On the Robustness and Anomaly Detection of Sparse Neural Networks
Abstract
The robustness and anomaly detection capability of neural networks are crucial topics for their safe adoption in the real-world. Moreover, the over-parameterization of recent networks comes with high computational costs and raises questions about its influence on robustness and anomaly detection. In this work, we show that sparsity can make networks more robust and better anomaly detectors. To motivate this even further, we show that a pre-trained neural network contains, within its parameter space, sparse subnetworks that are better at these tasks without any further training. We also show that structured sparsity greatly helps in reducing the complexity of expensive robustness and detection methods, while maintaining or even improving their results on these tasks. Finally, we introduce a new method, SensNorm, which uses the sensitivity of weights derived from an appropriate pruning method to detect anomalous samples in the input.
1 Introduction
With the need to deploy Machine Learning (ML) models in real-life systems such as autonomous vehicles, medical diagnosis, online fraud detection etc., building safe and reliable ML pipelines has become more critical than ever. However, there exist three well-known cases of changes to the in-distribution data – or anomalies – to which models are known to be brittle: adversarial attacks (AA), which are intentionally crafted but imperceptible perturbations that can fool a classifier Goodfellow et al. (2014); distribution shifts (DS), which are naturally occurring perturbations that can also change the model’s output Hendrycks & Dietterich (2019); and out-of-distribution (OOD) samples which come from an entirely different distribution, and that can surprisingly lead to highly confident but wrong predictions Hendrycks & Gimpel (2016). This latter case is notoriously known for generative models, which tend to assign higher likelihoods to samples coming from a distribution that they have not been trained on Nalisnick et al. (2018).
In an orthogonal line of work, Neural Networks (NN) are also known to be highly over-parameterized, which is made evident by the existence of sparse subnetworks that achieve the same accuracy performance as their dense counter-part Han et al. (2015). To find these subnetworks, many works have derived pruning criteria that assign scores to weights, and prune those with the lowest values Lee et al. (2018); Wang et al. (2020). However, the algorithms that attempt to find these subnetworks rarely evaluate them on other challenging tasks such as robustness and anomaly detection.
In this paper, we show that pruning can benefit robustness and anomaly detection by tackling the following four questions: 1) How does sparsity affect various properties of networks, beyond test accuracy? (Sec. 3), 2) Can we find sparse subnetworks within pre-trained dense networks that achieve better robustness and detection? (Sec. 4), 3) Can sparsity benefit tasks beyond deterministic single-network classification such as ensembles, Bayesian NN and generative models? (Sec. 5), and 4) Are pruning criteria useful for the detection of anomalies in the input? (Sec. 6) 111Project page including code at https://www.cs.cit.tum.de/daml/uncertainty-snn/
2 Related Work
Sparse Networks. Pruning can be performed either before training a model Lee et al. (2018); Wang et al. (2020), early in training Rachwan et al. (2022); You et al. (2020), or after the model has been fully trained Frankle et al. (2020a, b); LeCun et al. (1990); Morcos et al. (2019). It can be done either in an unstructured Nalisnick et al. (2018); Wang et al. (2020); Frankle et al. (2020a) or a structured manner Rachwan et al. (2022); Li et al. (2016); You et al. (2019), where unstructured pruning removes weights by setting them to 0 whereas structured pruning removes entire neurons or filters by reducing the size of the weight matrices involved. Additionally, pruning can be done globally Rachwan et al. (2022); Lee et al. (2018); Wang et al. (2020); Frankle et al. (2020a) or locally Ramanujan et al. (2020), where global pruning automatically decides how much to prune from each layer when given a desired total sparsity, whereas local pruning prunes the same percentage of weights at every layer. Unless otherwise specified, we use global pruning throughout the paper. We briefly introduce the 8 pruning algorithms we use in this paper:
Pruning Before Training.
SNIP Lee et al. (2018): A sensitivity-based pruning method (i.e. it scores weights based on their sensitivity to a certain metric) that aims at preserving the loss function. The score used is: , where is the loss and the weight.
GRASP Wang et al. (2020): A sensitivity-based pruning method that aims at increasing the gradient flow. The final score is: , where H denotes the Hessian.
CroPit Rachwan et al. (2022): A sensitivity-based pruning method that aims at preserving the gradient flow. The final score is: , where H denotes the Hessian. We also use its structured version CroPit-S.
Edge-popup Ramanujan et al. (2020): An optimization-based method that aims at finding sparse network by optimizing the mask directly instead of the weights. The sparse model is not trained further.
Pruning During Training.
IMP Frankle et al. (2020a): An iterative-based pruning method that prunes the smallest weights first. It goes through multiple train-prune-rewind cycles until it reaches its desired sparsity, where "rewind" corresponds to resetting the values of the remaining weights after each pruning phase to their value at an early point in training.
EarlyCroP: CroPit performed early in training instead of before training.
Pruning After Training.
SNIP-After: SNIP applied on a fully trained network.
Edge-popup-After: Edge-popup applied on a fully trained network instead of randomly initialized one.
Robustness and Anomaly Detection of Networks. While NN are constantly improving in terms of accuracy or generative capability, their weak robustness and anomaly detection pose challenges to their safe deployment in the real world Shafaei et al. (2018). Classifiers have shown to be un-calibrated, i.e. assign high confidence to wrong predictions, and works have tried to improve existing models Hendrycks et al. (2018); Liu et al. (2020); Huang et al. (2021) or come up with new methods that focus solely on the detection of anomalous inputs Tack et al. (2020). Generative models that can compute the log-likelihood of inputs have also been shown to assign higher likelihood to anomalous samples Nalisnick et al. (2018), leading to another body of works that attempts to understand and solve this problem Schirrmeister et al. (2020). Note that, unless otherwise specified, we use the common baseline Maximum-Softmax-Probability (MSP) Hendrycks & Gimpel (2016) to compute the AUC-ROC scores throughout the paper, which uses the predicted probability of an input as the confidence.
Robustness and Anomaly Detection of Sparse Networks. With the growing interest in sparsity of deep NN, the literature started addressing the question of whether sparse models would have different properties than their dense counterparts, beyond their test accuracy. Some works argue that an appropriate level of sparsity can improve robustness of models either to adversarial attacks Guo et al. (2018) or to distribution shifts Diffenderfer et al. (2021), while others argue the contrary Verdenius et al. (2020); Liebenwein et al. (2021). Another body of works focuses on simultaneously optimizing for high accuracy, robustness and sparsity by incorporating objectives that promote the latter two during training Madaan et al. (2020); Zhang et al. (2021); Sehwag et al. (2020). In contrast, we do not directly optimize weights for the tasks of robustness and detection, but evaluate the effect of existing sparsity methods on these tasks and propose new ways to take advantage of them.
3 Properties of Sparse Classification Networks
We start by addressing the question: How does sparsity affect various properties of networks, beyond test accuracy? Our goal is to give a comprehensive view on the effect of pruning on robustness to and detection of anomalies. We therefore evaluate models pruned with 8 different pruning algorithms, and make the distinction between pruning before, during or after training. Indeed, we expect the pruning time to affect the set of weights being preserved, and therefore their final performance on new tasks.
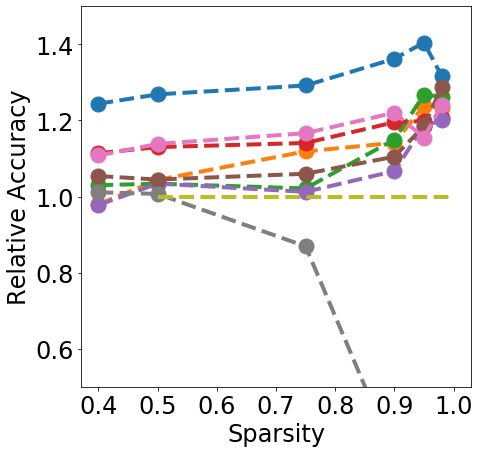
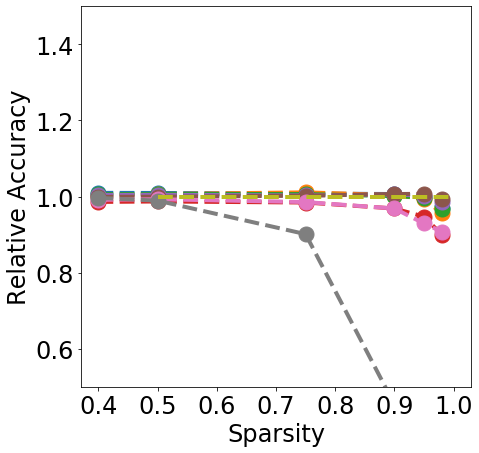
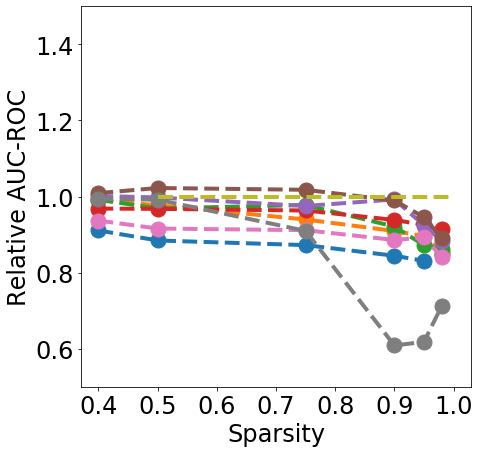
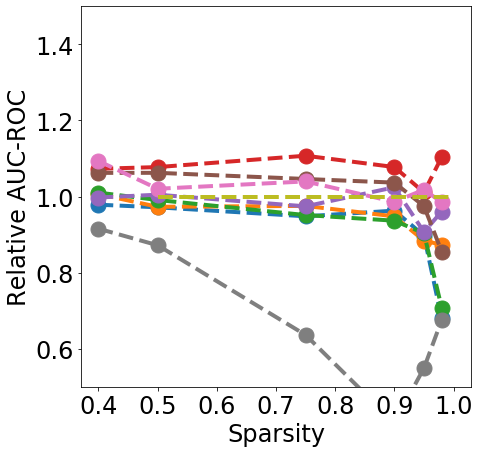
Setup. We train ResNet18 models on the CIFAR10 dataset. We use L- and L-2 FGSM attacks with , CIFAR10C as the DS dataset, and SVHN and CIFAR100 as the OOD datasets. We report relative accuracy (i.e. normalized with respect to the dense model) and relative AUC-ROC on attacks and shifts, and relative Brier score and relative AUC-ROC on OOD datasets. All models are trained with 3 different seeds and their average performance is reported.

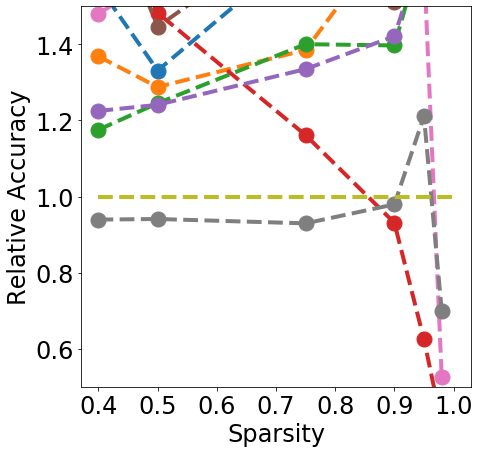
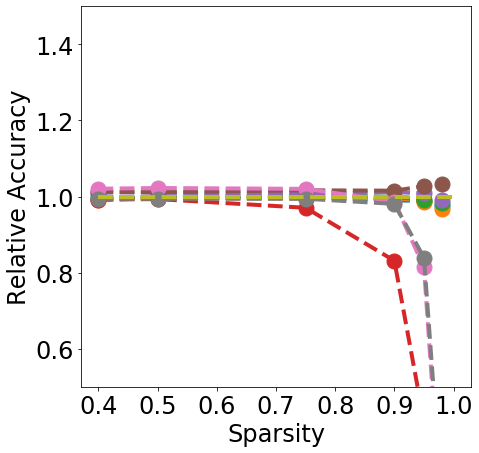
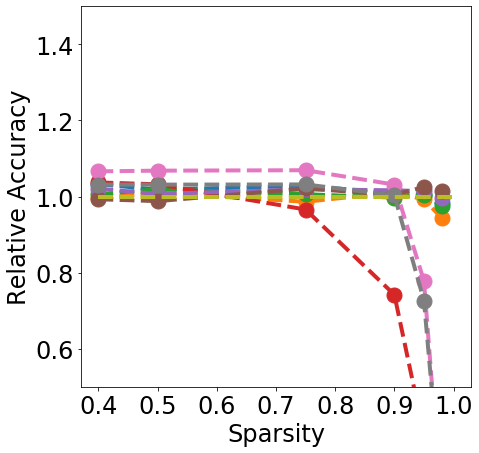
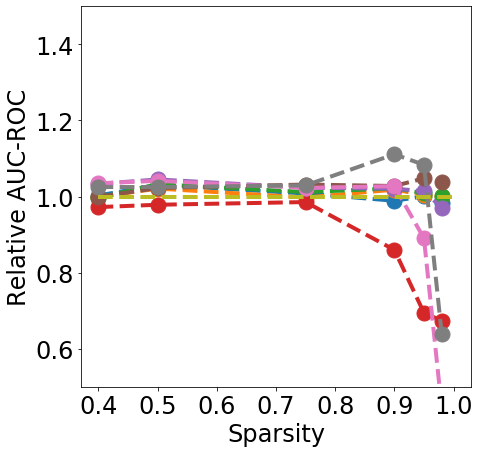

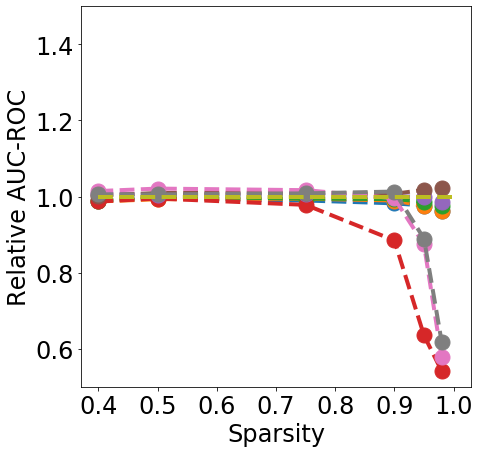
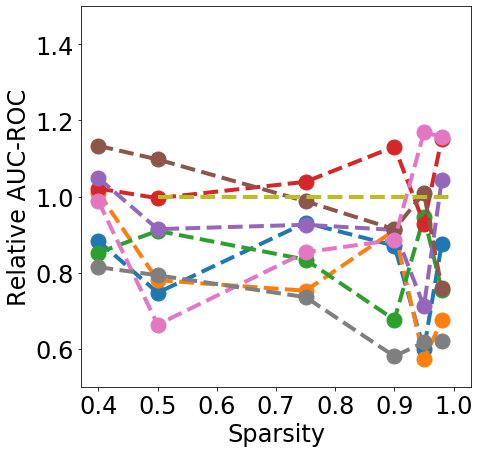
Discussion. Fig. 1 clearly shows that almost all pruning methods improve the robustness to L- FGSM attacks (a), but not to L-2 FGSM attacks (b). Indeed, the relation between L- and sparsity has already been discussed in Guo et al. (2018), and works such as Verdenius et al. (2020) have reported a decrease of robustness on L-2 based attacks such as Carlini-Wagner Carlini & Wagner (2017). We also observe that most methods maintain the robustness to DS (c), with During-Training methods performing slightly better than Before-Training methods at high sparsity.
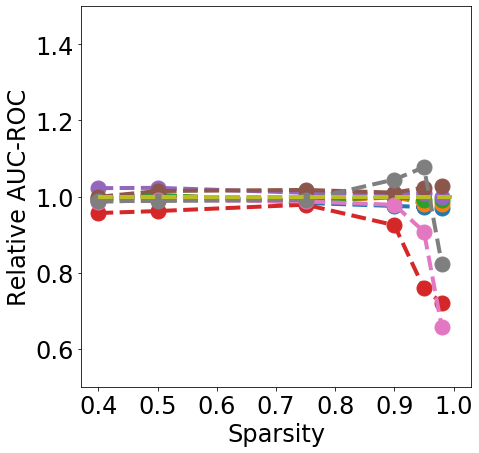
In terms of detection, Fig. 2 shows that generally all methods except Edge-popup can maintain the AUC-ROC on DS. SNIP-After also appears to provide better improvements at an appropriate sparsity than the remaining methods.
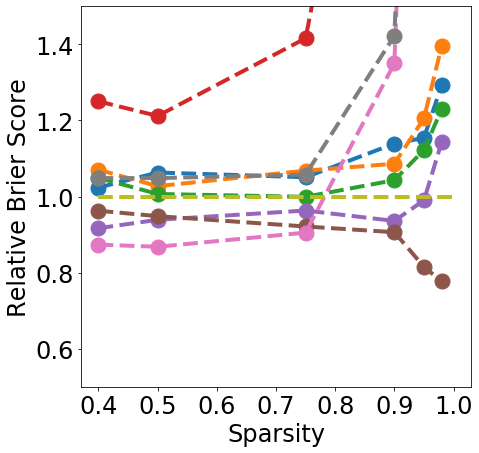
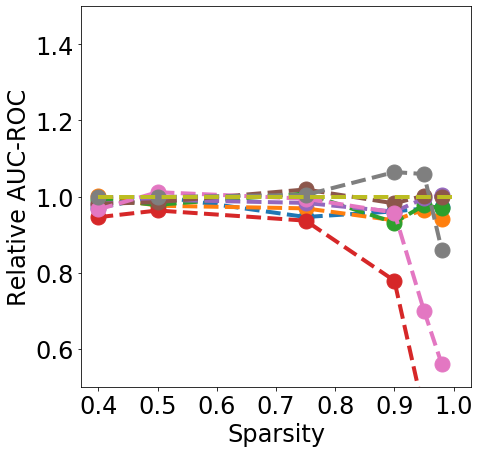
Finally, from Fig. 3 we can see that During or After-Training pruning methods perform better than the dense model in terms of Brier score (a) up until 90% sparsity, but only IMP does so at even higher sparsity. Generally all methods, except Edge-popup, can also maintain the AUC-ROC on the OOD datasets SVHN (b) and CIFAR100 (c). We report additional metrics and results on LeNet5 in App. C.
4 Finding robust subnetworks within non-robust dense networks
Next, we address the question: Can we find (sparse) sub-networks within dense pre-trained networks that achieve better robustness and detection? This question has been briefly tackled by Sehwag et al. (2020), but they only evaluated the robustness of the sparse models to adversarial attacks, while we aim to evaluate their robustness to both adversarial attacks and distribution shifts, as well as their OOD detection capability.
Setup. We train ResNet18 models on CIFAR10, and report the accuracy and AUC-ROC on FGSM attacks with and on CIFAR10C, as well as the AUC-ROC on SVHN. Similarly to Sehwag et al. (2020), we use the Edge-popup algorithm, which trains a mask over the weights instead of the weights themselves (App. B). However instead of using the standard cross-entropy objective , we augment the objective depending on the task we are trying to solve. In the following, refers to a clean batch, to its ground-truth labels, and to the model:
Adversarial Attacks: , with with the adversarial attack of , and the KL divergence between the predictions on and . The second term in ensures that the predictions on and do not deviate too much. We use .
Distribution Shifts: , with being a clean batch perturbed with gaussian noise. Indeed, training a model on clean inputs perturbed with gaussian noise can lead to a model more robust to natural perturbations Diffenderfer et al. (2021).
OOD Detection: , with being an OOD batch and a matrix of uniform distributions. The second term in ensures the predictions on OOD samples are as close as possible to (maximum uncertainty).
| Accuracy FGSM 8 | AUC-ROC FGSM 8 | AUC-ROC SVHN | Accuracy CIFAR10C | AUC-ROC CIFAR10C | |
| Dense | 19.9% | 79.5% | 90.3% | 66.2% | 68.4% |
| Edge-popup - AA Objective | 72.9% | 53.8% | 77.6% | 68.8% | 57.3% |
| Edge-popup - OOD Objective | 60.2% | 64.7% | 99.7% | 64.5% | 67.3% |
| Edge-popup - DS Objective | 64.4% | 56.7% | 78.0% | 70.0% | 54.5% |
Discussion. In Tab. 1, we report the metrics of interest for the three objectives on Edge-popup and compare to the original dense model. Each objective improves its corresponding metric the most, but sometimes also benefits others. For example, training on the OOD objective significantly improves the accuracy on FGSM attacks, a correlation which has already been noted in the literature Lee et al. (2020). This experiment shows that subnetworks that achieve much better performance on a certain objective do exist wihtin a pre-trained dense network. This suggests that dense networks focus on non-robust features as was shown in Ilyas et al. (2019), possibly due to their over-parameterization, and pruning eliminates some weights that focus on these features.
5 The Effect of Sparsity Beyond Single-Network Classification
In this section, we investigate the effect of sparsity on existing methods that improve the robustness or detection capability of networks, and try to answer the question: Can sparsity benefit tasks beyond deterministic single-network classification? We examine ensembles, Bayesian neural networks and generative models.
Ensembles. One popular method to improve robustness and calibration of classifiers is ensembles. It consists of training multiple networks independently, and then averaging their outputs to obtain more calibrated predictions Lakshminarayanan et al. (2016). Ensembles have been shown to be among the most calibrated methods against distribution shifts Ovadia et al. (2019). However, one major drawback is the expensive nature of this method, both in terms of memory and time. Structured pruning helps in overcoming both of these drawbacks, since it removes entire neurons and channels from the architecture, thereby reducing the training and inference time, but also the space complexity. For this experiment, we use the large model AlexNet trained on CIFAR10, and compare a single dense model and an ensemble of 5 dense models to an ensemble of 5 models pruned to 80% node sparsity each. We can see from Tab. 2 that the sparse ensemble reaches almost the same test accuracy as the dense ensemble, matches it in terms of AUC-ROC on SVHN, and is much more efficient than the dense ensemble in terms of training and inference time, and GPU RAM usage.
|
Test
Accuracy |
AUC-ROC SVHN | Training Time | Inference Time | RAM | |
| Dense - Deterministic | 85% | 83% | x1 | x1 | x1 |
| Dense - Ensemble | 90% | 89% | x5 | x4.8 | x5 |
| CroPit-S - Ensemble | 88.4% | 89% | x2.7 | x3.8 | x0.42 |
Bayesian Neural Networks. Bayesian NN also fall into the category of expensive uncertainty methods. They are both slower to train and infer on, and more memory intensive since they often require to learn more parameters than a dense model. To illustrate the potential of sparsity in such tasks, we turn our attention to the popular method presented in Blundell et al. (2015). It consists of learning both a mean and a standard deviation for each weight in the network. At test time, we sample a value for each weight when doing an inference, and repeat the process multiple times to obtain multiple predictions, similar to ensembles. This work suggests to remove weights with a low Signal-to-Noise Ratio (SNR) , but only evaluates the pruned model on the final accuracy. SNR is an intuitive pruning criterion, since it encourages the removal of weights with small means (similar to IMP which removes weights close to 0), and high standard deviation which indicates the uncertainty of the model and therefore the vulnerability of this weight to changes in the input. We extend this criterion to a structured one by simply summing the scores at each activation, which we call SNR-S, to take advantage of the removal of structures to achieve faster training and inference time. We train a dense Conv6 model on CIFAR10, a deterministic one, and two SNR-S models where pruning is done either during or after training. From Tab. 3, we observe that both versions of Bayesian SNR-S achieve better accuracy than the dense Bayesian, and SNR-S After achieves even better AUC-ROC than both dense models, while being more efficient than the dense Bayesian model.
| Test Accuracy | AUROC SVHN | Inference Time | |
|---|---|---|---|
| Dense - Deterministic | 0.874 | 0.834 | x1 |
| Dense - Bayesian | 0.864 | 0.873 | x2.6 |
| SNR-S (After) - Bayesian | 0.865 | 0.883 | x1.6 |
| SNR-S (During) - Bayesian | 0.871 | 0.882 | x1.6 |
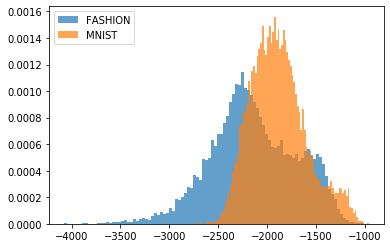
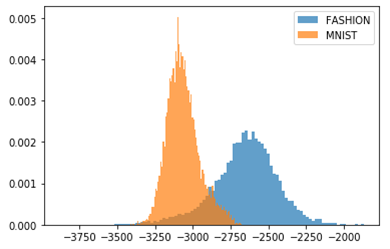
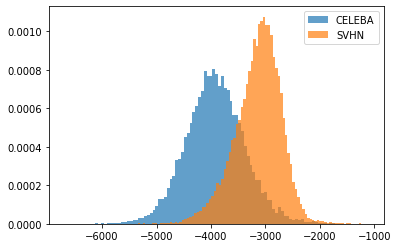
Generative Models. Sparsity in generative models has recently started to gain attention in the literature Kalibhat et al. (2020). However, to the best of our knowledge, its effect on OOD detection has not been investigated yet. Generative models, some of which are capable of computing the log-likelihood of input samples, are known for their counter-intuitive behavior on OOD samples: they assign higher likelihood to OOD samples than to their own training/testing in-distribution samples. In this experiment, starting with the pre-trained generative model Glow Kingma & Dhariwal (2018), we prune it using EarlyCroP locally. We observe that, in the FashionMNIST-MNIST combination, pruning greatly helps in better distinguishing the two types of datasets and correctly assign lower likelihoods to OOD samples. However, when moving to more complex cases (CIFAR10-SVHN or CELEBA-SVHN), we do not observe the same behavior. Nevertheless, the success on the FashionMNIST-MNIST combination encourages further exploration of the benefits of sparsity in generative models. Note that local pruning plays a crucial role here, as global pruning did not result in the same behavior on FashionMNIST. One possible explanation for this is that local pruning creates more bottlenecks in the network, which has been shown to help in OOD detection Kirichenko et al. (2020).
6 SensNorm - Detecting Anomalies Through Weight Sensitivity
We finally address the question: Are pruning criteria useful for the detection of anomalies in the inputs? Some pruning methods that operate before training have been shown to be independent of the batch being used to score the weights Su et al. (2020). This means that the weights being pruned and the final structure of the network do not depend much on the current task/dataset of interest. However, methods operating during training are believed to use information from the batch to keep the most important weights for the given task Su et al. (2020). Note that this applies to methods that use a sensitivity criterion, i.e. that assign a score to each weight (unlike IMP). Since pruning based on one or more batches will preserve the weights that are relevant for these batches, pruning based on batches that contain anomalies will attempt to preserve a different set of weights. Based on these observations, our key idea is to detect anomalies by measuring the distance between the sensitivity of weights on in-distribution (training) data, and that of each incoming test batch. Intuitively, the larger the distance the more likely the input batch contains anomalous samples.
Method. More formally, we are given a pre-trained model with weights , a train dataset , a test dataset , and a sensitivity scoring function where indicates one or more batches used to get the weights’ sensitivity. We first compute the sensitivity of weights on the training data by going through all training batches and accumulating the gradients. We also save the element-wise standard deviation over all batches . At test time, for every incoming batch , we compute . Finally, we compute the distance , where is the L-norm (in practice we use ). If , where is some pre-defined threshold, then is an anomalous batch; otherwise, it is an in-distribution batch. We refer to our method as SensNorm.
We rely on the SNIP score as our sensitivity score, since its purpose is to preserve the loss of the task at hand. However, we find that dropping the absolute value helps in achieving better performance. Indeed, the sign of a score in SNIP indicates whether a certain weight was increasing or decreasing the loss, which can help distinguish in-distribution from anomalous batches. We also standardize the test batch scores by their mean and standard deviation computed on the training data, so as to reduce the contribution of the weights that are highly variable on the in-distribution data itself. Our weight sensitivity function is therefore:
| (1) |
Discussion. Our method naturally lends itself to batch detection, but can also be applied for single-input prediction. Tab. 4 shows that, with 100 samples, our method can detect all types of inputs easily, and their detection remains high until a batch of size 5. The challenge arises for batches of size 2 and 1, since gradients will be very noisy for these cases. We therefore rely on augmentations to gain more information from the input sample (App. A). Note that, while originally conceived for detecting batches, SensNorm still outperforms MSP on batch size 1. We also compare our results to GradNorm, which uses gradient norms to detect anomalies, and find that SensNorm matches it or even outperforms it on small batch sizes.
| SVHN | CIFAR100 | FGSM | DS | OODom. | ||
| Batch size 100 | MSP | 100% | 100% | 100% | 98.7% | 51.3% |
| GradNorm | 100% | 100% | 99.8% | 91.9% | 33.3% | |
| SensNorm | 100% | 100% | 100% | 99.9% | 100% | |
| Batch size 5 | MSP | 98.5% | 92.7% | 87.7% | 84.5% | 50.8% |
| GradNorm | 99.8% | 98.6% | 94.9% | 92.3% | 32.9% | |
| SensNorm | 99.9% | 99.2% | 98.8% | 96.5% | 100% | |
| Batch size 2 | MSP | 92.2% | 85.5% | 81.2% | 79.1% | 51.6% |
| GradNorm | 98.8% | 92.9% | 88.3% | 87.0% | 33.1% | |
| SensNorm | 97.3% | 91.0% | 87.7% | 87.3% | 100% | |
| Batch size 1 | MSP | 90.3% | 83.3% | 79.5% | 77.1% | 53.4% |
| GradNorm | 96.7% | 85.2% | 80.4% | 81.0% | 33.0% | |
| SensNorm | 93.7% | 85.2% | 80.6% | 79.0% | 100% |
7 Conclusion
In conclusion, we show that the topics of pruning, robustness and detection are closely intertwined. First, most pruning algorithms can maintain the original uncertainty of the dense model on AA, DS and OOD. All pruning methods also greatly improve the accuracy to L- FGSM attacks, but not to the L- based attacks. Pruning methods that operate during training (i.e. EarlyCroP and IMP) often offer the best trade-off between good test performance and maintaining or even improving robustness and detection metrics. Second, we show that it is possible to find subnetworks within pre-trained dense networks that perform better than the original models in terms of robustness and detection. Third, we find that pruning can be beneficial in tasks such as ensembles, Bayesian NN and generative models, especially in terms of efficiency for the expensive uncertainty estimation methods. Finally, we introduce SensNorm, a new method for detecting batches of anomalous samples. SensNorm shows that weight sensitivity is a good indicator of the presence of anomalies in the input.
References
- Benton et al. (2020) Benton, G., Finzi, M., Izmailov, P., and Wilson, A. G. Learning invariances in neural networks. arXiv preprint arXiv:2010.11882, 2020.
- Blundell et al. (2015) Blundell, C., Cornebise, J., Kavukcuoglu, K., and Wierstra, D. Weight uncertainty in neural network. In International Conference on Machine Learning, pp. 1613–1622. PMLR, 2015.
- Carlini & Wagner (2017) Carlini, N. and Wagner, D. Towards evaluating the robustness of neural networks. In 2017 ieee symposium on security and privacy (sp), pp. 39–57. IEEE, 2017.
- Diffenderfer et al. (2021) Diffenderfer, J., Bartoldson, B. R., Chaganti, S., Zhang, J., and Kailkhura, B. A winning hand: Compressing deep networks can improve out-of-distribution robustness. arXiv preprint arXiv:2106.09129, 2021.
- Frankle et al. (2020a) Frankle, J., Dziugaite, G. K., Roy, D., and Carbin, M. Linear mode connectivity and the lottery ticket hypothesis. In International Conference on Machine Learning, pp. 3259–3269. PMLR, 2020a.
- Frankle et al. (2020b) Frankle, J., Dziugaite, G. K., Roy, D. M., and Carbin, M. Stabilizing the lottery ticket hypothesis, 2020b.
- Goodfellow et al. (2014) Goodfellow, I. J., Shlens, J., and Szegedy, C. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- Guo et al. (2018) Guo, Y., Zhang, C., Zhang, C., and Chen, Y. Sparse dnns with improved adversarial robustness. arXiv preprint arXiv:1810.09619, 2018.
- Han et al. (2015) Han, S., Mao, H., and Dally, W. J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015.
- Hendrycks & Dietterich (2019) Hendrycks, D. and Dietterich, T. Benchmarking neural network robustness to common corruptions and perturbations. arXiv preprint arXiv:1903.12261, 2019.
- Hendrycks & Gimpel (2016) Hendrycks, D. and Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv preprint arXiv:1610.02136, 2016.
- Hendrycks et al. (2018) Hendrycks, D., Mazeika, M., and Dietterich, T. Deep anomaly detection with outlier exposure. In International Conference on Learning Representations, 2018.
- Huang et al. (2021) Huang, R., Geng, A., and Li, Y. On the importance of gradients for detecting distributional shifts in the wild. Advances in Neural Information Processing Systems, 34, 2021.
- Ilyas et al. (2019) Ilyas, A., Santurkar, S., Tsipras, D., Engstrom, L., Tran, B., and Madry, A. Adversarial examples are not bugs, they are features. Advances in neural information processing systems, 32, 2019.
- Kalibhat et al. (2020) Kalibhat, N. M., Balaji, Y., and Feizi, S. Winning lottery tickets in deep generative models. arXiv preprint arXiv:2010.02350, 2020.
- Kingma & Dhariwal (2018) Kingma, D. P. and Dhariwal, P. Glow: Generative flow with invertible 1x1 convolutions. Advances in neural information processing systems, 31, 2018.
- Kirichenko et al. (2020) Kirichenko, P., Izmailov, P., and Wilson, A. G. Why normalizing flows fail to detect out-of-distribution data. arXiv preprint arXiv:2006.08545, 2020.
- Lakshminarayanan et al. (2016) Lakshminarayanan, B., Pritzel, A., and Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles. arXiv preprint arXiv:1612.01474, 2016.
- LeCun et al. (1990) LeCun, Y., Denker, J. S., and Solla, S. A. Optimal brain damage. In Advances in Neural Information Processing Systems 2. 1990.
- Lee et al. (2018) Lee, N., Ajanthan, T., and Torr, P. H. Snip: Single-shot network pruning based on connection sensitivity. arXiv preprint arXiv:1810.02340, 2018.
- Lee et al. (2020) Lee, S., Park, C., Lee, H., Yi, J., Lee, J., and Yoon, S. Removing undesirable feature contributions using out-of-distribution data. In International Conference on Learning Representations, 2020.
- Li et al. (2016) Li, H., Kadav, A., Durdanovic, I., Samet, H., and Graf, H. P. Pruning filters for efficient convnets. 2016.
- Liebenwein et al. (2021) Liebenwein, L., Baykal, C., Carter, B., Gifford, D., and Rus, D. Lost in pruning: The effects of pruning neural networks beyond test accuracy. Proceedings of Machine Learning and Systems, 3, 2021.
- Liu et al. (2020) Liu, J., Lin, Z., Padhy, S., Tran, D., Bedrax Weiss, T., and Lakshminarayanan, B. Simple and principled uncertainty estimation with deterministic deep learning via distance awareness. Advances in Neural Information Processing Systems, 33, 2020.
- Madaan et al. (2020) Madaan, D., Shin, J., and Hwang, S. J. Adversarial neural pruning with latent vulnerability suppression. In International Conference on Machine Learning, pp. 6575–6585. PMLR, 2020.
- Morcos et al. (2019) Morcos, A., Yu, H., Paganini, M., and Tian, Y. One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers. In Advances in Neural Information Processing Systems, 2019.
- Nalisnick et al. (2018) Nalisnick, E., Matsukawa, A., Teh, Y. W., Gorur, D., and Lakshminarayanan, B. Do deep generative models know what they don’t know? In International Conference on Learning Representations, 2018.
- Ovadia et al. (2019) Ovadia, Y., Fertig, E., Ren, J., Nado, Z., Sculley, D., Nowozin, S., Dillon, J. V., Lakshminarayanan, B., and Snoek, J. Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift. arXiv preprint arXiv:1906.02530, 2019.
- Rachwan et al. (2022) Rachwan, J., Charpentier, B., Zügner, D., Geisler, S., Ayle, M., and Günnemann, S. Winning the lottery ahead of time: Efficient early network pruning. In International Conference on Machine Learning. PMLR, 2022.
- Ramanujan et al. (2020) Ramanujan, V., Wortsman, M., Kembhavi, A., Farhadi, A., and Rastegari, M. What’s hidden in a randomly weighted neural network? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11893–11902, 2020.
- Scaman & Virmaux (2018) Scaman, K. and Virmaux, A. Lipschitz regularity of deep neural networks: analysis and efficient estimation. arXiv preprint arXiv:1805.10965, 2018.
- Schirrmeister et al. (2020) Schirrmeister, R., Zhou, Y., Ball, T., and Zhang, D. Understanding anomaly detection with deep invertible networks through hierarchies of distributions and features. Advances in Neural Information Processing Systems, 33, 2020.
- Sehwag et al. (2020) Sehwag, V., Wang, S., Mittal, P., and Jana, S. Hydra: Pruning adversarially robust neural networks. In NeurIPS, 2020.
- Shafaei et al. (2018) Shafaei, A., Schmidt, M., and Little, J. J. A less biased evaluation of out-of-distribution sample detectors. arXiv preprint arXiv:1809.04729, 2018.
- Su et al. (2020) Su, J., Chen, Y., Cai, T., Wu, T., Gao, R., Wang, L., and Lee, J. D. Sanity-checking pruning methods: Random tickets can win the jackpot. arXiv preprint arXiv:2009.11094, 2020.
- Tack et al. (2020) Tack, J., Mo, S., Jeong, J., and Shin, J. Csi: Novelty detection via contrastive learning on distributionally shifted instances. Advances in Neural Information Processing Systems, 33, 2020.
- Verdenius et al. (2020) Verdenius, S., Stol, M., and Forré, P. Pruning via iterative ranking of sensitivity statistics. arXiv preprint arXiv:2006.00896, 2020.
- Wang et al. (2020) Wang, C., Zhang, G., and Grosse, R. Picking winning tickets before training by preserving gradient flow. arXiv preprint arXiv:2002.07376, 2020.
- You et al. (2020) You, H., Li, C., Xu, P., Fu, Y., Wang, Y., Chen, X., Baraniuk, R. G., Wang, Z., and Lin, Y. Drawing early-bird tickets: Toward more efficient training of deep networks. In International Conference on Learning Representations, 2020.
- You et al. (2019) You, Z., Yan, K., Ye, J., Ma, M., and Wang, P. Gate decorator: Global filter pruning method for accelerating deep convolutional neural networks, 2019.
- Zhang et al. (2021) Zhang, D., Ahuja, K., Xu, Y., Wang, Y., and Courville, A. Can subnetwork structure be the key to out-of-distribution generalization? arXiv preprint arXiv:2106.02890, 2021.
Appendix A Experimental Setup
Architecture-Dataset Combinations For classification tasks, we focus on two popular architecture-dataset combinations: LeNet5 trained on MNIST, and ResNet18 trained on CIFAR10. For the Ensembles experiment, we use AlexNet trained on CIFAR10. For the Bayesian experiment, we use Conv6 trained on CIFAR10. For generative models, we use Glow trained on MNIST or CELEBA.
Train-Test Dataset Combinations
We evaluate the robustness of classification models on two types of dataset shifts:
Distribution Shifts (DS): we use the CIFAR10-C dataset on the ResNet18-CIFAR10 combination only.
Adversarial Attacks (AA): we use the Fast Gradient Sign Method (FGSM) with in the [0, 255] scale.
We also evaluate the uncertainty of classification models on the previous two dataset types, and the two following additional dataset types for all models:
Out-of-Distribution (OOD): For FashionMNIST, we use MNIST. For CIFAR10, we use SVHN and CIFAR100. For CELEBA, we use SVHN.
Out-of-Domain (OODom): this corresponds to the any OOD dataset but scaled in the [0, 255] range instead of the [0, 1] range.
Metrics We report the clean test accuracy as well as the accuracy on DS and AA (Acc.), the Area Under the Receiver Operating Characteristic curve (AUROC) or Area Under the Precision Recall curve (AUPR) for detection, the Brier score as an uncertainty measure (Brier), and a lower bound on the Lipschitz constant of models (Lip.).
Training Details Classifiers are trained using Adam optimizer, learning rate 2e-3 and batch size 512. ResNet18 and AlexNet are trained for 50 epochs, while LeNet5 is trained for 30. Glow is trained for 100k iterations, using a batch size of 64 and a learning rate of 1e-5.
Agumentations used in SensNorm We empirically find that rotation transformations in , horizontal and vertical flips, as well as other affine transformations using Benton et al. (2020), help improve the detection.
Appendix B Algorithms
Inputs: , pretrained network, x percentage to prune
Freeze F’s weights
kaiming_normal
for
Create subnetwork of (1-x)% highest scores in S
Do forward pass
Compute loss with desired objective % Adversarial, OOD or DS
Do backward pass through all scores and update them
subnetwork of (1-x)% highest scores in S
Appendix C Additional Results
We report additional information concerning the properties of sparse neural networks. Tab. 5 shows the Lipschitz constant Scaman & Virmaux (2018) of dense and sparse ResNet18 models. Note that, at the exception of Edgepop, all pruning methods result in a higher Lipschitz constant than the dense model. In Tab. 6, we look in details at the accuracy of pruned ResNet18 models on CIFAR10C, and whether or not it increased compared to the dense model. We note that the "saturate", "fog" and "contrast" corruptions are the most affected negatively among sparse models. Finally, Fig. 5, 6 and Fig. 7 show the robustness, detection and uncertainty of AA, DS and OOD of LeNet5 models trained on MNIST. Performance on robustness and detection of FGSM attacks resembles the results on ResNet18. However, there is a much much noticeable improvement of certain pruning methods on the MNIST dataset, and a much more noticeable drop in detection of the Omniglot dataset. Indeed, the latter consists of a white background with black symbols, instead of black background with white digits for MNIST.
| Lipschitz Constant | |
|---|---|
| Dense | 7.27e+18 |
| Edgepop (50%) | 2.92e+11 |
| CROP (50%) | 6.62e+27 |
| EarlyCROP (50%) | 8.95e+20 |
|
criterion |
gaussian noise |
impulse noise |
defocus blur |
frosted glass blur |
saturate |
shot noise |
elastic |
snow |
spatter |
fog |
frost |
gaussian blur |
speckle noise |
brightness |
pixelate |
jpeg compression |
contrast |
motion blur |
zoom blur |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dense | 0.227 | 0.243 | 0.520 | 0.360 | 0.812 | 0.264 | 0.642 | 0.633 | 0.707 | 0.700 | 0.521 | 0.410 | 0.313 | 0.850 | 0.491 | 0.658 | 0.292 | 0.569 | 0.576 |
| GRASP | 0.356 | 0.367 | 0.585 | 0.523 | 0.814 | 0.403 | 0.712 | 0.695 | 0.735 | 0.673 | 0.611 | 0.436 | 0.447 | 0.849 | 0.520 | 0.721 | 0.288 | 0.591 | 0.607 |
| SNIP | 0.360 | 0.316 | 0.526 | 0.473 | 0.804 | 0.431 | 0.677 | 0.680 | 0.730 | 0.667 | 0.581 | 0.387 | 0.464 | 0.847 | 0.505 | 0.713 | 0.277 | 0.584 | 0.579 |
| CROP | 0.324 | 0.305 | 0.597 | 0.489 | 0.821 | 0.372 | 0.713 | 0.703 | 0.724 | 0.678 | 0.598 | 0.469 | 0.409 | 0.855 | 0.513 | 0.701 | 0.273 | 0.623 | 0.646 |
| Edgepop | 0.437 | 0.333 | 0.515 | 0.475 | 0.775 | 0.477 | 0.698 | 0.686 | 0.747 | 0.576 | 0.618 | 0.423 | 0.489 | 0.832 | 0.494 | 0.730 | 0.269 | 0.577 | 0.582 |
| EarlyCROP | 0.323 | 0.292 | 0.527 | 0.455 | 0.822 | 0.387 | 0.704 | 0.690 | 0.735 | 0.688 | 0.607 | 0.405 | 0.433 | 0.853 | 0.527 | 0.702 | 0.298 | 0.606 | 0.584 |
| IMP | 0.278 | 0.272 | 0.590 | 0.442 | 0.832 | 0.337 | 0.693 | 0.703 | 0.726 | 0.665 | 0.614 | 0.507 | 0.370 | 0.869 | 0.544 | 0.704 | 0.265 | 0.586 | 0.645 |
| Edgepop-A | 0.445 | 0.352 | 0.585 | 0.475 | 0.807 | 0.464 | 0.705 | 0.715 | 0.735 | 0.724 | 0.642 | 0.476 | 0.466 | 0.880 | 0.432 | 0.710 | 0.387 | 0.613 | 0.634 |
| SNIP-A | 0.241 | 0.255 | 0.614 | 0.414 | 0.764 | 0.276 | 0.680 | 0.686 | 0.698 | 0.734 | 0.601 | 0.511 | 0.310 | 0.861 | 0.417 | 0.658 | 0.439 | 0.633 | 0.655 |