Object Retrieval for Visual Question Answering with Outside Knowledge
Abstract
Retrieval-augmented generation (RAG) with large language models (LLMs) plays a crucial role in question answering, as LLMs possess limited knowledge and are not updated with continuously growing information. Most recent work on RAG has focused primarily on text-based or large-image retrieval, which constrains the broader application of RAG models. We recognize that object-level retrieval is essential for addressing questions that extend beyond image content. To tackle this issue, we propose a task of object retrieval for visual question answering with outside knowledge (OR-OK-VQA), aimed to extend image-based content understanding in conjunction with LLMs. A key challenge in this task is retrieving diverse objects-related images that contribute to answering the questions. To enable accurate and robust general object retrieval, it is necessary to learn embeddings for local objects. This paper introduces a novel unsupervised deep feature embedding technique called multi-scale group collaborative embedding learning (MS-GCEL), developed to learn embeddings for long-tailed objects at different scales. Additionally, we establish an OK-VQA evaluation benchmark using images from the BelgaLogos, Visual Genome, and LVIS datasets. Prior to the OK-VQA evaluation, we construct a benchmark of challenges utilizing objects extracted from the COCO 2017 and VOC 2007 datasets to support the training and evaluation of general object retrieval models. Our evaluations on both general object retrieval and OK-VQA demonstrate the effectiveness of the proposed approach. The code and dataset will be publicly released for future research.
keywords:
Object retrieval , Visual Question Answering , Retrieval-Augmented Generation (RAG)equationEquationEquations\Crefname@preamblefigureFigureFigures\Crefname@preambletableTableTables\Crefname@preamblepagePagePages\Crefname@preamblepartPartParts\Crefname@preamblechapterChapterChapters\Crefname@preamblesectionSectionSections\Crefname@preambleappendixAppendixAppendices\Crefname@preambleenumiItemItems\Crefname@preamblefootnoteFootnoteFootnotes\Crefname@preambletheoremTheoremTheorems\Crefname@preamblelemmaLemmaLemmas\Crefname@preamblecorollaryCorollaryCorollaries\Crefname@preamblepropositionPropositionPropositions\Crefname@preambledefinitionDefinitionDefinitions\Crefname@preambleresultResultResults\Crefname@preambleexampleExampleExamples\Crefname@preambleremarkRemarkRemarks\Crefname@preamblenoteNoteNotes\Crefname@preamblealgorithmAlgorithmAlgorithms\Crefname@preamblelistingListingListings\Crefname@preamblelineLineLines\crefname@preambleequationEquationEquations\crefname@preamblefigureFigureFigures\crefname@preamblepagePagePages\crefname@preambletableTableTables\crefname@preamblepartPartParts\crefname@preamblechapterChapterChapters\crefname@preamblesectionSectionSections\crefname@preambleappendixAppendixAppendices\crefname@preambleenumiItemItems\crefname@preamblefootnoteFootnoteFootnotes\crefname@preambletheoremTheoremTheorems\crefname@preamblelemmaLemmaLemmas\crefname@preamblecorollaryCorollaryCorollaries\crefname@preamblepropositionPropositionPropositions\crefname@preambledefinitionDefinitionDefinitions\crefname@preambleresultResultResults\crefname@preambleexampleExampleExamples\crefname@preambleremarkRemarkRemarks\crefname@preamblenoteNoteNotes\crefname@preamblealgorithmAlgorithmAlgorithms\crefname@preamblelistingListingListings\crefname@preamblelineLineLines\crefname@preambleequationequationequations\crefname@preamblefigurefigurefigures\crefname@preamblepagepagepages\crefname@preambletabletabletables\crefname@preamblepartpartparts\crefname@preamblechapterchapterchapters\crefname@preamblesectionsectionsections\crefname@preambleappendixappendixappendices\crefname@preambleenumiitemitems\crefname@preamblefootnotefootnotefootnotes\crefname@preambletheoremtheoremtheorems\crefname@preamblelemmalemmalemmas\crefname@preamblecorollarycorollarycorollaries\crefname@preamblepropositionpropositionpropositions\crefname@preambledefinitiondefinitiondefinitions\crefname@preambleresultresultresults\crefname@preambleexampleexampleexamples\crefname@preambleremarkremarkremarks\crefname@preamblenotenotenotes\crefname@preamblealgorithmalgorithmalgorithms\crefname@preamblelistinglistinglistings\crefname@preamblelinelinelines\cref@isstackfull\@tempstack\@crefcopyformatssectionsubsection\@crefcopyformatssubsectionsubsubsection\@crefcopyformatsappendixsubappendix\@crefcopyformatssubappendixsubsubappendix\@crefcopyformatsfiguresubfigure\@crefcopyformatstablesubtable\@crefcopyformatsequationsubequation\@crefcopyformatsenumienumii\@crefcopyformatsenumiienumiii\@crefcopyformatsenumiiienumiv\@crefcopyformatsenumivenumv\@labelcrefdefinedefaultformatsCODE(0x5fe5a1597c60)
organization=School of Computer Science and Engineering, Central South University,postcode=410083, city=Changsha, state=Hunan, country=China \affiliationorganization=School of Automation, Central South University,postcode=410083, city=Changsha, state=Hunan, country=China \affiliationorganization=Dundee International Institute, Central South University,postcode=410083, city=Changsha, state=Hunan, country=China \affiliationorganization=College of Mechanical Engineering, Guizhou University,postcode=550025, city=Guiyang, state=Guizhou, country=China \affiliationorganization=Institute of Information Science, School of Computer and Information Technology, Beijing Jiaotong University,postcode=100044, city=Beijing, country=China \affiliationorganization=Beijing Key Laboratory of Advanced Information Science and Network Technology,postcode=100044, city=Beijing, country=China
1 Introduction
page\cref@result Visual Question Answering (VQA) [1] based on Large Vision-Language Models (LVLMs) [2, 3] has seen significant progress and growing attention. However, VQA becomes particularly challenging when the answer to a question is not explicitly present in the image [4]. To address this, current methods often rely on Retrieval-Augmented Generation (RAG) [5, 6], which operates in two phases: retrieval and generation. In the retrieval phase, contextually relevant information is fetched from a large pool of resources, while in the generation phase, LVLMs use this retrieved knowledge to formulate an answer. Given that the quality of retrieval directly impacts the accuracy of LVLMs’ responses, and since many questions pertain to specific objects within an image, it is crucial for retrieval to focus on object-level information rather than the entire image. As illustrated in \creffig:motivate1, when asked, “What is the most likely role of the person wearing the ‘DEXIA’ logo?”, it’s difficult to answer based solely on the given image. However, if multiple images related to the ‘DEXIA’ logo are retrieved, the LVLMs can deduce that this person is most likely a forward or defender. This motivates our goal of developing a robust object-centric retrieval method that identifies relevant images at the object level, enhancing precision and relevance for more accurate VQA.

page\cref@result
Object retrieval, as explored in existing research [8, 9], involves locating similar images containing a given object. However, this task is fraught with challenges, as target objects are often embedded in cluttered backgrounds, occupy small or unpredictable portions of an image, and can vary significantly in scale, viewpoint, color, and partial occlusions. While many object retrieval algorithms have been developed for specialized tasks such as person re-identification [10, 11], vehicle re-identification [12], clothing retrieval [13], and logo retrieval [8], these methods are often trained under independent and identically distributed (i.i.d.) assumptions. This limits their generalizability to non-i.i.d. scenarios, such as VQA. For example, an algorithm optimized for pedestrian datasets may excel at person retrieval but struggle with vehicle retrieval, making it unsuitable for the broad demands of VQA. To overcome this limitation, our objective is to develop a general object retrieval algorithm capable of handling both seen and unseen objects across diverse tasks, thus broadening its applicability to VQA.
In the context of general object retrieval, addressing the long-tailed distribution of objects is one of the primary challenges. This distribution pattern is a common occurrence in open-world VQA scenarios, as illustrated in \creffig:motivate. The majority of objects are concentrated within the head classes, making it more challenging to recognize or retrieve objects from the tail classes [14]. Furthermore, it’s important to note that the scale distribution also exhibits a long-tailed pattern, as demonstrated in the sub-distributions of \creffig:motivate. This presents an additional challenge as it becomes difficult to learn effective embeddings for small scale objects under unsupervised conditions.
In dynamic and open environments of VQA, most previously unseen objects belong to the tailed classes and possess small scales. This introduces challenges in the extraction and representation of such objects. While the segment anything model (SAM) [15] offers a potential solution for capturing object spatial context, and unsupervised representation learning algorithms like DINO [16], MoCo [17], iBOT [18], and STML [19] have demonstrated impressive performance in general image representation, employing these methods to obtain representations of open-vocabulary and small-scale objects may result in a degradation of performance. To tackle the long-tailed problem associated with objects and the corresponding scales in OR-OK-VQA, this paper introduces a multi-scale group collaborative embedding learning (MS-GCEL) method, designed to effectively learn object embeddings. The approach includes a potential object extraction network for object extraction and an MS-GCEL network for object embedding learning.
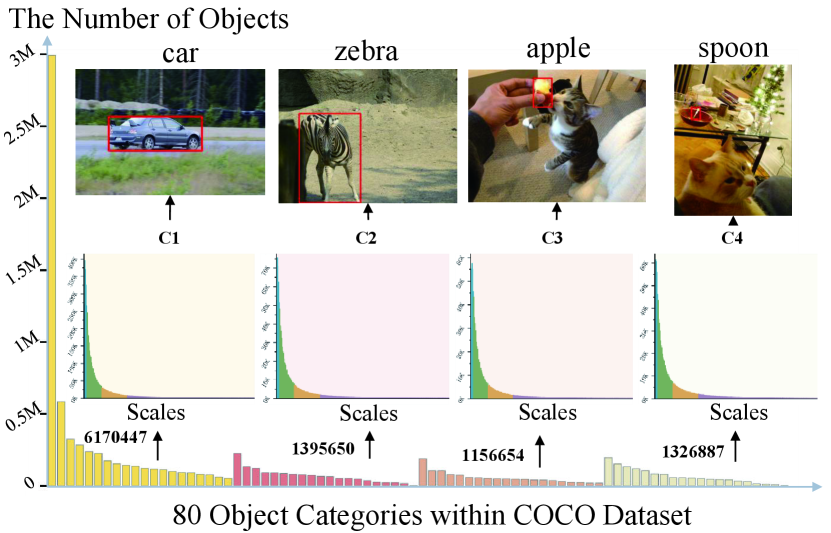
page\cref@result
Furthermore, existing datasets used for deep feature embedding, such as ImageNet [20], SOP [21], CUB [22], and Cars [23], primarily consist of images with uniform sizes. These samples may diverge considerably from those encountered in dynamic real-world VQA scenarios. Conversely, datasets employed for image retrieval tasks [24, 25], like Oxford5k [26] and Paris6k [27], enable the evaluation of retrieval performance for specific object categories. They fall short when it comes to training a model to represent a diverse range of objects in VQA. To better mimic real-world applications, we curate a new dataset by using the segment anything model (SAM) [15] to extract objects from the amalgamating of COCO 2017 [28] and VOC 2007 [29] datasets. This dataset serves as a valuable resource for training and evaluating open-vocabulary object retrieval models. Importantly, there are no strict category constraints imposed on either the training or test samples. Consequently, the model is trained on samples with uncertain categories and tested on samples with uncertain categories as well. To assess the generalization capability of the model, we conducted additional object retrieval experiments across several datasets, including BelgaLogos [7], Visual Genome [30], and LVIS [31]. It is important to emphasize that these datasets were not used during the training phase. Furthermore, we curated the OK-VQA evaluation benchmark by incorporating images from the BelgaLogos, Visual Genome, and LVIS datasets to highlight the significance of object retrieval in VQA. The contributions of this work are summarized as follows:
-
1.
We introduce the task of object retrieval for visual question answering with outside knowledge (OR-OK-VQA) and proposed a multi-scale group collaborative embedding learning (MS-GCEL) method for general object retrieval.
-
2.
We construct a benchmark of challenges by leveraging the SAM [15] to extract objects from the amalgamating of COCO 2017 [28] and VOC 2007 [29] datasets, facilitating the training and evaluation of general object retrieval models. Furthermore, we assemble a rigorous test set specifically designed for evaluating open-set object retrieval performance.
-
3.
In addition to our internally curated evaluation set, our object retrieval assessments encompass a variety of datasets which do not used during training, including BelgaLogos [7], Visual Genome [30], and LVIS [31]. Also, we curate an OR-OK-VQA evaluation benchmark to highlight the significance of object retrieval in VQA. Evaluation on both general object retrieval and OR-OK-VQA tasks proved the effectiveness of the proposed method.
2 Related Work
page\cref@result The task of object retrieval for visual question answering with outside knowledge (OR-OK-VQA), which involves general object retrieval and OK-VQA, both remain a formidable challenge with a well-established research history. In the following subsections, we provide an overview of prior work related to this topic, encompassing object retrieval and OK-VQA.
2.1 Object Retrieval
page\cref@result Early approaches frequently employed for object matching is to generate visual representations from the activations of convolutional layers [32] and transformer blocks [33]. These studies extensively utilized deep metric learning methods, which aims to learn discriminative features from images by minimizing the distance between samples of the same class and maximizing the distance between samples of different classes. In early deep metric learning methods, contrastive loss [34] was effectively employed to optimize the pairwise distances between samples. To explore more intricate relationships between samples, various metric loss functions, including triplet loss [35] and lifted structured loss [36], have been developed. These methods rely on supervised learning using image labels. However, in real-world object retrieval scenarios, objects are often unknown and lack labels. To learn representations of unlabeled objects, several techniques have been proposed. He et al. [37] introduced the momentum contrast (MoCo) method for unsupervised visual representation learning. Chen et al. [38] presented the simCLR framework, which is based on contrastive learning, for effective unsupervised visual representation learning.
In an effort to generate more robust pseudo-labels for unsupervised deep metric learning, Nguyen et al. [39] introduced a deep clustering loss to learn centroids. More recently, Kan et al. [40] proposed a relative order analysis (ROA) and optimization method for enhancing the relative ranking of examples in unsupervised deep metric learning. Li et al. [41] developed spatial assembly networks (SAN) to facilitate both supervised and unsupervised deep metric learning. Kim et al. [19] introduced an effective teacher-student learning pipeline for embedding learning of unlabeled images.
The methods mentioned above have primarily been investigated using evenly distributed class examples with images of the same size. Their performance may deteriorate when applied to VQA. Our work aims to develop a general object embedding method that is more representative of the scenario of VQA, setting it apart from the aforementioned works.
2.2 Visual Question Answering with Outside Knowledge
With the rise of large language models (LLMs) and retrieval-augmented generation (RAG), VQA with external knowledge has become increasingly popular [5, 6]. RAG addresses limitations of LLMs, particularly their tendency to produce ‘hallucinations’ when handling queries outside their training data or requiring real-time information. Prior RAG-based approaches have focused on retrieving relevant text descriptions [1] or identifying objects within large images to localize answer-relevant areas [3]. RAG methods are generally categorized into query-based, latent representation-based, logit-based, and speculative approaches [5]. In query-based RAG, user queries are enhanced with retrieved information, which is then fed into the generator’s input—exemplified by RetrieveGAN [42], which integrates image patches and bounding boxes to improve relevance and precision. Latent representation-based RAG leverages cross-attention to fuse retrieved objects as latent features [43]. Logit-based RAG introduces retrieval data at the decoding stage [44], while speculative RAG optimizes response time by selectively combining retrieval with generation. Our object retrieval method for VQA falls under query-based RAG, where we focus on enhancing retrieval accuracy to improve VQA performance.
3 Challenges in Object Retrieval for OK-VQA
page\cref@result
Different from visual question answering (VQA), which answers a question based on the image content, VQA with outside knowledge (OK-VQA) requires retrieve external information that related with objects that can help to answer the question. Thus, one of the key tasks in OK-VQA is object retrieval. Unlike object detection [45], which aims to recognize [46] and locate objects [47] within an image, object retrieval is focused on ranking images and locating objects within the retrieved images. Typically, object detection algorithms are employed as the initial step in object retrieval to extract objects. In VQA scenarios, object retrieval introduces a new challenge: the query object can be any object, making the extraction and retrieval of arbitrary objects a challenging task. To address this challenge, previous state-of-the-art methods have introduced approaches like MViT [48] and SAM [15] for extracting both known and unknown objects. However, the representation of objects for retrieval remains a challenge that has not been thoroughly explored. To investigate this matter, we conducted experiments using the state-of-the-art unsupervised STML [19] method based on MViT and SAM. These experiments were conducted using our carefully curated training and validation object sets, which consist of a total of 80 classes from COCO 2017 [28] and VOC 2007 [29].

To simulate open-vocabulary object retrieval in OK-VQA scenario, we followed the dataset partitioning in [49] and divided the dataset into 4 tasks, denoted as Task1 to Task4, with each task progressively adding 20 new classes. The model is trained on each task and subsequently evaluated under three different scenarios: close-set (known), open-set (unknown), and open-vocabulary (all). In this context, “known” signifies that the test classes match the training classes, “unknown” indicates that the test classes are distinct from the training classes, and “all” denotes that the model is tested on all 80 classes. The results on the validation set are presented in \creffig:challenges (a)-(c). It is apparent that, as we progress from Task1 to Task4, the object-level retrieval mAP scores exhibit a consistent decrease for both the MViT and SAM extraction methods across all three scenarios. The observed decline in object-level retrieval mAP scores within the close-set and open-set scenarios can be attributed to the challenges posed by the introduction of new class samples. Additionally, for known objects (\creffig:challenges (a)), the object-level mAP scores based on SAM are lower compared to those based on MViT. This can be attributed to the significantly higher number of objects extracted by SAM (averaging 89 per image) in comparison to MViT (averaging 14 per image).
However, from \creffig:challenges (c), we have observed that the inclusion of more class samples also results in a decrease in object-level mAP scores within the open-vocabulary scenario. Upon conducting a thorough analysis of the underlying causes of this phenomenon, we have discerned two principal contributing factors. The first factor pertains to the inherent properties of the newly added classes, specifically their relatively smaller object sizes. This characteristic can exacerbate the challenges of unsupervised training by introducing a heightened susceptibility to labeling errors. As demonstrated in \creffig:challenges (d), the retrieval mAP score decreases with the smaller scale of the query object. The second factor pertains to the distinct spatial distribution characteristics exhibited by the newly incorporated classes in comparison to the known classes. As illustrated in \creffig:motivation-distribution, the spatial distributions of the unknown objects differ between the training and validation sets. These variations in spatial attributes further compound the challenges encountered within this OK-VQA scenario. In response to these challenges, we introduce a novel multi-scale group collaborative embedding learning method designed to learn models for general object representation. Furthermore, it is observed that the unknown object retrieval mAP scores ( \creffig:challenges (b)) consistently outperform when utilizing the SAM for object extraction as compared to the MViT approach. Consequently, SAM is adopted as the preferred object extraction method in our experiments.
page\cref@result
4 Methods
This paper focuses on achieving general object retrieval for OK-VQA. In the following subsections, we introduce our proposed method, multi-scale group collaborative embedding learning (MS-GCEL), to attain this objective.
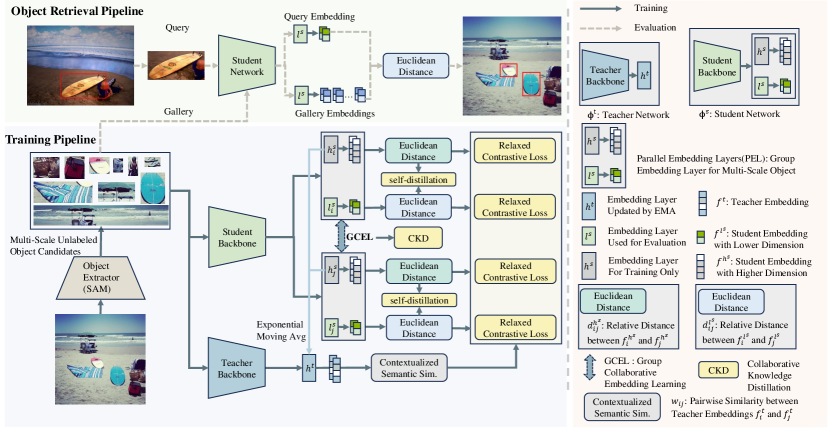
page\cref@result
4.1 Method Overview
fig:framework offers an overview of the MS-GCEL method proposed for object retrieval. Our primary objective, as shown in the object retrieval pipeline, is to train a universal object embedding network capable of representing any object. This network enables the extraction of embeddings for both query and gallery objects. Subsequently, we compute the Euclidean distances between the query embedding and the gallery embeddings. These distances are used for ranking, resulting in the retrieval of the top-k objects, which are then located within their respective images. Finally, these retrieved images are used to assist VQA for LVLM. Our method includes a potential object extraction network for object extraction and an MS-GCEL network for object embedding learning. The potential object extraction network is the SAM [15]. The MS-GCEL network can be configured using popular CNN-based or Transformer-based networks. In our experiments, we explored various backbone networks. In the literature, the teacher-student training paradigm has been demonstrated as effective for embedding learning [19]. Consequently, we have also implemented the teacher-student training pipeline to train the MS-GCEL network. In this approach, the teacher network maintains the same architecture as the student network , and its weights are updated with momentum using the exponentially moving average weights of the student network. The details of each part are described in the following sections.
4.2 Multi-Scale Group Collaborative Embedding Learning
fig:ms-gcel portrays the intricate pipeline of our MS-GCEL. As elaborated upon in \crefsec:motivation, the effectiveness of embedding learning is closely associated with the accuracy of labeling, which, in turn, is linked to the scale of the image. Generally, images with larger scales tend to yield higher labeling accuracy, while those with smaller scales may result in lower labeling accuracy.
Building upon the preceding analysis, we propose categorizing images according to their sizes. As depicted in the initial step of \creffig:ms-gcel, the data distribution exhibits a long-tailed nature. The horizontal axis represents the image sizes, arranged from small to large, while the vertical axis denotes the number of objects. To uniformly sample data across different scales, we segment this data into multiple groups with uniform distributions (e.g., 4), spanning from small to large based on image area.
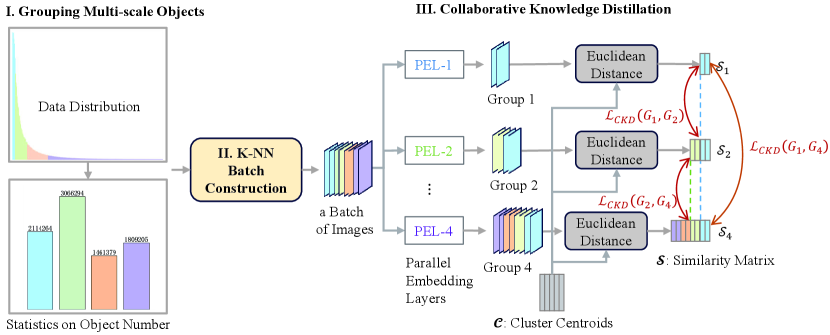
page\cref@result
Then, we explore the use of k-nearest neighbors (K-NN) to sample data from each group, forming a batch of images, as illustrated in the second step of \creffig:ms-gcel. Subsequently, we compute the collaborative knowledge distillation loss based on the grouped embeddings. Specifically, for the -th group, we denote the student output embedding vectors generated by as . To initiate the process, we employ the k-means clustering algorithm to cluster all the training embeddings, resulting in a set of clustering centroids, denoted as . We then compute the normalized similarity matrix between embeddings in group and cluster centroids in . For collaborative knowledge distillation (CKD) between group and group , we utilize the Kullback-Leibler divergence to calculate their CKD loss, which is defined as follows
In the formula, and represent the object image sets in group and , while denotes the set of identical object images found in both group and . The term corresponds to the number of images in . represents the indexed similarity vector between the embeddings of object and within the matrix . The function of Kullback-Leibler divergence is defined as follows
| (1) |
where , which is the total similarities between the embeddings of object , and . Finally, the CKD loss in all groups is computed as follows
| (2) |
where is calculated as , with representing the number of groups.
4.3 Overall Loss Function and OR-OK-VQA
To train the network, we utilize a combination of knowledge distillation and contrastive loss functions. The primary objective of the knowledge distillation loss is to extract more informative features from the more dependable embeddings. Meanwhile, the contrastive loss function serves as a metric loss, with the aim of learning a Mahalanobis distance metric. They were defined according to the following definitions. First, we define the loss functions and following the works of STML [19]. Let the student output embedding vectors generated by and in the -th group be denoted as and . The self-distillation loss is computed based on Kullback-Leibler divergence, as follows:
| (3) |
where / ) represents the relative distance between and . Similarly, represents the relative distance between and . The function corresponds to the softmax operation, and represents the number of samples in the -th group. The relaxed contrastive loss is defined as follows
| (4) |
where represents a pairwise similarity score between teacher embeddings and , and is a margin. It’s worth noting that the same training approach is applied to as well. The overall loss function is defined as follows
After training the network, the OR-OK-VQA task is performed in a human–computer interaction manner. First, gallery image features are extracted and indexed using the learned network with the MS-GCEL loss function. Given an input image and question, we crop a question-relevant object image and extract its features using the trained network. These object features are then used to retrieve relevant images from the gallery. Finally, the retrieved images and the question are fed into the large vision-language model (LVLM) to assist with the VQA task.
5 Experiments
5.1 Datasets and Implementation Details
Our training dataset is curated from pre-existing open-access object detection datasets, i.e., COCO 2017 [28] and VOC 2007 [29]. The testing dataset consists of publicly available object retrieval and object detection datasets, which serve to evaluate the performance of general object retrieval. We also established an OK-VQA evaluation benchmark using images from the BelgaLogos [7], Visual Genome [30], and LVIS [31] datasets. The details of our experimental datasets are summarized in \creftab:dataset_statistics. In the following, we provide a simple description of the datasets.
| Images | Objects | |
| training dataset | 121,298 | 8,035,395 |
| COCO-VOC test query | 9,904 | 51,757 |
| COCO-VOC test gallery | 9,904 | 862,861 |
| BelgaLogos test query | 55 | 55 |
| BelgaLogos test gallery | 10,000 | 939,361 |
| LVIS test query | 4726 | 50,537 |
| LVIS test gallery | 4726 | 433,671 |
| Visual Genome test query | 108,077 | 79,921 |
| Visual Genome test gallery | 108,077 | 9,803,549 |
page\cref@result
General object retrieval dataset. The training and validation sets are constructed by extracting objects from the training sets of COCO 2017 and VOC 2007, as well as the validation set of VOC 2007. The training set comprises 121,298 images, while the validation set contains 2,000 images. The test set is composed of objects extracted from the validation set of COCO 2017 and the test set of VOC 2007, totaling 9,904 images. To perform object extraction, we employed SAM [15]. The resulting partitioned sets consist of more than 8 million objects for the training set, 173K for the validation set, and 862K for the test set. In the zero-shot object retrieval setup, we partition the training set into four distinct groups, with each group comprising 20 object classes. These four group datasets are employed to create four tasks, with each task progressively introducing an additional set of 20 new classes. The classes utilized for training (known classes highlighted in light yellow) and testing (unknown classes highlighted in light blue) in each task are presented in Table 9. In Task 1, the training set consists of the most popular 20 classes, while the remaining 60 classes are used for testing. For Task 2, 20 new classes are introduced along with the original Task 1 classes for training, and the remaining 40 classes are designated for testing. Task 3 involves the addition of another set of 20 new classes to Task 2, with the remaining 20 classes used for testing. Finally, Task 4 incorporates all 80 classes for both training and testing phases.
Generalization evaluation dataset. To assess the generalization ability of the trained MS-GCEL model, we conducted evaluations on the BelgaLogos [7], Visual Genome [30], and LVIS [31] datasets. The BelgaLogos dataset consists of 10K images and 55 query logos, primarily used to evaluate the logo retrieval performance of an algorithm. The provided 55 query logo images of the BelgaLogos dataset are utilized as the query set, while the gallery set comprises 939,361 objects extracted using SAM[15]. In the case of the Visual Genome dataset, which contains 108K images and 2,516,939 labeled bounding boxes, we define a set of 79,921 objects as the query set and directly performed object retrieval using the trained model on the whole dataset. As for the LVIS dataset, it shares the same images as the COCO 2017 dataset but features 1000 class labels. We compute evaluation scores based on the labeled objects in the validation set of the LVIS dataset.
OK-VQA evaluation dataset. To evaluate the performance of OK-VQA, we constructed a specialized VQA dataset by selecting images from the BelgaLogos, Visual Genome, and LVIS datasets. A total of 36 questions are crafted for these images, with most answers requiring external knowledge beyond the information directly available in the images. To correctly answer these questions, relevant images must be retrieved from external datasets to provide additional contextual information.
Evaluation Metrics. We use Recall@1 and mean average precision (mAP) as the evaluation metrics for object retrieval. The Recall@1 is defined as follows: Recall@1 = , where represents the number of queries, and is equal to 1 if the top-1 returned objects contain the ground truth object, and 0 otherwise. The mAP is calculated as: mAP = , where represents the number of queries, and is the ranking index of a returned object that matches the ground truth. We calculate image-level and object-level retrieval scores. The image-level score is computed using an IoU threshold of , and the object-level score is computed using an IoU threshold of 0.3.
Implementation Details. In our experiments, we utilize SAM [15] and MViT [48] for object extraction. Specifically, the ViT-H backbone network was utilized for object extraction based on SAM. For object extraction based on MViT, the text prompts ’all objects,’ ’all entities,’ ’all visible entities and objects,’ and ’all obscure entities and objects’ were employed. Our teacher-student network is trained on two RTX 3090 (24GB) GPUs with a batch size of 120. The nearest neighbors are set to 5. Each batch contains images of various sizes for MS-GCEL learning. The group number of the MS-GCEL is set to 4, and the clustering number is set to 100 unless specified otherwise. The dimension of teacher embeddings was set to 1024, while the dimensions of student embeddings and were both set to 512. The to calculate and the margin are 3 and 1 respectively. The initial learning rate is set as on the backbone of GoogLeNet, and for MiT-B2 and ViT-B/16, both of which are scaled down by the cosine decay function[50]. During training, The Adamp[51] optimizer was employed with a weight decay set to 0.01. and the K-nearest neighbor sampling distance matrix was updated once every 1000 iterations.
5.2 Effectiveness Verification of the MS-GCEL Method
To assess the effectiveness of the MS-GCEL method, we conducted experiments using different backbone networks and various initialization methods. The results on the curated test set are presented in \creftab:effectiveness. In this table, methods based on the GoogLeNet and MiT-B2 backbone networks are initialized with parameters trained on the ImageNet-1K [20] dataset. Our method based on the ViT-B/16 [52] backbone network are initialized using parameters trained by the MoCo-V3 [17] and CLIP [53] methods, respectively, and then fine-tuned on our curated training dataset using the proposed MS-GCEL method.
From \creftab:effectiveness, it is evident that our method outperforms the state-of-the-art unsupervised STML [19] method, achieving an improvement of 2.65% and 10.03% in image level mAP for GoogLeNet and MiT-B2 backbone networks, respectively. To further verify the effect of multi-scale group collaborative embedding learning (MS-GCEL), we present the results for different sizes of query objects, as shown in \creftab:coco_MS_results_google and \creftab:coco_MS_results_MiT. Specifically, \creftab:coco_MS_results_google reports object retrieval results based on the GoogLeNet backbone, while \creftab:coco_MS_results_MiT presents results using the MiT backbone. We can see that the MS-GCEL obtained better performance in both the object- and image-level retrieval scores for different sizes of query objects. Moreover, the larger size of objects, the higher the performance for both the STML [19] and the MS-GCEL methods.
| Backbone | Methods | O-R@1 | O-mAP | I-R@1 | I-mAP |
|---|---|---|---|---|---|
| GoogLeNet [54] | STML [19] | 65.93 | 14.89 | 69.70 | 65.04 |
| MS-GCEL | 68.17 | 15.37 | 71.90 | 67.69 | |
| MiT-B2 [55] | STML [19] | 58.62 | 17.48 | 66.86 | 58.60 |
| MS-GCEL | 68.60 | 17.64 | 73.40 | 68.63 | |
| ViT-B/16 [52] | MoCo-V3 [17] | 77.40 | 15.94 | 81.29 | 81.26 |
| MS-GCEL | 77.88 | 16.84 | 82.04 | 82.12 | |
| CLIP [53] | 68.44 | 14.56 | 74.01 | 70.30 | |
| MS-GCEL | 69.07 | 16.07 | 74.49 | 70.97 |
page\cref@result
| Sizes | Methods | COCO-VOC | LVIS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| O-R@1 | O-mAP | I-R@1 | I-mAP | O-R@1 | O-mAP | I-R@1 | I-mAP | ||
| [0,] | STML [19] | 14.30 | 1.63 | 20.67 | 15.23 | 21.25 | 2.80 | 22.10 | 24.66 |
| MS-GCEL | 18.38 | 1.68 | 24.06 | 20.27 | 25.18 | 3.29 | 26.43 | 28.98 | |
| [,] | STML [19] | 42.72 | 3.61 | 49.25 | 44.50 | 52.48 | 5.88 | 53.22 | 57.72 |
| MS-GCEL | 52.20 | 3.75 | 57.11 | 53.64 | 58.77 | 7.01 | 59.58 | 63.89 | |
| [,] | STML [19] | 64.51 | 6.91 | 69.22 | 64.83 | 67.22 | 7.40 | 67.77 | 72.46 |
| MS-GCEL | 68.13 | 6.96 | 72.89 | 68.50 | 70.46 | 8.25 | 71.07 | 75.72 | |
| [,] | STML [19] | 78.05 | 14.73 | 81.83 | 76.06 | 76.14 | 8.46 | 76.85 | 81.25 |
| MS-GCEL | 79.74 | 15.34 | 83.32 | 78.25 | 78.47 | 9.24 | 79.32 | 83.53 | |
| [,] | STML [19] | 85.74 | 26.68 | 87.66 | 83.50 | 81.87 | 11.30 | 82.77 | 86.54 |
| MS-GCEL | 87.56 | 27.77 | 89.61 | 86.47 | 83.71 | 13.01 | 85.00 | 88.74 | |
page\cref@result
| Sizes | Methods | COCO-VOC | LVIS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| O-R@1 | O-mAP | I-R@1 | I-mAP | O-R@1 | O-mAP | I-R@1 | I-mAP | ||
| [0,] | STML [19] | 11.85 | 1.39 | 18,67 | 12.75 | 16.18 | 2.36 | 17.49 | 20.68 |
| MS-GCEL | 15.19 | 1.71 | 22.24 | 16.45 | 21.67 | 3.01 | 22.80 | 25.78 | |
| [,] | STML [19] | 34.82 | 4.55 | 43.88 | 35.67 | 42.99 | 5.56 | 44.59 | 49.30 |
| MS-GCEL | 46.11 | 3.72 | 52.56 | 47.93 | 57.16 | 7.03 | 58.39 | 62.55 | |
| [,] | STML [19] | 54.33 | 11.07 | 63.39 | 52.57 | 61.55 | 7.93 | 63.27 | 68.25 |
| MS-GCEL | 68.33 | 8.78 | 73.97 | 67.92 | 71.35 | 8.83 | 72.20 | 76.56 | |
| [,] | STML [19] | 67.86 | 19.39 | 77.06 | 65.58 | 66.30 | 10.41 | 70.39 | 74.52 |
| MS-GCEL | 80.86 | 18.25 | 85.61 | 79.11 | 79.04 | 11.03 | 80.31 | 84.15 | |
| [,] | STML [19] | 78.72 | 29.15 | 86.41 | 80.10 | 72.51 | 15.54 | 77.61 | 82.67 |
| MS-GCEL | 87.86 | 31.39 | 91.02 | 87.98 | 83.93 | 16.65 | 86.17 | 90.16 | |
page\cref@result
| Backbone | Methods | BelgaLogos | Visual Genome | LVIS | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| I-mAP | O-Recall@1 | O-mAP | I-Recall@1 | I-mAP | O-Recall@1 | O-mAP | I-Recall@1 | I-mAP | ||
| GoogLeNet [54] | STML [19] | 63.61 | 31.82 | 28.56 | 31.19 | 43.54 | 55.79 | 6.72 | 56.57 | 60.42 |
| MS-GCEL | 65.93 | 34.01 | 30.39 | 34.11 | 46.93 | 58.75 | 7.55 | 59.75 | 63.47 | |
| MiT-B2 [55] | STML [19] | 62.71 | 26.88 | 25.26 | 28.34 | 43.10 | 49.31 | 7.48 | 51.65 | 56.14 |
| MS-GCEL | 64.59 | 33.39 | 31.95 | 33.59 | 46.80 | 56.83 | 8.37 | 58.11 | 61.96 | |
| ViT-B/16 [52] | MoCo-V3 [17] | 86.32 | 43.13 | 39.47 | 44.07 | 67.33 | 64.95 | 11.04 | 67.12 | 71.51 |
| MS-GCEL | 86.69 | 42.77 | 38.95 | 43.67 | 66.67 | 65.14 | 11.19 | 67.10 | 71.59 | |
| CLIP [53] | 82.01 | 33.15 | 30.11 | 33.62 | 51.28 | 55.28 | 8.51 | 57.07 | 61.45 | |
| MS-GCEL | 83.73 | 33.41 | 30.35 | 33.75 | 51.80 | 55.69 | 8.70 | 57.44 | 61.95 | |
page\cref@result
5.3 Comparison and Analysis of General Object Retrieval and OK-VQA
Moreover, we conduct evaluation experiments on the BelgaLogos [7], LVIS [31] and Visual Genom datasets using the trained model. Results are shown in \creftab:comparison. We have observed that our approach using GoogLeNet [54] and MiT-B2 [55] backbone networks effectively enhances retrieval performance across various datasets. The object-level mAP scores demonstrated a 6.69% improvement on the Visual Genome dataset and a 0.89% improvement on the LVIS dataset when using the MiT-B2 backbone network. The highest mAP scores and Recall@1 scores on the BelgaLogos, Visual Genome, and LVIS dataset are achieved with the parameters initialized by the MoCo-V3. However, on the Visual Genome dataset, the performance of the MS-GCEL method with MoCo-V3 slightly decreases due to the lower-dimensional feature embeddings (512 v.s. 1000).
The object retrieval results for OK-VQA on the curated evaluation dataset are shown in \creftab:or-ok-vqa. We observe that enhancing the object retrieval model leads to improved VQA performance. \creffig:Results-case, \creffig:ok-vqa-1 and \creffig:ok-vqa-2 present VQA examples using GPT-4o, comparing results without and with the integration of STML and MS-GCEL methods. We can see that incorporating MS-GCEL results enables GPT-4o to answer the question accurately.
| Methods | Without Retrieval | STML | MS-GCEL |
|---|---|---|---|
| Scores | 25.00 | 33.33 | 36.11 |
page\cref@result
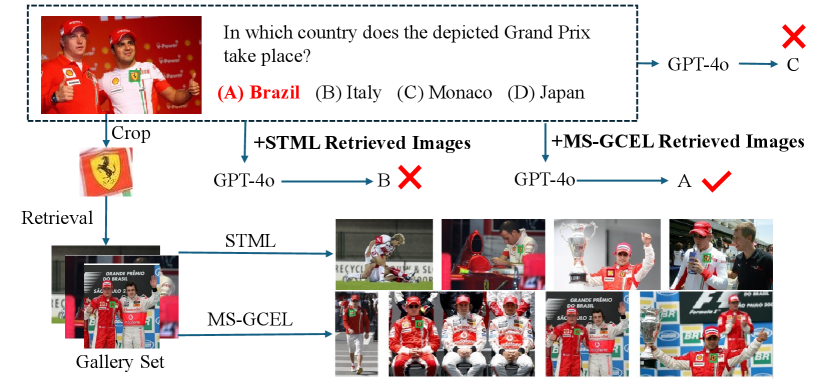
page\cref@result
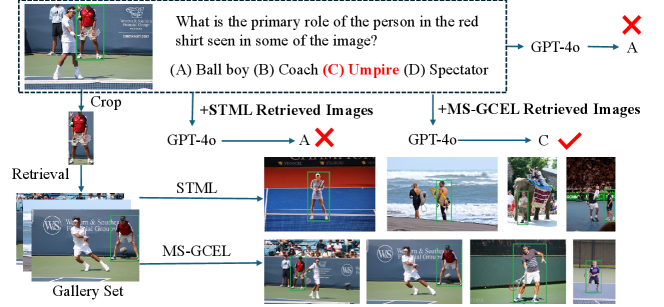
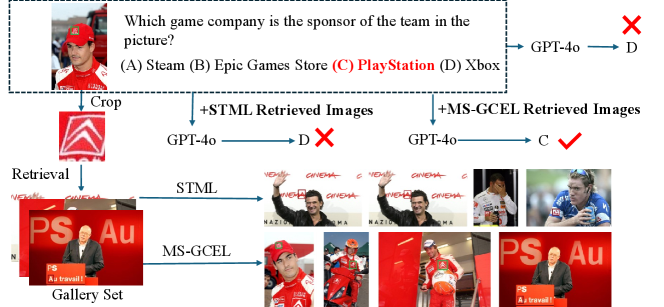
page\cref@result
5.4 Ablation Study
We conducted ablation studies on our curated object retrieval dataset using the GoogLeNet [54] backbone. In the subsequent ablation experiments, we utilize objects extracted by SAM for both training and validation.
(1) Impact of the MS-GCEL group number. We assessed the effect of the number of groups on the performance of the MS-GCEL method, with the cluster number fixed at 100. The results on the validation set are displayed in \creftab:ab-group, and they indicate that the best performance is attained when the number of groups is set to 4. Thus, in all of our experiments, we set the number of groups as 4.
(2) Impact of the clustering number. We examined the impact of the clustering number on deep feature embedding performance, with the number of groups fixed at 3. The results on the validation set are presented in \creftab:ab-cluster, and it is evident that the best performance is achieved when the number of clusters is set to 100.
(3) Impact of the MS-GCEL method. We assessed the influence of the PEL module and the CKD loss function in the proposed MS-GCEL approach on the object retrieval validation set. The ablation experiments are shown in \creftab:ab-gcml. The utilization of the PEL, which focuses on obtaining scale-specific information for feature encoding, enhances object-level retrieval performance. This indicates that the PEL assists in tackling the multi-scale challenge in object retrieval. The incorporation of the CKD loss function, which promotes information sharing and transfer among several PELs, significantly improves the model’s retrieval performance.
| Group Number | O-Recall@1 | O-mAP | I-Recall@1 | I-mAP |
|---|---|---|---|---|
| 2 | 70.16 | 17.74 | 74.05 | 72.57 |
| 3 | 70.60 | 18.25 | 74.69 | 72.47 |
| 4 | 70.78 | 18.25 | 74.91 | 72.60 |
| 5 | 69.68 | 17.75 | 73.92 | 71.72 |
page\cref@result
| Cluster Number | O-Recall@1 | O-mAP | I-Recall@1 | I-mAP |
|---|---|---|---|---|
| 50 | 70.43 | 17.95 | 74.42 | 72.47 |
| 100 | 70.60 | 18.25 | 74.69 | 72.47 |
| 200 | 69.98 | 17.75 | 74.11 | 71.99 |
| 1000 | 69.13 | 17.28 | 73.07 | 70.87 |
page\cref@result
| Methods | O-Recall@1 | O-mAP | I-Recall@1 | I-mAP |
|---|---|---|---|---|
| STML | 69.12 | 16.79 | 73.07 | 70.19 |
| STML+PEL | 69.29 | 17.62 | 72.98 | 71.13 |
| STML+PEL+CKD | 70.78 | 18.25 | 74.91 | 72.60 |
page\cref@result
5.5 More Retrieval Examples
page\cref@result \creffig:compare_case.png illustrates the comparison of three object retrieval examples between the MS-GCEL and STML[19] methods. The first retrieval example is based on the GoogLeNet backbone network, while the second and third retrieval examples are based on the MiT-B2 backbone network. These examples demonstrate that the MS-GCEL method is capable of returning more relevant objects associated with the query object.

page\cref@result

page\cref@result
fig:retrieval-examples provides logo retrieval example showcasing the effectiveness of the proposed MS-GCEL method. These examples illustrate the ability to ground multiple objects within the retrieved images.
In \creffig:supplemental_more_case, we present six retrieval examples. These examples were retrieved using the fine-tuned model based on the MS-GCEL method with parameters initialized using MoCo-V3 [17]. During retrieval, the top five images containing the query object were retrieved. Subsequently, object localization was conducted in these retrieved images using a similarity score (feature distance).
fig:failure_case.png shows two failure cases, the first line of the query image in the \creffig:failure_case.png is antenna, but the search returns ski-pole and mast. This is because antenna, ski-pole and mast are essentially the same in shape, and distinguishing between them requires more contextual semantic information. The image retrieved in the second row is the BASE logo. However, the fourth image is not the BASE logo, but other text patterns.

page\cref@result

page\cref@result
| Task1 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| person | bicycle | car | motorcycle | airplane | bus | train | boat | bird | cat | |
| dog | horse | sheep | cow | bottle | chair | couch | potted plant | dining table | tv | |
| truck | traffic light | fire hydrant | stop sign | parking meter | bench | elephant | bear | zebra | giraffe | |
| backpack | umbrella | handbag | tie | suitcase | microwave | oven | toaster | sink | refrigerator | |
| frisbee | skis | snowboard | sports ball | kite | baseball bat | baseball glove | skateboard | surfboard | tennis racket | |
| banana | apple | sandwich | orange | broccoli | carrot | hot dog | pizza | donut | cake | |
| bed | toilet | laptop | mouse | remote | keyboard | cell phone | book | clock | vase | |
| scissors | teddy bear | hair drier | toothbrush | wine glass | cup | fork | knife | spoon | bowl | |
| Task2 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| person | bicycle | car | motorcycle | airplane | bus | train | boat | bird | cat | |
| dog | horse | sheep | cow | bottle | chair | couch | potted plant | dining table | tv | |
| truck | traffic light | fire hydrant | stop sign | parking meter | bench | elephant | bear | zebra | giraffe | |
| backpack | umbrella | handbag | tie | suitcase | microwave | oven | toaster | sink | refrigerator | |
| frisbee | skis | snowboard | sports ball | kite | baseball bat | baseball glove | skateboard | surfboard | tennis racket | |
| banana | apple | sandwich | orange | broccoli | carrot | hot dog | pizza | donut | cake | |
| bed | toilet | laptop | mouse | remote | keyboard | cell phone | book | clock | vase | |
| scissors | teddy bear | hair drier | toothbrush | wine glass | cup | fork | knife | spoon | bowl | |
| Task3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| person | bicycle | car | motorcycle | airplane | bus | train | boat | bird | cat | |
| dog | horse | sheep | cow | bottle | chair | couch | potted plant | dining table | tv | |
| truck | traffic light | fire hydrant | stop sign | parking meter | bench | elephant | bear | zebra | giraffe | |
| backpack | umbrella | handbag | tie | suitcase | microwave | oven | toaster | sink | refrigerator | |
| frisbee | skis | snowboard | sports ball | kite | baseball bat | baseball glove | skateboard | surfboard | tennis racket | |
| banana | apple | sandwich | orange | broccoli | carrot | hot dog | pizza | donut | cake | |
| bed | toilet | laptop | mouse | remote | keyboard | cell phone | book | clock | vase | |
| scissors | teddy bear | hair drier | toothbrush | wine glass | cup | fork | knife | spoon | bowl | |
| Task4 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| person | bicycle | car | motorcycle | airplane | bus | train | boat | bird | cat | |
| dog | horse | sheep | cow | bottle | chair | couch | potted plant | dining table | tv | |
| truck | traffic light | fire hydrant | stop sign | parking meter | bench | elephant | bear | zebra | giraffe | |
| backpack | umbrella | handbag | tie | suitcase | microwave | oven | toaster | sink | refrigerator | |
| frisbee | skis | snowboard | sports ball | kite | baseball bat | baseball glove | skateboard | surfboard | tennis racket | |
| banana | apple | sandwich | orange | broccoli | carrot | hot dog | pizza | donut | cake | |
| bed | toilet | laptop | mouse | remote | keyboard | cell phone | book | clock | vase | |
| scissors | teddy bear | hair drier | toothbrush | wine glass | cup | fork | knife | spoon | bowl | |
page\cref@result
6 Conclusion
In this paper, we have addressed the challenges associated with general object retrieval for OK-VQA by introducing the multi-scale group collaborative embedding learning (MS-GCEL) method. We have established a comprehensive training and evaluation pipeline using objects extracted from the COCO 2017 and VOC 2007 datasets. Our experiments encompass different backbone networks and initialization methods, with evaluations conducted on BelgaLogos, Visual Genome, and LVIS datasets, and one curated OK-VQA dataset. The results demonstrated the effectiveness of the proposed MS-GCEL method in enhancing object retrieval performance in OK-VQA scenario. Nevertheless, there remains substantial room for improvement in this direction, as the target objects typically constitute a relatively small and unpredictable portion of an image, thereby impacting the overall object retrieval performance.
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant 62202499 and 62463002, in part by the State Key Program of National Natural Science Foundation of China under Grant 62233018, in part by the Beijing Natural Science Foundation under grant L231012. We are grateful to the High Performance Computing Center of Central South University for partial support of this work.
References
- [1] W. Lin, B. Byrne, Retrieval augmented visual question answering with outside knowledge, arXiv preprint arXiv:2210.03809 (2022).
- [2] H. Liu, C. Li, Q. Wu, Y. J. Lee, Visual instruction tuning, Advances in neural information processing systems 36 (2024).
- [3] P. Wu, S. Xie, V*: Guided visual search as a core mechanism in multimodal llms, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13084–13094.
- [4] K. Marino, M. Rastegari, A. Farhadi, R. Mottaghi, Ok-vqa: A visual question answering benchmark requiring external knowledge, in: Proceedings of the IEEE/cvf conference on computer vision and pattern recognition, 2019, pp. 3195–3204.
- [5] R. Zhao, H. Chen, W. Wang, F. Jiao, X. L. Do, C. Qin, B. Ding, X. Guo, M. Li, X. Li, et al., Retrieving multimodal information for augmented generation: A survey, arXiv preprint arXiv:2303.10868 (2023).
- [6] P. Zhao, H. Zhang, Q. Yu, Z. Wang, Y. Geng, F. Fu, L. Yang, W. Zhang, B. Cui, Retrieval-augmented generation for ai-generated content: A survey, arXiv preprint arXiv:2402.19473 (2024).
- [7] A. Joly, O. Buisson, Logo retrieval with a contrario visual query expansion, in: Proceedings of the 17th ACM international conference on Multimedia, 2009, pp. 581–584.
- [8] Y. Jiang, J. Meng, J. Yuan, J. Luo, Randomized spatial context for object search, IEEE Transactions on Image Processing 24 (6) (2015) 1748–1762.
- [9] G. Tolias, R. Sicre, H. Jégou, Particular object retrieval with integral max-pooling of cnn activations, in: ICLR 2016-International Conference on Learning Representations, 2016, pp. 1–12.
- [10] S. Kan, Y. Cen, Z. He, Z. Zhang, L. Zhang, Y. Wang, Supervised deep feature embedding with handcrafted feature, IEEE Transactions on Image Processing 28 (12) (2019) 5809–5823.
- [11] Y. Zhang, S. Wang, S. Kan, Z. Weng, Y. Cen, Y.-p. Tan, Poar: Towards open vocabulary pedestrian attribute recognition, in: ACM MUltimedia 2023, 2023, pp. 1–10.
- [12] S. Kan, Z. He, Y. Cen, Y. Li, V. Mladenovic, Z. He, Contrastive bayesian analysis for deep metric learning, IEEE Transactions on Pattern Analysis and Machine Intelligence (2022).
- [13] S. Kan, Y. Cen, Y. Li, M. Vladimir, Z. He, Local semantic correlation modeling over graph neural networks for deep feature embedding and image retrieval, IEEE Transactions on Image Processing 31 (2022) 2988–3003.
- [14] Z. Liu, Z. Miao, X. Zhan, J. Wang, B. Gong, X. Y. Stella, Open long-tailed recognition in a dynamic world, IEEE Transactions on Pattern Analysis and Machine Intelligence (2022).
- [15] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al., Segment anything, arXiv preprint arXiv:2304.02643 (2023).
- [16] M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, A. Joulin, Emerging properties in self-supervised vision transformers, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9650–9660.
- [17] X. Chen, S. Xie, K. He, An empirical study of training self-supervised vision transformers, in: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 9620–9629.
- [18] J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, T. Kong, ibot: Image bert pre-training with online tokenizer, arXiv preprint arXiv:2111.07832 (2021).
- [19] S. Kim, D. Kim, M. Cho, S. Kwak, Self-taught metric learning without labels, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 7431–7441.
- [20] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al., Imagenet large scale visual recognition challenge, International journal of computer vision 115 (2015) 211–252.
- [21] H. Oh Song, Y. Xiang, S. Jegelka, S. Savarese, Deep metric learning via lifted structured feature embedding, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4004–4012.
- [22] C. Wah, S. Branson, P. Welinder, P. Perona, S. Belongie, The caltech-ucsd birds-200-2011 dataset (2011).
- [23] J. Krause, M. Stark, J. Deng, L. Fei-Fei, 3d object representations for fine-grained categorization, in: Proceedings of the IEEE international conference on computer vision workshops, 2013, pp. 554–561.
- [24] Z. Hu, A. G. Bors, Co-attention enabled content-based image retrieval, Neural Networks 164 (2023) 245–263.
- [25] Z. Ji, Z. Li, Y. Zhang, H. Wang, Y. Pang, X. Li, Hierarchical matching and reasoning for multi-query image retrieval, Neural Networks 173 (2024) 106200.
- [26] J. Philbin, O. Chum, M. Isard, J. Sivic, A. Zisserman, Object retrieval with large vocabularies and fast spatial matching, in: 2007 IEEE conference on computer vision and pattern recognition, IEEE, 2007, pp. 1–8.
- [27] J. Philbin, O. Chum, M. Isard, J. Sivic, A. Zisserman, Lost in quantization: Improving particular object retrieval in large scale image databases, in: 2008 IEEE conference on computer vision and pattern recognition, 2008, pp. 1–8.
- [28] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft coco: Common objects in context, in: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, Springer, 2014, pp. 740–755.
- [29] M. Everingham, The pascal visual object classes challenge 2007 (voc2007) results, in: http://host.robots.ox.ac.uk/pascal/VOC/voc2007/, 2007.
- [30] R. Krishna, Y. Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y. Kalantidis, L.-J. Li, D. A. Shamma, et al., Visual genome: Connecting language and vision using crowdsourced dense image annotations, International journal of computer vision 123 (2017) 32–73.
- [31] A. Gupta, P. Dollar, R. Girshick, Lvis: A dataset for large vocabulary instance segmentation, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5356–5364.
- [32] G. Tolias, R. Sicre, H. Jégou, Particular object retrieval with integral max-pooling of cnn activations, in: ICLR 2016-International Conference on Learning Representations, 2016, pp. 1–12.
- [33] S. Kan, Y. Liang, M. Li, Y. Cen, J. Wang, Z. He, Coded residual transform for generalizable deep metric learning, Advances in Neural Information Processing Systems 35 (2022) 28601–28615.
- [34] R. Hadsell, S. Chopra, Y. LeCun, Dimensionality reduction by learning an invariant mapping, in: 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), Vol. 2, IEEE, 2006, pp. 1735–1742.
- [35] F. Schroff, D. Kalenichenko, J. Philbin, Facenet: A unified embedding for face recognition and clustering, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 815–823.
- [36] X. Wang, X. Han, W. Huang, D. Dong, M. R. Scott, Multi-similarity loss with general pair weighting for deep metric learning, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5022–5030.
- [37] K. He, H. Fan, Y. Wu, S. Xie, R. Girshick, Momentum contrast for unsupervised visual representation learning, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9729–9738.
- [38] T. Chen, S. Kornblith, M. Norouzi, G. Hinton, A simple framework for contrastive learning of visual representations, in: International conference on machine learning, PMLR, 2020, pp. 1597–1607.
- [39] B. X. Nguyen, B. D. Nguyen, G. Carneiro, E. Tjiputra, Q. D. Tran, T.-T. Do, Deep metric learning meets deep clustering: An novel unsupervised approach for feature embedding, arXiv preprint arXiv:2009.04091 (2020).
- [40] S. Kan, Y. Cen, Y. Li, V. Mladenovic, Z. He, Relative order analysis and optimization for unsupervised deep metric learning, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 13999–14008.
- [41] Y. Li, S. Kan, J. Yuan, W. Cao, Z. He, Spatial assembly networks for image representation learning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 13876–13885.
- [42] H.-Y. Tseng, H.-Y. Lee, L. Jiang, M.-H. Yang, W. Yang, Retrievegan: Image synthesis via differentiable patch retrieval, in: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VIII 16, 2020, pp. 242–257.
- [43] W. Chen, H. Hu, C. Saharia, W. W. Cohen, Re-imagen: Retrieval-augmented text-to-image generator, arXiv preprint arXiv:2209.14491 (2022).
- [44] Z. Fei, Memory-augmented image captioning, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35, 2021, pp. 1317–1324.
- [45] L. Huang, Z. Peng, F. Chen, S. Dai, Z. He, K. Liu, Cross-modality interaction for few-shot multispectral object detection with semantic knowledge, Neural Networks 173 (2024) 106156.
- [46] S. S. Roshan, N. Sadeghnejad, F. Sharifizadeh, R. Ebrahimpour, A neurocomputational model of decision and confidence in object recognition task, Neural Networks 175 (2024) 106318.
- [47] D. Peng, W. Zhou, J. Pan, D. Wang, Msednet: Multi-scale fusion and edge-supervised network for rgb-t salient object detection, Neural Networks 171 (2024) 410–422.
- [48] M. Maaz, H. Rasheed, S. Khan, F. S. Khan, R. M. Anwer, M.-H. Yang, Class-agnostic object detection with multi-modal transformer, in: European Conference on Computer Vision, Springer, 2022, pp. 512–531.
- [49] K. Joseph, S. Khan, F. S. Khan, V. N. Balasubramanian, Towards open world object detection, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 5830–5840.
- [50] I. Loshchilov, F. Hutter, Sgdr: Stochastic gradient descent with warm restarts, arXiv preprint arXiv:1608.03983 (2016).
- [51] B. Heo, S. Chun, S. J. Oh, D. Han, S. Yun, G. Kim, Y. Uh, J.-W. Ha, Adamp: Slowing down the slowdown for momentum optimizers on scale-invariant weights, in: International Conference on Learning Representations, 2021.
- [52] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020).
- [53] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., Learning transferable visual models from natural language supervision, in: International conference on machine learning, PMLR, 2021, pp. 8748–8763.
- [54] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich, Going deeper with convolutions, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1–9.
- [55] E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, P. Luo, Segformer: Simple and efficient design for semantic segmentation with transformers, Advances in Neural Information Processing Systems 34 (2021) 12077–12090.