Optimal Convergence Rates for the Orthogonal Greedy Algorithm
Abstract
We analyze the orthogonal greedy algorithm when applied to dictionaries whose convex hull has small entropy. We show that if the metric entropy of the convex hull of decays at a rate of for , then the orthogonal greedy algorithm converges at the same rate on the variation space of . This improves upon the well-known convergence rate of the orthogonal greedy algorithm in many cases, most notably for dictionaries corresponding to shallow neural networks. These results hold under no additional assumptions on the dictionary beyond the decay rate of the entropy of its convex hull. In addition, they are robust to noise in the target function and can be extended to convergence rates on the interpolation spaces of the variation norm. We show empirically that the predicted rates are obtained for the dictionary corresponding to shallow neural networks with Heaviside activation function in two dimensions. Finally, we show that these improved rates are sharp and prove a negative result showing that the iterates generated by the orthogonal greedy algorithm cannot in general be bounded in the variation norm of .
1 Introduction
Let be a Hilbert space and a dictionary of basis functions. An important problem in machine learning, statistics, and signal processing is the non-linear approximation of a target function by a sparse linear combinations of dictionary elements
| (1) |
where depend upon the function . Typical examples include non-linear approximation by redundant wavelet frames [25], shallow neural networks, which correspond to non-linear approximation by dictionaries of ridge functions [20], and gradient boosting [15], which corresponds to non-linear approximation by a dictionary of weak learners. Another important example is compressed sensing [13, 6, 8], where a function which is a sparse linear combination of dictionary elements is recovered from a small number of linear measurements.
In this work, we study the problem of algorithmically calculating an expansion of the form (1) to approximate a target function . A common class of algorithms for this purpose are greedy algorithms, specifically the pure greedy algorithm [25],
| (2) |
which is also known as matching pursuit, the relaxed greedy algorithm [17, 3, 2],
| (3) |
and the orthogonal greedy algorithm (also known as orthogonal matching pursuit) [28]
| (4) |
where is the residual and is the orthogonal projection onto the span of .
When applied to general dictionaries , greedy algorithms are often analyzed under the assumption that the target function lies in the convex hull of the dictionary . Specifically, following [31, 10, 19] we write the closed convex hull of as
| (5) |
and denote the gauge norm [30] of this set, which is often called the variation norm with respect to , as
| (6) |
A typical assumption then is that the target function satisfies . One notable exception is compressed sensing, where it is typically assumed that is a linear combination of a small number of elements . In this case, however, one needs an additional assumption on the dictionary , usually incoherence [14] or a restricted isometry property (RIP) [7]. The analysis of greedy algorithms under these assumptions is given in [35, 26, 27, 34] for instance. In this work we are interested in the case of general dictionaries which do not satisfy any incoherence or RIP conditions, however, so we will consider the convex hull condition on given above.
Given a function , a sampling argument due to Maurey [29] implies that there exists an -term expansion which satisfies
| (7) |
Here is the maximum norm of the dictionary and
| (8) |
is the set of -term non-linear dictionary expansions. One can even take the expansion in (7) to satisfy . It is also known that for general dictionaries , the approximation rate (7) is the best possible [19] up to a constant factor. The key problem addressed by greedy algorithms is whether the rate in (7) can be achieved algorithmically.
For simplicity of notation, we assume in the following that , i.e. that for all , which can always be achieved by scaling the dictionary appropriately. Relaxing this assumption changes the results in a straightforward manner. It has been shown that under these assumptions the orthogonal greedy algorithm [12] and a suitable version of the relaxed greedy algorithm [17, 3] satisfy
| (9) |
for a suitable constant (here and in the following , , and represent unspecified constants). Thus the orthogonal and relaxed greedy algorithms are able to algorithmically attain the approximation rate in (7) up to a constant. The behavior of the pure greedy algorithm is much more subtle. A sequence of improved upper bounds on the convergence rate of the pure greedy algorithm have been obtained in [12, 21, 33], which culminate in the bound
| (10) |
where satisfies a particular non-linear equation. Conversely, in [22] a dictionary is constructed for which the pure greedy algorithm satisfies
| (11) |
Thus the precise convergence rate of the pure greedy algorithm is still open, but it is known that it fails to achieve the rate (7) by a significant margin. A further interesting open problem concerns the pure greedy algorithm with shrinkage , which is given by
| (12) |
where again is the residual. This algorithm is important for understanding gradient boosting [15]. It is shown in [33] that the convergence order improves as decreases to a maximum of about as , but it is an open problem whether the optimal rate (7) can be achieved in the limit as .
The preceding results hold under the assumption that , i.e. that the target function is in the scaled convex hull of the dictionary. An important question is how robust the greedy algorithms are to noise. This is captured by the more general assumption that is not itself in the convex hull, but rather that is close to an element in the convex hull. Specifically, we assume that and that , which can be thought of as noise, is small. The convergence rate of the orthogonal and relaxed greedy algorithms are analyzed under these assumptions in [3]. Specifically, it is shown that for any and any , the iterates of the orthogonal greedy algorithm satisfy
| (13) |
This result is important for the statistical analysis of the orthogonal greedy algorithm, for instance in showing the universal consistency of the estimator obtained by applying this algorithm to fit a function based on samples [3]. It also gives a convergence rate for the orthogonal greedy algorithm on the interpolation spaces between and . The -functional of and is defined by
| (14) |
The interpolation space is defined by the norm . Intuitively, the interpolation spaces measure how efficiently a function can be approximated by elements with small -norm. We refer to [3] and [11], Chapter 6, for more information on interpolation spaces.
Although the approximation rate (7) is sharp for general dictionaries, for compact dictionaries the rate can be improved using a stratified sampling argument [24, 18, 36]. Specifically, the dictionary
| (15) |
where the activation function is the Heaviside function and a bounded domain was analyzed in [24]. There it was shown that for the approximation rate (7) can be improved to
| (16) |
This corresponds to an improved approximation rate for shallow neural networks with Heaviside (and also sigmoidal) activation function. For shallow neural networks with ReLUk activation function, the relevant dictionary [32] is
| (17) |
where is the unit sphere is and is the diameter of (assuming without loss of generality that ). Using the smoothness of the dictionary , it has been shown that for an approximation rate of
| (18) |
can be achieved, and that this rate is optimal if the coefficients of are bounded [32]. Given these improved theoretical approximation rates for shallow neural networks, it has been an important open problem whether they can be achieved algorithmically by greedy algorithms.
In this work, we show that the improved approximation rates (18) can be achieved using the orthogonal greedy algorithm. More generally, we show that the orthogonal greedy algorithm improves upon the rate (7) whenever the convex hull of the dictionary has small metric entropy. Specifically, we recall that the (dyadic) metric entropy of a set in a Banach space is defined by
| (19) |
The metric entropy gives a measure of compactness of the set and a detailed theory can be found in [23], Chapter 15. We show that if the dictionary satisfies
| (20) |
then the orthogonal greedy algorithm (4) satisfies
| (21) |
where only depends upon and . More generally, this analysis is also robust to noise in the sense considered in [3], i.e. for any and we have
| (22) |
Utilizing the metric entropy bounds proven in [32], this implies that the orthogonal greedy algorithm achieves the rate (18) for shallow neural networks with ReLUk activation function. We provide numerical experiments using shallow neural networks with the Heaviside activation function which confirm that these optimal rates are indeed achieved. Additional numerical experiments which confirm the theoretical approximation rates for shallow networks with ReLUk activation function can be found in [16], where the orthogonal greedy algorithm is used to solve elliptic PDEs.
We conclude the manuscript with a lower bound and negative result concerning the orthogonal greedy algorithm. Consider approximating by dictionary expansions with -bounded coefficients, i.e. from the set
| (23) |
It is known that the corresponding approximation rates are lower bounded by the metric entropy up to logarithmic factors. In particular, if for some and any , we have
| (24) |
then we must have . The result (21) shows that the orthogonal greedy algorithm achieves this rate. However, we note that these lower bounds do not a priori apply to the orthogonal greedy algorithm since the expansions generated will in general not have coefficients uniformly bounded in . In fact, we give an example demonstrating that the iterates generated by the orthogonal greedy algorithm may have arbitrarily large -norm. Nonetheless, we will show that the rate (21) is sharp and cannot be further improved for general dictionaries satisfying 20. We do not know whether there exists a greedy algorithm which can attain the improved approximation rate (21) while also guaranteeing a uniform -bound on the coefficients.
The paper is organized as follows. In the Section 2, we derive the improved convergence rate (21). Next, in Section 3 we provide numerical experiments which demonstrate the improved rates. Then, in Section 4, we give an example showing that the iterates generated by the orthogonal greedy algorithm cannot be bounded in and also show that the improved rates are tight. Finally, we give concluding remarks and further research directions.
2 Analysis of the Orthogonal Greedy Algorithm
We begin with the following key lemma.
Lemma 1.
Let and be a dictionary with
| (25) |
Then there exists a such that for any sequence , we have
| (26) |
where is the orthogonal projection onto the span of .
The intuituve idea behind this lemma is that if (26) fails, then the convex hull must contain a relatively large skewed simplex. A comparison of volumes then gives a lower bound on its entropy.
Proof.
By scaling the dictionary, we may assume without loss of generality that . Fix a and consider a sequence . Assume that
| (27) |
We will show that for sufficiently small this contradicts the entropy bound (25). Rescaling this value of by gives the desired bound (26).
Choose the indices for which is the smallest. For each , there are at least indices for which . This gives the inequality
| (28) |
so that by (27) we must have and thus
| (29) |
for each . Further, if we replace the projections by the orthogonal projection onto the span of , the length in (29) can only increase (since we are removing dictionary elements from the projection). Thus, by relabelling we obtain a sequence such that
| (30) |
for .
Let be the Gram-Schmidt orthogonalization of the sequence , i.e. . From (30), we obtain for each , and thus since the are orthogonal, we obtain the following bound
| (31) |
Here is the absolute convex hull of the sequence .
Next we use the fact that the change of variables between the and the is upper triangular with ones on the diagonal and thus has determinant (since ). This implies that
| (32) |
In other words the convex hull of the is a skewed simplex with large volume.
We now use the covering definition of the entropy, setting , and the fact that to get
| (33) |
where the right hand side is the volume of balls of radius .
Utilizing Sterling’s formula and taking -th roots, we get
| (34) |
for an absolute constant . For sufficiently small , this will contradict the bound (25), which completes the proof. ∎
Finally, we come to the main result of this section, which shows that the orthogonal greedy algorithm (4) achieves a convergence rate which matches the entropy for dictionaries whose entropy decays faster than . In fact, we prove a bit more, generalizing the result from [3] to obtain improved approximation rates for the interpolation spaces between and as well.
Theorem 1.
Let and suppose that is a dictionary which satisfies
| (35) |
for some constant . Let the iterates be given by algorithm (4), where . Further, let be arbitrary. Then we have
| (36) |
where depends only upon and . In particular, if , then
| (37) |
We note that although is a linear combination of dictionary elements , we do necessarily have that can be bounded in , as we show in Proposition 1. This is due to the fact that the coefficients in the expansion generated by the orthogonal greedy algorithm (4) cannot be bounded in .
Further, the bound (36) shows that the improved convergence behavior of the orthogonal greedy algorithm is robust to noise. This is critical for the statistical analysis of the algorithm, for instance for proving statistical consistency [3]. Further, it enables one to prove a convergence rate for functions in the interpolation space , analogous to the results in [3]. We remark that in [3] a Fourier integrability condition is given which guarantees membership in when is the dictionary corresponding to shallow neural networks with sigmoidal activation function. This generalizes the Fourier condition introduced by Barron in [2].
Corollary 1.
Let be a dictionary satisfying the assumptions of Theorem 1. Then for we have
| (38) |
where depends only upon and .
Proof.
Taking the square root of (36) we see that
| (39) |
for a new constant (we can take ). Taking the infemum over , we get
| (40) |
where is the -functional introduced in the introduction (see also [11], Chapter 6 for a more detailed theory). The definition of the interpolation space implies that
| (41) |
for all . Setting in (40) gives the desired result. ∎
Proof of Theorem 1.
Throughout the proof, let denote the projection onto and denote the residual. Since is the best approximation to from the space , we have
| (42) |
Next, we note that since is orthogonal to we have . In addition, as is orthogonal to , we see that
| (43) |
Setting , we can rewrite this as
| (44) |
which gives the lower bound
| (45) |
If is ever negative, then the desired result clearly holds for all since is decreasing. So we assume without loss of generality that in what follows.
Subtracting from equation (42) and using lower bound above, we get the recursion
| (46) |
Define the sequence , and we get the recursion
| (47) |
If , then this recursion implies that (since and thus ) and as remarked before the desired conclusion is easily seen to hold in this case. Hence we can assume without loss of generality that . In addition, if ever holds the result immediately follows for all . So we also assume without loss of generality in the following that .
Utilizing the approximation , we rewrite the recursion (47) as
| (48) |
At this point, we could expand the recursion and use that to get
| (49) |
where the last inequality is due to the fact that the sequence is decreasing. Applying Lemma 1 we obtain
| (50) |
Solving this gives the desired result up to logarithmic factors.
In order to remove the logarithmic factors, we use again that the sequence is decreasing and dyadically expand the recursion (48) to get
| (51) |
for each (if we interpret ).
Note that , where is the projection onto the space spanned by . Thus, applying Lemma 1 to the dictionary and the sequence , we get
| (52) |
Here we may assume, by decreasing if necessary, that . Next we will prove by induction that
This completes the proof since is decreasing, and so it implies that
| (53) |
with .
The proof by induction proceeds as follows. We note that for , . (Note that here we use that is taken .)
3 Numerical Experiments
In this section, we give numerical experiments which demonstrate the improved convergence rates derived in Section 2. The setting we consider is a special case of the situation considered in [20]. We consider the dictionary
| (55) |
where is the Heaviside activation function. Nonlinear approximation from this dictionary corresponds to approximation by shallow neural networks with Heaviside activation function. The results proved in [32] imply that the metric entropy of the convex hull of satisfies
| (56) |
We use the orthgonal greedy algorithm to approximate the target function
| (57) |
by a non-linear expansion from the dictionary . Note that the target function is smooth so that [2]. We approximate the norm on the domain by the empirical -norm on a set of sample points drawn uniformly at random from the square . The subproblem
| (58) |
becomes the combinatorial problem of determining the optimal splitting of the sample points by a hyperplane such that
| (59) |
is maximized. There are such hyperplane splittings and the optimal splitting can be determined using operations using a simple modification of the algorithm in [20] which is specific to the case of .
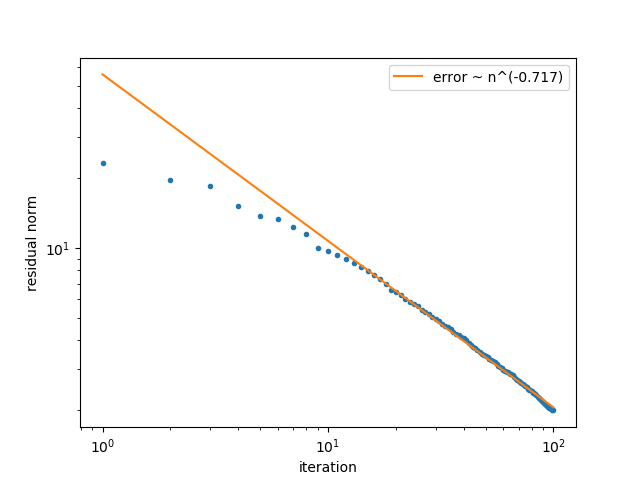
We run this algorithm with for a total of iteration111All of the code used to run the experiments and generate the plots shown here can be found at https://github.com/jwsiegel2510/OrthogonalGreedyConvergence. In Figure 1 we plot the error as a function of iteration on a log-log scale. Estimating the convergence order from this plot (here we have removed the first errors since the rate depends upon the tail of the error sequence) gives a convergence order of . Previous theoretical results for the orthogonal greedy algorithm [12, 3] only give a convergence rate of , while our bounds incorporating the compactness of the dictionary imply a convergence rate of . The empirically estimated convergence order is significantly better than and is very close to the rate predicted by Theorem 1.
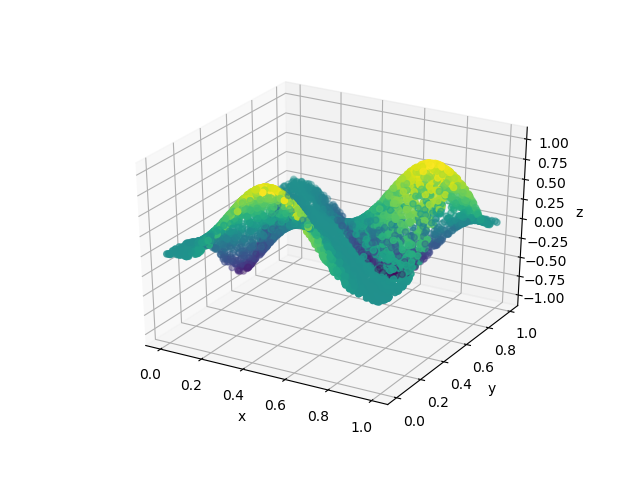
In Figure 2 we plot the target function and the approximants obtained at iterations , , and . This illustrates how the approximation of the target function generated by the orthogonal greedy algorithm improves as we add more dictionary elements to our expansion.
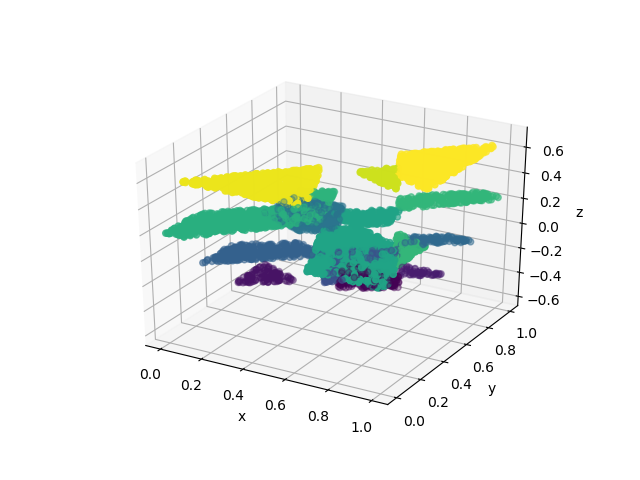
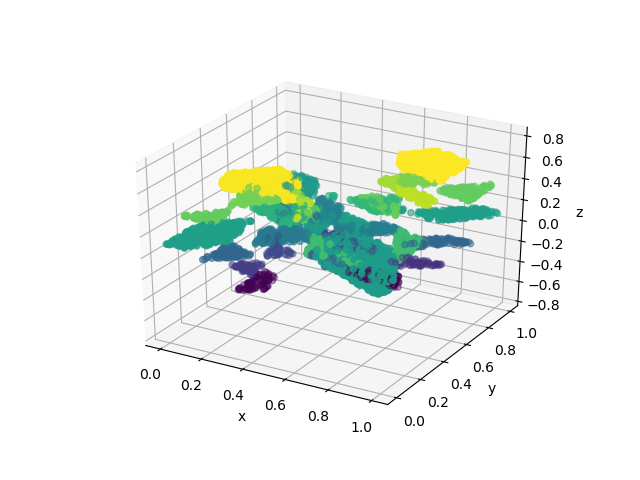
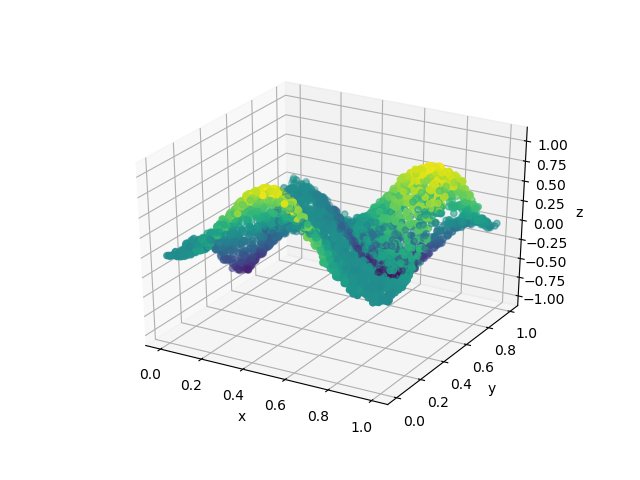
4 Lower Bounds
In this section, we show that the the iterates generated by the orthogonal greedy algorithm cannot be bounded in and that the rate derived in Theorem 1 cannot be further improved.
Proposition 1.
For each , there exists a (normalized) dictionary and an such that if is the iterate generated by the orthogonal greedy algorithm when applied to after steps, then
| (60) |
This shows that in the worst case the iterates generated by the orthogonal greedy algorithm are not bounded in the variation space .
Proof.
Let with orthonormal basis . Let and consider the dictionary given by
| (61) |
where is chosen so that for all . Consider the element
| (62) |
We claim that if , then the orthogonal greedy algorithm applied to and will select , , and in the first steps.
Indeed, we calculate
| (63) |
We now verify, by differentiating for example, that for we have
| (64) |
which implies that . The other inequalities are obvious (recalling that ) and so it holds that . Projecting orthogonal to , we get
Calculating inner products, we see that
| (65) |
Since , these relations imply that . Projecting orthogonal to , we get
Finally, computing inner products, we get
| (66) |
Again, since this implies that . Projecting orthogonal to , we obtain
| (67) |
Now, if , then by taking inner products with and , we see that and which implies that . Thus and since the are linearly independent, the are uniquely determined, and a simple calculation shows them to be
| (68) |
We finally get
| (69) |
Letting , we obtain the desired result.
∎
Proposition 2.
There exists a Hilbert space and a dictionary such that and for each
| (70) |
where is the -th iterate of the orthogonal greedy algorithm applied to .
This implies the optimality of the rates in Theorem 1 under the fiven assunmptions on the entropy of .
Proof.
Let and consider the dictionary
| (71) |
It is known that for a constant [1]. Let be an integer, and consider the element
| (72) |
We obviously have that . Moreover, it is clear that after iterations of the orthogonal greedy algorithm, the residual will satisfy
| (73) |
since the dictionary elements chosen at each iteration will be . Choosing , we get
| (74) |
∎
5 Conclusion
We have shown that the orthogonal greedy algorithm achieves an improved convergence rate on dictionaries whose convex hull is compact. An important point, however, is that the expansions thus derived generally do not have their coefficients bounded in . It is an important follow-up question whether the improved rates can be obtained by a greedy algorithm which satisfies this further restriction. Another interesting research direction is to extend our analysis to greedy algorithms for other problems such as reduced basis methods [9, 4] or sparse PCA [5].
6 Acknowledgements
We would like to thank Professors Russel Caflisch, Ronald DeVore, Weinan E, Albert Cohen, Stephan Wojtowytsch and Jason Klusowski for helpful discussions. We would also like to thank the anonymous referees for their helpful comments. This work was supported by the Verne M. Willaman Chair Fund at the Pennsylvania State University, and the National Science Foundation (Grant No. DMS-1819157 and DMS-2111387).
References
- [1] Ball, K., Pajor, A.: The entropy of convex bodies with “few” extreme points. In: Proceedings of the 1989 Conference in Banach Spaces at Strob. Austria. Cambridge Univ. Press (1990)
- [2] Barron, A.R.: Universal approximation bounds for superpositions of a sigmoidal function. IEEE Transactions on Information theory 39(3), 930–945 (1993)
- [3] Barron, A.R., Cohen, A., Dahmen, W., DeVore, R.A.: Approximation and learning by greedy algorithms. The annals of statistics 36(1), 64–94 (2008)
- [4] Binev, P., Cohen, A., Dahmen, W., DeVore, R., Petrova, G., Wojtaszczyk, P.: Convergence rates for greedy algorithms in reduced basis methods. SIAM journal on mathematical analysis 43(3), 1457–1472 (2011)
- [5] Cai, T.T., Ma, Z., Wu, Y.: Sparse pca: Optimal rates and adaptive estimation. The Annals of Statistics 41(6), 3074–3110 (2013)
- [6] Candès, E.J., Romberg, J., Tao, T.: Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Transactions on information theory 52(2), 489–509 (2006)
- [7] Candes, E.J., Tao, T.: Decoding by linear programming. IEEE transactions on information theory 51(12), 4203–4215 (2005)
- [8] Cohen, A., Dahmen, W., DeVore, R.: Compressed sensing and best -term approximation. Journal of the American mathematical society 22(1), 211–231 (2009)
- [9] DeVore, R., Petrova, G., Wojtaszczyk, P.: Greedy algorithms for reduced bases in banach spaces. Constructive Approximation 37(3), 455–466 (2013)
- [10] DeVore, R.A.: Nonlinear approximation. Acta numerica 7, 51–150 (1998)
- [11] DeVore, R.A., Lorentz, G.G.: Constructive approximation, vol. 303. Springer Science & Business Media (1993)
- [12] DeVore, R.A., Temlyakov, V.N.: Some remarks on greedy algorithms. Advances in computational Mathematics 5(1), 173–187 (1996)
- [13] Donoho, D.L.: Compressed sensing. IEEE Transactions on information theory 52(4), 1289–1306 (2006)
- [14] Donoho, D.L., Elad, M., Temlyakov, V.N.: Stable recovery of sparse overcomplete representations in the presence of noise. IEEE Transactions on information theory 52(1), 6–18 (2005)
- [15] Friedman, J.H.: Greedy function approximation: a gradient boosting machine. Annals of statistics pp. 1189–1232 (2001)
- [16] Hao, W., Jin, X., Siegel, J.W., Xu, J.: An efficient greedy training algorithm for neural networks and applications in pdes. arXiv preprint arXiv:2107.04466 (2021)
- [17] Jones, L.K.: A simple lemma on greedy approximation in hilbert space and convergence rates for projection pursuit regression and neural network training. The annals of Statistics 20(1), 608–613 (1992)
- [18] Klusowski, J.M., Barron, A.R.: Approximation by combinations of relu and squared relu ridge functions with and controls. IEEE Transactions on Information Theory 64(12), 7649–7656 (2018)
- [19] Kurková, V., Sanguineti, M.: Bounds on rates of variable-basis and neural-network approximation. IEEE Transactions on Information Theory 47(6), 2659–2665 (2001)
- [20] Lee, W.S., Bartlett, P.L., Williamson, R.C.: Efficient agnostic learning of neural networks with bounded fan-in. IEEE Transactions on Information Theory 42(6), 2118–2132 (1996)
- [21] Livshits, E.D.: Rate of convergence of pure greedy algorithms. Mathematical Notes 76(3), 497–510 (2004)
- [22] Livshits, E.D.: Lower bounds for the rate of convergence of greedy algorithms. Izvestiya: Mathematics 73(6), 1197 (2009)
- [23] Lorentz, G.G., Golitschek, M.v., Makovoz, Y.: Constructive approximation: advanced problems, vol. 304. Springer (1996)
- [24] Makovoz, Y.: Random approximants and neural networks. Journal of Approximation Theory 85(1), 98–109 (1996)
- [25] Mallat, S.G., Zhang, Z.: Matching pursuits with time-frequency dictionaries. IEEE Transactions on signal processing 41(12), 3397–3415 (1993)
- [26] Needell, D., Tropp, J.A.: Cosamp: Iterative signal recovery from incomplete and inaccurate samples. Applied and computational harmonic analysis 26(3), 301–321 (2009)
- [27] Needell, D., Vershynin, R.: Uniform uncertainty principle and signal recovery via regularized orthogonal matching pursuit. Foundations of computational mathematics 9(3), 317–334 (2009)
- [28] Pati, Y.C., Rezaiifar, R., Krishnaprasad, P.S.: Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In: Proceedings of 27th Asilomar conference on signals, systems and computers, pp. 40–44. IEEE (1993)
- [29] Pisier, G.: Remarques sur un résultat non publié de b. maurey. Séminaire Analyse fonctionnelle (dit “Maurey-Schwartz") pp. 1–12 (1981)
- [30] Rockafellar, R.T.: Convex analysis. 28. Princeton university press (1970)
- [31] Siegel, J.W., Xu, J.: Improved approximation properties of dictionaries and applications to neural networks. arXiv preprint arXiv:2101.12365 (2021)
- [32] Siegel, J.W., Xu, J.: Sharp bounds on the approximation rates, metric entropy, and -widths of shallow neural networks. arXiv preprint arXiv:2101.12365 (2021)
- [33] Sil’nichenko, A.: Rate of convergence of greedy algorithms. Mathematical Notes 76(3), 582–586 (2004)
- [34] Tropp, J.A.: Greed is good: Algorithmic results for sparse approximation. IEEE Transactions on Information theory 50(10), 2231–2242 (2004)
- [35] Tropp, J.A., Gilbert, A.C.: Signal recovery from random measurements via orthogonal matching pursuit. IEEE Transactions on information theory 53(12), 4655–4666 (2007)
- [36] Xu, J.: Finite neuron method and convergence analysis. Communications in Computational Physics 28(5), 1707–1745 (2020). DOI https://doi.org/10.4208/cicp.OA-2020-0191. URL http://global-sci.org/intro/article_detail/cicp/18394.html