On the boosting ability of top-down decision tree learning algorithm for multiclass classification
Abstract
We analyze the performance of the top-down multiclass classification algorithm for decision tree learning called LOMtree, recently proposed in the literature Choromanska and Langford (2014) for solving efficiently classification problems with very large number of classes. The algorithm online optimizes the objective function which simultaneously controls the depth of the tree and its statistical accuracy. We prove important properties of this objective and explore its connection to three well-known entropy-based decision tree objectives, i.e. Shannon entropy, Gini-entropy and its modified version, for which instead online optimization schemes were not yet developed. We show, via boosting-type guarantees, that maximizing the considered objective leads also to the reduction of all of these entropy-based objectives. The bounds we obtain critically depend on the strong-concavity properties of the entropy-based criteria, where the mildest dependence on the number of classes (only logarithmic) corresponds to the Shannon entropy.
Keywords: multiclass classification, decision trees, boosting, online learning
1 Introduction
This paper focuses on the multiclass classification problem with very large number of classes which becomes of increasing importance with the recent widespread development of data-acquisition web services and devices. Straightforward extensions of the binary approaches to the multiclass setting, such as one-against-all approach Rifkin and Klautau (2004), do not often work in the presence of strict computational constraints. In this case, hierarchical approaches seem particularly favorable since, due to their structure, they potentially can significantly reduce the computational costs. This paper is motivated by very recent advances in the area of multiclass classification, and considers a hierarchical approach for learning a multiclass decision tree structure in a top-down fashion, where splitting the data in every node of the tree is based on the value of a very particular objective function. This objective function controls the balancedness of the splits (thus the depth of the tree) and the statistical error they induce (thus the statistical error of the tree), and was initially introduced in Choromanska and Langford (2014) along with the algorithm optimizing it in an online fashion called LOMtree. The algorithm was empirically shown to obtain high-quality trees in logarithmic (in the label complexity) train and test running times, simultaneously outperforming state-of-the-art comparators, yet the objective underlying it is still not-well understood. The main contribution of this work is an extensive theoretical analysis of the properties of this objective, and the algorithm111We do not discuss the algorithm here, we refer the reader to the original paper. optimizing it. And in particular, the analysis includes exploring, via the boosting framework, a relation of this objective to some more standard entropy-based decision tree objectives, i.e. Shannon entropy222Throughout the paper we refer to Shannon entropy as simply entropy., Gini-entropy and its modified version, for which online optimization schemes in the context of multiclass classification were not yet developed.
The multiclass classification problem was relatively recently explored in the literature, and there exist only few works addressing the problem. In this work we focus on decision tree-based approaches. Filter tree Beygelzimer et al. (2009b) considers simplified instance of the problem where the tree structure over the labels is assumed given. It is provably consistent and achieves regret bound which depends logarithmically on the number of classes. The conditional probability tree Beygelzimer et al. (2009a) instead learns the tree structure and uses the node splitting criterion which compromises between obtaining balanced split in a tree node and violating the recommendation for the split from the node regressor. The authors also provide regret bounds which scales with the tree depth. Other works, which come with no guarantees, consider splitting the data in every tree node by optimizing efficiency with accuracy constraints allowing fine-grained control of the efficiency-accuracy tradeoff Deng et al. (2011), or by performing clustering Bengio et al. (2010); Madzarov et al. (2009). The splitting criterion (objective function) analyzed in this paper differs from the criteria considered in previous works and comes with much stronger theoretical justification given in Section 2.
The main theoretical analysis of this paper is kept in the boosting framework Schapire and Freund (2012) and relies on the assumption of the existence of weak learners in the tree nodes, where the top-down algorithm we study will amplify this weak advantage to build a tree achieving any desired level of accuracy wrt. entropy-based criteria. We add new theoretical results to the theory of boosting for the multiclass classification problem (the multiclass boosting is largely ununderstood, we refer the reader to Mukherjee and Schapire (2013) for comprehensive review), and we show that LOMtree is a boosting algorithm reducing standard entropy-based criteria, where the obtained bounds depend on the strong concativity properties of these criteria. Our work extends two previous works: it significantly adds to the theoretical analysis of Choromanska and Langford (2014), where only Shannon entropy is considered, in which case we also slightly improve their bound, and it extends beyond the boosting analysis of the binary case of Kearns and Mansour (1999). The main theoretical results are presented in Section 3. Numerical experiments (Section 4) and brief discussion (Section 5) conclude the paper.
2 Objective function and its theoretical properties
In this section we describe the objective function that is of central interest to this paper, and we provide its theoretical properties.
2.1 Objective function
We receive examples , with labels . We assume access to a hypothesis class where each is a binary classifier, , and each node in the tree consists of a classifier from . The classifiers are trained in such a way that ( denotes the classifier in node of the tree; for fixed node we will refer to simply as ) means that the example is sent to the right subtree of node , while sends to the left subtree. When we reach a leaf node, we predict according to the label with the highest frequency amongst the examples reaching that leaf.
Notice that from the perspective of reducing the computational complexity, we want to encourage the number of examples going to the left and right to be balanced. Furthermore, for maintaining good statistical accuracy, we want to send examples of class almost exclusively to either the left or the right subtree. A measure of whether the examples of each class reaching the node are then mostly sent to its one child node (pure split) or otherwise to both children (impure split) is referred to as the purity of a tree node. These two criteria, purity and balancedness, were discussed in Choromanska and Langford (2014). This work also proposes an objective (convex) expressing both criteria, and thus measuring the quality of a hypothesis in creating partitions at a fixed node in the tree. The objective is given as follows
| (1) |
where denotes the proportion of label amongst the examples reaching this node, and denote the fraction of examples reaching for which , marginally and conditional on class respectively. It was shown that this objective can be effectively maximized over hypotheses , giving high-quality partitions, in an online fashion (recall that it remains unclear how to online optimize some of the more standard decision tree objectives such as entropy-based objectives). Despite that, this objective and its properties (including the relation to the more standard entropy-based objectives) remain not fully understood. Its exhaustive analysis is instead provided in this paper.
2.2 Theoretical properties of the objective function
We first define the concept of balancedness and purity of the split which are crucial for providing the theoretical properties of the objective function under consideration in this paper.
Definition 1 (Purity and balancedness, Choromanska and Langford (2014))
The hypothesis induces a pure split if
where , and is called the purity factor.
The hypothesis induces a balanced split if
where , and is called the balancing factor.
A partition is called maximally pure if (each class is sent exclusively to the left or to the right). A partition is called maximally balanced if (equal number of examples are sent to the left and to the right).
Next we show the first theoretical property of the objective function . Lemma 2 contains a stronger statement than the one in the original paper Choromanska and Langford (2014) (Lemma 2).
Lemma 2
For any hypothesis , the objective satisfies . Furthermore, induces a maximally pure and balanced partition iff .
Lemma 2 characterizes the behavior of the objective at the optimum where . In practice however we do not expect to have hypotheses producing maximally pure and balanced splits, thus it is of importance to be able to show that larger values of the objective correspond simultaneously to more pure and more balanced splits. This statement would fully justify why it is desired to maximize . We next focus on showing this property. We start by showing that increasing the value of the objective leads to more balanced splits.
Lemma 3
For any hypothesis , and any distribution over examples the balancing factor satisfies .
Thus the larger (closer to ) the value of is, the narrower the interval from Lemma 3 is, leading to more balanced splits ( closer to ).
The next lemma, which we borrow from the literature, relates the balancing and purity factor, and it will be used to show that increasing the value of the objective function corresponds not only to more balanced splits, but also to more pure splits.
Lemma 4 (Choromanska and Langford (2014))
For any hypothesis , and any distribution over examples , the purity factor and the balancing factor satisfy .
Recall that Lemma 3 shows that increasing the value of leads to a more balanced split ( closer to ). From this fact and Lemma 4 it follows that increasing the value of leads to the upper-bound on being closer to which also corresponds to a more pure split. Thus maximizing the objective recovers more balanced and more pure splits.
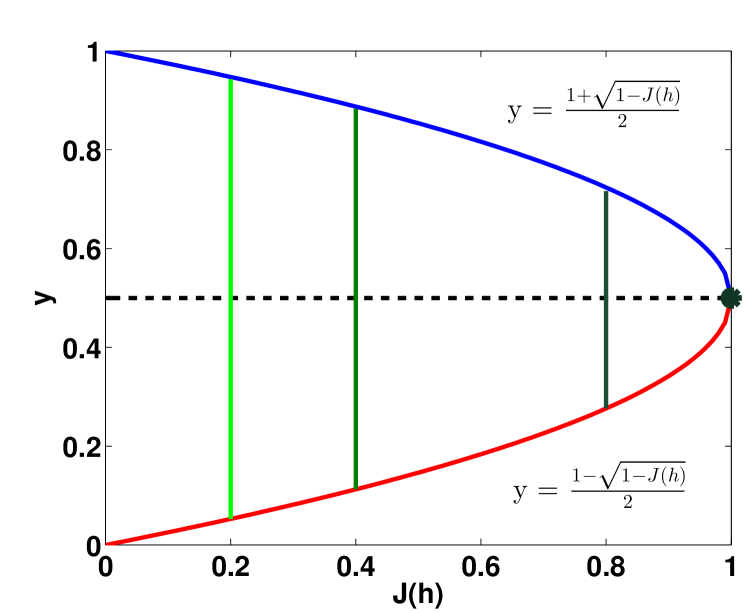
|
Proof [Lemma 2] The proof that and that if induces a maximally pure and balanced partition then was done in Choromanska and Langford (2014) (Lemma 2). We therefore prove here the remaining statement in Lemma 2 that if then induces a maximally pure and balanced partition.
Without loss of generality assume each . Recall that , and let . Also recall that . Thus . The objective is certainly maximized in the extremes of the interval , where each is either or (also note that at maximum, where , it cannot be that all ’s are or all ’s are ). The function is differentiable in these extremes ( is non-differentiable only when , but at considered extremes the left-hand side of this equality is in whereas the right-hand side is either or ). We then write
where and . Also let (clearly and in the extremes of the interval where is maximized). We then can compute the derivatives of with respect to , where , everywhere where the function is differentiable as follows
and note that in the extremes of the interval where is maximized , since , , and each . Since is convex, and by the fact that in particular the derivative of with respect to any cannot be in the extremes of the interval where is maximized, it follows that the can only be maximized () at the extremes of the interval. Thus we already proved that if then induces a maximally pure partition. We are left with showing that if then induces also a maximally balanced partition. We prove it by contradiction. Assume . Denote as before and . Recall . Thus
where the last inequality comes from the fact that the quadratic form is equal to only when , and otherwise it is smaller than . Thus we obtain the contradiction which ends the proof.
Proof [Lemma 3] As before we use the following notation: , and . Also let and . Recall that , and . We split the proof into two cases.
-
•
Let . Then
Thus which, when solved, yields the lemma.
-
•
Let (thus ). Note that can be written as
since and . Let , and . Note that and . Also note that . Thus
Thus as before we obtain which, when solved, yields the lemma.
We next consider the quality of the entire tree as we add more nodes. We aim to maximize the objective function in each node we split. In the next section we show that optimizing the objective leads to the reduction of the more standard decision tree entropy-based objectives. We consider three different objectives in this paper. We focus on the boosting framework, where the analysis depends on the weak learning assumption. Three different entropy-based criteria lead to three different theoretical statements, where we bound the number of splits required to reduce the value of the criterion below given level. The bounds we obtain, and their dependence on , critically depend on the strong concativity properties of the considered entropy-based criteria. In our analysis we use elements of the proof techniques from Kearns and Mansour (1999) (the proof of Theorem 10) and Choromanska and Langford (2014) (the proof of Theorem 1). We show all the steps for completeness as we make modifications compared to these works.
3 Main theoretical results
We begin from explaining the notation. Let denote the tree under consideration. ’s denote the probabilities that a randomly chosen data point drawn from , where is a fixed target distribution over , has label given that reaches node (note that ), denotes the set of all tree leaves, denotes the number of internal tree nodes, and is the weight of leaf defined as the probability a randomly chosen drawn from reaches leaf (note that ). We study a tree construction algorithm where we recursively find the leaf node with the highest weight, and choose to split it into two children. Consider the tree constructed over steps where in each step we take one leaf node and split it into two ( corresponds to splitting the root, thus the tree consists of one node (root) and its two children (leaves) in this step). Let be the heaviest node at time and its weight be denoted by for brevity. We measure the quality of the tree at any given time using three different entropy-based criteria:
-
•
The entropy function :
-
•
The Gini-entropy function :
-
•
The modified Gini-entropy :
where is a constant such that .
These criteria are natural extensions of the criteria used in Kearns and Mansour (1999) in the context of binary classification, to the multiclass classification setting333Note that there is more than one way of extending the entropy-based criteria from Kearns and Mansour (1999) to the multiclass classification setting, e.g. the modified Gini-entropy could as well be defined as where . This and other extensions will be investigated in future works.. We will next present the main results of this paper which will be followed by their proofs. We begin with introducing the weak hypothesis assumption.
Our theoretical analysis is held in the boosting framework and critically depends on the weak hypothesis assumption, which ensures that the hypothesis class is rich enough to guarantee ’weakly’ pure and ’weakly’ balanced split in any given node.
Definition 5 (Weak Hypothesis Assumption, Choromanska and Langford (2014))
Let denotes any node of the tree , and let and . Furthermore, let be such that for all , . We say that the weak hypothesis assumption is satisfied when for any distribution over at each node of the tree there exists a hypothesis such that .
We next state the three main theoretical results of this paper captured in Theorem 6, 7, and 8. They guarantee that the top-down decision tree algorithm which optimizes , such as the one in Choromanska and Langford (2014), will amplify the weak advantage, captured in the weak learning assumption, to build a tree achieving any desired level of accuracy wrt. entropy-based criteria.
Theorem 6
Under the Weak Hypothesis Assumption, for any , to obtain it suffices to make
Theorem 7
Under the Weak Hypothesis Assumption, for any , to obtain it suffices to make
Theorem 8
Under the Weak Hypothesis Assumption, for any , to obtain it suffices to make
Clearly, different criteria lead to bounds with different dependence on the number of classes , where the most advantageous dependence (only logarithmic in ) is obtained for the entropy criterion. This is a consequence of the strong concativity properties of the entropy-based criteria considered in this paper. We next discuss in details the mathematical properties of the entropy-based criteria, which are important to prove the above theorems.
3.1 Properties of the entropy-based criteria
Each of the presented entropy-based criteria has a number of useful properties that we give next with their proofs.
Bounds on the entropy-based criteria
We first give bounds on the values of the entropy-based functions.
Lemma 9
The entropy function at time is bounded as
Proof The lower-bound follows from the fact that the entropy of each leaf is non-negative. We next prove the upper-bound. Note that
where the first inequality comes from the fact that uniform distribution maximizes the entropy, and the last equality comes from the fact that a tree with internal nodes has leaves (also recall that is the weight of the heaviest node in the tree at time which is what we will also use in the next lemmas).
Before proceeding to the Gini-entropy criterion we first introduce the helpful result captured in Lemma 10 and Corollary 11.
Lemma 10 (The inequality between Euclidean and arithmetic mean)
Let be a set of non-negative numbers. Then Euclidean mean upper-bounds the arithmetic mean as follows .
Corollary 11
Let be a set of non-negative numbers. Then .
Proof
By Lemma 10 we have .
We next proceed to the Gini-entropy.
Lemma 12
The Gini-entropy function at time is bounded as
Proof The lower-bound is straightforward since all ’s are non-negative. The upper-bound can be shown as follows (the last inequality results from Corollary 11):
Lemma 13
The modified Gini-entropy function at time is bounded as
Proof
The lower-bound can be shown as follows. Recall that the function
is concave and therefore it is certainly minimized on the extremes of the interval, meaning where each is either or . Let and let . Thus . Combining this result with the fact that gives the lower-bound.
We next prove the upper-bound. Recall that from Lemma 10 it follows that
By Jensen’s inequlity . Thus
So far we have been focusing on the time step , where was the heaviest node and it had weight . Consider splitting this leaf to two children and . For the ease of notation let and , and , and furthermore let and be the shorthands for and respectively. Recall that and . Notice that and . Let be the -element vector with entry equal to . Finally, let , , and . Before the split the contribution of node to resp. , , and was resp. , , and . Note that and are the probabilities that a randomly chosen drawn from has label given that reaches nodes and respectively. For brevity, let and be denoted respectively as and . Let be the -element vector with entry equal to and let be the -element vector with entry equal to . Notice that . After the split the contribution of the same, now internal, node changes to resp. , , and . We denote the difference between the contribution of node to the value of the entropy-based objectives in times and as
| (2) |
| (3) |
| (4) |
Strong concativity properties of the entropy-based criteria
The next three lemmas, Lemma 14, 16, and 18, describe the strong concativity properties of the entropy, Gini-entropy and modified Gini-entropy which can be used to lower-bound , , and (Equations 2, 3, and 4 corresponds to a gap in the Jensen’s inequality applied to the strongly concave function).
Lemma 14
The entropy function is strongly concave with respect to -norm with modulus , and thus the following holds
We introduce one more lemma and then proceed with Gini-entropy.
Lemma 15 (Shalev-Shwartz (2007)(Lemma 14))
If the function is twice differentiable, then the sufficient condition for strong concativity of is that for all , , , where is the Hessian matrix of at , and is the strong concativity modulus.
Lemma 16
The Gini-entropy function is strongly concave with respect to -norm with modulus , and thus the following holds
Proof
Note that , and apply Lemma 15.
Before showing the strong concativity guarantee for the modified Gini-entropy, we first show the statement that will be useful to prove the lemma.
Lemma 17 (Zhukovskiy (2003), Remark 2.2.4.)
The sum of strongly concave functions on with modulus is strongly concave with the same modulus.
Lemma 18
The modified Gini-entropy function is strongly concave with respect to -norm with modulus , and thus the following holds
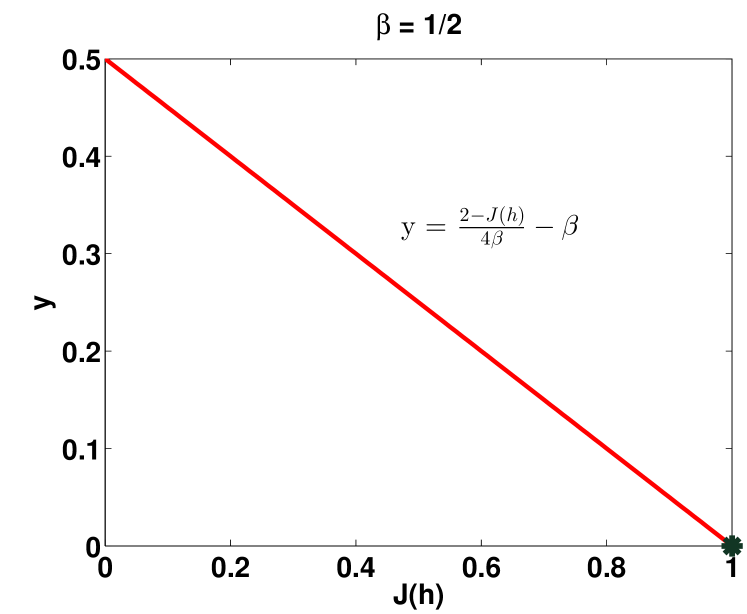
|
Proof Consider functions , where , , and . Also let , where . It is easy to see, using Lemma 15, that function is strongly concave with respect to -norm with modulus , thus
| (5) |
where and . Also note that is strongly concave with modulus in its domain (the second derivative of is ). The strong concativity of implies that
where . Let and . Then we obtain
| (6) |
Note that
where the second inequality results from Equation 5 and the last (third) inequality results from Equation 6. Finally note that the first derivative of is thus
and combining this result with previous statement yields
thus is strongly concave with modulus . By Lemma 17, is also strongly concave with the same modulus.
3.2 Proof of the main theorems
We finally proceed to proving all three theorems. We first introduce some mathematical tools that will be used in the following proofs. The next two lemma are fundamental. The first one relates -norm and -norm and the second one is a simple property of the exponential function.
Lemma 19
Let then .
Lemma 20
For the following holds .
Proof For the entropy it follows from Equation 2 and Lemma 14 that
| (7) | |||||
where the last inequality comes from the fact that (see the definition of in the weak hypothesis assumption) and (see weak hypothesis assumption). For the Gini-entropy criterion notice that from Equation 3, Lemma 16 and Lemma 19, it follows that
| (8) |
where the last inequality is obtained similarly as the last inequality in Equation 7. And finally for the modified Gini-entropy it follows from Equation 4, Lemma 18 and Lemma 19 that
| (9) | |||||
where the last inequality is obtained as before.
Clearly the larger the objective is at time , the larger the entropy reduction ends up being, which confirms the plausibility of the approach in Choromanska and Langford (2014) where the goal is to maximize . Let
| (10) |
For simplicity of notation assume corresponds to either , or , or , and stands for , or , or . Thus , and we obtain the recurrence inequality
One can now compute the minimum number of splits required to reduce below , where . Assume .
where . Recall that
where the last step follows from Lemma 20. Also note that by the same lemma . Thus
| (11) |
Therefore to reduce (where ’s are defined in Theorems 6, 7, and 8) it suffices to make splits such that splits. Since , where . Thus
| (12) |
Recall that by resp. Lemma 9, 12, and 13 we have resp. , , .
We consider the worst case setting (giving the largest possible number of split) thus we assume , , and .
Combining that with Equation 10 and Equation 12 yields statements of the main theorems.
4 Numerical experiments
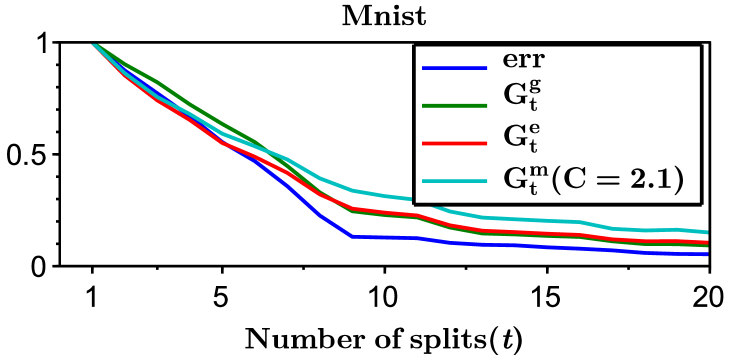
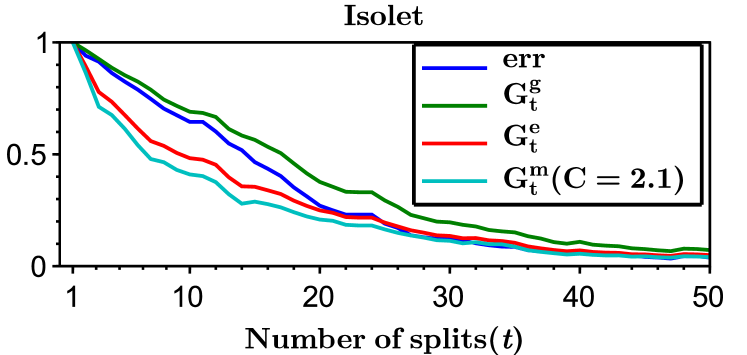
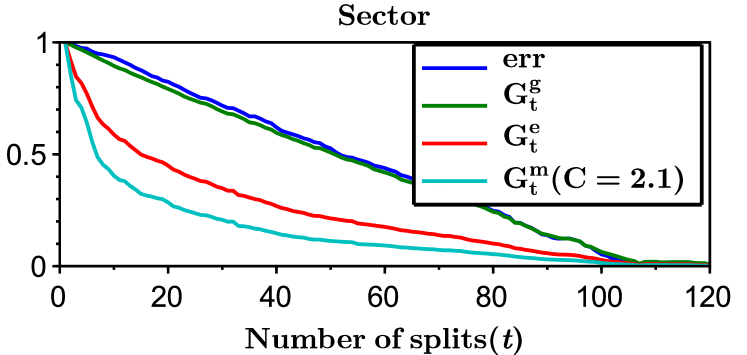
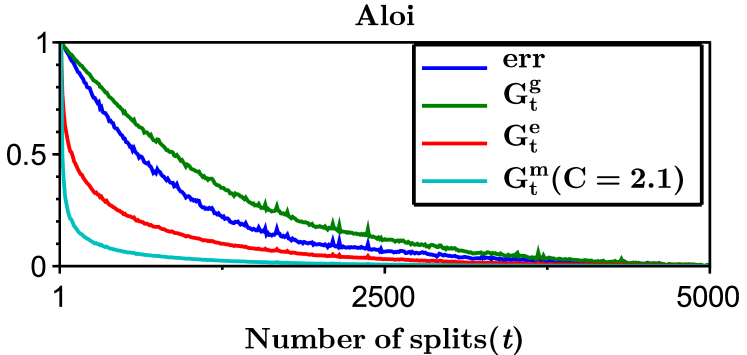
We run LOMtree algorithm, which is implemented in the open source learning system Vowpal Wabbit Langford et al. (2007), on four benchmark multiclass datasets: Mnist ( classes, downloaded from http://yann.lecun.com/exdb/mnist/), Isolet ( classes, downloaded from http://www.cs.huji.ac.il/~shais/datasets/ClassificationDatasets.html), Sector ( classes, downloaded from http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/multiclass.html), and Aloi ( classes, downloaded from http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/multiclass.html). The datasets were divided into training () and testing (), where of the training dataset was used as a validation set. The regressors in the tree nodes are linear and were trained by SGD Bottou (1998) with epochs and the learning rate chosen from the set . We investigated different swap resistances555see Choromanska and Langford (2014) for details chosen from the set . We selected the learning rate and the swap resistance as the one minimizing the validation error, where the number of splits in all experiments were set to .
|
|
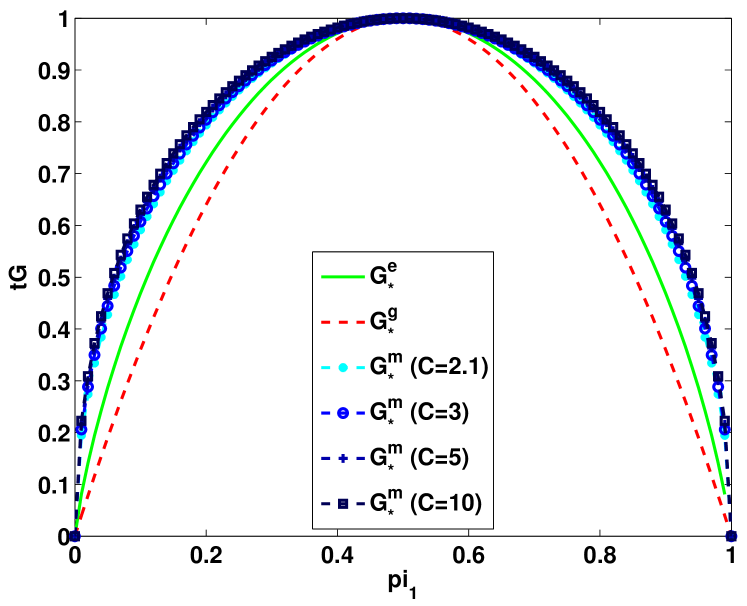
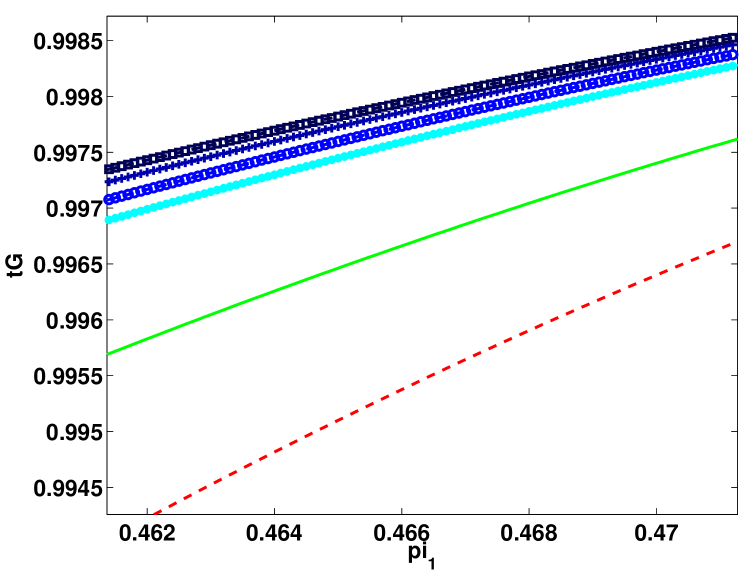
Figure 3 shows the entropy, Gini-entropy, modified Gini-entropy, and the error, all normalized to the interval , as the function of the number of splits. The behavior of the entropy and Gini-entropy match the theoretical findings. However, the modified Gini-entropy instead drops the fastest with the number of splits, which in particular suggests that in this case perhaps tighter bounds could possibly be proved (for the binary case tighter analysis was shown in Kearns and Mansour (1999), but it is highly non-trivial to generalize this analysis to the multiclass classification setting). Furthermore, it can be observed that the behavior of the error closely mimics the behavior of the Gini-entropy.
5 Conclusions
This paper focuses on the properties of the recently proposed LOMtree algorithm. We provide an exhaustive theoretical analysis of the objective function underlying the algorithm. We show a unified framework for analyzing the boosting ability of the algorithm by exploring the connection of its objective to entropy-based criteria, such as entropy, Gini-entropy and its modified version. We show that the strong concativity properties of these criteria have critical impact on the character of the obtained bounds. The experiments suggest that perhaps tighter bound is possible in particular for the modified version of the Gini-entropy.
References
- Bengio et al. (2010) S. Bengio, J. Weston, and D. Grangier. Label embedding trees for large multi-class tasks. In NIPS, 2010.
- Beygelzimer et al. (2009a) A. Beygelzimer, J. Langford, Y. Lifshits, G. B. Sorkin, and A. L. Strehl. Conditional probability tree estimation analysis and algorithms. In UAI, 2009a.
- Beygelzimer et al. (2009b) A. Beygelzimer, J. Langford, and P. D. Ravikumar. Error-correcting tournaments. In ALT, 2009b.
- Bottou (1998) L. Bottou. Online algorithms and stochastic approximations. In Online Learning and Neural Networks. Cambridge University Press, 1998.
- Choromanska and Langford (2014) Anna Choromanska and John Langford. Logarithmic time online multiclass prediction. CoRR, abs/1406.1822, 2014.
- Deng et al. (2011) J. Deng, S. Satheesh, A. C. Berg, and L. Fei-Fei. Fast and balanced: Efficient label tree learning for large scale object recognition. In NIPS, 2011.
- Kearns and Mansour (1999) M. Kearns and Y. Mansour. On the boosting ability of top-down decision tree learning algorithms. Journal of Computer and Systems Sciences, 58(1):109–128 (also In STOC, 1996), 1999.
- Langford et al. (2007) J. Langford, L. Li, and A. Strehl. http://hunch.net/~vw, 2007.
- Madzarov et al. (2009) G. Madzarov, D. Gjorgjevikj, and I. Chorbev. A multi-class svm classifier utilizing binary decision tree. Informatica, 33(2):225–233, 2009.
- Mukherjee and Schapire (2013) I. Mukherjee and R. E. Schapire. A theory of multiclass boosting. Journal of Machine Learning Research, 14:437–497, 2013.
- Rifkin and Klautau (2004) R. Rifkin and A. Klautau. In defense of one-vs-all classification. J. Mach. Learn. Res., 5:101–141, 2004. ISSN 1532-4435.
- Schapire and Freund (2012) R. E. Schapire and Y. Freund. Boosting: Foundations and Algorithms. The MIT Press, 2012.
- Shalev-Shwartz (2007) S. Shalev-Shwartz. Online Learning: Theory, Algorithms, and Applications. PhD thesis, The Hebrew University of Jerusalem, 2007.
- Shalev-Shwartz (2012) S. Shalev-Shwartz. Online learning and online convex optimization. Found. Trends Mach. Learn., 4(2):107–194, 2012.
- Zhukovskiy (2003) V.I. Zhukovskiy. Lyapunov Functions in Differential Games. Stability and Control: Theory, Methods and Applications. Taylor & Francis, 2003.