Online Adversarial Stabilization of
Unknown Linear Time-Varying Systems
Abstract
This paper studies the problem of online stabilization of an unknown discrete-time linear time-varying (LTV) system under bounded non-stochastic (potentially adversarial) disturbances. We propose a novel algorithm based on convex body chasing (CBC). Under the assumption of infrequently changing or slowly drifting dynamics, the algorithm guarantees bounded-input-bounded-output stability in the closed loop. Our approach avoids system identification and applies, with minimal disturbance assumptions, to a variety of LTV systems of practical importance. We demonstrate the algorithm numerically on examples of LTV systems including Markov linear jump systems with finitely many jumps.
I Introduction
Learning-based control of linear-time invariant (LTI) systems in the context of linear quadratic regulators (LQR) has seen considerable progress. However, many real-world systems are time-varying in nature. For example, the grid topology in power systems can change over time due to manual operations or unpredictable line failures [1]. Therefore, there is increasing recent interest in extending learning-based control of LTI systems to the linear time-varying (LTV) setting [2, 3, 4, 5, 6].
LTV systems are widely used to approximate and model real-world dynamical systems such as robotics [7] and autonomous vehicles [8]. In this paper, we consider LTV systems with dynamics of the following form:
| (1) |
where , and denotes the state, the control input, and the bounded and potentially adversarial disturbance, respectively. We use to succinctly denote the system matrices at time step .
On the one hand, offline control design for LTV systems is well-established in the setting where the underlying LTV model is known [9, 10, 11, 12, 13]. Additionally, recent work has started focusing on regret analysis and non-stochastic disturbances for known LTV systems [2, 14].
On the other hand, online control design for LTV systems where the model is unknown is more challenging. Historically, there is a rich body of work on adaptive control design for LTV systems [15, 16, 17]. Also related is the system identification literature for LTV systems [18, 19, 20], which estimates the (generally assumed to be stable) system to allow the application of the offline techniques.
In recent years, the potential to leverage modern data-driven techniques for controller design of unknown linear systems has led to a resurgence of work in both the LTI and LTV settings. There is a growing literature on “learning to control” unknown LTI systems under stochastic or no noise [21, 22, 23]. Learning under bounded and potentially adversarial noises poses additional challenges, but online stabilization [24] and regret [25] results have been obtained.
In comparison, there is much less work on learning-based control design for unknown LTV systems. One typical approach, exemplified by [3, 26, 27], derives stabilizing controllers under the assumption that offline data representing the input-output behavior of (1) is available and therefore an offline stabilizing controller can be pre-computed. Similar finite-horizon settings where the algorithm has access to offline data [28], or can iteratively collect data [29] were also considered. In the context of online stabilization, i.e., when offline data is not available, work has derived stabilizing controllers for LTV systems through the use of predictions of , e.g., [30]. Finally, another line of work focuses on designing regret-optimal controllers for LTV systems [31, 6, 4, 5, 32]. However, with the exception of [30], existing work on online control of unknown LTV systems share the common assumption of either of open-loop stability or knowledge of an offline stabilizing controller. Moreover, the disturbances are generally assumed to be zero or stochastic noise independent of the states and inputs.
In this paper, we propose an online algorithm for stabilizing unknown LTV systems under bounded, potentially adversarial disturbances. Our approach uses convex body chasing (CBC), which is an online learning problem where one must choose a sequence of points within sequentially presented convex sets with the aim of minimizing the sum of distances between the chosen points [33, 34]. CBC has emerged as a promising tool in online control, with most work making connections to a special case called nested convex body chasing (NCBC), where the convex sets are sequentially nested within the previous set [35, 36]. In particular, [37] first explored the use of NCBC for learning-based control of time-invariant nonlinear systems. NCBC was also used in combination with System Level Synthesis to design a distributed controller for networked systems [24] and in combination with model predictive control [38] for LTI system control as a promising alternative to system identification based methods. However, this line of work depends fundamentally on the time invariance of the system, which results in nested convex sets. LTV systems do not yield nested sets and therefore represent a significant challenge.
This work addresses this challenge and presents a novel online control scheme (Algorithm 1) based on CBC (non-nested) techniques that guarantees bounded-input-bounded-output (BIBO) stability as a function of the total model variation , without predictions or offline data under bounded and potentially adversarial disturbances for unknown LTV systems (Theorem 1). This result implies that when the total model variation is finite or growing sublinearly, BIBO stability of the closed loop is guaranteed (Corollaries 1 and 2). In particular, our result depends on a refined analysis of the CBC technique (Lemma 1) and is based on the perturbation analysis of the Lyapunov equation. This contrasts with previous NCBC-based works for time-invariant systems, where the competitive ratio guarantee of NCBC directly applies and the main technical tool is the robustness of the model-based controller, which is a proven using a Lipschitz bound of a quadratic program in [24] and is directly assumed to exist in [37].
We illustrate the proposed algorithm via numerical examples in Section IV to corroborate the stability guarantees. We demonstrate how the proposed algorithm can be used for data collection and complement data-driven methods like [27, 3, 28]. Further, the numerics highlight that the proposed algorithm can be efficiently implemented by leveraging the linearity of (1) despite the computational complexity of CBC algorithms in general (see Section III-B for details).
Notation. We use to denote the unit sphere in and for positive integers. For , we use as shorthand for the set of integers and for . Unless otherwise specified, is the operator norm. We use for the spectral radius of a matrix.
II Preliminaries
In this section, we state the model assumptions underlying our work and review key results for convex body chasing, which we leverage in our algorithm design and analysis.
II-A Stability and model assumptions
We study the dynamics in (1) and make the following standard assumptions about the dynamics.
Assumption 1
The disturbances are bounded: for all .
Assumption 2
The unknown time-varying system matrices belong to a known (potentially large) polytope such that for all . Moreover, there exists such that and is stabilizable for all .
Bounded and non-stochastic (potentially adversarial) disturbances is a common model both in the online learning and control problems [39, 40]. Since we make no assumptions on how large the bound is, 1 models a variety of scenarios, such as bounded and/or correlated stochastic noise, state-dependent disturbances, e.g., the linearization and discretization error for nonlinear continuous-time dynamics, and potentially adversarial disturbances. 2 is standard in learning-based control, e.g. [41, 42].
We additionally assume there is a quadratic known cost function of the state and control input at every time step to be minimized, e.g. , with . For a given LTI system model and cost matrices , we denote as the optimal feedback gain for the corresponding infinite-horizon LQR problem.
Remark 1
Representing model uncertainty as convex compact parameter sets where every model is stabilizable is not always possible. In particular, if a parameter set has a few singular points where loses stabilizability such as when , a simple heuristic is to ignore these points in the algorithm since we assume the underlying true system matrices must be stabilizable.
II-B Convex body chasing
Convex Body Chasing (CBC) is a well-studied online learning problem [35, 36]. At every round , the player is presented a convex body/set . The player selects a point with the objective of minimizing the cost defined as the total path length of the selection for rounds, e.g., for a given initial condition . There are many known algorithms for the CBC problem with a competitive ratio guarantee such that the cost incurred by the algorithm is at most a constant factor from the total path length incurred by the offline optimal algorithm which has the knowledge of the entire sequence of the bodies. We will use CBC to select ’s that are consistent with observed data.
II-B1 The nested case
A special case of CBC is the nested convex body chasing (NCBC) problem, where . A known algorithm for NCBC is to select the Steiner point of at [36]. The Steiner point of a convex set can be interpreted as the average of the extreme points of and is defined as , where and the expectation is taken with respect to the uniform distribution over the unit ball. The intuition is that Steiner point remains “deep” inside of the (nested) feasible region so that when this point becomes infeasible due to a new convex set, this convex set must shrink considerably, which indicates that the offline optimal must have moved a lot. Given the initial condition , the Steiner point selector achieves competitive ratio of against the offline optimal such that for all , , where OPT is the offline optimal total path length. There are many works that combine the Steiner point algorithm for NCBC with existing control methods to perform learning-based online control for LTI systems, e.g., [24, 37, 38].
II-B2 General CBC
For general CBC problems, we can no longer take advantage of the nested property of the convex bodies. One may consider naively applying NCBC algorithms when the convex bodies happen to be nested and restarting the NCBC algorithm when they are not. However, due to the myopic nature of NCBC algorithms, which try to remain deep inside of each convex set, they no longer guarantee a competitive ratio when used this way. Instead, [33] generalizes ideas from NCBC and proposes an algorithm that selects the functional Steiner point of the work function.
Definition 1 (Functional Steiner point)
For a convex function , the functional Steiner point of is
| (2) |
where denotes the normalized value of on the set , and
| (3) |
is the Fenchel conjugate of .
The CBC algorithm selects the functional Steiner point of the work function, which records the smallest cost required to satisfy a sequence of requests while ending in a given state, thereby encapsulating information about the offline-optimal cost for the CBC problem.
Definition 2 (Work function)
Given an initial point , and convex sets , the work function at time step evaluated at a point is given by:
| (4) |
Importantly, it is shown that the functional Steiner points of the work functions are valid, i.e., for all [33]. On a high level, selecting the functional Steiner point of the work function helps the algorithm stay competitive against the currently estimated offline optimal cost via the work function, resulting in a competitive ratio of against the offline optimal cost (OPT) for general CBC problems,
| (5) |
Given the non-convex nature of (2) and (4), we note that, in general, it is challenging to compute the functional Steiner point of the work function. However, in the proposed algorithm, we are able to leverage the linearity of the LTV systems and numerically approximate both objects with efficient computation in Section III-B.
III Main Results
We present our proposed online control algorithm to stabilize the unknown LTV system (1) under bounded and potentially adversarial disturbances in Algorithm 1. After observing the latest transition from to at according to (1) (line 1), the algorithm constructs the set of all feasible models ’s (line 1) such that the model is consistent with the observation, i.e., there exists an admissible disturbance satisfying 1 such that the state transition from to can be explained by the tuple (, ). We call this set the consistent model set and we note that the unknown true dynamics belongs to . The algorithm then selects a hypothesis model out of the consistent model set using the CBC algorithm by computing the functional Steiner point (2) of the work function (4) with respect to the history of the consistent parameter sets (line 1). In particular, we present an efficient implementation of the functional Steiner point chasing algorithm in Section III-B by taking advantage of the fact that ’s are polytopes that can be described by intersection of half-spaces. The implementation is summarized in Algorithm 2. Based on the selected hypothesis model , a certainty-equivalent LQR controller is synthesized (line 1) and the state-feedback control action is computed (line 1).
Note that, by construction, at time step we perform certainty-equivalent control based on a hypothesis model computed using retrospective data, even though the control action () is applied to the dynamics () that we do not yet have any information about. In order to guarantee stability, we would like for to be stabilizing the “future” dynamics (). This is the main motivation behind our choice of the CBC technique instead of regression-based techniques for model selection. Thanks to the competitive ratio guarantee (5) of the functional Steiner point selector, when the true model variation is “small,” our previously selected hypothesis model will stay “consistent” in the sense that can be stabilizing for despite the potentially adversarial or state-dependent disturbances. On the other hand, when the true model variation is “large,” does not stabilize , and we see growth in the state norm. Therefore, our final state bound is in terms of the total variation of the true model.
We show in the next section that, by drawing connections between the stability of the closed-loop system and the path length cost of the selected hypothesis model via CBC, we are able to stabilize the unknown LTV system without any identification requirements, e.g., the selected hypothesis models in Algorithm 1 need not be close to the true models. It is observed that even in the LTI setting, system identification can result in large-norm transient behaviors with numerical stability issues if the underlying unknown system is open-loop unstable or under non-stochastic disturbances; thus motivating the development of NCBC-based online control methods [25, 24, 37]. In the LTV setting, it is not sufficient to use NCBC ideas due to the time-variation of the model; however, the intuition for the use of CBC is similar. In fact, it can be additionally beneficial to bypass identification in settings where the true model is a moving target, thus making identification more challenging. We illustrate this numerically in Section IV.
III-A Stability Analysis
The main result of this paper is the BIBO stability guarantee for Algorithm 1 in terms of the true model variation and the disturbance bound. We sketch the proof in this section and refer Section -C for the formal proof. This result depends on a refined analysis of the competitive ratio for the functional Steiner point chasing algorithm introduced in [33], which is stated as follows.
Lemma 1 (Partial-path competitive ratio)
For , let and , and let be a convex compact set. Denote as the partial-path cost of the functional Steiner point selector during interval and as the (overall) offline optimal selection for . The functional Steiner point chasing algorithm has the following competitive ratio,
on interval , where denotes the diameter of and .
Proof.
See Section -A. ∎
Theorem 1 (BIBO Stability)
Proof Sketch: At a high level, the structure of our proof is as follows. We first use the fact that our time-varying feedback gain is computed according to a hypothesis model from the consistent model set. Therefore, we can characterize the closed-loop dynamics in terms of the consistent models and . Specifically, consider a time step where we take the action after observing . Then, we observe and select a new hypothesis model that is consistent with this new observation. Since we have selected a consistent hypothesis model, there is some admissible disturbance satisfying 1 such that
Without loss of generality, we assume initial condition . We therefore have
| (6) |
We have two main challenges in bounding in (6):
- 1.
-
2.
Naively applying submultiplicativity of the operator norm for (6) results in bounding . However, even if satisfies , in general the operator norm can be greater than 1.
To address the first challenge, our key insight is that by selecting hypothesis models via CBC technique, in any interval where the true model variation is small, our selected hypothesis model also vary little. Specifically, by Lemma 1, we can bound the partial-path variation of the selected hypothesis models with the true model partial-path variation as follows.
| (7) |
where and are from 2. A consequence of (7) is that, during intervals where the true model variation is small, we have .
For the second challenge, we leverage the concept of sequential strong stability [43], which allows bounding approximately with times .
We now sketch the proof. The helper lemmas are summarized in Section -B and the formal proof can be found in Section -C. Consider with such that
We use as shorthand for the interval . Then each summand in (6) can be bounded as
| (8) |
Therefore showing BIBO stability comes down to bounding individual terms in (8). In particular we will show that by selecting appropriate and , term (a) is bounded by a constant that depends on system theoretical properties of the worst-case parameter in . For (b) and (c), we isolate the instances when
| (9) |
for some chosen . For instances where (9) holds, we use the perturbation analysis of the Lyapunov equation involving the matrix (Lemma 6 for (b) and Lemma 4 for (c)) to bound (b) and (c) in terms of the partial-path movement of the selected parameters . Specifically, Lemma 6 implies
| (10) |
where are constants. We also show that from Lemma 4,
| (11) |
for and a constant.
We now plug (10) and (11) into (8). Denote by the number of pairs with where (9) fails to hold. Let be the true model partial-path variation. Then (8) can be bounded as
for constants and for the dimension of the parameter space for . In the second inequality, we used the observation that and in the last inequality we used Lemma 1. Combined with (6) and 1, this proves the desired bound.
An immediate consequence of Theorem 1 is that when the model variation in (1) is bounded or sublinear, Algorithm 1 guarantees BIBO stability. This is summarized below.
Corollary 1 (Bounded variation)
Suppose (1) has model variation for a constant . Then,
Corollary 2 (Unbounded but sublinear variation)
Let and . Suppose (1) is such that for each , , implying a total model variation . Then for large enough , , and therefore
Corollary 1 can be useful for scenarios where the mode of operation of the system changes infrequently and for systems such that as [44]. As an example, consider power systems where a prescribed set of lines can potentially become disconnected from the grid and thus change the grid topology. Corollary 2 applies to slowly drifting systems [45].
III-B Efficient implementation of CBC
In general, implementation of the functional Steiner point of the work function may be computationally inefficient. However, by taking advantage of the LTV structure, we are able to design an efficient implementation in our setting. The key observation here is that for each , (Algorithm 1, line 1) can be described by the intersection of half-spaces because the ambient parameter space is assumed to be a polytope and the observed online transition data from to specifies two half-space constraints at each time step due to linearity of (1). Our approach to approximate the functional Steiner point for chasing the consistent model sets is inspired by [34] where second-order cone programs (SOCPs) are used to approximate the (nested set) Steiner point of the sublevel set of the work functions for chasing half-spaces.
Denote as the collection of half-space constraints describing , i.e., . To approximate the integral for the functional Steiner point (2) of , we sample number of random directions , evaluate the Fenchel conjugate of the work function at each with an SOCP, and take the empirical average. Finally we project the estimated functional Steiner point back to the set of consistent model . Even though the analytical functional Steiner point (2) is guaranteed to be a member of the consistent model set, the projection step is necessary because we are integrating numerically, which may result in an approximation that ends up outside of the set. We summarize this procedure in Algorithm 2. Specifically, given a direction , the Fenchel conjugate of the work function at time step is
This can be equivalently expressed as the following SOCP with decision variables :
| (12) | ||||||
| s.t. | ||||||
Another potential implementation challenge is that the number of constraints in the SOCP (12) grows linearly with time due to the construction of the work function (4). This is a common drawback of online control methods based on CBC and NCBC techniques and can be overcome through truncation or over-approximation in of the work functions in practice. Additionally, if the LTV system is periodic with a known period, then we can leverage Algorithm 1 during the initial data collection phase. Once representative (persistently exciting) data is available, one could employ methods like [3] to generate a stabilizing controller for the unknown LTV system. In Section IV, we show that data collection via Algorithm 1 results in a significantly smaller state norm than random noise injection when the system is unstable.
IV Simulation
In this section, we demonstrate Algorithm 1 in two LTV systems. Both of the systems we consider are open-loop unstable, thus the algorithms must work to stabilize them. We use the same algorithm parameters for both, with , LQR cost matrices and .
IV-A Example 1: Markov linear jump system
We consider the following Markov linear jump system (MLJS) model from [46], with
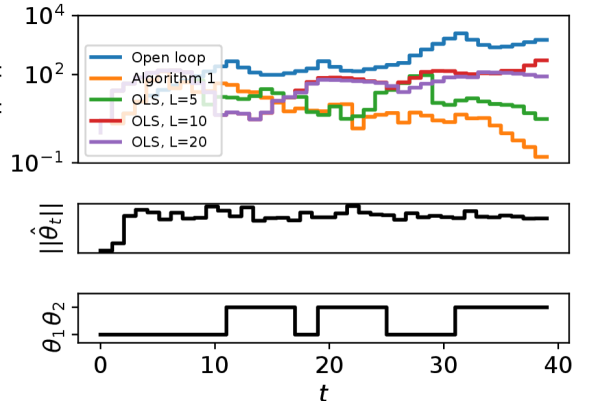
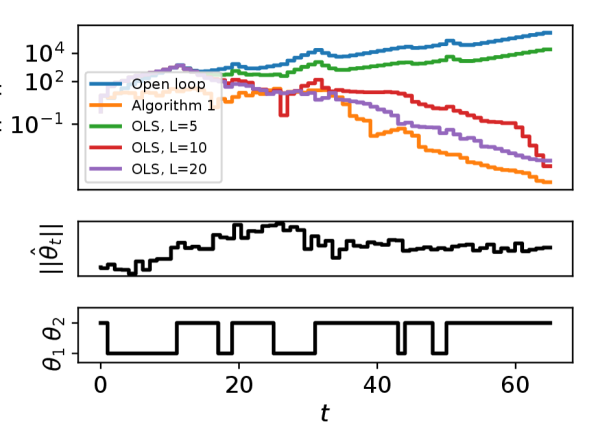
where is the transition probability matrix from to and vice versa. We inject uniformly random disturbances such that where is the all-one vector. We set the disturbances to be zero for the last 10 time steps to make explicit the stability of the closed loop. We implement certainty-equivalent control based on online least squares (OLS) with different sliding window sizes and a exponential forgetting factor of [47] as the baselines.
We show two different MLJS models generated from 2 random seeds and show the results in Figure 1. For both systems, the open loop is unstable. In Figure 1(a) the OLS-based algorithms fail to stabilize the system for window size of , while stabilizing the system but incurring larger state norm than the proposed algorithm for . On the other hand, in Figure 1(b), OLS with results in unstable closed loop. This example highlights the challenge of OLS-based methods, where the choice of window size is crucial for the performance. Since the underlying LTV system is unknown and our goal is to control the system online, it is unclear how to select appropriate window size to guarantee stability for OLS-based methods a priori. In contrast, Algorithm 1 does not require any parameter tuning.
We note that while advanced least-squares based identification techniques that incorporate sliding window with variable length exist, e.g. [4, 47], due to the unknown system parameters, it is unclear how to choose the various algorithm parameters such as thresholds for system change detection. Therefore, we only compare Algorithm 1 against fixed-length sliding window OLS methods as baselines.
IV-B Example 2: LTV system
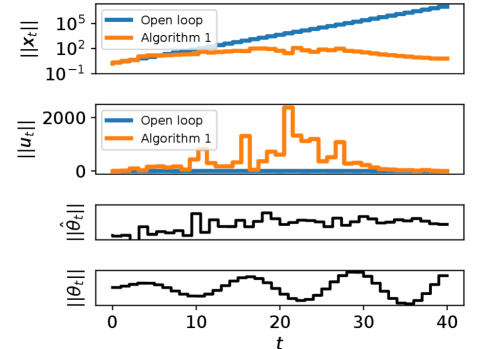
Our second example highlights that Algorithm 1 is a useful data-collection alternative to open-loop random noise injection. We consider the LTV system from [3, 28], with
where we modified from 1 to 1.5 to increase the instability of the open loop in the beginning; thus making it more challenging to stabilize. We consider no disturbances here, which is a common setting in direct data-driven control, e.g., [3, 26, 27]. In particular, we compare the proposed algorithm against randomly generated bounded inputs from . We also modify the control inputs from Algorithm 1 to be with so that we can collect rich data in the closed loop. This is motivated by the growing body of data-driven control methods such as [3, 27, 28] that leverage sufficiently rich offline data to perform control design for unknown LTV systems. However, most of these works directly inject random inputs for data collection. It is evident in Figure 2 that when the open-loop system is unstable it may be undesirable to run the system without any feedback control. Therefore, Algorithm 1 complements existing data-driven methods by allowing safe data collection with significantly better transient behavior.
V Concluding remarks
In this paper, we propose a model-based approach for stabilizing an unknown LTV system under arbitrary non-stochastic disturbances in the sense of bounded input bounded output under the assumption of infrequently changing or slowly drifting dynamics. Our approach uses ideas from convex body chasing (CBC), which is an online problem where an agent must choose a sequence of points within sequentially presented convex sets with the aim of minimizing the sum of distances between the chosen points. The algorithm requires minimal tuning and achieves significantly better performance than the naive online least squares based control. Future work includes sharpening the stability analysis to go beyond the BIBO guarantee in this work, which will require controlling the difference between the estimated disturbances and true disturbances. Another direction is to extend the current results to the networked case, similar to [24].
References
- [1] D. Deka, S. Backhaus, and M. Chertkov, “Structure learning in power distribution networks,” IEEE Transactions on Control of Network Systems, vol. 5, no. 3, pp. 1061–1074, Sep. 2018.
- [2] P. Gradu, E. Hazan, and E. Minasyan, “Adaptive regret for control of time-varying dynamics,” arXiv preprint arXiv:2007.04393, 2020.
- [3] B. Nortmann and T. Mylvaganam, “Data-driven control of linear time-varying systems,” in 2020 59th IEEE Conference on Decision and Control (CDC). IEEE, 2020, pp. 3939–3944.
- [4] Y. Luo, V. Gupta, and M. Kolar, “Dynamic regret minimization for control of non-stationary linear dynamical systems,” Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 6, no. 1, pp. 1–72, 2022.
- [5] Y. Lin, J. Preiss, E. Anand, Y. Li, Y. Yue, and A. Wierman, “Online adaptive controller selection in time-varying systems: No-regret via contractive perturbations,” arXiv preprint arXiv:2210.12320, 2022.
- [6] E. Minasyan, P. Gradu, M. Simchowitz, and E. Hazan, “Online control of unknown time-varying dynamical systems,” Advances in Neural Information Processing Systems, vol. 34, pp. 15 934–15 945, 2021.
- [7] R. Tedrake, “Underactuated robotics: Learning, planning, and control for efficient and agile machines course notes for mit 6.832,” Working draft edition, vol. 3, p. 4, 2009.
- [8] P. Falcone, F. Borrelli, H. E. Tseng, J. Asgari, and D. Hrovat, “Linear time-varying model predictive control and its application to active steering systems: Stability analysis and experimental validation,” International Journal of Robust and Nonlinear Control: IFAC-Affiliated Journal, vol. 18, no. 8, pp. 862–875, 2008.
- [9] K. S. Tsakalis and P. A. Ioannou, Linear time-varying systems: control and adaptation. Prentice-Hall, Inc., 1993.
- [10] R. Tóth, Modeling and identification of linear parameter-varying systems. Springer, 2010, vol. 403.
- [11] J. Mohammadpour and C. W. Scherer, Control of linear parameter varying systems with applications. Springer Science & Business Media, 2012.
- [12] W. Zhang, Q.-L. Han, Y. Tang, and Y. Liu, “Sampled-data control for a class of linear time-varying systems,” Automatica, vol. 103, pp. 126–134, 2019.
- [13] R. Mojgani and M. Balajewicz, “Stabilization of linear time-varying reduced-order models: A feedback controller approach,” International Journal for Numerical Methods in Engineering, vol. 121, no. 24, pp. 5490–5510, 2020.
- [14] G. Goel and B. Hassibi, “Regret-optimal estimation and control,” IEEE Transactions on Automatic Control, 2023.
- [15] K. Tsakalis and P. Ioannou, “Adaptive control of linear time-varying plants,” Automatica, vol. 23, no. 4, pp. 459–468, 1987.
- [16] J.-J. Slotine and J. Coetsee, “Adaptive sliding controller synthesis for non-linear systems,” International Journal of Control, vol. 43, no. 6, pp. 1631–1651, 1986.
- [17] R. Marino and P. Tomei, “Adaptive control of linear time-varying systems,” Automatica, vol. 39, no. 4, pp. 651–659, 2003.
- [18] M. Verhaegen and X. Yu, “A class of subspace model identification algorithms to identify periodically and arbitrarily time-varying systems,” Automatica, vol. 31, no. 2, pp. 201–216, 1995.
- [19] B. Bamieh and L. Giarre, “Identification of linear parameter varying models,” International Journal of Robust and Nonlinear Control: IFAC-Affiliated Journal, vol. 12, no. 9, pp. 841–853, 2002.
- [20] T. Sarkar, A. Rakhlin, and M. Dahleh, “Nonparametric system identification of stochastic switched linear systems,” in 2019 IEEE 58th Conference on Decision and Control (CDC), 2019.
- [21] S. Dean, S. Tu, N. Matni, and B. Recht, “Safely learning to control the constrained linear quadratic regulator,” in 2019 American Control Conference (ACC). IEEE, 2019, pp. 5582–5588.
- [22] S. Talebi, S. Alemzadeh, N. Rahimi, and M. Mesbahi, “On regularizability and its application to online control of unstable lti systems,” IEEE Transactions on Automatic Control, 2021.
- [23] S. Lale, K. Azizzadenesheli, B. Hassibi, and A. Anandkumar, “Reinforcement learning with fast stabilization in linear dynamical systems,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2022, pp. 5354–5390.
- [24] J. Yu, D. Ho, and A. Wierman, “Online adversarial stabilization of unknown networked systems,” Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 7, no. 1, pp. 1–43, 2023.
- [25] X. Chen and E. Hazan, “Black-box control for linear dynamical systems,” in Conference on Learning Theory. PMLR, 2021.
- [26] M. Rotulo, C. De Persis, and P. Tesi, “Online learning of data-driven controllers for unknown switched linear systems,” Automatica, vol. 145, p. 110519, 2022.
- [27] S. Baros, C.-Y. Chang, G. E. Colon-Reyes, and A. Bernstein, “Online data-enabled predictive control,” Automatica, vol. 138, p. 109926, 2022.
- [28] B. Pang, T. Bian, and Z.-P. Jiang, “Data-driven finite-horizon optimal control for linear time-varying discrete-time systems,” in 2018 IEEE Conference on Decision and Control (CDC), 2018, pp. 861–866.
- [29] S.-J. Liu, M. Krstic, and T. Başar, “Batch-to-batch finite-horizon lq control for unknown discrete-time linear systems via stochastic extremum seeking,” IEEE Transactions on Automatic Control, vol. 62, no. 8, pp. 4116–4123, 2016.
- [30] G. Qu, Y. Shi, S. Lale, A. Anandkumar, and A. Wierman, “Stable online control of linear time-varying systems,” in Learning for Dynamics and Control. PMLR, 2021, pp. 742–753.
- [31] Y. Ouyang, M. Gagrani, and R. Jain, “Learning-based control of unknown linear systems with thompson sampling,” arXiv preprint arXiv:1709.04047, 2017.
- [32] Y. Han, R. Solozabal, J. Dong, X. Zhou, M. Takac, and B. Gu, “Learning to control under time-varying environment,” arXiv preprint arXiv:2206.02507, 2022.
- [33] M. Sellke, “Chasing convex bodies optimally,” in Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms. SIAM, 2020, pp. 1509–1518.
- [34] C. Argue, A. Gupta, Z. Tang, and G. Guruganesh, “Chasing convex bodies with linear competitive ratio,” Journal of the ACM (JACM), vol. 68, no. 5, pp. 1–10, 2021.
- [35] N. Bansa, M. Böhm, M. Eliáš, G. Koumoutsos, and S. W. Umboh, “Nested convex bodies are chaseable,” in Proceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms. SIAM, 2018, pp. 1253–1260.
- [36] S. Bubeck, B. Klartag, Y. T. Lee, Y. Li, and M. Sellke, “Chasing nested convex bodies nearly optimally,” in Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms. SIAM, 2020.
- [37] D. Ho, H. Le, J. Doyle, and Y. Yue, “Online robust control of nonlinear systems with large uncertainty,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2021, pp. 3475–3483.
- [38] C. Yeh, J. Yu, Y. Shi, and A. Wierman, “Robust online voltage control with an unknown grid topology,” in Proceedings of the Thirteenth ACM International Conference on Future Energy Systems, 2022, pp. 240–250.
- [39] B. Ramasubramanian, B. Xiao, L. Bushnell, and R. Poovendran, “Safety-critical online control with adversarial disturbances,” in 2020 59th IEEE Conference on Decision and Control (CDC). IEEE, 2020.
- [40] E.-W. Bai, R. Tempo, and H. Cho, “Membership set estimators: size, optimal inputs, complexity and relations with least squares,” IEEE Transactions on Circuits and Systems I: Fundamental Theory and Applications, vol. 42, no. 5, pp. 266–277, 1995.
- [41] A. Cohen, T. Koren, and Y. Mansour, “Learning linear-quadratic regulators efficiently with only sqrt(t) regret,” in International Conference on Machine Learning. PMLR, 2019, pp. 1300–1309.
- [42] N. Agarwal, B. Bullins, E. Hazan, S. Kakade, and K. Singh, “Online control with adversarial disturbances,” in International Conference on Machine Learning. PMLR, 2019, pp. 111–119.
- [43] A. Cohen, A. Hasidim, T. Koren, N. Lazic, Y. Mansour, and K. Talwar, “Online linear quadratic control,” in International Conference on Machine Learning. PMLR, 2018, pp. 1029–1038.
- [44] W. Hahn et al., Stability of motion. Springer, 1967, vol. 138.
- [45] F. Amato, G. Celentano, and F. Garofalo, “New sufficient conditions for the stability of slowly varying linear systems,” IEEE Transactions on Automatic Control, vol. 38, no. 9, pp. 1409–1411, 1993.
- [46] J. Xiong and J. Lam, “Stabilization of discrete-time markovian jump linear systems via time-delayed controllers,” Automatica, vol. 42, no. 5, pp. 747–753, 2006.
- [47] J. Jiang and Y. Zhang, “A revisit to block and recursive least squares for parameter estimation,” Computers & Electrical Engineering, vol. 30, no. 5, pp. 403–416, 2004.
- [48] U. Shaked, “Guaranteed stability margins for the discrete-time linear quadratic optimal regulator,” IEEE Transactions on Automatic Control, vol. 31, no. 2, pp. 162–165, 1986.
- [49] A. S. Householder, The theory of matrices in numerical analysis. Courier Corporation, 2013.
- [50] M. Simchowitz and D. Foster, “Naive exploration is optimal for online lqr,” in International Conference on Machine Learning. PMLR, 2020.
- [51] P. Gahinet and A. Laub, “Computable bounds for the sensitivity of the algebraic riccati equation,” SIAM journal on control and optimization, vol. 28, no. 6, pp. 1461–1480, 1990.
-A Proof of Lemma 1
We have
| (13) |
where (a) is due to the definition (2). For (b), we used the observation that is non-decreasing in time. For (c), by definition of the Fenchel conjugate (3), we have that . Denote as the optimal solution to the problem . It is clear that where in the last inequality we used Cauchy-Shwarz and . Similarly, we also have .
Denote as the minimizing trajectory to where . This last equality is by the observation that if , then by definition (4), thus contradicting that is defined to be the minimizer of . We also denote as the minimizing trajectory to . To reduce notation, we denote and . Then we have
where (c) holds because if and , then we can replace the portion of the optimal trajectory with and achieve a lower cost for , thus contradicting the optimality of . To see why the fictitious trajectory achieves lower cost than , we compare the total movement cost during the interval ,
which means the fictitious trajectory achieves lower overall cost. Therefore (c) must hold.
-B Auxiliary results
Here we summarize the helper lemmas used in the proof sketch of Theorem 1. First, we define some useful notation.
Lyapunov equation. Let with and . Define to be the unique positive definite solution to the Lyapunov equation . For a stabilizable system with optimal infinite-horizon LQR feedback with cost matrices , we define
and
We also define the shorthand for the following:
| (14) |
Constants. Throughout the proof, we will reference the following system-theoretical constants for the parameter set defined in 2:
We also quantify the stability of every model in under its corresponding optimal LQR gain. Let
be such that for all , , and , . By Lemma 2 which is stated below and 2, such and always exist. Further, we define
To justify the existence of these constants, note that discrete-time optimal LQR controller has guaranteed stability margin [48] and that by Lemma 2 and the fact that the solution to Lyapunov equation has the following closed form,
| (15) |
we have that for all ,
We can similarly derive . By definition of the Lyapunov solution (15), .
Lemma 2 ([49, page 183])
For a matrix , with , there exist constants such that for any positive integer
where is the size of the largest Jordan block corresponding to eigenvalue of in Jordan block form representation of .
Lemma 3 ([50, Proposition 6])
Let be a stabilizable system, with optimal controller and . Let be an estimate of , the optimal controller for the estimate, and . Then if :
Lemma 4 ([50, Theorem 8])
Let be a stabilizable system, with , and . Let be an estimate of satisfying . Consider certainty equivalent controller . Then if is such that , we have
Lemma 5 ([51])
Let be the solution to the Lyapunov equation , and let be the solution to the perturbed problem
The following inequality holds for the spectral norm:
Lemma 6
Proof of Lemma 6. For notational brevity, we drop the time index for and in the proof. Applying Lemma 5 with , and and , and we have
where in the second inequality we used Lemma 3 to bound and in the last inequality we use the assumption .
To show for some , it suffices to show that for all vectors , . With the preceding calculation, we have
This proves the desired bound, with and
-C Proof of Theorem 1
Recall that the closed loop dynamics can be characterized as (6). Therefore,
| (16) |
Define
where is defined in (14). This gives,
Therefore, each summand in (16) can be bounded as
| (17) |
where we used as shorthand for the interval .
Bounding (a). We directly use the system-theoretical constant introduced in Section -B so that (a) .
Bounding (b). Lemma 6 directly implies that for all , . Therefore, we have
Hence with the fact that ’s are symmetric,
| (18) |
Bounding (c). Lemma 4 implies that if then
This in turn implies that
This in turn implies that . To summarize,
| (19) |
for some constant such that for all ,
Combining (a,b,c). We now plug in the bounds (18) and (19) into (17). Let be the partial-path movement of the selected hypothesis models and be the true model partial-path variation. We also denote by the number of pairs with where . Note that . Therefore,
where is the dimension of the parameter space for . Finally plugging the above in (16) gives