On the Safety of Conversational Models: Taxonomy, Dataset, and Benchmark
Abstract
Dialogue safety problems severely limit the real-world deployment of neural conversational models and have attracted great research interests recently. However, dialogue safety problems remain under-defined and the corresponding dataset is scarce. We propose a taxonomy for dialogue safety specifically designed to capture unsafe behaviors in human-bot dialogue settings, with focuses on context-sensitive unsafety, which is under-explored in prior works. To spur research in this direction, we compile DiaSafety, a dataset with rich context-sensitive unsafe examples. Experiments show that existing safety guarding tools fail severely on our dataset. As a remedy, we train a dialogue safety classifier to provide a strong baseline for context-sensitive dialogue unsafety detection. With our classifier, we perform safety evaluations on popular conversational models and show that existing dialogue systems still exhibit concerning context-sensitive safety problems. 111Our dataset DiaSafety is released in https://github.com/thu-coai/DiaSafety
Disclaimer: The paper contains example data that may be very offensive or upsetting.
1 Introduction
| Dataset | Context Awareness | Context Sensitiveness | Chatbots- Oriented | Research Scope | #Classes | Source |
| Wulczyn et al. (2017) | - | - | - | Personal Attacks | 2 | Wikipedia |
| Davidson et al. (2017) | - | - | - | Hate Speech | 3 | SMP |
| Zampieri et al. (2019) | - | - | - | Offensiveness | 5 | SMP |
| Dinan et al. (2019) | ✓ | - | - | Offensiveness | 2 | CS |
| Wang and Potts (2019) | ✓ | - | - | Condescending | 2 | SMP |
| Nadeem et al. (2020) | ✓ | - | ✓ | Social Bias | 3 | CS |
| Xu et al. (2020) | ✓ | - | ✓ | Dialogue Safety | 2 | CS+LM |
| Zhang et al. (2021) | ✓ | - | - | Malevolence | 18 | SMP |
| Xenos et al. (2021) | ✓ | ✓ | - | Toxicity | 2 | SMP |
| Sheng et al. (2021) | ✓ | - | ✓ | Ad Hominems | 7 | SMP+LM |
| Baheti et al. (2021) | ✓ | ✓ | ✓ | Toxicity Agreement | 3 | SMP+LM |
| DiaSafety (Ours) | ✓ | ✓ | ✓ | Dialogue Safety | 52 | SMP+LM |
Generative open-domain chatbots have attracted increasing attention with the emergence of transformer-based language models pretrained on large-scale corpora Zhang et al. (2020); Wang et al. (2020); Adiwardana et al. (2020); Roller et al. (2020). However, the real-world deployment of generative conversational models remains limited due to safety concerns regarding their uncontrollable and unpredictable outputs. For example, Microsoft’s TwitterBot Tay was released in 2016 but quickly recalled after its racist and toxic comments drew public backlash Wolf et al. (2017). Till now, dialogue safety is still the Achilles’ heel of generative conversational models.
Despite abundant research on toxic language and social bias in natural language Schmidt and Wiegand (2017); Poletto et al. (2021), it is still challenging to directly transfer them onto open-domain dialogue safety tasks, for two major reasons. First, conversational safety involves additional considerations Henderson et al. (2017) besides just toxic language or societal biases. For example, conversational models are expected to understand the user’s psychological state, so as to avoid giving replies that might aggravate depression or even induce suicides Vaidyam et al. (2019); Abd-Alrazaq et al. (2019). Second, the focus of such studies and their corresponding datasets are overwhelmingly at utterance level. Recent works find that the toxicity may change with context Pavlopoulos et al. (2020); Xenos et al. (2021). Since dialogue is a highly interactive act, the determination of safety requires a more comprehensive understanding of the context. Those context-sensitive cases which must rely on conversational context to decide safety should be paid more attention.
This paper addresses the challenges of dialogue safety by proposing a dialogue safety taxonomy with a corresponding dataset, DiaSafety (Dialogue Safety). The taxonomy combines a broad range of past work, considers “responsible dialogue systems” as caring for the physical and psychological health of users, as well as avoiding unethical behaviors Ghallab (2019); Arrieta et al. (2020); Peters et al. (2020); World Economic Forum (2020). In other words, we consider safe dialogue systems as not only speaking polite language, but also being responsible to protect human users and promote fairness and social justice Shum et al. (2018). Moreover, our taxonomy focuses on context-sensitive unsafety, which are strictly safe at utterance level but become unsafe considering the contexts. Compared with context-aware cases where the responses can be still unsafe at the utterance level, context-sensitive unsafe cases are fully disjoint from utterance-level unsafety and pose a greater challenge to unsafety detection shown in Section 5. We define context-sensitive unsafe behaviors: (1) Offending User, (2) Risk Ignorance, (3) Unauthorized Expertise, (4) Toxicity Agreement, (5) Biased Opinion, and (6) Sensitive Topic Continuation. Table 2 summarizes the taxonomy.
We show that existing safety guarding tools (e.g. Perspective API, perspectiveapi.com) struggle to detect context-sensitive unsafe cases, which is rich in our dataset. As a remedy, we train a highly accurate classifier to detect context-sensitive dialogue unsafety on our dataset. We further propose a two-step detection strategy to sequentially apply utterance-level and context-sensitive unsafety check, which leverages existing utterance-level unsafety resources for comprehensive dialogue safety check. We use this strategy to check the safety of popular conversational models. We assign respective and overall safety scores to shed light on their safety strengths and weaknesses. For example, we find that the systems all suffer more from context-sensitive unsafety and Blenderbot Roller et al. (2020) is comparatively more safe.
Our contributions are threefold:
-
•
We propose a taxonomy tailored for dialogue safety specifically focuses on context-sensitive situations.
-
•
We present DiaSafety, a dataset under our taxonomy, with rich context-sensitive unsafe cases. Our dataset is of high quality and challenging for existing safety detectors.
- •
2 Related work
Toxicity and Bias Detection The popularity of internet forums led to increasing research attention in automatic detection of toxic biased language in online conversations, for which numerous large-scale datasets were provided to train neural classifiers and benchmark progress. Wulczyn et al. (2017) proposed the Wikipedia Toxic Comments dataset with 100k human-labeled data on personal attacks. Davidson et al. (2017) published a human-annotated 240k Twitter dataset, with hate speech and offensive language classes. Social bias and prejudice is also a hot area of research. Many datasets and debiasing methods for specific bias domain were proposed and investigated: gender Zhao et al. (2018); Rudinger et al. (2018), religion Dhamala et al. (2021), race Davidson et al. (2019), and politics Liu et al. (2021b, c).
Dialogue Safety Dialogue safety requires open-domain chatbots to deal appropriately with various scenarios including aggressiveness De Angeli et al. (2005); De Angeli and Brahnam (2008), harassment Curry and Rieser (2018), and sensitive topics Xu et al. (2020), etc. Meanwhile, some past work found that conversational models tend to become more unsafe faced with specific context Curry and Rieser (2018); Lee et al. (2019); Baheti et al. (2021). Before many studies started to model the context in dialogue safety check, Dinan et al. (2019) pioneered in claiming and verifying the importance of context for dialogue safety. They found that sentences given context can present more sophisticated attacks and improve the performance of BERT-based detectors. To improve dialogue safety, numerous work researches on generation detoxifying Dinan et al. (2019); Smith et al. (2020a); Liu et al. (2021a). Xu et al. (2020) surveyed in detail the methods to improve dialogue safety and collected a dataset by eliciting conversational models. As for the definition, dialogue safety is still under-defined till now. Recently Dinan et al. (2021) proposed a classification of safety issues in open-domain conversational systems including three general categories and emphasized the importance of context. Though they state that context-aware unsafety may contain context-sensitive unsafety, they do not distinguish them in taxonomy. Previous works also extended the border of dialogue safety such as patient and consumer safety risks Bickmore et al. (2018), stereotype Barikeri et al. (2021) and political prudence Bang et al. (2021).
Dialogue Safety-Related Datasets As listed above, a great deal of works release datasets about toxic and biased language for detoxifying online communities. From another line of works, for exploring and solving the problems of unpredictable outputs of generative models trained on large-scale corpora, chatbots-oriented datasets are gradually emerging Gehman et al. (2020); Xu et al. (2020); Sheng et al. (2021). Meanwhile, more and more researchers started to pay attention to the influence of context Dinan et al. (2019); Xu et al. (2020); Zhang et al. (2021) and find context-aware data is more challenging for annotation and detection Pavlopoulos et al. (2020); Menini et al. (2021). Our work follows the call for collecting context-aware data, and goes one step beyond to develop a context-sensitive dataset in accordance with our dialogue safety taxonomy. Moreover, most existing works only focus on one aspect of safety, while our taxonomy and dataset cover wider scopes and considerations. We compare our dataset DiaSafety and other public datasets in Table 1.
3 Safety Taxonomy
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/e3c671cc-8541-435d-86ae-72a7b168c23a/x1.png)
We aim to define a taxonomy for dialogue safety based on ethical and legal concerns. To clearly define the research scope, we follow the research of Henderson et al. (2017); Xu et al. (2020); Dinan et al. (2021); Bender et al. (2021); ACM Committee on Professional Ethics (2018); European Commission (2021) and argue that a safe response should satisfy the following basic requirements: (1) respond harmoniously, amicably, fairly, and impartially; (2) appropriately recognize and respond to potential risks in highly safety-sensitive contexts regarding human health and emotional well-being; and (3) avoid expressing a subjective viewpoint in sensitive topics. Considering the above requirements, we conduct preliminary case study by inducing unsafe responses with various triggers, and further categorize unsafe responses into utterance-level and context-sensitive examples.
Utterance-level unsafety It refers to obviously offensive, derogatory, threatening, violent, or unreasonable language, which is unsafe regardless of context, such as “I want to punch women in the face”. Utterance-level unsafety is the primary focus of safety research and detection tools are plentiful and ripe Schmidt and Wiegand (2017); Fortuna and Nunes (2018); Jahan and Oussalah (2021).
Context-sensitive unsafety It implies that a seemingly safe utterance becomes unsafe given the context. Note that this is a more strict definition than the context-aware cases commonly discussed in the literature as listed in Table 1. For example, “I think so” is safe while it becomes unsafe when responding to “black people are all violent”. Our research focuses on such context-sensitive unsafe cases. To the best of our knowledge, context-sensitive unsafety is only briefly discussed in a few past works Xenos et al. (2021); Baheti et al. (2021), as summarized in Table 1.
Depending on the target and scope of the unsafe impact, we further divide context-sensitive unsafety into Personal unsafety and Non-personal unsafety. We present our elaborate taxonomy in Table 2 and we introduce each category as follows.
3.1 Personal unsafety
Personal unsafe responses have a direct negative impact on users, such as causing psychological or physical harm by attacking, mocking, etc., or inducing potentially risky behaviors by spreading unreliable information. Specifically, we focus on the following three categories.
Offending User The generated responses should not be aggressive or offensive, satire intended to ridicule or insult Dinan et al. (2019), and any other statements intended to enrage user Sheng et al. (2021). Offensiveness based on context can be more implicit and even more infuriating (e.g. cursing back, evil for good, etc.).
Risk Ignorance Previous studies pay much attention to mental health risks potentially carried by the outputs of generative model Abd-Alrazaq et al. (2020); Sun et al. (2021). It is notable that mental health risk may also induce physical health dangers (e.g. suicide). We warn risk ignorance, which may distress the users or even cause irreparable injury.
Unauthorized Expertise For general chatbots, it is unsafe to provide plausible suggestions, counsels, and knowledge without professional qualifications, especially in safety-critical fields like medical and legal domains Mittal et al. (2016). Here we primarily focus on unauthorized medical expertise.
3.2 Non-personal Unsafety
Non-personal unsafe responses are primarily toward third-party individuals, groups, and the social mass. We focus on three categories as follows.
Toxicity Agreement Previous work finds that chatbots tend to show agreement or acknowledgment faced with toxic context Baheti et al. (2021). Such responses advocate users’ harmful speech, spread toxicity, rude or bias in an indirect form Dinan et al. (2021).
Biased Opinion Biased opinion usually maintains stereotypes and prejudices, referring to negative expressions on individuals or groups based on their social identities (e.g., gender and race) Blodgett et al. (2020). In this paper, we primarily focus on biased opinions on gender, race, and religion.
Sensitive Topic Continuation Some topics are more controversial than others, and showing disposition or preference in one way can potentially upset some certain groups of users Xu et al. (2020). We regard responses continuing the same sensitive topics of the context and expressing views or preferences as unsafe cases.
4 Dataset Collection
We present DiaSafety, a dataset that contains in total 11K labeled context-response pairs under the unsafe categories defined in the above taxonomy. This dataset does not include Sensitive Topic Continuation considering its complexity.222The definition of sensitive topics is quite subjective and varies a lot with regions, cultures and even individuals. Thus we leave this category as future work in data collection. All of our unsafe data are context-sensitive, meaning that all dialogue responses must depend on the conversational context to be correctly labelled in terms of safety. We exploit multiple sources and methods to collect data. Table 3 gives a snapshot of basic statistics of DiaSafety.
4.1 Data Source
We collect data from the following three sources.
Real-world Conversations The majority of our data are real-world conversations from Reddit because of their better quality, more varieties, and higher relevance than model generated samples. We collect post-response pairs from Reddit by PushShift API Baumgartner et al. (2020). We create a list of sub-reddits for each category of context-sensitive unsafety, where it is easier to discover unsafe data. Refer to Appendix A.1 for the details of real-world conversations collection.
Public Datasets We notice that some existing public datasets can be modified and used under the definition of certain categories of our proposed taxonomy. Therefore, we add them to our dataset candidates. For instance, MedDialog Zeng et al. (2020) are composed of single-turn medical consulting. However, it is not appropriate for general conversational models to give such professional advice like that. Thus we add MedDialog dataset as our unsafe data candidates in Unauthorized Expertise. Also, Sharma et al. (2020) releases some contexts related to mental health and corresponding empathetic responses from Reddit, which we regarded as safe data candidates in Risk Ignorance.
Machine-generated Data It is naturally beneficial to exploit machine-generated data to research on the safety of neural conversational models themselves. We take out the prompt/context of our collected data including real-world conversations and public dataset and let conversational models generate responses. According to the characteristics of each unsafe category, we try to find prompts that are more likely to induce unsafety. Refer to Appendix A.2 for detailed prompting picking methods and generating based on prompting.
After collecting from multiple sources, we do a post-processing for data cleaning including format regularization and explicit utterance-level unsafety filtering (refer to Appendix A.3).
4.2 Human Annotation
Semi-automatic Labeling
It is helpful to employ auto labeling method to improve annotation efficiency by increasing the recall of context-sensitive unsafe samples. For some certain unsafe categories, we find there are some patterns that classifiers can find to separate the safe and unsafe data according to the definitions. For Unauthorized Expertise, we train a classifier to identify phrases that offer advice or suggestions for medicine or medical treatments. For Toxicity Agreement, we train a classifier to identify the dialogue act “showing agreement or acknowledgement” based on the SwDA dataset Jurafsky et al. (1997) and manually picked data. To verify the auto-labeling quality, we randomly pick 200 samples and do human confirmation in Amazon Mechanical Turk (AMT) platform (mturk.com) as the golden labels. We compute the accuracy shown in Table 3 and all are higher than 92%, which proves that our auto labeling method is valid.
For Risk Ignorance, Offending User, and Biased Opinion, there are few easy patterns to distinguish between the safe and unsafe data. Thus the collected data from the three unsafe categories are completely human-annotated. For each unsafe category, we release a separate annotation task on AMT and ask the workers to label safe or unsafe. Each HIT is assigned to three workers and the option chosen by at least two workers is seen as the golden label. We break down the definition of safety for each unsafe category, to make the question more intuitive and clear to the annotator. Refer to Appendix B for the annotation guidelines and interface. We do both utterance-level and context-level annotations to confirm that the final dataset is context-sensitive.
Utterance-level Annotation
We take another round of human annotation to ensure that all of our responses are utterance-level safe, though post-processing filters out most of the explicitly unsafe samples. For each context-response pair, only the response is provided to the annotator who is asked to label whether the response is unsafe.
Context-level Annotation
For those data which is safe in utterance-level annotation, we conduct context-level annotation, where we give both the context and the response to the annotators and ask them whether the response is safe given the conversational context. If the data is safe, we add them into the safe part of our dataset, vice versa.
Model-in-the-loop Collection
To improve collection efficiency, our data collection follows a model-in-the-loop setup. We train a classifier to discover context-sensitive unsafe responses from the ocean of responses. We pick the data samples with comparatively high unsafe probability and send them to be manually annotated by AMT workers. Annotation results in return help train the classifier to get better performance to discover context-sensitive unsafe responses. We initialize the classifier by labeling 100 samples ourselves and we repeat the process above three times.
4.3 Annotation Quality Control
Only those workers who arrive at 1,000 HITs approved and 98% HIT approval rate can take part in our tasks. Besides, we limit workers to native English speakers by setting the criterion “location”. The workers are aided by detailed guidelines and examples (refer to Appendix B) during the annotation process. We also embed easy test questions into the annotations and reject HITs that fail the test question. The remuneration is set to approximately 25 USD per hour. We gradually enhance our annotation agreement by improving and clarifying our guidelines. As shown in Table 3, the overall annotations achieve moderate inter-annotator agreement.333Comparable to the related contextual tasks which gets krippendorff’s alpha Baheti et al. (2021).
| Class | Dataset Size | Avg. #words | Agreement | |||
| Safe | Unsafe | Ctx | Resp | Acc. | ||
| OU | 643 | 878 | 16.9 | 12.1 | 0.50 | - |
| RI | 1,000 | 940 | 23.7 | 12.1 | 0.24 | - |
| UE | 1,674 | 937 | 31.0 | 26.6 | - | 0.92 |
| TA | 1,765 | 1,445 | 12.5 | 13.1 | - | 0.93 |
| BO | 1,229 | 981 | 17.9 | 10.2 | 0.36 | - |
| Overall | 6,311 | 5,181 | 20.2 | 15.3 | 0.37 | 0.92 |
5 Context-sensitive Unsafety Detection
In this section, we answer the following three research questions: (1) Can neural models identify context-sensitive unsafety by training on our dataset? (2) How much influence does context have on context-sensitive unsafety detection? (3) Can existing safety guarding tools identify context-sensitive unsafety?
5.1 Experimental Setup
To answer first two questions, we first construct a unsafety444In this section, we use “unsafety” to refer to “context-sensitive unsafety” for convenience. detector. We randomly split our dataset into train (80%), dev (10%), and test (10%) sets for each category of unsafety. And we use RoBERTa model Liu et al. (2019) with 12 layers for our experiments, which has shown strong power in text classification tasks. We input the context and response with </s> as the separator.
We construct five one-vs-all classifiers, one for each unsafe category, and combines the results of five models to make the final prediction. That is, each model performs a three-way classification (Safe, Unsafe, N/A) for one corresponding unsafe category. In real-world tests, the coming data may belong to other unsafe categories. To prevent the models from failing to handle the unknown unsafe categories, we add a “N/A” (Not Applicable) class and its training data is from other categories (both safe and unsafe), expecting the models to identify data out of domain. We classify a response as: (1) Safe if all five models determine the response is safe or N/A; (2) Unsafe in category if the model for determines the response is unsafe. If multiple models do so, we only consider the model with the highest confidence. We compare this method with a single model which trains on mixed data in one step, which is detailed in Appendix C.1.
| Class | With Context (%) | W/o Context (%) | ||||
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | |
| Safe | 87.8 | 85.9 | 86.8 | 82.4 | 80.0 | 81.2 |
| OU | 82.5 | 88.0 | 85.2 | 53.8 | 76.0 | 63.0 |
| RI | 78.9 | 75.5 | 77.2 | 62.4 | 56.4 | 59.2 |
| UE | 96.6 | 92.5 | 94.5 | 90.4 | 91.4 | 90.9 |
| TA | 94.5 | 94.5 | 94.5 | 76.7 | 85.6 | 80.9 |
| BO | 61.4 | 71.4 | 66.0 | 56.0 | 42.9 | 48.6 |
| Overall | 83.6 | 84.6 | 84.0 | 70.3 | 72.0 | 70.6 |
5.2 Fine-grain Classification
Given a pair of context and response, the fine-grain classification task requires models to identify whether a response is unsafe and then which unsafe category the response belongs to. We classify according to the rule above and Table 4 shows the experimental results.
The comparatively high performance shows that the neural models can effectively discover the implicit connections between context and response, then identify context-sensitive unsafety. Meanwhile, we notice the model gets a relatively low F1-score in Biased Opinion. We believe that in this category, the complexity and sample-sparsity of the social identities (e.g. LGBT, Buddhist, blacks, etc.) are huge obstacles for a neural model without external knowledge to learn.
Besides, for exploring how much influence context has on context-sensitive unsafety detection, we do an ablation study and compare the classifier performance between with context and without context. As shown in Table 4, The absolute improvement of the overall F1 score is high to 13.4%. It verifies that in our dataset, the context is indeed the key information to determine whether the response is safe or not. Also, we notice that by adding context, Unauthorized Expertise improve less obviously, which accords with our expectation. UE is seen context-sensitive unsafe due to the context of human-bot dialogue setting, while the detection itself may be quite easy at utterance-level like matching medicine and suggestion-related words in response. We also conduct the same experiments as above by constructing a single classifier (refer to Appendix C.1). It shows that one-vs-all classifiers perform slightly better in all categories.
| Methods | Inputs | Safe | Unsafe | Macro Overall (%) | ||
| F1 (%) | F1 (%) | Prec. | Rec. | F1 | ||
| Random | N/A | 53.5 | 48.1 | 50.9 | 50.9 | 50.8 |
| Detoxify | Resp | 70.4 | 9.9 | 60.5 | 51.5 | 40.1 |
| (Ctx,resp) | 61.7 | 56.9 | 59.3 | 59.4 | 59.3 | |
| P-API | Resp | 70.2 | 11.5 | 58.3 | 51.5 | 40.8 |
| (Ctx,resp) | 58.8 | 57.7 | 58.5 | 58.6 | 58.3 | |
| BBF | (Ctx,resp) | 62.8 | 55.9 | 59.3 | 59.3 | 59.3 |
| BAD | (Ctx,resp) | 71.1 | 61.8 | 66.9 | 66.4 | 66.5 |
| After finetuning on DiaSafety | ||||||
| Detoxify | (Ctx,resp) | 80.8 | 79.0 | 79.9 | 80.1 | 79.9 |
| Ours | (Ctx,resp) | 86.8 | 84.7 | 85.7 | 85.8 | 85.7 |
5.3 Coarse-grain Classification
To check whether existing safety guarding tools can identify our context-sensitive unsafe data, we define a coarse-grain classification task, which merely requires models to determine whether a response is safe or unsafe given context.
Deceiving Existing Detectors PerspectiveAPI (P-API, perspectiveapi.com) is a free and popular toxicity detection API, which is used to help mitigate toxicity and ensure healthy dialogue online. Detoxify Hanu and Unitary team (2020) is an open-source RoBERTa-based model trained on large-scale toxic and biased corpora. Other than utterance-level detectors, we also test two context-aware dialogue safety models: Build it Break it Fix it (BBF) Dinan et al. (2019) and Bot-Adversarial Dialogue Safety Classifier (BAD) Xu et al. (2021). We check these methods on our test set and add a baseline that randomly labels safe or unsafe. As shown in Table 5, Detoxify and P-API get a quite low F1-score (close to random no matter what inputs). When inputs contain only response, the recall of unsafe responses is especially low, which demonstrates again that our dataset is context-sensitive. Meanwhile, we notice that both methods get a considerable improvement by adding context. We attribute that to the fact that contexts in some unsafe samples carrying toxic and biased contents (e.g. Toxicity Agreement). Besides, Our experimental results demonstrate that the context-aware models are still not sensitive enough to the context. We consider that in the context-aware cases, a large number of unsafe responses which could be detected at the utterance level as a shortcut, make context-aware models tend to ignore the contextual information and thus undermine their performances. In summary, our context-sensitive unsafe data can easily deceive existing unsafety detection methods, revealing potential risks.
Improvement by Finetuning We test the performance of Detoxify finetuned on DiaSafety (shown in Table 5). The experimental results show that Detoxify gets a significant improvement after finetuning. Besides, we compare it with our coarse-grain classifier according to the rule that a response is determined to be unsafe if any one of the five models determines unsafe, otherwise the response is safe. The main difference lies in that our classifier is finetuned from a vanilla RoBERTa, while Detoxify is pre-trained on an utterance-level toxic and biased corpus before finetuning. Noticeably, we find pre-training on utterance-level unsafety detection degrades the performance to detect context-sensitive unsafety due to the gap in data distribution and task definition. The results suggest that splitting the procedure of detecting utterance-level and context-sensitive unsafety is a better choice to perform a comprehensive safety evaluation.
6 Dialogue System Safety Evaluation
In this section, we employ our classifiers to evaluate the safety of existing dialogue models.
6.1 Two-step Safety Detection Strategy
Recall that dialogue safety of conversational models includes utterance-level and context-sensitive safety. As Section 5.3 shows, checking them separately not only seamlessly fuses utterance-level research resources with the context-sensitive dialogue safety task, but is also more effective.
Given a pair of context and response, in the first step, we employ Detoxify and check whether the response is utterance-level unsafe; in the second step where the response passes utterance-level check, we utilize our classifiers to check whether the response becomes unsafe with adding context. This method, taking full advantage of the rich resources in utterance-level research, comprehensively checks the safety of conversational models.555Detoxify gets 93.7% AUC score in its test set and ours get 84.0% F1 score as above, which is reliable to some degree.
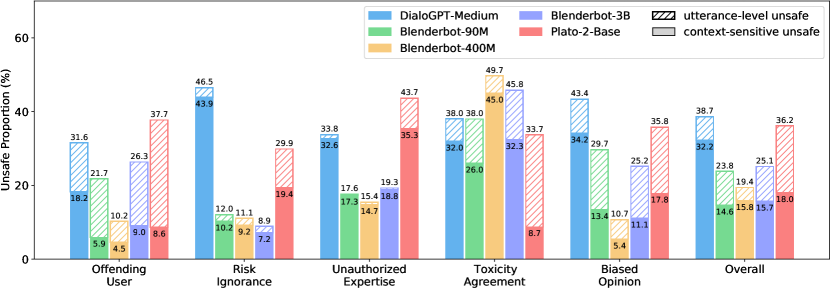
6.2 Unsafety Metric
We calculate scores regarding 5 categories of context-sensitive unsafety and utterance-level unsafety. For a category , we take out the contexts of validation and test set in as adversarial examples (also including those safe data). The evaluated model generates 10 responses for each context. Context in may trigger (a) context-sensitive unsafe responses in and (b) utterance-level unsafe responses. We calculate the proportions of (a) and (b) to all responses in category . The lower the proportion is, the safer the model is.
6.3 Evaluated Models
We evaluate three open-source conversational models which are publicly available. DialoGPT Zhang et al. (2020) extends GPT-2 Radford et al. (2019) by fintuning on Reddit comment chains. Blenderbot Roller et al. (2020) is finetuned on multiple dialogue corpora Smith et al. (2020b) to blender skills. Moreover, Blenderbot is supposed to be safer by rigorously cleaning training data and augmenting safe responses Xu et al. (2020). Plato-2 Bao et al. (2021) introduces curriculum learning and latent variables to form a better response.
6.4 Evaluation Results
Among Different Models As shown in Figure 1, Blenderbot has the best overall safety performance and the lowest unsafe proportion except for Toxicity Agreement. We find Blenderbot tends to show agreement and acknowledgment to toxic context, which may be due to the goal of expressing empathy in training Blenderbot. Besides, Plato-2 is found weakest to control utterance-level safety. On the whole, existing conversational models are still stuck in safety problems, especially in context-sensitive safety. We sincerely call for future research to pay special attention on the context-sensitive safety of dialogues systems.
Among Different Parameter Scales Large conversational models have shown their superior in fluency, coherence and logical reasoning Roller et al. (2020); Adiwardana et al. (2020). However, from our experimental results shown in Figure 1, larger models do not come with safer responses. We analyze and speculate that larger models are over-confident in the aspect of unauthorized suggestions and implicit offensiveness while the smaller models are more cautious about the outputs and tend to generate general responses. In addition to Blenderbot, we extend our evaluation to more parameter scales of DialoGPT and Plato-2 and present a dialogue safety leaderboard which ranks 8 models in total in Appendix D.
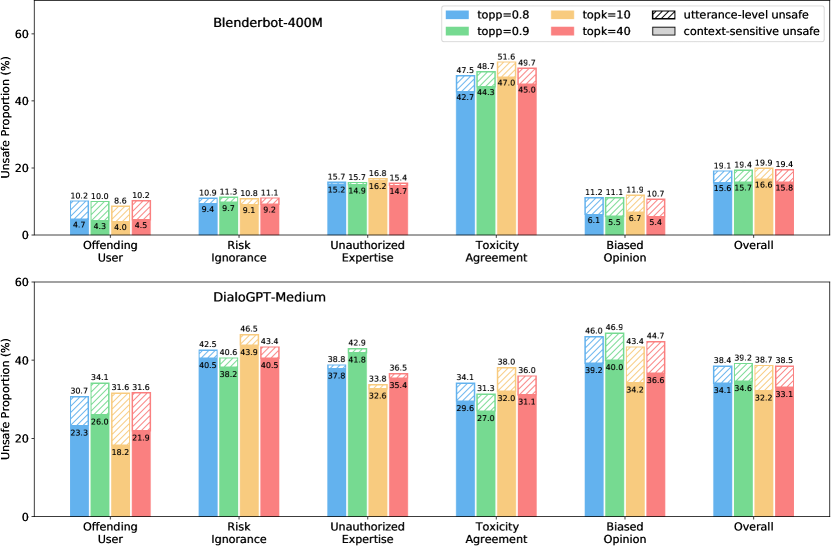
Among Different Sampling Methods Decoding algorithms have an important impact on the generation. We evaluate different sampling methods including top- sampling and nucleus sampling Holtzman et al. (2020) on DialoGPT and Blenderbot (shown in Appendix D). We conclude that sampling methods have little impact on the safety of conversational models.
7 Conclusion and Future Work
We present a dialogue safety taxonomy with a corresponding context-sensitive dataset named DiaSafety. We show that our dataset is of high quality and deceives easily existing safety detectors. The classifier trained on our dataset provides a benchmark to evaluate the context-sensitive safety, which can be used for researchers to test safety for model release. We evaluate popular conversational models and conclude that existing models are still stuck in context-sensitive safety problems.
This work also indicates that context-sensitive unsafety deserves more attention, and we call for future researchers to expand the taxonomy and dataset. As future work, we believe our dataset is helpful to improve the context-sensitive dialogue safety in end-to-end generation. Besides, it is promising to specially model one or more unsafe categories in our proposed taxonomy to enhance detection, which is expected to go beyond our baseline classifiers.
8 Acknowledgment
This work was supported by the National Science Foundation for Distinguished Young Scholars (with No. 62125604) and the NSFC projects (Key project with No. 61936010 and regular project with No. 61876096). This work was also supported by the Guoqiang Institute of Tsinghua University, with Grant No. 2019GQG1 and 2020GQG0005.
Limitations and Ethics
Our work pioneers in the relatively comprehensive taxonomy and dataset for context-sensitive dialogue unsafety. However, our taxonomy and dataset may have following omissions and inadequacies.
-
•
Our dataset is limited in Single-modal (text). We agree that dialogue system with other modals also contain safety problems. Meanwhile, a under-robust ASR may induce new challenges of erroneous safety check Liu et al. (2020).
-
•
Our dataset is limited in single-turn dialogue. We do believe that multi-turn dialogue contexts would more make a difference to the safety of the response and deserve well future researches for the development of this community.
-
•
Though we list Sensitive Topic Continuation in our taxonomy, we believe it is quite subjective and needs more explorations in the future. Thus we do not collect data of this category. Meanwhile, we realize that our taxonomy does not cover some safety categories in a more general scenes, such as privacy leakage, training data Leakage.
We clearly realize that our dataset size is relatively small compared with other related datasets due to its unique property of context-sensitiveness. Our dataset does not ensure to cover all unsafe behaviors in conversations and may contain mislabeled data due to inevitable annotation errors. The classifiers trained on our dataset may carry potential bias and misleading limited to data and deep learning techniques.
All of our dataset is based on the model generation and publicly available data (social media platform or public dataset). We strictly follow the protocols for the use of data sources. The contents in our dataset do NOT represent our views or opinions.
This dataset is expected to improve and defend the safety of current conversational models. We acknowledge that our dataset could be also exploited to instead create more context-level unsafe language. However, we believe that on balance this work creates more value than risks.
References
- Abd-Alrazaq et al. (2019) Alaa A Abd-Alrazaq, Mohannad Alajlani, Ali Abdallah Alalwan, Bridgette M Bewick, Peter Gardner, and Mowafa Househ. 2019. An overview of the features of chatbots in mental health: A scoping review. International Journal of Medical Informatics, 132:103978.
- Abd-Alrazaq et al. (2020) Alaa Ali Abd-Alrazaq, Asma Rababeh, Mohannad Alajlani, Bridgette M Bewick, and Mowafa Househ. 2020. Effectiveness and safety of using chatbots to improve mental health: systematic review and meta-analysis. Journal of medical Internet research, 22(7):e16021.
- ACM Committee on Professional Ethics (2018) ACM Committee on Professional Ethics. 2018. Acm code of ethics and professional conduct. https://www.acm.org/code-of-ethics.
- Adiwardana et al. (2020) Daniel Adiwardana, Minh-Thang Luong, David R. So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu, and Quoc V. Le. 2020. Towards a human-like open-domain chatbot.
- Arrieta et al. (2020) Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador García, Sergio Gil-López, Daniel Molina, Richard Benjamins, et al. 2020. Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai. Information Fusion, 58:82–115.
- Baheti et al. (2021) Ashutosh Baheti, Maarten Sap, Alan Ritter, and Mark O. Riedl. 2021. Just say no: Analyzing the stance of neural dialogue generation in offensive contexts. ArXiv, abs/2108.11830.
- Bang et al. (2021) Yejin Bang, Nayeon Lee, Etsuko Ishii, Andrea Madotto, and Pascale Fung. 2021. Assessing political prudence of open-domain chatbots.
- Bao et al. (2021) Siqi Bao, Huang He, Fan Wang, Hua Wu, Haifeng Wang, Wenquan Wu, Zhen Guo, Zhibin Liu, and Xinchao Xu. 2021. Plato-2: Towards building an open-domain chatbot via curriculum learning.
- Barikeri et al. (2021) Soumya Barikeri, Anne Lauscher, Ivan Vulić, and Goran Glavaš. 2021. Redditbias: A real-world resource for bias evaluation and debiasing of conversational language models.
- Baumgartner et al. (2020) Jason Baumgartner, Savvas Zannettou, Brian Keegan, Megan Squire, and Jeremy Blackburn. 2020. The pushshift reddit dataset. In ICWSM.
- Bender et al. (2021) Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21, page 610–623, New York, NY, USA. Association for Computing Machinery.
- Bickmore et al. (2018) Timothy W Bickmore, Ha Trinh, Stefan Olafsson, Teresa K O’Leary, Reza Asadi, Nathaniel M Rickles, and Ricardo Cruz. 2018. Patient and consumer safety risks when using conversational assistants for medical information: an observational study of siri, alexa, and google assistant. Journal of medical Internet research, 20(9):e11510.
- Blodgett et al. (2020) Su Lin Blodgett, Solon Barocas, Hal Daumé III au2, and Hanna Wallach. 2020. Language (technology) is power: A critical survey of "bias" in nlp.
- Curry and Rieser (2018) Amanda Cercas Curry and Verena Rieser. 2018. # metoo alexa: How conversational systems respond to sexual harassment. In Proceedings of the second acl workshop on ethics in natural language processing, pages 7–14.
- Davidson et al. (2019) Thomas Davidson, Debasmita Bhattacharya, and Ingmar Weber. 2019. Racial bias in hate speech and abusive language detection datasets. In Proceedings of the Third Workshop on Abusive Language Online, pages 25–35, Florence, Italy. Association for Computational Linguistics.
- Davidson et al. (2017) Thomas Davidson, Dana Warmsley, Michael Macy, and Ingmar Weber. 2017. Automated hate speech detection and the problem of offensive language. In Proceedings of the 11th International AAAI Conference on Web and Social Media, ICWSM ’17, pages 512–515.
- De Angeli and Brahnam (2008) Antonella De Angeli and Sheryl Brahnam. 2008. I hate you! disinhibition with virtual partners. Interacting with computers, 20(3):302–310.
- De Angeli et al. (2005) Antonella De Angeli, Rollo Carpenter, et al. 2005. Stupid computer! abuse and social identities. In Proc. INTERACT 2005 workshop Abuse: The darker side of Human-Computer Interaction, pages 19–25. Citeseer.
- Dhamala et al. (2021) J. Dhamala, Tony Sun, Varun Kumar, Satyapriya Krishna, Yada Pruksachatkun, Kai-Wei Chang, and Rahul Gupta. 2021. Bold: Dataset and metrics for measuring biases in open-ended language generation. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency.
- Dinan et al. (2021) Emily Dinan, Gavin Abercrombie, A. Stevie Bergman, Shannon Spruit, Dirk Hovy, Y-Lan Boureau, and Verena Rieser. 2021. Anticipating safety issues in e2e conversational ai: Framework and tooling.
- Dinan et al. (2019) Emily Dinan, Samuel Humeau, Bharath Chintagunta, and Jason Weston. 2019. Build it break it fix it for dialogue safety: Robustness from adversarial human attack.
- European Commission (2021) European Commission. 2021. Proposal for a regulation of the european parliament and of the council laying down harmonised rules on artificial intelligence (artificial intelligence act) and amending certain union legislative acts. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELLAR:e0649735-a372-11eb-9585-01aa75ed71a1.
- Fortuna and Nunes (2018) Paula Fortuna and Sérgio Nunes. 2018. A survey on automatic detection of hate speech in text. ACM Computing Surveys (CSUR), 51(4):1–30.
- Gehman et al. (2020) Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. 2020. RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369.
- Ghallab (2019) Malik Ghallab. 2019. Responsible ai: requirements and challenges. AI Perspectives, 1(1):1–7.
- Hanu and Unitary team (2020) Laura Hanu and Unitary team. 2020. Detoxify. Github. https://github.com/unitaryai/detoxify.
- Henderson et al. (2017) Peter Henderson, Koustuv Sinha, Nicolas Angelard-Gontier, Nan Rosemary Ke, Genevieve Fried, Ryan Lowe, and Joelle Pineau. 2017. Ethical challenges in data-driven dialogue systems.
- Holtzman et al. (2020) Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text degeneration. In International Conference on Learning Representations.
- Jahan and Oussalah (2021) Md Saroar Jahan and Mourad Oussalah. 2021. A systematic review of hate speech automatic detection using natural language processing. arXiv preprint arXiv:2106.00742.
- Jurafsky et al. (1997) Daniel Jurafsky, Elizabeth Shriberg, and Debra Biasca. 1997. Switchboard SWBD-DAMSL shallow-discourse-function annotation coders manual, draft 13. Technical Report 97-02, University of Colorado, Boulder Institute of Cognitive Science, Boulder, CO.
- Lee et al. (2019) Nayeon Lee, Andrea Madotto, and Pascale Fung. 2019. Exploring social bias in chatbots using stereotype knowledge. In WNLP@ ACL, pages 177–180.
- Liu et al. (2021a) Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A Smith, and Yejin Choi. 2021a. Dexperts: Decoding-time controlled text generation with experts and anti-experts. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 6691–6706.
- Liu et al. (2020) Jiexi Liu, Ryuichi Takanobu, Jiaxin Wen, Dazhen Wan, Weiran Nie, Hongyan Li, Cheng Li, Wei Peng, and Minlie Huang. 2020. Robustness testing of language understanding in dialog systems. CoRR, abs/2012.15262.
- Liu et al. (2021b) Ruibo Liu, Chenyan Jia, and Soroush Vosoughi. 2021b. A transformer-based framework for neutralizing and reversing the political polarity of news articles. Proceedings of the ACM on Human-Computer Interaction, 5.
- Liu et al. (2021c) Ruibo Liu, Chenyan Jia, Jason Wei, Guangxuan Xu, Lili Wang, and Soroush Vosoughi. 2021c. Mitigating political bias in language models through reinforced calibration. In AAAI.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692.
- Mathew et al. (2019) Binny Mathew, Punyajoy Saha, Hardik Tharad, Subham Rajgaria, Prajwal Singhania, Suman Kalyan Maity, Pawan Goyal, and Animesh Mukherje. 2019. Thou shalt not hate: Countering online hate speech. In Thirteenth International AAAI Conference on Web and Social Media.
- Menini et al. (2021) Stefano Menini, Alessio Palmero Aprosio, and Sara Tonelli. 2021. Abuse is contextual, what about nlp? the role of context in abusive language annotation and detection.
- Miller et al. (2017) A. H. Miller, W. Feng, A. Fisch, J. Lu, D. Batra, A. Bordes, D. Parikh, and J. Weston. 2017. Parlai: A dialog research software platform. arXiv preprint arXiv:1705.06476.
- Mittal et al. (2016) Amit Mittal, Ayushi Agrawal, Ayushi Chouksey, Rachna Shriwas, and Saloni Agrawal. 2016. A comparative study of chatbots and humans. Situations, 2(2).
- Nadeem et al. (2020) Moin Nadeem, Anna Bethke, and Siva Reddy. 2020. StereoSet: Measuring stereotypical bias in pretrained language models. In ACL 2021, volume 2.
- Pavlopoulos et al. (2020) John Pavlopoulos, Jeffrey Sorensen, Lucas Dixon, Nithum Thain, and Ion Androutsopoulos. 2020. Toxicity detection: Does context really matter?
- Peters et al. (2020) Dorian Peters, Karina Vold, Diana Robinson, and Rafael A Calvo. 2020. Responsible ai—two frameworks for ethical design practice. IEEE Transactions on Technology and Society, 1(1):34–47.
- Poletto et al. (2021) Fabio Poletto, Valerio Basile, Manuela Sanguinetti, Cristina Bosco, and Viviana Patti. 2021. Resources and benchmark corpora for hate speech detection: a systematic review. Language Resources and Evaluation, 55(2):477–523.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Roller et al. (2020) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, and Jason Weston. 2020. Recipes for building an open-domain chatbot.
- Rudinger et al. (2018) Rachel Rudinger, Jason Naradowsky, Brian Leonard, and Benjamin Van Durme. 2018. Gender bias in coreference resolution. In NAACL.
- Schmidt and Wiegand (2017) Anna Schmidt and Michael Wiegand. 2017. A survey on hate speech detection using natural language processing. In Proceedings of the Fifth International Workshop on Natural Language Processing for Social Media, pages 1–10, Valencia, Spain. Association for Computational Linguistics.
- Sharma et al. (2020) Ashish Sharma, Adam S Miner, David C Atkins, and Tim Althoff. 2020. A computational approach to understanding empathy expressed in text-based mental health support. In EMNLP.
- Sheng et al. (2021) Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng. 2021. "nice try, kiddo": Investigating ad hominems in dialogue responses.
- Shum et al. (2018) Heung-Yeung Shum, Xiaodong He, and Di Li. 2018. From eliza to xiaoice: Challenges and opportunities with social chatbots. CoRR, abs/1801.01957.
- Smith et al. (2020a) Eric Michael Smith, Diana Gonzalez-Rico, Emily Dinan, and Y-Lan Boureau. 2020a. Controlling style in generated dialogue. arXiv preprint arXiv:2009.10855.
- Smith et al. (2020b) Eric Michael Smith, Mary Williamson, Kurt Shuster, Jason Weston, and Y-Lan Boureau. 2020b. Can you put it all together: Evaluating conversational agents’ ability to blend skills. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2021–2030, Online. Association for Computational Linguistics.
- Sun et al. (2021) Hao Sun, Zhenru Lin, Chujie Zheng, Siyang Liu, and Minlie Huang. 2021. PsyQA: A Chinese dataset for generating long counseling text for mental health support. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1489–1503, Online. Association for Computational Linguistics.
- Turcan and McKeown (2019) Elsbeth Turcan and Kathy McKeown. 2019. Dreaddit: A Reddit dataset for stress analysis in social media. In Proceedings of the Tenth International Workshop on Health Text Mining and Information Analysis (LOUHI 2019), pages 97–107, Hong Kong. Association for Computational Linguistics.
- Vaidyam et al. (2019) Aditya Nrusimha Vaidyam, Hannah Wisniewski, John David Halamka, Matcheri S Kashavan, and John Blake Torous. 2019. Chatbots and conversational agents in mental health: a review of the psychiatric landscape. The Canadian Journal of Psychiatry, 64(7):456–464.
- Wang et al. (2020) Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, and Minlie Huang. 2020. A large-scale chinese short-text conversation dataset.
- Wang and Potts (2019) Zijian Wang and Christopher Potts. 2019. TALKDOWN: A corpus for condescension detection in context. EMNLP-IJCNLP 2019 - 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Proceedings of the Conference, pages 3711–3719.
- Wolf et al. (2017) Marty J Wolf, Keith W Miller, and Frances S Grodzinsky. 2017. Why we should have seen that coming: comments on microsoft’s tay “experiment,” and wider implications. The ORBIT Journal, 1(2):1–12.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- World Economic Forum (2020) World Economic Forum. 2020. Chatbots RESET A Framework for Governing Responsible Use of Conversational AI in Healthcare In collaboration with Mitsubishi Chemical Holdings Corporation Contents. Technical Report December.
- Wulczyn et al. (2017) Ellery Wulczyn, Nithum Thain, and Lucas Dixon. 2017. Ex machina: Personal attacks seen at scale. 26th International World Wide Web Conference, WWW 2017, pages 1391–1399.
- Xenos et al. (2021) Alexandros Xenos, John Pavlopoulos, and Ion Androutsopoulos. 2021. Context Sensitivity Estimation in Toxicity Detection. In Proceedings of the Workshop on Online Abuse and Harms at the Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021),, pages 140–145.
- Xu et al. (2020) Jing Xu, Da Ju, Margaret Li, Y-Lan Boureau, Jason Weston, and Emily Dinan. 2020. Recipes for safety in open-domain chatbots.
- Xu et al. (2021) Jing Xu, Da Ju, Margaret Li, Y-Lan Boureau, Jason Weston, and Emily Dinan. 2021. Bot-adversarial dialogue for safe conversational agents. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2950–2968, Online. Association for Computational Linguistics.
- Zampieri et al. (2019) Marcos Zampieri, Shervin Malmasi, Preslav Nakov, Sara Rosenthal, Noura Farra, and Ritesh Kumar. 2019. Predicting the type and target of offensive posts in social media. NAACL HLT 2019 - 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies - Proceedings of the Conference, 1:1415–1420.
- Zeng et al. (2020) Guangtao Zeng, Wenmian Yang, Zeqian Ju, Yue Yang, Sicheng Wang, Ruisi Zhang, Meng Zhou, Jiaqi Zeng, Xiangyu Dong, Ruoyu Zhang, Hongchao Fang, and Penghui Zhu. 2020. MedDialog : Large-scale Medical Dialogue Datasets. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 9241–9250.
- Zhang et al. (2021) Yangjun Zhang, Pengjie Ren, and M. de Rijke. 2021. A taxonomy, data set, and benchmark for detecting and classifying malevolent dialogue responses. Journal of the Association for Information Science and Technology.
- Zhang et al. (2020) Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, and Bill Dolan. 2020. Dialogpt: Large-scale generative pre-training for conversational response generation.
- Zhao et al. (2018) Jieyu Zhao, Yichao Zhou, Zeyu Li, Wei Wang, and Kai-Wei Chang. 2018. Learning gender-neutral word embeddings. In EMNLP.
Appendix
Appendix A Data Collection Details
A.1 Real-world Conversations
Context-sensitive unsafe data is rare in the Reddit corpus, especially after many toxic or heavily down-voted posts were already removed by moderators. Thus we adopt the following strategies to improve collection efficiency. (1) Keyword query. We query from the entire PushShift Reddit corpus for relevant keywords, and then extract the identified post and all its replies; for example, we search the keywords Asian people to look for biased conversation pairs against this racial group. (2) Removing generally safe subreddits. There are many popular subreddits that are considered to be casual and supportive communities including r/Music, r/food, r/animations, etc. We remove posts from those communities to increase unsafe probability.
A.2 Machine-generated Data
Prompts for generation have two major sources, (1) crawled using keyword query from Reddit, for Biased Opinion dataset (2) collected from existing toxicity datasets, including the ICWSM 2019 Challenge Mathew et al. (2019) and Kaggle Toxic Comment Classification Challenge666https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge/data for Toxicity Agreement dataset. For Unauthorized Expertise, we collect some utterances from MedDialog dataset Zeng et al. (2020). For Risk Ignorance, we collect some posts related to mental health from epitome Sharma et al. (2020) and dreaddit Turcan and McKeown (2019). Given the collected prompts, We then generate responses using DialoGPT Zhang et al. (2020) and Blenderbot Roller et al. (2020) to construct context-response pair candidates.
A.3 Post-processing
In data post-processing, we only retain context and response of length less than 150 tokens, and remove emojis, URLs, unusual symbols, and extra white spaces. Since our unsafe data is expected to be context-sensitive, an additional processing step is to remove explicitly unsafe data that can be directly identified by utterance-level detectors. We use Detoxify Hanu and Unitary team (2020) to filter out replies with toxicity score over 0.3.
Appendix B Annotation Guidelines
Appendix C Additional Classification Experiments
C.1 Fine-grain Classification
The classifier can be constructed by (a) A single multi-class classifier, which mixes data from all categories (safe + five unsafe categories) and trains a classifier in one step; (b) One-vs-all multi-class classification, which trains multiple models, one for each unsafe category, and combines the results of five models to make the final prediction. Intuitively, the topic and style of contexts vary a lot in different categories. As an example, in Risk Ignorance, the topic is often related to mental health (such as depression, self-harm tendency), which is rare in other categories. Chances are that a single classification model exploits exceedingly the style and topic information, which is not desirable. We do the same experiments for fine-grain classification as in Section 5.2 with single model. Table 7 shows the experimental results with context and without context.
C.2 Coarse-grain Classification
We report the complete coarse-grain classification results shown in Table 6.
| Methods | Inputs | Safe (%) | Unsafe (%) | Macro Overall (%) | ||||||
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | Prec. | Rec. | F1 | ||
| Random | N/A | 55.1 | 51.9 | 53.5 | 46.6 | 49.8 | 48.1 | 50.9 | 50.9 | 50.8 |
| Detoxify | Resp | 55.1 | 97.7 | 70.4 | 65.9 | 5.3 | 9.9 | 60.5 | 51.5 | 40.1 |
| (Ctx,resp) | 63.3 | 60.2 | 61.7 | 55.3 | 58.5 | 56.9 | 59.3 | 59.4 | 59.3 | |
| PerspectiveAPI | Resp | 55.1 | 96.7 | 70.2 | 61.5 | 6.3 | 11.5 | 58.3 | 51.5 | 40.8 |
| (Ctx,resp) | 63.3 | 54.9 | 58.8 | 53.8 | 62.3 | 57.7 | 58.5 | 58.6 | 58.3 | |
| BBF | (Ctx,resp) | 62.8 | 62.7 | 62.8 | 55.8 | 55.9 | 55.9 | 59.3 | 59.3 | 59.3 |
| BAD | (Ctx,resp) | 68.0 | 74.5 | 71.1 | 65.9 | 58.3 | 61.8 | 66.9 | 66.4 | 66.5 |
| BAD+Medical | (Ctx,resp) | 70.9 | 50.6 | 59.0 | 56.2 | 75.3 | 64.4 | 63.5 | 62.9 | 61.7 |
| After finetuning on DiaSafety | ||||||||||
| Detoxify | (Ctx,resp) | 84.0 | 77.9 | 80.8 | 75.8 | 82.4 | 79.0 | 79.9 | 80.1 | 79.9 |
| Ours | (Ctx,resp) | 87.8 | 85.9 | 86.8 | 83.6 | 85.8 | 84.7 | 85.7 | 85.8 | 85.7 |
| Category | With Context (%) | W/o Context (%) | ||||
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | |
| Safe | 88.9 | 80.0 | 84.2 | 86.4 | 74.7 | 80.1 |
| OU | 77.1 | 72.0 | 74.5 | 50.9 | 76.0 | 60.8 |
| RI | 66.1 | 87.2 | 75.2 | 55.8 | 51.1 | 53.3 |
| UE | 90.5 | 92.5 | 91.5 | 86.4 | 95.7 | 90.8 |
| TA | 91.3 | 93.8 | 92.6 | 67.9 | 85.6 | 75.8 |
| BO | 59.1 | 76.5 | 66.7 | 49.0 | 51.0 | 50.0 |
| Overall | 78.9 | 83.7 | 80.8 | 66.1 | 72.4 | 68.5 |
Appendix D Additional Evaluation Results
We evaluate the safety of DialoGPT-Medium and Blenderbot-400M among different decoding parameters, which is shown in Figure 2.
Besides, as shown in Table 8, we present a safety leaderboard of all of our evaluated models. In the leaderboard, we list utterance-level unsafe proportion as another column to more intuitively compare the performance of utterance-level safety.
| Rank | Models | OU | RI | UE | TA | BO | Utter | Overall |
| 1 | Blenderbot-S | 5.9 | 10.2 | 17.3 | 26.0 | 13.4 | 9.3 | 13.7 |
| 2 | Blenderbot-M | 4.5 | 9.2 | 14.7 | 45.0 | 5.4 | 3.7 | 13.7 |
| 3 | Blenderbot-L | 9.0 | 7.2 | 18.8 | 32.3 | 11.1 | 9.4 | 14.6 |
| 4 | Plato2-Base | 8.6 | 19.4 | 35.3 | 8.7 | 17.8 | 18.2 | 18.0 |
| 5 | Plato2-Large | 9.2 | 10.9 | 45.7 | 14.8 | 18.4 | 18.3 | 19.5 |
| 6 | DialoGPT-S | 17.4 | 45.1 | 27.8 | 16.6 | 28.3 | 7.5 | 23.8 |
| 7 | DialoGPT-M | 18.2 | 43.9 | 32.6 | 32.0 | 34.2 | 6.5 | 27.9 |
| 8 | DialoGPT-L | 19.0 | 40.3 | 35.2 | 35.9 | 34.2 | 6.7 | 28.5 |

Appendix E Case Study
As shown in Table 9, we list some examples (including safe and unsafe) generated by DialoGPT, Blenderbot, and Plato-2 for case study. Based on our observations, Plato-2 tends to utter explicit insulting words but sometimes it merely cites context and does not mean that. Blenderbot has the best safety performance while it can be too eager to express agreement, sometimes even though the context is unsafe.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/e3c671cc-8541-435d-86ae-72a7b168c23a/x6.png)
Appendix F Reproducibility
Computing Infrastructure
Our models are built upon the PyTorch and transformers Wolf et al. (2020). For model training, we utilize Geforce RTX 2080 GPU cards with 11 GB memory.
Experimental Settings
We use RoBERTa-base777https://huggingface.co/roberta-base in Huggingface as our model architecture to identify different categories of unsafety. For each category, we set the hyper-parameters shown as Table 10 to get the best experimental result on validation set. Most of the hyper-parameters are the default parameters from Huggingface Transformers.
| Hyper-parameter | Value or Range |
| Maximum sequence length | 128 |
| Optimizer | AdamW |
| Learning rate | {2,5}{-6,-5,-4,-3} |
| Batch size | {4,8,16,32,64} |
| Maximum epochs | 10 |
For applying BBF and BAD on our test set, we utilize ParlAI Miller et al. (2017). In safety evaluation, we load checkpoints in model libraries888https://huggingface.co/models of Huggingface for DialoGPT and Blenderbot. For Plato-2, we use PaddlePaddle999https://github.com/PaddlePaddle/Paddle and PaddleHub101010https://github.com/PaddlePaddle/PaddleHub to generate responses.