OC-NMN: Object-centric Compositional Neural Module Network for Generative Visual Analogical Reasoning
Abstract
A key aspect of human intelligence is the ability to imagine — composing learned concepts in novel ways — to make sense of new scenarios. Such capacity is not yet attained for machine learning systems. In this work, in the context of visual reasoning, we show how modularity can be leveraged to derive a compositional data augmentation framework inspired by imagination. Our method, denoted Object-centric Compositonal Neural Module Network (OC-NMN), decomposes visual generative reasoning tasks into a series of primitives applied to objects without using a domain-specific language. We show that our modular architectural choices can be used to generate new training tasks that lead to better out-of-distribution generalization. We compare our model to existing and new baselines in proposed visual reasoning benchmark that consists of applying arithmetic operations to MNIST digits.
1 Introduction
Humans have the remarkable ability to adapt to new unseen environments with little experience (Lake et al., 2017). In contrast, machine learning systems are sensitive to distribution shifts (Arjovsky et al., 2019; Su et al., 2019; Engstrom et al., 2019). One of the key aspects that makes human learning so robust is the ability to produce or acquire new knowledge by composing a few learned concepts in novel ways, an ability known as compositional generalization (Fodor and Pylyshyn, 1988; Lake et al., 2017). The question of how to achieve such compositional generalization in both humans and machines remains an active area of research (Ruis and Lake, 2022).
Both imagination and abstraction are core to human intelligence. Objects, in particular, are an important representation used by the human brain when applying analogical reasoning (Spelke, 2000). For instance, we can infer the properties of a new object by transferring our knowledge of these properties from similar objects (Mitchell, 2021). This realization has inspired a recent body of work that focuses on learning models that discover objects in a visual scene without supervision (Eslami et al., 2016b; Kosiorek et al., 2018; Greff et al., 2017; van Steenkiste et al., 2018; Greff et al., 2019; Burgess et al., 2019; van Steenkiste et al., 2019; Locatello et al., 2020). Many of these works propose inductive biases that lead to a decomposition of the visual scene in terms of its constituting objects. The expectation is that such an object-centric decomposition would lead to better generalization since it better represents the underlying structure of the physical world (Parascandolo et al., 2018).
Most visual reasoning benchmarks revolve around variations of Raven’s Progressive Matrices (RPM) (James, 1936; Zhang et al., 2019; Barrett et al., 2018; Hoshen and Werman, 2017), all of which are discriminative tasks in which the solver chooses from a set of candidate answers. However, in a recent survey, Mitchell (2021) argues that models trained on discriminative tasks are prone to shortcut learning and thus recommends evaluating models on generative tasks that focus on human core knowledge (Spelke, 2000). Mitchell (2021) also argues that systems that generate answers are in many cases more interpretable. To that end, Chollet (2019) proposed a generative reasoning task, the Abstract Reasoning Corpus (ARC), where the model is given a few examples of input-output (I/O) pairs and has to understand the underlying common program that was applied to the inputs to obtain the outputs. ARC tasks rely only on the innate core knowledge systems, including intuitive knowledge about objects, agents and their goals, numerosity, and basic spatial-temporal concepts. However, ARC remains a challenging task unapproachable by current deep learning methods. In this work, we take a step towards addressing the ARC challenge by designing a new and simpler generative benchmark, which we call Arith-MNIST. Using this benchmark, we evaluate the systematic compositional generalization of models on a set of controlled and easily extendable axes and show the benefits of object-centric inductive biases.
To tackle Arith-MNIST, we propose the Object-centric Compositional- Neural Module Network (OC-NMN), an example of how object-centric inductive biases can be exploited to (1) design a modular architecture that can solve generative visual reasoning tasks like ARC, and (2) derive a compositional data augmentation paradigm that we lead to better out-of-distribution generalization. The core idea underlying OC-NMN is to predict a neural template (Reed and De Freitas, 2015; Cai et al., 2017; Li et al., 2020) that specifies a task-specific composition of neural modules. The neural modules can be reassembled in unseen ways to invent new tasks.
Our contribution is as follows:
-
•
We propose a benchmark Arith-MNIST that serves as a test-bed to evaluate compositional generalization capabilities of both visual analogical reasoning models and object-centric perception models. The benchmark is constructed around a set of controllable primitives (e.g., arithmetic operations over visual digits) that can be easily extended.
-
•
We propose the model OC-NMN that adapts neural module networks (NMN) (Andreas et al., 2016) to solve visual generative analogical reasoning tasks.
-
•
We show how such modular inductive biases can be leveraged to derive a compositional imagination framework. We show that samples created within this framework help with systematic generalization.
-
•
Finally, we show that the ability of the perception part of the models to represent and disentangle object-level attributes is key to generalizing to unseen combinations of attributes.
2 Related Work
Object-centric Representation.
A recent research direction explores unsupervised object-centric representation learning from visual inputs (Locatello et al., 2020; Burgess et al., 2019; Greff et al., 2019; Eslami et al., 2016a; Crawford and Pineau, 2019; Stelzner et al., 2019; Lin et al., 2020; Geirhos et al., 2019). The main motivation behind this line of work is to disentangle a latent representation in terms of objects composing the visual scene (e.g., slots). Recent approaches to slot-based representation learning focus on the generative abilities of the models; in our case, we study the impact of object-centric inductive biases on the systematic generalization of models in a visual reasoning task. We observe that the modularity of representations is as important as the mechanisms that operate on them (Goyal et al., 2020, 2021). Additionally, we show that object-centric inductive biases of both representations and mechanisms allow us to derive a compositional imagination framework that leads to better systematic generalization.
Modularity.
Extensive work from the cognitive neuroscience literature (Baars, 1997; Dehaene et al., 2017) suggests that the human brain represents knowledge in a modular way, with different parts (e.g., modules) interacting with a working memory bottleneck via attention mechanisms. Following these observations, a line of work in machine learning (Goyal and Bengio, 2020; Goyal et al., 2019, 2020, 2021; Ostapenko et al., 2021; Goyal and Bengio, 2022) has proposed to translate these characteristics into architectural inductive biases for deep neural networks. Recent approaches have explored architectures composed of independently parameterized modules competing with each other to communicate and attend or process the input (Goyal et al., 2019, 2020, 2021). Such architectures are inspired by the notion of independent mechanisms (Pearl, 2009; Bengio et al., 2019; Goyal et al., 2019; Goyal and Bengio, 2022), which suggests that a set of independently parameterized modules capturing causal mechanisms should remain robust to distribution shifts caused by interventions, as adapting one module should not require adapting the others. The hope is that out-of-distribution (OOD) generalization would be facilitated by making it possible to sequentially compose the computations performed by these modules, whereby novel combinations of existing concepts can explain new situations. Neural Module Networks (NMNs) (Andreas et al., 2016) have also been shown to be a promising approach for systematic generalization in the context of Visual Question Answering (VQA) (Bahdanau et al., 2019b, 2018). Their main inductive bias is selecting a question-specific neural network layout containing a sequence of sub-tasks where each sub-task corresponds to a module. In this work, we adapt NMNs main inductive bias to solve generative visual analogical reasoning tasks. We also show how our modular architectural choices can be exploited to derive a compositional data augmentation framework that allows better compositional generalization; we do so by explicitly exposing the model to data samples composed of novel combination of learned concepts.
Imagination, Dreaming, and Generalization
Dreams are a form of imagination that has inspired significant influential work (Hinton et al., 2006; Ellis et al., 2021; Hafner et al., 2019, 2020). An interesting explanation for such a phenomenon is the overfitted brain hypothesis (OBH) (Hoel, 2021), which states that dreaming improves the generalization and robustness of learned representations. The idea is that, while dreaming, the brain recombines patterns seen during wake time. This results in artificial data augmentation in the form of dreams that regularizes the brain and prevent overfitting the patterns seen while awake.
Dreamcoder (Ellis et al., 2021) is a recent example where training on imagined patterns improves generalization for program induction. Program induction is a challenging problem because the search space is combinatorially large, and new unseen programs have low likelihood. To address these challenges, Dreamcoder leverages a wake-sleep algorithm that reduces the search space by learning a domain-specific language (DSL) while learning to search programs efficiently. During training, Dreamcoder undergoes a dreaming phase where the model learns to solve new tasks generated by sampling programs from a DSL and applying them to inputs seen during the wake phase. Although Dreamcoder is promising for program induction, the DSL is a major roadblock to solving open-ended visual reasoning tasks where the input consists of raw pixels rather than symbols. In this work, we show promising results on overcoming these challenges by relying on object-centric inductive biases.
3 Arith-MNIST: Generative Arithmetic Visual Analogical Reasoning

Arith-MNIST is made of visual generative analogical reasoning tasks. In generative analogical reasoning tasks such as the ones in ARC (Chollet, 2019), a model is presented with a few input-output examples (the support set) and is asked to predict the output of new input queries of the same task (the query set). The outputs from the support set are obtained by applying a program (the same for all the elements of one support set) to the inputs. To predict the right outputs of the input query set, a model needs to infer the program applied to the support and apply this program to the queries. Given that current ML systems still struggle to tackle ARC, we propose a simpler set of tasks that involve a set of controlled arithmetic operations on digits.
In our benchmark, inputs are images with three colored MNIST digits (unsigned) placed at three different positions. These visual digits can have values between and and their color represents their sign. There are six different colors in total ( of them are negative and the remaining are positive). The program applied to the inputs is a sequence of arithmetic operations in a specified order. The order in which we select the digits is given by a sequence of conditions (e.g. position in the image, maximum digit, etc…). We give those primitives in Table 1 and more details in the Appendix.
The benchmark is split into different datasets that are composed of a varying number of tasks and examples per task. These split and their composition is given in Table 1. The hard split approaches the ARC setting the most since only a handful of examples per tasks are in the training set. Since we want to measure models’ compositional generalization we create different sub-splits that aim at evaluating different axes of compositional generalization. We give more details about the splits and the sub-splits in Section 5.2 and the Appendix. We give an example of the benchmark in Figure 1.
| Dataset | Primitives | of Training Tasks | |
|---|---|---|---|
| Split | Conditions | Operations | |
| Easy | position | add, sub | 5 |
| Medium | position, max, min | add, sub, or, xor, cat, invcat | 150 |
| Hard | position, max, min | add, sub, or, xor, cat, invcat | 1980 |
| Percep | position | add, sub | 5 |
Text mode.
We provide users the option to skip the perception part (understanding the images) by providing a textual version of our dataset. This enables evaluating compositional generalization reasoning capabilities of existing large language models (LLMs). In this version, each image/output pair is described in natural language text (e.g., There is a blue four on the left, a red five on the right, and a green seven at the bottom. The result is 4).
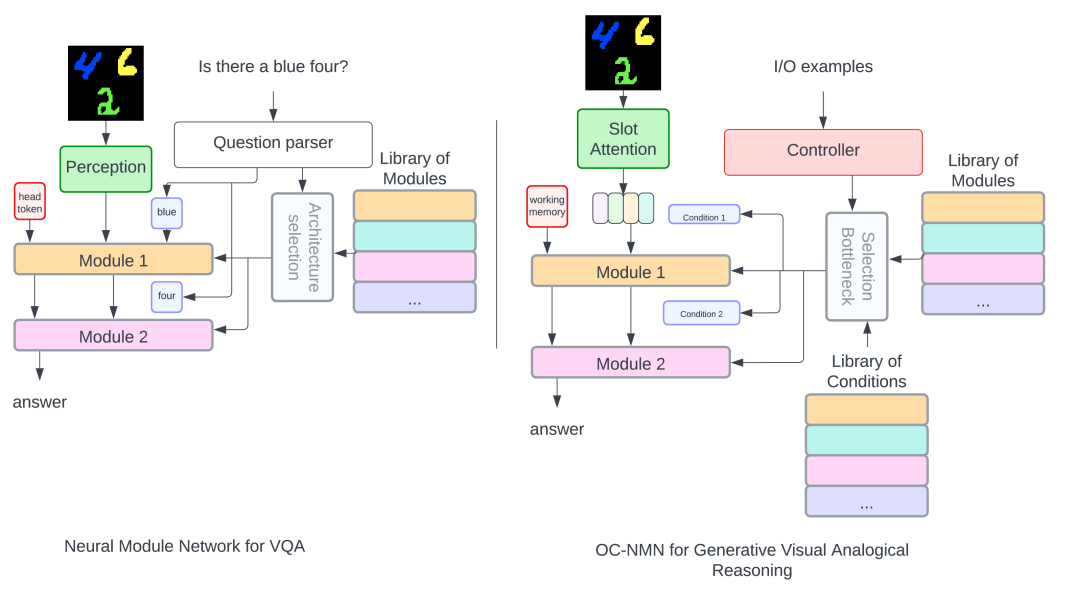
4 Object-centric Compositional Neural Module Network
Our model OC-NMN (Object-centric Compositional Neural Module Network) can be seen as part of the neural module networks (NMNs) family of models, adapted to generative visual analogical reasoning tasks like ARC. NMNs are mainly used in the context of visual question answering and assemble a question-specific composition of network modules, a neural template. This neural template can further be applied to different input images to answer the same question. NMNs typically consist of two main components: the controller module and the execution module. The controller module processes the input question and generates a neural template that, when executed, generates the answer to the question. This neural template specifies the sequence of modules to be executed along with their arguments (coming from the question). The execution module takes the neural template predicted by the controller, along with the input image, and generates the answer by assembling the modules specified by the template.
Following this general structure of NMNs, OC-NMN also predicts a sequence of modules to be assembled along with their arguments; however, our module generation differs from that of NMNs in two ways: (1) the model does not have access to the program (e.g. the parsed question in the VQA setting) and needs to infer it from the demonstration pairs in the support set, and, (2) the arguments to the modules come directly from the visual input query. Our model overview is given in Figure 2
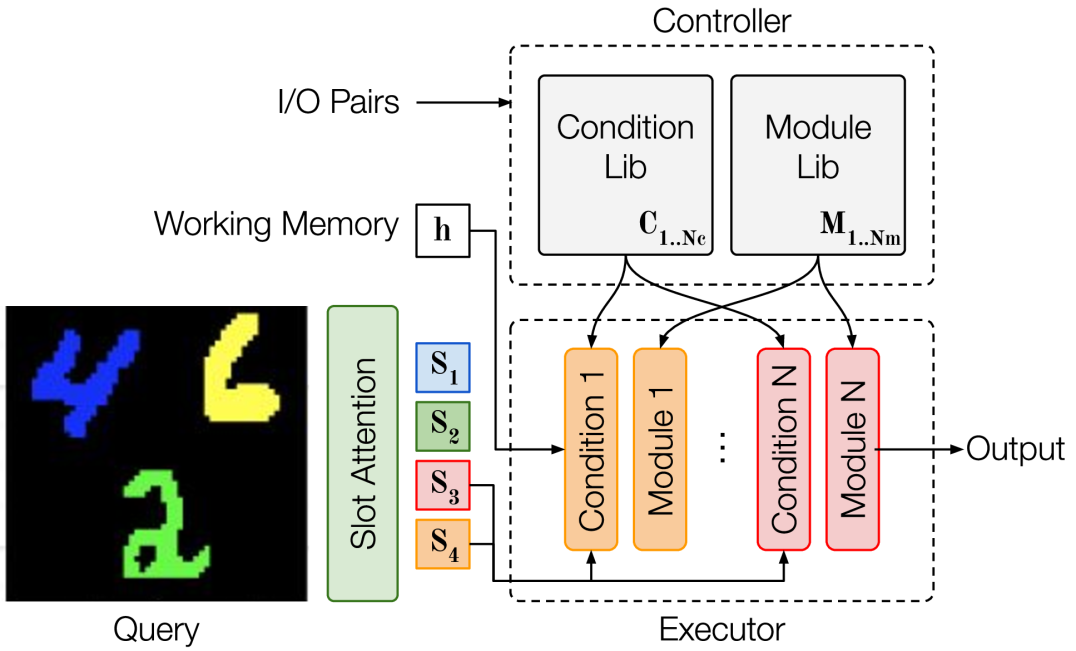
The computation steps (and parts of OC-NMN) are the following : (1) A perception network maps the visual inputs to object-centric slots using a slot attention (Locatello et al., 2020) mechanism then, (2) a controller takes the support set as input and outputs a task embedding . (3) A selection bottleneck translates this task embedding into a sequential neural template; finally, (4) the executor takes this neural network template along with an input query (i.e., its object-centric slots) and performs the sequential updates. The controller module’s architecture is the same for all the baselines considered (including our model) and corresponds to the Differentiable Neural Computer controller (Graves et al., 2016) proposed in Neural Abstract Reasoner (Kolev et al., 2020). Our contribution resides in the design of the executor and the Selection Bottleneck that we detail below.
4.1 Executor
The executor takes a visual input query and a neural template. The execution consists of sequentially transforming a working memory : at each time-step . The neural template specifies a module (from a learnt modules library) that will transform the working memory and a condition (from a learnt conditions library) that will select an argument from the visual input query .
The visual input is first mapped to a set of object-centric slots that is later used as candidate arguments for each update of the working memory. The executor is composed of a library of learned modules (e.g. rules, implemented as small GRU cells) and condition values. The conditions are expected to encode how to select an argument (for instance: select the highest digit among slots) for the update. Both modules and conditions are indexed by learned tags and .
The neural template comes from the selection bottleneck. It specifies:
-
•
the number of updates the executor needs to perform. A sequence of scalar gates specifies it at each time step, which we denote by ;
-
•
the sequence of modules that will perform the updates of the working memory, which we denote [, …, ];
-
•
the sequence of conditions that select the slots used as arguments, denoted [, …, ].
Argument Selection.
At each time step, a slot argument is selected through a key-query attention mechanism. At time-step , the condition vector is compared against all the input slots to select the one that corresponds best to the features encoded in the condition (e.g., select the slot at the “top-left” of the image). In the attention mechanism, the query comes from the condition vector and the keys come from the slots (transformed by a self-attention module to extract the keys).The selected slot argument at time-step is given by:
| (1) |
Sequential Update.
Given a sequence of modules [, …, ], a sequence of input arguments [, …, ] and a sequence of gates [, …, ], the executor updates a working memory whose state at time step is denoted by such that:
| (2) |
For ease of notation, we let be the result of applying the neural template to .
4.2 Selection Bottleneck
We describe here the component that translates the task embedding from the controller to a neural template that the execution module will use. At each time-step we need to predict a module (from a learnt modules library) and a condition vector (from a learnt conditions library). We propose to predict those with a key-query attention mechanism: at each time-step , the task embedding is compared to the learned module tags and the learned conditions tags . The keys are extracted from the condition/module tags, whereas the query is extracted from the task embedding (using two MLPs and ) such that the -th element of each sequence is obtained with:
| (3) |
and the resulting update is given by the following weighted sum :
| (4) |
Similarly, the conditions are obtained through:
| (5) |
with denoting the set of learned condition vectors.
Finally, the sequence of step gates is obtained directly from the sequence of such that .
For ease of notation, we let denote the neural template obtained from the task embedding .
5 Experiments
In this section, we present the experimental results of applying OC-NMN to different splits of the Arith-MNIST dataset, and compare it against several baseline approaches. We analyze the results in Section 5.3, and make the following three observations. (1) The modular inductive biases employed by OC-NMN alone are not sufficient for our model to achieve systematic generalization to unseen combinations of known concepts. (2) However, the same inductive biases can be used to derive a compositional imagination framework that shows promising results in systematic generalization. (3) We highlight that the ability of the perception model to disentangle object-level attributes is key for generalization to unseen configurations of digit-colors and motivates future work in that direction.
5.1 Baselines
Our model can be seen as an adaptation of Neural Module Networks to work on generative visual analogical reasoning tasks. Neural Module Networks are traditionally evaluated in the VQA setting, where a question can be parsed to induce a modular neural network architecture (eg. neural template) that acts as an executor. In our setting, the question is not given and the correct architecture needs to be inferred from a few input/output support examples. To the best of our knowledge, the only existing neural network model that can readily tackle generative visual reasoning tasks is the Neural Abstract Reasoner (NAR) (Kolev et al., 2020). We compare our model to an object-centric version of NAR (replacing its image encoder with a Slot Attention module and concatenating the slots). We also propose two additional baselines, both having no selection bottleneck: a non-modular baseline, where the executor consists of a single GRU cell that takes as input the query slots and the tasks embedding coming from the controller. We denote this baseline DNC-GRU. The second baseline consists of a stack of Transformer encoder layers, and takes as input a set composed of the query slots, the controller output, and a CLS token from which we retrieve the final answer. We denote this model DNC-Transformer. All architectural details and hyperparameters are described in the Appendix.
We consider two versions of our model, depending on the number of modules/conditions compared to the ground truth number of concepts in the tasks (e.g. conditions and arithmetic operations). When the number of modules/conditions is less than the actual primitives needed to solve the training set, we denote our model by OC-NMN - less; otherwise, we we denote it by OC-NMN - enough.
Text Version.
In the text version of the benchmark (where each image/output pair is described in natural language), we consider two state-of-the-art language models: FLAN-T5 (Chung et al., 2022) fine-tuned on our task and GPT-4. We evaluate GPT-4 on the easy split and obtain an accuracy of 16 in the best case. More details about the GPT-4 training can be found in the Appendix.
| Dataset | Easy | Medium | Hard | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Val | Op | Order | Val | Op | Order | Val | Op | Order |
| NAR | |||||||||
| DNC-GRU | |||||||||
| DNC-Transformer | 25.2 ±0.4 | 37.8 ±1.1 | |||||||
| OC-NMN - less | |||||||||
| OC-NMN - enough | |||||||||
| Text Modality | |||||||||
| FLAN-T5 | 100 | 100 | 99.7 | 86.0 | 40.8 | 50.6 | 52.0 | 39.0 | 47.6 |
5.2 Splits
The different splits we propose and describe in Section 3 are designed to evaluate several axes of compositional generalization of both the reasoning and perception components of the models. We want to evaluate: (1) The ability of the model to generalize to unseen sequences of operations/orders with varying numbers of primitive concepts (e.g., arithmetic operation and condition selection) and samples per task. The hardest split approaches the ARC setting as only a handful of examples per task are seen. Table 2. (2) The ability of the perception component to disentangle important factors of variation such as color and digit, which are crucial for solving the tasks at hand (e.g., color represents the number sign). Table 3. We also report the performance of a state-of-the-art language model baseline FLAN-T5 on the text equivalent tasks.
5.3 Results
Compositional Generalization.
In Table 2 we report the performance of the different models on the easy, medium and hard splits. Accuracies are averaged over the 3 best seeds for each model. For each split, we are interested in 2 forms of generalization: performance of the model on a set of different sequences of operations (e.g. Op) and performance of the model on digits taken in different order (e.g. Order). The following is a summary of the key observations. (1) Interestingly, all the visual models fail to systematically generalize to both different orders and different operations. It is also the case for OC-NMN, despite the fact that modularity of NMNs have been shown to improve systematic generalization in the context of VQA (Andreas et al., 2016; Bahdanau et al., 2019a). (2) As expected, OC-NMN fails to learn the tasks at hand when it does not have enough modules and conditions. This is the case where the model has fewer learned modules/conditions than there are primitive concepts (e.g. selection conditions and operations) in the training tasks. (3) The non-modular DNC-GRU baseline is on par with the others on the easy set, but when the tasks get more complicated (i.e. more concepts required to be learnt and assembled to solve the tasks) it performs subsequently worse than other executors. (4) DNC-Transformer performs better (in-distribution) than OC-NMN on the medium split but not on the hardest one where only a handful of examples are sampled per task. Note that the DNC-Transformer already contains a form of modularity in the way it processes the input slots (e.g. multi-head attention operations but no selection bottleneck). Overall, OC-NMN and DNC-Transofmer are comparable in performance. (5) The language model FLAN-T5 finetuned on the same underlying tasks systematically generalizes OOD when it has enough examples per task. However, it fails to generalize on the hardest split, which is closer to the ARC setting.
Object-level Attribute Disentanglement.
We evaluate the ability of the perception model to disentangle factors of variation that are relevant to the task (e.g. color and digit, where the color indicates the sign of the digit). We consider two cases that depend on whether the Slot Attention is pretrained on all or only a subset of the digit-color configurations. Once the initial pretraining of the perception module is complete, all the models undergo training on a subset of digit-color configurations and are subsequently tested on held-out configurations. We report the results of out experiments in Table 3. The table illustrates the following observations: (1) There is a significant decrease in out-of-distribution generalization when the model is pretrained on all versus a subset of the digit-color combinations (even as in-distribution generalization remains high in both cases); and (2) when pretrained on all digit-color combinations, the supervised model successfully generalizes to unseen combinations. Thus, when the perception model is pretrained on all configurations, supervised training on reasoning tasks does not influence generalization to unseen combinations, even if the reasoning module has not been exposed to such combinations during training. These results show that the pretraining of the Slot Attention module is key for good generalization to unseen combinations of digit-color pairs. This emphasizes the importance of a perception model capable of representing any digit-color configuration during unsupervised pretraining, as this significantly enhances the generalization capabilities of the model to novel combinations.

In Figure 3 we visualize the reconstructed images from the learned slots after training in both pretraining settings. Ground-truth images correspond to digit-color configurations that have been held out during training. In the case where pretraining is done on all configurations, we notice that training did not influence the ability of the Slot Attention to represent held-out configurations. However, when pretraining is done on the same subset of configurations as training, the slot attention model is not able to represent held-out configurations. It tends to modify the shape and color of digits so that they correspond to configurations it has previously learned to represent. These findings underscore the need for designing better inductive biases for unsupervised systematic generalization to unseen combinations of object-level attributes and motivate future work for the object-centric community.
| Slot Attention Pretraining | Pretrain Subset | Pretrain All | ||
|---|---|---|---|---|
| Model/Split | Val | OOD Test | Val | OOD Test |
| NAR | 94.1 | 12.8 | 100 | 96.8 |
| DNC-GRU | 99.3 | 11.6 | 100 | 97.4 |
| DNC-Transformer | 99.3 | 46.1 | 100 | 91.6 |
| OC-NMN | 99.6 | 43.6 | 100 | 96.5 |
Compositional Imagination.
While abstractions, like objects, allow for reasoning and planning beyond direct experience, novel configurations of experienced concepts are possible through imagination. Hoel (2021) takes this notion further by suggesting that dreaming, a form of data augmentation, enhances the generalization and robustness of learned representations. Dreams achieve this by generating new data instances composed of concepts learned or experienced during wake time. In this work, we show that the modularity of our model can be used to derive a new paradigm for compositional imagination.
The idea here is that in the same way we select a neural template (sequence of modules, conditions, and gates) using the task embedding output by the controller, we can also sample them at random (from a uniform distribution) to create new imagined scenarios. We then train the controller to predict the neural template that generated those imagined samples. The associated loss is called the imagination loss , which can be split into 3 cross-entropies predicting the step gate values, the conditions vector indices, and the processing module indices. During training, we introduce this loss after a warming period during which the model is trained only on the training data available. We detail the hyperparameters in the Appendix.
The pseudo-code and training details for this compositional imagination framework are given in the Appendix.
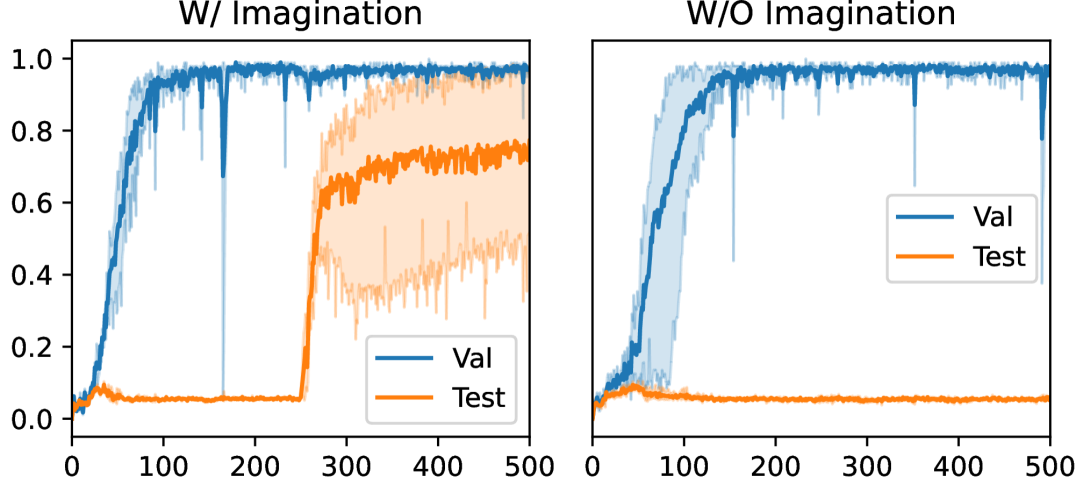
In Figure 4, we show the effect of the imagination loss on the training dynamics, leading to better OOD generalization in the easy split. However, we found that this compositional imagination framework is detrimental in harder splits and suggest that a better prior on how to sample modules/conditions in a non-uniform way is needed. We leave that direction for future work. Additional ablations are given in the Appendix.
6 Conclusion
The problem of visual generative reasoning remains challenging for current ML systems (Mitchell, 2021; Chollet, 2019). In this work, we explore the use of neural module networks (Andreas et al., 2016) for solving such tasks by leveraging object-centric representations, resulting in our proposed approach called OC-NMN. However, we discovered that while NMN’s modular inductive biases exhibit strong performance in systematic generalization for visual question answering (VQA) problems (Andreas et al., 2016; Bahdanau et al., 2019a), such modularity is not enough for the visual generative reasoning setting we propose. This disparity can be attributed to the difference in the access to questions in VQA, which provide guidance on assembling the modules into a neural network layout, compared to our setting where the model must infer the appropriate layout based on input-output pairs. To address this challenge, we leverage the generative nature of the problem setup and show how OC-NMN modular inductive biases can be used to “imagine” new unseen problems. This involves composing the learned modules in novel ways, applying them to previously seen inputs to create a support set, and training the model to predict back the proper neural network layout. In encouraging results, we found that this imagination framework helps bridge the generalization gap for easy problems while further research is needed for more complex scenarios. Additionally, we show that the ability of the perception to disentangle object-level attributes is key to achieving generalization to unseen digit-color configurations. Our findings underscore the need for designing better inductive biases for object-centric perception models to achieve such disentanglement in an unsupervised manner.
Limitations.
Despite the progress made in our research, it is important to acknowledge the limitations. The benchmarks used in our study are relatively simplistic and do not fully capture real-world complexity. Our method performs well in the easier setting but may struggle with more challenging scenarios. Additionally, the number of hidden ground truth reasoning steps used in our setups remains small (at most 2 operations). These limitations provide opportunities for future research to develop more comprehensive benchmarks, extend the method’s applicability, improve complex reasoning capabilities, and ensure practicality in real-world applications.
References
- Andreas et al. [2016] J. Andreas, M. Rohrbach, T. Darrell, and D. Klein. Neural module networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 39–48, 2016.
- Arjovsky et al. [2019] M. Arjovsky, L. Bottou, I. Gulrajani, and D. Lopez-Paz. Invariant risk minimization. arXiv preprint arXiv:1907.02893, 2019.
- Baars [1997] B. J. Baars. In the theatre of consciousness: Global workspace theory, a rigorous scientific theory of consciousness. Journal of Consciousness Studies, 4(4):292–309, 1997.
- Bahdanau et al. [2018] D. Bahdanau, S. Murty, M. Noukhovitch, T. H. Nguyen, H. de Vries, and A. C. Courville. Systematic generalization: What is required and can it be learned? CoRR, abs/1811.12889, 2018. URL http://arxiv.org/abs/1811.12889.
- Bahdanau et al. [2019a] D. Bahdanau, H. de Vries, T. J. O’Donnell, S. Murty, P. Beaudoin, Y. Bengio, and A. Courville. Closure: Assessing systematic generalization of clevr models. arXiv preprint arXiv:1912.05783, 2019a.
- Bahdanau et al. [2019b] D. Bahdanau, H. de Vries, T. J. O’Donnell, S. Murty, P. Beaudoin, Y. Bengio, and A. C. Courville. CLOSURE: assessing systematic generalization of CLEVR models. CoRR, abs/1912.05783, 2019b. URL http://arxiv.org/abs/1912.05783.
- Barrett et al. [2018] D. Barrett, F. Hill, A. Santoro, A. Morcos, and T. Lillicrap. Measuring abstract reasoning in neural networks. In International conference on machine learning, 2018.
- Bengio et al. [2019] Y. Bengio, T. Deleu, N. Rahaman, R. Ke, S. Lachapelle, O. Bilaniuk, A. Goyal, and C. Pal. A meta-transfer objective for learning to disentangle causal mechanisms. arXiv:1901.10912, 2019.
- Burgess et al. [2019] C. P. Burgess, L. Matthey, N. Watters, R. Kabra, I. Higgins, M. Botvinick, and A. Lerchner. Monet: Unsupervised scene decomposition and representation, 2019.
- Cai et al. [2017] J. Cai, R. Shin, and D. Song. Making neural programming architectures generalize via recursion. In International Conference on Learning Representations, 2017.
- Chollet [2019] F. Chollet. On the measure of intelligence. arXiv preprint arXiv: Arxiv-1911.01547, 2019.
- Chung et al. [2022] H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y. Tay, W. Fedus, E. Li, X. Wang, M. Dehghani, S. Brahma, et al. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- Crawford and Pineau [2019] E. Crawford and J. Pineau. Spatially invariant unsupervised object detection with convolutional neural networks. In AAAI Conference on Artificial Intelligence, 2019.
- Dehaene et al. [2017] S. Dehaene, H. Lau, and S. Kouider. What is consciousness, and could machines have it? Science, 358(6362):486–492, 2017. doi: 10.1126/science.aan8871. URL https://www.science.org/doi/abs/10.1126/science.aan8871.
- Ellis et al. [2021] K. Ellis, C. Wong, M. Nye, M. Sablé-Meyer, L. Morales, L. Hewitt, L. Cary, A. Solar-Lezama, and J. B. Tenenbaum. Dreamcoder: Bootstrapping inductive program synthesis with wake-sleep library learning. In Proceedings of the 42nd acm sigplan international conference on programming language design and implementation, pages 835–850, 2021.
- Engstrom et al. [2019] L. Engstrom, B. Tran, D. Tsipras, L. Schmidt, and A. Madry. Exploring the landscape of spatial robustness. In International conference on machine learning, pages 1802–1811. PMLR, 2019.
- Eslami et al. [2016a] S. Eslami, N. Heess, T. Weber, Y. Tassa, D. Szepesvari, K. Kavukcuoglu, and G. E. Hinton. Attend, infer, repeat: Fast scene understanding with generative models. arXiv preprint arXiv:1603.08575, 2016a.
- Eslami et al. [2016b] S. M. A. Eslami, N. Heess, T. Weber, Y. Tassa, D. Szepesvari, K. Kavukcuoglu, and G. E. Hinton. Attend, infer, repeat: Fast scene understanding with generative models, 2016b.
- Fodor and Pylyshyn [1988] J. A. Fodor and Z. W. Pylyshyn. Connectionism and cognitive architecture: A critical analysis. Cognition, 28(1-2):3–71, 1988.
- Geirhos et al. [2019] R. Geirhos, P. Rubisch, C. Michaelis, M. Bethge, F. A. Wichmann, and W. Brendel. Imagenet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. In International Conference on Learning Representations, 2019.
- Goyal and Bengio [2020] A. Goyal and Y. Bengio. Inductive biases for deep learning of higher-level cognition. CoRR, abs/2011.15091, 2020. URL https://arxiv.org/abs/2011.15091.
- Goyal and Bengio [2022] A. Goyal and Y. Bengio. Inductive biases for deep learning of higher-level cognition. Proc. A, Royal Soc., arXiv:2011.15091, 2022.
- Goyal et al. [2019] A. Goyal, A. Lamb, J. Hoffmann, S. Sodhani, S. Levine, Y. Bengio, and B. Schölkopf. Recurrent independent mechanisms. arXiv preprint arXiv:1909.10893, 2019.
- Goyal et al. [2020] A. Goyal, A. Lamb, P. Gampa, P. Beaudoin, S. Levine, C. Blundell, Y. Bengio, and M. Mozer. Object files and schemata: Factorizing declarative and procedural knowledge in dynamical systems. arXiv preprint arXiv: Arxiv-2006.16225, 2020.
- Goyal et al. [2021] A. Goyal, A. Didolkar, N. R. Ke, C. Blundell, P. Beaudoin, N. Heess, M. Mozer, and Y. Bengio. Neural production systems. arXiv preprint arXiv:2103.01937, 2021.
- Graves et al. [2016] A. Graves, G. Wayne, M. Reynolds, T. Harley, I. Danihelka, A. Grabska-Barwinska, S. G. Colmenarejo, E. Grefenstette, T. Ramalho, J. P. Agapiou, A. P. Badia, K. M. Hermann, Y. Zwols, G. Ostrovski, A. Cain, H. King, C. Summerfield, P. Blunsom, K. Kavukcuoglu, and D. Hassabis. Hybrid computing using a neural network with dynamic external memory. Nature, 538:471–476, 2016.
- Greff et al. [2017] K. Greff, S. van Steenkiste, and J. Schmidhuber. Neural expectation maximization, 2017.
- Greff et al. [2019] K. Greff, R. L. Kaufman, R. Kabra, N. Watters, C. Burgess, D. Zoran, L. Matthey, M. Botvinick, and A. Lerchner. Multi-object representation learning with iterative variational inference, 2019.
- Hafner et al. [2019] D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603, 2019.
- Hafner et al. [2020] D. Hafner, T. P. Lillicrap, M. Norouzi, and J. Ba. Mastering atari with discrete world models. In International Conference on Learning Representations, 2020.
- Hinton et al. [2006] G. E. Hinton, S. Osindero, and Y. W. Teh. A fast learning algorithm for deep belief nets. Neural Computation, 18:1527–1554, 2006.
- Hoel [2021] E. Hoel. The overfitted brain: Dreams evolved to assist generalization. Patterns, 2(5):100244, 2021.
- Hoshen and Werman [2017] D. Hoshen and M. Werman. Iq of neural networks. arXiv preprint arXiv:1710.01692, 2017.
- James [1936] C. James. Raven. mental tests used in genetic studies: The performance of related individuals on tests mainly educative and mainly reproductive. Unpublished master’s thesis, University of London, 1936.
- Kingma and Ba [2014] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Kolev et al. [2020] V. Kolev, B. Georgiev, and S. Penkov. Neural abstract reasoner. CoRR, abs/2011.09860, 2020. URL https://arxiv.org/abs/2011.09860.
- Kosiorek et al. [2018] A. R. Kosiorek, H. Kim, I. Posner, and Y. W. Teh. Sequential attend, infer, repeat: Generative modelling of moving objects, 2018.
- Lake et al. [2017] B. M. Lake, T. D. Ullman, J. B. Tenenbaum, and S. J. Gershman. Building machines that learn and think like people. Behavioral and brain sciences, 40, 2017.
- Li et al. [2020] Q. Li, S. Huang, Y. Hong, Y. Chen, Y. N. Wu, and S.-C. Zhu. Closed loop neural-symbolic learning via integrating neural perception, grammar parsing, and symbolic reasoning. In International Conference on Machine Learning, pages 5884–5894. PMLR, 2020.
- Lin et al. [2020] Z. Lin, Y.-F. Wu, S. Peri, B. Fu, J. Jiang, and S. Ahn. Improving generative imagination in object-centric world models. In International Conference on Machine Learning, 2020.
- Locatello et al. [2020] F. Locatello, D. Weissenborn, T. Unterthiner, A. Mahendran, G. Heigold, J. Uszkoreit, A. Dosovitskiy, and T. Kipf. Object-centric learning with slot attention. arXiv preprint arXiv: Arxiv-2006.15055, 2020.
- Mitchell [2021] M. Mitchell. Abstraction and analogy-making in artificial intelligence. Annals of the New York Academy of Sciences, 1505(1):79–101, 2021.
- Moskvichev et al. [2023] A. Moskvichev, V. V. Odouard, and M. Mitchell. The conceptarc benchmark: Evaluating understanding and generalization in the arc domain, 2023.
- Ostapenko et al. [2021] O. Ostapenko, P. Rodriguez, M. Caccia, and L. Charlin. Continual learning via local module composition. Advances in Neural Information Processing Systems, 34:30298–30312, 2021.
- Parascandolo et al. [2018] G. Parascandolo, N. Kilbertus, M. Rojas-Carulla, and B. Schölkopf. Learning independent causal mechanisms. In International Conference on Machine Learning, 2018.
- Pearl [2009] J. Pearl. Causality: Models, Reasoning and Inference. Cambridge University Press, 2nd edition, 2009.
- Reed and De Freitas [2015] S. Reed and N. De Freitas. Neural programmer-interpreters. arXiv preprint arXiv:1511.06279, 2015.
- Ruis and Lake [2022] L. Ruis and B. Lake. Improving systematic generalization through modularity and augmentation. arXiv preprint arXiv:2202.10745, 2022.
- Spelke [2000] E. S. Spelke. Core knowledge. American psychologist, 55(11):1233, 2000.
- Stelzner et al. [2019] K. Stelzner, R. Peharz, and K. Kersting. Faster attend-infer-repeat with tractable probabilistic models. In International Conference on Machine Learning, 2019.
- Su et al. [2019] J. Su, D. V. Vargas, and K. Sakurai. One pixel attack for fooling deep neural networks. IEEE Transactions on Evolutionary Computation, 23(5):828–841, 2019.
- van Steenkiste et al. [2018] S. van Steenkiste, M. Chang, K. Greff, and J. Schmidhuber. Relational neural expectation maximization: Unsupervised discovery of objects and their interactions, 2018.
- van Steenkiste et al. [2019] S. van Steenkiste, K. Greff, and J. Schmidhuber. A perspective on objects and systematic generalization in model-based RL. CoRR, abs/1906.01035, 2019. URL http://arxiv.org/abs/1906.01035.
- Webb et al. [2022] T. Webb, K. J. Holyoak, and H. Lu. Emergent analogical reasoning in large language models. arXiv preprint arXiv:2212.09196, 2022.
- Webb et al. [2020] T. W. Webb, I. Sinha, and J. D. Cohen. Emergent symbols through binding in external memory. arXiv preprint arXiv:2012.14601, 2020.
- Zhang et al. [2019] C. Zhang, F. Gao, B. Jia, Y. Zhu, and S.-C. Zhu. Raven: A dataset for relational and analogical visual reasoning. In Conference on Computer Vision and Pattern Recognition, 2019.
Appendix A Arith-MNIST
Arith-MNIST is composed of different splits of varying difficulty in terms of the number of primitive concepts that compose the tasks at hand, the number of total tasks, and the number of examples per task. Each task in the dataset has the same template and consists of a sequence of arithmetic operations applied in a particular order. Each operation and condition to select an argument is sampled from a set of pre-defined concepts. In Table 4 and Table 5 we detail the meaning of all the primitive selection conditions and operations we consider. Since all the tasks share the same template (e.g. ORDER - OPERATIONS), our benchmark is easily extendable to more tasks.
Splits.
We construct the different splits by selecting: a set of primitive concepts and the number of training tasks. The number of training tasks is given by the number of operations-conditions that we consider. For each of the splits, we fix independently a number of operation sequences, and a number of condition sequences. The exact sequences are then sampled at random among all possible sequences. The test splits are then composed of those held-out sequences. In Table 6 we describe the compositions of the splits we consider in our evaluations. For example, in the easy dataset the sequences of operations seen during training are: (add, sub), (add, add),(sub, sub), (add), (sub) and the left-out operation sequence is (sub, add). The training sequence is (left, right,bottom).
| Conditions | Meaning |
|---|---|
| position(X) | Select the digit at position X. X can be left, right or bottom |
| max | Select the digit with the maximum value. (Default order = left, right, bottom) |
| min | Select the digit with the minimum value. (Default order = left, right, bottom) |
| Operations | Meaning |
|---|---|
| add(X,Y) | X + Y. X and Y are the digits values. |
| sub(X,Y) | X - Y. X and Y are the digits values. |
| or(X,Y) | Take the value of (binary(X) OR binary(Y)). |
| xor(X,Y) | Take the value of (binary(X) XOR binary(Y)). |
| cat(X,Y) | X*10 + Y. X and Y are the digits value. |
| invcat(X,Y) | Y*10 + X. X and Y are the digits value. |
| Dataset | Primitives | of Training Sequences | Dataset size | ||
|---|---|---|---|---|---|
| conditions | operations | of conditions sequences | of operations sequences | ||
| Easy | position | add, sub | 1 | 5 | 5000 |
| Medium | position, max, min | add, sub, or, xor, cat, invcat | 5 | 30 | 30000 |
| Hard | position, max, min | add, sub, or, xor, cat, invcat | 55 | 36 | 30000 |
| Percep | position | add, sub | 1 | 5 | 5000 |
Appendix B OC-NMN and Compositional Imagination
Here we describe the training details of the compositional imagination framework. We give in Algorithm 1 the steps of the compositional imagination training. We noticed that good out-of-distribution generalization within this framework was very sensitive to a number of hyperparameters: the most crucial ones were the use of gumbel-softmax in the selection bottleneck, a warm-up phase without imagination, and the learning rate warm-up. We show in LABEL:fig_:abla the effects of the identified important hyperparameters.
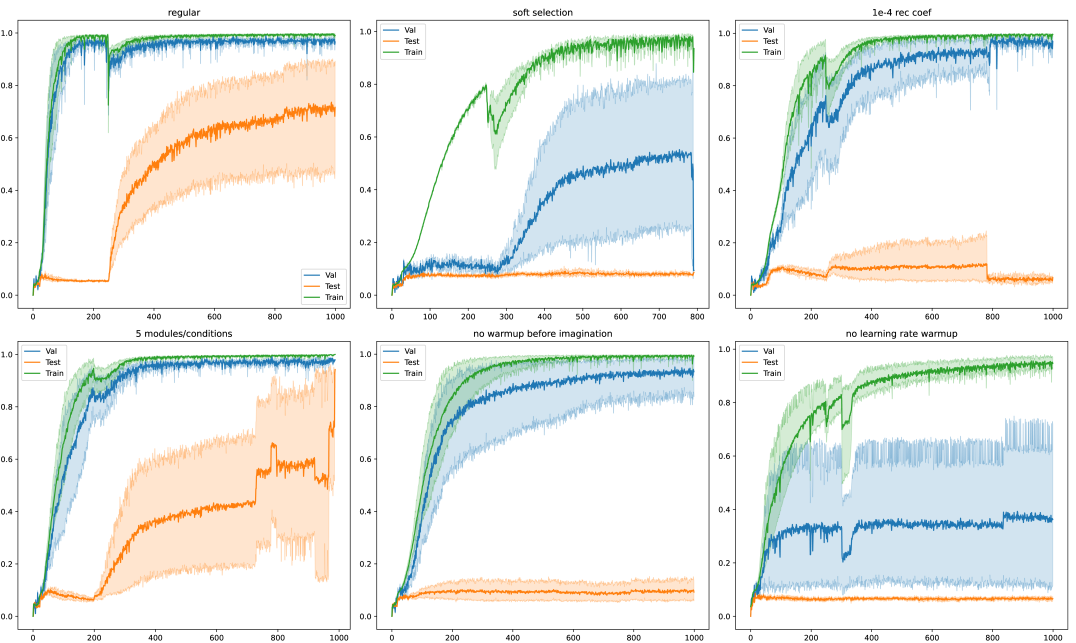
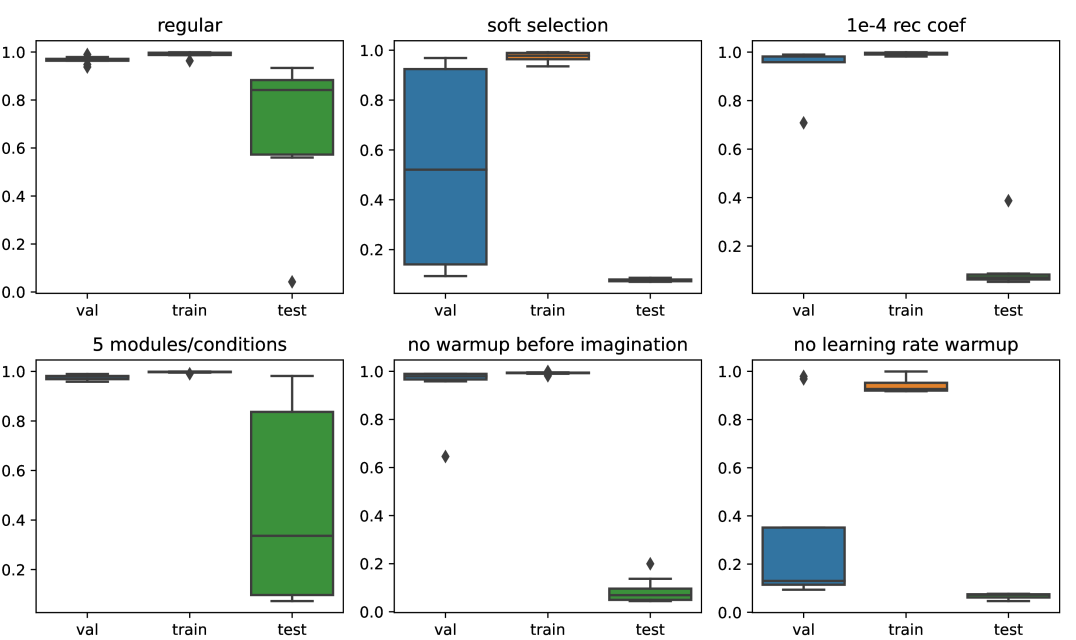
Ablation Study.
We conduct an ablation study of OC-NMN on the easy split to highlight the important hyperparameters of the training that made the compositional imagination framework get good compositional generalization performance. We notice that the use of gumble-softmax and a warm-up period before the imagination loss is introduced is crucial for pushing the selection to be discrete. The coefficient in front of the image reconstruction objective is also important, as it speeds up the training. We also notice that the learning rate warm-up prevents a collapse mode, in which many seeds simply overfit the training set and would require more regularization. See Figures 5 and 6.
Selection Bottleneck.
The selection bottleneck selects an argument and a module that will update the working memory at each time-step. Here, we give more explanation behind the design of this module, especially the argument selection mechanism. The selection bottleneck uses a condition vector to compare it against the candidate slot arguments with a dot product attention mechanism. However, some conditions (e.g. max, min) require knowledge of other objects in the scene. For that reason, we included an optional stack of 4 self-attention layers before the dot product is applied to the candidate input slots. We use these self-attention layers only for the hard split.
Appendix C Training and Models Hyperparameters
In this section, we details of the hyperparameters of the models we considered in our evaluation.
Perception Model.
All the models share the same perception model, which is Slot Attention. For this module, we keep the hyperparameters suggested in the original paper, with latent slot size of , maximum of slots and different Gaussian parameters per slot to sample the initial guess.
Controller.
We did not try to optimize the controller architecture. We base our model on the Neural Abstract Reasoner Controller [Kolev et al., 2020] and only modify the number of layers of the Differentiable Neural Computer and the perception module to better fit it to an object-centric setting like ours. For all models, we perform hyperparameter search to select the best architecture for each split. In Table 7 we detail the hyperparameters selected for the DNC-based controller for all the models and splits.
| Hyperparameter/Module | Value | Meaning |
|---|---|---|
| 512 | Hidden dimmension of LSTM | |
| 6 | Number of LSTM layers | |
| Memory size of DNC | ||
| 16 | Number of read heads | |
| GRU | GRUCell(64,64) | GRU that transforms the last output of the DNC to a sequence of instructions |
| NAR Executor | ||
|---|---|---|
| Hyperparameter/Module | Value | Meaning |
| Number of layers in executor | ||
| = 4 (easy split), = 16 ( medium and hard splits) | Number of attention heads in each layer | |
| , | 128, 128 | input dimension, output dimension of attention layers. |
| 128 | residual MLP hidden dimension | |
| 64 | slot dimension | |
| MLP(256,128) | MLP that transforms input scene representation | |
| MLP(128, num bits) followed by sigmoid | MLP that makes the final prediction | |
| num | 11 | Number of binary bits to represent the answer |
| DNC-Transformer Executor | ||
| Number of layers in executor | ||
| = 6 | Number of attention heads in each layer | |
| , | 128, 128 | input dimension, output dimension of attention layers. |
| 128 | residual MLP hidden dimension | |
| 64 | slot dimension | |
| MLP(64,128) | MLP that transforms each slot representation | |
| MLP(128, num bits) followed by sigmoid | MLP that makes the final prediction | |
| num | 11 | Number of binary bits to represent the answer |
| DNC-GRU Executor | ||
| Hyperparameter/module | Value | Meaning |
| 4 | Maximum number of updates | |
| MLP(128, 1) followed by sigmoid | MLP that predicts the update gate | |
| GRU | GRUCell(256, 256) | GRU Cell that updates the hidden working memory |
| 256 | Working memory dimension | |
| 64 | slot dimension | |
| MLP(256,128) | MLP that transforms the input scene representation | |
| MLP(128, num bits) followed by sigmoid | MLP that makes the final prediction | |
| num | 11 | Number of binary bits to represent the answer |
| OC-NMN Executor | ||
| Hyperparameter | Value | Meaning |
| 2 (easy) 4 (medium, hard splits) | Maximum number of updates | |
| MLP(64,64) | MLP that transforms each slot representation to be used by the executor | |
| GRU module | GRUCell(64,64) | Module in the learnt module library |
| Param() | Learnt conditions queries for the argument selection. | |
| MLP query | MLP(64,64) | MLP to extract keys from the slot for the argument selection. |
| MLP(64, 1) followed by sigmoid | MLP that predicts the update gate | |
| MLP(64, num bits) followed by sigmoid | MLP that makes the final prediction | |
| num | 11 | Number of binary bits to represent the answer |
C.1 Executor Modules
We describe here the different executor modules along with their hyperparameters. All the hyperparameter values are listed in Table 8.
NAR.
The NAR executor is composed of a stack of layers composed of a self attention and a cross-attention step. The self-attention is performed on the set of support and query input representations. Let denote the concatenation of the support and query input representation (e.g. concatenated object-centric slots for each scene representation), the output from the controller, and the multi head dot product attention operation over queries , keys , and values followed by a residual MLP layer. The output of a layer in the NAR executor corresponds to:
| (6) | ||||
| (7) | ||||
| (8) | ||||
| (9) |
The NAR executor consists of a stack of a layers described above. The final output is taken from the token that corresponds to the query position.
DNC-GRU.
The DNC-GRU executor corresponds to the non-modular version of our OC-NMN. It does not have any selection bottleneck and is composed of a single GRU cell that performs a sequential update of working memory from which the final answer is retrieved. Let denote the working memory at time step , the output from the controller and the query input representations. The working memory at time-step is updated as follows:
| (10) |
where corresponds to an update gate that controls the number of updates performed to the working memory in a soft way.
DNC-Transformer.
Let denote the set of object-centric slot representation of the input query and the output from the controller. The DNC-Transformer executor consists of a stack of transformer layers that is performed over the set composed of the inputs slots, a CLS token, and the output of the controller . The final result is retrieved from the CLS token at the end of stack.
C.2 Training
Unsupervised pretraining.
All models are trained with the same Slot Attention perception module. This perception module is pretrained with the same hyperparameters described in the original Slot Attention article [Locatello et al., 2020] with a maximum of slots and different learned Gaussian parameter per slot. In our setting, we found that at the end of the pretraining phase, each slot corresponds to a fixed position in the image (left, right, or bottom).
Supervised training.
After pretraining, the slot attention module weights are loaded and trained along with the rest of the model. In order to keep the object-centric property for the remainder of the training, we add the same reconstruction loss that was used for the pretraining weighted by . All the models are trained with an Adam optimizer [Kingma and Ba, 2014] with a learning rate of and a batch size of . In the compositional imagination experiments, we found that using a learning rate warm-up of 20 epochs helps the model not to collapse.
OC-NMN optimization hyperparameters.
As shown by the ablations in Appendix B, OC-NMN is sensitive to a couple of hyperpermaters in the compositional imagination setting. We list them in Table 9.
| Hyperparameter | Value | Meaning |
|---|---|---|
| 250 | Number of epochs without imagination loss | |
| 20 | Number of epochs of linear learning rate warm-up | |
| 50 | Imagination coefficient | |
| Image reconstruction coefficient | ||
| 3 | Gumbel-Softmax Temperature | |
| lr | Learning rate |
Appendix D GPT-4 Experiments
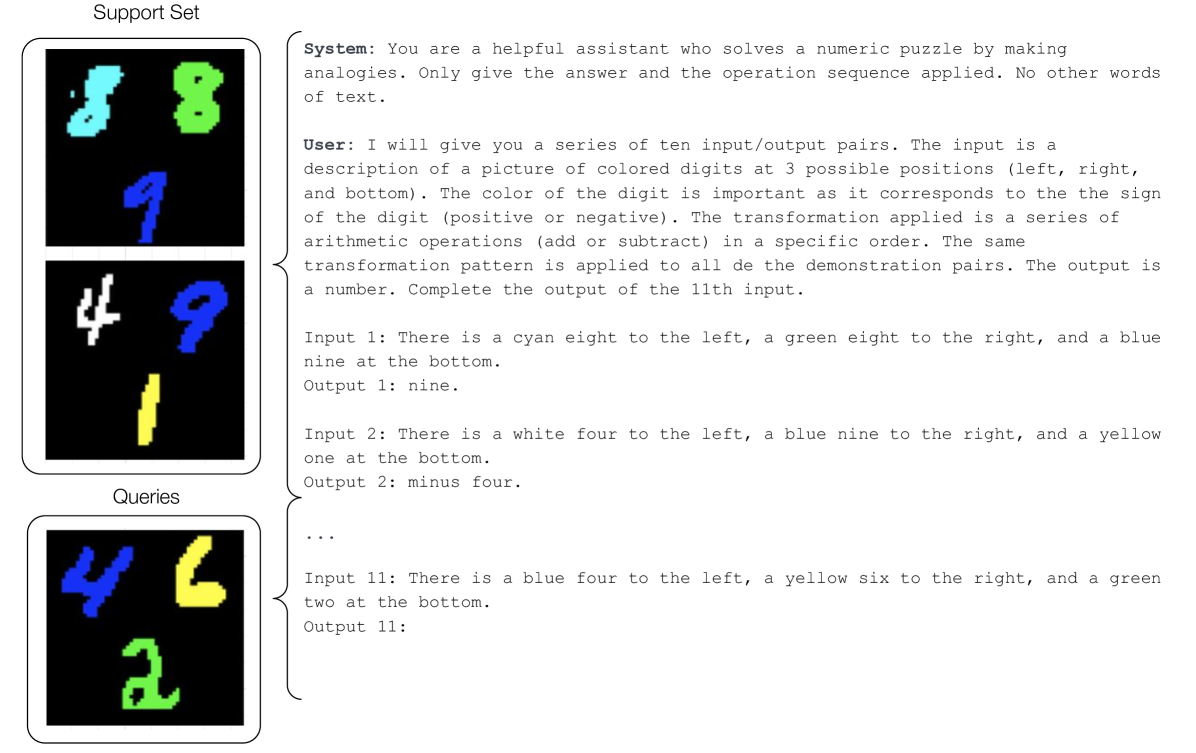
Inspired by the growing interest in large language models and their analogical reasoning capabilities [Webb et al., 2022], we test GPT-4 on a subset of the tasks in Arith-MNIST. GPT-4 is a multi-modal AI system created by OpenAI and is known to have zero-shot reasoning capabilities on a wide range of tasks [Webb et al., 2020]. Since we test on the language-only version of GPT-4, we convert the visual input of Arith-MNIST into a textual description of what is seen in the image. We then use the API provided by OpenAI to prompt GPT-4 using its “system” and “user” components to introduce the problem setup and pass on the individual task descriptions. We use a prompt structure similar to [Moskvichev et al., 2023], although we give the model some more context and information about the problem. We test GPT-4 on 100 samples from the easy split. See Figure 7.
The accuracy of GPT-4 on the 100 easy samples from Arith-MNIST is 11% when we consider only the output number (ignoring the predicted sequence of operations). In only 4% of cases, GPT-4 could correctly predict the sequence of operations that would generate the correct answer.
In an attempt to improve GPT-4 performance, we experimented with different prompts having different levels of granularity: giving one full example in the initial prompt, providing a step-by-step guide to the solution, asking GPT-4 to explain its reasoning for each sample solution. The best test result we obtained was 16% on the same test samples.
Appendix E Comparison with Neural Module Networks