On the Infimal Sub-differential Size of Primal-Dual Hybrid Gradient Method and Beyond
Abstract
Primal-dual hybrid gradient method (PDHG, a.k.a. Chambolle and Pock method [10]) is a well-studied algorithm for minimax optimization problems with a bilinear interaction term. Recently, PDHG is used as the base algorithm for a new LP solver PDLP that aims to solve large LP instances by taking advantage of modern computing resources, such as GPU and distributed system. Most of the previous convergence results of PDHG are either on duality gap or on distance to the optimal solution set, which are usually hard to compute during the solving process. In this paper, we propose a new progress metric for analyzing PDHG, which we dub infimal sub-differential size (IDS), by utilizing the geometry of PDHG iterates. IDS is a natural extension of the gradient norm of smooth problems to non-smooth problems, and it is tied with KKT error in the case of LP. Compared to traditional progress metrics for PDHG, such as duality gap and distance to the optimal solution set, IDS always has a finite value and can be computed only using information of the current solution. We show that IDS monotonically decays, and it has an sublinear rate for solving convex-concave primal-dual problems, and it has a linear convergence rate if the problem further satisfies a regularity condition that is satisfied by applications such as linear programming, quadratic programming, TV-denoising model, etc. Furthermore, we present examples showing that the obtained convergence rates are tight for PDHG. The simplicity of our analysis and the monotonic decay of IDS suggest that IDS is a natural progress metric to analyze PDHG. As a by-product of our analysis, we show that the primal-dual gap has convergence rate for the last iteration of PDHG for convex-concave problems. The analysis and results on PDHG can be directly generalized to other primal-dual algorithms, for example, proximal point method (PPM), alternating direction method of multipliers (ADMM) and linearized alternating direction method of multipliers (l-ADMM).
1 Introduction
Linear programming (LP) [5, 16] is a fundamental problem in mathematical optimization and operations research. The traditional LP solvers are essentially based on either simplex method or barrier method. However, it is highly challenging to further scale up these two methods. The computational bottleneck of both methods is solving linear equations, which does not scale well on modern computing resources, such as GPUs and distributed systems. Recently, a numerical study [2] demonstrates that an enhanced version of Primal-Dual Hybrid Gradient (PDHG) method, called PDLP111The solver is open-sourced at Google OR-Tools. , can reliably solve LP problems to high precision. As a first-order method, the computational bottleneck of PDHG is matrix-vector multiplication, which can efficiently leverage GPUs and distributed system. It sheds light on solving huge-scale LP where the data need to be stored in a distributed system.
This work is motivated by this recent line of research on using PDHG for solving large-scale LP. The convergence guarantee of PDHG, for generic convex-concave problems or for LP, has been extensively studied in the literature [66, 10, 11, 1, 4]. Most of the previous convergence analyses on PDHG are based on either the primal-dual gap or the distance to the optimal solution setting. However, it can be highly non-trivial to compute these metrics while running the algorithms. For primal-dual gap, the iterated solutions when solving LP are often infeasible to the primal and/or the dual problem until the algorithm identifies an optimal solution; thus, the primal-dual gap at any iterates may likely be infinity. For the distance to the optimal solution set, it is not computable unless the optimal solution set is known. Furthermore, even if these values can be computed, they often oscillate dramatically in practice, which makes it hard to evaluate the solving progress. Motivated by these issues, the goal of this paper is to answer the following question:
Is there an evaluatable and monotonically decaying progress metric for analyzing PDHG?
We provide an affirmative answer to the above question by proposing a new progress metric for analyzing PDHG, which we dub infimal sub-differential size (IDS). IDS essentially measures the distance between and the sub-differential set of the objective. It is a natural extension of the gradient norm to potentially non-smooth problems. Compared with other progress measurements for PDHG, such as primal-dual gap and distance to optimality, IDS always has a finite value and can be computable directly only using the information of the current solution without the need of knowing the optimal solution set. More importantly, IDS decays monotonically during the solving process, making it a natural progress measurement for PDHG. The design of IDS also take into consideration the geometry of PDHG by using a natural norm of PDHG.
Furthermore, most previous PDHG analyzes [10, 11] focus on the ergodic rate, that is, the performance of the average PDHG iterates. On the other hand, it is frequently observed that the last iteration of PDHG has comparable and sometimes superior performance compared to the average iteration in practice [2]. Our analysis on IDS provides an explanation of such behavior. We show that IDS of the last iterate of PDHG has convergence rate for convex-concave problems. As a direct byproduct, the primal dual gap at the last iterate has convergence rate, which is inferior to the convergence of the average iterate [11]. This explains why the average iterate can be a good option. Furthermore, we show that if the problem further has metric sub-regularity, a condition that is satisfied by many optimization problems, IDS and primal dual gap both enjoy linear convergence, whereas average iterates can often have sublinear convergence. This, accompanied with other results under metric sub-regularity in literature, explains the numerical observation that the last iteration may have superior behaviors.
More formally, we consider a generic minimax problem with a bilinear interaction term:
| (1) |
where , are simple proper lower semi-continuous convex functions and is a matrix. Note that functions and can encode the constraints and by using an indicator function. Throughout the paper, we assume that there is a finite optimal solution to the minimax problem (1).The primal-dual form of linear programming can be formulated as an instance of (1):
Beyond LP, problems of form (1) are ubiquitous in statistics and machine learning. For example,
-
•
In image processing, total variation (TV) denoising model [7] plays a central role in variational methods for imaging and it can be reformulated as , where is the differential matrix.
- •
- •
Primal-dual hybrid gradient method (PDHG, a.k.a. Chambolle and Pock algorithm [10]) described in Algorithm 3 is one of the most popular algorithms for solving the structured minimax problem (1). It has been extensively used in the field of image processing: total-variation image denoising [7], multimodal medical imaging [38], computation of nonlinear eigenfunctions [28], and many others. More recently, PDHG also serves as the base algorithm for a new large-scale LP solver PDLP [2, 3, 4].
The contribution of the paper can be summarized as follows:
-
•
We propose to identify the “right” progress metric when studying an optimization algorithm. We propose a new progress metric IDS for analyzing PDHG, and show that it monotonically decays (see Section 2).
- •
-
•
We show that IDS converges to with a linear convergence rate if the problem satisfies metric sub-regularity, which is satisfied by many applications.
-
•
We extend the above results of PDHG to other classic algorithms for minimax problems, including proximal point method, alternating direction method of multipliers and linearized alternating direction method of multipliers.
-
•
The proofs of the above results are surprisingly simple, which is in contrast to the recent literature on the last iterate convergence for cousin algorithms.
1.1 Related literature
Convex-concave minimax problems. There have been several lines of research that develop algorithms for convex-concave minimax problems and general monotone variational inequalities. The two most classic algorithms may be proximal point method (PPM) and extragradient method (EGM). Rockafellar introduces PPM for monotone variational inequalities [55] and, around the same time, Korpelevich proposes EGM for solving the convex-concave minimax problem [40]. Convergence analysis on PPM and EGM has been flourishing since then. Tseng proves the linear convergence for PPM and EGM on strongly-convex-strongly-concave minimax problems and on unconstrained bilinear problems [58]. Nemirovski shows that EGM, as a special case of mirror-prox algorithm, exhibits sublinear rate for solving general convex-concave minimax problems over a compact and bounded set [51]. Moreover, the connection between PPM and EGM is strengthened in [51], i.e., EGM approximates PPM. Another line of research investigates minimax problems with a bilinear interaction term (1). For such problems, the two most popular algorithms are perhaps PDHG [10] and Douglas-Rachford splitting (DRS) [22, 24]. Recently, motivated by application in statistical and machine learning, there has been renewed interest in minimax problems. In particular, for bilinear problem ( in (1)), [17, 50] show that the Optimistic Gradient Descent Ascent (OGDA) enjoys a linear convergence rate with full rank and [50] proves that EGM and PPM also converge linearly under the same condition. Besides, [50] builds up the connection between OGDA and PPM: OGDA is an approximation to PPM for bilinear problems. Under the framework of ODE, [46] investigates the dynamics of unconstrained primal-dual methods and yields tight condition under which different algorithms exhibit linear convergence.
Primal-dual hybrid gradient method (PDHG). The early works on PDHG were motivated by applications in image processing and computer vision [66, 14, 25, 34, 10]. Recently, PDHG is the base algorithm used in a large-scale LP solver [2, 3, 4]. The first convergence guarantee of PDHG was in the average iteration and was proposed in [10]. Later, [11] presented a simplified and unified analysis of the ergodic rate of PDHG. More recently, many variants of PDHG have been proposed, including adaptive version [59, 49, 54, 29] and stochastic version [9, 1, 47]. PDHG was also shown to be equivalent to DRS [53, 45].
Ergodic rate vs non-ergodic rate. In the literature on convex-concave minimax problems, the convergence is often described in the ergodic sense, i.e., on the average of iterates. For example, Nemirovski [51] shows that EGM (or more generally the mirror prox algorithm) has primal-dual gap for the average iterate; Chambolle and Pock [10, 11] show that PDHG has primal-dual gap on the average iteration. More recently, the convergence rate of last iterates (i.e., non-ergodic rate) attracts much attention in the machine learning and optimization community due to its practical usage. Most of the works on last iterates study the gradient norm when the problem is differentiable. For example, [30, 31] show that the squared norm of gradient of iterates from EGM converges at sublinear rate. [61] proposes an extra anchored gradient descent algorithm converges with faster rate when the objective function is smooth. The recent works [8, 32] study the last iteration convergence of EGM and OGDA in the constrained setting for EGM and OGDA. More specifically, [8] utilizes the sum-of-squares (SOS) programming to analyze the tangent residual and [32] uses semi-definite programming (SDP) and Performance Estimation Problems (PEPs) to derive the last iteration bounds of a complicated potential function for the two algorithms. The tangent residual can be viewed as a special case of IDS when and are the sum of a smooth function and an indicator function, and IDS can handle general non-smooth terms.
Another related line of works is the study of squared distance between successive iterates for splitting schemes [18, 19]. Although there are connections between IDS and distance between successive iterates, the geometric interpretations are quite different: IDS is a direct quality metric to characterize the size of the sub-differential at current iterate while the distance between successive iterates measures fixed-point residual, which is an indirect characterization of the quality of the solution. In terms of the primal-dual gap, [30] shows that the last iterate of EGM has rate, which is slower than the average iterate of EGM, and [18, 27] shows rate of objective errors for some primal-dual methods. As a by-product of our analysis, we show that the last iterate of PDHG also has rate in the primal-dual gap.
On the other hand, linear convergence of primal-dual algorithms are often observed in the last iterate. To obtain the linear convergence rate, additional conditions are required. There are three different types of conditions studied in the literature: strong-convexity-concavity [58] (i.e. strong monotoncity), interaction dominance/negative comonotonicity [33, 43], and metric sub-regularity [42, 44, 1, 26]. The metric used in the above analysis is usually the norm of gradient for differentiable problems or the distance to optimality. The linear convergence under additional assumptions partially explains the behavior that practitioners may choose to favor the last iterate over the average iterate.
Metric sub-regularity. The notion of metric sub-regularity is extensively studied in the community of variational analysis [36, 37, 20, 41, 63, 64, 65, 21]. It was first introduced in [36] and later the terminology “metric sub-regularity” was suggested in [20], which is also closely related to calmness [35]. For more detail in this direction, see [21].
The regularity condition holds for many important applications. For example, [65, 42] show that the problem with piecewise linear quadratic functions on a compact set satisfies the regularity condition, including Lasso and support vector machines, etc. Partially due to this reason, recently there arises extensive interest in analyzing first-order methods under the assumption of metric sub-regularity. For convex minimization, [23] shows that the metric sub-regularity of sub-gradient is equivalent to the quadratic error bound. The results for primal-dual algorithms are also fruitful [42, 44, 1, 26, 48]. In the context of PDHG, under metric sub-regularity, [42, 26] proves the linear rate of deterministic PDHG and [1] shows the linear convergence of stochastic PDHG in terms of distance to the optimal set.
1.2 Notations
We use to denote Euclidean norm and for its associated inner product. For a positive definite matrix , we denote . Let be the norm induced by the inner product . Let be the distance between point and set under the norm , that is, . Denote as the optimal solution set to (1). Let be the minimum nonzero singular value of a matrix . Denote the operator norm of a matrix . Let be the indicator function of the set . denote that for sufficiently large , there exists constant such that and denote that for sufficiently large , there exists constant such that . The proximal operator is defined as . Denote , and as the sub-differential of the objective. For a matrix , denote a pseudo-inverse of and the range of .
2 Infimal sub-differential size (IDS)
In this section, we introduce a new progress measurement, which we dub infimal sub-differential size (IDS), for PDHG. IDS is a natural extension of the squared norm of gradient for smooth optimization problems to non-smooth optimization problems. Compared to other progress measurements for PDHG, such as primal-dual gap and distance to optimality, IDS always has a finite value and is computable directly without the need to know the optimal solution set. More importantly, unlike the other metric that may oscillate over time, the IDS monotonically decays along the iteration of the PDHG, further suggesting that the IDS is a natural progress measurement for PDHG. Here is the formal definition of IDS:
Definition 1.
The infimal sub-differential size (IDS) at solution for PDHG with step-size is defined as:
| (2) |
where is the PDHG norm and is the sub-differential of the objective .
Note that the first-order optimality condition of (1) is . In other words, if the original minimax problem (1) is feasible and bounded, the minimization problem
| (3) |
has optimal value , and furthermore (3) and (1) share the same optimal solution set, thus IDS is a valid progress measurement.
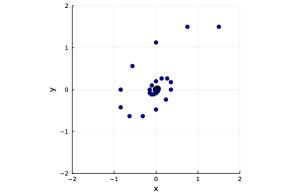
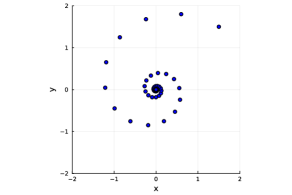
When measuring the distance between and the set , a crucial part is the choice of the norm. The simplest norm which is also used in practice is the norm. However, this may not be the natural norm for all algorithms. To understand the intuition, Figure 1 plots the trajectory of PDHG and proximal point method (PPM) to solve a simple unconstrained bilinear problem
We can observe that the iterations of two algorithms exhibit spiral patterns toward the unique saddle point . Nevertheless, in contrast to the circular pattern of PPM, the spiral of PDHG spins in a tilting elliptical manner. The fundamental reason for such an elliptical structure is the asymmetricity of the primal and dual steps in PDHG. The elliptical structures of the iterates can be captured by the choice of norms in the analysis. This is consistent with the fact that while the analysis of PPM [55] utilizes norm, the analysis of PDHG [11, 4, 34] often utilizes a different norm defined by . The has already been used in analyzing PDHG, for example, [34] studies the contraction of PDHG under norm and motivate variants of PDHG from this perspective. We here propose to use in the sub-differentiable (dual) space.
In previous works, the convergence guarantee of PDHG is often stated with respect to the duality gap [10, 11], , or the distance to the optimal solution set [4, 26], . Unfortunately, these values are barely computable or informative because the iterates are usually infeasible until the end of the algorithms (thus, the duality gap at the iterates is often infinity) and the optimal solution set is unknown to the users beforehand. In practice, people instead use residual as a performance metric because of its computational efficiency. For example, the KKT residual, i.e., the violation of primal feasibility, dual feasibility, and complementary slackness, is widely used in the LP solver as the performance metric. Indeed, the KKT residual of LP is upper bounded by IDS upto a constant. More formally, consider the primal-dual form of standard LP
and the corresponding KKT residual for , is given by .
Then it holds for any , that
where is an upper bound for the norm of iterates and is the normalized duality gap defined in [4, Equation (4a)]. The first inequality follows from [4, Proposition 5] and the second inequality uses [4, Lemma 4]. Therefore, IDS under norm is an upper bound of KKT residual for LP. Since all norms in finite-dimensional Hilbert space are equivalent (upto a constant), this showcases that the IDS under norm also provides an upper bound on KKT residual.
Since is in the dual space, we utilized the dual norm of in the definition of IDS. In fact, for the simple bilinear problem in Figure 1, the use of norm is the key to guarantee the monotonic decay of IDS for PDHG iterates. Indeed, this monotonicity result holds for any convex-concave problems and can be formalized in the below proposition:
Proposition 1.
Proof.
First, notice that the iterate update of Algorithm 3 can be written as
| (4) |
Note that PDHG is a forward-backward algorithm [13], we can rewrite the proximal operators in Algorithm 3 as the following
| (5) | ||||
We arrive at (4) by rearranging (5):
Now denote , then it holds for any that
where the inequality utilizes is a monotone operator due to the convexity-concavity of the objective , thus , and the second equality uses . Now choose , and we obtain
which finishes the proof. ∎
We end this section by making two remarks on the proof of Proposition 1:
Remark 1.
The proof of Proposition 1 not only shows the monotonicity of IDS, but also provides a bound on its decay:
| (6) |
where and .
Remark 2.
In the proof of Proposition 1 and the convergence proof in Section 3 and Section 4, the only information we use from PDHG is the update rule (4) and the fact that is a positive definite matrix. This makes it easy to generalize the results of PDHG to other algorithms. For example, PPM to solve the convex-concave minimax problem has the following update rule:
and the iterate update is also a special case of (4) where and . Thus, all of the analysis and results we develop herein for PDHG can be directly extended to PPM in parallel.
3 Sublinear convergence of IDS
In this section, we present the sublinear convergence rate of IDS. Our major result is stated in Theorem 1. As a direct consequence, the result implies sublinear rate of non-ergodic iterates on duality gap.
Theorem 1.
Proof.
Recall the update of PDHG (4). Then we have for any that:
It holds for any iteration that
where the inequality comes from the monotonicity of operator and notices . Thus, we have
| (7) |
As a direct consequence of Theorem 1, we can obtain convergence rate on the primal-dual gap for the last iteration of PDHG. The last iteration of PDHG has a slower convergence rate compared to the average iteration, which has rate on the primal-dual gap [11]. This is consistent with the recent discovery that the last iteration has a slower convergence than the average iteration in a smooth convex-concave saddle point for the extragradient method [30], Douglas-Rachford splitting [19, 18], and primal-dual coordinate descent method [27].
Corollary 1.
Under the same assumption and notation as Theorem 1, it holds for any iteration , and any optimal solution that
Proof.
Denote , and . Then
| (8) | ||||
where the first inequality uses the convexity of and and the last one follows from Cauchy-Schwarz inequality. Notice (8) holds for any , we can choose and thus . Then it holds that
where the second inequality is due to Theorem 1; the third inequality follows from the triangle inequality, and the last inequality uses . ∎
4 Linear convergence of IDS
In previous sections, we show that the IDS monotonically decays along iterates of PDHG and has a sublinear convergence rate for a convex-concave minimax problem. In this section, we further show that the IDS has linear convergence if the minimax problem further satisfies a regularity condition. This regularity condition is satisfied by many applications, such as unconstrained bilinear problem, linear programming, strongly-convex-strongly-convex problems, etc.
We begin by introducing the following regularity condition.
Definition 2.
We say that the minimax problem (1), or equivalently the operator , satisfies metric sub-regularity with respect to matrix on set if it holds for any that
| (9) |
Remark 3.
We comment that the metric sub-regularity condition we defined above is a special case of the traditional definition of metric sub-regularity [21] with a set-valued function and a vector .
Recently, the metric sub-regularity and related sharpness conditions have been used to analyze primal-dual algorithms [26, 48, 1, 4, 60, 62]. In particular, it has been shown that strongly-convex-strongly-concave problems satisfy this condition globally, and piecewise linear quadratic functions satisfy this condition on a compact set [65, 42]. This includes many examples, such as LASSO, support vector machine, linear programming and quadratic programming on a compact region in the primal-dual formulation. Suppose the step-size satisfies , one can show that unconstrained bilinear problem and generic linear program satisfy the regularity condition (9). Below we list a few concrete examples that satisfy metric subregularity:
Example 1 (Unconstrained bilinear problem).
The unconstrained bilinear problem
| (10) |
satisfies global metric sub-regularity with and .
Example 2 (Linear programming).
For any optimal solution , the primal-dual form of linear programming
| (11) |
satisfies the metric sub-regularity condition on a bounded region with , where is the Hoffman constant of the KKT system of the LP and . Furthermore, the iterates of PDHG from initial solution stay in the bounded region .
Example 3 (Strongly-convex-strongly-concave problem).
Consider minimax problem:
| (12) |
where , are -strongly convex functions. Then, the problem satisfies the metric sub-regularity condition with .
The next theorem presents the linear convergence of IDS for PDHG under metric sub-regularity:
Theorem 2.
Proof.
For any iteration , suppose for a non-negative integer . It follows from Theorem 1 that for any , we have
| (13) | ||||
Taking the minimum over in the RHS of (13), we obtain
| (14) | ||||
where the second inequality utilizes condition (9). Recursively using (14), we arrive at
where the last two inequalities are due to the monotonicity of (see Proposition 1) and , respectively. ∎
Remark 4.
Theorem 2 implies that we need in total iterations to find an -close solution such that .
5 Tightness
In this section, we demonstrate that the derived sublinear and linear rates of the last iteration of PDHG in previous sections are tight, i.e., there exists an instance on which the obtained convergence rate cannot be improved. The tightness herein does not refer to a lower bound result, i.e., this argument does not rule out primal-dual first-order algorithms that can achieve even better performance in the decay of IDS.
5.1 Linear convergence
To begin with, Theorem 3 presents a convex-concave instance that satisfies the metric sub-regularity condition (9), on which the last iteration of PDHG requires at least iterations to identify a solution such that . Combined with Theorem 2, we conclude that for problems satisfying condition (9) the linear rate derived in Theorem 2 is tight up to a constant.
Theorem 3.
To construct tight instances, we utilize the following intermediate result from [4, Section 5.2]:
Proposition 2.
Consider a 2-dimensional vector sequence such that
with and . Then, it holds for any that
Proof of Theorem 2.
Let , and with . Set the initial point as the first standard basis vector. Then, we have
where the first inequality uses . Furthermore, the PDHG update can be rewritten following from (4) as
which is equivalent to the update rule
| (16) |
thus it holds that
where in the second equality we plug in the update rule (16) and the third equality uses the non-singularity of matrix .
Notice that is a diagonal matrix, thus we have
| (17) | ||||
where denotes the -th coordinate of gradient vector . The first and last inequalities are due to the choice of step-size such that , and the third inequality follows from Proposition 2 and the fact that is diagonal.
We finish the proof by noticing for this instance that (see Example 1). ∎
5.2 Sublinear convergence
Next, Theorem 4 presents a convex-concave instance on which PDHG requires at least to achieve a solution such that . Combined with Theorem 1, we conclude that the sublinear rate derived in Theorem 1 is tight upto a constant.
Theorem 4.
For any iteration and step-size with , there exist a convex-concave minimax problem (1) and an initial point such that the PDHG iterates satisfy
| (18) |
Proof.
To prove Theorem 4, we utilize the same instance constructed in Theorem 3 with carefully chosen singular values of the matrix . In particular, we set and . Then we have and .
6 Efficient Computation and Numerical Results
In this section, we present a linear-time algorithm to compute IDS for a general problem (1), and present preliminary numerical experiments on linear programming that validate our theoretical results.
6.1 Linear-time computation of IDS
Computing IDS (2) involves computing the projection of onto the sub-differential set with respect to the norm , which may not always be trivial. Here, we present a principle approach to efficiently compute IDS in linear time by using Nesterov’s accelerated gradient descent (AGD), under the assumption that the non-smooth part of is simple. In our numerical experiments, usually 15 iterations of AGD can lead to a high-resolution solution to IDS.
Consider the convex-concave minimax problem (1). The sub-differential at a solution is given by
We denote and , then the projection problem can be formulated as solving the following quadratic programming:
| (21) | ||||
For most of the applications of PDHG, the sub-gradient set as well as the projection onto are straight-forward to compute. For example, when is an indicator function of closed convex set , the subdifferential is its normal cone, that is, . If is norm, then .
Notice that (21) is a convex quadratic programming. A natural algorithm for solving the QP (21) is Nesterov’s accelerated gradient descent, which we formally present in Algorithm 2. Recall that throughout the section, we assume the step size satisfies . Thus, we have and the condition number of is . As the result, this QP is easy to solve and the complexity of AGD for solving the problem is [52]. Since the complexity is independent of the dimension of the problem, we have a linear time computation of IDS. In our numerical experiments, we found that it usually takes less than 15 iterations of Nesterov’s accelerated methods to solve the subproblem (21) almost exactly, which further verifies the effectiveness of AGD.
6.2 Numerical experiments on PDHG for LP
Here, we present preliminary numerical results on PDHG for LP that verify our theoretical results in the previous sections.
Datasets. We utilize the root-node LP relaxation of three datasets from MIPLIB, enlight_hard, supportcase14 and nexp-50-20-4-2. The dimension (i.e. and ) of the three datasets are summarized in Table 1. These instances are chosen such that vanilla PDHG converges to an optimal solution within a reasonable number of iterations, and similar results hold for other instances.
Implementation details. We run PDHG (Algorithm 3) on the three instances from MIPLIB with step-size . We calculate IDS using AGD (Algorithm 2). We terminate Algorithm 2 when the first order optimality condition of (21) holds with tolerance (this effectively means we solve the subproblem (21) up to the machine precision). We summarize the average iterations of AGD in Table 1.
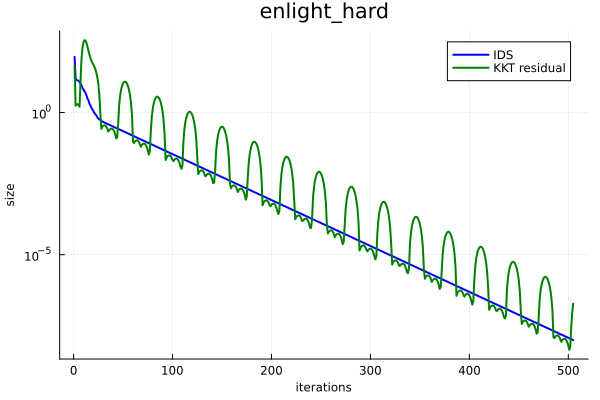
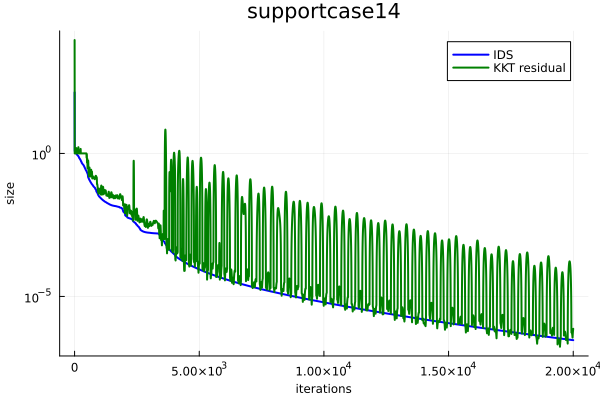
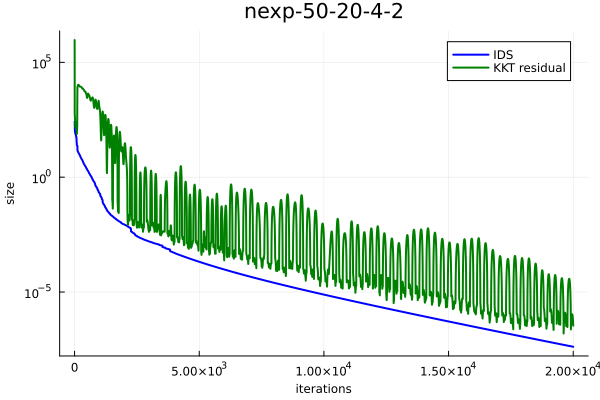
Results. Figure 2 presents IDS and KKT residual versus number of iterations of PDHG for the three LP instances. To make them at the same scale, we square KKT residual (recall that the definition of IDS also has a square). As we can see, IDS monotonically decays, which verifies Proposition 1. In contrast, there can be a huge fluctuation in KKT residual, which showcases that IDS is a more natural progress metric for PDHG. Furthermore, as we can see, the decay of IDS follows a linear rate, which verifies our theoretical results in Theorem 2.
| Instance | Size | Average iteration of AGD |
|---|---|---|
| enlight_hard | 12.6 | |
| supportcase14 | 15.0 | |
| nexp-50-20-4-2 | 13.04 |
7 Extensions to Other Algorithms
The results on IDS in Section 2-4 are not limited to PDHG. In this section, we showcase how to extend these results to three classic algorithms, proximal point methods (PPM), alternating direction method of multipliers (ADMM) and linearized ADMM (l-ADMM).
The cornerstone of the analysis in Section 2-4 is to identify a positive definite matrix such that the update rule for iterate has the form
| (22) |
This is the only fact of PDHG that we used in our analysis. Indeed, if an algorithm can be formulated as (22), we can define IDS as
| (23) |
and the corresponding monotonicity (Proposition 1) and complexity analysis of IDS (Theorem 1 and Theorem 2) can be shown with exactly the same analysis as PDHG.
In the rest of this section, we show how to reformulate the iterate updates of PPM, ADMM and l-ADMM as an instance of (22), and present the corresponding results for the three algorithms. A mild difference between ADMM and the other algorithms is that the matrix in ADMM is not full rank, and the inverse is not well-defined. We overcome this by defining IDS along the subspace where is full rank.
We also would like to comment that positive semidefinite matrix of different algorithms can be different. For example, in PDHG, in PPM, in ADMM and in l-ADMM. Consequently, the distance in the definition of IDS are chosen differently, and the trajectories of different algorithms may follow a different ellipsoid specified by the matrix in Figure 1.
7.1 Proximal Point Method (PPM)
Consider a convex-concave minimax problem:
| (24) |
where is a potentially non-differentiable function that is convex in and concave in . Proximal point method (PPM) [55] (Algorithm 3) is a classic algorithm for solving (24), and some of the other classic algorithms, such as extra-gradient method [51], can be viewed as approximation of PPM.
Denote . We can rewrite the update rule of PPM as follows:
7.2 Linearized ADMM
Consider a minimization problem of form:
| (25) |
where and are convex but potentially non-smooth functions. Examples of (25) include LASSO [12, 57], SVM [6, 15], regularized logistic regression [39], image recovery [10, 7], etc. The primal-dual formulation of (25) is
| (26) |
where is the conjugate function of . Linearized ADMM (l-ADMM) [56] is a variant of ADMM that avoids solving linear equations. Algorithm 4 presents l-ADMM for solving (25).
As the first step, we here aim to find the appropriate differential inclusion form of the update rule, that is, find a positive (semi-)definite matrix such that the update of the algorithm can be rewritten as
where .
Notice that
| (27) | ||||
where the second equality uses the update of and the third equality follows from the basic property of proximal operator .
Then, utilizing exactly the same analysis on IDS that we have developed for PDHG in Section 2-4, we reach the results for linearized ADMM:
7.3 Alternating Direction Method of Multipliers (ADMM)
In this subsection, we study the property of IDS of vanilla ADMM for solving (25). Similar to the previous sections, we first rewrite the update rule of ADMM as an instance of (22).
Notice that
| (29) | ||||
where the second equality uses the update of and the third equality follows from the basic property of proximal operator .
A key difference between ADMM and the other methods we present is that is not invertible, thus in IDS is not well-defined. Fortunately, this can be overcome by redefining IDS along the non-singular subspace of as following:
Definition 3.
The infimal sub-differential size (IDS) at solution for algorithm with update rule for solving convex-concave minimax problem (1) is defined as:
| (31) |
where is the pseudo-inverse of and is the range of matrix . is the sub-differential of the objective .
Notice that (31) is still a valid progress metric of the solution, by noticing implies that . More formally, if IDS equals to zero, it holds that and thus .
All the results we developed before holds for the refined IDS for ADMM with a similar proof, and we present the difference of the proof in Appendix A):
8 Conclusions and future direction
In this paper, we introduce a new progress metric for analyzing PDHG for convex-concave minimax problems, which we call infimal sub-differential size (IDS). IDS is a natural generalization of the gradient norm to non-smooth problems. Compared to other progress metric, IDS is finite, easy to compute, and monotonically decays along the iterates of PDHG. We further show the sublinear convergence rate and linear convergence rate of IDS. The monotonicity and simplicity of the analysis suggest that IDS is the right progress metric for analyzing PDHG. All of the results we obtain here can be directly extended to PPM, ADMM and l-ADMM. A direct future direction is whether the properties of IDS hold for other primal-dual algorithms. Another future direction is whether IDS suggests good step-size and/or preconditioner for primal-dual algorithms.
Acknowledgement
The authors would like to thank David Applegate, Oliver Hinder, Miles Lubin and Warren Schudy for the helpful discussions that motivated the authors to identify a monotonically decaying progress metric for PDLP.
References
- [1] Ahmet Alacaoglu, Olivier Fercoq, and Volkan Cevher, On the convergence of stochastic primal-dual hybrid gradient, arXiv preprint arXiv:1911.00799 (2019).
- [2] David Applegate, Mateo Díaz, Oliver Hinder, Haihao Lu, Miles Lubin, Brendan O’Donoghue, and Warren Schudy, Practical large-scale linear programming using primal-dual hybrid gradient, Advances in Neural Information Processing Systems 34 (2021).
- [3] David Applegate, Mateo Díaz, Haihao Lu, and Miles Lubin, Infeasibility detection with primal-dual hybrid gradient for large-scale linear programming, arXiv preprint arXiv:2102.04592 (2021).
- [4] David Applegate, Oliver Hinder, Haihao Lu, and Miles Lubin, Faster first-order primal-dual methods for linear programming using restarts and sharpness, arXiv preprint arXiv:2105.12715 (2021).
- [5] Dimitris Bertsimas and John N Tsitsiklis, Introduction to linear optimization, vol. 6, Athena Scientific Belmont, MA, 1997.
- [6] Bernhard E Boser, Isabelle M Guyon, and Vladimir N Vapnik, A training algorithm for optimal margin classifiers, Proceedings of the fifth annual workshop on Computational learning theory, 1992, pp. 144–152.
- [7] Kristian Bredies and Martin Holler, A tgv-based framework for variational image decompression, zooming, and reconstruction. part i: Analytics, SIAM Journal on Imaging Sciences 8 (2015), no. 4, 2814–2850.
- [8] Yang Cai, Argyris Oikonomou, and Weiqiang Zheng, Tight last-iterate convergence of the extragradient method for constrained monotone variational inequalities, arXiv preprint arXiv:2204.09228 (2022).
- [9] Antonin Chambolle, Matthias J Ehrhardt, Peter Richtárik, and Carola-Bibiane Schonlieb, Stochastic primal-dual hybrid gradient algorithm with arbitrary sampling and imaging applications, SIAM Journal on Optimization 28 (2018), no. 4, 2783–2808.
- [10] Antonin Chambolle and Thomas Pock, A first-order primal-dual algorithm for convex problems with applications to imaging, Journal of mathematical imaging and vision 40 (2011), no. 1, 120–145.
- [11] , On the ergodic convergence rates of a first-order primal–dual algorithm, Mathematical Programming 159 (2016), no. 1-2, 253–287.
- [12] Shaobing Chen and David Donoho, Basis pursuit, Proceedings of 1994 28th Asilomar Conference on Signals, Systems and Computers, vol. 1, IEEE, 1994, pp. 41–44.
- [13] Patrick L Combettes, Laurent Condat, J-C Pesquet, and BC Vũ, A forward-backward view of some primal-dual optimization methods in image recovery, 2014 IEEE International Conference on Image Processing (ICIP), IEEE, 2014, pp. 4141–4145.
- [14] Laurent Condat, A primal–dual splitting method for convex optimization involving lipschitzian, proximable and linear composite terms, Journal of optimization theory and applications 158 (2013), no. 2, 460–479.
- [15] Corinna Cortes and Vladimir Vapnik, Support-vector networks, Machine learning 20 (1995), no. 3, 273–297.
- [16] George B Dantzig, Linear programming, Operations research 50 (2002), no. 1, 42–47.
- [17] Constantinos Daskalakis, Andrew Ilyas, Vasilis Syrgkanis, and Haoyang Zeng, Training GANs with optimism, International Conference on Learning Representations, 2018.
- [18] Damek Davis and Wotao Yin, Convergence rate analysis of several splitting schemes, Splitting methods in communication, imaging, science, and engineering, Springer, 2016, pp. 115–163.
- [19] , Faster convergence rates of relaxed peaceman-rachford and admm under regularity assumptions, Mathematics of Operations Research 42 (2017), no. 3, 783–805.
- [20] Asen L Dontchev and R Tyrrell Rockafellar, Regularity and conditioning of solution mappings in variational analysis, Set-Valued Analysis 12 (2004), no. 1, 79–109.
- [21] , Implicit functions and solution mappings, vol. 543, Springer, 2009.
- [22] Jim Douglas and Henry H Rachford, On the numerical solution of heat conduction problems in two and three space variables, Transactions of the American mathematical Society 82 (1956), no. 2, 421–439.
- [23] Dmitriy Drusvyatskiy and Adrian S Lewis, Error bounds, quadratic growth, and linear convergence of proximal methods, Mathematics of Operations Research 43 (2018), no. 3, 919–948.
- [24] Jonathan Eckstein and Dimitri P Bertsekas, On the Douglas—Rachford splitting method and the proximal point algorithm for maximal monotone operators, Mathematical Programming 55 (1992), no. 1-3, 293–318.
- [25] Ernie Esser, Xiaoqun Zhang, and Tony F Chan, A general framework for a class of first order primal-dual algorithms for convex optimization in imaging science, SIAM Journal on Imaging Sciences 3 (2010), no. 4, 1015–1046.
- [26] Olivier Fercoq, Quadratic error bound of the smoothed gap and the restarted averaged primal-dual hybrid gradient, (2021).
- [27] Olivier Fercoq and Pascal Bianchi, A coordinate-descent primal-dual algorithm with large step size and possibly nonseparable functions, SIAM Journal on Optimization 29 (2019), no. 1, 100–134.
- [28] Guy Gilboa, Michael Moeller, and Martin Burger, Nonlinear spectral analysis via one-homogeneous functionals: overview and future prospects, Journal of Mathematical Imaging and Vision 56 (2016), no. 2, 300–319.
- [29] Tom Goldstein, Min Li, and Xiaoming Yuan, Adaptive primal-dual splitting methods for statistical learning and image processing, Advances in Neural Information Processing Systems, 2015, pp. 2089–2097.
- [30] Noah Golowich, Sarath Pattathil, Constantinos Daskalakis, and Asuman Ozdaglar, Last iterate is slower than averaged iterate in smooth convex-concave saddle point problems, Conference on Learning Theory, PMLR, 2020, pp. 1758–1784.
- [31] Eduard Gorbunov, Nicolas Loizou, and Gauthier Gidel, Extragradient method: last-iterate convergence for monotone variational inequalities and connections with cocoercivity, arXiv preprint arXiv:2110.04261 (2021).
- [32] Eduard Gorbunov, Adrien Taylor, and Gauthier Gidel, Last-iterate convergence of optimistic gradient method for monotone variational inequalities, arXiv preprint arXiv:2205.08446 (2022).
- [33] Benjamin Grimmer, Haihao Lu, Pratik Worah, and Vahab Mirrokni, The landscape of the proximal point method for nonconvex-nonconcave minimax optimization, arXiv preprint arXiv:2006.08667 (2020).
- [34] Bingsheng He and Xiaoming Yuan, Convergence analysis of primal-dual algorithms for a saddle-point problem: from contraction perspective, SIAM Journal on Imaging Sciences 5 (2012), no. 1, 119–149.
- [35] René Henrion, Abderrahim Jourani, and Jiri Outrata, On the calmness of a class of multifunctions, SIAM Journal on Optimization 13 (2002), no. 2, 603–618.
- [36] AD Ioffe, Necessary and sufficient conditions for a local minimum. 1: A reduction theorem and first order conditions, SIAM Journal on Control and Optimization 17 (1979), no. 2, 245–250.
- [37] Alexander D Ioffe and Jiří V Outrata, On metric and calmness qualification conditions in subdifferential calculus, Set-Valued Analysis 16 (2008), no. 2, 199–227.
- [38] Florian Knoll, Martin Holler, Thomas Koesters, Ricardo Otazo, Kristian Bredies, and Daniel K Sodickson, Joint mr-pet reconstruction using a multi-channel image regularizer, IEEE transactions on medical imaging 36 (2016), no. 1, 1–16.
- [39] Kwangmoo Koh, Seung-Jean Kim, and Stephen Boyd, An interior-point method for large-scale l1-regularized logistic regression, Journal of Machine learning research 8 (2007), no. Jul, 1519–1555.
- [40] Galina M Korpelevich, The extragradient method for finding saddle points and other problems, Matecon 12 (1976), 747–756.
- [41] Alexander Y Kruger, Error bounds and metric subregularity, Optimization 64 (2015), no. 1, 49–79.
- [42] Puya Latafat, Nikolaos M Freris, and Panagiotis Patrinos, A new randomized block-coordinate primal-dual proximal algorithm for distributed optimization, IEEE Transactions on Automatic Control 64 (2019), no. 10, 4050–4065.
- [43] Sucheol Lee and Donghwan Kim, Fast extra gradient methods for smooth structured nonconvex-nonconcave minimax problems, Advances in Neural Information Processing Systems 34 (2021), 22588–22600.
- [44] Jingwei Liang, Jalal Fadili, and Gabriel Peyré, Convergence rates with inexact non-expansive operators, Mathematical Programming 159 (2016), no. 1, 403–434.
- [45] Yanli Liu, Yunbei Xu, and Wotao Yin, Acceleration of primal–dual methods by preconditioning and simple subproblem procedures, Journal of Scientific Computing 86 (2021), no. 2, 1–34.
- [46] Haihao Lu, An -resolution ODE framework for discrete-time optimization algorithms and applications to convex-concave saddle-point problems, arXiv preprint arXiv:2001.08826 (2020).
- [47] Haihao Lu and Jinwen Yang, Nearly optimal linear convergence of stochastic primal-dual methods for linear programming, arXiv preprint arXiv:2111.05530 (2021).
- [48] Meng Lu and Zheng Qu, An adaptive proximal point algorithm framework and application to large-scale optimization, arXiv preprint arXiv:2008.08784 (2020).
- [49] Yura Malitsky and Thomas Pock, A first-order primal-dual algorithm with linesearch, SIAM Journal on Optimization 28 (2018), no. 1, 411–432.
- [50] Aryan Mokhtari, Asuman Ozdaglar, and Sarath Pattathil, A unified analysis of extra-gradient and optimistic gradient methods for saddle point problems: Proximal point approach, International Conference on Artificial Intelligence and Statistics, 2020.
- [51] Arkadi Nemirovski, Prox-method with rate of convergence O(1/t) for variational inequalities with lipschitz continuous monotone operators and smooth convex-concave saddle point problems, SIAM Journal on Optimization 15 (2004), no. 1, 229–251.
- [52] Yurii Nesterov, Introductory lectures on convex optimization: A basic course, vol. 87, Springer Science & Business Media, 2003.
- [53] Daniel O’Connor and Lieven Vandenberghe, On the equivalence of the primal-dual hybrid gradient method and douglas–rachford splitting, Mathematical Programming 179 (2020), no. 1, 85–108.
- [54] Thomas Pock and Antonin Chambolle, Diagonal preconditioning for first order primal-dual algorithms in convex optimization, 2011 International Conference on Computer Vision, IEEE, 2011, pp. 1762–1769.
- [55] R. Tyrrell Rockafellar, Monotone operators and the proximal point algorithm, SIAM Journal on Control and Optimization 14 (1976), no. 5, 877–898.
- [56] Ernest K Ryu and Wotao Yin, Large-scale convex optimization: Algorithms & analyses via monotone operators, Cambridge University Press, 2022.
- [57] Robert Tibshirani, Regression shrinkage and selection via the lasso, Journal of the Royal Statistical Society: Series B (Methodological) 58 (1996), no. 1, 267–288.
- [58] Paul Tseng, On linear convergence of iterative methods for the variational inequality problem, Journal of Computational and Applied Mathematics 60 (1995), no. 1-2, 237–252.
- [59] Maria-Luiza Vladarean, Yura Malitsky, and Volkan Cevher, A first-order primal-dual method with adaptivity to local smoothness, Advances in Neural Information Processing Systems 34 (2021), 6171–6182.
- [60] Wei Hong Yang and Deren Han, Linear convergence of the alternating direction method of multipliers for a class of convex optimization problems, SIAM journal on Numerical Analysis 54 (2016), no. 2, 625–640.
- [61] TaeHo Yoon and Ernest K Ryu, Accelerated algorithms for smooth convex-concave minimax problems with rate on squared gradient norm, International Conference on Machine Learning, PMLR, 2021, pp. 12098–12109.
- [62] Xiaoming Yuan, Shangzhi Zeng, and Jin Zhang, Discerning the linear convergence of admm for structured convex optimization through the lens of variational analysis., J. Mach. Learn. Res. 21 (2020), 83–1.
- [63] Xi Yin Zheng and Kung Fu Ng, Metric subregularity and constraint qualifications for convex generalized equations in banach spaces, SIAM Journal on Optimization 18 (2007), no. 2, 437–460.
- [64] Xi Yin Zheng and Kung Fu Ng, Metric subregularity and calmness for nonconvex generalized equations in banach spaces, SIAM Journal on Optimization 20 (2010), no. 5, 2119–2136.
- [65] , Metric subregularity of piecewise linear multifunctions and applications to piecewise linear multiobjective optimization, SIAM Journal on Optimization 24 (2014), no. 1, 154–174.
- [66] Mingqiang Zhu and Tony Chan, An efficient primal-dual hybrid gradient algorithm for total variation image restoration, UCLA Cam Report 34 (2008), 8–34.
Appendix A Analysis for ADMM
In this section, we consider algorithms with update rule as follows: for some positive semi-definite matrix ,
| (32) |
The previous results for IDS require matrix to be positive definite. Here we extend the notion of IDS to handle positive semi-definite but not necessarily full rank . We start with the following definition of IDS. Note that for positive definite , it reduces to Definition 1.
Definition 4.
There are two major differences to deal this case with singular . First, pseudo-inverse of is used since the inverse is not well-defined. Furthermore, in contrast to in Definition 1, here we consider in that is positive definite along the subspace but not necessarily the whole space.
IDS under Definition 4 is still a valid metric for optimality, namely, if is small, then is a good approximation to the solution. Moreover, it also keeps the desirable properties: monotonic decay, sublinear convergence and linear rate under metric sub-regularity. The results are summarized in the following propositions.
Proposition 3.
Proof.
The proof is similar to Proposition 1. First, notice that the iterate update is given by
and it is also obvious that
Hence we have
Now denote , then it holds for any that
where the inequality utilizes is a monotone operator due to the convexity-concavity of the objective , thus . The second equality uses . and the fifth equality follows from that .
Now choose , and we obtain
which finishes the proof. ∎
Provided the monotonic decay, sublinear convergence holds and thus under metric sub-regularity under -norm, IDS converges linearly. The proofs are identical to Theorem 1 and Theorem 2 respectively.