Optimal Probabilistic Catalogue Matching for Radio Sources
Abstract
Cross-matching catalogues from radio surveys to catalogues of sources at other wavelengths is extremely hard, because radio sources are often extended, often consist of several spatially separated components, and often no radio component is coincident with the optical/infrared host galaxy. Traditionally, the cross-matching is done by eye, but this does not scale to the millions of radio sources expected from the next generation of radio surveys. We present an innovative automated procedure, using Bayesian hypothesis testing, that models trial radio-source morphologies with putative positions of the host galaxy. This new algorithm differs from an earlier version by allowing more complex radio source morphologies, and performing a simultaneous fit over a large field. We show that this technique performs well in an unsupervised mode.
keywords:
catalogues – surveys – methods: statistical1 Introduction
Techniques for automated cross-matching catalogues of optical and infrared (IR) sources are well-established, resulting in services such as Vizier (Ochsenbein, Bauer & Marcout 2000), Simbad (Wenger et al. 2000), NASA Extragalactic Database (NED; Mazzarella, Madore & Helou 2001), NASA/IPAC Infrared Science Archive (IRSA), and SkyQuery (Malik et al. 2003; Budavari, Dobos & Szalay 2013).
Cross-matching radio sources to optical/IR catalogues is much more difficult, because about 10% of radio sources consist of extended radio lobes resulting from the interaction of relativistic jets of electrons emitted from the environs of a super-massive black hole (SMBH) in the nucleus of the host galaxy. Sometimes this central core is visible in the radio, resulting in a triple radio source, and sometimes only the lobes are visible, resulting in a double radio source.
For clarity in this paper, we distinguish between a radio “component”, consisting of a single blob of radio emission, and a radio “source”, consisting of all the radio emission associated with one host galaxy. In general, one radio source will consist of several radio components.
One consequence is that a pair of radio components might either be two separate galaxies, or a pair of radio lobes surrounding one galaxy. Often, this question can only be resolved by comparing the radio image with the optical/IR image, so that the process of cross-identification merges with the process of classification.
Another consequence is that there is often no radio component coincident with the host galaxy, so that associating radio catalogues with optical/IR catalogues needs to take account of the overall radio source morphology, ruling out the use of simple nearest-neighbour of likelihood-ratio algorithms (e.g., Weston et al., 2018). As a result, this cross-matching has traditionally been done by eye, but this becomes impractical for future radio surveys in which tens of millions of objects are likely to be discovered (Norris, 2017). This present paper is primarily driven by the Evolutionary Map of the Universe (EMU) project (Norris et al., 2011) which hopes to catalogue about 70 million radio sources.
One response to this challenge has been the development of Radio Galaxy Zoo (Banfield et al., 2015), in which citizen scientists cross-match radio sources with their infrared counterparts. Another response has been the development of the rapidly growing field of machine-learning (ML) approaches to classifying and cross-matching radio and IR/optical sources (e.g., Aniyan & Thorat, 2017; Alger et al., 2018; Lukic et al., 2018; Wu et al., 2019; Galvin et al., 2019; Ralph et al., 2019).
As an alternative to ML approaches, we presented (Fan et al., 2015) a Bayesian approach in which, for each source, we constructed a number of hypotheses. In each hypothesis we identified individual radio components as lobes or core sources, and trialled putative associations with the host galaxy, chosen from a catalogue of infrared sources. We then chose the hypothesis for each source that had the highest probability. The ILP differs from ML techniques in that it uses prior expert knowledge about the morphology of radio galaxies, whereas supervised ML techniques (e.g., Wu et al., 2019) use the knowledge derived from training sets, and unsupervised ML techniques (e.g., Galvin et al., 2020) use no prior knowledge but rely on large samples to establish the common morphologies. It is currently unclear which technique will be most effective for large radio survey. Instead, all three approaches (ILP, supervised ML, unsupervised ML) need to be tested on real large data sets.
In this paper, we extend the algorithm of Fan et al. (2015) in two ways: (1) We use a more sophisticated radio source model in which we allow the line connecting the lobes of the source with the nucleus to be bent. (2) Having constructed a number of hypotheses for each source, we then choose a solution that maximizes the likelihood over the whole field, rather than focusing on the likelihood for each source separately. In this paper we call the earlier algorithm used by Fan et al. (2015) the “greedy” approach, and we call the present approach “ILP”, for Integer Linear Programming.
2 Matching for Radio Sources
In Fan et al. (2015) we introduced the Bayesian formalism for including realistic morphology of a radio source into the cross-identification process. We evaluate the marginal likelihood of the competing hypotheses, namely with possible configurations describing a given set of radio sources and their counterparts. Conceptually, one considers any combination of radio and other objects to (numerically) compute the probability of the data given those assumptions. For example, if we are looking at a possible association of two radio detections and one infrared source, it could be that we see the core in both the radio and infrared, and a single lobe in the radio, or it could be that the infrared source is the core but the radio shows two lobes. But the list of possible hypotheses is much longer: maybe all sources are from a separate source or the lobes are from one object but the infrared is another object and so on. Our computer program iterates through every possible combination and evaluates an objective quality, the marginal likelihood, for each.
Here we make two improvements to our previously successful automated procedure. First, we explicitly allow for morphology where the lobes are not along a straight line connected through the core. This requires us to introduce a prior on the possible angles but the model is more realistic than simply assuming they fall along a straight line as before. The beauty of the Bayesian treatment is that the marginal likelihoods of the competing hypotheses are well-defined for this more advanced model, and so we simply have to marginalize over one more parameters. The second and most crucial improvement comes from a global optimization that considers the matched catalogue as a whole instead of using a greedy procedure to pick out the associations.
2.1 Flexible Model for Radio Morphology
For any given hypothesis, we introduce the true position of the assumed latent object (i.e., the host galaxy). We consider every possible position of the host galaxy relative to the radio components, and let the available data (measured positions and their uncertainty) provide appropriate weighting via the likelihood function, e.g., a Gaussian. The computational methods for efficient evaluations are discussed in Fan et al. (2015) in detail.
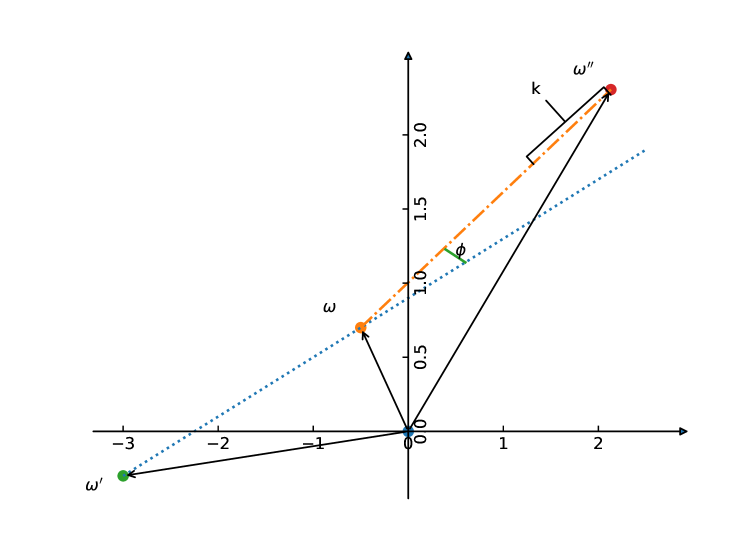
The updated model is illustrated in Figure 1 in the tangent plane. For the calculations, we chose the position of the infrared detection as the origin. In this 2D coordinate system, the radio core is at and the lobes are at and . The following equations describe their relations to each other using additional model parameters : allows for the lobes to be at different distances from the core, and permits (slight) bending.
| (1) |
where is the usual 22 matrix of the rotation by . All model parameters are involved in the assessment of the associations along with their priors, which we can write as
| (2) |
due to the appropriate (in)dependencies. Hereafter we assume that is isotropic (or uniform on the surface of the sphere) and depends only on the separation of the two positions. Furthermore, we will assume simple Gaussian priors for and with 0 mean, a combination that corresponds to a straight and symmetric configuration of the two lobes.
2.2 Matched Catalogues as Partitions of Detections
Following the approach of Budavári & Loredo (2015) and Shi et al. (2019) we ideally consider all possible matched catalogues with every possible combinations of associated detections. Let represent the th detection (or an internal identifier) in catalogue with measured position . The collection of all detections is the set of all measurements. We adopt the use of the Fisher (1953) distribution for the likelihood calculation,
| (3) |
that essentially corresponds to a Gaussian in the usual flat sky limit for small uncertainty, where the compactness parameter , and the is the positional error from the catalogue.
The final cross-matched catalogue will consist of multiple associations, which we will call objects, and index them by . A particular object will have an set of detections in its association. In fact, we can think of matching radio observations as if the radio catalogue appeared multiple times according to what roles the radio detections play in a particular association: a core or one of the two possible lobes. So, for matching IR and radio observations, we order the collections as follows: corresponds to the IR catalogue, represents radio core detections, and correspond to lobes. Conceptually, the catalogues corresponding to , , and are identical copies of the radio observations. In practice, however, they really are just views of the catalogue; there is no need for duplication of the data. Naturally, a given radio detection can only appear in one association , which we will enforce explicitly when looking for the optimal catalogue.
If the measurements in correspond to one object, the marginal likelihood of that is calculated by the integral
| (4) |
where the prior has an index to signify the possibility that different catalogues could have different sky coverage, hence different overlapping regions would yield different priors, see discussion in Budavári & Szalay (2008) and Budavári & Loredo (2015). The member likelihoods are simply given by the Fisher distribution at the appropriate true positions,
| (5) |
where is really a function of all parameters, as given by eq.(1) above. To find the optimal catalogue, we need to find the set of objects such that the product of their marginal likelihoods, , is maximal.
In addition, we also introduce the marginal likelihood of “no association”, where each detection is considered by itself as a separate object. The integrals simplify to the familiar product
| (6) |
with which we can define a Bayes factor for object as
| (7) |
Considering that the product of the marginal likelihoods over all in a matched catalogue always contains the same terms corresponding to every detection, the product is constant across every possible partitioning. This means that the optimal catalogue will also have maximal value. Using the latter over the product of marginals has the advantage that for the orphan objects that consist of a single detection, and hence their contribution to the product can neglected.
2.3 Combinatorial Optimization
To formalize the above maximization of the global cross-match catalogue likelihood (Budavári & Basu, 2016), one first has to enumerate all possible associations. Following Shi et al. (2019) we index these by and introduce a binary variable that is 1 if the association is selected for the cross-match catalogue and 0 otherwise. Since a radio detection should be used only from exactly one of the three catalogues , we must not have any variables that correspond to a set of detections where the same detection is used from more than one catalogues . More precisely, we do not include a variable for any set which contains and such that but .
The Bayes factors can be (numerically) evaluated for every one of the candidates, . Formally, the optimization over can now be written as
| (8) |
where , but further constraints are required to ensure that every detection appears exactly once in the resulting catalogue, and each radio detection appears only in one of the three possible roles (, , ). Considering that orphans have no contributions to the above objective as their , we can write inequalities that are better handled by optimization algorithms. For example,
| (9) |
means that every detection can appear at most in one association of a matched catalogue: the sum goes over all that include . For the radio detections, we have further constraints to ensure that each and every one of them only appears (at most) in one role, i.e., , or , which we can write as
| (10) |
where is the set of indices of the detections in the radio catalogue, i.e., . Such an optimization problem falls in the realm of Integer Linear Programming (hereafter ILP) for which various commercial and research solvers are available off the shelf.
2.4 Priors on Matched Catalogues
The above optimization considers only the marginal likelihoods of the associations, which neglects any prior information about the resulting catalogues. If we had such knowledge, the objective could be easily updated to include that. For example, one might have a distribution of the expected number of objects in a catalogue, or perhaps know the relative frequency of occurrence for the different kinds of matches, such as radio triples, doubles, etc. We expect that with more data, a hierarchical modeling approach will be eventually developed to simultaneously learn the population distributions and the assignments, but for now we will resort to the simplest possible scenario: In order to maximise the number of radio components in each association, we minimize the number of final associations. In case that, a group of three radio components is more likely to be associated with a single galaxy, than three separate galaxies, if these two scenarios each have the same calculated probability.
Our modified optimization would now have two terms,
| (11) |
where expresses the strength of our preference for fewer objects. This objective is also linear, and hence does not add to the complexity of the problem. Our input data consists only of the directions of the detections, with inherent uncertainties, and ignores other information that could in principle be used as constraints. For example, we expect that additional shape and flux measurements will play a key role in defining scientific catalogues, but these need to be studied further with more data. With these caveats and ideas in mind, we will explore solutions using the multi-objective approach, as in eq.(11).
3 Application to SWIRE & ATLAS CDFS
Here we apply our new approach to two catalogues discussed by Norris et al. (2006): (1) the Spitzer Wide-area InfraRed Extragalactic Survey (SWIRE; Lonsdale et al., 2003) over Chandra Deep Field South (CDFS): SWIRE CDFS Region Fall ’05 Spitzer Catalogue111SWIRE CDFS Region Fall ’05 Spitzer can be searched and downloaded on https://irsa.ipac.caltech.edu/cgi-bin/Gator/nph-scan?mission=irsa&submit=Select&projshort=SPITZER and (2) the Australia Telescope Large Area Survey (ATLAS) of the CDFS. The SWIRE catalogue contains 221,535 entries, but for consistency and a fair comparison, we append 119 additional detections per the work of Norris et al. (2006); see their Table 6 and the discussion therein. The ATLAS collection lists 784 radio components, which appear in Table 4 in * Norris et al. (2006).
3.1 Practical Considerations
The cross-matching process consists of several steps. The first step is to remove highly unlikely associations, using a spatial two-way matching between the IR and radio catalogues. This helps in the efficiency of the method by reducing the number of variables in the optimization (see the discussion in Section 2.3). In particular, when two measurements are far from each other on the sky, they are unlikely to be related. We set the angular separation threshold for the preprocessing to 2′, which is a safe limit considering that the farthest components in the radio triples associated by Norris et al. (2006) are 61.5″apart.
In the second step, all possible hypotheses are enumerated as possible candidates for associations. When considering two lobes we break the degeneracy by considering the farthest lobe to be at and the closer one at , then we evaluate the marginal likelihoods for all combinations of detections. For the member likelihood functions, we choose ″ astrometric uncertainty for SWIRE, ″ for the radio cores and ″ for the lobes, whose position is harder to determine due to their more extended and somewhat asymmetric nature.
The prior probability density function in eq.(2) is assumed to be isotropic over (see discussions in Budavári & Szalay (2008) and Budavári & Loredo (2015)). The conditional PDF is assumed to be a function of only the angular separation of and , and its radial dependence has the shape of the Rayleigh distribution with . The dimensionless parameter that describes the difference in the lobe separations from the core is assumed to have a Gaussian prior with a standard deviation of . The angle that describes how bent the geometry is also assumed to be a Gaussian with 0 mean and degrees. The 15 degrees is training from Norris et al. (2006), of which maximal angle is 16.96 degrees.
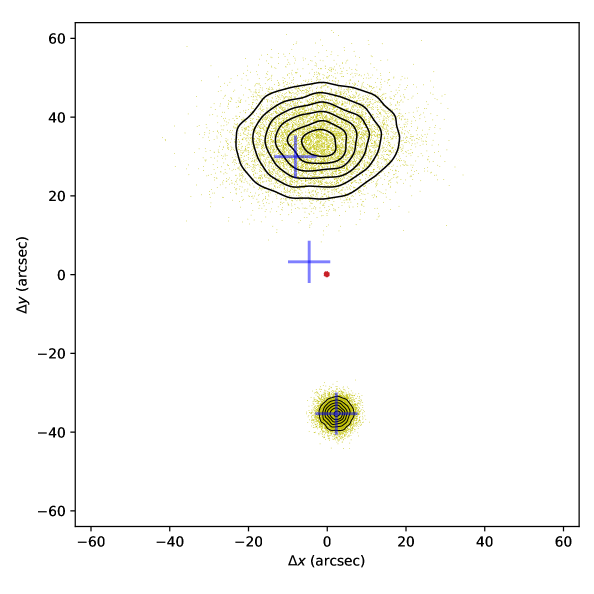
With those in hand, our implementation numerically integrates the marginal likelihoods and computes the Bayes factors. For an efficient integration, we sample from the IR core’s likelihood function and from the farthest radio lobe’s likelihood. Given those and random samples from the Gaussian priors for and , we can generate a random and evaluate the contribution of that sample to the integral. Figure 2 illustrates 10,000 sample points for a known radio triple, whose positions are shown by large blue crosses. Red contours around (0,0) represent the density of samples, which are highly concentrated due to the small uncertainty of the IR source, and therefore appear as a red dot at the origin. The core radio component (the blue cross near the origin) is located a small distance from the origin due to its larger uncertainty – its likelihood is evaluated at . The black contours and the yellow points toward the bottom of the figure show the samples from the likelihood function of the radio lobe. The contours on top for show the samples that are a combination of all model parameters, , , and .
When every is computed, we solve the minimization using the ILP implementation by Gurobi Optimization (2019) for the binary variables using the aforementioned objectives and constraints. Gurobi has builtin routines to handle the multi-objective optimization of eq.(11), for which we adopt to prefer solutions with fewer objects, i.e., larger associations of detections. Considering that the average weight is significant for selected associations, the weighting effectively is by a which in our experiments is about one fifth.
3.2 Results and Discussion
First, some caveats: Norris et al. (2006) associate the SWIRE and ATLAS measurements by eye. Expert radio astronomers look at the IR images on top of which multiple contours show the details of radio intensity, and they annotate the catalogues based on such rich views of the data. In comparison, our current approach considers only the positions of the detections and their uncertainty but not their brightness nor their shapes. We consider the expert matched catalogue as our ground truth, hereafter called the “reference catalogue”, to which we compare our results. We hope that our approach can approximately recover many of the known associations without introducing too many spurious matches. However, we also caution that in some cases the classifications are ambiguous, and even experts will sometimes disagree over the correct classification, so the “reference catalogue” is not always reliable. The reference catalogue primarily consists of IR detections associated with radio triples, doubles and singles but also lists six complex associations, see Table 2, which do not fit the usual model. We will discuss all these scenarios in turn.
| Association type | Found | Common | Missed | Extra |
|---|---|---|---|---|
| Radio triples | 12 | 10 | 0 | 2 |
| Radio doubles | 31 | 21 | 4 | 10 |
| Radio singles | 684 | 680 | 5 | 4 |
| Cplx | SID | SWIRE designated name | Radio Components | Comment from the Visual Inspection |
|---|---|---|---|---|
| #1 | S136 | SWIRE3_J032825.92-271701.3 | C141, C148, C151 | Radio double with connecting jet |
| #2 | S349 | (336555) | C366, C369, C376 | complex jet structure |
| #3 | S409 | SWIRE3_J033210.74-272635.5 | C437, C440, C446 | weird complex source with tails. z(g) |
| #4 | S631 | SWIRE3_J033437.35-272652.2 | C679, C681, C683 | Radio double |
| #5 | S707 | SWIRE3_J033533.90-273310.9 | C759, C760, C761, C764 | Centre of a linear complex (jets or grav arc?) |
| #6 | S719 | SWIRE3_J033542.52-274344.1 | C774, C775, C777 | Radio double |
Our implementation produces an optimal cross-matched catalogue under the morphology model described in Section 2. Table 1 lists the best solution along with the number of discovered associations with radio triples, doubles and singles. In fact, we separate them into three categories based on whether they appear in the reference catalogue as common, missed, or extra. We see that our code finds all 10 of the radio triples in the reference catalogue with only two extra associations. Out of the 25 radio doubles we find 21 with an additional 10 extra. To determine how good these results really are, we now examine in turn the associations with radio triples, doubles and singles.
3.3 Radio Triples
Since the code finds all radio triples in the reference catalogue, we study the two extra associations that our approach also identifies:
-
1.
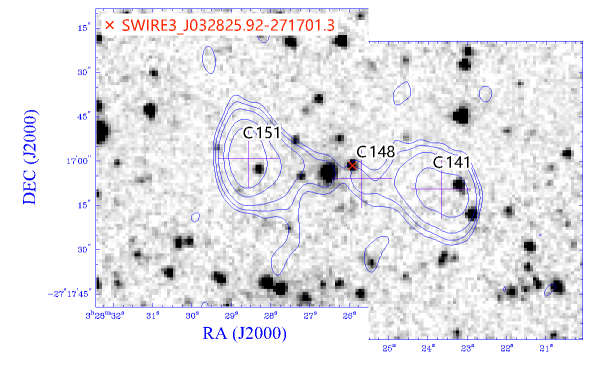
The radio components C148–C151–C141 (shown in Figure 3) associated with SWIRE3_J032825.92-271701.3 also appear in the reference catalogue but not as a triple, because there is no central radio component associated with an IR source. Instead they form complex #1 with the comment: “Radio double with connecting jet”. The ILP has identified the IR source SWIRE3_J032825.92-271701.3 as the host galaxy. While this is well separated from the radio component C148, there is low-level radio emission associated with this SWIRE source, so it possible that this is the correct host galaxy, even though it does not seem to be associated with the listed central radio component.
-
2.
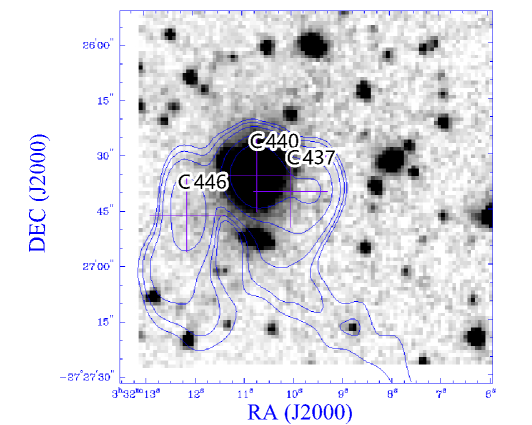
The radio components C440–C446–C437 associated with SWIRE3_J033210.74-272635.5 shown Figure 4 also appear in the reference catalogue as complex #3 with the comment “weird complex source with tails. z(g)”. It was not classified as a triple in the reference catalogue because to do so would ignore the bent tails, probably resulting from an interaction with an intra-cluster medium. However, here we focus only on the positions of the components, and in those terms this source is correctly classified as a triple.
So, we conclude that, provided only the positions of the components are considered, one of the two extra sources is correctly classified as a triple. So our procedure associates radio triples with a 92% success rate, with the only failure being a source that closely resembles a triple, although lacking a central core.
3.4 Radio Doubles
Our procedure correctly classified 21 of the 31 doubles, missed 4, and incorrectly identified a further 10 sources as doubles. However, we caution that, as discussed in Section 3.2 above, the reference catalogue can occasionally be unreliable. In some cases below, it is hard to tell, with the given data, whether the Reference catalogue or the ILP is more likely to be correct.
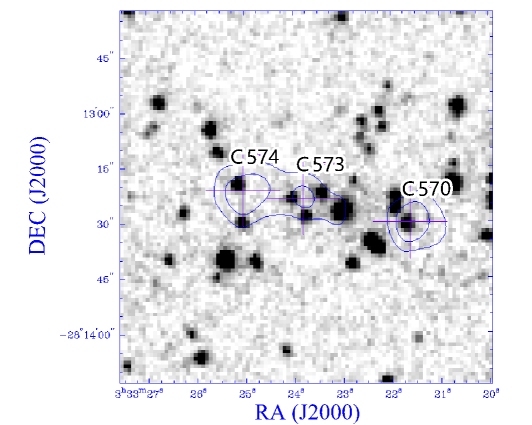
Our procedure misses four of the radio doubles in the reference catalogue: C089–C091, C393–C398, C500–C501, and C573–C574, as shown in Figure 5 .
C089–C091 with SWIRE3_J032731.61-275245.5 is classified in the reference catalogue as “complex region, but probably core-jet with C091 core, C089 jet”; ILP classified C089–C091 with the other SWIRE3_J032730.87-275247.6 as a “LOBE–LOBE”.
C393–C398 with SWIRE3_J033145.54-281955.0 is classified in the reference catalogue as “Probably asymmetric radio double”; ILP classified C393–C398 with the other SWIRE3_J033145.28-281956.1 as a “CORE–LOBE”.
C500–C501 with SWIRE3_J033242.82-273817.6 is classified in the reference catalogue as “Radio double”; ILP classified C500–C501 with the other SWIRE3_J033242.60-273816.0 as “LOBE–LOBE” (i.e. a double), so the only difference here is the choice of the host galaxy.
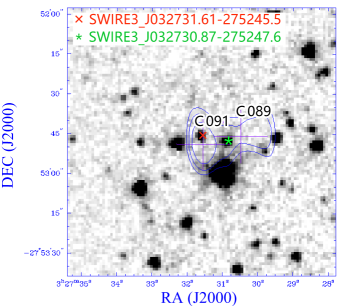
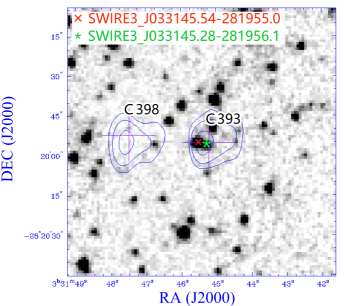
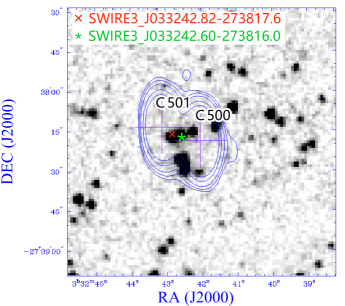
Interestingly, the first three of them actually appear as extra doubles, but in associations with different SWIRE measurements. Upon visual inspection, these mismatches appear to be a result of limited information in the positions only considered in this paper. It is possible that including brightness or shape measurements might help find the correct associations, but this needs to be studied further.
The fourth double of C573–C574 also appears in our catalogue, but it is separated into two singles due to two SWIRE detections close to the radio components, see bottom left image of Figure 5. The reference catalogue comment reads “M-test classifies it as double with C573, but C574 has good ID so C573 is probably a jet”.
Our code produces seven extra radio doubles: six of them were classified as “complex” as shown in Table 3. For example, #6 was classified as a double in the comments to the reference catalogue, and has been correctly identified as such by the ILP, but it also contains a third component, C774, as an extension to one of the lobes, and is therefore classified as complex in the reference catalogue rather than as a simple double. Thus the ILP’s classification as “double” in this case is possibly a more useful classification than “complex”.
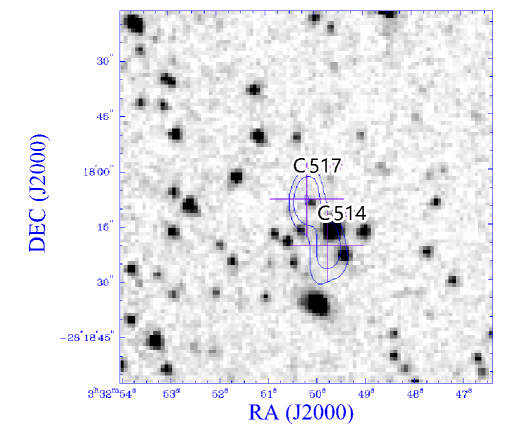
The remaining C517–C514 is classified by ILP as a Core-Lobe configuration, but the reference catalogue lists them as two singles, as shown the bottom right image of Figure 5. Given the astrometric uncertainty, it is difficult to tell whether C517 and C514 are associated with the IR sources, so in this case it is hard to tell whether the disagreement represents an error in ILP or an error in the reference catalogue.
| Cplx | Radios Components | Associations by ILP |
|---|---|---|
| #2 | C366, C369, C376 | C376–C366 as Core--Lobe |
| C369–C381 as Lobe--Lobe | ||
| #4 | C679, C681, C683 | C679 not in ILP result |
| C683–C681 as Lobe--Lobe | ||
| #5 | C759, C760, C761, C764 | C759–C760 as Lobe--Lobe |
| C761–C764 as Core--Lobe | ||
| #6 | C774, C775, C777 | C774 as extra Single |
| C775–C777 as Lobe--Lobe |
3.5 Radio Singles
Singles are individual radio components associated with a SWIRE detection. Out of the 685 single associations in the reference catalogue, our approach identifies 680, with 4 extra associations.
Out of the five missed (C381, C475, C514, C517, C763), three C381, C514, C517 are listed in the reference catalogue as parts of doubles. The reference catalogue comment for C475 (see Figure 6) is “strong spitzer ID at one end of core-jet src.”, but this source is too far from that SWIRE source to pass our detection threshold (see Section 3.1), resulting in a low Bayes factor for this association.
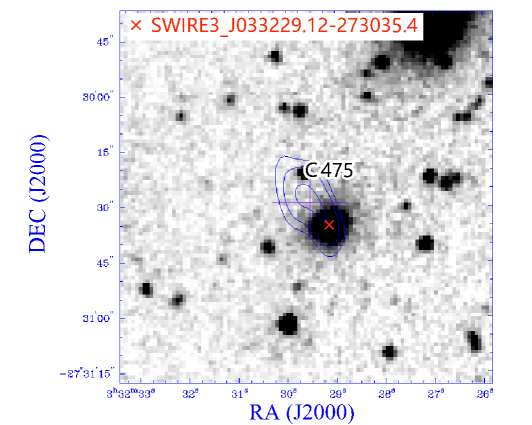
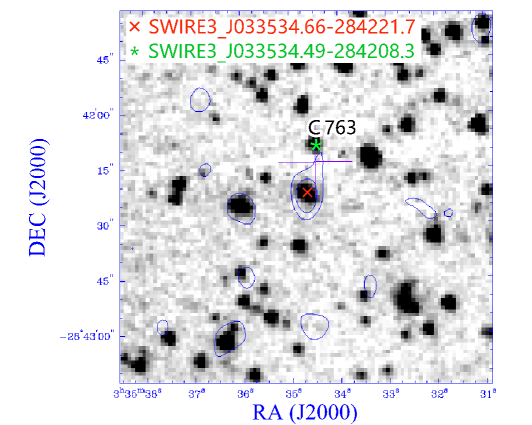
Finally, C763 (see Figure 6) is associated with a different SWIRE object from the reference catalogue, so it is listed as an extra. The ILP associates the radio source with a weak SWIRE detection, instead of a brighter source farther away. It is interesting that the reference catalogue identification is associated with the peak of the contours, but the ILP association is with the catalogue position, which is significantly different from the peak of the contours, suggesting an error in the reference catalogue.
There are 4 extra singles, most of them are mentioned above, except for C774, which is part of the complex #6, which is discussed above in Section 5.
3.6 Multiple solutions
As discussed in Section 2.2. the ILP technique generates many slightly different hypotheses, just one of which is chosen as the optimal solution.
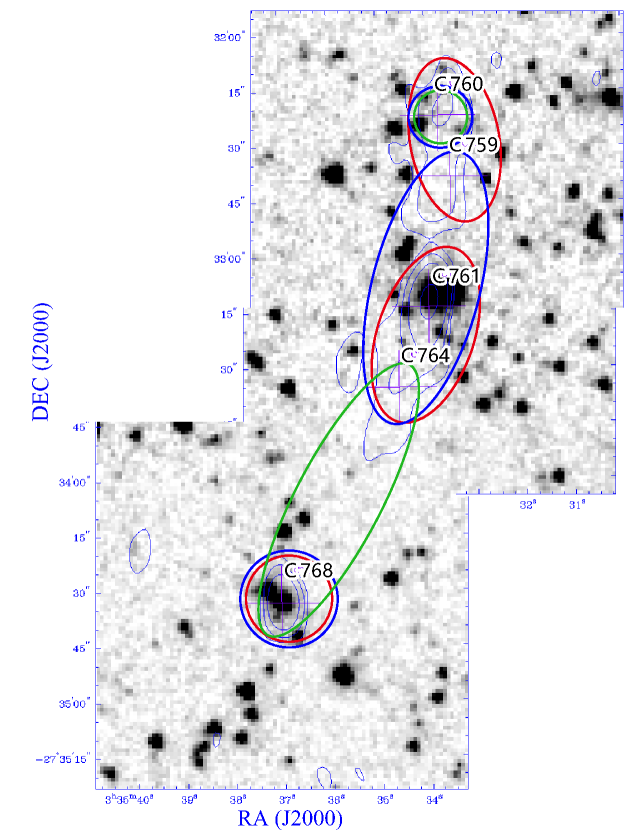
In addition to the best solution, our approach can also create similarly good but slightly sub-optimal associations. We studied the first 3 solutions, which show surprisingly little variation. The difference is due to the assignments of C759, C760, C761, C764 and C768, which we illustrate in Figure 7. These actually form complex #5 with comment “Centre of a linear complex (jets or grav arc?)”.
The differences are as follows: In the best solution, C759–C760 appears as a Lobe-Lobe combination and C761–C764 is a Core-Lobe with C768 being single. In the second solution, lists C761–C759–C764 as a radio triple with singles C760 and C768. In the third solution, there C761 and C759 do not appear, and C764–C768 is a Lobe-Lobe, with single C760, as summarized in Table. 4
| Solution | C760 | C759 | C761 | C764 | C768 |
|---|---|---|---|---|---|
| 1 | \colorredLobe - Lobe | \colorblueCore - Lobe | \colorblackSingle | ||
| 2 | \colorredSingle | \colorblueLobe - Core - Lobe | \colorblackSingle | ||
| 3 | \colorredSingle | \colorblueLobe - Lobe | |||
Our algorithm will, of course, perform correctly only if there are no errors in the catalogue. In particular, we assume that the catalogue lists one position per radio component, which is true for the data being considered here, and generally true for the source finder (Selavy) used for the EMU surveys (Norris et al., 2011). However, we are aware that some source finders can generate several Gaussian components for one radio component. While we have not tried the ILP algorithm on catalogues produced by such source finders, we suspect a pre-processing stage may be need to consolidate the listed components into one per radio component.
4 Conclusions
Our new method for radio cross-identification has two major improvements over previous automatic attempts. Its flexibility to model the morphology of bent radio lobes is proven vital to recover all triples in Norris et al. (2006). The biggest conceptual changes is in the creating of the associations, which are not chosen to be globally optimal or the entire matched catalogue. The success of this combinatorial optimization approach based on the marginal likelihoods of hypothesised objects is due to our efficient formulation of the problem as integer linear programming, following ideas put forward by Shi et al. (2019). The results from this automated approach match closely the current state of the art catalogue manually created by experts (Norris et al., 2006).
For the morphological modeling, each parameter has priors motivated by observations and their uncertainties. The range of values they take appear to be physically meaningful and in line with our current understanding. That said, we expect great improvements in the future when more data will be available. In such setting, a hierarchical approach will be possible to simultaneously learn the population distributions of the parameters and finding the best associations. Additional improvements are expected from the inclusion of brightness and shape measurements but their role and effect are to be studied further.
Also, prior information on possible matched catalogues will play an important role. The current method is essentially based on marginal likelihoods, and does not take into account the frequency of various radio configurations in the universe. A first we take in this position is the inclusion of a prior that prefers smaller number of objects in the final catalogue, which helps with creating associations in situations where other hypotheses are equally likely. In practice, such a bias is preferred because based on additional data (e.g., during visual inspections) the associated detections could potentially be broken apart easily, but going the other way is impossible.
While the optimal algorithm processes the entire data collection in one large ILP solver, we note that in practice the candidate associations will most likely not build a single connected component. Using standard graph analytics, we can split the problem up by finding the actual connected components and process them separately. This is expected to make a huge different in the wall-clock time due to the combinatorial nature of the problem. In our study, we found that such pre-processing was not needed because the entire analysis took only a few minutes.
We are looking forward to running the ILP algorithm on new datasets from large new surveys such as those on ASKAP (Norris et al., 2011) and MWA (White et al., 2020), and comparing the results with other algorithms, particularly ML algorithms. The ASKAP data are similar in sensitivity and resolution to the ATLAS data used here, and so we expect to be able to use ILP on ASKAP data with only modest retraining. MWA data, which is quite different from the sample used in this paper, appear broadly similar in the statistical characteristics of the radio data, but will pose a great challenge because of the large difference in the resolution of the radio and IR data, so significant retraining will be necessary. It is difficult to predict how ILP will fare on these datasets, and so it is important to experiment.
In preparation for these upcoming surveys, we are currently working with much larger catalogues containing 162 thousand radio detections and 329 million IR sources for which a depth-first cluster finding yields over a factor a 100 speed-up, which takes 66 minutes to run the whole cross-matching.
Acknowledgements
DF acknowledges support from Joint Research Fund in Astronomy (U1931132, U1731243) under cooperative agreement between the National Natural Science Foundation of China (NSFC) and Chinese Academy of Sciences (CAS), the CAS Scholarship, and the China National Astronomical Data Center (NADC). TB gratefully acknowledges support from National Science Foundation (NSF) grants AST-1412566, AST-1814778 and AST-1909709, as well as NASA via STSCI-51038. AB gratefully acknowledges support from National Science Foundation (NSF) grant CMMI1452820 and Office of Naval Research (ONR) grant N000141812096.
Data availability
The data underlying this article are available in China-VO PaperData Repository, at https://doi.org/10.12149/101026.
References
- Alger et al. (2018) Alger, M. J., Banfield, J. K., Ong, C. S., et al. 2018, MNRAS, 478, 5547
- Aniyan & Thorat (2017) Aniyan, A. K. & Thorat, K. 2017, ApJS, 230, 20
- Banfield et al. (2015) Banfield, J. K., Wong, O. I., Willett, K. W., et al. 2015, MNRAS, 453, 2326
- Budavári & Basu (2016) Budavári, T. & Basu, A. 2016, AJ, 152, 86
- Budavári & Loredo (2015) Budavári, T. & Loredo, T. J. 2015, Annual Review of Statistics and Its Application, 2, 113
- Budavári & Szalay (2008) Budavári, T. & Szalay, A. S. 2008, ApJ, 679, 301
- Fan et al. (2015) Fan, D., Budavári, T., Norris, R. P., et al. 2015, MNRAS, 451, 1299
- Fisher (1953) Fisher, R. 1953, Royal Society of London Proceedings Series A, 217, 295
- Galvin et al. (2019) Galvin, T. J., Huynh, M., Norris, R. P., et al. 2019, PASP, 131, 108009
- Galvin et al. (2020) Galvin, T. J., Huynh, M., Norris, R. P., et al. 2020, MNRAS, doi:10.1093/mnras/staa1890
- Gurobi Optimization (2019) Gurobi Optimization L., 2019, Gurobi Optimizer Reference Manual, http://www.gurobi.com
- Lonsdale et al. (2003) Lonsdale, C. J., Smith, H. E., Rowan-Robinson, M., et al. 2003, PASP, 115, 897
- Lukic et al. (2018) Lukic, V., Brüggen, M., Banfield, J. K., et al. 2018, MNRAS, 476, 246
- Norris (2017) Norris, R. P. 2017, Nature Astronomy, 1, 671
- Norris et al. (2006) Norris, R. P., Afonso, J., Appleton, P. N., et al. 2006, AJ, 132, 2409
- Norris et al. (2011) Norris, R. P., Hopkins, A. M., Afonso, J., et al. 2011, Publ. Astron. Soc. Australia, 28, 215
- Ralph et al. (2019) Ralph, N. O., Norris, R. P., Fang, G., et al. 2019, PASP, 131, 108011
- Shi et al. (2019) Shi, X., Budavári, T., & Basu, A. 2019, ApJ, 870, 51
- Weston et al. (2018) Weston, S. D., Seymour, N., Gulyaev, S., et al. 2018, MNRAS, 473, 4523
- White et al. (2020) White, S. V., Franzen, T. M. O., Riseley, C. J., et al. 2020, Publ. Astron. Soc. Australia, 37, e018
- Wu et al. (2019) Wu, C., Wong, O. I., Rudnick, L., et al. 2019, MNRAS, 482, 1211
-
* Norris et al. (2006) [dataset]* Norris R., et al., 2006, Deep ATLAS radio observations of CDFS, http://cdsarc.unistra.fr/viz-bin/cat/J/AJ/132/2409