On maximizers of convolution operators in spaces
Abstract
We consider a convolution operator in with kernel in acting from to , where . The main theorem states that if , then there exists an function of unit norm on which the -norm of the convolution is attained. A number of questions, related to the statement and proof of the main theorem, are discussed. Also the problem of computing best constants in the Hausdorff-Young inequality for the Laplace transform, which prompted this research, is considered.
Keywords: convolution, Young inequality, existence of extremizer, concentration compactness, tight sequence, Laplace transform, best constants.
MSC 44A35, 49J99, 44A10, 41A44
1 Introduction
Let denote the Lebesgue space of measurable complex-valued functions with norm , where , or with norm . Throughout, denotes the conjugate exponent. We consider a convolution operator with kernel ,
As long as there is no ambiguity, we use shorthand notation: instead of , instead of , and instead of . (If is a family of kernels depending on a parameter, we write instead of .) In formulations and proofs of statements it is assumed that the dimension and the kernel are fixed.
Let . If and the relation
| (1.1) |
holds, then the operator acts boundedly from to and its norm (to be called the -norm333Emphasizing that is the extremum of the symmetric bilinear form . ) has an upper bound given by Young’s inequality . A function is called a maximizer of the convolution operator with respect to the pair of exponents if and .
The main result of the paper is the theorem on existence of a maximizer.
Theorem 1.
Let and the relation (1.1) holds. Then for any kernel there exists a maximizer of the operator with respect to the pair of exponents .
In a narrow sense, the only predecessor of this result that we are aware of is the paper by M. Pearson [25]. In it, the existence of a maximizer is proved under the following assumptions: the function is radially symmetric, nonnegative, decreasing away from the origin; besides, an “extra room of integrability”, , is required.
In a wider sense, our paper’s context is related, on the one hand (from the motivation side), to the business of sharp constant in analytical inequalities, and on the other hand, to techniques of proving the existence of extremizers in variational problems with non-compact groups of symmetries.
The starting point of this work was computation of the norms of the Laplace transorm as an operator from to () on (that is, of sharp constants in G.H. Hardy’s [16] inequality), reported here in Section 6. An equivalent problem is to compute the corresponding norms of the convolution operators on with kernels . Hardy’s original estimate can be improved by making use of W. Beckner’s sharp form [6] of Young’s inequality.444The labels , etc. refer to the comments (8), (8) etc. in Section 8.
| (1.2) |
The so improved estimate — see (6.8) — is found in the 2005’s M. Sc. Thesis of E. Setterqvist [27, Theorem 2.2].
The equality in Beckner’s inequality (1.2) takes place only in the case of a Gaussian kernel . Furhter analytical enhancement of the estimate (6.8) should in principle be possible by using recent subtle results of M. Christ [11, 12].
Our numerical results on the norms (lacking full justification) allow one to make judgement about comparative strength of the available analytical estimates (see Section 6). For , the existence of maximizers was first observed experimentally. (If , there is no maximizer as one can easily see.) Since the kernel is not symmetric, Pearson’s theorem is not applicable. The question about possible weaker conditions sufficient for the existence of a maximizer naturally presented itself. Somewhat surprisingly, it turned out that no artificial conditions are needed at all.
A difficulty in proving the existence of a maximizer of a convolution operator, as well as in similar situations, owes to the problem’s invariance with respect to a non-compact group of transformations (the additive group of translations, in our case). A natural attempt is to begin with some normalized maximizing sequence , , , and, referring to the Banach-Alaoglu theorem, to find a weakly converging subsequence . There is no chance to prove strong convergence of the subsequence since it may “run away” to infinity, thus weakly converging to zero.
However one can take shifted functions hoping to chose the shifts so as to obtain a relatively compact sequence . (In terms of inequalities it amounts to establishing suitable uniform estimates). If this idea works out, a weakly converging subsequence of the shifted sequence will converge strongly and its limit will be a maximizer.
Person’s proof exploits the fact that in the case of a radially symmetric kernel the functions can also be made radially symmetric. This is due to M. Riesz’s inequality for nondecreasing rearrangements [19, Theorem 3.7]. We do not know of any substitute (analog, generalization) for Riesz’s inequality in the case of a non-symmetric kernel, which would allow a generalization of Pearson’s argument. Availability of full analytical control of the kernel in all directions (like in the case of ) does not help. Our approach is completely different. Absent a natural reference point, we develop an intrinsic way to describe localization of near-maximizers.
The scheme and some elements of our proof exhibit clear similarities with the concentration compactness method of P. L. Lions [20]. Moreover, the class of variational problems described in the introductory section of Lions’ paper [20] includes the problem of finding the -norm of a convolution operator as one of the simplest representatives of the class..
For this reason one may wonder at the absence (to the best of our knowledge) of Theorem 1 in the existing literature. Note though that the proof presented here does not depend on Lions’ work, whether directly or indirectly.
Let us outline the paper’s structure. The proof of Theorem 1 is given in Sections 2–4. In Section 2 we introduce relevant terminology and describe the proof “in the large”. Properties required at the steps of the proof are mentioned and references to the places where they are treated in detail are given. Detailed formulations and proofs of the required properties as well as auxiliary intermediate results are contained in Sections 3 and 4. The key Lemmas 3.5–3.7 of Section 3 provide uniform control on the size of “near-supports” of member functions of a maximizing sequence, to exclude a possibility of diffusion. (It helps to always ask in the course of the proof, where it fails when , , in which case there is no maximizer if ). The lemmas of Section 4 deal with compactness and shifts.
In Section 5, a number of diverse results related to Theorem 1 and its proof are treated. In particular, we discuss the cases of exponents and , the equation satisfied by a maximizer, the lower bounds for convolution operators, etc. A survey of the results is given in Subsection 5.0.
Section 6 is devoted to computation of the norms of the Laplace transform from to ; the equivalent problem being, as mentioned before, the calculation of the norms of convolutions with kernels as operators from to . The obtained numerical results are compared with several analytical estimates. The numerical method used is straightforward; however, its convergence remains an empirical fact.
The short Section 7 contains some open questions and conjectures that lie close to the paper’s contents.
In the final Section 8, bibliographical and terminological comments are gathered.
———————
The following equivalent forms of the relation (1.1) will be used repeatedly as convenient. Let in any order. Then
Consequently, with equality if and only if .
2 Preliminaries and the proof in the large
The exponents and the convolution kernel are assumed fixed.
By definition of the norm of the operator , for any there exists a function such that and . Any such function will be called an -maximizer.
Definition 2.1.
A sequence of norm one functions from is a maximizing sequence (for the operator ) if as .
The proof of Theorem 1 aims, quite obviously, at constructing a maximizing sequence for the operator that converges in norm. The limit will be a norm one function and a maximizer. We will start out with an arbitrarily chosen maximizing sequence, apply to its members certain “improving operators” and shifts (translations), and finally select a suitable, strongly convergent subsequence.
Note a few trivial but important properties.
(1) If a function is an -maximizer and , then is also an -maximizer.
(2) The set of -maximizers is shift-invariant (since convolution operators commute with shifts).
(3) Any subsequence of a maximizing sequence is itself a maximizing sequence.
Let us introduce some notions to be used in the proof: a special -maximizer, -near-centered function, a tight sequence, and a few more.
Definition 2.2.
The operator appears naturally in the necessary condition of extremum, i.e. the equation that must be satisfied by a maximizer if one exists (Section 5.4).
A crucial property of the operator that justifies the qualifier “improving” (as opposed to “not-worsening”, say) is the fact that the -image of a weakly convergent sequence of functions converges in norm on bounded sets (and moreover, on any sets of finite measure) in (Lemma 4.11).
Definition 2.3.
Given a function and a unit vector555We use the standard Euclidean inner product and the Euclidean norm in . , the -diameter of the function of order in the direction is the nonnegative number
In this formula we implicitly assume that . If this is not the case (in particular, if ) we define .
Suppose and are such that and . The existence of such and is obvious. We say that the segment is the -near-support of the function of order in the direction and denote it . The function is -near-centered of order in the direction if and
Let us fix, once for all, an orthonormal basis in (that is, fix the coordinate axes).
We say that the function is -near-centered of order if is -near-centered of order in the direction for .
Clearly, any function can be made -near-centered by means of a suitable shift. However, different values of may require different shifts.
The transformation of functions corresponding to the argument shift by a vector will be denoted ; that is, .
Remark 2.1.
The above defined centering can be called a mass-centering. As a natural alternative, one might propose the geometric centering, whereby the -near-support of a -near-centered function in the given direction would be a symmetric interval . However this latter approach is not suitable for our proof because Lemma 4.12 would be lost.
Definition 2.4.
A sequence of functions is relatively tight if for any there exists such that
A sequence of functions is tight if for any it is -near-finite (of order ), which means that there exist and a cube in with edges parallel to the coordinate axes, such that for
As it turns out (see Lemma 4.15), a relatively tight sequence is tight provided the -finiteness property holds for just one sufficiently small (depending on ) positive .
We are ready to present a high-level structure of the proof of Theorem 1.
Proof of Theorem 1 .
Introduce the following classes of function sequences in defined in terms of imposed constraints.
-
1.
The class comprises all maximizing sequences (for the convolution operator ).
-
2.
The class comprises all special maximizing sequences, that is, maximizing sequences of the form , where .
-
3.
The class comprises all relatively tight sequences.
-
4.
The class comprises all tight sequences.
-
5.
The class comprises all weakly convergent sequences.
-
6.
The class comprises all locally convergent sequences, i.e. sequences converging in norm on any bounded measurable subset of .
-
7.
The class comprises all sequences converging in .
Note that a subsequence of a sequence that belongs to any of these classes also belongs to that class.
The construction.
1. We start out with an arbitrary sequence .
2. Applying the operator to its members we get the sequence .
4. Putting (any is as good), we can find vectors such that the shifted functions are -near-centered (Lemma 4.12).
5. Lemma 4.14 implies .
6. The operator commutes with shifts. (It is a rather trivial fact, yet it is stated as Lemma 4.5). Consequently, . The class is shift-invariant, hence .
7. (This is the most subtle step from the logic of proof viewpoint: we “undo” the operator in order to select a subsequence in the pre-image). The sequence is bounded in , hence it contains a weakly converging subsequence, which we denote , avoiding multilevel subscripts.
8. Put . Then, on the one hand, is a subsequence of the sequence thus inheriting the class memberships of the latter. On the other hand, since , Lemma 4.11 implies . As a result, .
9. Applying Lemma 4.16 we conclude that . Let . Then and by continuity. The function is a maximizer.
Theorem 1 is proved modulo the statements referred to at the various steps of the construction. Proofs of all those statements are given in the next two sections.
3 Estimates for -diameters of near-maximizers
The main technical result of this Section is Lemma 3.7, while the conceptual conclusion is Corollary 3.10. We approach the proof of Lemma 3.7 through a chain of preparatory results, of which all but Lemma 3.5 are very simple.
The indicator function of a set will be denoted ; if the set is defined by means of a property (or predicate) , then the indicator function is written as .
Lemma 3.1.
If , and , then
where .
Proof.
For the function is convex and symmetric about . We may assume that . By convexity, we have the chain of inequalities
which proves the Lemma. ∎
Lemma 3.2.
Let be a measure space, , and . Suppose that with norm is split into the sum and the summands satisfy () and . Then
with , the same as in Lemma 3.1.
Proof.
Since , we have . It remains to apply Lemma 3.1 with . ∎
Lemma 3.3.
Let and . Then for any there exists , such that
Proof.
Suppose ; otherwise the inequality is a tautology. The function defined for is continuous and satisfies the inequality
It suffices to choose as the point of minimum, and recall that . ∎
Lemma 3.4.
Let . Given , a unit vector and , there exists such that
Proof.
We may assume that and . The result follows by applying Lemma 3.3 to the one-variable function considered on the interval . ∎
Definition 3.1.
Let be a map from to , where and are some spaces of measurable functions in . Suppose and a unit vector in are given. We say that the map is an -expander in the direction if the property a.e. for , where , implies the property a.e. for .
The next Lemma utilizes the notions and notation introduced in Definition 2.3.
Lemma 3.5.
Let be a linear bounded operator from to , where . Suppose is an -expander in the direction . Let and . For any there are two possibilities: (i) either or (ii) and
| (3.1) |
where and , consistent with notation in Lemma 3.1.
Proof.
The cases (where ) and are trivial. Therefore we assume that and . Let and are such that
Clearly, . By Lemma 3.4 there exists such that
| (3.2) |
Denote (see Fig. 1)
Then and , , . Applying Lemma 3.2 to the pair of functions and we get .
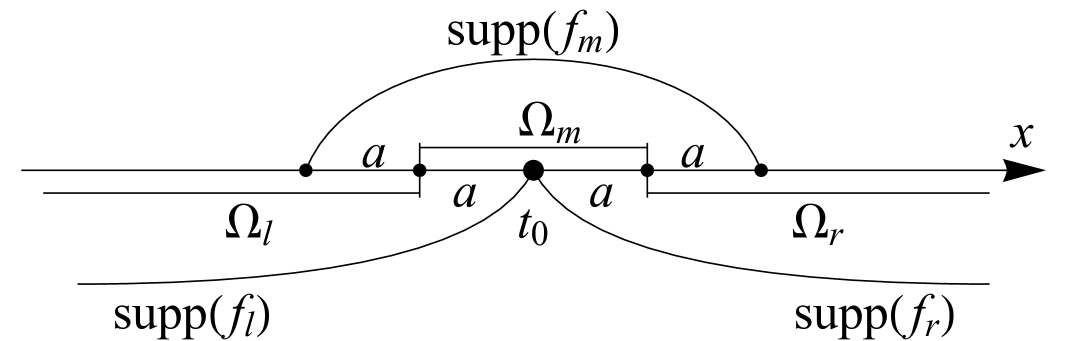
The subsets in defined by the inequalities
are pairwise disjoint and . We have
Therefore
Q.E.D. ∎
Lemma 3.6.
Suppose the operator satisfies the assumptions of Lemma 3.5. Suppose also that and . Then for any the -diameter satisfies the inequality
Proof.
Put and apply Lemma 3.5. Suppose the case (ii) takes place. Then
a contradiction. Therefore the case (i) takes place and we are done. ∎
Lemma 3.7.
Let , , and let be the convolution operator with kernel . Put . Suppose and are given. If is small enough, so that
then for any unit vector and any -maximizer of the operator the inequality
| (3.3) |
holds with
Remark 3.8.
The function is nonincreasing. Hence for fixed and , given two kernels and with a.e., a weaker estimate (i.e. a smaller value of or larger value of in the r.h.s. of the inequality (3.3)) takes place for that of the two kernels with smaller norm of the corresponding convolution operator.
Proof.
Put and . Without loss of generality we may assume that . Let and is the convolution operator with kernel . We have and, by Young’s inequality, . In particular, .
Fix an -maximizer for the operator . We have . Therefore,
The operator is an -expander in the direction . Let us apply Lemma 3.6 with and . We have , where
(due to the Bernoulli inequality and the inequality relating , ).
Corollary 3.9.
Corollary 3.10.
Any maximizing sequence of functions for the convolution operator is relatively tight.
4 Lemmas for construction of a convergent maximizing sequence
Recall that we always assume the relation .
Introduce the operation , where , , and the bar stands for complex conjugation. Thus, and .
4.1 Auxiliary numerical inequalities
Lemma 4.1.
For any the following inequalities hold:
(a) for ,
| (4.1) |
(b) for ,
| (4.2) |
(This Lemma will be used in the proof of Lemma 4.6.)
Proof.
(a) Put . Due to the symmetry between and we may assume that . The inequality (4.1) reduces to the following:
Using the Cosine Theorem and putting , we can restate the required inequality in the form
By concavity, , hence
If , then
and (4.1) holds (even with a better constant), since .
(b) Similarly, in order to prove the inequality (4.2) it suffices to show that for
Comparing the right-hand sides of the identities with and and using the Bernoulli inequality , we get the required result. ∎
4.2 The improving operator
Denote , , . Transposition of the convolution operator amounts to changing the original kernel into the kernel with tilde, i.e.
Clearly,
Let be the operator of radial projection onto the unit sphere in ,
Hereinafter we assume that the function acted upon by the operator is nonzero.
Suppose , , so that and hence . Introduce the operator by the formula
(Its domain is the set .) Interchanging the exponents we have the operator . Explicitly,
The improving operator is the composition
Remark 4.2.
In the ¡¡symmetric¿¿ case the operator , whose square is , is already a self-map of . As such, it can be used for the purposes of the proof instead of the operator . With this approach, the case in Lemma 4.6 is not needed; also the proof of Lemma 4.11 becomes one-step. One property of the operator that lacks is the analog of the necessary condition of extremum (see Proposition 5.4 in Section 5.4). One can instead propose that a maximizer in the case must satisfy the equation with a shift. We do not know whether this condition is indeed necessary.
Lemma 4.3.
Let , , and . Then
| (4.3) |
Proof.
Using the definition of the operator , we rewrite the inequality (4.3) to be proved in the form
(The identities and are used.)
Since , the left-hand side is estimated as
The lemma is proved. ∎
Corollary 4.4.
If and the function is an -maximizer for the convolution operator , then it belongs to the domain of , and is also an -maximizer for the operator .
Proof.
Lemma 4.5.
The operator commutes with shifts: for any . (If one side of the formula is defined, then the other is defined too.)
Proof.
We have , therefore, , and similarly for . The claimed equality follows. ∎
Lemma 4.6.
Let and . Then the map from to is continuous.
Proof.
Consider two cases.
1. In the case the continuity of easily follows from the numerical inequality (4.1):
2. In the case we use the numerical inequality (4.2) and Hölder’s inequality and find
Since and (by concavity), we get
This concludes the proof. ∎
Corollary 4.7.
The operators , and are continuous on their domains with respect to the norm topologies in the preimage and image spaces.
Proof.
Each of these operators is a composition of continuous maps; Lemma 4.6 provides the continuity in the only place where it is not a commonly known fact. ∎
4.3 A compactness lemma
Lemma 4.8.
Let and . Then the integral operator with kernel ,
maps any weakly convergent sequence to a sequence convergent in norm.
Proof.
Without loss of generality we may assume that for all . Let in ; then .
Consider first the case . Since , we have , hence the sequence converges pointwise. Besides, , therefore
The majorant in the right-hand side lies in . By the Dominated Convergence Theorem we conclude that .
Now let us withdraw the assumption . Let be the operator of convolution with truncated function . As follows from the previous, . The proof is finished by use of the trick. Given we find such that . Let be such that when . Then for we have
(The nd and rd terms in the middle are estimated by Young’s inequality.) The proof is complete. ∎
Corollary 4.9.
Let and be a set of finite measure. If the sequence is weakly convergent in , then the sequence of convolution restrictions strongly converges in .
4.4 Special maximizers and strong convergence on sets of finite measure
Lemma 4.10.
Let and a weakly convergent sequence in be given. Put and . If for , then for any set of finite measure the sequence restricted onto converges in norm to ,
Also the weak convergence holds in .
Proof.
1. Put , , and , Then . By Corollary 4.9, in . Since , it follows that in . The tilde operation commutes with passing to the limit. Applying Lemma 4.6 we get .
2. Let us now prove that for any . Suppose is given. Fix a set of fonite measure and such that . By part 1, there exists such that for . Then for we have
It is clear now that .
The lemma is proved. ∎
Lemma 4.11.
Let be a maximizing sequence of functions for the convolution operator . Put ; according to Corollary 4.4, is also a maximizing sequence for the operator . If the sequence converges weakly in , then there exists a function such that
(i) in ;
(ii) for any set of finite measure, as .
4.5 Shifts, centering, and tightness
The lemmas of this subsection are but various technical expressions of the simple idea: if a mass is concentrated near the origin, then a long distance shift is incompatible with centering.
Let us first turn to the notions introduced in Definition 2.3 and prove boundedness of the set of shift vectors that provide -near-centering of a given function for varying but small values of .
Lemma 4.12.
Let . Fix , and a unit vector . Put . Let be the vector for which the function is -near-centered in the direction . If a function is -near-centered in the direction for some and , then .
Proof.
Assume, without loss of generality, that . Introducing the one-variable function
we reduce the general case to the case , , (where now stands for from the line above.)
Now and are scalars. Let . Due to the assumed centerings we have, first,
Next,
Suppose that . Then
a contradiciton. Likewise, the assumption leads to a contradiciton. We conclude that . The lemma is proved. ∎
Further lemmas of this subsection pertain to the notions introduced in Definition 2.4.
Lemma 4.13.
Suppose the sequence of vectors is bounded. If the sequences and in are related by shifts, , and one of them is tight, then the other one is tight, too.
Proof.
Let for all . For any coordinate cube , the shifted cube is contained in the -independent cube concentric with and with side length which exceeds that of by . Therefore for any the sequence is -near-finite if and only if such the same is true about the sequence . The lemma is proved. ∎
Lemma 4.14.
Suppose the sequence () is relatively tight and for all . Suppose further that all the functions are -near-centered (of order ) with some . Then the sequence is tight.
Proof.
Without loss of generality we may assume that for and all vectors of the fixed orthonormal basis in the condition in the last part of Definition 2.4 holds with . Thus there is such that for any ,
It suffices to verify the condition of -near-finiteness for any given .
Fix ; we may assume that . Let us select the vectors so as to obtain -near-centered functions . By Lemma 4.12, for all and we have .
By definition of a relatively tight sequence, there exist and such that for all and . Then
for and .
Put . The complement of the cube is the union of the sets , . Therefore, .
The condition of -near-finiteness is affirmed, and the Lemma is proved. ∎
The next lemma, though not used in the proof of Theorem 1, is included as it further clarifies the connection between the notions of relative tightness and tightness.
Lemma 4.15.
Suppose is a relative tight sequence in () and for all . If the sequence is -near-finite for some , then it is tight.
Proof.
Consider the -near-centered sequence , obtained from by means of suitable shifts, . Let us show that the sequence of vectors is bounded in .
We may assume that the coordinate cube in the definition of -near-finiteness has the origin as its center and is described by the inequalities , . If , then
which contradicts the function being -near-centered. Therefore, . Similarly . Thus, .
4.6 The final lemma
Lemma 4.16.
Suppose that the sequence of functions in possesses the following properties:
-
(i)
normalization: ;
-
(ii)
tightness (see Definition 2.4);
-
(iii)
local convergence: there exists a function to which converges on bounded sets: for any bounded set .
Then in . In particular, .
Proof.
Let be given. Take a bounded set such that .
Due to the assumptions (i) and (ii), there are and a cube in such that for .
Put . Due to the assumption (iii), there is such that for . Clearly, for we have the inequalities
The lemma is proved. ∎
5 Supplementary results
5.0 A survey
In this section we put together diverse, relatively simple results related to various aspects and details of formulation and proof of Theorem 1. Some other related, but unsolved questions are considered in Section 7.
Subsection 5.1. Limit cases. Theorem 1 excludes the cases where at least one of the exponents , , in Young’s inequality equals or . We analyse all such cases. A summary of the results is presented on Fig. 2.
Subsection 5.2. Convolution on compact groups. The analog of Theorem 1 for compact groups is an easy result. The groups need not be commutative.
Subsection 5.3. Counterexample: a near-convolution without a maximizer. We give a counterexample to demonstrate that the assumptions in Theorem 1 cannot be relaxed by allowing integral operators with non-translation-invariant kernels, even under the assumption that the kernel is pointwise dominated by the kernel of an admissible convolution operator. Another possibility to relax the assumptions is to consider compact or even finite-dimensional perturbations of a convolution operator. In that case, we were unable to prove or disprove the existence of a maximizer; see Question 3 in Section 7.
Subsection 5.4. Necessary condition of extremum. First, using the standard Lagrange multipliers method, we derive a nonlinear integral equation that must be satisfied by a maximizer. Then we prove an “approximative” version of the necessary condition of extremum: if the norm of the convolution is close to and , then satisfies the mentioned equation up to a small error.
Subsection 5.5. Convergence to a maximizer in the class rather than in . In the course of the proof of Theorem 1 we have established that any special (that is, lying in the image of the improving operator ) maximizing sequence becomes relatively compact after applying appropriate shifts. Here we show that the same is true for arbitrary maximizing sequences.
This simple result is perhaps of minor significance, but we included it due to an authoritative motivation.
Subsection 5.6. Kernel approximation and convergence of maximizers. Given a sequence of convolution kernels converging in to a kernel , is it true that a maximizer for the operator can be obtained as a limit (in ) of maximizers for the operators ? Proposition 5.7 answers this question in the affirmative. The result can be of use, for example, when one has to compute a maximizer for convolution with non-compact and, possibly, weakly singular kernel: the kernel can be approximated by bounded and finitely supported truncations.
Subsection 5.7. On boundedness and integrability of maximizers
If one has “a spare room of integrability”, (as in Pearson’s theorem), then a maximizer belongs to , where does not depend on . See also Question 5 in Section 7.
Subsection 5.8. On the lower bound of convolution operators’ norms. The estimate in Lemma 3.7 becomes less efficient as the norm of the operator decreases. (Cf. Remark 3.8). This fact has no adverse consequences for the proof of Theorem 1, but one should keep it in mind if the results of Section 3 are to be used for obtaining uniform estimates (over some family of kernels ). In particular, suppose that the absolute value of the kernel fixed; then how small can the norm be? Proposition 5.10 states that .
5.1 Limit cases
For the relation (1.1) defines the exponent if and only if , equivalently, if . If , then . Consider the coordinate -plane with , . The domain corresponding to admissible pairs in Young’s inequality is the triangle formed by the lines (I) (i.e. ), (II) (i.e. ) and (III) (i.e. ). Correspondingly we have three limit cases and subcases corresponding to the vertices of the triangle. The results are summarized on Fig. 2.
In the conditions considered below we always assume that pointwise equalities and inequalities are fulfilled a.e.
Case I. .
Subcase I(A). , .
. If , then any function with is a maximizer. Obviuosly, the same holds true for functions of the form , where , .
. If is not a function with constant complex argument (in the real case — a sign-changing function), then a maximizer does not exist. Indeed, one can choose a maximizing sequence to be a -sequence, so ; but the equality in the integral Minkowski inequality
is impossible (if ).
Subcase I(B). , .
. Let us show that if , then there is no maximizer.
In this case . Indeed, the sequence of pairs with
is a maximizing sequence for the bilinear form . Then and
A hypothetical maximizer would satisfy the equality
which is the case of equality in the Minkowski integral inequality. This, in turn, would imply the existence of a function such that for almost all , . But this is clearly impossible unless .
. Let us show that generally (for not-constant-sign functions) a maximizer can exist. Let . The operator acts in the Hilbert space and is unitary equivalent to multiplication by the continuous function , where is the Fourier transform with unitary normalization. Let . A maximizer exists if and only if the set has positive measure. This is possible. For example, let be a “hat” function: , everywhere, and in some neighborhood of zero, . Then and .
The question as to whether a maximizer can exist in the case is left open. (See Question 2 in Section 7).
Subcase I(C). , . A maximizer exists: for instance, . Indeed, and
whence .
Case II. . The operator acts from to . We assume that , since the subcase is explored earlier, in I(A).
Subcase II(A). , . A maximizer does not exist. Indeed, a -sequence is a maximizing sequence: in , so that . The situation is similar to the one we have encountered in , with functions and interchanged. A hypothetical maximizer would realize the case of equality in Minkowski’s inequality
but this is impossible.
Subcase II(B). , . Put . One readily sees that . If is a set of positive measure, then a maximizer trivially exists. If is a set of measure zero, then both existence and non-existence of a maximizer are possible. We give a partial criterion of existence in the case of a nonnegative kernel .
Proposition 5.1.
Suppose that , , and . Put . In order for a maximizer of the convolution operator to exist it is necessary that for all , and sufficient that there are vectors such that the union
has positive measure.
Proof.
1) Necessity. Suppose . Then . Let and . We will prove that is not a maximizer. Take . Due to absolute continuity of the Lebesgue integral (see e.g. [7, v. 1, Theorem 2.5.7]) there exists such that for any set of measure . Let be such that . Then for any we have . Hence
Therefore , as claimed.
2) Sufficiency. Let be a set of finite positive measure. We will show that is a maximizer. Indeed, we have
But . Hence whenever and . Due to -continuity of the shift operator, in some neighbourhood of the point we have . We conclude that . Since is arbitrary, .
The Proposition is proved. ∎
For example (in the one-dimensional case), for the kernels or there is no maximizer, while for the kernel a maximizer exists.
Case III. , . It suffices to assume that , since the subcases and have been already covered — see. I(C) and II(B).
The present case is simple; a maximizer does exist. Given , put (using notation introduced in Section 4.2) . Then the case of equality in Hölder’s inequality is realized:
and hence, too, the case of equality in Young’s inequality:
so that is a maximizer.
It is instructive to compare this case with II(A), since the two cases deal with operators which are the transposes of each other. The relevant bilinear form in both cases is formally the same, however the conclusions about the existence of a maximizer are opposite.
Let . We fix the symbol to mean the operator of convolution with kernel acting from to . The transposed operator, acting from to , as in II(A), will be denoted . We have
Our conclusions on (non-)existence of a maximizer can be expressed by means of the formula
where cannot be replaced by . The underlying cause of the difference is of course the non-reflexivity of . If we allow , then becomes attainable. More precisely, by the Hahn-Banach theorem there exists , such that
where is a maximizer for the operator . In order to describe the matters explicitly, let us note that the image of the operator lies in the closed subspace of continuous functions vanishing at infinity. The space is the space of finite Borel measures. The element realizing the equality
is the measure , where is a point of maximum of .
5.2 Convolution on compact groups
Proposition 5.2.
Let be a compact topological group with Haar measure , the spaces defined with respect to this measure. Let . Then the convolution operator acts boundedly from to , where, as everywhere in this paper, , and there exists a maximizer :
Proof.
Boundedness of the operator (Young’s inequality) is a well-known fact. (Sufficient assumption is that the group is locally compact and unimodular, see e.g. [18, (20.18), (20.19)].) Now, take any maximizing sequence and select a weakly convergent subsequence. The improving operator maps it to a strongly convergent one; a proof of the required analog of Lemma 4.8 is even easier here: we do not need a “truncation in the horizontal direction” to obtain a compaclty supported function. The limit is a maximizer. ∎
5.3 Counterexample: a near-convolution without a maximizer
It is natural to ask about possible relaxation of conditions of Theorem 1 and to try to exhibit sufficient conditions that the kernel of the integral operator should satisfy, not necessarily being translation-invariant, in order to guarantee the existence of a maximizer. As the example below demonstrates, conditions of such a sort, if possible at all, cannot be stated in terms of integral and pointwise inequalities only: here, there is no maximizer, although we have a pointwise majorization with .
Proposition 5.3.
Let be as in Theorem 1 and . Let and everywhere. Consider the integral operator with kernel , where is monotone increasing and , . The operator is continuous. A maximizer for the operator does not exist.
Proof.
One readily sees that . If () is a maximizer for the operator , then the function must be a maximizer for the convolution operator . But it is clear that , a contradiction. ∎
5.4 Necessary condition of extremum
The notation from Section 4.2 will be used. The next Proposition does not refer to the existence of maximizer result, so we allow the case .
Proposition 5.4.
Suppose that and . (The relation (1.1) is assumed as always.) A maximizer of the convolution operator , if it exists, satisfies the equation .
Proof.
We have the optimization problem (with given function and unknown and ):
under the constraints
Let us use the Lagrange multipliers method to derive the system of equations to be satisfied by the extremal pair of functions . The relevant Lagrange functional can be taken in the form
Computing the partial variation with respect to , we get
where . Therefore the pair that yields an extremum of the functional must satisfy the equation
Similarly, equating the partial variation to zero, we come to the equation
where .
Taking into account the normalization of and and the identities , , the obtained system of equations can be written as
Elimination of results in the equation . ∎
In Subsection 5.5 we will need an approximative version of the necessary condition of extremum.
Proposition 5.5.
For any there exists (depending on and the convolution kernel ) such that if and , then .
Proof.
We make use of the approximative version of Hölder’s inequality due to H. Hanche-Olsen [15, Lemma 2]:
For any there exists such that if and , then .
Consider an improvement of the estimate in the proof of Lemma 4.3. Using the notation of Section 4.2 (in particular, recall: is the radial projection onto the unit sphere in , and ), put . Note that , hence .
Further, denote and .
The calculation in the proof of Lemma 4.3 implies that . In particular, .
We have . Assuming that , we get
Therefore, .
Let be given. Find the corresponding as in Hanche-Olsen’s lemma. Define by the equation . According to the above, we have the inequality , as required. ∎
5.5 Convergence to a maximizer in the class (rather than in )
Proposition 5.6.
Let be a maximizing sequence for the convolution operator with kernel . There exists a subsequence and shift vectors such that the sequence converges in as (its limit automatically being a maximizer for the operator ).
5.6 Kernel approximation and convergence of maximizers
Proposition 5.7.
Suppose a sequence of function converges (strongly) to a nonzero . Then there exists a sequence of maximizers for the convolution operators that converges strongly to a function . The function is a maximizer for the convolution operator .
Proof.
An arbitrary sequence of maximizers for the operators is obviously a maximizing sequencefor the operator . Applying Proposition 5.6, we obtain the claim as stated. ∎
5.7 On boundedness and integrability of maximizers
Proposition 5.8.
Let and be a maximizer for the convolution operator from to . (We assume that neither of , and is or .)
(a) If for some , then .
(b) If for some , then , where
( for ).
Proof.
The only information we need is that satisfies the equation (see Subsection 5.4). Put (in notation of Subsection 4.2).
(a) Suppose that for with some . The identity
shows that if . Therefore, if , where .
Note that implies , so that implies .
Since , we have similarly: if for , , then for , where . Also implies .
Combining the above said, we conclude: if , , and , then , where either , or and , where . Since and , we have . Iterating, we get in a finite number of steps.
The conclusion is obtained under the assumpiton that lies in with some , and in the derivation we used just the inclusion . Let us now make use of the condition , assuming only that . Put . Interchanging the roles of at the first half-step of the iteration (where we estimate the exponent of the space containing ), we conclude that , where . If , we apply the above described iteration with initial value of parameter .
(b) Repeating the argument of part (a), we obtain: if for , then for , . Symmetrically, if for , then for , .
The essential difference with part (a) is that the conditions are no longer equivalent. For instance, means that . The value can happen to be less than .
With this remark in mind, we parallel the proof of part (a). The condition implies with some . Putting and , we obtain at an iteration step: either (i) , or (ii) , or (iii) , where . In the case (iii) we continue to iterate. Eventually, in a finite number of steps one of the cases (i) or (ii) occurs.
The exponent in the terminal case (i) is determined above: . The calculation
shows that the condition is equivalent to the inequality . ∎
Remark 5.9.
The asymmetry of the result ( being a “more common” property than ) is ultimately due to the fact that convolution inherits best local properties of the two its operands, but worst global properties.
5.8 On the lower bound of convolution operators’ norms
Proposition 5.10.
Let , and . Let be a nonnegative function. The operator of convolution with complex-valued kernel acting from to can have arbitrarily small norm. Specifically, as .
Proof.
It is easy to see that the set of functions for which the statement if true is closed in . Therefore without loss of generality we may assume that .
Denote the operator of convolution with function .
In the case , the validity of the claim of the Proposition is established below, in Lemma 5.11. The general case follows from this particular one by an interpolation argument as follows.
Suppose (otherwise one considers the transposed operator). On the coordinate plane, let us pass a line through the points . Let be the point where it meets the horizontal axis. Due to the inequalities we have . Put , . The fact that can be written as
where .
Given , Lemma 5.11 tells us that for a large enough . On the other hand, due to the assumption we made at the beginning of the proof, we have . By Hölder’s inequality,
Applying now the Riesz-Thorin theorem, we conclude that
The proposition is proved. ∎
Lemma 5.11.
Let . Denote and
the Fourier transform of . Then as .
Consequently, the norm of the convolution with as an operator in tends to as .
Proof.
By a density argument, it suffices to prove the Lemma under the assumption .
For we have the Plancherel identity
Both sides are defined and continuous in the region , . Therefore the equality extends to the boundary , . Thus,
Putting , we obtain in the left-hand side of the latter inequality, while , so that . The esimate
follows and the proof is complete. ∎
6 Best constants in the Hausdorff-Young inequality for the Laplace transform on
Denote by the Laplace transform on ,
and by the Fourier transform on ,
For , the Hausdorff-Young (HY) inequalities
and
hold. They are first established under the assumption , when the integral definitions of and have direct meaning, and then they are used to extend and by continuity to the operators acting from to .
The exponent in the left-hand sides of the HY inequalities cannot be replaced by any other number. This follows from “dimensional analysis”, that is, changing into the function with the same norm, where is an arbitrary scaling parameter. It is also known that inequalities of this type do not hold when . In the case of Fourier transform, an explicit argument to that effect can be found, e.g., in Titchmarsch’s monograph [31, § 4.11].
The optimal values of the constants , that is, the operator norms , have been found by W. Beckner [6] (and earlier by K.I. Babenko [4] in the case ):
| (6.1) |
where the constant is defined in (1.2).
Analytical expressions for the optimal values of the constants , that is, the operator norms , are unknown. The problem of determining is equivalent to the problem of determining the norm of the convolution operator with kernel , see (6.6) below, acting from to .
In Figure 3 and in Table 1 we present the numerical values of . In order to mark the distiction between the true value of and the computed approximation to it, we designate the latter as . The numerical method used is briefly outlined at the end of this Section.
The minimum of the norm occurs at ,
| (6.2) |
The curves in Fig. 3 present the numerically evaluated norms and several analytical estimates for the norms, which we describe below.
1. The simplest estimate is obtained by interpolation. The equality is immediate and the equality is readily obtained as the supremum of the spectrum of the self-adjoint operator in . The Riesz-Thorin interpolation theorem yields the estimate666The constants are subscripted in accordance with: RT=Riesz-Thorin, F=via Fourier norm, H=Hardy, S=Setterqvist.
| (6.3) |
2. One can show that
| (6.4) |
Using the Hausdorff-Young estimate in the right-hand side we come again to the estimate (6.3), but one can instead use Beckner’s sharp constant. As a result, one gets a better estimate,
| (6.5) |
Let us comment on the inequality (6.4). Consider the family of operators , depending on complex parameter ,
The analytic operator-valued function is defined in the strip and its values at are the composition of the Fourier transform with restrictions onto the negative, resp., positive real half-line. The value at is but the Laplace transform. The inequality in question follows by applying Stein’s interpolation theorem [28, Ch. 5, Theorem 4.2]. Using this approach, the second author and A.E. Merzon have obtained a variant of the HY inequality for the Laplace transform with variable on a ray in the complex plane (unpublished).
3. The substitutions
reduce the Laplace transform to the convolution operator
where
| (6.6) |
It is easy to see that the -norms of the functions (defined on ) and (defined on ) coincide; the same is true for the -norms of the functions and . Therefore, is the norm of the convolution operator with kernel acting from to . Since (here ), the Young inequality yields the estimate
| (6.7) |
G.H. Hardy [16] was the first to derive this estimate in 1933, using the method just outlined.
4. Combining Hardy’s reduction with case of Beckner’s sharp form (1.2) of Young’s inequality, Setterqvist [27, Theorem 2.2] obtained the estimate
| (6.8) |
The maximum relative error of the estimate (6.8) is about . The following empirical approximation has absolute error less :
The numerical method
In notation of Section 4.2, we have the equation to solve. Its solution (if it exists) is also a solution of the equation , which any maximizer must satisfy. In practice, we solve the equation , where both the function and the shift parameter are to be determined. We employ the direct iteration method defined by
| (6.9) |
The shift parameter at each step is determined by the condition
The recurrence (6.9) implies that for all . Due to Lemma 4.3, the sequence of norms is nondecreasing; due to the Young inequality, it is bounded; hence a limit exists. The computation is stopped when , where is the given tolerance. We chose this criterion because we are not concerned (here) with computation of the solution .
The error of the numerical method has two sources besides the machine arithmetics and finiteness of the number of iterations.
(I) Domain compactification: the line is replaced by a finite interval and the convolution on is replaced by the cyclic convolution on .
(II) Discretization: the functions of continuous variable are replaced by the functions of a discrete parameter. We use the uniform grid with nodes.
As we have noted in Remark 4.2, the existence of solution of the equation has not been proved. This is not an important issue though: one can follow even-numbered iterations, since and the existence of solution of the equation is known.
The essential gaps in the justification of our numerical method are the following:
(a) a proof of convergence of the iterations (6.9) (even of the even-numbered iterations) is lacking;
(b) there is no result on uniqueness (up to a shift) of solution of the equation , which means that the limit may in principle depend on the initial condition.
In practice, for a fixed compactification we observed a geometric convergence of the norms (and, moreover, a geometric convergence of in norm), the faster the closer is to . The limit function appears to be the same for different initial conditions. (We tried the initial conditions being either the Gaussians with various dispersions or the indicator functions of intervals.) In order to control the accuracy of the results, we performed computations with doubling of the number of nodes until stabilization. (In most cases, nodes were sufficient.)
As regards the compactification, the Young inequality and the triangle inequality provide an upper bound for the error of the computed norm when the support of the kernel gets truncated. It is also easy to estimate the error due to the use of the cyclic convolution instead of the convolution on . Contrary to the situation with convergence of iterations, the compactification appears to run into trouble as approaches 1, as the convolution kernel (6.6) becomes slowly decreasing in the negative directon. For instance, for . However, when truncating the support of the function , we are concerned not with absolute values of the cut-out, but with its -norm. Since and , the truncation parameter can be set uniformly in . Computations support these considerations. For the purpose of control we used the doubling of the support of the truncation of (and the corresponding doubling of the length of the circumference obtained by identifying the ends of the interval).
7 Open questions
Question 1.
Let and , be two maximizers for the operator from to . Is it true that there exist and a vector such that ?
Having posed (and solved) the question of the existence of a minimizer, it is natural to ask about its uniqueness up to the trivial transformations. We suppose that in general there is no uniqueness. It looks probable however that one can formulate conditions sufficient for uniqueness and embracing some narrow but meaningful class of functions (positive? unimodular?…). Exploring a finite-dimensional analog — the convolution on — might help to understand what effects one should anticipate.
In the case non-uniqueness is revealed, a number of further questions can be asked, concerning non-maximizer solutions of the equation , bifurcation phenomena, Morse indices etc.
Question 2.
Let , . Does there exist a nonzero kernel , for which the convolution operator possesses a maximizer?
The affirmative answer in the case is given in Subsection 5.1 (subcase ).
Question 3.
Let and be a compact operator from to . Is it true that a maximizer for the operator exists? Is this true in the particular case when is a rank one operator?
An answer to this question would yield either an extension of the class of admissible integral kernels in Theorem 1 or an yet another counterexample, in addition to the one given in Subsection 5.3, stressing the role of translation-invariance towards the existence of a maximizer.
Question 4.
Generalize Theorem 1 to embrace a certain class of locally compact groups (in particular, a (sub)class of discrete finitely generated groups).
The proof of Theorem 1 goes through in with trivial modifications.777The situation in the limit cases differs between and , cf. end of comment (8). One can try to get a clue about the case of discrete non-commutative groups by studying convolution on the free groups with two generators. One should be aware of the fact that the condition (1.1) on the exponents in the Young inequality is, for a general locally-compact group, not necessary, cf. [26].
Question 5.
Investigate the local and global properties of a maximizer as depending on the properties of the kernel .
We have stated this question in a broad and imprecise form. Here are more specific sample questions, which we would be interested to have answered.
Question 5A. What is a guaranteed rate of decay of a maximizer provided has finite support?
Question 5B. What condition on (“a room of integrability”) beyond the assumed is sufficient to guarantee that a maximizer lies in ?
According to Proposition 5.8, it is sufficient that with arbitrarily small . Isn’t an “inner room of integrability” of the kernel ( with respect to ) and/or a maximizer (with respect to ) already sufficient? By an “inner room of integrability” we mean that, for example, belongs to some Orlicz space properly contained in . In the proof of Proposition 5.8, one can replace the reference to Young’s inequality by the reference to O’Neil’s inequality [24] (concerning convoulution in Orlicz spaces), but it is unclear how far one can get with this approach.
Question 6.
Conjecture. For any there exists (depending on and the convolution kernel ) such that if and , then , where is the set of all maximizers for the operator .
Question 7.
Find a lower bound for the -distance from the function defined by (6.6) to the set of Gaussians, that is, estimate from below the quantity
This question is a step to the analytical improvement of the inequality (6.8):
where the constants and are from (6.8) and (6.7), respectively, and is the constant in the (one-dimensional) Christ inequality, see comment (8) in Section 8.
Question 8.
Prove the convergence of the iterations (6.9).
This question allows a broad interpretation (convergence of the iterations under some general assumptions), as well as a narrow interpretation: explain analytically why the iterations converge in the concrete situation of Section 6.
A potential non-uniqueness of solution of the equation (cf. Question 1) may call for certain adjustments of the question in its broad interpretation.
Note that in order to compute just the norm of the operator (and not a maximizer) all that matters is not the convergence of iterations but exactly the absence of an extraneous solution with a small norm.
8 Comments
Section 1
(8) The inequality (1.2) has been proved independently and almost at the same time in [6] and in [8]. See also the textbook [19, Theorem 4.2]. We note a simple proof given in [5] (essintially based but on Hölder’s inequality) and a particularly elegant proog in [10] (exploiting monotonicity of the trilinear form under heat equation evolution of the functions ).
A discussion of the Young inequality on locally compact groups with emphasis on admissible exponents and sharpness of the constants can be found in [14, 26].
(8) For review-style expositions of the results and methods of Christ’s work [11, 12] we refer to [13], [32].
The result particularly relevant to a possible improvement of Setterqvist’s estimate (6.8) is [12, Corollary 1.5]:
Let () and . Put (which is Beckner’s constant in ) and denote the set of all Gaussian functions,
where , and is a positive definite quadratic form. There exists a constant (which depends on the dimension ) such that
where
In order to use the stated result for improvement of the estimate (6.8), one needs the numerical value of the constant (for ), which is not given in [12], as well as a lower estimate for the -distance from the kernel to the set of Gaussians. We offer the latter calcluation as an open question, see Question7 in Section 7.
(8) In [20, § I.1] the minimization problem for the functional of the form
under the constraint is considered. Here
, are given real-valued functions, ; are elements of a given function space on . Denote
A particular case with -independent functions , is referred to, in the general context, as “problems at infinity”.
Our problem concerning the norm of the operator corresponds to
i.e. , , , . The lower bound then is
| (8.1) |
What Lions’ method provides is not a single general theorem but a general approach to proving the existence of extermizers in a broad class of variational problems of analysis and mathematical physics. It contains heuristic elements, so that details may vary and require a concrete, problem-specific approach.
The monograph [30] treats many aspects of the concentration compactness method, with emphasis on convergence in Hilbert (Sobolev) spaces. A Russian-language reader may find Ch. 5 in the textbook [21] as a useful reference concerning Lions’ method.
By all indications, it should be possible to prove Theorem 1 in the framework of Lions’ method; however, this would be a separate and not quite trivial project. Note that our proof neither refers to the Concentration Compactness Lemma [20, Lemma I.1], [21, Lemma 5.1] nor contains its close analog; the variants of “vanishing” and “dichotomy” are implicitly eliminated by other means.
(8) In T. Tao’s methodical article [29, § 1.6], a technique of “profile decomposition” is discussed: a “profile” (a function sequence) is decomposed into a sum of shifts of fixed functions and a relatively compact sequence (cf. [30, § 3.3, Theorem 3.1]). As an application, a “toy theorem” is proved, asserting that the discrete convolution operator acting from to by the formula has a maximizer. Note that in the corresponding case II(A) of Subsection 5.1 a maximizer in does not exist.
Section 2
(8) Some notions (the “-near” ones) introduced in Definitions 2.3–2.4 are there just to suit our local purposes, while other notions, with their origins in Probability Theory, have been used in different contexts. Among the latter, the term tight is standard, cf. e.g. [7, v. 2, § 8.6]. Let us comment on the remaining two.
1. The -diameter introduced in Definition 2.3 is Lévy’s dispersion function [17, Section 1.1, Supplement 4] in disguise. Specifically, for a fixed with unit -norm and a unit vector , we have the distribution function in the sense of probability theory
The corresponding Lévy concentration function [17] is
The inverse function is known as the dispersion function for the measure ; in our notation it is
2. We thought it useful to have a shorter name for the property of a function sequence to be tight up to translations; we call such a sequence relatively tight. P. L. Lions, in the formulation of his Concentration Compactness Lemma [20, Lemma I.1], chose to characterize the said property as the “case of compactness” rather than to devise a descriptive adjective.
Section 3
(8) The inequality of Lemma 3.1 is interpreted in Lions’ theory as the subadditivity property (of crucial importance) of the fucntion , cf. (8.1). Note that the exponent in the final application of Lemma 3.1 (see Lemma 3.7) coincides with that in (8.1).
(8) The function in the left-hand side of the inequality of Lemma 3.3 is known as Steklov’s averaging of the function ; the lemma states one of its most elementary properties. The quantifiers can be swapped (“there exists such that for any …”) at the expense of putting an appropriate constant in the numerator of the right-hand side; this follows from the Hardy-Littlewood maximal inequality.
(8) Perhaps, this place in our proof — the reference to Lemma 3.2 in the proof of Lemma 3.5 — most closely corresponds to Lions’ thesis “prevent the possible splitting of minimizing sequences by keeping them concentrated” [20, p.114], and also reflects the “asymptotic orthogonality” phenomenon [29].
Subsection 4.3
(8) For general integral operators in spaces, sufficient conditions for compactness usually require some spare room in the space exponents as compared with sufficient conditions for boundedness, cf. e.g. [22, Theorem 7.1].888Note that the usual notation (or ) corresponds to in [22]. As it is readily seen, there is no such “spare room” in the conditions of Lemma 4.8.
A very general study of compositions of convolution and multiplication operators in Lebesgue spaces is found in the paper [9]. Our Lemma 4.8 is a particular case of Theorem 6.4 of [9]; however, it seems easier to give an independent proof, as we did, than to scrutinize involved notation and conditions.
Subsection 5.0
(8) It is harder (likely, much harder) to prove, under the assumptions of Proposition 5.5, the approximative property in the spirit of M. Christ’s results mentioned in the comment (8). Cf. Question 6 in Section 7.
(8) One of general heuristic principles stated by P. L. Lions reads “All minimizing sequences are relatively compact up to a translation iff [a certain] strict subadditivity inequality holds”. [20, p. 114] We took it as a hint that what is now Proposition 5.6 should be valid, although we did not need it in the proof of Theorem 1.
Adapting a notion of shift-compactness [17, Section 5.1.1] to our situation, the short summary can be stated: under the assumptions of Theorem 1, every maximizing sequence of the convolution operator is shift-compact.
(8) The result of Subsection 5.8 is complementary to the results of the paper [23], in which the norms are estimated from below in terms of (absolute values of) the integrals of the kernel over certain families of sets, which are different for positive kernels and general real-valued kernels.
Subsection 5.4
References
- [3] J. M. Aldaz, “A stability version of Hölder’s inequality”, J. Math. Anal. Appl. 43, 842–852 (2008).
- [4] K. I. Babenko, “An inequality in the theory of Fourier integrals”, Amer. Math. Soc. Transl. (II), 44, 115–128 (1965).
- [5] F. Barthe, “Optimal Young s inequality and its converse: a simple proof”, GAFA, Geom. func. anal. 8, 234–242; https://arxiv.org/pdf/math/9704210.pdf (1998).
- [6] W. Beckner, “Inequalities in Fourier analysis”, Ann. of Math. 102, 159–182 (1975).
- [7] V. I. Bogachev, Measure Theory (vol. 1, 2), Springer, 2007.
- [8] H. J. Brascamp, E. H. Lieb, “Best Constants in Young’s Inequality, Its Converse, and Its Generalization to More than Three Functions”, Adv. in Math. 20, 151–173 (1976).
- [9] R.C. Busby, H.A. Smith, “Product-convolution operators and mixed-norm spaces”, Trans. AMS, 263 (2), 309–341 (1981).
- [10] E. A. Carlen, E. H. Lieb, M. Loss “A sharp analog of Young’s inequality on and related entropy inequalities”, J. Geom. Anal. 14 (3), 487–520 (2004).
- [11] M. Christ, Near-extremizers of Young’s Inequality for , https://arxiv.org/pdf/1112.4875.pdf (2011).
- [12] M. Christ, A sharpened Hausdorff-Young inequality, https://arXiv.org/pdf/1406.1210.pdf (2014).
- [13] A. Culiuc, “A sharpened Hausdorff-Young inequality”, in: Summer School “Sharp Inequalities in Harmonic Analysis” (Kopp, 2015), R. Frank, D. Oliviera e Silva, C. Thiele (eds.), 11–15 (2015).
- [14] J. Fournier, “Sharpness in Young s inequality for convolution”, Pacific J. Math. 72 (3), 383–397 (1977).
- [15] H. Hanche-Olsen, “On the uniform convexity of ”, Proc. Amer. Math. Soc. 134 (8), 2359–2362 (2006).
- [16] G. H. Hardy, “The constants of certain inequalities”, J. London Math. Soc. 8, 114–119 (1933).
- [17] W. Hengartner, R. Theodorescu, Concentration functions, Academic Press, New York-London, 1973.
- [18] E. Hewitt, K. A. Ross, Abstract harmonic analysis, vol. 1, Springer-Verlag, Berlin, 1963.
- [19] E. H. Lieb, M. Loss, Analysis (2ed.), AMS, 2001.
- [20] P. L. Lions, “The concentration-compactness principle in the calculus of variations. The locally compact case, part 1”, Ann. de l’I.H.P. Section C, 1, 109–145 (1984).
- [21] M. O. Korpusov, A. G. Sveshnikov, Nonlinear functional analysis and mathematical modeling in physics. Methods of analysis for nonlinear operators, KRASAND, Moscow, 2011. (In Russian.)
- [22] M. A. Krasnoselskii, P. P. Zabreiko, E. I. Pustylnik, P. E. Sobolevskii, Integral operators in spaces of summable functions, Noordhoff Int. Publ., Leyden, 1976.
- [23] E. D. Nursultanov, K. S. Saidahmetov, “On lower bound of the norm of integral convolution operator”, Fundam. Prikl. Mat. 8 (1), 141–150 (2002). (In Russian.)
- [24] R. O’Neil, “Fractional Integration in Orlicz Spaces. I”, Trans. AMS, 115, 300–328 (1965).
- [25] M. Pearson, “Extremals for a class of convolution operators”, Houston J. Math. 25, 43–54 (1999).
- [26] T. S. Quek, L. Y. H. Yap, “Sharpness of Young s inequality for convolution”, Math. Scand. 53, 221–237 (1983).
- [27] E. Setterqvist, Unitary equivalence: a new approach to the Laplace operator and the Hardy operator, M. Sc. thesis, Luleå Univ. of Technology,, http://ltu.diva-portal.org/smash/get/diva2:1032398/FULLTEXT01.pdf (2005).
- [28] E. M. Stein, G. Weiss, Introduction to Fourier Analysis on Euclidean Spaces, Princeton Univ. Press, 1971.
- [29] T. Tao, “Concentration compactness and the profile decompositition”, in: Poincaré’s legacies: pages from year two of a mathematical blog, Part II, , AMS, 2009. http://terrytao.wordpress.com/2008/11/05
- [30] K. Tintarev, K.-H. Fieseler, Concentration compactness. Functional-analytic grounds and applications, London, Imperial College Press, 2007.
- [31] E. T. Titchmarsch, Introduction to the Theory of Fourier Integrals, Oxford Univ. Press, 1948.
- [32] M. Vitturi, Fine structure of some classical affine-invariant inequalities, additive combinatorics and near extremizers (account of a talk by Michael Christ); http://www.maths.ed.ac.uk/~s1251909/christ_talk.pdf (2014).