OGMP: Oracle Guided Multi-mode Policies for
Agile and Versatile Robot Control
Abstract
The efficacy of reinforcement learning for robot control relies on the tailored integration of task-specific priors and heuristics for effective exploration, which challenges their straightforward application to complex tasks and necessitates a unified approach. In this work, we define a general class for priors called oracles that generate state references when queried in a closed-loop manner during training. By bounding the permissible state around the oracle’s ansatz, we propose a task-agnostic oracle-guided policy optimization. To enhance modularity, we introduce task-vital modes, showing that a policy mastering a compact set of modes and transitions can handle infinite-horizon tasks. For instance, to perform parkour on an infinitely long track, the policy must learn to jump, leap, pace, and transition between these modes effectively. We validate this approach in challenging bipedal control tasks: parkour and diving—using a 16-DoF dynamic bipedal robot, HECTOR. Our method results in a single policy per task, solving parkour across diverse tracks and omnidirectional diving from varied heights up to in simulation, showcasing versatile agility. We demonstrate successful sim-to-real transfer of parkour, including leaping over gaps up to of the leg length, jumping over blocks up to of the robot’s nominal height, and pacing at speeds of up to m/s, along with effective transitions between these modes in the real robot.
I Introduction
Deep reinforcement learning (RL) has shown remarkable success in synthesizing control policies for hybrid and underactuated legged robots [1], particularly in enabling inherently stable quadrupedal robots to achieve extreme parkour [2, 3, 4], agile [5], and robust [6] locomotion. Following a common philosophy: 1) define an exhaustive observation space, 2) engineer task-specific rewards and/or curriculum, 3) perform policy distillation, and 4) extensively randomize, these methods rely on task-specific tricks in each step, lacking a systematic approach for robot control. Specifically, since Deep RL methods are quasi-solvers for unconstrained optimization, they are prone to anomalous, case-specific local optima. Hence, practitioners often resort to task-specific reward shaping [2, 5, 6] and heuristics [3] for a structured exploration and to meet the intended performance. Furthermore, the established approach for robot control is privileged training and policy distillation: training teacher policies [3, 4] with privileged information, solving a pseudo-MDP with RL, and distilling it into a single policy for the true POMDP. In contrast, we aim to find an optimal policy by structured exploration in the true POMDP guided by priors.

Guided Policy Optimization (GPO) aims to improve sample efficiency and mitigate poor local optima. GPO methods are either Control-guided or Reference-guided. Control-guided approaches require control trajectories: [7, 8] employ prior controllers and policy-trajectory constraints, while [9, 10] alternate trajectory optimization and minimize RL variance. [11, 12, 13] demonstrate quadrupedal locomotion but relying on pre-existing model-based controllers, limiting complex tasks (e.g., parkour). Reference-guided methods like [14, 15, 16, 17, 18] use morphologically similar state-reference trajectories to guide RL to learn the corresponding optimal actions for character control. However, with pre-generated open-loop reference, policy exploration is confined to the demonstration’s scenario, thus hindering the emergent behaviors(like recovery) seen in from-scratch RL methods [1, 3, 2], which explore full-order dynamics and challenging randomization in simulation, crucial for real robot control. Therefore, we propose a reference-guided policy optimization using closed-loop state-reference generators(oracles) that can be queried dynamically to produce references from any state, with a novel hyperparameter to address local optima in complex tasks.
Alternatively, imitation learning (IL) proves to be a reliable task-agnostic strategy for robot manipulation with dynamically consistent demonstrations through proficient human teleoperation, which solves the intended task [19]. In contrast, we have dynamically inconsistent demonstrations for locomotion that partially solve a task, challenging the direct application of IL. For instance, to parkour with a bipedal robot, we may have demonstrations for runs, leaps, and jumps from motion capture on humans, which suffer from morphological dissimilarity due to source-target mismatches [20]. Moreover, naive imitation of partial demonstrations (run, leap, etc.) does not guarantee to solve the overarching task (parkour), requiring high-level RL-trained policy for transitions and emergent behaviors [21, 20, 22]. Besides demonstrations, robot tasks have rich priors like heuristics [23], task/motion planners [24], and model-based controllers[25], which can guide learning, leading to regularized behaviors [13]. While the idea of imitating such priors has been studied, we instead propose building a “trust region” in the state space around the prior’s solution. Thus, the more we “trust” a prior, the tighter the trust region could be and vice versa. Formally defining a general class for priors: oracle, an oracle-guided policy optimization can be performed by bounding the policy’s permissible state space within the local neighborhood of an oracle’s ansatz. Empirically, we observe that the right choice of this bound helps escape erroneous local optima providing an optimal balance between emergent and regularized behaviors ideal for robot control, making it an effective hyperparameter in practice.
On the other hand, solving complex tasks requires behavioral multi-modality. Classical multi-mode control [26, 27]involves switching among a finite set of pre-designed controllers to address high-level tasks, creating a pseudo-hybrid system. Learning methods leave multi-modality in control to emerge implicitly [5, 3], lacking a methodical synthesis. [22] propose encoding a dataset of demonstrations to a latent space and latent conditioning to train multi-skilled policies. However, the notion of skill is poorly defined. For instance, solving a task requires not only mastering discrete modes (e.g., walking, jumping) but also continuous parameter variation of the same (e.g., speed, height) and inter-skill transitions. [2] trains multiple low-level controllers and a high-level mode-switching policy for quadrupedal parkour, requiring diverse reward shaping and training routines. [28] shows that a “fixed” set of uni-mode controllers limits complex transition maneuvers, introducing a single multi-mode policy for mastering a set of modes and transitions to handle new tasks zero-shot. In line with this approach, we aim to achieve a single policy that learns a finite set of modes with “infinite” parameter variations and transitions through reference-guided policy optimization. Unlike switching fixed controllers, we hypothesize that reference-guided exploration can better accommodate emergent control modes. To this end, we first show task-vital multi-modality as a way to decompose tasks into their principal modes and transcribe them into our proposed OGMP framework. Thus, the major contributions of our paper are twofold:
-
•
Oracle Guided Multi-mode Policies: A theoretical framework for task-centered control synthesis leveraging oracle-guided optimization to effectively search through bounded exploration and task-vital multi-modality for versatile control.
-
•
Experimental validation on agile bipedal control tasks requiring versatility, such as parkour and diving. A single policy per task demonstrates the ability to perform diverse variants of the task-vital modes realized in simulation and the real-robot on the 16-Dof bipedal robot Hector.
II Oracle Guided Multi-mode Policies
This section presents our theoretical framework with two synergetic ideas: oracle-guided policy optimization and task-vital multi-modality. Specifically, we aim to prune undesirable local optima by bounding exploration to the local neighborhood of an oracle and by designing the learning of multiple behavior modes and transitions to effectively solve tasks.
II-1 Oracle Guided Policy Optimization(OGPO)
Let be an infinite horizon task with a task parameter set, . Sufficiently solving requires maximizing a task objective, over the task parameter distribution, . Given the corresponding state space (or task space) of interest, let , denote a state at time and a state trajectory from time respectively. We define to be a receding horizon oracle that provides a finite horizon state trajectory () from any given state () until into the future for any task-variant (), such that is always within an of an optimal state trajectory. Formally,
| (1a) | ||||
| s.t. | (1b) | |||
| (1c) | ||||
where is the maximum deviation bound, a constant for a given pair , and is a diagonal weight matrix111Note that are unknown and are only provided for constructing the conceptual argument. We aim to obtain the optimal policy from a policy class guided by that sufficiently solves . Since provides a reference in the state space, we propose constraining the permissible states for to be within a -neighbourhood of the oracle’s guidance. Formally,
| (2a) | ||||
| s.t. | (2b) | |||
Where are the states visited while rolling out policy , is the permissible state-bound for oracle-guided exploration.
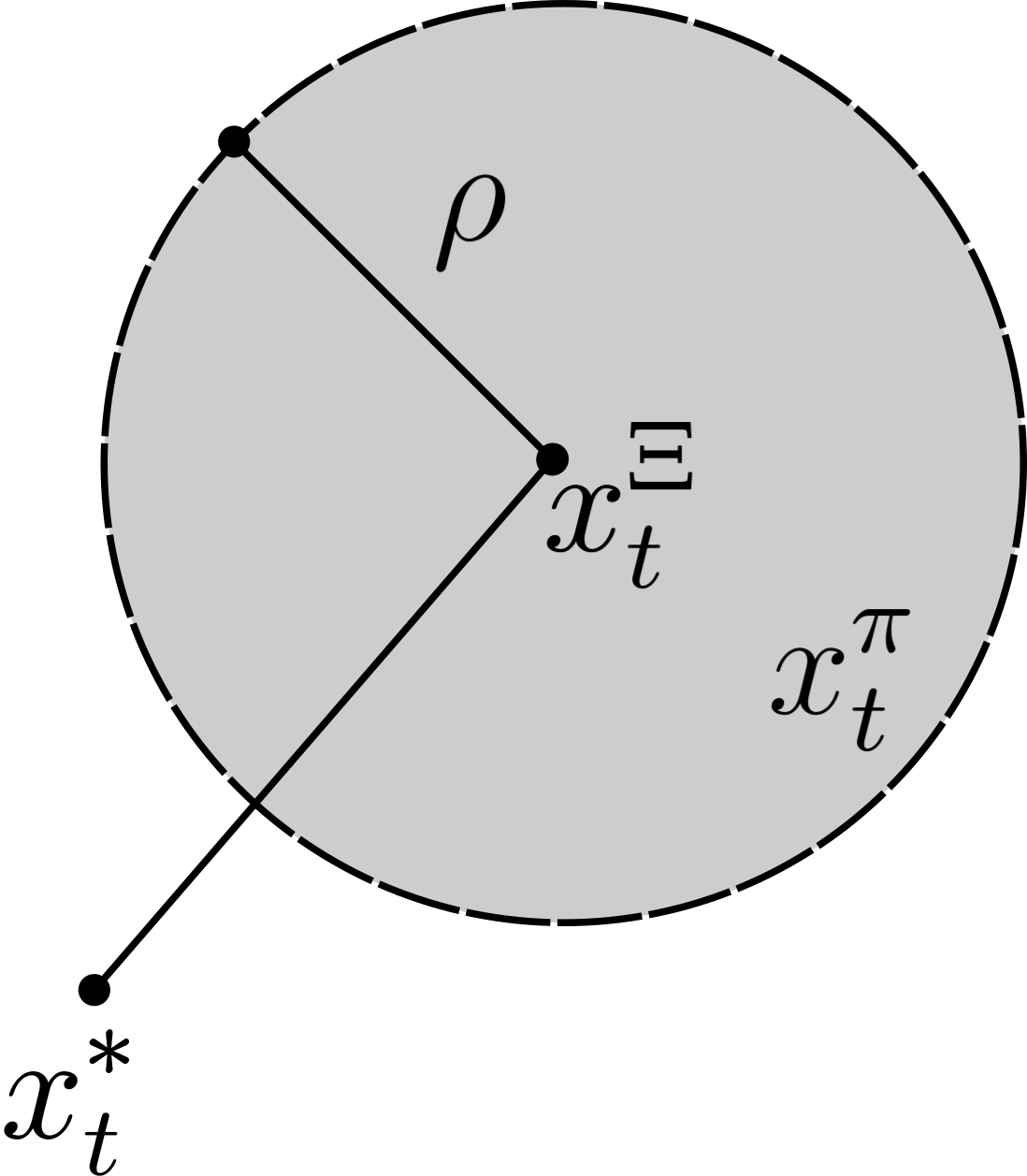
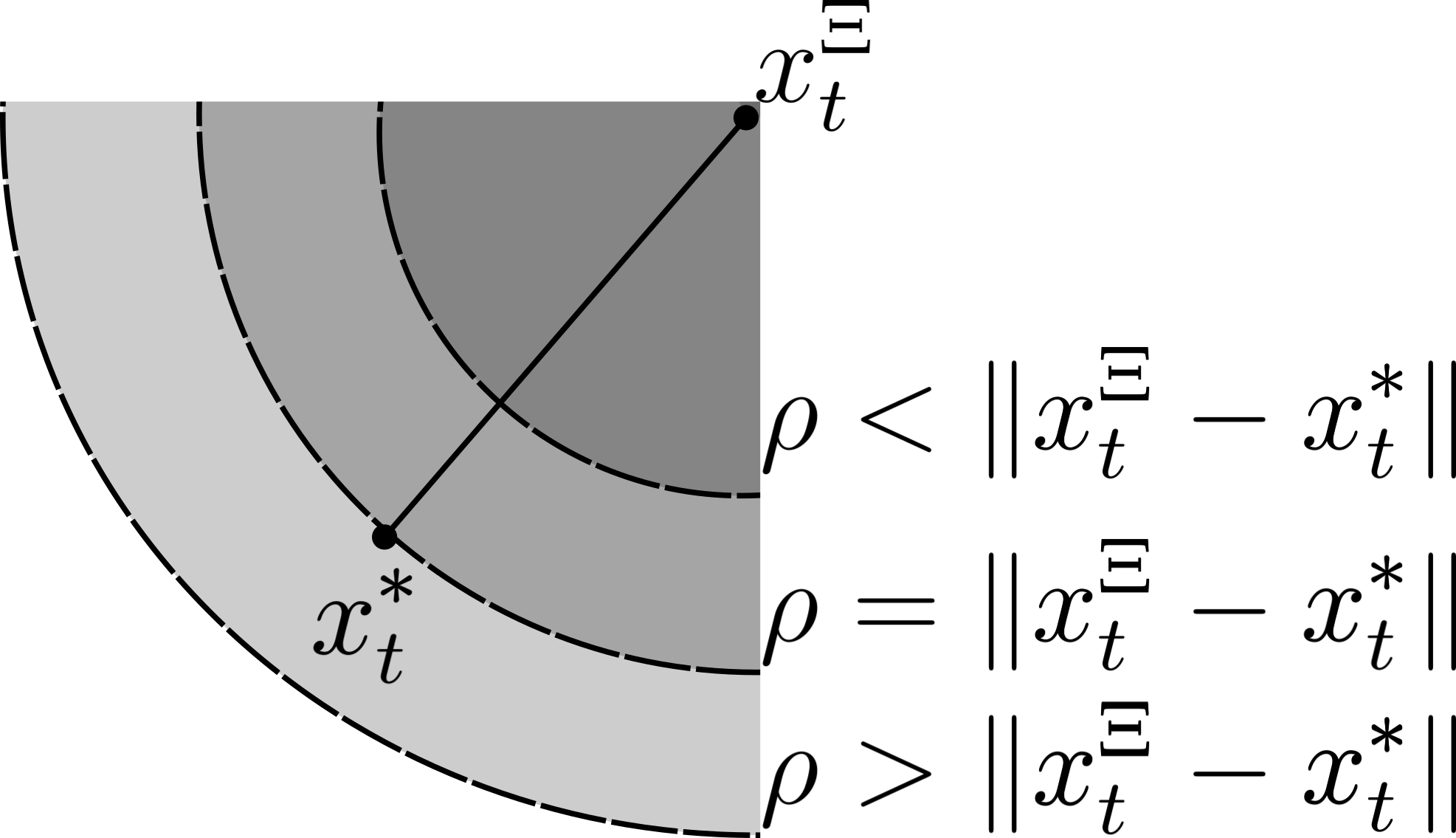
With the above setup, one can observe that the bounded set of permissible states visualized in Fig. 2i is given by
| (3) |
Thus, should be chosen so that is reachable by , which requires the lower bound in Eq. 3, to be non-positive. Therefore as shown in Fig 2ii, for to be within the permissible states of , must satisfy
| (4) |
By definition (Eq. 1.c), since a sufficient choice of to satisfy Eq 4 for all time , is
| (5) |
being maximum deviation of , an oracle with low will generate references closer to thus, the exploration can be bounded to tight-neighborhood to filter out most local optima in the objective landscape In contrast, for a “poor” oracle with high , there should be sufficient search space for to explore around and converge to . From Eq 5, as , the optimization is unguided, thus needing (a standard RL setting). Conversely, as , an arbitrarily small satisfying Eq 5 could be chosen to avoid local optima by localizing the search while still being able to converge . In practice, as is unknown, we perform a grid search over for any given .
II-2 Task Vital Multi-modality
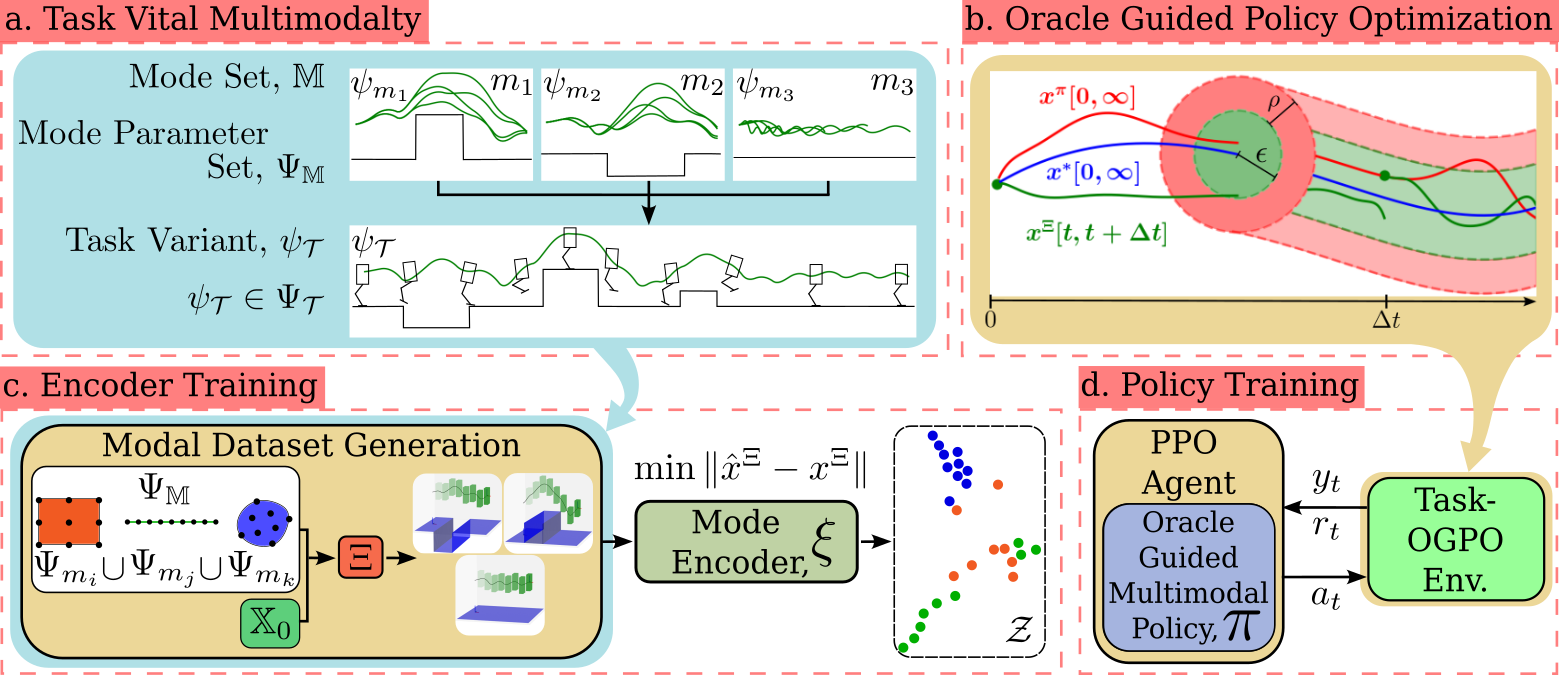
A policy learning to solve a task, , can be seen as mastering a “bundle” of spacetime trajectories in the task space, corresponding to . Simple tasks allow straightforward oracle construction satisfying Eq 1. However, complex and infinite-horizon tasks make intractable. For instance, an oracle for indefinite parkour requires knowledge of an infinite track apriori, which is impractical. To address this, we define modes as finite spacetime segments that preserve some spatial and/or temporal invariances. Like in parkour, modes like jump and leap remain consistent regardless of location or time. Therefore, we define a finite set of modes, , having a temporal length of , vital for . Each (like jump) can have continuous parameters (like jump height). Then the mode parameter set is related to the task parameter set as , where is the number of horizons. Thus, by mastering modes in (jump, leap, and pace) and transitions over varying (speeds, distances, and heights ), task (indefinite parkour, ) can be solved as visualized in Fig 3.a.
III Design Methodology
This section presents the design methodology using OGMP for the bipedal control tasks: parkour and dive, as shown in Fig 3. For a given task, we first define the task-vital modes—such as jump, leap, and pace for parkour—and design a reference generation scheme for each (Fig. 3.a).Spanning the mode parameter set, we employ the oracle to generate a custom dataset of diverse behaviors and train a mode encoder to construct a compact latent space for command conditioning (Fig 3.c). Finally, we train a multi-mode policy guided by the oracle (Fig 3.d). During policy optimization, the oracle is periodically queried to generate references online, bounding the policy’s search space to a reference’s local neighborhood for effective exploration(Fig 3.b) The above approach is explained in detail as follows.
III-A Task description:
We apply the proposed framework to two bipedal control tasks: parkour and dive, with varying objectives and extent of multi-modality as shown in table I. Note that the choice of task-vital multi-mode is user-defined, and table I simply reflects our choice for the same. Evident from table I, is task-dependent. Recent attempts in quadruped parkour [2, 3], and locomotion [6, 1] show some well-shaped candidates for , albeit case-specific. In general, a reasonable could be hard to design (for instance, the dive task); a compelling unified alternative would be to “track” the oracle’s -neighbourhood reference to the optimal solution. Hence, we propose minimizing the task-independent surrogate objective: . ’s applicability is studied in Sec. IV-B and a reward is proposed in Sec III-C for an equivalent maximization objective.
| () | ||
| Mode | Parameters | |
| dive: flip and land | settle | |
| flip | ||
| parkour: traverse the track indefinitely | pace | |
| jump | ||
| leap | ||
III-B Oracle Design
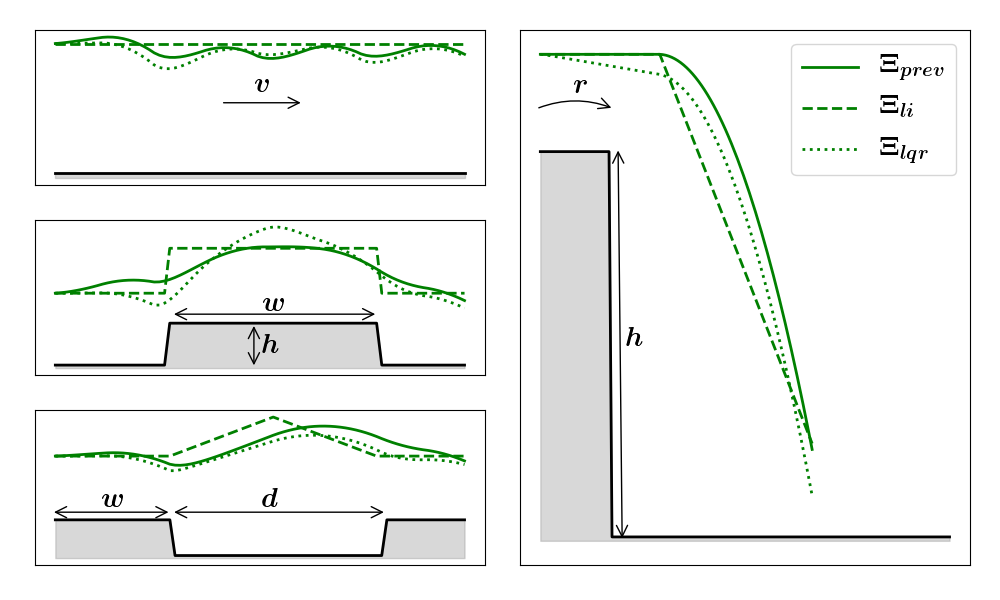
For any locomotion task, a simple heuristic for an oracle would be linearly interpolating the relevant state variables from the initial to the desired goal states. In parkour, to advance along the track, the heading position can be linearly interpolated along the track while adapting to the terrain height, as shown in Fig. 4 (left). For dive, the oracle can linearly interpolate the base height and corresponding rotational DoF from to . Naming this heuristic oracle as (Fig. 4), its high is obvious as the generated ansatz do not consider the system’s inertia and gravity. Hence oracles that capture the dominant dynamics of the hybrid system are required. To this end, we have used a modified version of the simplified Single Rigid Body (SRB) model[25] whose dynamics in the world coordinates are given by:
| (6) | |||
| (7) |
where , is the robot COM acceleration and the angular velocity, are the position, force and moment vectors from the contact point and are the mass, moment of inertia and gravity. Typically, is from a predefined contact schedule, leading to time-varying dynamics. Since, by definition, an oracle need not provide realistic control, we define an auxiliary control , encompassing the overall moment, making the dynamics time-invariant. Additionally, the rotation and rotation rate matrices are made constant by considering the average reference orientation over a horizon. Upon these approximations to Eq. 6 and discretization leads to a linear time-invariant (LTI) system over the current horizon, where are the gravity-augmented state, relevant output, and control vectors. Thus, oracles can be constructed considering two distinct phases: flight and contact. In flight, as there are no contacts, and during contact, an optimizer of choice can be used to compute the optimal control for a given objective, . The reference state trajectory is obtained by applying the corresponding control and forward simulating Eq. 7. Using as the reference for a quadratic tracking objective on the LTI system, optimizing with preview control [29] and LQR results in oracles, and respectively, having a smaller than as shown in Fig 4


III-C Multi-mode Policy:
Mode Encoder: We train a mode encoder, , on diverse locomotion modes to obtain a compact conditioning space ideal for commanding our policy. Similar to [28], the encoder, , maps the trajectory space to a latent space (). Uniformly sampling from a mode parameter set, and a set of initial states, , we generate a rich and balanced modal dataset by querying the oracle, as shown in Fig. 3.c. Minimizing the reconstruction loss for a neurons single hidden layer LSTM auto-encoder on the custom dataset generates a set of latent mode points with a structured clustering as visualized in Fig. 3.c.
Mode Conditioned Policy: Our choice of action space for a stationary policy is from [28]. Given the inherent partial observability of the system, for the observation space we choose , where is the robot’s proprioceptive feedback, is the latent mode command, is a clock signal [28] and is optional task-based feedback (like terrain scan for parkour). The per-step reward for a task-agnostic surrogate tracking objective is defined as
| (8) | ||||
where are the errors in base position and orientations. Thus, minimizes an error in the task space, and regularizes the motion for enhancing sim-to-real. Note for the diverse modes across both the tasks (parkour and dive) the reward weights remain the same, hinting a sense of algorithmic robustness that arises from guided learning. The proposed permissible state constraint (Sec. II) is programmed as a termination condition, terminate episode:= . and are set to for the parkour and dive tasks, respectively, with the remaining entries as zero. For solving the resulting random horizon POMDP, we use off-the-shelf PPO to train a policy: nodes per layer, layer LSTM network, where each episode is an arbitrary variant of the task uniformly sampled from .
IV Results
IV-A Performance
To achieve extreme agility and mode versatility, a single multi-mode policy is trained per task: for parkour and for diving. The supplementary video and Fig 1 show successfully navigating challenging parkour tracks with blocks and gaps placed randomly, demonstrating versatile agility over leap lengths and jump heights. performs omnidirectional flips from different heights and transitions smoothly to landing. Despite lacking a reference for the actuated DoFs, learns an emergent behavior to curl and extend its legs for flips and landings, modulating the torso angular velocity and landing impact. As seen in the video, significantly deviates from the oracle’s reference to find the optimal behavior, yet results in regularized motion due to the oracle bound. Sim-to-real transfer of ’s modes and transitions can be seen in Fig 1,5 and supplementary video.
IV-A1 Agility
For quantitative benchmarking of agility, we report the sample mean of performance metrics: Maximum Heading Acceleration (M.H.A), Froude number (M.F), Maximum Heading Speed (M.H.S), Episode Length (E.L), measured over episode rollouts in table II. We define a test environment with a track length of m, an episode length of steps for the parkour, and an episode length of for the dive. In each case, the episode is terminated only if the episode length is reached or the robot falls down (terrain-relative base height m).
| metric, units | ||||||
|---|---|---|---|---|---|---|
| M.H.A | 4.7g | 3.5g | 3.2g | 3.6g | 3.5g | 3.1g |
| M.H.S () | 1.4 | 1.57 | 1.66 | 1.74 | 1.74 | 1.77 |
| M.F () | 0.48 | 0.56 | 0.64 | 0.69 | 0.70 | 0.72 |
| % E.L | 0.18 | 0.43 | 0.63 | 0.80 | 0.66 | 0.84 |
On average, we find to reach accelerations of with heading speeds of m/s, and Froude numbers between while completing of the track as shown in table II. dynamically advances along the track, avoiding conservative motions with precise foot placements for landing and take-off, leading to agile manevours. The measured Fraude numbers and resulting motion are consistent with [30], where a switch from energy-efficient walking to agile jumping gaits was observed in bipedalism for a value around .
IV-A2 Mode Versatility
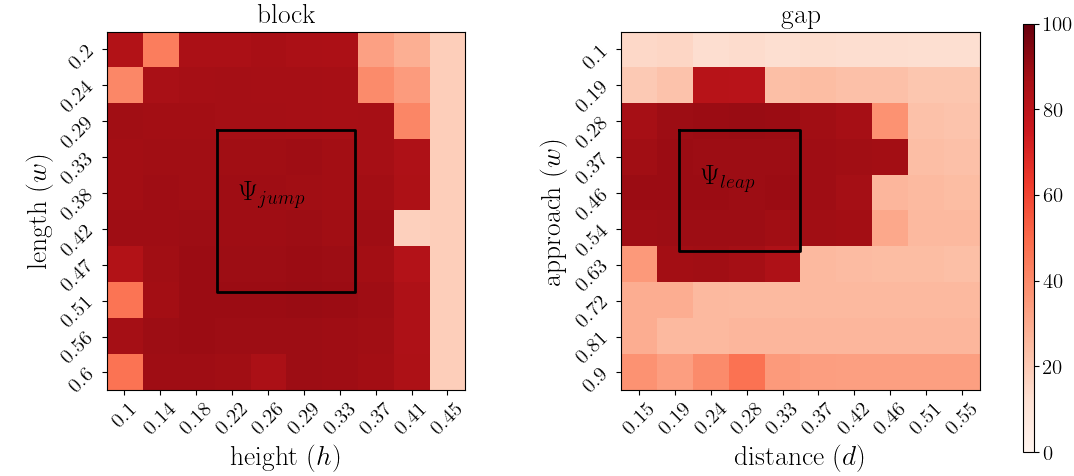
Since the defined of our training is a compact set, we leverage it to visualize the generalization of over mode parameters. Dilating and defining higher test ranges for each parameter, we test for both in-domain (ID) and out-of-domain (OD) generalization. Discretizing this test set, we evaluate and plot the undiscounted returns obtained for blocks and gaps with varying dimensions in Fig 6ii. Different blocks and gaps require jumps and leaps of varying magnitudes, showcasing our policies’ versatility. The training sets are the regions within the boundary marked in black in each plot. Thus, shows consistent performance for variants within the black boundary (ID) while also extrapolating its skills by jumping and leaping over unseen terrain variants outside the black boundary (OD) as seen in the supplementary video and Fig 6ii.
IV-B Ablations and Analysis
Finally, we analyze our choice of surrogate and design choices that impact performance (measured via undiscounted returns). For parkour, a potential true objective, , is the displacement along the track. Thus the validity of using can be quantified through its disparity with .
Choice of observation space : Ablation of observation space components (excluding ) shows that variants with consistently outperform their counterparts (Fig. 6i.a). Variants without are myopic and aggressive, with higher accelerations (table II) as they purely rely on compressed for terrain feedback, making them sub-optimal compared to terrain-aware variants. From Fig. 6i.a, we observe that latent conditioning does not improve performance (see [] and []), hence is purely for analysis and reusability. However, a conditioned can use the oracle as a closed-loop reactive planner during inference, driving the system to the commanded mode. From Fig.6i.a and b, a similar trend of and shows no disparity caused by observation space variations.
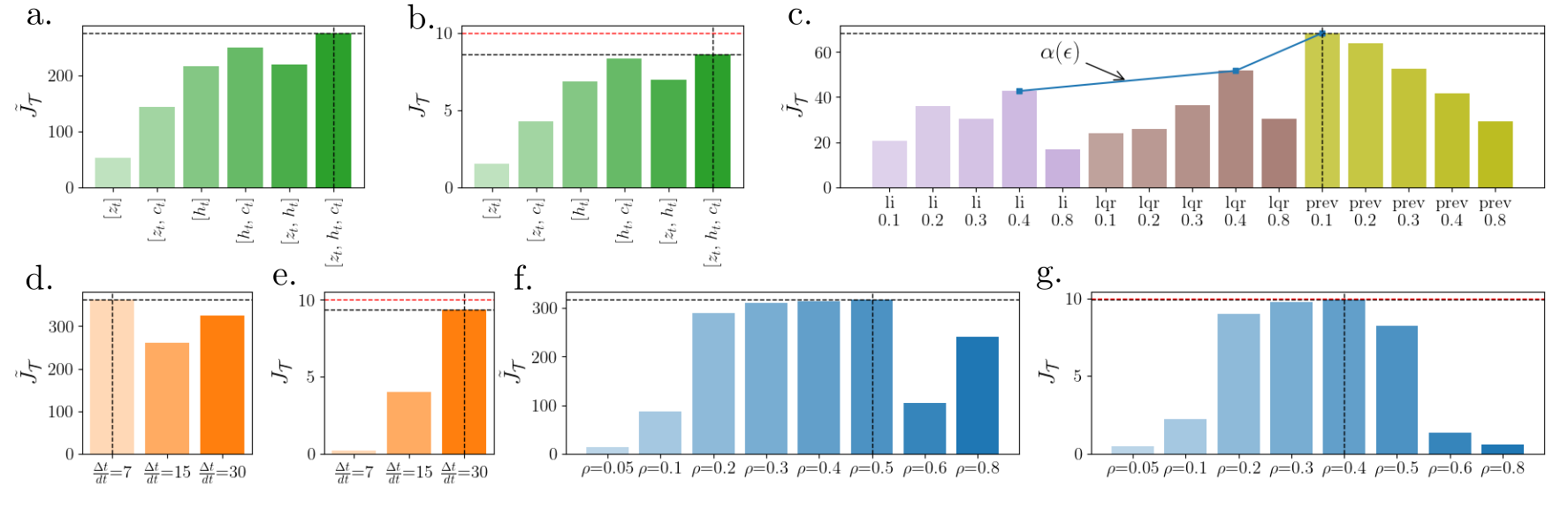
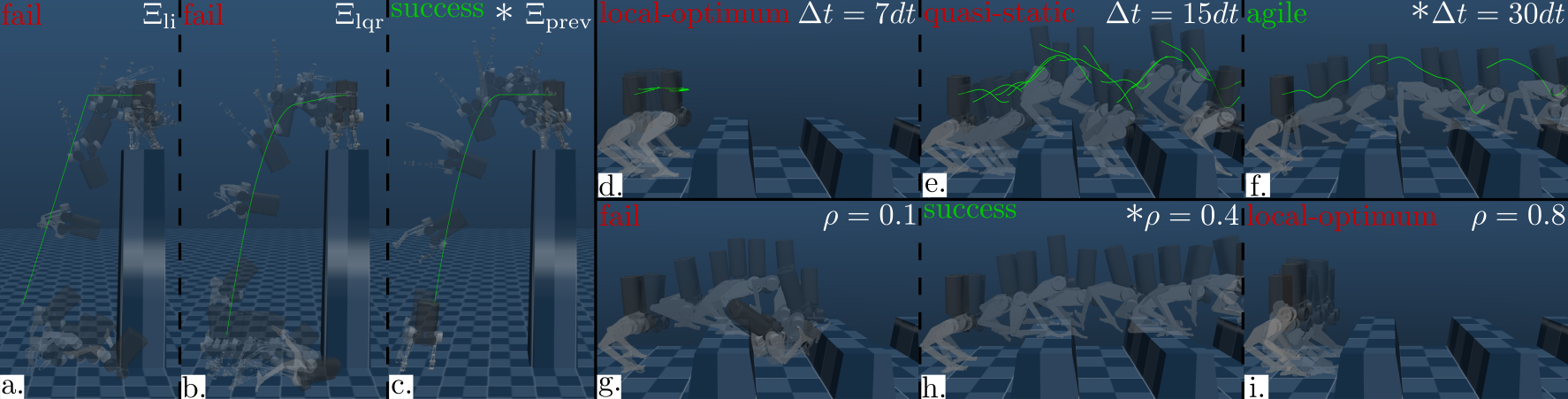
Choice of oracle : The three oracles, , , and , have a non-increasing trend in maximum deviation bound, . As the optimal exploration bound () depends on , we vary from 0.1 to 0.8 for each oracle. For parkour, different oracles show no significant performance difference (see video results). However, for dive, variants perform significantly better (Fig. 6i.c and 6iii.c).A tighter bound () works best for , as it has the lowest . Conversely, higher exploratory deviation () performs best for and . Thus, , affirming Eq 5 .
Choice of oracle’s horizon : We evaluate policy performance across different horizons: , , and for parkour. The shortest horizon, , leads to a myopic behavior, maintaining a high but low as it remains stationary by exploiting the high replanning frequency (Fig. 6iii.d and 6i.d, e) as also observed by [13]. Although advancing forward, fails to anticipate farther terrain, resulting in quasi-static maneuvers (Fig. 6iii.e). Conversely, enables the robot to leap efficiently from block to block, demonstrating agility and achieving the optimal outcome (Fig. 6iii.f). Increasing aligns with the true task objective, (Fig. 6i.d, e).
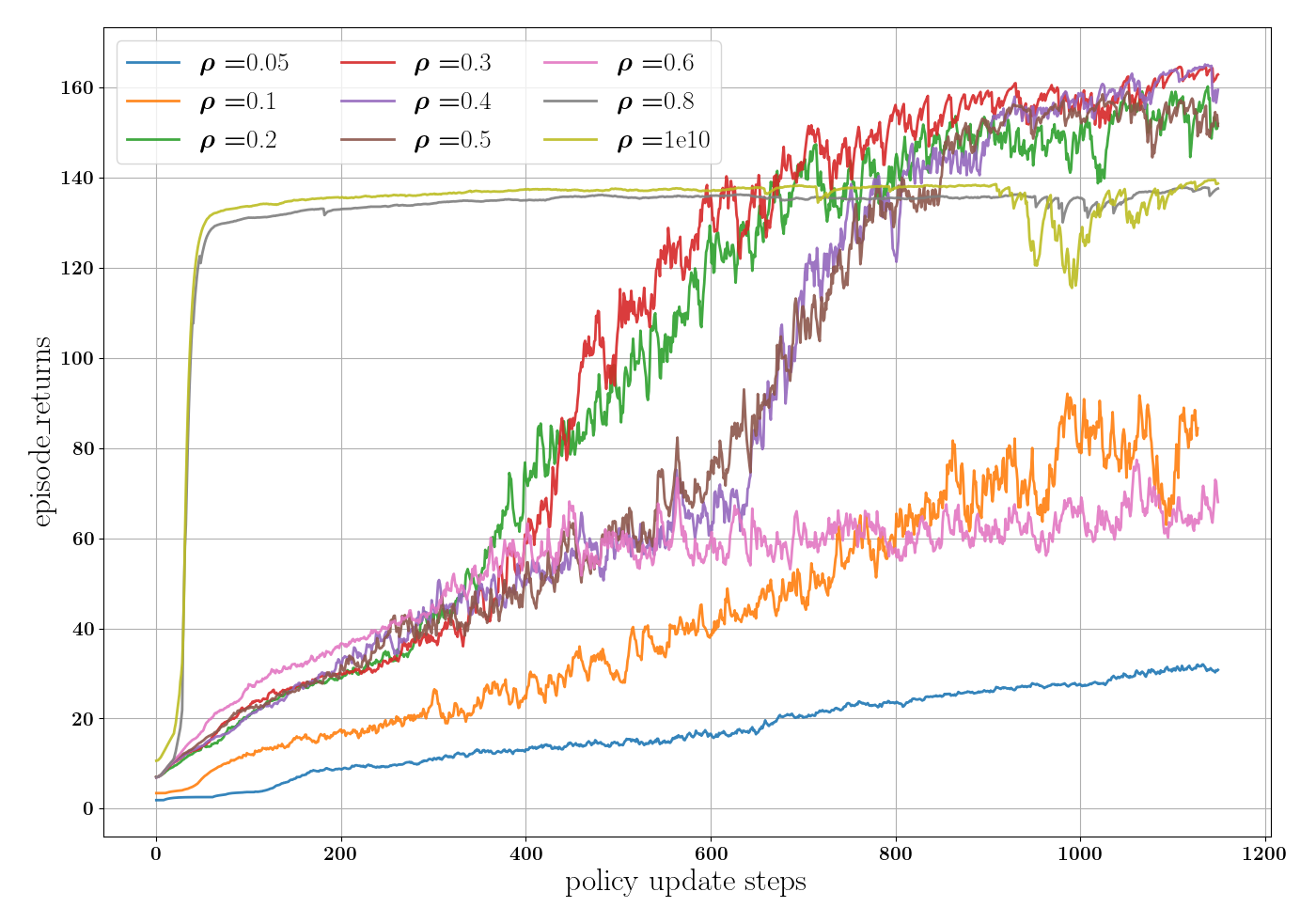
Choice of permissible state bound : For in parkour, we varied from to (Fig. 6i.f and g). We found an optimal with performance decreasing away from this value. For , the optimal solution may lie outside the -neighborhood of (Fig. 6iii.g and Fig. 6iv). Conversely, increases local optima within , leading to sub-optimal solutions (high ), seen in Fig. 6iii.i for , where the policy stagnates without advancing (low ). Training curves in Fig. 6iv show that converges to the global optima, while the rest settle at local optima. Note that is standard PPO as it optimizes unguided by . Vanilla unguided PPO () falls into the same local optima as . Thus, oracle-guided optimization improves standard PPO by escaping local optima with the right choice of .
V Conclusion
This paper introduces a framework for guided policy optimization through prior-bounded permissible states and task-vital multi-modality to tackle complex tasks. A single OGMP (per task) successfully solved agile bipedal parkour and diving, showcasing versatile agility. Future work will aim to extend to contact-rich open-world loco-manipulation tasks. Furthermore, by restricting the reachable states to a subset of the state space, we forgo the possibility of OGMP being a global policy. Consequently, any state outside the -neighbourhood of the oracle’s references may result in failure. Since current Deep RL methods lack any global convergence guarantees, this is nonrestrictive but highlights the need for future extensions for stronger algorithms.
References
- [1] J. Siekmann, K. Green, J. Warila, A. Fern, and J. Hurst, “Blind Bipedal Stair Traversal via Sim-to-Real Reinforcement Learning,” in RSS, 2021.
- [2] D. Hoeller, N. Rudin, D. Sako, and M. Hutter, “Anymal parkour: Learning agile navigation for quadrupedal robots,” Science Robotics, 2024.
- [3] X. Cheng, K. Shi, A. Agarwal, and D. Pathak, “Extreme parkour with legged robots,” in RoboLetics: Workshop @CoRL 2023, 2023.
- [4] Z. Zhuang, Z. Fu, J. Wang, C. G. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao, “Robot parkour learning,” in CoRL, 2023.
- [5] N. Rudin, D. Hoeller, M. Bjelonic, and M. Hutter, “Advanced skills by learning locomotion and local navigation end-to-end,” in IEEE IROS, 2022.
- [6] T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V. Koltun, and M. Hutter, “Learning robust perceptive locomotion for quadrupedal robots in the wild,” Science Robotics, 2022.
- [7] S. Levine and V. Koltun, “Guided policy search,” in Proceedings of the 30th International Conference on Machine Learning (S. Dasgupta and D. McAllester, eds.), vol. 28 of Proceedings of Machine Learning Research, (Atlanta, Georgia, USA), pp. 1–9, PMLR, 17–19 Jun 2013.
- [8] S. Levine and V. Koltun, “Learning complex neural network policies with trajectory optimization,” in Proceedings of the 31st International Conference on Machine Learning (E. P. Xing and T. Jebara, eds.), vol. 32 of Proceedings of Machine Learning Research, (Bejing, China), pp. 829–837, PMLR, 22–24 Jun 2014.
- [9] I. Mordatch and E. Todorov, “Combining the benefits of function approximation and trajectory optimization,” in Proceedings of Robotics: Science and Systems, (Berkeley, USA), July 2014.
- [10] R. Cheng, A. Verma, G. Orosz, S. Chaudhuri, Y. Yue, and J. Burdick, “Control regularization for reduced variance reinforcement learning,” in Proceedings of the 36th International Conference on Machine Learning (K. Chaudhuri and R. Salakhutdinov, eds.), vol. 97 of Proceedings of Machine Learning Research, pp. 1141–1150, PMLR, 09–15 Jun 2019.
- [11] J. Carius, F. Farshidian, and M. Hutter, “Mpc-net: A first principles guided policy search,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 2897–2904, 2020.
- [12] S. Gangapurwala, A. Mitchell, and I. Havoutis, “Guided constrained policy optimization for dynamic quadrupedal robot locomotion,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3642–3649, 2020.
- [13] F. Jenelten, J. He, F. Farshidian, and M. Hutter, “Dtc: Deep tracking control,” Science Robotics, 2024.
- [14] X. B. Peng, P. Abbeel, S. Levine, and M. van de Panne, “Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,” ACM Trans. Graph., vol. 37, pp. 143:1–143:14, July 2018.
- [15] X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa, “Amp: adversarial motion priors for stylized physics-based character control,” ACM Trans. Graph., vol. 40, jul 2021.
- [16] E. Vollenweider, M. Bjelonic, V. Klemm, N. Rudin, J. Lee, and M. Hutter, “Advanced skills through multiple adversarial motion priors in reinforcement learning,” in ICRA 2023, pp. 5120–5126.
- [17] Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath, “Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control,” 2024.
- [18] Z. Luo, J. Wang, K. Liu, H. Zhang, C. Tessler, J. Wang, Y. Yuan, J. Cao, Z. Lin, F. Wang, J. Hodgins, and K. Kitani, “Smplolympics: Sports environments for physically simulated humanoids,” 2024.
- [19] C. Chi, S. Feng, Y. Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” 2023.
- [20] S. Bohez, S. Tunyasuvunakool, P. Brakel, F. Sadeghi, L. Hasenclever, Y. Tassa, E. Parisotto, J. Humplik, T. Haarnoja, R. Hafner, et al., “Imitate and repurpose: Learning reusable robot movement skills from human and animal behaviors,” arXiv preprint arXiv:2203.1713, 2022.
- [21] T. Haarnoja, B. Moran, G. Lever, S. H. Huang, D. Tirumala, J. Humplik, M. Wulfmeier, S. Tunyasuvunakool, N. Y. Siegel, R. Hafner, M. Bloesch, K. Hartikainen, A. Byravan, L. Hasenclever, Y. Tassa, F. Sadeghi, N. Batchelor, F. Casarini, S. Saliceti, C. Game, N. Sreendra, K. Patel, M. Gwira, A. Huber, N. Hurley, F. Nori, R. Hadsell, and N. Heess, “Learning agile soccer skills for a bipedal robot with deep reinforcement learning,” Science Robotics, vol. 9, no. 89, p. eadi8022, 2024.
- [22] L. Hasenclever, F. Pardo, R. Hadsell, N. Heess, and J. Merel, “CoMic: Complementary task learning &; mimicry for reusable skills,” in ICML, PMLR, 2020.
- [23] M. H. Raibert, “Legged robots,” Communications of the ACM, vol. 29, no. 6, pp. 499–514, 1986.
- [24] J. Norby and A. M. Johnson, “Fast global motion planning for dynamic legged robots,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020.
- [25] J. Li and Q. Nguyen, “Force-and-moment-based model predictive control for achieving highly dynamic locomotion on bipedal robots,” in IEEE CDC, 2021.
- [26] T. Koo, G. Pappas, and S. Sastry, “Multi-modal control of systems with constraints,” in Proceedings of the 40th IEEE Conference on Decision and Control (Cat. No.01CH37228), vol. 3, pp. 2075–2080 vol.3, 2001.
- [27] E. Asarin, O. Bournez, T. Dang, O. Maler, and A. Pnueli, “Effective synthesis of switching controllers for linear systems,” Proceedings of the IEEE, vol. 88, no. 7, pp. 1011–1025, 2000.
- [28] L. Krishna and Q. Nguyen, “Learning multimodal bipedal locomotion and implicit transitions: A versatile policy approach,” in IEEE IROS, 2023.
- [29] M. Murooka, M. Morisawa, and F. Kanehiro, “Centroidal trajectory generation and stabilization based on preview control for humanoid multi-contact motion,” IEEE RAL, 2022.
- [30] R. M. Alexander, “The gaits of bipedal and quadrupedal animals,” IJRR, 1984.