On Automatic Parsing of Log Records
Abstract
Software log analysis helps to maintain the health of software solutions and ensure compliance and security. Existing software systems consist of heterogeneous components emitting logs in various formats. A typical solution is to unify the logs using manually built parsers, which is laborious.
Instead, we explore the possibility of automating the parsing task by employing machine translation (MT). We create a tool that generates synthetic Apache log records which we used to train recurrent-neural-network-based MT models. Models’ evaluation on real-world logs shows that the models can learn Apache log format and parse individual log records. The median relative edit distance between an actual real-world log record and the MT prediction is less than or equal to 28%. Thus, we show that log parsing using an MT approach is promising.
1 Introduction
Modern software solutions consist of a stack of hardware and software components [1, 2]. A failure of a component may lead to an outage, affecting the solution’s customers. It is crucial to quickly detect such a failure and identify the potential root cause of the problem to create a fix. Detection of the root cause is a daunting task, taking up to 40% of the time needed to fix the problem [3]. Finding the root causes is done by examining the logs emitted by the solution’s components [3, 4, 5, 6]. Additionally, these logs may be used in the detection of cyberattacks [1] or auditing compliance with policies [1, 7].
There exist tools that do automatic log examinations and speed up diagnostics [3, 4, 5, 6]. Unfortunately, components have individual log formats, while analysis tools prefer the logs in a unified format [2]. Thus, maintainers need to manually create individual converters for every log format [8]. Given that a solution may have thousands of components, this becomes laborious [2, 9]. If one can create a tool that parses logs automatically, this tool will speed up defect detection and repair, allowing developers to focus on creating new functionality and reducing maintenance efforts.
There exists a significant body of literature on recognizing formats. Researchers worked on detecting field type111Note that it is relatively easy to detect some patterns, e.g., dates, using basic RegEx. But a basic RegEx may have challenges understanding if a date belongs to the log record’s timestamp field or if the date is part of a log message itself, which implies that developers will have to code up additional rules. in a structured record set [10], developing parsers rapidly and incrementally [11], extracting specific information from a log string [12, 13, 8, 7], and detecting log formats by comparing multiple similar log strings [14, 9, 15]. But can we individually parse a complete raw log string (so that we can convert it to a universal format) without comparing it to other log records emitted by the same component?
This leads us to the following research question (RQ): How can we automatically parse an individual raw log string? To answer our RQ, we reduce parsing to a machine translation (MT) task. That is, we need to create an Oracle that, given a raw log string as input, will produce a string of tokens, showing which particular field a character in the input string belongs to. A toy example of the input and output is given in Figure 1.
How should an Oracle look? In the field of MT for natural languages, the best models are currently based on deep neural networks (DNNs) following an encoder-decoder architecture that implements sequence-to-sequence learning. We will discuss the details of the models in Section 2.
DNNs require large volumes of data for training. Thus, we create a tool to generate synthetic logs mimicking real ones. We will further discuss synthetic data generation and real logs (used for validation of the models) in Section 3. We will then discuss the setup of our experiments in Section 4, followed by a comparison of the performance of our models in Section 5 and a summary of our findings in Section 6. Finally, we will provide details for accessing the tool and the logs in Section 7.
2020-09-20 jane ERROR file not found
tttttttttt_uuuu_lllll_iiiiiiiiiiiiii
2 Models
We chose DNN architectures, popular for machine translation of natural language. First, we compared recurrent neural networks using gated recurrent units (GRU) [16] against those using long short-term memory (LSTM) [17] cells. Our preliminary experiments showed that LSTM-based translators outperformed the GRU-based ones (hinting that extra memory-related gates present in the LSTM cell but absent in the GRU cell may be necessary for our task). Thus, we focused on LSTM-based translators and converged on three architectures.
The first one, deemed , is based on the classic neural MT architecture akin to [18] with LSTM-based encoder and decoder layers. The second one, deemed , is similar to but added the attention layer as per Bahdanau et al. [19]. The third one, deemed , is based on the seq2seq architecture [20] with the LSTM layers and Luong et al. attention mechanism [21]. During our initial tests we evaluated with and without beam search decoding [22]. We ended up using with regular inference as initial tests found beam search evaluation to be inferior for our datasets.
3 Logs under study
In this work, we focus on log formats of the Apache HTTP server [23]. The ubiquitousness of this product makes it a good candidate for our tests.
We will discuss our generator tool, designed to create synthetic Apache log records in Section 3.1. Then we will discuss the real-world datasets in Section 3.2, followed by the description of the synthetic datasets used for training the Oracle in Section 3.3.
3.1 Synthetic logs’ generator
As discussed above, to train DNNs, we need large volumes of data. There exist tools for generating synthetic logs, e.g., [24, 25]. However, for the training of the DNNs, we need not only the raw log strings, which will serve as input to a DNN, but also the information about the log strings’ format that will be used as output from the model.
Most of the generators use the Apache Common Log Format (hereby referred to as CLF) or Combined Log Format (an extended version of CLF hereby referred to as ELF). Explanations of what these formats look like can be found in Table 1 (for details, see Apache manual [26]).
While CLF and ELF are the most common forms of Apache logs, we did not feel confident that a DNN trained solely on CLF and ELF could accomplish our goal of recognizing the fields of any Apache log. Additionally, the existing fake log generators did not vary much in their generated data, often using the current date of generation as the date for each log record and using a small subset of fake websites and sub-pages for which it would create requests. Furthermore, in order to train the DNNs, we needed ‘ground truth’ output strings, which would be easier to generate alongside the log strings rather than after the fact.
Thus, we created our own Python-based generator, which extends and combines the Faker [24] and fake-useragent [27] libraries. These libraries were used to realistically generate specifically-formatted fields, such as the user agent field and IPv6 addresses.
Our generator creates synthetic log records based on 15 fields222There are permutations of log formats that can be generated from these 15 fields. For efficiency, we only implemented these 15 fields out of 43 total possible Apache fields [23]. The generator can be easily extended with additional fields, if required. and one separator field listed in Table 2. The user should specify the total number of the log records to produce and the type of format (random or fixed). The tool then generates raw log records (input) and the associated translations (outputs). An example of the generated data is shown in Figure 2.
| Name | Fields (acronyms) |
|---|---|
| Common Log Format (CLF) | h l u t "r" s b |
| Combined Log Format (ELF) | h l u t "r" s b "R" "i" |
| Field | Field |
| acronym | description |
| h | IP address of the client host. Can be IPv4 or IPv6. |
| l | The remote logname. We were unable to find a good example of what kinds of values are returned by Apache servers, thus for this paper we only supplied the commonly-given value ‘-’. This field could not be omitted as it is present in both the ELF and CLF formats. |
| u | The remote username. Can be empty (‘-’) |
| t | The datetime of the request, presented in the default [day/month/year:hour:minute:second zone] format. |
| r | The request line from the client. Made up of the method, path and querystring, and protocol. |
| s | The status of the request. |
| b | The number of bytes sent. |
| m | The request method. |
| U | The requested URI path. |
| H | The request protocol. |
| q | The request querystring. |
| v | The canonical servername of the server servicing the request. |
| V | The servername according to UseCanonical. In our generator, this field is identical to the v field. |
| i | The user agent of the request333 In a real Apache HTTP server deployment, this field is extracted from the %i log parameter, see [23] for details.. |
| R | The referrer of the request3. |
| _ | Represents a separator between log fields. |
1: 41.193.93.229 - - 10/Jul/7983:05:08:49 +0100 "GET explore/category/home.html HTTP/2" 302 65953
2: hhhhhhhhhhhhh_l_u_tttttttttttttttttttttttttt_rrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr_sss_bbbbb
3: 192.168.4.25 - - [22/Dec/2016:16:11:41 +0300] "POST /DVWA/login.php HTTP/1.1" 200 1532 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; w3af.sf.net"
4: hhhhhhhhhhhh_l_u_[tttttttttttttttttttttttttt]_"rrrrrrrrrrrrrrrrrrrrrrrrrrrrr"_sss_bbbb_"R"_"iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii"
5: PUT ycgmvjc.com HTTP/2 - 102186 - d8idf~gyck.html
6: mmm_VVVVVVVVVVV_HHHHHH_l_bbbbbb_F_UUUUUUUUUUUUUUU
3.2 Real logs
To validate the generalizability of the DNNs trained on synthetic log records produced by the generator discussed in Section 3.1, we take three publicly available log files and deem the validation datasets [28], [29], and [30]. The first two logs capture execution results of two web vulnerability scanners, namely, Netsparker and Acunetix [31]. The third one is a sample Apache web server log file that can be processed by Elastic software. The summary statistics of the log files is shown in Table 3.
The log format of the validation logs is (or is extremely similar to) ELF444The log records of and were wrapped in quotes ("), which makes them a slightly different format from ELF. While this is likely a product of processing and these quotes could be removed, we opted to keep them for training completeness.. We have parsed the log records from these three files using custom scripts to produce the correct character-to-field mapping strings.
3.3 Synthetic datasets
Using our log generator (covered in Section 3.1), we create synthetic logs for training and testing, while varying the number of log records and their formats. We create five synthetic datasets that may help us uncover various challenges of the “log translation” task. The datasets summary statistics are given in Table 3; their details are as follows.
The first dataset, deemed , contains trivial-to-learn data. The triviality of this dataset refers to the ability of models trained on this set to learn the fields and correctly interpret the validation datasets. consists of 100K ELF mock logs. The models trained on this dataset should be able to recognize the ELF-based log records from our validation datasets very well. However, the generalizability to other formats would be mediocre.
The second dataset, deemed , has easy-to-learn data. It contains 20K lines using a mix of the formats: ELF, CLF, and randomly generated records, which are generated based on all the fields in Table 2. The random and CLF records are added to assess the generalizability of the model. Hypothetically, models trained on and validated on datasets will have worse performance than those trained on , because it has fewer log records and the model has to learn of multiple formats.
The third dataset, deemed , contains moderately-difficult-to-learn data. contains a mix of formats: of 100K records are in the CLF format and have randomly generated formats. Based on Table 1, CLF is similar to ELF, but two of the fields (R and i) are missing. Thus, it will be harder for the model to recognize ELF records in .
The fourth dataset, deemed , is a shorter version of containing only 20K records. The more observations a dataset has, the more information a machine learning model will obtain for training. However, this comes at a cost of increased training time. Thus, we want to see how the change in observations affects models’ performance. will help us assess how much data are needed for training.
The fifth dataset, deemed , carries hard-to-learn data. This dataset contains 100K randomly generated records, and none of them look like CLF or ELF. Thus, models trained on this dataset must learn the nature of the fields well in order to properly parse log records in .
| Dataset | Log records | Log records length | Log records’ format description | ||
| count | min | median | max | ||
| 100,000 | 136 | 272 | 1173 | ELF | |
| 20,000 | 4 | 250 | 1173 | of the ELF format, of the CLF format, and of randomly drawn and reshuffled fields shown in Table 2. The random strings have to records in them. | |
| 100,000 | 4 | 161 | 1294 | of the CLF format and of the randomly generated records using the same approach as in the case. The random strings have to fields in them. | |
| 20,000 | 4 | 162 | 1527 | Identical to the one of . | |
| 100,000 | 4 | 291 | 1528 | of the randomly generated records using the same approach as in the case. The random strings have to fields in them. | |
| 7,314 | 194 | 238 | 602 | 100% ELF | |
| 6,539 | 79 | 238 | 4398 | 100% ELF | |
| 10,000 | 81 | 231 | 1363 | 100% ELF | |
4 Experimental Setup
We want to assess the generalizability of our approach. To do this, we create three groups of experiments where a model is trained on Training Datasets (described in Section 3.3). We train the neural networks for up to 300 epochs with a mini-batch size of 64 log records. Optimization is done using the Adam algorithm555We used learning rate of , , , and . [32]. Each dataset is randomly split into 90% training data and 10% validation data during training. The best model, preserved for further evaluation, is the one with the lowest cross-entropy loss for and and sparse categorical cross-entropy loss for . Translation is done at the character-level, i.e., we do not do any log record prepossessing.
We have tuned the models’ hyper-parameters. For and , we have experimented with different number of cells in these layers, namely . This was done to assess the degree of ‘freedom’ required to recognize different log formats. We also varied the dropout rates in the encoder and decoders layer, setting them to . This was done to regularize the model and reduce overtraining.
We evaluate the performance of the models on three real-world log files (discussed in Section 3.2). The performance is measured using the Levenshtein (a.k.a. the edit) distance [33], which computes the number of changes needed to transform a string returned by the Oracle into an expected (ground truth) string. We report the absolute and relative Levenshtein distances, deemed and , respectively. For a given log record, is computed by dividing by the log record length. and lie within range: the closer to — the better.
5 Results
5.1 Comparison approach
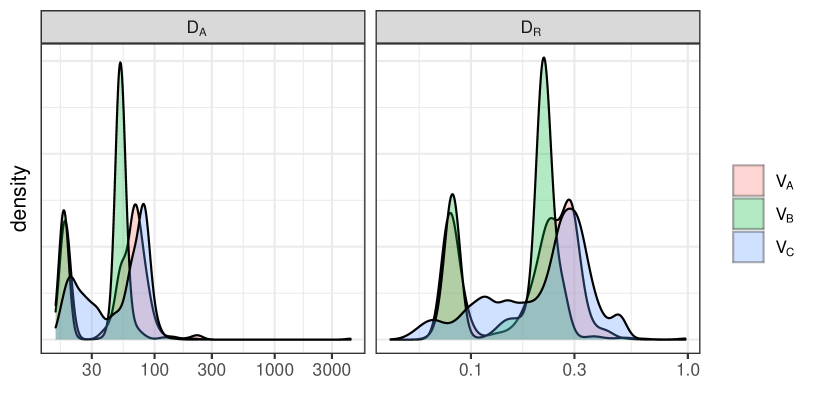
It is easy to measure and for individual strings. However, how to aggregate the measurements for a particular dataset? Let us look at the distributions of the and values. For the sake of brevity, we show the distributions only for the models trained on in Figure 3. As we can see, the distributions have a long right tail: although the median values of are between 51 and 61, the max values go up to 4283. This is due to the presence in and of a small number of long log records (as shown in Table 3). Namely, less than 0.2% of log records are longer than 1000 characters, while the median length of the log records is between 231 and 238 characters for all three . Once we normalize the results using the , we can see that the amount of changes is proportional to the string’s length, with the median between 21 and 25%.
To preserve space and allow quantitative comparison, we present the summary statistics for the remaining evaluations by computing min, max, mean, and various quantiles of the distributions. The results for the top models, based on the lowest values of and for a given quantile, are shown in Table 4.
Trained on min avg max min avg max min avg max 7 33 13 21 101 119 224 298 7 22 14 14 17 33 105 4150 2 22 9 17 78 83 169 419 13 43 22 32 121 151 277 426 11 30 23 23 25 51 140 3566 7 23 18 24 33 59 77 1050 10 35 20 25 59 122 305 491 10 29 19 20 22 45 136 4145 6 22 13 21 37 102 174 853 21 63 56 78 100 122 305 477 22 61 58 58 65 78 204 4242 17 70 70 91 113 116 184 1281 17 55 59 71 86 92 203 240 16 51 51 53 57 59 124 4283 15 56 61 80 88 93 108 1146 15 69 68 88 113 135 233 476 16 60 59 61 67 97 201 4285 15 66 66 85 105 110 202 1241 0.03 0.11 0.06 0.08 0.33 0.36 0.50 0.59 0.03 0.06 0.06 0.06 0.06 0.11 0.34 2.18 0.01 0.12 0.04 0.09 0.27 0.50 1.75 2.02 0.05 0.15 0.08 0.10 0.39 0.46 0.61 0.71 0.05 0.10 0.10 0.10 0.10 0.17 0.43 0.82 0.03 0.10 0.08 0.09 0.15 0.35 0.47 0.77 0.05 0.12 0.08 0.09 0.20 0.40 0.69 0.82 0.04 0.09 0.08 0.08 0.10 0.15 0.46 0.94 0.03 0.11 0.05 0.10 0.20 0.51 0.63 0.75 0.09 0.23 0.23 0.26 0.33 0.39 0.70 0.80 0.09 0.22 0.24 0.24 0.29 0.29 0.61 0.97 0.09 0.30 0.29 0.36 0.43 0.59 0.69 0.94 0.07 0.20 0.23 0.28 0.30 0.33 0.42 0.58 0.06 0.18 0.21 0.22 0.25 0.26 0.37 0.97 0.04 0.24 0.25 0.31 0.36 0.42 0.48 0.84 0.07 0.25 0.28 0.31 0.40 0.45 0.63 0.79 0.06 0.21 0.25 0.25 0.26 0.35 0.61 0.97 0.06 0.28 0.27 0.32 0.43 0.63 0.64 0.91
5.2 Discussion
5.2.1 Architecture comparison
The models with the attention mechanisms ( and ) underperformed and are not shown in Table 4; the -based models are the winners. The poor performance may suggest that the attention mechanisms, which work well for natural language translation, are less suited for our problem.
5.2.2 Hyperparameters
Table 4 shows that the models with 512 cells prevailed, which may imply that we do need some degree of freedom to learn the patterns but not too much to overwhelm the optimizer.
The dropout rate is the best in all cases, except for models trained on . In this particular case, a dropout of and provide similar results. We expected the dropout to be positive as our goal is to generalize the learning process, and these expectations were met.
5.2.3 Dataset size
Comparison of results for and in Table 4 suggests that the larger number of observations improves performances of the model. However, we can observe the diminishing returns: increasing the dataset size by a factor of five (as in the case of and ) leads to incremental improvements in the and values.
Moreover, compare the results for models trained on and : the model trained on 20K of simpler observations from performs better than the model trained on 100K harder records from . This implies that the quality of the input matters more than the quantity.
5.2.4 Training time
We used Nvidia Tesla P100 and Titan X Pascal GPUs for the training. The training time per epoch (for datasets with 100K log records) ranged between one and three hours, depending on the models and inputs. Thus, training the model for hundreds of epochs is time-consuming. We observed that the validation loss would often reach the lowest (best) values between 60 and 150 epochs during models’ training, which enabled us to perform early stopping and save time.
5.2.5 Training datasets vs. models’ performance
As expected, the resulting models’ performance degrades as the difficulty of the training dataset increases. The -based model came up first (with the exception of a few high quantiles): it had to learn only the fields’ beginning and end while the fields’ order stayed the same. The -based model came last: not only did the model have to understand the beginning and ends of the fields, but also it had to learn the field’s order while never been able to see a single example of the ELF record. To our pleasant surprise, the -based model did not fall behind their competitors significantly and was quite close to the -based model, with the median between and , and the 90-th quantile of between and . This implies that the -based model was able to learn the concept of fields relatively well.
6 Summary
Our RQ was: How can we automatically parse an individual raw log string? To answer the RQ, we reformulated parsing as an MT task and explored three MT architectures. We showed that the models based on the classic LSTM MT architecture are the most promising. Moreover, the model trained on randomly generated log records was able to partially parse the log records in a format that it did not see in training: 50% of log records per evaluation dataset were parsed with the and 90% of records with the . This implies that parsing of the individual strings using MT is possible.
This work is of interest to researchers as it provides novel insights into the log parsing field. The quality of our models’ translation is not adequate for the practitioner at this stage, but we hope that this work will inspire others to explore various MT approaches and improve upon our results.
To aid these researchers, we created a tool for generating synthetic logs in Apache format used for creating training data for the models. We also found and parsed three real-world validation logs for models’ evaluation.
7 Data Availability
References
- [1] T. Yen, A. Oprea, K. Onarlioglu, T. Leetham, W. K. Robertson, A. Juels, and E. Kirda, “Beehive: large-scale log analysis for detecting suspicious activity in enterprise networks,” in Annual Computer Security Applications Conference, ACSAC ’13. ACM, 2013, pp. 199–208. [Online]. Available: https://doi.org/10.1145/2523649.2523670
- [2] A. V. Miranskyy, A. Hamou-Lhadj, E. Cialini, and A. Larsson, “Operational-log analysis for big data systems: Challenges and solutions,” IEEE Software, vol. 33, no. 2, pp. 52–59, 2016. [Online]. Available: https://doi.org/10.1109/MS.2016.33
- [3] S. S. Murtaza, A. Hamou-Lhadj, N. H. Madhavji, and M. Gittens, “An empirical study on the use of mutant traces for diagnosis of faults in deployed systems,” Journal of Systems and Software, vol. 90, pp. 29–44, 2014. [Online]. Available: https://doi.org/10.1016/j.jss.2013.11.1094
- [4] A. V. Miranskyy, N. H. Madhavji, M. Gittens, M. Davison, M. Wilding, and D. Godwin, “An iterative, multi-level, and scalable approach to comparing execution traces,” in Proceedings of the 6th joint meeting of the European Software Engineering Conference and the ACM SIGSOFT International Symposium on Foundations of Software Engineering, 2007. ACM, 2007, pp. 537–540. [Online]. Available: https://doi.org/10.1145/1287624.1287704
- [5] I. Beschastnikh, Y. Brun, M. D. Ernst, and A. Krishnamurthy, “Inferring models of concurrent systems from logs of their behavior with csight,” in 36th International Conference on Software Engineering, ICSE ’14. ACM, 2014, pp. 468–479. [Online]. Available: https://doi.org/10.1145/2568225.2568246
- [6] L. Mariani, M. Pezzè, and M. Santoro, “Gk-tail+ an efficient approach to learn software models,” IEEE Transactions on Software Engineering, vol. 43, no. 8, pp. 715–738, 2017. [Online]. Available: https://doi.org/10.1109/TSE.2016.2623623
- [7] F. Dernaika, N. Cuppens-Boulahia, F. Cuppens, and O. Raynaud, “Semantic mediation for A posteriori log analysis,” in Proceedings of the 14th International Conference on Availability, Reliability and Security, ARES 2019. ACM, 2019, pp. 88:1–88:10. [Online]. Available: https://doi.org/10.1145/3339252.3340104
- [8] P. He, J. Zhu, Z. Zheng, and M. R. Lyu, “Drain: An online log parsing approach with fixed depth tree,” in 2017 IEEE International Conference on Web Services, ICWS 2017. IEEE, 2017, pp. 33–40. [Online]. Available: https://doi.org/10.1109/ICWS.2017.13
- [9] S. Messaoudi, A. Panichella, D. Bianculli, L. C. Briand, and R. Sasnauskas, “A search-based approach for accurate identification of log message formats,” in Proceedings of the 26th Conference on Program Comprehension, ICPC 2018. ACM, 2018, pp. 167–177. [Online]. Available: https://doi.org/10.1145/3196321.3196340
- [10] M. Hulsebos et al., “Sherlock: A deep learning approach to semantic data type detection,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019. ACM, 2019, pp. 1500–1508. [Online]. Available: https://doi.org/10.1145/3292500.3330993
- [11] O. Nierstrasz, M. Kobel, T. Gîrba, M. Lanza, and H. Bunke, “Example-driven reconstruction of software models,” in 11th European Conference on Software Maintenance and Reengineering, Software Evolution in Complex Software Intensive Systems, CSMR 2007. IEEE Computer Society, 2007, pp. 275–286. [Online]. Available: https://doi.org/10.1109/CSMR.2007.23
- [12] Q. Fu, J. Lou, Y. Wang, and J. Li, “Execution anomaly detection in distributed systems through unstructured log analysis,” in ICDM 2009, The Ninth IEEE International Conference on Data Mining. IEEE Computer Society, 2009, pp. 149–158. [Online]. Available: https://doi.org/10.1109/ICDM.2009.60
- [13] A. Makanju, A. N. Zincir-Heywood, and E. E. Milios, “A lightweight algorithm for message type extraction in system application logs,” IEEE Transactions on Knowledge and Data Engineering, vol. 24, no. 11, pp. 1921–1936, 2012. [Online]. Available: https://doi.org/10.1109/TKDE.2011.138
- [14] M. Du and F. Li, “Spell: Streaming parsing of system event logs,” in IEEE 16th International Conference on Data Mining, ICDM 2016. IEEE Computer Society, 2016, pp. 859–864. [Online]. Available: https://doi.org/10.1109/ICDM.2016.0103
- [15] D. El-Masri, F. Petrillo, Y. Guéhéneuc, A. Hamou-Lhadj, and A. Bouziane, “A systematic literature review on automated log abstraction techniques,” Information and Software Technology, vol. 122, p. 106276, 2020. [Online]. Available: https://doi.org/10.1016/j.infsof.2020.106276
- [16] K. Cho, B. van Merrienboer, Ç. Gülçehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio, “Learning phrase representations using RNN encoder-decoder for statistical machine translation,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, A meeting of SIGDAT, a Special Interest Group of the ACL. ACL, 2014, pp. 1724–1734. [Online]. Available: https://doi.org/10.3115/v1/d14-1179
- [17] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997. [Online]. Available: https://doi.org/10.1162/neco.1997.9.8.1735
- [18] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” in Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, 2014, pp. 3104–3112. [Online]. Available: http://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks
- [19] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” in 3rd International Conference on Learning Representations, ICLR 2015, 2015. [Online]. Available: http://arxiv.org/abs/1409.0473
- [20] D. Britz, A. Goldie, M. Luong, and Q. V. Le, “Massive exploration of neural machine translation architectures,” CoRR, vol. abs/1703.03906, 2017. [Online]. Available: http://arxiv.org/abs/1703.03906
- [21] T. Luong, H. Pham, and C. D. Manning, “Effective approaches to attention-based neural machine translation,” in Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015. The Association for Computational Linguistics, 2015, pp. 1412–1421. [Online]. Available: https://doi.org/10.18653/v1/d15-1166
- [22] Y. Wu et al., “Google’s neural machine translation system: Bridging the gap between human and machine translation,” CoRR, vol. abs/1609.08144, 2016. [Online]. Available: http://arxiv.org/abs/1609.08144
- [23] Apache module mod_log_config. [Online]. Available: https://httpd.apache.org/docs/current/mod/mod_log_config.html
- [24] Faker package documentation. [Online]. Available: https://faker.readthedocs.io/en/master/#
- [25] kiritbasu/fake-apache-log-generator: Generate a boatload of fake apache log files very quickly. [Online]. Available: https://github.com/kiritbasu/Fake-Apache-Log-Generator
- [26] Log files. [Online]. Available: https://httpd.apache.org/docs/1.3/logs.html#combined
- [27] fake-useragent package documentation. [Online]. Available: https://fake-useragent.readthedocs.io/en/stable/
- [28] apache-http-logs/netsparker.txt at master · ocatak/apache-http-logs. [Online]. Available: https://github.com/ocatak/apache-http-logs/blob/master/netsparker.txt
- [29] apache-http-logs/acunetix.txt at master · ocatak/apache-http-logs. [Online]. Available: https://github.com/ocatak/apache-http-logs/blob/master/acunetix.txt
- [30] examples/apache_logs at master · elastic/examples. [Online]. Available: https://github.com/elastic/examples/blob/master/Common%20Data%20Formats/apache_logs/apache_logs
- [31] M. B. Seyyar, F. Özgür Çatak, and E. Gül, “Detection of attack-targeted scans from the apache http server access logs,” Applied Computing and Informatics, vol. 14, no. 1, pp. 28–36, 2018. [Online]. Available: https://doi.org/10.1016/j.aci.2017.04.002
- [32] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in 3rd International Conference on Learning Representations, ICLR 2015, Conference Track Proceedings, 2015. [Online]. Available: http://arxiv.org/abs/1412.6980
- [33] V. I. Levenshtein, “Binary codes capable of correcting deletions, insertions, and reversals,” in Soviet physics doklady, vol. 10, no. 8, 1966, pp. 707–710.
- [34] J. Rand and A. Miranskyy. (2021) Log generating tool. [Online]. Available: https://github.com/WulffHunter/log_generator
- [35] ——. (2021) Log parsing: generators. [Online]. Available: https://doi.org/10.5281/zenodo.4536575
- [36] ——. (2021) Log parsing: datasets. [Online]. Available: https://doi.org/10.5281/zenodo.4536514