Object-Pose Estimation With Neural Population Codes
Abstract
Robotic assembly tasks require object-pose estimation, particularly for tasks that avoid costly mechanical constraints. Object symmetry complicates the direct mapping of sensory input to object rotation, as the rotation becomes ambiguous and lacks a unique training target. Some proposed solutions involve evaluating multiple pose hypotheses against the input or predicting a probability distribution, but these approaches suffer from significant computational overhead. Here, we show that representing object rotation with a neural population code overcomes these limitations, enabling a direct mapping to rotation and end-to-end learning. As a result, population codes facilitate fast and accurate pose estimation. On the T-LESS dataset, we achieve inference in 3.2 milliseconds on an Apple M1 CPU and a Maximum Symmetry-Aware Surface Distance accuracy of 84.7% using only gray-scale image input, compared to 69.7% accuracy when directly mapping to pose.
I INTRODUCTION
Robotic manipulation requires object pose estimation; particularly, for assembly, we need accurate object orientation for part alignment. Traditionally, part alignment has been solved using mechanical constraints, where the orientation of a part is physically restricted at the pick-up location or where the gripper is engineered in a way to force a certain part orientation. These mechanical constraints, however, increase setup time and costs. Moreover, they cannot prevent failure, e.g., due to part jamming.
Therefore, optical sensing of object pose is preferred. Pose consists of both object orientation and location. Here, orientation presents the primary challenge, as in many manufacturing settings, the mathematical representation of object rotation is not unique. For symmetric parts, multiple rotation matrices or quaternions can represent the same pose. This ambiguity creates a problem for learning algorithms, such as those mapping images to poses, since a neural feedforward network requires a unique target for each input and fails when encountering multiple possible outputs [1].
As a solution, some works proposed to learn pose candidates, which are then down-selected on the sensory data [2, 3]. Alternatively, data can be mapped onto a feature space, e.g., with an autoencoder [4], which is then compared against the feature-space representation of a dense set of possible poses. But these indirect mappings have also disadvantages: they are slower, the algorithms are more complex, and they are less flexible in terms of mapping auxiliary information onto pose.
Here, we propose a representation for object orientation that allows a direct mapping onto pose and end-to-end learning. We take inspiration from information-encoding in the mammalian cortex. There many variables, like object orientation [5], have been found to be encoded by a population of neurons, where each neuron maximally responds to a preferred value, and the activation of the group of neurons resembles a probability distribution of the encoded variable [6]. The population code can represent object symmetry and the corresponding pose ambiguity as multiple activation peaks in the code.
For each input image, we predict the entire population code of the object rotation. We tested our population code on the T-LESS dataset and compared against alternative pose representations using the same network architecture and training data. As a result, we observe significantly improved rotation accuracies with fast inference (3.2 msec on an Apple M1 CPU).
II RELATED WORK
Related to our work are methods that predict a probability distribution of pose or predict multiple possible pose outcomes.
II-A Probability Over Rotations
Pose ambiguity can be dealt with by estimating a probability distribution over the group of rotations in 3D, [7, 8]. The distribution may be represented parametrically, e.g., with a Gaussian mixture model [7] or non-parametrically [8]. The former has the disadvantage of being hard to train [7], e.g., due to local minima [1].
In the non-parametric method by Murphy et al., the distribution is predicted implicitly, i.e., a neural network computes the probability for any input matrix and input image [8]. The disadvantage of this strategy is that has to be normalized across a large sample of rotation matrices that all have to be fed through the network, resulting in a computationally expensive and slow training.
Given a normalized probability and a ground-truth rotation matrix , the loss function is defined as follows [8]
| (1) |
For inference, the rotation with maximum probability is chosen from a set of centers of an equivolumetric partitioning of SO(3) [8],
| (2) |
II-B Multiple Pose Hypotheses
Manhardt et al. train a network to predict multiple pose hypotheses to learn alternative (ambiguous) poses [9]. The network output is a fixed number of possible rotations. For training, the loss function combines a minimum loss , the minimum mean squared error (MSE) between the ground truth and the outcomes, with an average loss , which is the average MSE across the outcomes,
| (3) |
where the parameter is gradually reduced from 0.05 to 0.01.
Inference is more complicated since we do not know a probability for each of the outcomes. Instead, the outcomes are clustered, and the median for each cluster is computed. The results can be compared against the input image to find the best fit [9]. Though this strategy involves again an extra selection step as mentioned above.
III METHODOLOGY
The key element of our new method is to represent object orientation with a neural population code. This code can be the last layer in any neural network architecture. In the following, we describe the population code and the specific architecture that we used in our real-world experiments.
III-A Orientation Code
To encode the orientation with a neural population code, we first transform the rotation matrix into a rotation axis and a rotation angle. For the axis, the preferred values of each neuron are arranged on a sphere. To obtain a near uniform distribution of axes, we compute a Fibonacci lattice on a sphere [10]. For the rotation angle, the preferred values are arranged in a circle. To combine axis with angle, our population code has for each point on the Fibonacci sphere a circle of neurons for the rotation angle. So, the space to represent the orientation is a direct product of a sphere and a circle.
Given a rotation axis and angle, we activate all neurons using Gaussian tuning curves,
| (4) |
where is the angle between the encoded axis and the preferred axis on the sphere for neuron , the angle between the encoded angle and the preferred angle of neuron , and is the tuning width, here .
To compute the target population code from a ground truth transformation matrix, , we compute activations for all symmetry transformations of ,
| (5) |
where is the set of symmetry transformations for a given object (in a manufacturing setting, the symmetry of an object is known a priori). The target population code is the sum of all activations over all symmetry transformations (Fig. 1).
The transformation from rotation matrix to axis/angle, /, is not unique since and is an equivalent axis/angle combination. Therefore, for each symmetry transformation, we compute the tuning-curve activations also for and and add those to the target activations (resulting in four peaks in Fig. 1).
For objects with a symmetry axis, which would result in infinitely many equivalent poses, we compute a variant of our population code: since the population code for the rotation angle would show uniform activations, we simplify the code and omit the rotation angle neurons and just use the neurons encoding the rotation axis on the Fibonacci sphere. Here, the code is computed simply as
| (6) |
without having to superimpose activations for symmetries. So, our population code can leverage the rotation symmetry.
Input Image Population Code


For inference, we predict the entire population code and choose the neuron with the highest activation,
| (7) |
Neuron corresponds to a rotation axis and angle, which we convert into a rotation matrix. For objects with symmetry axis, we pick a random angle. This inference is similar to (2) from the probabilistic method [8] with the crucial difference that we only need to evaluate our network once, resulting in a faster pose estimate.
III-B Network Architecture

Our neural network maps gray-scale images of size 128x128 pixels onto a population code, which is a vector of size , where is the number of preferred axes and the number of preferred angles. Here, we used and , matching the number of rotation candidates used in [4].
The images are fed through four convolutional layers (see Fig. 2 regarding the kernel size and number of features). The first three convolutional layers are followed by batch normalization and ReLU activation functions. This architectural choice was inspired by the Augmented Autoencoder [4]. The fourth convolutional layer with kernel size 1x1 is followed by a GeLU non-linear function. This architectural element was inspired by [11], which demonstrated its benefit.
After the convolutional layers, the features are mapped through three hidden linear layers onto the population code, which itself acts like a linear layer. Each hidden layer is followed by a Leaky ReLU activation function.
IV EVALUATION
We evaluated our method on synthetic and real-world data.
IV-A Synthetic-Data Experiment
The synthetic-data experiment demonstrates the benefit of the population code. Here, we predict the one-dimensional orientation of shapes inside 64x64 pixels images (Fig. 3). As training data, we used either a set of randomly generated bar or arrow images (800/200 train/test split).
Bars

Arrows
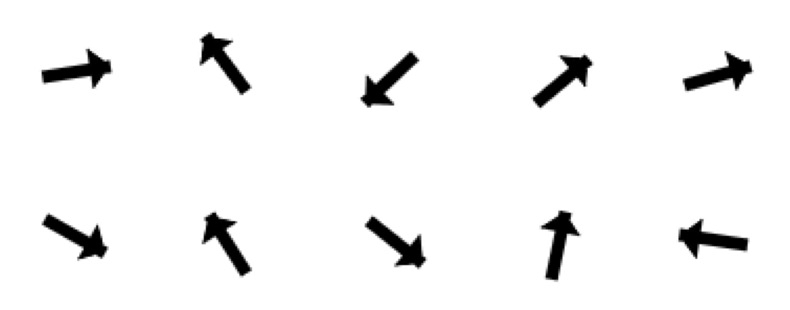
For the synthetic data, we used a simplified neural network comprising three convolutional layers (feature sizes: 32, 64, and 128) and 4 linear layers. All layers except for the output layer were followed by a ReLU activation function, and for the convolutional layers, we added max pooling (2x2).
For the output, we used either a population code vector of 36 neurons or a scalar orientation angle. The population code had preferred angles uniformly distributed in a circle in increments of and Gaussian tuning curves with width . For the one-hot vector, we use the same output layer as for the population code.
We trained the network with MSE loss for single variable and population code. For the one-hot vector, we tested both MSE and Cross Entropy loss. In addition, tor training the population code, we compared two strategies: 1) having a single activation peak at the ground truth angle and 2) having two activation peaks apart for shapes with symmetry.
We repeated train and test runs 10 times, including new train/test splits for each run. As a result, learning the population code with symmetry (two peaks) had the lowest error (Tab. I). Omitting symmetry during training resulted in a slightly larger error, but was not catastrophic. In contrast, learning failed when mapping directly onto the orientation angle for the symmetric bar.
| Method | Arrows | Bars |
|---|---|---|
| Single Variable | ||
| One Hot (MSE) | ||
| One Hot (Cross Entropy) | ||
| Population Code | ||
| Population Code (Sym) | N/A |
IV-B Evaluation Metrics
For the real-world data, we computed six different metrics to evaluate the accuracy of estimating pose; specifically, we evaluated the rotation error, assuming a perfect translation estimate. We chose metrics that are suitable for symmetric objects. The first three metrics are used by the BOP: Benchmark for 6D Object Pose Estimation [12]. The remaining three have been also used in the literature.
Maximum Symmetry-Aware Surface Distance (MSSD)
Given a set of model vertices, , the MSSD error is computed as
| (8) |
where is a set of symmetry transforms, s. th., . The MSSD accuracy is the mean recall rate of with ranging from 5% to 50% of the object diameter in steps of 5% [12].
Maximum Symmetry-Aware Projection Distance (MSPD)
The MSPD error is similar to the MSSD error, except that it takes into account only the projection onto the image plane,
| (9) |
where is the projection onto the image plane. The MSPD accuracy is the average recall rate of with ranging from to in steps of , where is the image width in pixels [12].
Visible Surface Discrepancy (VSD)
The VSD error measures the mismatch in appearance between the model in the ground-truth pose and the same model in the estimated pose,
| (10) |
where and are the projected shapes of the model onto the image plane for estimate and ground truth, and and are the estimated and ground-truth depths of the model at pixel . The VSD accuracy is the average recall rate of with parameter ranging from 5% to 50% of the object diameter in steps of 5% and ranging from 0.05 to 0.5 in steps of 0.05 [12].
In this variant, the accuracy is the ratio of errors below threshold 0.3 with . We adopt this metric since it was used by Sundermeyer et al for the augmented autoencoder [4].
Visual Surface Similarty (VSS)
VSS is a variant of VSD where , i.e., the error in depth is ignored. This metric has been used for the multiple pose hypotheses method [9].
Average Distance of Model Points - Indistinguishable Views (ADI)
ADI is a variant of the Average Distance of Model Points metric, adapted for symmetric objects [13]. The minimization takes into account ambiguous poses.
| (11) |
To compute the ADI accuracy, we computed the ratio of with equal to 5% of the object diameter. Here, we used a different threshold than in [13], who used 15%, because with % of diameter, all our experiments would show a 100% accuracy.
Sensitivity to rotation error
We found large differences in sensitivity to rotation error between metrics (Fig. 4). Particularly, for roughly spherical objects most metrics failed to reflect large errors. Moreover, only MSSD and ADI are invariant to the viewpoint since the other metrics compute a projection onto the image plane. To conclude, we found MSSD to be the most suitable metric to estimate rotation accuracy.

IV-C Comparison Methods
On the real-world data, we compared our method with three other methods. All of them used the same network architecture, as described in Section III, and the same data augmentation. This ensures a direct comparison of the impact of the representations. In contrast, results across publications are difficult to compare because architecture and data augmentation significantly affect the outcomes but are often hard to replicate due to a lack of detailed information. This section describes the alternative methods.
Multiple Pose Hypotheses
We adapted the multiple pose hypotheses method [9] to our network, predicting quaternions in the last layer (size: ). For training, we used the loss in (3), and for inference, we computed mean-shift clustering on the predicted quaternions [9] and picked the mean of the largest cluster.
Single Variable
For objects with a symmetry axis, we can directly predict the three coordinates of the axis since there is no ambiguity. Here, the last layer of our network had only three elements, and for training, we used the MSE to the ground truth axis.
For objects with discrete symmetries, we computed the minimum loss to the closest target (one for each equivalent pose). Here, the last layer of our network was 6 dimensional for storing two columns of the rotation matrix R. Learning two columns has been shown to be advantageous over other representations like quaternions due to the continuity of the R6 space [14]. This representation was also used by one of the best performing methods for asymmetric objects [15], and, as we will see, for asymmetric objects, mapping onto R6 does indeed work well (Tab. II). The entire rotation matrix can be reconstructed from the two columns using Gram-Schmidt orthonormalization. For training, we used the L1 loss.
One-Hot Vector
Instead of treating the output layer as a population code, we used it as a one-hot vector, where each element/index represents a rotation. As common for one-hot vectors, we used the Cross-Entropy loss for training. For inference, we picked the index with the largest logit/probability.
IV-D Real-World-Data Experiment
We carried out our real-world experiments with the T-LESS dataset [16], which contains feature-less and mostly symmetric objects. Table II shows all 30 objects.
| Object | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object1.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object2.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object3.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object4.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object5.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object6.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object7.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object8.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object9.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object10.png) |
|---|---|---|---|---|---|---|---|---|---|---|
| Symmetries | Continuous | Continuous | Continuous | Continuous | 2 | 2 | 2 | 2 | 2 | 2 |
| Trained on Objects | 1, 2 | 1, 2 | 3, 4 | 3, 4 | 5, 6 | 5, 6 | 7, 8 | 7, 8 | 9 | 10 |
| Test Instances | 818 | 465 | 397 | 619 | 194 | 100 | 250 | 150 | 249 | 145 |
| Single Variable | 80.4% | 80.9% | 90.3% | 84.1% | 66.0% | 64.9% | 21.9% | 34.9% | 58.7% | 64.0% |
| One Hot Vector | 71.0% | 74.5% | 82.1% | 78.5% | 69.0% | 50.7% | 41.5% | 30.9% | 41.6% | 51.5% |
| Population Code | 81.8% | 84.1% | 91.6% | 86.8% | 89.6% | 91.5% | 83.2% | 89.1% | 92.2% | 92.5% |
| Object | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object11.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object12.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object13.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object14.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object15.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object16.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object17.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object18.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object19.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object20.png) |
| Symmetries | 2 | 2 | Continuous | Continuous | Continuous | Continuous | Continuous | None | 2 | 2 |
| Trained on Objects | 11, 12 | 11, 12 | 13, 14 | 13, 14 | 15, 16 | 15, 16 | 17 | 18 | 19, 20 | 19, 20 |
| Test instances | 185 | 148 | 148 | 150 | 148 | 198 | 150 | 149 | 198 | 245 |
| Single Variable | 74.5% | 73.5% | 86.6% | 84.1% | 93.5% | 89.0% | 94.4% | 85.2% | 47.7% | 34.0% |
| One Hot Vector | 60.9% | 62.2% | 84.0% | 84.9% | 86.4% | 87.4% | 88.0% | 44.3% | 35.0% | 19.1% |
| Population Code | 86.8% | 84.9% | 90.9% | 86.1% | 95.8% | 93.0% | 96.1% | 75.9% | 82.6% | 74.0% |
| Object | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object21.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object22.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object23.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object24.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object25.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object26.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object27.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object28.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object29.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b3a685f9-0b00-4a78-b066-1af5d52374f0/object30.png) |
| Symmetries | None | None | 2 | Continuous | 2 | 2 | 4 | 2 | 2 | Continuous |
| Trained on Objects | 21, 22 | 21, 22 | 23 | 24 | 25, 26 | 25, 26 | 27 | 28 | 29 | 30 |
| Test instances | 184 | 195 | 250 | 195 | 98 | 100 | 96 | 195 | 99 | 148 |
| Single Variable | 62.7% | 64.0% | 66.4% | 92.4% | 75.9% | 79.8% | 7.8% | 15.8% | 18.6% | 89.7% |
| One Hot Vector | 34.5% | 27.8% | 34.6% | 86.2% | 41.3% | 34.9% | 17.8% | 20.7% | 31.2% | 87.4% |
| Population Code | 60.1% | 59.7% | 89.0% | 93.9% | 83.5% | 85.3% | 58.9% | 79.2% | 88.3% | 94.0% |
For training, we used the images from the BlenderProc4BOP dataset [17], extracting all instances of an object with at least 60% visibility. We augmented these data with the T-LESS Primesense camera images [16]. For all images, we used the provided bounding boxes and made square cutouts by using the maximum of width and height plus a 10% padding. The resulting cutouts were scaled to 128x128 pixels. We supplemented these images with 8,000 generated images per object using pyrender and the 3D model files from the T-LESS dataset. This combination resulted in about 20,000 to 22,000 images per object.
We combined some pairs of visually similar objects into one dataset and trained a single model for both objects (Tab. II). This strategy resulted a small improvement (Tab. VI) and also points to the ability of our architecture and population-code representation to generalize across objects.
We trained all methods for 80 epochs, using the Adam optimizer with a learning rate of 0.0002 and a batch size of 64. As the loss function, we used MSE, except as specified differently above (Section IV.C). During training, we augmented the data for the pyrender-generated images by 1) adding random brightness, a uniformly-distributed value between -0.2 and 0.2 to all pixels with a 50% probability and 2) adding a background image with a 70% probability. Moreover, for all training images, we added Gaussian noise (std: 0.02) with a 50% probability, did contrast normalization, and shifted the image in the image plane ( pixels in x and y) with 90% probability.

For testing, we used the official test set from the BOP Pose Estimation Challenge [17]. Since our focus was on rotation estimation rather than object detection, we used the provided ground truth bounding boxes. We compared Single Variable, One-Hot Vector, and Population Code across all 30 objects (Tab. II), whereas Multiple Pose Hypotheses was evaluated only on objects 4 and 5, as its performance was no better than random weights (Tab. IV and V). This suggests that the approach cannot learn from scratch and requires a pre-trained network backbone, as used by [9].
For our method, the average inference time was 3.2 msec on a Macbook Air M1 2020, which makes our method suitable for edge devices and real-time applications. In comparison, Multiple Pose Hypotheses required 115 msec for inference due to the costly clustering.
For the population code, the average MSSD accuracy across all objects was 84.7% (Tab. III). This value compares favorably against the best result on the BOP leaderboard for RGB-only input in the category Localization of Seen Objects: 81.4% (https://bop.felk.cvut.cz/leaderboards/pose-estimation-bop19/t-less/ accessed on 9/14/2024). The limitation is that we did not estimate the translation but instead used the ground truth translation.
Our average was 87.3% across all objects (Tab. III). In comparison, using the same ground-truth bounding boxes, Sundermeyer et al reported a 38.34% accuracy from RGB input and 84.04% with ICP refinement on the depth data [4]. However, the same caveat as above holds regarding estimating the translation.
Predicting a single variable performed well when there was no ambiguity in the target (Tab. III) but struggled with ambiguous poses (Tab. III). In contrast, our population code method performed equally well under ambiguity (Tab. III). Moreover, population code targets consistently outperformed one-hot vectors by large margins (Tab. II).
We also observed that our network faithfully learned the entire distribution of the population code (Fig. 5) and not just the peaks. This behavior is expected since we compute the MSE across all neurons of a population code. Interestingly, even without providing symmetry information during training, the performance drop was relatively small (Tab. VI); i.e., the network could still learn to represent the ambiguity caused by symmetry.
| Without Ambiguity | ||||
|---|---|---|---|---|
| Method | VSD | MSSD | MSPD | |
| Single Variable | 73.41% | 83.35% | 85.74% | 84.74% |
| One Hot Vector | 65.26% | 73.27% | 75.89% | 78.81% |
| Population Code | 75.33% | 84.68% | 86.07% | 88.04% |
| With Ambiguity | ||||
| Method | VSD | MSSD | MSPD | |
| Single Variable | 44.70% | 49.60% | 43.51% | 43.01% |
| One Hot Vector | 43.17% | 40.12% | 35.31% | 43.04% |
| Population Code | 72.59% | 84.74% | 79.61% | 86.23% |
| All Objects | ||||
| Method | VSD | MSSD | MSPD | |
| Single Variable | 61.77% | 69.67% | 68.62% | 67.82% |
| One Hot Vector | 56.31% | 59.83% | 59.44% | 64.31% |
| Population Code | 74.22% | 84.70% | 83.46% | 87.31% |
| Approach | VSD | MSSD | MSPD | VSS | ADI | |
|---|---|---|---|---|---|---|
| Random Weights | 8.2% | 9.0% | 14.4% | 6.6% | 55.5% | 7.1% |
| Multiple Poses | 8.4% | 6.3% | 9.6% | 2.6% | 57.5% | 4.9% |
| Single Variable | 74.4% | 84.1% | 86.2% | 85.0% | 89.1% | 87.1% |
| One-Hot Vector | 68.5% | 78.5% | 80.6% | 81.6% | 86.7% | 82.6% |
| Population Code | 80.0% | 86.8% | 88.5% | 89.5% | 90.3% | 90.5% |
| Approach | VSD | MSSD | MSPD | VSS | ADI | |
|---|---|---|---|---|---|---|
| Random Weights | 17.4% | 1.7% | 0.9% | 4.6% | 68.0% | 11.3% |
| Multiple Poses | 20.7% | 3.3% | 2.3%. | 9.8% | 69.0% | 30.4% |
| Single Variable | 61.5% | 66.0% | 61.4% | 73.2% | 87.2% | 82.5% |
| One-Hot Vector | 69.3% | 69.0% | 66.6% | 82.5% | 89.9% | 87.1% |
| Population Code | 83.4% | 89.6% | 87.8% | 94.9% | 94.1% | 96.9% |
| Ablation | VSD | MSSD | MSPD |
|---|---|---|---|
|
Original
Trained on objects 5 & 6 |
83.4% | 89.6% | 87.8% |
| Trained only on object 5 | 82.8% | 88.2% | 86.6% |
|
Trained only on object 5,
removed 1x1 conv layer |
81.4% | 87.1% | 84.7% |
|
Trained only on object 5,
trained without symmetry |
77.7% | 84.9% | 82.3% |
V CONCLUSIONS
Representing object orientation with a population code allows end-to-end training of a pose-estimation network from scratch and solves the ambiguity problem caused by object symmetry. This strategy results in fast and accurate inference. The speed allows real-time operation on edge devices. We found that the population-code results in higher accuracies compared to other methods using the same training data and network. For robotic control, the population code could be also directly mapped onto a grasp posture (omitting rotation matrices), which we speculate is the operation used also by our brains.
References
- [1] H. Hoffmann, Unsupervised Learning of Visuomotor Associations, ser. MPI Series in Biological Cybernetics. Logos Verlag Berlin, 2005, vol. 11.
- [2] B. Wen, W. Yang, J. Kautz, and S. Birchfield, “Foundationpose: Unified 6d pose estimation and tracking of novel objects,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 17 868–17 879.
- [3] J. Liu, W. Sun, H. Yang, Z. Zeng, C. Liu, J. Zheng, X. Liu, H. Rahmani, N. Sebe, and A. Mian, “Deep learning-based object pose estimation: A comprehensive survey,” arXiv preprint arXiv:2405.07801, 2024.
- [4] M. Sundermeyer, Z.-C. Marton, M. Durner, and R. Triebel, “Augmented autoencoders: Implicit 3d orientation learning for 6d object detection,” International Journal of Computer Vision, vol. 128, no. 3, pp. 714–729, 2020.
- [5] D. H. Hubel and T. N. Wiesel, “Receptive fields of single neurones in the cat’s striate cortex.” J Physiol, vol. 148, no. 3, pp. 574–591, Oct 1959.
- [6] A. Pouget, P. Dayan, and R. Zemel, “Information processing with population codes,” Nature Reviews Neuroscience, vol. 1, no. 2, pp. 125–132, 2000.
- [7] I. Gilitschenski, R. Sahoo, W. Schwarting, A. Amini, S. Karaman, and D. Rus, “Deep orientation uncertainty learning based on a bingham loss,” in International conference on learning representations, 2019.
- [8] K. Murphy, C. Esteves, V. Jampani, S. Ramalingam, and A. Makadia, “Implicit-pdf: Non-parametric representation of probability distributions on the rotation manifold,” arXiv preprint arXiv:2106.05965, 2021.
- [9] F. Manhardt, D. M. Arroyo, C. Rupprecht, B. Busam, T. Birdal, N. Navab, and F. Tombari, “Explaining the ambiguity of object detection and 6d pose from visual data,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 6841–6850.
- [10] R. A. Dixon, Mathographics. Dover Publications, 1991.
- [11] Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 976–11 986.
- [12] T. Hodaň, M. Sundermeyer, B. Drost, Y. Labbé, E. Brachmann, F. Michel, C. Rother, and J. Matas, “BOP challenge 2020 on 6D object localization,” in Computer Vision–ECCV 2020 Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16. Springer, 2020, pp. 577–594.
- [13] T. Hodaň, J. Matas, and Š. Obdržálek, “On evaluation of 6d object pose estimation,” in Computer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10 and 15-16, 2016, Proceedings, Part III 14. Springer, 2016, pp. 606–619.
- [14] Y. Zhou, C. Barnes, J. Lu, J. Yang, and H. Li, “On the continuity of rotation representations in neural networks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5745–5753.
- [15] G. Wang, F. Manhardt, F. Tombari, and X. Ji, “GDR-Net: Geometry-guided direct regression network for monocular 6D object pose estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16 611–16 621.
- [16] T. Hodan, P. Haluza, Š. Obdržálek, J. Matas, M. Lourakis, and X. Zabulis, “T-LESS: An RGB-D dataset for 6d pose estimation of texture-less objects,” in 2017 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2017, pp. 880–888.
- [17] T. Hodaň, M. Sundermeyer, B. Drost, Y. Labbé, E. Brachmann, F. Michel, C. Rother, and J. Matas, “Bop challenge 2020 on 6d object localization,” in Computer Vision–ECCV 2020 Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16. Springer, 2020, pp. 577–594.