On the Optimality of the Kautz-Singleton Construction in Probabilistic Group Testing
Abstract
We consider the probabilistic group testing problem where random defective items in a large population of items are identified with high probability by applying binary tests. It is known that tests are necessary and sufficient to recover the defective set with vanishing probability of error when for some . However, to the best of our knowledge, there is no explicit (deterministic) construction achieving tests in general. In this work, we show that a famous construction introduced by Kautz and Singleton for the combinatorial group testing problem (which is known to be suboptimal for combinatorial group testing for moderate values of ) achieves the order optimal tests in the probabilistic group testing problem when . This provides a strongly explicit construction achieving the order optimal result in the probabilistic group testing setting for a wide range of values of . To prove the order-optimality of Kautz and Singleton’s construction in the probabilistic setting, we provide a novel analysis of the probability of a non-defective item being covered by a random defective set directly, rather than arguing from combinatorial properties of the underlying code, which has been the main approach in the literature. Furthermore, we use a recursive technique to convert this construction into one that can also be efficiently decoded with only a log-log factor increase in the number of tests.
I Introduction
The objective of group testing is to efficiently identify a small set of defective items in a large population of size by performing binary tests on groups of items, as opposed to testing the items individually. A positive test outcome indicates that the group contains at least one defective item. A negative test outcome indicates that all the items in the group are non-defective. When is much smaller than , the defectives can be identified with far fewer than tests.
The original group testing framework was developed in 1943 by Robert Dorfman [1]. Back then, group testing was devised to identify which WWII draftees were infected with syphilis, without having to test them individually. In Dorfman’s application, items represented draftees and tests represented actual blood tests. Over the years, group testing has found numerous applications in fields spanning biology [2], medicine [3], machine learning [4], data analysis [5], signal processing [6], and wireless multiple-access communications [7, 8, 9, 10].
I-A Non-adaptive probabilistic group testing
Group testing strategies can be adaptive, where the test is a function of the outcomes of the previous tests, or non-adaptive, where all tests are designed in one shot. A non-adaptive group testing strategy can be represented by a binary matrix , where indicates that item participates in test . Group testing schemes can also be combinatorial [11, 12] or probabilistic [13, 14, 15, 16, 17, 18, 19, 20].
The goal of combinatorial group testing schemes is to recover any set of up to defective items with zero-error and require at least tests [21, 22]. A strongly explicit construction111We will call a matrix strongly explicit if any column of the matrix can be constructed in time . A matrix will be called explicit if it can be constructed in time . that achieves was introduced by Kautz and Singleton in [23]. A more recent explicit construction achieving was introduced by Porat and Rothschild in [24]. We note that the Kautz-Singleton construction matches the best known lower bound in the regime where for some . However, for moderate values of (e.g., ), the construction introduced by Porat and Rothschild achieving is more efficient and the Kautz-Singleton construction is suboptimal in this regime.
I-B Our contributions
To best of our knowledge, all known probabilistic group testing strategies that achieve tests are randomized (i.e., is randomly constructed) [13, 14, 15, 16, 17, 18, 19, 20]. Recently, Mazumdar [25] presented explicit schemes (deterministic constructions of ) for probabilistic group testing framework. This was done by studying the average and minimum Hamming distances of constant-weight codes (such as Algebraic-Geometric codes) and relating them to the properties of group testing strategies. However, the explicit schemes in [25] achieve , which is not order-optimal when is poly-logarithmic in . It is therefore of interest to find explicit, deterministic schemes that achieve tests.
This paper presents a strongly explicit scheme that achieves in the regime where . We show that Kautz and Singleton’s well-known scheme is order-optimal for probabilistic group testing. This is perhaps surprising because for moderate values of (e.g., ), this scheme is known to be sub-optimal for combinatorial group testing. We prove this result for both the noiseless and noisy (where test outcomes can be flipped at random) settings of probabilistic group testing framework. We prove the order-optimality of Kautz and Singleton’s construction by analyzing the probability of a non-defective item being “covered” (c.f. Section II) by a random defective set directly, rather than arguing from combinatorial properties of the underlying code, which has been the main approach in the literature [23, 24, 25].
We say a group testing scheme, which consists of a group testing strategy (i.e., ) and a decoding rule, achieves probability of error and is efficiently decodable if the decoding rule can identify the defective set in -time complexity with probability of error. While we can achieve the decoding complexity of with the “cover decoder” (c.f. Section II)222Common constructions in group testing literature have density , therefore, the decoding complexity can be brought to ., our goal is to bring the decoding complexity to . To this end, we use a recursive technique inspired by [26] to convert the Kautz-Singleton construction into a strongly explicit construction with tests and decoding complexity . This provides an efficiently decodable scheme with only a log-log factor increase in the number of tests. Searching for order-optimal explicit or randomized constructions that are efficiently decodable remains an open problem.
I-C Outline
The remainder of this paper is organized as follows. In Section II, we present the system model and necessary prerequisites. The optimality of the Kautz-Singleton construction in the probabilistic group testing setting is formally presented in Section III. We propose an efficiently decodable group testing strategy in Section IV. We defer the proofs of the results to their corresponding sections in the appendix. We provide, in Section V, a brief survey of related results on group testing and a detailed comparison with Mazumdar’s recent work in [25]. Finally, we conclude our paper in Section VI with a few interesting open problems.
II System Model and Basic Definitions
For any matrix , we use to refer to its ’th column and to refer to its ’th entry. The support of a column is the set of coordinates where has nonzero entries. For an integer , we denote the set by . The Hamming weight of a column of will be simply referred to as the weight of the column.
We consider a model where there is a random defective set of size among the items . We define as the set of all possible defective sets, i.e., the set of subsets of of cardinality and we let be uniformly distributed over .333This assumption is not critical. Our results carry over to the setting where the defective items are sampled with replacement. The goal is to determine from the binary measurement vector of size taking the form
| (1) |
where measurement matrix indicates which items are included in the test, i.e., if the item is participated in test , is a noise term, and denotes modulo-2 addition. In words, the measurement vector is the Boolean OR combination of the columns of the measurement matrix corresponding to the defective items in a possible noisy fashion. We are interested in both the noiseless and noisy variants of the model in (1). In the noiseless case, we simply consider , i.e., . Note that the randomness in the measurement vector is only due to the random defective set in this case. On the other hand, in the noisy case we consider for some fixed constant , i.e., each measurement is independently flipped with probability .
Given and , a decoding procedure forms an estimate of . The performance measure we consider in this paper is the exact recovery where the average probability of error is given by
and is taken over the realizations of and (in the noisy case). The goal is to minimize the total number of tests while achieving a vanishing probability of error, i.e., satisfying .
II-A Disjunctiveness
We say that a column is covered by a set of columns with if the support of is contained in the union of the supports of columns . A binary matrix is called -disjunct if any column of is not covered by any other columns. The -disjunctiveness property ensures that we can recover any defective set of size with zero error from the measurement vector in the noiseless case. This can be naively done using the cover decoder (also referred as the COMP decoder [15, 17]) which runs in -time. The cover decoder simply scans through the columns of , and returns the ones that are covered by the measurement vector . When is -disjunct, the cover decoder succeeds at identifying all the defective items without any error.
In this work, we are interested in the probabilistic group testing problem where the 0-error condition is relaxed into a vanishing probability of error. Therefore we can relax the -disjunctiveness property. Note that to achieve an arbitrary but fixed average probability of error in the noiseless case, it is sufficient to ensure that at least fraction of all possible defective sets do not cover any other column. A binary matrix satisfying this relaxed form is called an almost disjunct matrix [25, 27, 28, 29] and with this condition one can achieve the desired average probability of error by applying the cover decoder.
II-B Kautz-Singleton Construction
In their work [23], Kautz and Singleton provide a construction of disjunct matrices by converting a Reed-Solomon (RS) code [30] to a binary matrix. We begin with the definition of Reed-Solomon codes.
Definition 1.
Let be a finite field and be distinct elements from . Let . The Reed-Solomon code of dimension over , with evaluation points is defined with the following encoding function. The encoding of a message is the evaluation of the corresponding degree polynomial at all the ’s:
The Kautz-Singleton construction starts with a RS code with and . Each -ary symbol is then replaced by a unit weight binary vector of length , via “identity mapping” which takes a symbol and maps it to the vector in that has a 1 in the ’th position and zero everywhere else. Note that the resulting binary matrix will have tests. An example illustrating the Kautz-Singleton construction is depicted in Figure 1. This construction achieves a -disjunct binary matrix with by choosing the parameter appropriately. While the choice is appropriate for the combinatorial group testing problem, we will shortly see that we need to set in order to achieve the order-optimal result in the probabilistic group testing problem.
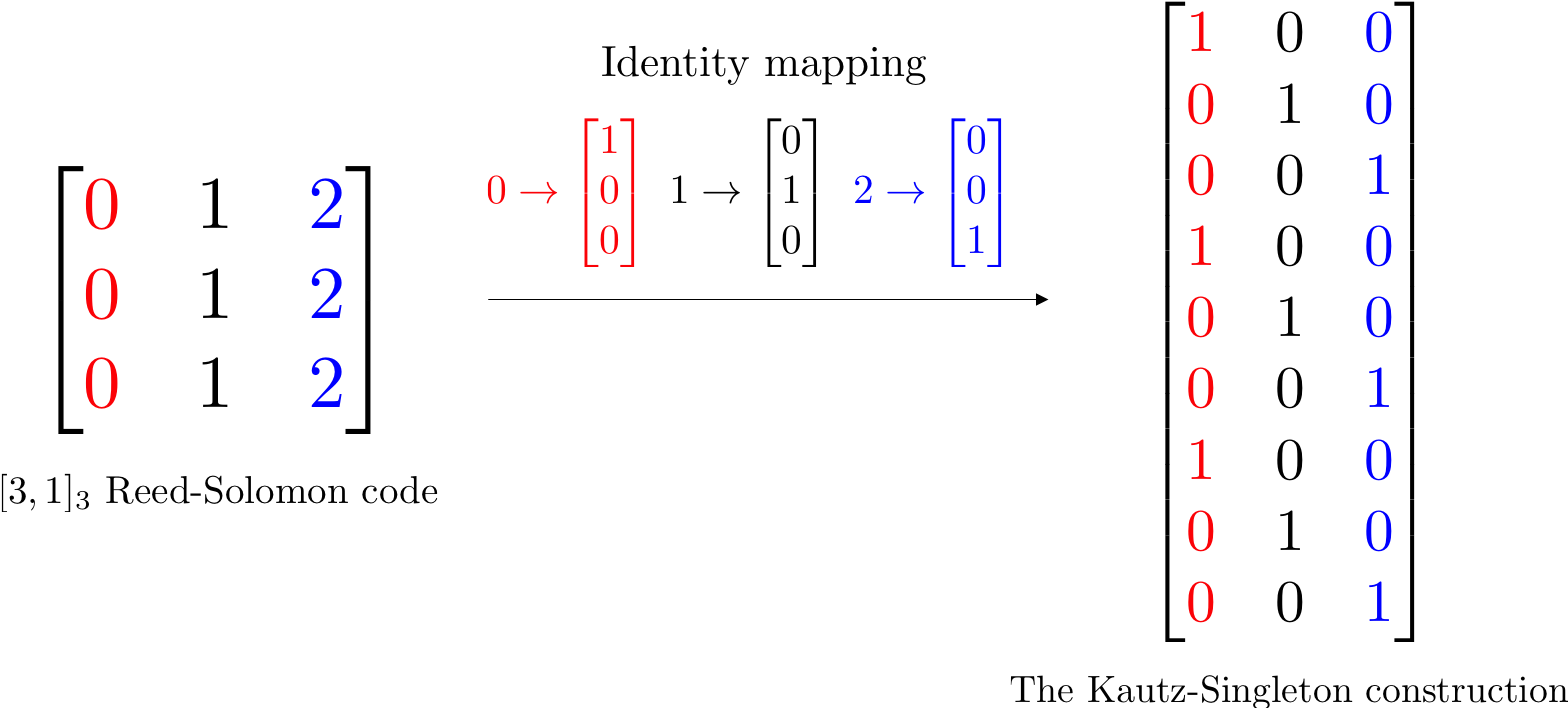
While this is a strongly explicit construction, it is suboptimal for combinatorial group testing in the regime : an explicit construction with smaller (achieving ) is introduced by Porat and Rothschild in [24]. Interestingly, we will show in the next section that this same strongly explicit construction that is suboptimal for combintorial group testing in fact achieves the order-optimal result in both the noiseless and noisy versions of probabilistic group testing.
III Optimality of the Kautz-Singleton construction
We begin with the noiseless case ( in (1)). The next theorem shows the optimality of the Kautz-Singleton construction with properly chosen parameters and .
Theorem 1.
Let . Under the noiseless model introduced in Section II, the Kautz-Singleton construction with parameters for any and has average probability of error under the cover decoder in the regime .
The proof of the above theorem can be found in Appendix -A. We note that the Kautz-Singleton construction in Theorem 1 has tests, therefore, achieving the order-optimal result in the probabilistic group testing problem in the noiseless case. It is further possible to extend this result to the noisy setting where we consider for some fixed constant , i.e., each measurement is independently flipped with probability . Our next theorem shows the optimality of the Kautz-Singleton construction in this case.
Theorem 2.
Let . Under the noisy model introduced in Section II with some fixed noise parameter , the Kautz-Singleton construction with parameters for any and for any has average probability of error under the modified version of cover decoder in the regime .
The proof of the above theorem can be found in Appendix -B. Similar to the noiseless setting, the Kautz-Singleton construction provides a strongly explicit construction achieving optimal number of tests in the noisy case.
Given that the Kautz-Singleton construction achieves a vanishing probability of error with order-optimal number of tests, a natural question of interest is how large the constant is and how the performance of this construction compares to random designs for given finite values of and . To illustrate the empirical performance of the Kautz-Singleton construction in the noiseless case, we provide simulation results in Figure 2 and 3 for different choices of and and compare the results to random designs considered in the literature. We used the code in [31] (see [32] for the associated article) for the Kautz-Singleton construction. For comparison, we take two randomized constructions from the literature, namely the Bernoulli design (see [17]) and the near-constant column weight design studied in [18]. We use the cover decoder for decoding. The simulation results illustrate that the Kautz-Singleton construction achieves better success probability for the same number of tests, which suggests that the implied constant for the Kautz-Singleton construction may be better than those for these random designs; we note that similar empirical findings were observed in [32]. Since the Kautz-Singleton construction additionally has an explicit and simple structure, this construction may be a good choice for designing measurement matrices for probabilistic group testing in practice.
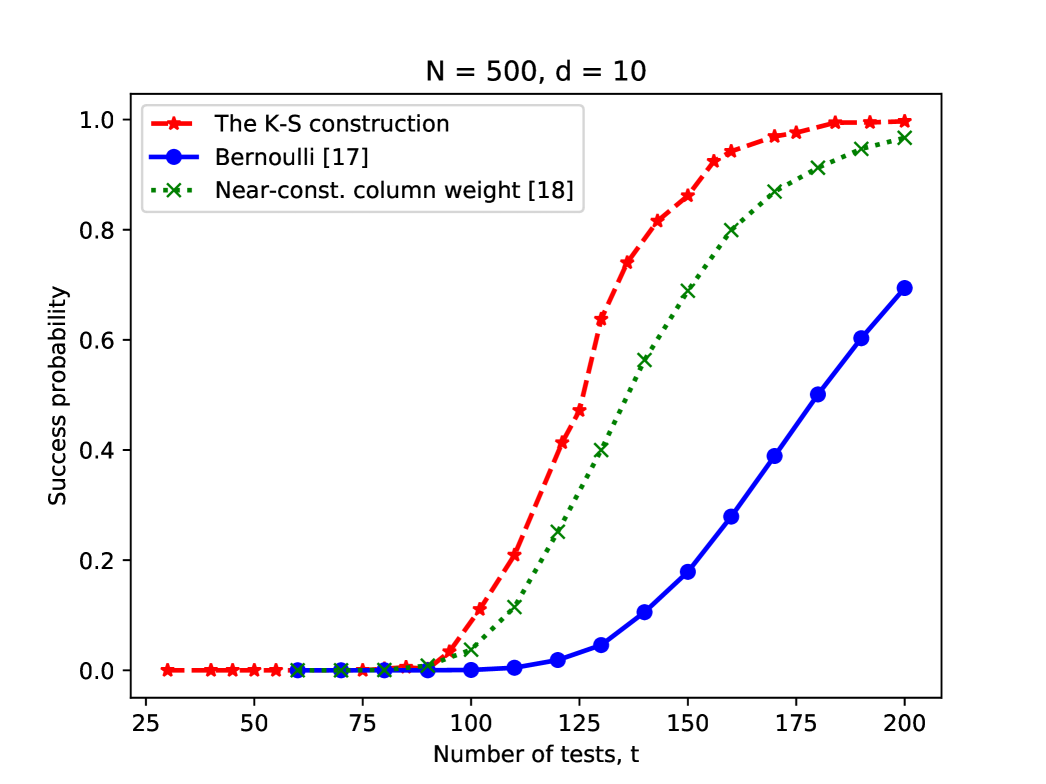
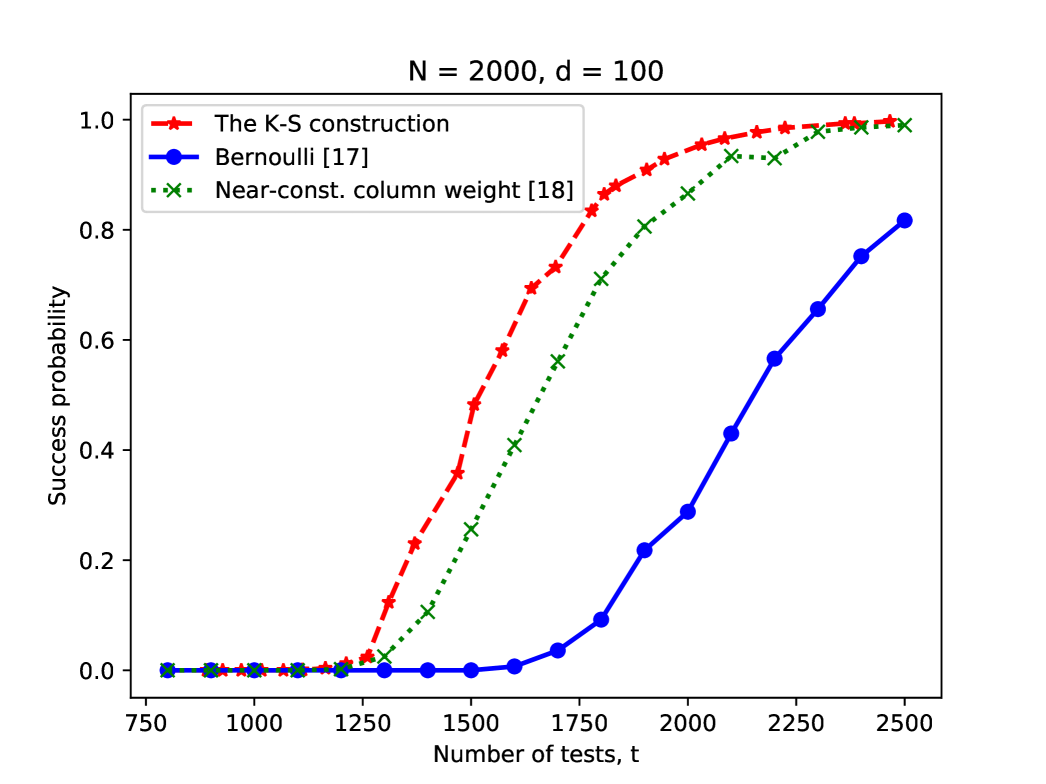
IV Decoding
While the cover decoder, which has a decoding complexity of , might be reasonable for certain applications, there is a recent research effort towards low-complexity decoding schemes due to the emerging applications involving massive datasets [33, 34, 26, 35, 36]. The target is a decoding complexity of . This is an exponential improvement in the running time over the cover decoder for moderate values of . For the model we consider in this work (i.e., exact recovery of the defective set with vanishing probability of error), there is no known efficiently decodable scheme with optimal tests to the best of our knowledge. The work [35] presented a randomized scheme which identifies all the defective items with high probability with tests and time complexity . Another recent result, [36], introduced an algorithm which requires tests with decoding complexity. Note that the decoding complexity reduces to when which is order-optimal (and sub-linear in the number of tests), although the number of tests is not. In both [35] and [36], the number of tests is away from the optimal number of tests by a factor of .
We can convert the strongly explicit constructions in Theorem 1 and 2 into strongly explicit constructions that are also efficiently decodable by using a recursive technique introduced in [26] where the authors construct efficiently decodable error-tolerant list disjunct matrices. For the sake of completeness, we next discuss the main idea applied to our case.
The cover decoder goes through the columns of and decides whether the corresponding item is defective or not. This results in decoding complexity . Assume we were given a superset such that is guaranteed to include the defective set , i.e. , then the cover decoder could run in time over the columns corresponding to , which depending on the size of could result in significantly lower complexity. It turns out that we can construct this small set recursively.
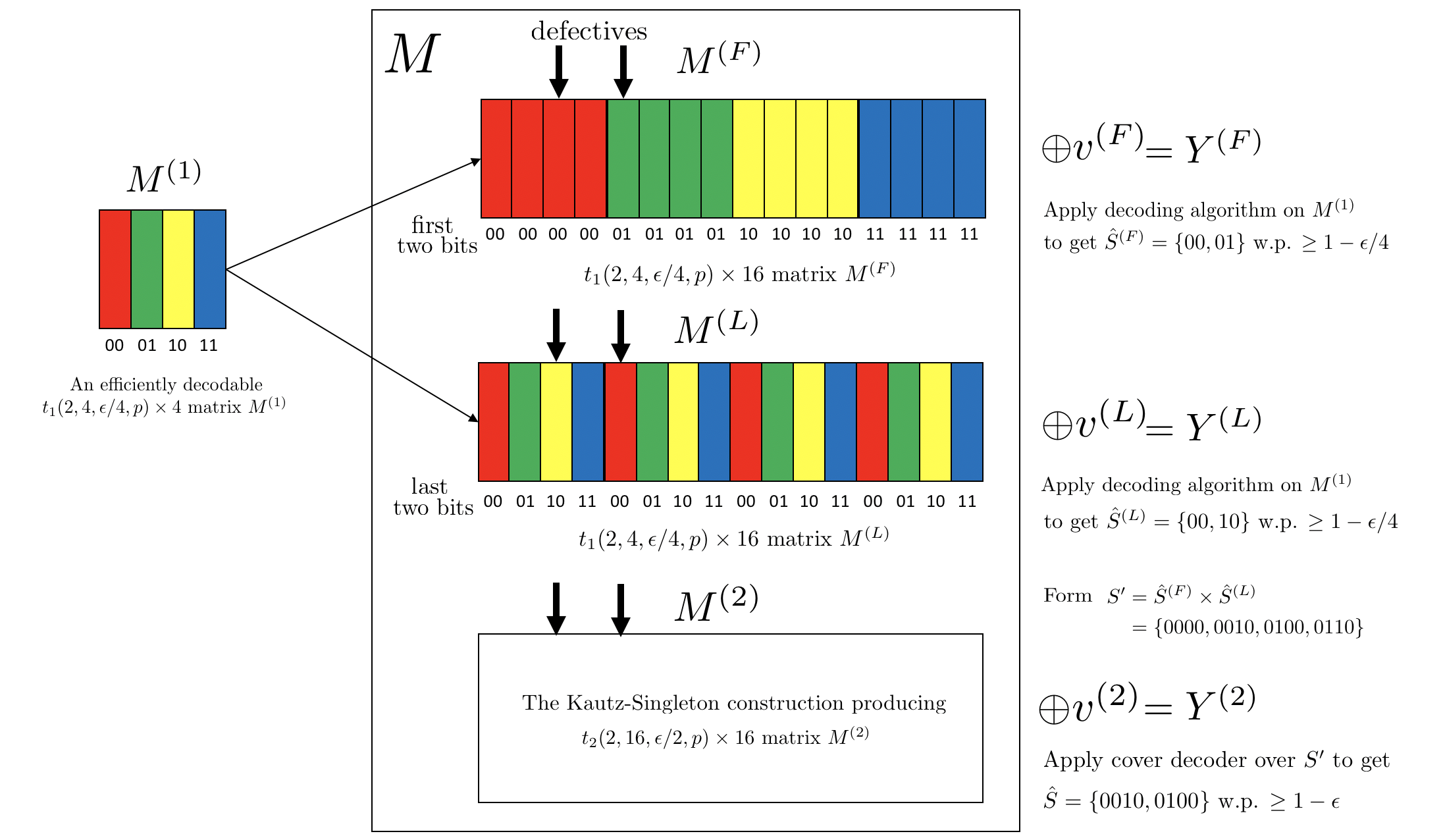
Suppose that we have access to an efficiently decodable matrix which can be used to detect at most defectives among items with probability of error when the noise parameter is by using tests. We construct two matrices and using as follows. For , the ’th column of is equal to ’th column of if the first bits in the binary representation of are given by the binary representation of for . Similarly, for , the ’th columns of is equal to the ’th column of if the last bits in the binary representation of are given by the binary representation of for .
The final matrix matrix is constructed by vertically stacking , and a matrix which is not necessarily efficiently decodable (e.g., the Kautz-Singleton construction). As before, is the number of tests for , which we assume can be used to detect defectives among items with probability of error when the noise parameter is . The decoding works as follows. We obtain the measurement vectors , , and given by , , and respectively where , , and are the noise terms corrupting the corresponding measurements. We next apply the decoding algorithm for to and to obtain the estimate sets and respectively. Note that the sets and can decode the first and last -bits of the defective items respectively with probability at least by the union bound. Therefore, we can construct the set where denotes the Cartesian product and obtain a super set that contains the defective set with error probability at most . We further note that since and , we have . We finally apply the naive cover decoder to by running it over the set to compute the final estimate which can be done in additional time. Note that by the union bound the probability of error is bounded by . Figure 4 illustrates the main idea with the example of and . We provide this decoding scheme in Algorithm 1 for the special case for some non-negative integer although the results hold in the general case and no extra assumption beyond is needed. The next theorem is the result of applying this idea recursively.
Theorem 3.
Under the noiseless/noisy model introduced in Section II, there exists a strongly explicit construction and a decoding rule achieving an arbitrary but fixed average probability of error with number of tests that can be decoded in time in the regime .
The proof of the above theorem can be found in Appendix -C. We note that with only extra factor in the number of tests, the decoding complexity can be brought to the desired complexity. We further note that the number of tests becomes order-optimal in the regime for some . In Table I we provide the results presented in this work along with the related results in the literature.
| Reference | Number of tests | Decoding complexity | Construction |
|---|---|---|---|
| [17, 37] | Randomized | ||
| [25] | Strongly explicit | ||
| [35] | Randomized | ||
| [36] | Randomized | ||
| This work | Strongly explicit | ||
| This work | Strongly explicit |
V Related Work
The literature on the non-adaptive group testing framework includes both explicit and random test designs. We refer the reader to [12] for a survey. In combinatorial group testing, the famous construction introduced by Kautz and Singleton [23] achieves tests matching the best known lower bound [21, 22] in the regime where for some . However, this strongly explicit construction is suboptimal in the regime where . An explicit construction achieving was introduced by Porat and Rothschild in [24]. While is the best known achievability result in combinatorial group testing framework, there is no strongly explicit construction matching it to the best of our knowledge. Regarding efficient decoding, recently Indyk, Ngo and Rudra [34] introduced a randomized construction with tests that could be decoded in time . Furthermore, the construction in [34] can be derandomized in the regime . Later, Ngo, Porat and Rudra [26] removed the constraint on and provided an explicit construction that can be decoded in time . The main idea of [34] was to consider list-disjunct matrices; a similar idea was considered by Cheraghchi in [33], which obtained explicit constructions of non-adaptive group testing schemes that handle noisy tests and return a list of defectives that may include false positives.
There are various schemes relaxing the zero-error criteria in the group testing problem. For instance, the model mentioned above, where the decoder always outputs a small super-set of the defective items, was studied in [33, 38, 39, 40]. These constructions have efficient (-time) decoding algorithms, and so can be used alongside constructions without sublinear time decoding algorithms to speed up decoding. Another framework where the goal is to recover at least a -fraction (for any arbitrarily small ) of the defective set with high probability was studied in [35] where the authors provided a scheme with order-optimal tests and the computational complexity. There are also different versions of the group testing problem in which a test can have more than two outcomes [41, 42] or can be threshold based [43, 44, 45]. More recently, sparse group testing frameworks for both combinatorial and probabilistic settings were studied in [46, 47, 48].
When the defective set is assumed to be uniformly random, it is known that is order-optimal for achieving the exact recovery of the defective set with vanishing probability of error (which is the model considered in this work) in the broad regime for some using random designs and information-theoretical tools [37, 16]. These results also include the noisy variants of the group testing problem. Efficient recovery algorithms with nearly optimal number of tests were introduced recently in [35] and [36]. Regarding deterministic constructions of almost disjunct matrices, recently Mazumdar [25] introduced an analysis connecting the group testing properties with the average Hamming distance between the columns of the measurement matrix and obtained (strongly) explicit constructions with tests. While this result is order-optimal in the regime where for some , it is suboptimal for moderate values of (e.g., ). The performance of the Kautz-Singleton construction in the random model has been studied empirically [32], but we are not aware of any theoretical analysis of it beyond what follows immediately from the distance of Reed-Solomon codes. To the best of our knowledge there is no known explicit/strongly explicit construction achieving tests in general for the noiseless/noisy version of the probabilistic group testing problem.
VI Conclusion
In this work, we showed that the Kautz-Singleton construction is order-optimal in the noiseless and noisy variants of the probabilistic group testing problem. To the best of our knowledge, this is the first (strongly) explicit construction achieving order-optimal number of tests in the probabilistic group testing setting for poly-logarithmic (in ) values of . We provided a novel analysis departing from the classical approaches in the literature that use combinatorial properties of the underlying code. We instead directly explored the probability of a non-defective item being covered by a random defective set using the properties of Reed-Solomon codes in our analysis. Furthermore, by using a recursive technique, we converted the Kautz-Singleton construction into a construction that is also efficiently decodable with only a log-log factor increase in number of tests which provides interesting tradeoffs compared to the existing results in the literature.
There are a number of nontrivial extensions to our work. Firstly, it would be interesting to extend these results to the regime . Another interesting line of work would be to find a deterministic/randomized construction achieving order-optimal tests and is also efficiently decodable.
-A Proof of Theorem 1
Let be the number of items and be the size of the random defective set. We will employ the Kautz-Singleton construction which takes a RS code and replaces each -ary symbol by a unit weight binary vector of length using identity mapping. This corresponds to mapping a symbol to the vector in that has a 1 in the ’th position and zero everywhere else (see Section II-B for the full description). Note that the resulting binary matrix has tests. We shall later see that the choice and is appropriate, therefore, leading to tests.
We note that for any defective set the cover decoder provides an exact recovery given that none of the non-defective items are covered by the defective set. Recall that a column is covered by a set of columns with if the support of is contained in the union of the supports of columns . Note that in the noiseless case the measurement vector is given by the Boolean OR of the columns corresponding to the defective items. Therefore, the measurement vector covers all defective items, and the cover decoder can achieve exact recovery if none of the non-defective items are covered by the measurement vector (or equivalently the defective set).
For , we define as the event that there exists a non-defective column of that is covered by the defective set . Define as the event that the non-defective column () is covered by the defective set . We can bound the probability of error as follows:
| (2) |
where in the last equation is uniformly distributed on the sets of size among the items in and denotes the indicator function of an event.
Fix any distinct elements from . We denote . We note that due to the structure of mapping to the binary vectors in the Kautz-Singleton construction, a column is covered by the random defective set if and only if the corresponding symbols of are contained in the union of symbols of in the RS code for all rows in . Recall that there is a degree polynomial corresponding to each column in the RS code and the corresponding symbols in the column are the evaluation of at . Denoting as the polynomial corresponding to the column , we have
We note that the columns of the RS code contain all possible (at most) degree polynomials, therefore, the set is sweeping through all possible (at most) degree polynomials except the zero polynomial. Therefore, the randomness of that generates the random set can be translated to the random set of polynomials that is generated by picking nonzero polynomials of degree (at most) without replacement. This gives
We define the random polynomial . Note that
We next bound the number of roots of the polynomial . We will use the following result from [49].
Lemma 1 ([49, Lemma 3.9]).
Let denote the set of nonzero polynomials over of degree at most that have exactly distinct roots in . For all powers and integers
Let denote the number of roots of a random nonzero polynomial of degree at most . One can observe that by noting that there is exactly one value of that makes for any fixed and and the inequality is due to excluding the zero polynomial. Furthermore, using Lemma 1, we get
where the first inequality is due to from Lemma 1. Hence we can bound . We denote as the number of roots of the polynomial and as the number of roots of the polynomial . Note that . We will use the following Bernstein concentration bound for sampling without replacement [50]:
Proposition 1 ([50, Proposition 1.4]).
Let be a finite population of points and be a random sample drawn without replacement from . Let and . Then for all ,
where is the mean of and is the variance of .
We apply the inequality above to and obtain
We have , hence, under the regime , the last quantity is bounded by for some constant . Hence the number of roots of the polynomial is bounded by with high probability.
Given the condition that the number of roots of the polynomial is bounded by and the random set of polynomials is picked from the nonzero polynomials of degree at most without replacement, due to the symmetry in the position of the roots of the randomly selected polynomials, we claim that the probability of satisfying for all is bounded by the probability of covering elements from a field of size by picking elements randomly without replacement. We next prove this claim. We define the set and we emphasize that this is not a multiset, i.e., the repeated roots appear as a single element. We begin with the following observation.
Claim 1.
Let , and condition on the event that . Then is uniformly distributed among all sets of size .
Proof.
For , we can write
where is the corresponding multiplicity of the root and does not have any linear factor. We note that this decomposition is unique. For of size , let
Let such that and . Then . Indeed, let be a bijection such that . Then given by
and is a bijection.
We further note that , so
where is due to and we pick uniformly without replacement. ∎
Based on this, if we ensure , then it follows that
Let us fix . We then have
Therefore, is bounded by
Applying the summation over all in (2), we obtain . Therefore, under the regime , the average probability of error can be bounded as by choosing . The condition required in the proof is also satisfied under this regime. Note that the resulting binary matrix has tests.
-B Proof of Theorem 2
We begin with describing the decoding rule. Since we are considering the noisy model, we will slightly modify the cover decoder employed in the noiseless case. For any defective item with codeword weight , in the noiseless outcome the tests in which this item participated will be all positive. On the other hand, when the noise is added, of these tests will flip in expectation. Based on this observation (see No-CoMa in [37] for a more detailed discussion), we consider the following decoding rule. For any item , we first denote as the weight of the corresponding column and as the number of rows where both and . If , then the th item is declared as defective, else it is declared to be non-defective.
Under the aforementioned decoding rule, an error event happens either when for a defective item or for a non-defective item . Using the union bound, we can bound the probability of error as follows:
| (3) | ||||
where we denote the first term of (3) as and the second one as in the last equation. We point out that in the first term of (3) the randomness is both due to the noise and the defective set that is uniformly distributed among the items in whereas in the second term the randomness is due to the noise.
We will employ the Kautz-Singleton construction which takes a RS code and replaces each -ary symbol by unit weight binary vectors of length using identity mapping. This corresponds to mapping a symbol to the vector in that has a 1 in the ’th position and zero everywhere else (see Section II-B for the full description). Note that the resulting binary matrix has tests. We shall later see that the choice and is appropriate, therefore, leading to tests. Fix any distinct elements from . We denote .
We begin with . Fix any defective set in with size and fix an arbitrary element of this set. We first note that due to the structure of the Kautz-Singleton construction. We further note that before the addition of noise the noiseless outcome will have positive entries corresponding to the ones where . Therefore only depends on the number of bit flips due to the noise. Using Hoeffding’s inequality, we have
Summing over the defective items , we get .
We continue with . We fix an item and note that . We similarly define the random polynomial . Let be the event of having at most number of roots. We then have
| (4) |
Following similar steps as in the proof of Theorem 1 we obtain for some constant in the regime .
We next bound the first term in (4). We choose and define the random set . We then have
Let us first bound the second term . We note that
where in the last equality the random set of polynomials is generated by picking nonzero polynomials of degree at most without replacement. This holds since and the columns of the RS code contain all possible (at most) degree polynomials, therefore, the randomness of can be translated to the random set of polynomials that is generated by picking nonzero polynomials of degree (at most) without replacement. Following similar steps of the proof of Theorem 1 we can bound by considering the probability of having at least symbols from when we pick symbols from uniformly at random without replacement. Hence, if we ensure , then we have
where we use in the second inequality.
We continue with . Note that . We further note that
Since we have . Using Hoeffding’s inequality, we have
where the condition or can be satisfied with our choice of free parameter since . Combining everything, we obtain
where in the last step we pick . Therefore, under the regime , the average probability of error can be bounded as by choosing . The condition required in the proof is also satisfied under this regime. Note that the resulting binary matrix has tests.
-C Proof of Theorem 3
We begin with the noiseless case. We will use a recursive approach to obtain an efficiently decodable group testing matrix. Let denote such a matrix with columns in the recursion and denote the matrix with columns obtained by the Kautz-Singleton construction. Note that the final matrix is . Let and denote the number of tests for and respectively to detect at most defectives among columns with average probability of error . We further define to be the decoding time for with rows.
We first consider the case for some non-negative integer . The base case is , i.e., for which we can use individual testing and have and . For , we use matrix to construct two matrices and as follows. The th column of for is identical to all th columns of for if the first bits of is where and are considered as their respective binary representations. Similarly, the th column of for is identical to all th columns of for if the last bits of is . We finally construct that achieves average probability of error and stack , , and to obtain the final matrix . Note that, this construction gives us the following recursion in terms of the number of tests
When , note that and . To solve for , we iterate the recursion as follows.
| (5) | ||||
| (6) |
where in (5) for simplicity we ignore the term in the probability of error for Theorem 1 and take . Replacing and in (6), it follows that
Note that this gives in the case where .
In the more general case, let be the smallest integer such that . It follows that . We can construct from by removing its last columns. We can operate on as if the removed columns were all defective. Therefore the number of tests satisfies .
We next describe the decoding process. We run the decoding algorithm for with the components of the outcome vector corresponding to and to compute the estimate sets and . By induction and the union bound, the set contains all the indices with error probability at most . We further note that . We finally apply the naive cover decoder to the component of corresponding to over the set to compute the final estimate which can be done with an additional time. By the union bound overall probability of error is bounded by . This decoding procedure gives us the following recursion in terms of the decoding complexity
When , to solve for , we iterate the recursion as follows.
| (7) |
where (7) is obtained in the same way as (6). Replacing and in (7), it follows that
Note that this gives in the case where .
The noisy case follows similar lines except the difference is that in the base case where , we cannot use individual testing due to the noise. In this case we can do individual testing with repetitions which requires and . We can proceed similarly as in the noiseless case and show that and .
Acknowledgements
The third author would like to thank Atri Rudra and Hung Ngo for helpful conversations. We thank the anonymous reviewers for helpful comments and suggestions.
References
- [1] R. Dorfman, “The detection of defective members of large populations,” The Annals of Mathematical Statistics, vol. 14, no. 4, pp. 436–440, 1943.
- [2] H-B. Chen and F. K. Hwang, “A survey on nonadaptive group testing algorithms through the angle of decoding,” Journal of Combinatorial Optimization, vol. 15, no. 1, pp. 49–59, 2008.
- [3] A. Ganesan, S. Jaggi, and V. Saligrama, “Learning immune-defectives graph through group tests,” IEEE Transactions on Information Theory, 2017.
- [4] D. Malioutov and K. Varshney, “Exact rule learning via boolean compressed sensing,” in International Conference on Machine Learning, 2013, pp. 765–773.
- [5] A. C. Gilbert, M. A. Iwen, and M. J. Strauss, “Group testing and sparse signal recovery,” in Signals, Systems and Computers, 2008 42nd Asilomar Conference on. IEEE, 2008, pp. 1059–1063.
- [6] A. Emad and O. Milenkovic, “Poisson group testing: A probabilistic model for nonadaptive streaming boolean compressed sensing,” in Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE, 2014, pp. 3335–3339.
- [7] T. Berger, N. Mehravari, D. Towsley, and J. Wolf, “Random multiple-access communication and group testing,” Communications, IEEE Transactions on, vol. 32, no. 7, pp. 769 – 779, jul 1984.
- [8] J. K. Wolf, “Born again group testing: Multiaccess communications,” Information Theory, IEEE Transactions on, vol. 31, no. 2, pp. 185–191, 1985.
- [9] J. Luo and D. Guo, “Neighbor discovery in wireless ad hoc networks based on group testing,” in Communication, Control, and Computing, 2008 46th Annual Allerton Conference on. IEEE, 2008, pp. 791–797.
- [10] A. K. Fletcher, V.K. Goyal, and S. Rangan, “A sparsity detection framework for on-off random access channels,” in Information Theory, 2009. ISIT 2009. IEEE International Symposium on. IEEE, 2009, pp. 169–173.
- [11] H. Q. Ngo and D-Z. Du, “A survey on combinatorial group testing algorithms with applications to dna library screening,” Discrete mathematical problems with medical applications, vol. 55, pp. 171–182, 2000.
- [12] D. Du and F. K. Hwang, Combinatorial group testing and its applications, vol. 12, World Scientific, 2000.
- [13] G. K. Atia and V. Saligrama, “Boolean compressed sensing and noisy group testing,” Information Theory, IEEE Transactions on, vol. 58, no. 3, pp. 1880–1901, 2012.
- [14] D. Sejdinovic and O. Johnson, “Note on noisy group testing: Asymptotic bounds and belief propagation reconstruction,” CoRR, vol. abs/1010.2441, 2010.
- [15] C. L. Chan, P. H. Che, S. Jaggi, and V. Saligrama, “Non-adaptive probabilistic group testing with noisy measurements: Near-optimal bounds with efficient algorithms,” in 2011 49th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Sept 2011, pp. 1832–1839.
- [16] J. Scarlett and V. Cevher, “Phase Transitions in Group Testing,” in ACM-SIAM Symposium on Discrete Algorithms (SODA), 2016.
- [17] M. Aldridge, L. Baldassini, and O. Johnson, “Group testing algorithms: Bounds and simulations,” IEEE Transactions on Information Theory, vol. 60, no. 6, pp. 3671–3687, June 2014.
- [18] O. Johnson, M. Aldridge, and J. Scarlett, “Performance of group testing algorithms with near-constant tests per item,” IEEE Transactions on Information Theory, vol. 65, no. 2, pp. 707–723, Feb 2019.
- [19] J. Scarlett and V. Cevher, “Near-optimal noisy group testing via separate decoding of items,” IEEE Journal of Selected Topics in Signal Processing, vol. 12, no. 5, pp. 902–915, Oct 2018.
- [20] J. Scarlett and O. Johnson, “Noisy Non-Adaptive Group Testing: A (Near-)Definite Defectives Approach,” ArXiv e-prints, Aug. 2018.
- [21] A. G. D’yachkov and V. V. Rykov, “Bounds on the length of disjunctive codes,” Problemy Peredachi Informatsii, vol. 18, no. 3, pp. 7–13, 1982.
- [22] Z. Furedi, “On r-cover-free families,” Journal of Combinatorial Theory, Series A, vol. 73, no. 1, pp. 172–173, 1996.
- [23] W. Kautz and R. Singleton, “Nonrandom binary superimposed codes,” IEEE Transactions on Information Theory, vol. 10, no. 4, pp. 363–377, October 1964.
- [24] E. Porat and A. Rothschild, “Explicit non-adaptive combinatorial group testing schemes,” Automata, Languages and Programming, pp. 748–759, 2008.
- [25] A. Mazumdar, “Nonadaptive group testing with random set of defectives,” IEEE Transactions on Information Theory, vol. 62, no. 12, pp. 7522–7531, Dec 2016.
- [26] H. Q. Ngo, E. Porat, and A. Rudra, “Efficiently decodable error-correcting list disjunct matrices and applications,” in Automata, Languages and Programming, Berlin, Heidelberg, 2011, pp. 557–568, Springer Berlin Heidelberg.
- [27] A. J. Macula, V. V. Rykov, and S. Yekhanin, “Trivial two-stage group testing for complexes using almost disjunct matrices,” Discrete Applied Mathematics, vol. 137, no. 1, pp. 97 – 107, 2004.
- [28] M. B. Malyutov, “The separating property of random matrices,” Math. Notes, vol. 23, no. 1, pp. 84––91, 1978.
- [29] A. Zhigljavsky, “Probabilistic existence theorems in group testing,” J. Statist. Planning Inference, vol. 115, no. 1, pp. 1–43, 2003.
- [30] I. S. Reed and G. Solomon, “Polynomial codes over certain finite fields,” Journal of the Society for Industrial and Applied Mathematics, vol. 8, no. 2, pp. 300–304, 1960.
- [31] Y. Erlich, “Combinatorial pooling using RS codes,” https://github.com/TeamErlich/pooling, 2017.
- [32] Y. Erlich, A. Gilbert, H. Ngo, A. Rudra, N. Thierry-Mieg, M. Wootters, D. Zielinski, and O. Zuk, “Biological screens from linear codes: theory and tools,” bioRxiv, 2015.
- [33] M. Cheraghchi, “Noise-resilient group testing: Limitations and constructions,” in Fundamentals of Computation Theory, Berlin, Heidelberg, 2009, pp. 62–73, Springer Berlin Heidelberg.
- [34] P. Indyk, H. Q. Ngo, and A. Rudra, “Efficiently decodable non-adaptive group testing,” in Proceedings of the Twenty-First Annual ACM-SIAM Symposium on Discrete Algorithms. Society for Industrial and Applied Mathematics, 2010, pp. 1126–1142.
- [35] K. Lee, R. Pedarsani, and K. Ramchandran, “Saffron: A fast, efficient, and robust framework for group testing based on sparse-graph codes,” in Information Theory (ISIT), 2016 IEEE International Symposium on. IEEE, 2016, pp. 2873–2877.
- [36] S. Cai, M. Jahangoshahi, M. Bakshi, and S. Jaggi, “Efficient algorithms for noisy group testing,” IEEE Transactions on Information Theory, vol. 63, no. 4, pp. 2113–2136, April 2017.
- [37] C. L. Chan, S. Jaggi, V. Saligrama, and S. Agnihotri, “Non-adaptive group testing: Explicit bounds and novel algorithms,” IEEE Transactions on Information Theory, vol. 60, no. 5, pp. 3019–3035, May 2014.
- [38] A. G. D’yachkov and V. V. Rykov, “A survey of superimposed code theory,” Problems Control Inform. Theory/Problemy Upravlen. Teor. Inform., vol. 12, pp. 229–242, 1983.
- [39] A. De Bonis., L. Gasieniec, and U. Vaccaro, “Optimal two-stage algorithms for group testing problems,” SIAM J. Comput., vol. 34, no. 5, pp. 1253–1270, 2005.
- [40] A. M. Rashad, “Random coding bounds on the rate for list-decoding superimposed codes,” Problems Control Inform. Theory/Problemy Upravlen. Teor. Inform., vol. 19(2), pp. 141–149, 1990.
- [41] M. Sobel, S. Kumar, and S. Blumenthal, “Symmetric binomial group-testing with three outcomes,” in Proc. Purdue Symp. Decision Procedure, 1971, pp. 119–160.
- [42] F. Hwang, “Three versions of a group testing game,” SIAM Journal on Algebraic Discrete Methods, vol. 5, no. 2, pp. 145–153, 1984.
- [43] H-B. Chen and H-L. Fu, “Nonadaptive algorithms for threshold group testing,” Discrete Applied Mathematics, vol. 157, no. 7, pp. 1581 – 1585, 2009.
- [44] M. Cheraghchi, “Improved constructions for non-adaptive threshold group testing,” CoRR, vol. abs/1002.2244, 2010.
- [45] T. V. Bui, M. Kuribayashi, M. Cheraghchi, and I. Echizen, “Efficiently decodable non-adaptive threshold group testing,” CoRR, vol. abs/1712.07509, 2017.
- [46] H. A. Inan, P. Kairouz, and A. Ozgur, “Sparse group testing codes for low-energy massive random access,” in 2017 55th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Oct 2017, pp. 658–665.
- [47] V. Gandikota, E. Grigorescu, S. Jaggi, and S. Zhou, “Nearly optimal sparse group testing,” in 2016 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Sept 2016, pp. 401–408.
- [48] H. A. Inan, P. Kairouz, and A. Ozgur, “Energy-limited massive random access via noisy group testing,” in Information Theory (ISIT), 2018 IEEE International Symposium on. IEEE, 2018, pp. 1101–1105.
- [49] T. Hartman and R. Raz, “On the distribution of the number of roots of polynomials and explicit weak designs,” Random Structures & Algorithms, vol. 23, no. 3, pp. 235–263, 2003.
- [50] R. Bardenet and O-A. Maillard, “Concentration inequalities for sampling without replacement,” Bernoulli, vol. 21, no. 3, pp. 1361–1385, 08 2015.