Online Distributed Trajectory Planning for Quadrotor Swarm with Feasibility Guarantee using Linear Safe Corridor
Abstract
This paper presents a new online multi-agent trajectory planning algorithm that guarantees to generate safe, dynamically feasible trajectories in a cluttered environment. The proposed algorithm utilizes a linear safe corridor (LSC) to formulate the distributed trajectory optimization problem with only feasible constraints, so it does not resort to slack variables or soft constraints to avoid optimization failure. We adopt a priority-based goal planning method to prevent the deadlock without an additional procedure to decide which robot to yield. The proposed algorithm can compute the trajectories for 60 agents on average 15.5 ms per agent with an Intel i7 laptop and shows a similar flight distance and distance compared to the baselines based on soft constraints. We verified that the proposed method can reach the goal without deadlock in both the random forest and the indoor space, and we validated the safety and operability of the proposed algorithm through a real flight test with ten quadrotors in a maze-like environment.
I INTRODUCTION
The trajectory planning algorithm must guarantee collision avoidance and dynamical feasibility when operating a quadrotor swarm, as one accident can lead to total failure. Also, the need to handle a large number of agents requests a scalable online distributed algorithm. However, there are two main challenges to generate a safe trajectory online. First, it is difficult to find feasible collision avoidance constraints if the agents are crowded in a narrow space. Many researchers adopt soft constraints to avoid an infeasible optimization problem, but many of them cannot guarantee collision avoidance [1, 2, 3, 4]. Second, if the obstacles have a non-convex shape, it is difficult to solve deadlock even in sparse environments using distributed planning approaches. The centralized methods like conflict-based search (CBS) [5] can solve this problem, but they are not appropriate for online planning due to their long computation time.
In this letter, we present an online trajectory planning algorithm that guarantees feasibility of the optimization problem. The key idea of the proposed method is a linear safe corridor (LSC), which allows the feasible set of collision avoidance constraints by utilizing the trajectory at the previous step. We design the LSC to combine the advantages of the buffered Voronoi cell (BVC) [6] and the relative safe flight corridor (RSFC) [7]. First, the LSC can prevent collision between agents without non-convex constraints or slack variables, similar to the BVC. Second, since the LSC has a similar form to the RSFC, the LSC can reflect the previous solution to the current optimization problem. Hence it can reduce the flight time and distance to a similar level to on-demand collision avoidance [1] or discretization-based method [3] while guaranteeing the collision avoidance which was not done in the previous works. By adopting the LSC, the proposed algorithm always returns a safe trajectory without optimization failure. Furthermore, we introduce priority-based goal planning to solve deadlock in maze-like environments. Despite the limited performance in very dense environments due to the nature of a distributed approach, it can find the trajectory to the goal in sparse environments using the previous trajectories to decide which robot to yield. We compared the proposed algorithm with state-of-the-art methods, BVC [6], DMPC [1], EGO-Swarm [3] in simulations, and we conducted flight tests to demonstrate that the proposed algorithm can be applied to real-world settings. (See Fig. 1). We will release the source code of this work in https://github.com/qwerty35/lsc_planner.
We summarize the main contributions as follows.
-
•
An online multi-agent trajectory planning algorithm that guarantees to generate safe, feasible trajectory in cluttered environments without potential optimization failure by using the linear safe corridor.
-
•
Linear safe corridor that fully utilizes the previous solution to ensure collision avoidance and feasibility of the constraints.
-
•
Decentralized priority-based goal planning that prevents the deadlock in a sparse maze-like environment without an additional procedure to decide which robot to yield.

II RELATED WORK
II-A Online Multi-Agent Collision Avoidance
To achieve online planning, many recent works adopt discretization method, which apply the constraints only at some discrete points, not the whole trajectory [1, 2, 3, 4]. However, this approach can occur the collision if the interval between discrete points is too long. Moreover, most of the works utilize slack variables or soft constraints to avoid the infeasible optimization problem, which increases the probability of collisions. A velocity obstacle (VO)-based method [8, 9] can be considered, but they can cause a collision either since the agents do not follow the constant velocity assumption. On the contrary, the proposed algorithm guarantees collision avoidance for all trajectory points, and it ensures feasibility of the optimization problem without the slack variables or soft constraints.
There are several works that can guarantee both collision avoidance and feasibility. In [6], buffered Voronoi cell (BVC) is presented to confine the agents to a safe region, and in [10], a hybrid braking controller is applied for safety if the planner faces feasibility issues. However, these methods require conservative collision constraints. On the other hand, the proposed method employs less conservative constraints because it constructs the LSC considering the previous trajectories. The authors of [11] suggest an asynchronous planning method using a collision check-recheck scheme. This method guarantees feasibility by executing only verified trajectories through communication. However, it often takes over few seconds for replanning since it blocks the update if it receives the other agent’s trajectories during the planning. Conversely, the proposed method uses a synchronized replanning method, which takes constant time to update trajectories.
II-B Decentralized Deadlock Resolution
A deadlock can occur if the agents are crowded in a narrow space without a centralized coordinator. One approach to solve this is a right-hand rule [13], which rotates the goal to the right when the agent detects the deadlock. However, it often causes another deadlock in cluttered environments. In [14], the agents are sequentially asked to plan an alternative trajectory until the deadlock is resolved. However, it requires an additional procedure to decide which robot to yield. On the other hand, the proposed method does not require such a decision process because it determines the priority by the distance to the goal. The authors of [15] present a cooperative strategy based on bidding to resolve the deadlock. However, this method takes more time for replanning as the number of agents increases because it updates only the trajectory of the winning bidder. A similar approaches to our proposed method can be found in [16]. It utilizes the grid-based planner to avoid conflict between agents. However, it often fails to find the discrete path in a compact space because it treats all other agents as static obstacles. To solve this, the proposed method imposes the priority on the agents so that the agents ignore the lower-priority agents while planning the discrete path.
III PROBLEM FORMULATION
In this section, we formulate a distributed trajectory optimization problem that guarantees feasibility. We suppose that there are agents in an obstacle environment , and each agent has the mission to move from the start point to the goal point . Our goal is to generate a safe, continuous trajectory so that all agents can reach the goal point without collision or exceeding the agent’s dynamical limits. Throughout this paper, the calligraphic uppercase letter means set, the bold lowercase letter means vector, and the italic lowercase letter means scalar value. The superscript of each symbol shows the index of the associated agent.
III-A Assumption
We assume that all agents start their mission with the collision-free initial configuration and they can follow the trajectory accurately. We suppose that all agents can share their current positions, goal points and the trajectories planned in the previous step without delay or loss of communication. We also assume that the free space of the environment is given as prior knowledge.
III-B Trajectory Representation
Due to the differential flatness of quadrotor dynamics [17], we represent the trajectory of agent at the replanning step , , with the piecewise Bernstein polynomial:
| (1) |
where is degree of polynomial, is the control point of the segment of the trajectory, is Bernstein basis polynomials, is the start time of the replanning step , , is duration of each segment, and . Thus, the control points of the piecewise polynomial, for and , are the decision variables of our optimization problem. Here, the Bernstein basis can be replaced with another one that satisfies the convex hull property, such as [18]. In this paper, we denote the segment of the trajectory as and the vector that contains all control points of the trajectory as .
III-C Objective Function
III-C1 Error to goal
We minimize the distance between the agent and the current goal point so that the agent can reach the final goal point.
| (2) |
where is the weight coefficient and is the Euclidean norm.
III-C2 Derivatives of trajectory
We minimize the derivatives of trajectory to penalize aggressive maneuvers of the agent.
| (3) |
where is the weight coefficient. In this work, we set the weights to minimize the jerk.
III-D Convex Constraints
The trajectory should satisfy the initial condition to match the agent’s current position, velocity and acceleration. Also, the trajectory should be continuous up to the acceleration for smooth flight. Due to the dynamical limit of quadrotor, the agents should not exceed their maximum velocity and acceleration. We can formulate these constraints in affine equality and inequality constraints using the convex hull property of the Bernstein polynomials [19]:
| (4) |
| (5) |
III-E Collision Avoidance Constraints
III-E1 Obstacle avoidance constraint
To avoid collision with static obstacle, we formulate the constraint as follows:
| (6) |
| (7) |
where is the Minkowski sum, is the free space of the environment, and is an obstacle collision model that has sphere shape, and is the radius of agent .
III-E2 Inter-collision avoidance constraint
We can represent the collision avoidance constraint between the agents and as follows:
| (8) |
where is the inter-collision model, which is a compact convex set that satisfies to maintain symmetry between agents. In this work, we adopt the ellipsoidal collision model to consider the downwash effect of the quadrotor:
| (9) |
where and is the downwash coefficient. Since (8) is a non-convex constraint, we linearize it using the convex hull property of Bernstein polynomial:
| (10) |
| (11) |
where is the convex hull of the control points of relative trajectory between the agents and , is a set of agents, and is the convex hull operator that returns a convex hull of the input set.
Theorem 1.
If the trajectories of all agents satisfy the condition (10), then there is no collision between agents.
Proof.
For any pair of the agents and , the relative trajectory between two agents is a piecewise Bernstein polynomial:
| (12) |
Due to the convex hull property of the Bernstein polynomial and (10), we obtain the following for .
| (13) |
| (14) |
Thus, there is no collision between agents because they satisfy the collision constraint (8) for any segment . ∎
IV Algorithm
In this section, we introduce the trajectory planning algorithm that guarantees to return the feasible solution. Alg. 1 summarizes the overall process. First, we receive the current positions, goal points and trajectories at the previous step for all agents as inputs. Then, we plan initial trajectories using the trajectory at the previous replanning step (line 2, Sec. IV-A). Next, we construct collision avoidance constraints based on the initial trajectories (lines 4-7, Sec. IV-B, IV-C). After that, we determine the intermediate goal using the grid-based path planner (line 8, Sec. IV-D). Finally, we obtain the safe trajectory by solving the quadratic programming (QP) problem (line 9, Sec. IV-E). We will prove the feasibility of the optimization problem by showing that the initial trajectory satisfies all the constraints.
IV-A Initial Trajectory Planning
We utilize the trajectory at the previous replanning step, , as an initial trajectory. If it is the first step of the planning, we then use the current position instead. Suppose that the replanning period is equal to the segment time . Then we can represent the initial trajectory as piecewise Bernstein polynomial.
| (15) |
where is the initial trajectory at the replanning step . We denote the segment of the initial trajectory as and the control point of this segment as . Note that the control point of initial trajectory can be represented using the previous ones (e.g. for ) and there is no collision between initial trajectories if there is no collision between the previous ones.
IV-B Safe Flight Corridor Construction
A safe flight corridor (SFC), , is a convex set that prevents the collision with the static obstacles:
| (16) |
To guarantee the feasibility of the constraints, we construct the SFC using the initial trajectory and the SFC of the previous step.
| (17) |
where is a convex set that contains the point and satisfies . Note that the SFC in (17) always exists for all replanning steps if the control points of the initial trajectory do not collide with static obstacles. We can find this using the axis-search method [7].
Assume that the control points of is confined in the corresponding SFC, i.e. for and :
| (18) |
Then, there is no collision with static obstacles due to the convex hull property of the Bernstein polynomial [20]. Also, we can prove that the control points of the initial trajectory always belong to the corresponding SFC for all replanning steps.
Lemma 1.
(Feasibility of SFC) Assume that for at the replanning step . Then, for .
IV-C Linear Safe Corridor Construction
We define the LSC as a linear constraint that satisfies the following conditions:
| (19) |
| (20) |
| (21) |
where is the normal vector, is the safety margin and . Let is the convex hull of the control points of relative initial trajectory, i.e. . Lemmas 2 and 3 present the main properties of LSC.
Lemma 2.
(Safety of LSC) If , for then we obtain which implies that the agent does not collide with the agent .
Lemma 3.
(Existence and Feasibility of LSC) If for , then there exists that satisfies the definition of LSC and for .
Proof.
and are disjoint compact convex sets. Thus, by the hyperplane seperation theorem [21], there exists such that:
| (27) |
where . Here, we set the normal vector and the safety margin of as follows:
| (28) |
| (29) |
We can observe that they fulfill the definition of LSC. Furthermore, we have due to (27). It indicates that for . ∎
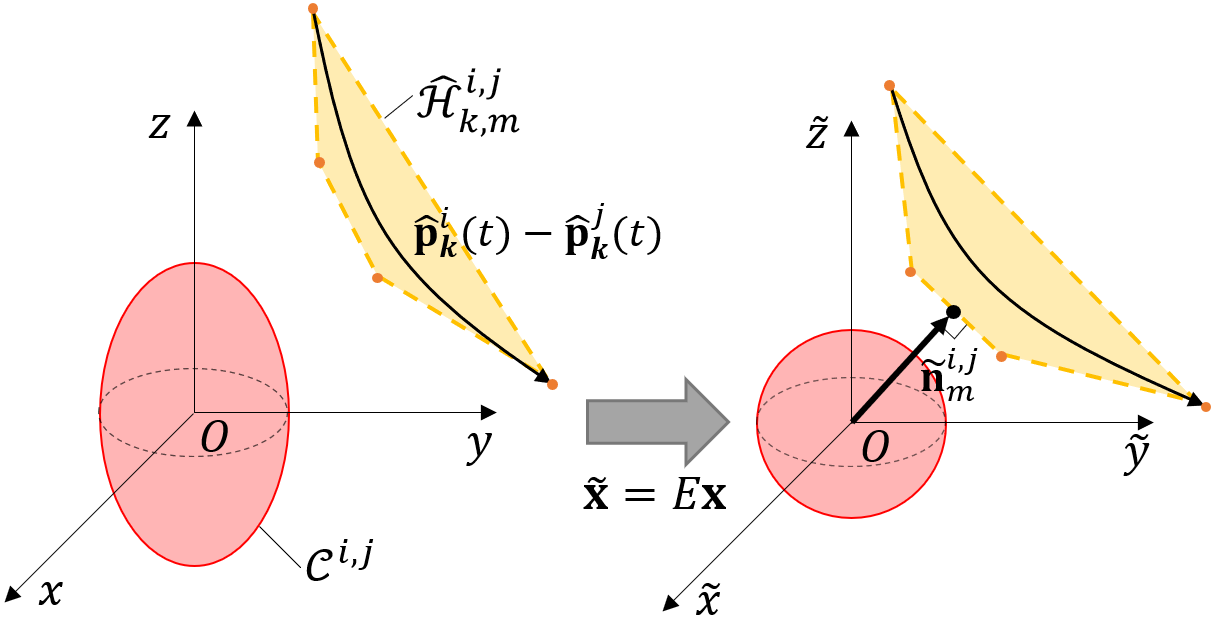
We construct the LSC based on Lemma 3. First, we perform the coordinate transformation to convert the collision model to the sphere as shown in Fig. 2. Next, we conduct the GJK algorithm [22] to find the closest points between and the collision model. Then, we determine the normal vector utilizing the vector crossing the closest points and compute the safety margin using (29). Finally, we obtain the LSC by reversing the coordinate transform.
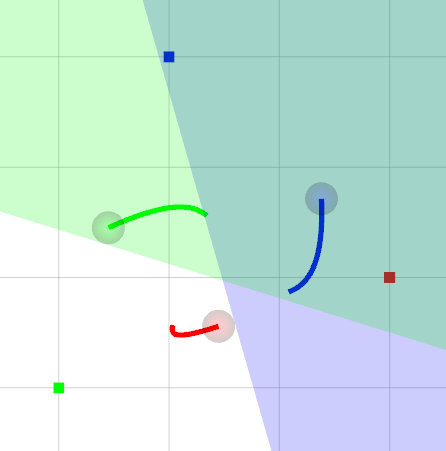
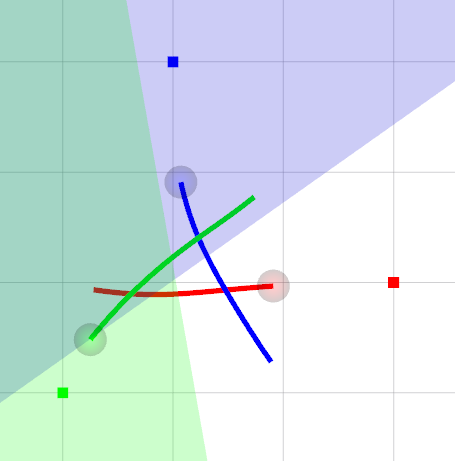
We compare the LSC with the BVC [6] in Fig. 3. Since the BVC is generated using the agent’s current position only, the desired trajectories from the BVC remain within each static cell, which leads to a conservative maneuver as shown in Fig. 3(a). On the other hand, we construct the LSC utilizing the full trajectory at the previous step. Thus, we can obtain more aggressive maneuver while ensuring collision avoidance, as depicted in Fig. 3(b).
IV-D Goal Planning
In this work, we adopt the priority-based goal planning to prevent the deadlock in cluttered environments. Alg. 2 describes the proposed goal planning method. We give the higher priority to the agent that has a smaller distance to the goal (30). However, we assign the lowest priority to the goal-reached agent to prevent them from blocking other agent’s path (31). If an agent moves away from the current agent, then we do not consider the priority of that agent for smooth traffic flow (32) (lines 1-6).
| (30) |
| (31) |
| (32) |
Next, we find the nearest agent among the higher priority agents. If the distance to the nearest agent is less than the threshold , then we assign the goal to increase the distance to the closest agent (lines 7-9). It is necessary to prevent agents from clumping together. If there is no such agent, we search a discrete path using a grid-based path planner. Here, the higher-priority agent is considered as a static obstacle. If the planner fails to find a solution, then we retry to find the path without considering the higher-priority agent (line 11). Finally, we find the LOS-free goal in the discrete path (line 12). The LOS-free goal means that the line segment between the goal and the agent’s current position does not collide with higher priority agents and static obstacles.
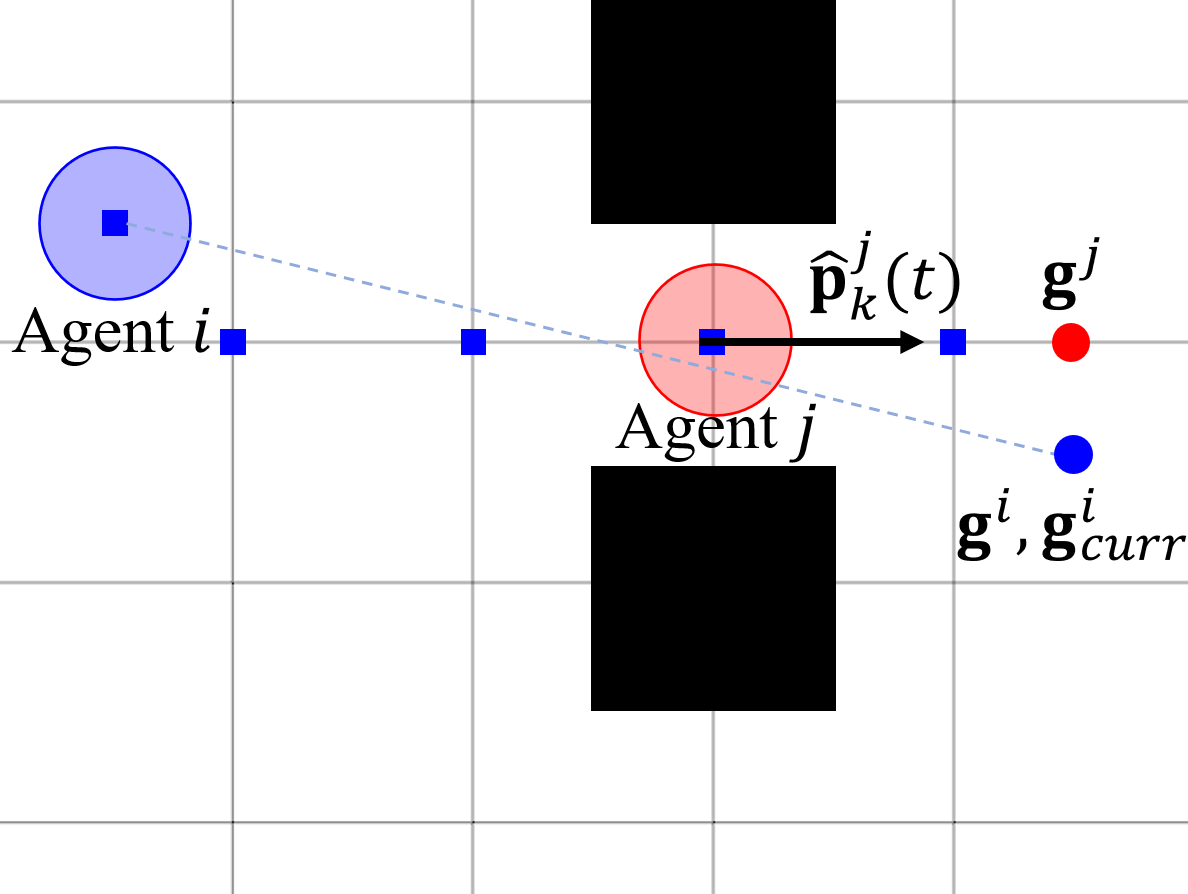
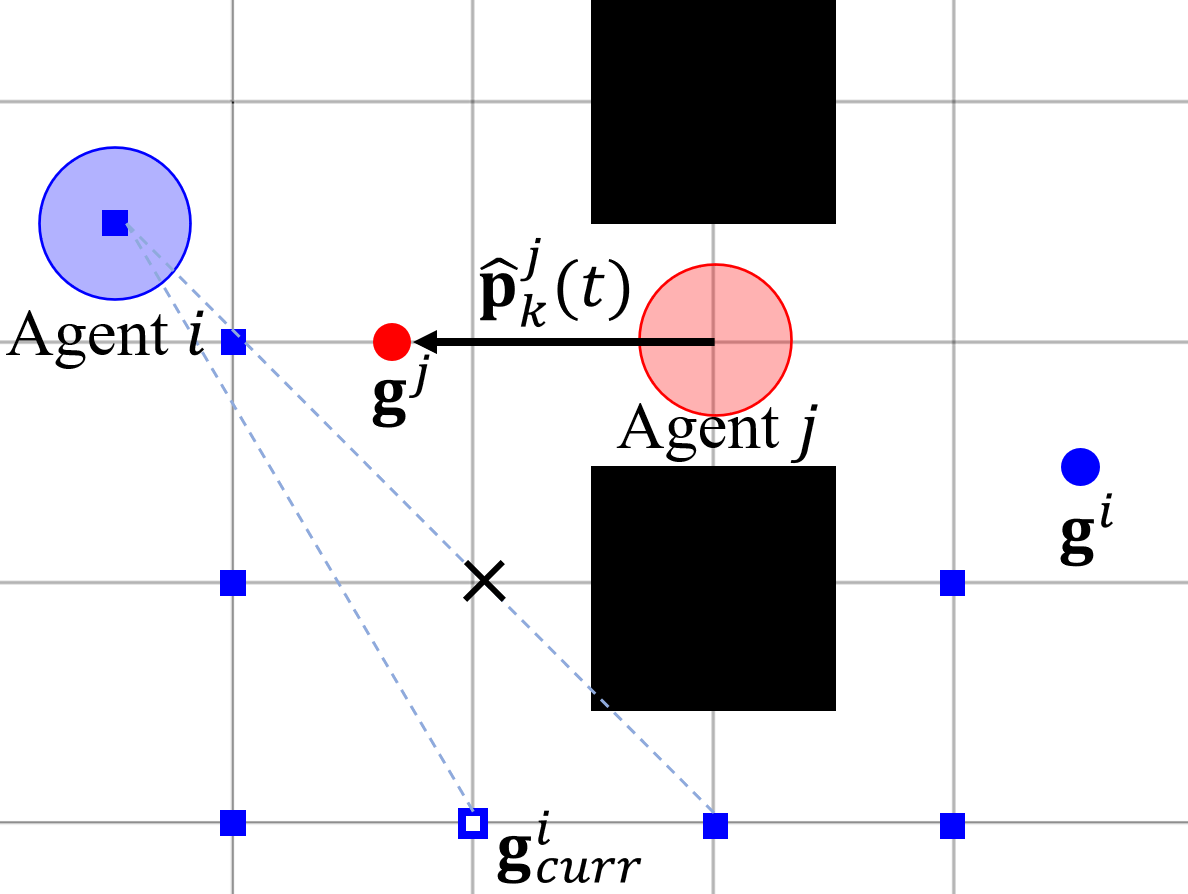
Fig. 4 describes the mechanism of the Alg. 2. In the left figure, the agent has lower priority because it is moving away from the agent . Due to that, the agent ignores the agent when planning the discrete path. On the other hand, the agent in the right figure has higher priority because it moves to the agent and has a smaller distance to the goal. Thus, the agent finds the LOS-free goal in the discrete path that detours the agent and static obstacles.
IV-E Trajectory Optimization
We reformulate the distributed trajectory optimization problem as a quadratic programming (QP) problem using the SFC and LSC:
| (33) | ||||||
| subject to | ||||||
Here, we add the last constraint to guarantee dynamic feasibility of the initial trajectory. Note that the constraints in (33) guarantees collision-free due to the SFC and Lemma 2. Furthermore, Thm. 2 shows that this problem consists of feasible constraints. Therefore, we can obtain a feasible solution from Alg. 1 for all replanning steps by using a conventional convex solver.
Theorem 2.
Suppose that there is no collision in the initial configuration and the replanning period is equal to the segment time . Then, the solution of (33) always exists for all replanning steps.
Proof.
If , then we obtain for by the assumption. Hence the control points of the initial trajectory are the solution to (33) by Lemmas 1, 3.
If there exists a solution at the previous replanning step , then the initial trajectory satisfies , , and for due to (15) and Lemma 1. Also, we have for by Lemma 2. Here, we can derive that for using the fact that for and . Thus, we obtain by Lemma 3. To summarize, the control points of the initial trajectory satisfies all constraints of (33). Therefore, the solution of (33) always exists for all replanning steps by the mathematical induction. ∎
If we conduct the mission with actual quadrotors, the assumption used in Thm. 2 may not be satisfied due to external disturbance or tracking error. To solve this problem, we adopt event-triggered replanning proposed in [1]. This method ignores the tracking error when the error is small. In other word, it utilizes the desired state from the previous trajectory () as the initial condition of the current optimization problem (4). If the detected disturbance is too large, we replace the planner with our previous work [12] until the error vanished.
V EXPERIMENTS
All simulation and experiments were conducted on a laptop running Ubuntu 18.04. with Intel Core i7-9750H @ 2.60GHz CPU and 32G RAM. All methods used for comparison were implemented in C++ except for DMPC tested in MATLAB R2020a. We modeled the quadrotor with radius m, downwash coefficient , maximum velocity m/s, maximum acceleration m/ based on the experimental result with Crazyflie 2.0. We use the Octomap [23] to represent the obstacle environment. We formulated the piecewise Bernstein polynomial with the degree of polynomials , the number of segments and the segment time s, where the total time horizon is 1 s. We set the parameters for the objective function and Alg. 2 to , , m, m and m. We used the openGJK package [24] for GJK algorithm and the CPLEX QP solver [25] for trajectory optimization. When we execute the proposed algorithm, we set the interval between trajectory update to s to match the assumption in Thm. 2. It means that all agents begin to plan the trajectories at the same time and update it with the rate of 5 Hz.
V-A Simulation in Obstacle-free Space
To validate the performance of the proposed method, we compare four online trajectory planning algorithms at the obstacle-free space: 1) DMPC (input space) [1], 2) BVC [6] with right-hand rule, 3) LSC with right-hand rule (LSC-RH), 4) LSC with priority-based goal planning (LSC-PB). We conducted the simulation with 10 to 60 quadrotors in a 3 m 3 m 2 m empty space. We executed 30 missions with randomly allocated start and goal points for each number of agents. When judging the collision, we use a smaller model with m and for DMPC because it uses soft constraints, while the other methods use the original one.
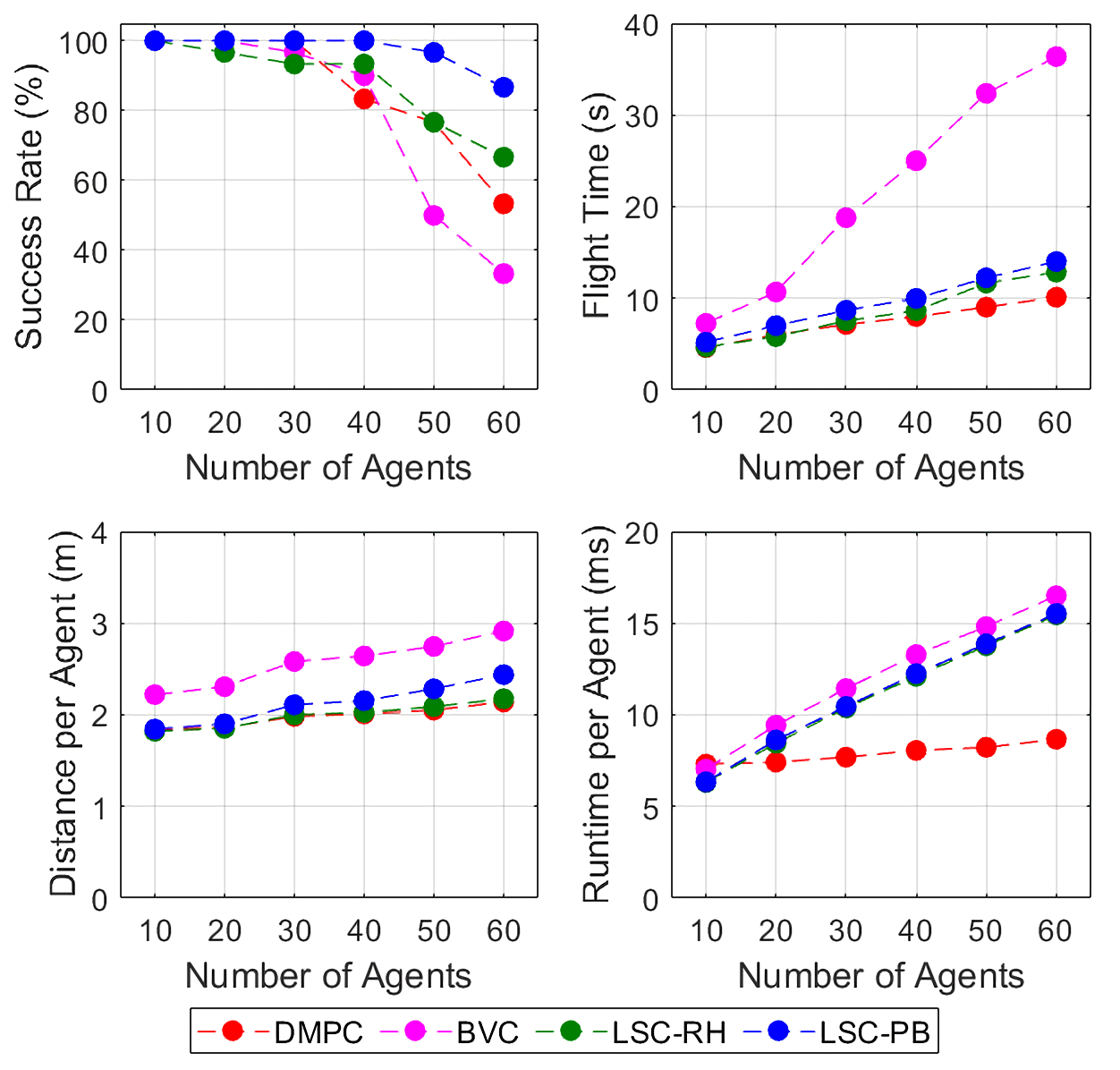
The top-left graph of Fig. 5 describes the success rate of each method. We observed that the collision occurred in all failure cases of DMPC even though we adopted the smaller collision model. It implies that collision constraint including the slack variable cannot guarantees the safety in a dense environment even with the bigger safety margin. On the contrary, there was no collision when we use BVC and LSC-based methods, and the deadlock was the only reason for failure. It indicates that the proposed method does not cause optimization failure as guaranteed by Thm. 2. Among the four algorithms, the LSC with priority-based goal planning method shows the highest success rate for all cases. This result shows that priority-based goal planning can solve deadlock better than the right-hand rule.
The top-right and bottom-left figures of Fig. 5 show the total flight time and flight distance per agent, respectively. The proposed method has less flight time and less flight distance on average compared to the BVC-based method. Such performance is similar to DMPC, but the proposed algorithm still guarantees collision avoidance. Compared to the right-hand rule, the priority-based goal planning costs more flight time and more flight distance, but it is acceptable considering the increase in success rate.
The bottom-right graph of Fig. 5 describes the average computation time per agent. The proposed method takes 10.5 ms for 30 agents and 15.5 ms for 60 agents. The proposed algorithm consumes similar computation time to BVC, but needs more computation time than DMPC because it involves more constraints to guarantee collision avoidance.

| Env. | Method | ||||
|---|---|---|---|---|---|
| Forest (20 agents) | EGO-Swarm | 50 | 18.2 | 8.69 | 4.7 |
| LSC-PB | 100 | 18.4 | 8.93 | 9.1 | |
| Indoor (20 agents) | EGO-Swarm | 0 | - | - | 53.0 |
| LSC-PB | 100 | 42.0 | 14.6 | 9.2 |
V-B Simulation in Cluttered Environments
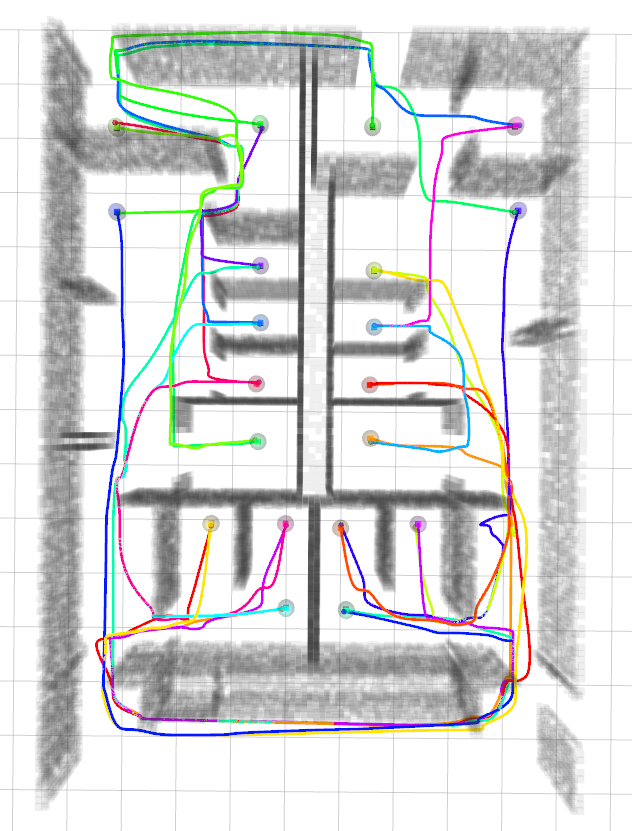
We compared the proposed algorithm with the EGO-Swarm [3] in two types of obstacle environment. One is a random forest consisting of 10 static obstacles. We deployed 20 agents in a circle with 4 m radius and 1 m height, and we assigned the goal points to antipodes of the start points, as shown in Fig. 6(a). The other is an indoor space with the dimension 10 m 15 m 2.5 m. For a fair comparison, we increased the sensor range of EGO-Swarm enough to recognize all obstacles. We randomly assigned the start and goal points among the 20 predetermined points as depicted in Fig. 6(b). We executed 30 simulations for each environment changing the obstacle’s position (random forest) or the start and goal points (indoor space).
Table I shows the planning result of both methods in cluttered environments. Ego-Swarm shows faster computation speed in the random forest because it optimizes the trajectory without any hard constraints. However, the success rate of this method is success rate, indicating that EGO-Swarm cannot guarantee collision avoidance. On the other hand, the proposed method shows a perfect success rate and has similar flight time and distance compared to EGO-Swarm. This result shows that the LSC is as efficient as the soft constraint of EGO-Swarm but still guarantees collision avoidance in obstacle environments.
Unlike the random forest, EGO-Swarm fails to find the trajectory to the goal points in the indoor space. It is because EGO-Swarm cannot find the topological trajectory detouring the wall-shaped obstacle. On the other hand, the proposed method reaches the goal for all cases due to the priority-based goal planning.
V-C Flight Test
We conducted the flight test with ten Crazyflie 2.0 quadrotors in the maze-like environment depicted in Fig. 1. We confined the quadrotors in 10 m x 6 m x 1 m space to prevent them from bypassing the obstacle region completely. We assign the quadrotors a mission to patrol the two waypoints to validate the operability of the proposed algorithm. We sequentially computed the trajectories for all agents in a single laptop, and we used the Crazyswarm [26] to broadcast the control command to quadrotors. We utilized the Optitrack motion capture system to observe the agent’s position at 120 Hz. The full flight is presented in the supplemental video.
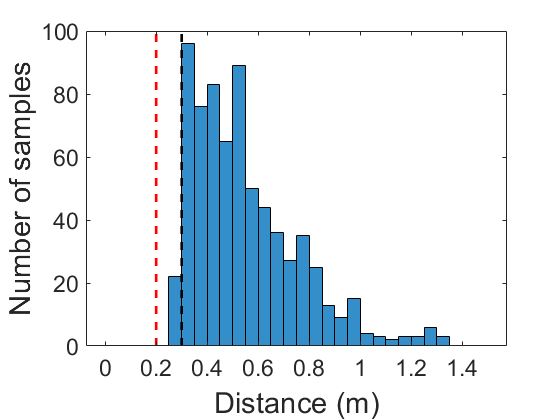
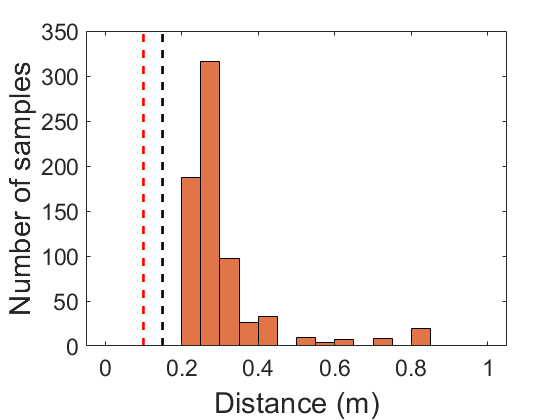
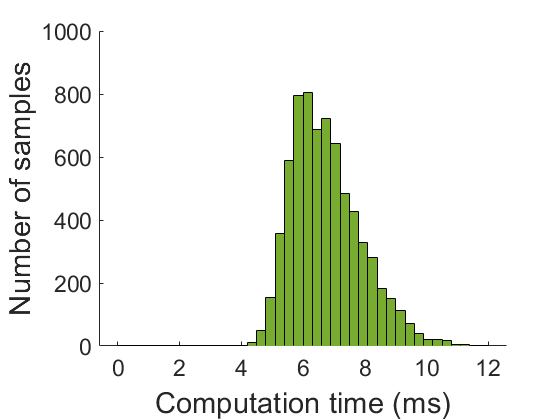
The flight test was conducted for around 70 seconds, and there was no huge disturbance triggering the planner change. We accumulated the history of the smallest inter-agent distance and agent-to-obstacle distance in Fig. 7(a) and 7(b) respectively. Fig. 7(a) shows that the agents invade desired safe distance for some sample times due to the tracking error. However, there was no physical collision during the entire flight. The computation time per agent is reported in Fig. 7(c), and the average computation time was 6.8 ms.
VI CONCLUSIONS
We presented the online distributed trajectory planning algorithm for quadrotor swarm that guarantees to return collision-free, and dynamically feasible trajectory in cluttered environments. We constructed the collision avoidance constraints using the linear safe corridor so that the feasible set of the constraints always contains the initial trajectory. We utilized these constraints to reformulate the trajectory generation problem as convex optimization, and we proved that this problem ensures feasibility for all replanning steps. We verified that the prioritized-based goal planning solves deadlock better than the right-hand rule and EGO-Swarm. The proposed method shows the highest success rate compared to the state-of-the-art baselines and yields less flight time and less flight distance compared to the BVC-based method. We validated the operability of our algorithm by intensive flight tests in a maze-like environment.
References
- [1] C. E. Luis, M. Vukosavljev, and A. P. Schoellig, “Online trajectory generation with distributed model predictive control for multi-robot motion planning,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 604–611, 2020.
- [2] S. Kandhasamy, V. B. Kuppusamy, and S. Krishnan, “Scalable decentralized multi-robot trajectory optimization in continuous-time,” IEEE Access, vol. 8, pp. 173 308–173 322, 2020.
- [3] X. Zhou, X. Wen, J. Zhu, H. Zhou, C. Xu, and F. Gao, “Ego-swarm: A fully autonomous and decentralized quadrotor swarm system in cluttered environments,” arXiv preprint arXiv:2011.04183, 2020.
- [4] X. Zhou, Z. Wang, X. Wen, J. Zhu, C. Xu, and F. Gao, “Decentralized spatial-temporal trajectory planning for multicopter swarms,” arXiv preprint arXiv:2106.12481, 2021.
- [5] G. Sharon, R. Stern, A. Felner, and N. R. Sturtevant, “Conflict-based search for optimal multi-agent pathfinding,” Artificial Intelligence, vol. 219, pp. 40–66, 2015.
- [6] D. Zhou, Z. Wang, S. Bandyopadhyay, and M. Schwager, “Fast, on-line collision avoidance for dynamic vehicles using buffered voronoi cells,” IEEE Robotics and Automation Letters, vol. 2, no. 2, pp. 1047–1054, 2017.
- [7] J. Park, J. Kim, I. Jang, and H. J. Kim, “Efficient multi-agent trajectory planning with feasibility guarantee using relative bernstein polynomial,” in 2020 IEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 434–440.
- [8] J. Van Den Berg, S. J. Guy, M. Lin, and D. Manocha, “Reciprocal n-body collision avoidance,” in Robotics research. Springer, 2011, pp. 3–19.
- [9] S. H. Arul and D. Manocha, “Dcad: Decentralized collision avoidance with dynamics constraints for agile quadrotor swarms,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1191–1198, 2020.
- [10] L. Wang, A. D. Ames, and M. Egerstedt, “Safety barrier certificates for collisions-free multirobot systems,” IEEE Transactions on Robotics, vol. 33, no. 3, pp. 661–674, 2017.
- [11] J. Tordesillas and J. P. How, “Mader: Trajectory planner in multiagent and dynamic environments,” IEEE Transactions on Robotics, 2021.
- [12] J. Park and H. J. Kim, “Online trajectory planning for multiple quadrotors in dynamic environments using relative safe flight corridor,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 659–666, 2020.
- [13] H. Zhu and J. Alonso-Mora, “B-uavc: Buffered uncertainty-aware voronoi cells for probabilistic multi-robot collision avoidance,” in 2019 International Symposium on Multi-Robot and Multi-Agent Systems (MRS). IEEE, 2019, pp. 162–168.
- [14] M. Jager and B. Nebel, “Decentralized collision avoidance, deadlock detection, and deadlock resolution for multiple mobile robots,” in IEEE/RSJ International Conference on Intelligent Robots and Systems., vol. 3. IEEE, 2001, pp. 1213–1219.
- [15] V. R. Desaraju and J. P. How, “Decentralized path planning for multi-agent teams with complex constraints,” Autonomous Robots, vol. 32, no. 4, pp. 385–403, 2012.
- [16] B. Şenbaşlar, W. Hönig, and N. Ayanian, “Robust trajectory execution for multi-robot teams using distributed real-time replanning,” in Distributed Autonomous Robotic Systems. Springer, 2019, pp. 167–181.
- [17] D. Mellinger and V. Kumar, “Minimum snap trajectory generation and control for quadrotors,” in Robotics and Automation (ICRA), 2011 IEEE International Conference on. IEEE, 2011, pp. 2520–2525.
- [18] J. Tordesillas and J. P. How, “Minvo basis: Finding simplexes with minimum volume enclosing polynomial curves,” arXiv preprint arXiv:2010.10726, 2020.
- [19] M. Zettler and J. Garloff, “Robustness analysis of polynomials with polynomial parameter dependency using bernstein expansion,” IEEE Transactions on Automatic Control, vol. 43, no. 3, pp. 425–431, 1998.
- [20] S. Tang and V. Kumar, “Safe and complete trajectory generation for robot teams with higher-order dynamics,” in 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2016, pp. 1894–1901.
- [21] S. Boyd, S. P. Boyd, and L. Vandenberghe, Convex optimization. Cambridge university press, 2004.
- [22] E. G. Gilbert, D. W. Johnson, and S. S. Keerthi, “A fast procedure for computing the distance between complex objects in three-dimensional space,” IEEE Journal on Robotics and Automation, vol. 4, no. 2, pp. 193–203, 1988.
- [23] A. Hornung, K. M. Wurm, M. Bennewitz, C. Stachniss, and W. Burgard, “Octomap: An efficient probabilistic 3d mapping framework based on octrees,” Autonomous robots, vol. 34, no. 3, pp. 189–206, 2013.
- [24] M. Montanari and N. Petrinic, “Opengjk for c, c# and matlab: Reliable solutions to distance queries between convex bodies in three-dimensional space,” SoftwareX, vol. 7, pp. 352–355, 2018.
- [25] I. CPLEX, “12.7. 0 user’s manual,” 2016.
- [26] J. A. Preiss, W. Honig, G. S. Sukhatme, and N. Ayanian, “Crazyswarm: A large nano-quadcopter swarm,” in International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 3299–3304.