Note on Follow-the-Perturbed-Leader in
Combinatorial Semi-Bandit Problems
Abstract
This paper studies the optimality and complexity of Follow-the-Perturbed-Leader (FTPL) policy in size-invariant combinatorial semi-bandit problems. Recently, Honda et al. (2023) and Lee et al. (2024) showed that FTPL achieves Best-of-Both-Worlds (BOBW) optimality in standard multi-armed bandit problems with Fréchet-type distributions. However, the optimality of FTPL in combinatorial semi-bandit problems remains unclear. In this paper, we consider the regret bound of FTPL with geometric resampling (GR) in size-invariant semi-bandit setting, showing that FTPL respectively achieves regret with Fréchet distributions, and the best possible regret bound of with Pareto distributions in adversarial setting. Furthermore, we extend the conditional geometric resampling (CGR) to size-invariant semi-bandit setting, which reduces the computational complexity from of original GR to without sacrificing the regret performance of FTPL.
1 Introduction
The combinatorial semi-bandit is a sequential decision-making problem under uncertainty, which is a generalization of the classical multi-armed bandit problem. It is instrumental in many practical applications, such as recommender systems (Wang et al., 2017), online advertising (Nuara et al., 2022), crowdsourcing (ul Hassan and Curry, 2016), adaptive routing (Gai et al., 2012) and network optimization (Kveton et al., 2014). In this problem, the learner chooses an action from an action set , where is the dimension of the action set. In each round , the loss vector is determined by the environment, and the learner incurs a loss and can only observe the loss for all such that . The goal of the learner is to minimize the cumulative loss over all the rounds. The performance of the learner is often measured in terms of the pseudo-regret defined as , which describes the gap between the expected cumulative loss of the learner and of the optimal arm fixed in hindsight.
Since the introduction by Chen et al. (2013), combinatorial semi-bandit problem has been widely studied, which mainly focus on two settings on the formulation of the environment to decide the loss vector, namely the stochastic setting and the adversarial setting. In the stochastic setting, the sequence of loss vectors is assumed to be independent and identically distributed (i.i.d.) from an unknown but fixed distribution over with mean . The fixed single optimal action is defined as , and we present the minimum suboptimality gap as . CombUCB (Kveton et al., 2015) and Combinatorial Thompson Sampling (Wang and Chen, 2018) can achieves a gap-dependent regret bounds of for general action sets and for matroid semi-bandits, where denotes the maximum size of any action in the set .
In the adversarial setting, the loss vectors is determined from by an adversary in an arbitrary manner, which are not assumed to follow any specific distribution (Kveton et al., 2015; Neu, 2015; Wang and Chen, 2018). For this setting, the regret bound of can be achieved by some policies, such as OSMD (Audibert et al., 2014) and FTRL with hybrid-regularizer (Zimmert et al., 2019), which matches the lower bound of (Audibert et al., 2014).
In practical scenarios, the environment to determine the loss vectors is often unknown. Therefore, policies that can adaptively address both stochastic and adversarial settings have been widely studied, particularly in the context of standard multi-armed bandit problems. The Tsallis-INF policy (Zimmert and Seldin, 2021) policy, which is based on Follow-the-Regularized-Leader (FTRL), has demonstrated the ability to achieve the optimality in both settings. For combinatorial semi-bandit problems, there also exist some work on this topic (Wei and Luo, 2018; Zimmert et al., 2019; Ito, 2021; Tsuchiya et al., 2023).
Howerver, some BOBW policies, such as FTRL, require an explicit computation of the arm-selection probability by solving a optimization problem. This leads to computational inefficiencies, and the complexity substantially increase in for combinatorial semi-bandits. In light of this limitation, the Follow-the-Perturbed-Leader (FTPL) policy, has gained significant attention due to its optimization-free nature. Recently, Honda et al. (2023) and Lee et al. (2024) demonstrated that FTPL achieves the Best-of-Both-Worlds (BOBW) optimality in standard multi-armed bandit problems with Fréchet-type perturbations, which inspires researchers to explore the optimality of FTPL in combinatorial semi-bandit problems. A preliminary effort by Zhan et al. (2025) aimed to tackle this setting, though their analysis contains a technical flaw. In fact, the analysis becomes substantially more complex in the combinatorial semi-bandit setting, which needs more furter investigation.
Contributions of This Paper
Firstly, we investigate the optimality of FTPL with geometric resampling with Fréchet or Pareto distributions in adversarial size-invariant semi-bandit problems. We show that FTPL respectively achieves regret with Fréchet distributions, and the best possible regret bound of with Pareto distributions in this setting. To the best of our knowledge, this is the first work that provides a correct proof of the regret bound for FTPL with Fréchet-type distributions in adversarial combinatorial semi-bandit problems. Furthermore, we extend the technique called Conditional Geometric Resampling (CGR) (Chen et al., 2025) to size-invariant semi-bandit setting, which reduces the computational complexity from of the original GR to without sacrificing the regret guarantee of the one with the original GR.
1.1 Related Work
1.1.1 Technical Issues in Zhan et al. (2025)
The most closely related work is by Zhan et al. (2025). In their paper, they consider the FTPL policy with Fréchet distribution with shape in the size-invariant semi-bandits, which is a special case of combinatorial semi-bandit problems. They provide a proof to claim that FTPL with Fréchet distribution with shape achieves regret in adversarial setting and a logrithmic regret bound in stochastic setting. However, their proof includes a serious issue that renders the main result incorrect, which is explained below.
A function is analyzed in Lemma 4.1 in Zhan et al. (2025), which is later used in their evaluation of a component of the regret called the stability term. In this lemma, they evaluate the function for two cases, and the second case is just mentioned as “can be shown by the same argument” without a proof. However, upon closer inspection, this claim cannot be justified by an analogy. In Section 9, we highlight the detailed step where the analogy fails, and further support this observation with numerical verification, which demonstrates that the claimed result does not hold.
The main difficulty of the optimal regret analysis of FTPL lies in the analysis in the stability term (Honda et al., 2023; Lee et al., 2024), which is also the problem we mainly addressed. Unfortunately, this main difficulty lies behind these skipped or incorrect arguments, and thus we need an essentially new technique to complete the regret analysis for this problem. In this paper, we evaluate the stability term in a totally different way in Lemmas 3–6, which demonstrates that the stability term can be bounded by the maximum of simple quantities each of which is associated with a subset of base-arms.
2 Problem Setup
In this section, we formulate the problem and introduce the framework of FTPL with geometric resampling. We consider an action set , where each element is called an action. For each base-arm , we assume that there exists at least an action such that . In this paper, we consider a special case of action sets in combinatorial semi-bandit, referred to as size-invariant semi-bandit. In this setting, we define the action set , where is the number of selected base-arms at each round. At each round , the environment determines a loss vector , and the learner takes an action and incurs a loss . In the semi-bandit setting, the learner only observes the loss for all such that , whereas that corresponds to is not observed.
In this paper, we only consider the setting that the loss vector is determined in an adversarial way. In this setting, the loss vectors are not assumed to follow any specific distribution, and they are determined in an arbitrary manner, which may depend on the past history of the actions and losses .
The performance of the learner is evaluated in terms of the pseudo-regret, which is defined as
2.1 Follow-the-Perturbed-Leader
| Symbol | Meaning |
|---|---|
| Action set | |
| Dimensionality of action set | |
| for any | |
| Learning rate | |
| Loss vector | |
| Estimated loss vector | |
| Cumulative estimated loss vector | |
| Rank of -th element of in in descending order, omitted when | |
| The number of arms (including itself) whose cumulative losses do not exceed , i.e., | |
| Left-end point of perturbation | |
| -dimensional perturbation | |
| Probability distribution function of perturbation | |
| Cumulative distribution function of perturbation | |
| Fréchet distribution with shape | |
| Pareto distribution with shape |
We consider the Follow-the-Perturbed-Leader (FTPL) policy, whose entire procedure is given in Algorithm 1. In combinatorial semi-bandit problems, FTPL policy maintains a cumulative estimated loss and plays an action
where is the learning rate, and denotes the random perturbation i.i.d. from a common distribution with a distribution function . In this paper, we consider two types of perturbation distributions. The first is Fréchet distribution , with the probability density function and the cumulative distribution function given by
The second is Pareto distribution , whose density and cumulative distribution functions are defined as
Denote the rank of -th element in in descending order as . The probability of selecting base-arm and given is written as . Then, for , letting be the sorted elements of such that , can be expressed as
| (1) |
where is defined as . Here, denotes the left endpoint of the support of .
Then, we write the probability of selecting the base-arm as , where for
| (2) |
Table 1 summarizes the notation used in this paper.
2.2 Geometric Resampling
Since the loss in every round is partially observable in the setting of semi-bandit feedback, for the unbiased loss estimator, many policies generally use an estimator for the loss vector . Then, the cumulative estimated loss vector is obtained as . In standard multi-armed bandit problems, many policies like FTRL often employ an importance-weighted (IW) estimator , where means the chosen arm at round , and the arm-selection probability is explicitly computed. However, in the combinatorial semi-bandit setting, the individual probability of each base-arm is not available, which complicates the construction of the unbiased estimator. To address this issue, Neu and Bartók (2016) proposed a technique called Geometric Resampling (GR). With this technique, for each selected base-arm , FTPL policy can efficiently compute an unbiased estimator for . The procedure of GR is shown in Algorithm 2, where the notation denotes the element-wise product of two vectors and , i.e., for all .
Now we consider the computational complexity of GR. Let denote the number of resampling taken by geometric resampling at round until switches from to . Here, is equal to in GR. Then, the expected number of total resampling given can be bounded as
For each resampling, the generation of perturbation requires the complexity of , and thus the total complexity of GR at each round is , which is independent of . Compared with many other policies, in combinatorial semi-bandit problems, FTPL with GR is computationally more efficient. However, in standard -armed bandit problems, the computational complexity of FTPL with GR still maintains . Though FTPL remains efficient for moderate size of (Honda et al., 2023), primarily thanks to its optimization-free nature, the running time increases substantially as grows to a large number. To overcome this limitation, Chen et al. (2025) proposed an improved technique called Conditional Geometric Resampling (CGR), which reduces the complexity to and demonstrates superior runtime performance. Inspired by this, we extend CGR to size-invariant semi-bandit setting in this paper, which is presented in Section 5.
3 Regret Bounds
In this section, we summarize the regret bound of FTPL in adversarial size-invariant semi-bandit setting.
3.1 Main Results
Combining Lemma 2 from this section and Lemma 6 given in Section 4, we can obtain the regret bound of FTPL in adversarial setting in the following theorem.
Theorem 1.
In the adversarial setting, when perturbation follows Fréchet distribution with shape , FTPL with learning rate
satisfies
whose order is , where is the gamma function. When perturbation follows Pareto distribution with shape , FTPL with learning rate
satisfies
whose order is .
3.2 Regret Decomposition
To evaluate the regret of FTPL, we firstly decompose the regret which is expressed as
This can be decomposed in the following way, whose proof is given in Section 6.
Lemma 2.
For any and ,
| (3) |
We refer to the first and second terms of (3) as stability term and penalty term, respectively.
4 Stability of Arm-selection Probability
In the standard multi-armed bandit problem, the core and most challeging part in analyzing the regret of FTPL lies on the analysis of the arm-selection probability function (Abernethy et al., 2015; Honda et al., 2023; Lee et al., 2024). This challenge is further amplified in the combinatorial semi-bandit setting, where the base-arm selection probability given in (2) exhibits significantly greater complexity. To this end, this section firstly introduces some tools used in the analysis and then derives properties of , which is the main difficulty of the analysis of FTPL.
4.1 General Tools for Analysis
Since the probability of some events in different base-arm set will be considered in the subsequent analysis, we introduce the parameter into . Denote the rank of -th element of in in descending order as . We define
| (4) |
where .
Under this definition, means the probability that the base-arm ranks -th among the base-arm set . Based on (4), we define
which represents the probability of selecting base-arm when the base-arm set and the number of selected base-arms are respectively set as and in size-invariant semi-bandit setting. Since the definition above is an extension of (1) and (2), we have
For analysis on the derivative, based on (4) we define
and
When and , we simply write
In the following, we write to denote the number of arms (including itself) whose cumulative losses do not exceed , i.e., . Without loss of generality, in the subsequent analysis we always assume (ties are broken arbitrarily) so that for notational simplicity. To derive an upper bound, we employ the tools introduced above to provide lemmas related to the relation between the base-arm selection probability and its derivatives.
4.2 Important Lemmas
Lemma 3.
It holds that
where
Based on this result, the following lemma holds.
Lemma 4.
If , that is, is the -th smallest among (ties are broken arbitrarily), then
Next, following the steps in Honda et al. (2023) and Lee et al. (2024), we extend the analysis to the combinatorial semi-bandit setting and obtain the following lemma.
Lemma 5.
For any and , it holds that
By using the above lemma, we can express the stability term as follows.
Lemma 6.
For any , and , it holds that
5 Conditional Geometric Resampling for Size-Invariant Semi-Bandit
Building on the idea proposed by Chen et al. (2025), this section introduces an extension of Conditional Geometric Resampling (CGR) to the size-invariant semi-bandit setting. This algorithm is designed to provide multiple unbiased estimators in a more efficient way, which is based on the following lemma.
Lemma 7.
Let be an be an arbitrary necessary condition for
| (5) |
Consider resampling of from conditioned on until (5) is satisfied. Then, the number of resampling for base-arm satisfies
From this lemma, we can use
as an unbiased estimator of for sampled from conditioned on .
Proof.
Define
Consider , the probability that base-arm is selected, with the condition . can be expressed as
| (6) |
Note that is an arbitrary necessary condition for , which implies that
Therefore, from (6) we immediately obtain
| (7) |
Now we consider the expected number of resampling for base-arm . Recall that is sampled from conditioned on until (5) is satisfied, that is, . Then follows geometric distribution with probability mass function
Therefore, the expected number of resampling given and is expressed as
| (8) |
Combining (7) and (8), we obtain
∎
For base arm such that , we now consider resampling from the perturbation distribution conditioned on
that is, the event that lies among the top- largest of the base-arms whose cumulative estimated losses are no worse than . By the symmetry nature of the i.i.d. perturbations, we can sample from this conditional distribution with simple operation, which corresponds to Lines 3–3 in Algorithm 3. For each base-arm such that , the resampling procedure in our proposed algorithm is the same as the original GR. By Lemma 7, we can derive the properties of CGR in size-invariant semi-bandit setting as follows.
Lemma 8.
Proof.
Let denote the probability distribution of after the value-swapping operation, and denote the rank of among . Then, we have . Given and , for any realization in of we have
| (10) |
By symmetry of , we have
| (11) |
for any suth that . Then we have
which means that (11) is equal to . Therefore, from (10) we have
| (12) |
By symmetry, each probability term in the RHS of (12) is equal. Therefore, we have
with which we immediately obtain
| (13) |
For the LHS of (13), since for any we have , we have
| (14) |
On the other hand, for any and we have
| (15) |
and
Then, for the RHS of (13) we have
| (16) |
Combining (13), (14) and (16), we have
which means that CGR samples from the conditional distribution of conditioned on . Combining this fact and (15) with Lemma 7, for we have
Note that for satisfying , the resampling method is the same as the original GR. For such we have
Therefore, for any ,
serves as an unbiased estimator for . Then, the expected number of resampling given in CGR is bounded by
∎
Average Complexity
Now we analyze the average complexity of CGR, which can be expressed as
| (17) |
where is the cost of scanning the base-arms and determining whether to include them in the set (Lines 3–3), and is the cost of each resampling. For the former, the condition that requires is only evaluated when . Then, we have
| (18) |
For the resampling process, as shown in Algorithm 3, base-arms in and those not in are resampled differently, since the former involves an additional value-swapping operation (Lines 3–3). However, this operation does not change the order of the resampling cost, which remains in both cases. Combining (9), (17) and (18), we have
Remark 1.
In this paper, though we only analyze the regret bound of FTPL with the original GR, the analysis of FTPL with CGR is similar, as we only need to replace the expression of expectation of the estimator in (59). In fact, the regret bound of FTPL with CGR can attain a slightly better regret bound compared with the one with the original GR. This is because the variance of becomes
where the latter is no larger than the former.
6 Proofs for regret decomposition
In this section, we provide the proof of Lemma 2. Firstly, similarly to Lemma 3 in Honda et al. (2023), we prove the general framework of the regret decomposition that can be applied to general distributions.
Lemma 9.
Proof.
Let us consider random variable that independently follows Fréchet distribution or Pareto distribution , and is independent from the randomness of the environment and the policy. Define , where . Then, since and are identically distributed given , we have
| (19) |
Denote the optimal action as . Recalling , we have
and recursively applying this relation, we obtain
and therefore
For Fréchet and Pareto distributions, we bound in the following lemma.
Lemma 10.
For and , we have
Proof.
Let be the -th largest perturbation among i.i.d. sampled from for . Then, we have
| (20) |
Pareto Distribution
Fréchet Distribution
7 Analysis on Stability Term
7.1 Proof for Monotonicity
Lemma 11.
Let denote a non-negative function that is independent of . If and is the cumulative distribution function of Fréchet or Pareto distributions, then
is monotonically increasing in .
Proof.
Let
The derivative of with respect to is expressed as
If , we have
where the last equality holds since . On the other hand, if , we have
In both cases, we have
Similarly, we have
Next, we divide the proof into two cases.
Fréchet Distribution
When is the cumulative distribution function of Fréchet distribution, we define . Under this definition, we have
and
Here, by an elementary calculation we can see
where the last inequality holds since is monotonically increasing in for . Therefore, when is the cumulative distribution function of Fréchet distribution, we have , which implies that is monotonically increasing in .
Pareto Distribution
When is the cumulative distribution function of Pareto distribution, we have
and
Here, by an elementary calculation we can see
where the last inequality holds because is monotonically increasing in for . Therefore, we have , which concludes the proof. ∎
Lemma 12.
Let , , where . If both and are monotonically increasing in , then for any , we have
Provided that exists, for any we have
Proof.
According to the assumption, we have
If , then we have
On the other hand, if , then we have
Let , where . Then, we have
which means that is monotonically increasing in . Therefore, we have
Combining both cases, we have
for any . If exists, the result for the infinite case follows directly by taking the limit of . ∎
Lemma 13.
For and , let be such that and for all . Then, we have
Proof.
For , we define
where the probability can be expressed as
| (25) |
Here, . Corresponding to this, we define
| (26) |
Considering the event
we have
By definition, we can see that
Therefore, we can docompose the expression of the probability as
| (27) |
Similarly, by definition we have
| (28) |
Consider the expression of and respectively given by (25) and (26). By Lemma 11, it follows that
because of the monotonic increase in . Then, since both and do not depend on , we have
| (29) | ||||
where the inequality (29) holds by recalling that the same relation as (27) and (28) holds for in Lemma 12. ∎
The following lemma presents a special case of Lemma 13, where we take .
Lemma 14.
Let . If , we have
| (30) |
If , we have
| (31) |
Proof.
Inequality (30)
Recall that
where . Note that
where . Then, can be rewritten as
| (32) |
Taking the limit of on both sides of (32), since , the first term of the RHS of (32) vanishes, and the second term becomes independent of . Then, can be expressed as
| (33) |
By the same argument, we also have
| (34) |
By Lemma 13, (33) and (34), we have
| (35) | ||||
where (35) holds since both and exist and nonzero.
Inequality (31)
7.1.1 Proof of Lemma 3
Proof.
In this proof, we locally use to denote a sequence of -dimensional vectors defined as follows. Define , for we have
Consequently, we have
We are now ready to derive the result. Firstly, to address all , for , we only need to show that
| (36) |
holds for , which is trivial. For , we prove (36) holds for all by mathematical induction. We have
We begin by verifying the base case of the induction. When , the statement becomes
If , the statement is immediate, since is expressed as
which is monotonically increasing in all by Lemma 11. Otherwise, by applying Lemma 13, we have
Therefore, the statement holds for .
We assume, as the inductive hypothesis, that the statement holds for , i.e.,
| (37) |
If we can prove the statement holds for , then by induction, the statement holds for all , thereby establishing the desired result in (36). Now we aim to prove it for , i.e., we want to show that
To prove this, it suffices to show the following inequality holds:
| (38) |
since this, together with the induction hypothesis (37), implies that
Now we prove (38) holds for . For each term in the LHS of (38) given by
we consider the following two cases.
-
•
Case 1: .
In this case, we have . Similarly to the analysis on the base case, by Lemma 11, for any ,is monotonically increasing in . Applying this to , we have
(39) where the last inequality holds since and .
-
•
Case 2: .
In this case, since , we have . On the other hand, since , we have and thus . Combining these, we have . Since , by applying Lemma 13 again, we have(40) where the last inequality holds since .
Combining (39) and (40), we see that (38) holds and thus the statement holds for , completing the inductive step. By the principle of mathematical induction, the statement (36) holds for . By letting , we have
| (41) |
Now we address all the base-arms in , i.e., all satisfying . We prove
| (42) |
by mathematical induction on . We begin by verifying the base case of the induction. When , the statement becomes
If , we consider each term in the RHS of (41) in two cases. For such that , it follows that
which is monotonically increasing in for all by Lemma 11. Taking the limit , we have and thus
For such that , by applyng Lemma 14 to base-arm , we obtain
Combining the above two cases, by (41) we have
where the last inequality holds since and for any . On the other hand, if , by Lemma 14 and (41), we obtain
where the last inequality holds since for any . Therefore, the statement holds for base case .
Now we assume, as the inductive hypothesis, that the statement holds for , i.e.,
| (43) |
If we can prove the statement holds for , then by induction, the statement holds for all , thereby establishing the desired result in (42). Now we aim to prove it for , i.e., we want to show that
To prove this, by induction hypothesis (43), we only need to show that the following inequality holds:
| (44) |
We consider each term in the LHS of the above inequality with and in the following three cases.
-
•
Case 1: .
In this case, since and , we haveOn the other hand, since , we have . Combining these, it follows that . Similarly to the analysis on the base case, by Lemma 11, for any ,
is monotonically increasing in . Taking the limit , it follows that
where the last inequality holds since and .
-
•
Case 2: and .
In this case, since we have . Combining it with , it follows that . Since , we have . By applying Lemma 14 to base-arm , we havewhere the last inequality holds since and .
-
•
Case 3: and .
In this case, since and , we have . On the other hand, since we have . Combining these, it follows that . By applying Lemma 14 to base-arm , we havewhere the last inequality holds since and .
Combining the three cases, we see that (44) holds, and thus the statement holds for , completing the inductive step. By induction, the statement (42) holds for . By letting , we immediately obtain
| (45) |
Note that we have
| (46) |
and
| (47) |
Since each term in the RHS of both (46) and (47) is positive, we have
| (48) |
Combining (45) and (48), we have
which concludes the proof. ∎
7.2 Proof of Lemma 4
7.2.1 Pareto Distribution
Let us consider the case . Recall that the probability density function and cumulative distribution function of Pareto distribution are given by
Then, for , we have
and
Then, it holds that
where denotes the Beta function. Similarly, we have
Therefore, we have
| (49) |
Similarly to the proof of Lee et al. (2024), we bound (49) as follows. For , we have
| (by ) | ||||
| (by ) | ||||
| (by Gautschi’s inequality) | ||||
| (equality holds when ) |
Since , we have
Therefore, we have
Recall that as previously noted for notational simplicity. By Lemma 3, for any , we have
7.2.2 Fréchet Distribution
Before proving the statement in the case , we need to give the following lemma.
Lemma 15.
Let denote the cumulative distribution function of Fréchet distribution with shape . For , we have
| (50) |
Proof.
By letting , the inequality (50) can be rewritten as
Equivalently, multiplying both sides by
we arrive at
| (51) |
and thus we only need to prove it to conclude the proof. The LHS of (51) can be expressed as
and the RHS of (51) can be expressed as
By an elementary calculation we can see
| (52) |
By letting , we have
| (53) |
Since is monotonically increasing in , and , the LHS of (53) is monotonic in the same direction as , whose derivative is expressed as
where the inequality holds since . Therefore, the LHS of (53) is monotonically increasing in . This implies that the expression in (52) is non-positivive, which concludes the proof. ∎
We now prove Lemma 4 in the case by applying Lemma 15. Recall that the probability density function and cumulative distribution function of Pareto distribution are given by
Then, for , we have
and
Define
Then, by Lemma 15, we immediately obtain
| (54) |
Similarly to the proofs of Honda et al. (2023) and Lee et al. (2024), we bound the RHS of (54) as follows. By letting , both and can be expressed by Gamma function as
and
Replacing with , we have
| (55) |
By Lemma 16, Gautschi’s inequality, we have
Combining this result with (55), we obtain
Since , we have
Recall that as previously noted for notational simplicity. By Lemma 3 and (54), for any , we have
7.3 Proof of Lemma 5
Following the proofs of Honda et al. (2023) and Lee et al. (2024), we extend the statement to combinatorial semi-bandit setting.
Proof.
Define
and
Then, we have
Since , we immediately have
with which we have
| (56) |
Recalling that is expressed as
we see that is expressed as
Now we divide the proof into two cases.
Fréchet distribution
Pareto distribution
Here note that follows the geometric distribution with expectation , given and , which satisfies
| (59) |
Since when , for we obtain
| (by Lemma 4) |
∎
7.4 Proof of Lemma 6
By Lemma 5, we have the following result.
7.4.1 Fréchet Distribution
When , we have
7.4.2 Pareto Distribution
When , we have
8 Technical Lemmas
Lemma 16 (Gautschi’s inequality).
For and ,
Lemma 17.
(Malik, 1966, Eq. (3.7)) Let be the -th order statistics of i.i.d. RVs from for , where . Then, we have
Lemma 18.
Let and be CDFs of some random variables such that for all . Let (resp. ) be RVs i.i.d. from (resp. ), and (resp. ) be its -th order statistics for any . Then, holds.
Proof.
Let be uniform random variable over and let and , where and are the left-continuous inverses of and , respectively. Then, holds almost surely and the marginal distributions satisfy and . Therefore, if when take as i.i.d. copies of this , we see that holds almost surely, which proves the lemma. ∎
Lemma 19.
Let (resp. ) be the -th order statistics of i.i.d. RVs from and for . Then, holds.
Proof.
Letting and be the CDFs of and , we have
where is the CDF of for . Then, it holds from Lemma 18 that . ∎
9 Issues in Proof of Claimed Extension to the Monotone Decreasing Case
In this section, we use the same notation as Zhan et al. (2025) and reconstruct their missing arguments in Lemma 4.1 in Zhan et al. (2025). The claim proposed by them is as follows.
Claim 1 (Lemma 4.1 in Zhan et al. (2025)).
For any , , such that and any , let
Then, for all , is increasing in for and , while decreasing in for .
In their paper, they consider the case that is the cumulative distribution function of Fréchet distribution with shape , which is expressed as
and thus we also adopt the same setting in this section. For this claim, they only gave the proof of the monotonic increase for the former case and it is written that the monotonic decrease for the latter case “can be shown by the same argument”. Nevertheless, the monotonic decrease is not proved by the same argument, and it is highly likely that the statement itself does not hold as we will demonstrate below.
Now we follow the line of the proof of monotone increasing case in Zhan et al. (2025), giving an attempt to prove that for all , is monotonically decreasing on for . For , denote
Hence,
| (60) |
Letting , we have
Here, it is worth noting that and share no common factors, and thus no factor can be hidden in .
By an elementary calculation, we have
| (61) |
Here, for (61), one can see that when , the first term becomes negative. On the other hand, when , the first term becomes positive. Define
If can be shown to be monotonically decreasing, then (60) is negative, that is, the claim holds. However, the derivative of is given as
where one can see that is not always negative, and thus is not monotonic in .
By the analysis above, we can see that the monotone decreasing case can not be proved by the same argument as in increasing case.
Numerical Simulation
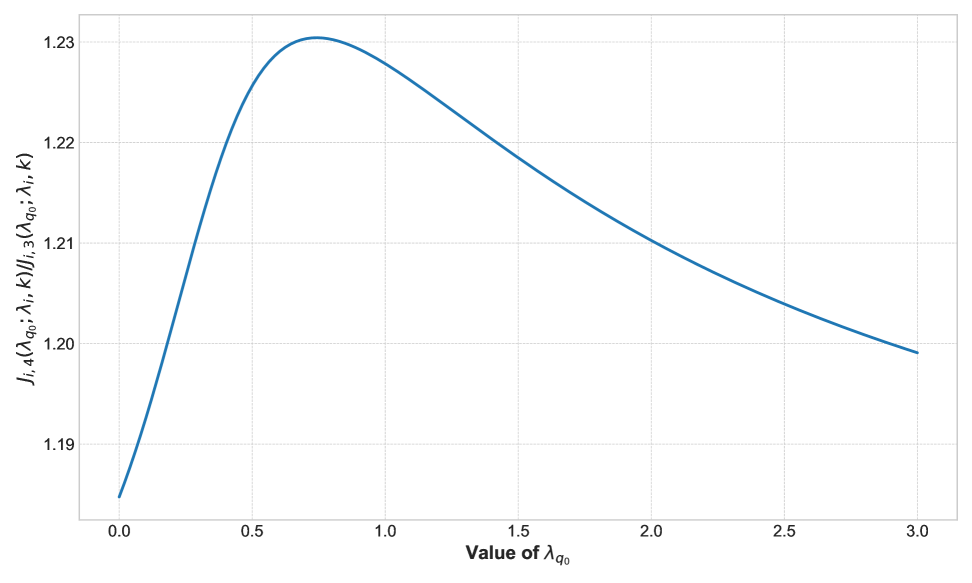
We now turn to a numerical simulation implemented in Python to illustrate this failure. As a counterexample, it is sufficient to show one special case where , and for all . Then, we consider the expression
Here, we set and , which are the parameters used in the subsequent analysis in Zhan et al. (2025). Treating this expression as a function of , we can observe from Figure 1 that the function is not monotonic in , and it does not hold that for some .
From these arguments, it is highly likely that Lemma 4.1 in Zhan et al. (2025) does not hold, and at least the current proof is not complete. On the other hand, our analysis is constructed in a way that does not need the monotonicity of , which becomes the key to the extension of the results for the MAB to the combinatorial semi-bandit setting.
Acknowledgements
We thank Dr. Jongyeong Lee for pointing out the error in the proof of Lemma 10 in the previous version.
References
- Abernethy et al. (2015) Jacob D Abernethy, Chansoo Lee, and Ambuj Tewari. Fighting bandits with a new kind of smoothness. Advances in Neural Information Processing Systems, 28, 2015.
- Audibert et al. (2014) Jean-Yves Audibert, Sébastien Bubeck, and Gábor Lugosi. Regret in online combinatorial optimization. Mathematics of Operations Research, 39(1):31–45, 2014.
- Chen et al. (2025) Botao Chen, Jongyeong Lee, and Junya Honda. Geometric resampling in nearly linear time for follow-the-perturbed-leader with best-of-both-worlds guarantee in bandit problems. In International conference on machine learning. PMLR, 2025. In press.
- Chen et al. (2013) Wei Chen, Yajun Wang, and Yang Yuan. Combinatorial multi-armed bandit: General framework and applications. In International conference on machine learning, pages 151–159. PMLR, 2013.
- Gai et al. (2012) Yi Gai, Bhaskar Krishnamachari, and Rahul Jain. Combinatorial network optimization with unknown variables: Multi-armed bandits with linear rewards and individual observations. IEEE/ACM Transactions on Networking, 20(5):1466–1478, 2012.
- Honda et al. (2023) Junya Honda, Shinji Ito, and Taira Tsuchiya. Follow-the-Perturbed-Leader Achieves Best-of-Both-Worlds for Bandit Problems. In Proceedings of The 34th International Conference on Algorithmic Learning Theory, volume 201 of PMLR, pages 726–754. PMLR, 20 Feb–23 Feb 2023.
- Ito (2021) Shinji Ito. Hybrid regret bounds for combinatorial semi-bandits and adversarial linear bandits. Advances in Neural Information Processing Systems, 34:2654–2667, 2021.
- Kveton et al. (2014) Branislav Kveton, Zheng Wen, Azin Ashkan, Hoda Eydgahi, and Brian Eriksson. Matroid bandits: fast combinatorial optimization with learning. In Uncertainty in Artificial Intelligence, pages 420–429, 2014.
- Kveton et al. (2015) Branislav Kveton, Zheng Wen, Azin Ashkan, and Csaba Szepesvari. Tight regret bounds for stochastic combinatorial semi-bandits. In Artificial Intelligence and Statistics, pages 535–543. PMLR, 2015.
- Lee et al. (2024) Jongyeong Lee, Junya Honda, Shinji Ito, and Min-hwan Oh. Follow-the-perturbed-leader with fréchet-type tail distributions: Optimality in adversarial bandits and best-of-both-worlds. In Conference on Learning Theory, pages 3375–3430. PMLR, 2024.
- Malik (1966) Henrick John Malik. Exact moments of order statistics from the pareto distribution. Scandinavian Actuarial Journal, 1966(3-4):144–157, 1966.
- Neu (2015) Gergely Neu. First-order regret bounds for combinatorial semi-bandits. In Conference on Learning Theory, pages 1360–1375. PMLR, 2015.
- Neu and Bartók (2016) Gergely Neu and Gábor Bartók. Importance weighting without importance weights: An efficient algorithm for combinatorial semi-bandits. Journal of Machine Learning Research, 17(154):1–21, 2016.
- Nuara et al. (2022) Alessandro Nuara, Francesco Trovò, Nicola Gatti, and Marcello Restelli. Online joint bid/daily budget optimization of internet advertising campaigns. Artificial Intelligence, 305:103663, 2022.
- Tsuchiya et al. (2023) Taira Tsuchiya, Shinji Ito, and Junya Honda. Further adaptive best-of-both-worlds algorithm for combinatorial semi-bandits. In International Conference on Artificial Intelligence and Statistics, pages 8117–8144. PMLR, 2023.
- ul Hassan and Curry (2016) Umair ul Hassan and Edward Curry. Efficient task assignment for spatial crowdsourcing: A combinatorial fractional optimization approach with semi-bandit learning. Expert Systems with Applications, 58:36–56, 2016.
- Wang and Chen (2018) Siwei Wang and Wei Chen. Thompson sampling for combinatorial semi-bandits. In International Conference on Machine Learning, pages 5114–5122. PMLR, 2018.
- Wang et al. (2017) Yingfei Wang, Hua Ouyang, Chu Wang, Jianhui Chen, Tsvetan Asamov, and Yi Chang. Efficient ordered combinatorial semi-bandits for whole-page recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 31, 2017.
- Wei and Luo (2018) Chen-Yu Wei and Haipeng Luo. More adaptive algorithms for adversarial bandits. In Conference On Learning Theory, pages 1263–1291. PMLR, 2018.
- Zhan et al. (2025) Jingxin Zhan, Yuchen Xin, and Zhihua Zhang. Follow-the-perturbed-leader approaches best-of-both-worlds for the m-set semi-bandit problems. arXiv preprint arXiv:2504.07307v2, 2025.
- Zimmert and Seldin (2021) Julian Zimmert and Yevgeny Seldin. Tsallis-inf: An optimal algorithm for stochastic and adversarial bandits. Journal of Machine Learning Research, 22(28):1–49, 2021.
- Zimmert et al. (2019) Julian Zimmert, Haipeng Luo, and Chen-Yu Wei. Beating stochastic and adversarial semi-bandits optimally and simultaneously. In International Conference on Machine Learning, pages 7683–7692. PMLR, 2019.