Optimal estimation of some random quantities of a Lévy process
Abstract.
In this paper we present new theoretical results on optimal estimation of certain random quantities based on high frequency observations of a Lévy process. More specifically, we investigate the asymptotic theory for the conditional mean and conditional median estimators of the supremum/infimum of a linear Brownian motion and a stable Lévy process. Another contribution of our article is the conditional mean estimation of the local time and the occupation time measure of a linear Brownian motion. We demonstrate that the new estimators are considerably more efficient compared to the classical estimators studied in e.g. [6, 14, 29, 30, 38]. Furthermore, we discuss pre-estimation of the parameters of the underlying models, which is required for practical implementation of the proposed statistics.
Key words and phrases:
conditioning to stay positive, local time, Lévy processes, occupation time measure, optimal estimation, self-similarity, supremum, weak limit theorems2000 Mathematics Subject Classification:
62M05, 62G20, 60F05 (primary), 62G15, 60G18, 60G51 (secondary)1. Introduction
During the past decades the increasing availability of high frequency data in economics and finance has led to an immense progress in high frequency statistics. In particular, high frequency functionals of Itô semimartingales have received a great deal of attention in the statistical and probabilistic literature, where the focus has been on estimation of quadratic variation, realised jumps and related (random) quantities. A detailed discussion of numerous high frequency methods and their applications to finance can be found in the monographs [1, 31].
Despite large amount of literature on high frequency statistics, the question of optimality has rarely been addressed. To fix ideas we consider a stochastic process with a known law and an associated random quantity , where is a measurable functional. The major problem of interest is outlined by the following question:
Given observations , what is the optimal estimator of the random variable and its asymptotic properties as ?
Let us stress that we are interested in for a particular realization of , which is observed over a dense grid, and not just in its law.
Of course, the formulated problem is hard to address in full generality. But even for particular model classes the assessment of optimality is far from trivial, which is mainly due to the randomness of . Indeed, the classical methods such as minimax theory, Le Cam theory or Cramér-Rao bounds, do not apply in this setting. There are only a few results in the literature that discuss optimality in high frequency statistics. In [21] the authors apply the infinite dimensional version of local asymptotic mixed normality to obtain lower efficiency bounds for estimation of integrated functionals of volatility in the setting of diffusion models with a particular structure. In particular, their result shows that the standard estimator of the quadratic variation, the realised volatility, is indeed asymptotically efficient for the considered class of models. In a later paper [22] similar lower bounds have been obtained in the framework of certain jump diffusions. The paper [38] discusses estimation of the occupation time measure for continuous diffusion models and the authors prove that is the optimal rate of convergence (however, they do not discuss efficiency bounds). The articles [3, 4, 5] investigate estimation of integral functionals for various Markovian and non-Markovian models. The main focus here is on deriving error bounds and weak limit theorems for Riemann sum type estimators, which heavily depend on the smoothness of . In several settings they also prove rate optimality in the case of Brownian motion.
The aim of our paper is to study optimal estimation of extrema, local time and occupation time measure of certain Lévy processes. Accurate estimation of these random functionals is important for numerous applications. For instance, supremum is a key quantity in insurance, queueing, financial mathematics, optimal stopping and various applied domains such as environmental science where maximal level of pollution is often of interest. It is noted that our theory can also be used in Monte Carlo simulation of extrema via discretization, but this is not our main focus since much better algorithms exist [17]; see also [27] for exact simulation of the supremum of a stable process. These algorithms, however, can not handle, e.g., the diameter of the range of , whereas our estimators still apply. Accurate estimation of local times is required in a number of statistical methods including estimation of the volatility coefficient in a diffusion model [24], estimation of the skewed Brownian motion [34] and estimation of the reflected fractional Brownian motion [28], just to name a few.
The estimation of the aforementioned random quantities has been studied in several papers. The standard estimator of the supremum of a stochastic process is given by the maximum of its high frequency observations. In the setting of a linear Brownian motion the corresponding non-central limit theorem has been proven in [6]; their result has been later extended in [29] to the class of Lévy processes satisfying certain regularity assumption. Statistical inference for local times has been investigated in [14, 30], who showed asymptotic mixed normality for kernel type estimators in the framework of continuous SDEs. Finally, [5, 38] discussed the estimation of the occupation time measure via Riemann sums.
In this paper we show that the standard estimators proposed in the literature are indeed rate optimal, but they are not asymptotically efficient. Instead of certain intuitive constructions, we consider the conditional mean and conditional median estimators, which turn out to be manageable in some important cases. It is well known that the conditional mean is the optimal -predictor when . In many cases considered below, however, the random variable will not have a finite second moment. Then we use the conditional median estimator , which is optimal in sense given that . Additionally, we still do consider the conditional mean which is a very natural estimator even when the second moment is infinite. Importantly, it is optimal with respect to the Bregman distance: with being a strictly convex differentiable function [8]. It is only required here that and are finite. We often have and for some , and hence we may take to produce an optimality statement for the conditional mean estimator. Finally, the conditional median is optimal with respect to for an increasing function which in our case can be taken as for , see [26] and references therein.
In the case of supremum, the conditional mean and median estimators have a rather explicit and simple form, but their performance assessment is not a trivial task. Importantly, self-similarity of (up to measure change) is the key property when evaluating such estimators and establishing the corresponding weak limit theory. Thus we consider the following two classes of processes: (i) linear Brownian motions and (ii) non-monotone self-similar Lévy processes. In the case of local/occupation time we only work with the class (i) of linear Brownian motions and focus on the conditional mean estimators exclusively, which is dictated by the structure of the problem and the tools currently available. Importantly, our conditional mean estimator of the local time fits the framework of [30] and yields an asymptotically optimal statistic in some large class in the case of continuous SDEs, see Remark 2. We find that our new optimal estimators are considerably more efficient than the standard ones and that they do have narrower confidence intervals. In the case of supremum, this is illustrated by a numerical study. Furthermore, we discuss several modifications of our statistics including pre-estimation of unknown parameters of the underlying model.
This paper is structured as follows. §2 is devoted to the supremum and its conditional mean and median estimators with the corresponding weak limit theory in the case of a self-similar Lévy process with a known law. Here we also treat the case of a linear Brownian motion, and comment on the conditional mean estimator of the range diameter. In §3 we present the conditional mean estimators of the local time and occupation time together with the asymptotic theory in the case of a linear Brownian motion. Then in §4 we study modified statistics based on pre-estimation of the unknown parameters of the model. In particular, we show that reasonable pre-estimation of the model parameters does not affect the asymptotic theory. Furthermore, the effect of truncation of the potentially infinite product involved in the construction of the supremum estimators is discussed, and some comments concerning a general Lévy process are given. Numerical illustrations for the case of supremum are presented in §5, where both a linear Brownian motion and a one-sided stable processes are considered. The proofs are collected in Appendix A and Appendix B for the supremum and local/occupation time, respectively. The former also requires some additional theory for Lévy processes conditioned to stay positive which is given in Appendix C.
2. Optimal estimation of supremum for a self-similar Lévy process
In this section we assume that is a non-monotone -self-similar Lévy process, i.e.
where necessarily . Assuming that the law of (or its parameters) is known, we focus on optimal estimation of the supremum and infimum of on the interval from high-frequency observations. The case corresponds to a strictly -stable process, whereas for we have a scaled Brownian motion, and the respective simplified expressions for the statistics and their limits can be found in §2.4. In fact, §2.4 considers a more general setting of a linear Brownian motion, which is not self-similar but becomes such under Girsanov change of measure. Some further results concerning estimation of infimum and the range diameter are given in §2.5.
We introduce the notation
to denote the running supremum and infimum process, respectively. Furthermore, the time of supremum will often be needed, and thus we define
In fact, the process as considered here does not jump at its supremum time almost surely and thus we could have used the term maximum instead. The standard distribution free estimator of is given by the empirical maximum of the observed data:
| (1) |
We remark, however, that is always downward biased. Finally, estimation of the infimum amounts to estimation of the supremum of , and thus no additional theory is needed. The joint estimation of supremum and infimum is discussed in §2.5.
In the following we will often use the notion of stable convergence. We recall that a sequence of random variables defined on is said to converge stably with limit () defined on an extension of the original probability space , iff for any bounded, continuous function and any bounded -measurable random variable it holds that
| (2) |
The notion of stable convergence is due to Renyi [39]. We also refer to [2] for properties of this mode of convergence.
2.1. Preliminaries
We will now review the asymptotic theory for the estimator , which will be useful for studying conditional mean and median estimators. In order to state the limit theorem for , we need to introduce an auxiliary process . It is defined as the following weak limit:
| (3) |
see [9]. Here and in the following it is tacitly assumed that the left hand side is when . The functional convergence is always with respect to the Skorokhod topology, unless specified otherwise. It may be useful to think of as the process seen from its supremum as the time horizon tends to infinity.
It is well known that and are independent finite Feller processes starting at . Various representations of these processes exist and a number of important properties have been established, see e.g. [19] and references therein. The latter process when started at a positive level is often referred to as conditioned to stay positive (the negative of the former is conditioned to stay negative); here conditioning is understood in a certain limiting sense. The law of the limiting process is not explicit except when is a Brownian motion and then both parts of are -dimensional Bessel processes scaled by , the standard deviation of . In all cases inherits self-similarity from , and hence both parts (when started from positive values) are positive self-similar Markov processes admitting Lamperti representation studied in detail in [16].
Due to self-similarity of the process it holds that
| (4) |
where again when . In other words, the process arises from zooming-in on at its supremum point. We refer the reader to [6, 29] for the case of a linear Brownian motion and a general Lévy process, respectively.
The following result is an instructive application of the convergence in (4). It is a particular case of [29, Thm. 5] extending the result of [6] for Brownian motion.
Theorem 1.
For a non-monotone -self-similar Lévy process we obtain the stable convergence as :
| (5) |
where and the standard uniform are mutually independent, and independent of .
Let us mention the underlying intuition, which will be important to understand our main result in Theorem 2 given below. Note the identity
| (6) |
where stands for the fractional part of . The random time has a density [18] and thus according to [31, 33]
which together with (4) hint at (5). It is noted that the convergence in (4) is, in fact, stable with being independent of . Intuitively, zooming-in at the supremum makes the values of at some fixed times irrelevant. We stress that this only provides intuition and the proof is far from being complete, see [29] and also [13] providing the necessary corrections.
2.2. Optimal estimators
Let us proceed to construct our optimal estimators given by the conditional mean and median. For this purpose we introduce the conditional distribution of given the terminal value via
| (7) |
We choose a version continuous in which is, in fact, jointly continuous in as will be shown in Lemma 3 below. By self-similarity we also have
Next, consider the conditional distribution of given the observations:
where and the second line follows from the stationarity and independence of increments. We note that is continuous and strictly increasing in . Finally, we introduce the conditional mean and conditional median estimators of :
| (8) | ||||
| (9) |
where in the first line we use the integrated tail formula. Interestingly, even when , see Remark 3. When evaluating our statistics defined in (8) and (9) we need access to the function . This function, however, is explicit only in the Brownian case analyzed in §2.4 and is semi-explicit in the case of one-sided jumps, see Proposition 4. Thus, in the case of general strictly stable process one needs to assess numerically, which may necessitate truncation of the product in the definition of . Such modifications are discussed in §4.2.
2.3. Limit theory
We start by noting that -almost surely, whereas has a non-trivial limit. Observe that is the rescaled distance of the th observation following from the supremum. Thus
where we tacitly assume that the factors with evaluate to . In view of Theorem 1 it is intuitive that the limit is
| (10) |
where the random quantities and are defined in Theorem 1. By substitution we obtain the identities
| (11) | ||||
| (12) |
which suggest the asymptotic behaviour of our estimators defined in (8) and (9). We formalise this in one of our main results:
Theorem 2.
Assume that is a non-monotone -self-similar Lévy process. Then the random function is continuous and strictly increasing with and -a.s. and
| (13) |
with respect to the uniform topology, where and are defined in (5) and (10), respectively. Furthermore, our estimators satisfy
| (14) | ||||
| (15) |
where the limit random variables are finite.
It is noted that the proof of this result is far from trivial, since it requires precise understanding of the tail function for large and the rate of growth of as (uniformly in ) among other things. The identities (11) and (12) show that the statistics and are first order equivalent to the standard estimator , and the knowledge of the distribution of only enters through the -order term. This fact will prove to be important in Section 4, where the parameters of the law of will need to be estimated.
Recall that for . Moreover, all moments of are finite when is a Brownian motion or a strictly -stable process with no positive jumps. In the latter cases the conditional mean estimator is optimal in sense. In the case the conditional median is optimal in sense and the conditional mean is optimal with respect to the above mentioned Bregman distance , where . Finally, the conditional median is optimal with respect to the loss function for and any .
2.4. Linear Brownian motion
Consider a linear Brownian motion with drift parameter and scale parameter , which is self-similar (and hence Theorem 2 applies) only when . Nevertheless, can be obtained from a scaled Brownian motion by Girsanov change of measure and, in particular, the conditional distribution does not depend on , see §A.4.1. Hence our estimators have exactly the same form as in the case of , see §2.2. Furthermore, the conditional distribution function is explicit in this case and is given by
| (16) |
which follows from [42] or earlier sources, see also [15, 1.1.8]. Thus
| (17) |
Interestingly, also the limit theorem has exactly the same form. The main reason for this is that the limit in (4) does not depend on either, see [6]. In the following result we prefer to choose the scaling rather than so that the respective quantities correspond to the standard Brownian motion.
Corollary 1.
For a linear Brownian motion with drift parameter and scale we have
| (18) | ||||
| (19) |
where and
with being the two-sided 3-dimensional Bessel process and a standard uniform, which are mutually independent and independent of .
Additionally, we show that (18) extends to convergence of moments, see Lemma 1 below. In particular, the asymptotic MSE of the optimal is given by
Lemma 1.
For a linear Brownian motion and any we have
2.5. Joint estimation of supremum and infimum
Consider the process and the associated conditional mean estimator of its supremum , which is the negative of the infimum of . According to Proposition 3 there is the symmetry:
for all , and so also the asymptotic theory is the same. Furthermore, we have the following joint convergence (linear Brownian motion included with and then the limit corresponds to the case ):
Corollary 2.
For it holds that
where and are identically distributed, mutually independent, and independent of . Their common distribution is the limiting law in (14).
This, for example, readily yields the limit result for the conditional mean estimator of the range diameter .
3. Optimal estimation of local time and occupation time measure for a linear Brownian motion
In this section denotes a linear Brownian motion with drift parameter and scale , and denotes the corresponding local time process at the level , which is a continuous increasing process given as the almost sure limit:
Furthermore, stands for the occupation time in the interval :
| (20) |
Our aim here is to establish limit theorems for the conditional mean estimators of and .
3.1. Basic formulae
An important role will be played by the functions
where corresponds to the law of the standard Brownian motion. Both functions and have explicit formulae in terms of the density and survival function of the standard normal distribution. Some basic observations and these formulae are collected in the following result.
Lemma 2.
There are the identities
| (21) | |||
| (22) |
Moreover, the functions and are bounded on and satisfy . For we have the formulae
3.2. Estimators and the limit theory
The conditional mean estimators of and are easily derived using stationarity and independence of increments of together with Lemma 2:
| (23) | ||||
| (24) | ||||
where . It is noted that the lower order terms can be written down explicitly (they are when is an integer), but we keep them implicit, because they do not have an influence on the limit theorem presented below.
Theorem 3.
Assume that is a linear Brownian motion with drift parameter and scale . Then for any we have the functional stable convergence:
| (25) | ||||
| (26) |
where is a Brownian motion independent of and
Importantly, our conditional mean estimator (23) is a particular example of a more general class of statistics investigated in [30] in the context of continuous diffusion processes. The expression for in [30] is rather lengthy and hard to evaluate, because of the generality assumed therein. In our case, is the conditional expectation and, in fact, a rather short direct proof can be given yielding the constant at the same time, see Appendix B.
Remark 1.
The above can be compared to obtained when instead of the optimal one uses the kernel depending on only, see [30, (1.27)]. The corresponding estimator (for ) is , which does not take the increment following into account.
Remark 2.
Consider the class of continuous SDEs defined via the equation
where is a standard Brownian motion and are such that the above SDE has a unique strong solution. In [30] the author considers statistics of the form
When and with bounded and satisfying for some , the stable convergence
holds, see [30, Theorem 1.2]. Furthermore, the positive constant (and the proof of stable convergence) stems from the simpler model . Hence, we can conclude that our estimator is asymptotically optimal within the class of statistics in the general setting of continuous SDEs. We believe that the restriction to the class is not required and is asymptotically efficient for continuous SDEs. Furthermore, when the function is unknown the coefficient can be estimated with a -accuracy [24] and we can build a feasible statistic without affecting the asymptotic theory (cf. Proposition 2 below).
4. Some modifications of the proposed statistics
The main goal of this section is to show that the above developed theory also applies in the setting when the law of is not known, but a consistent estimator of the parameters is available. Furthermore, we construct certain simplified estimators of the supremum in order to cope with potential numerical issues.
4.1. Unknown parameters
The main results of Theorem 2 and Theorem 3 above assume that the law of the process is known, which is hard to accept in practice. At most, we are willing to assume that the process belongs to some parametric class, and we distinguish between the following two:
- (i)
-
(ii)
Non-monotone self-similar Lévy process which is naturally parameterized [43, §I.5] by a triplet , where is the positivity parameter and is related to the scale. It is noted that for , and for which excludes monotone processes. This parametrization, unlike the one with skewness parameter, is continuous in the sense that convergence of parameters holds iff the processes converge.
Suppose now that we have a consistent estimator of the true parameter . Feasible estimators for supremum, local time and occupation time measure are now obtained via the plug-in approach. In particular, we have
where , and
The construction of estimators of the unknown parameter for models (i) and (ii) is a well understood problem in the statistical literature. In particular, in class (i) the maximum likelihood estimator of is given by
and it holds that . Numerous theoretical results on parametric estimation of model (ii) can be found in e.g. [35]. Since the maximum likelihood estimator of is not explicit, we rather propose to use the following statistics:
where . Additionally, we need to ensure that our parameters are legal, and in particular , when larger than , is truncated at . Due to self-similarity of and the law of large numbers we have that
which gives the idea behind the construction of . Indeed, all estimators are weakly consistent and since for we easily conclude that
The proposed estimators are not efficient, but they suffice for our purposes, see Proposition 1 below.
It turns out that the limit theory presented in Theorem 2 and Theorem 3 continues to hold under a rather weak assumption on a consistent estimator of ; in particular, this assumption is satisfied by estimators we proposed above. In other words, the difference between the modified and original estimators is negligible in the right sense.
Proposition 1.
This shows that the estimators and are asymptotically efficient in the sense that they are asymptotically equivalent to the respective optimal estimators relying on the knowledge of true parameters. In class (ii) the true is not known, but in view of Proposition 1 the assumption guarantees that
Furthermore, the limit distributions are well approximated by their analogues corresponding to parameter , and so we may construct asymptotic confidence intervals for the estimators and .
With respect to local/occupation time we have the following result.
Proposition 2.
Consider class (i) and assume that
| (27) |
Then for any it holds that
This again shows that the estimators and are asymptotically efficient, and provides the respective asymptotic confidence bounds. Condition (27) is quite expected in the case of local times since is the corresponding rate of convergence in (25), but it is surprising that this condition is also sufficient to conclude the asymptotic efficiency of . Roughly speaking, the reason for condition (27) to be sufficient in the latter case is that partial derivatives of correspond to the local time asymptotics thus changing the convergence rate from to . We refer to §B.3 for more details.
4.2. Truncation of products in supremum estimators
Here we return to the assumption that the law of is known. Consider supremum estimators defined in §2.2 in terms of the conditional distribution function . When the number of observations is large, it may be desirable to reduce the number of terms in the product defining , in order to avoid numerical issues and to speed-up the calculations. This is especially true when is not a linear Brownian motion and so the function is not explicit.
Intuitively, we may want to keep the terms which are formed from the observations closest to the maximum. Thus, we let for be the analogue of , but such that the product has at most terms and, in particular, the indices are chosen such that with being the index of the maximal observation. Define and as before but using instead of .
Letting be the unique number satisfying (it achieves the minimum in (5)), we define
We now have the limit result analogous to Theorem 2:
Corollary 3.
For any it holds that
| (28) | ||||
| (29) |
It turns out that we do not need to exclude in the case of modified conditional mean estimator, because the number of terms is kept finite.
4.3. Comments on the general case in supremum estimation
It is likely that Theorem 2 can be generalized to an arbitrary Lévy process satisfying the following weak regularity condition:
for some positive function and necessarily self-similar Lévy process . Importantly, the general versions of (4) and (5) are proven in [29]; here the limiting objects correspond to .
There are, however, two very serious difficulties. Firstly, joint convergence does not necessarily imply convergence of the conditional distributions. Thus, one needs to use the underlying structure to show that
Secondly, the proof of uniform negligibility of truncation in §A.3.2 crucially depends on being self-similar. This part may be notoriously hard for a general Lévy process .
5. Numerical illustration of the limit laws
In this section we perform some numerical experiments in order to illustrate the limit laws in Theorem 2 and Theorem 3. For simplicity we take to be a standard Brownian motion and, additionally, a one-sided stable process in supremum estimation which is motivated by the semi-explicit formula for the function in Proposition 4. All the densities are obtained from independent samples using standard kernel estimates. The number of samples is reduced to in the case of the one-sided stable process.
5.1. Supremum estimation for Brownian motion
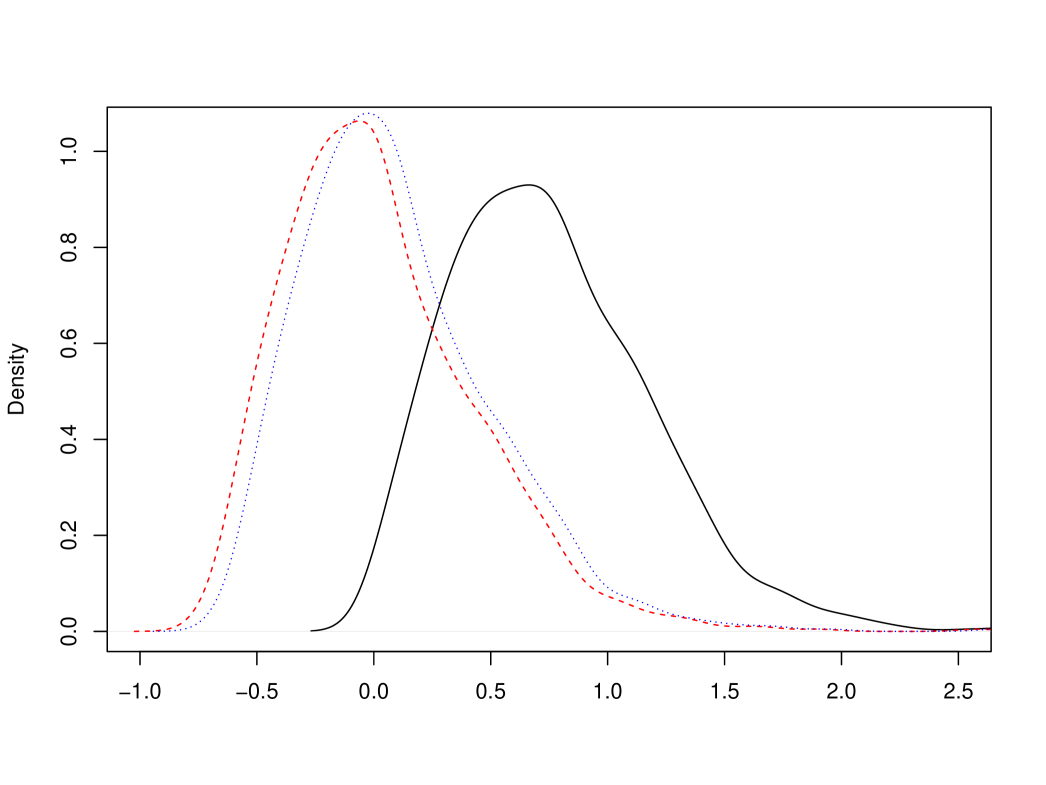
Consider a standard Brownian motion and the limiting random variable in (5), as well as and in (14) and (15), respectively. Recall that all of these quantities are explicit, see also Corollary 1, but they all depend on infinitely many observations of the two-sided 3-dimensional Bessel process . We approximate these quantities by setting for or , which effectively amounts to considering 100 epochs centered around 0; choosing twice as many epochs had negligible effect on the results below. The resulting densities are depicted in Figure 1. In Table 1 we report the Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), and the narrowest -confidence interval length for each of the limiting distributions. It is noted that, indeed, has the smallest RMSE and has the smallest MAE, and the respective distribution are very similar.
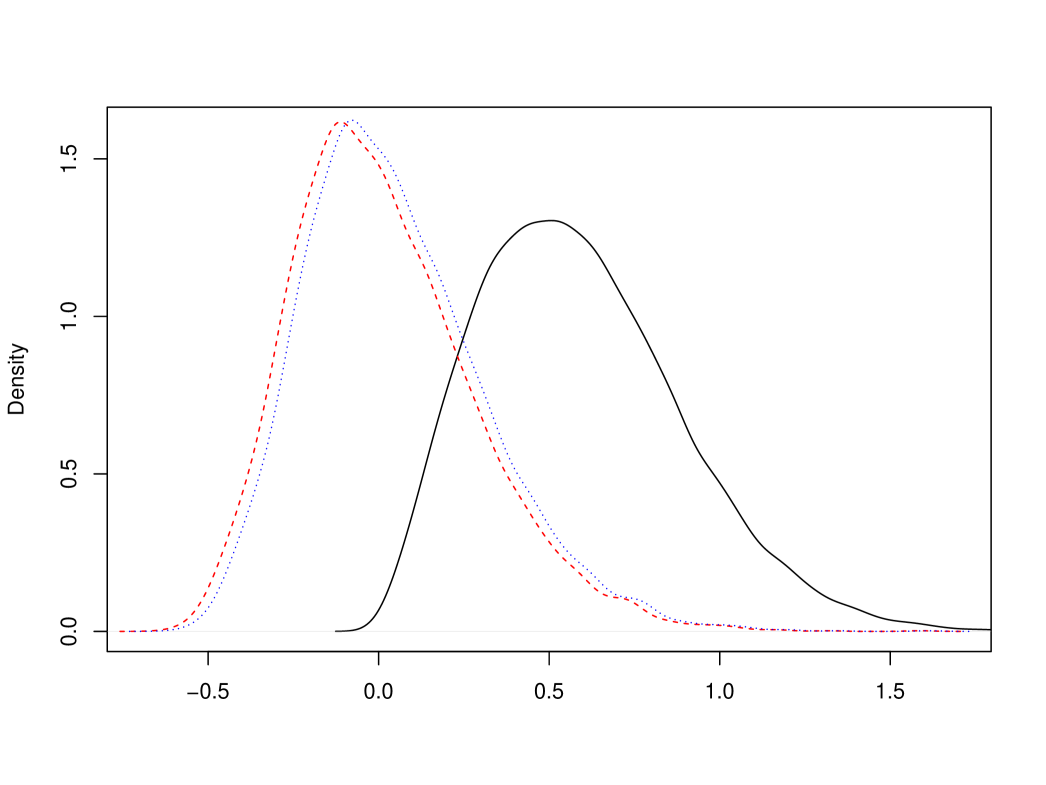
| RMSE | 0.66 | 0.26 | 0.27 | 0.30 | 0.29 |
|---|---|---|---|---|---|
| MAE | 0.59 | 0.21 | 0.21 | 0.24 | 0.22 |
| conf. int. length | 1.14 | 1.03 | 1.03 | 1.14 | 1.06 |
Observe that the main problem of the standard estimator is that it is downward biased and so is not centered. This, however, can be easily remedied since according to [6]
where is the Riemann zeta function. In other words, we may consider an asymptotically centered estimator , which leads to . Finally, we also consider the truncated conditional mean estimator based on , which is a product of two terms and thus only moderately more complicated to evaluate as compared to , see §4.2. The respective limit is denoted by . Relative comparison of the latter two together with is provided in Figure 2, see also Table 1.
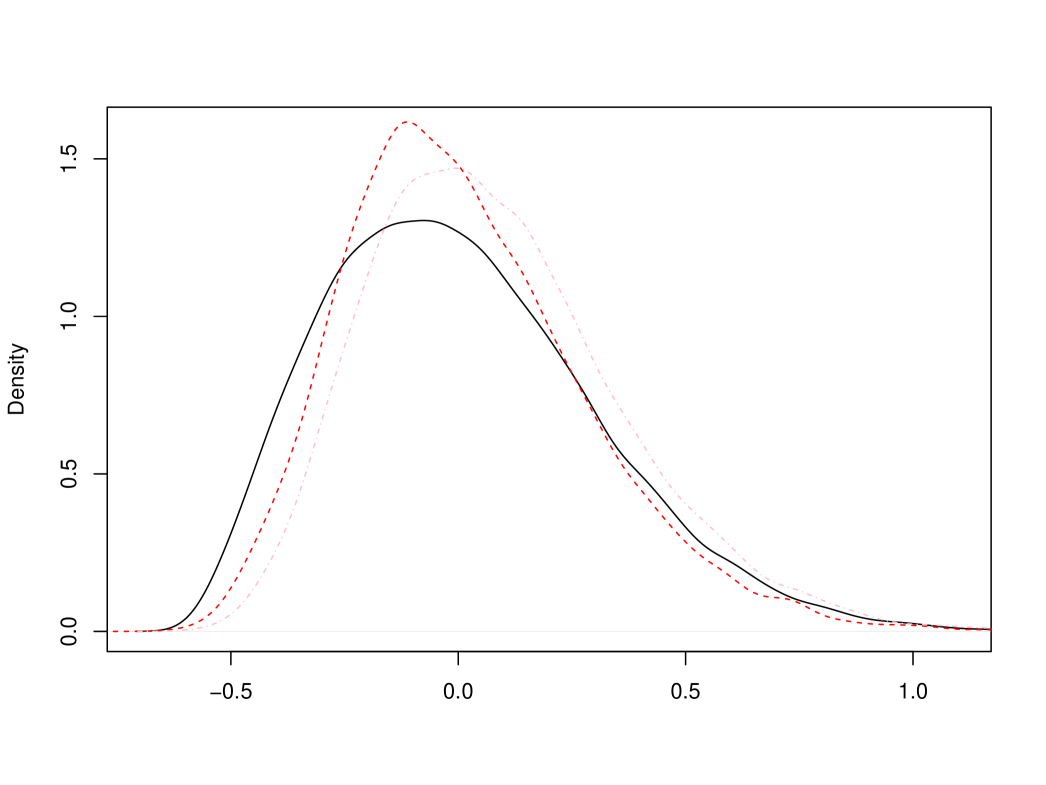
In conclusion, the conditional mean and conditional median estimators are very similar to each other and considerably better than the standard estimator in terms of RMSE and MAE. Nevertheless, the other simple estimators discussed above are only slightly worse than the optimal ones.
5.2. Supremum for one-sided stable process
Here we consider a strictly stable Lévy process with , standard scale and only negative jumps present, i.e., the skewness parameter is . Note that the results in the opposite case must be similar according to Proposition 3. The conditional distribution function is numerically evaluated using the expressions in Proposition 4, see Figure 3(a).
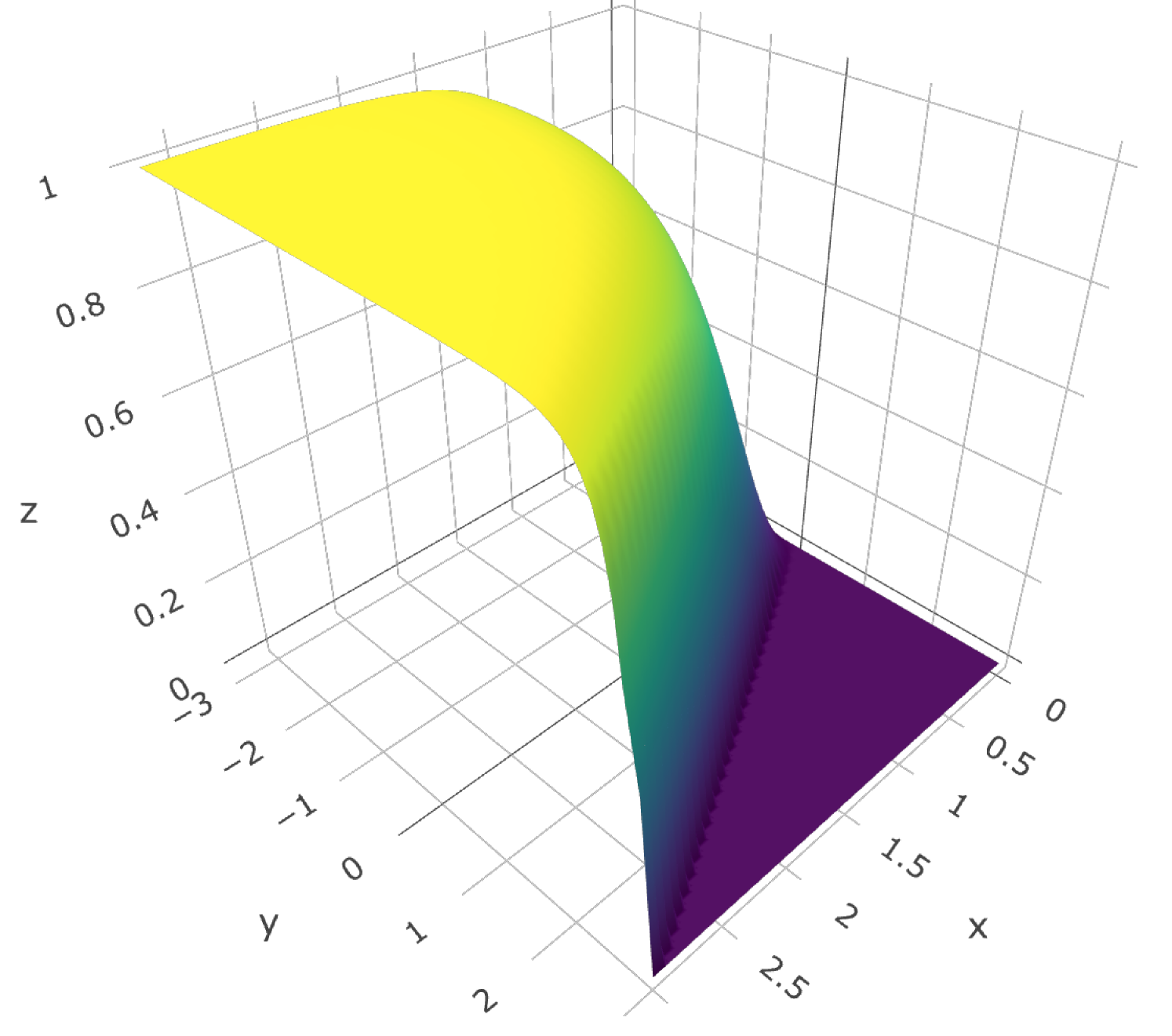
In this case we perform a number of approximations. Firstly, simulation of is not obvious (unlike the Brownian case) and so we approximate the limiting object by with , see (13). Instead of scaling with we perform the simulation of the process on the interval , which is allowed by self-similarity of . Furthermore, is simulated on the grid with step-size for , which yields an approximation of further corrected by the easily computable asymptotic mean error , see [7]. Next, we take (at most) terms in the product defining based on the observations closest to the maximum, that is we replace it by defined in §4.2. Finally, is approximated using the trapezoidal rule with step size and truncation at , see Figure 3(b); the same approximation is used in calculation of the inverse.
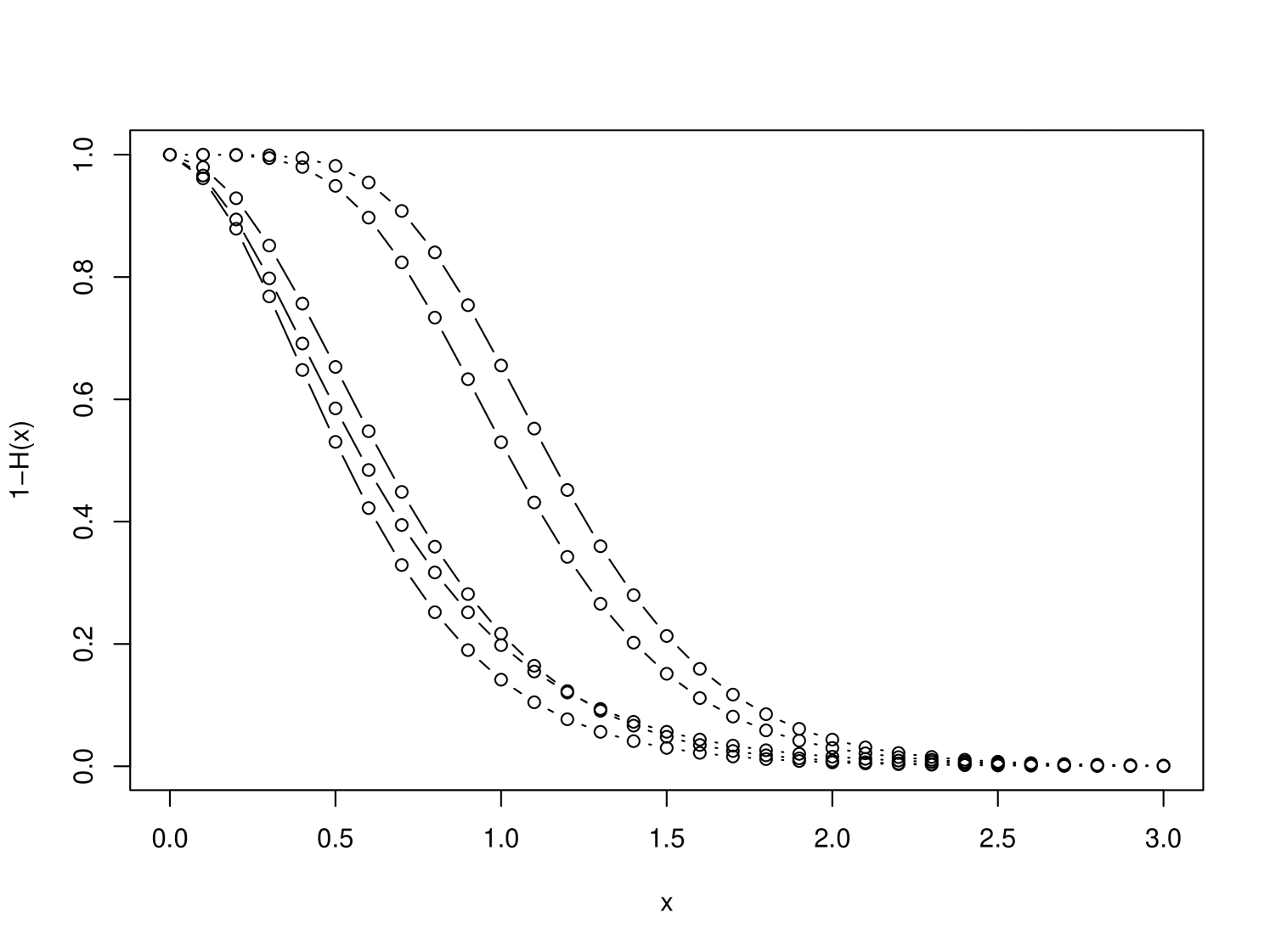
The results are presented in Figure 4 and Table 2. They are quite similar to the results in the Brownian case.
| RMSE | 0.87 | 0.41 | 0.42 | 0.43 |
|---|---|---|---|---|
| MAE | 0.75 | 0.32 | 0.32 | 0.34 |
| conf. int. length | 1.45 | 1.42 | 1.42 | 1.45 |
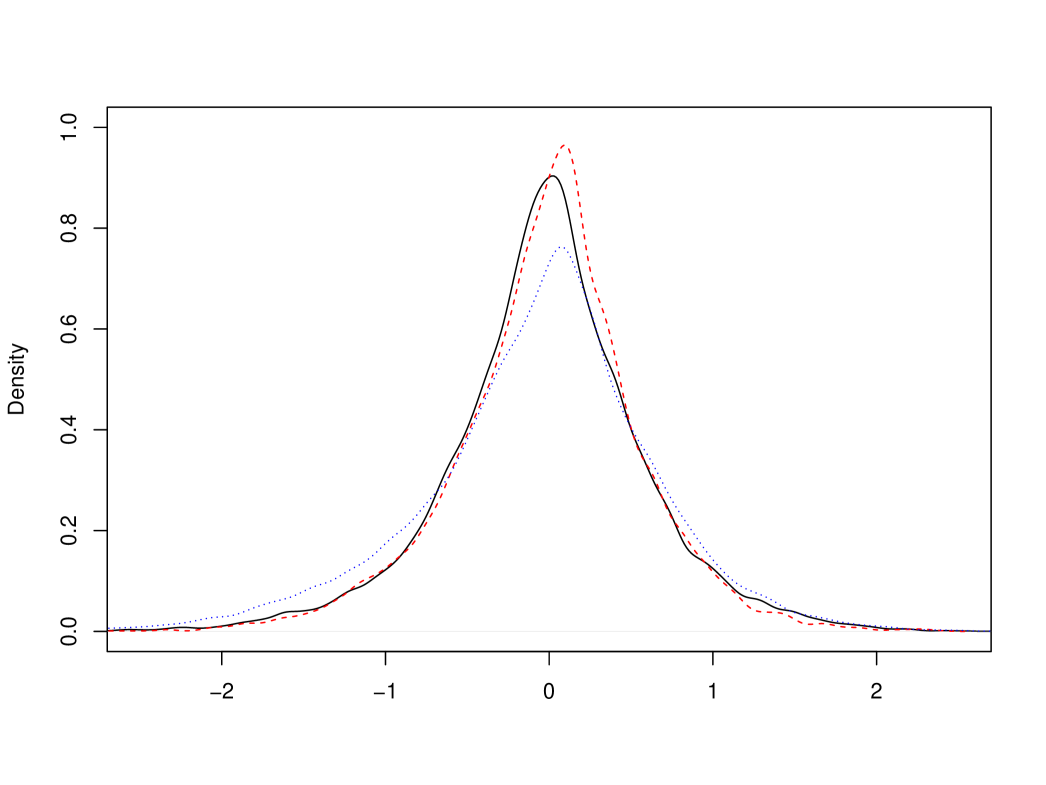
5.3. Local time and occupation time for Brownian motion
Let again be a standard Brownian motion and choose . We use with as a substitute for the true , which then allows to sample (approximately) from the limit distribution in (25). Next, we use the same sample path to construct with , which allows to sample from the pre-limit expression in (25). Finally, we also take a standard estimator for . The respective densities are depicted in Figure 5. The ratio of variances for is , which can be compared to for the more advanced estimator mentioned in Remark 1 (here we use the exact expressions of the limits).
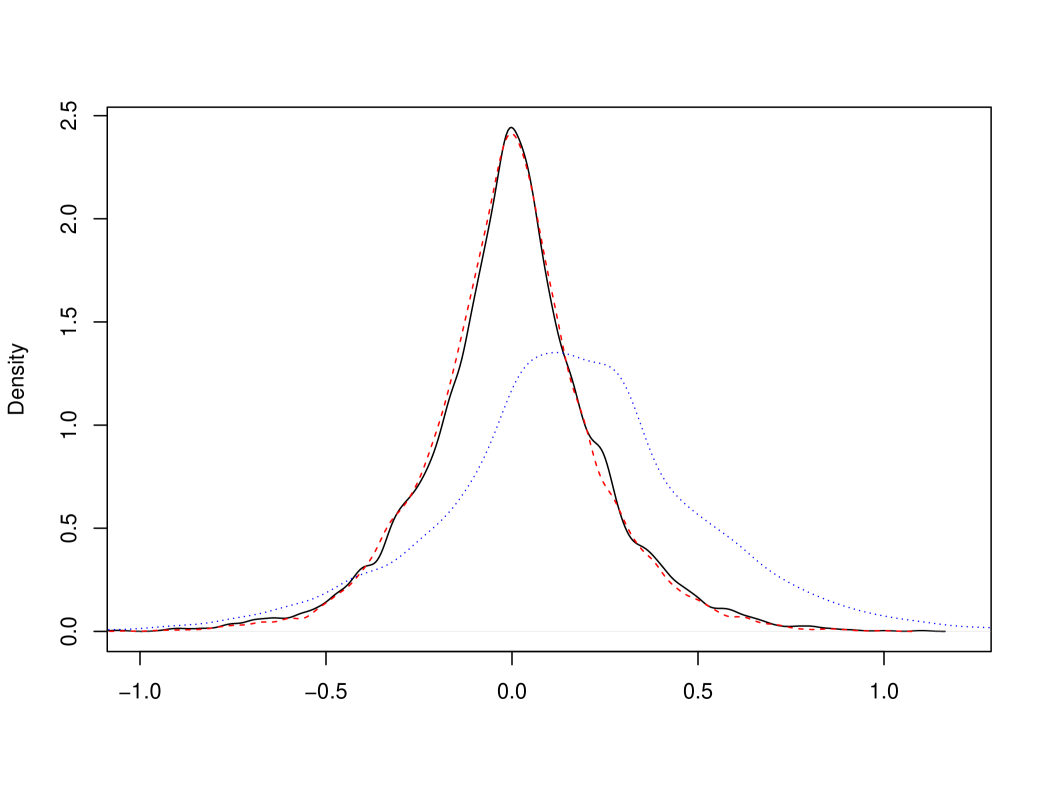
We perform a similar procedure for the occupation time in . Here the standard estimator is . The respective densities are given in Figure 6, and we see a very substantial improvement. The ratio of variances for is .
Acknowledgements
We would like to express our gratitude to Johan Segers for his comments concerning pre-estimation of model parameters.
Appendix A Proofs for supremum estimation
In the following all positive constants will be denoted by although the may change from line to line.
A.1. Duality
In this section we establish a duality result for a general Lévy process . Even though it is not needed for the proofs, we present this duality, because it explains certain structure in the main results. To this end, consider the process and the associated quantities , see §2.2.
Proposition 3.
Let be an arbitrary Lévy process. Then
Furthermore, .
Proof.
We take , which has the law of (standard time-reversal). Then , because does not jump at almost surely. Letting be the observation of we find that
Finally,
and the same reasoning works for when time-reverting at . ∎
In view of Proposition 3, the errors and have the same distribution as the respective errors for the process . Thus, the corresponding limit results must stay the same when the skewness parameter is flipped to the opposite. In the proofs we may safely assume that , say.
A.2. On the function in the stable case
Before starting the proof of the main result we establish some basic properties of the conditional probability in the case of a strictly -stable process when it is not explicit. Throughout this subsection we assume that is a strictly -stable process with skewness parameter . Note that the boundary values and correspond to spectrally negative and spectrally positive processes, respectively; in both cases we must have , because we have excluded monotone processes.
It is well known [41, p. 88] that has a continuous strictly positive bounded density, call it . Moreover, by self-similarity
| (30) |
Furthermore, as when , and otherwise it decays faster than an exponential function [41, Eq. (14.37)].
Let us define the first passage times above and below a given level .
Lemma 3.
The function is jointly continuous. Moreover, for , and otherwise
| (31) | ||||
| (32) |
where .
Proof.
Assume for the moment that . By time reversal (or from Proposition 3) we get
| (33) |
Using the strong Markov property we find that
is a version of the density of the measure on the left of (33). This expression coincides with (31) according to (30). Similarly, (32) is a version of the density of the measure on the right of (33), and hence both expressions coincide for almost all .
Next, we show that the expressions in (31) and (32) are jointly continuous on , and thus must coincide on this domain. We do this for the first expression only, since the other can be treated in the same way. By the basic properties of Lévy processes [10] we see that and is continuous on an event of probability 1. Hence we only need to show that the dominated convergence theorem applies. Choose an arbitrary sequence converging to with . Now for some (further down in the sequence). Note that for some and all ; in the spectrally positive case the decay is even faster. Hence the term under the expectation is bounded by and we are done.
It is left to show that either one of (31) and (32) converges to as with and (the boundary of the domain); this would imply . In the case use (31) and the above reasoning, while for use (32). It is left to analyze the case of . Note that (31) is lower bounded by the same expression with the indicator replaced by the indicator of . But now the dominated convergence theorem applies and yields the limit . The upper bound is by construction, and the limit is again . The proof is thus complete. ∎
We are now ready to provide some bounds on . In the one-sided cases the bounds can be considerably improved, but this is not needed in this work and so we prefer a simpler statement.
Lemma 4.
There exists a constant such that for all :
Proof.
Suppose that . We know that . According to (31) we then have
Assume that . In this case with and as , see [41, Eq. (14.37)]. Furthermore, the asymptotics of has a similar form [12, Prop. 3b]. Observe that for all . Hence, from (32) we get the bound
which for leads to the claimed bound . For we find from (31) that
which readily implies the bound . Similar analysis yields the bound in the case . ∎
It is noted that we may also derive a bound
for by using (32) instead of (31). This bound is better when and worse when . For our purpose any of these bounds is sufficient.
Finally, we derive a semi-explicit expression of in the one-sided case. This expression is in terms of the density .
Proposition 4.
In the spectrally one-sided cases we have for all :
Proof.
A.3. Proof of Theorem 2
In the following we frequently use the inequality
| (34) |
Let be the index of the first observation to the right of the supremum time, and put
In other words, are the rescaled distances from the supremum to the observations indexed with respect to the time of supremum. Now we can represent the quantities appearing in (13) as follows:
where by convention if either of is infinite. According to [29] (or [6] in the case of Brownian motion) we have the following weak convergence for every :
| (35) |
Intuitively, this limit can be understood as arising from (4) together with the fact that converges to an independent uniform on . This explains (of course, only intuitively) the form of the result in Theorem 2.
A.3.1. Convergence of the truncated versions
Let be the same as , but with the product running over :
where again when the index is out of range. We also define the analogous object formed from the limiting quantities:
Note that are continuous and strictly increasing in which is inherited from . Furthermore, , whereas their value at 0 is not necessarily 0. In the following the inverse of an increasing function is defined as usual: .
Lemma 5.
For any as we have
with respect to the uniform topology. Moreover,
where the limit variables are finite almost surely.
Proof.
In view of (35) we only need to establish the continuity of the respective maps. Consider -dimensional vectors and converging to some vectors and , respectively, where the entries of and are non-negative and the entries of are finite. Observe using (34) that
where convergence of is uniform in since the limit function is continuous and non-decreasing in , and is upper bounded (Polya’s theorem). Thus, the first statement is now proven.
Concerning the second statement, we find that
and it is left to show that each summand converges to 0, i.e. that the dominated convergence theorem applies. According to Lemma 4 both and are bounded by , because of monotonicity of in the first argument and the fact that ; the decay is even faster in the case of or when is a Brownian motion. The proof of the second statement is now complete, since finiteness of the limit is shown in the same way. ∎
A.3.2. Uniform negligibility of truncation
Showing that truncation at a finite is uniformly negligible (in the sense of [11, Thm. 3.2]) is the crux of the proof. Firstly, we will need the following representation-in-law of the sequences , which builds on [9] and self-similarity of .
Lemma 6.
There exists a process having the law of and a sequence of random variables such that and are non-negative non-decreasing sequences and the following is true: Let
for all , and otherwise . Then for all .
Proof.
By self-similarity has the same law as . According to [9], the law of the latter process when seen from the supremum, see (3), coincides with a certain process killed outside of the interval , where . It is noted that is constructed using juxtaposition of the excursions of in half-lines according to their signs, and it does not depend on . Clearly, and are non-decreasing sequences going to , and the laws of and defined by (3) coincide. It is now left to recall the definition of . ∎
We will also need asymptotic bounds on the process , which can be read of [25, Cor. 3.3] or [20], see also [37] for the Brownian case.
Lemma 7.
For any such that it holds that
In particular, the probability of the event
tends to as .
The following result establishes convergence of certain series, which is only needed for the case of a stable process with two-sided jumps.
Lemma 8.
Assume that and consider
Then there exist such that and the following series are convergent for any :
| (36) | ||||
| (37) |
Proof.
Assume that . Let us show that there exists a natural number and
such that for all . The th inequality reads as with being a continuous function such that iff . Note that it is sufficient to pick the smallest such that , where the latter denotes th iterate. To see that such exists, simply observe that converges to as .
Choose close enough to so that and
| (38) |
According to Lemma 5 in §C, for any we have
because on the respective event. Now for any we have
according to (38). Summing up over completes the proof of (36), because on the event we have for large enough. Moreover, the first interval can be replaced by without any change required.
Next, assume that and choose . Similarly, to the above calculation we find that it is sufficient to additionally guarantee that
This is always possible when . ∎
We are now ready to establish that truncation is indeed uniformly negligible:
Lemma 9.
For any we have
| (39) | |||
| (40) |
Moreover, almost surely it holds that
| (41) | |||
as .
Proof.
We start by showing (39). Using (34) we find that
where the summand is 0 when either of is infinite. By monotonicity of in the first argument, and the fact that can be made arbitrarily small by choosing large enough (recall that ), it is sufficient to show that
| (42) |
where we have replaced by having the same law as defined in Lemma 6. Note also that the sum here runs over since the other part () can be handled in the same way.
Choose with such that the conclusion of Lemma 8 is satisfied when . Note that we may restrict to the event for a large enough , see Lemma 7; that is, we have for all .
First, assume that and . According to Lemma 4 we have the bound (this bound is 0 when or is infinite)
where , see the definition of in Lemma 6. Now (42) follows by Markov’s inequality from
see Lemma 8. In the case and the above becomes
respectively, which is obviously true.
Next we show (40). With respect to the second statement we only need to show that
In the case the upper of Lemma 3 reads
for . Integrating over we get the bound and the proof is again completed by the Markov’s inequality and Lemma 8. In the case the bound is
and a similar bound holds for .
Finally, similar (but simpler) arguments show that there is convergence in probability in (41). But the product is monotone for each . Thus we have uniform convergence almost surely. For we find using above arguments that the integral is finite almost surely. Now the dominated convergence theorem applies. ∎
Proof of Theorem 2.
Let us show the stated properties of . It is clear that is non-decreasing and takes values in . Moreover, since one of the terms in the product is 0. Observe that (41) implies convergence of to uniformly in on the set of probability 1. Thus is continuous and , because the same is true about . Finally, is strictly monotone, since for every which follows from positivity of and (41).
Stable convergence statements in (13) and (14) follow from Lemma 5 and Lemma 9 by means of [11, Thm. 3.2] extended to the setting of stable convergence. Concerning (15) we apply Skorokhod’s representation theorem to the sequence (the underlying space of continuous functions with a limit at is indeed separable, as it can be time-changed into the space of continuous functions on ). The inverse is continuous and finite on and hence we have convergence of respective inverses [40, Prop. 0.1]. ∎
A.4. Related results
Here we provide the proofs (or just the main ingredients) of the results related to Theorem 2.
A.4.1. Linear Brownian motion
Proof of Corollary 1.
Firstly, note that the scaling can be indeed taken out as in (18) and (19) . This is true in general, because we may always rescale the process and the corresponding observations before the analysis. Thus we may assume that in the following.
Now suppose that and so is not self-similar. Recall that the estimators are the same as in the case . Furthermore, according to [6] the convergence in (35) is still true, where the limit variables are defined in terms of the same 3-dimensional Bessel process. The main difficulty is that Lemma 6 is no longer true and the proof of uniform negligibility of truncation fails.
By Girsanov’s theorem, we may introduce arbitrary drift using exponential change of measure with appropriately chosen constants . But then
where is arbitrary. But as the of this expression converges to , which can be made arbitrarily small. Thus (39) holds for an arbitrary linear Brownian motion, and the same argument works for (40). ∎
Proof of Lemma 1.
It is only required to show that is bounded for an arbitrarily large and all . Furthermore, we may again restrict our attention to a driftless Brownian motion by change of measure and Cauchy-Schwarz inequality. The fact that for any is bounded was established in [6], and so it is sufficient to show that
is bounded. The right-hand side is increased by pulling the sum out. Using the explicit expression for we see that it is left to consider
where we used that . Moreover, can be dropped out, because of Cauchy-Schwarz inequality and boundedness of . Finally, use Lemma 6 to get the bound:
The above is bounded by
The first sum is finite, because the inequality between arithmetic and quadratic means, , and the definition of Bessel-3 process imply that the respective terms are bounded by the quantity where is standard normal. By Tauberian theorem this quantity behaves as for large with being a positive constant, and the first sum is indeed finite. The second sum can be treated using the arguments from Appendix C. In particular, we can show that , and hence we are left to consider again. The proof is now complete. ∎
A.4.2. Joint estimation: proof of Corollary 2
A.4.3. On simplified estimators: proof of Corollary 3
We only need to show that the analogue of (35) is true, where we take the respective elements in the vectors on the left. One can not apply the continuous mapping theorem for the infinite sequences though. We consider truncated sequences, apply the continuous mapping theorem, and then show uniform negligibility of truncation. The latter follows from the fact that
for any , which readily follows from the representation of as in Lemma 6 in the self-similar case.
A.4.4. Unknown parameters: proof of Proposition 1
We will show that when , and the same is true for the conditional median estimator for all . The proof of continuity of the limit disributions follows similar steps, see also [29] for the convergence of the respective processes . The above readily translates into
respectively. We focus on the class of strictly stable Lévy processes (the proof for the class (i) is similar but easier) and let be the process with parameters . Furthermore we write and for the analogues of conditional distribution and density .
We claim that it is sufficient to establish that converges to continuously, i.e.
| (43) |
For this note that is arbitrarily close to with high probability, and thus the arguments from the proof of Theorem 2 apply essentially without a change.
Thus we are left to prove (43) by reexamining the proof of Lemma 3. Firstly, we observe that under weakly converges to the respective quantity under , which follows by the (generalized) continuous mapping theorem and weak convergence of the Lévy processes. Secondly, the function
converges to the obviously defined continuously on the domain , which follows from continuous convergence of the density of , see Lemma 10 below. Hence we have weak convergence of the quantity under the expectation in (31), and so it is left to show that the respective quantities are bounded. Lemma 10 completes the proof.
Lemma 10.
There is the uniform convergence: as . Moreover, for any it holds that
Proof.
The characteristic function of is given by according to with being a complex constant with positive real part (converging to ), see [43, Thm. C.4]. Thus by inversion formula we have
but this converges to 0 by the dominated convergence theorem, since the real parts of are positive and bounded away from 0.
With respect to the second statement we need to show that
is bounded for all and all , where ; the integral over is hadled in the same way, whereas the rest is clearly bounded by 2. Using integration by parts we find that it is sufficient to show that
is bounded, or equivalently the boundedness of
where . But and we are done. ∎
Appendix B Proofs for local and occupation times
Here denotes a linear Brownian motion with drift parameter and scale .
Proof of Lemma 2.
The fact that does not depend on follows readily by applying exponential change of measure, for example. Thus we may assume that and consider the process with being the standard Brownian motion. Using self-similarity of we find
and we readily find the stated expression for from the definition of . For further reference let us also note that
| (44) |
The formula for is obtained similarly, or directly from (20).
Next, we note that follow easily from symmetry, and so we assume in the following that . From [15, 1.3.8] we find
which indeed evaluates to the given expression. Next, we recall the Mill’s ratio: as . Hence
| (45) |
showing that is bounded since .
Finally, is clearly bounded by 1 and the given formulae are found from the occupation density formula , see (20). ∎
B.1. Local time
Proof of (25).
Firstly, we may replace by on the left hand side of (25), see [30, Rem. 2]. The result would follow from [30, Thm. 2.1] if we show that satisfies condition [30, (B-)] for some . But this follows from the bound for all , see the proof of Lemma 13.
Now we have the stated convergence, but the constant in front of the limit needs to be identified. The expressions in [30] are lengthy and non-trivial to evaluate, because of the generality assumed therein. In our case, is the conditional expectation and, in fact, a rather short direct proof can be given yielding the constant.
Direct Proof: As in [30] we observe that it is sufficient to consider the case , which can be extended to an arbitrary using change of measure argument. Importantly, is a functional of and this functional does not depend on . Next, consider a standard Brownian motion and assume that our result is proven for . Noting that as well as we find that
It is left to replace the process by having the same law. Thus we may assume in the following that is a standard Brownian motion.
Let be the pre-limiting object, where
and denotes the local time at in the interval . Firstly, observe using the scaling property (44) that
Thus we have
and similarly we find that
where for , and .
Let us show that for are bounded and in . By Minkowski’s and Jensen’s inequality we have the bound . Using additivity of we deduce that
where the latter moment is finite and is the first passage time of into the level . Finally, note that
and hence by symmetry are integrable. Thus according to [30, Thm. 1.1] we have
where the convergence is uniform on compact intervals of time. This immediately yields that
| (46) | |||
Finally, let be a continuous bounded martingale orthogonal to , i.e. . For define the process . Then the martingale representation theorem implies the existence of a progressively measurable process such that
Since we conclude that
| (47) |
The result now follows from [32, Thm. 7.28]. Moreover, we have a simple expression for which is evaluated in Lemma 11 below. ∎
It is left to calculate , which is the integrated reduction in variance when is replaced by its conditional mean :
Lemma 11.
For a standard Brownian motion we have
Proof.
Recalling that we find
According to [15, 1.3.4] we calculate
and
where in both cases we first integrate in . Combine these formulae to get the result.∎
B.2. Occupation time
Proof of (26).
We may assume that and let . Supposing that the result is true for we get
and so we assume that is a standard Brownian motion in the following.
Letting
and using
we find that
where for .
It is left to prove that are bounded and in for . The result then follows from [30, Thm. 1.1] and [32, Thm. 7.28] as for the local time. It would be sufficient to show the same property for where is arbitrary, because is the conditional expectation of given . When we take and observe that which is bounded and integrable over , see the local time case. When we take and observe that and the same conclusion is true. The proof is complete upon calculation of which is given in Lemma 12 below. ∎
Lemma 12.
For a standard Brownian motion we have
Proof.
Note that
because for the integrand can be rewritten as corresponding to the occupation time in and its conditional expectation, and it is left to apply symmetry.
The density of the occupation time is given in [15, 1.4.4] and reads as
Thus we find by integrating in first.
Similar trick works in the calculation of
Combination of these expressions yields the result. ∎
B.3. Unknown parameters
Let us define together with .
Lemma 13.
For any there exist constants and such that
for all .
Proof.
Recall that and so we may assume that . Furthermore, it is sufficient to establish the stated property for . This is so, because , the derivative is continuous in away from and integrable in . Hence
and the bound follows.
It is sufficient to establish the bound for :
locally uniformly in . This is so, because satisfies the analogous bound, see (45).
Writing for , respectively, we find from Lemma 2 for that
By L’Hôpitale and Mill’s ratio this quantity tends to 0 as , and thus this quantity is bounded for all locally uniformly in .
Next, we consider where
Note that and so the above terms stay bounded when implying that . Moreover, is bounded and so it is left to consider as . For this is bounded by and otherwise by , which is sufficient. ∎
Proof of Proposition 2.
Observe that
According to (27) we may assume that for an arbitrary and all large . By mean value theorem and Lemma 13 we have an upper bound
where . But verifies condition (B-0) in [30] and thus our upper bound converges to in probability, where is a certain finite random variable, see [30, Thm. 1.1]. The proof is complete since can be arbitrarily small. The corresponding proof for the occupation time measure follows exactly the same arguments. ∎
Appendix C On conditioned to stay positive
Throughout this section we assume that and . Let us recall that is a Feller process and, as usual, we denote its law when started from by . Such a process can be seen as conditioned to stay positive in a certain limiting sense, see [19, 16] for the basic properties of this process. The law of is then conditioned to stay positive, and the following bound holds without a change.
Proposition 5.
There exists a constant such that for all with we have
The proof will be at the end of this section. Let us note that the restriction can not be removed in the above bound. We start with a simpler result where :
Lemma 14.
There exists such that for all we have
Proof.
Let be the negativity parameter. Recall the semigroup of the conditioned process [16]:
Hence
Recall that as , and hence the first integral is upper bounded by
and the second has a similar bound. The result now follows. ∎
The following is an immediate consequence of the Doob’s -transform representation of the kernel; here .
Lemma 15.
For any it holds that
Proof.
For we have
and the result follows. ∎
Lemma 16.
There exists such that for all we have
Proof.
We only show the first statement, since the second follows the same arguments. According to Lemma 15 we find that
We may restrict the integration to the interval in view of Lemma 14. Thus it is sufficient to establish that
for all and . But the quantity on the left is upper bounded by
where according to Lemma 4; for bounded the result is obvious. Finally, observe that is bounded away from 0; here we may use Lemma 4 applied to the process . The proof is complete. ∎
References
- [1] Y. Aït-Sahalia and J. Jacod. High-frequency financial econometrics. Princeton University Press, 2014.
- [2] D. J. Aldous and G. K. Eagleson. On mixing and stability of limit theorems. Ann. Probability, 6(2):325–331, 1978.
- [3] R. Altmeyer. Central limit theorems for discretized occupation time functionals. Preprint arXiv:1909.00474, 2019.
- [4] R. Altmeyer. Estimating occupation time functionals. Preprint arXiv:1706.03418, 2019.
- [5] R. Altmeyer and J. Chorowski. Estimation error for occupation time functionals of stationary Markov processes. Stochastic Process. Appl., 128(6):1830–1848, 2018.
- [6] S. Asmussen, P. Glynn, and J. Pitman. Discretization error in simulation of one-dimensional reflecting Brownian motion. Ann. in Appl. Probab., pages 875–896, 1995.
- [7] S. Asmussen and J. Ivanovs. Discretization error for a two-sided reflected Lévy process. Queueing Syst., 89(1-2):199–212, 2018.
- [8] A. Banerjee, X. Guo, and H. Wang. On the optimality of conditional expectation as a Bregman predictor. IEEE Trans. Inform. Theory, 51(7):2664–2669, 2005.
- [9] J. Bertoin. Splitting at the infimum and excursions in half-lines for random walks and Lévy processes. Stochastic Process. Appl., 47(1):17–35, 1993.
- [10] J. Bertoin. Lévy processes, volume 121 of Cambridge Tracts in Mathematics. Cambridge University Press, Cambridge, 1996.
- [11] P. Billingsley. Convergence of probability measures. John Wiley & Sons, 1999. 2nd edition.
- [12] N. H. Bingham. Maxima of sums of random variables and suprema of stable processes. Z. Wahrscheinlichkeitstheorie und Verw. Gebiete, 26:273–296, 1973.
- [13] K. Bisewski and J. Ivanovs. Zooming-in on a Lévy process: Failure to observe threshold exceedance over a dense grid. Preprint arXiv:1904.06162, 2019.
- [14] A. N. Borodin. On the character of convergence to Brownian local time. I, II. Probab. Theory Relat. Fields, 72(2):231–250, 251–277, 1986.
- [15] A. N. Borodin and P. Salminen. Handbook of Brownian motion—facts and formulae. Probability and its Applications. Birkhäuser Verlag, Basel, second edition, 2002.
- [16] M. E. Caballero and L. Chaumont. Conditioned stable lévy processes and the Lamperti representation. Journal of Applied Probability, 43(4):967–983, 2006.
- [17] J. G. Cázares, A. Mijatović, and G. U. Bravo. Geometrically convergent simulation of the extrema of Lévy processes. Preprint arXiv:1810.11039, 2018.
- [18] L. Chaumont. On the law of the supremum of Lévy processes. Ann. Probab., 41(3A):1191–1217, 2013.
- [19] L. Chaumont and R. A. Doney. On Lévy processes conditioned to stay positive. Electron. J. Probab., 10(28):948–961, 2005.
- [20] L. Chaumont and J. C. Pardo. The lower envelope of positive self-similar Markov processes. Electron. J. Probab., 11:no. 49, 1321–1341, 2006.
- [21] E. Clément, S. Delattre, and A. Gloter. An infinite dimensional convolution theorem with applications to the efficient estimation of the integrated volatility. Stochastic Process. Appl., 123(7):2500–2521, 2013.
- [22] E. Clément, S. Delattre, and A. Gloter. Asymptotic lower bounds in estimating jumps. Bernoulli, 20(3):1059–1096, 2014.
- [23] R. A. Doney and M. S. Savov. The asymptotic behavior of densities related to the supremum of a stable process. Ann. Probab., 38(1):316–326, 2010.
- [24] D. Florens-Zmirou. On estimating the diffusion coefficient from discrete observations. J. Appl. Probab., 30(4):790–804, 1993.
- [25] S. Fourati. Inversion de l’espace et du temps des processus de Lévy stables. Probab. Theory Related Fields, 135(2):201–215, 2006.
- [26] T. Gneiting. Making and evaluating point forecasts. J. Amer. Statist. Assoc., 106(494):746–762, 2011.
- [27] J. I. González Cázares, A. Mijatović, and G. U. Bravo. Exact simulation of the extrema of stable processes. Adv. in Appl. Probab., 51(4):967–993, 2019.
- [28] Y. Hu and C. Lee. Drift parameter estimation for a reflected fractional Brownian motion based on its local time. J. Appl. Probab., 50(2):592–597, 2013.
- [29] J. Ivanovs. Zooming in on a Lévy process at its supremum. The Annals of Applied Probability, 28(2):912–940, 2017.
- [30] J. Jacod. Rates of convergence to the local time of a diffusion. Annales de l’I.H.P. (B), 34(4):505–544, 1998.
- [31] J. Jacod and P. Protter. Discretization of processes, volume 67 of Stochastic Modelling and Applied Probability. Springer, Heidelberg, 2012.
- [32] J. Jacod and A. N. Shiryaev. Limit theorems for stochastic processes, volume 288 of Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences]. Springer-Verlag, Berlin, 1987.
- [33] P. Kosulajeff. Sur la répartition de la partie fractionnaire d’une variable. Math. Sbornik, 2(5):1017–1019, 1937.
- [34] A. Lejay. Estimation of the bias parameter of the skew random walk and application to the skew Brownian motion. Stat. Inference Stoch. Process., 21(3):539–551, 2018.
- [35] H. Masuda. Parametric estimation of Lévy processes. In Lévy Matters IV, pages 179–286. Springer, 2015.
- [36] Z. Michna. Explicit formula for the supremum distribution of a spectrally negative stable process. Electron. Commun. Probab., 18:no. 10, 6, 2013.
- [37] M. Motoo. Proof of the iterated logarithm through diffusion equation. Ann. Inst. Statist. Math., 10:21–28, 1959.
- [38] H.-L. Ngo and S. Ogawa. On the discrete approximation of occupation time of diffusion processes. Electron. J. Stat., 5:1374–1393, 2011.
- [39] A. Rényi. On stable sequences of events. Sankhyā Ser. A, 25:293 302, 1963.
- [40] S. I. Resnick. Extreme values, regular variation and point processes. Springer Series in Operations Research and Financial Engineering. Springer, New York, 2008. Reprint of the 1987 original.
- [41] K.-I. Sato. Lévy processes and infinitely divisible distributions, volume 68 of Cambridge Studies in Advanced Mathematics. Cambridge University Press, Cambridge, 2013.
- [42] L. A. Shepp. The joint density of the maximum and its location for a Wiener process with drift. J. Appl. Probab., 16(2):423–427, 1979.
- [43] V. M. Zolotarev. One-dimensional stable distributions, volume 65 of Translations of Mathematical Monographs. American Mathematical Society, Providence, RI, 1986. Translated from the Russian by H. H. McFaden, Translation edited by Ben Silver.