Opinion models, data, and politics
Abstract
We investigate the connection between Potts (Curie-Weiss) models and stochastic opinion models in the view of the Boltzmann distribution and stochastic Glauber dynamics. We particularly find that the q-voter model can be considered as a natural extension of the Zealot model which is adapted by Lagrangian parameters. We also discuss weak and strong effects continuum limits for the models.
We then fit four models (Curie-Weiss, strong and weak effects limit for the q-voter model, and the reinforcement model) to election data from United States, United Kingdom, France and Germany. We find that particularly the weak effects models are able to fit the data (Kolmogorov-Smirnov test), where the weak effects reinforcement model performs best (AIC).
The resulting estimates are interpreted in the view of political sciences, and also the importance of this kind of model-based approaches to election data for the political sciences is discussed.
keywords: Opinion dynamics; Potts models; Glauber dynamics; q-voter model; reinforcement model; weak and strong effects continuum limit; data analysis and model comparison; elections; voting behavior; interdisciplinarity.
1 Introduction
The search for common compromises in a discursive social process is at the heart of all democracies. In these debates, citizens seek their standpoint on the basis of information and news, but also based on discussions with family, colleagues, and acquaintances. Opinion dynamics aims to model
the basic structure of precisely this process [34, 51, 10].
Many opinion dynamics models are constructed on communications graphs, where the nodes represent persons, who only interact with neighboring persons [67]. Basically, there are two groups of models: Either individuals are equipped with one of a finite number of opinions (typically pro and contra), or their opinions are characterized by a continuous spectrum of possibilities (typically the interval , see [66]). Particularly the models with a continuous state space are often used to investigate whether a consensus can be reached in the long run [23, 2, 4].
Most papers do not aim to validate their models in analyzing empirical data in a quantitative way [65].
Those papers which do address empirical data mainly focus on the dynamics of two opinions within homogeneous groups and do not use an underlying graph structure [13, 16, 32, 12, 45, 41, 7, 31], as many interesting aspects, like different interaction patterns or phase transitions, already appear in models describing homogeneous
populations, and do not require interaction graphs.
Here we find a parallel in mathematical epidemiology, where is it clear that infections spread via contact graphs, but most quantitative models and methods aiming at the description and prediction of the dynamics of a real-world outbreak are based on models that assume homogeneous mixing [3, 22]. Also in the present work, we find that these simple models are sufficiently rich to meet the structure of empirical data. Technically, the main objective of those more empirically oriented papers is to obtain the invariant distribution of the underlying stochastic process and then to use this result in order to fit model parameters to data. In that, these papers are able discuss possible mechanisms that generate striking patterns in data [16, 32, 12, 45, 41],
aim to reveal changes in communication patterns in the course of time [7], or address spatial communication distances [31].
Not only in political processes, but also in other fields as vaccination hesitancy, opinion models contribute to an adequate description of the underlying communication mechanisms, and in that potentially open up ways to handle (in this case) public health problems [33, 55, 65]. It is, however, noticeable that all these aforementioned approaches from socio-physics and socio-mathematics up to now only have a small or no echo in the social and political sciences.
In the present paper, we aim to achieve three goals: In the first part, we connect two different approaches to opinion models, one driven by stochastic dynamics, and the other one originating in statistical physics; in the second part, we target on a model comparison, to find out which models are able to explain empirical data. The third part will then discuss the usefulness of mathematical models of this type for political sciences.
First part of the paper: If we review the literature, we find two main approaches to describe opinion models: One approach formulates mechanisms about how people change their minds when interacting with others in the form of stochastic dynamics. In the simplest case, the voter model [47], it is assumed that a person copies faithfully the opinion of some randomly chosen other person. A slightly more refined version of this idea introduces zealots (also called stubborns or activists) who never change their mind [52, 58], which results in the zealot (or noisy voter) model. In the long run, we find an equilibrium in the opinion dynamics, which is termed stationary distribution. This distribution can be used to analyze empirical data. A completely different approach originates in the statistical physics of spin systems. Herein, not the dynamics of the opinions is considered, but it is assumed that only little is known about the state of the population. E.g., surveys could inform us about the abundance of some opinions. To express this partial knowledge appropriately, a distribution is constructed which maximizes the Shannon entropy under the constraint of the known information. This distribution is called the Boltzmann distribution.
We connect both approaches in identifying a dynamical stochastic model (first approach) which generates a stationary distribution that coincides with a Boltzmann distribution (second approach). In this way, we associate a dynamical model with a statistical physics model and vice versa. This dynamics is called Glauber dynamics. The advantage of this procedure is the construction of a unifying framework for both approaches. Based on this framework, we construct the q-voter model [11, 53, 57] as the Glauber dynamics of a family of models which
has the zealot model as a basis.
We aim to apply the models to data. Election data usually aggregate information about a large number of people, as constituencies usually comprise thousands to hundreds of thousands of voters. Therefore, a continuum limit is of interest. Here we note that the zealot model is identical to the Moran model [54], which forms the basis of population genetics [40]. In population genetics, two different diffusion limits have been established, the weak and the strong effects limit. These two approaches differ in the assumptions about the scaling of the parameters with respect to the population size. We investigate ways to transfer this idea to general opinion models.
In the second part, we analyze election data from the United States (US), United Kingdom (UK), France (FRA), and Germany (GER) based on four opinion dynamics models (the Curie-Weiss model, the weak and strong effects continuum limit of the q-voter model, and additionally the weak effects limit of the reinforcement model [55]). We use this analysis to test the models to find out to what extent they are able to describe the data not only qualitatively but also quantitatively. The central finding is that models derived by a weak effects limit perform much better than their strong version. Potentially, these findings will be useful for future empirical studies.
In the last part, we again change the focus and turn to the interpretation of our results in the light of political science. In particular, political processes and changes in social interactions potentially leave their traces in the election data, and therewith in the estimated parameters. However, this conjecture can only be confirmed based on in-depth political research. These considerations lead us to another important aspect, which is the question of the extent to which socio-mathematical models of this kind could also be a fruitful instrument as an integral part of political science, or whether the methods, objectives and research questions of socio-mathematics and socio-physics on the one hand and political science on the other are too different.
2 General structure
In this section, we first introduce the notation before introducing the two different types of models that we will investigate.
We consider a population of individuals numbered , where each of the individuals supports either opinion A or opinion B. The opinions are coded by (for A) and (for B). The state space is given by , such that the ’th component of state indicates the opinion of individual . We consider Cannings models [9], that is, all individuals are exchangeable and the population is homogeneous. Particularly, we do not have an interaction graph, respectively the interaction graph is the full graph. We introduce the functions
which count the supporters of opinion A (function ), respectively the supporters of opinion B (function ). Our knowledge about the opinion distribution in the population will be expressed by a random measures
on .
Due to the assumption of Cannings models, the random measures necessarily are invariant w.r.t. permutations of individuals: two states with have the same probability.
That is, any random measure describing the state of the population induces a random measure on the state space , which indicates the number of opinion-A supporters. Let be a given state with , then for combinatorial reasons
| (1) |
We will find out later that the binomial coefficient, which appears here for symmetry reasons, plays a distinct role in the theory developed below.
In the next two sections, we introduce two very different ways used in the literature to construct random measures for the opinion state of the population, that is, on respectively . The first approach is based on stochastic processes, while the second is statistical in design. We should keep in mind that – due to the symmetry discussed –
every rate and every function used to define the models can be constructed in such a way that it depends on only via
and the population size .
2.1 Opinion process
A stochastic opinion process is a -valued Markov process , where single persons reconsider their opinion at rate . There is a certain probability that this person indeed changes her mind. These probabilities depend on the opinion distribution in the population; as mentioned above, this dependency is established via and not via the fine-structure of the state (which individual is an A- and which individual is a B-supporter). For mathematical convenience, but without loss of generality, we assume that the rate for to switch from to is a function of and , while that to switch from to depends on and ,
| at rate | (2a) | ||||
| at rate | (2b) | ||||
To get a feeling for which terms to use for , we can look at the voter model. Herein, represents the rate at which a person reconsiders her opinion, and interacts with some randomly chosen person in the population (with so-called selfing, that is, the person might also choose herself). The functions simply specify the probability of interacting with a person of the other opinion. Below we also consider other examples, where the probability to change the mind is slightly more involved, but the overall structure of the terms will be similar. All other entries in state are not affected by a flip of the ’th person’s opinion.
As mentioned above, the -valued process induces a -valued process via . The transition rates of are given by
| at rate | (3a) | ||||
| at rate | (3b) | ||||
We call a Markov process with transition rates given in this form an opinion process. It is straightforward to determine the stationary distribution of an opinion process if we have no absorbing states. As we aim at a specific notation that parallels the usual notation of Potts models, we derive the stationary distribution step by step. In what follows we suppress the dependency of on .
Proposition 2.1 (stationary distribution)
Assume for . Let furthermore defined by
| (4) |
Denoting the probability of state in the stationary distribution by , we have
| (5) |
Proof: The detailed balance equation for the stationary distribution yields
| (6) |
Hence,
where is determined by . Together with the definition of , , and , this formula proves the proposition.
Interestingly, the corresponding stationary distribution on can be written as
| (7) |
where if , and if ; similarly for .
Each individual has an independent contribution to the
probability of state , where depend on the global statistics of the state via .
That is, can be regarded as the environment of individual , which determines the probability of the opinion that individual has adopted. It is
furthermore interesting to observe that the population size does not explicitly appear
in the expression . Only indirectly the number of the opposite-opinion-supporters
comes in, as and add up to the given population size .
For obvious reasons, we call the functions the environmental conditions, or simply the environments, of the opinion process.
We have a degree of freedom in eqn. (5). We might add a real constant in the exponent,
.
Then, is still defined as the normalizing constant, guaranteeing that . Thus, also in the term appears, such that cancels out and does not affect the value of . Below, in the definition of the Boltzmann distribution, we will find a similar invariance. This invariance will be used later to eliminate singularities appearing in Section 3.2, where we investigate the large population limit with weak effects.
For now let us discuss the freedom given by this invariance more in detail, and particularly explore the implication for the choice of the environments. If we replace by
,
where we choose in accordance to , and require to satisfy
then the stationary distribution is not affected. Furthermore, by specifying and we specify the full freedom we do have at this point. We now go backward and determine transition rates that produce the new environments. Hereto we use such that
Since we have
The function indeed cancels out in the detailed balance equation (6).
Corollary 2.2
Given the stationary distribution for the rates respectively environments , the set of all opinion processes generating this stationary distribution is characterized by
| (8) |
where are functions satisfying and
| (9) |
2.2 Potts machinery
Next, we introduce Potts models,
where we again consider
Potts models only on a full graph. Potts models on a full graph are often termed mean-field or Curie-Weiss models.
In agreement with the literature,
we return for the moment to the individual-based formulation of the opinion model, that is, we use as state space.
We do not know the state of the population. The knowledge we assume to have is the results of some polls. For example, we could observe/measure the fraction of individuals with opinion . Consequently, we will know the expected number of persons in state , that is, . As the Potts models originate in physics, we follow the tradition and call these polls “observations”, and accordingly, the function an “observable”.
In general, observables are defined as functions without further restrictions. Another example of an observable that is often used is the number of pairs with identical opinions minus the number of pairs with different opinions,
This observable incorporates information about correlations in the population.
Let us assume that we have observables . Our knowledge about the state of the population is restricted to the knowledge of , . We represent our knowledge, and particularly the absence of complete knowledge about the state, in the form of a random measure on . We of course require that , such that does express our partial knowledge appropriately. However, there are many random measures that will satisfy this requirement. We express this lack of complete knowledge by the condition that maximizes the Shannon entropy , under the constraints . The random measure we construct in this way is called the Boltzmann distribution.
We restrict ourselves to Cannings models, such that the observables only depend on via , and thus can be defined as maps . Also the Boltzmann measure can be defined directly on via . As if , this formula defines consistently. However, as the lack of knowledge still concerns the state of the population in , we do not use the original Shannon entropy for , but measure the entropy for by the entropy for the associated measure on ,
Proposition 2.3
Let denote the number of observables, and , the observables themselves. The Boltzmann distribution is the distribution which maximizes the Shannon entropy under the constraint . If the Boltzmann distribution exists, then
| (10) |
where , , are Langrange multipliers.
Proof: The proof consists of a short computation (see e.g. [56, 46]), based on the standard Lagrangian approach for maximization of under the constraints , , and . Let denote the set of probabilities for . We determine all values , by maximizing the function
Fix . If we equate the derivative of with respect to to zero, we find
and . We obtain by the condition that the probabilities sum up to , that is, .
Remark 2.4
(a) In accordance with the literature, the Lagrangian multipliers are not specified to actually determine a Boltzmann distribution that indeed satisfies , but instead the Lagrangian multipliers are from now considered on as parameters of the Boltzmann distribution.
(b) We note that additive constants in the Hamiltonian do not affect the stationary distribution, as these constants appear in a multiplicative way in numerator as well as in the denominator
of the stationary distribution.
We make use of this observation below to get rid of singularities appearing in the weak effects limit.
The Curie-Weiss model in sensu stricto is defined by observables that are polynomials of second order, as we will discuss in Section 4.1. For the time being (Section 2.3 and Section 3) we allow for more general functions as observables, as this is necessary to obtain and utilize a connection between the Curie-Weiss models and the opinion processes, which we discuss next.
2.3 Connection between opinion processes and the Curie-Weiss model
An opinion process has an invariant distribution, and a Potts model a Boltzmann distribution. In order to connect opinion processes and Potts models, we ask which conditions the observables (Potts models) respectively the environments (opinion processes) need to satisfy such that the invariant distribution of an opinion model coincides with the Boltzmann distribution. If we combine Propositions 2.1 and Proposition 2.3, we find the following corollary.
Corollary 2.5
The stationary distribution of an opinion model with population size and environment and the Boltzmann distribution for observables coincide, if
| (11) |
Note that this corollary only states sufficient but not necessary conditions. Corollary 2.2 allows, for example, to construct more observables that generate the same distribution. Considering the settings of this corollary for general , we observe
A Boltzmann distribution with observables derived from environments of an opinion process is, for general , the stationary distribution of the opinion process with transition rates
| at rate | (12a) | ||||
| at rate | (12b) | ||||
We call this family of opinion models the Glauber family for the given observables/environments. Please note that the standard Glauber dynamics for the spin up/spin down mean-field Ising model [46] utilized the freedom discussed in Corollary 2.2 in choosing a non-trivial function .
3 Large population limits
Below we consider applications of opinion processes to data, where often the population size is in the magnitude of . Therefore, a continuity limit is of interest. As above, we might consider the dynamics (opinion process) and work out a diffusion limit, or we might focus on the Boltzmann distribution, and consider a continuum limit for that distribution. The interesting point is to understand the connection between the two resulting objects. Herein we note that the rates , the corresponding environments respectively the observables incorporate parameters which might scale differently for large . In that, different assumptions about this scaling yield the weak and the strong effects limits (please do not confuse the weak effects limit, which refers to the scaling of the parameters, with a weak limit, which refers to the topology of convergence).
We assume throughout the current section that and depend on for , that is, on the share of an opinion in the population instead on the absolute number of supporters of a given opinion,
| is replaced by | ||||
| is replaced by |
where
such that , are well-defined for all .
Since the observables are defined via , we rewrite them separately, see Section 3.1 below.
For given, the old and the new scaling are mathematically equivalent. However, if we aim at a limit , the new scaling is a reasonable and very helpful assumption, that the most commonly used models actually fulfill.
3.1 Strong effects limit
In the strong effects limit, we assume that approximate functions for , such that
| (13) |
is well-defined. For clarity of notation, we write the limiting of rate functions, environments, and observables for in bold. To adapt the definition region of the associated environments from the discrete state space to the continuous state space , we re-define the environments as
For , , we get back the environments as defined in Proposition 2.1. Therewith, also the environments satisfy a proper limit for ,
| (14) |
We also introduce a limit for the observables. Here, a certain subtlety appears: We have . As , this formula becomes . In leading order, the observables are . We thus scale them by , and define
| (15) |
We emphasize at this point that, when using below, we need to take the scale , introduced at this point, into account.
To obtain the behavior of the opinion process under the strong effects limit, we briefly sketch the Kramers Moyal [36] expansion of the model, which is – as usual – truncated at the second order to obtain a Fokker-Planck (or Kolmogorov forward) equation.
Proposition 3.1
The Kramers Moyal expansion up to second order for the Glauber family with limiting observables is given by
Proof: We start with the master equations
If we now assume that for some smooth probability density , where and , we have , and
Taylor expansion of the last two terms up to second order, neglecting the error term, and using the limit of for yields the Kramers Moyal expansion.
Next, we turn to the Boltzmann distribution. In the continuum limit, we will denote the Boltzmann distribution (and later also the stationary distribution of a limiting stochastic opinion process) by .
Proposition 3.2
The Boltzmann distribution for observables and large is given in leading order by the Hamiltonian
| (17) |
where is the binary entropy. The limiting Boltzmann distribution reads , where .
The result is a consequence of eqn. (10), the scale of w.r.t. introduced in (15), and the well-known approximation of the binomial coefficient by means of the binary entropy
| (18) |
The connection between the stationary distributions of the Kramers Moyal expansion eqn. (3.1) and the stationary distribution eqn. (17) is not clear - though they are derived from the associated Potts models and opinion processes, they look rather different. The next proposition clarifies the connection.
Proposition 3.3
Proof: We first investigate the Boltzmann distribution. Since
we have a critical point of H(x) at . The second derivative reads, again using ,
Hence, . Locally, at , the stationary distribution behaves as with
Next, we proceed to the stationary distribution based on the Kramers Moyal expansion (3.1). The leading order terms of the linearization of the drift and the noise term at yield the Ornstein-Uhlenbeck approximation
where we used in the noise term. In order to identify the stationary distribution, we substitute with into the term bracketed with curly brackets,
This term becomes zero, and therewith an invariant measure, if . Therefore, the stationary distribution of this approximate Fokker-Planck equation is a normal distribution , where
3.2 Weak effects limit
The idea of the weak effects limit is to take a simple reference model as a basis and to perturb this model in such a way that for the transition rates converge back to that of the reference model. For good reasons, as we will find out later, we use the voter model as the reference model. In the voter model, at rate a person copies the opinion of a randomly chosen person in the population (inclusive “selfing”, that does mean that the focal person might by chance copy her opinion from herself). Therewith,
| at rate | (20a) | ||||
| at rate | (20b) | ||||
and hence, . For the weak effects limit, we allow for rates which depend on , as long as . Also the Lagrangian parameters are allowed to depend on , , and the paradigm of weak effects requires again . Therefore, the expansion of w.r.t. has as zero order term, and some arbitrary (well-behaved) function as first order coefficient. Similarly, the zero order term of the expansion of is , while the first order terms are some parameters , which we are free to choose. All in all, the Glauber family suited for the weak effects limit assumes the form
| (21) |
As we will see, for the weak effects limit, we not only assume the appropriate scaling of the parameters, but also rescale time. In that, even for , we still obtain a non-trivial limiting process and do not simply return to the voter model.
As a consequence, we need to re-consider the large population limit done in (14) and (15) more in detail, and also pay attention to terms of order .
Proposition 3.4
Consider the observables for the opinion process defined by (21),
With the definition
| (22) |
the leading order terms of the expansion of in reads
Proof: We first rewrite the sum such that it extends to instead of ,
Next, we replace the sum by an integral. Here we take the Euler-McLaurin correction terms into account in the step from sum to integral. Furthermore, we note that an additive constant in the Hamiltonian does not change the stationary distribution. Instead of we can change the lower starting value to any value independent on , and might e.g. consider instead. Only the upper bound of the sum matters: We only need an anti-derivative. To express this fact, we skip the lower bound of the integral and proceed (where the first equal sign has to be interpreted with the knowledge that we did drop some irrelevant term)
Note that (in the sense that is a possible limiting anti-derivative), such that this integral only contributes to terms of order or higher. We introduce
Therewith, we are in the position to establish the following proposition.
Proposition 3.5
Assume that the functions scale with as described above,
and scale the Lagrangians by . Then, in leading order, the Hamiltonian reads
| (23) |
with .
Proof: Recall . With the scaling , we obtain
We use the approximation of the binomial coefficient (18) to obtain the result with , where we drop terms independent of and terms of higher order in .
It is remarkable and typical for the weak effects scaling that the Hamiltonian, and in that also the Boltzmann distribution, becomes independent of . We now turn to the underlying opinion process, and discuss the Kramers Moyal expansion under the scaling assumed.
Proposition 3.6
The Kramers Moyal expansion of the Glauber family under the weak effects-scaling in rescaled time is given by
Proof: The Glauber family with the weak effects scaling is defined by
while the rate reads and that for is . The drift term becomes in leading order
(where h.o.t. is a placeholder for higher order terms) and the coefficient of the noise term becomes in leading order
If we rescale time we obtain the result.
The Karmers-Moyal expansion in rescaled time becomes, as the Hamiltonian, independent of .
Proposition 3.7
The stationary distribution of the Kramers Moyal expansion is identical with the Boltzmann distribution , where the Hamiltonian is given in (23).
Proof: We plug the Boltzmann distribution into the right-hand side of the Kramers Moyal expansion. Thereto we note that
Furthermore, , such that
If we take the derivative of this equation w.r.t. we indeed find that is a stationary solution of eqn. (3.6).
Remark 3.8
For the weak effects limit, we have chosen the voter model with as the reference model. If , the rates of the model at hand converge back to this model. This choice looks, at first glance, arbitrary. It is, however, up to the freedom characterized in Corollary 2.2, a unique choice: The binary entropy generates in the Hamiltonian terms and . For a weak effects limit to exist, these terms of order need to be balanced and annihilated by the environments of the reference model, which already forces the reference model to be the voter model (or some model which is, according to Corollary 2.2, equivalent to the voter model).
4 Four models: Curie-Weiss, weak and strong q-voter model, and reinforcement
We use the framework introduced above to briefly introduce four opinion models we intend to apply to data.
4.1 Curie-Weiss model
To introduce the classical Curie-Weiss model, we start with the Potts machinery. Recall that the central ingredients are observables, that is functions , which form constraints when determining the random measure maximizing the Shannon entropy. Perhaps the most simple, non-trivial case is given by observables which are polynomials of second order,
We do not need a zero order term, as additive constants in the Hamiltonian do not influence the Boltzmann distribution. Furthermore, we scale the quadratic term by to balance the squared terms in case of large . With this setting, the Hamilton defined in (10) reads
We might rewrite the quadratic terms as
We define and appropriately (e.g. ).
Furthermore, for historical reasons, we introduce and drop terms independent of . Therewith, we obtain
| (25) |
which is the standard form of the model on the state space [46]. We can still reduce the number of parameters from four () to three with as the additive constant, which appears, can again be dropped.
Last, we check existence of the strong and the weak effects limit. The strong effects limit can be derived trivially, simply by replacing the binomial coefficient by , cf. (18),
The binary entropy introduces logarithmic terms of order into the Hamiltonian . As the observables of the Curie-Weiss model consist of polynomial terms, they cannot cancel these logarithmic terms, such that the Hamiltonian always incorporates nontrivial terms of order . In the proper weak effects limit, however, terms of this order are not present. Thus, a weak effects limit for the Curie-Weiss model is not possible (cf. Remark 3.8). This will be different for the other models we shall discuss next.
4.2 Two flavors of the q-voter model
For the q-voter model, we do not start with the stationary distribution but the transition rates. Perhaps the most simple extension of the voter model where no opinion can die out is the zealot model, where we have zealots for the opinion . Palombi and Toti [58, p. 337] call zealots ”stubborn agents […] who never change political preference”. In our case, zealots are not real persons but represent sources of information that stand for a specific opinion. These could be politicians, friends, newspapers, or social media channels. As in the voter model, individuals copy their opinion from a randomly chosen person, now also from the zealots, which leads to
The corresponding Glauber family is given by
| at rate | (26a) | ||||
| at rate | (26b) | ||||
For , this is the q-voter model for a homogeneous population [11]. In the case of , we are back in the zealot model: A person simply copies the opinion of another person or a zealot. If , the model can be interpreted as follows: The person will ask other persons for their opinion, and will only change her opinion if all these other persons have the identical opinion.
4.2.1 q-voter model – strong effects
We consider the strong effects limit: If , that is, if the number of zealots scales linearly with the population size where are the proportionality constants,
such that becomes independent of , and . Therewith, the limiting
observables are given by
where is a constant.
The stationary distribution in the strong effects limit is given by ,
where
In the last formula, we again made use of the fact that we are allowed to drop constant terms from the Hamiltonian.
4.2.2 q-voter model – weak effects
We now go into the weak effects limit for the q-voter model. The basis is the zealot model with For the weak effects limit, the number of zealots does not scale with the population size, and in that, zealots become rare if becomes large. We can choose the time units, and in this, we have a degree of freedom in the form of a multiplicative positive constant. This freedom can be used to replace the original denominator by , and work with
That is, for our particular choice the functions are independent of . Recall that we also expand the Lagrangians in terms of and write .
To obtain the weak effects limit, we note that
and obtain the Hamiltonian
with the corresponding stationary distribution
| (28) |
The invariant distribution becomes a beta distribution in the case of the zealot model (); this result was first derived in the context of population genetics, where the zealot model is termed Moran model [29, page 108]. The extension to the weak effects limit of the Glauber family presented here is novel.
4.3 Reinforcement model – weak effects
We add one more model, which also allows for a strong as well as weak effects limit, and which is, as the q-voter model, also a descendant from the zealot model: The reinforcement model [55]. The idea of the reinforcement model is to express the psychological mechanisms which lead to filter bubbles and echo chambers: Several kinds of cognitive biases let individuals communicate with persons of the opposite opinion with less awareness than with individuals of their own opinion. Some interactions with the opposite group are ignored. In that, the effective size of the opposite group is reduced by a factor . The zealot model is described by
We focus on the weak effects limit and hence keep (as in the weak limit of the q-voter model) independent of . Furthermore, we choose such that we return to the voter model if becomes large; the Lagrangians are taken to be and are not scaled. It turns out that the computations assume a simpler form (additive constants will vanish below in the first order term of the expansion) if we use a trivial time scale, such that a multiplicative term appears in the rates,
Therewith we obtain the expansion of the rates w.r.t. ,
Consequently, we obtain
and the stationary distribution (we use eqn. (23) with )
| (29) |
If we compare the stationary distribution of the weak effects q-voter model and the weak effects reinforcement model, we find a striking similarity: In both cases, the measure is an adaptation of the beta distribution,
where and in the q-voter case, while and
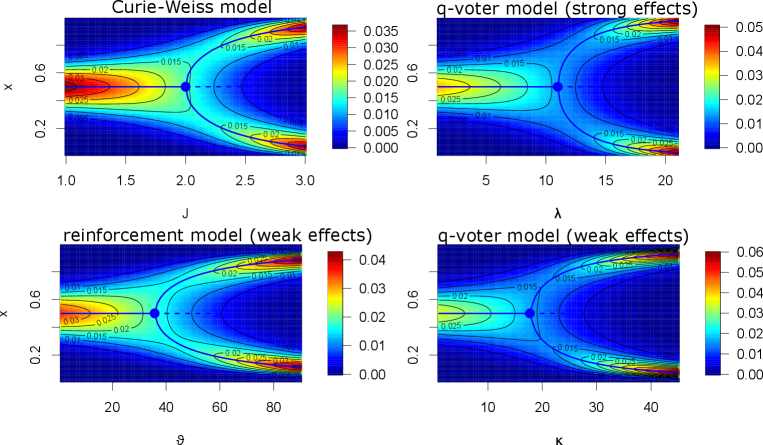
in the reinforcement case. As both functions resemble each other in that , , and both are convex, we expect very similar behavior for the two models if we take (also inspect Figure 1).
As a last remark, we note that we do allow in the weak q-voter model and the weak reinforcement model not only for positive parameter values and but also for negative values. While positive values for these parameters lead to filter bubbles and echo chambers (a person hesitates to change her mind), negative values have the interpretation that the person are open-minded and pay particular attention to the opposite opinion. In the case of the functioning of democracies and its institutions, open-minded people are much more preferable because it is easier to find compromises for solving political problems.
4.4 Model behavior
We will not go deeper into the analysis (which can be found, e.g. for the Curie-Weiss model in [56, 46], for the q-voter model in the strong effects limit in [11] and for the reinforcement model in [55]), but simply refer to Figure 1, which shows that all four models undergo a phase transition if the coupling between the individuals is sufficiently large. We emphasize that also the models based on the voter- and zealot model (which per se do not allow for phase transitions), the two kinds of q-voter model and the reinforcement model, exhibit phase transitions. The mechanisms modifying the effects of zealots target on in/outgroup communication. If in/outgroup communication is sufficiently strong, a bimodal distribution appears via a phase transition. Also the behavior under non-symmetric conditions (parameters) leads to similar behavior of all four models.
It is interesting to note that the Curie-Weiss and the strong effects q-voter model incorporate the population size explicitly, while the (weak effects limit of) the q-voter and the reinforcement model become independent of . Usually, in applications, is very large, and if we naively take to the population size, the variance generated by the model is much smaller than the variance that is present in empirical data. The way out is to assume that individuals cluster together and to estimate an effective population size along with the other parameters, which of course is slightly dubious, but pragmatic [56]. The weak effects models elegantly circumvent this difficulty.
5 Data analysis
We use data from four different Western democracies which represent different types of government and electoral systems (see [38, pp 145–161, 271] and [63] and Table 1 for further details). Concerning the governmental system we have one presidential (US), one semi-presidential (France), and two parliamentary systems (UK, Germany). In the case of the electoral systems we have two majority systems with a first-past-the-post design and relative majority (US, UK) and one majority system in France with a two-round system and absolute majority. In Germany we have a mixed member proportional system that combines both a first-past-the-post vote and proportional representation. Finally, for each country we study different numbers of elections (US: six presidential elections, 2000-2020; UK: 20 parliamentary elections, 1945-2019; FRA: second round of five presidential elections, 2002-2022; GER: two parliamentary elections, 2017-2021; the data sources are indicated in the data availability statement).
| US | UK | France | Germany | |
| Government system | presidential | parliamentary | semi-presidential | parliamentary |
| Electoral system | Plurality/ majority: single-member districts, first-past-the-post, relative majority | Plurality/ majority: single-member districts, first-past-the-post, relative majority | Plurality/ majority: two-round system, absolute majority | Mixed: mixed member proportional |
| Election years covered in the analysis | 2000-2020 (6 presidential elections) | 1945-2019 (20 parliamentary elections) | 2002-2022 (5 presidential elections, second round) | 2017-2021 (2 parliamentary elections) |
Such a design is useful to understand how the models used can explain the dynamics in different institutional settings with different political cultures and in varying periods of time. This comparative approach gives us more information about the functioning of the mechanisms in different contexts (e.g. [32, 12]) and contributes to the existing research often based on single-case studies (e.g. [35, 58]).
In the analysis, we consider each election district as an i.i.d. repetition of the election. Herein we obviously reduce the complexity of the data by neglecting social co-factors and spatial effects. In that, we obtain an empirical distribution of vote shares and can use a maximum likelihood estimator. Please find the technical details, particularly the algorithm used to perform the maximum-likelihood estimation, in Appendix A.
The present approach to data analysis is based on a steady-state assumption, that is, the opinion formation process is assumed to be approximately in equilibrium. If there is a huge shift in the vote share of a candidate or party in recent times, this assumption steady-state might not be met. The tables with estimates, p-values for the Kolmogorov-Smirnov test, and AICs can be found in Appendix A.
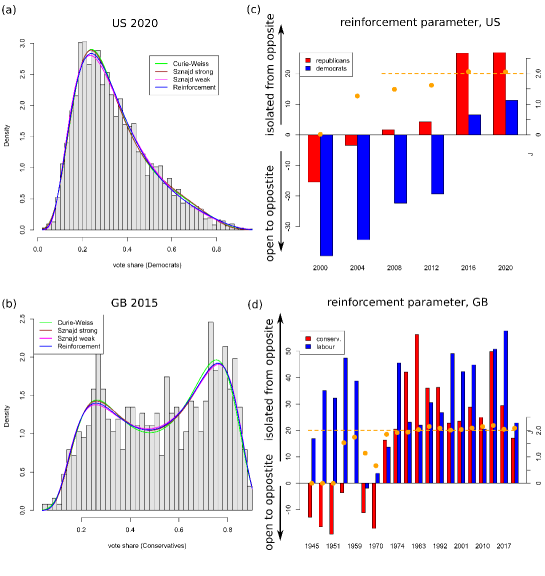
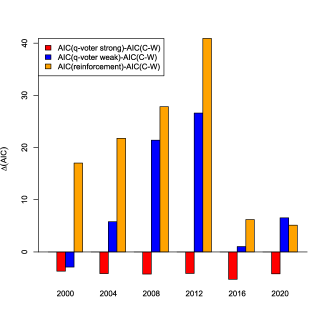
United States data: The densities of the four models (Curie-Weiss, weak and strong q-voter model and reinforcement model) are rather similar (Fig. 2 (a)), and also the Kolmogorov-Smirnov tests resemble each other (see table in Section A.1). Only in the year 2000, the p-values of this test are small (between and ); in that year, apart from the democrats and the republicans, also the green candidate did win a small but reasonable fraction of votes, such that the dichotomous models might not be completely suited. In 2016, we have also about four percent of third-party votes, but at that point, the models fit better. Maybe this is due to the fact, that polarization in the American society has already grown during these past 16 years. The AIC selects always the (weak) reinforcement model as best-suited model but in the year 2020, where the weak q-voter model fits best. However, in this year the reinforcement model and the weak q-voter model are very close. The strong models always perform worse (Fig. 5). We clearly find a trend in the parameters which shows that the model moves in time more and more towards a phase transition.
United Kingdom data: The trend in the reinforcement parameters/coupling is particularly interesting (Fig. 2, (d)). As can be clearly visualized in the empirical and the estimated distributions for the election from 2015, the UK indeed became super-critical. We observe a bimodal distribution in 2015. It is most interesting to see that the theoretical prediction of possible phase transitions is realized in the UK.
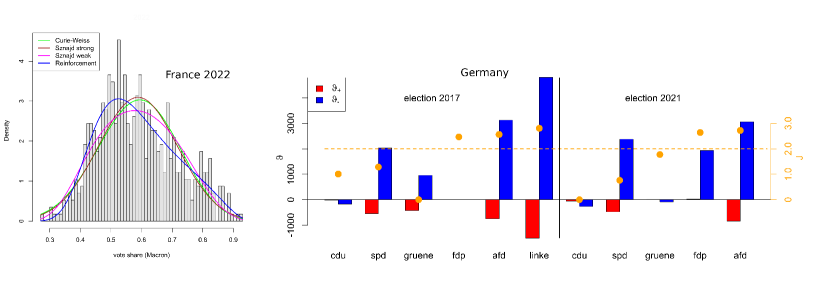
France data: Particularly in 2022, the empirical distribution of vote shares is screwed. The strong effects models have difficulties dealing with this result, while the weak effects models are more flexible; particularly the reinforcement model still performs well.
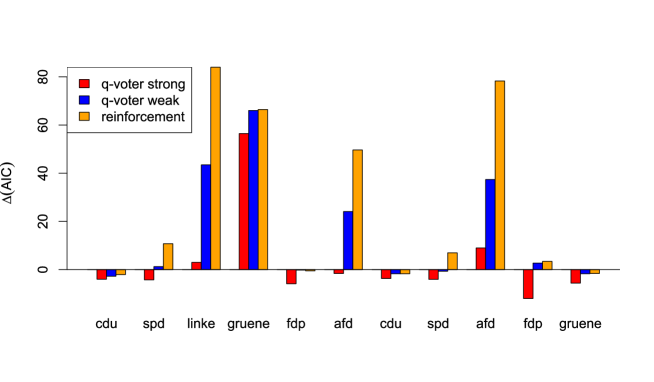
German data: As we have a proportional electoral system, the dichotomous model requires adaptation: For each party, we distinguish between the votes in favor of this party versus the votes for all other parties. In Fig. 3 we find the reinforcement parameters together with the coupling of the Curie-Weiss model for those parties in the 2017 and 2021 elections that did receive at least 5% of the votes (where we did disregard the CSU, as this is a Bavarian local party which only stands for election in few election districts). If we focus on the best models (lowest AIC), these models indeed are able to meet the empirical vote share distributions quite well (Kolmogorov-Smirnov test), with only one exception: The left-wing party Left Party (die linke) in the election 2017. Due to historical reasons, this party performs very differently in the federal states coming from the former East respectively West Germany. Though also these historical effects can be understood to be based on opinion dynamics and in/out-group behavior, all models have difficulties to capturing this data structure. The assumption of a homogeneously mixed population may no longer be appropriate; instead, a two-island model would capture the communication structure better. Also the (relatively recent) right-wing party AfD, which also performs rather differently in the two regions (former East/West Germany), poses a problem for all models but the reinforcement model, at least according to the Kolmogorov-Smirnov test. However, the difference in the two regions is less pronounced than in the case of the Left Party, which might also be the reason why the reinforcement model is still able to handle the vote share data of the AfD.
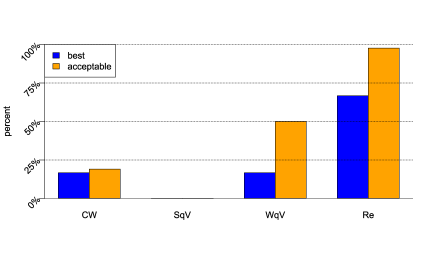
| CW | Curie-Weiss |
| SqV | strong effects q-voter |
| WqV | weak effects q-voter |
| Re | reinforcement |
Summary of the estimations: In almost all elections, at least some of the models describe the empirical data adequately (according to the Kolmogorov-Smirnov test). If we compare the performance of the models according to the AIC, we find that the weak effects models outperform the strong effects models, and the weak effects reinforcement model is superior to the weak effects q-voter model (Fig. 4). It is interesting, that – though the structure of the weak effects models are very similar – nevertheless we find a difference in their suitability for practical applications.
We should keep in mind that we work with aggregated data (only the outcome of election in election districts which typically have a population of hundreds of thousands of individuals). We might consider the model parameters as a reduction of the data complexity to a low-dimensional parameter space, which allows us to better interpret the data. As the Kolmogorov-Smirnov test indicates the appropriateness of the models, we can be confident that the models capture at least some fundamental structure in the data. In that, the interpretation of the parameters suggested by the models will be appropriate.
5.1 Political Science Interpretations
United States: Looking at the parameters measuring the actual strength of reinforcement in the reinforcement model, we can see that since the year 2000, there has been a continuous trend for a much more polarized voting behavior in the United States. For the voters of the Republican party, the switch could be seen already in 2008 with the election of Barack Obama and it continued in his re-election while it became dominant in 2016 and 2020 when Donald Trump became candidate of the Republican party. The voters for the Democratic party clearly also changed from open- to closed-mindedness in the political realm. In fact, what we can see is that during 20 years the political discourse became so polarized in the US public arena that now both the parties and their voters are becoming clearly more and more separated from each other. As Binder [6] for example shows is that the frequency of legislative gridlock has risen since the 1990s and other studies show that polarization in the US citizenry is not going down [1].
Great Britain: Due to the electoral system (first-past-the-post) and the governmental system (parliamentary) it is clearly useful for the two dominant parties – the Labour Party on the left and the Conservative Party (Tories) on the right – to keep a certain or even a high degree of polarization so that they can form the government on their own. The bars of the reinforcement model show this clearly for Labour for almost all elections since 1945, but for the Tories, this strategy started only in the 1970s and became very dominant since the second election in 1974 and the Thatcher years 1979-1990. Additionally, we can see that in 2019 the reinforcement parameters had not been so strong. This might be the result of the Brexit decision in 2016 and its political aftermath in which the Conservatives had become the party of the Leavers (in support of Brexit) and the Remainers have split between Labour and the Liberal Democrats [61].
France: The French Party System has undergone a political change in the last years since 2017 so some already argue that we may see the rise of a new French Party System [37]. In 2017, both presidential candidates of the traditional left-wing (Parti Socialiste) and right-wing parties (Les Républicains) were disqualified in the first round of the presidential elections [26]. And this happened again in 2022, when both Emmanuel Macron of the centrist ”La République En Marche” and Marine Le Pen of the new-named right-wing populist “Rassemblement National” were for the second time the political opponents in the second round of the election [27]. That said we can see in Figure 7 for the previous elections the models didn’t explain so much for the second round.
Germany: Here we can see that the right-wing populist party Alternative for Germany (AfD) was able in both elections to create their own space for resonating with their voters. In 2017, both the Social Democrats (SPD), the Left Party, and the Greens had been able to mobilize their voters against the AfD, but in 2021 it was the SPD and the liberal party (FDP). Compared to the left parties, the FDP tried to position itself as the party of Freedom where some parts of the party raised also their critical voice against the political means the former government of the two conservative parties CDU and CSU and the Social Democrats used during the Covid-19 pandemic. This can be observed in their parliamentary work where they used so called “Kleine Anfragen” to question the government parties the most compared to all the other remaining opposition parties in the German Bundestag [24]. Therefore, they had been a competitor both to the AfD and the other left and center parties and gained also a lot of support by young voters [30].
6 Discussion of the findings and their interpretation in political sciences
In the present paper, we first discussed the connection between Potts models and stochastic opinion models, both for well mixing populations. Particularly, we did provide an alternative approach to the q-voter model as a natural extension of the Zealot model in the view of the Glauber dynamics. Consequently, motivated by similar constructions in population genetics, we introduced a strong and particularly also a weak effects continuum limit. While the strong continuum limit is generically possible (and approximates locally a normal distribution), the weak effects limit requires additional structure. In that, the Curie-Weiss model only allows for the strong limit, while the q-voter model has both limits. Afterwards, we additionally introduced the reinforcement model, which has its foundation not in the Potts machinery but is derived based on considerations about the impact of the several kinds of cognitive biases on communication, especially on the resulting in/out-group communication strategies. Also that model allows for both continuum limits, where it turned out that the weak q-voter and the weak reinforcement model are very similar in their mathematical structure. Basically both are an adaptation of the beta distribution, which is the well-known weak effects limit of the zealot (or Moran) model [29]. We also found that only models that are based on the voter model allow for a weak effect limit, which indicates that these models are in some sense special.
After these theoretical considerations, we turned to test the models based on election data. Herein, we used each election district as an i.i.d. repetition of the election, neglecting social co-factors which vary between election districts, as well as spatial factors. We also assume the opinion process to be approximately in equilibrium, such that the stationary distribution is an adequate description of the data; in case of a large shift in the vote share of a candidate or party, also this assumption can be called into question. Though the simplicity of the approach, mostly we found that the models meet the data quite well, where the weak models performed better than the strong models, and the weak reinforcement model outperformed the weak q-voter model. It is interesting that the weak effect models seem to be better suited to describe the data appropriately. The comparison of models and data always is challenging, but it seems that also in population genetics, where the weak effects as weak selection are often used, rather supports that these kind of models are well suited for real-world applications [49]. The background could be that striking and immediately disruptive events are rare. Most stimuli are weak and require time to unfold their effect. If this observation is correct, weak effect models with their slow time scale might indeed be a better description of reality than strong effect models with a fast time scale. As a practical consequence, we propose to use in empirical studies rather weak effects opinion models than strong effects models, which also has the advantage that we do not need to choose an appropriate population size, which is a well-known problem in itself [29, 56]. Though the models allowing for a weak effect limit are rather special, they seem to be a powerful description of reality and still have sufficient flexibility to address different mechanisms and different real-world (electorate) systems.
Elections are at the centre stage of modern representative democracies. Correspondingly, research on elections and attempts to explain the formation of their results are also central. Prominent and established approaches use statistical data concerning the social characteristics of voters to determine their voting behavior (e.g. [48]). But there is an ongoing debate among scholars, that the correlation between social characteristics and voting behavior has diminished over the last decades (e.g. [18, 42, 44]). Additionally, party membership is also in decline which has also consequences for voter turnout and voting behavior (e.g. [5, 64]). As Clarke et al. [14] bluntly declared, for understanding electoral choice one has to look elsewhere. It is not that the classic approaches have lost all their explanatory power, but it makes sense to look for explanations that are less context dependent.
By focusing on the dynamics of opinion formation preceding the act of voting, the models discussed in this paper promise insights both into the empirical explanation of elections as such as well as important aspects of the theory of democracy.
Our leading assumption, ensuring a larger independence of specific social contexts, is opinion formation via frequently contacting social sources of information constituting a ubiquitous mechanism of collective decision-making. For sure, this assumption also holds for elections. The sources of information here may be real persons or media of all kinds. Pamphlets, newspapers, magazines, radio, TV, and the diversity of social media have accompanied political discussion since the early modern period. Albeit the basic mechanism is taken to be the same everywhere, its effects may be modulated by the impact of or the interaction with other mechanisms of other sections within an “organized complexity “. Electoral systems in their specific forms are nested within the broader construction of a political system. The effects of opinion formation processes concerning elections are shaped by specific institutional settings as well as the political culture of the respective countries.
The model’s reduction to only two opinions may look like to crude a simplification. But it is not such implausible as it may appear at first glance. As Denver and Johns [20] stress, when preparing their decisions, voters don’t “sit down before an election to comb through the parties’ manifestos and make detailed calculations of the costs and benefits of voting for each party. (…) Such a process is neither realistic nor particularly rational [20, p.294]”. Rather voters base their decision on just a few subjects dominating the discussion. “Issue Voting” and “Valence Voting” denominate the approaches based on that assumption. Where Issue Voting stresses the main issues of the election campaign like economic questions or social policy, Valence Voting focuses for example on the performance of the incumbent government. “Neither involves complex calculations; indeed, the simpler versions of both approaches have fared better when confronted with the empirical evidence (ibid.)”. And both aspects fare better than explaining results with respect to voters’ social characteristics. Therefore, looking at opinion and opinion formation in this simple form offers a promising starting point to delve deeper into campaigning and voting.
In this view, the models in their present form may be interpreted as to suppose a stage of the election process, where the main issues are already settled. From here the model may be enhanced by stepwise nesting the basic opinion formation process within a whole set of similar modeled ones. The determination of the salient issues and valences may be the next step. The party that succeeds in putting its topics in place may be an advantage. A variant of the Issue Voting approach stresses, that it is not alone the preferences on the specific topics of the very election of today that affect the voter’s decision but general values and principles [20, p.295]. We can think of processes concerning ideological backgrounds running on a larger time scale spanning across two or more elections affecting the probability with which a voter makes up his mind. Another perspective would look at the developments within the zealots in particular. This would mean looking at the development of party programmes and strategies also in the form of opinion formation among party members. The possibilities are manifold.
The reinforcement model in particular also highlights important aspects concerning the theory of democracies. Especially in the liberal tradition of democracy, it is a common view to interpret campaigning and elections as a market analogous competition, where votes are exchanged for programmes and personal (see [17]). Competition appears as a form of regulated and so limited conflict. The opponent’s purpose is not to harm the antagonist, but only to be better. The idea behind this is, that the aspiration to trump the adversary leads to the advancement of a common good, qualitatively better, or cheaper products and processes in economy, better theories and methods in science, and better programmes and personnel in politics.
The zealot model, as a predecessor of the reinforcement model, was used before in economics for market analysis [43]. But behind this application lies a model designed to explain foraging processes of ant colonies [59]. It describes a form of collective information processing against an uncertain environment. Time and again the colony has to leave an established feeding ground and look for another in time. It is inspiring to see the similarities. Political communities also have to alter their processes and organization because of altering circumstances, for example transforming their way of living to a more sustainable way. In this way an open political process, defining problems and looking for solutions is a collective information processing, too. This idea was emphasized by Karl Popper [60], for example, and further developed by John Dryzek [25]. It is not implausible to assume, that a part of the success of democracies in general is their dealing with the world’s shakiness in an analogous way to modern science.
Whatever makes the workers of the ant colony change their paths, the driving force behind the parliamentary process, at least from the perspective of the liberal standard model of democracy, is party competition. Since party competition is itself affected by special interests and personal ambition of politicians, democracies need additional features to balance these forces and bring the wanted effects of the competition to the fore. This has been part of considerations from Harrington [39] to Tocqueville [19] to Dewey [21] but shall not be the point here.
What the reinforcement model enables us to see is the possible polarization between the opponents. It is important to note, that polarization indicating a higher grade of conflict is not a problem per se as well as higher grades of conflict aren’t. As sociologist Lewis Coser (1967) [15] argued for, conflicts in the first place point to societal problems within a society urging to deal with their causes. If the community is productively addressing that challenge, society reintegrates on a new level. We could see such effects for example in the course of the environmental movement in the 70s to 90s in Germany. The polarization on the side of the Greens was high in the beginning, when they cracked open the consensus of the established parties on the use of nuclear power, and became lower again, when environmental issues were successfully established on the agenda.
Polarization may become problematic when the reinforcement effects are strong on both sides of the debate. Conflicts can be disruptive too. American philosopher of law Ronald Dworkin was asking already in 2006 [28] looking at the polarization in the US “Is Democracy possible here?”. The polarization in the US is not in decline since then (Pew Research Center 2022, [1]). Polarization may also become problematic when actors show no tendency to consent or compromise enabling reintegration. This appears to be the case with the populist movements and parties of the last decade. On the other hand, party polarization may generate stronger party attachments, which could also be a desirable strategy for political competitors [50, p. 350]. And probably here is the point, where political scientists (at least at the moment) have to reach out for other methods than mathematical modeling, too. Qualitative analysis of texts or focus groups may be an appropriate means here.
However, it should be ascertained that the reinforcement model supplies us with a strong indicator concerning an important variable of political processes. And since the claim that a society is polarized is also often used in an alarmist way, impeding compromise, the more it is helpful to have this indicator. And it should be ascertained further that because of its context independence, the model will be useful, when we look not alone at well-established democracies of the West but also on young ones or democracies in other world regions.
Data availability
United States Data.
https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/VOQCHQ
All data from the US have been accessed at 6-24-2021.
France data.
2002-2012:
https://www.data.gouv.fr/fr/posts/les-donnees-des-elections/
2017:
https://www.data.gouv.fr/fr/datasets/election-presidentielle-des-23-avril-et-7-mai-2017-resultats-definitifs-du-2nd-tour/
2022:
https://www.data.gouv.fr/fr/datasets/election-presidentielle-des-10-et-24-avril-2022-resultats-definitifs-du-2nd-tour/
All France data are accessed at 12-8-2023.
United Kingdom data.
https://commonslibrary.parliament.uk/research-briefings/cbp-8647
All UK data are accessed at 11-5-2021.
German data.
https://www.bundeswahlleiter.de/en/bundeswahlleiter.html
The German data for the 2017 election have been accessed at 7-8-2018, that for the 2021 election at 10-5-2022.
References
- [1] Pew research center, august 2022, “as partisan hostility grows, signs of frustration with the two-party system”. https://www.pewresearch.org/politics/2022/08/09/as-partisan-hostility-grows-signs-of-frustration-with-the-two-party-system/. Accessed: 2024-01-08.
- [2] B. D. O. Anderson and M. Ye. Recent advances in the modelling and analysis of opinion dynamics on influence networks. International Journal of Automation and Computing, 16(2):129–149, 2019.
- [3] H. Andersson and T. Britton. Stochastic Epidemic Models and Their Statistical Analysis. Springer New York, 2000.
- [4] C. Bernardo, C. Altafini, A. Proskurnikov, and F. Vasca. Bounded confidence opinion dynamics: A survey. Automatica, 159:111302, 2024.
- [5] I. v. Biezen and T. Poguntke. The decline of membership-based politics. Party Politics, 20(2):205–216, 2014.
- [6] S. Binder. The dysfunctional congress. Annual Review of Political Science, 18(1):85–101, 2015.
- [7] D. Braha and M. A. de Aguiar. Voting contagion: Modeling and analysis of a century of us presidential elections. PloS one, 12(5):e0177970, 2017.
- [8] K. P. Burnham and D. R. Anderson. Multimodel inference: Understanding aic and bic in model selection. Sociological Methods and Research, 33(2):261–304, 2004.
- [9] C. Cannings. The latent roots of certain markov chains arising in genetics: A new approach, i. haploid models. Advances in Applied Probability, 6(2):260–290, 1974.
- [10] C. Castellano, S. Fortunato, and V. Loreto. Statistical physics of social dynamics. Reviews of Modern Physics, 81(2):591–646, 2009.
- [11] C. Castellano, M. A. Muñoz, and R. Pastor-Satorras. Nonlinear -voter model. Phys. Rev. E, 80:041129, Oct 2009.
- [12] A. Chatterjee, M. Mitrović, and S. Fortunato. Universality in voting behavior: an empirical analysis. Scientific Reports, 3(1), jan 2013.
- [13] D. D. Chinellato, I. R. Epstein, D. Braha, Y. Bar-Yam, and M. A. de Aguiar. Dynamical response of networks under external perturbations: exact results. Journal of Statistical Physics, 159(2):221–230, 2015.
- [14] H. D. Clarke, D. Sanders, M. C. Stewart, and P. Whiteley. Political Choice in Britain. Oxford University PressOxford, 2004.
- [15] L. A. Coser. Continuities in the study of social conflict. Free Press, 1967.
- [16] R. Costa Filho, M. Almeida, J. Andrade, J. Moreira, et al. Scaling behavior in a proportional voting process. Physical Review E, 60(1):1067, 1999.
- [17] R. A. Dahl. Polyarchy. Participation and Opposition. Yale University Press, 1972.
- [18] R. J. Dalton and S. E. Flanagan. Electoral Change in Advanced Industrial Democracies Realignment or Dealignment? Princeton University Press, 1984.
- [19] A. de Tocqueville, H. C. Mansfield, and D. Winthrop. Democracy in America. University of Chicago Press, 2000.
- [20] D. Denver and R. Johns. Elections and Voters in Britain. Cham: Palgrave Macmillan, 2020.
- [21] J. Dewey. The public and its problems an essay in political inquiry. Swallow Press, 2016.
- [22] O. Diekmann, H. Heesterbeek, and T. Britton. Mathematical Tools for Understanding Infectious Disease Dynamics. Princeton University Press, dec 2012.
- [23] Y. Dong, M. Zhan, G. Kou, Z. Ding, and H. Liang. A survey on the fusion process in opinion dynamics. Information Fusion, 43:57–65, sep 2018.
- [24] B. Donovan. The political exploitation of covid-19: The afd as challenger party and the impact on parliament. Zeitschrift für Parlamentsfragen, 52(4):824–843, 2021.
- [25] J. S. Dryzek. Discursive Democracy. Cambridge University Press, 1990.
- [26] A. Durovic. The french elections of 2017: shaking the disease? West European Politics, 42(7):1487–1503, 2019.
- [27] A. Durovic. Rising electoral fragmentation and abstention: the french elections of 2022. West European Politics, 46(3):614–629, 2022.
- [28] R. M. Dworkin. Is Democracy Possible Here? Principles for a New Political Debate. Princeton University Press, 2006.
- [29] W. J. Ewens. Mathematical Population Genetics. Springer New York, 2004.
- [30] T. Faas and T. Klingelhöfer. German politics at the traffic light: new beginnings in the election of 2021. West European Politics, 45(7):1506–1521, 2022.
- [31] J. Fernández-Gracia, K. Suchecki, J. J. Ramasco, M. San Miguel, and V. M. Eguíluz. Is the voter model a model for voters? Physical Review Letters, 112(15):158701, 2014.
- [32] S. Fortunato and C. Castellano. Scaling and universality in proportional elections. Physical Review Letters, 99(13):138701, 2007.
- [33] S. Funk, M. Salathé, and V. A. A. Jansen. Modelling the influence of human behaviour on the spread of infectious diseases: a review. Journal of The Royal Society Interface, 7(50):1247–1256, may 2010.
- [34] S. Galam. Sociophysics: A review of galam models. International Journal of Modern Physics C, 19, 03 2008.
- [35] S. Galam. The trump phenomenon: An explanation from sociophysics. International Journal of Modern Physics B, 31(10):1742015, 2017.
- [36] C. W. Gardiner. Stochastic methods. Springer, 2009.
- [37] F. Gougou and S. Persico. A new party system in the making? the 2017 french presidential election. French Politics, 15(3):303–321, 2017.
- [38] R. Hague, J. McCormick, and M. Harrop. Comparative Government and Politics An Introduction. Palgrave, London, 2016.
- [39] J. Harrington. The Commonwealth of Oceana and A System of Politics. Cambridge University Press, 1992.
- [40] V. Hösel, C. Kuttler, and J. Müller. Mathematical Population Genetics and Evolution of Bacterial Cooperation. WORLD SCIENTIFIC, apr 2020.
- [41] V. Hösel, J. Müller, and A. Tellier. Universality of neutral models: decision process in politics. Palgrave Communications, 5(1), feb 2019.
- [42] L. Karvonen and S. Kuhnle. Party Systems and Voter Alignments Revisited. Taylor & Francis Group, 2001.
- [43] A. Kirman. Ants, Rationality, and Recruitment. The Quarterly Journal of Economics, 108(1):137–156, 1993.
- [44] H. Kitschelt and P. Rehm. Party alignments: Change and continuity. In P. Beramendi, S. Häusermann, H. Kitschelt, and H. Kriesi, editors, The Politics of Advanced Capitalism, pages 179–201. Cambridge University Press, 2015.
- [45] A. Kononovicius. Empirical analysis and agent-based modeling of the lithuanian parliamentary elections. Complexity, 2017, 2017.
- [46] P. L. Krapivsky, S. Redner, and E. Ben-Naim. A Kinetic View of Statistical Physics. Cambridge University Press, 2017.
- [47] T. Liggett. Interacting Particle Systems. Springer, 1985.
- [48] S. M. Lipset. Party Systems and Voter Alignments. Free Press, 1967.
- [49] L. Loewe and W. G. Hill. The population genetics of mutations: good, bad and indifferent. Philosophical Transactions of the Royal Society B: Biological Sciences, 365(1544):1153–1167, 2010.
- [50] N. Lupu. Party Polarization and Mass Partisanship: A Comparative Perspective. Political Behavior, 37(2):331–356, 2014.
- [51] J. Mimkes. A thermodynamic formulation of social science. Econophysics and Sociophysics: Trends and Perspectives, pages 279–309, 2006.
- [52] M. Mobilia. Does a single zealot affect an infinite group of voters? Physical Review Letters, 91(2):028701, 2003.
- [53] M. Mobilia. Nonlinear -voter model with inflexible zealots. Phys. Rev. E, 92:012803, Jul 2015.
- [54] P. Moran. Random processes in genetics. Mathematical Proceedings of the Cambridge Philosophical Societ, 54:60–71, 1958.
- [55] J. Müller, A. Tellier, and M. Kurschilgen. Echo chambers and opinion dynamics explain the occurrence of vaccination hesitancy. Royal Society Open Science, 9(10), oct 2022.
- [56] L. Nicolao and M. Ostilli. Critical states in political trends. How much reliable is a poll on twitter? The Potts model and the inverse problem in Social Science. Physica A: Statistical Mechanics and its Applications, 533:121920, 2019.
- [57] P. Nyczka, K. Sznajd-Weron, and J. Cisło. Phase transitions in the -voter model with two types of stochastic driving. Phys. Rev. E, 86:011105, Jul 2012.
- [58] F. Palombi and S. Toti. Stochastic dynamics of the multi-state voter model over a network based on interacting cliques and zealot candidates. Journal of Statistical Physics, 156(2):336–367, may 2014.
- [59] J. Pasteels, J. Deneubourg, S. Goss, I. Prigogine, and M. Sanglier. Transmission and amplification of information in a changing environment: The case of insect societies. In I. Prigogine and M. Sanglier, editors, Law of Nature and Human Conduct. Bruxelles: Cordes, 1987.
- [60] K. R. Popper. The Open Society and Its Enemies. Princeton University Press, 1966.
- [61] C. Prosser. The end of the eu affair: the uk general election of 2019. West European Politics, 44(2):450–461, 2020.
- [62] R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2023.
- [63] A. Reynolds. Electoral system design. International Institute for Democracy and Electoral Assistance, 2005.
- [64] A. Siaroff. The decline of political participation: An empirical overview of voter turnout and party membership. In J. DeBardeleben and J. H. Pammett, editors, Activating the Citizen: Dilemmas of Participation in Europe and Canada, pages 41–59. Palgrave Macmillan UK, London, 2009.
- [65] P. Sobkowicz. Whither now, opinion modelers? Frontiers in Physics, 8, 2020.
- [66] A. Sîrbu, V. Loreto, V. D. P. Servedio, and F. Tria. Opinion Dynamics: Models, Extensions and External Effects, pages 363–401. Springer International Publishing, 2016.
- [67] M. Ye. Opinion Dynamics and the Evolution of Social Power in Social Networks. Springer, 2019.
Appendix A Data analysis
The maximum likelihood estimates have been performed in R [62], based on the optimizer nlm. In case of the Curie-Weiss and the strong q-voter model, all parameters have been optimized in one run.
The weak effects models have two parameters related to the zealots ( respectively ), and two parameters related to ingroup/outgroup communication structures (, , and ). Here, we used an EM-like algorithm by alternately optimizing the parameters for the zealots and holding the in/outgroup parameters, and then optimizing the parameters for in/outgroup while holding the zealot parameters, until the vector of parameters becomes approximately constant.
The Kolmogorov-Smirnov test is performed to test for the appropriateness of the current model, and the AIC is determined in order to compare the models. The columns of the tables are to read specifically for the model, e.g. the column holds in case of the Curie-Weiss model, for the strong q-voter model, and for the weak q-voter model and reinforcement model.
In the resulting tables, we mark the models that have the minimal AIC (best performing models) for the corresponding elections in yellow. Of course, if the AIC of two models is close, it is not sensible to dismiss one of the two models. Burnham et al. [8] suggest that models which have a difference of at most two do perform comparably. These models are marked in gay. Additionally, we provide a graphic for the differences in the AIC’s. Here, we use for each given election the AIC of the Curie-Weiss model as a reference, and provide
That is, if this value is positive, the “other model” performs better than the Curie-Weiss model, if it is negative, the Curie-Weiss model performs better. Moreover, if is e.g. larger for the weak q-voter model than for the reinforcement model, then the weak q-voter model performs better than the reinforcement model.
A.1 United States data
US presidential elections in the years 2000-2020 are analyzed, where we only consider democrats and republicans and the vote share of the democrats (e.g. votes for democrats/(votes for democrats or republicans), and dismiss the votes for any other candidate. The performance of the AICs for the models is shown in Fig. 5.
year model J// h// // // N AIC 2000 Curie-Weiss 0.015 -0.38 15.1 -4299.2 0.04 2000 q-voter strong 7 19.5 -2.7 -12.7 12.2 -4295.5 0.046 2000 q-voter weak 3.7 0.00031 -3.2 -22.1 -4296.3 0.023 2000 reinforcement 3 6.9e-06 -15.5 -39.6 -4316.3 0.1 2004 Curie-Weiss 1.3 -0.2 31.8 -4150.6 0.39 2004 q-voter strong 31.9 50.2 36.6 69.4 31.5 -4146.4 0.43 2004 q-voter weak 6.8 2.8e-06 7.5 -21.2 -4156.4 0.29 2004 reinforcement 4.4 0.12 -3.5 -34.3 -4172.4 0.48 2008 Curie-Weiss 1.5 -0.11 34.2 -3489.9 0.31 2008 q-voter strong 15.8 20.3 23.3 32.7 35 -3485.6 0.23 2008 q-voter weak 7.9 0.04 11.1 -17.3 -3511.3 0.49 2008 reinforcement 5 1.3 1.7 -22.4 -3517.7 0.28 2012 Curie-Weiss 1.6 -0.13 31.7 -3074.7 0.15 2012 q-voter strong 22 25.2 35.5 42.8 31.8 -3070.6 0.19 2012 q-voter weak 6.5 0.018 10.5 -14.7 -3101.3 0.3 2012 reinforcement 4.3 0.92 4.2 -19.3 -3115.6 0.88 2016 Curie-Weiss 2.1 -0.085 56.8 -3167.7 0.71 2016 q-voter strong 4.9 8 10.1 19.3 58.2 -3162.5 0.79 2016 q-voter weak 9.3 2.4 22.3 -5 -3168.7 0.3 2016 reinforcement 6.4 4.1 26.7 6.5 -3173.9 0.59 2020 Curie-Weiss 2.1 -0.084 55.7 -3066 0.51 2020 q-voter strong 13.8 25.3 25.7 59.7 56.6 -3061.8 0.59 2020 q-voter weak 9.2 3.5 21.5 -2 -3072.5 0.84 2020 reinforcement 6.5 5.2 26.9 11.3 -3071.1 0.69
A.2 UK data
We investigate the vote share of the conservative among the conservative and Labour votes. The performance of the AICs for the models is shown in Fig. 6.
year model J// h// // // N AIC 1945 Curie-Weiss 3.3e-08 -0.26 12.1 -593.4 0.86 1945 q-voter strong 7.6 0.67 -6.1 -0.56 9.5 -589.6 0.84 1945 q-voter weak 1.1 11.2 -13.7 10.6 -592.6 0.16 1945 reinforcement 3.3 11.7 -12.8 16.9 -596.7 0.64 1950 Curie-Weiss 7.1e-08 -0.039 12.2 -628.5 0.64 1950 q-voter strong 4.2 4.1 -24 -23 3.7 -624.9 0.61 1950 q-voter weak 0.098 21.3 -21.7 40.3 -643.4 0.98 1950 reinforcement 2.8 15 -16.5 35.1 -646.2 0.96 1951 Curie-Weiss 6.4e-07 0.013 13.1 -652.9 0.34 1951 q-voter strong 2.6 -0.0066 -9.4 -0.68 6.5 -651.4 0.45 1951 q-voter weak 3.3e-08 29.3 -26.1 60.6 -666.4 0.92 1951 reinforcement 2.6 14.4 -19.3 32.2 -669.4 0.94 1955 Curie-Weiss 1.5 0.018 43.8 -715.8 0.65 1955 q-voter strong 17.9 16.5 28.5 25.5 43.4 -711.8 0.74 1955 q-voter weak 1.7 17.7 -16.5 31.9 -730 0.96 1955 reinforcement 5.3 16.8 -3.5 47.4 -734.2 0.87 1959 Curie-Weiss 1.7 0.022 63.2 -699.5 0.47 1959 q-voter strong 27.2 24 49.4 41.4 61.6 -695.4 0.52 1959 q-voter weak 3.3 17.9 -11.8 33.4 -709.4 0.82 1959 reinforcement 5.7 14 0.018 38.8 -710.9 0.88 1964 Curie-Weiss 1.1 -0.011 22.4 -639 0.72 1964 q-voter strong 9.6 9.5 11.3 11.1 21.9 -635 0.75 1964 q-voter weak 2 5.5 -9.1 0.89 -638.4 0.87 1964 reinforcement 3.1 5.3 -11.2 -1.9 -639.2 0.95 1970 Curie-Weiss 0.66 0.017 15.1 -625.1 0.41 1970 q-voter strong -0.62 0.56 0.73 2.2 67.9 -628.9 0.96 1970 q-voter weak 0.35 10 -15.3 13.8 -630.3 0.91 1970 reinforcement 1.9 6.5 -17.1 3.8 -631.7 0.89 1974 Curie-Weiss 1.9 0.0039 50.5 -497.5 0.7 1974 q-voter strong 5.7 5.6 11.6 11.2 50.6 -493.5 0.69 1974 q-voter weak 8.2 7.7 10 8.8 -495.7 0.65 1974 reinforcement 7.3 6.6 16.4 13.7 -495.9 0.74 1974 Curie-Weiss 1.9 -0.018 51.7 -450.8 0.15 1974 q-voter strong 0.042 0.22 1 1.5 178.1 -460.5 0.88 1974 q-voter weak 7.1 14.2 6.8 26.8 -459.8 0.34 1974 reinforcement 7.1 13.2 20.5 45.6 -462.6 0.89 1979 Curie-Weiss 1.9 0.021 57.5 -473.5 0.31 1979 q-voter strong 10.4 3.8 25.4 6.7 59.7 -470.8 0.37 1979 q-voter weak 18.4 7.8 37 7.1 -478 0.63 1979 reinforcement 12.6 7.7 42.2 23.1 -478.7 0.65 1983 Curie-Weiss 2 0.072 32.8 -327.7 0.044 1983 q-voter strong 1.4 0.04 5 0.81 108.1 -360 0.54 1983 q-voter weak 22.2 5.3 51.4 3.8 -361.5 0.51 1983 reinforcement 14.2 5.6 56.3 22 -365.3 0.67
year model J// h// // // N AIC 1987 Curie-Weiss 2.1 0.029 51.9 -293.6 0.21 1987 q-voter strong 0.016 0.011 1 1 692.9 -302.4 0.61 1987 q-voter weak 11.1 8.6 23.6 17.9 -305.4 0.55 1987 reinforcement 8.6 6.7 36.1 30.6 -303.7 0.57 1992 Curie-Weiss 2.1 0.017 52.5 -309.1 0.2 1992 q-voter strong 0.2 0.099 1.5 1.2 114.1 -313.9 0.44 1992 q-voter weak 12.3 8.1 25.8 14.3 -317.8 0.47 1992 reinforcement 9.2 6.7 36.3 26.8 -317.7 0.6 1997 Curie-Weiss 2 -0.056 40.4 -376 0.34 1997 q-voter strong 0.07 1.8 0.83 6 96.3 -392.6 0.52 1997 q-voter weak 6.2 16 7.3 33.8 -394.1 0.9 1997 reinforcement 6.2 13.1 22.8 49.1 -395.5 0.54 2001 Curie-Weiss 2 -0.044 44.6 -363.2 0.48 2001 q-voter strong 0.039 0.15 1 1.4 183.1 -374.3 0.22 2001 q-voter weak 6.7 15.2 9.1 32.2 -376.9 0.37 2001 reinforcement 6.2 11.3 23.5 42.3 -376.3 0.22 2005 Curie-Weiss 2.1 -0.018 56.5 -316.5 0.2 2005 q-voter strong 0.052 0.13 1.1 1.3 173.7 -325.2 0.17 2005 q-voter weak 7.9 16.6 12.2 37.1 -328.7 0.21 2005 reinforcement 7.1 11 28.9 44.9 -327.5 0.18 2010 Curie-Weiss 2.1 0.021 39.4 -211.1 0.061 2010 q-voter strong 0.0093 0.0073 1 1 709.6 -218.4 0.15 2010 q-voter weak 7.7 6.1 15.6 11.9 -221 0.12 2010 reinforcement 6.2 4.9 25 20.4 -220.1 0.17 2015 Curie-Weiss 2.2 0.0076 83.4 -307.9 0.71 2015 q-voter strong 1.7 1.6 4.9 4.4 86.9 -304.2 0.71 2015 q-voter weak 13.8 14.1 30.8 32.4 -307.5 0.79 2015 reinforcement 10.5 10.4 49.9 50.8 -307.3 0.79 2017 Curie-Weiss 2 0.0039 76 -416.3 0.47 2017 q-voter strong 4.9 5.1 10.8 11.6 77 -412.5 0.5 2017 q-voter weak 8.7 17.8 10.9 38.8 -430.6 0.45 2017 reinforcement 8.2 14.4 29.4 57.7 -432.4 0.61 2019 Curie-Weiss 2.1 0.036 45.5 -314.8 0.77 2019 q-voter strong 0.043 0.065 1.1 1.2 143.9 -314.2 0.57 2019 q-voter weak 6.3 7.6 9.2 15.5 -317.5 0.8 2019 reinforcement 5.3 5.9 17.1 22.9 -316.6 0.77
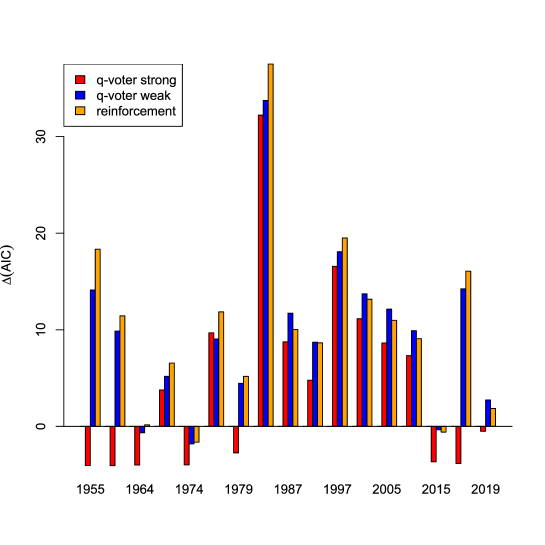
A.3 France data
This is the second round of the presidential election, and we consider the vote share of the winning candidate. The performance of the AICs for the models is shown in Fig. 7.
year model J// h// // // N AIC 2002 Curie-Weiss 0.95 0.98 58 -1672.5 0.11 2002 q-voter strong 35.5 6 14 2 47 -1668.1 0.099 2002 q-voter weak 23.5 5 -56.5 -7 -1672.5 0.16 2002 reinforcement 533 9 1275.5 -452.7 -1676.5 0.32 2007 Curie-Weiss 0.097 0.11 41.8 -1297.7 0.58 2007 q-voter strong 3.2 2.9 -280.7 -241.6 1.1 -1295.7 0.66 2007 q-voter weak 41.1 5.3e-05 56.2 -57 -1297.3 0.48 2007 reinforcement 23.2 6.1e-05 -0.32 -86.2 -1300.7 0.29 2012 Curie-Weiss 1.4e-07 0.082 29.9 -1138 0.2 2012 q-voter strong 2.8 2.6 -162.4 -145.5 1.2 -1134.7 0.23 2012 q-voter weak 0.006 0.00031 -33.9 -30.4 -1136.2 0.22 2012 reinforcement 0.54 0.0014 -66.8 -64.1 -1136.8 0.24 2017 Curie-Weiss 1.2e-07 0.74 14.3 -819.2 0.18 2017 q-voter strong 8.1 4.5 -817 -343.8 0.41 -821 0.25 2017 q-voter weak 0.064 1 -27.6 -8.8 -824.7 0.24 2017 reinforcement 109.6 6.3 325.2 -61.2 -855 0.95 2022 Curie-Weiss 1.5e-09 0.38 13.4 -718.8 0.0077 2022 q-voter strong 0.009 0.029 -206.6 -129.5 0.085 -720.5 0.003 2022 q-voter weak 85.1 0.11 192 -49.2 -739.6 0.097 2022 reinforcement 65.6 7.4 211.9 -17.2 -764.5 0.96
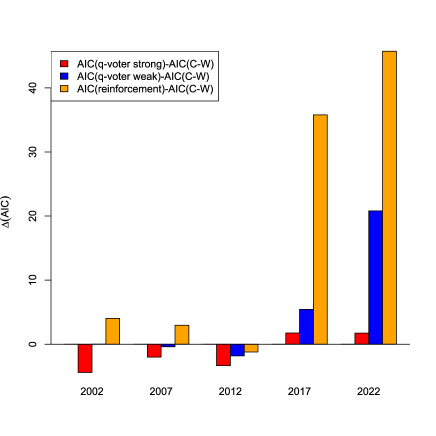
A.4 German data
We include all parties which did reach a vote share of at least 5%, but the CSU, which is a local party and thus only stands for election in few districts. Note that ”die linke” is present in the parliament of 2021 though this party did not reach 5%, and in that, we did exclude this party in 2021. In order to fit our dichotomy model, we focus on the vote share of the focal party, essentially distinguishing between supporters of this party, and supporters of any other party. The performance of the AICs for the models is shown in Fig. 8.
year model Party J// h// // // N AIC 2017 Curie-Weiss cdu 1 -0.41 123.1 -745.2 0.81 2017 q-voter strong cdu 22.6 48.9 19.8 57.9 123.4 -741.2 0.81 2017 q-voter weak cdu 14 26.7 -15 -56.3 -742.5 0.87 2017 reinforcement cdu 14.4 9.4e-05 -14.7 -173 -743.1 0.83 2017 Curie-Weiss spd 1.3 -0.63 68.7 -814.1 0.23 2017 q-voter strong spd 7.2 31.3 5 33.1 55.5 -809.8 0.17 2017 q-voter weak spd 10.1 0.27 18.9 -80.6 -815.3 0.18 2017 reinforcement spd 19.6 752.9 -545.5 2039.8 -824.8 0.4 2017 Curie-Weiss linke 2.8 -0.11 81.9 -1068.6 3.6e-08 2017 q-voter strong linke 0.06 20.5 0.6 82 108.6 -1071.6 2.7e-07 2017 q-voter weak linke 9.1 2.7 42.8 9.3 -1112.1 5.7e-07 2017 reinforcement linke 14.2 1800.1 -1509.8 4806 -1152.6 6e-05 2017 Curie-Weiss gruene 2e-06 -2.8 19.2 -1047.3 2.6e-06 2017 q-voter strong gruene 0.95 45.2 0.72 12.5 50.8 -1103.8 0.26 2017 q-voter weak gruene 4.7 0.063 15.3 -164.1 -1113.4 0.7 2017 reinforcement gruene 4.4 472.5 -421.4 961.3 -1113.8 0.71 2017 Curie-Weiss fdp 2.5 -0.21 244.3 -1320.7 0.5 2017 q-voter strong fdp 11.9 116.1 1.3 8.4 131.5 -1314.9 0.34 2017 q-voter weak fdp 17.2 5.4 53.7 -308.8 -1320.5 0.57 2017 reinforcement fdp 14 117.1 0.14 1.1 -1320.2 0.57 2017 Curie-Weiss afd 2.6 -0.088 110 -985.3 0.0082 2017 q-voter strong afd 1.1 23 2.2 86.7 117.5 -983.7 0.011 2017 q-voter weak afd 14.5 8.9 54.5 23.7 -1009.4 0.094 2017 reinforcement afd 22.4 1081.9 -747.5 3127.1 -1035 0.77 2021 Curie-Weiss cdu 2.6e-07 -1.3 64 -778.3 0.6 2021 q-voter strong cdu 16.6 53 -40 -215.2 30.8 -774.6 0.75 2021 q-voter weak cdu 1.8 8.8 -31 -156.9 -776.6 0.76 2021 reinforcement cdu 3.5 0.8 -60.7 -261.1 -776.6 0.75 2021 Curie-Weiss spd 0.76 -0.7 72.8 -829.6 0.74 2021 q-voter strong spd 13.1 38.5 5.3 21.2 63 -825.5 0.74 2021 q-voter weak spd 13.1 1.2 14 -97.2 -828.9 0.74 2021 reinforcement spd 38.7 827.5 -477 2376.9 -836.6 0.93 2021 Curie-Weiss afd 2.7 -0.12 71.9 -971.4 1.3e-05 2021 q-voter strong afd 0.044 14.9 0.59 56.4 122.8 -980.4 7.7e-05 2021 q-voter weak afd 8.6 4.1 37.3 11 -1008.8 0.0014 2021 reinforcement afd 13.7 1092.2 -841 3064.4 -1049.7 0.21 2021 Curie-Weiss fdp 2.6 -0.032 430.3 -1424.6 0.37 2021 q-voter strong fdp 19.7 170.3 1.5 11.5 198.3 -1412.6 0.15 2021 q-voter weak fdp 40.9 254 74.7 703.9 -1427.3 0.64 2021 reinforcement fdp 43.3 522.6 19 1933.9 -1428 0.79 2021 Curie-Weiss gruene 1.8 -0.61 52.2 -813.8 0.18 2021 q-voter strong gruene 1.2 24.7 0.98 21.2 36.2 -808.2 0.081 2021 q-voter weak gruene 3.8 22.1 -2.1 -21.3 -812.1 0.13 2021 reinforcement gruene 3.8 0.3 13.9 -87.8 -812.2 0.13