Optimal Prediction using Learning and Shape Optimization
Abstract
This paper investigates the problem of optimal predictor design for distributed parameter systems using neural networks and shape optimization. Sensors with various shapes are placed on the domain of the distributed parameter system. Data provided by these sensors are fed into a re-constructor to generate a full state of the system. After that, a trained neural-network predictor produces a prediction of the state at future time steps. The cost of prediction is defined as the weighted sensor area plus the squared norm of the prediction error. The location and shape of a sensor influences the prediction cost as well as the predictor performance. With the aid of the gradient of the network with respect to its inputs, an outer optimization layer is augmented to find optimized locations and shapes of the sensors. Simulation results show good agreement between the predicted and the true states as well as a significant reduction in cost by sensors with optimized locations and shapes.
1 Introduction
Estimation is of fundamental importance in many disciplines. For example, it is important in climate science to predict the temperature changes in the Earth atmosphere (Park et al., 2019). Estimation is also used to find sea surface temperature in order to predict weather (Nielsen-Englyst et al., 2018). In economics, estimation is used to predict investment risks. In control theory, estimation is used to feedback from the state of the system at locations not accessible by sensors. Most commonly, estimation is used to reconstruct the state of a system modeled by partial differential equations such as the heat and wave equations.
In recent years, machine learning methods have been used to extract predictive models from large sets of data provided by sensors. These methods can further find a symbolic representation of the model (symbolic regression) and also discover the hidden physics. Among the machine learning methods, deep neural networks have gained considerable attention (LeCun et al., 2015). Evolutionary algorithms (Vaddireddy et al., 2020), compressive sensing (Candès & Wakin, 2008), and sparse optimization (Candès et al., 2008) are also machine learning algorithms used for logistic regression. In (Long et al., 2018), a PDE-net approach is proposed to predict the dynamics of systems modeled by partial differential equations (PDEs) from sensor data. The network is also able to uncover the underlying PDE model. In (Lu et al., 2018), it is shown that deep neural networks such as ResNet, PolyNet, FractalNet, and RevNet can be interpreted as different numerical discretizations of differential equations. This interpretation is further used to design new deep neural networks. In (Liu et al., 2010, 2013), training data for image restoration is used to create a learning-based PDE model for computer vision tasks. The problem is stated as an optimal control problem where the inputs and outputs are training images. The authors show the effectiveness of their model by numerical experiments on image denoising and inpainting problems in image restoration.
The shape optimization of sensors and actuators in the context of PDEs has been discussed in relatively few works. In (Privat et al., 2013), the optimal shape and position of an actuator for the wave equation in one spatial dimension are discussed. An actuator is placed on a subset with a constant Lebesgue measure for some . The optimal actuator minimizes the norm of a Hilbert Uniqueness Method (HUM)-based control; such control steers the system from a given initial state to zero state in finite time. In (Privat et al., 2017), the optimal actuator shape and position for linear parabolic systems are discussed. This paper adopts the same approach as in (Privat et al., 2013) but with initial conditions that have randomized Fourier coefficients. The cost is defined as the average of the norm of HUM-based controls. In (Kalise et al., 2018), optimal actuator design for linear diffusion equations has been discussed. A quadratic cost function is considered, and shape and topological derivatives of this function are derived. Numerical results show significant improvement in the cost and performance of the control. In (Edalatzadeh et al., 2019), the optimal shape of actuators for vibration control of flexible beams is investigated using a linear-quadratic performance index and shape optimization.
Optimal sensor design problems are in many ways similar to the optimal actuator design problem. In (Privat et al., 2014), optimal sensor shape design has been studied where the observability is being maximized over all admissible sensor shapes. Optimal actuator design problems for nonlinear distributed parameter systems have also been studied. In (Edalatzadeh & Morris, 2019), it is shown that under certain conditions on the nonlinearity and the cost function, an optimal input and actuator design exist, and optimality conditions are derived. Results are applied to the nonlinear railway track model as well as to the semi-linear wave model in two spatial dimensions. Numerical techniques to calculate the optimal actuator shape design are mostly limited to linear quadratic regulator problems, see, \eg, (Allaire et al., 2010). For controllability-based approaches, numerical schemes have been studied in (Münch & Periago, 2011; Münch, 2007; Münch & Periago, 2013).
In this paper, we combine shape optimization with learning-based PDE models to find the optimal shape of sensors, as well as an estimator of the full state of the PDE. In \crefsection:estimator_design, the neural-network predictor is formulated, which recovers the full PDE state from limited sensor data and predicts the state at the subsequent time step. \Crefsection:shape_optimization discusses the shape optimization of sensors. Simulations results are presented in \crefsection:simulation_results. Concluding remarks are given in \crefsection:conclusion.
2 Estimator design
Consider a first-order dynamical system with state , initial condition , state space , and linear or nonlinear operator on :
| (1) |
In our applications, is a second-order partial differential (PDE) operator acting on functions in one or two spatial dimensions. The evolution of the state in discrete time with sufficiently small time increment can be described, using for simplicity an explicit Euler method, as
| (2) |
with initial value . For numerical computation, we also need to discretize in space. For simplicity of notation, we currently assume to be a space of functions on a one-dimensional interval, which we discretize with a mesh of equidistant points. The results provided in \crefsection:simulation_results include two-dimensional examples as well. Discretizing accordingly, here using a finite difference method, we obtain from \eqrefeq:first-order_system_discrete_in_time the fully discrete evolution
| (3) |
Each element in the vector represents an approximation of the true state at one of the spatial grid points and time .
A neural-network predictor takes the current state vector (or a reconstruction thereof) and predicts the solution at the next time step . The estimator network is trained over simulation data or acquired real-life data. In most cases, the state cannot be fully measured by an array of sensors. Therefore, the data provided by the sensors available represents an incomplete state vector and the full state vector is reconstructed first before being fed into the predictor network.
The reconstruction of an incomplete state reading works as follows. A sensor arrangement is encoded in a -dimensional vector . Each element of indicates the weight of the presence of a sensor at the respective vertex. Weights less than 0.5 will be treated as no sensor present. The function provides an approximate reconstruction based on an interpolation of neighboring sensors measurements, \Creffig-recons. That is, we have . A cubic spline interpolation is used in the one-dimensional simulations. This interpolation is a suitable choice for PDEs with second-order spatial derivatives.
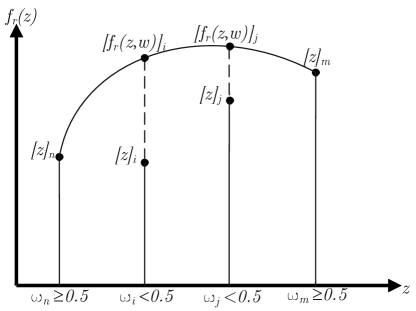
The function provides a neural-network prediction of the state using reconstructed data; that is
| (4) |
Different types of neural networks lead to different formulations for the predictor function . Examples are given in \crefsection:simulation_results.
3 Sensor shape optimization
In this section, we consider an optimization of the sensor configuration encoded in the weight vector .
Clearly, from the prediction point of view, it is beneficial to have sensors everywhere.
In this case, we would have since no interpolation is necessary.
On the other hand, we associate a cost with each sensor placed.
Our goal is to obtain a compromise between the number of sensors and the accuracy of the predictions of the state , based on the partially observed previous state .
We express this goal in terms of the cost function
{multline}
J(ω)
=
α ∑_i=1^c[ω]_i
+
∑_k=0^K-1 ∑_i=1^c \paren[big][]f_n(f_r(z_k,ω)) - z_k+1_i^2 h_i Δt
.
Here denotes the number of grid points in time.
Notice that the second term in \eqrefeq:cost_function represents a discretized version of the mean squared error.
The sequence depends on the spatial mesh size and the quadrate scheme used; for instance, implements the trapezoidal rule with mesh size .
A similar formula holds in two spatial dimensions.
The derivative of with respect to (\wrt) the sensor weight vector is
{multline}
[J’(ω)]_i
=
α
+
2∑_k=0^K-1 ∑_i=1^c \paren[big][]\paren[big]()f_n(f_r(z_k,ω)) - z_k+1^\transpZ_k+1’_i h_i Δt
.
Here is the derivative of \wrt .
From the chain rule, we obtain
| (5) |
where the right hand side is a product of two matrices. The first factor represents the derivative of the estimator network’s output \wrt its input vector, while the second factor is the derivative of the outcome of the spline interpolation \wrt . The latter derivative is zero except when there are components of right at the threshold . In this case, the derivative becomes a Dirac function. Simulation results, however, indicate that the first term in \eqrefeq:chain_rule is sufficient to provide search directions suitable to reduce the cost function. Therefore, we use the approximation
| (6) |
to evaluate the derivative in \eqrefeq:derivative_of_cost_function. Its transpose, the approximate gradient , is then used in a trust-region optimization algorithm to find an improved sensor configuration vector .
4 Simulation results
In this section, we provide numerical results for a range of different PDE models. Our goal is to demonstrate that, in each case, optimized sensor configurations and properly trained predictor networks can obtain sufficiently accurate predictions of the state vector. To this end, we show that the cost for an optimized weight is significantly lower than the cost for the all-sensor case , , for which the lower bound is valid. The overall procedure is described in \crefalgorithm:deep_learning_and_shape_optimization.
For each example, we build an estimator neural network using the deep learning package Keras (version 2.4.0). We employ a linear activation function and the mean squared error (MSE) loss function in the networks and use the Adam optimizer for training. The Adam optimizer and the MSE loss function yielded better performance compared to the rest of available optimization algorithms and loss functions. For PDE models in one space dimension, the network layout consists of two dense layers, where each layer has as many neurons as grid nodes. For PDE models in two space dimensions, a convolutional neural network with one layer, one filter and kernel size and zero padding is considered. In each case, the gradient of the network is calculated using the method backend in Keras.
In the implementation of the reconstructor function , the sensor data is reconstructed using the Python package interpolate. For PDE models in one space dimension, CubicSpline is used, whereas interp2d is chosen in two space dimensions.
Simulations are presented for a variety of PDE models in the following subsections. In figures and formulas, denotes the true (simulated) solution, which corresponds to in the notation of \crefsection:estimator_design,section:shape_optimization. Moreover, denotes the predicted solution corresponding to according to \eqrefeq:reconstruction_followed_by_prediction.
4.1 One-dimensional heat equation
Consider the following heat equation in one space dimension over
| (7) |
A forward-in-time and space-centered finite difference method is used to discretize the model and extract the solution data . The predictor neural network is then trained on the solution data. The estimation performance is shown in \creffig-snapshots-heat-IC1,fig-snapshots-heat-IC2,fig-snapshots-heat-IC3,fig-snapshots-heat-step for various initial conditions . The sensor weight is set to 5; mesh size is set to (resulting in ); time increment is set to ; and conductivity is set to .
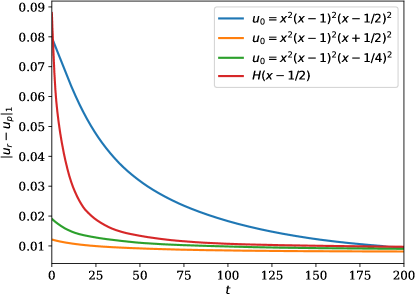
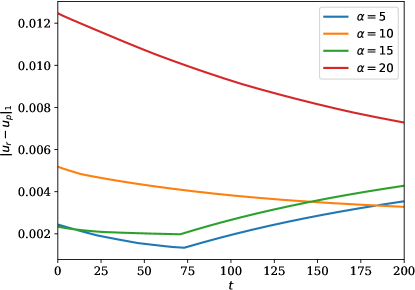
fig-l1norm-linearheat shows the -norm of the error over time, \ie,
| (8) |
which is small compared to the solution although only a fraction of the sensors is being used in each case, see \creffig-snapshots-heat-IC1,fig-snapshots-heat-IC2,fig-snapshots-heat-IC3,fig-snapshots-heat-step. In these figures, 17% of the PDE region is covered with sensors.
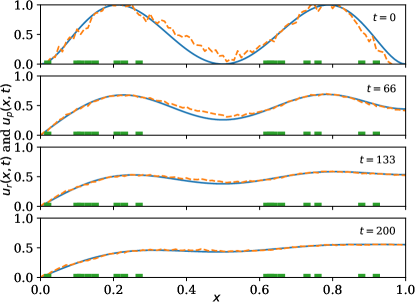
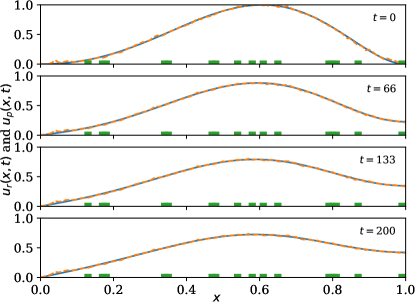
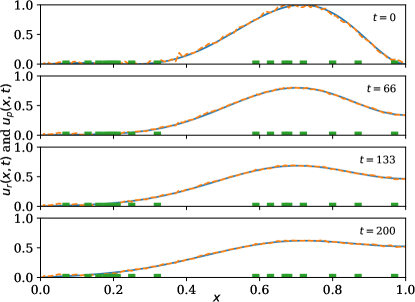
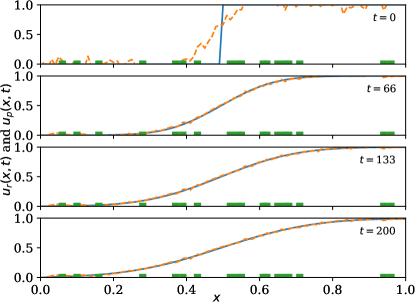
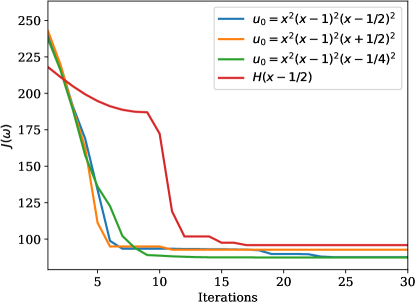
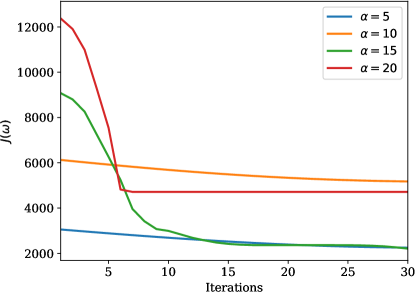
The reduction in cost over iteration is shown in \creffig-cost-heat-linear.
4.2 One-dimensional wave equation
Consider the following linear one-dimensional wave equation over
| (9) |
A time-centered and space-centered finite difference method is used to discretize the wave model and extract the solution data. The estimation performance is shown in \creffig-snapshots-wave-IC1,fig-snapshots-wave-IC2,fig-snapshots-wave-IC3 for various initial conditions . The sensor weight is set to 2, the mesh size is set to (resulting in ); time increment is set to ; and squared wave speed is set to .
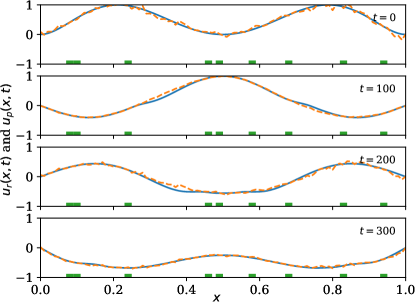
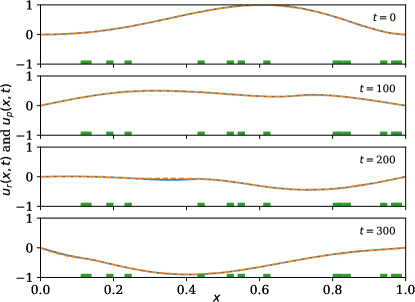
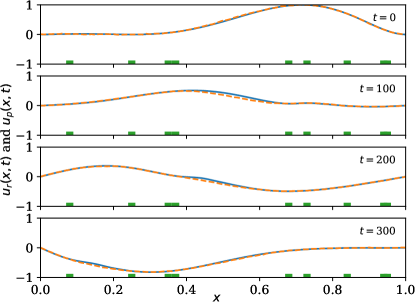
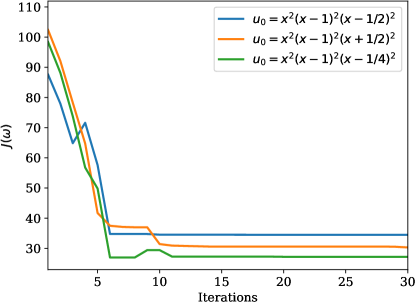
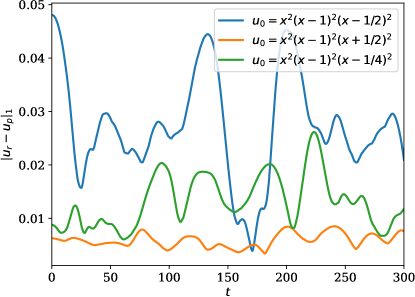
Similar to the previous example, we observe good agreement between the predicted and the true state (\creffig-linftynorm-wave-linear) although only very few sensors are in use. In \creffig-snapshots-wave-IC1 and \creffig-snapshots-wave-IC3, only 9% of the wave region is covered with sensors, and in \creffig-snapshots-wave-IC2, this number is 14%. The reduction in cost over iteration is shown in \creffig-cost-wave-linear.
4.3 Two-dimensional heat equation
Consider the following heat equation in two space dimensions over
| (10) |
The discretization is similar as in \crefsubsection:1Dlinearheat. The mesh size is uniform with length ; time increment is set to ; and conductivity is set to . The initial condition is set to , scaled to .
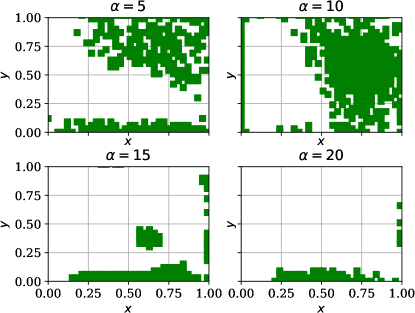
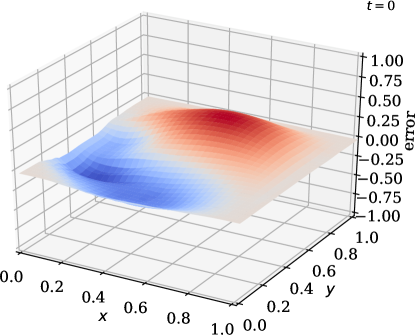
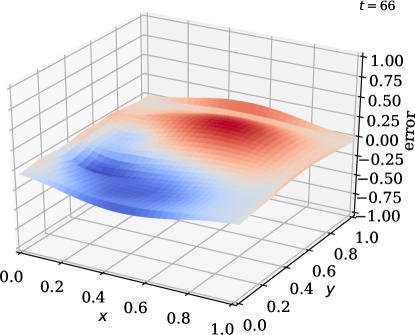
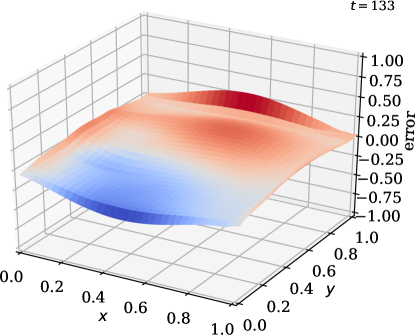
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/25520ab0-a9bc-4d7f-b538-3b893d567291/x17.png)
In this example, we vary the value of the sensor weight coefficient . Once again, we observe good agreement between the predicted and the true state (\creffig-norm-2D-heat) although only few sensors are in use; see \creffig-optimal-sensor-2D-heat,fig-snapshots-2D-heat. The reduction in cost over iteration is shown in \creffig-cost-2D-heat.
5 Conclusion
Optimal prediction for distributed parameter systems was discussed in this paper. The optimal predictions involves two steps. In the first step, a neural network predictor is designed. In the second step, sensor shapes are optimized using the gradient of the network. Computer simulations are conducted for several models including heat and wave equation in one and two space dimensions. The results show a significant reduction in cost of prediction as well as improvement in the predictor performance. The computer codes are accessible in the repository \urlhttps://github.com/TUCMath/optimal-predictor.
References
- Allaire et al. (2010) Allaire, G., Münch, A., and Periago, F. Long time behavior of a two-phase optimal design for the heat equation. SIAM Journal on Control and Optimization, 48(8):5333–5356, 2010. doi: 10.1137/090780481.
- Candès & Wakin (2008) Candès, E. J. and Wakin, M. B. An introduction to compressive sampling. IEEE Signal Processing Magazine, 25(2):21–30, 2008. doi: 10.1109/msp.2007.914731.
- Candès et al. (2008) Candès, E. J., Wakin, M. B., and Boyd, S. P. Enhancing sparsity by reweighted minimization. Journal of Fourier Analysis and Applications, 14(5-6):877–905, 2008. doi: 10.1007/s00041-008-9045-x.
- Edalatzadeh & Morris (2019) Edalatzadeh, M. S. and Morris, K. A. Optimal actuator design for semilinear systems. SIAM Journal on Control and Optimization, 57(4):2992–3020, 2019. doi: 10.1137/18m1171229.
- Edalatzadeh et al. (2019) Edalatzadeh, M. S., Kalise, D., Morris, K. A., and Sturm, K. Optimal actuator design for vibration control based on LQR performance and shape calculus. arXiv: \hrefhttps://arxiv.org/abs/1903.075721903.07572, 2019.
- Kalise et al. (2018) Kalise, D., Kunisch, K., and Sturm, K. Optimal actuator design based on shape calculus. Mathematical Models and Methods in Applied Sciences, 28(13):2667–2717, 2018. doi: 10.1142/s0218202518500586.
- LeCun et al. (2015) LeCun, Y., Bengio, Y., and Hinton, G. Deep learning. Nature, 521(7553):436–444, 2015. doi: 10.1038/nature14539.
- Liu et al. (2010) Liu, R., Lin, Z., Zhang, W., and Su, Z. Learning PDEs for image restoration via optimal control. In Computer Vision ECCV 2010, pp. 115–128. Springer Berlin Heidelberg, 2010. doi: 10.1007/978-3-642-15549-9_9.
- Liu et al. (2013) Liu, R., Lin, Z., Zhang, W., Tang, K., and Su, Z. Toward designing intelligent PDEs for computer vision: An optimal control approach. Image and Vision Computing, 31(1):43–56, 2013. doi: 10.1016/j.imavis.2012.09.004. arXiv: \hrefhttps://arxiv.org/abs/1109.10571109.1057.
- Long et al. (2018) Long, Z., Lu, Y., Ma, X., and Dong, B. PDE-Net: Learning PDEs from data. In Dy, J. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp. 3208–3216, Stockholmsmässan, Stockholm, Sweden, 2018. PMLR. URL \urlhttp://proceedings.mlr.press/v80/long18a.html.
- Lu et al. (2018) Lu, Y., Zhong, A., Li, Q., and Dong, B. Beyond finite layer neural networks: bridging deep architectures and numerical differential equations. In Dy, J. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp. 3276–3285, Stockholmsmässan, Stockholm, Sweden, 2018. PMLR. URL \urlhttp://proceedings.mlr.press/v80/lu18d.html.
- Münch (2007) Münch, A. Optimal location of the support of the control for the 1-D wave equation: numerical investigations. Computational Optimization and Applications, 42(3):443–470, 2007. doi: 10.1007/s10589-007-9133-x.
- Münch & Periago (2011) Münch, A. and Periago, F. Optimal distribution of the internal null control for the one-dimensional heat equation. Journal of Differential Equations, 250(1):95–111, 2011. doi: 10.1016/j.jde.2010.10.020.
- Münch & Periago (2013) Münch, A. and Periago, F. Numerical approximation of bang–bang controls for the heat equation: An optimal design approach. Systems & Control Letters, 62(8):643–655, 2013. doi: 10.1016/j.sysconle.2013.04.009.
- Nielsen-Englyst et al. (2018) Nielsen-Englyst, P., Høyer, J. L., Pedersen, L. T., Gentemann, C. L., Alerskans, E., Block, T., and Donlon, C. Optimal estimation of sea surface temperature from AMSR-E. Remote Sensing, 10(2):229, 2018. doi: 10.3390/rs10020229.
- Park et al. (2019) Park, I., Kim, H. S., Lee, J., Kim, J. H., Song, C. H., and Kim, H. K. Temperature prediction using the missing data refinement model based on a long short-term memory neural network. Atmosphere, 10(11):718, 2019. doi: 10.3390/atmos10110718.
- Privat et al. (2013) Privat, Y., Trélat, E., and Zuazua, E. Optimal location of controllers for the one-dimensional wave equation. Annales de l’Institut Henri Poincare (C) Non Linear Analysis, 30(6):1097–1126, 2013. doi: 10.1016/j.anihpc.2012.11.005.
- Privat et al. (2014) Privat, Y., Trélat, E., and Zuazua, E. Optimal shape and location of sensors for parabolic equations with random initial data. Archive for Rational Mechanics and Analysis, 216(3):921–981, 2014. doi: 10.1007/s00205-014-0823-0.
- Privat et al. (2017) Privat, Y., Trélat, E., and Zuazua, E. Actuator design for parabolic distributed parameter systems with the moment method. SIAM Journal on Control and Optimization, 55(2):1128–1152, 2017. doi: 10.1137/16m1058418.
- Vaddireddy et al. (2020) Vaddireddy, H., Rasheed, A., Staples, A. E., and San, O. Feature engineering and symbolic regression methods for detecting hidden physics from sparse sensor observation data. Physics of Fluids, 32(1):015113, 2020. doi: 10.1063/1.5136351.