2021
[2]\fnmKai \surLiu
1]\orgdivDepartment of Computer Science, \orgnameCity University of Hong Kong, \orgaddress\cityHong Kong, \countryChina
[2]\orgdivDepartment of Infectious Diseases and Public Health, \orgnameCity University of Hong Kong, \orgaddress\cityHong Kong, \countryChina
3]\orgdivDepartment of Production Animal Health, Faculty of Veterinary Medicine, \orgnameUniversity of Calgary, \orgaddress\cityCalgary, \stateAlberta, \countryCanada
4]\orgdivSwine Teaching and Research Center, School of Veterinary Medicine, \orgnameUniversity of Pennsylvania, \orgaddress\cityKennett Square, \statePennsylvania, \countryUSA
Occlusion-Resistant Instance Segmentation of Piglets in Farrowing Pens Using Center Clustering Network
Abstract
Computer vision enables the development of new approaches to monitor the behavior, health, and welfare of animals. Instance segmentation is a high-precision method in computer vision for detecting individual animals of interest. This method can be used for in-depth analysis of animals, such as examining their subtle interactive behaviors, from videos and images. However, existing deep-learning-based instance segmentation methods have been mostly developed based on public datasets, which largely omit heavy occlusion problems; therefore, these methods have limitations in real-world applications involving object occlusions, such as farrowing pen systems used on pig farms in which the farrowing crates often impede the sow and piglets. In this paper, we adapt a Center Clustering Network originally designed for counting to achieve instance segmentation, dubbed as CClusnet-Inseg. Specifically, CClusnet-Inseg uses each pixel to predict object centers and trace these centers to form masks based on clustering results, which consists of a network for segmentation and center offset vector map, Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm, Centers-to-Mask (C2M), and Remain-Centers-to-Mask (RC2M) algorithms. In all, 4,600 images were extracted from six videos collected from three closed and three half-open farrowing crates to train and validate our method. CClusnet-Inseg achieves a mean average precision (mAP) of 84.1 and outperforms other methods compared in this study. We conduct comprehensive ablation studies to demonstrate the advantages and effectiveness of core modules of our method. In addition, we apply CClusnet-Inseg to multi-object tracking for animal monitoring, and the predicted object center that is a conjunct output could serve as an occlusion-resistant representation of the location of an object.
keywords:
Precision livestock farming, Deep learning, Computer vision, Animal monitoring, Farrowing crate1 Introduction
The behavior, health, and welfare of animals are attracting increasing attention, and an assessment of these factors often requires long-term monitoring. However, manual observation and recording over long periods is time-consuming and labor-intensive; therefore, an automated, sensor-based system is required. Owing to their low-cost operation and non-intensive requirements, computer vision systems have been widely used to monitor various animal species such as cattle (Chen et al, 2021), broiler chickens (Liu et al, 2021), goats (Wang et al, 2018), fish (White et al, 2006), and pigs (Gan et al, 2021). Although these computer vision tools capture a large number of videos and images, the analysis of these digital data remains a challenge.
For the analysis of animals in videos or images, a common practice is to first detect individual objects in each image (e.g., representative pixels of each object and the corresponding location of the object) and to then extract other information such as the posture and movement of an object in a video. Three detection methods and the corresponding representations are usually used: object detection with bounding boxes, keypoint detection with keypoints, and instance segmentation with masks. In instance segmentation, each distinct object of interest in an image is delineated by using masks, and objects can be assigned to different classes with pixel-level accuracy, thus narrowing the gap between the large bounding boxes in object detection and the sparse keypoints in target representation; this method has considerable potential for use in animal monitoring (Brünger et al, 2020).
Instance segmentation has been used in several animal monitoring applications in which instance segmentation of individual animals is required. For example, using instance segmentation, pixels corresponding to a sow were identified so that its body length and withers height could be extracted to estimate its body weight (Shi et al, 2016). Instance segmentation masks were used to generate eigenvectors, which were then used by a kernel extreme learning machine to identify pig mounting behavior (Li et al, 2019). Instance segmentation was used as a key preprocessing step in the selection of regions of a pig for automatic weight measurement of the pig (He et al, 2021a). Instance segmentation with multi-object tracking was used to reduce the variance in the predicted weight of pigs (He et al, 2021b). Nevertheless, these applications limited to large-size pigs and with no heavy occlusion. Therefore, the application of instance segmentation in farrowing pen remains to be verified.
Deep-learning-based methods have emerged as the predominant choice in instance segmentation due to their high accuracy and ability to automatically extract target features. For example, Mask R-CNN was a representative two-stage instance segmentation method that it generated region-of-interests (ROIs) in the first stage and then segmented these ROIs in the second stage to achieve instance segmentation (He et al, 2017). Generally, these two-stage instance segmentation methods are unable to obtain real-time speeds (30 FPS), e.g., PANet (Liu et al, 2018) and Mask Scoring R-CNN (Huang et al, 2019). In contrast, YOLACT++ was a representative one-stage instance segmentation approach that it generated a set of prototype masks and then combined them using per-instance mask coefficients to achieve instance segmentation (Bolya et al, 2020). Other one-stage instance segmentation method includes CenterMask (Lee and Park, 2020), SOLO (Wang et al, 2020a), and PolarMask (Xie et al, 2020).
However, most of the deep-learning-based methods for instance segmentation were developed using public datasets (e.g., Microsoft COCO; (Lin et al, 2014)). When these methods are used to monitor animals in commercial production settings, many scenarios may arise that are seldom featured in public datasets, such as frequently occurring occlusions. For instance, in pig farrowing pens, farrowing crates are widely used to restrict the movement of sows in order to reduce piglet mortality (Moustsen et al, 2013; Johnson and Marchant-Forde, 2009). These farrowing crates introduce inevitable visual occlusions into the images and videos captured by computer vision systems. Such occlusions have non-negligible consequences for piglet due to piglets’ small size (e.g., only the head of a piglet may be visible while the other parts of the animal are occluded by farrowing crates). Huang et al (2021b) found that occlusions occurred in 97.7% of the images collected from farrowing pens with farrowing crates. These unexpected occlusions may decrease the accuracy and even cause the failure of deep-learning-based methods (Huang et al, 2021a). For example, there are three common types of detection errors due to occlusion: (1) Duplicate detection (Fig. 1a, by Blendmask (Chen et al, 2020)), where two or more duplicate detections overlap on a single object which is separated by occlusions; (2) Wrong association detection (Fig. 1b, by Mask R-CNN (He et al, 2017)), where a disconnected part of a body (e.g., a head) is wrongly associated to another adjacent target; (c) Incomplete detection (Fig. 1c, by HoughNet (Samet et al, 2020)), where some parts of the body are missed in the detection due to occlusions. Therefore, it is essential to develop a deep-learning-based instance segmentation method that can address occlusion problems.

This study aims to develop a novel occlusion-resistant instance segmentation method for piglets in farrowing pens with frequently occurring occlusions. We propose CClusnet-Inseg, a Center Clustering Network for instance segmentation, based on a previous object-counting model called Center Clustering Network (CClusnet-Count; (Huang et al, 2021b)). CClusnet-Count is designed for object counting, which predicts scatter object centers, and ends with the group number determined by the Mean-shift algorithm. We adapt this model to achieve instance segmentation. Our main contributions are summarized as follows:
-
[1.]
-
1.
We adapt a Center Clustering Network to a new framework for instance segmentation (CClusnet-Inseg) in farrowing pens. We change the original Mean-shift algorithm to a faster Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm, add a Centers-to-Mask (C2M) step, and further add a Remain-Centers-to-Mask (RC2M) step to fully use every pixel to form masks. CClusnet-Inseg is an anchor-free method with a high utilization of visible pixels in an image, and thus could manage heavy occlusion problems and outperform other instance segmentation methods.
-
2.
We predict a unique object center along with instance segmentation for piglets. This predicted object center can be an occlusion-resistant representation of the object’s location even when an object is largely occluded.
-
3.
We apply our method to multi-object tracking as a potential application for animal monitoring, and generate further animal characterizations including animal movement, trajectory, average speed, body pixel size, space usage, and spatial distribution. We demonstrate the limit of general instance segmentation and the necessity of our occlusion-resistant object center for animal monitoring under occlusion.
2 Materials and methods
2.1 Data
The data was from a previously published study (Ceballos et al, 2020) conducted at the Swine Teaching and Research Center, University of Pennsylvania School of Veterinary Medicine, United States, where 39 lactating sows and their offspring (Line 241; DNA Genetics, Columbus, NE) were initially used. All animal procedures in the previous study were approved by the University of Pennsylvania’s Institutional Animal Care and Use Committee (Protocol #804656). Six top-view videos collected from 6:00 to 18:00 in June 2018 were selected for the development of the method in the current study (Tables 1). The six videos, with a frame rate of 7 FPS and a resolution of 1024×768 pixels, were captured by overhead cameras located 2 m above the farrowing crates. Six datasets, containing 4,600 images in total, were extracted from the six videos and labeled for piglet centers, individual piglet masks, and sow masks (Huang et al, 2021b). Datasets 1, 2, and 3 contained data from pens with half-open farrowing crates, and Datasets 4, 5, and 6 contained data from pens with closed crates (Fig. 2). Each video included one sow, and the number of visible piglets varied from 7 to 17 (an average of 11.4).
Two types of partial occlusion on piglets were defined: body-separated occlusion (BSO) and part-missing occlusion (PMO) (Huang et al, 2021b). In BSO, the occlusions (e.g., occlusions from farrowing crates) separated a target into two or more parts, whereas in PMO, a terminal part of a target (e.g., the head of a piglet) was occluded. The statistical summary showed that on an average, 3.7 piglets were affected by BSO, 4.2 piglets were affected by PMO, and 1.7 piglets were affected by both BSO and PMO per image. BSO occurred in 95.4% of the images, and PMO occurred in 92.3% of the images. Piglets were completely occluded (e.g., occluded by the sow, sow feeder, and farrowing crates) in 19.1% of the images. Overall, 98.7% of the images had at least one type of partial occlusion (BSO or PMO).

| Description111BSO, body-separated occlusion; PMO, part-missing occlusion; NA, not available. | Dataset 1222Four piglets were removed from the pen due to low vitality or death. | Dataset 2 | Dataset 3 | Dataset 4 | Dataset 5333One piglet was removed from the pen due to low vitality or death. | Dataset 6 | Total |
|---|---|---|---|---|---|---|---|
| Number of days after farrowing | 5 | 5 | 5 | 4 | 5 | 5 | NA |
| Farrowing crates | Half-open | Half-open | Half-open | Closed | Closed | Closed | NA |
| Images extracted | 1,100 | 1,000 | 1,000 | 500 | 500 | 500 | 4,600 |
| Visible piglets444Per image, values in parentheses represent the average. | 7–13 (8.9) | 7–9 (8.9) | 7–13 (12.6) | 10–17 (16.0) | 11–17 (15.6) | 9–11 (10.9) | 7–17 (11.4) |
| Piglets affected by BSO444Per image, values in parentheses represent the average. | 0–6 (2.0) | 0–7 (2.9) | 0–9 (4.4) | 0–12 (4.2) | 0–13 (6.4) | 0–10 (4.0) | 0–13 (3.7) |
| Piglets affected by PMO444Per image, values in parentheses represent the average. | 0–5 (1.4) | 0–7 (2.3) | 0–11 (5.7) | 2–16 (8.1) | 2–13 (7.2) | 0–11 (4.4) | 0–13 (4.2) |
| Piglets affected by both BSO and PMO444Per image, values in parentheses represent the average. | 0–4 (0.8) | 0–5 (0.9) | 0–7 (1.9) | 0–9 (2.8) | 0–8 (3.3) | 0–9 (2.5) | 0–9 (1.7) |
| Images with BSO | 87.0% | 98.3% | 99.4% | 95.4% | 99.4% | 96.2% | 95.4% |
| Images with PMO | 78.0% | 89.7% | 99.7% | 100.0% | 100% | 98.8% | 92.3% |
| Images with complete occlusion | 9.6% | 8.3% | 24.7% | 52.4% | 29.6% | 6.2% | 19.1% |
| Images with partial occlusion (BSO or PMO) | 94.8% | 99.7% | 100.0% | 100.0% | 100.0% | 99.8% | 98.7% |
2.2 CClusnet-Inseg
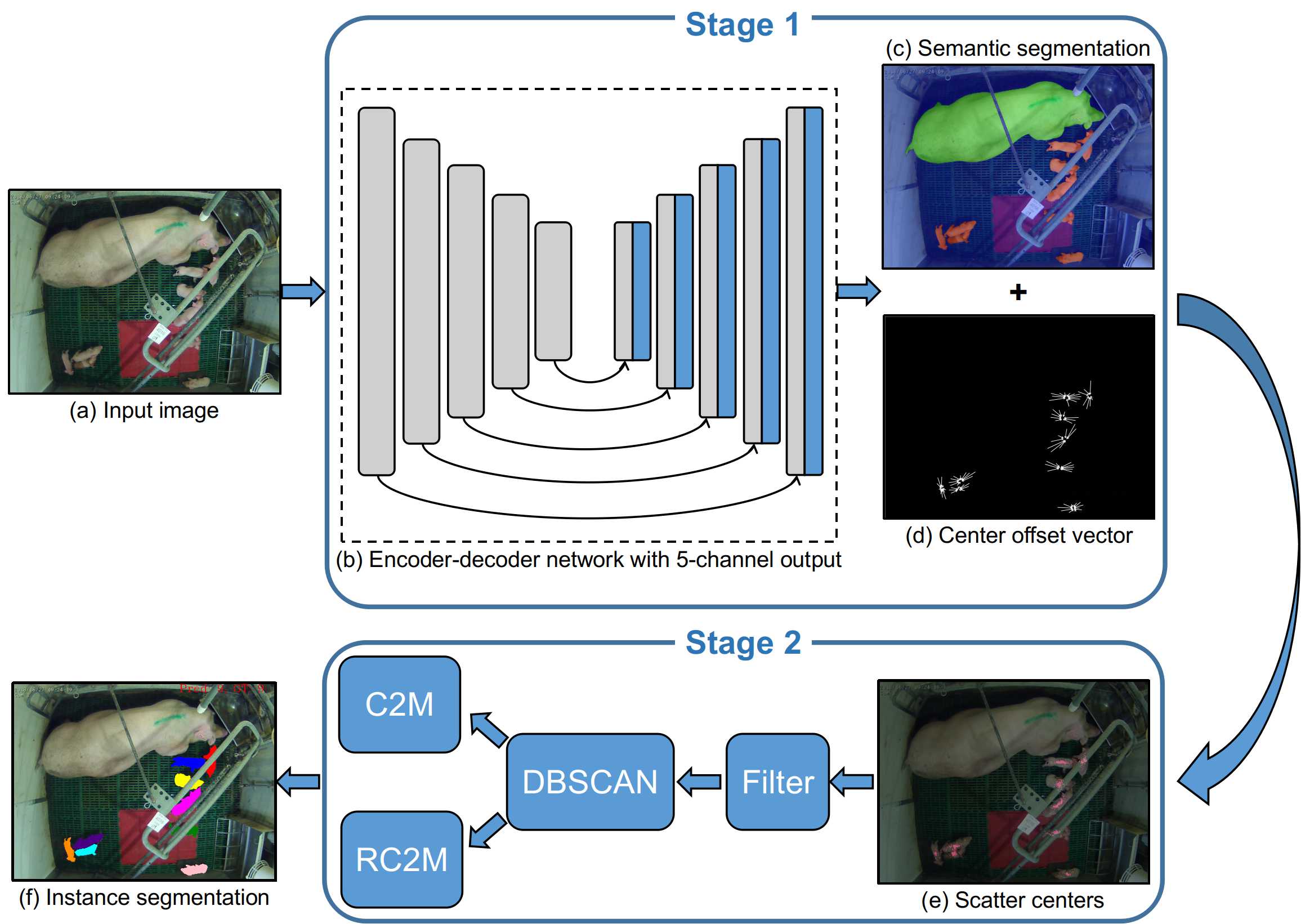
Overview. The flow of CClusnet-Inseg is as follows: First, we feed an input image to an encoder–decoder network (Figs. 3b and 4); the network generates a semantic segmentation map (Fig. 3c) and a center offset vector map (Fig. 3d) as output. For each pixel belonging to a piglet, a center point is predicted using its corresponding offset vector, and thus we obtain scatter center points (Fig. 3e). In the second stage, we filter these predicted scatter center points to eliminate outliers (Eq. 6 in (Huang et al, 2021b)) and then we cluster them into different groups through the DBSCAN algorithm (Ester et al, 1996). After the clustering, a C2M step traces these clustered center points back to their original pixels, and original pixels whose center points are in the same group form a mask of an instance. As some centers are filtered or clustered as noise in the DBSCAN algorithm, we perform a RC2M step to further cluster these centers and trace them back to their original pixels in the same manner as in the C2M step.
2.2.1 Network structure and loss function
Our encoder–decoder network (Fig. 3b) structure, which is adapted from CClusnet-Count (Huang et al, 2021b), is shown in Fig. 4. The input image is resized to pixels and then fed to the network. Two separate heads, with two convolutional layers for semantic segmentation and four convolutional layers for the generation of the center offset vector, are attached at the end of the network. For the semantic segmentation task, the focal loss (Lin et al, 2017) is defined as
| (1) |
where
| (2) |
and is the number of pixels. is the class weight for different classes, and and are the predicted and true class probability vectors, respectively, for each pixel is a focusing parameter that forces the model to focus on difficult examples.For the center offset vector generation task, the loss function is defined as
| (3) |
where and are the ground truth and predicted displacement matrices, respectively, and is the binary mask of the piglet based on the semantic segmentation map, where 1 indicates that a pixel belongs to the piglet, and 0 indicates that it does not. The operation is the Hadamard product-the element-wise product of two matrices.
The final loss is
| (4) |
where and are the weights of and , respectively. The main difference between the network structures of CClusnet-Inseg and CClusnet-Count is that CClusnet-Inseg consists of two separate convolutional layers in two heads, as these heads perform different functions.
2.2.2 Centers-to-Mask (C2M) and Remain-Centers-to-Mask (RC2M)
After the semantic segmentation map and center offset map are produced in the stage 1 (Fig. 3), the scatter center points are generated as
| (5) |
where is the pixel set belonging to piglets in the semantic segmentation map and is the corresponding offset vector set in the center offset map. The DBSCAN algorithm is applied to these scatter center points to cluster them into different groups, and then the C2M step traces the clustered center points back to their original pixels in order to achieve instance segmentation. The number of groups determined by the DBSCAN algorithm is denoted as . Each group is represented as
| (6) |
where is a function that maps a piglet pixel to its group ID. The group ID ranges from 0 to , where 0 means the group of points that are clustered as noise or filtered before the clustering algorithm.
The image consists of instances of piglets, which can be represented by binary mask matrices as:
| (7) |
where represents each pixel in the mask. As each image consisted of only one sow, the segmentation results for a sow could be directly used as instance segmentation results:
| (8) |
The above step is called C2M. However, as the DBSCAN algorithm clusters some center points as noise and some centers are filtered before the clustering algorithm, some center points remain without a valid group. For each existing group, the average of the points in each group is used as its cluster center:
| (9) |
where calculates the average location of the center points in a group. The remaining unclassified center points in the group can be updated using the nearest cluster centers as follows:
| (10) |
Therefore, we assign the group ID of the nearest cluster center to these unclassified center points. All of these unclassified center points are assigned a valid group ID. Then, the C2M step described above is performed to update the instance segmentation results. The step that uses the remaining unclassified centers to update the instance segmentation is called RC2M. The RC2M step does not affect the clustering but only the instance segmentation results.
2.3 Performance evaluation and comparison
The mean average precision (mAP), the most commonly used metric for instance segmentation, is used as the performance metric. To demonstrate and evaluate the performance of CClusnet-Inseg, we 1) perform an ablation study to determine the contributions and effects of each module—DBSCAN (compared with mean-shift as adopted in CClusnet-Count) and RC2M, and 2) compare it with six state-of-the-art instance segmentation methods—Mask R-CNN (He et al, 2017), SOLOv2 (Wang et al, 2020b), Blendmask (Chen et al, 2020), CondInst (Tian et al, 2020), YOLACT++ (Bolya et al, 2020), and HoughNet (Samet et al, 2020). The same training set and test set are used in all of the evaluations.
2.4 Applications of the method
To demonstrate the potential applications of our method in animal monitoring, we apply the instance segmentation of piglets directly in the implementation of multi-object tracking in farrowing pens, which provides a solid foundation for subsequent in-depth animal monitoring tasks such as the characterization of the spatiotemporal distribution patterns of piglets. We select a half-minute video clip, from the video used in the generation of Dataset 1 and in which piglets and the sow are active, as a sample video. CClusnet-Inseg detects each frame in the video clip and provides the instance segmentation results as output. For pairing objects between two consecutive frames, the Intersection-over-Union (IoU) is calculated and used as the single metric to determine whether two instances are the same. We determine the object pair that had the maximum IoU among unpaired objects between two consecutive frames and assign the same ID to these objects. Then, we repeat the process for the remaining unpaired objects until no object pairs can be found. The unpaired new object in the current frame is assigned a new ID, and the unpaired old object in the previous frame is removed.
From the multi-object tracking based on instance segmentation, we further extract six types of information—individual animal movement (accumulated movement in the video), trajectory, average speed, body pixel size, spatial usage, and spatial distribution. When generating animal movement, trajectory, and average speed, the predicted object center—a conjunct output of CClusnet-Inseg—is used to represent the location of an object. This predicted object center is valid even when an object is partially occluded. When calculating the body pixel size, the mean of the top five maximum mask areas of an object is used to exclude the case in which an object is partially occluded. To represent the spatial distribution, we generate a heat map by accumulating all of the pixels that an object had occupied in the video over its entire duration.
2.5 Experimental setup
All of the images from Datasets were used; they were randomly divided such that of the images were used as a training set, as a validation set, and as a test set. Thus, a training set of 2,760 images was constructed to train the model, which was validated and tested on a validation set and a test set that contained 920 images each. Image augmentations, such as rotation, flips, Gaussian blur, and pseudo-occlusion generation, were applied simultaneously to the training set during the training. The optimizer Adam (Kingma and Ba, 2014) with a learning rate of was chosen for training. The weight was set to (Eq. 4). The epoch was set to 300 iterations, and the batch size was set to 8. The three hyperparameters-threshold (Eq. 6 in Huang et al (2021b)), radius , and the minimum number of points in DBSCAN-were set to 20, 2.5, and 50, respectively, based on the best results from the validation set. All experiments were conducted using Pytorch on a single NVIDIA GeForce RTX 3090 GPU.
3 Results and discussion
3.1 Ablation study
To demonstrate the improvement and influence of each extension (i.e., DBSCAN and RC2M), an ablation study was conducted (Table 2). The results showed that the accuracy of the model using DBSCAN (82.8 mAP in Model 2) was improved than that of the model using mean-shift (81.1 mAP in Model 1), whereas the clustering speed of the model using DBSCAN (0.152 s/image) was approximately 20 times as fast as that of the model using mean-shift (2.846 s/image), leading to a faster total inference speed in the model using DBSCAN (0.229 s/image as against 2.939 s/image in the model using mean-shift). This difference in speed was mainly due to the algorithm itself, i.e., the time complexity of the DBSCAN algorithm is , which is less than that of the mean-shift algorithm, which is . The RC2M improved the instance segmentation accuracy by 1.3 mAP (an improvement from an mAP of 82.8 in Model 2 to 84.1 in Model 3) because it reused the unclassified center points. However, this step resulted in additional computations, and therefore, the inference time increased slightly by . Thus, the use of the RC2M involves a trade-off between speed and accuracy. Finally, when all these extensions were included, CClusnet-Inseg achieved an mAP of 84.1. Therefore, the inclusion of all extensions was used as the default setting for our method in the subsequent experiments.
| Model (clustering algorithm) | RC2M | mAP | Clustering Speed | Total Speed |
|---|---|---|---|---|
| 1. CClusnet-Inseg (mean-shift) | × | 81.1 | 2.846 s/image | 2.939 s/image |
| 2. CClusnet-Inseg (DBSCAN) | × | 82.8 | 0.152 s/image | 0.229 s/image |
| 3. CClusnet-Inseg (DBSCAN) | ✓ | 84.1 | 0.151 s/image | 0.234 s/image |
| \botrule |
3.2 Comparison with other methods
The results of the performance comparison of our method with other instance segmentation approaches are shown in Table 3. Houghnet, Mask R-CNN, SOLOv2, Blendmask, CondInst, and YOLACT++ achieved an mAP of 41.1, 74.4, 76.6, 79.8, 80.6, 80.9, respectively. CClusnet-Inseg outperformed these methods by achieving an mAP of 84.1.
for different instance segmentation methods
| Method | mAP | Speed |
|---|---|---|
| HoughNet (Samet et al, 2020) | 41.1 | 0.10 s/image |
| Mask R-CNN (He et al, 2017) | 74.4 | 0.06 s/image |
| SOLOv2 (Wang et al, 2020b) | 76.6 | 0.15 s/image |
| Blendmask (Chen et al, 2020) | 79.8 | 0.07 s/image |
| CondInst (Tian et al, 2020) | 80.6 | 0.09 s/image |
| YOLACT++ (Bolya et al, 2020) | 80.9 | 0.08 s/image |
| CClusnet-Inseg (Ours) | 84.1 | 0.23 s/image |
| \botrule |
The instance segmentation results of these methods applied on the test set were visualized (Fig. 5). The HoughNet showed a great error for the sow and even wrongly classified the piglet pixels with the bounding box of the sow as a part of the sow (Figs. 5a1, 5a2, and 5a5). Similarly, the Mask R-CNN also did not accurately detect the large sow object, as the method misclassified farrowing crates that occluded the sow as a part of the sow (Figs. 5b1-b4). YOLACT++ undetected some piglets in two cases (Figs. 5f2 and 5f5). SOLOv2, Blendmask, and CondInst all showed double detection of a single piglet in Fig. 5c1, Figs. 5d2 and 5d4-5d6, and Figs. 5e2-5e6, respectively. This happened especially when a piglet was separated into different parts for Blendmask (Fig. 5d6) and CondInst (Fig. 5e6). CClusnet-Inseg demonstrated better instance segmentation results than other methods. Even in the space between two farrowing crates, our method correctly detected the piglets (Fig. 5g3) and the sow (Fig. 5g2).

3.3 Extension to other applications
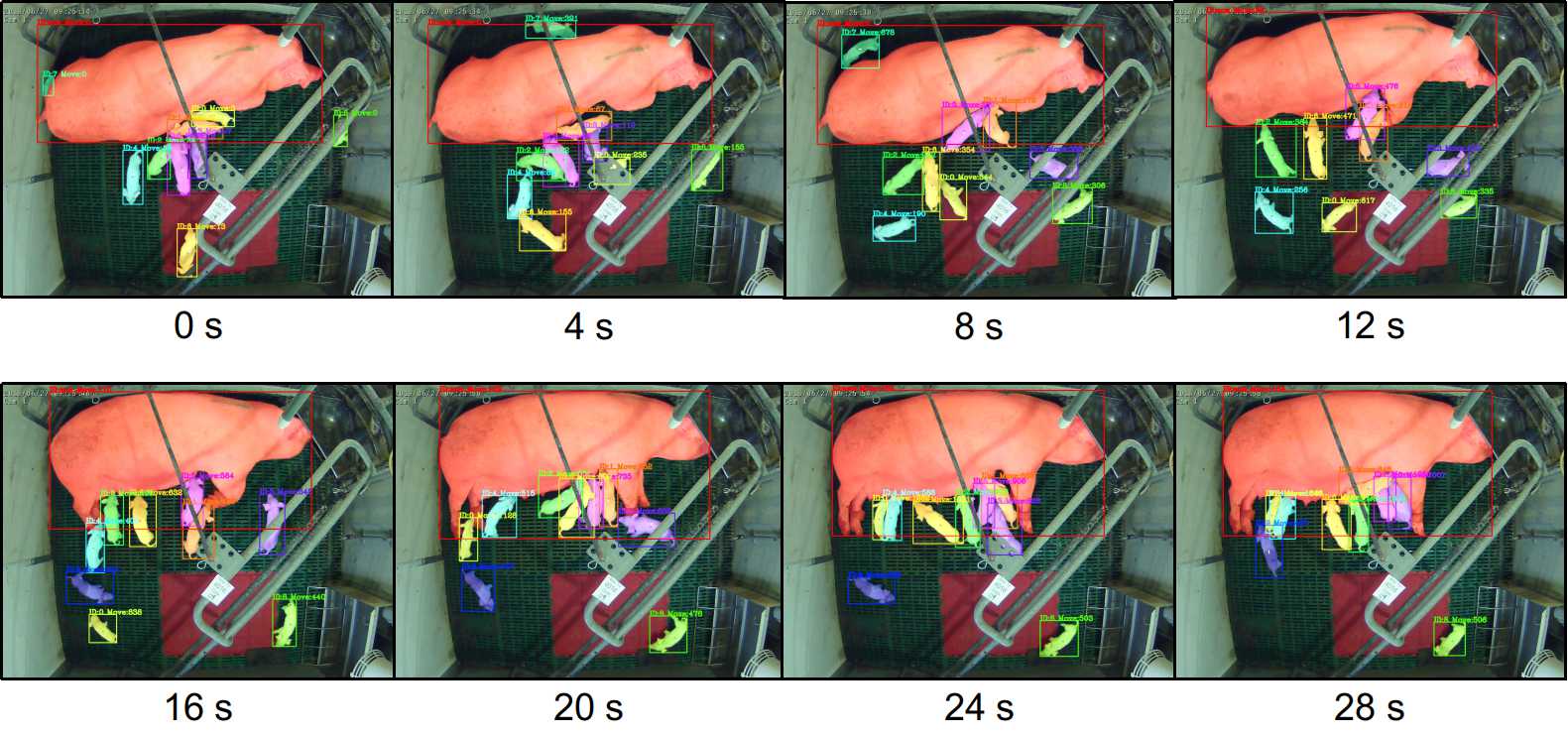
To demonstrate the potential applications of our method in animal monitoring, the instance segmentation results were directly applied to multi-object tracking. The video file is available in the Appendix and at https://www.samcityu.com/insegcclusnet. Screenshots from the video are shown in Fig. 6. From the video, it can be observed that due to its pixel-level accuracy, instance segmentation with IoU showed a small number of errors when pairing objects in consecutive frames, as long as the instance segmentation results were correct. The results of multi-object tracking produced six additional animal characterizations, i.e., trajectory (Fig. 7a), spatial distribution (Figs. 7b–e), movement, speed, body size, and space usage (Table 4) for individual objects.
The trajectory and spatial distribution with spatial usage could be used to estimate animal comfort, e.g., to determine whether sows make full use of the extra space resulting from opening the crates, and to determine whether the heat pad is effective based on its usage by the piglets (Fig. 2). The movement or average speed of an individual piglet could serve as a piglet vitality index and could be used as a warning of piglet mortality if a piglet does not show movement for a long period. This monitoring is especially important for piglets in the pre-weaning phase. The body pixel size could be used as an interim index for body size estimation and, thus, for body weight and growth estimation; however, the relationship needs further investigation.

| Object | Movement (pixel) | Average Speed (pixel/s) | Body Pixel Size (pixel) | Space Usage |
|---|---|---|---|---|
| Sow | 155 | 5.4 | 158,341 | 26.9% |
| Piglet (ID: 0) | 1,383 | 47.9 | 3,375 | 7.3% |
| Piglet (ID: 1) | 893 | 30.9 | 4,880 | 3.7% |
| Piglet (ID: 2) | 1,044 | 36.2 | 6,042 | 7.7% |
| \botrule |
Our proposed method is not an end-to-end method and consists of two stages to achieve instance segmentation. Consequently, one of the most critical limitations of our method is the low speed of instance segmentation in comparison with other methods (e.g., Mask R-CNN and YOLACT++). A faster algorithm or even a real-time algorithm is necessary for practical applications; therefore, additional efforts are required for improving the speed, e.g., exploring ways to directly generate the object center as output instead of using a clustering algorithm.
For generalization, our proposed method uses all visible pixels to detect a target, thus a high utilization of the available information in an image. This high utilization enables our method to manage heavy occlusion cases even though a target is largely occluded. In addition, our method is a target-sensitive and non-occlusion-specific method, since we only detect the pixels belonging to a target and classify all non-target pixels as background. As a result, our method is only sensitive to target pixels, and what the occluder is, what shape it is, and how many parts a target is divided into have few effects on our method. This increases the generalization of our method to be applied to other scenes with different occlusions. Furthermore, our proposed framework can be further expanded using other modules. For example, the encoder-decoder networks can use light networks, including MobileNet (Howard et al, 2017), EfficientNet (Tan and Le, 2019), and GhostNet (Han et al, 2020); the clustering algorithm can also be replaced by other algorithms including K-Means and Gaussian Mixed Model. The multiple selections in both two stages enhance the flexibility of our approaches between speed and accuracy, and thus enhance the capacity to fit different animal applications.
The object center detected and predicted through our method serves an accurate representation of the object’s location, especially when an object is occluded. When occlusions occur, general instance segmentation can identify only the visible pixels of an occluded piglet, and therefore, the location of the piglet (i.e., the center of the physical geometry of the piglet) cannot be accurately represented (Fig. 8). Our method was able to generate an occlusion-resistant object location (using predicted object centers) and, thus, occlusion-resistant movement and trajectory. Thus, our method is advantageous in applications related to animal monitoring, especially for scenes with heavy occlusion. Nevertheless, the detection and prediction of object centers increase the workload related to data labeling in our method.
We presented only a simple video as an example. Future studies could explore the numerous possibilities in multi-object tracking, e.g., use of the Hungarian algorithm (Kuhn, 1955) for object pairing and Kalman filter (Kalman, 1960) for trajectory prediction. In future work, we will explore robust multi-object tracking, and systematic animal monitoring and analysis.

4 Conclusion
We developed CClusnet-Inseg, a deep-learning-based instance segmentation method that was specifically designed for pigs in farrowing pens. The main extensions—the DBSCAN algorithm, C2M, and RC2M—were described. The results of an ablation study showed that the model using DBSCAN achieved approximately the same accuracy as and 20 times the speed of the model using mean-shift; and RC2M improved the mAP of instance segmentation by 1.3 mAP but increased the computation cost by 2.2%. CClusnet-Inseg achieved an mAP of 84.1 and outperformed other state-of-the-art methods. Our method could be applied in multi-object tracking to generate several animal characterizations (i.e., animal movement, trajectory, average speed, body pixel size, space usage, and spatial distribution), and the predicted object center that is a conjunct output could serve as an occlusion-resistant representation of the object location.
Acknowledgments Thanks to the staff at the swine teaching and research center, School of Veterinary Medicine, University of Pennsylvania for animal care. Funding was provided in part by the National Pork Board and the Pennsylvania Pork Producers Council in the U.S., and the new research initiatives at City University of Hong Kong (Project number: 9610450), Hong Kong SAR, China.
Statements and Declarations
Competing Interests and Funding
The authors have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Funding was provided in part by the National Pork Board and the Pennsylvania Pork Producers Council in the U.S., and the new research initiatives at City University of Hong Kong (Project number: 9610450), Hong Kong SAR, China.
Animal ethics statement
The datasets were generated from animal videos collected in one of our previous studies which was approved by the University of Pennsylvania’s Institutional Animal Care and Use Committee (Protocol #804656).
References
- \bibcommenthead
- Bolya et al (2020) Bolya D, Zhou C, Xiao F, et al (2020) Yolact++: Better real-time instance segmentation. IEEE transactions on pattern analysis and machine intelligence
- Brünger et al (2020) Brünger J, Gentz M, Traulsen I, et al (2020) Panoptic segmentation of individual pigs for posture recognition. Sensors 20(13):3710
- Ceballos et al (2020) Ceballos MC, Góis KCR, Parsons TD (2020) The opening of a hinged farrowing crate improves lactating sows’ welfare. Applied Animal Behaviour Science 230(June):105,068. 10.1016/j.applanim.2020.105068
- Chen et al (2021) Chen C, Zhu W, Norton T (2021) Behaviour recognition of pigs and cattle: Journey from computer vision to deep learning. Computers and Electronics in Agriculture 187(January):106,255. 10.1016/j.compag.2021.106255
- Chen et al (2020) Chen H, Sun K, Tian Z, et al (2020) Blendmask: Top-down meets bottom-up for instance segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 8573–8581
- Ester et al (1996) Ester M, Kriegel HP, Sander J, et al (1996) A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In: Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, pp 226–231
- Gan et al (2021) Gan H, Ou M, Zhao F, et al (2021) Automated piglet tracking using a single convolutional neural network. Biosystems Engineering 205:48–63. 10.1016/j.biosystemseng.2021.02.010
- Han et al (2020) Han K, Wang Y, Tian Q, et al (2020) Ghostnet: More features from cheap operations. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1580–1589
- He et al (2021a) He H, Qiao Y, Li X, et al (2021a) Automatic weight measurement of pigs based on 3D images and regression network. Computers and Electronics in Agriculture 187(May):106,299. 10.1016/j.compag.2021.106299
- He et al (2021b) He H, Qiao Y, Li X, et al (2021b) Optimization on multi-object tracking and segmentation in pigs’ weight measurement. Computers and Electronics in Agriculture 186(November 2020):106,190. 10.1016/j.compag.2021.106190
- He et al (2017) He K, Gkioxari G, Dollár P, et al (2017) Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision, pp 2961–2969
- Howard et al (2017) Howard AG, Zhu M, Chen B, et al (2017) Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:170404861
- Huang et al (2021a) Huang E, Mao A, Ceballos MC, et al (2021a) Capacity limit of deep learning methods on scenarios of pigs in farrowing pen under occlusion. In: 2021 ASABE Annual International Virtual Meeting, American Society of Agricultural and Biological Engineers, p 1
- Huang et al (2021b) Huang E, Mao A, Gan H, et al (2021b) Center clustering network improves piglet counting under occlusion. Computers and Electronics in Agriculture 189(August):106,417. 10.1016/j.compag.2021.106417
- Huang et al (2019) Huang Z, Huang L, Gong Y, et al (2019) Mask scoring R-CNN. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2019-June:6402–6411. 10.1109/CVPR.2019.00657, https://arxiv.org/abs/arXiv:1903.00241
- Johnson and Marchant-Forde (2009) Johnson AK, Marchant-Forde JN (2009) Welfare of Pigs in the Farrowing Environment. In: The Welfare of Pigs. Springer Netherlands, Dordrecht, p 141–188, 10.1007/978-1-4020-8909-1_5
- Kalman (1960) Kalman RE (1960) A new approach to linear filtering and prediction problems. Journal of Fluids Engineering, Transactions of the ASME 82(1):35–45. 10.1115/1.3662552
- Kingma and Ba (2014) Kingma DP, Ba J (2014) Adam: A Method for Stochastic Optimization. 3rd International Conference on Learning Representations, ICLR 2015 - Conference Track Proceedings pp 1–15. https://arxiv.org/abs/arXiv:1412.6980
- Kuhn (1955) Kuhn HW (1955) The Hungarian method for the assignment problem. Naval research logistics quarterly 2(1-2):83–97
- Lee and Park (2020) Lee Y, Park J (2020) CenterMask: Real-time anchor-free instance segmentation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition pp 13,903–13,912. 10.1109/CVPR42600.2020.01392, https://arxiv.org/abs/arXiv:1911.06667
- Li et al (2019) Li D, Chen Y, Zhang K, et al (2019) Mounting behaviour recognition for pigs based on deep learning. Sensors 19(22):4924
- Lin et al (2014) Lin TY, Maire M, Belongie S, et al (2014) Microsoft coco: Common objects in context. In: European conference on computer vision, Springer, pp 740–755
- Lin et al (2017) Lin TY, Goyal P, Girshick R, et al (2017) Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision, pp 2980–2988
- Liu et al (2021) Liu D, Vranken E, van den Berg G, et al (2021) Separate weighing of male and female broiler breeders by electronic platform weigher using camera technologies. Computers and Electronics in Agriculture 182(October 2020). 10.1016/j.compag.2021.106009
- Liu et al (2018) Liu S, Qi L, Qin H, et al (2018) PANet: Path Aggregation Network for Instance Segmentation. (arXiv:1803.01534v3 [cs.CV] UPDATED). Cvpr pp 8759–8768. URL http://arxiv.org/abs/1803.01534
- Moustsen et al (2013) Moustsen VA, Hales J, Lahrmann HP, et al (2013) Confinement of lactating sows in crates for 4 days after farrowing reduces piglet mortality. Animal 7(4):648–654. 10.1017/S1751731112002170
- Samet et al (2020) Samet N, Hicsonmez S, Akbas E (2020) Houghnet: Integrating near and long-range evidence for bottom-up object detection. In: European Conference on Computer Vision, Springer, pp 406–423
- Shi et al (2016) Shi C, Teng G, Li Z (2016) An approach of pig weight estimation using binocular stereo system based on LabVIEW. Computers and Electronics in Agriculture 129:37–43
- Tan and Le (2019) Tan M, Le Q (2019) Efficientnet: Rethinking model scaling for convolutional neural networks. In: International conference on machine learning, PMLR, pp 6105–6114
- Tian et al (2020) Tian Z, Shen C, Chen H (2020) Conditional convolutions for instance segmentation. In: European conference on computer vision, Springer, pp 282–298
- Wang et al (2018) Wang D, Tang JL, Zhu W, et al (2018) Dairy goat detection based on Faster R-CNN from surveillance video. Computers and Electronics in Agriculture 154(April):443–449. 10.1016/j.compag.2018.09.030
- Wang et al (2020a) Wang X, Kong T, Shen C, et al (2020a) Solo: Segmenting objects by locations. In: European Conference on Computer Vision, Springer, pp 649–665
- Wang et al (2020b) Wang X, Zhang R, Kong T, et al (2020b) Solov2: Dynamic and fast instance segmentation. Advances in Neural information processing systems 33:17,721–17,732
- White et al (2006) White DJ, Svellingen C, Strachan NJ (2006) Automated measurement of species and length of fish by computer vision. Fisheries Research 80(2-3):203–210. 10.1016/j.fishres.2006.04.009
- Xie et al (2020) Xie E, Sun P, Song X, et al (2020) PolarMask: Single shot instance segmentation with polar representation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition pp 12,190–12,199. 10.1109/CVPR42600.2020.01221, https://arxiv.org/abs/arXiv:1909.13226