On Novel Fixed-Point-Type Iterations with Structure-Preserving Doubling Algorithms for Stochastic Continuous-time Algebraic Riccati equations
Abstract
In this paper we mainly propose efficient and reliable numerical algorithms for solving stochastic continuous-time algebraic Riccati equations (SCARE) typically arising from the differential state-dependent Riccati equation technique from the 3D missile/target engagement, the F16 aircraft flight control and the quadrotor optimal control etc. To this end, we develop a fixed point (FP)-type iteration with solving a CARE by the structure-preserving doubling algorithm (SDA) at each iterative step, called FP-CARE_SDA. We prove that either the FP-CARE_SDA is monotonically nondecreasing or nonincreasing, and is R-linearly convergent, with the zero initial matrix or a special initial matrix satisfying some assumptions. The FP-CARE_SDA (FPC) algorithm can be regarded as a robust initial step to produce a good initial matrix, and then the modified Newton (mNT) method can be used by solving the corresponding Lyapunov equation with SDA (FPC-mNT-Lyap_SDA). Numerical experiments show that the FPC-mNT-Lyap_SDA algorithm outperforms the other existing algorithms.
1 Introduction
The nonlinear dynamics of the stochastic state-dependent control system in continuous-time subject to multiplicative white noises can be described as
| (1.1) |
wher , , , for , and are the state and the control input, is a standard Wiener process satisfying that each is a standard Brownian motion. Under the nonlinear dynamical system (1.1), we consider the cost functional with respect to the control with a given initial
| (1.2) |
in which , , and with .
Recently, the state-dependent Riccati equation (SDRE) [3] generalizes the well-known linear quadratic regulator (LQR) [23] and attacks broad attention in nonlinear optimal controls [26, 16, 25]. The SDRE scheme manifests state and control weighting functions to ameliorate the overall performance [9], as well as, capabilities and potentials of other performance merits as global asymptotic stability [21, 19, 4]. In practical applications such as the differential SDRE with impact angle guidance strategies [20, 24] models a 3D pursuer/target trajecting tracking or interception engagement, finite-time SDRE for F16 aircraft flight controls [6], SDRE optimal control design for quadrotors for enhancing the robustness against unmodeled disturbances [5], and position/velocity controls for a high-speed vehicle [1]. However, these application problems are real-world manipulation, the stochastic SDRE (SSDRE) should indispensably be considered. That is, the goal in SSDRE control is to minimize the cost function (1.2) and compute the optimal control at each fixed/frozen state .
Assume that, with , , , , ,
-
(c1) The pair is stabilizable, i.e., there exists such that the linear differential equation
is exponentially stable, i.e., is exponentially stable;
-
(c2) The pair is detectable with , that is, is stabilizable with and .
For a fixed state , if both (c1) and (c2) hold, then the stochastic continuous-time algebraic Riccati equation (SCARE) corresponding to (1.1) and (1.2)
| (1.3) |
has a unique positive semi-definite (PSD) stabilizing solution [11] such that the system is stable with
| (1.4) |
In fact, is a stabilizing solution if and only if the closed-loop system
is exponentially stable.
For convenience for discussion of convergence, the SCARE (1.3) can be rewritten as
| (1.5) |
where
| (1.6) |
Note that if , then and it also holds that
| (1.7) |
The main task of this paper is to develop an efficient, reliable, and robust algorithm for solving SCARE in (1.3) or (1.5). Several numerical methods, such as the fixed-point (FP) method [13], Newton (NT) method [10], modified Newton (mNT) method [8, 12, 15], structure-preserving double algorithms (SDAs) [13], have been proposed for solving the positive semi-definite (PSD) solutions for SCARE in (1.3). In fact, based on the FP, NT, mNT and SDA methods, we can combine these methods to propose various algorithms to efficiently solve SCARE (1.3) or (1.5). Nevertheless, factors such as the conditions for convergence, monotonic convergence, convergence speed, accuracy of residuals and computational cost of iterative algorithms can ultimately determine the effectiveness, reliability and robustness of a novel algorithm.
We consider the following four algorithms for solving SCARE.
-
(i) FP-CARE_SDA: We rewrite (1.5) as
(1.8) where and are defined in (2.2b), (2.2c) and (2.2d), respectively. We frozen in and as a fixed-point iteration and solve the CARE (1.8) by SDA [14, 22], called the FP-CARE_SDA.
Let be a PSD solution of SCARE (1.5). The sequence generated by FP-CARE_SDA with is monotonically nondecreasing and R-linearly convergent to a PSD (see Theorem 3.3). On the other hand, if such that is stable, and , FP-CARE_SDA generates a monotonically nonincreasing sequence which converges R-linearly to a PSD (see Theorem 3.4).
-
(ii) NT-FP-Lyap_SDA: The SCARE (1.5) can be regarded as a nonlinear equation and solved by Newton’s method in (1.9) which has been derived by [10]
(1.9) where , and are given in (4.2b), (4.2c) and (4.2d), respectively. To solve the Newton’s step (1.9), we frozen in as a fixed-point iteration and solve the associated Lyapunov equation by the special L-SDA in Algorithm 2.
-
(iii) mNT-FP-Lyap_SDA: The method NT-FP-Lyap_SDA proposed in (ii) can be accelerated by the modified NT (mNT) step [12]. That is, the Lyapunov equation (1.9) with the frozen term only solved once for approximating the modified Newton step:
If with such that is stable, and for all generated by mNT-FP-Lyap_SDA algorithm, is monotonically nonincreasing and converges to a PSD (see Theorem 5.4).
-
(iv) FP: In [13], the authors used the Möbius transformation to transform the SCARE (1.5) into a stochastic discrete-time algebraic Riccati equation (SDARE) and proposed following fixed-point (FP) iteration to solve SDARE:
where , , and are defined in (8.1). The convergence of the fixed-point iteration has been proved in [13].
This paper is organized as follows. We propose the FP-CARE_SDA (FPC) algorithm for solving SCARE (1.3) in Section 2 and prove its monotonically nondecreasing/nonincreasing convergence with suitable initial matrices in Section 3. We propose the mNT-FP-Lyap_SDA algorithm and prove its monotonic convergences in Sections 4 and 5, respectively. Moreover, for the practical applications, we proposed FPC-NT-FP-Lyap_SDA and FPC-mNT-FP-Lyap_SDA algorithms, which are combined FP-CARE_SDA with NT-FP-Lyap_SDA and mNT-FP-Lyap_SDA algorithms. In Section 6, numerical examples from benchmarks show the convergence behavior of proposed algorithms. The real-world practical applications demonstrate the robustness of FP-CARE_SDA and the efficiency of the FPC-mNT-FP-Lyap_SDA.
2 Fixed-Point CARE_SDA method
In this section, we propose a FP-CARE_SDA algorithm to solve (1.5). Let
| (2.1) |
Then equation (1.5) is equivalent to
or
| (2.2a) | ||||
| with | ||||
| (2.2b) | ||||
| (2.2c) | ||||
| (2.2d) | ||||
For a given , we denote
| (2.3) |
and consider the following CARE
| (2.4) |
where from (2.3).
Proposition 2.1.
If is stabilizable, is stabilizable.
Proof.
Let with . Suppose . This implies that , i.e., . Then we have , , which implies that by stabilzability of . ∎
Proposition 2.2.
Let (a full rank decomposition). Suppose that . If is detectable, is detectable and for .
Proof.
Theorem 2.1.
For a given , the CARE of (2.4) has a unique PSD stabilizing solution .
Proof.
It has been shown in [14, 22] that the structure-preserving doubling algorithm (SDA) can be applied to solve (2.4) with quadratic convergence. In this paper, we consider using the SDA as an implicit fixed-point iteration, called FP-CARE_SDA as stated in Algorithm 1, for solving the SCARE (1.5).
3 Convergence Analysis for FP-CARE_SDA Method
In this section, we will study the convergence analysis of the FP-CARE_SDA algorithm. Let be a PSD solution of SCARE (1.3). With different initial conditions of , the sequence generated by FP-CARE_SDA is monotonically nondecreasing/nonincreasing to and R-linearly convergent to some PSD solution , respectively, with .
Let
| (3.6) |
where , , and are given in (2.1). Then the Schur complement of the block matrix has the form
| (3.7) |
where , and in (2.2) are the coefficient matrices of CARE (2.2a).
Lemma 3.1.
Let be defined in (3). Then
| (3.8) |
Proof.
Suppose that . From (3.6), (2.1) and (1), we have
Now, we show that (3.8). For any , since , we have
| (3.13) |
It is easily seen that and are Schur complement of and , respectively. Suppose that such that
Let
| (3.18) |
Note that is the Schur complement of . Since and , it follows from (3.13) that . Hence,
| (3.19) |
From (3.18), we obtain that the entries of and are and , respectively. It follows from (3.19) that for any . This implies that (3.8) holds. ∎
Let be a sequence generated by Algorithm 1. Suppose that . From Theorem 2.1, it holds that the CARE
| (3.21) |
has a PSD solution . That is,
| (3.22) |
We now state a well-known result [18] to show the monotonicity of .
Lemma 3.2.
[18] Let with stable and . Then the solution of the Lyapunov equation is PSD.
Theorem 3.3.
Proof.
(i). We prove the assertion by induction for each . For , we have and . Since is the stabilizing PSD solution of
where is stabilizable and is detectable, we have . Now, we claim that is stable. From Lemma 3.1 and using the fact that , we have
| (3.23) |
Suppose that is not stable. Then there exist and Re such that . From (3), we have
Since and Re, we obtain that and . This implies that which is a contradiction because of the detectabity of . Hence, is stable. We now assume that the assertion (i) is true for and is the stabilizing solution of the CARE
Then we have is stable and
From Lemma 3.1 and using the fact that , we have
Hence, by Lemma 3.2. Using the fact that and Lemma 3.1, we have
This leads to because is stable. Now, we claim that is stable. After calculation, it holds that
| (3.24a) | ||||
| Similarly, using the fact that and Lemma 3.1, we have | ||||
| (3.24b) | ||||
Assume that is not stable. Then there exist and such that . From (3.24) and , we obtain that and hence,
Since , we obtain that and . This means that
which contradicts the detectability of . Therefore, is stable. The induction process is complete.
(ii). Since the sequence is monotonically nondecreasing and bounded above by , we have , where is a solution of SCARE (1.5).
(iii). By (i), all are stable, by continuity . ∎
From another perspective, we can prove that is monotonically nonincreasing if the initial satisfies some strict conditions.
Theorem 3.4.
Proof.
(i). We prove the assertion by mathematical induction on . First, we show that if , . From (3.22), we have
| (3.25) |
Since and is a solution of SCARE (1.5), it follows from Lemma 3.1 that
Since and is stable, it follows from (3) and Lemma 3.2 that . Since , we obtain that for each .
Next, we show that the sequence is monotonically nonincreasing. First, we show that . Since is the stabilizing solution of
we have
Since is stable, from Lemma 3.2, . Suppose that and stabilizing solution of
Since is stabilizing solution satisfying (3.22), we have is stable. On the other hand,
From Lemma 3.1 and using the fact that , we have
Hence, by Lemma 3.2. Since , we find that is a monotonically nonincreasing sequence by mathematical induction. Finally, we show that for each . Since is monotonically nonincreasing, from Lemma 3.1 we have
(ii). Since the sequence is monotonically nonincreasing and bounded below by , we have , where is a solution of SCARE (1.5). (iii). Using the fact that is stable for each , by continuity . ∎
Remark 2.
From Theorems 3.3 and 3.4, we proved that the sequence generated by the FP-CARE_SDA converges monotonically. Suppose that
From (2.4), we have the implicit relation between and as
where , , and . Let be the set of all Hermitian matrices and
be the Frèchet partial derivative with respect to and , respectively, i.e.,
| (3.26a) | ||||
| (3.26b) | ||||
From the implicit function theorem in Banach space, it holds that
| (3.27) |
From (3.27), we can derive the derivation of the explicit expression of .
From (3.26b) follows that
| (3.28) |
Furthermore, the Frèchet derivatives of , and at are
| (3.29c) | ||||
| (3.29d) | ||||
| (3.29e) | ||||
From (3.26a) and (3.29), we have
| (3.30) |
Theorem 3.5.
Suppose monotonically by SDA-CARE. If , then converges to R-linearly with
for some and being any matrix norm.
Proof.
From implicit function theorem, there is a function such that
| (3.31) |
Then
By implicit function Theorem, we have
| (3.32) |
Since , there exists a matrix norm and a constant such that and
| (3.33) |
Therefore, it implies
That is
Hence, for some . ∎
4 Newton method and Modified Newton method
Newton’s method for solving the SCARE (1.5) has been studied in [10]. The associated Newton’s iteration is
| (4.1) |
provided that the Frèchet derivative are all invertible. The iteration in (4.1) is equivalent to solve of the nonlinear matrix equation
| (4.2a) | ||||
| where | ||||
| (4.2b) | ||||
| (4.2c) | ||||
| (4.2d) | ||||
| with | ||||
| (4.2e) | ||||
The sequence computed by Newton’s method converges to the maximal solution of (1.5) under mild conditions.
Theorem 4.1 ([10]).
Assume that there exists a solution to and a stabilizing matrix (i.e., is stable and ). Then,
- (i)
-
, for all .
- (ii)
-
is the maximal solution of (1.5).
The authors in [10] provided the convergence analysis in Theorem 4.1. However, it lacks the numerical methods for solving (4.2a). A method of solving (4.2a) is the following fixed-point iteration
| (4.3) |
for with .
The Lyapunov equation in (4.3) is a special case of CARE. As shown in [14], we can find the Möbius transformation with to transform (4.3) into a DARE
| (4.4a) | ||||
| with | ||||
| (4.4b) | ||||
| (4.4c) | ||||
Therefore, the Lyapunov equation (4.3) can be solved efficiently by L-SDA in Algorithm 2.
Algorithm 3, called the NT-FP-Lyap_SDA algorithm, states the processes of solving SCARE in (1.5) by combining Newton’s iteration in (4.2a) with fixed-point iteration in (4.3). Steps 2-13 are the outer iterations of Newton’s method. The inner iterations in Steps 6-10 are the fixed-point iteration to solve the nonlinear matrix equation in (4.2a).
It is well-known that the fixed-point iteration in (4.3) has only a linear convergence if it converges. Even if the convergence of Newton’s method is quadratic, the overall iterations for solving (4.2a) by (4.3) can be large. To reduce the iterations, as the proposed method in [12], we modify the Newton’s iteration in (4.2a) as
| (4.5) |
and solve it by L-SDA in Algorithm 2. Solving (4.5) is equival to solve (4.2a) by using one iteration of fixed-point iteration in (4.3) with . We state the modified Newton’s iteration in Algorithm 4 and call it as mNT-FP-Lyap_SDA algorithm.
In Theorem 4.1, a stabilizing matrix is needed to guarantee the convergence of Newton’s method. However, the initial is generally not easy to find. To tackle this drawback, we integrate FP-CARE_SDA (FPC) method in Algorithm 1 into Algorithm 3. We take a few iterations of Algorithm 1, e.g. , to obtain and then use as an initial in Algorithm 3. We summarize it in Algorithm 5, called the FPC-NT-FP-Lyap_SDA method.
5 Convergence Analysis for Modified Newton Method
In this section, we study the convergence of the modified Newton’s method. For the special case that and , , Guo has shown the following result in [12].
Theorem 5.1.
Now, we consider the general case, i.e., . Here, we assume that the sequence exists and for all . Under this posterior assumption, we have the monotonic convergence of .
Lemma 5.2.
Let . Assume that and is detectable. Suppose that is a sequence generated by mNT-FP-Lyap_SDA algorithm (Algorithm 4). Then is stable if .
Proof.
From (2.1), (4.2c) and (4.2d), we have
| (5.1) |
Substituting (4.2b) and (5.1) into (4.5), the modified Newton’s iteration in (4.5) is equivalent to solve the following equation
| (5.2) |
The matrix in (2.2d) is PSD and satisfies for . Suppose that in Theorem 3.3 is the minimal PSD solution of SCARE (1.5). From (3.29c), the Frèchet derivative of at is given by
| (5.5) |
where is Hermitian, , and . Note that if , then . In the following theorem, we show the monotonically nondecreasing property if the initial is close enough to the solution .
Theorem 5.3.
Let in Theorem 3.3 be the minimal PSD solution of SCARE (1.5). Assume that there exists such that the Frèchet derivative of at satisfies for all . Let be close enough to the solution and . Suppose that with for all is a sequence generated by mNT-FP-Lyap_SDA algorithm (Algorithm 4). Then
- (i)
-
, , for each .
- (ii)
-
.
Proof.
Since , from Lemma 5.2, is stable for . We first show that
| (5.8) |
for . From the first-order expansion, we have
Using the fact that for , is bounded and is sufficiently close to , by continuity we have
Hence,
From Lemma 3.1, we have , and then
This shows that (5.8).
Now, we prove assertion (i) by induction. For , we already have and . From (5.1), we have
Since is stable, by Lemma 3.2, we obtain that . We now assume that assertion (i) is true for . From (5.2), we obtain that
Using the fact that is a solution of SCARE, it follows from (5.8) that
Therefore, by Lemma 3.2. Now, we show that and . Since
and , we have
From (5.8), we have . Then we obtain that
Hence, The induction process is complete.
(ii). From the assertion (i), we have the sequence is monotonically nondecreasing and bounded above by . This implies that . ∎
Next, we show the monotonically nonincreasing property and the convergence of as follows.
Theorem 5.4.
Proof.
(i). Since , from Lemma 5.2, is stable for . Now, we prove by induction that for each ,
| (5.9) |
For , we already have and . From (5.1), we have
Since is stable, by Lemma 3.2, we obtain that . We now assume that (5.9) is true for . From (5.2) and Lemma 3.1, we obtain that
Therefore, by Lemma 3.2. Now, we show that and . From Lemma 3.1, and satisfies (5.2), we have
Then we obtain that
Hence, . The induction process is complete.
(ii). From the assertion (i), we have the sequence is monotonically nonincreasing and bounded below by . This implies that , where is a solution of SCARE (1.5). (iii). Since is stable for each , by continuity . ∎
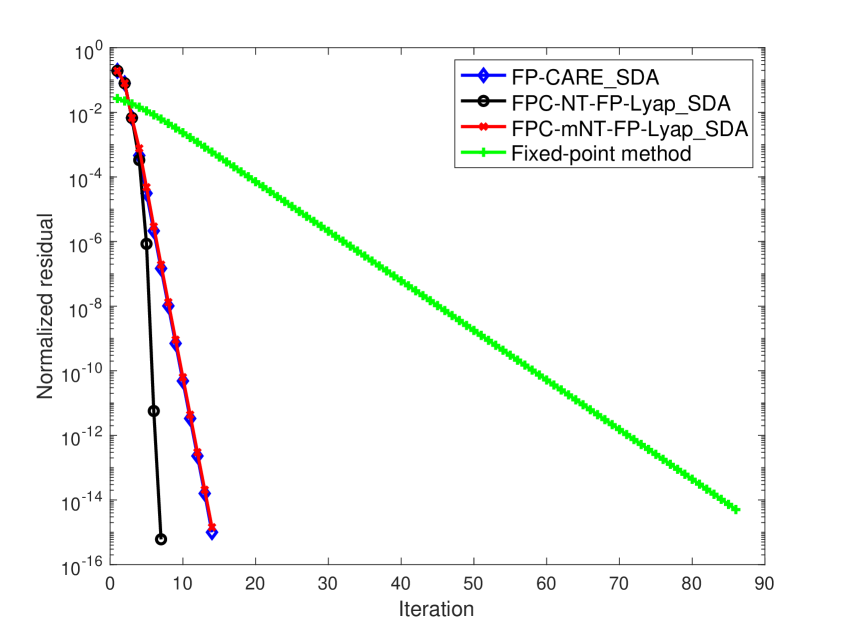
In practice, solving Lyapunov equation by Algorithm 2 outperforms solving CARE by SDA algorithm. However, it is difficult to find an initial matrix satisfying the conditions in Theorem 5.3 or Theorem 5.4. Moreover, comparing the Lyapunov equation in (4.5) with the CARE in (2.4), the CARE is more approximated the SCARE (1.5) than the Lyapunov equation. The convergence of FP-CARE_SDA algorithm will be better than that of mNT-FP-Lyap_SDA algorithm as shown in Figure 1.
To preserve the advantage and tackle the drawbacks of mNT-FP-Lyap_SDA algorithm, we proposed a practical algorithm that integrates FP-CARE_SDA and mNT-FP-Lyap_SDA algorithms. If we ignore the quadratic term in (5.2), then (5.2) is equal the CARE in (2.4). Assume that in (5.2) is closed to the nonnegative solution of the SCARE (1.5). The norm of this quadratic term will be small, which means that FP-CARE_SDA and mNT-FP-Lyap_SDA algorithms will have the similar convergence. Furthermore, from Theorem 3.3, produced by FP-CARE_SDA with is monotonically nondecreasing and for all . Therefore, we can use FP-CARE_SDA method in Algorithm 1 with to obtain , which is close enough to and . Based on Theorem 5.3, such can be used as an initial matrix of the mNT-FP-Lyap_SDA algorithm to improve the convergence of the mNT-FP-Lyap_SDA algorithm. We call this integrating method as the FPC-mNT-FP-Lyap_SDA method and state in Algorithm 6.
6 Numerical experiments
In this section, we construct eight examples of SCAREs, in which , , , come from the references and , are constructed in this paper. In the first four examples, we find an initial satisfying the conditions in Theorems 3.4 and 5.4 to numerically validate produced by FP-CARE_SDA and mNT-FP-Lyap_SDA algorithms to be monotonically nonincreasing and compare the convergence of the FP-CARE_SDA, NT-FP-Lyap_SDA and mNT-FP-Lyap_SDA algorithms. Such initial is difficult to find in Examples 5 - 8, then we use as the initial matrix. Theorem 3.3 shows to be monotonically nondecreasing for the FP-CARE_SDA algorithm. Numerical results show the failure of the convergence for the NT-FP-Lyap_SDA and mNT-FP-Lyap_SDA algorithms. However, the FPC-NT-FP-Lyap_SDA and FPC-mNT-FP-Lyap_SDA algorithms converge well to demonstrate the robustness of FP-CARE_SDA algorithm.
We use the normalized residual
to measure the precision of the calculated solutions , where . In Subsections 6.1 and 6.2, we demonstrate the convergence behaviors of for FP-CARE_SDA (Algorithm 1), NT-FP-Lyap_SDA (Algorithm 3), mNT-FP-Lyap_SDA (Algorithm 4), FPC-NT-FP-Lyap_SDA (Algorithm 5), FPC-mNT-FP-Lyap_SDA (Algorithm 6), and fixed-point iteration in (8.2) proposed by Guo and Liang [13]. The efficiency of these algorithms is demonstrated in Subsection 6.3.
All computations in this section are performed in MATLAB 2023a with an Apple M2 Pro CPU.
6.1 Numerical Validation of the convergence
Example 1.
Example 2.
Example 3.
Example 4.
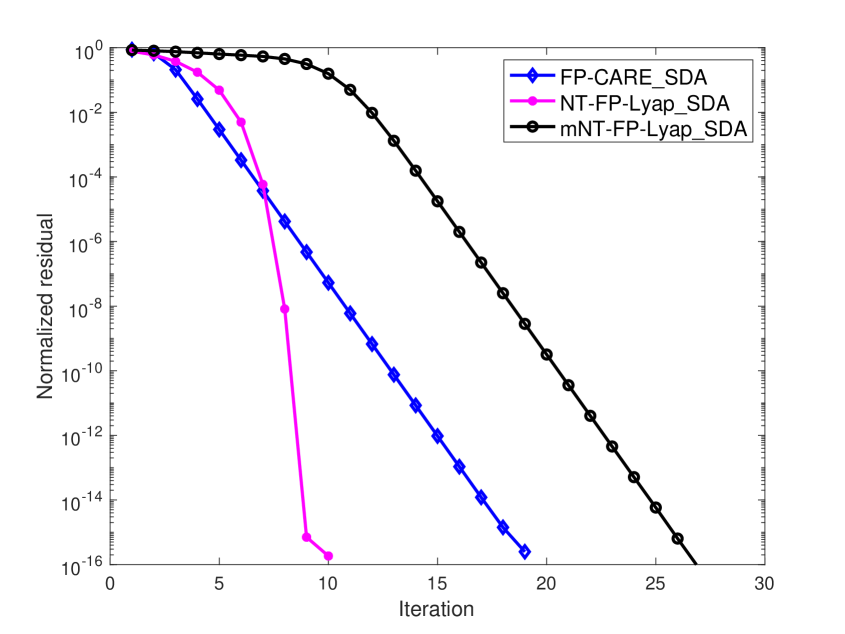
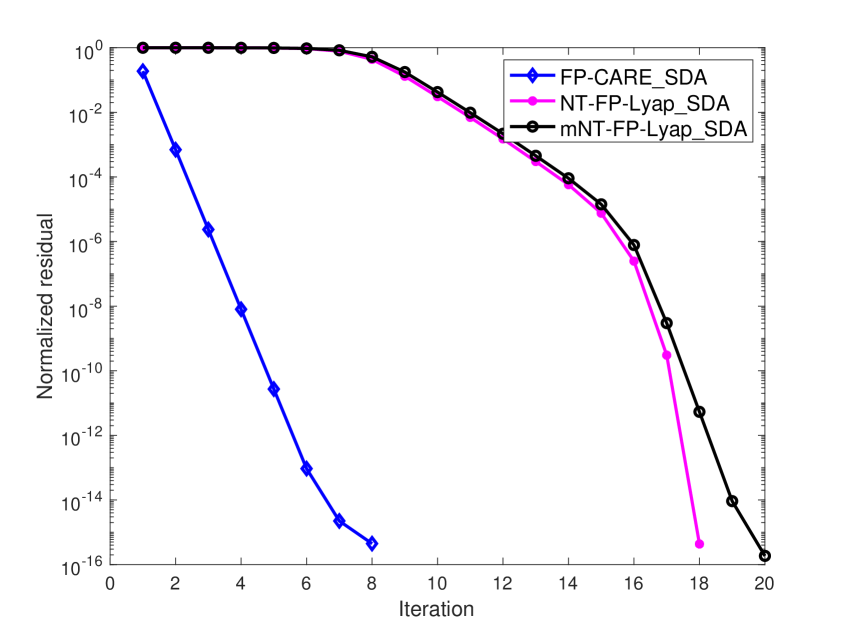
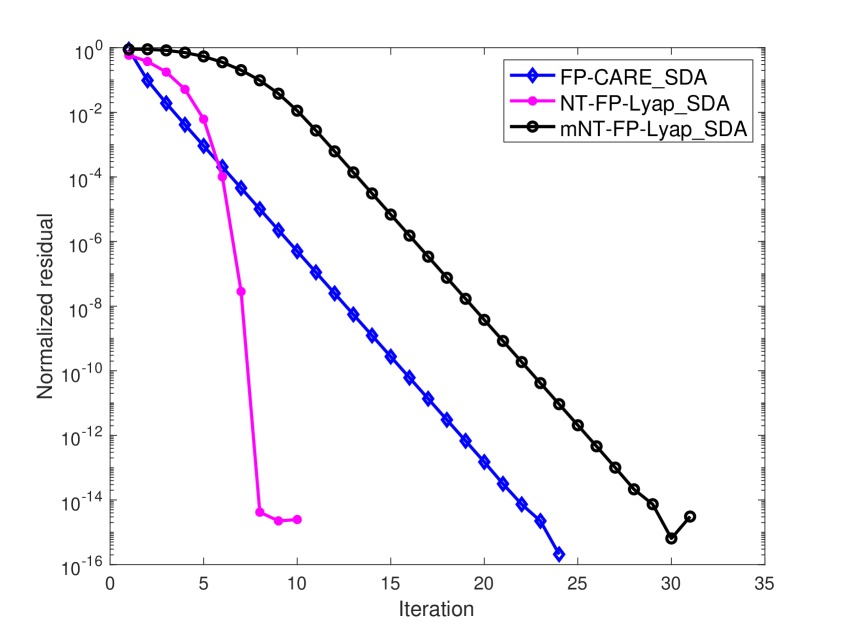
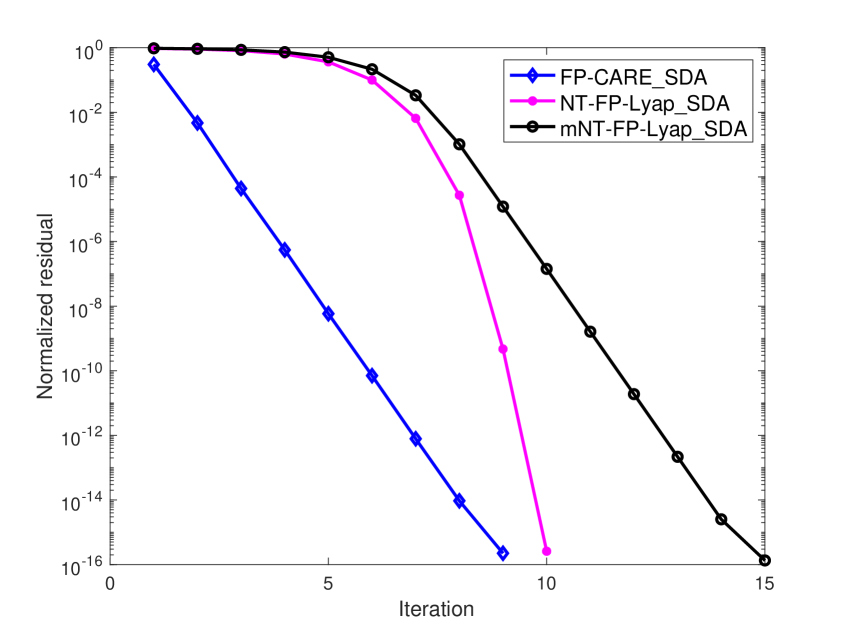
In Examples 1 - 4, we firstly take as the initial matrix for FP-CARE_SDA, NT-FP-Lyap_SDA and mNT-FP-Lyap_SDA algorithms. FP-CARE_SDA has a monotonically nondecreasing convergence as shown in Theorem 3.3. The numerical result shows that (i) the produced sequence converges to the solution of the SCARE; (ii) NT-FP-Lyap_SDA and mNT-FP-Lyap_SDA algorithms fail to converge to .
Next, we choose an initial with , , being stable and so that produced by the FP-CARE_SDA, NT-FP-Lyap SDA and mNT-FP-Lyap SDA algorithms are monotonically nonincreasing and converge to the solution of the SCARE. Using the same initial for FP-CARE_SDA, NT-FP-Lyap_SDA and mNT-FP-Lyap_SDA algorithms, the normalized residual of the algorithms are shown in Figure 1. Numerical results show that for these four examples.
The numerical results in Figure 1 show that the convergence of the FP-CARE_SDA algorithm is obviously better than that of the mNT-FP-Lyap_SDA algorithm. Furthermore, the normalized residuals at the first few iterations of the FP-CARE_SDA algorithm are less than those of the NT-FP-Lyap_SDA and mNT-FP-Lyap_SDA algorithms. These indicate that we can use a few iterations of FP-CARE_SDA algorithm to produce a good initial matrix for the NT-FP-Lyap_SDA and mNT-FP-Lyap_SDA algorithms, which are, called FPC-NT-FP-Lyap_SDA and FPC-mNT-FP-Lyap_SDA, respectively, used to improve the convergence and efficiency of the algorithms.
6.2 Robustness of FP-CARE_SDA algorithm
Due to the difficulty in selecting the initial matrix for Theorems 3.4 and 5.4, based on Theorem 3.3, we take as the initial matrix so that the FP-CARE_SDA algorithm has monotonically nondecreasing convergence. Numerical results show that the NT-FP-Lyap_SDA and mNT-FP-Lyap_SDA algorithms with fail to converge. In the following, we introduce four typical practical examples and discuss the convergence of the FPC-NT-FP-Lyap_SDA and FPC-mNT-FP-Lyap_SDA algorithms for these examples to demonstrate the robustness of FP-CARE_SDA algorithm.
Example 5.
The coefficient matrices, , , , , and of a mathematical model of position and velocity controls for a string of high-speed vehicles [1] can be described as,
where is the number of vehicles. Furthermore, the multiplicative white noises are
where wgn is a MATLAB built-in function used to generate white Gaussian noise.
Example 6.
The differential SDRE with impact angle guidance strategies models the 3D missile/target interception engagement [20, 24]. The nonlinear dynamics can be expressed as in (1.1), where the system, the control and the white noise matrix are given by
| (6.1a) | ||||
| (6.1b) | ||||
in which measures the distance between missile and target, (respective to ) are the azimuth and elevation angles (respective to missile) corresponding to the initial frame (respective the line-of-sight (LOS) frame). Furthermore, the state vector is defined by , , , with and being prescribed final angles, is a slow varying stable auxiliary variable governed by , , and are highly nonlinear functions on , , , , , , , and (see [24] for details), where are the azimuth and elevation angles of the target to the LOS frame, and are the lateral accelerations for the target, and is the control vector for the maneuverability of missile.
For a fixed state at the state-dependent technique of SDRE [20], the coefficient matrices of the SCARE (1.3) associated with the optimization problem (1.2) under the nonlinear dynamics for the missile/target engagement have the forms.
Example 7.
[6] Finite-time SDRE of F16 aircraft flight control system [6] can be described as
where is the gravity force, is the aircraft mass, , are the aircraft velocity and angular velocity vectors, respectively, for roll , pitch and yaw angles, ’s parameters are the suitable combinations of coefficients of the aircraft inertial matrix, the control vector consists of the thrust, the resulted rolling, pitch and yawing moments from the layout of ailerons, elevators and rudders, is the position of the thrust point.
Example 8.
[5] The SDRE optimal control design for quadrotors for enhancing robustness against unmodeled disturbances [5] can be described as in (1.1) and (1.2) with , ,
where , , and , is the gravity force, is the quadrotor mass, and are the velocity and the angular velocity on the body-fixed frame, respectively, for roll , pitch and yaw angles, is a slow varying stable auxiliary variable governed by , , , , , and , , , are initial parameters.
For a fixed state with , , and , the coefficient matrix has the form
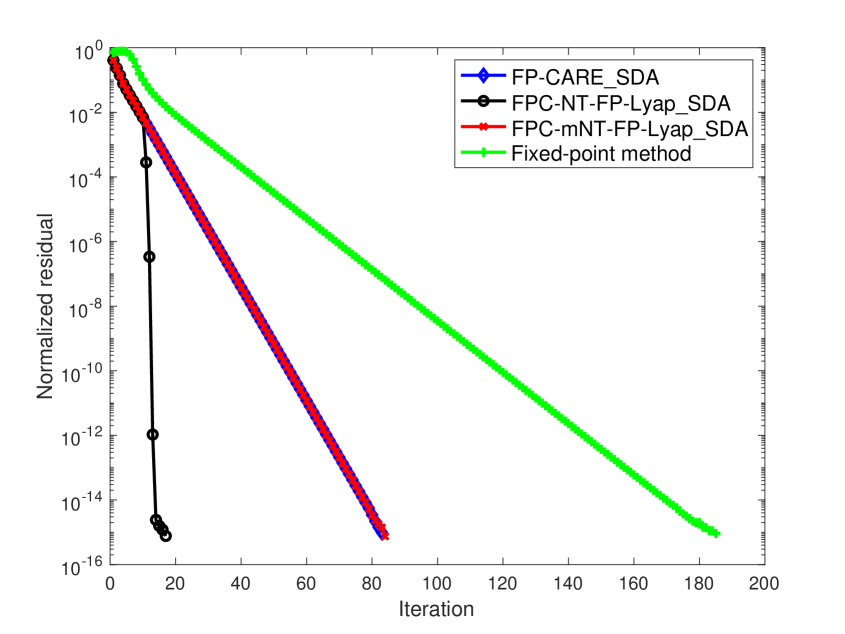
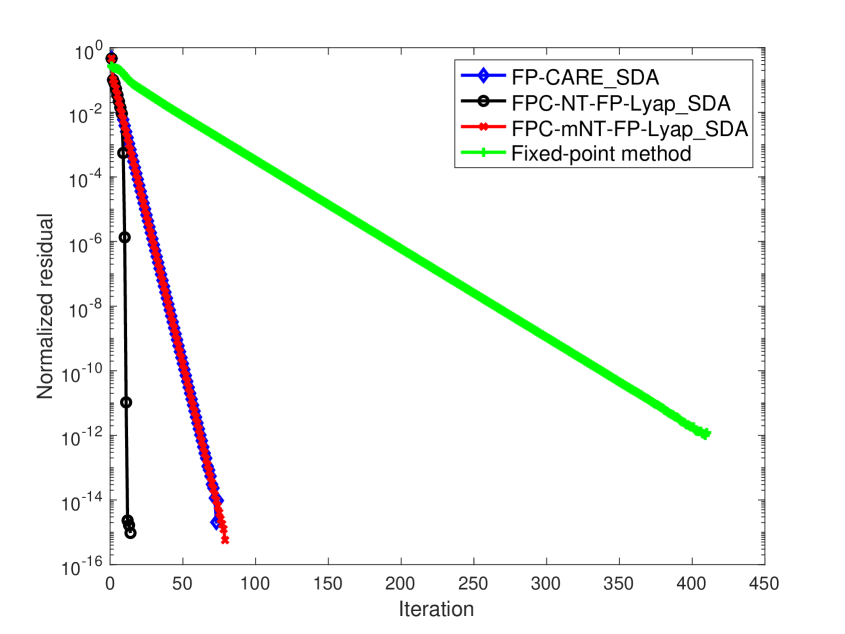
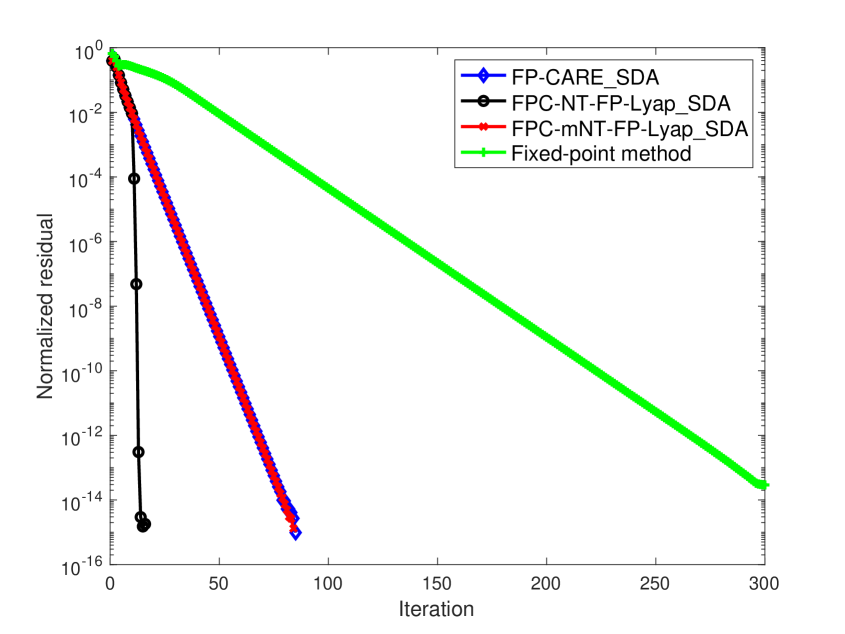
In Examples 5 - 8, we use as the initial matrix so that is monotonically non-decreasing for the FP-CARE_SDA algorithm. The associated convergence of for these examples is presented in Figure 2. Numerical results show that
-
•
It is well known that Newton’s method (NT-FP-Lyap_SDA algorithm) is highly dependent on the initial choice . When or is randomly constructed, NT-FP-Lyap_SDA does not converge to for these four examples. However, in Figure 2, after a few iterations of FP-CARE_SDA for obtaining with , is closed to and Newton’s method with initial (i.e. FPC-NT-FP-Lyap_SDA algorithm) has quadratic convergence.
-
•
Numerical results in Figure 2 show that the fixed-point method, FP-CARE_SDA and FPC-mNT-FP-Lyap_SDA algorithms have linear convergence. But, the iteration number of the fixed-point method is obviously larger than that of the other methods. Comparing the results in Figure 2 with those in Figure 1, the iteration number of mNT-FP-Lyap_SDA algorithm in Figure 1 is obviously larger than that of FP-CARE_SDA algorithm. As shown in (5.2), the quadratic term is small when is used as an initial matrix of mNT-FP-Lyap_SDA algorithm. We can expect that the mNT-FP-Lyap_SDA algorithm with initial (i.e. FPC-mNT-FP-Lyap_SDA algorithm) has the same convergent behavior of the FP-CARE_SDA algorithm as presented in Figure 2. Without such initial (i.e., with or a randomly initial ), mNT-FP-Lyap_SDA algorithm will not converge for Examples 5 - 8. This demonstrates the importance and robustness of the FP-CARE_SDA algorithm.
- •
From the results in Figures 1 and 2, the FP-CARE_SDA algorithm has a linear convergence. Moreover, the FP-CARE_SDA algorithm also provides a good initial matrix for the NT-FP-Lyap_SDA algorithm and the modified Newton’s iteration in (4.5) so that the FPC-NT-FP-Lyap_SDA and FPC-mNT-FP-Lyap_SDA algorithms have quadratic and linear convergence, respectively. These two algorithms can not compute the solution without such an initial matrix. Therefore, our proposed FP-CARE_SDA algorithm is a reliable and robust algorithm.
6.3 Efficiency of algorithms
In each iteration of the FP-CARE_SDA (Algorithm 1), FPC-NT-FP-Lyap_SDA (Algorithm 5), and FPC-mNT-FP-Lyap_SDA (Algorithm 6), solving the CARE and Lyapunov equation are the most computationally intensive steps. To compare the efficiency of these methods, we first show the total numbers of solving CARE (2.4), Lyapunov equation (4.3)/(4.5), and fixed-point iteration (8.2) for each method in Table 1. The third and fifth columns show that we only need a few iterations of the FP-CARE_SDA algorithm to get a good initial matrix in FPC-NT-FP-Lyap_SDA and FPC-mNT-FP-Lyap_SDA algorithms.
| FP-CARE_SDA | FPC-NT-FP-Lyap_SDA | FPC-mNT-FP-Lyap_SDA | FP | |||
| solving (2.4) | solving (2.4) | solving (4.3) | solving (2.4) | solving (4.5) | solving (8.2) | |
| Exa. 5 | 14 | 3 | 16 | 3 | 11 | 86 |
| Exa. 6 | 83 | 10 | 111 | 10 | 74 | 185 |
| Exa. 7 | 74 | 8 | 114 | 8 | 71 | 410 |
| Exa. 8 | 85 | 10 | 107 | 10 | 74 | 300 |
| CPU times (seconds) | ||||
|---|---|---|---|---|
| FP-CARE_SDA | FPC-NT-FP-Lyap_SDA | FPC-mNT-FP-Lyap_SDA | FP | |
| Exa. 5 | 7.947e-1 | 8.112e-1 | 5.729e-1 | 5.790 |
| Exa. 6 | 6.151e-3 | 4.632e-3 | 3.928e-3 | 9.634e-3 |
| Exa. 7 | 5.527e-3 | 4.897e-3 | 3.816e-3 | 2.041e-2 |
| Exa. 8 | 1.217e-2 | 7.759e-3 | 6.627e-3 | 3.804e-2 |
-
•
The fourth and sixth columns of Table 1 show that the FPC-NT-FP-Lyap_SDA algorithm still has a quadratic convergence, the convergence of the fixed-point iteration (4.3) for the FPC-NT-FP-Lyap_SDA algorithm is linear so that the total number of solving Lyapunov equations is larger than that for the FPC-mNT-FP-Lyap_SDA algorithm. As shown in Table 2, the performance of the FPC-mNT-FP-Lyap_SDA algorithm is better than that of the FPC-NT-FP-Lyap_SDA algorithm.
-
•
Sum of the numbers in the fifth and sixth columns of Table 1 is almost equal to the number in the second column. However, the computational cost for solving CARE (2.4) by SDA in [14] is larger than for solving Lyapunov equation (4.5) by L-SDA in Algorithm 2. This indicates that the FPC-mNT-FP-Lyap_SDA algorithm outperforms the FP-CARE_SDA algorithm as shown in the comparison of the CPU time in Table 2.
-
•
The dimension of the coefficient matrix for the linear system of the fixed-point iteration in (8.2) is . Compared to the other three algorithms, in which matrix dimensions are , the fixed-point iteration needs more computational cost to solve the linear systems. On the other hand, as shown in Figures 1-2 and the last column in Table 1, the fixed-point iteration needs a large iteration number to get the solution. These lead to the performance of the fixed-point iteration being worse than that of the other three algorithms as shown in Table 2.
Summarized above results, we can see that the FPC-mNT-FP-Lyap_SDA algorithm outperforms the FP-CARE_SDA, FPC-NT-FP-Lyap_SDA algorithms, and fixed-point iteration.
7 Conclusions
We propose a reliable FP-CARE_SDA for solving the SCARE (1.3) and prove its monotonically non-decreasing convergence with , its monotonically non-increasing convergence with and being stable. Furthermore, we propose the mNT-FP-Lyap_SDA algorithm to be used to accelerate the convergence with the FP-CARE_SDA as a robust initial step and prove its monotonically non-decreasing convergence under the assumption that the resulting . Numerical experiments of real-world practical applications from the 3D missile/target engagement, the F16 aircraft flight control, and the quadrotor optimal control show the robustness of our proposed FPC-mNT-FP-Lyap_SDA algorithm.
8 Appendix
In [13], the authors proposed a fixed-point iteration to solve stochastic discrete-time algebraic Riccati equations (SDAREs) and proved the convergence of the fixed-point iteration. Moreover, the Möbius transformation is applied to transform the SCARE (1.5) into a SDARE so that the proposed fixed-point iteration can be applied to solve the associated solution . Now, we state the fixed-point iteration for solving SCARE. Let
and be the permutations satisfying
and
Give so that is nonsingular. Define . By Möbius transformation, we have
| (8.1a) | ||||
| (8.1b) | ||||
| (8.1c) | ||||
Then, the fixed-point iteration in [13] is given as
| (8.2) |
for .
Each iteration in (8.2) only needs to compute by the direct method. However, the dimension of the coefficient matrix is enlarged to . It needs to have more and more computational cost as is large. On the other hand, the iteration can not preserve the symmetric property of the solution.
Acknowledgments
This work was partially supported by the National Science and Technology Council (NSTC), the National Center for Theoretical Sciences, and the Nanjing Center for Applied Mathematics. T.-M. Huang, Y.-C. Kuo, and W.-W. Lin were partially supported by NSTC 110-2115-M-003-012-MY3, 110-2115-M-390-002-MY3 and 112-2115-M-A49-010-, respectively.
References
- [1] J. Abels and P. Benner. CAREX - a collection of benchmark examples for continuous-time algebraic Riccati equations. SLICOT Working Note 1999-16 (Version 2.0), December 1999. Available online at slicot.org/working-notes/.
- [2] J. Abels and P. Benner. DAREX – a collection of benchmark examples for discrete-time algebraic Riccati equations. SLICOT Working Note 1999-14 (Version 2.0), December 1999. Available online at slicot.org/working-notes/.
- [3] R. Babazadeh and R. Selmic. Distance-based multi-agent formation control with energy constraints using SDRE. IEEE Trans. Aerosp. Electron. Syst., 56(1):41–56, 2020.
- [4] P. Benner and J. Heiland. Exponential stability and stabilization of extended linearizations via continuous updates of Riccati-based feedback. Int. J. Robust Nonlinear Control, 28(4):1218–1232, 2018.
- [5] S.-W. Cheng and H.-A. Hung. Robust state-feedback control of quadrotor. International Automatic Control Conference, 2022.
- [6] M. Chodnicki, P. Pietruszewski, M. Weso ̵lowski, and S. Stȩpień. Finite-time SDRE control of F16 aircraft dynamics. Arch. Control Sci., 32:557–576, 2022.
- [7] E. K.-W. Chu, H.-Y. Fan, and W.-W. Lin. A structure-preserving doubling algorithm for continuous-time algebraic Riccati equations. Linear Algebra Appl., 396:55–80, 2005.
- [8] E. K.-W. Chu, T. Li, W.-W. Lin, and C.-Y. Weng. A modified Newton’s method for rational Riccati equations arising in stochastic control. In 2011 International Conference on Communications, Computing and Control Applications (CCCA), pages 1–6, 2011.
- [9] T. Çimen. Survey of state-dependent Riccati equation in nonlinear optimal feedback control synthesis. J. Guid. Control Dyn., 35(4):1025–1047, 2012.
- [10] T. Damm and D. Hinrichsen. Newton’s method for a rational matrix equation occurring in stochastic control. Linear Algebra Appl., 332-334:81–109, 2001.
- [11] V. Dragan, T. Morozan, and A.-M. Stoica. Mathematical Methods in Robust Control of Linear Stochastic Systems. Springer-Verlag, 2013.
- [12] C.-H. Guo. Iterative solution of a matrix Riccati equation arising in stochastic control. In Linear Operators and Matrices, pages 209–221. Birkhäuser Basel, 2002.
- [13] Z.-C. Guo and X. Liang. Stochastic algebraic Riccati equations are almost as easy as deterministic ones theoretically. arXiv, 2207.11220v3, 2023.
- [14] T.-M. Huang, R.-C. Li, and W.-W. Lin. Structure-Preserving Doubling Algorithms for Nonlinear Matrix Equations. Society for Industrial and Applied Mathematics, Philadelphia, PA, 2018.
- [15] I. G. Ivanov. Iterations for solving a rational Riccati equation arising in stochastic control. Comput. Math. Appl., 53:977–988, 2007.
- [16] S. Kim and S. J. Kwon. Nonlinear optimal control design for underactuated two-wheeled inverted pendulum mobile platform. 22(6):2803–2808, 2017.
- [17] P. Lancaster and L. Rodman. Existence and uniqueness theorems for the algebraic Riccati equation. Int. J. Control, 32:285–309, 1980.
- [18] P. Lancaster and L. Rodman. Algebraic Riccati Equations. Oxford Science Publications. Oxford University Press, 1995.
- [19] L.-G. Lin, Y.-W. Liang, and L.-J. Cheng. Control for a class of second-order systems via a state-dependent Riccati equation approach. SIAM J. Control Optim., 56(1):1–18, 2018.
- [20] L.-G. Lin, R.-S. Wu, P.-K. Huang, M. Xin, C.-T. Wu, and W.-W. Lin. Fast SDDRE-based maneuvering-target interception at prespecified orientation. pages 1–8, 2023.
- [21] L.-G. Lin and M. Xin. Alternative SDRE scheme for planar systems. IEEE Trans. Circuits Syst. II-Express Briefs, 66(6):998–1002, 2019.
- [22] W.-W. Lin and S.-F. Xu. Convergence analysis of structure-preserving doubling algorithms for Riccati-type matrix equations. SIAM J. Matrix Anal. Appl., 28(1):26–39, 2006.
- [23] Y. Meng, Q. Chen, X. Chu, and A. Rahmani. Maneuver guidance and formation maintenance for control of leaderless space-robot teams. IEEE Trans. Aerosp. Electron. Syst., 55(1):289–302, 2019.
- [24] R. V. Nanavati, S. R. Kumar, and A. Maity. Spatial nonlinear guidance strategies for target interception at pre-specified orientation. Aerosp. Sci. Technol., 114:106735, 2021.
- [25] S. R. Nekoo. Tutorial and review on the state-dependent Riccati equation. 8(2):109–166, 2019.
- [26] V. Polito. Nonlinear business cycle and optimal policy: A VSTAR perspective. CESifo Working Paper Series, (8060):1–54, 2020.
- [27] P. C.-Y. Weng and F. K.-H. Phoa. Perturbation analysis and condition numbers of rational Riccati equations. Ann. Math. Sci. Appl., 6:25–49, 2021.