On the Mathematics of
Data Centre Network Topologies
Abstract
The theory of combinatorial designs has recently been used in order to build switch-centric data centre networks incorporating a large number of servers, in comparison with the popular Fat-Tree data centre network. The construction employed, called the -step method, revolves around an appropriately chosen (but relatively small) bipartite graph and a transversal design. In this paper, we clarify and extend these recent results. In particular, we prove the following path diversity results: in a one-to-one context, we prove that in these data centre networks there are pairwise link-disjoint paths joining all the servers adjacent to some switch with all the servers adjacent to any other switch so that we retain control of the path lengths (these results are optimal in terms of the numbers of paths constructed and we prove that we have a wide choice of bipartite graph and transversal design to which we can apply the -step method); and in a one-to-many context, we prove that there are pairwise link-disjoint paths from all the servers adjacent to some switch to any identically-sized collection of target servers where these target servers need not be adjacent to the same switch (again, we keep control of the path lengths). Our constructions and analysis are undertaken on bipartite graphs with the applications to data centre networks being easily derived. Our results strengthen the overall competitiveness of data centre networks constructed using the -step method, in comparison with Fat-Tree data centre networks, and, more generally, show the potential of results and methodologies from combinatorics to data centre network design.
keywords:
data centre networks , switch-centric data centre networks , Fat-Trees , combinatorial designs , bipartite graphs , path diversity1 Introduction
1.1 The data centre network context
Data centres are expanding both in terms of their size and their importance as computational platforms for cloud computing, web search, social networking, and so on. There is an increasing demand that data centres incorporate more and more servers but so that overall computational efficiency is not compromised through excessive traffic. A key factor as to the eventual performance of a data centre is the data centre network (DCN); that is, the interconnection fabric of the servers and switches within the data centre. As we strive to incorporate more and more servers, new topologies are being developed so as to cope with the increase in scale and best utilize the additional computational power. It is with topological aspects of DCNs that we are concerned in this paper.
The traditional design of a DCN is switch-centric so that the routing intelligence resides amongst the switches, with the servers behaving only as computational nodes. In switch-centric DCNs, there are no direct server-to-server links; only server-to-switch and switch-to-switch links. Switch-centric DCNs are traditionally tree-like with servers located at the ‘leaves’ of the tree-like structure. Examples include ElasticTree [9], VL2 [8], HyperX [2], Portland [12], and Flattened Butterfly [1], although the dominating switch-centric DCN is Fat-Tree [3]. Whilst it is generally acknowledged that tree-like, switch-centric DCNs have their limitations when it comes to, for example, scalability, due to the size of routing tables at the switches, switch-centric DCNs remain popular and can usually be constructed from commodity hardware. A more recent paradigm, namely the server-centric DCN, has emerged so that deficiencies of the tree-like, switch-centric DCNs might be ameliorated. Server-centric DCNs reflect that the routing intelligence resides within the servers with switches operating only as dumb crossbars. In server-centric DCNs there are only server-to-switch and server-to-server links. However, server-centric DCNs also suffer from deficiencies such as packet relay overheads caused by the need to route packets within the server; moreover, server-centric DCNs have yet to make it into the commercial mainstream (the reader is referred to [10] for an overview of the state of the art as regards DCN architectural design). It is with the construction of switch-centric DCNs that we are concerned here.
It is difficult to design computationally efficient (switch-centric) DCNs so as to incorporate large numbers of servers as there are additional considerations to take into account. For example, switches and (especially) servers in data centres have a limited number of ports with a consequence being that the more servers there are, the greater the average or worst-case link-count between two distinct servers; hence, there is a packet latency overhead to be borne. Also, so as to better support routing, fault-tolerance, and load-balancing, we would prefer that there are numerous alternative paths within the DCN joining any two distinct servers; that is, that there is path diversity. There are many other design parameters to bear in mind relating to, for example, incremental scalability, throughput, cost, oversubscription, energy consumption, latency, and security (see, for example, [15] for an overview). The upshot is that the DCN designer has to simultaneously secure a number of performance characteristics, some of which are competing against each other; this makes the DCN design space difficult to work in.
1.2 Using combinatorial designs to build DCNs
A recent proposal in [13] advocated the use of combinatorial design theory in order to design switch-centric DCNs; these DCNs have beneficial properties as regards incorporating more servers and possessing path diversity yet it is possible to limit the worst-case link-length of server-to-server shortest paths (and so, ultimately, achieve better control over packet latency in a DCN). The use of combinatorial designs within the study of general interconnection networks is not new and originated in [4] where the targeted networks involved processors communicating via buses (the reader is referred to [5] for a range of applications of combinatorial design theory within computer science). A hypergraph framework was developed in [4] where the hypergraph nodes represent the processors and the hyperedges the buses. Likewise, an analogous framework was developed in [13] but where the hypergraph nodes and edges both represent switches so that the pendant servers ‘hang off’ some of the switches (we present a detailed description of this framework in Section 3.3). In [13], the ubiquitous switch-centric Fat-Tree DCN from [3] was used as a yardstick against which to compare the new DCN designs developed in [13] under the normalization that all DCNs are to have the same worst-case link-length of server-to-server shortest paths, namely , as this equals the worst-case link-length of server-to-server shortest paths in the Fat-Tree DCN. It was shown that more servers can be incorporated within the new DCNs yet, crucially, the resulting DCNs have good path diversity. It is the algebraic properties (relating to symmetry and balance) possessed by transversal designs that enable the constructions and analysis as described in [13]. One slight difficulty with the original and novel approach taken in [13] is that some of the path diversity results derived there are incorrect (as we explain later in Section 4.1).
1.3 Our contribution
In this paper we return to the framework of [13] and formulate and prove path diversity results for the switch-centric DCNs constructed using the methods of that paper. As our concern is entirely with topological properties of DCNs, henceforth we abstract our DCNs as undirected graphs where the nodes are to represent servers and switches and the edges point-to-point links. The crux of the construction in [13] is (essentially) to build a bipartite graph using a systematic method, called the -step method, involving a different ‘base’ bipartite graph and a transversal design, and to convert the resulting bipartite graph into switch-centric DCNs (in a variety of ways). After explaining how hypergraphs and transversal designs can all be considered as bipartite graphs in Section 2, in Section 3 we provide a detailed description of the 3-step framework from [13] and explain how the bipartite graphs constructed are converted into switch-centric DCNs. Next, we revisit the results from [13]. In particular, in Section 4 we correct and extend the analysis in [13] and affirm that using the -step method from [13], we can build switch-centric DCNs: with many more servers than the Fat-Tree DCN yet so that, like the Fat-Tree, every server-to-server shortest path has length at most ; and so that (assuming some numeric conditions on the base bipartite graph and the transversal design) we can find pairwise link-disjoint paths from all of the servers adjacent to a particular switch to all of the servers adjacent to any other switch. Moreover, we provide an upper bound on the lengths of the paths constructed in terms of the diameter of the base bipartite graph (see Theorem 4). We also deal with a scenario missing from [13] (see part (b) of Theorem 4). As we explain, the general situation is more subtle than was assumed in [13].
The DCN path diversity, as we have described it above, comes about from building bipartite graphs (which are subsequently converted to DCNs) so that given any two distinct nodes, there are numerous node-disjoint paths joining these two nodes; that is, these bipartite graphs have one-to-one path diversity. In Section 5, we go on to show that we can actually build numerous edge-disjoint paths from a source node to different destination nodes in our bipartite graphs; that is, we have one-to-many path diversity. The DCNs obtained from these bipartite graphs are such that (assuming some numeric conditions on the base bipartite graph and the transversal design) we can find pairwise link-disjoint paths from all of the servers adjacent to some switch to any identically-sized collection of servers (irrespective of which switch they are adjacent to). Consequently, we show that our DCNs provide support for additional communication patterns that are prevalent within data centre networks. It should be noted that one-to-many and many-to-many communication patterns are commonplace in data centres; for example in applications involving MapReduce.
This paper is unashamedly theoretical. However, we demonstrate that not only is there interesting combinatorics within the practical world of DCN design but that combinatorial mathematics can potentially contribute to the DCN design space on a practical level. We feel that the mathematical aspects of DCNs have so far remained almost completely unexamined and we advocate a closer theoretical scrutiny of DCNs both as a model of computation and in relation to the vast swathes of research on general interconnection networks. We mention some practical considerations and directions for further research in the Conclusion.
2 Basic Concepts
We begin by briefly reviewing some architectural aspects of switch-centric DCNs that are pertinent to our subsequent research. We then move on to the discrete structures featuring in [4, 13], namely hypergraphs, bipartite graphs, and transversal designs. So that we might fully describe and understand the constructions in [4, 13], as well as our own upcoming analysis of switch-centric DCNs, we eventually amalgamate hypergraphs, bipartite graphs, and transversal designs so that by the end of this section, we will have developed an encompassing bipartite graph framework for the design of switch-centric DCNs. General graph-theoretic concepts can be obtained in [7].
2.1 Switch-centric DCNs
A switch-centric DCN is abstracted as a graph (which we also refer to as a DCN) where the nodes are partitioned into two sets: there are server-nodes; and there are switch-nodes. Of course, the server-nodes correspond to servers in the DCN and the switch-nodes to switches; note that immediately there are practical design limitations imposed by the number of ports in a real switch and the number of NIC ports in a real server (we sometimes talk of the number of ports of a switch-node rather than its degree). Furthermore, in switch-centric DCNs there are no links joining one server-node directly to another server-node (because all routing within a switch-centric DCN falls within the purview of the switches). Of concern to us in this paper will be incorporating a comparatively large number of server-nodes within our DCNs but so that the maximum length of a shortest path joining any two server-nodes, that is, the diameter of the DCN, is kept within a given bound, where the length of such a path is the number of distinct links on the path. Essentially, we will be comparing DCNs as to how many server-nodes they incorporate but when their diameters are normalized.
However, DCNs must also possess other properties to make them usable within a data centre context. For example, they also need to: be scalable and incrementally scalable (that is, have the capacity to cope with increases in components and data); have low message latency; provide for high overall throughput (under a range of traffic patterns); be able to tolerate (a limited number of) faults; be energy efficient; be both economically and physically viable; and support virtualization (that is, the partitioning of the DCN into virtual networks on a dynamic basis), amongst many other things. Support for some of these properties can be measured using graph theory; for example, the diameter of the DCN gives guidance as regards the expected message latency. Of particular interest to us will be path diversity which we define (somewhat informally) as the capacity to send data without inducing additional congestion or so as to cope with existing congestion or faults. There are two contexts of interest to us: the one-to-one (or unicast) context, when a source server-node wishes to send data to a destination server-node by the utilization of independent paths (we will return to what we mean by ‘independent’ soon); and the one-to-many (or multicast) context, when a source server-node wishes to send data to a number of destination server-nodes so that the different transmissions do not induce congestion. Path diversity is highly relevant to a number of the above properties such as latency and scalability, where different paths are used to split and balance loads, and fault tolerance, where different paths provide alternative means of transit in the case of faults. That this is the case in the one-to-one context is obvious; however, the need for data centres to support data replication and applications like MapReduce [6] makes path diversity crucial in a one-to-many context too. As we shall soon see, just as with latency, the independence of paths can be considered graph-theoretically.
2.2 Hypergraphs
Hypergraphs provide the original framework for the -step construction (to be defined later) as employed in [4, 13]: in [4], hypergraphs were used to model bus interconnection networks; and in [13], hypergraphs were used to model data centre networks. For the moment, and in order to appreciate the context of [4, 13], we retain this hypergraph framework before we phrase all content in this introduction within an encompassing bipartite graph framework.
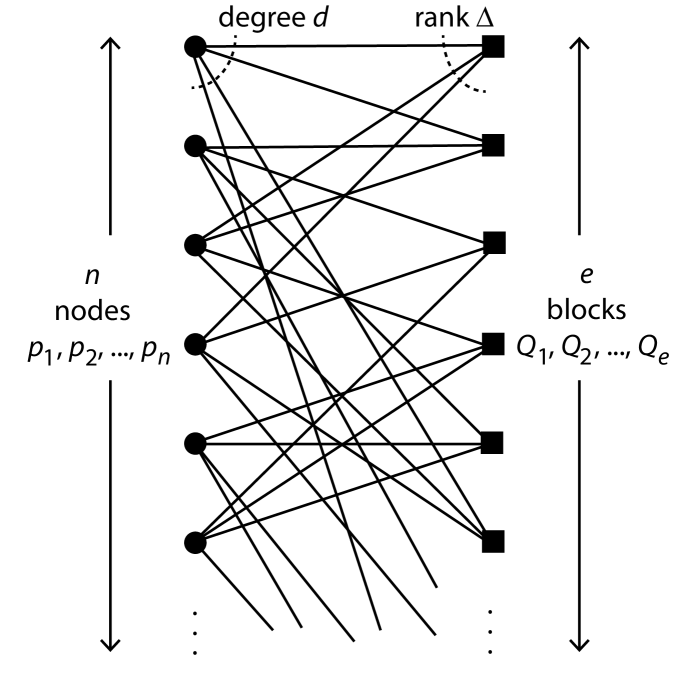
A hypergraph consists of a finite set of nodes together with a finite set of hyperedges where each hyperedge is a non-empty set of nodes and each node appears in at least one hyperedge. The degree of a node is the number of hyperedges containing it and the rank of a hyperedge is its size as a subset of . A hypergraph is regular (resp. uniform) if every node has the same degree (resp. every hyperedge has the same rank) with this degree (resp. rank) being the degree (resp. rank) of the hypergraph. Every graph has a natural representation as a hypergraph: the nodes of the hypergraph are ; and the hyperedges are , where the hyperedge consists of the pair of nodes incident with the edge of .
2.3 Hypergraphs and bipartite graphs
We can represent any hypergraph as a bipartite graph: the node set of the bipartite graph is ; and there is an edge , for and , in the bipartite graph if, and only if, in the hypergraph. It is clear that this yields a one-to-one correspondence between hypergraphs and bipartite graphs (without isolated nodes) that come complete with a partition of the elements into a ‘left-hand side’, which will correspond to the nodes of the hypergraph, and a ‘right-hand side’, which will correspond to the hyperedges of the hypergraph. We assume (henceforth) that every bipartite graph comes equipped with such a partition and for clarity from now on we refer to the nodes on the left-hand side as nodes and the nodes on the right-hand side as blocks (this is in keeping with our upcoming realisation of transversal designs as bipartite graphs). Likewise, we refer to the degree of a node as its degree and the degree of a block as its rank. A bipartite graph corresponding to a regular, uniform hypergraph of degree and rank is called a -bipartite graph. Every bipartite graph (and so every hypergraph) also describes its dual bipartite graph (or alternatively its dual hypergraph) where the roles of the nodes on the left-hand side and the blocks on the right-hand side of the partition are reversed in the definition of the bipartite graph; so, for example, the dual bipartite graph of a -bipartite graph is regular of degree and uniform of rank .
Note that if is a bipartite graph then it corresponds to a hypergraph via our representation above and it also corresponds to a hypergraph via the natural representation highlighted in Section 2.2. The two hypergraphs corresponding to the same bipartite graph are different and we are never interested in the representation of a bipartite graph as a hypergraph via the natural representation of Section 2.2.
2.4 Paths in hypergraphs
A path in some hypergraph (or the corresponding bipartite graph) is an alternating sequence of nodes and hyperedges so that all nodes are distinct, all hyperedges are distinct, and a node follows or preceeds a hyperedge in the sequence only if in the hypergraph (or is an edge in the corresponding bipartite graph). The first element of some path is the source and the final element the destination. The length of any path is its length in the bipartite graph corresponding to the hypergraph, and the distance between two distinct elements of is the length of a shortest path joining these two elements in the corresponding bipartite graph. The diameter of is the maximum of the distances between every pair of distinct nodes of , and the line-diameter of is the maximum of the distances between every pair of distinct hyperedges of .
We have two remarks. First, we have traditional notions of diameter and line-diameter in any bipartite graph. Note that our notion of diameter in a bipartite graph, which is the longest shortest node-to-node path (and so ignores node-to-block and block-to-block paths), is different from the usual graph-theoretic notion of diameter in a bipartite graph (the same comment can be made as regards line-diameter). When we talk of the diameter or line-diameter of a bipartite graph, we mean with respect to our notion of diameter or line-diameter, respectively; if we need to talk of the traditional notion of graph diameter then we will make this clear. Second, our notion of path length in a hypergraph differs from that in [13] where the length is the number of nodes (resp. hyperedges) in a hyperedge-to-hyperedge (resp. node-to-node) path. There is no real consequence to this difference; essentially, our notion of path length is double that in [13]. However, we shall soon move to an exclusively bipartite graph-theoretic formulation in which our notion of length is the natural one to adopt.
We shall be interested in building sets of paths in some hypergraph so that the paths might have the same sources or destinations; moreover, we shall require that these paths do not ‘interfere’ with one another (or are ‘independent’ as we mentioned earlier). We say that a set of paths in is:
-
1.
pairwise internally-disjoint if any source or destination only appears as a source or destination, and any node or hyperedge that is not a source or destination appears on at most one path
-
2.
pairwise edge-disjoint if every pair is such that follows or precedes on some path at most once across all paths from this set.
2.5 Hypergraphs as switch-centric DCNs
Given some hypergraph , our intention is to ultimately transform this hypergraph into a DCN by considering both the nodes and the hyperedges as switch-nodes so that the switch-nodes corresponding to the nodes (which we shall later call the level- switch-nodes, with the switch-nodes corresponding to the hyperedges the level -switch-nodes) also have adjacent server-nodes, which we have yet to define (this intention is best appreciated by working with the corresponding bipartite graph rather than the hypergraph; the upcoming Fig. 3.3 provides a visualization of what we mean). Consequently, we can regard a hypergraph as modelling a switch-centric DCN where there are two levels of switch-nodes.
Suppose that we have a set of pairwise internally-disjoint paths from one node of to another node of . This translates to a set of pairwise internally-disjoint paths in from a level- switch-node to another level- switch-node. We can use these paths for the simultaneous transfer of data from server-nodes adjacent to the source level- switch-node to server-nodes adjacent to the destination level- switch-node. In order to facilitate this data transfer we require that level- switch-nodes are non-blocking whereas the level- switch-nodes can be blocking; recall that a switch-node is non-blocking when no contention arises when simultaneously sending data through the switch-node on two distinct input links and out on two distinct output links, and blocking otherwise. If our paths in are only pairwise edge-disjoint then we require that all switch-nodes of are non-blocking.
2.6 Transversal designs
The notion of a transversal design is crucial to what follows.
Definition 1.
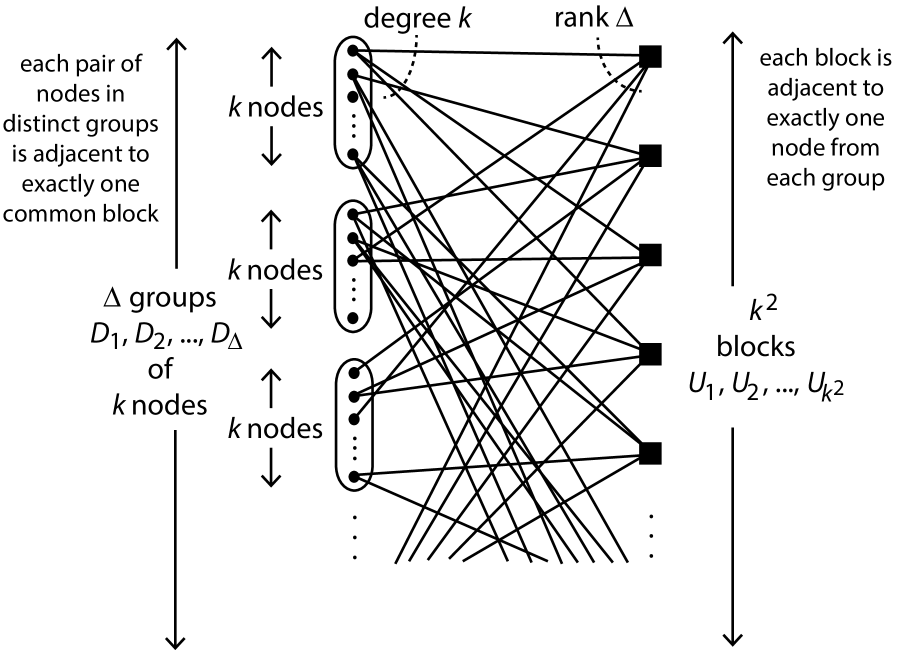
Let . A -transversal design is a triple where: ; is a partition of into equal-sized groups (each of size ); and is a family of subsets of , each of size and called a block, so that
-
1.
, for ,
-
2.
each pair of elements , where , and , is contained in exactly block.
We adopt a graph-theoretic perspective on transversal designs as defined in Definition 1: we think of the -transversal design as a bipartite graph where the elements of (resp. ) lie on the left-hand side (resp. right-hand side) of the partition, and so are called nodes (resp. blocks) within the bipartite graph, and so that in this bipartite graph there is an edge , for and , if, and only if, in the transversal design the element is in the block . Note that the bipartite graph corresponding to the transversal design from Definition 1 is a -bipartite graph. Henceforth, we adopt our bipartite graph framework and regard both hypergraphs and transversal designs as bipartite graphs (unless we state otherwise).
There is an intimate relationship involving transversal designs, orthogonal arrays and mutually orthogonal latin squares, although there is no need to give definitions here. However, it is well known: that there are mutually orthogonal latin squares of order if, and only if, there is a -orthogonal array if, and only if, there is a -transversal design; and that there are at most mutually orthogonal latin squares of order (see, for example, [14]). Hence, if we have a -transversal design then . Also, if is a prime power then a -transversal design exists whenever (again, see [14]). We shall use these facts later on. The study of the existence of -transversal designs, for various and , is a long-standing area of research.
We require one final bit of notation. If is some transversal design, as in Definition 1, and and are nodes in distinct groups then we refer to the unique block adjacent to both and as the block generated by and .
3 The -step Construction and its Extensions
We now describe the -step construction for building bipartite graphs (or, equivalently, hypergraphs) by using a ‘base’ bipartite graph and a transversal design (which we think of as a bipartite graph). This construction originated in [4] and was used in [13]. We then explain how this construction was subsequently extended in [13] both by iteration and by composition so as to yield switch-centric DCNs.
3.1 The -step construction
The -step construction proceeds as follows.
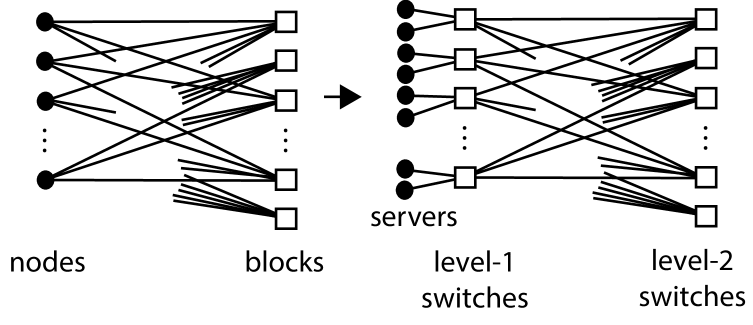
Step 1: Let be a connected -bipartite graph so that there are nodes (on the left-hand side of the partition, each of degree ) and blocks (on the right-hand side, each of rank ). Such an can be visualized as in Fig. 1 (ordinarily, we represent nodes as circles and blocks as squares).
Step 2: Let be a -transversal design. In particular, there are groups of nodes (on the left-hand side) as well as blocks (on the right-hand side). Such a can be visualized as in Fig. 2. Build the bipartite graph as follows. For every node of , introduce a group of nodes of ; we say that the group of nodes of is associated with the node of . For every block of , adjacent to the nodes in , introduce a copy of , denoted , rooted on the groups of nodes ; so, associated with the block of , we have a set of blocks in . We refer to the groups of nodes as the roots of the copy of in . Such a bipartite graph can be visualized as in Fig. 3 where two of the copies of are partially shown (note that they might have some roots in common but their respective sets of blocks are always disjoint as are their sets of edges). The bipartite graph provides a template as to how we introduce copies of to form .
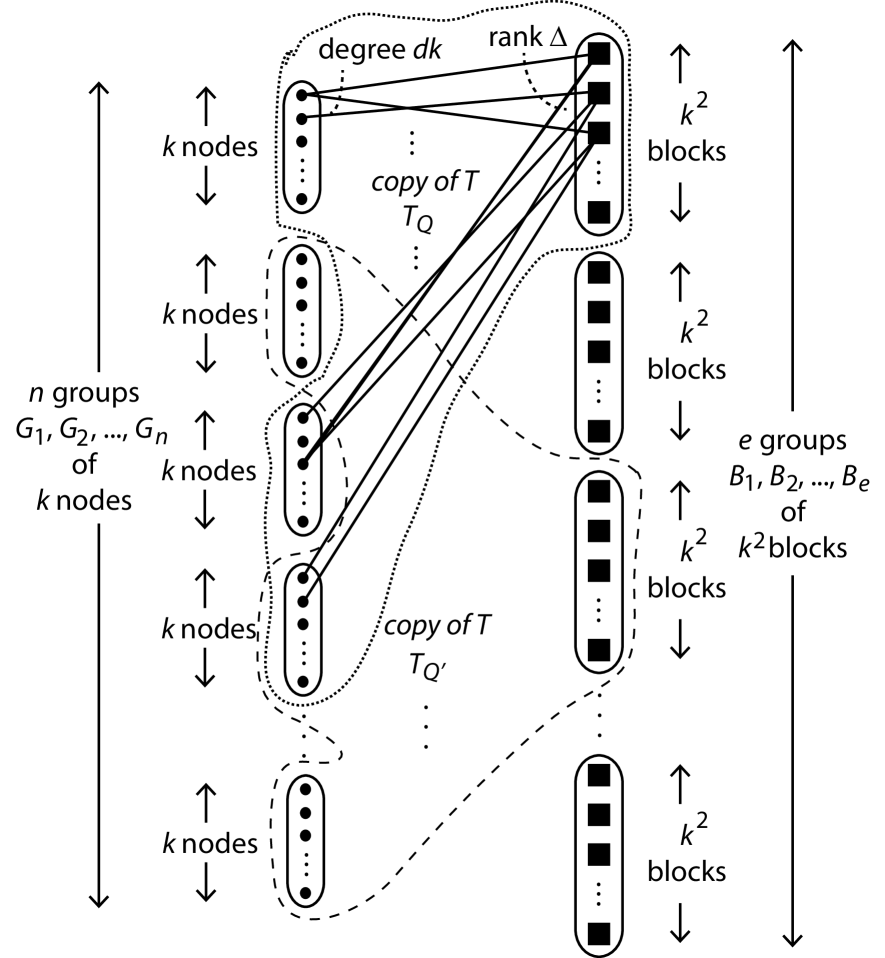
Note that:
-
1.
each node of can be indexed as , where and , so that is the node of to which the group in which sits is associated and is the index of the node in this group
-
2.
each block of can be indexed as , where and , so that is the block of to which the set of blocks in which sits is associated and is the block of to which corresponds.
In addition, each node of can be indexed , where and , so that is the group of nodes in which sits and is the index of in that group.
Step 3: Let be the bipartite graph obtained from the bipartite graph by reversing the roles of nodes and blocks (so, is the dual bipartite graph of ). Note that the bipartite graph is regular of degree and uniform of rank .
We refer to the -bipartite graph (resp. the -bipartite graph ) constructed above as having been constructed by the -step (resp. -step) method using the -bipartite graph and the -transversal design . Note that (resp. ) has nodes (resp. nodes) and blocks (resp. blocks).
Our intention with our constructions is to ultimately design switch-centric DCNs with beneficial properties (as we outlined in Section 2.5). Whilst there are many properties we would like our DCNs to have, it is important that DCNs can integrate a large number of server-nodes so that the server-node-to-server-node distances are short and so that there is redundancy as to which (short) server-node-to-server-node routes we choose to use. In our framework of bipartite graphs, this translates as building bipartite graphs with a large number of nodes and with redundant (short) node-to-node paths. As a first step, the following result was proven in [4] (it is actually derivable from the proofs of our upcoming results) and allows us control over the length of shortest block-to-block paths in -step constructions (and so shortest node-to-node paths in -step constructions).
Theorem 2 ([4]).
Suppose that the -bipartite graph has been constructed using the -step method using the -bipartite graph and the -transversal design . If has line-diameter then has line-diameter .
Of course, if is the dual bipartite graph of in Theorem 2 then it has diameter . We reiterate that our notion of diameter and line-diameter differs from that in [4, 13] (where the length of a block-to-block path is the number of nodes on that path; so, in [4, 13] the bound in our Theorem 2 appears as ).
3.2 Iteration
We can iterate the -step construction (as was done in [13]). Note that if is a -bipartite graph of line-diameter , with nodes and blocks, then the bipartite graph resulting from the -step construction (using and some -transversal design ) is a -bipartite graph of line-diameter . So, repeating the -step construction but with replacing (we keep the same , although we do not have to) yields a -bipartite graph of line-diameter . By iterating this construction, we can clearly obtain a -bipartite graph of line-diameter . Converting into results in a bipartite graph with nodes, with blocks, with diameter , and that is regular of degree and uniform of rank .
3.3 Composition
New methods of composing bipartite graphs (built according to the -step construction) so as to obtain switch-centric DCNs were also derived in [13]. In [13], such methods were given: Methods , and are different cases of Method , below; and Method is Method .
In what follows, let be a -bipartite graph where and where there are nodes and blocks.
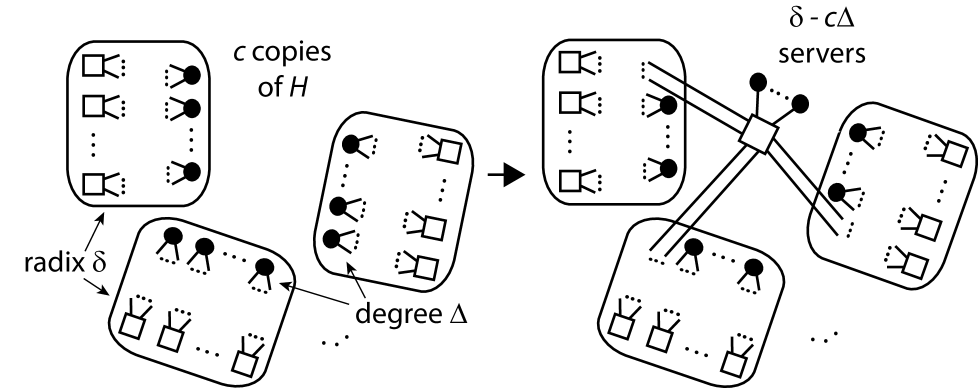
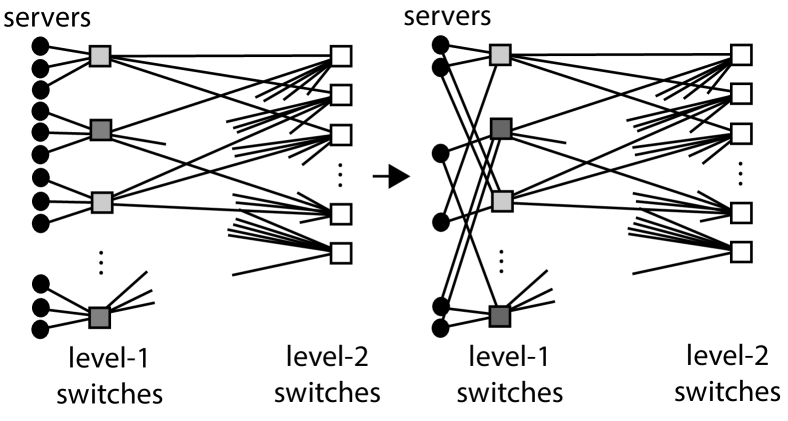
Method : We take copies of where and . For each node of : we remove the corresponding node in each of the copies of and introduce a new switch-node (common to all copies of ); we make all of the edges incident with the original nodes incident with this new switch-node; and we attach pendant server-nodes to the new switch-node. All blocks of are considered as switch-nodes. We follow [13] and call the new switch-nodes level- switch-nodes and the original switch-nodes level- switch-nodes. The construction of the switch-centric DCN from via this method can be visualised as in Fig. 4, where we only show the construction for the nodes coresponding to one node of . Note that every switch-node of has ports. Also, there is some choice as regards the parameter (so that choosing different values for yields different values for ). We illustrate the special case when in Fig. 5, where is a -bipartite graph. The general case when corresponds to Method of [13]; the special case when corresponds to Method ; and the special case when corresponds to Method . In this latter case, the aim is to ensure that every level- switch-node is adjacent to roughly the same number of level- switch-nodes as it is server-nodes. Note that: the number of server-nodes in is ; the number of level- switch-nodes is ; and the number of level- switch-nodes is .
Method : We now work with a switch-centric DCN as constructed by Method . Let every level- switch-node have adjacent server-nodes. Suppose that there is an even number of level- switch-nodes. Partition the set of level- switch-nodes into pairs. For each pair of switch-nodes : remove server-nodes that are adjacent to and remove server-nodes that are adjacent to ; and make every server-node that is adjacent to the switch-node or the switch-node also adjacent to the other switch-node. Note that the number of ports of any switch-node has not changed but that every server-node is now adjacent to switch-nodes. The philosophy behind this construction is to better tolerate the failure of a level-1 switch-node. The construction can be visualized as in Fig. 6 where paired level- switch-nodes have the same shade of grey and where .
3.4 Some illustrations of DCNs
In [13], switch-centric DCNs constructed using the -step method allied with Methods and were favourably compared with the -level Fat-Tree DCN from [3] with regard to the number of server-nodes therein when the diameter and the number of ports of a switch-node are held constant. The reader is referred to [3, 13] for full details as regards the topology of Fat-Tree and to Tables 2–4 in [13] for the complete comparison; however, we include a replicated table here purely for illustrative purposes. In Table 1 (which is Table 2 from [13]): the number of ports of any switch-node is forced to be ; the diameters of the DCNs resulting from using the -step method, iteration and composition are forced to be (at most) (like that of Fat-Tree); and the numbers of server-nodes and switch-nodes in the resulting DCNs are as given (note that the length of a server-node-to-server-node path as defined in [13] is the number of switch-nodes on it, which is one less than our notion of length which is the number of links on the path).
| network | # switch ports | diameter | # server-nodes | # switch-nodes |
|---|---|---|---|---|
| Fat-Tree | ||||
-
1.
The bipartite graph is obtained using the -step method starting with a -bipartite graph , that has nodes, blocks, and diameter and line-diameter (such a bipartite graph exists; see [11]), and a -transversal design . The DCN in Table 1 is the DCN obtained by simply regarding every node of the bipartite graph as a server-node (note that in this DCN we require that every server-node has NIC ports); the DCN (resp. , ) is obtained by employing Method with (resp. , ); and the DCN is obtained by employing Method with (note that the number of switch-nodes entry in Table 2 in [13] is incorrect).
-
2.
The bipartite graph is obtained using the -step method iterated twice, starting with a -bipartite graph , that has nodes, blocks, and diameter and line-diameter (such a bipartite graph exists; see [11]), and a -transversal design (actually, in [13] this transversal design is not mentioned; it does, however, exist). The DCN in Table 1 is the DCN obtained by simply regarding every node of the bipartite graph as a server-node (note that the number of server-nodes entry in Table 2 in [13] is incorrect, though the correct number is stated in the text); and the DCN is obtained by employing Method with (note that the numbers of server-nodes and of switch-nodes entries in Table 2 in [13] are incorrect).
It is clear from Table 1 (and from [13]) that we can build much bigger server-centric DCNs using the -step method and the subsequent iterations and compositions than Fat-Tree but without increasing the diameter (which is a proxy for latency); of course, we would wish the new DCNs to have other properties that make them attractive within a data centre context. Establishing such properties was essentially the whole point of [13] and we continue with this line of research in what follows.
Before we move to our main results, let us comment on using the -step method as opposed to the -step method when building our switch-centric DCNs (the same comment was made in [13]). Note that when one uses the (iterated) -step method, whilst the rank of the resulting bipartite graph stays the same, the degree grows. Were we to attach server-nodes to the switch-nodes that replace the nodes of the -step bipartite graph , rather than the -step bipartite graph , the number of ports of the level- switch-nodes (which would be ) would be much less than the number of ports of the level- switch-nodes. Hence, it makes more sense to proceed as we have done above.
4 One-to-one path diversity
So far, we have set the scene from [13] and described a method by which we can build bipartite graphs (the -step method) which can then be transformed into switch-centric DCNs with many more servers than Fat-Tree whilst maintaining the diameter of Fat-Tree, i.e., . However, as we mentioned earlier, there are many more aspects to the design of DCNs with an important one being path diversity. In what follows, we highlight some problems with the proofs of one-to-one path diversity in [13] for bipartite graphs built using the -step method. We then provide not only correct proofs as regards one-to-one path diversity but we also extend and improve the analysis in [13] with new results. We end the section by applying our constructions so as to build DCNs with good one-to-one path diversity properties.
4.1 Difficulties with proofs
In order to detail the difficulties in [13], we adopt the terminology of [13]. There are slight problems with the proof of Theorem 2 in [13] (although they are easily surmountable). For example, in Subcases (1.2) and (2.2), and consequently we cannot generate the blocks and . Also, in Subcase (2.1), the situation where is not considered; it could be that , for some .
An attempt was also made in [13] to extend Theorem 2 of [13]: see Theorem 3 of [13]. Assumptions concerning the connectivity of are made and the existence of additional paths in to those constructed in the proof of Theorem 2 are claimed in the situation when the two blocks and are such that (recall our method of indexing in Section 3.1 which we adopt here). However, there are serious flaws in the proof of Theorem 3 of [13], so much so that the theorem is untrue. In short, Theorem 3 of [13] claims that if there are pairwise internally-disjoint paths in from to then there are pairwise internally-disjoint paths in from to . This does not make sense: the maximum number of pairwise internally-disjoint paths in from to is (as the bipartite graph has rank ) and so we must have that . For instance, in Example 1 of [13], the bipartite graph is the cycle of length ( is derived from the cycle of length using its natural representation as a hypergraph; see Section 2.2), so that , , and there internally-disjoint paths from any block of to any other block of . A -transversal design is used and the bipartite graph built by the -step method has rank and degree . However, if Theorem 3 of [13] were true then there would be pairwise disjoint paths from to in which clearly cannot be the case.
4.2 The one-to-one scenario
We now resurrect (some of) the proofs of the main results from [13] and extend the results claimed in that paper. The following lemma proves most useful.
Lemma 3.
Let be some -transversal design with groups of nodes . Let be some block of . For each , let be the unique node of that is adjacent to . Set . Let be a set of distinct pairs of nodes so that: exactly one node of any pair in is in and no node of is in more than one pair of ; and no pair in is such that both nodes lie in the same group. The blocks generated by the pairs in are all distinct and different from .
Proof.
Suppose that , where with and where . Let be the block generated by and . If then is adjacent to the distinct nodes and in which yields a contradiction.
Suppose that , where . Let be the block generated by and . Suppose that ; hence, is adjacent to both and with . As any two nodes lying in distinct groups in are adjacent to a unique block of , we must have that ; but this yields a contradiction as above. Hence, the blocks generated by the pairs in are all distinct and all different from . ∎
We use this lemma throughout, both explicitly and implicitly.
Our main result in the one-to-one context is concerned with building as many pairwise internally-disjoint paths as we can from any block to any other block in the bipartite graph built using the -step method (or, equivalently, from any node to any other node in the bipartite graph built using the -step method). We explain the impact of the existence of these paths on the path diversity of subsequently built DCNs presently. One added and significant complication in the proof of the following result comes about when the transversal design is a -transversal design (so, there is the potential for paths).
Theorem 4.
Let . Let be built by the -step method from the -bipartite graph using the -transversal design .
-
(a)
Let and be distinct blocks of so that there are pairwise internally-disjoint paths in from to , each of length at most . There are pairwise internally-disjoint paths from any block of to any other block of . Furthermore, if then there are pairwise internally-disjoint paths from any block of to any other block of . All paths have length at most .
-
(b)
If and are distinct blocks of then there are pairwise internally-disjoint paths from to , each of length at most and lying entirely within .
Proof.
Recall that we mentioned in Section 2.6 that necessarily .
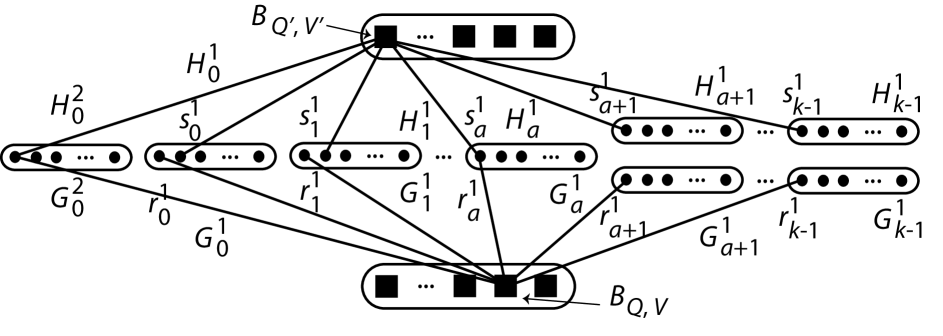
Case (a)(i): Suppose that: ; ; and the distinct nodes and are common neighbours in of and .
We ‘batch’ the groups of nodes of and together so that in each of and , the groups of nodes form batch of groups and batch of group as follows:
-
1.
for , define
-
2.
the remaining groups within are and the remaining groups within are so that:
-
(a)
any group of the form , where , is associated with some node of that is adjacent to both and if, and only if, the group is associated with the same node of (so, if and are associated with the same node of then they are the same group in ).
-
(a)
For each , let (resp. ) be the unique node of (resp. ) that is adjacent to (resp. ) in . Note that the pair and lie in the same group of nodes in if, and only if, both and are associated with the same node of and this node is adjacent to both and in . The situation can be visualized as in Fig. 7 (where in this case and have common neighbours in and where, for example, but ).
Let and so that:
-
1.
if then , for
-
2.
if then , and , for .
We are now ready to generate some blocks within and in . For each :
-
1.
let be the unique block of in generated by the nodes and
-
2.
let be the unique block of in generated by the nodes and .
So, we have generated blocks in and blocks in . Note that any block of is necessarily distinct from any block of . By Lemma 3 applied twice to both and , all blocks of are distinct and different from , and all blocks of are distinct and different from . Call these two sets of blocks our working sets of blocks.
We are now in a position to build some paths from to in . If then define the paths:
-
1.
as
-
2.
as , if , and as , if (note that ).
If then define the paths:
-
1.
as (note that )
-
2.
as (note that ).
We’ll now build paths from to using nodes from the groups . For each :
-
1.
if then define the path:
-
(a)
as (note that )
-
(a)
-
2.
if then define the path:
-
(a)
as .
-
(a)
Note that out of all of the ‘-paths’ constructed above, the only way that we can have that two of our paths are not internally-disjoint is when but (in which case and share the common node ). In this case, choose . Let be the block of in generated by and , and let be the block of in generated by and (in essence, we have dispensed with the blocks and and replaced them with the blocks and in our working sets of blocks). The conditions of Lemma 3 still hold and so the blocks in our working sets of blocks are all distinct and different from and . Redefine the paths:
-
1.
as
-
2.
as .
The paths from the resulting set of -paths are now pairwise internally-disjoint and each has length at most .
Let (resp. ) be the unique node of (resp. ) that is adjacent to (resp. ) in . Suppose that . In this case, we build the path defined as . This path is clearly internally-disjoint from all of the -paths constructed above. Alternatively, suppose that . If then there is a node . Let be the block of within generated by and , and let be the block of within generated by and . By Lemma 3, these blocks are different from , and all other blocks used within the -paths constructed above (even when we make the amendments to our working sets of blocks as detailed in the preceding paragraph). Define the path as . This path has length and is clearly internally-disjoint from all of the -paths constructed above.
On the other hand, suppose that ; so, . In particular, a -transversal design exists. We deal with this case from scratch.
Lemma 5.
There is exactly one -transversal design up to isomorphism and this is the transversal design depicted in Fig. 8.
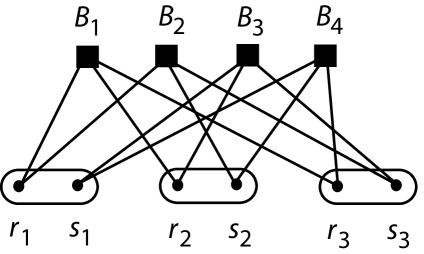
Proof.
In some -transversal design, let the set of blocks be and let the group of nodes be , for . W.l.o.g., we must have the set of edges
W.l.o.g., the node is adjacent to , and is adjacent to one other block. The only possible block that can be adjacent to is (as otherwise we would have two nodes in different groups adjacent to distinct blocks).∎
Name the blocks and nodes of as in Fig. 5. W.l.o.g. suppose that (it is easy to see that there is an automorphism of mapping any block to any other block). There are two cases to consider: when and have common neighbours in ; and when they have only common neighbours in . However, before we deal with these cases, choose any distinct nodes in . A tedious case-by-case analysis yields that no matter which nodes are chosen, there are pairwise internally-disjoint paths from to the nodes within . For example, suppose that the chosen nodes are , and . The paths are: ; ; and . It turns out that if the chosen nodes are in different groups then the length of any path is at most , whereas if the chosen nodes are in different groups then the length of any path is at most .
Suppose that and have common neighbours in . Choose the nodes in as the neighbours of in . Consequently, from above, we clearly obtain pairwise internally-disjoint paths from to as required. Moreover, each path has length at most .
Suppose that and have only common neighbours in where the groups corresponding to these neighbours are and , with , . Choose nodes in as the two neighbours of in and , call them and , plus one other node, call it , say, from one of these groups, with the remaining unchosen node from these two groups being denoted by . By above, there are pairwise internally-disjoint paths, , and , in from to , and , and we may assume that these paths do not involve ; for if one does then it must be the path to , in which case we simply choose as our third chosen node, above, instead of (it is not difficult to see that the path to has length at most ). By above, there are also pairwise internally-disjoint paths, , and , in from to , and , each of length at most ; moreover, these paths do not share any nodes with the paths , and apart from the end-nodes. Consequently, we clearly obtain pairwise internally-disjoint paths from to as required. Moreover, each path has length at most .
Case (a)(ii): Suppose that: ; ; and there is exactly one common neighbour in of and , namely the node .
As , there is a path in of the form where and where does not appear on this path (note that ). We ‘batch’ our groups similarly to as we did before:
-
1.
define , and
-
2.
the remaining groups within are and the remaining groups in are .
Note that we necessarily have that the groups and are distinct, for (as are the groups and ).
For each , let (resp. ) be the unique node of (resp. ) that is adjacent to (resp. ) in . Also, let (resp. ) be the unique node of (resp. ) that is adjacent to (resp. ) in .
We construct the paths , for , exactly as we did in Case (a)(i). In addition, define the paths as and as . If we can find a path in from to so that no node or block of this path, apart from the nodes and blocks of and , lies in or then we are done. In : there is a path of length lying entirely within so that the source is and the destination is some node ; there is a path of length lying entirely within so that the source is and the destination is some node ; ; there is a path of length lying entirely within so that the source is and the destination is . We clearly have a required path of length at most . So, we have constructed pairwise internally-disjoint paths from to so that of these paths have length at most and the remaining path has length at most .
Case (a)(iii): Suppose that: ; ; and there are no common neighbours in of and .
As , there are paths in of the form and where and where these paths are internally-disjoint.
We ‘batch’ our groups similarly to as we did before:
-
1.
define and
-
2.
choose groups within (different from ) as and choose groups in (different from ) as .
Note that we necessarily have that the groups and are distinct, for .
For each , let (resp. ) be the unique node of (resp. ) that is adjacent to (resp. ) in . Let and . For each , let be the block of generated by and , and let be the block of generated by and . By Lemma 3 applied twice to both and , all blocks of are distinct and different from , and all blocks of are distinct and different from .
For , let be the path and let be the path . Define the path as and the path as . In : there are paths of length from the nodes of to distinct nodes of , respectively, so that all blocks on these paths lie in and are distinct; there are paths of length from the nodes of to distinct nodes of , respectively, so that all blocks on these paths lie in and are distinct; ; and there are paths of length from to the nodes of , respectively, so that all blocks on these paths lie in and are distinct. We can clearly piece all of the paths together to obtain pairwise internally-disjoint paths from to so that each path has length at most .
We can build another path from to that is internally-disjoint from the paths just constructed by proceeding exactly as we did above or in Case (a)(ii), corresponding to the alternative path from to in . This path has length at most .
Case (a)(iv): Suppose that or .
By choosing the appropriate construction from the cases above, depending upon whether there is a common neighbour of and in , we can clearly construct pairwise internally-disjoint paths from to so that: if there is a common neighbour of and in , all paths have length at most ; and if there is no common neighbour of and in , all paths have length at most .
Case (b): Consider the case when our two blocks are and . Suppose that the block of is adjacent to the nodes . For each , let be adjacent to in and let be adjacent to in . W.l.o.g. suppose that , for , and that , for .
Suppose that . For each , let be the block of that is generated by and , and let be the block of that is generated by and . By Lemma 3, all blocks are distinct and different from and . Hence: if is the path , for ; if is the path ; and if is the path , for , then paths in the resulting set are pairwise internally-disjoint, with each path having length at most .
If then the above construction trivially yields paths of length from to . Suppose that . Choose and let (resp. ) be the block of generated by and (resp. and ). Clearly, , , and are all distinct. So, if is the path and is the path , for , then we obtain pairwise internally-disjoint paths, with all paths having length except one which has length .∎
Theorem 4 is clearly optimal in the sense that the maximal number of pairwise internally-disjoint paths is always constructed (this follows from a simple application of Menger’s Theorem). Also, irrespective of the erroneous proofs in [13], Theorem 4(b) extends the claimed results in [13] by deriving pairwise internally-disjoint paths from any block in to any block (this scenario was not dealt with in [13]). Note also that the chance to obtain more than pairwise internally-disjoint paths comes about when we force and choose a -transversal design (if one exists).
Of course, Theorem 4 yields path diversity in any DCN constructed using the -step method with Methods and . Suppose that Method has been used to construct a DCN where the number of server-nodes adjacent to some level- switch-node is at most the number of level- switch-nodes adjacent to the level- switch-node. If all level- switch-nodes are non-blocking then we can simultaneously facilitate data transfers from all the server-nodes adjacent to some level- switch-node to all the server-nodes adjacent to any other level- switch-node (in fact, we need only that the source and destination level- switch-nodes are non-blocking; all other level- switch-nodes can be blocking).
4.3 Applying our construction
In this section, we apply Theorem 4 and p[rovide ome concrete illustrations of how we can obtain switch-centric DCNs that have the same diameter as Fat-Tree yet have more server-nodes and significant one-to-one path diversity.
The primary difficulty in the proof of Theorem 4 is in dealing with when the -transversal design is such that (recall, ). However, dealing with this difficulty is worth it as having the capability to use -transversal designs when applying the construction means that we obtain more flexibility as to the number of switch ports necessarily required in the resulting DCNs, as we illustrate now. In what follows, we limit ourselves (on the grounds of practicality) to switch-nodes with at most ports. If we were only to use -transversal designs where (note that each of these -transversal designs exists; see Section 2.6) in the (one-iteration) -step method then (assuming that we use bipartite graphs that have the same number of nodes as blocks; that is, for which ) we need level- switch-nodes with , , , , , , , or ports. If we allow -transversal designs where (again, note that each of these -transversal designs exists; see Section 2.6) then we have added flexibility in that we can also build DCNs with level- switch-nodes with , , , , , or ports; of course, to ensure that we obtain full path diversity, we need that has at least internally-disjoint paths joining any two distinct blocks.
As regards finding large, regular, uniform bipartite graphs of line-diameter and so that there are at least internally-disjoint paths joining any two distinct blocks, this is not as straightforward as it is if we drop the second stipulation. There is an extensive literature as regards the construction of regular, uniform bipartite graphs of a given degree and where the degree is equal to the rank (see, for example, [11]) but in so far as we are aware, the construction of such graphs with any added stipulations (relating to connectivity, for example) has not been considered. Nevertheless, there are simple constructions that enable us to apply Theorem 4 to the full, as we now illustrate.
From [11], there is a regular, uniform bipartite graph of degree and rank with nodes and blocks, and which has graph-theoretic diameter . Enumerate the nodes as and the blocks as . Take two disjoint copies of this graph and add edges joining in one graph to in the other graph; moreover, the nodes (resp. blocks) of the new bipartite graph are exactly the nodes (resp. blocks) of the original disjoint copies. The resulting graph is a regular, uniform bipartite graph of degree and rank with graph-theoretic diameter at most ; furthermore, there are clearly at least internally-disjoint paths joining any pair of distinct blocks or any pair of distinct nodes where these paths have length at most . Take this bipartite graph as .
Apply the -step method using a -transversal design. This results in a bipartite graph with nodes, blocks, degree , and rank . Now apply Method with and we obtain a DCN of diameter and with server-nodes, level- switch-nodes, level- switch-nodes and so that all switch-nodes have ports. By Theorem 4, there are paths from the server-nodes adjacent to the same level- switch-node to the server-nodes adjacent to another level- switch-node so that the only switch-nodes that lie on more than one of these paths are and and so that the length of each of these paths is at most . In addition, we have spare capacity at the level- switch-nodes and as links to level- switch-nodes are not used.
Alternatively (for an increase in the number of server-nodes incorporated and in path diversity but so that more ports are required on switch-nodes), apply the -step method using a -transversal design. This results in a bipartite graph with nodes, blocks, degree , and rank . Now apply Method with and we obtain a DCN of diameter and with server-nodes, level- switch-nodes, level- switch-nodes and so that all switch-nodes have ports. By Theorem 4, there are paths from the server-nodes adjacent to the same level- switch-node to the server-nodes adjacent to another level- switch-node so that the only switch-nodes that lie on more than one of these paths are and and so that the length of each of these paths is at most . The actual construction used will be dominated by the available hardware; that is, numbers of server-nodes and switch-nodes and the radix of switch-nodes.
Undertaking more iterations of the -step construction before building our DCNs yields that if we use -transversal designs where then we need level- switch-nodes with, , or ports; and if we use -transversal designs where then we need level- switch-nodes with an alternative range of port numbers. As an illustration, iterating the -step method by mixing the use of - and -transversal designs, we can build DCNs where the level- switch-nodes need , , , , , , , , , , , and ports. What is more, by Theorem 4, any bipartite graph built using the -step method iterated more than once necessarily has maximal path diversity (as applying the -step method once always yields a bipartite graph where there are at least internally-disjoint paths joining any two distinct blocks).
It has already been established in [13] that the -step and -step methodologies are viable when it comes to building switch-centric DCNs that can host more server-nodes than a Fat-Tree and retain an acceptable level of (one-to-one) path diversity whilst maintaining a diameter of ; we further cement this viability in this paper. An important point to note is that we need not choose our bipartite graph to be as large as we can; as we have shown, smaller bipartite graphs might yield DCNs with a sufficiently large number of server-nodes and optimal one-to-one path diversity.
5 One-to-many path diversity
We now work towards building pairwise edge-disjoint paths from any block in some bipartite graph built using the -step method to the blocks of any given multi-set of blocks (so, there might possibly be repeated blocks; here, and are as in the statement of Theorem 4 but where ). Henceforth, when we write ‘set’ we often mean ‘multi-set’. We begin by working only within some transversal design.
Theorem 6.
Let be any -transversal design where and where . Let be any block and let be any nodes or blocks, called target-nodes or target-blocks, as appropriate, where there may be repetitions. For each , there is a path from to of length at most so that these paths are pairwise edge-disjoint.
Proof.
For each group of nodes within , where , let be the (unique) node of adjacent to the block ; we call the nodes root-nodes. Consider some group . There may be target-nodes that are identical to the root-node ; call these target-nodes rooted, with the remaining target-nodes in called non-rooted. Call the number of rooted target-nodes in the multiplicity of the root-node .
There are two essential cases: (a) we have target-nodes and no target-blocks; (b) we have at least target-block.
Case (a): Suppose that we have target-nodes and no target-blocks.
We rank the groups of as in decreasing order of the number of occurrences of non-rooted target nodes within the group, with ties broken according to decreasing multiplicity of the root-nodes (and then arbitrarily). We attempt to match the non-rooted target-nodes in with the root-nodes in this order but only if the root-node has multiplicity (that is, we skip over root-nodes of non-zero multiplicity; note that any skipped root-node is identical to at least target-node). If we are successful then we attempt to match the non-rooted target-nodes in by continuing down our list of root-nodes (again, skipping over root-nodes of non-zero multiplicity). If we are successful then we attempt to match the non-rooted target-nodes in , and so on. There are three possibilities.
-
(i)
We successfully match every non-rooted target-node without running out of root-nodes (of multiplicity ). This happens when has non-zero multiplicity or when there is a root-node with multiplicity at least .
-
(ii)
We successfully match all but one of the non-rooted target-nodes and the final non-rooted target-node does not lie in , in which case we match this target-node with . This happens when has multiplicity , every root-node has multiplicity at most , and there is a non-rooted target-node that does not lie in .
-
(iii)
We have one non-rooted target-node of remaining to be matched and also the root-node unmatched. This happens when all of the non-rooted target-nodes lie in and has multiplicity .
Consider Sub-case (ii). We extend our matching so that every root-node of multiplicity is matched with the unique target-node that is identical to it. We have a complete matching of root-nodes to target-nodes so that no target-node is matched with the root-node in its own group unless the target-node is (the unique target-node) identical to the root-node. For every pair where is a root-node matched with a target-node and so that and do not lie in the same group, let be the block generated by and . Call the resulting set of blocks the -blocks. By Lemma 3, all of the -blocks are distinct and different from . If is a -block then define the path as ; and if the target-node is identical to the root-node then define the path as . The resulting paths are pairwise internally-disjoint.
Consider Sub-case (iii). We have an almost complete matching of root-nodes to target-nodes so that no target-node is matched with the root-node in its own group, except that some target-node of is not matched and nor is the root-node . As we did above, we generate a set of -blocks, one for each matched-pair. Again, these -blocks are all distinct and different from , and by proceeding as above we obtain pairwise internally-disjoint paths from to target-nodes.
Consider and . As , there is some node in the group that is neither a root-node nor a target-node. Let (resp. ) be the block generated by and (resp. and ). By Lemma 3, is different from and every -block; also, is different from and . However, it could be that is identical to some -block (for this to happen we would need that is identical to some other target-node). If is the target-node of matched with then is different from . Hence, there are at most -blocks with which might be identical. As we have at least choices for in (recall, ), we can always choose so that is different from every -block. Define the path as . The resulting paths from to the target-nodes are pairwise internally-disjoint.
Consider Sub-case (i). We can extend our matching so that every root-node of non-zero multiplicity is matched with one target-node that is identical to it. Hence, we have a partial matching of root-nodes to target-nodes so that no target-node is matched with the root-node in its own group unless the target-node is identical to the root-node. As we did above, we generate a set of -blocks, one for each matched-pair where the root-node in the pair is different from its matched target-node. Again, these -blocks are all distinct and different from , and we obtain pairwise internally-disjoint paths from to all of the target-nodes involved. We also obtain paths of length from to every target-node that is identical to a root-node and has been matched with it. If there are no root-nodes of multiplicity greater than then the resulting paths are pairwise internally-disjoint and we are done. So, suppose that we have paths that are pairwise internally-disjoint and that there are root-nodes of multiplicity at least with unmatched root-nodes (so, is the number of target-nodes remaining to be dealt with; of course, ). Note that any group in which some hitherto unmatched root-node lies, apart from if is still unmatched (that is, has multiplicity ), contains no target-nodes (because of the order in which we initially match target-nodes to root-nodes) and the groups containing unmatched root-nodes are either , if is matched, or , if is unmatched.
Suppose that ; hence, there is exactly one root-node , where , of multiplicity greater than and this multiplicity is . W.l.o.g. let the solitary target-node remaining to be dealt with be (which is identical to both and some other target-node ), with the solitary root-node remaining to be dealt with being either or , as appropriate. If then we must have and with and so that the two target nodes and are both equal to (note that in this case we define no -blocks). Let (resp. , ) be the block generated by and (resp. and , and ). The blocks , , and are all distinct. Define the path as and the path as ; the two paths are internally-disjoint and we are done.
Alternatively, suppose that and (and so ). If then there is a non-rooted target-node in each , for , with the unmatched root-node being . Choose . Otherwise, if then contains at most target-node, which, if it exists, is rooted, with the unmatched root-node being either or . Choose . Whichever is the case, let be the unmatched root-node (and so ). Let (resp. ) be the block generated by and (resp. and ). By Lemma 3, the -blocks, , and are all distinct. Define the path as so as to obtain pairwise internally-disjoint paths from to the target-nodes; hence, we are done.
Now suppose that (note that ). As stated above, the root-nodes remaining to be dealt with are either or . Suppose that the root-nodes remaining to be dealt with are and the target-nodes remaining to be dealt with are (of course, every such target-node is identical to an already matched root-node). For each , let and choose (from our earlier remark, there are no target-nodes in ). For each , let be the block generated by and , and let be the block generated by and ; call these blocks the -blocks. By Lemma 3, the -blocks are distinct and each -block is different from every -block and . For each , let be the block generated by and ; call these blocks the -blocks. By Lemma 3, each -block is different from , every -block and from every -block (note that any is a root-node and so not adjacent to any -block or -block). However, it is possible that , for (for this to happen we would need that , as otherwise we would have two root-nodes adjacent to both and another block). Note that for each : we have possible choices within for ; and for , where , the block , generated by and , is different from the block , generated by and .
Choose and . Suppose we have that ; if so then re-choose . Necessarily, . Choose . Suppose that ; if so then re-choose . Suppose that ; if so then re-choose . Necessarily, are distinct. Proceed in this way until have been chosen. Note that as , the above procedure can always be completed. What results is the set of distinct blocks . For each , define the path as , and define the path as . The resulting paths from to the target-nodes are pairwise internally-disjoint.
Alternatively, suppose that the root-nodes remaining to be dealt with are . We proceed exactly as above except that we start from a node that is different from any target-node (such a node exists). We obtain our pairwise internally-disjoint paths as before.
Case (b): Suppose that there is at least target-block.
W.l.o.g. we may assume that the target-nodes , where , lie within the groups and that the target-blocks are . Suppose that some target-block is adjacent to some root-node of some group , where and . Remove the target-block (temporarily) from our set of targets and include the new target-node . Iterate this process. Hence, w.l.o.g. we may assume that: our target-nodes are the original target-nodes along with the new target-nodes , where each new target-node is adjacent to the now removed old target-block ; and our target-blocks are with none of these target-blocks adjacent to any root-node in the groups . For each : let the node be adjacent to ; and (temporarily) remove the target-block and include the new target-node .
Apply the construction in Case (a) to our new set of target-nodes. We obtain paths, one from to each of our target-nodes so that these paths are internally-disjoint. Consider some new target-node , where . By the construction of our paths, the path corresponding to this new target-node is and does not appear on any other path (there is no repetition of in our set of target-nodes). Extend the path to the path , for . Consider some new target-node , where . Suppose that the edge appears on some path. By the construction of our paths, the only way that this can happen is if this edge is the last edge on the path from to . If this is the case then truncate this path at . Alternatively, if the edge does not appear on some path then we extend the path from to by the addition of the edge to . Consequently, we obtain a set of paths from to each of our original target-nodes and target-blocks so that these paths are pairwise edge-disjoint. Note that: target-nodes only appear as destinations and apart from possibly target-nodes, no node appears on more than one path; and no block appears on more than one path except possibly for some target-blocks (which might appear as internal nodes on paths). The result follows.∎
Note that the construction in Theorem 6 is weaker than those in the previous section as we obtain only that paths are pairwise edge-disjoint rather than pairwise internally-disjoint. However, we do obtain the following result as an immediate corollary of the construction in Theorem 6.
Corollary 7.
Let be any -transversal design where and where . Let be any block and let be any nodes, called target-nodes, where there may be repetitions. For each , there is a path from to of length at most , so that the paths are pairwise internally-disjoint.
We now build some many-to-many edge-disjoint paths within some transversal design.
Theorem 8.
Let be any -transversal design where and . Let where . Suppose that we are given nodes, the target-nodes, and blocks, the target-blocks, so that there might be repetitions amongst the target-nodes and target-blocks. Suppose that is a group of nodes that contains no target-nodes. There exists a set of distinct nodes of such that there are pairwise internally-disjoint paths, each of length at most , the sources of which are the nodes of and the destinations of which are all the target-nodes and target-blocks.
Proof.
Suppose that (we’ll deal with the case when later) and suppose that the distinct target-blocks are , so that the target-blocks all lie in . Furthermore, suppose that for each , the target-block is repeated times in the set of target-blocks. So, . We define that , for if, and only if, and are adjacent to the same node of . Let (where ) be representatives from the resulting equivalence classes (so, ) and let be the node of adjacent to , for . Thus, we immediately obtain paths of length from distinct nodes of to the target-blocks .
For ease of notation, we rename some of the groups of nodes of as so that no target-node lies in any of these groups (note that the number of such groups is and so this is possible). For each and each , choose , and for each and each , choose , so that all chosen nodes are distinct. For each and each , let be the unique node adjacent to , and for each and each , let be the unique node adjacent to .
For each and each , let be the block generated by and , and for each and each , let be the block generated by and . Call the resulting blocks generated the -blocks. In particular, as every -block is adjacent to a different node of , all -blocks are distinct. Moreover, as no target-block is adjacent to the same node of that any -block is adjacent to, every -block is different from every target-block. For each and each , define the path as , and for each and each , define the path as . The paths from the set are clearly internally-disjoint.
Write and suppose that the target-nodes are . Let be distinct nodes of . For each , let be the block generated by and . As above, all such blocks are distinct and different from any block generated so far. For each , define the path as . The resulting set of paths is as required.
Alternatively, if then we dispense with the above construction of paths to target-blocks and proceed identically as regards the target-nodes. The result clearly follows. ∎
Theorem 9.
Let so that . Let be built by the -step method applied to the connected -bipartite graph using the -transversal design . Let be some block of and let be blocks of that are not necessarily distinct but different from . There exists paths from to so that no edge of appears in more than one of these paths.
Proof.
Let be the exact distinct blocks of such that contains the blocks within (in particular, ), and let be the block of such that contains the block within . Let be a tree within that is rooted at and is such that: every block of appears in ; and all leaves of are blocks within . We use the tree as a skeleton so as to build our required paths in .
Call the blocks the -target-blocks. Label every node (resp. block ) in with a non-negative integer (resp. ) detailing the number of -target-blocks that are associated with a block of that is a descendant of (resp. a descendent of or with itself). So, for example, the root is such that and any leaf (block) of is such that is the number of -target-blocks within .
Suppose that is some node of whose children are all leaves (and so blocks). Suppose that w.l.o.g. these children are . For each , by Theorem 8, there exists a set of nodes of the group of nodes of associated with the node of so that there are pairwise internally-disjoint paths from the nodes of to the -target-blocks associated with where each of these paths has length at most (note that the edges of these paths lie in ; of course, the edges of are disjoint from the edges of , for any ). Consequently, we obtain a multi-set of nodes in the group of nodes in associated with the node of so that there are paths in from the nodes of to the -target-blocks associated with the blocks . These paths are pairwise internally-disjoint but they might have common sources.
Suppose that is some non-root block of whose children are w.l.o.g. and so that the following holds:
-
1.
associated with each child is a multi-set of nodes in the group of nodes of associated with the node of
-
2.
for each child , there are paths from the nodes of to the -target-blocks associated with blocks that are descendants of in so that all of these paths have length at most
-
3.
no edge of appears in more than one of the paths that are associated with some child of .
Let be the node of that is the parent of . By Theorem 8, there is a set of nodes in the group of nodes of associated with together with paths from the nodes of to the nodes of in union with the -target-blocks associated with where the paths are pairwise internally-disjoint and each path has length at most . Hence, by concatenating the paths involved, we have paths from the nodes of to the -target-blocks associated with all descendant blocks of in where no edge of appears in more than one of these paths and the length of any of these paths is at most .
Finally, suppose that the children of in are w.l.o.g. and are such that the following holds:
-
1.
associated with each child is a multi-set of nodes in the group of nodes of associated with the node of
-
2.
for each child , there are paths from the nodes of to the -target-blocks associated with blocks that are descendants of in so that all of these paths have length at most
-
3.
no edge of appears in more than one of the paths that are associated with some child of .
By Theorem 6, we obtain paths from to the nodes of in union with the multi-set of blocks associated with so that no edge of appears in more than one of these paths and all paths have length at most . Consequently, by concatenating paths, we obtain paths from to so that no edge of appears in more than one of these paths and the paths have length at most . The result follows by induction. Moreover, it is easy to see that if the depth of is then the length of the longest of these paths is at most . ∎
We have two remarks as regards Theorem 9: first, note the additional bound of on the lengths of the paths derived in the proof of Theorem 9 in terms of the height of the tree ; and, second, this theorem is weaker than Theorem 4 in that in Theorem 9 the paths constructed are pairwise edge-disjoint rather than pairwise internally-disjoint as they are in Theorem 4.
Of course, armed with the constructions of switch-centric DCNs from Section 3.3, it should be clear how we can obtain pairwise edge-disjoint paths joining all the server-nodes adjacent to some level- switch-node in some appropriately constructed DCN to any identically-sized set of distinct server-nodes (irrespective of whether they are adjacent to different level- switch-nodes), so long as the number of server-nodes adjacent to some level- switch-node is no more than the number of level- switch-nodes adjacent to it.
6 Conclusion
In this paper, we have shown how combinatorial design theory can be used to build switch-centric DCNs of diameter at most and with many more server-nodes than the Fat-Tree DCN but so that there is still considerable one-to-one and one-to-many path diversity. We regard the more general demonstration that combinatorial mathematics can enhance the design of modern-day computational infrastructures such as data centres as one of the primary contributions of this paper. Whilst we have demonstrated that combinatorial mathematics has the potential to add to and improve the design of DCNs, the DCNs obtained by our constructions need to be studied in much greater detail with regard to the numerous other properties that a switch-centric DCN has to have in order to make it viable as a practical DCN. For example: although we bound the diameter of our DCNs, we need to derive (optimal) routing algorithms (within bipartite graphs built using the -step method) so as to meet these bounds; and (as was noted in [13], it would be beneficial if the bisection width of the DCNs constructed in this paper could be ascertained (bisection width is often used as a proxy for throughput in DCNs).
Our results also throw up some directions for further research and we mention three such directions now.
It would be interesting to discover more mechanisms for converting bipartite graphs constructed using the -step method into DCNs than those developed in [13] and detailed in Section 3.3. We envisage that such a study would go hand-in-hand with research into building DCNs which possess yet more beneficial properties as regards their efficacy as DCNs (as highlighted above).
As we mention in Section 4.3, our constructions have drawn attention to a hitherto unstudied problem in combinatorics namely the construction of regular, uniform bipartite graphs with additional properties such as having at least internally-disjoint paths joining any two blocks. It would be interesting to study problems such as this in a solely mathematical context.
Our results have hinted that the study of transversal designs as bipartite graphs and in a graph-theoretic context is worth pursuing. For example, if one looks at Theorem 4 then there are pairwise internally-disjoint paths, each of length at most , joining any two distinct blocks in some transversal design ; and if one looks at Theorem 6 then, if , there are pairwise edge-disjoint paths, each of length at most , joining any given source block with any given multi-set of target blocks in some transversal design . Such results might be of independent interest within some appropriate network context. Within a DCN built using the -step method, there are many ‘copies’ of the bipartite graph corresponding to the chosen transversal design. These copies and the above constructions might be utilized where there is traffic localization, e.g., in a virtualization context where many guest DCNs are embedded within the DCN .
References
- [1] D. Abts, M.R. Marty, P.M. Wells, P. Klausler and H. Liu, “Energy Proportional Datacenter Networks”, Proc. of 37th Ann. Int. Symp. on Computer Architecture, 2010, pp. 338–347.
- [2] J.H. Ahn, N. Binkert, A. Davis, M. McLaren and R.S. Schreiber, “HyperX: Topology, Routing, and Packaging of Efficient Large-scale Networks”, Proc. of Conf. on High Performance Computing Networking, Storage and Analysis, 2009, article no. 41.
- [3] M. Al-Fares, A. Loukissas and A. Vahdat, “A Scalable, Commodity Data Center Network Architecture”, SIGCOMM Computer Communication Review, vol. 38, no. 4, 2008, pp. 63–74.
- [4] J.C. Bermond, J. Bond and S. Djelloul, “Dense Bus Networks of Diameter 2”, Proc. Workshop on Interconnection Networks, DIMACS Ser., vol. 21, Annals New York Academy of Sciences, 1995, pp. 9–18.
- [5] C.J. Colbourn, J.H. Dinitz and D.R. Stinson, “Applications of Combinatorial Designs to Communications, Cryptography and Networking”, Surveys in Combinatorics (ed. J.D. Lamb and D.A. Preece), Cambridge University Press, 1999, pp. 37–100.
- [6] J. Dean and S. Ghemawat, “MapReduce: Simplified Data Processing on Large Clusters”, Proc. of 6th Symp. on Operating System Design and Implementation, 2004, pp. 137–150.
- [7] R. Diestel, Graph Theory, Springer, 2010.
- [8] A. Greenberg, J.R. Hamilton, N. Jain, S. Kandula, C. Kim, P. Lahiri, D.A. Maltz, P. Patel and S. Sengupta, “VL2: A Scalable and Flexible Data Center Network”, SIGCOMM Computer Communication Review, vol. 39, no. 4, 2009, pp. 51–62.
- [9] B. Heller, S. Seetharaman, P. Mahadevan, Y. Yiakoumis, P. Sharma, S. Banerjee and N. McKeown, “ElasticTree: Saving Energy in Data Center Networks”, Proc. 7th USENIX Conf. on Networked Systems Design and Implementation”, 2006, pp. 249–264.
- [10] Y. Liu, J.K. Muppala, M. Veeraraghavan, D. Lin and J. Katz, Data Centre Networks: Topologies, Architectures and Fault-Tolerance Characteristics, Springer, 2013.
- [11] M. Miller and J. Siran, “Moore graphs and beyond: a survey of the degree/diameter problem”, Electronic Journal of Combinatorics, vol. 20, no. 2, 2013, article DS14.
- [12] R.N. Mysore, A. Pamboris, N. Farrington, N. Huang, P. Miri, S. Radhakrishnan, V. Subramanya and A. Vahdat, “Portland: A Scalable Fault-tolerant Layer 2 Data Center Network Fabric”, SIGCOMM Computer Communication Review, vol. 39, no. 4, 2009, pp. 39–50.
- [13] G. Qu, Z. Fang, J. Zhang and S.-Q. Zheng, “Switch-centric Data Center Network Structures based on Hypergraphs and Combinatorial Block Designs”, IEEE Transactions on Parallel and Distributed Systems, vol. 26, no. 4, 2015, pp. 1154–1164.
- [14] D.R. Stinson, Combinatorial Designs: Constructions and Analysis, Spring-er, 2004.
- [15] K. Wu, J. Xiao and L.M. Ni, “Rethinking the Architecture Design of Data Center Networks”, Frontiers of Computer Science, vol. 6, no. 5, 2012, pp. 596–603.