On the unification of the graph edit distance and graph matching problems
Abstract
Error-tolerant graph matching gathers an important family of problems. These problems aim at finding correspondences between two graphs while integrating an error model. In the Graph Edit Distance (GED) problem, the insertion/deletion of edges/nodes from one graph to another is explicitly expressed by the error model. At the opposite, the problem commonly referred to as “graph matching” does not explicitly express such operations. For decades, these two problems have split the research community in two separated parts. It resulted in the design of different solvers for the two problems. In this paper, we propose a unification of both problems thanks to a single model. We give the proof that the two problems are equivalent under a reformulation of the error models. This unification makes possible the use on both problems of existing solving methods from the two communities.
Keywords— Graph edit distance, graph matching, error-correcting graph matching, discrete optimization
1 Introduction
Graphs are frequently used in various fields of computer science, since they constitute a universal modeling tool which allows the description of structured data. The handled objects and their relations are described in a single and human-readable formalism. Hence, tools for graphs supervised classification and graph mining are required in many applications such as pattern recognition (Riesen, 2015), chemical components analysis, transfer learning (Das and Lee, 2018). In such applications, comparing graphs is of first interest. The similarity or dissimilarity between two graphs requires the computation and the evaluation of the “best” matching between them. Since exact isomorphism rarely occurs in pattern analysis applications, the matching process must be error-tolerant, i.e., it must tolerate differences on the topology and/or its labeling. The Graph Edit Distance (GED)(Riesen, 2015) problem and the Graph Matching problem (GM) (Swoboda et al., 2017) provide two different error models. These two problems have been deeply studied but they have split the research community into two groups of people developing separately quite different methods.
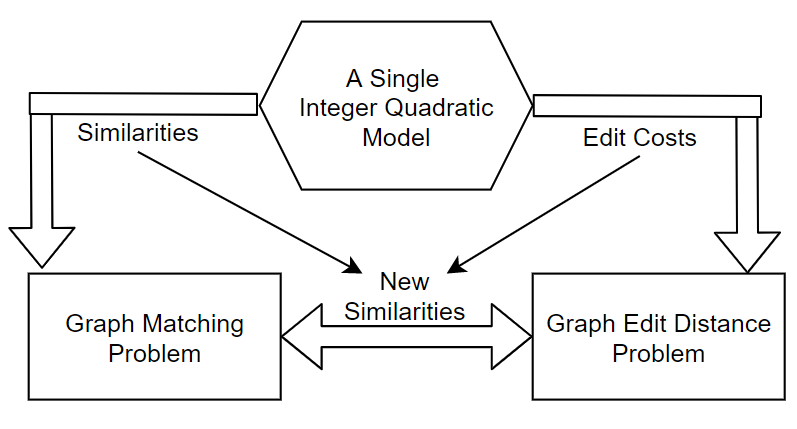
In this paper, we propose to unify the GED problem and the GM problem in order to unify the work force in terms of methods and benchmarks. We show that the GED problem can be equivalent to the GM problem under certain (permissive) conditions. The paper is organized as follows: Section 2, we give the definitions of the problems. Section 3, the state of the art on GM and GED is presented along with the literature comparing GED and GM to other problems. Section 4, a specific related work is detailed since it is the basement of our reasoning. Section 5, our proposal is described and a proof is given. Section 6, experimental results are presented to validate empirically our proposal. Finally, conclusions are drawn.
2 Definitions and problems
In this section, we define the problems to be studied. An attributed graph is considered as a set of 4 tuples (,,,) such that: = (,,,). is a set of vertices. is a set of edges such as . is a vertex labeling function which associates a label to a vertex. is an edge labeling function which associates a label to an edge.
2.1 Graph matching problem
The objective of graph matching is to find correspondences between two attributed graphs and . A solution of graph matching is defined as a subset of possible correspondences , represented by a binary assignment matrix , where and denote the number of nodes in and , respectively. If matches , then , and otherwise. We denote by , a column-wise vectorized replica of . With this notation, graph matching problems can be expressed as finding the assignment vector that maximizes a score function as follows:
Model 1.
Graph matching model (GMM)
| (1a) | ||||
| subject to | (1b) | |||
| (1c) | ||||
| (1d) | ||||
The function measures the similarity of graph attributes, and is typically decomposed into a first order similarity function for a node pair and , and a second-order similarity function for an edge pair and . Thus, the objective function of graph matching is defined as:
| (2) | ||||
In essence, the score accumulates all the similarity values that are relevant to the assignment. The GM problem has been proven to be -hard by (Garey and Johnson, 1979).
2.2 Graph Edit Distance
The graph edit distance (GED) was first reported in (Tsai et al., 1979). GED is a dissimilarity measure for graphs that represents the minimum-cost sequence of basic editing operations to transform a graph into another graph by means classically included operations: insertion, deletion and substitution of vertices and/or edges. Therefore, GED can be formally represented by the minimum cost edit path transforming one graph into another. Edge operations are taken into account in the matching process when substituting, deleting or inserting their adjacent vertices. From now on and for simplicity, we denote the substitution of two vertices and by (), the deletion of vertex by () and the insertion of vertex by (). Likewise for edges and , () denotes edges substitution, () and () denote edges deletion and insertion, respectively.
An edit path () is a set of edit operations . This set is referred to as Edit Path and it is defined in Definition 1.
Definition 1.
Edit Path
A set of edit operations that transform completely into is called an (complete) edit path.
Let be the cost function measuring the strength of an edit operation . Let be the set of all possible edit paths (). The graph edit distance problem is defined by Problem 3.
Problem 1.
Graph Edit Distance
Let = (,,,) and = (,,,) be two graphs, the graph edit distance between and is defined as:
| (3) |
The GED problem is a minimization problem and is the best distance. In its general form, the GED problem (Problem 3) is very versatile. The problem has to be refined to cope with the constraints of an assignment problem. First, let us define constraints on edit operations in Definition 2.
Definition 2.
Edit operations constraints
-
1.
Deleting a vertex implies deleting all its incident edges.
-
2.
Inserting an edge is possible only if the two vertices already exist or have been inserted.
-
3.
Inserting an edge must not create more than one edge between two vertices.
Second, let us define constraints on edit paths ) in Definition 3. This type of constraint prevents the edit path to be composed of an infinite number of edit operations.
Definition 3.
Edit path constraints
-
1.
is a finite positive integer.
-
2.
A vertex/edge can have at most one edit operation applied on it.
Finally, let us define the topological constraint in Definition 4. This type of constraints avoids edges to be matched without respect to their adjacent vertices.
Definition 4.
Topological constraint
The topological constraint implies that matching (substituting) two edges and is valid if and only if their incident vertices are matched and .
An important property of the GED can be inferred from the topological constraint defined in Definition 4.
Property 1.
The edges matching are driven by the vertices matching
Assuming that constraint defined in Definition 4 is satisfied then three cases can appear :
Case 1: If there is an edge = and an edge = , edges substitution between and is performed (i.e., ()).
Case 2: If there is an edge = and there is no edge between and then an edge deletion of is performed (i.e., ()).
Case 3: If there is no edge between and and there is an edge between and an edge = then an edge insertion of is performed (i.e., ()).
2.3 Related problems and models
GED and GM problems fall into the family of error-tolerant graph matching problems. GED and GM problems can be equivalent to another problem called Quadratic Assignment Problem (QAP) (Bougleux et al., 2017; Cho et al., 2013). In addition, GED and GM problems can be equivalent to a constrained version of the Maximum a posteriori (MAP)-inference problem of a Conditional Random Field (CRF) (Swoboda et al., 2017). All these problems can be expressed by mathematical models. A mathematical model is composed of variables, constraints and an objective functions. A single problem can be expressed by many different models. An Integer Quadratic Program (IQP) is a model with a quadratic objective function of the variables and linear constraints of the variables. We chose to present the GM problem as an IQP (Model 1). At the opposite, an Integer Linear Program (ILP) is a mathematical model where the objective function is a linear combination of the variables. The objective function is constrained by linear combinations of the variables.
3 State of the art
In this section, the state of the art is presented. First, the solution methods for GED and GM are described. Finally, papers comparing GED to other matching problems are mentioned.
3.1 State of the art on GM and GED
The GED and GM problems have been proven to be -hard. So, unless , solving the problem to optimality cannot be done in polynomial time of the size of the input graphs. Consequently, the runtime complexity of exact methods is not polynomial but exponential with respect to the number of vertices of the graphs. On the other hand, heuristics are used when the demand for low computational time dominates the need to obtain optimality guarantees.
GM methods
Many solver paradigms were put to the test for GM. These include relaxations based on Lagrangean decompositions (Swoboda et al., 2017; Torresani et al., 2013), convex/concave quadratic (Liu and Qiao, 2014) (GNCCP) and semi-definite programming (Schellewald and Schnörr, 2005) , which can be used either directly to obtain approximate solutions or just to provide lower bounds. To tighten these bounds several cutting plane methods were proposed (Bazaraa and Sherali, 1982). On the other side, various primal heuristics, both (i) deterministic, such as graduated assignment methods (Gold and Rangarajan, 1996), fixed point iterations (Leordeanu et al., 2009) (IPFP), spectral technique and its derivatives (Cour et al., 2007; Leordeanu and Hebert, 2005) and (ii) non-deterministic (stochastic), like random walk (Cho et al., 2010) were proposed to provide approximate solutions to the problem. Many of these methods were published in TPAMI, NIPS, CVPR, ICCV.
GED methods
Exact GED algorithms were proposed based on tree search (Tsai et al., 1979; Riesen et al., 2007; Abu-Aisheh et al., 2015). Another way to build exact methods is to model the problem by Integer Linear Programs. Then, a black box solver is used to obtain solutions (Justice and Hero, 2006; Lerouge et al., 2017). In addition, the GED community worked on simplifications of the GED problem to the Linear Sum Assignment Problem (LSAP) (Bougleux et al., 2017; Serratosa, 2015; Riesen and Bunke, 2009). The GED problem was modeled as a QAP (Bougleux et al., 2017). Let us named this model GEDQAP. The GEDQAP model has extra variables to cope with the insertion and deletions cases and all costs are represented by a matrix . The cost matrix can be decomposed as follows into four blocks of size . The left upper block of the matrix contains all possible edge substitutions, the diagonal of the right upper matrix represents the cost of all possible edge deletions and the diagonal of the bottom left corner contains all possible edge insertions. Finally, the bottom right block elements cost is set to a large constant which concerns the matching of edges. The GEDQAP model has variables and constraints. The cost matrix size is . Based on this GEDQAP model, modified versions of IPFP (Bougleux et al., 2017) and GNCCP (Bougleux et al., 2017) were proposed. Finally, many GED methods were published in PRL, PR, Image and Vision Computing, GbR, SSPR.
3.2 State of the art on comparing GED problems to others
Neuhaus and Bunke (Neuhaus and Bunke., 2007) have shown that if each operation cost satisfies the criteria of a distance (positivity, uniqueness, symmetry, triangular inequality) then the edit distance defines a metric between graphs and it can be inferred that if . Furthermore, it has been shown that standard concepts from graph theory, such as graph isomorphism, subgraph isomorphism, and maximum common subgraph, are special cases of the GED problem under particular cost functions (Bunke, 1997, 1999; Brun et al., 2012).
Deadlocks, contributions and motivations
From the literature, two main deadlocks can be drawn. First, GED and GM problems split the research community in two parts. People working on GED do not work on GM and vice and versa. They do not contribute to the same journals and conferences. Second, these two communities do not use the same methods to solve their problem while they have mainly the same applications fields (computer vision, chemoinformatics, …). Researchers working on GM problems have concentrated their efforts on the QAP and MAP-inference solvers (Frank-Wolfe like methodology (Leordeanu et al., 2009; Liu and Qiao, 2014), Lagrangian decomposition methods (Swoboda et al., 2017; Torresani et al., 2013), …). On the other hand, the community working on the GED problem has favored LSAP-based and tree-based methods.
Our motivation is to gather people working on GED and GM problems because methods and benchmarks built from one community could help the other. A first step forward has been done by (Bougleux et al., 2017) by modelling the GED problem as a specific QAP and using modified solvers from the graph matching community. However, our proposal stands apart from their work because we propose a single model to express the GM and the GED problems. In this direction, we propose more investigations to compare GED and GM problems. We propose a theoretical study to relate GM and GED problems. Our contribution is to prove that GED and GM problems are equivalent in terms of solutions under a reformulation of the similarity function. Consequently, all the methods solving the GM problem can be used to solve the GED problems.
4 Related works: Integer Linear Program for GED
In (Lerouge et al., 2017), an ILP was proposed to model the GED problem. This model will play an important role in our proposal so we propose to give a brief definition of this model. For each type of edit operation, a set of corresponding binary variables is defined in Table 1.
| Name | Card | Role |
|---|---|---|
| =1 if is substituted with | ||
| =1 if is substituted with | ||
| =1 if is deleted from | ||
| =1 if is deleted from | ||
| =1 if is inserted in | ||
| =1 if is inserted in |
The objective function (4) is the overall cost induced by an edit path that transforms a graph into a graph . In order to get the graph edit distance between and , this objective function must be minimized.
| (4) | ||||
Now, the constraints are presented. They are mandatory to guarantee that the admissible solutions of the ILP are edit paths that transform in . The constraint (5a) ensures that each vertex of is either mapped to exactly one vertex of or deleted from , while the constraint (5b) ensures that each vertex of is either mapped to exactly one vertex of or inserted in :
| (5a) | |||
| (5b) | |||
The same applies for edges:
| (6a) | |||
| (6b) | |||
The topological constraints defined in Definition 4 can be expressed with the following constraints (7) and (8):
and can be mapped only if their head vertices are mapped:
| (7) |
and can be mapped only if their tail vertices are mapped:
| (8) |
The insertions and deletions variables , , and help the reader to understand how the objective function and the constraints were obtained, but they are unnecessary to solve the GED problem. In the equation (4), the variables are replaced by their expressions deduced from the equations (5a), (5b), (6a) and (6b). For instance, from the equation (5a), the variable is deduced: and replaced in the equation (4), the part of the objective function concerned by variable becomes:
| (9) | ||||
Consequently, a new objective function is expressed as follows:
| (10) | ||||
Equation (10) shows that the GED can be obtained without explicitly computing the variables . Once the formulation solved, all insertion and deletion variables can be a posteriori deduced from the substitution variables.
The vertex mapping constraints (5a) and (5b) are transformed into inequality constraints, without changing their role in the program. As a side effect, it removes the and variables from the constraints:
| (11) |
| (12) |
In fact, the insertions and deletions variables and of the equations (5a) and (5b) can be seen as slack variables to transform inequality constraints to equalities and consequently providing a canonical form. The entire formulation is called F2 and described as follows :
Model 2.
F2
| (13a) | ||||
| subject to | (13b) | |||
| (13c) | ||||
| (13d) | ||||
| (13e) | ||||
| with | (13f) | |||
| (13g) | ||||
5 Proposal on the unification of the two problems
In this paragraph, we propose to draw a relation between the graph matching and graph edit distance problems. Especially, we create a link between both problems through a change of similarity functions. Our proposal can be stated as follows:
Proposition 1.
GM and GED problems are equivalent in terms of solutions under a reformulation of the similarity function and
To intuitively demonstrate the exactness of the proposition, we proceed as follows :
-
1.
We start from the GED problem expressed by model F2 (see Model 13).
-
2.
We link the similarity function with the cost function thanks to a new similarity function .
-
3.
With this similarity function , we show that F2 turns to be a maximization problem and we call this new model F2’.
-
4.
F2’ is modified by switching from a linear to a quadratic model called GMM’.
-
5.
GMM’ is identical to GMM. It is sufficient to show that both models express the same problem, that is to say, the graph matching problem.
Proof.
-
1.
By setting and , we can rewrite the objective function of F2 as follows :
(14) -
2.
does not depend on variables so it does not impact the optimization problem. Therefore can be removed.
-
3.
By setting and similarly, , we can rewrite the objective function of the model F2 to obtain .
(15) -
4.
In a general way, minimizing is equivalent to maximize -. So, minimizing is equivalent to maximize .
-
5.
The linear objective function can be turned into a quadratic function by removing variables and replacing them by product of variables.
(16) -
6.
Topological constraints (Equations (13d) and (13e)) in F2 are not necessary anymore and they can be removed. The product of and is enough to ensure that an edge can be matched to an edge only if the head vertices and , on the one hand, and if the tail vertices and , on the other hand, are respectively matched.
-
7.
We obtain the new model named GMM’:
Model 3.
GMM’
(17a) subject to (17b) (17c) with (17d) -
8.
Model GMM’ = Model GMM. This was to be demonstrated. Proposition 1 is right.
∎
Under the condition of Proposition 1, the optimal assignment obtains when solving the graph matching problem can be used to reconstruct an optimal solution of the GED problem. An instance of GED and an instance of GM are presented in Figure 1. Solutions of the GED instance are presented with respect to the cost function while the graph matching solutions are presented with respect to the similarity function . The optimal matching of both instances are the same.
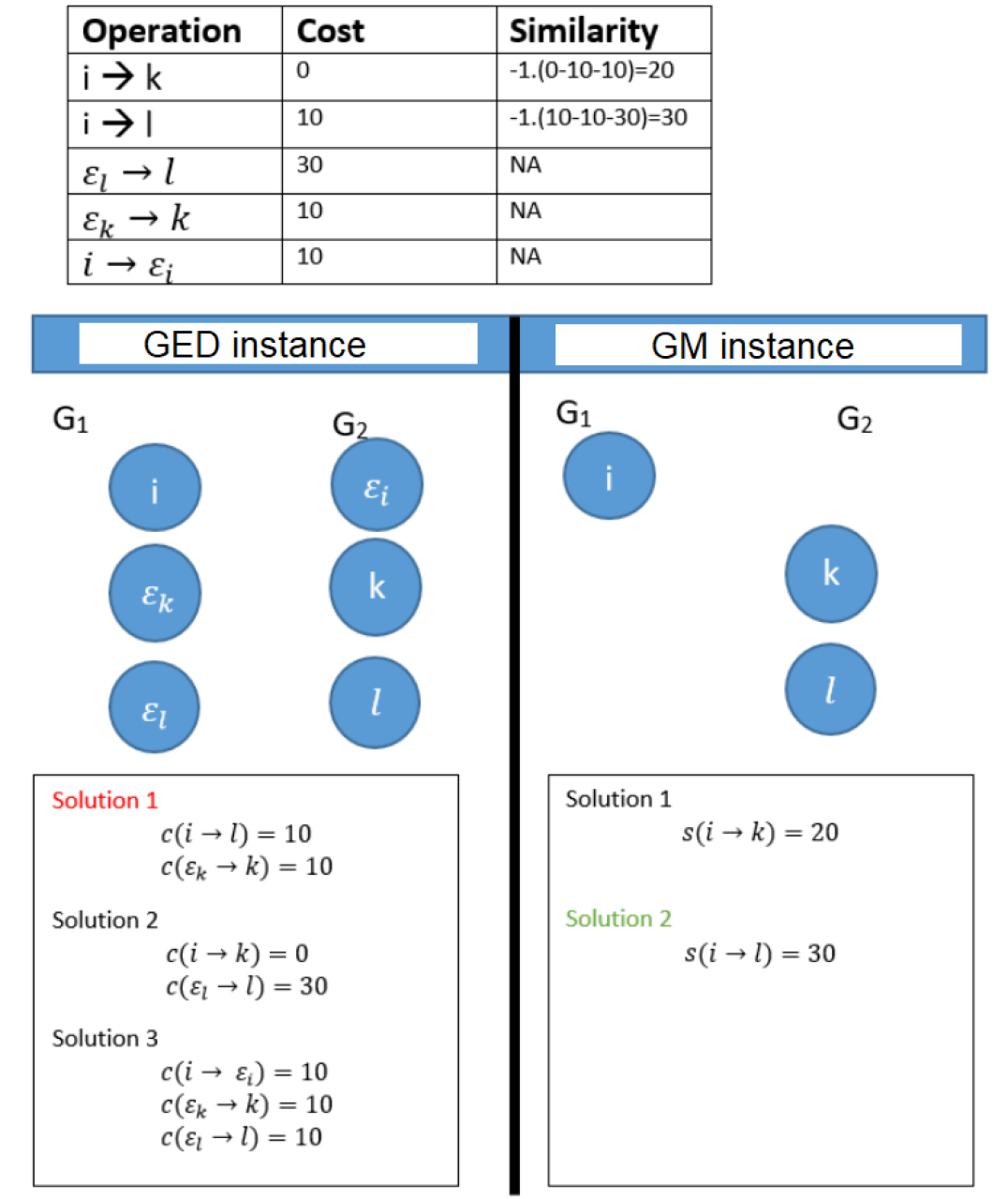
Model GMM’ has variables and constraints. Similarity functions can be represented by a similarity matrix of size is .
Proposition 1 is a first attempt toward the unification of two communities working respectively on GED and GM problems. All the methods solving the graph matching problem can be used to solve the graph edit distance problem under a specific similarity function .
6 Experiments
In this section, we show the results of our numerical experiments to validate our proposal that the model GMM’ can model the GED problem if . We based our protocol on the ICPR GED contest111 https://gdc2016.greyc.fr/ (Abu-Aisheh et al., 2017). Among the data sets available, we chose the GREC data set for two reasons. First, graphs sizes range from 5 to 20 nodes and these sizes are amendable to compute optimal solutions. Second, the GREC cost function, defined in the contest, is complex enough to cover a large range of matching cases. This cost function is not a constant value and includes euclidean distances between point coordinates. The reader is redirected to (Abu-Aisheh et al., 2017) for the full definition of the cost function. From the GREC database, we chose the subset of graphs called ”MIXED” because it holds 10 graphs of various sizes. We computed all the pairwise comparisons to obtain 100 solutions. We compared the optimal solutions obtained by our Model GMM’ and the optimal solutions found by the straightforward ILP formulation called F1 (Lerouge et al., 2017). We computed the average difference between the GED values and the objective function values of our model GMM’. The average difference is exactly equal to zero. This result corroborates our theoretical statement. Detailed results and codes can be found on the website https://sites.google.com/view/a-single-model-for-ged-and-gm.
7 Conclusion
In this paper, an equivalence between graph matching and graph edit distance problems was proven under a reformulation of the similarity functions between nodes and edges. These functions should take into account explicitly the deletion and insertion costs. That’s the major difference between GM and GED problems. In the GED problem, costs to delete or to insert vertices or edges are explicitly introduced in the error model. On the other hand, deletion costs are implicitly set to a specific value (that is to say 0) in the GM problem. Many learning methods aim at learning edit costs (Serratosa, 2020; Martineau et al., 2020) or matching similarities (Zanfir and Sminchisescu, 2018; Caetano et al., 2007). Learned matching similarities may include implicitly deletion and insertion costs. Does it help the learning algorithm to learn separately insertion and deletion costs? That is still an open question. However, with this paper, we stand for a rapprochement of the research communities that work on learning graph edit distance and learning graph matching because edit costs can be hidden in the learned similarities.
References
- Riesen (2015) K. Riesen, Structural Pattern Recognition with Graph Edit Distance - Approximation Algorithms and Applications, Advances in Computer Vision and Pattern Recognition, Springer, 2015.
- Das and Lee (2018) D. Das, C. G. Lee, Sample-to-sample correspondence for unsupervised domain adaptation, Engineering Applications of Artificial Intelligence 73 (2018) 80 – 91.
- Swoboda et al. (2017) P. Swoboda, C. Rother, H. Abu Alhaija, D. Kainmuller, B. Savchynskyy, A study of lagrangean decompositions and dual ascent solvers for graph matching, in: CVPR, 2017.
- Garey and Johnson (1979) M. R. Garey, D. S. Johnson, Computers and Intractability; A Guide to the Theory of NP-Completeness, W. H. Freeman Co., USA, 1979.
- Tsai et al. (1979) W.-h. Tsai, S. Member, K.-s. Fu, Pattern Deformational Model and Bayes Error-Correcting Recognition System, IEEE Transactions on Systems, Man, and Cybernetics 9 (1979) 745–756.
- Zeng et al. (2009) Z. Zeng, A. K. H. Tung, J. Wang, J. Feng, L. Zhou, Comparing stars: On approximating graph edit distance, PVLDB 2 (2009) 25–36.
- Bougleux et al. (2017) S. Bougleux, L. Brun, V. Carletti, P. Foggia, B. Gauzere, M. Vento, Graph edit distance as a quadratic assignment problem, Pattern Recognition Letters 87 (2017) 38 – 46. Advances in Graph-based Pattern Recognition.
- Cho et al. (2013) M. Cho, K. Alahari, J. Ponce, Learning graphs to match, in: ICCV, 2013, pp. 25–32.
- Torresani et al. (2013) L. Torresani, V. Kolmogorov, C. Rother, A dual decomposition approach to feature correspondence, TPAMI 35 (2013) 259–271.
- Liu and Qiao (2014) Z. Liu, H. Qiao, Gnccp—graduated nonconvexityand concavity procedure, TPAMI 36 (2014) 1258–1267.
- Schellewald and Schnörr (2005) C. Schellewald, C. Schnörr, Probabilistic subgraph matching based on convex relaxation, in: A. Rangarajan, B. Vemuri, A. L. Yuille (Eds.), Energy Minimization Methods in Computer Vision and Pattern Recognition, Springer Berlin Heidelberg, Berlin, Heidelberg, 2005, pp. 171–186.
- Bazaraa and Sherali (1982) M. S. Bazaraa, H. D. Sherali, On the use of exact and heuristic cutting plane methods for the quadratic assignment problem, Journal of the Operational Research Society 33 (1982) 991–1003.
- Gold and Rangarajan (1996) S. Gold, A. Rangarajan, A graduated assignment algorithm for graph matching, TPAMI 18 (1996) 377–388.
- Leordeanu et al. (2009) M. Leordeanu, M. Hebert, R. Sukthankar, An integer projected fixed point method for graph matching and map inference, in: Y. Bengio, D. Schuurmans, J. D. Lafferty, C. K. I. Williams, A. Culotta (Eds.), NIPS, Curran Associates, Inc., 2009, pp. 1114–1122.
- Cour et al. (2007) T. Cour, P. Srinivasan, J. Shi, Balanced graph matching, in: B. Schölkopf, J. C. Platt, T. Hoffman (Eds.), NIPS, MIT Press, 2007, pp. 313–320.
- Leordeanu and Hebert (2005) M. Leordeanu, M. Hebert, A spectral technique for correspondence problems using pairwise constraints, in: ICCV, volume 2, 2005, pp. 1482–1489 Vol. 2.
- Cho et al. (2010) M. Cho, J. Lee, K. M. Lee, Reweighted random walks for graph matching, in: K. Daniilidis, P. Maragos, N. Paragios (Eds.), ECCV, Springer Berlin Heidelberg, Berlin, Heidelberg, 2010, pp. 492–505.
- Riesen et al. (2007) K. Riesen, S. Fankhauser, H. Bunke, Speeding up graph edit distance computation with a bipartite heuristic, in: Mining and Learning with Graphs, Proceedings, 2007.
- Abu-Aisheh et al. (2015) Z. Abu-Aisheh, R. Raveaux, J. Ramel, P. Martineau, An exact graph edit distance algorithm for solving pattern recognition problems, in: ICPRAM, 2015, pp. 271–278.
- Justice and Hero (2006) D. Justice, A. Hero, A binary linear programming formulation of the graph edit distance, TPAMI 28 (2006) 1200–1214.
- Lerouge et al. (2017) J. Lerouge, Z. Abu-Aisheh, R. Raveaux, P. Héroux, S. Adam, New binary linear programming formulation to compute the graph edit distance, Pattern Recognition 72 (2017) 254–265.
- Bougleux et al. (2017) S. Bougleux, B. Gaüzère, L. Brun, A hungarian algorithm for error-correcting graph matching, in: P. Foggia, C.-L. Liu, M. Vento (Eds.), Graph-Based Representations in Pattern Recognition, Springer International Publishing, Cham, 2017, pp. 118–127.
- Serratosa (2015) F. Serratosa, Computation of graph edit distance: Reasoning about optimality and speed-up, Image Vision Comput. 40 (2015) 38–48.
- Riesen and Bunke (2009) K. Riesen, H. Bunke, Approximate graph edit distance computation by means of bipartite graph matching, Image Vision Comput. 27 (2009) 950–959.
- Neuhaus and Bunke. (2007) M. Neuhaus, H. Bunke., Bridging the gap between graph edit distance and kernel machines., Machine Perception and Artificial Intelligence. 68 (2007) 17–61.
- Bunke (1997) H. Bunke, On a relation between graph edit distance and maximum common subgraph, Pattern Recognition Letters 18 (1997) 689–694.
- Bunke (1999) H. Bunke, Error correcting graph matching: On the influence of the underlying cost function, TPAMI 21 (1999) 917–922.
- Brun et al. (2012) L. Brun, B. Gaüzère, S. Fourey, Relationships between Graph Edit Distance and Maximal Common Unlabeled Subgraph, Technical Report, 2012.
- Abu-Aisheh et al. (2017) Z. Abu-Aisheh, B. Gauzere, S. Bougleux, et al, Graph edit distance contest: Results and future challenges, Pattern Recognition Letters 100 (2017) 96 – 103.
- Serratosa (2020) F. Serratosa, A general model to define the substitution, insertion and deletion graph edit costs based on an embedded space, Pattern Recognition Letters 138 (2020) 115 – 122.
- Martineau et al. (2020) M. Martineau, R. Raveaux, D. Conte, G. Venturini, Learning error-correcting graph matching with a multiclass neural network, Pattern Recognition Letters 134 (2020) 68 – 76.
- Zanfir and Sminchisescu (2018) A. Zanfir, C. Sminchisescu, Deep learning of graph matching, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 2684–2693.
- Caetano et al. (2007) T. S. Caetano, Li Cheng, Q. V. Le, A. J. Smola, Learning graph matching, in: 2007 IEEE 11th International Conference on Computer Vision, 2007, pp. 1–8.