Occlusion-Robust FAU Recognition by Mining
Latent Space of Masked Autoencoders
Abstract
Facial action units (FAUs) are critical for fine-grained facial expression analysis. Although FAU detection has been actively studied using ideally high quality images, it was not thoroughly studied under heavily occluded conditions. In this paper, we propose the first occlusion-robust FAU recognition method to maintain FAU detection performance under heavy occlusions. Our novel approach takes advantage of rich information from the latent space of masked autoencoder (MAE) and transforms it into FAU features. Bypassing the occlusion reconstruction step, our model efficiently extracts FAU features of occluded faces by mining the latent space of a pretrained masked autoencoder. Both node and edge-level knowledge distillation are also employed to guide our model to find a mapping between latent space vectors and FAU features. Facial occlusion conditions, including random small patches and large blocks, are thoroughly studied. Experimental results on BP4D and DISFA datasets show that our method can achieve state-of-the-art performances under the studied facial occlusion, significantly outperforming existing baseline methods. In particular, even under heavy occlusion, the proposed method can achieve comparable performance as state-of-the-art methods under normal conditions.
keywords:
Occlusion-robust FAU recognition , masked autoencoders , knowledge distillation1 Introduction
The Facial Action Coding System (FACS) [1] is a comprehensive system that breaks down facial expressions into individual components of muscle movement, which are called Action Units (AUs). It is widely adopted to describe fine-grained facial behaviors. Automatic action unit detection enables efficient facial analysis and can be used in a wide range of applications including security, clinic, entertainment, and education [2].
With the recent advancement of deep neural networks (DNNs) and high-quality image datasets, the performance of computer vision tasks has been improved tremendously including facial action unit (FAU) detection. Some pioneering studies (e.g., [3, 4, 5, 6, 7]) take advantage of DNNs to extract local and global facial appearance features, and they have remarkably improved the accuracy of FAU detection over traditional approaches using hand-crafted features [8, 9]. More recently, works [10, 11] further improve the detection performance by combining the appearance features with domain knowledge of dependencies between AUs. To further capture these AU dependencies automatically, Luo et al. [12] propose ME-GraphAU, a node and edge feature learning approach that can achieve state-of-the-art performance in FAU recognition. Despite the promising performance of these methods, they all rely on high-quality images and videos gathered from well-controlled lab environments with full facial region and action units exposed. As a result, directly applying these methods often suffers from significant performance degradations in the presence of occlusion, particularly for heavily occluded face images. Indeed, even for ME-GraphAU [12], the state-of-the-art approach, our preliminary studies show that its F1-score drops sharply from 65.5% to 30.7% by randomly masking 50% of facial regions.
In many real-world scenes, the captured face images can be partially or even heavily occluded. Thus, the inference on occluded facial images has been a long-standing problem in face recognition-related tasks, e.g., occlusion-roust face identification and recognition [13, 14, 15, 16]. However, to our best knowledge, there have been no explorations yet specifically developed for the occluded FAU recognition task. Facial occlusion is often characterized as an intractable problem, thus it presents particular challenges to existing occlusion-unaware methods [16]. First, a large portion of data that contains discriminative appearance features may be missing, which leads to severe performance degradation. Earlier region-based AU prediction models that only infer from local features will fail because of missing information on occluded regions [5]. Some other typical models considering dependencies among AUs by graph models will also encounter the problem of missing node features [10, 17, 12]. Second, we often do not have prior information about the occluded regions (e.g., position, shape), further increasing the difficulty of producing accurate FAU predictions.
Recent studies in compressed sensing theory reveal an intriguing phenomenon that, image signals contain much redundant information such that missing image regions may be recovered with high probability under proper sampling conditions [18, 19, 20]. Moreover, different facial AUs often mutually influence each other [12], thus the activation status of one missing AU may be inferred from neighboring AUs. Based on these observations, as the first attempt, we aim to exploit and reconstruct missing AUs from occluded facial images prior to FAU recognition. To show the feasibility of the concept, we explore the adoption of masked autoencoder (MAE) structure [21] for image reconstruction, which achieves state-of-the-art performance in the self-supervised learning regime. In particular, MAE has been demonstrated to well recover an image even with 75% randomly masked missing regions. Despite the effectiveness of MAE in reconstructing natural images, there are two key issues that may hinder the direct employment of MAE for occluded FAU recognition. First, the decoding process of MAE requires the location information of occluded regions as a priori; while usually we don’t have such information or need extra efforts to obtain it in a real test scene. Moreover, the decoding network in MAE also causes a large computational overhead.
To address these challenges above, we propose a simple yet effective and efficient framework based on off-the-shelf masked autoencoders. In our preliminary study, we leverage a pretrained MAE to predict occluded missing facial regions and observe surprisingly good overall reconstruction quality. This key observation indicates that the bottleneck layer of a pretrained MAE is capable of capturing essential knowledge of relations between different action units, thus well recovering missing facial action units. We are then motivated to mine discriminative feature information from the latent space of the MAE. Meanwhile, we can bypass the redundant decoding process to be much more efficient. To make the learning process more effective, we propose to perform node and edge knowledge distillation simultaneously to further aid the model find the mapping between the latent space vector of MAE and features needed for FAU recognition. The superior performance is validated through experiments on benchmark datasets under different facial occlusion conditions.
The contributions of this paper can be summarized as follows:
-
1.
As the first attempt, we specifically explore the facial action unit recognition task and investigate its feasibility under heavily occluded conditions.
-
2.
We propose a novel and effective reconstruction-based FAU recognition approach by mining the latent space of off-the-shelf masked autoencoders.
-
3.
We further improve the efficiency of the occlusion-insensitive model by transferring the latent space feature of the masked autoencoder to FAU features.
-
4.
We perform experiments on two benchmark datasets and demonstrate that our method can achieve comparable performances with occlusion-free images even for 50% heavily occluded facial images.
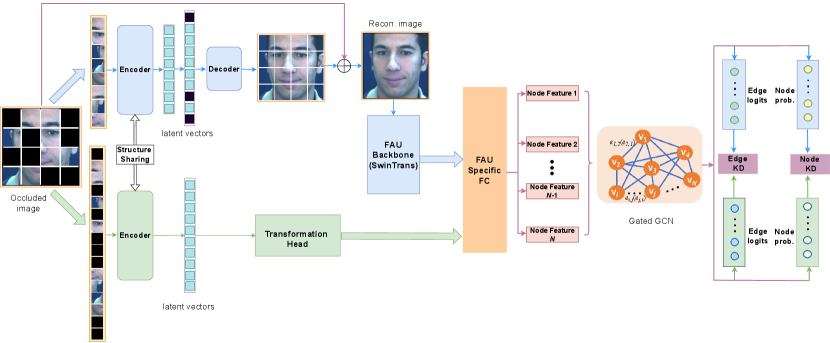
2 Related Work
In this part, we will briefly review existing works that are closely related to our proposed approach, including deep learning-based FAU detection models, masked autoencoders, and knowledge distillation techniques.
2.1 Facial Action Unit Detection
Early works treat action unit detection as a patch-learning problem where detected landmarks define the region of interest. In JPML [3], joint patch and multi-label learning are introduced where a discriminative subset of patches are used to identify target AUs. The authors further improved their method in DRML [22] by combining deep region and multi-label learning into a unified deep network using a specifically designed region layer to replace conventional convolutional layers. The region layer can capture the local appearance change of different facial regions. In EAC-Net [6], authors design a fixed attention map based on facial landmarks to enhance the AU feature learning in regions of interest (ROI). JAA-Net [11] jointly estimates the location of landmarks and the presence of action units. In this work, the adaptive attention map for each action unit is computed separately using estimated landmarks, yielding precise local features. Work [23] uses the ROI attention module to predict attention maps directly using the supervision from landmarks. SEV-Net [24] combines the embeddings of semantic description of AUs with visual features to generate a cross-modality attention map, assisting the model to learn discriminative features from meaningful regions.
Besides learning better local features, the focus of FAU detection gradually shifts towards AU relationship modeling. DSIN [7] uses a recurrent neural network to perform structure inference on fused local and global features. The authors propose an iterative structure inference process to simulate the fully connected graph which captures the relationship between AUs. AU-GCN [10] proposes a graph convolutional network-based framework for modeling AU relationships. Individual AU features are fed into a GCN as nodes, and a fixed connection matrix is constructed based on statistical results on each training set. In the work of UGN [17], a probabilistic mask is used on graph edges to simultaneously capture dependencies and underlying uncertain information among AUs. The uncertainties are also used to select hard samples to improve training efficiency. Unlike the previous GCN-based methods where the adjacency matrix only represents the connectivity between nodes, ME-GraphAU [12] employs edge feature learning where a pair of multi-dimensional edge features are learned between each pair of AUs. The combination of node and edge features captures both the activation status of each AU and the association between them. This method extracts reliable task-specific relationship cues for AU recognition and achieved state-of-the-art results on two widely used AU datasets. Although learning rich node and edge features, ME-GraphAU still relies on the visibility of the full facial region where heavy occlusion causes significant degeneration in performance. This work improves ME-GraphAU in the presence of heavy occlusions.
2.2 Masked Image Modeling
Performing computer vision tasks on masked images is called masked image modeling (MIM). Models can learn meaningful representations by reconstructing masked images, and it is promising to apply MIM for self-supervised pre-training. BEiT [25] is one of the first works to use masked image modeling tasks to pretrain vision transformers where the goal is to recover original visual tokens from a masked image. SimMIM [26] proposes a simple framework to demonstrate that masked image modeling provides the model superior representation-learning performance by experiments on large-size masked patches, simple pixel-wise regression, and lightweight prediction heads. MAE [21] adopts an asymmetric encoder-decoder architecture to produce informative latent representation by training image reconstruction tasks on 75% masked images. MAE can learn models with high capacities that generalize well, not only producing high-quality image reconstruction but also improving the performance of downstream learning tasks. Here we consider heavy occlusion as a masked image modeling task where representational features learned from non-occluded parts should benefit from reconstructing the occlusion portion and provide meaningful information to the FAU detection task.
2.3 Knowledge Distillation
In a real-world deployment, it is desirable that an FAU recognition model is lightweight, to be resource-efficient. However, a smaller FAU model is often associated with performance degradation. Therefore, we aim to leverage knowledge distillation (KD) to create a lightweight FAU model while preserving high accuracy.
KD is a popular model compression method where smaller models learn from models with higher knowledge capacity [27, 28]. KD is commonly used in multi-class classification tasks. Different KD methods have been proposed, such as logit-based KD [29], feature-based KD [30], self-supervision signals guided KD, etc [31, 32]. KD is also commonly used in multi-label classification tasks to simplify large models size or improve performances through distilled knowledge. [33] builds an efficient multi-label image classification model by distilling knowledge from a weakly supervised detection model. CPSD [34] boosts the performance of multi-label image classification through self-distillation. [35] proposes uncertainty distillation to address the problem of hard samples in multi-label image classification. In this work, we intend to perform KD for both nodes and edge features, where we formulate them as multi-label KD and multi-class KD, respectively.
3 Methodology
In this section, we present the framework of the proposed method as shown in Fig. 1. The overall framework consists of three modules: the MAE reconstruction module, the FAU detection module, and the knowledge distillation module. We elaborate on each component individually as follows.
3.1 MAE Reconstruction Module
The MAE reconstruction module is rooted in the idea of the masked autoencoder (MAE), a state-of-the-art masked imaging modeling method where the original image can be reconstructed by observing only partial signals. More specifically, the encoder MAE firstly maps observed patches into a latent space representation. Then, empty latent space vectors representing masked patches are added at corresponding positions in the latent representation and then projected back to the image space through a decoder. Finally, the pixel values of masked patches are reconstructed in the encoding and decoding process. In this module, there are mainly four components: masking, patch encoding, latent space representation decoding, and image reconstruction.
The masking process is to simulate random occlusions on facial images. MAE is a vision transform (ViT) [36] based method that operates on image tokens, where images are divided into non-overlapping patches. To better simulate real-world random occlusions, we consider two types of patch-based masking occlusions: random small-patch masking and large-block masking. The former type of masking is similar to conventional MAE settings where a random subset of small patches is selected. This type of masking strategy is to simulate random and small-patch occlusions on faces (e.g., hair, sunglasses, fingers). The latter masking strategy is used to simulate large-block occlusion regions (e.g., covered by facial masks or palms). In this case, a random large-block region consisting of many patches is chosen to be masked. Such large block occlusion further increases the difficulty of both image reconstructions and FAU detection since only signals from distant patches are available.
The encoder component of the reconstruction module only takes in unmasked patches. The encoder follows standard ViT [36] operations to obtain a latent space representation: applying a linear projection to construct patch embedding, incorporating positional embedding to provide the position information of each image patch, and passing through a series of transformer blocks. Taking advantage of self-generated masks with known positions, the encoder by design can only operate on visible patches saving a large amount of computation and memory.
A decoder component is used to map the latent space representation back to the image space including the reconstruction of previously masked patches. Different from the large encoder that operates only on unmasked patches, the smaller decoder takes both encoded visible patches and learned mask tokens as input. A shared vector representing mask token is filled at each position where the missing patch needs to be predicted. After filling tokens to the set, additional positional embedding is added on all tokens to provide necessary location information, especially for mask tokens. A smaller amount of transformer blocks is used in the decoder to save computation.
As for the image reconstruction step, an MAE directly reconstructs the pixel values of masked patches. MAE uses the pixel-wise metric to measure the quality of reconstruction on masked image patches, and the loss can be written as,
| (1) |
where represents the masked pixels set, is the number of masked pixels, and corresponds to predicted pixel values and original pixel values, respectively.
However, the reconstructed image suffers from significant block artifacts due to unconstrained visible patch reconstruction. To reduce the noise caused by such artifacts on downstream FAU tasks, we again use the positional information of masks to combine the visible patches from the original image with reconstructed masked patches and form a better-quality facial image for the next FAU detection module.
3.2 FAU Detection Module
This module is a self-contained facial action unit detection where the inputs are regular RGB images and the outputs are the activation probability of each facial action unit. To guarantee a good FAU detection performance, this module is based on the state-of-the-art FAU detection method [12]. The detection module can be further split into AU feature generation and graph learning components.
To generate AU features, the face feature map (, , and correspond to the height, width, and channels of the feature map) is extracted by standard computer vision backbones. different fully connected layers are used on AUs respectively to selectively extract features that are specific to each AU from the full-face feature map. Global average pooling is used on each AU-specific feature map to generate feature vectors as AU-specific representations.
To better model the relationships between AUs, we adopt a graph neural network approach incorporating both node and edge feature learning. This is a two-stage learning method. Node feature learning is conducted in the first stage where the learning target is to produce node features containing both the AU activation status and associations with each other on each facial display. In this stage, each AU representation is used as graph node features and the similarity between these node features determines the connectivity among nodes. More specifically, and , where represents the connection between node and in adjacency graph , and represents the out-degree of each node to their closest neighbors. After the construction of nodes and edges, one GCN layer is used to update the AUs’ activation status by fusing information from most related AUs. The updated AU representations can be written as,
| (2) |
where , is a non-linear activation function, represents the batch normalization function, and denote linear layers with weight and bias. To provide a probabilistic prediction of the activation status of each action unit, a similarity calculation strategy is used here, where cosine similarity is computed between a trainable vector and an updated representation vector . The vector is trained to be a representation of the active status of the th AU. The probability of the th AU being activated can be written as,
| (3) |
where denotes a function that computes the cosine similarity between two vectors.
To supervise the learning of node features, a multi-label classification loss is adopted. However, there are two significant label imbalance issues due to the nature of FAU dataset collection process: First, the negative label dominates on each AU; Second, the occurrence frequency of each AU is dramatically different. To address these issues, we adopted the weighted asymmetric loss proposed in ME-GraphAU and added additional degrees of freedom to compensate for the noisiness caused by image reconstruction. We first applied asymmetric probability shifting [37] on the estimated probability ,
| (4) |
where denotes a margin to discard low-probability negative samples. This strategy helps reject mislabeled negative samples generated in the image reconstruction process. The AU loss now can be written as,
| (5) |
where is pre-generated by occurrence rate of the -th AU in the training dataset, is the ground truth binary label, and is the hyperparameter only applies to negative sample to adjust the contribution from easy negative samples. In this stage, only AU nodes with similar feature representations are connected, which forces the model to extract AU features containing both activation and association information.
The second stage builds on top of the AU features learned in the first stage. In addition to associations encoded in node features, this stage aims for learning edge features that describe fine-grained relationships between AUs through additional supervision. Edge features contain much richer information than binary connectivity in the adjacency matrix. Far away nodes in terms of similarity can still have critical relationship information contributing to the detecting activation of AUs. To acquire meaningful edge features, the model conducts two cross-attention operations,
| (6) |
where are learned weights that apply a linear transformation on the query, key, and value in the attention mechanism, and is a scaling factor that is equal to the number of channels in term. Firstly, a cross-attention operation is conducted between each AU-specific feature map and the full-face feature map, acquiring the AU activation status in terms of global face feature representation,
| (7) |
Then, between each pair of AUs, another cross-attention operation is used to extract features that are related to both AUs,
| (8) |
With global average pooling on the above features map describing the relationship between pair of AUs, the edge feature vectors is obtained. Thus, we can form a graph containing both node and edge features. Multiple layers of GatedGCN [38] are used on the graph to allow information propagation between AUs leading to more accurate AU activation status and richer edge features. The activation probability is generated using the similarity calculation strategy as in the node feature learning in the first stage. To further guide edge feature learning, one additional classification head is added to the final edge features. The classification head classifies 1 of the 4 possible activation status combinations of two AUs that the edge connects to. Categorical cross-entropy loss is used for edge classification, and it can be written as,
| (9) |
where is the categorical cross-entropy function, is a one-hot vector indicating 1 of the 4 co-occurrence patterns of the edge between the -th and -th nodes, denote the logits output from the edge classification head. In the second stage, the model focuses on node and edge feature learning with an MAE reconstruction module. The loss in this stage can be written as,
| (10) |
where is a hyperparameter that adjusts the importance of edge classification results.
3.3 Student Module
Using the above two modules, we now have a complete occlusion-robust FAU detection pipeline that can be trained end to end by learning from regular images with generated masks. By using reconstructed images from the MAE reconstruction module as input, the FAU detection module can estimate the activation status of the heavily occluded face. The purpose of reconstructing the masked facial image in RGB space is to provide supervision on creating high-quality FAU-aware face reconstruction, and reconstructed images allow maximum flexibility in terms of FAU detection model selection. However, because of the process of facial image reconstruction and FAU feature extraction, the complexity of the model greatly increases. Besides, during the testing phase, the reconstruction process requires explicit knowledge of occluded positions which is often unknown in practice. Furthermore, the square artifacts in the reconstructed facial images can potentially cause error propagation in the downstream FAU detection tasks. In the next module, we want to maintain the effectiveness of this occlusion-robust FAU detection pipeline (the teacher model) while addressing the problems by introducing feature alignment and knowledge distillation.
Since the latent space representation in MAE is capable of reconstructing masked patches of arbitrary images, it should contain generic information extracted from visible patches. Meanwhile, in the previous pipeline, FAU-related features are then extracted from the reconstructed image. This indicates that the FAU-specific features can be derived directly from the generic MAE latent space features without reconstructing the missing patches. In standard MAE training, masks are generated during the forward propagation process and the position information of masks is used in several places including selecting visible patches before the encoder, adding masked tokens in the corresponding place in the latent space representation, and combining visible patches with reconstructed ones to form better quality images. In the proposed student network, to better simulate random occlusions in a realistic scenario, we intentionally avoid the use of position information of occlusion. In the student network, tokens of all patches are fed into the encoder with additional positional embeddings indicating the location of patches. This produces the latent space representation with the same dimensionality as standard MAE latent space representation after adding mask tokens. To mitigate the gap between MAE latent space representation and the FAU face feature map, we add a simple feature alignment component between these two feature spaces. The proposed feature alignment component uses a downsampling layer and multiple fully connected layers to selectively project MAE latent space representation into features that are significant for FAU detection.
With features projected into the same space as features generated in the FAU detection module, the AU-specific feature generation and graph learning components from the original pipeline can be seamlessly adopted. Nevertheless, there is a large gap in terms of knowledge capacity between the model with reconstruction and the student model directly projecting features from the latent space of MAE. To efficiently transfer the rich knowledge of the well-trained large model to this compact model, we apply knowledge distillation losses on both FAU detection and edge classification targets.
FAU detection is modeled as a multi-label classification problem where the ground truth label indicates the occurrence of certain AU. The output of the teacher model contains probabilistic estimations of the occurrence which provides meaningful likelihood information that binary ground truth labels do not have. To incorporate probability information learned from the teacher model, we minimize the per AU Kullback-Leibler (KL) divergence between the output from the teacher and student model. The AU distillation loss can be written as,
| (11) |
where denotes the KL divergence function and are activation probability outputs for the -th AU from the student and teacher models, respectively.
The edge features are also critical in the detection algorithm, so a 4-class classification problem is set up to guide the model to learn representative association features between AUs. To efficiently transfer knowledge in terms of edge features, we adopt a typical knowledge distillation on the logit layer output of the edge classification head [29], the edge distillation loss can be written as,
| (12) |
where is the temperature hyperparameter that adjusts the smoothness of probability, and are logit output from the edge classification head of student and teacher models, respectively.
The overall knowledge distillation loss can be written as,
| (13) |
where are hyperparameters to adjust the relative weight between AU distillation loss and edge distillation loss.
Finally, we have our overall training loss for the student network by combining with the AU detection loss, edge classification loss, and knowledge distillation loss,
| (14) |
4 Experiments
In this section, we will empirically demonstrate the effectiveness of the proposed FAU recognition method in the presence of different occlusion conditions. We first describe our experimental setup (e.g., datasets, metrics) and then present comparison results with state-of-the-art methods on two benchmark datasets. Experimental results show that the proposed method significantly outperforms state-of-the-art methods in the presence of heavy occlusions.
| AU1: Inner Brow Raiser | AU2: Outer Brow Raiser | AU4: Brow Lowerer | AU6: Cheek Raiser | AU7: Lid Tightener |
|---|---|---|---|---|
| AU9: Nose Wrinkler | AU10: Upper Lip Raiser | AU12: Lip Corner Puller | AU14: Dimpler | AU15: Lip Corner Depressor |
| AU17: Chin Raiser | AU23: Lip Tightener | AU24: Lip Pressor | AU25: Lips Part | AU26: Jaw Drop |
4.1 Datasets
Our occlusion-robust model is evaluated on two widely-used datasets for AU detection: BP4D [39] and DISFA [40]. Descriptions and sample images for AUs contained in these datasets are shown in Table 1. For both datasets, we evaluated our proposed method using three-fold cross-validation and reported the mean performance values over the folds. For a fair comparison, we adopt the folds split following prior works [11, 12].
The BP4D dataset [39] contains images from 41 young adults (18 male and 23 female) of various ethnicity. Each subject is asked to perform 8 tasks corresponding to different target emotions. There are 328 videos collected, including around 140,000 frames with binary occurrence AU labels (present or absent) on 12 AUs (1, 2, 4, 6, 7, 10, 12, 14, 15, 17, 23, 24). The original resolution of the frames is and each contains exactly one front-facing face in the middle of the frame. To avoid the situation that testing data and training data share images from the same person, training and testing partitions in each fold only contain images from different people.
The DISFA [40] dataset contains video recordings from 27 subjects (15 males and 12 females) when watching video clips. The dataset contains around 130,000 valid face color images with a resolution of , each of which is with intensity labels on 8 AUs (1, 2, 4, 6, 9, 12, 25, 26). Following prior work, AUs with an intensity equal to or greater than 2 are considered present while others are treated as absent. The same training and testing split strategy as in BP4D is applied to this dataset. This dataset has a more significant AU occurrence imbalance problem, where certain AU could have 5 times more occurrence when compared to the ones with lower occurrence.
Due to a lack of real-world annotated FAU occlusion datasets, we simulate the occlusions by masks following ideas from existing face recognition work [15]. Specifically, we generate two types of masks: small block patches with a size of to simulate randomly placed gadgets (e.g., sunglasses, stains), and a relatively large block to simulate large objects e.g., facial masks or palms. In the first type of mask (Figure 2 (a)), considering that FAU describes very subtle facial muscle movement, we limited the overall masking ratio to around 50% to avoid covering all FAU-related regions. In the second type (Figure 2 (b)), the block region is set to be 30%. It is worth mentioning that our proposed method can be applied to many real-world occlusions by simply adding a pre-processing procedure, i.e., detecting occlusion regions and converting them to binary masks, though obtaining AU annotations for such real-world occluded images remains a challenge currently.

4.2 Evaluation Metric
We follow the previous AU detection studies [11, 23, 12] and use the F1-score as the metric to evaluate the performance of our approach. F1-score is the harmonic mean of the precision and the recall , i.e., , and it is considered a better metric in the case of imbalanced classes (e.g., here negative classes dominate in AU detection). The F1-score for each individual AU is reported, and the average score of all AUs is also computed for comparison purposes.
4.3 Implementation Details
For each face image, we performed face alignment through a series of similarity transformations based on the provided face landmarks from both BP4D and DISFA datasets. The transformation is shape-preserving which has no impact on the activation status of AUs. The face alignment gives colored images, from which we perform data argumentation including cropping, horizontal flipping, and color jittering, and obtain images as training inputs. During training, we use AdamW [41] with and the weight decay of . For training in the first stage, we choose to use nearest neighbors for both BP4D and DISFA datasets. In both the second stage teacher training and knowledge distillation student training, we give the edge classification loss weight .
In knowledge distillation training, we adopt in and select the weight , for overall loss and respectively. For teacher model training, we train up to 30 epochs in stage 1 with an initial learning rate of and on BP4D and DISFA, respectively. We also train 20 epochs for the second stage with an initial learning rate of and on BP4D and DISFA datasets, respectively. For knowledge distillation on the student model, 10 epochs of training are used with an initial learning rate of on both datasets. All the phases of training are done on a single RTX 3090 GPU with a batch size of 48. The initialization of MAE models used in both teacher and student networks are trained on ImageNet[42]. To fine-tune a pretrained MAE on facial datasets, we set the learning rate on MAE model parameters to 1/100 of the learning rate of rest parameters. The backbone used in the FAU detection module is also pretrained on ImageNet.
| Method | AU | Avg. | ||||||||||||||
| 1 | 2 | 4 | 6 | 7 | 10 | 12 | 14 | 15 | 17 | 23 | 24 | |||||
| JAA-Net[11] | 47.2 | 44.0 | 54.9 | 77.5 | 74.6 | 84.0 | 86.9 | 61.9 | 43.6 | 60.3 | 42.7 | 41.9 | 60.0 | |||
| AU-GCN[10] | 46.8 | 38.5 | 60.1 | 80.1 | 79.5 | 84.8 | 88.0 | 67.3 | 52.0 | 63.2 | 40.9 | 52.8 | 62.8 | |||
| UGN-B[17] | 54.2 | 46.4 | 56.8 | 76.2 | 76.7 | 82.4 | 86.1 | 64.7 | 51.2 | 63.1 | 48.5 | 53.6 | 63.3 | |||
| SEV-Net[24] | 58.2 | 50.4 | 58.3 | 81.9 | 73.9 | 87.8 | 87.5 | 61.6 | 52.6 | 62.2 | 44.6 | 47.6 | 63.9 | |||
| ME-GraphAU[12] | 52.7 | 44.3 | 60.9 | 79.9 | 80.1 | 85.3 | 89.2 | 69.4 | 55.4 | 64.4 | 49.8 | 55.1 | 65.5 | |||
|
15.12 | 0.50 | 35.28 | 4.16 | 23.44 | 57.58 | 74.23 | 65.30 | 24.44 | 16.53 | 16.12 | 36.11 | 30.73 | |||
|
41.44 | 47.40 | 45.41 | 69.90 | 66.02 | 79.47 | 86.74 | 62.88 | 32.11 | 57.91 | 34.37 | 27.98 | 54.30 | |||
\hdashline
|
51.55 | 46.40 | 55.84 | 78.61 | 78.33 | 83.11 | 88.16 | 66.72 | 50.08 | 63.81 | 50.28 | 47.63 | 63.38 | |||
|
50.61 | 43.21 | 56.56 | 77.97 | 78.65 | 82.95 | 87.72 | 66.43 | 47.62 | 63.66 | 45.71 | 49.67 | 62.56 | |||
|
40.19 | 42.27 | 46.52 | 66.41 | 52.76 | 79.39 | 78.50 | 60.77 | 30.13 | 53.11 | 29.73 | 29.92 | 50.81 | |||
|
42.00 | 45.21 | 49.59 | 72.63 | 68.12 | 76.85 | 83.68 | 55.62 | 26.20 | 54.01 | 24.86 | 27.39 | 52.18 | |||
\hdashline
|
47.15 | 43.37 | 55.90 | 77.04 | 77.58 | 81.57 | 87.09 | 67.62 | 51.77 | 62.02 | 44.64 | 49.37 | 62.09 | |||
|
48.37 | 44.30 | 57.46 | 76.73 | 77.35 | 81.51 | 85.09 | 66.36 | 48.56 | 61.23 | 42.87 | 45.09 | 61.24 | |||
| Method | AU | Avg. | ||||||||||
| 1 | 2 | 4 | 6 | 9 | 12 | 25 | 26 | |||||
| JAA-Net[11] | 43.7 | 46.2 | 56.0 | 41.4 | 44.7 | 69.6 | 88.3 | 58.4 | 56.0 | |||
| AU-GCN[10] | 32.3 | 19.5 | 55.7 | 57.0 | 61.4 | 62.7 | 90.9 | 60.0 | 55.0 | |||
| UGN-B[17] | 43.3 | 48.1 | 63.4 | 49.5 | 48.2 | 72.9 | 90.8 | 59.0 | 60.0 | |||
| SEV-Net[24] | 55.3 | 53.1 | 61.5 | 53.6 | 38.2 | 71.6 | 95.7 | 41.5 | 58.8 | |||
| ME-GraphAU[12] | 54.6 | 47.1 | 72.9 | 54.0 | 55.7 | 76.7 | 91.1 | 53.0 | 63.1 | |||
|
25.29 | 22.91 | 47.72 | 27.83 | 25.44 | 50.63 | 69.53 | 31.30 | 37.58 | |||
|
40.82 | 34.37 | 61.64 | 31.85 | 44.19 | 73.09 | 89.84 | 61.95 | 54.72 | |||
\hdashline
|
60.58 | 48.64 | 60.48 | 46.60 | 44.08 | 73.43 | 91.14 | 59.96 | 60.62 | |||
|
53.83 | 54.31 | 67.02 | 49.15 | 41.22 | 73.19 | 91.06 | 60.19 | 61.25 | |||
|
35.66 | 23.47 | 54.87 | 26.42 | 28.13 | 57.04 | 67.84 | 42.66 | 42.01 | |||
|
40.03 | 28.92 | 55.91 | 26.03 | 35.00 | 66.01 | 74.48 | 49.31 | 47.00 | |||
\hdashline
|
48.43 | 42.04 | 61.69 | 48.13 | 46.35 | 69.98 | 83.41 | 48.98 | 56.13 | |||
|
50.66 | 43.20 | 59.64 | 47.62 | 38.94 | 68.52 | 81.53 | 44.88 | 54.37 | |||
4.4 Experimental Results
In this section, we compare our results with several state-of-the-art methods on both datasets under a few different settings. Table 2 reports the occurrence detection results of 12 AUs on BP4D dataset in terms of F1-score. The top section of the table contains results under the occlusion-free conditions from different recent baseline methods (i.e. JAA-Net[11], AU-GCN[10], SEV-Net[24] and ME-GraphAU[12]), which are reported to have better performance than representative earlier methods including JPML[3], DRML[22], EAC-Net[6] and DSIN [7] etc. The bottom section contains experimental results under various occlusion conditions. As we can see from the table, even with 30% to 50% occlusions, both the teacher and student models we proposed can achieve the same level of performance as other models under occlusion-free conditions. As mentioned in the previous section, the state-of-the-art models trained on regular high-quality images degenerated significantly when we introduce different occlusion conditions. E.g., for ME-GraphAU, the F1-score drops from 65.5% to 30.73% and 50.81% on 50% and 30% occlusion respectively. Reconstructing occluded images using the ImageNet pre-trained MAE does help in the AU detection performance by filling in the missing information, especially for the high percentage sparse occlusion case where the F1-score is increased from 30.73% to 54.3% for ME-GraphAU. However, this accuracy is still over 10% away from its original performance on occlusion-free images. By contrast, our proposed models are forced to learn rich AU features and reliable AU relationships from only visible areas. And the performance of AU detection under 50% random occlusion is boosted to 63.38% and 62.56% in our reconstruction-based teacher model and the efficient student model respectively. In the case of 30% occlusion, our proposed models again significantly improve the performance by 10% over the ME-GraphAU model, achieving non-occlusion level performance with an F1-score of 62.09% and 61.24% when using the teacher and student models respectively.
In Table 3, we show experimental results on the DISFA dataset using the same 30% block and 50% random occlusion configurations. From the table, our proposed models again improve the performance of occurrence detection on 8 AUs under the occluded conditions by a large margin. Our proposed models can achieve 60.62% and 61.25% under the 50% random occlusion condition, which is even better than most other methods under the occlusion-free condition. For the 50% random occlusion condition, the student model using latent space features achieves a better result than the reconstruction-based teacher model in our experiments. Unlike the BP4D dataset, the data variance of DISFA is much smaller. The reconstruction module could suffer from overfitting the training data by reconstructing similar images again and again because of the small number of unique images from the DISFA dataset. The overfitting phenomenon is further exaggerated on the block masking experiments on DISFA dataset where we found some occluded regions are reconstructed with blocks from other faces from the training dataset. Such an overfitting problem could cause huge noise in supervision and thus limit the ability for efficient learning. As seen from the 30% block masking experimental results, though better than the state-of-art ME-GraphAU, the performance gains of our proposed models are limited.
By comparing the results from the 30% block occlusion condition and the 50% random occlusion condition, we can see that the occlusion condition has a very pronounced effect on the relationship and feature learning. Although the single large block type of occlusion has a smaller coverage, it brings more challenges in AU detection. Normally, under the non-occlusion condition, the activation of each AU is mostly determined by local features with the aid of the relationship between AUs. Under the large block occlusion, all nearby regions could be occluded and the models are forced to use only features from the far-away region and inter-relationship information between occluded and visible regions to do the inference. We can see that, for the BP4D dataset, the state-of-the-art model ME-GraphAU has only a 2% performance gain from reconstruction under the large block occlusion setting, while a 24% gain under the random occlusion setting. Our models also have lower performance gains under the large block occlusion than under the random occlusion, because limited local information can be extracted for reconstruction as well as for AU detection.
Based on the above experiments, we observe that our proposed models can significantly improve the AU detection performance under various heavy occlusions, achieving comparable performances with other state-of-the-art models under occlusion-free conditions.
4.5 Robustness Assessment
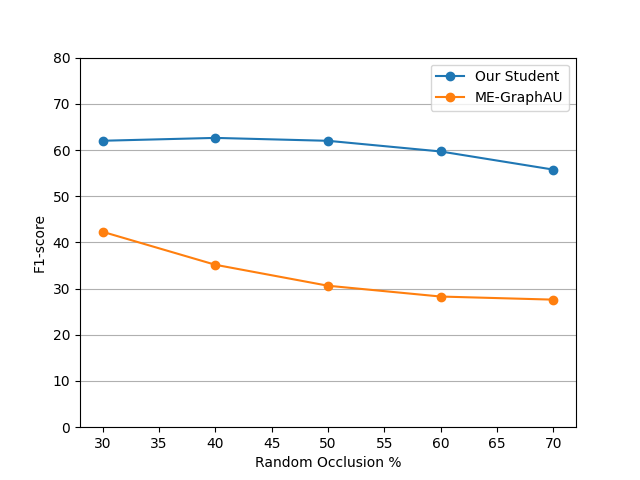
In this section, we aim to show the robustness of our proposed model against different levels of occlusions. In this study, we choose 1 of the 3 folds from the BP4D dataset. Our model is trained with 50% small patch random occlusions. We reported in Fig. 3 the F1-score comparisons between our model and the SOTA model ME-GraphAU on the testing dataset under various levels of occlusions. As we can see, the performance of our proposed model in terms of F1-score is relatively stable under occlusion rations from 30% to 70%, confirming that our model is robust against different occlusions. In particular, even on face images under 70% occlusion conditions, our model can still achieve an F1-score as high as 55.8%, significantly outperforming the SOTA model ME-GraphAU.
4.6 Computation Efficiency Comparison
In addition to performance comparisons, this section compares the computation efficiency between our proposed model and the state-of-the-art FAU recognition model. In Table 4, we show the computational complexity and the number of parameters of ME-GraphAU, our teacher and student models. We can note that, although our reconstruction-based teacher model generally achieves the best performances under occlusion settings on BP4D and DISFA datasets, it also requires a high computational cost (50% more than that of ME-GraphAU) and a larger number of model parameters (100% more than that of ME-GraphAU). While our proposed student model, maintaining high performance under heavy occlusion conditions, has slightly less computational complexity as well as model size when compared with ME-GraphAU.
Model Computational Complexity No. of Parameters ME-GraphAU[12] 21.28 GMACs 94.38 M Teacher (ours) 30.29 GMACs 201.47 M Student (ours) 18.63 GMACs 91.26 M
5 Conclusion
This work proposed a novel framework for facial action unit recognition under heavy occlusion conditions. Our reconstruction-based model, taking advantage of masked image modeling, is robust against heavy occlusions by learning the rich FAU-related features only from the visible parts of the facial image. The proposed models incorporate graph edge feature learning to further mitigate the influence of occlusion by shifting the focus from local feature learning to AU relationship learning. Further, we improve the efficiency of our model by transferring the latent space features of the masked autoencoder to FAU features by performing both edge-level and node-level knowledge distillation. The results on two commonly used datasets demonstrate that the proposed models under the 50% random occlusion can achieve comparable results with the state-of-the-art method under occlusion-free conditions. Our proposed occlusion-robust facial action unit recognition methods are modular by design and can be easily extended to other similar problems to enhance the robustness under heavy occlusions.
References
- [1] P. Ekman, W. V. Friesen, Facial action coding system: a technique for the measurement of facial movement, 1978.
-
[2]
R. Zhi, M. Liu, D. Zhang, A
comprehensive survey on automatic facial action unit analysis, Vis. Comput.
36 (5) (2020) 1067–1093.
doi:10.1007/s00371-019-01707-5.
URL https://doi.org/10.1007/s00371-019-01707-5 - [3] K. Zhao, W.-S. Chu, F. De la Torre, J. F. Cohn, H. Zhang, Joint patch and multi-label learning for facial action unit detection, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 2207–2216.
- [4] S. Jaiswal, M. Valstar, Deep learning the dynamic appearance and shape of facial action units, in: 2016 IEEE winter conference on applications of computer vision (WACV), IEEE, 2016, pp. 1–8.
- [5] W. Li, F. Abtahi, Z. Zhu, L. Yin, Eac-net: A region-based deep enhancing and cropping approach for facial action unit detection, in: 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), IEEE, 2017, pp. 103–110.
- [6] W. Li, F. Abtahi, Z. Zhu, L. Yin, Eac-net: A region-based deep enhancing and cropping approach for facial action unit detection, in: 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), 2017, pp. 103–110. doi:10.1109/FG.2017.136.
- [7] C. Corneanu, M. Madadi, S. Escalera, Deep structure inference network for facial action unit recognition, in: Proceedings of the european conference on computer vision (ECCV), 2018, pp. 298–313.
- [8] J. F. Cohn, A. J. Zlochower, J. Lien, T. Kanade, Automated face analysis by feature point tracking has high concurrent validity with manual facs coding, Psychophysiology 36 (1) (1999) 35–43.
- [9] J. Whitehill, C. W. Omlin, Haar features for facs au recognition, in: 7th international conference on automatic face and gesture recognition (FGR06), IEEE, 2006, pp. 5–pp.
- [10] Z. Liu, J. Dong, C. Zhang, L. Wang, J. Dang, Relation modeling with graph convolutional networks for facial action unit detection, in: International Conference on Multimedia Modeling, Springer, 2020, pp. 489–501.
- [11] Z. Shao, Z. Liu, J. Cai, L. Ma, Deep adaptive attention for joint facial action unit detection and face alignment, in: Proceedings of the European conference on computer vision (ECCV), 2018, pp. 705–720.
- [12] C. Luo, S. Song, W. Xie, L. Shen, H. Gunes, Learning multi-dimensional edge feature-based au relation graph for facial action unit recognition, arXiv preprint arXiv:2205.01782 (2022).
- [13] L. Song, D. Gong, Z. Li, C. Liu, W. Liu, Occlusion robust face recognition based on mask learning with pairwise differential siamese network, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 773–782.
- [14] Y. Zhang, X. Wang, M. S. Shakeel, H. Wan, W. Kang, Learning upper patch attention using dual-branch training strategy for masked face recognition, Pattern Recognition 126 (2022) 108522.
- [15] H. Qiu, D. Gong, Z. Li, W. Liu, D. Tao, End2end occluded face recognition by masking corrupted features, IEEE Transactions on Pattern Analysis and Machine Intelligence (2021).
- [16] D. Zeng, R. Veldhuis, L. Spreeuwers, A survey of face recognition techniques under occlusion, IET biometrics 10 (6) (2021) 581–606.
- [17] T. Song, L. Chen, W. Zheng, Q. Ji, Uncertain graph neural networks for facial action unit detection, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35, 2021, pp. 5993–6001.
- [18] M. Rani, S. B. Dhok, R. B. Deshmukh, A systematic review of compressive sensing: Concepts, implementations and applications, IEEE Access 6 (2018) 4875–4894.
- [19] K. Kulkarni, S. Lohit, P. Turaga, R. Kerviche, A. Ashok, Reconnet: Non-iterative reconstruction of images from compressively sensed measurements, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 449–458.
- [20] Y. Wang, H. Palangi, Z. J. Wang, H. Wang, Revhashnet: Perceptually de-hashing real-valued image hashes for similarity retrieval, Signal processing: Image communication 68 (2018) 68–75.
- [21] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, R. Girshick, Masked autoencoders are scalable vision learners, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16000–16009.
- [22] K. Zhao, W.-S. Chu, H. Zhang, Deep region and multi-label learning for facial action unit detection, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3391–3399.
- [23] G. M. Jacob, B. Stenger, Facial action unit detection with transformers, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7680–7689.
- [24] H. Yang, L. Yin, Y. Zhou, J. Gu, Exploiting semantic embedding and visual feature for facial action unit detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10482–10491.
-
[25]
H. Bao, L. Dong, S. Piao, F. Wei,
BEit: BERT
pre-training of image transformers, in: International Conference on Learning
Representations, 2022.
URL https://openreview.net/forum?id=p-BhZSz59o4 - [26] Z. Xie, Z. Zhang, Y. Cao, Y. Lin, J. Bao, Z. Yao, Q. Dai, H. Hu, Simmim: A simple framework for masked image modeling, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 9653–9663.
- [27] J. Gou, B. Yu, S. J. Maybank, D. Tao, Knowledge distillation: A survey, International Journal of Computer Vision 129 (6) (2021) 1789–1819.
- [28] X. Ding, Y. Wang, Z. Xu, Z. J. Wang, W. J. Welch, Distilling and transferring knowledge via cgan-generated samples for image classification and regression, Expert Systems with Applications 213 (2023) 119060.
- [29] G. Hinton, O. Vinyals, J. Dean, et al., Distilling the knowledge in a neural network, arXiv preprint arXiv:1503.02531 2 (7) (2015).
- [30] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, Y. Bengio, FitNet: Hints for thin deep nets, in: International Conference on Learning Representations, 2015.
- [31] G. Xu, Z. Liu, X. Li, C. C. Loy, Knowledge distillation meets self-supervision, in: European Conference on Computer Vision, Springer, 2020, pp. 588–604.
- [32] Y. Wang, Y. Wang, J. Cai, T. K. Lee, C. Miao, Z. J. Wang, Ssd-kd: A self-supervised diverse knowledge distillation method for lightweight skin lesion classification using dermoscopic images, Medical Image Analysis (2022) 102693.
- [33] Y. Liu, L. Sheng, J. Shao, J. Yan, S. Xiang, C. Pan, Multi-label image classification via knowledge distillation from weakly-supervised detection, in: Proceedings of the 26th ACM international conference on Multimedia, 2018, pp. 700–708.
- [34] J. Xu, S. Huang, F. Zhou, L. Huangfu, D. Zeng, B. Liu, Boosting multi-label image classification with complementary parallel self-distillation, arXiv preprint arXiv:2205.10986 (2022).
- [35] L. Song, J. Wu, M. Yang, Q. Zhang, Y. Li, J. Yuan, Handling difficult labels for multi-label image classification via uncertainty distillation, in: Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 2410–2419.
- [36] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020).
- [37] E. Ben-Baruch, T. Ridnik, N. Zamir, A. Noy, I. Friedman, M. Protter, L. Zelnik-Manor, Asymmetric loss for multi-label classification, arXiv preprint arXiv:2009.14119 (2020).
- [38] X. Bresson, T. Laurent, Residual gated graph convnets, arXiv preprint arXiv:1711.07553 (2017).
- [39] X. Zhang, L. Yin, J. F. Cohn, S. Canavan, M. Reale, A. Horowitz, P. Liu, A high-resolution spontaneous 3d dynamic facial expression database, in: 2013 10th IEEE international conference and workshops on automatic face and gesture recognition (FG), IEEE, 2013, pp. 1–6.
- [40] S. M. Mavadati, M. H. Mahoor, K. Bartlett, P. Trinh, J. F. Cohn, Disfa: A spontaneous facial action intensity database, IEEE Transactions on Affective Computing 4 (2) (2013) 151–160.
- [41] I. Loshchilov, F. Hutter, Decoupled weight decay regularization, arXiv preprint arXiv:1711.05101 (2017).
- [42] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, L. Fei-Fei, Imagenet: A large-scale hierarchical image database, in: 2009 IEEE conference on computer vision and pattern recognition, IEEE, 2009, pp. 248–255.