OAS-Net: Occlusion Aware Sampling Network for Accurate Optical Flow
Abstract
Optical flow estimation is an essential step for many real-world computer vision tasks. Existing deep networks have achieved satisfactory results by mostly employing a pyramidal coarse-to-fine paradigm, where a key process is to adopt warped target feature based on previous flow prediction to correlate with source feature for building 3D matching cost volume. However, the warping operation can lead to troublesome ghosting problem that results in ambiguity. Moreover, occluded areas are treated equally with non occluded regions in most existing works, which may cause performance degradation. To deal with these challenges, we propose a lightweight yet efficient optical flow network, named OAS-Net (occlusion aware sampling network) for accurate optical flow. First, a new sampling based correlation layer is employed without noisy warping operation. Second, a novel occlusion aware module is presented to make raw cost volume conscious of occluded regions. Third, a shared flow and occlusion awareness decoder is adopted for structure compactness. Experiments on Sintel and KITTI datasets demonstrate the effectiveness of proposed approaches.
Index Terms— Optical Flow, Convolutional Neural Networks (CNNs), Sampling Based Correlation, Occlusion Aware Module
1 Introduction
Optical flow estimation is a longstanding and fundamental task in computer vision. It plays a key role for many real-world applications, such as object tracking [1], action recognition [2] and scene understanding [3].




With the development of Convolutional Neural Networks (CNNs), deep learning based optical flow networks [4, 5, 6] are proposed together with large synthetic training datasets. Dosovitskiy et al. [4] firstly apply CNNs to optical flow and put forward two networks named FlowNetS and FlowNetC. Though its performance is slightly worse than traditional methods, the running speed is several orders of magnitude faster. The successor FlowNet2 [5] outperforms variational solutions by stacking several basic models and training on multiple datasets with carefully designed learning schedules. However, the large number of parameters hinder it from mobile applications. Concurrently, the liteweight SPyNet [7] constructs image pyramid and warps the second image to the first one according to prior prediction to estimate residual flow in a coarse-to-fine manner. Nevertheless, it suffers from large performance decline and computation burden.
Recently, PWC-Net [6] and LiteFlowNet [8] similarly adopt pyramid feature, warping operation and correlation layer in each level to estimate residual flow from coarse to fine. They obtain improvement in both prediction accuracy and model size. Following this, IRR-PWC [9] proposes shared flow estimators among different scales for iterative residual estimation, which can reduce learnable parameters and speed up convergence. FDFlowNet [10] improves original pyramid structure with a compact U-shape network and proposes efficient partial fully connected flow estimator for fast and accurate inference. Recently, Devon [11] builds deformable cost volume with multiple dilated rates to capture small fast moving objects and alleviate warping artifacts.
Though benchmark results are constantly being promoted, there are still challenges blocking further progresses. Since the high efficiency on reducing large displacement, warping operation appears in almost all advanced flow architectures [5, 7, 6, 8, 9, 12, 10]. However, as shown in Fig 1c, the warped target image suffers from ghosting problem, e.g., the yellow cross region, which leads to ambiguity of original scene structure and will further damage performance. Another challenge is the inevitable occlusion, such as the red cross shown in Fig 1. To solve above problems, we propose a lightweight and efficient occlusion aware sampling network, termed OAS-Net, for accuracy optical flow estimation. We summarize our contributions as follows:
A novel sampling based cost volume is adopted to avoid ghosting phenomenon and reduce matching ambiguity.
An occlusion aware module is seamless embedded into the coarse-to-fine flow architecture to endow raw matching cost better occlusion awareness.
With shared optical flow and occlusion awareness decoder, a new lightweight yet efficient OAS-Net is constructed, which achieves state-of-the-art performance.
2 Method
2.1 Overall Network Architecture
Given input frames of , our OAS-Net estimates optical flow in a coarse-to-fine manner like many approaches [6, 8, 12, 10], where a feature extraction network is adopted to build pyramid features . Each pyramid scale in OAS-Net contains two convolution layers and the first stride 2 convolution down samples spatial resolutions. Commonly, we set an incremental 16, 32, 64, 96, 128 and 160 feature maps from level 1 to level 6 respectively.
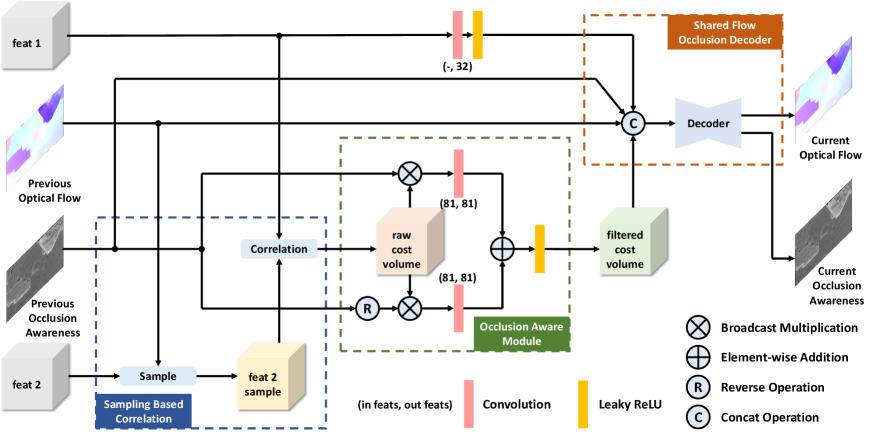
As shown in Fig 2, 5 sub-networks sharing the same structure for occlusion aware optical flow estimation are employed in each level to refine upsampled flow fields together with occlusion awareness maps. For completeness, we first describe the shared optical flow and occlusion decoder. Since there is no dilated context network [6, 9] utilized by OAS-Net, we set a sequential connected decoder with three more convolution layers to enlarge receptive field for fair comparison, which outputs 128, 128, 128, 128, 128, 96, 64 and 32 channels. The final flow and occlusion maps are predicted by two separate convolution heads making OAS-Net lightweight and efficient. To keep meaningful range of occlusion awareness map, we add a non-linear sigmoid activation to restrict output from 0 to 1. Unlike [9] which relys on both flow and occlusion ground-truth for co-training, our model only requires optical flow label, while the occlusion awareness is automatically learned by flow supervision.
2.2 Sampling Based Correlation
One key step in optical flow approaches is to build cost volume which can provide better correspondence representation than direct convolution feature. To deal with the challenging large displacement, mainstream solution is to leverage bilinear sampling based warping operation [7, 6, 8, 9, 12] to reduce offset between source and target corresponding feature according to the roughly estimated flow field. When the target feature is warped to the source one, followed matching cost volume can be built by calculating feature similarity within a local searching area. As shown in Fig 1c, this warping based cost volume can be formulated as:
| (1) |
Where means warped target feature in level , means spatial coordinates and represents searching offsets. is to calculate innner product for similarity measurement.
As mentioned above, the warping based cost volume suffers from duplicate artifacts, which is also known as ghosting. To solve the problem, we build cost volume with a novel sampling based approach as shown in Fig 1d that avoids warping and ghosting issues. This operation can be formulated as:
| (2) |
Where the new vector denotes previous optical flow field in the location of coordinate . Different from a dilated differential volume in [11], we adopt inner product based volume whose traverses a searching square with radius 4. Compared to Eq 1, the flow based warping operation is replaced by directly sampling flow guided searching grids in the target pyramid feature. Experiments will show proposed sampling based correlation method helps to improve performance.
2.3 Occlusion Aware Module
Although sampling based cost volume can bypass annoying ghosting feature, another challenging occlusion problem is unavoidable. As shown in Fig 1, the red cross pointing bush in the source image is covered by the moving arm in the target image. This type of occluded region is unrecoverable no matter to take either correlation methods.
In regard to supervised methods [4, 5, 7, 6, 8, 12, 10, 11], little attention has been paid to handle occlusion explicitly during pure supervison by densely labeled optical flow. To endow flow estimation with occlusion awareness, we present a novel occlusion aware module to better handle two types of matching regions in raw cost volume separately, which can be seamlessly embedded into the coarse-to-fine structure.
As depicted in Fig 2, there are four steps to build occlusion aware cost volume. First, previous upsampled occlusion awareness is subtracted from a full one tensor to create a reversed occlusion awareness map. Second, the complementary occlusion maps separately multiply raw cost volume to extract two occlusion reweighted cost volumes. Third, two disparate convolution layers are employed to filter above occlusion aware cost volumes respectively. Finally, two filtered matching costs are merged by addition following a leaky ReLU layer. The whole process can be formulated as:
| (3) |
Where means occlusion awareness map, represents broadcast multiplication and stands for element-wise addition. Referring to Eq 3, proposed occlusion awareness map can also be interpreted as occlusion probability map, which can be viewed as one type of self-attention mechanism [13]. We will visualize occlusion awareness and demonstrate our occlusion aware cost volume can improve optical flow accuracy, especially in fast-moving scenarios.
3 Experiments
3.1 Training Details
We adopt the two stage training schedule in FlowNet2 [5]. OAS-Net is firstly trained on FlyingChairs dataset [4] with learning schedule, i.e., initial learning rate is set to and decays half at and iterations with total iterations. Then, the pretrained model is fine-tuned on FlyingThings3D dataset [14] following the schedule, i.e., with initial learning rate and decays half at and iterations with total iterations. For FlyingChairs, batch size is set to 8 and crop size is set to , and for FlyingThings3D, we take batch size 4 and adopt crops. Multiple data augmentation methods, including mirror, translate, rotate, zoom, squeeze and color jitter are employed to enrich training distribution and prevent overfitting. Since pyramid structure of OAS-Net is the same with PWC-Net [6] and LiteFlowNet [8], we use the same multi-scale L2 loss [6] for supervised learning. Adam [15] optimizer is adopted in all stages, and our experiments are conducted on one NVIDIA GTX 1080Ti GPU with PyTorch.
3.2 Ablation Study
| Correlation | Occlusion | Sintel | KITTI |
|---|---|---|---|
| Method | Awareness | Final | 2012 |
| Warping | 4.05 | 4.62 | |
| Warping | ✓ | 3.98 | 4.37 |
| Sampling | 3.86 | 4.44 | |
| Sampling | ✓ | 3.79 | 4.11 |
To explore and verify value of proposed approaches, we conduct ablation with 4 variations based on pairwise combinations. For sake of effective comparison, all variants follow above two stage training schedule and are evaluated on Sintel Final, KITTI 2012 training datasets, as listed in Table 1.
| Method | Sintel Clean | Sintel Final | KITTI 2012 | Parameters | Time | |||
|---|---|---|---|---|---|---|---|---|
| train | test | train | test | train | test | (M) | (s) | |
| FlowNetC [4] | 4.31 | 6.85 | 5.87 | 8.51 | 9.35 | - | 39.18 | 0.050 |
| SPyNet [7] | 4.12 | 6.64 | 5.57 | 8.36 | 9.12 | 4.7 | 1.20 | 0.055 |
| FlowNet2 [5] | 2.02 | 4.16 | 3.14 | 5.74 | 4.09 | 1.8 | 162.49 | 0.120 |
| LiteFlowNet [8] | 2.48 | 4.54 | 4.04 | 5.38 | 4.00 | 1.6 | 5.37 | 0.055 |
| PWC-Net [6] | 2.55 | 4.39 | 3.93 | 5.04 | 4.14 | 1.7 | 8.75 | 0.035 |
| IRR-PWC [9] | - | 3.84 | - | 4.58 | - | 1.6 | 6.36 | 0.150 |
| HD3-Flow [12] | 3.84 | 4.79 | 8.77 | 4.67 | 4.65 | 1.4 | 39.56 | 0.080 |
| Devon [11] | - | 4.34 | - | 6.35 | - | 2.6 | - | 0.050 |
| OAS-Net (Ours) | 2.55 | 3.65 | 3.79 | 5.01 | 4.11 | 1.4 | 6.16 | 0.030 |
Compared with the baseline method, which adopts warping based correlation and does not include occlusion awareness module, only replacing warping based cost volume with sampling based one reduces end point error of on Sintel Final and on KITTI 2012. While only adding occlusion awareness module reduces error of on Sintel and on KITTI. It concludes that sampling is more remarkable on Sintel which contains more non-rigid motion and has higher requirement on distinct scene structure, while occlusion awareness is more effective on KITTI that involves large movement and occluded regions. Finally, combining these two approaches gets best results that reduces end point error of on Sintel Final and on KITTI 2012, demonstrating our contributions are cooperative and complementary.
3.3 Benchmark Results






To compare with state-of-the-art methods [5, 8, 6, 9, 12], we first evaluate above two stage trained OAS-Net on Sintel [16] and KITTI [17] training sets. For comparison on Sintel test benchmark, we fine-tune OAS-Net on mixed Sintel datasets, where we adopt batch size 4, with 2 from Clean, and 2 from Final. Similar to IRR-PWC [9], learning rate is initially set to and disturbed every iterations over total iterations. To evaluate on KITTI 2012 test benchmark, we fine-tune OAS-Net on mixed KITTI 2012 and KITTI 2015 training sets following the same schedule on Sintel while reducing amplitude of spatial augmentation. All results together with model size and running speed (measured on Sintel resolution) are listed in Table 2.




OAS-Net performs better than all the other approaches on Sintel Clean test dataset, it improves about than the second one. OAS-Net also surpasses PWC-Net [6] on Sinel Final test set slightly, but is exceeded by IRR-PWC [9] and HD3-Flow [12]. However, our model has less learnable parameters, i.e., M vs MM and runs several times faster, i.e., s vs ss. We further evaluate it on a more challenging real-world KITTI dataset. As shown in Table 2, OAS-Net achieves the same best result as HD3-Flow [12] on KITTI 2012 test benchmark with end point error of , which reduces error than LiteFlowNet [8].
To verify our approaches visually, we show one example on each Sintel Final test and KITTI training sets, as depicted in Fig 3 and Fig 4. It can be seen that our occlusion awareness maps have correctly emphasized the probable occluded regions, and help to improve optical flow accuracy, such as the left bottom corner of Fig 3 and fast moving edges in Fig 4.
4 Conclusion
In this paper, we have presented a new OAS-Net for accuracy optical flow estimation. To keep clear scene structure, we propose to use sampling based correlation instead of noisy warping method. Then, we embed novel occlusion aware module into the coarse-to-fine flow architecture to endow raw cost volume better occlusion awareness. Finally, our optical flow and occlusion awareness share the same decoder making OAS-Net lightweight and fast. Experiments on both synthetic Sintel and real-world KITTI datasets demonstrate the effectiveness of proposed approaches and show its state-of-the-art results on challenging benchmarks.
References
- [1] T. Dang, C. Hoffmann, and C. Stiller, “Fusing optical flow and stereo disparity for object tracking,” in Proceedings. The IEEE 5th International Conference on Intelligent Transportation Systems, 2002.
- [2] Karen Simonyan and Andrew Zisserman, “Two-stream convolutional networks for action recognition in videos,” in Advances in Neural Information Processing Systems 27. 2014.
- [3] Junhwa Hur and Stefan Roth, “Joint optical flow and temporally consistent semantic segmentation,” in Computer Vision – ECCV 2016 Workshops, Gang Hua and Hervé Jégou, Eds., 2016.
- [4] Philipp Fischer, Alexey Dosovitskiy, Eddy Ilg, Philip Häusser, Caner Hazirbas, Vladimir Golkov, Patrick van der Smagt, Daniel Cremers, and Thomas Brox, “Flownet: Learning optical flow with convolutional networks,” 2015 IEEE International Conference on Computer Vision (ICCV), 2015.
- [5] Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy, and Thomas Brox, “Flownet 2.0: Evolution of optical flow estimation with deep networks,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [6] Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz, “Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [7] Anurag Ranjan and Michael J. Black, “Optical flow estimation using a spatial pyramid network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- [8] Tak-Wai Hui, Xiaoou Tang, and Chen Change Loy, “Liteflownet: A lightweight convolutional neural network for optical flow estimation,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [9] Junhwa Hur and Stefan Roth, “Iterative residual refinement for joint optical flow and occlusion estimation,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [10] Lingtong Kong and Jie Yang, “Fdflownet: Fast optical flow estimation using a deep lightweight network,” in 2020 IEEE International Conference on Image Processing (ICIP), 2020.
- [11] Yao Lu, Jack Valmadre, Heng Wang, Juho Kannala, Mehrtash Harandi, and Philip Torr, “Devon: Deformable volume network for learning optical flow,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), March 2020.
- [12] Zhichao Yin, Trevor Darrell, and Fisher Yu, “Hierarchical discrete distribution decomposition for match density estimation,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [13] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, L ukasz Kaiser, and Illia Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems 30. 2017.
- [14] N. Mayer, E. Ilg, P. Häusser, P. Fischer, D. Cremers, A. Dosovitskiy, and T. Brox, “A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation,” in IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [15] Diederik Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” International Conference on Learning Representations, 2014.
- [16] D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black, “A naturalistic open source movie for optical flow evaluation,” in European Conf. on Computer Vision (ECCV), 2012.
- [17] Andreas Geiger, Philip Lenz, and Raquel Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in Conference on Computer Vision and Pattern Recognition (CVPR), 2012.