Opinion Optimization in Directed Social Networks
Abstract
Shifting social opinions has far-reaching implications in various aspects, such as public health campaigns, product marketing, and political candidates. In this paper, we study a problem of opinion optimization based on the popular Friedkin-Johnsen (FJ) model for opinion dynamics in an unweighted directed social network with nodes and edges. In the FJ model, the internal opinion of every node lies in the closed interval , with 0 and 1 being polar opposites of opinions about a certain issue. Concretely, we focus on the problem of selecting a small number of nodes and changing their internal opinions to 0, in order to minimize the average opinion at equilibrium. We then design an algorithm that returns the optimal solution to the problem in time. To speed up the computation, we further develop a fast algorithm by sampling spanning forests, the time complexity of which is , with being the number of samplings. Finally, we execute extensive experiments on various real directed networks, which show that the effectiveness of our two algorithms is similar to each other, both of which outperform several baseline strategies of node selection. Moreover, our fast algorithm is more efficient than the first one, which is scalable to massive graphs with more than twenty million nodes.
1 Introduction
As an important part of our lives, online social networks and social media have dramatically changed the way people propagate, exchange, and formulate opinions (Ledford 2020). Increasing evidence indicates that in contrast to traditional communications and interaction, in the current digital age online communications and discussions have significantly influenced human activity in an unprecedented way, leading to universality, criticality and complexity of information propagation (Notarmuzi et al. 2022). In order to understand mechanisms for opinion propagation and shaping, a variety of mathematical models for opinion dynamics have been established (Jia et al. 2015; Proskurnikov and Tempo 2017; Dong et al. 2018; Anderson and Ye 2019). Among different models, the Friedkin-Johnsen (FJ) model (Friedkin and Johnsen 1990) is a popular one, which has been applied to many aspects (Bernardo et al. 2021; Friedkin et al. 2016). For example, the concatenated FJ model has been recently adapted to capture and reproduce the complex dynamics behind the Paris Agreement negotiation process, which explains why consensus was achieved in these multilateral international negotiations (Bernardo et al. 2021).
A fundamental quantity for opinion dynamics is the overall opinion or average opinion, which reflects the public opinions about certain topics of interest. In the past years, the subject of modifying opinions in a graph has attracted considerable attention in the scientific community (Gionis, Terzi, and Tsaparas 2013; Abebe et al. 2018; Chan, Liang, and Sozio 2019; Xu et al. 2020), since it has important implications in diverse realistic situations, such as commercial marketing, political election, and public health campaigns. For example, previous work has formulated and studied the problem of optimizing the overall or average opinion for the FJ model in undirected graphs by changing a certain attribute of some chosen nodes, including internal opinion (Xu et al. 2020), external opinion (Gionis, Terzi, and Tsaparas 2013), and susceptibility to persuasion (Abebe et al. 2018; Chan, Liang, and Sozio 2019), and so on. Thus far, most existing studies about modifying opinions focused on undirected graphs. In this paper, we study the problem of minimizing or maximizing average opinion in directed graphs (digraphs), since they can better mimic realistic networks. Moreover, because previous algorithms for unweighted graphs do not carry over to digraphs, we will propose an efficient linear-time approximation algorithm to solve the problem.
We adopt the discrete-time FJ model in a social network modeled by a digraph with nodes and arcs. In the model, each node is endowed with an internal/innate opinion in the interval , where 0 and 1 are two polar opposing opinions regarding a certain topic. Moreover, each node has an expressed opinion at time . During the opinion evolution process, the internal opinions of all nodes never change, while the expressed opinion of any node at time evolves as a weighted average of and the expressed opinions of ’s neighbors at time . For sufficiently large , the expressed opinion of every node converges to an equilibrium opinion . We address the following optimization problem OpinionMin (or OpinionMax): Given a digraph and a positive integer , how to choose nodes and change their internal opinions to (or 1), so that the average overall steady-state opinion is minimized (or maximized).
The main contributions of our work are as follows. We formalize the problem OpinionMin (or OpinionMax) of optimizing the average equilibrium opinion by optimally selecting nodes and modifying their internal opinions to (or 1), and show that both problems are equivalent to each other. We prove that the OpinionMin problem has an optimal solution and give an exact algorithm, which returns the optimal solution in time. We then provide an interpretation for the average equilibrium opinion from the perspective of spanning converging forests, based on which and Wilson’s algorithm we propose a sampling based fast algorithm. The fast algorithm has an error guarantee for the main quantity concerned, and has a time complexity of , where is the number of samplings. Finally, we perform extensive experiments on various real networks, which shows that our fast algorithm is almost as effective as the exact one, both outperforming several natural baselines. Furthermore, compared with the exact algorithm, our fast algorithm is more efficient, and scales to massive graphs with more than twenty million nodes.
2 Related Work
In this section, we briefly review the existing work related to ours.
Establishing mathematical models is a key step for understanding opinion dynamics and various models have been developed in the past years (Jia et al. 2015; Proskurnikov and Tempo 2017; Dong et al. 2018; Anderson and Ye 2019). Among existing models, the FJ model (Friedkin and Johnsen 1990) is a classic one, which is a significant extension of the DeGroot model (Degroot 1974). Due to its theoretical and practical significance, the FJ model has received much interest since its development. A sufficient condition for stability of the FJ model was obtained in (Ravazzi et al. 2015), its average innate opinion was inferred in (Das et al. 2013), and the vector of its expressed opinions at equilibrium was derived in (Das et al. 2013; Bindel, Kleinberg, and Oren 2015). Moreover, some explanations of the FJ model were also provided (Ghaderi and Srikant 2014; Bindel, Kleinberg, and Oren 2015). Finally, in recent years many variants or extensions of the FJ model have been introduced and studied by incorporating different factors affecting opinion formation, such as peer pressure (Semonsen et al. 2019), cooperation and competition (He et al. 2020; Xu et al. 2020), and interactions among higher-order nearest neighbors (Zhang et al. 2020).
In addition to the properties, interpretations and extensions of the FJ model itself, some social phenomena have been quantified based on the FJ model, such as disagreement (Musco, Musco, and Tsourakakis 2018), conflict (Chen, Lijffijt, and De Bie 2018), polarization (Matakos, Terzi, and Tsaparas 2017; Musco, Musco, and Tsourakakis 2018), and controversy (Chen, Lijffijt, and De Bie 2018), and a randomized algorithm approximately computing polarization and disagreement was designed in (Xu, Bao, and Zhang 2021), which was later used in (Tu and Neumann 2022). Also, many optimization problems for these quantities in the FJ model have been proposed and analyzed, including minimizing polarization (Musco, Musco, and Tsourakakis 2018; Matakos, Terzi, and Tsaparas 2017), disagreement (Musco, Musco, and Tsourakakis 2018), and conflict (Chen, Lijffijt, and De Bie 2018; Zhu and Zhang 2022), by different strategies such as modifying node’s internal opinions (Matakos, Terzi, and Tsaparas 2017), allocating edge weights (Musco, Musco, and Tsourakakis 2018) and adding edges (Zhu, Bao, and Zhang 2021). In order to solve these problems, different algorithms were designed by leveraging some mathematical tools, such as semidefinite programming (Chen, Lijffijt, and De Bie 2018) and Laplacian solvers (Zhu, Bao, and Zhang 2021).
Apart from polarization, disagreement, and conflict, another important optimization objective for opinion dynamics is the overall opinion or average opinion at equilibrium. For example, based on the FJ model, maximizing or minimizing the overall opinion has been considered by using different node-based schemes, such as changing the node’s internal opinions (Xu et al. 2020), external opinions (Gionis, Terzi, and Tsaparas 2013), and susceptibility to persuasion (Abebe et al. 2018; Chan, Liang, and Sozio 2019). On the other hand, for the DeGroot model of opinion dynamics in the presence of leaders, optimizing the overall opinion or average opinion was also heavily studied (Luca et al. 2014; Yi, Castiglia, and Patterson 2021; Zhou and Zhang 2021). An identical problem was also considered for a vote model (Yildiz et al. 2013), the asymptotic mean opinion of which is similar to that in the extended DeGroot model (Yi, Castiglia, and Patterson 2021). The vast majority of previous studies concentrated on unweighted graphs, with the exception of a few works (Ahmadinejad et al. 2015; Yi, Castiglia, and Patterson 2021), which addressed opinion optimization problems in digraphs and developed approximation algorithms with the time complexity of at least . In comparison, our fast algorithm is more efficient since it has linear time complexity.
3 Preliminary
This section is devoted to a brief introduction to some useful notations and tools, in order to facilitate the description of problem formulation and algorithms.
3.1 Directed Graph and Its Laplacian Matrix
Let denote an unweighted simple directed graph (digraph) with nodes (vertices) and directed edges (arcs), where is the set of nodes, and is the set of directed edges. The existence of arc means that there is an arc pointing from node to node . In what follows, and are used interchangeably to represent node if incurring no confusion. An isolated node is a node with no arcs pointing to or coming from it. Let denote the set of nodes that can be accessed by node . In other words, . A path from node to is an alternating sequence of nodes and arcs ,,,, ,, in which nodes are distinct and every arc is from to . A loop is a path plus an arc from the ending node to the starting node. A digraph is (strongly) connected if for any pair nodes and , there is a path from to , and there is a path from to at the same time. A digraph is called weakly connected if it is connected when one replaces any directed edge with two directed edges and in opposite directions. A tree is a weakly connected graph with no loops. An isolated node is considered as a tree. A forest is a particular graph that is a disjoint union of trees.
The connections of digraph are encoded in its adjacency matrix , with the element at row and column being if and otherwise. For a node in digraph , its in-degree is defined as , and its out-degree is defined as . In the sequel, we use to represent the out-degree . The diagonal out-degree matrix of digraph is defined as , and the Laplacian matrix of digraph is defined to be . Let and be the two -dimensional vectors with all entries being ones and zeros, respectively. Then, by definition, the sum of all entries in each row of is equal to obeying . Let be the -dimensional identity matrix.
In a digraph , if for any arc , the arc exists, is reduced to an undirected graph. When is undirected, holds for an arbitrary pair of nodes and , and thus holds for any node . Moreover, in undirected graph both adjacency matrix and Laplacian matrix of are symmetric, satisfying .
3.2 Friedkin-Johnsen Model on Digraphs
The Friedkin-Johnsen (FJ) model (Friedkin and Johnsen 1990) is a popular model for opinion evolution and formation. For the FJ opinion model on a digraph , each node/agent is associated with two opinions: one is the internal opinion , the other is the expressed opinion at time . The internal opinion is in the closed interval , reflecting the intrinsic position of node on a certain topic, where 0 and 1 are polar opposites of opinions regarding the topic. A higher value of signifies that node is more favorable toward the topic, and vice versa. During the process of opinion evolution, the internal opinion remains constant, while the expressed opinion evolves at time as follows:
| (1) |
Let denote the vector of internal opinions, and let denote the vector of expressed opinions at time .
Lemma 3.1
(Bindel, Kleinberg, and Oren 2015) As approaches infinity, converges to an equilibrium vector satisfying .
Let be the element at the -th row and the -th column of matrix , which is called the fundamental matrix of the FJ model for opinion dynamics (Gionis, Terzi, and Tsaparas 2013). The fundamental matrix has many good properties (Chebotarev and Shamis 1997, 1998). It is row stochastic, since . Moreover, for any pair of nodes and . The equality holds if and only if and there is no path from node to node ; and holds if and only if the out-degree of nodes is 0. Then, according to Lemma 3.1, for every node , its expressed opinion is given by , a convex combination of the internal opinions for all nodes.
4 Problem Formulation
An important quantity for opinion dynamics is the overall expressed opinion or the average expressed opinion at equilibrium, the optimization problem for which on the FJ model has been addressed under different constraints (Gionis, Terzi, and Tsaparas 2013; Ahmadinejad et al. 2015; Abebe et al. 2018; Xu et al. 2020; Yi, Castiglia, and Patterson 2021). In this section, we propose a problem of minimizing average expressed opinion for the FJ opinion dynamics model in a digraph, and design an exact algorithm optimally solving the problem.
4.1 Average Opinion and Structure Centrality
For the FJ model in digraph , the overall expressed opinion is defined as the sum of expressed opinions of every node at equilibrium. By Lemma 3.1, and . Given the vector for the equilibrium expressed opinions , we use to denote the average expressed opinion. By definition,
| (2) |
Since , related problems and algorithms for and are equivalent to each other. In what follows, we focus on the quantity .
Equation (2) tells us that the average expressed opinion is determined by two aspects: the internal opinion of every node, as well as the network structure characterizing interactions between nodes encoded in matrix , both of which constitute the social structure of opinion system for the FJ model. The former is an intrinsic property of each node, while the latter is a structure property of the network, both of which together determine the opinion dynamics system. Concretely, for the equilibrium expressed opinion of node , indicates the convex combination coefficient or contribution of the internal opinion for node . And the average of the -th column elements of , denoted by , measures the contribution of the internal opinion of node to . We call as the structure centrality (Friedkin 2011) of node in opinion dynamics modelled by the FJ model, since it catches the long-run structure influence of node on the average expressed opinion. Note that matrix is row stochastic and for any pair of nodes and , holds for every node , and .
Using structure centrality, the average expressed opinion is expressed as , which shows that the average expressed opinion is a convex combination of the internal opinions of all nodes, with the weight for being the structure centrality of node .
4.2 Problem Statement
As shown above, for a given digraph , its node centrality remains fixed. For the FJ model on with initial vector of internal opinions, if we choose a set of nodes and persuade them to change their internal opinions to 0, the average equilibrium opinion, denoted by , will decrease. It is clear that for , . Moreover, for two node sets and , if , then . Then the problem OpinionMin of opinion minimization arises naturally: How to optimally select a set with a small number of nodes and change their internal opinions to 0, so that their influence on the overall equilibrium opinion is maximized. Mathematically, it is formally stated as follows.
Problem 1 (OpinionMin)
Given a digraph , a vector of internal opinions, and an integer , we aim to find the set with nodes, and change the internal opinions of these chosen nodes to , so that the average equilibrium opinions is minimized. That is,
| (3) |
Similarly, we can define the problem OpinionMax for maximizing the average equilibrium opinion by optimally selecting a set of nodes and changing their internal opinions to 1. The goal of problem OpinionMin is to drive the average equilibrium opinion towards the polar value 0, while the of goal of problem OpinionMax is to drive towards polar value 1. Although the definitions and formulations of problems OpinionMin and OpinionMax are different, we can prove that they are equivalent to each other. In the sequel, we only consider the OpinionMin problem.
4.3 Optimal Solution
Although the OpinionMin problem is seemingly combinatorial, we next show that there is an exact algorithm optimally solving the problem in time.
Theorem 4.1
The optimal solution to the OpinionMin problem is the set of nodes with the largest product of structure centrality and internal opinion. That is, for any node and any node , .
Proof. Since the modifying of the internal opinions does not change the structure centrality of any node , the optimal set of nodes for the OpinionMin problem satisfies
which finishes the proof.
Theorem 4.1 shows that the key to solve Problem 1 is to compute for every node . In Algorithm 1, we present an algorithm Exact, which computes exactly. The algorithm first computes the inverse of matrix , which takes time. Based on the obtained , the algorithm then computes for each in time, by using the relation . Finally, Algorithm 1 constructs the set of nodes with the largest value of , which takes time. Therefore, the total time complexity of Algorithm 1 is .
Due to the high computation complexity, Algorithm 1 is computationally infeasible for large graphs. In the next section, we will give a fast algorithm for Problem 1, which is scalable to graphs with twenty million nodes.
5 Fast Sampling Algorithm
In this section, we develop a linear time algorithm to approximately evaluate the structure centrality of every node and solve the OpinionMin problem by using the connection of the fundamental matrix and the spanning converging forest. Our fast algorithm is based on the sampling of spanning converging forests, the ingredient of which is an extention of Wilson’s algorithm (Wilson 1996; Wilson and Propp 1996).
5.1 Interpretation of Structure Centrality
For a digraph , a spanning subgraph of is a subgraph of with node set being and edge set being a subset of . A converging tree is a weakly connected digraph, where one node, called the root node, has out-degree 0 and all other nodes have out-degree 1. An isolated node is considered as a converging tree with the root being itself. A spanning converging forest of digraph is a spanning subdigraph of , where all weakly connected components are converging trees. A spanning converging forest is in fact an in-forest in (Agaev and Chebotarev 2001; Chebotarev and Agaev 2002).
Let be the set of all spanning converging forests of digraph . For a spanning converging forest , let and denote its node set and arc set, respectively. By definition, for each node , there is at most one node obeying . For a spanning converging forest , define , which is actually the set of roots of all converging trees that constitute . Since each node in belongs to a certain converging tree, we define function to map node to the root of the converging tree including . Thus, if we conclude that , and nodes and belong to the same converging tree in . Define to be the set of those spanning converging forests, where for each spanning converging forest nodes and are in the same converging tree rooted at node . That is, . Then, we have .
Spanning converging forests have a close connection with the fundamental matrix of the FJ model, which is in fact the in-forest matrix of a digraph introduced (Chebotarev and Shamis 1997, 1998). Using the approach in (Chaiken 1982), it is easy to derive that the entry of the fundamental matrix can be written as .
With the notions mentioned above, we now provide an interpretation and another expression of structure centrality for any node . For the convenience of description, we introduce some more notations. For a node and a spanning converging forest of digraph , let be a set defined by . By definition, for any , if , ; if , is equal to the number of nodes in the converging tree in , whose root is node . For two nodes and and a spanning converging forest , define as a function taking two values, 0 or 1:
| (4) |
Then, the structure centrality of node is recast as
| (5) |
which indicates that is the average number of nodes in the converging trees rooted at node in all , divided by .
5.2 An Expansion of Wilson’s Algorithm
We first give a brief introduction to the loop-erasure operation to a random walk (Lawler and Gregory 1980), which is a process obtained from the random walk by performing an erasure operation on its loops in chronological order. Concretely, for a random walk , the loop-erasure to is an alternating sequence of nodes and arcs obtained inductively in the following way. First set and append to . Suppose that sequence , , , , , , has been added to for some . If , then and is the last node in . Otherwise, define , where .
Based on the loop-erasure operation on a random walk, Wilson proposed an algorithm to generate a uniform spanning tree rooted at a given node (Wilson 1996; Wilson and Propp 1996). Following the three steps below, we introduce Wilson’s algorithm to get a spanning tree of a connected digraph , which is rooted at node . (i) Set with . Choose . Then create an unbiased random walk starting at node . At each time step, the walk jumps to a neighbor of current position with identical probability. The walk stops, when the whole walk reaches some node in . (ii) Perform loop-erasure operation on the random walk to get , , , , , , and add the nodes and arcs in to . Then update with the nodes in . (iii) If , repeat step (ii), otherwise end circulation and return .
For a digraph , connected or disconnected, we can also apply Wilson’s Algorithm to get a spanning converging forest , by using the method similar to that in (Avena and Gaudillière 2018; Pilavcı et al. 2021), which includes the following three steps. (i) We construct an augmented digraph of , obtained from by adding a new node and some new edges. Concretely, in , and for all . (ii) Using Wilson’s algorithm to generate a uniform spanning tree for the augmented graph , whose root node is . (iii) Deleting all the edges we get a spanning forest of . Assigning as the set of roots for trees makes become a converging spanning forest of .
The spanning converging forest obtained using the above steps is uniformly selected from (Avena and Gaudillière 2018). In other words, for any spanning converging forest in , we have . Following the three steps above for generating a uniform spanning converging forest of digraph , in Algorithm 2 we present an algorithm to generate a uniform spanning converging forest of digraph , which returns a list RootIndex with the -th element RootIndex[] recording the root of the tree in node belongs to. That is, RootIndex[]=.
Below we give a detailed description for Algorithm 2. InForest is a list recording whether a node is in the forest or not in the random walk process. In line 1, we initialize InForest to false, for all . If node is not a root of any tree in the forest , Next[] is the node satisfying ; if node belongs to the root set , Next[] . We initialize Next[] in line 2. We start a random walk at node in the extended graph in line 5 to create a forest branch of . The probability of visiting node starting from is . In line 7, we generate a random real number in using function Rand(). If the random number satisfies the inequality in line 8, the walk jumps to node at this step. According to the previous analysis, in extended graph , those nodes that point directly to belong to the root set . In lines 9-11, we set the node as a root node and update InForest[], Next, and RootIndex. If the inequality in line 8 does not hold, we use function RandomSuccessor() to return a node randomly selected from the neighbors of in in line 13. Then we update to Next[] and go back to line 6. The loop stops when the random walk goes to a node already existing in the forest. When the loop stops, we get a newly created branch. In lines 15-20, we add the loop-erasure of the branch to the forest and then update RootIndex.
We now analyze the time complexity of Algorithm 2. Before doing this, we present some properties of the diagonal element of matrix for all nodes .
Lemma 5.1
For any , the diagonal element of matrix sastisfies .
Lemma 5.2
For any unweighted digraph , the expected time complexity of Algorithm 2 is .
Proof. Wilson showed that the expected running time of generating a uniform spanning tree of a connected digraph rooted at node is equal to a weighted average of commute time between the root and the other nodes (Wilson 1996). Marchal rewrote this average of commute time in terms of graph matrices in Proposition 1 in (Marchal 2000). According to Marchal’s result, the expected running time of Algorithm 2 is equal to the trace of matrix . Using Lemma 5.2, we have Thus, the expected time complexity of Algorithm 2 is .
5.3 Fast Approximation Algorithm
Here by using (5.1), we present an efficient sampling-based algorithm Fast to estimate for all and approximately solve the problem OpinionMin in linear time.
The ingredient of the approximation algorithm Fast is the variation of Wilson’s algorithm introduced in the preceding subsection. The details of algorithm Fast are described in Algorithm 3. First, by applying Algorithm 2 we generate random spanning converging forests . Then, we compute for all . Note that each of these spanning converging forests has the same probability of being created from all spanning converging forests in (Avena and Gaudillière 2018). Thus, we have , which implies that in Algorithm 3 is an unbiased estimation of . Then, is an unbiased estimation of . Finally, we choose nodes from with the top- values of .
Theorem 5.3
The time complexity of Algorithm 3 is .
Running Algorithm 2 requires determining the number of sampling , which determines the accuracy of as an approximation of . In general, the larger the value of , the more accurate the estimation of to . Next, we bound the number of required samplings of spanning converging forests to guarantee a desired estimation precision of by applying the Hoeffding’s inequality (Hoeffding and Wassily 1963).
We now demonstrate that with a proper choice of , as an estimator of has an approximation guarantee for all . Specifically, we establish an -approximation of : for any small parameters and , the approximation error is bounded by with probability at least . Theorem 5.4 shows how to properly choose so that is an -approximation of .
Theorem 5.4
For any and , if is chosen obeying , then for any , .
Recall that our problem aims to determine the optimal set , which consists of nodes with the largest . To avoid calculating directly, we propose a fast algorithm (Algorithm 3), which returns a set containing top nodes of the highest . Based on the result of Theorem 5.4, we can get a union bound between and , as stated in the following theorem.
Theorem 5.5
For given parameters , if is chosen according to Theorem 5.4, the inequality holds with high probability.
Proof. According to Theorem 5.4, we suppose now inequalities hold for any . Since the nodes in set have the top value of , we have
By Theorem 5.4, one obtains
which completes the proof.
Therefore, for any fixed , the number of samples does not depend on .
6 Experiments
In this section, we conduct extensive experiments on various real-life directed networks, in order to evaluate the performance of our two algorithms Exact and Fast in terms of effectiveness and efficiency. The data sets of selected real networks are publicly available in the KONECT (Kunegis 2013) and SNAP (Leskovec and Sosič 2016), the detailed information of which is presented in the first three columns of Table 1. In the dataset networks, the number of nodes ranges from about 1 thousand to 24 million, and the number of directed edges ranges from about 2 thousand to 58 million. All our experiments are programmed in Julia using a single thread, and are run on a machine equipped with 4.2 GHz Intel i7-7700 CPU and 32GB of main memory.
6.1 Effectiveness
We first compare the effectiveness of our algorithms Exact and Fast with four baseline schemes for node selection: Random, In-degree, Internal opinion, and Expressed opinion. Random selects nodes at random. In-degree chooses nodes with the largest in-degree, since a node with a high in-degree may has a strong influence on other nodes (Xu et al. 2020). For Internal opinion and Expressed opinion, they have been used in (Gionis, Terzi, and Tsaparas 2013). Internal opinion returns nodes with the largest original internal opinions, while Expressed opinion selects nodes with the largest equilibrium expressed opinions in the FJ model corresponding to the original internal opinion vector.
| Network | Nodes | Arcs | Running time () for Exact and Fast | Relative error () | |||||
| Optimal | |||||||||
| Filmtrust | 874 | 1,853 | 0.023 | 0.019 | 0.037 | 0.042 | 1.08 | 0.55 | 0.11 |
| Humanproteins | 2,239 | 6,452 | 0.251 | 0.032 | 0.039 | 0.056 | 0.19 | 0.16 | 0.03 |
| Adolescenthealth | 2,539 | 12,969 | 0.354 | 0.034 | 0.068 | 0.134 | 0.72 | 0.59 | 0.09 |
| P2p-Gnutella08 | 6,301 | 20,777 | 4.825 | 0.067 | 0.123 | 0.244 | 0.83 | 0.64 | 0.04 |
| Wiki-Vote | 7,115 | 103,689 | 7.405 | 0.078 | 0.156 | 0.312 | 1.13 | 0.87 | 0.13 |
| Dblp | 12,590 | 49,744 | 40.870 | 0.106 | 0.210 | 0.419 | 0.38 | 0.13 | 0.08 |
| Wikipedialinks | 17,649 | 296,918 | 110.744 | 0.248 | 0.477 | 0.932 | 1.32 | 0.97 | 0.06 |
| Twitterlist | 23,370 | 33,101 | 259.484 | 0.127 | 0.250 | 0.498 | 0.25 | 0.12 | 0.01 |
| P2p-Gnutella31 | 62,586 | 147,892 | - | 0.628 | 1.236 | 2.550 | - | - | - |
| Soc-Epinions | 75,879 | 508,837 | - | 1.260 | 2.501 | 4.973 | - | - | - |
| Email-EuAll | 265,009 | 418,956 | - | 3.016 | 5.929 | 11.844 | - | - | - |
| Stanford | 281,903 | 2,312,500 | - | 7.474 | 14.908 | 29.815 | - | - | - |
| NotreDame | 325,729 | 1,469,680 | - | 4.823 | 9.574 | 19.232 | - | - | - |
| BerkStan | 685,230 | 7,600,600 | - | 14.021 | 28.009 | 56.130 | - | - | - |
| 875,713 | 5,105,040 | - | 26.583 | 53.655 | 106.005 | - | - | - | |
| NorthwestUSA | 1,207,940 | 2,820,770 | - | 27.758 | 55.509 | 110.410 | - | - | - |
| WikiTalk | 2,394,380 | 5,021,410 | - | 20.277 | 37.622 | 75.105 | - | - | - |
| Greatlakes | 2,758,120 | 6,794,810 | - | 64.391 | 128.167 | 255.147 | - | - | - |
| FullUSA | 23,947,300 | 57,708,600 | - | 559.147 | 1116.550 | 2230.770 | - | - | - |
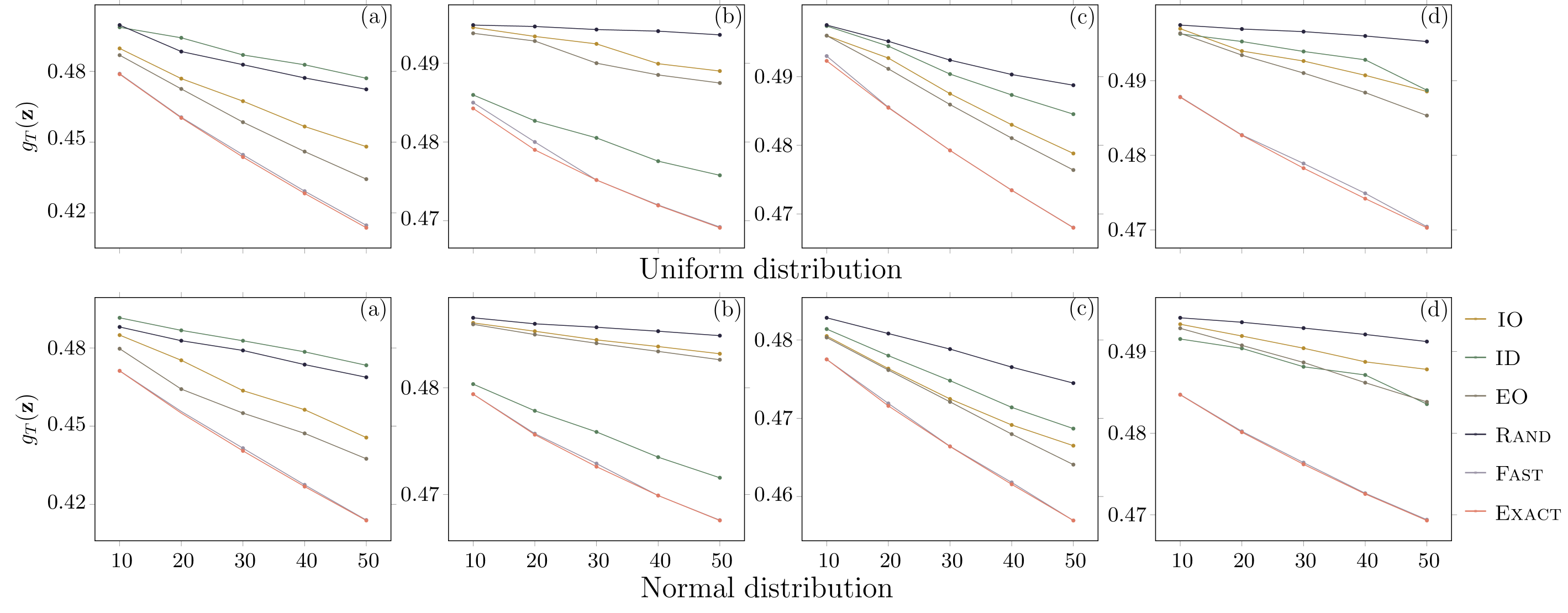
In our experiment, the number of samplings in algorithm Fast is set be . For each node , its internal opinion is generated uniformly in the interval . For each real network, we first calculate the equilibrium expressed opinions of all nodes and their average opinion for the original internal opinions. Then, using our algorithms Exact and Fast and the four baseline strategies, we select nodes and change their internal opinions to 0, and recompute the average expressed opinion associated with the modified internal opinions. We also execute experiments for other distributions of internal opinions. For example, we consider the case that the internal opinions follow a normal distribution with mean and variance . For this case, we perform a linear transformation, mapping the internal opinions into interval , so that the smallest internal opinion is mapped to 0, while the largest internal opinion corresponds to 1. As can be seen from Figure 1, for each network algorithm Fast always returns a result close to the optimal solution corresponding to algorithm Exact for both uniform distribution and standardized normal distribution, outperforming the four other baseline strategies.
For the cases that internal opinions obey power-law distribution or exponential distribution, here we do not report the results since they are similar to that observed in Figure 1.
6.2 Efficiency and Scalability
As shown above, algorithm Fast has similar effectiveness to that of algorithm Exact. Below we will show that algorithm Fast is more efficient than algorithm Exact. To this end, in Table 1 we compare the performance of algorithms Exact and Fast. First, we compare the running time of the two algorithms on the real-life directed networks listed in Table 1. For our experiment, the internal opinion of all nodes in each network obeys uniform distribution from , is equal to 50, and is chosen to be 500, 1000, and 2000. As shown in Table 1, Fast is significantly faster than Exact for all , which becomes more obvious when the number of nodes increases. For example, Exact fails to run on the last 11 networks in Table 1, due to time and memory limitations. In contrast, Fast still works well in these networks. Particularly, algorithm Fast is scalable to massive networks with more than twenty million nodes, e.g., FullUSA with over nodes.
Table 1 also reports quantitative comparison of the effectiveness between algorithms Exact and Fast. Let and denote the average opinion obtained, respectively, by algorithms Exact and Fast, and let be the relative error of with respect to . The last three columns of Table 1 present the relative errors for different real networks and various numbers of samplings. From the results, we can see that for all networks and different , the relative error is negligible, with the largest value being less than . Moreover, for each network, is decreased when increases. This again indicates that the results returned by Fast are very close to those corresponding to Exact. Therefore, algorithm Fast is both effective and efficient, and scales to massive graphs.
7 Conclusions
In this paper, we studied how to optimize social opinions based on the Friedkin-Johnsen (FJ) model in an unweighted directed social network with nodes and edges, where the internal opinion , , of every node is in interval . We concentrated on the problem of minimizing the average of equilibrium opinions by selecting a set of nodes and modifying their internal opinions to 0. Although the problem seems combinatorial, we proved that there is an algorithm Exact solving it in time, which returns the optimal nodes with the top values of , , where is the structure centrality of node .
Although algorithm Exact avoids the naïve enumeration of all cases for set , it is not applicable to large graphs. To make up for this deficiency, we proposed a fast algorithm for the problem. To this end, we provided an interpretation of in terms of rooted spanning converging forests, and designed a fast sampling algorithm Fast to estimate for all nodes by using a variant of Wilson’s Algorithm. The algorithm simultaneously returns nodes with largest values of in time, where denotes the number of samplings. Finally, we performed experiments on many real directed networks of different sizes to demonstrate the performance of our algorithms. The results show that the effectiveness of algorithm Fast is comparable to that of algorithm Exact, both of which are better than the baseline algorithms. Furthermore, relative to Exact, Fast is more efficient, since is Fast is scalable to massive graphs with over twenty million nodes, while Exact only applies to graphs with less than tens of thousands of nodes. It is worth mentioning that it is easy to extend or modify our algorithm to weighed digraphs and apply it to solve other optimization problems for opinion dynamics.
Acknowledgements
Zhongzhi Zhang is the corresponding author. This work was supported by the Shanghai Municipal Science and Technology Major Project (No. 2018SHZDZX01), the National Natural Science Foundation of China (Nos. 61872093 and U20B2051), ZJ Lab, and Shanghai Center for Brain Science and Brain-Inspired Technology.
References
- Abebe et al. (2018) Abebe, R.; Kleinberg, J.; Parkes, D.; and Tsourakakis, C. E. 2018. Opinion dynamics with varying susceptibility to persuasion. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1089–1098. ACM.
- Agaev and Chebotarev (2001) Agaev, R. P.; and Chebotarev, P. Y. 2001. Spanning forests of a digraph and their applications. Automation and Remote Control, 62(3): 443–466.
- Ahmadinejad et al. (2015) Ahmadinejad, A. M.; Dehghani, S.; Hajiaghayi, M. T.; Mahini, H.; and Yazdanbod, S. 2015. Forming external behaviors by leveraging internal opinions. In Proceedings of 2015 IEEE Conference on Computer Communications, 2728–2734. IEEE.
- Anderson and Ye (2019) Anderson, B. D.; and Ye, M. 2019. Recent advances in the modelling and analysis of opinion dynamics on influence networks. International Journal of Automation and Computing, 16(2): 129–149.
- Avena and Gaudillière (2018) Avena, L.; and Gaudillière, A. 2018. Two applications of random spanning forests. Journal of Theoretical Probability, 31(4): 1975–2004.
- Bernardo et al. (2021) Bernardo, C.; Wang, L.; Vasca, F.; Hong, Y.; Shi, G.; and Altafini, C. 2021. Achieving consensus in multilateral international negotiations: The case study of the 2015 Paris Agreement on climate change. Science Advances, 7(51): eabg8068.
- Bindel, Kleinberg, and Oren (2015) Bindel, D.; Kleinberg, J.; and Oren, S. 2015. How bad is forming your own opinion? Games and Economic Behavior, 92: 248–265.
- Chaiken (1982) Chaiken, S. 1982. A combinatorial proof of the all minors matrix tree theorem. SIAM J. Alg. Disc. Meth., 3(3): 319–329.
- Chan, Liang, and Sozio (2019) Chan, T.-H. H.; Liang, Z.; and Sozio, M. 2019. Revisiting opinion dynamics with varying susceptibility to persuasion via non-convex local search. In Proceedings of the 2019 World Wide Web Conference, 173–183. ACM.
- Chebotarev and Agaev (2002) Chebotarev, P.; and Agaev, R. 2002. Forest matrices around the Laplacian matrix. Linear Algebra and its Applications, 356(1-3): 253–274.
- Chebotarev and Shamis (1997) Chebotarev, P. Y.; and Shamis, E. V. 1997. The matrix-forest theorem and measuring relations in small social groups. Automation and Remote Control, 58(9): 1505–1514.
- Chebotarev and Shamis (1998) Chebotarev, P. Y.; and Shamis, E. V. 1998. On proximity measures for graph vertices. Automation and Remote Control, 59(10): 1443–1459.
- Chen, Lijffijt, and De Bie (2018) Chen, X.; Lijffijt, J.; and De Bie, T. 2018. Quantifying and minimizing risk of conflict in social networks. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1197–1205. ACM.
- Das et al. (2013) Das, A.; Gollapudi, S.; Panigrahy, R.; and Salek, M. 2013. Debiasing social wisdom. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 500–508. ACM.
- Degroot (1974) Degroot, M. H. 1974. Reaching a consensus. Journal of the American Statistical Association, 69(345): 118–121.
- Dong et al. (2018) Dong, Y.; Zhan, M.; Kou, G.; Ding, Z.; and Liang, H. 2018. A survey on the fusion process in opinion dynamics. Information Fusion, 43: 57–65.
- Friedkin (2011) Friedkin, N. E. 2011. A formal theory of reflected appraisals in the evolution of power. Administrative Science Quarterly, 56(4): 501–529.
- Friedkin and Johnsen (1990) Friedkin, N. E.; and Johnsen, E. C. 1990. Social influence and opinions. Journal of Mathematical Sociology, 15(3-4): 193–206.
- Friedkin et al. (2016) Friedkin, N. E.; Proskurnikov, A. V.; Tempo, R.; and Parsegov, S. E. 2016. Network science on belief system dynamics under logic constraints. Science, 354(6310): 321–326.
- Ghaderi and Srikant (2014) Ghaderi, J.; and Srikant, R. 2014. Opinion dynamics in social networks with stubborn agents: Equilibrium and convergence rate. Automatica, 50(12): 3209–3215.
- Gionis, Terzi, and Tsaparas (2013) Gionis, A.; Terzi, E.; and Tsaparas, P. 2013. Opinion maximization in social networks. In Proceedings of the 2013 SIAM International Conference on Data Mining, 387–395. SIAM.
- He et al. (2020) He, G.; Zhang, W.; Liu, J.; and Ruan, H. 2020. Opinion dynamics with the increasing peer pressure and prejudice on the signed graph. Nonlinear Dynamics, 99: 1–13.
- Hoeffding and Wassily (1963) Hoeffding; and Wassily. 1963. Probability Inequalities for Sums of Bounded Random Variables. Journal of the American Statistical Association, 58(301): 13–30.
- Jia et al. (2015) Jia, P.; MirTabatabaei, A.; Friedkin, N. E.; and Bullo, F. 2015. Opinion dynamics and the evolution of social power in influence networks. SIAM Review, 57(3): 367–397.
- Kunegis (2013) Kunegis, J. 2013. Konect: the koblenz network collection. In Proceedings of the 22nd International World Wide Web Conference, 1343–1350. ACM.
- Lawler and Gregory (1980) Lawler; and Gregory, F. 1980. A self-avoiding random walk. Duke Mathematical Journal, 47(3): 655–693.
- Ledford (2020) Ledford, H. 2020. How Facebook, Twitter and other data troves are revolutionizing social science. Nature, 582(7812): 328–330.
- Leskovec and Sosič (2016) Leskovec, J.; and Sosič, R. 2016. SNAP: A general-purpose network analysis and graph-mining library. ACM Transactions on Intelligent Systems and Technology, 8(1): 1.
- Luca et al. (2014) Luca, V.; Fabio, F.; Paolo, F.; and Asuman, O. 2014. Message passing optimization of harmonic influence centrality. IEEE Transactions on Control of Network Systems, 1(1): 109–120.
- Marchal (2000) Marchal, P. 2000. Loop-erased random walks, spanning trees and Hamiltonian cycles. Electronic Communications in Probability, 5: 39–50.
- Matakos, Terzi, and Tsaparas (2017) Matakos, A.; Terzi, E.; and Tsaparas, P. 2017. Measuring and moderating opinion polarization in social networks. Data Mining and Knowledge Discovery, 31(5): 1480–1505.
- Musco, Musco, and Tsourakakis (2018) Musco, C.; Musco, C.; and Tsourakakis, C. E. 2018. Minimizing polarization and disagreement in social networks. In Proceedings of the 2018 World Wide Web Conference, 369–378.
- Notarmuzi et al. (2022) Notarmuzi, D.; Castellano, C.; Flammini, A.; Mazzilli, D.; and Radicchi, F. 2022. Universality, criticality and complexity of information propagation in social media. Nature Communications, 13: 1308.
- Pilavcı et al. (2021) Pilavcı, Y. Y.; Amblard, P.-O.; Barthelme, S.; and Tremblay, N. 2021. Graph Tikhonov regularization and interpolation via random spanning forests. IEEE transactions on Signal and Information Processing over Networks, 7: 359–374.
- Proskurnikov and Tempo (2017) Proskurnikov, A. V.; and Tempo, R. 2017. A tutorial on modeling and analysis of dynamic social networks. Part I. Annual Reviews in Control, 43: 65–79.
- Ravazzi et al. (2015) Ravazzi, C.; Frasca, P.; Tempo, R.; and Ishii, H. 2015. Ergodic randomized algorithms and dynamics over networks. IEEE Transactions on Control of Network Systems, 1(2): 78–87.
- Semonsen et al. (2019) Semonsen, J.; Griffin, C.; Squicciarini, A.; and Rajtmajer, S. 2019. Opinion dynamics in the presence of increasing agreement pressure. IEEE Transactions on Cybernetics, 49(4): 1270–1278.
- Tu and Neumann (2022) Tu, S.; and Neumann, S. 2022. A viral marketing-based model for opinion dynamics in online social networks. In Proceedings of the Web Conference, 1570–1578.
- Wilson (1996) Wilson, D. B. 1996. Generating random spanning trees more quickly than the cover time. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing, 296–303.
- Wilson and Propp (1996) Wilson, D. B.; and Propp, J. G. 1996. How to get an exact sample from a generic markov chain and sample a random spanning tree from a directed graph, both within the cover time. In Proceedings of the Seventh Annual ACM-SIAM Symposium on Discrete Algorithms, 448–457.
- Xu et al. (2020) Xu, P.; Hu, W.; Wu, J.; and Liu, W. 2020. Opinion maximization in social trust networks. In Proceedings of the 29th International Joint Conference on Artificial Intelligence, 1251–1257.
- Xu, Bao, and Zhang (2021) Xu, W.; Bao, Q.; and Zhang, Z. 2021. Fast evaluation for relevant quantities of opinion dynamics. In Proceedings of The Web Conference, 2037–2045. ACM.
- Yi, Castiglia, and Patterson (2021) Yi, Y.; Castiglia, T.; and Patterson, S. 2021. Shifting opinions in a social network through leader selection. IEEE Transactions on Control of Network Systems, 8(3): 1116–1127.
- Yildiz et al. (2013) Yildiz, E.; Ozdaglar, A.; Acemoglu, D.; Saberi, A.; and Scaglione, A. 2013. Binary opinion dynamics with stubborn agents. ACM Transactions on Economics and Computation, 1(4): 1–30.
- Zhang et al. (2020) Zhang, Z.; Xu, W.; Zhang, Z.; and Chen, G. 2020. Opinion dynamics incorporating higher-order interactions. In Proceedings of the 20th IEEE International Conference on Data Mining, 1430–1435. IEEE.
- Zhou and Zhang (2021) Zhou, X.; and Zhang, Z. 2021. Maximizing influence of leaders in social networks. In Proceedings of the 27th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2400–2408. ACM.
- Zhu, Bao, and Zhang (2021) Zhu, L.; Bao, Q.; and Zhang, Z. 2021. Minimizing polarization and disagreement in social networks via link recommendation. Advances in Neural Information Processing Systems, 34: 2072–2084.
- Zhu and Zhang (2022) Zhu, L.; and Zhang, Z. 2022. A Nearly-Linear Time Algorithm for Minimizing Risk of Conflict in Social Networks. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2648–2656.