Normal approximation for fire incident simulation using permanental Cox processes
Abstract
Estimating the number of natural disasters benefits the insurance industry in terms of risk management. However, the estimation process is complicated due to the fact that there are many factors affecting the number of such incidents. In this work, we propose a Normal approximation technique for associated point processes for estimating the number of natural disasters under the following two assumptions: 1) the incident counts in any two distinct areas are positively associated and 2) the association between these counts in two distinct areas decays exponentially with respect to distance outside some small local neighborhood. Under the stated assumptions, we extend previous results for the Normal approximation technique for associated point processes, i.e., the establishment of non-asymptotic bounds for the functionals of these processes [28]. Then we apply this new result to permanental Cox processes that are known to be positively associated. Finally, we apply our Normal approximation results for permanental Cox processes to Thailand’s fire data from 2007 to 2020, which was collected by the Geo-Informatics and Space Technology Development Agency of Thailand.
Keywords: Correlation inequality, Cox process, Local dependence, Random fields, Natural disaster, Positive association
JEL: C020 Mathematical Methods
1 Introduction
Probability and statistical models have been widely used in most business sectors, including the insurance business. They are major tools for estimating loss, claim severity, claim count and claim probabilities, as these factors significantly affect their business operations. Since claim occurrences are used in determining policy premiums and are usually not predictable, claim simulation and prediction are some of the main tools for handling the situation. Simulation and prediction techniques for the insurance industry have attracted researchers’ attention for quite some time (see [14], [1] and [12] and references therein).
The loss can be estimated as the product of the frequency of risk events and some overall measure of severity. Therefore, approximating the number of occurrences of risk events and claim probabilities is key to successful loss estimation. These related topics have been studied and developed in various directions. For instance, the works [17] and [16] improved statistical and stochastic methods for estimating the probability and frequency of flood events. Machine learning techniques have also been applied to estimate claims and reserves (see [23], [29] and [5], for example).
A point process (sometimes called a random point field) is one of the most powerful tools in probability. These processes, which have been widely developed from their root, namely, the Poisson point process, have been applied in several areas, including insurance (see[30], [27] and [2]). Intuitively, a point process is an appropriate tool for modeling the occurrences of risk events and insurance claims, as it explains random natural phenomenon across space and time. Many researchers have proposed different approaches based on point processes for modeling natural disasters, especially fires. In 2007, in [25], it was shown that a simple point process outperforms the Burning Index in predicting wildfire incidents in Los Angeles County. In 2011, the work [30] extended the model in [25] by considering relevant covariates, such as historical spatial burn patterns and wind direction. Also, in 2015, the work [27] used a spatial point process to study the risk associated with insurance customers using geographical information systems.
Some point processes, such as the classic Poisson point process, have the property that the intensities in the relevant areas are independent. However, when considering natural disasters or insurance claims, a dependency structure must be introduced. In 2009, the work [15] proposed a copula approach to finding the joint probability distribution for hydrological variables and then using it to study the spatial dependence in extreme river flows and precipitation. When exact distributions are unknown, approximate distributions can be used to estimate probabilities of risk events. For example, the work [16] applied a theoretical result related to an approximation of a conditional distribution in [13] to develop a new method for estimating the probability of widespread flood events. In our work, we use a Normal approximation for associated point processes to estimate the total number of fire incidents. When approximating distributions, the major issue is dependency. Stein’s method ([26]) is one of the best tools for handling dependency. This well-known method for approximating limiting distributions has the additional benefit of providing non-asymptotic bounds for these distributions . In this work, we use the concept of local dependency, which can be handled by Stein’s method, as shown in [7].
This work is divided into two parts. First, we extend the theoretical results in [28] to provide non-asymptotic bounds for the functionals of associated point processes under more general assumptions. These assumptions are motivated by the nature of natural disasters, as discussed later in this section. We also apply our main theoretical results to the permanental Cox process detailed in Section 2, which is known to be positively associated. In the second part, we simulate Thailand’s fire incidents using permanental Cox processes based on the satellite data on Thailand ‘s fire occurrences collected by the Geo-Informatics and Space Technology Development Agency (GISTDA) from 2007 to 2020. Finally, we check our Normal approximation results from the first part using our simulation results in the second part.
Stein’s method has been used to obtain bounds for point processes under various assumptions and Poisson processes (see [3], [4], [8], [9] and [10] for examples). However, association properties did not appear in the context of Normal approximations for point processes until the work [22] proved a central limit theorem for their functionals under certain conditions and the work [28] obtained rates of convergence using Stein’s method under a stronger assumption.
Next, we state our assumptions regarding natural disasters. Based on the literature, natural disaster incidents in a particular area seem to affect such incidents in another area. For instance, according to [30], wind may cause fire to extend to nearby areas . Thus, we are inspired to claim that for some natural disasters, such as fires, there is some positive relation between the incident counts for two distinct areas. Moreover, we also claim that the further apart the two areas are, the weaker the relation should be. Therefore, we make the following two assumptions in our work:
-
(A1)
The chances of incidents in any two areas are positively associated. Thus, incident counts in any two distinct areas are positively associated.
-
(A2)
The association between the incident counts in two distinct areas decays exponentially with respect to the distance between the areas. However, the decay is assumed to begin outside some small local neighborhood.
Though our assumptions are quite intuitive, to the best of our knowledge, we are unaware of any other works that use a dependent structure with respect to location to model natural disaster incidents.
The remainder of this work is organized as follows. We provide some necessary background and definitions in Section 2. Then the theoretical results are stated and proved in Section 3. Section 4 is devoted to the simulation of fires in Thailand using the dataset from GISTDA and checking our normal approximation results based on this simulation. Finally, a conclusion is provided in Section 5.
2 Some background and definitions
We devote this section to a review of the theoretical background of point processes, permanental Cox processes and Stein’s method.
2.1 Point and permanental Cox processes
A point process is a collection of random points on some mathematical space, such as Euclidean space . As mentioned earlier, point processes are popular tools in the insurance industry (see [2], [27] and [30]).
Let with be a point process. For , the cardinality of , let
The point process is said to be simple if a.s. for all . Also, the process is said to be locally finite if it takes values in
The process is said to be negatively associated if for all coordinate-wise increasing functions and and for all families of pairwise disjoint Borel sets and such that
| (1) |
we have
Similarly, the point process is said to be positively associated if the above inequality is reversed and the families of Borel sets are not necessarily assumed to satisfy (1). In addition, a point process is said to be associated if it is either negatively or positively associated.
Next, we state the definition of the nth order intensity functions of point processes with respect to Lebesgue measure. Let and . If there exists a non-negative function such that
for all locally integrable functions , then is called the nth order intensity function of . Now, for , let
| (2) |
It follows that
Cox processes are well-known point processes. They are considered to be generalizations of the Poisson point processes for which the intensity is a random measure. A permanental Cox process [19] is the Cox process with intensity functions
| (3) |
where is a random measure defined as
| (4) |
where the are independent, zero-mean, real-valued Gaussian random fields with covariance function .
In this work, we consider the case where the Gaussian random fields are stationary; hence, only depends on , where denotes the vector max norm. Also, we consider just the specific case when
| (5) |
where and are constants. This process has been used, for instance, in [20], [31] and [21]. It is known to be positively associated (see [11] and [18]).
2.2 Stein’s bound for local dependent random variables
Stein’s method, introduced by Charles Stein [26] in 1972, is a widely known technique for finding non-asymptotic bounds for approximations of probability distributions. It was motivated by the idea that has the standard Normal distribution if and only if
for all absolutely continuous functions with . This identity leads to the differential equation
| (6) |
where is a standard Normal random variable and is a test function. If for some Borel set and we replace by a random variable , the error in the distributional approximation of by on can be bounded by obtaining the non-asymptotic bound of the expectation of the supremum of the right-hand side of (6) over . In general, doing so is much simpler than computing the left-hand side of (6) directly. Taking , where , we obtain
This distance is known as or the Wasserstein distance. Stein’s method has been used in various applications, and it is one of the best ways to handle dependent situations (see [6] and [24]). One of the classic dependent cases, handled by Stein’s method, is the local dependent structure introduced in [7]. A collection of random variable has dependency neighborhoods if is independent of for all . Next, we state a version of the local dependence bound that appeared in the note [24].
Theorem 2.1 ([24])
Let be random variables such that , , , and define . Let the collection have dependency neighborhoods , , and also define . Then for , a standard Normal random variable, we have
We apply Theorem 2.1 to obtain our main results in the next section.
3 Main results
In this section, we state and prove our main result, which is extended from [28] and then apply it to permanental Cox Processes. In this work, we relax the assumption in [28] that the covariance of the second-order intensity decays exponentially and assume that it decays exponentially outside of some local neighborhood. Let be an associated point process and
| (7) |
where the are real-valued measurable functions and the are defined as -dimensional unit cubes centered at . Note that the union of forms a covering of .
We let denote the vector with all components , and write inequalities such as for vectors when they hold component-wise. In this work, we consider
| (8) |
The work [22] obtained a CLT for the sum above with replaced by any sequence of strictly increasing finite domains of . Let be any -dimensional cube centered at with fixed and with fixed side length . We state our main result for . We then add a remark after the theorem to discuss how to generalize this result. In the following, for , we denote .
Theorem 3.1
For , let be a locally finite simple associated point process on . For , let be as in (8), with given in (7), and . Assume that the following conditions are satisfied:
-
(a)
The first two intensity functions of are well defined;
-
(b)
;
-
(c)
for some and with ;
-
(d)
for some .
Then, for the standard Normal random variable ,
where is the distance,
and
Proof: We prove this theorem by applying Theorem 2.1 stated above and Theorem 3.1 in [28], handling local dependence and non-local dependence separately. First, we address local dependence only by assuming that for . Invoking Theorem 2.1 with , Assumption (b) that and and using Assumption (d), we have that the distance is bounded by
| (9) |
We now assume that Assumption (c) is true for all . Invoking Theorem 3.1 in [28], we have that the distance is bounded by
| (10) |
The distance is bounded by the sum of (9) and (10) because the local neighborhood covariance terms and the remaining covariance terms have been handled by (9) and (10), respectively.
Remark 3.2
-
1.
The associated assumption and Assumption (c) are motivated by (A1) and (A2) in the introduction, respectively.
-
2.
The size of the local neighborhood is , which is flexible and can be increasing in .
-
3.
The above theorem can be extended to the case where and are greater than one by following the same proof. The bound will end up with a larger constant.
Note that we added the assumption that (c) is true for all in the above proof after the local covariance terms had been handled. Although doing so may make the constant larger, the rate of convergence is unaffected.
Next, we apply the above theorem to the permanental Cox process on , which is known to be positively associated. In this theorem, we consider a function defined by
| (11) |
where is a bounded function supported on sets having exactly elements such that when for some fixed and . Here, we denote . Also, we focus specifically on the case that . We note here that if and , is the number of points in or , where . The result is stated as follows:
Theorem 3.3
Let and be a permanental Cox process with intensity functions as in (3) and as in (4), where the , are independent, mean-zero, real-valued Gaussian random fields. Let be defined as in (11) with be bounded and when for some fixed and . Letting with be such that , assume that
| (12) |
for some and with , and
| (13) |
Then for , there exists such that
| (14) |
where is a standard Normal random variable.
Proof: To prove the theorem, we follow the same argument as that used in the proof of Theorem 4.3 in [28]. It requires the use of Theorem 3.1, where the assumptions (12) and (13) are needed. Because Theorem 4.3 of [28] is for determinantal point processes, the variance condition used in its proof cannot be used here; thus, the proofs differ at this point. Therefore, it is sufficient to show that
which can be proved by adapting the proof of Lemma B.6 in [22] for the case where is a permanental Cox process. It is sufficient to verify that the term (B.4) in that proof is bounded for . For the term , we show that the intensity is bounded as follows:
where , with . Note that we have used Hölder’s inequality and the fact that is Normal and its central moment is
.
As we only consider the case , the term is obvious. Thus, the order of the variance is verified.
Remark 3.4
We remark here that in the proof of Theorem 3.3, we set , which could be large. However, in our application, we later set the to be equal for all and , where is the maximum number of fires in area , as derived from the historical data, which is assumed to be bounded.
4 Application to the Thai fire dataset
In this section, we use our main results to simulate Thailand’s fires via permanental Cox processes. We use the GISTDA Thai fire dataset, collected from 2007 to 2020 by satellite. The dataset consists of the latitudes and longitudes of all fire incident locations. Recall that we claim that the fire counts from two distinct areas should be positively correlated. Moreover, we claim that their covariance begins to decay exponentially outside some small local neighborhood. We split this section into three subsections. We first explore the dataset and check to see that Assumptions (A1) and (A2) are not contradicted by the data in the first subsection. The second subsection is devoted to applying our main results to fire simulations. In the last subsection, we evaluate the effect of varying the decay parameter for the permanental Cox processes.
4.1 Exploring the dataset
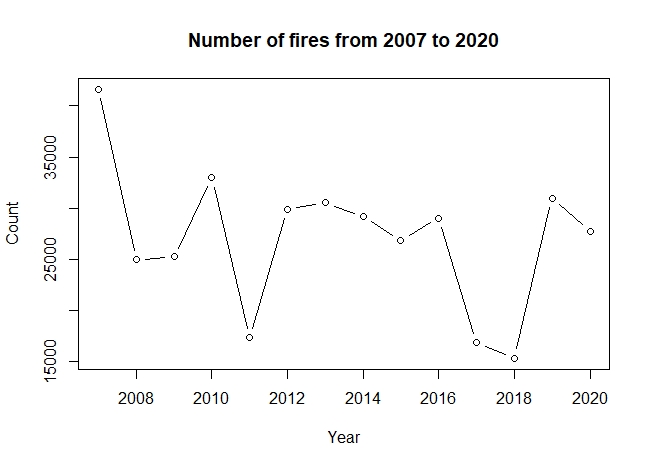
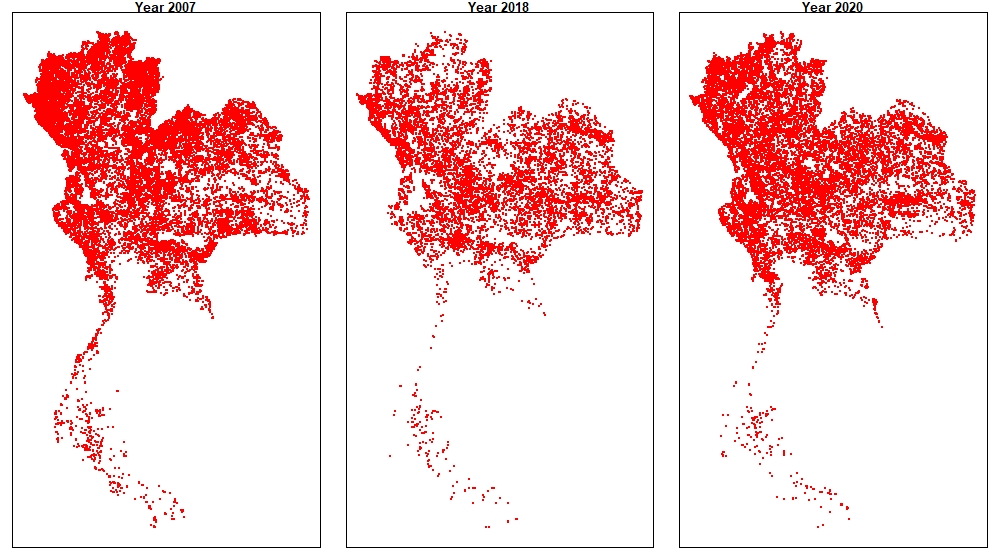
In this subsection, we first explore the dataset and verify that it does not contradict the assumptions in Theorem 3.3. We follow the process outlined in Figure 1. Figure 2 shows the total number of fires each year in Thailand, where the mean and the standard deviation were 27,048 and 6,980.94, respectively. Figure 3 shows the locations of fires in 2007, 2014 and 2020, respectively, from left to right.
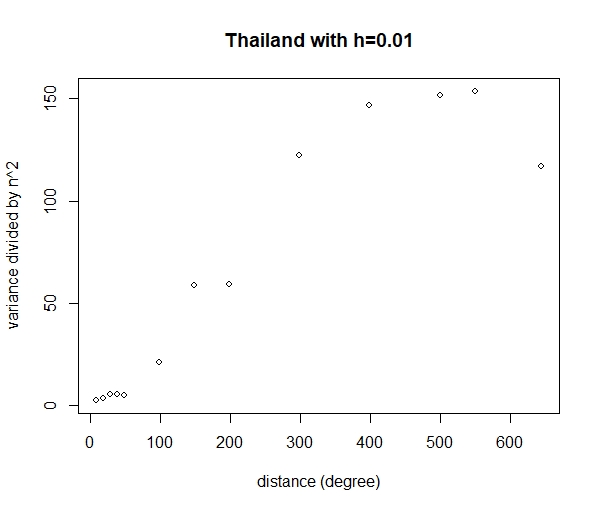
We now examine whether the fire dataset follows assumptions (12) and (13). As the actual intensity function is unknown and cannot be obtained from the dataset, we can only check the covariances between fire counts in two distinct areas separated by a distance . We first check to see if the covariance does not decay in a small local neighborhood. Then we further check to see if the covariance decays exponentially as the distance between areas increases. We also show the variances of the fire counts corresponding to , with going from 10 to 645, where is the greatest distance possible in Thailand (1 unit equals to 0.01 degrees of latitude or longitude). Note that the total area of Thailand is 513,120 square kilometers, which equals . Since 1 degree is about 111 kilometers, the total area is approximately square degrees, which is equivalent to square units when 1 unit is 0.01 degrees. Therefore, the largest possible in Thailand is 645.
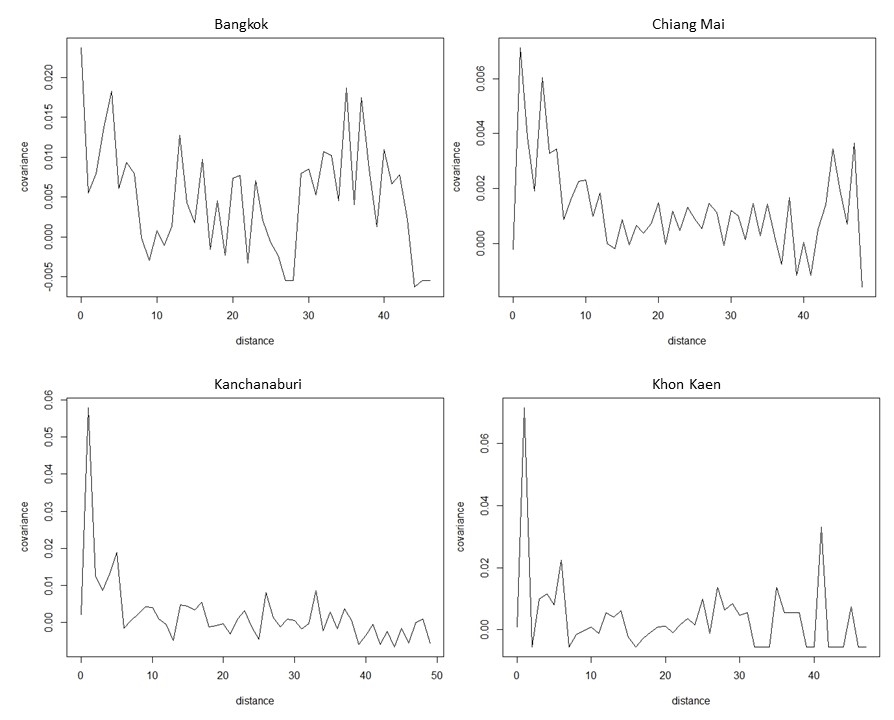
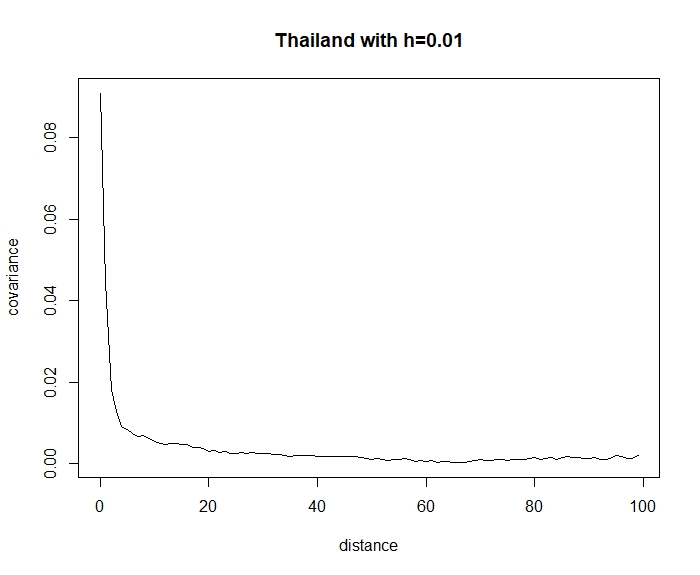
As the entire country is too large to be considered a small local neighborhood, we specifically check four provinces from four regions, including Bangkok, Chaing Mai, Kanchanaburi and Khon Kaen. Note that we did not select a province from Southern Thailand, as the number of fires in this region was too low. Figure 4 shows no sign of exponential decay in the covariance pattern for these provinces when the unit distance is 0.002 degrees ( meters). Figure 5 shows the covariance decay pattern based on distance for all of Thailand. We obtain an exponential decay rate of 0.15 when we use a unit distance of 0.01 degrees ( kilometers). Figure 6 shows the values of for from 10 to 645. Obviously, assumption 13 is not contradicted.
4.2 Simulation of Thai fires using the permanental Cox process
We devote this subsection to simulating fires in Thailand via the process outlined in Figure 7.
We first model Thailand’s fires using permanental Cox processes. Note that when we refer to the area , we are referring to a unit square that has at the top left corner, where and 1 unit equals 0.01 degrees of latitude or longitude. We estimate the variances of and from
by using the first two sample moments. We set the means of the data and process to be equal and seek the closest variances. Writing for each and using the fact that the for are zero-mean, independent Gaussian random variables, we set equal to the sample mean of area and equal to the sample variance of area . We then set for all for simplicity and solve for the closest and .
Denoting and as the mean and variance of the total fires in the unit cube at position from the dataset, we have
Then setting
and substituting , we have
For simplicity, we set . Although the ’s differ for different , we can choose the largest . For a with a smaller , we set equal to zero for all the remaining terms.
To estimate the covariance function of the Gaussian processes from (5), we need estimates of and . Plugging in , we have ; thus, it suffices to estimate . We seek a from a fine grid from 0 to 0.5 that results in the covariance decay rate closest to the 0.15 from the real dataset. Note that the decay rate of 0.15 is computed from the number of fires, whereas is the decay rate of the covariance function for the Gaussian process. Therefore, it is not possible to set directly.
By following the procedure above, we find the largest , i.e., , and closest ). Figure 8 shows an example of a simulation with parameters estimated from the procedure above and 6 iterations.
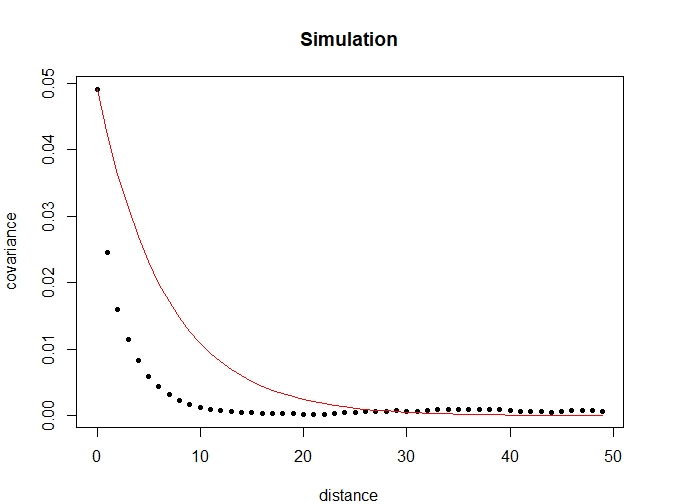
Next, we simulate fire counts for the whole country for 20 iterations and check that the covariance decays exponentially with distance. Since the number of areas in the entire country at a unit distance of 0.01 degrees from another area is extremely large, 20 is a reasonable number of iterations for the simulation. Figure 9 shows the covariance plot and the decay rate of 0.15 from the real dataset.
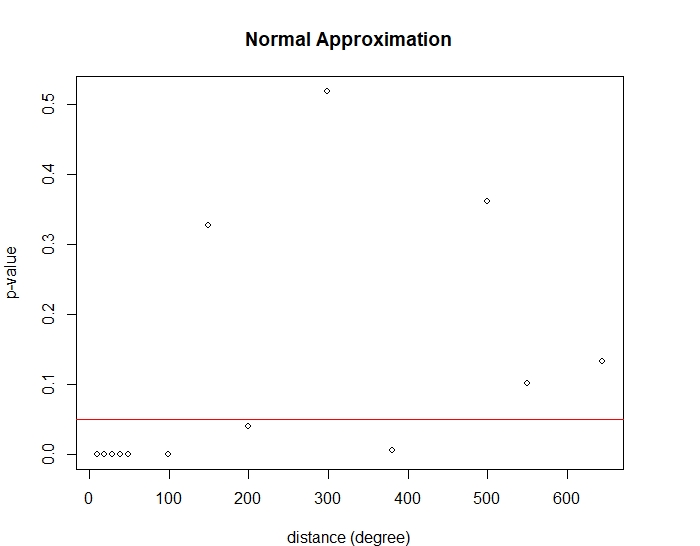
Then we simulate fires across the whole country for 500 iterations to check that the variance is on the order of and to compare the results with the Normal approximation from Theorem 3.3. As in Subsection 4.1, we take from 10 to 645, where units is the greatest distance possible in Thailand (1 unit equals 0.01 degrees of latitude or longitude). We preliminarily check the normality of the simulated fire counts using the Shapiro–Wilk test. Figure 10 shows the Shapiro–Wilk p-values based on , while the red horizontal line indicates the 0.05 significance level. We can see that when is large, the null hypothesis that the total number of fires is Normally distributed is not rejected.
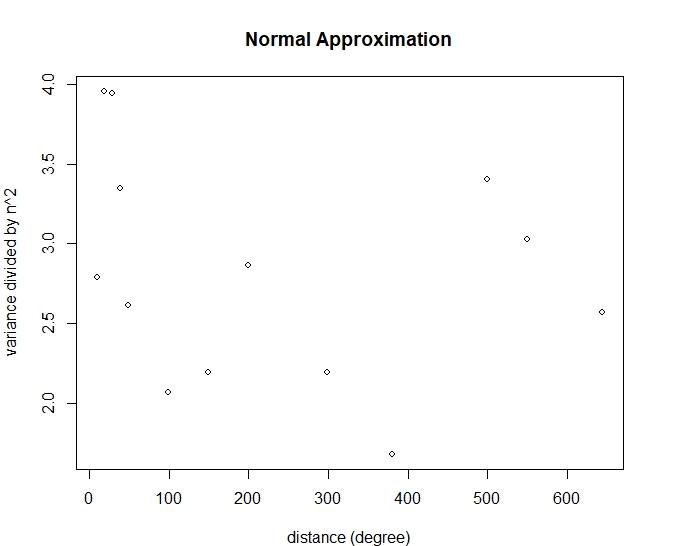
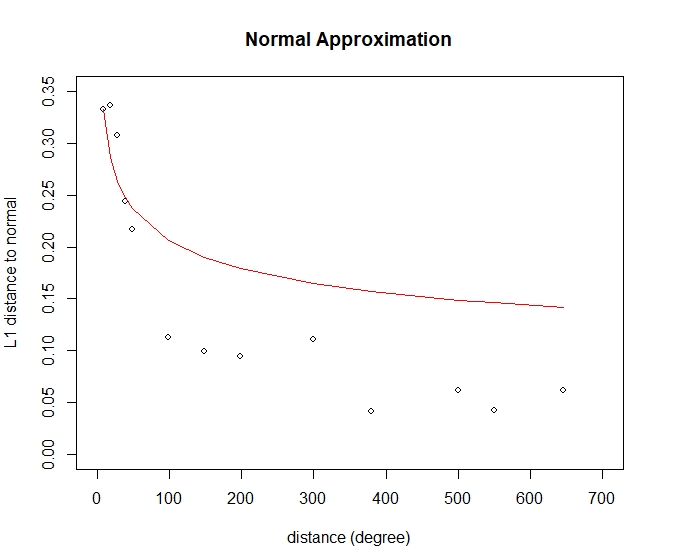
We end this section by checking the variance assumption in assumption (13) and compare the simulation’s distance to the bound in (14). Figure 11 shows a random pattern for the variances of fire counts divided by , which agrees with assumption (13). Figure 12 shows the distances between the standardized fire counts from our simulation and a standard Normal distribution . We also plot the rate of convergence of from Theorem 3.3. The rate from our simulation tends to follow the rate from our main bound.
4.3 The effect of changing the covariance decay rate
The main assumptions that we made in this work is that the fire counts for two distinct areas are positively associated and their covariance decays exponentially with respect to their distance from each other. Nevertheless, the decay rate may vary from country to country or area to area and may also change over time. Therefore, in this section, we are interested in examining the Normal approximation results for different covariance decay rates through the parameter from (5).
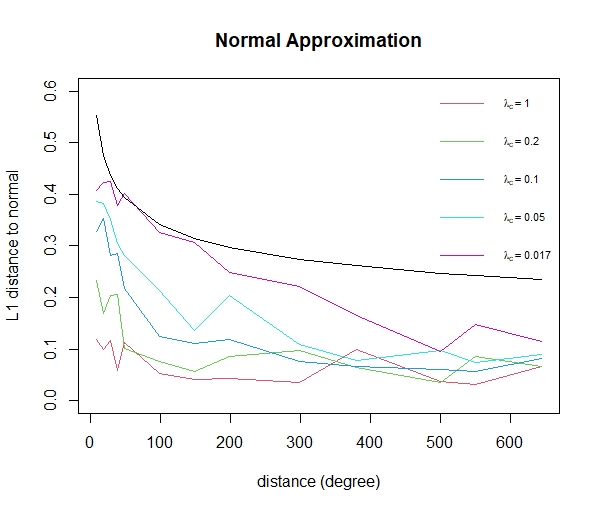
Figure 13 shows that the distances between the standardized fire counts from our simulation and a standard Normal distribution for areas ranging in size from 9 to 645 square degrees when . The black line shows the rate of convergence of from Theorem 3.3. Intuitively, the distribution should be closer to the Normal distribution when is larger, as a larger value implies that the fire counts in the areas are closer to independence. This reasoning agrees with the simulation results shown in Figure 13.
5 Discussion and conclusion
In this work, we break our contribution into two parts: developing theories and simulating Thailand fire counts. For the first part, we generalize the normal approximation of a functional of the associated point processes in [28] by relaxing the assumption that the covariance decays exponentially everywhere to exempting local neighborhoods. Then we apply the main result (Theorem 3.1) to permanental Cox processes, which are known to be positively associated. Unlike the main theorem involving hypercubes of size in , Theorem 3.3 is flexible in that it covers Normally approximating a functional of permanental Cox processes in an area of any shape of size , which allows us to apply this result to the fire counts in Thailand.
For the simulation, we use a permanental Cox process to simulate fire counts in Thailand. We assume that the fire counts for two distinct areas are positively correlated. Moreover, we assume that their covariance decays exponentially outside of some small local neighborhood. We use the GISTDA Thailand fire dataset collected by Thailand’s satellites from 2007 to 2020 to estimate the parameters for the process. The distance between the total number of fires from our simulated fire counts and the Normal distribution agrees with the rate from the bound in Theorem 3.3. By varying the covariance parameter in (5), we can vary the distances from our simulated results. Nevertheless, Normality still holds, and the rates do not contradict the one in our main theorem.
In real-world applications, the new approach proposed in this research may be used to model any natural disaster incidents or model claims by area for property insurance firms. Thus, it benefits policymakers both in government and the private sector in terms of managing risk. Moreover, future researchers can use our idea to simulate natural disaster incidents or insurance claims with some other point processes that are not necessarily well-known but satisfy the assumptions of Theorem 3.1.
Acknowledgment
The authors would like to thank the Geo-Informatics and Space Technology Development Agency (GISTDA) for use of the fire dataset.
Declarations
Funding: This work was supported financially by the TSRI Fundamental Fund 2020 (Grant Number: 64A306000047).
Conflicts of interest/Competing interests: No potential conflicts of interest were reported by the authors.
Availability of data and material: This dataset is under the license of the Geo-Informatics and Space Technology Development Agency.
Code availability: Available upon request.
IRB approval: Not applicable.
References
- [1] Abledu, G. K., Dadey, E. and Kobina , A., Probability modeling and simulation of insurance claims in Ghana, Global Journal of Commerce & Management Perspective, 3(5) (2014) 41–49.
- [2] Albrecher, H., Araujo-Acuna, J. C. and Beirlant, J., Fitting non-stationary Cox process: an application to fire insurance data, North American Actuarial Journal, 0(0) (2020) 1–28.
- [3] Barbour, A. D., Stein’s method and Poisson process convergence, Journal of Applied Probability, 25 (1988) 175–184.
- [4] Barbour, A. D. and Brown, T. C., Stein’s method and point process approximation, Stochastic Processes and their Applications, 43(1) (1992) 9–31.
- [5] Bärtl, M. and Krummaker, S., Prediction of claims in export credit finance: a comparison of four machine learning techniques, Risks, 8(22) (2020) 1–29.
- [6] Chen, L.Y.H., Goldstein, L. and Shao, Q.M., Normal Approximation by Stein’s Method, Springer, New York, 2011.
- [7] Chen, L.Y.H. and Shao, Q.M., Normal approximation under local dependence, Annals of Probability, 32 (2004) 1985–2028.
- [8] Chen, L.Y.H. and Xia, A., Stein’s method, Palm theory and Poisson process approximation, Annals of Probability, 32(3) (2004) 2545–2569.
- [9] Chen, L.Y.H. and Xia, A., Poisson process approximation: from Palm theory to Stein’s method, IMS Lecture Notes-Monograph Series: Time Series and Related Topics, 52 (2006) 236–244.
- [10] Chen, L.Y.H. and Xia, A., Poisson process approximation for dependent superposition of point processes, Bernoulli, 17(2) (2011) 530–544.
- [11] Eisenbaum, N., Characterization of positively correlated squared Gaussian processes, The Annals of Probability, 42(2) (2014) 559–575.
- [12] Gabrielli, A. and Wüthrich, M. V., An individual claims history simulation machine, Risks, 6(29) (2018) 1–33.
- [13] Heffernan, J.E. and Resnick, S.I., Limit laws for random vectors with an extreme component, Annals of Applied Probability, 17 (2007) 537–571.
- [14] Jessen A.H., Mikosch T. and Samorodnitsky G., Prediction of outstanding payments in a Poisson cluster model, Scandinavian Actuarial Journal, 3(2011) 214–237.
- [15] Keef, C., Svensson C. and Tawn, J.A., Spatial dependence in extreme river flows and precipitation for Great Britain, Journal of Hydrology, 378 (2009) 240–252.
- [16] Keef, C., Tawn, J. A. and Lamb, R., Estimating the probability of widespread flood events, Environmetrics, 24 (2013) 13–21.
- [17] Lamb, R., Rainfall-runoff modelling for flood frequency estimation, Encyclopedia of Hydrological Sciences, Anderson MG (eds). John Wiley & Sons(2005) 1923–1954.
- [18] Last, G., Szekli, R., Yogeshwaran, D., Some remarks on associated random fields, random measures and point processes, ALEA Latin American Journal of Probability and Mathematical Statistics, 17 (2020) 355–374.
- [19] McCullagh, P., Møller, J., The permanental process, Advances in Applied Probability, 38(4) (2006) 873–888.
- [20] McCullagh, P., Yang, J., Stochastic classification models, International Congress of Mathematicians, 3 (2006) 669–686.
- [21] Mustafa, H. A., Ekti, A. R., Shakir, M. Z., Imran, M. A., Tafazolli, R., Intracell interference characterization and cluster interference for D2D communication, IEEE Transactions on Vehicular Technology, 67(9) (2018) 8536–8548.
- [22] Poinas, A., Delyon, B. and Lavancier, F., Mixing properties and central limit theorem for associated point processes, Bernoulli, 25(3) (2019) 1724–1754.
- [23] Quan, Z. and Valdez, E.A., Predictive analytics of insurance claims using multivariate decision trees, Dependence Modeling, 6 (2018) 377–407.
- [24] Ross, N. Fundamentals of Stein’s method. Probability Surveys, 8 (2011) 210–293.
- [25] Schoenberg, F.P., Chang, C., Keeley, J., Pompa, J., Woods, J. and Xu, H., A critical assessment of the burning index in Los Angeles County, California, International Journal of Wildland Fire, 16(4) (2007) 473–483.
- [26] Stein, C., A bound for the error in the normal approximation to the distribution of a sum of dependent random variables. Proceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability University of California Press, 2 (1972) 210–293.
- [27] Törnqvist, G., Modelling insurance claims with spatial point process: an applied case-control study to improve the use of geographical information in insurance pricing, Master thesis, Umeå University, 2015
- [28] Wiroonsri, N., Normal approximation for associated point processes via Stein’s method with applications to determinantal point processes, Journal of Mathematical Analysis and Applications, 480(1) (2019) 123396.
- [29] Wüthrich M. V., Machine learning in individual claims reserving, Scandinavian Actuarial Journal, (2018) 1–16.
- [30] Xu, H. and Schoenberg F.P., Point process modeling of wildfire hazard in Los Angeles County, California, The Annals of Applied Statistics, 5(2011) 684–704.
- [31] Yang, J., Miescke, K., McCullagh, P., Classification based on a permanental process with cyclic approximation, Biometrika, 99(4) (2012) 775–786.