follows because and Theorem 2.
Next, we show that the error in Theorem 2 is minimax optimal (up to logarithmic factors) and cannot be improved by any estimation method.
Proposition 5.
Let where is an absolute constant. Then for any estimator of we have
where is a constant that is independent of but can depend on system level parameters.
Proof 5.5.
Assume the contrary that
Then recall that and . Similarly we have . Define
If , then since we can conclude that
which contradicts Theorem 5 in (Goldenshluger, 1998). Thus, .
5.2 Model Selection
At a high level, we want to choose from such that is a good estimator of . Our idea of model selection is motivated by (Goldenshluger, 1998). For any , the error from can be broken as:
We would like to select a such that it balances the truncation and estimation error in the following way:
where are absolute constants. Such a balancing ensures that
| (14) |
Note that such a balancing is possible because the estimation error increases as grows and truncation error decreases with . Furthermore, a data dependent upper bound for estimation error can be obtained from Theorem 2. Unfortunately are unknown and it is not immediately clear on how to obtain such a bound for truncation error.
To achieve this, we first define a truncation error proxy, i.e., how much do we truncate if a specific is used. For a given , we look at for . This measures the additional error incurred if we choose as an estimator for instead of for . Then we pick as follows:
| (15) |
Recall that , where denotes how much estimation error is incurred in learning Hankel submatrix, the extra is incurred because we need a data dependent, albeit coarse, upper bound on the estimation error.
A key step will be to show that for any , whenever
ensures that
and there is no gain in choosing a larger Hankel submatrix estimate. By picking the smallest for which such a property holds for all larger Hankel submatrices, we ensure that a regularized model is estimated that “agrees” with the data.
Output
We now state the main estimation result for for as chosen in Algorithm 2. Define
| (16) |
where
| (17) |
A close look at Eq. (17) reveals that picking ensures the balancing of Eq. (14). However, depends on unknown quantities and is unknown. In such a case, in Eq. (15) becomes a proxy for . From an algorithmic stand point, we no longer need any unknown information; the unknown parameter only appear in , which is only required to make the theoretical guarantee of Theorem 6 below.
Theorem 6.
Whenever we have we have with probability at least that
The proof of Theorem 6 can be found as Proposition 9 in Appendix 13. We see that the error between and can be upper bounded by a purely data dependent quantity. The next proposition shows that does not grow more that logarithmically in .
Proposition 7.
The effect of unknown quantities, such as the spectral radius, are subsumed in the finite time condition and appear in an upper bound for ; however this information is not needed from an algorithmic perspective as the selection of is agnostic to the knowledge of . The proof of proposition can be found as Propositions 7 and 4.
5.3 Parameter Recovery
Next we discuss finding the system parameters. To obtain system parameters we use a balanced truncation algorithm on where is the output of Algorithm 2. The details are summarized in Algorithm 3 where .
Input
Output System Parameters:
To state the main result we define a quantity that measures the singular value weighted subspace gap of a matrix :
where and is arranged into blocks of singular values such that in each block we have , i.e.,
where are diagonal matrices, is the singular value in the block and are the minimum and maximum singular values of block respectively. Furthermore,
for , and . Informally, the measure the singular value gaps between each blocks. It should be noted that , the number of separated blocks, is a function of itself. For example: if then the number of blocks correspond to the number of distinct singular values. On the other hand, if is very large then .
Theorem 8.
Let be the true unknown model and
Then whenever , we have with probability at least :
where and .
The proof of Theorem 8 follows directly from Theorem 9 where we show
and Proposition 2. Theorem 8 provides an error bound between parameters (of model order ) when true order is unknown. The subspace gap measure, , is bounded even when . To see this, note that when , corresponds exactly to . In that case, the number of blocks correspond to the number of distinct singular values of , and then corresponds to singular value gap between the unequal singular values. As a result . Then the bound decays as for singular values , but for much smaller singular values the bound decays as .
To shed more light on the behavior of our bounds, we consider the special case of known order. If is the model order, then we can set . If , then for large enough one can ensure that
i.e., is less than the singular value gap and small enough that the spectrum of is very close to that of . Consequently and we have that
| (18) |
This upper bound is (nearly) identical to the bounds obtained in Oymak and Ozay (2018) for the known order case. The major advantage of our result is that we do not require any information/assumption on the LTI system besides . Nonparametric approaches to estimating have been studied in Tu et al. (2017).
5.4 Order Estimation Lower Bound
In Theorem 8 it is shown that whenever we can find an accurate –order approximation. Now we show that if then there is always some non–zero probability with which we can not recover the singular vector corresponding to the . We prove the following lower bound for model order estimation when inputs are active and bounded which we define below
Definition 5.6.
An input sequence is said to be active if is allowed to depend on past history . The input sequence is bounded if for all .
Active inputs allow for the case when input selection can be adaptive due to feedback.
Theorem 9.
Fix . Let be two LTI systems and be the -Hankel singular values respectively. Let and . Then whenever we have
Here means generates data points in response to active and bounded inputs and is any estimator.
Proof 5.7.
The proof can be found in appendix in Section 15 and involves using Fano’s (or Birge’s) inequality to compute the minimax risk between the probability density functions generated by two different LTI systems:
| (19) |
are Schur stable whenever .
Theorem 9 shows that when the time required to recover higher order models depends inversely on the condition number. Specifically, to correctly distinguish between an order and order model where is the condition number of the -order model. We compare this to our upper bound in Theorem 8 and Eq. (18), assume for all and , then since parameter error, , is upper bounded as
we need
to correctly identify -order model. The ratio is equal to the condition number of the Hankel matrix. In this sense, the model selection followed by singular value thresholding is not too conservative in terms of (the signal-to-noise ratio) and conditioning of the Hankel matrix.
6 Experiments
The experiments in this paper are for the single trajectory case. A detailed analysis for system identification from multiple trajectories can be found in Tu et al. (2017). Suppose that the LTI system generating data, , has transfer function given by
| (20) |
where . is a finite dimensional LTI system or order with parameters as . For these illustrations, we assume a balanced system and choose . We estimate , pick and respectively.
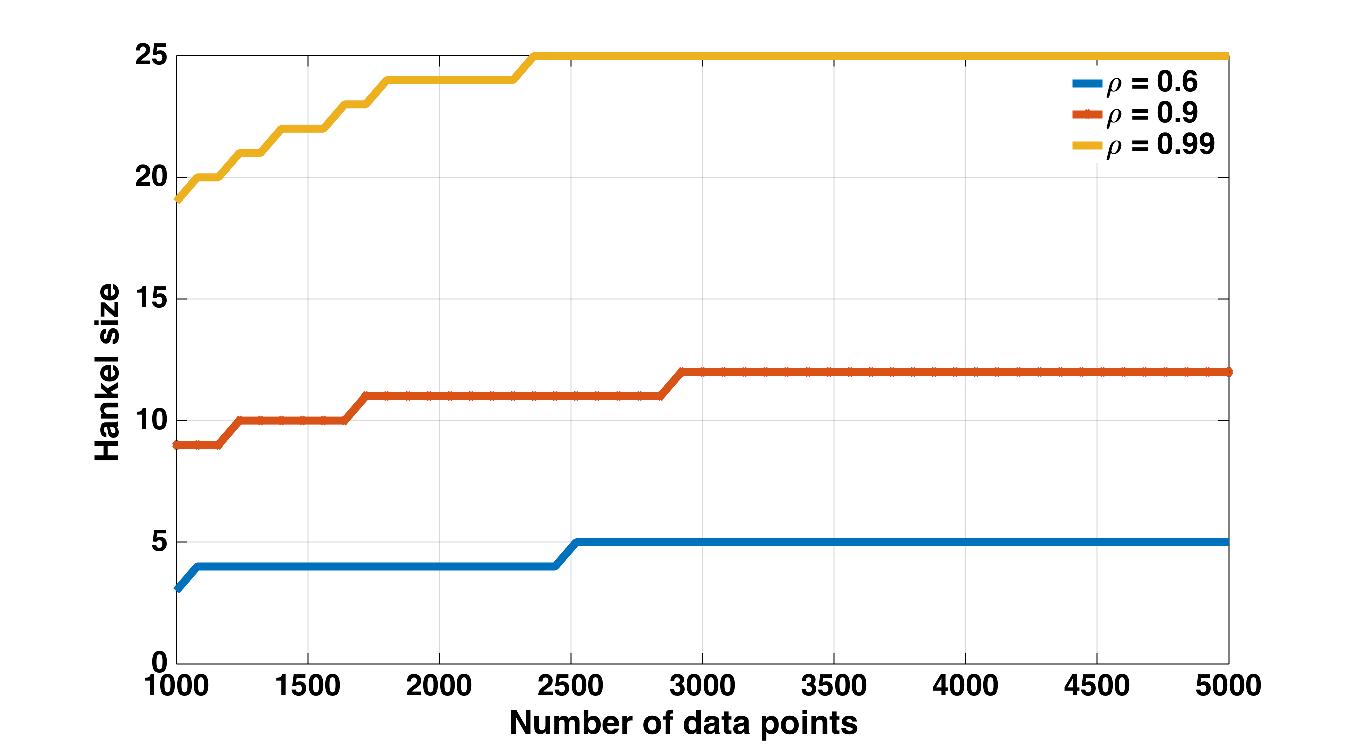
Fig. 1 shows how change with the number of data points for different values of . When , i.e., small, does not grow too big with even when the number of data points is increased. This shows that a small model order is sufficient to specify system dynamics. On the other hand, when , i.e., closer to instability the required is much larger, indicating the need for a higher order. Although implicitly captures the effect of spectral radius, the knowledge of is not required for selection.
In principle, our algorithm increases the Hankel size to the “appropriate” size as the data increases. We compare this to a deterministic growth policy and the SSREGEST algorithm Ljung et al. (2015). The SSREGEST algorithm first learns a large model from data and then performs model reduction to obtain a final model. In contrast, we go to reduced model directly by picking a small . This reduces the sensitivity to noise.
In Fig. 2 shows the model errors for a deterministic growth policy and our algorithm. Although the difference is negligible when (small), we see that our algorithm does better due to its adaptive nature, i.e., responds faster for our algorithm.
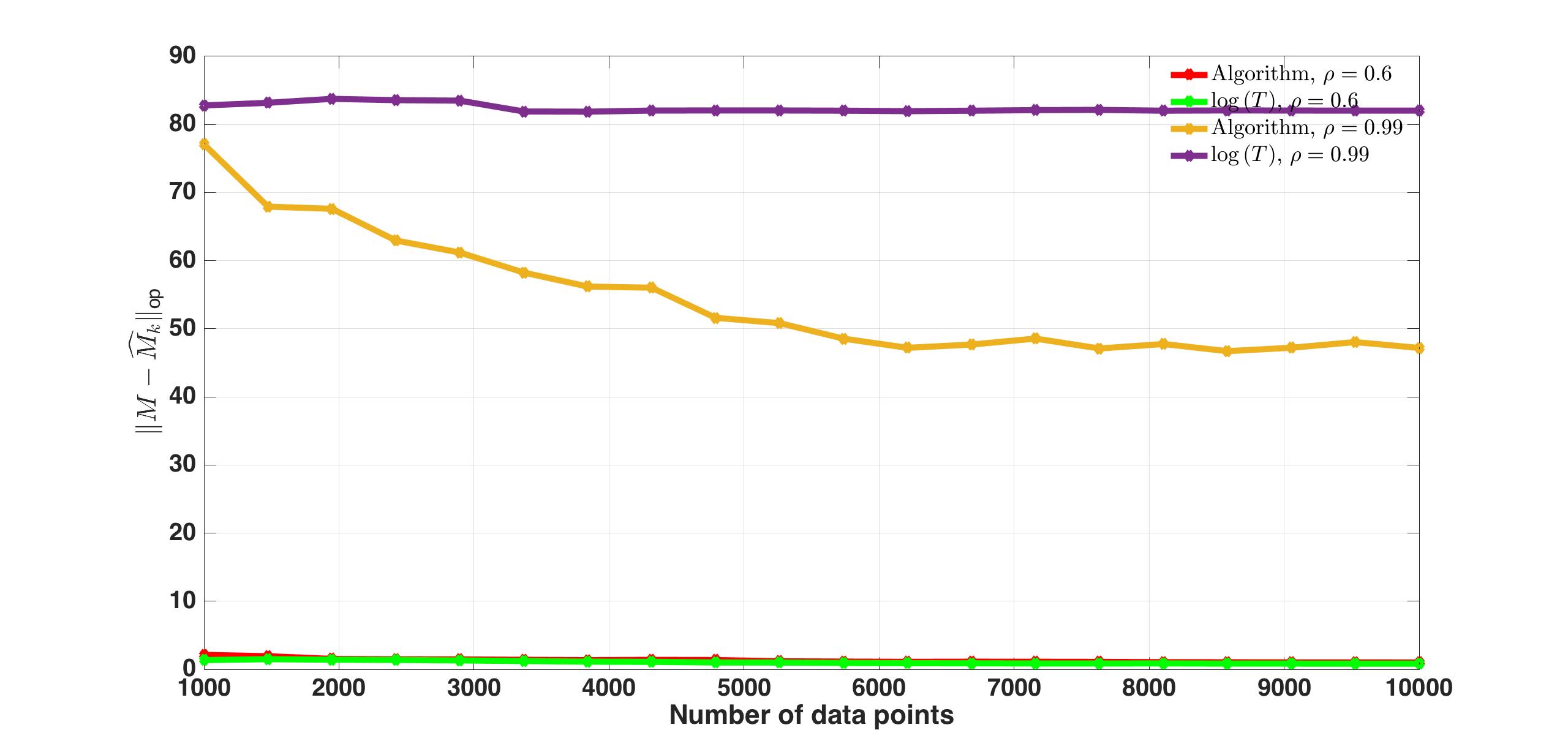
Finally, for the case when , we show the model errors for SSREGEST and our algorithm as increases. Although asymptotically both algorithms perform the same, it is clear that for small our algorithm is more robust to the presence of noise.
| T | SSREGEST | Our Algorithm |
|---|---|---|
7 Discussion
We propose a new approach to system identification when we observe only finite noisy data. Typically, the order of an LTI system is large and unknown and a priori parametrizations may fail to yield accurate estimates of the underlying system. However, our results suggest that there always exists a lower order approximation of the original LTI system that can be learned with high probability. The central theme of our approach is to recover a good lower order approximation that can be accurately learned. Specifically, we show that identification of such approximations is closely related to the singular values of the system Hankel matrix. In fact, the time required to learn a –order approximation scales as where is the –the singular value of system Hankel matrix. This means that system identification does not explicitly depend on the model order , rather depends on through . As a result, in the presence of finite data it is preferable to learn only the “significant” (and perhaps much smaller) part of the system when is very large and . Algorithm 1 and 3 provide a guided mechanism for learning the parameters of such significant approximations with optimal rules for hyperparameter selection given in Algorithm 2.
Future directions for our work include extending the existing low–rank optimization-based identification techniques, such as (Fazel et al., 2013; Grussler et al., 2018), which typically lack statistical guarantees. Since Hankel based operators occur quite naturally in general (not necessarily linear) dynamical systems, exploring if our methods could be extended for identification of such systems appears to be an exciting direction.
References
- Abbasi-Yadkori et al. (2011) Yasin Abbasi-Yadkori, Dávid Pál, and Csaba Szepesvári. Improved algorithms for linear stochastic bandits. In Advances in Neural Information Processing Systems, pages 2312–2320, 2011.
- Açıkmeşe et al. (2013) Behçet Açıkmeşe, John M Carson, and Lars Blackmore. Lossless convexification of nonconvex control bound and pointing constraints of the soft landing optimal control problem. IEEE Transactions on Control Systems Technology, 21(6):2104–2113, 2013.
- Agarwal et al. (2018) Anish Agarwal, Muhammad Jehangir Amjad, Devavrat Shah, and Dennis Shen. Time series analysis via matrix estimation. arXiv preprint arXiv:1802.09064, 2018.
- Allen-Zhu and Li (2016) Zeyuan Allen-Zhu and Yuanzhi Li. Lazysvd: Even faster svd decomposition yet without agonizing pain. In Advances in Neural Information Processing Systems, pages 974–982, 2016.
- Bauer (2000) Dietmar Bauer. Order estimation for subspace methods. 2000.
- Boucheron et al. (2013) Stéphane Boucheron, Gábor Lugosi, and Pascal Massart. Concentration inequalities: A nonasymptotic theory of independence. Oxford university press, 2013.
- Campi and Weyer (2002) Marco C Campi and Erik Weyer. Finite sample properties of system identification methods. IEEE Transactions on Automatic Control, 47(8):1329–1334, 2002.
- Dempster et al. (1977) Arthur P Dempster, Nan M Laird, and Donald B Rubin. Maximum likelihood from incomplete data via the em algorithm. Journal of the royal statistical society. Series B (methodological), pages 1–38, 1977.
- Faradonbeh et al. (2017) Mohamad Kazem Shirani Faradonbeh, Ambuj Tewari, and George Michailidis. Finite time identification in unstable linear systems. arXiv preprint arXiv:1710.01852, 2017.
- Fazel et al. (2013) Maryam Fazel, Ting Kei Pong, Defeng Sun, and Paul Tseng. Hankel matrix rank minimization with applications to system identification and realization. SIAM Journal on Matrix Analysis and Applications, 34(3):946–977, 2013.
- Glover (1984) Keith Glover. All optimal hankel-norm approximations of linear multivariable systems and their -error bounds. International journal of control, 39(6):1115–1193, 1984.
- Glover (1987) Keith Glover. Model reduction: a tutorial on hankel-norm methods and lower bounds on l2 errors. IFAC Proceedings Volumes, 20(5):293–298, 1987.
- Goldenshluger (1998) Alexander Goldenshluger. Nonparametric estimation of transfer functions: rates of convergence and adaptation. IEEE Transactions on Information Theory, 44(2):644–658, 1998.
- Grussler et al. (2018) Christian Grussler, Anders Rantzer, and Pontus Giselsson. Low-rank optimization with convex constraints. IEEE Transactions on Automatic Control, 2018.
- Hardt et al. (2016) Moritz Hardt, Tengyu Ma, and Benjamin Recht. Gradient descent learns linear dynamical systems. arXiv preprint arXiv:1609.05191, 2016.
- Hazan et al. (2018) Elad Hazan, Holden Lee, Karan Singh, Cyril Zhang, and Yi Zhang. Spectral filtering for general linear dynamical systems. arXiv preprint arXiv:1802.03981, 2018.
- Ho and Kalman (1966) BL Ho and Rudolph E Kalman. Effective construction of linear state-variable models from input/output functions. at-Automatisierungstechnik, 14(1-12):545–548, 1966.
- Kung and Lin (1981) S Kung and D Lin. Optimal hankel-norm model reductions: Multivariable systems. IEEE Transactions on Automatic Control, 26(4):832–852, 1981.
- Ljung (1987) Lennart Ljung. System identification: theory for the user. Prentice-hall, 1987.
- Ljung et al. (2015) Lennart Ljung, Rajiv Singh, and Tianshi Chen. Regularization features in the system identification toolbox. IFAC-PapersOnLine, 48(28):745–750, 2015.
- Meckes et al. (2007) Mark Meckes et al. On the spectral norm of a random toeplitz matrix. Electronic Communications in Probability, 12:315–325, 2007.
- Oymak and Ozay (2018) Samet Oymak and Necmiye Ozay. Non-asymptotic identification of lti systems from a single trajectory. arXiv preprint arXiv:1806.05722, 2018.
- Peña et al. (2008) Victor H Peña, Tze Leung Lai, and Qi-Man Shao. Self-normalized processes: Limit theory and Statistical Applications. Springer Science & Business Media, 2008.
- Sarkar and Rakhlin (2018) Tuhin Sarkar and Alexander Rakhlin. How fast can linear dynamical systems be learned? arXiv preprint arXiv:1812.0125, 2018.
- Shah et al. (2012) Parikshit Shah, Badri Narayan Bhaskar, Gongguo Tang, and Benjamin Recht. Linear system identification via atomic norm regularization. In 2012 IEEE 51st IEEE Conference on Decision and Control (CDC), pages 6265–6270. IEEE, 2012.
- Shibata (1976) Ritei Shibata. Selection of the order of an autoregressive model by akaike’s information criterion. Biometrika, 63(1):117–126, 1976.
- Simchowitz et al. (2018) Max Simchowitz, Horia Mania, Stephen Tu, Michael I Jordan, and Benjamin Recht. Learning without mixing: Towards a sharp analysis of linear system identification. arXiv preprint arXiv:1802.08334, 2018.
- Tu et al. (2017) Stephen Tu, Ross Boczar, Andrew Packard, and Benjamin Recht. Non-asymptotic analysis of robust control from coarse-grained identification. arXiv preprint arXiv:1707.04791, 2017.
- Tu et al. (2018a) Stephen Tu, Ross Boczar, and Benjamin Recht. On the approximation of toeplitz operators for nonparametric –norm estimation. In 2018 Annual American Control Conference (ACC), pages 1867–1872. IEEE, 2018a.
- Tu et al. (2018b) Stephen Tu, Ross Boczar, and Benjamin Recht. Minimax lower bounds for -norm estimation. arXiv preprint arXiv:1809.10855, 2018b.
- Tyrtyshnikov (2012) Eugene E Tyrtyshnikov. A brief introduction to numerical analysis. Springer Science & Business Media, 2012.
- van de Geer and Lederer (2013) Sara van de Geer and Johannes Lederer. The bernstein–orlicz norm and deviation inequalities. Probability theory and related fields, 157(1-2):225–250, 2013.
- Van Der Vaart and Wellner (1996) Aad W Van Der Vaart and Jon A Wellner. Weak convergence. In Weak convergence and empirical processes, pages 16–28. Springer, 1996.
- Van Overschee and De Moor (2012) Peter Van Overschee and BL De Moor. Subspace identification for linear systems: Theory—Implementation—Applications. Springer Science & Business Media, 2012.
- Venkatesh and Dahleh (2001) Saligrama R Venkatesh and Munther A Dahleh. On system identification of complex systems from finite data. IEEE Transactions on Automatic Control, 46(2):235–257, 2001.
- Vershynin (2010) Roman Vershynin. Introduction to the non-asymptotic analysis of random matrices. arXiv preprint arXiv:1011.3027, 2010.
- Wedin (1972) Per-Åke Wedin. Perturbation bounds in connection with singular value decomposition. BIT Numerical Mathematics, 12(1):99–111, 1972.
- Zhou et al. (1996) K Zhou, JC Doyle, and K Glover. Robust and optimal control, 1996.
8 Preliminaries
Theorem 1 (Theorem 5.39 Vershynin (2010)).
if is a matrix with independent sub–Gaussian isotropic rows with subGaussian parameter then with probability at least we have
Proposition 2 (Vershynin (2010)).
We have for any and any that
Theorem 3 (Theorem 1 Meckes et al. (2007)).
] Suppose are independent, for all , and are independent random variables. Then where
Theorem 4 (Hanson–Wright Inequality).
Given a subgaussian vector with . Then for any and
Proposition 5 (Lecture 2 Tyrtyshnikov (2012)).
Suppose that is the lower triangular part of a matrix . Then
Let be a nondecreasing, convex function with and a random variable. Then the Orlicz norm is defined as
Let be an arbitrary semi–metric space. Denote by is the minimal number of balls of radius needed to cover .
Theorem 6 (Corollary 2.2.5 in Van Der Vaart and Wellner (1996)).
The constant can be hosen such that
where is the diameter of and .
Theorem 7 (Theorem 1 in Abbasi-Yadkori et al. (2011)).
Let be a filtration. Let be stochastic processes such that are measurable and is -conditionally for some . For any , define . Then for any and all we have with probability at least
Proof 8.1.
Lemma 8.
For any , we have that
Here is defined as follows: .
and .
Proof 8.2.
For the matrix we have
It is clear that and for any matrix , does not change if we interchange rows of . Then we have
Proposition 9 (Lemma 4.1 Simchowitz et al. (2018)).
Let be an invertible matrix and be its condition number. Then for a –net of and an arbitrary matrix , we have
Proof 8.3.
For any vector and be such that we have
9 Control and Systems Theory Preliminaries
9.1 Sylvester Matrix Equation
Define the discrete time Sylvester operator
| (21) |
Then we have the following properties for .
Proposition 1.
Let be the eigenvalues of then is invertible if and only if for all
Define the discrete time Lyapunov operator for a matrix as . Clearly it follows from Proposition 1 that whenever we have that the is an invertible operator.
9.2 Properties of System Hankel matrix
-
•
Rank of system Hankel matrix: For , the system Hankel matrix, , can be decomposed as follows:
(23) It follows from definition that and as a result . The system Hankel matrix rank, or , which is also the model order(or simply order), captures the complexity of . If , then . By noting that
we have obtained a way of recovering the system parameters (up to similarity transformations). Furthermore, uniquely (up to similarity transformation) recovers .
-
•
Mapping Past to Future: can also be viewed as an operator that maps “past” inputs to “future” outputs. In Eq. (1) assume that . Then consider the following class of inputs such that for all but may not be zero for . Here is chosen arbitrarily. Then
(24)
9.3 Model Reduction
Given an LTI system of order with its doubly infinite system Hankel matrix as . We are interested in finding the best order lower dimensional approximation of , i.e., for every we would like to find of model order such that is minimized. Systems theory gives us a class of model approximations, known as balanced truncated approximations, that provide strong theoretical guarantees (See Glover (1984) and Section 21.6 in Zhou et al. (1996)). We summarize some of the basics of model reduction below. Assume that has distinct Hankel singular values.
Recall that a model is equivalent to with respect to its transfer function. Define
For two positive definite matrices it is a known fact that there exist a transformation such that where is diagonal and the diagonal elements are decreasing. Further, is the singular value of . Then let . Clearly is equivalent to and we have
| (25) |
Here is a balanced realization of .
Proposition 2.
Let . Here . Then
The triple is a balanced realization of . For any matrix , (or ) denotes the submatrix with only columns (or rows) through .
Proof 9.1.
Let the SVD of . Then can constructed as follows: are of the form
where is the transformation which gives us Eq. (25). This follows because
Then and
We do a similar computation for .
It should be noted that a balanced realization is unique except when there are some Hankel singular values that are equal. To see this, assume that we have
where . For any unitary matrix , define
| (26) |
Then every triple satisfies Eq. (25) and is a balanced realization. Let where
| (27) |
Here is the submatrix and corresponding partitions of . The realization is the –order balanced truncated model. Clearly which gives us , i.e., the balanced version of the true model. We will show that for the balanced truncation model we only need to care about the top singular vectors and not the entire model.
Proposition 3.
For the order balanced truncated model , we only need top singular values and singular vectors of .
Proof 9.2.
From the preceding discussion in Proposition 2 and Eq. (27) it is clear that the first block submatrix of (corresponding to the top singular vectors) gives us . Since
we observe that depend only on the top singular vectors and corresponding singular values. This can be seen as follows: denotes the submatrix of with top rows removed. Now in each column of is scaled by the corresponding singular value. Then the submatrix depends only on top rows of and the top columns of which correspond to the top singular vectors.
10 Isometry of Input Matrix: Proof of Lemma 1
Theorem 10.1.
Define
where each and isotropic. Then there exists an absolute constant such that satisfies:
whenever with probability at least .
Proof 10.2.
Define
Since
we can reformulate it so that each column is the output of an LTI system in the following sense:
| (28) |
where and . From Theorem 1 we have that
with probability at least whenever . Define then,
| (29) |
It can be easily checked that and consequently
Define and is a block matrix. Then
Use Lemma 1 to show that
| (30) |
with probability at least . Then
From Theorem 1 we have with probability atleast that
| (31) |
whenever . Observe that
The matrix is the lower triangular submatrix of a random Toeplitz matrix with i.i.d entries as in Theorem 3. Then using Theorem 3 and Proposition 5 we get that with probability at least we have
| (32) |
Then with probability at least . By ensuring that Eqs. (30), (31) and (32) hold simultaneously we can ensure that and for large enough and absolute constant .
Lemma 1.
Let be independent random vectors. Define for all and
Then with probability at least we have
Proof 10.3.
Since s are block matrices, the techniques in Meckes et al. (2007) cannot be directly applied. However, by noting that can be broken into a sum of matrices where the norm of each matrix can be bounded by a Toeplitz matrix we can use the result from Meckes et al. (2007). For instance if and are independent random variables then we have
Now,
then . Furthermore for each we have
and . The key idea is to show that are Toeplitz matrices (after removing the zeros in the blocks) and we can use the standard techniques described in proof of Theorem 1 in Meckes et al. (2007). Then we will show that each with high probability and .
For brevity, we will assume for now that are scalars and at the end we will scale by . By standard techniques described in proof of Theorem 1 in Meckes et al. (2007), we have that the finite Toeplitz matrix is submatrix of the infinite Laurent matrix
Consider as an operator on in the canonical way, and let denote the usual linear trigonometric isometry . Then is the operator correpsonding to
Therefore,
where . Furthermore note that has the following form
| (33) |
Here and . For any and assuming , we have from Theorem 4
| (34) |
The tail behavior of is not strictly subgaussian and we need to use Theorem 6. The function can be found as Eq. 1 of van de Geer and Lederer (2013) (equivalent upto universal constants) with and its inverse being
We have that
where and is the minimal number of balls of radius needed to cover where is the pseudometric. Since has distribution as in Eq. (34), it follows that for some absolute constant . Then
for some universal constant . This ensures that . Since we have that . This implies , and using Proposition 5 we have . Furthermore, we can make a stronger statement because which implies that
with probability at least . Then recalling that in the general case that s of were block matrices we scale by and get with probability at least
where the union is over all elements being less that .
11 Error Analysis for Theorem 5.1
For this section we assume that .
11.1 Proof of Theorem 2
| (35) |
Assume for now that we have data points instead of . It is clear that
where
| (36) |
or
where
It is show in Theorem 10.1 that is invertible with probability at least . So in our analysis we can write this as
From this one can conclude that
| (37) |
Here as we can observe grow with in dimension. Based on this we divide our error terms in two parts:
| (38) |
and
| (39) | |||
Then the proof of Theorem 5.1 will reduce to Propositions 1–3. We first analyze
The analysis of will be almost identical and will only differ in constants.
Proposition 1.
For , we have with probability at least
where .
Proof 11.1.
We proved that with high probability, then
| (40) |
Define the following . Observe that have contributions from etc. and do not immediately satisfy the conditions of Theorem 3. Instead we will use the fact that is independent of for all .
Define . are vectors when LTI system is MIMO. Then . Let . Then consider the matrix
Observe that the matrix which follows from Lemma 8. Then
Here and recall that is independent of for all . Let . Define where is the sigma algebra containing the set with . Then . Furthermore, since are measurable and is conditionally (on ) subGaussian, we can use Theorem 3 on (where in the notation of Theorem 3). Then with probability at least we have
| (41) |
For any fixed . With probability at least , we know from Theorem 10.1 that . By combining this event and the event in Eq. (41) and setting , we get with probability at least that
| (42) |
Replacing , we get from Eq. (40)
with probability at least . Since we get our desired result.
Then similar to Proposition 1, we analyze
Proposition 2.
For and large enough , we have with probability at least
where
Proof 11.2.
Note with probability at least for large enough . Here is matrix. Then define and the vector as . Then
where is a real value. Let , then . This allows us to write in a form that will enable us to apply Theorem 3.
| (43) |
Here is . It is known from Theorem 10.1 that with high probability and consequently . Define as the sigma field generated by . Furthermore is measurable, and is measurable and we can apply Theorem 3. Now the proof is similar to Proposition 1. Following the same steps as before we get with probability at least
and substituting we get
and
| (44) |
The proof for noise and covariate cross terms is almost identical to Proposition 2 but easier because of independence. Finally note that .
Proposition 3.
For , we have with probability at least
Here where
.
By taking the intersection of all the aforementioned events for a fixed we then have with probability at least
12 Subspace Perturbation Results
In this section we present variants of the famous Wedin’s theorem (Section 3 of Wedin (1972)) that depends on the distribution of Hankel singular values. These will be “sign free” generalizations of the gap–Free Wedin Theorem from Allen-Zhu and Li (2016). First we define the Hermitian dilation of a matrix.
The Hermitian dilation has the property that . Hermitian dilations will be useful in applying Wedin’s theorem for general (not symmetric) matrices.
Proposition 1.
Let be symmetric matrices and . Further, let correspond to the eigenvector of respectively such that and . Then we have
| (45) |
if either or is not zero.
Proof 12.1.
Let and , wlog assume . Define
Since are eigenvectors of and respectively.
Proposition 1 gives an eigenvector subjective Wedin’s theorem. Next, we show how to extend these results to arbitrary subsets of eigenvectors.
Proposition 2.
For , let be two symmetric matrices such that . Let
Let correspond to the eigenvectors of singular values , correspond to the eigenvectors of singular values and are the remaining ones. Define a similar partition for . Let
Proof 12.2.
The proof is similar to before. have a spectral decomposition of the form
Let and since is orthogonal to and similarly for
Diving both sides by
Let be the best rank approximations of respectively. We develop a sequence of results to see how varies when as a function of .
Proposition 3.
Let be such that
Furthermore, let be such that
| (46) |
and be the left and right singular vectors of corresponding to . There exists a unitary transformation such that
Proof 12.3.
Let . First divide the indices into 3 parts . Although we focus on only three groups extension to general case will be a straight forward extension of this proof. Define the Hermitian dilation of as respectively. Then we know that the eigenvalues of are
Further the eigenvectors corresponding to these are
Similarly define the respective quantities for . Now clearly, since . Then by Weyl’s inequality we have that
Now we can use Proposition 1. To ease notation, define and and let the corresponding eigenvectors be for and for respectively. Note that we can make the assumption that for every . This does not change any of our results because are just stacking of left and right singular vectors and is identical for and .
Then using Proposition 1 we get for every and
| (47) |
similarly
| (48) |
Since
and we have by adding Eq. (47),(48) that
Define to be the matrix formed by the orthornormal vectors and to be the matrix formed by the orthonormal vectors . Define similar quantities for . Then
| (49) |
Now corresponds to eigenvectors where singular values , corresponds to eigenvectors where singular values . We are in a position to use Proposition 2. Using that on Eq. (49) we get the following relation
| (50) |
In the Eq. (50) we need to upper bound . To this end we will exploit the fact that all singular values corresponding to are the same. Since , then
Then by pre–multiplying and post–multiplying we get
Let then
Since then
Similarly
Since combining this with Eq. (50) we get
| (51) |
Since
for Eq. (51), we use the inequality whenever which is true when Eq. (46) is true. This means that there exists unitary transformation such that
Remark 12.4.
Note that will be Hermitian dilations of respectively in our case. Since the singular vectors of (and ) are simply stacked version of singular vectors of (and ), our results hold directly for the singular vectors of (and )
Let . First divide the indices into 3 parts .
Proposition 4 (System Reduction).
Let and the singular values of be arranged as follows:
Furthermore, let be such that
| (52) |
Define , then
and . Here and .
Proof 12.5.
Since and likewise for , we can separate the analysis for as follows
Now . Recall that and by conditions on we are guaranteed that for all . We will combine our previous results in Proposition 1–3 to prove this claim. Specifically from Proposition 3 we have
On the remaining term we will use Proposition 3 on each column
In the context of our system identification, and . will be made compatible by padding it with zeros to make it doubly infinite. Then (after padding) has infinite rows. Define (both infinite length) and similarly we will have . Note that from a computational perspective we do not need to ; we only need to work with and since most of it is just zero padding we can simply compute on .
Proposition 5.
Assume . Furthermore, and let be such that
| (53) |
then
where .
Proof 12.6.
Note that , then
Now, , since is a submatrix of and is a submatrix of we have and
13 Hankel Matrix Estimation Results
In this section we provide the proof for Theorem 6. For any matrix , we define its doubly infinite extension as
| (54) |
Proposition 1.
Fix . Then we have
Proof 13.1.
Define as follows
Now pad with zeros to make it a doubly infinite matrix and call it and we get that
Note here that and are infinite matrices. Further . Then
Further .
Proposition 2.
For any , we have
Proof 13.2.
Since from Proposition 1. It is clear that . Then
Proposition 3.
Fix . Then
Proof 13.3.
Remark 13.4.
Next we show that and defined in Eq. (16) given by
| (55) |
The existence of is predicated on the finiteness of which we discuss below.
13.1 Existence of
Construct two sets
| (56) | ||||
| (57) |
Clearly, . A key assumption in the statement of our results is that . We will show that it is indeed true. Let .
Proposition 4.
For a fixed , with . Here .
Proof 13.5.
The intuition behind is the following: grows at most logarithmically in , as is clear from the previous proof. Then is the point where is still growing as (i.e., “mixing” has not happened) but at a slightly reduced rate.
Proposition 5.
For a fixed , .
Proof 13.6.
Recall from the proof of Proposition 1 that . Now can be written as
Define . Let be such that for every and
| (58) |
Clearly such a would exist because but . Then observe that . Then for every we have that
Let
| (59) |
where . Assume that (if not then are condition is trivially true). Then simple computation shows that
This implies that for prescribed as above (ensured by Proposition 2). But from our discussion above we also have
This means that if
then
which implies that . The inequality follows from the definition of . Furthermore, if , whenever is greater than a certain finite threshold of Eq. (59).
Eq. (58) happens when where and . It should be noted that the dependence of on is worst case, i.e., there exists some “bad” LTI system that gives this dependence and it is quite likely is much smaller. The condition simply requires that we capture some reasonable portion of the dynamics and not necessarily the entire dynamics.
13.2 Proof of Theorem 6
Proposition 6.
Let and then
Proof 13.7.
Recall the adaptive rule to choose in Algorithm 1. From Theorem 2 we know that for every we have with probability at least .
Let . Then consider the following adaptive rule
| (61) | ||||
| (62) |
for the same universal constant as Theorem 2. Let be as Eq. (55). Recall that is the point where estimation error dominates the finite truncation error. Unfortunately, we do not have apriori knowledge of to use in the algorithm. Therefore, we will simply use Eq. (62) as our proxy. The goal will be to bound
Proposition 7.
Proof 13.8.
Let . First for all , we note
We use the property that . Furthermore, because of the properties of we have
and
| (63) |
and
This implies that and the assertion follows.
We have the following key lemma about the behavior of .
Lemma 8.
For a fixed , whenever we have with probability at least
| (64) |
Furthermore, .
Proof 13.9.
In the following we will use for shorthand.
Proposition 9.
Fix , and . Then
with probability at least .
Proof 13.10.
Assume that . Recall the following functions
It is clear that for any . Assume the following
-
•
(This relation is true whenever ),
-
•
,
-
•
.
The key will be to show that with high probability that all three assumptions can not hold with high probability. For shorthand we define and . Let . Then this implies that
Since by definition of we have
and by assumptions then as a result
where the last inequality follows from . Now by assumption
it is clear that
and we can conclude that, since ,
which implies that . This is because by definition of we know that is the minimum such that
and furthermore from Proposition 2 we have for any
This contradicts Assumption 3. So, this means that one of three assumptions do not hold. Clearly if assumption is invalid then we have a suitable lower bound on the chosen , i.e., since we get
which implies from Lemma 8 that (since we pick , for large enough ) and we have
Similarly, if assumption is invalid then we get that
and because and we get in a similar fashion to Proposition 6
Replacing it is clear that for any
| (65) |
If then we can simply apply Lemma 8 and our assertion holds.
14 Model Selection Results
Proposition 1.
Let and
Let be arranged into blocks of singular values such that in each block we have
for some , i.e.,
where are diagonal matrices and is the singular value in the block . Then there exists an orthogonal transformation, , such that
Here and
for , and .
Proof 14.1.
Let and where . is arranged into blocks of singular values such that in each block we have , i.e.,
where are diagonal matrices and is the singular value in the block . Furthermore, . From define as follows:
| (66) |
where is a matrix and . The key idea of the proof is the following: where is a orthogonal transformation and we will show that there exists a block diagonal unitary matrix of the form
| (67) |
such that each block corresponds to a orthogonal matrix of dimensions and that is small if is small. Each of the blocks correspond to the set of singular values where the inter-singular value distance is “small”. To start off, note that from Propositon 4 there must exist a that is block diagonal with orthogonal entries such that
| (68) |
Here
for , and . Informally, the measure the singular value gaps between each blocks.
Furthermore, it can be shown that for any of the form in Eq. (67)
because . Note that . Now, when , then ; on the other hand when then and this implies that
Finally,
Our assertion follows since .
Proposition 2.
Let and
Let be arranged into blocks of singular values such that in each block we have
for some , i.e.,
where are diagonal matrices and is the singular value in the block . Then there exists an orthogonal transformation, , such that
Here and
for , and .
15 Order Estimation Lower Bound
Lemma 15.1 (Theorem 4.21 in Boucheron et al. (2013)).
Let be probability laws over and let be disjoint events. If ,
| (69) |
Lemma 15.2 (Le Cam’s Method).
Let be two probability laws then
Proposition 1.
Let be two multivariate Gaussians with mean and covariance matrix respectively. Then the .
In this section we will prove a lower bound on the finite time error for model approximation. In systems theory subspace based methods are useful in estimating the true system parameters. Intuitively, it should be harder to correctly estimate the subspace that corresponds to lower Hankel singular values, or “energy” due to the presence of noise. However, due to strong structural constraints on Hankel matrix finding a minimax lower bound is a much harder proposition for LTI systems. Specifically, it is not clear if standard subspace identification lower bounds can provide reasonable estimates for a structured and non i.i.d. setting such as our case. To alleviate some of the technical difficulties that arise in obtaining the lower bounds, we will focus on a small set of LTI systems which are simply parametrized by a number . Consider the following canonical form order and LTI systems respectively with and let be the noise-to-signal ratio bound.
| (70) |
are Schur stable whenever .
| (71) |
Here are the Hankel matrices generated by respectively. It is easy to check that for we have where are Hankel singular values. Further the rank of is and that of is at least . Also, .
This construction will be key to show that identification of a particular rank realization depends on the condition number of the Hankel matrix. An alternate representation of the input–output behavior is
| (72) |
where . We will prove this result for a general class of inputs, i.e., active inputs. Then we will follow the same steps as in proof of Theorem 2 in Tu et al. (2018b).
Here is the active rule for choosing from past data. From Eq. (15) it is clear that conditional on , is Gaussian with mean given by . Then we use Birge’s inequality (Lemma 15.1). In our case where is given in Eq. (15). We will apply a combination of Lemma 15.1, Proposition 1 and assume are i.i.d Gaussian to obtain our desired result. Note that but . Therefore, from Proposition 1 where . For any , set in Proposition 15.1, then we get whenever
| (73) |
we have . For we use Le Cam’s method in Lemma 15.2 and show that if then . Since when for an absolute constant, our assertion holds.