Optimal and two-step adaptive quantum detector tomography
Abstract
Quantum detector tomography is a fundamental technique for calibrating quantum devices and performing quantum engineering tasks. In this paper, we design optimal probe states for detector estimation based on the minimum upper bound of the mean squared error (UMSE) and the maximum robustness. We establish the minimum UMSE and the minimum condition number for quantum detectors and provide concrete examples that can achieve optimal detector tomography. In order to enhance the estimation precision, we also propose a two-step adaptive detector tomography algorithm to optimize the probe states adaptively based on a modified fidelity index. We present a sufficient condition on when the estimation error of our two-step strategy scales inversely proportional to the number of state copies. Moreover, the superposition of coherent states is used as probe states for quantum detector tomography and the estimation error is analyzed. Numerical results demonstrate the effectiveness of both the proposed optimal and adaptive quantum detector tomography methods.
keywords:
Quantum detector tomography, quantum system identification, adaptive estimation, quantum systems, , ,
1 Introduction
In the past decades, we have witnessed significant progress in a variety of fields of quantum science and technology, including quantum computation [1], quantum communication [2] and quantum sensing [3]. In these applications, a fundamental task is to develop efficient estimation and identification methods to acquire information of quantum states, system parameters and quantum detectors. There are three typical classes of quantum estimation and identification tasks: (i) quantum state tomography (QST) which aims to estimate unknown states [4, 5, 6]; (ii) quantum process tomography which targets in identifying parameters of evolution operators [7, 8, 9, 10, 11] (e.g., the system Hamiltonian [12, 13, 14, 15, 16, 17]); and (iii) quantum detector tomography (QDT) which aims to identify and calibrate quantum measurement devices. In this paper, we focus on QDT and aim to present optimal and adaptive strategies for enhancing the efficiency and precision of QDT.
For general QDT protocols, the first solution was proposed in [18] using maximum likelihood estimation (MLE). Subsequent works divide quantum detectors into phase-insensitive detectors and phase-sensitive detectors. Phase-insensitive detectors only have diagonal elements in the photon number basis, and therefore are relatively straightforward to be characterized using linear regression [19], function fitting [20], or convex optimization [21, 22, 23]. In experiment, a regularized least-square method was used in [24, 25] for phase-insensitive detectors. For phase-sensitive detectors, non-diagonal elements can be nonzero and they are usually more challenging to reconstruct. The work in [26, 27] formulated QDT as a convex quadratic optimization problem for this type of detectors. Ref. [28] proposed a two-stage solution with an analytical computational complexity and error upper bound. Ref. [29] further studied a binary detector tomography method with lower computational complexity by projection. Self-characterization of one-qubit QDT was proposed in [30] which does not rely on precisely calibrated probe states.
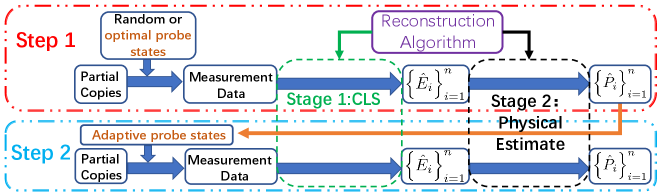
In this paper, we consider optimal QDT and adaptive QDT which are applicable to both phase insensitive and phase sensitive detectors. The general tomography procedures are shown in Fig. 1. For optimal QDT, we only consider Step 1 where we obtain measurement data and then use the two-stage reconstruction algorithm in [28] to identify the unknown detectors. A natural question would be which input probe states are optimal, according to some requirements or criteria. Here we use the upper bound of the mean squared error (UMSE) [28] and the robustness described by the condition number against measurement errors as two criteria [31]. We prove that the minimum UMSE is where is the dimension of detector matrices, is the number of detector matrices and is the resource number (i.e., number of copies of probe states). We also prove the minimum condition number is . We then provide two examples of optimal probe states–SIC (symmetric informationally complete) states with the smallest and MUB (mutually unbiased) states for where is the type of probe states. When restricted to product states, we prove the minimum of UMSE is and that of the condition number is where is the number of qubits.
Another focus we consider is to develop adaptive QDT to enhance the identification accuracy of quantum detectors. Adaptive strategies have been employed in QST and existing results show that adaptive QST has great potential to enhance the estimation precision of quantum states [32, 33, 34, 35, 36, 37]. Inspired by adaptive QST, we propose a two-step adaptive QDT as shown in Fig. 1. Step 1 is the same as optimal QDT, and adaptive probe states are chosen in Step 2 based on a rough detector estimation in Step 1. With these adaptive probe states, we can improve the infidelity from to optimal value . We also use the superposition of coherent states to realize QDT and use numerical examples to demonstrate the effectiveness of our optimal and adaptive QDT.
This paper is organized as follows. In Section 2, we present background knowledge and reconstruction algorithm. In Section 3, we propose optimal QDT and provide concrete examples. In Section 4, we present a two-step adaptive QDT. In Section 5, we give numerical examples of optimal and adaptive QDT. Conclusions are presented in Section 6.
Notation: For a matrix , means is positive semidefinite. The conjugation and transpose of is . The trace of is . The identity matrix is . The real and complex domains are and , respectively. The tensor product is . The set of all -dimensional complex/real vectors is . Row and column vectors also denoted as and , respectively. The Frobenius norm for matrix and 2-norm for vector are . The Kronecker delta function is . . The column vectorization function is . The diagonal elements of a diagonal matrix are the elements in and is a vector. The estimation of variable denotes . For any positive semidefinite with spectral decomposition define or as . Pauli matrices are , , . The fidelity between quantum states and is .
2 Preliminaries
Here we present the background knowledge and briefly introduce the two-stage QDT reconstruction algorithm in [28], which will be employed as a critical part for developing optimal QDT.
2.1 Quantum state and measurement
For a -dimensional quantum system, its state can be described by a Hermitian matrix , satisfying . When for some , we call a pure state, and its purity reaches the maximum value . Otherwise, is called a mixed state, and can be represented using pure states where and .
A quantum detector connects the classical and quantum world through a set of operators known as positive-operator-valued measure (POVM). A set of POVM elements is a set of Hermitian and positive semidefinite operators , which is the mathematical representation of quantum detectors, satisfying the completeness constraint . We directly call a POVM element in this paper. The operators may be finite or infinite dimensional in theory. When infinite dimensional, we usually truncate them at a finite dimension in practice. When is measured using , the probability of obtaining the -th result is given by the Born’s rule
| (1) |
Because of the completeness constraint, we have . In practical experiments, suppose (called resource number) identical copies of are prepared and the -th result occurs times. Then is the experimental estimation of the true value .
2.2 Problem formulation of QDT
By applying known quantum states to an unknown quantum detector and obtaining the measurement results, one can estimate the detector, which is called quantum detector tomography (QDT). Denote the true value of the detector as . We design different types of quantum states (called probe states), where each state use the same resource number thus their total number of copies is . One can formulate the problem of QDT as [28]:
Problem 1.
Given experimental data , solve
such that for and .
There are various methods to formulate and solve the problem of QDT. For maximum likelihood estimation (MLE) [18], if large data are given, the MLE can asymptotically reach the Cramr-Rao bound for parameter estimation while the computational complexity is usually high. There also exist several convex optimization approaches [21, 22, 23] which might be more efficient. However, an analytical error upper bound is missing for MLE and convex optimization approaches, making it difficult to optimize the input probe states in the general case without available prior information about the detector. Here we choose the linear regression method due to its simplicity and computational efficiency. Moreover, Ref. [28] presents the two-stage QDT solution to Problem 1, giving an analytical error upper bound in favor of optimizing general input states. We thus review this solving procedure as follows.
Let be a complete basis set of orthonormal operators with -dimension. Without loss of generality, let , where except . Then we parameterize the detector and probe states as
| (2) | ||||
where and are real. Using Born’s rule, we can obtain
| (3) |
where , is the parameterization of and , respectively. Suppose the outcome for appears times, then . Denote the estimation error as . According to the central limit theorem, converges in distribution to a normal distribution with mean zero and variance . We thus have the linear regression equation
| (4) |
Let be the vector of all the unknown parameters to be estimated. Collect the parameterization of the probe states as . Let , , , , , . Then the regression equations can be rewritten in a compact form [28]:
| (5) |
with a linear constraint
| (6) |
Now Problem 1 can be transformed into the following equivalent form:
Problem 2.
Given experimental data , solve
such that and for , where is the parametrization of .
In [28], Problem 2 is split into two approximate subproblems:
Problem 2.
Given experimental data , solve such that where is the parametrization of .
Problem 2.
Given , solve
such that and for .
The reconstruction algorithm has two stages, as shown in Fig. 1. In Stage 1, Problem 2.1 is solved by Constrained Least Squares (CLS) method and the form of the solution is further simplified. In Stage 2, Problem 2.2 is solved by matrix decomposition. We briefly review the two-stage QDT reconstruction algorithm in [28] in the next subsection.
2.3 Two-stage QDT reconstruction algorithm
In Stage 1, we directly give the simplified form of the CLS solution to Problem 2.1 as
| (7) |
where for and .
Let the -th block be
and the Stage 1 estimate is which may have negative eigenvalues. Thus, Stage 2 is designed to obtain a physical estimate by eigenvalue correction with three substages.
Firstly, we decompose with . We then perform a spectral decomposition to obtain . Assume there are nonpositive eigenvalues for , and they are in decreasing order. Thus, the best decomposition in the sense of minimizing is
, and
,
.
Secondly, we apply decomposition
,
and hence .
Let which is positive semidefinite and . For any unitary , holds. Therefore, can also be an estimate
of the detector. To neutralize the effect of on , we define an optimal unitary matrix to minimize [28] and its analytical expression is .
Therefore, the final estimate is . This general algorithm can be used for arbitrary .
3 Optimal quantum detector tomography
In detector tomography as shown in Step 1 in Fig. 1, a natural way to reduce the tomography error is to carefully choose the probe states according to a certain optimality criterion, which should be independent of the detector. In this section, we propose a criterion based on two non-conflicting indices (UMSE and condition number), subsequently present the conditions on achieving optimal detector tomography and provide illustrative examples.
3.1 Optimality criterion
One index to evaluate probe states is to score their worst performance, i.e., their upper bounds of estimation errors. Let denote the expectation w.r.t. all possible measurement results. The Stage 1 error between the estimate and its true value is bounded by UMSE (upper bound of the mean squared error ) [28]
| (8) | ||||
and the final estimation error for all detectors
is bounded by [28]
| (9) | ||||
Since in (8) and (9) the parts dependent on probe states are both , we take it as our first criterion. For general QDT, we have no special prior knowledge on the detectors, and the following conditions are equivalent: (i) the detector can not be uniquely identified; (ii) the probe states do not span the space of all -dimensional states; (iii) is singular; (iv) the UMSE is infinite. From (i) and (iv), it is thus reasonable to take as an evaluation index. We require the optimal probe states to minimize . This criterion is conservative and its limitation is that the UMSE might not be tight. The relation (8) is only tight for the case and (9) is always loose. Therefore, minimizing UMSE is not equivalent to minimizing MSE. In addition, UMSE depends on the assumption that there only exists statistics error in the measurement data from finite state copies (discussed in Remark 4). Despite these limitations, numerical results in [28] (e.g., Fig. 4 therein) indicate a very similar behavior between UMSE and MSE when changing the probe states while maintaining the other parameters , , fixed. Hence, UMSE is also a useful index evaluating the probe state set.
The second index we consider is, for a set of probe states, how robust the generated estimation result is w.r.t. measurement noise. Note that our CLS estimation (7) is in fact equivalent to the least squares estimation of the linear regression problem
| (10) |
Typically, the sensitivity of a linear system solution to perturbations in the data is evaluated by the condition number of the coefficient matrix, defined (among several possible choices) in this paper as , where is the maximum/minimum singular value of . Hence, to maximize the estimation robustness w.r.t. measurement noise amounts to minimizing the condition number in (10) . Therefore, the second evaluation index is chosen as . To sum up, the optimal probe states should minimize and minimize simultaneously. In the following we give specific characterization and show that the two optimal indices can be achieved simultaneously for several examples.
3.2 Optimal probe states
We now give the condition on optimal probe states (OPS).
Theorem 1.
For a -dimensional detector with matrices, assume each type of probe states has the same number of copies, altogether summed to copies. Then the minimum of UMSE is and the minimum of is . These minima are achieved simultaneously if and only if there exist different types of probe states such that is diagonal and its eigenvalues are and .
We assume that different types of probe states are used, since clearly is not optimal. Denote the eigenvalues of as . For minimizing UMSE, it can be formulated as
| min | (11) | |||
| s.t. |
For maximizing robustness, it can be formulated as
| min | (12) | |||
| s.t. |
The constraint comes from the purity requirement. For the parameterization of each probe state, we have
| (13) | ||||
Thus for the parameterization matrix of probe states, we have
| (14) | ||||
The second constraint is from the matrix element satisfying
| (15) |
in our chosen basis .
For (11) and (12), using Lagrange multiplier method as in [4], the minimum of is , achieved when and . Hence, the minimum of UMSE is
| (16) | ||||
which does not rely on the type number of probe states . The minimum of is because and . These minima can be achieved at the same time if and only if and .
Now, we show that is a diagonal matrix. Assume . For , we have
| (17) | ||||
where . Thus, and where is a dimensional orthogonal matrix. Therefore, we have
| (18) | ||||
which is a diagonal matrix.
Our results also show that the description of OPS in Assumption in [28] needs to be more precise. For certain , if there exist OPS, all of them must be pure states because from (14). This indicates that pure states are better than mixed states. However, it is not clear whether these OPS exist for arbitrary . Thus, whether we can always find a pure state set which is better than arbitrary mixed state set for given is still an open problem.
Remark 1.
In system identification, the similar problem called input design problem has been widely discussed. There are many existing results, e.g., D,A,E-optimal input design [38]. The common idea behind the problem of our optimal probe states and optimal input design is that both problems consider minimizing the trace of the covariance matrix, which is A-optimal input design [38]. The difference is that we also consider robustness and other physical eigenvalue constraints (e.g., purity) for probe states. Thus, we cannot directly adapt classical input design problem for the quantum case.
Remark 2.
If we only want to reach the minimum condition number without considering UMSE, we need to ensure which can be satisfied even for mixed states. For example, for a concentric sphere inside the Bloch sphere, we can also find the corresponding platonic solid on it which has the smallest condition number (this case will be discussed later). Therefore, if we only consider minimum condition number, we cannot obtain the minimum UMSE. However, if we only consider minimum UMSE, the eigenvalues also satisfy the requirement of minimum condition number. Hence, when we solve the optimization problem and analyze optimal probe states, it suffices to only consider minimum UMSE.
Remark 3.
In quantum state tomography, the condition number for the optimal measurement is , achieved by special measurement such as the optimal generalized Pauli operators [39]. However, in QDT, OPS need to satisfy the unit-trace constraint. Therefore, the largest eigenvalue must be equal to or larger than and the minimum condition number is .
Remark 4.
We consider two criteria for optimization–upper bound of the mean squared error (UMSE) and the robustness described by the condition number. For UMSE, we assume there only exists statistics error from finite state copies and the analytical upper bound depends on this assumption. If this assumption is not satisfied, the UMSE should be adjusted by adding the unmodeled noise (e.g., apparatus noise) to the error in (5). For robustness, condition number characterizes the sensitivity of the estimation result to errors in measurement data. Hence, this criterion is unrelated to the specific sources of the errors.
We then give two examples of OPS for and which are motivated by projection measurements.
The first example is motivated from SIC-POVM. To reconstruct an unknown quantum state , a generalized measurement must have at least linear independent elements, which is called informationally complete. Furthermore, if the measurement results are maximally independent, the POVM is called symmetric informationally complete POVM (SIC-POVM). The simplest mathematical definition of an SIC-POVM is a set of normalized vectors in satisfying [40]
| (19) |
It has been conjectured that SIC-POVMs exist for all dimensions [40] and their existence has been given for , and some other sporadic values [41]. When SIC-POVMs exist in dimension, we define the pure states to be SIC states if they satisfy (19).
Proposition 3.2.
-dimensional SIC states (when they exist) are a set of OPS with the smallest as .
Note that choosing different orthogonal bases does not change the inner product between vectors. Therefore, for parameterization of the SIC states, we have
| (20) |
and . We assume the standard singular value decomposition of is where is a diagonal matrix, and and are unitary matrices. According to (20), we have
| (21) |
Thus, and
| (22) | ||||
The largest eigenvalue of is and the other eigenvalues are , which satisfies Theorem 1. Therefore, SIC states are OPS. Also, among all -dimensional OPS, SIC states have the smallest as . If , it is not informationally complete, and the detector cannot be uniquely determined without other prior knowledge. The second example is motivated from MUB measurement. Two sets of orthogonal bases and are called mutually unbiased if and only if [42]
| (23) |
In particular, one can find maximally sets of mutually unbiased bases in Hilbert spaces of prime-power dimension with a prime and a positive integer [43]. When sets of MUB measurement exist in , we view each projective MUB measurement operator as a pure state and we call them MUB states. Thus, MUB states always exist for -qubit systems .
Proposition 3.3.
-dimensional MUB states (when they exist) are a set of OPS for .
For MUB states in (23), we have . For their parameterization, we have
| (24) |
We assume the standard singular value decomposition of is . Thus, we have
| (25) |
where denotes a matrix and all the elements are . We have
| (26) | ||||
where the largest eigenvalue is and the remaining eigenvalues are . They are OPS because their eigenvalues satisfy Theorem 1. For and , we leave it an open problem when there always exist OPS satisfying the two indices simultaneously. For two-qubit detectors, from the above results we know the optimal probe states can be constructed using -dimensional MUB states and SIC states as shown in Appendix A. A similar two-qubit problem for QST was discussed in [4] to determine the optimal measurement based on UMSE and in [39] based on condition number.
For one-qubit probe states, they have simple geometric property; i.e., they are in the Bloch sphere. The pure states are on the surface and the mixed states are inside the sphere. Hence, an alternative method to search for one-qubit OPS is based on geometric symmetry. For , when the probe states are on the surface of Bloch sphere and become the four vertices of a tetrahedron concentric with Bloch sphere, they are OPS. In fact, they are also SIC states. For , one can construct OPS similarly using octahedron, and they are also MUB states. We also have cube, icosahedron, dodecahedron for , respectively, which are OPS. We conjecture all one-qubit OPS are constructed from the five platonic solids on the Bloch sphere in this way, and we show there do not exist OPS for in Appendix B. For multi-qubit states, we still do not fully know the geometric property and it is thus an open problem to find other optimal probe states.
3.3 Product probe state
In experiment, product states are among the ones most straightforwardly to be implemented. In this subsection we consider the case for some integer and each probe state is an -qubit tensor product state as where and there are different types of one-qubits for the -th qubit of the product states. The total number of these -qubit tensor product states is thus . We then give their optimal UMSE and condition number.
Theorem 3.4.
The minimum UMSE of -qubit product probe state is and the minimum condition number is . These minima are achieved simultaneously if and only if each qubit is among optimal one-qubit states.
Assume the parameterization of all the -th single-qubit states is . We thus have
| (27) | ||||
and therefore,
| (28) |
where comes from for . Thus, the UMSE is . For condition number,
| (29) |
where comes from for . We can reach these minima if and only if for each , is an OPS set.
Here we compare the two criteria–UMSE and condition number between OPS and optimal product states for an -qubit detector with the dimension . The UMSEs are for OPS and for optimal product states. UMSE of optimal probe states is always smaller than that of optimal product states for . For , they are both . For condition number, it is for OPS and for optimal product states. Thus, for both UMSE and condition number, OPS play better than optimal product states in multi-qubit systems. Because most of the OPS are entangled states, this is an example showcasing the advantage of entanglement in QDT.
We give an example of two-qubit product probe states. Let the parameterization of the -th two-qubit product probe state be
| (30) |
where is the parameterization of the -th qubit of . Since optimal one-qubit probe states are pure states, . Denote the eigenvalues of as . We can obtain three constraints as
| (31) |
| (32) |
| (33) | ||||
Thus, the optimization problem is
| min | (34) | |||
| s.t. | ||||
It can be proven that reaches its minimum and the minimum UMSE is when , . It can be verified that this minimum UMSE can be reached by using the tensor of platonic solid states such as (Cube). The minimum condition number is .
3.4 Superposition of coherent probe state
In quantum optics experiments, the preparation of number states (or Fock states) is usually a difficult task, especially when is large. Therefore, it is also difficult to prepare SIC and MUB states. Coherent states, more straightforward to be prepared, are more commonly used as probe states for QDT in practice. Thus, a good approach is to use the superposition of several coherent states to approximate SIC states and MUB states.
A coherent state is denoted as where and it can be expanded using number states as
| (35) |
The inner product relationship between two states and is
| (36) |
Let . Coherent states are in essence infinite dimensional. To estimate a -dimensional detector, we employ as the approximate description of , and we assume that the discarded part has a small enough influence such that it can be neglected. A matrix or vector with subscript means it is truncated in dimension.
Remark 5.
It can lead to significant error to approximate a general pure state using only one coherent state instead of the superposition of many. This problem is often referred to as the nonclassicality of states. As an example, we now consider a Fock state . The infidelity is
The minimum infidelity is obtained by and for , the minimum infidelity is , respectively. Thus, the distance between one Fock state and one coherent state may be quite large. This also shows that the Fock state becomes more and more non-classical as the value increases [44].
In quantum state engineering, a central problem is how to construct a pure state by superposition of coherent states. There are two main approaches to do this. One is to write the pure state as a superposition of coherent states along the real axis in phase space
| (37) |
where is the distribution function. The other choice is the superposition on a circle
| (38) |
where is the radius of the circle and a circle distribution function. The analytical solutions of and were given in [45]. They also gave the discrete superposition of coherent states to construct pure states by discretizing the above equations. Ref. [46] evaluated the performance to construct squeezed displaced number states and [45] gave a representation of a Fock state by coherent states. If we can construct all Fock states with high accuracy, we can use these Fock states to construct all the ideal pure states we need. However, in practice, the technique to superpose many coherent states arbitrarily is still developing.
In this paper, we use the finite superposition of coherent states to approximate an ideal pure state where indicates that it has not been normalized. Hence, is not yet a quantum state in the most strict sense. To find the superposition state , at first sight it can be formulated as an optimization problem to maximize fidelity as
| (39) |
Since the fidelity is . However, for the purpose of QDT, this cost function is not the most suitable. The most important part of the superposed state is its direction. We hope to align it in the same direction as , even if the norm can be different from . Hence, we need the normalized state to be a good approximation to , which thus leads to the numerator of (40). Also, if is too small, we cannot neglect elements in the dimension larger than and the corresponding measurement data will be small, leading to low measurement accuracy for given the same resource number . Therefore, we add a penalty to prevent the norm from being too small. Thus, we design a new cost function as
| (40) |
This optimization problem is usually non-convex, and thus we select different initial points and numerically search for the best solution.
3.5 Error analysis for state preparation
When we prepare probe states such SIC states and MUB states in experiment, there usually exist state preparation errors. For example, if we use superposition of coherent states, there exists approximation error between the ideal target probe state and the superposition of coherent states when the number of coherent states for superposition is not large enough. We give the error analysis on UMSE and condition number when there exists state preparation error.
Theorem 3.5.
Given two probe state sets and , if and , the corresponding error in is upper bounded by where is the smallest eigenvalue of the parameterization matrix and the corresponding error on condition number is upper bounded by where is the largest eigenvalue of .
See Appendix C.
4 Adaptive detector tomography
As shown in Fig. 1, after employing partial resources to obtain a rough estimate of the detector through Step 1, one can design new probe states dependent on the specific estimation value of the detector to further improve the accuracy in Step 2. Our adaptive QDT scheme is applicable for arbitrary reconstruction algorithm.
4.1 Evaluation index
In quantum information, fidelity (or infidelity) has profound physical meaning to characterize the distance and similarity between two quantum states (or operations). It has been a widely used metric [2, 47, 48]. In developing adaptive QDT, we also employ infidelity as the evaluation index.
The fidelity between two arbitrary states and is defined by
| (41) |
which has three basic properties:
| (42) |
| (43) |
| (44) |
To extend the fidelity definition from states to detectors, a natural idea is to normalize the POVM element such that it has the same mathematical property as a quantum state. This leads to the definition
| (45) |
This definition has been widely used in QDT [21, 22, 27] to evaluate the estimation performance, and corresponding infidelity is defined as . However, we find that this definition is not always appropriate, because in certain circumstances the third property (44) dose not hold for (45) (we call this phenomenon distortion). More specifically, for certain detector , distortion means there exists such that for all while fails for at least one . For example, suppose the detector is and the estimations are , , where , and are three arbitrary positive numbers satisfying . The fidelities for the three detectors are all maximum , but the estimation is in fact usually not accurate. We characterize when the evaluation index (45) will distort in the following proposition, and present its proof in Appendix D.
Proposition 4.6.
The evaluation index (45) will distort if and only if are linearly dependent, i.e., there exists nonzero such that . Specially, if , there must exist distortion.
When distortion happens, fails. That is, the estimation can be on a wrong track even if the fidelity approaches to 1. To fix this problem, we add and propose a new detector fidelity as
| (46) | ||||
The fidelity (46) takes values in and we give the proof of the lower bound in Appendix E. When , we must have (and vice versa), solving the distortion problem of (45). For the rest of this paper, we refer to “fidelity” as (46), unless otherwise declared. The infidelity is defined as .
4.2 Two-step adaptive quantum detector tomography
Let be the eigenvectors of for given , where the zero eigenvalues are . We can view and as two quantum states. Thus, we may use the analysis in [37] to obtain the Taylor series expansion of the new infidelity based on (46) up to the second order as
| (47) | ||||
where . Crucially, the new term is in the second order instead of in the first order, and we can thus imitate the analysis for QST in [37]. Note that we use a perturbation method thus (47) is valid only around . The condition can be guaranteed because we are analyzing the asymptotic behavior as tends to infinity (large enough).
According to the Taylor series, the scaling performance of the infidelity depends on the rank of the detector. For instance, for a full-rank POVM element, the first-order term vanishes and the infidelity scales as using just non-adaptive QDT. For a rank deficient , the first-order term dominates and thus the infidelity scales as by QDT which only has Step 1 in Fig. 1. The optimal scaling of infidelity is for unbiased estimate in QST [49] and the optimal scaling of is always not worse than . Thus, the optimal scaling of infidelity or is also . From [37], we know the second-order terms always scale as . Therefore, for rank-deficient detectors, the behavior of the infidelity can be corrected to if one can eliminate the influence of the first-order term [37]. This depends on the diagonal coefficients of in the kernel of , which suggests performing QDT in a basis aligning with the eigenvectors of [37].
The detailed adaptive procedure is as follows. To simplify the expression, we use to represent each POVM element . For , given a probe state set , we choose one among them (e.g., ) and its spectral decomposition is . The spectral decomposition of is . To perform QDT in a basis that agrees with the eigenvectors of [37], we change each probe state to by a common conjugation as
| (48) |
However, in practice, we do not know . Therefore, we have two steps as shown in Fig. 1. In Step 1, we obtain an estimator by applying non-adaptive QDT on an ensemble of size . Then in Step 2, we use new probe states as
| (49) |
for an ensemble of size , where . For each POVM element, we need to repeat the above procedure.
Furthermore, to guarantee that the infidelity scaling is improved to , one needs to carefully choose the probe states. Before showcasing how to do this, we first introduce several basic definitions. For a -dimensional Hermitian space, we define bases consisting of the following elements,
| (50) |
| (51) |
| (52) |
where the set is an arbitrary orthogonal basis. Note that all the operators are orthogonal w.r.t. the inner product . For a given basis , denote as the set of all finite real linear combinations of . If , we say and are equivalent. If the span of the probe state set contains all -dimensional Hermitian matrices and , we say the probe state set is complete. If we further have , we say it is over-complete.
In this section, we assume the true value of a rank POVM element is , the Step 1 estimation is and the Step 2 estimation is . The spectral decomposition of is where , . In (50)-(52), if we change to for , we call this new basis ideal bases. If we change to with restricted in , we call the set of these new elements as the null bases of . If we change to with restricted in , we call the set of these new elements as the range bases of . After Step 1, we obtain an estimate and the spectral decomposition is . If we change to for , we call this new basis estimated bases. If we change to with restricted in , we call the set of these new elements estimated null bases.
Then we give the following theorem as a guideline to design the probe state set.
Theorem 4.7.
For two-step adaptive QDT using arbitrary reconstruction algorithm with an scaling for the MSE, suppose the resource number is in Step 1 and in Step 2, both evenly distributed for each probe state. The infidelity of any rank-deficient POVM element scales as if
-
c1)
the probe states in Step 1 are complete or over-complete;
-
c2)
the probe states in Step 2 are complete or over-complete;
-
c3)
the probe state set in Step 2 includes a subset equivalent to the estimated null basis from Step 1.
From Condition c1), we obtain a rank estimation and the spectral decomposition is where , . Thereby, the inner product between the eigenvectors of and their estimates obtained from [37] is
| (53) | ||||
In the estimated basis , the true value matrix can be uniquely represented as
| (54) |
Then in Step 2, according to Conditions c2) and c3), we can obtain an estimate
| (55) |
For Step 2 estimation, the first-order term is
| (56) | ||||
Then we show the first-order term scales as
| (57) |
and the detailed calculation can be found in Appendix F.
Note that the estimated null bases are not probe states. Hence, we cannot directly use them. We need to use the linear combinations of these estimated null bases to construct quantum states. According to Condition c3), the probe state set includes a subset equivalent to the estimated null bases . We assume the practical measurement results are and the ideal measurement results are for these probe states. For , the measurement results are used to estimate the null bases of , and for the other measurement results, they are used to estimate the range bases of . Even though we do not know ideal measurement results , we can still use them like (F.98) and (F.99) because we focus on infidelity. Using the linear combinations of , we can obtain and for for certain real numbers and . The relation (F.99) also holds because . Then we assume for certain real numbers . From condition c3), are linear combinations of the estimated null bases , and thus . Hence, like (F.101), we have
| (58) | ||||
Therefore, using probe states satisfying Conditions c1)-c3), the first-order term scales as
| (59) |
Finally, the second-order term scales as
| (60) | ||||
We have the following corollary if we use GPB (generalized Pauli basis) states shown in (A.70)–(A.72) in Step 2,
Corollary 4.8.
For a POVM element , using GPB states in Step 2, the infidelity reaches the optimal scaling if for certain .
The proof is straightforward. If the POVM element is full rank, it does not have first-order term and the infidelity scales as . If is rank deficient with an unknown rank , GPB states always satisfy Conditions c1)-c3) and thus the infidelity still scales as by choosing for certain . Because GPB states are effective for all cases, we will show their performance in Numerical Examples (Section 5).
We may use three methods to further make the estimation from Step 1 more accurate if the rank is not precise. The first one is to use Corollary 4.8. We use GPB states which always span the null basis. The second one is the possible scenario where we know the rank value from prior information. The third method is, from the rough estimation of Step 1, we may know an exact rank interval of the to-be-estimated POVM element. Since we know the upper bound of the estimated error as (9) here, we thus know the variation range of all the eigenvalues from Lemma Appendix C.9. Assume the rank interval is where , and is the unknown rank. The more accurate is the estimation result from Step 1, the smaller is the interval length . Then to ensure the infidelity scaling is , a conservative method is to add quantum states spanning the estimated null basis .
Remark 6.
The key in proving Theorem 4.7 is to characterize the first-order term in (56), which is unaffected by the added term comparing (46) with (45). Hence, when (45) holds without distortion (see Proposition 4.6), one can still use (45) as the definition of fidelity, and GPB states still reach scaling for the infidelity.
The choice of plays a key role in the performance of the two-step adaptive QDT. In this paper, we choose and the infidelity scales as . Note that the infidelity behavior for different detector matrices can be different, even for binary detectors. For example, if for certain unitary and , ’s eigenvalues are . Since has one zero eigenvalue, the infidelity reaches by non-adaptive QDT. However, if , ’s eigenvalues are . Since has no zero eigenvalues, the infidelity can reach by non-adaptive QDT. Therefore, for a complete characterization and analysis, we need to calculate the infidelity for every POVM element.
5 Numerical Examples
Both the non-adaptive and adaptive QDT protocols need to prepare certain (in this paper pure) states (we call them ideal states) as the probe states, which can be difficult to achieve in practice. As stated in Sec. 3.4, a realistic way in quantum optics experiments is to use the superposition of coherent states to approximate the ideal states. In this section we demonstrate the performance of our optimal and adaptive protocols both using ideal probe states and using superposed coherent probe states. We use the two-stage QDT reconstruction algorithm for numerical simulations.
5.1 Optimal detector tomography
TABLE I. Comparison of various four-dimensional QDT protocols. Protocol Probe states Number() Eqs or Ref 1 SIC 16 (A.68) 2 MUB 20 (A.67) 3 36 (A.69) 4 GPB 16 (A.70),(A.71),(A.72) 5 Random Pure 32 [50, 51] 6 1-coherent SIC 16 (40) 7 1-coherent MUB 20 (40) 8 1-coherent Random 32 [28] 9 2-coherent SIC 16 (40) 10 2-coherent MUB 20 (40) 11 2-coherent Random 32 [28] 12 3-coherent SIC 16 (40) 13 3-coherent MUB 20 (40) 14 3-coherent Random 32 [28]
-
*
This is the optimal value.
-
**
Cube states are product probe states.
For non-adaptive QDT in systems, we test different protocols using different probe states in Table I. In protocols 1-5, we compare and condition numbers of ideal pure states such as MUB, Cube, SIC, GPB probe states which are constructed as in Appendix A. “Cube” states here are product states of one-qubit MUB states, assuming that the system here is the composition of two systems. GPB states are shown in (A.70)–(A.72), similar to the optimal measurement-generalized Pauli operators in [39]. “Random Pure” means that we generate random pure states using the algorithm in [50, 51] where and condition number are obtained by the average of results. We find SIC states and MUB states have the minimum value of as and minimum condition number as , satisfying Theorem 1. For two-qubit product states–Cube states which are easier to generate in experiment, the values of UMSE and conidtion number are and , respectively, a little larger than the optimal values and satisfying Theorem 3.4.
In protocols 6-14, we use superposition of coherent states (denoted as -coherent SIC/MUB) to approximate the four-dimensional SIC and MUB states by solving the optimization problem (40). The case of is using one coherent state without superposition. As a comparison, we also add the protocols of using the superposition of random coherent states (denoted as -coherent Random). The random algorithm is the same as the coherent states preparation procedure in [28]. The optimization landscape might have local minima. Therefore, we run the optimization algorithm with different initial values and choose the best result.
We find for one coherent state, it cannot approximate SIC and MUB states well and both the condition number and UMSE are large. For the superposition of two and three coherent states, they can approximate SIC and MUB states well and the corresponding condition number and UMSE are close to the optimal values, and smaller than 2,3-coherent Random protocols. Also, with increasing, the superposition result becomes close to ideal probe states and thus the UMSE and condition number decrease.
5.2 Adaptive QDT using ideal probe states
5.2.1 Binary detectors
For binary detectors , and can be simultaneously diagonalized by a common unitary [29]. Hence, the eigenvalues of will affect the eigenvalues of . This determines the rank of , which will further influence the scaling of non-adaptive tomography. Let
| (61) |
With non-adaptive tomography, when , is full-ranked and the infidelity of estimating scales as , while for , is rank-deficient and the infidelity of estimating scales as .
Therefore, we firstly consider a binary detector for where
| (62) |
This detector is fully specified by the projection measurement . The matrix is randomly generated using the algorithm in [50, 52]. For each resource number, we run the algorithm times and obtain the average infidelity and standard deviation.
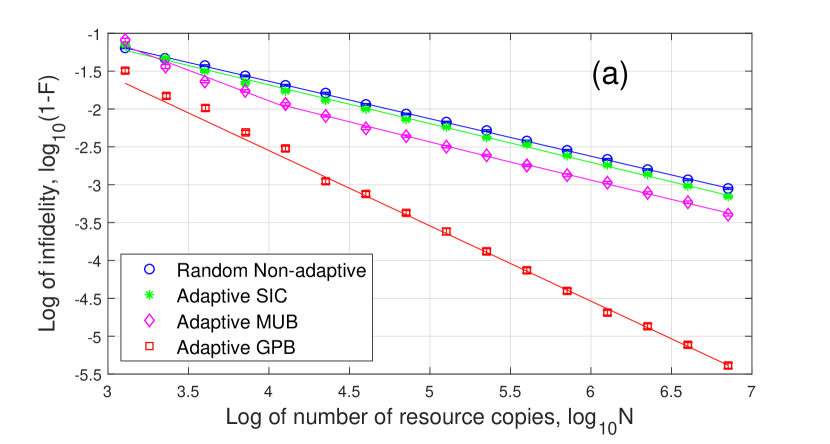
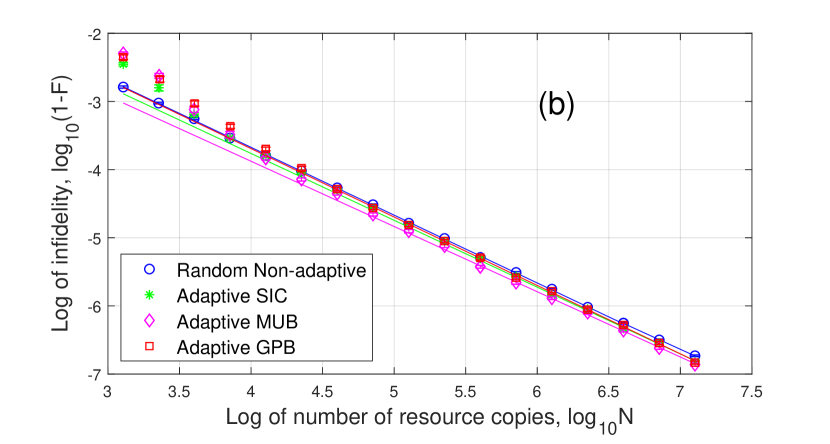
The four curves in Fig. 2 are as follows:
As shown in Fig. 2, Random Non-adaptive tomography only reaches for both and because they both have zero eigenvalues and the first-order term scales as . Adaptive GPB tomography can reach for and as proved in Corollary 4.8. For adaptive SIC and MUB tomography, they can only reach for probably because adaptive SIC and MUB states do not have a subset equivalent to the estimated null bases and does not satisfy Condition c3) in Theorem 4.7. They can reach for because adaptive SIC and MUB states have a subset equivalent to the estimated null basis and satisfy Condition c3).
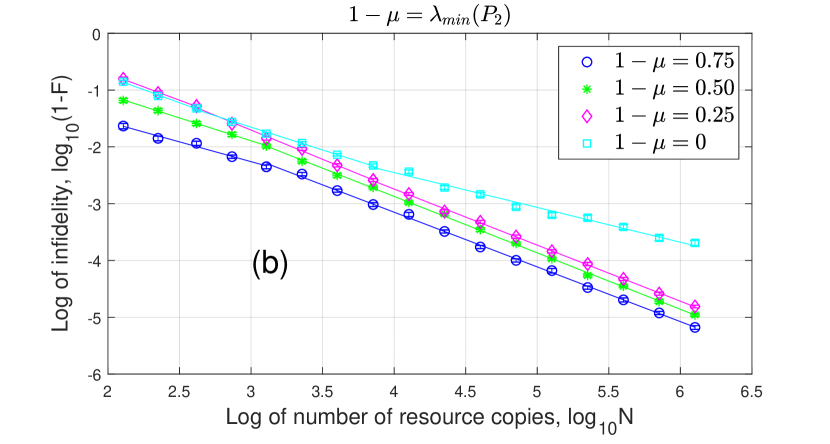
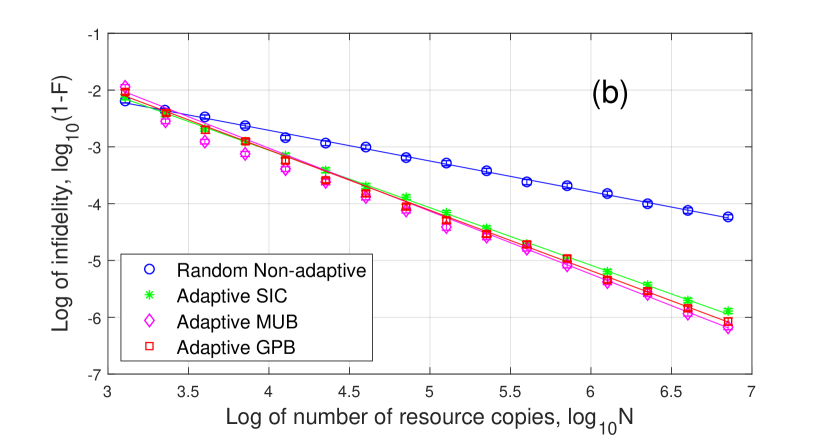
Then we show infidelity for non-adaptive tomography with different eigenvalues in (61) of binary detectors in Fig. 3. For each resource number, we run the algorithm times and obtain the average infidelity and the standard deviation. Because is always rank deficient, the infidelity for scales as . As increases, the measurement accuracy increases and thus the infidelity of becomes smaller for a given . Because is full rank for , its infidelity scales as . In addition, the infidelity of becomes larger as increases for a given . When increases to , both the infidelities of and scale as because they are both rank deficient.
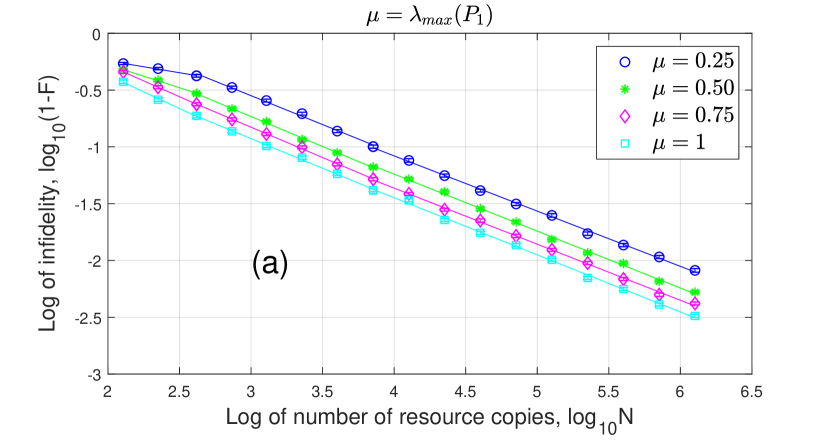
To test the robustness of our adaptive protocol, we perform adaptive QDT on random binary detectors in the form of (62) by changing the unitary matrix which is randomly created using the algorithm in [50, 52]. For each , we run our tomography algorithm times and obtain the mean infidelities for given resource number . Then we calculate the mean values and the standard deviations of these mean infidelities. The result is shown in Fig. 4. It is clear that Adaptive GPB tomography can reach for and . In addition, all the standard deviations are small, which demonstrates that our Adaptive GPB protocol is robust.
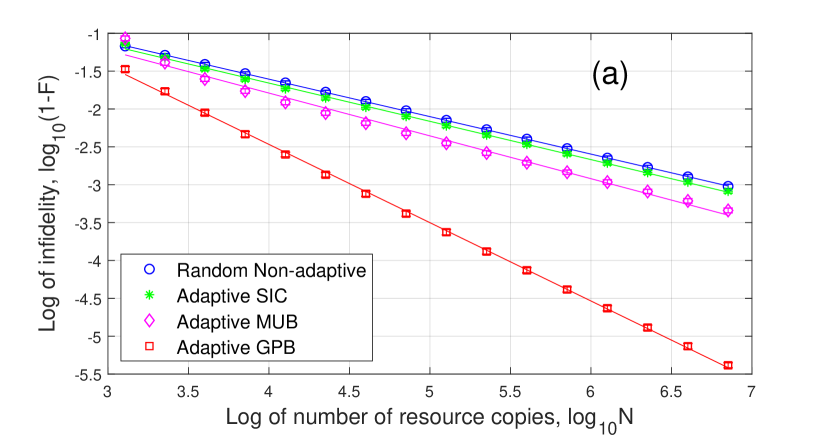
We then consider the case that is a perturbed projection measurement,
| (63) | ||||
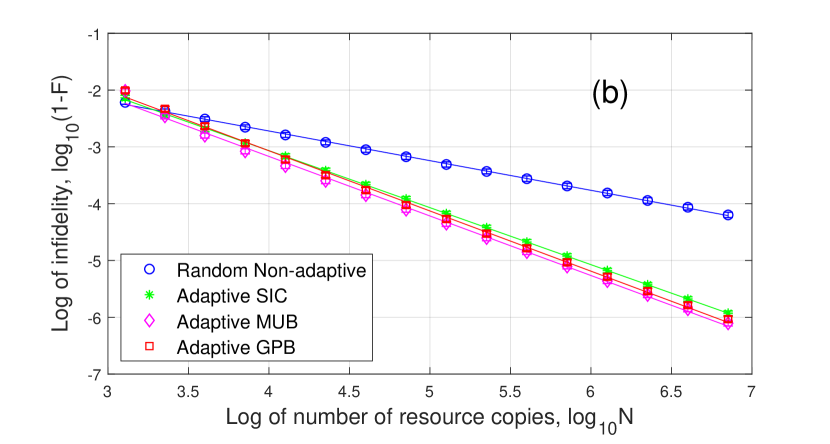
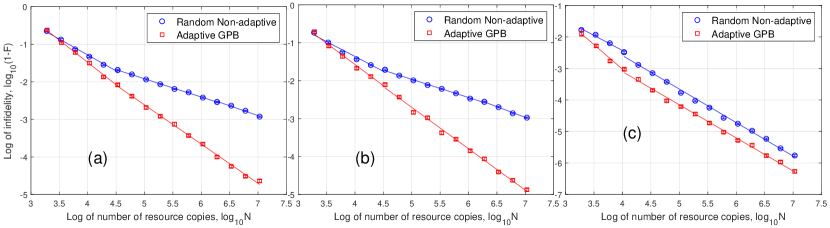
The tomography errors are shown in Fig. 5. From Fig. 5(a), we can see that the curves of adaptive QDT can be roughly divided into three segments from left to right for the detector , which is similar to the phenomenon in QST [36]. In the first segment, the resource number is not large enough () and the near-zero eigenvalues are not strong enough to make a difference from zero. The performance is thus the same as projection measurement. Hence, the infidelity decreases as firstly. When the resource number increases (), the near-zero eigenvalues start to take effect. We cannot distinguish them from zero accurately and thus the infidelity scales as . Finally, when the resource number is large enough () to clearly distinguish between the near-zero eigenvalues and zero, we are performing full rank detector tomography actually, which has decay rate for infidelity. For Random Non-adaptive tomography, it can be divided into two segments. When the resource number is not enough () to estimate the near-zero eigenvalues accurately, the infidelity decreases as . When the resource number is large enough () to clearly distinguish between the near-zero eigenvalues and zero, the infidelity scales as . Overall, the Adaptive GPB tomography is the best among these methods.
For detector , all the eigenvalues are significantly larger than zero, and is full-rank. Hence, the infidelity decreases as for both non-adaptive and adaptive tomography.
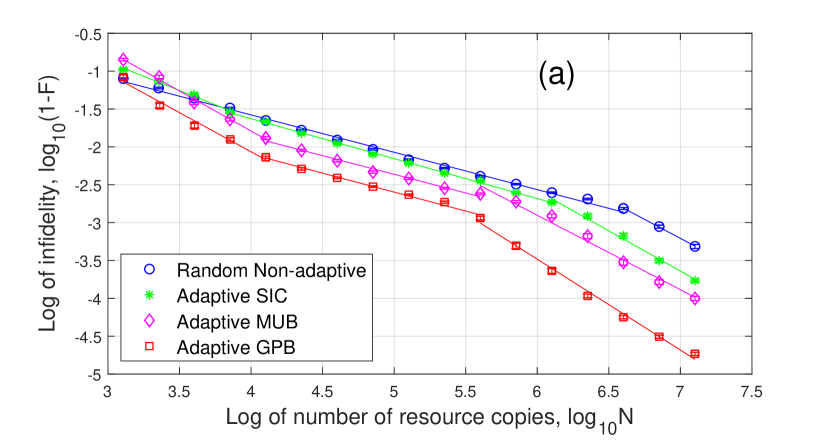
5.2.2 Three-valued detectors
Three-valued detectors is different from binary detectors because three-valued detector matrices generally cannot be diagonalized by the same unitary matrix like binary detectors. We consider a three-valued detector as
| (64) | ||||
This detector is constructed from two-qubit MUB measurement (see Appendix A). The first detector is from where we product a coefficient and conjugate a unitary rotation . In a similar way, is from where we product a coefficient and conjugate a unitary rotation . We can prove that is always positive semidefinite. The unitary rotations and are generated by the random unitary algorithm in [50, 52]. For each resource number, we run the algorithm times and obtain the average infidelity and standard deviation.
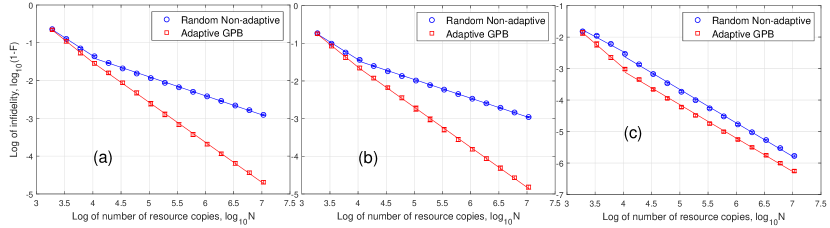
We focus on the comparison between Adaptive GPB tomography and Random Non-adaptive tomography. The simulation result is in Fig. 6 where our adaptive tomography can reach for and as proved in Corollary 4.8, improving the scaling of non-adaptive tomography. For , all the eigenvalues are far from zero and both tomography methods can reach . We also test robustness by performing adaptive QDT on random three-valued detectors in the form of (64) by changing unitary matrices and , which is similar as binary detectors. The result is shown in Fig. 7. For and , the adaptive tomography is robust (with small standard deviation) and their infidelities can reach . For full rank , both tomography methods can reach .
Then we consider that and have three small eigenvalues as
| (65) | ||||
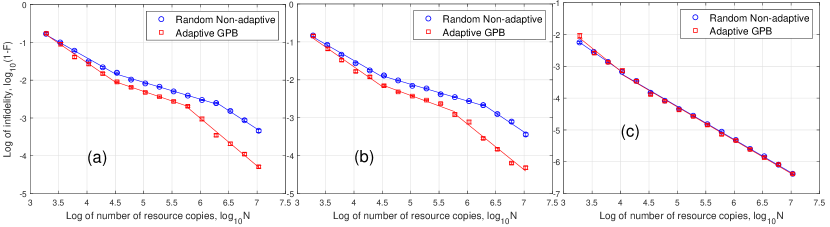
The results for and can also be divided into three segments as shown in Fig. 8 and we have explained for binary detectors. For , all the eigenvalues are far from zero and hence, both tomography can reach .
5.3 Adaptive QDT using coherent states
Since the adaptive GPB states can improve the infidelity for all detectors if they have zero or near-zero eigenvalues, in this part, we use the superposition of coherent states to approximate the ideal adaptive GPB states. We consider binary detectors as (62). We use -coherent states as shown in Fig. 9 where .
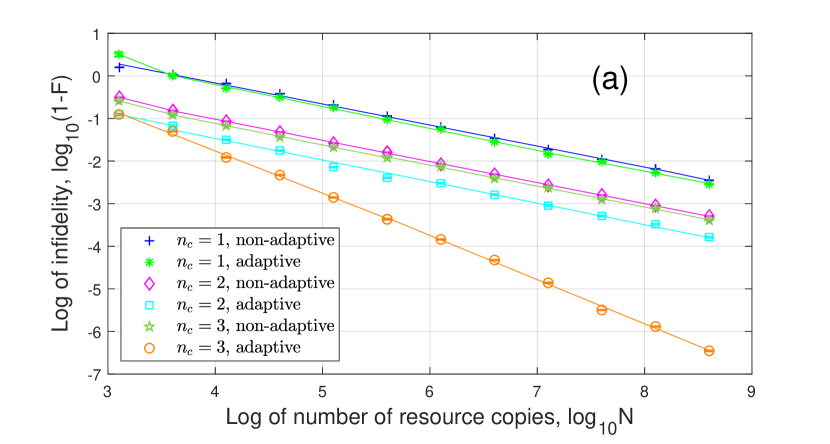
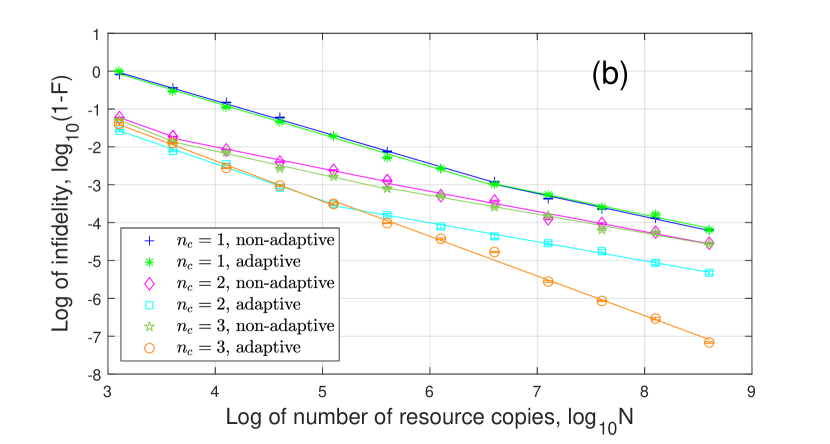
For given , the adaptive tomography performance is usually better than non-adaptive one. As increases, the approximation error decreases. When the resource number is not large enough to distinguish the approximation error, the infidelity scales close to , like , adaptive for in Fig. 9(b) when . When , the infidelity scales to because of the approximation error.
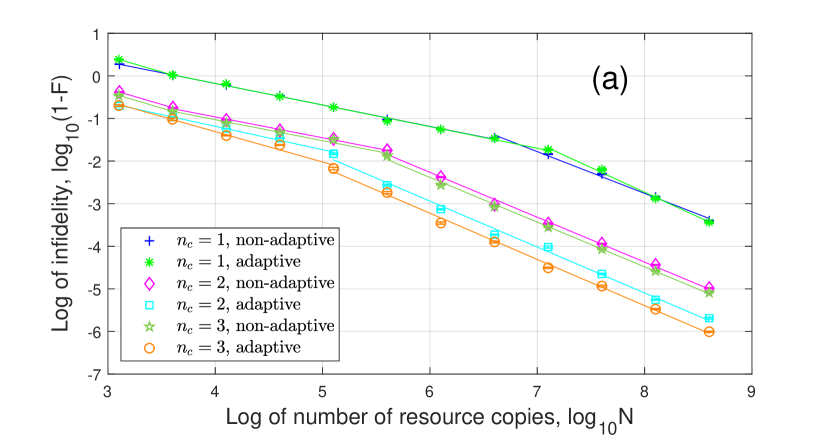
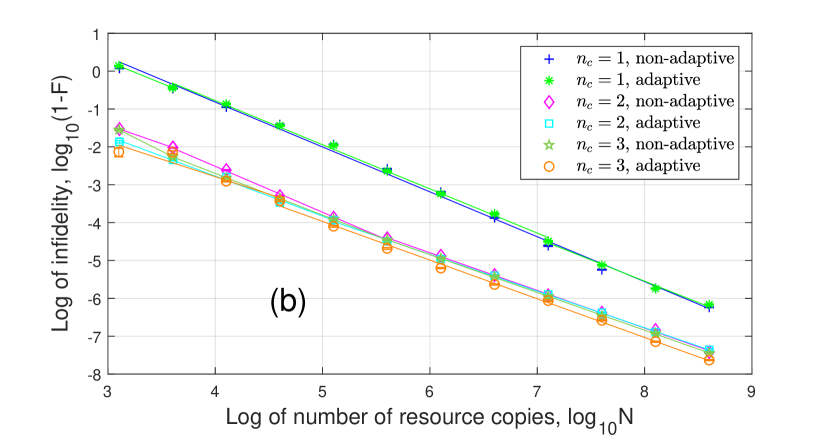
For , all the curves can be roughly divided into two segments. For 1-coherent state, the infidelity scales as when and scales as when . For 2,3-coherent states, the infidelity scales as when and scales as when . This result is similar to Fig. 5 without the first segment. For , the infidelity scales as because all the eigenvalues are significantly larger than zero.
6 Conclusion
In this paper we have investigated how to optimize the probe states in quantum detector tomography. We have characterized the optimal probe state sets based on minimizing the UMSE and minimizing the condition number. We have proven that SIC and MUB states are optimal. In the adaptive scenario we have proposed a two-step strategy to adaptively optimize the probe states, and proven that our strategy can improve the modified infidelity from to under certain conditions. Numerical examples were presented to demonstrate the effectiveness of our strategies.
Y. Wang would like to thank Prof. Howard M. Wiseman for the helpful discussion. We thank the anonymous referees and the Associate Editor for the constructive comments.
Appendix Appendix A Several two-qubit measurements and the induced probe states
Five MUB measurement sets for two-qubit quantum states [42] are
| (A.66) |
and
| (A.67) | ||||
where , , and . This protocol was applied in the QST experiment in [42]. In this paper, is a projection measurement and is called a MUB state.
For two-qubit SIC POVM, one expression [53], ignoring overall phases and normalization, is
| (A.68) |
where and is the -th column of (A.68). In this paper, the set of consists of SIC states.
For Cube measurement [54], it is based on the projections onto all the 36 tensor products of the eigenstates of the standard single-qubit Pauli operators
| (A.69) |
In this paper, is a Cube state which is a product state of two single-qubit MUB states.
For GPB (generalized Pauli basis) states, they are
| (A.70) |
where and
| (A.71) |
| (A.72) |
where . The set of states with is an arbitrary orthonormal basis. The total number of these states is . To generate new GPB states in Step 2 of adaptive QDT, we replace the set by which are the eigenvectors of Step 1 estimation.
Appendix Appendix B Optimal one-qubit states
For one-qubit state, we can expand them in Pauli matrices as
| (B.73) |
where . The parameterization for one-qubit states are
| (B.74) |
If these states are OPS, by Theorem 1, we have
| (B.75) |
| (B.76) |
| (B.77) |
and
| (B.78) |
We conjecture that real solutions exists for these equations (i.e., OPS exist) if and only if and , corresponding to the five platonic solids on the Bloch sphere. We prove this is true for .
For , if there exist OPS, then we construct a parameterization matrix of probe states as
| (B.79) |
where the columns of are orthogonal to each other and their 2-norm is all . The 2-norm of each row of is . Using Gram-Schmidt process, there must exist a vector such that is an orthogonal matrix. By considering its row-norm, we know each element of squares to , and thus is either or . However, such can never be orthogonal to the first column of , contradicting the fact that is an orthogonal matrix. Thus, there do not exist OPS for .
Appendix Appendix C Proof of Theorem 3.5
a) Preliminary calculations
The parameterization error in one probe state is
| (C.80) |
Hence, the total parameterization error in is
| (C.81) |
For the error in , we thus have
| (C.82) |
where and similarly .
b) Error in the UMSE
We introduce Weyl’s perturbation theorem, which can be found in [55],
Lemma Appendix C.9.
[55] Let be Hermitian matrices with eigenvalues and , respectively. Then
| (C.83) |
Lemma Appendix C.9 was for the operator norm, not larger than its Frobenius norm for any finite dimension square matrix [55]. Therefore, it also holds for the Frobenius norm. Suppose the eigenvalues of are and the eigenvalues of are . Thus, using Lemma Appendix C.9, we have
| (C.84) |
and therefore,
| (C.85) |
For UMSE, we have
| (C.86) |
because for .
c) Error in the condition number
For condition number, we have
| (C.88) | ||||
Appendix Appendix D On the distortion of in (45)
According to the definition, distortion happens when there exists such that for all , which means for all . This indicates that the vector and are different. Note that and . Hence, the following linear equation
| (D.89) |
has at least two different solutions and . Therefore, , and thus are linearly dependent.
Conversely, if are linearly dependent, (D.89) will have non-trivial homogeneous general solutions, among which we randomly pick a non-zero solution . Since (D.89) already has a trivial solution , we choose small enough, such that has all the elements strictly positive. Hence, is another set of positive numbers not equal to such that . Let the estimation be , and distortion happens.
Notice that there are real degrees of freedom in , and hence the row rank of LHS of (D.89) is at most . If , we must have and there must exist distortion.
Appendix Appendix E Lower bound of the new fidelity (46)
We show a tight lower bound of our new fidelity (46) as . One can arbitrarily approximate this lower bound but cannot reach it.
We assume that the spectral decomposition of and are where , and where , . Define . According to Theorem 2.1 in [56], we have
| (E.90) |
Therefore,
| (E.91) |
and we only need to consider the lower bound of . We have
| (E.92) | ||||
If , we have
| (E.93) | ||||
where the last inequality can be obtained by analyzing the derivative on . Similarly, if , we have
| (E.94) |
The minimum is achieved if and only if one of and is an identity matrix and the other is a zero matrix, which cannot happen in practice. Hence, cannot be achieved. Finally, consider for example and where . Then as tends to zero, can be arbitrarily close to . Hence, is a tight but unattainable lower bound.
Appendix Appendix F Detailed calculation of the first-order term in infidelity
Firstly, we analyze the error between real coefficients and estimated coefficients .
Using a reconstruction algorithm whose MSE scales as such as two-stage QDT reconstruction algorithm in [28] and MLE in [18], the mean squared error from Step 2 for the detector is bounded by , and thus
| (F.95) | ||||
Therefore, the errors between real coefficients and estimated coefficients all scale as . Also,
| (F.96) |
and thus,
| (F.97) | ||||
Similarly, and
.
Therefore, the total error for the first term in RHS of (56) scales as . Similarly, the same scaling holds for the second term in RHS of (56).
Finally, we calculate the third term in RHS of (56) and also divide it into two cases. For the first case, we consider and have
| (F.100) | ||||
References
- [1] D. P. DiVincenzo, “Quantum computation,” Science, vol. 270, no. 5234, pp. 255–261, 1995.
- [2] M. A. Nielsen and I. L. Chuang, Quantum Computation and Quantum Information. Cambridge University Press, 2010.
- [3] C. L. Degen, F. Reinhard, and P. Cappellaro, “Quantum sensing,” Review of Modern Physics, vol. 89, p. 035002, 2017.
- [4] B. Qi, Z. Hou, L. Li, D. Dong, G.-Y. Xiang, and G.-C. Guo, “Quantum state tomography via linear regression estimation,” Scientific Reports, vol. 3, no. 1, pp. 1–6, 2013.
- [5] Z. Hou, H. S. Zhong, Y. Tian, D. Dong, B. Qi, L. Li, Y. Wang, F. Nori, G.-Y. Xiang, C.-F. Li, and G.-C. Guo, “Full reconstruction of a 14-qubit state within four hours,” New Journal of Physics, vol. 18, no. 8, p. 083036, 2016.
- [6] B. Mu, H. Qi, I. R. Petersen, and G. Shi, “Quantum tomography by regularized linear regressions,” Automatica, vol. 114, p. 108837, 2020.
- [7] Y. Wang, Q. Yin, D. Dong, B. Qi, I. R. Petersen, Z. Hou, H. Yonezawa, and G.-Y. Xiang, “Quantum gate identification: Error analysis, numerical results and optical experiment,” Automatica, vol. 101, pp. 269 – 279, 2019.
- [8] J. Fiurášek and Z. Hradil, “Maximum-likelihood estimation of quantum processes,” Physical Review A, vol. 63, p. 020101, 2001.
- [9] Q. Yu, D. Dong, Y. Wang, and I. R. Petersen, “Adaptive quantum process tomography via linear regression estimation,” in Proc. of 2020 IEEE International Conference on Systems, Man, and Cybernetics, pp. 4173–4178, 2020.
- [10] Q. Yu, Y. Wang, D. Dong, and I. R. Petersen, “On the capability of a class of quantum sensors,” Automatica, vol. 129, p. 109612, 2021.
- [11] S. Xiao, S. Xue, D. Dong, and J. Zhang, “Identification of time-varying decoherence rates for open quantum systems,” IEEE Transactions on Quantum Engineering, vol. 2, pp. 1–12, 2021.
- [12] Y. Wang, D. Dong, B. Qi, J. Zhang, I. R. Petersen, and H. Yonezawa, “A quantum Hamiltonian identification algorithm: Computational complexity and error analysis,” IEEE Transactions on Automatic Control, vol. 63, no. 5, pp. 1388–1403, 2018.
- [13] Y. Wang, D. Dong, A. Sone, I. R. Petersen, H. Yonezawa, and P. Cappellaro, “Quantum Hamiltonian identifiability via a similarity transformation approach and beyond,” IEEE Transactions on Automatic Control, vol. 65, no. 11, pp. 4632–4647, 2020.
- [14] J. Zhang and M. Sarovar, “Quantum Hamiltonian identification from measurement time traces,” Physical Review Letters, vol. 113, p. 080401, 2014.
- [15] A. Sone and P. Cappellaro, “Hamiltonian identifiability assisted by a single-probe measurement,” Physical Review A, vol. 95, p. 022335, 2017.
- [16] J. Zhang and M. Sarovar, “Identification of open quantum systems from observable time traces,” Physical Review A, vol. 91, no. 5, p. 052121, 2015.
- [17] A. Sone and P. Cappellaro, “Exact dimension estimation of interacting qubit systems assisted by a single quantum probe,” Physical Review A, vol. 96, p. 062334, 2017.
- [18] J. Fiurášek, “Maximum-likelihood estimation of quantum measurement,” Physical Review A, vol. 64, p. 024102, 2001.
- [19] S. Grandi, A. Zavatta, M. Bellini, and M. G. A. Paris, “Experimental quantum tomography of a homodyne detector,” New Journal of Physics, vol. 19, no. 5, p. 053015, 2017.
- [20] J. J. Renema, G. Frucci, Z. Zhou, F. Mattioli, A. Gaggero, R. Leoni, M. J. A. de Dood, A. Fiore, and M. P. van Exter, “Modified detector tomography technique applied to a superconducting multiphoton nanodetector,” Optics Express, vol. 20, no. 3, pp. 2806–2813, 2012.
- [21] A. Feito, J. S. Lundeen, H. Coldenstrodt-Ronge, J. Eisert, M. B. Plenio, and I. A. Walmsley, “Measuring measurement: theory and practice,” New Journal of Physics, vol. 11, no. 9, p. 093038, 2009.
- [22] J. S. Lundeen, A. Feito, H. Coldenstrodt-Ronge, K. L. Pregnell, C. Silberhorn, T. C. Ralph, J. Eisert, M. B. Plenio, and I. A. Walmsley, “Tomography of quantum detectors,” Nature Physics, vol. 5, no. 1, pp. 27–30, 2009.
- [23] C. M. Natarajan, L. Zhang, H. Coldenstrodt-Ronge, G. Donati, S. N. Dorenbos, V. Zwiller, I. A. Walmsley, and R. H. Hadfield, “Quantum detector tomography of a time-multiplexed superconducting nanowire single-photon detector at telecom wavelengths,” Optics Express, vol. 21, no. 1, pp. 893–902, 2013.
- [24] G. Brida, L. Ciavarella, I. P. Degiovanni, M. Genovese, A. Migdall, M. G. Mingolla, M. G. A. Paris, F. Piacentini, and S. V. Polyakov, “Ancilla-assisted calibration of a measuring apparatus,” Physical Review Letters, vol. 108, p. 253601, 2012.
- [25] G. Brida, L. Ciavarella, I. P. Degiovanni, M. Genovese, L. Lolli, M. G. Mingolla, F. Piacentini, M. Rajteri, E. Taralli, and M. G. A. Paris, “Quantum characterization of superconducting photon counters,” New Journal of Physics, vol. 14, no. 8, p. 085001, 2012.
- [26] L. Zhang, H. B. Coldenstrodt-Ronge, A. Datta, G. Puentes, J. S. Lundeen, X.-M. Jin, B. J. Smith, M. B. Plenio, and I. A. Walmsley, “Mapping coherence in measurement via full quantum tomography of a hybrid optical detector,” Nature Photonics, vol. 6, no. 6, p. 364, 2012.
- [27] L. Zhang, A. Datta, H. B. Coldenstrodt-Ronge, X.-M. Jin, J. Eisert, M. B. Plenio, and I. A. Walmsley, “Recursive quantum detector tomography,” New Journal of Physics, vol. 14, no. 11, p. 115005, 2012.
- [28] Y. Wang, S. Yokoyama, D. Dong, I. R. Petersen, E. H. Huntington, and H. Yonezawa, “Two-stage estimation for quantum detector tomography: Error analysis, numerical and experimental results,” IEEE Transactions on Information Theory, vol. 67, no. 4, pp. 2293–2307, 2021.
- [29] Y. Wang, D. Dong, and H. Yonezawa, “Tomography of binary quantum detectors,” in Proc. of 2019 IEEE 58th Conference on Decision and Control, pp. 396–400, 2019.
- [30] A. Zhang, J. Xie, H. Xu, K. Zheng, H. Zhang, Y.-T. Poon, V. Vedral, and L. Zhang, “Experimental self-characterization of quantum measurements,” Physical Review Letters, vol. 124, p. 040402, 2020.
- [31] S. Xiao, Y. Wang, D. Dong, and J. Zhang, “Optimal quantum detector tomography via linear regression estimation,” in Proc. of 2021 IEEE 60th Conference on Decision and Control, 2021.
- [32] F. Huszár and N. M. T. Houlsby, “Adaptive Bayesian quantum tomography,” Physical Review A, vol. 85, p. 052120, 2012.
- [33] G. I. Struchalin, I. A. Pogorelov, S. S. Straupe, K. S. Kravtsov, I. V. Radchenko, and S. P. Kulik, “Experimental adaptive quantum tomography of two-qubit states,” Physical Review A, vol. 93, p. 012103, 2016.
- [34] K. S. Kravtsov, S. S. Straupe, I. V. Radchenko, N. M. T. Houlsby, F. Huszár, and S. P. Kulik, “Experimental adaptive Bayesian tomography,” Physical Review A, vol. 87, p. 062122, 2013.
- [35] D. H. Mahler, L. A. Rozema, A. Darabi, C. Ferrie, R. Blume-Kohout, and A. M. Steinberg, “Adaptive quantum state tomography improves accuracy quadratically,” Physical Review Letters, vol. 111, p. 183601, 2013.
- [36] B. Qi, Z. Hou, Y. Wang, D. Dong, H.-S. Zhong, L. Li, G.-Y. Xiang, H. M. Wiseman, C.-F. Li, and G.-C. Guo, “Adaptive quantum state tomography via linear regression estimation: Theory and two-qubit experiment,” npj Quantum Information, vol. 3, no. 1, 2017.
- [37] L. Pereira, L. Zambrano, J. Cortés-Vega, S. Niklitschek, and A. Delgado, “Adaptive quantum tomography in high dimensions,” Physical Review A, vol. 98, p. 012339, 2018.
- [38] S. Boyd and L. Vandenberghe, Convex Optimization. Cambridge University Press, 2004.
- [39] A. Miranowicz, K. Bartkiewicz, J. Peřina, M. Koashi, N. Imoto, and F. Nori, “Optimal two-qubit tomography based on local and global measurements: Maximal robustness against errors as described by condition numbers,” Physical Review A, vol. 90, p. 062123, 2014.
- [40] J. M. Renes, R. Blume-Kohout, A. J. Scott, and C. M. Caves, “Symmetric informationally complete quantum measurements,” Journal of Mathematical Physics, vol. 45, no. 6, pp. 2171–2180, 2004.
- [41] A. J. Scott, “SICs: Extending the list of solutions,” arXiv preprint arXiv:1703.03993, 2017.
- [42] R. B. A. Adamson and A. M. Steinberg, “Improving quantum state estimation with mutually unbiased bases,” Physical Review Letters, vol. 105, p. 030406, 2010.
- [43] T. Durt, B.-G. Englert, I. Bengtsson, and K. Życzkowski, “On mutually unbiased bases,” International Journal of Quantum Information, vol. 08, no. 04, pp. 535–640, 2010.
- [44] A. Wünsche, V. Dodonov, O. Man’ko, and V. Man’ko, “Nonclassicality of states in quantum optics,” Fortschritte der Physik, vol. 49, no. 10‐11, pp. 1117–1122, 2001.
- [45] S. Szabo, P. Adam, J. Janszky, and P. Domokos, “Construction of quantum states of the radiation field by discrete coherent-state superpositions,” Physical Review A, vol. 53, pp. 2698–2710, 1996.
- [46] J. Janszky, P. Domokos, S. Szabó, and P. Adam, “Quantum-state engineering via discrete coherent-state superpositions,” Physical Review A, vol. 51, pp. 4191–4193, 1995.
- [47] R. Jozsa, “Fidelity for mixed quantum states,” Journal of Modern Optics, vol. 41, no. 12, pp. 2315–2323, 1994.
- [48] M. Hübner, “Explicit computation of the bures distance for density matrices,” Physics Letters A, vol. 163, no. 4, pp. 239 – 242, 1992.
- [49] H. Zhu, Quantum State Estimation and Symmetric Informationally Complete POMs. PhD thesis, National University of Singapore, 2012.
- [50] K. Zyczkowski and M. Kus, “Random unitary matrices,” Journal of Physics A: Mathematical and General, vol. 27, no. 12, pp. 4235–4245, 1994.
- [51] J. A. Miszczak, “Generating and using truly random quantum states in Mathematica,” Computer Physics Communications, vol. 183, no. 1, pp. 118 – 124, 2012.
- [52] N. Johnston, “QETLAB: A MATLAB toolbox for quantum entanglement, version 0.9,” Jan. 2016.
- [53] I. Bengtsson, “From SICs and MUBs to Eddington,” Journal of Physics: Conference Series, vol. 254, p. 012007, 2010.
- [54] M. D. de Burgh, N. K. Langford, A. C. Doherty, and A. Gilchrist, “Choice of measurement sets in qubit tomography,” Physical Review A, vol. 78, p. 052122, 2008.
- [55] R. Bhatia, Matrix Analysis. Springer-Verlag New York, 1997.
- [56] L. Zhang and S.-M. Fei, “Quantum fidelity and relative entropy between unitary orbits,” Journal of Physics A: Mathematical and Theoretical, vol. 47, no. 5, p. 055301, 2014.