Online algorithms for Nonnegative Matrix Factorization with the Itakura-Saito divergence
Abstract
Nonnegative matrix factorization (NMF) is now a common tool for audio source separation. When learning NMF on large audio databases, one major drawback is that the complexity in time is when updating the dictionary (where is the dimension of the input power spectrograms, and the number of basis spectra), thus forbidding its application on signals longer than an hour. We provide an online algorithm with a complexity of in time and memory for updates in the dictionary. We show on audio simulations that the online approach is faster for short audio signals and allows to analyze audio signals of several hours.
1 Introduction
In audio source separation, nonnegative matrix factorization (NMF) is a popular technique for building a high-level representation of complex audio signals with a small number of basis spectra, forming together a dictionary (Smaragdis et al., 2007; Févotte et al., 2009; Virtanen et al., 2008). Using the Itakura-Saito divergence as a measure of fit of the dictionary to the training set allows to capture fine structure in the power spectrum of audio signals as shown in (Févotte et al., 2009).
However, estimating the dictionary can be quite slow for long audio signals, and indeed intractable for training sets of more than a few hours. We propose an algorithm to estimate Itakura-Saito NMF (IS-NMF) on audio signals of possibly infinite duration with tractable memory and time complexity. This article is organized as follows : in Section 2, we summarize Itakura-Saito NMF, propose an algorithm for online NMF, and discuss implementation details. In Section 3, we experiment our algorithms on real audio signals of short, medium and long durations. We show that our approach outperforms regular batch NMF in terms of computer time.
2 Online Dictionary Learning for the Itakura-Saito divergence
Various methods were recently proposed for online dictionary learning (Mairal et al., 2010; Hoffman et al., 2010; Bucak and Gunsel, 2009). However, to the best of our knowledge, no algorithm exists for online dictionary learning with the Itakura-Saito divergence. In this section we summarize IS-NMF, then introduce our algorithm for online NMF and explain briefly the mathematical framework.
2.1 Itakura-Saito NMF
Define the Itakura-Saito divergence as . Given a data set , Itakura-Saito NMF consists in finding , that minimize the following objective function :
| (1) |
The standard approach to solving IS-NMF is to optimize alternately in and and use majorization-minimization (Févotte and Idier, in press). At each step, the objective function is replaced by an auxiliary function of the form such that with equality if :
| (2) |
where and are given by:
| (3) |
Thus, updating by yields a descent algorithm. Similar updates can be found for so that the whole process defines a descent algorithm in (for more details see, e.g., (Févotte and Idier, in press)). In a nutshell, batch IS-NMF works in cycles: at each cycle, all sample points are visited, the whole matrix is updated, the auxiliary function in Eq. (2) is re-computed, and is then updated. We now turn to the description of online NMF.
2.2 An online algorithm for online NMF
When is large, multiplicative updates algorithms for IS-NMF become expensive because at the dictionary update step, they involve large matrix multiplications with time complexity in (computation of matrices and ). We present here an online version of the classical multiplicative updates algorithm, in the sense that only a subset of the training data is used at each step of the algorithm.
Suppose that at each iteration of the algorithm we are provided a new data point , and we are able to find that minimizes . Let us rewrite the updates in Eq. (3). Initialize and at each step compute :
| (4) |
Now we may update each time a new data point is visited, instead of visiting the whole data set. This differs from batch NMF in the following sense : suppose we replace the objective function in Eq. (1) by
| (5) |
where is an infinite sequence of data points, and the sequence is such that minimizes . Then we may show that the modified sequence of updates corresponds to minimizing the following auxiliary function :
| (6) |
If is fixed, this problem is exactly equivalent to IS-NMF on a finite training set. Whereas in the batch algorithm described in Section 2.1, all is updated once and then all , in online NMF, each new is estimated exactly and then is updated once. Another way to see it is that in standard NMF, the auxiliary function is updated at each pass through the whole dataset from the most recent updates in , whereas in online NMF, the auxiliary function takes into account all updates starting from the first one.
Extensions
Prior information on or is often useful for imposing structure in the factorization (Lefèvre et al., 2011; Virtanen, 2007; Smaragdis et al., 2007). Our framework for online NMF easily accomodates penalties such as :
-
•
Penalties depending on the dictionary only.
-
•
Penalties on that are decomposable and expressed in terms of a concave increasing function (Lefèvre et al., 2011): .
2.3 Practical online NMF
| Input training set, , , , , , , . |
| repeat |
| draw from the training set. |
| if |
| for |
| end for |
| end if |
| until |
We provided a description of a pure version of online NMF, we now discuss several extensions that are commonly used in online algorithms and allow for considerable gains in speed.
Finite data sets.
When working on finite training sets, we cycle over the training set several times, and randomly permute the samples at each cycle.
Sampling method for infinite data sets.
When dealing with large (or infinite) training sets, samples may be drawn in batches and then permuted at random to avoid local correlations of the input.
Fresh or warm restarts.
Minimizing is an inner loop in our algorithm. Finding an exact solution for each new sample may be costly (a rule of thumb is iterations from a random point). A shortcut is to stop the inner loop before convergence. This amounts to compute only an upper-bound of . Another shortcut is to warm restart the inner loop, at the cost of keeping all the most recent regression weights in memory. For small data sets, this allows to run online NMF very similarly to batch NMF : each time a sample is visited is updated only once, and then is updated. When using warm restarts, the time complexity of the algorithm is not changed, but the memory requirements become .
Mini-batch.
Updating every time a sample is drawn costs : as shown in simulations, we may save some time by updating only every samples i.e., draw samples in batches and then update . This is also meant to stabilize the updates.
Scaling past data.
In order to speed up the online algorithm it is possible to scale past information so that newer information is given more importance :
| (7) |
where we choose . We choose this particular form so that when , . Moreover, is taken to the power so that we can compare performance for several batch sizes and the same parameter . In principle this rescaling of past information amounts to discount each new sample at rate , thus replacing the objective function in Eq. (5) by :
| (8) |
Rescaling .
In order to avoid the scaling ambiguity, each time is updated, we rescale so that its columns have unit norm. , must be rescaled accordingly (as well as when using warm restarts). This does not change the result and avoids numerical instabilities when computing the product .
Dealing with small amplitude values.
The Itakura-Saito divergence is badly behaved when either or . As a remedy we replace it in our algorithm by . The updates were modified consequently in Algorithm 1.
Overview.
Algorithm 1 summarizes our procedure. The two parameters of interest are the mini-batch size and the forgetting factor . Note that when , and , the online algorithm is equivalent to the batch algorithm.
3 Experimental study
In this section we validate the online algorithm and compare it with its batch counterpart. A natural criterion is to train both on the same data with the same initial parameters (and when applicable) and compare their respective fit to a held-out test set, as a function of the computer time available for learning. The input data are power spectrogram extracted from single-channel audio tracks, with analysis windows of samples and samples overlap. All silent frames were discarded.
We make the comparison for small, medium, and large audio tracks (resp. time windows). is initialized with random samples from the train set. For each process, several seeds were tried, the best seed (in terms of objective function value) is shown for each process. Finally, we use which is well below the hearing threshold.
Small data set (30 seconds).
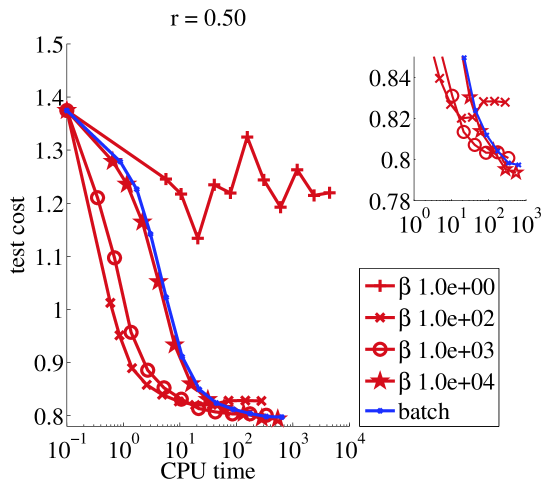
We ran online NMF with warm restarts and one update of every sample. From Figure 1, we can see that there is a restriction on the values of that we can use : if then should be chosen larger than . On the other hand, as long as , the stability of the algorithm is not affected by the value of . In terms of speed, clearly setting is crucial for the online algorithm to compete with its batch counterpart. Then there is a tradeoff to make in : it should picked larger than to avoid instabilities, and smaller than the size of the train set for faster learning (this was also shown in (Mairal et al., 2010) for the square loss).
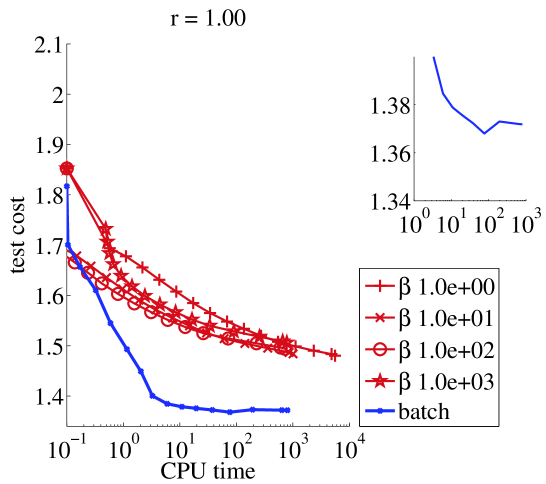 |
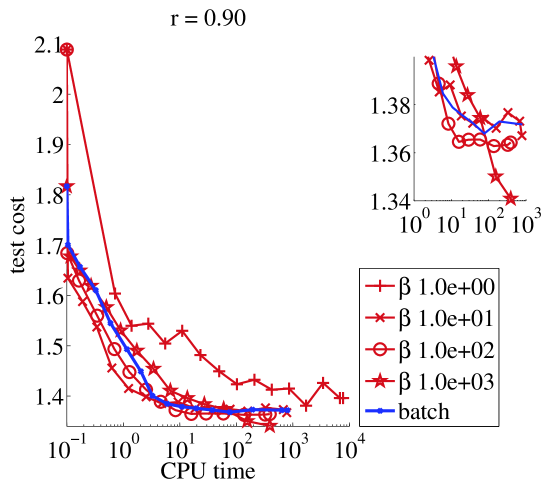 |
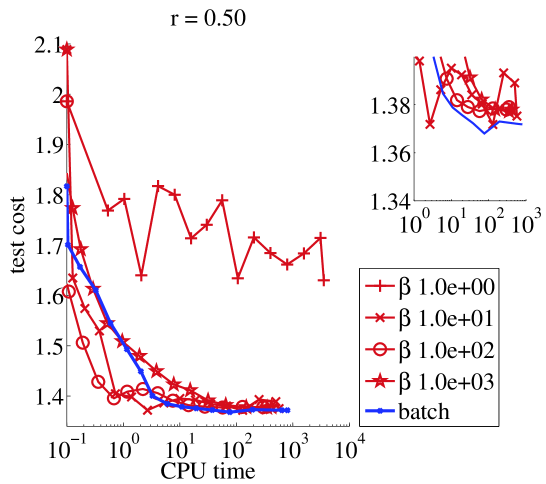 |
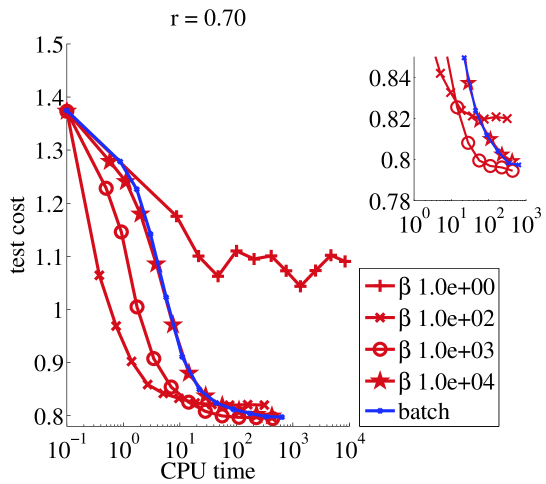
Medium data set (4 minutes).
We ran online NMF with warm restarts and one update of every sample. The same remarks apply as before, moreover we can see on Figure 2 that the online algorithm outperforms its batch counterpart by several orders of magnitude in terms of computer time for a wide range of parameter values.
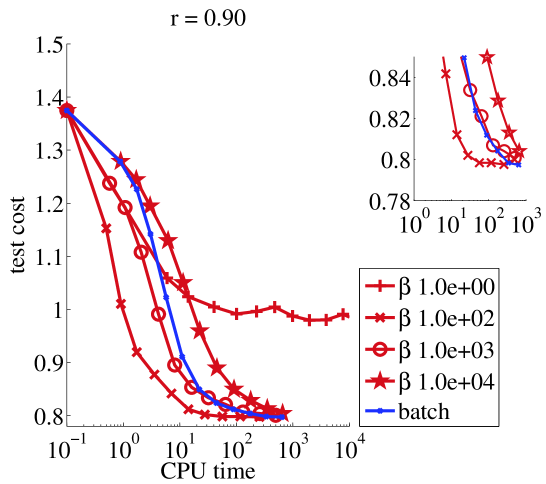 |
 |
 |
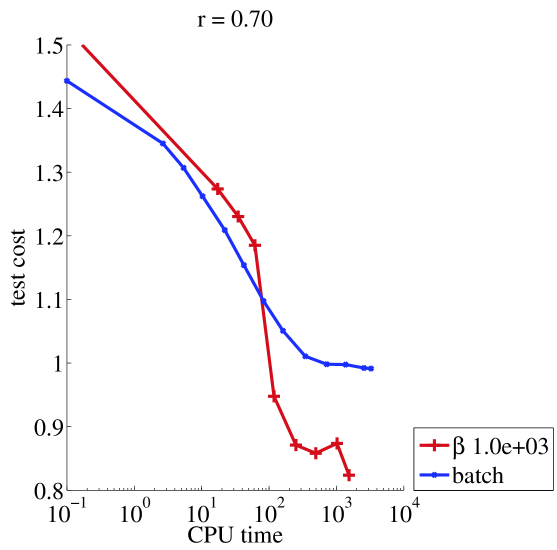
Large data set (1 hour 20 minutes).
For the large data set, we use fresh restarts and updates of for every sample. Since batch NMF does not fit into memory any more, we compare online NMF with batch NMF learnt on a subset of the training set. In Figure 3, we see that running online NMF on the whole training set yields a more accurate dictionary in a fraction of the time that batch NMF takes to run on a subset of the training set. We stress the fact that we used fresh restarts so that there is no need to store offline.
Summary.
The online algorithm we proposed is stable provided minimal restrictions on the values of the parameters : if , then any value of is stable. If then should be chosen large enough. Clearly there is a tradeoff in choosing the mini-batch size , which is explained by the way it works : when is small, frequent updates of are an additional cost as compared with batch NMF. On the other hand, when is small enough we take advantage of the redundancy in the training set. From our experiments we find that choosing and yields satisfactory performance.
4 Conclusion
In this paper we make several contributions : we provide an algorithm for online IS-NMF with a complexity of in time and memory for updates in the dictionary. We propose several extensions that allow to speedup online NMF and summarize them in a concise algorithm (code will be made available soon). We show that online NMF competes with its batch counterpart on small data sets, while on large data sets it outperforms it by several orders of magnitude. In a pure online setting, data samples are processed only once, with constant time and memory cost. Thus, online NMF algorithms may be run on data sets of potentially infinite size which opens up many possibilities for audio source separation.
References
- Bucak and Gunsel [2009] S. Bucak and B. Gunsel. Incremental subspace learning via non-negative matrix factorization. Pattern Recognition, 42(5):788–797, 2009.
- Févotte and Idier [in press] C. Févotte and J. Idier. Algorithms for nonnegative matrix factorization with the beta-divergence. Neural Computation, in press.
- Févotte et al. [2009] C. Févotte, N. Bertin, and J.-L. Durrieu. Nonnegative matrix factorization with the Itakura-Saito divergence: With application to music analysis. Neural Comput., 21(3):793–830, 2009.
- Hoffman et al. [2010] Matthew D. Hoffman, David M. Blei, and Francis Bach. Online learning for latent dirichlet allocation. In Neural Information Processing Systems, 2010.
- Lefèvre et al. [2011] A. Lefèvre, F. Bach, and C. Févotte. Itakura-Saito nonnegative matrix factorization with group sparsity. In Proc. Int. Conf. on Acous., Speech, and Sig. Proc. (ICASSP), 2011.
- Mairal et al. [2010] J. Mairal, F. Bach, J. Ponce, and G. Sapiro. Online learning for matrix factorization and sparse coding. Journal of Machine Learning Research, 11:19–60, 2010.
- Smaragdis et al. [2007] P. Smaragdis, B. Raj, and M.V. Shashanka. Supervised and semi-supervised separation of sounds from single-channel mixtures. In Proc. Int. Conf. on ICA and Signal Separation. London, UK, September 2007.
- Virtanen et al. [2008] T. O. Virtanen, A. T. Cemgil, and S. J. Godsill. Bayesian extensions to nonnegative matrix factorisation for audio signal modelling. In Proc. of IEEE ICASSP, Las Vegas, 2008. IEEE.
- Virtanen [2007] T.O. Virtanen. Monaural sound source separation by non-negative matrix factorization with temporal continuity and sparseness criteria. IEEE Trans. on Audio, Speech, and Lang. Proc., 15(3), March 2007.