Optimal Strategies for Graph-Structured Bandits
Abstract
We study a structured variant of the multi-armed bandit problem specified by a set of Bernoulli distributions with means and by a given weight matrix , where is a finite set of arms and is a finite set of users. The weight matrix is such that for any two users . This formulation is flexible enough to capture various situations, from highly-structured scenarios () to fully unstructured setups (). We consider two scenarios depending on whether the learner chooses only the actions to sample rewards from or both users and actions. We first derive problem-dependent lower bounds on the regret for this generic graph-structure that involves a structure dependent linear programming problem. Second, we adapt to this setting the Indexed Minimum Empirical Divergence (IMED) algorithm introduced by Honda and Takemura (2015), and introduce the IMED-GS⋆ algorithm. Interestingly, IMED-GS⋆ does not require computing the solution of the linear programming problem more than about times after steps, while being provably asymptotically optimal. Also, unlike existing bandit strategies designed for other popular structures, IMED-GS⋆ does not resort to an explicit forced exploration scheme and only makes use of local counts of empirical events. We finally provide numerical illustration of our results that confirm the performance of IMED-GS⋆.
Keywords: Graph-structured stochastic bandits, regret analysis, asymptotic optimality, Indexed Minimum Empirical Divergence (IMED) algorithm.
1 Introduction
The multi-armed bandit problem is a popular framework to formalize sequential decision making problems. It was first introduced in the context of medical trials (Thompson, 1933, 1935) and later formalized by Robbins (1952). In this paper, we consider a contextual and structured variant of the problem, specified by a set of distributions with means , where is a finite set of arms and is a finite set of users. Such is called a (bandit) configuration where each can be seen as a classical multi-armed bandit problem. The streaming protocol is the following: at each time , the learner deals with a user and chooses an arm , based only on the past. We consider two scenarios: either the sequence of users is deterministic (uncontrolled scenario) or the learner has the possibility to choose the user (controlled scenario), see Section 1.1. The learner then receives and observes a reward sampled according to conditionally independent from the past. We assume binary rewards: each is a Bernoulli distribution with mean and we denote by the set of such configurations. The goal of the learner is then to maximize its expected cumulative reward over rounds, or equivalently minimize regret given by
For this problem one can run, for example, a separate instance of a bandit algorithm for each user , but we would like to exploit a known structure among the users (which we detail below).
Unstructured bandits
The classical bandit problem (when ) received increased attention in the middle of the century. The seminal paper Lai and Robbins (1985) established the first lower bounds on the cumulative regret, showing that designing a strategy that is optimal uniformly over a given set of configurations comes with a price. The study of the lower performance bounds in multi-armed bandits successfully lead to the development of asymptotically optimal strategies for specific configuration sets, such as the KL-UCB strategy (Lai, 1987; Cappé et al., 2013; Maillard, 2018) for exponential families, or alternatively the DMED and IMED strategies from Honda and Takemura (2011, 2015). The lower bounds from Lai and Robbins (1985), later extended by Burnetas and Katehakis (1997) did not cover all possible configurations, and in particular structured configuration sets were not handled until Agrawal et al. (1989) and then Graves and Lai (1997) established generic lower bounds. Here, structure refers to the fact that pulling an arm may reveal information that enables to refine estimation of other arms. Unfortunately, designing efficient strategies that are provably optimal remains a challenge for many structures at the cost of a high computational complexity.
Structured configurations
Motivated by the growing popularity of bandits in a number of industrial and societal application domains, the study of structured configuration sets has received increasing attention over the last few years: The linear bandit problem is one typical illustration (Abbasi-Yadkori et al., 2011; Srinivas et al., 2010; Durand et al., 2017), for which the linear structure considerably modifies the achievable lower bound, see Lattimore and Szepesvari (2017). The study of a unimodal structure naturally appears in the context of wireless communications, and has been considered in Combes and Proutiere (2014) from a bandit perspective, providing an explicit lower bound together with a strategy exploiting this structure. Other structures include Lipschitz bandits (Magureanu et al., 2014), and we refer to the manuscript Magureanu (2018) for other examples, such as cascading bandits that are useful in the context of recommender systems. Combes et al. (2017) introduced a generic strategy called OSSB (Optimal Structured Stochastic Bandit), stepping the path towards generic multi-armed bandit strategies that are adaptive to a given structure.
Graph-structure
In this paper, we consider the following structure: For a given weight matrix inducing a metric on , we assume that for any two users , . We see the matrix as an adjacency matrix of a fully connected weighted graph where each vertex represents a user and each weigh measures proximity between two users, hence we call this a “graph structure”. The motivation to study such a structure is two-fold. On the one hand, in view of paving the way to solving generic structured bandits, the graph structure yields nicely interpretable lower bounds that show how effectively modifies the achievable optimal regret and suggests a natural strategy, while being flexible enough to interpolate between a fully unstructured and a highly structured setup. On the other hand, multi-armed bandits have been extensively applied to recommender systems: In such systems it is natural to assume that users may not react arbitrarily differently from each other, but that two users that are "close" in some sense will also react similarly when presented with the same item (action). Now, the similarity between any two users may be loosely or accurately known (by studying for instance activities of users on various social networks and refining this knowledge once in a while): The weight matrix enables to summarize such imprecise knowledge. Indeed means that two users behave identically, while is not informative on the true similarity that can be anything from arbitrarily small to . Hence, studying this structure is both motivated by a theoretical challenge and more applied considerations. To our knowledge this is the first work on graph structure. Other structured problems such as Clustered bandits (Gentile et al., 2014), Latent bandits (Maillard and Mannor, 2014), or Spectral bandits (Valko et al., 2014) do not deal with this particular setting.
Goal
The primary goal of this paper is to build a provably optimal strategy for this flexible notion of structure. To do so, we derive lower bounds and use them to build intuition on how to handle structure, which enables us to establish a novel bandit strategy, that we prove to be optimal. Although specialized to this structure, the mechanisms leading to the strategy and introduced in the proof technique are novel and are of independent interest.
Outline and contributions
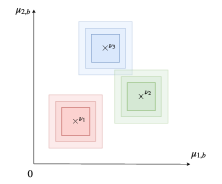
We formally introduce the graph-structure model in Section 1.2. Graph structure is simple enough while interpolating between a fully unstructured case and highly-structured settings such as clustered bandits (see Figure 1): This makes it a convenient setting to study structured multi-armed bandits. In Section 2, we first establish in Proposition 5 a lower bound on the asymptotic number of times a sub-optimal couple must be pulled by any consistent strategy (see Definition 3), together with its corresponding lower bound on the regret (see Corollary 8) involving an optimization problem. In Section 3, we revisit the Indexed Minimum Empirical Divergence (IMED) strategy from Honda and Takemura (2011) introduced for unstructured multi-armed bandits, and adapt it to the graph-structured setting, making use of the lower bounds of Section 2. The resulting strategy is called IMED-GS in the controlled scenario and IMED-GS2 in the uncontrolled scenario. Our analysis reveals that in view of asymptotic optimality, these strategies may still not optimally exploit the graph-structure in order to trade-off information gathering and low regret. In order to address this difficulty, we introduce the modified IMED-GS⋆ strategy for the controlled scenario (and IMED-GS in the uncontrolled one). We show in Theorem 11, which is the main result of this paper, that both IMED-GS⋆ and IMED-GS are asymptotically optimal consistent strategies. Interestingly, IMED-GS⋆ does not compute a solution to the optimization problem appearing in the lower bound at each time step, unlike for instance OSSB introduced for generic structures, but only about times after steps. Also, if forced exploration does not seem to be avoidable for this problem, IMED-GS⋆ does not make use of an explicit forced exploration scheme but a more implicit one, based on local counters of empirical events. Up to our knowledge, IMED-GS⋆ is the first strategy with such properties, in the context of a structure requiring to solve an optimization problem, that is provably asymptotically optimal. On a broader perspective, we believe the mechanism used in IMED-GS⋆ as well as the proof techniques could be extended beyond the considered graph-structure, thus opening promising perspective in order to build structure-adaptive optimal strategies for generic structures. Last, we provide in Section 4 numerical illustrations on synthetic data. They show that IMED-GS⋆ is also numerically efficient in practice, both in terms of regret minimization and computation time; this contrasts with some bandit strategies introduced for other structures (as in Combes et al. (2017), Lattimore and Szepesvari (2017)), that in practice suffer from a prohibitive burn-in phase.
1.1 Setting
Let us recall that the goal of the learner is to maximize its expected cumulative reward over rounds, or equivalently minimize regret given by
As mentioned, for this problem one can run, for example, a separate instance of bandit algorithms for each user , but we would like to exploit the graph structure. We consider two typical scenarios.
Uncontrolled scenario
The sequence of users is assumed deterministic and does not depend on the strategy of the learner. At each time step , the user is revealed to the learner.
Controlled scenario
The sequence of users is strategy-dependent and at each time step , the learner has to choose a user to deal with, based only on the past.
Both scenarios are motivated by practical considerations: uncontrolled scenario is the most common setup for recommender systems, while controlled scenario is more natural in case the learner interacts actively with available users as in advertisement campaigns. In an uncontrolled scenario, the frequencies of user-arrivals are imposed and may be arbitrary, while in a controlled scenario all users are available and the learner has to deal with them with similar frequency (even if this means considering a subset of users). We formalize the notion of frequency in the following definition.
Definition 1 (Log-frequency of a user)
A sequence of user has log-frequencies if, almost surely, the number of times the learner has dealt with user is 111We say that , if the two sequences and are equivalent.. In this case, almost surely we have
In an uncontrolled scenario, we assume that the sequence of users has positive log-frequencies , with unknown to the learner. In a controlled scenario, we focus only on strategies that induce sequences of users with same log-frequencies, hence all equal to , independently on the considered configuration, that is strategies such that, almost surely, for all user .
1.2 Graph Structure
In this section, we introduce the graph structure. We assume that all bandit configurations belong to a set of the form:
where is a weight matrix known to the learner. Intuitively, when the weights are close to , we expect no change to the agnostic situation. But, when the weights are close to , we expect significantly lower achievable regret.
Remark 2
For the specific case where , corresponds to user and known to be perfectly clustered. The weight matrix given in Figure 1 models three smooth clusters of users. Each cluster is included in a ball of diameter for the infinite norm .
In the sequel we assume the following properties on the weights.
Assumption 1 (Metric weight property)
The weight matrix satisfies:
-
-
and for all ,
-
-
and for all .
This comes without loss of generality, since for the first property, if two users share exactly the same distribution we can see them as one unique user. For the second property, considering leads to the same set of configuration and it holds , . Such a weight matrix naturally induces a metric on .
1.3 Notations
Let denote the optimal mean for user and the set of optimal arms for this user. We define for a couple its gap . Thus a couple is optimal if its gap is equal to zero and sub-optimal if it is positive. We denote by the set of optimal couples. Thanks to the chain rule we can rewrite the regret as follows:
is the number of pulls of arm and user up to time .
2 Regret Lower bound
In this subsection, we establish lower bounds on the regret for the structure . In order to obtain non trivial lower bounds we consider, as in the classical bandit problem, strategies that are consistent (uniformly good) on .
Definition 3 (Consistent strategy)
A strategy is consistent on if for all configuration , for all sub-optimal couple , for all ,
Remark 4
When , and we recover the usual notion of consistency (Lai and Robbins, 1985).
Before we provide below the lower bound on the cumulative regret, let us give some intuition: To that end, we fix a configuration and a sub-optimal couple . One key observation is that if for all it holds , this means we can form an environment such that for all couples except , and such that satisfies . Indeed, in this novel environment, still holds but is now optimal. Hence, we can transform the sub-optimal couple in an optimal one without moving the means of the other users. Thanks to this remarkable property, and introducing to denote the Kullback-Leibler divergence between two Bernoulli distributions and with the usual conventions, one can prove then that for all consistent strategy
which is the lower bound that we get without graph structure. This suggests that only the users such that provide information about the behavior of user . This justifies to introduce for each couple the fundamental set
It is also convenient to introduce its frontier, denoted . Now, in order to report the lower bounds while avoiding tedious technicalities, we slightly restrict the set . To this end, we introduce the set
This definition is justified since the closure of is indeed (we only remove from sets of empty interior). We can now state the following proposition.
Proposition 5 (Graph-structured lower bounds on pulls)
Let us consider a consistent strategy. Then, for all configuration , almost surely it holds for all sub-optimal couple ,
| (1) |
We then introduce the notion of Pareto-optimality based on the lower bounds given in Proposition 5.
Definition 6 (Pareto-optimality)
A strategy is asymptotically Pareto-optimal if for all ,
with the convention .
Remark 7
This proposition reveals that the set plays a crucial role in the graph structure. The definition of excludes specific situations when there exists , , , that belong to the close set . Extending the result to seems possible but at the price of clarity due to the need to handle degenerate cases.
In order to derive an asymptotic lower bound on the regret from these asymptotic lowers bounds, we have to characterize the growth of the counts .
Corollary 8 (Lower bounds on the regret)
Let us consider a consistent strategy and sequences of users with log-frequencies independently of the considered configuration in . Then, for all configuration
Hence such a strategy is asymptotically optimal if for all
Remark 9
In the previous corollary, log-frequencies may be either strategy dependent or independent. In an uncontrolled scenario, is imposed by the setting and does not depend on the followed strategy, while in a controlled scenario we consider strategies that impose .
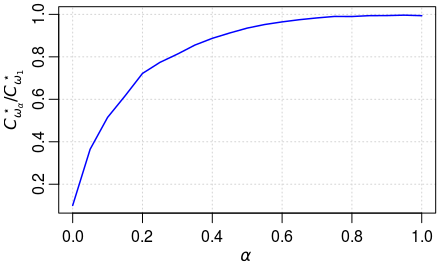
Like other structured bandit problems (as in Combes et al. (2017), Lattimore and Szepesvari (2017)) this lower bound is characterized by a problem-dependent constant solution to an optimization problem. In the agnostic case we recover the lower bound of the classical multi-armed bandit problem. Indeed, let us introduce for the weight matrix where all the weights are equal to (except for the zero diagonal). is the same weight matrix as in Figure 1 but only for one cluster. Then when there is no structure (), we obtain the explicit constant
| (3) |
that corresponds to solving bandit problems in parallel (independently the ones from the others). Thus the graph structure allows to interpolate smoothly between independent bandit problems and a unique one when all the users share the same distributions. In order to illustrate the gain of information due to the graph structure we plot in Figure 2 the expectation of the ratio between the constant in the structured case (8) and that in the agnostic case (3), where denotes the uniform distribution over , .
3 IMED type strategies for Graph-structured Bandits
In this section, we present for both the controlled and uncontrolled scenarios, two strategies: IMED-GS⋆ that matches the asymptotic lower bound of Corollary 8 and IMED-GS with a lower computational complexity but weaker guaranty. Both are inspired by the Indexed Minimum Empirical Divergence (IMED) proposed by Honda and Takemura (2011). The general idea behind this algorithm is to enforce, via a well chosen index, the constraints (1) that appears in the optimization problem (8) of the asymptotic lower bound. These constraints intuitively serve as tests to assert whether or not a couple is optimal.
3.1 IMED type strategies for the controlled scenario
We consider the controlled scenario where the sequence of users is strategy-dependent and at each time step , the learner has to choose a user and an arm , based only on the past.
3.1.1 The IMED-GS strategy.
We denote by if , otherwise, the empirical mean of the rewards from couple . Guided by the lower bound (1) we generalize the IMED index to take into account the graph structure as follows. For a couple and at time we define
| (4) |
where is the current best mean for user , the current set of optimal couple is
and the current set of informative users for an empirical sub-optimal couple is
This quantity can be seen as a transportation cost for “moving222This notion refers to the generic proof technique used to derive regret lower bounds. It involves a change-of-measure argument, from the initial configuration in which the couple is sub-optimal to another one chosen to make it optimal.” a sub-optimal couple to an optimal one, plus exploration terms (the logarithms of the numbers of pulls). When an optimal couple is considered, the transportation cost is null and only the exploration part remains. Note that, as stated in Honda and Takemura (2011), is an index in the weaker sense since it is not determined only by samples from the couple but also uses empirical means of current optimal arms. We define IMED-GS (Indexed Minimum Empirical Divergence for Graph Structure) to be the strategy consisting of pulling a couple with minimum index in Algorithm 1. It works well in practice, see Section 4, and has a low computational complexity (proportional to the number of couples). However, it is known for other structures, see Lattimore and Szepesvari (2017), that such greedy strategy does not exploit optimally the structure of the problem. Indeed, at a high level, pulling an apparently sub-optimal couple allows to gather information not only about this particular couple but also about other couples due to the structure. In order to attain optimality one needs to find couples that provide the best trade-off between information and low regret. This is exactly what is done in the optimization problem (8).
3.1.2 The IMED-GS⋆ strategy
In order to address this difficulty we first, thanks to the (weak) indexes, decide whether we need to exploit or explore. In the second case, in order to explore optimally according to the graph structure we solve the optimization problem (8) parametrized by the current estimates of the means and then track the optimal numbers of pulls given by the solution of this problem. More precisely at each round we choose but not immediately pull a couple with minimum index
Exploitation: If this couple is currently optimal, , we exploit, that is pull this couple.
Exploration: Else we explore arm . To this end, let be a solution of the empirical version of with , that is
The current optimal numbers of pulls given by
| (6) |
We then track
| (7) |
Asymptotically, we expect that all the sub-optimal couples are pulled roughly times. Therefore, for all sub-optimal couple , the index should be of order . Thus we asymptotically recover in the definition of the optimal number of pulls of couple , that is as suggested in Corollary 8. Finally we pull the selected couple . In order to ensure optimality, however, such a direct tracking of the current optimal number of pulls is still a bit too aggressive and we need to force exploration in some exploration rounds. We proceed as follows: when we explore arm we automatically pull a couple if its number of pulls is lower than the logarithm of the number of time we decided to explore this arm. See Algorithm 2 for details. This does not hurt the asymptotic optimally because we expect to explore a sub-optimal arm not more than times. On the bright side, this is still different than the traditional forced exploration. Indeed, only few rounds are dedicated to exploration thanks to the first selection with the indexes and among them only a logarithmic number will consist of pure exploration: Thus, we expect an overall rounds of forced exploration. Note also that all the quantities involved in this forced exploration use empirical counters. Putting all together we end up with strategy IMED-GS⋆ described in Algorithm 2.
Comparison with other strategies
IMED-GS⋆ combines ideas from IMED introduced by Honda and Takemura (2011) and from OSSB by Combes et al. (2017). More precisely, it generalizes the index from IMED to the graph structure. From OSSB it borrows the tracking of the optimal counts given by the asymptotic lower bound (see also Lattimore and Szepesvari (2017)) and the way to force exploration sparingly. The main difference with OSSB is that IMED-GS⋆ leverages the indexes to deal with the exploitation-exploration trade-off. In particular IMED-GS⋆ does not need to solve at each round the optimization problem (8). This greatly improves the computational complexity. Also, note that OSSB requires choosing a tuning parameter that must be positive to ensure theoretical guarantees but that must be set equal to to work well in practice. This is not the case for IMED-GS⋆ that requires no parameter tuning and that works well both in theory and in practice (see Section 4).
Algorithm 1 IMED-GS (controlled scenario) 0: Weight matrix . for do Pull end for Algorithm 2 IMED-GS⋆ (controlled scenario) 0: Weight matrix . for For do Choose if then Choose else Set if then Choose else Choose end if end if Pull end for
3.2 IMED type strategies for the uncontrolled scenario
In this section, an uncontrolled scenario is considered where the sequence of users is assumed deterministic and does not depend on the strategy of the learner. We adapt the two previous strategies IMED-GS and IMED-GS⋆ to this scenario.
IMED-GS2 strategy
At time step the choice of user is no longer strategy-dependent but is imposed by the sequence of users which is assumed to be deterministic in the uncontrolled scenario. The learner only chooses an arm to pull knowing user . We define IMED-GS2 to be the strategy consisting of pulling an arm with minimum index in Algorithm 3 of Appendix C. IMED-GS2 suffers the same advantages and shortcomings as IMED-GS. It does not exploit optimally the structure of the problem but it works well in practice, see Section 4, and has a low computational complexity.
IMED-GS strategy
In order to explore optimally according to the graph structure in the uncontrolled scenario, we also track the optimal numbers of pulls. may be at first glance different from . This requires some normalizations. First, for all time step , now denotes a solution of the empirical version of with where estimates log-frequency of user . Second, we have to consider normalized indexes for couples in order to have as in the controlled scenario. An additional difficulty is that at a given time step , while the indexes indicate to explore, the current tracked user (see Equation 7) given is likely to be different from user with whom the learner deals. This difficulty is easy to circumvent by postponing and prioritizing the exploration until the learner deals with the tracked user. Priority in exploration phases is given to first delayed forced-exploration and delayed exploration based on solving optimization problem (8), then exploration based on current indexes (see Algorithm 4 in Appendix C). IMED-GS corresponds essentially to IMED-GS⋆ with some delays due to the fact that the tracked and the current users may be different. This has no impact on the optimality of IMED-GS since log-frequencies of users are enforced to be positive.
3.3 Asymptotic optimality of IMED type strategies
In order to prove the asymptotic optimality of IMED-GS⋆ we introduce the following mild assumptions on the configuration considered.
Definition 10 (Non-peculiar configuration)
A configuration is non-peculiar if the optimization problem (8) admits a unique solution and each user admits a unique optimal arm .
In Theorem 11 we state the main result of this paper, namely, the asymptotic optimality of IMED-GS⋆ and IMED-GS. We prove this result for IMED-GS⋆ in Appendix E and adapt this proof in Appendix G for IMED-GS. Please refer to Proposition 20 (Appendix D) for more refined finite-time upper bounds. As a byproduct of this analysis we deduce the Pareto-optimality of IMED-GS and IMED-GS2 stated in Proposition 12 and proved in Appendix G.
Theorem 11 (Asymptotic optimality)
Both IMED-GS⋆ and IMED-GS are consistent strategies. Further, they are asymptotically optimal on the set of non-peculiar configurations, that is, for all non-peculiar, under IMED-GS⋆ the sequence of users has log-frequencies and we have
and, under IMED-GS, assuming a sequence of users with log-frequencies , we have
Proposition 12 (Asymptotic Pareto-optimality)
Both IMED-GS and IMED-GS2 are consistent strategies. Further, they are asymptotically Pareto-optimal on the set of non-peculiar configurations, that is, under IMED-GS or IMED-GS2, for all non-peculiar,
Discussion
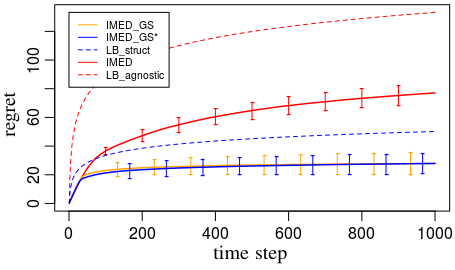
Removing forced exploration remains the most challenging task for structured bandit problems. In the context of this structure, forced exploration would have been to use criteria like "if , then pull couple " for some constants that depends on the minimization problem coming from the lower bound and where can be interpreted as an estimator of the theoretical asymptotic lower bound on the numbers of pulls of couple . In stark contrast, in IMED-GS⋆ there is no forced exploration in choosing the arm to explore and, in choosing the user to explore, the used criteria is more intrinsic as it reads "if , then pull couple ", where but really depends on . Thus, the used criteria are not asymptotic, and do not dependent on the time but on the current numbers of pull of sub-optimal arms. Since theoretical asymptotic lower bounds on the numbers of pulls are significantly larger than the current numbers of pulls in finite horizon (see Figure 3), IMED-GS⋆ strategy is also expected to behave better than strategies based on usual (conservative) forced exploration. Although entirely removing forced exploration would be nicer, in IMED-GS⋆, forced exploration is only done in a sparing way.
4 Numerical experiments
In this section, we compare empirically the following strategies introduced beforehand: IMED-GS and IMED-GS⋆ described respectively in Algorithms 1, 2, IMED-GS2 and IMED-GS described respectively in Algorithms 3, 4 and the baseline IMED by Honda and Takemura (2011) that does not exploit the structure. We compare these strategies on two setups, each with users and arms. For the uncontrolled scenario we consider the round-robin sequence of users. As expected the strategies leveraging the graph structure perform better than the baseline IMED that does not exploit it. Furthermore, the plots suggest that IMED-GS and IMED-GS⋆ (respectively IMED-GS2 and IMED-GS) perform similarly in practice.
Fixed configuration
Figure 3: Left – For these experiments we investigate these strategies on a fixed configuration. The weight matrix and the configuration are given in Appendix I. This enables us to plot also the asymptotic lower bound on the regret for reference: We plot the unstructured lower bound (LB_agnostic) in dashed red line, and the structured lower bound (LB_struct) in dashed blue line.
Random configurations
Figure 3: Right – In these experiments we average regrets over random configurations. We proceed as follows: At each run we sample uniformly at random a weight matrix and then sample uniformly at random a configuration .
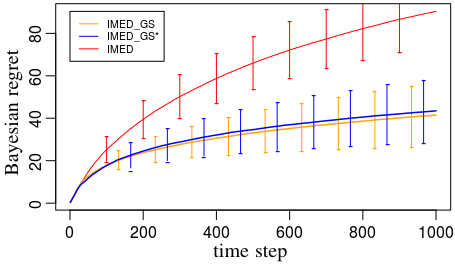
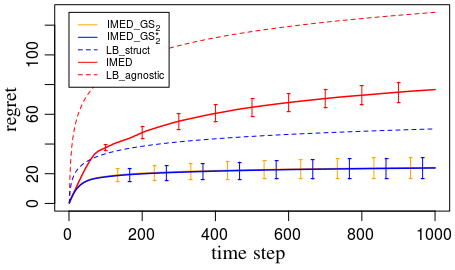
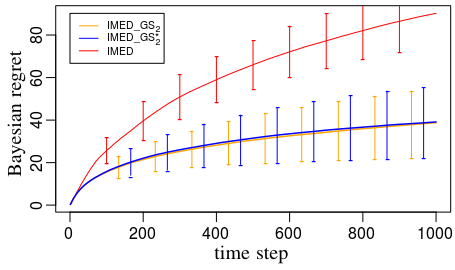
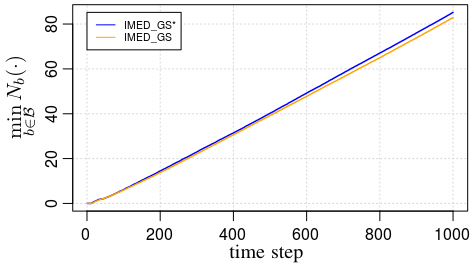
Additional experiments in Appendix I confirm that both IMED-GS and IMED-GS⋆ induce sequences of users with log-frequencies all equal to .
Acknowledgments
This work was supported by CPER Nord-Pas de Calais/FEDER DATA Advanced data science and technologies 2015-2020, the French Ministry of Higher Education and Research, the French Agence Nationale de la Recherche (ANR) under grant ANR-16- CE40-0002 (project BADASS), and Inria Lille – Nord Europe.
References
- Abbasi-Yadkori et al. (2011) Yasin Abbasi-Yadkori, Dávid Pál, and Csaba Szepesvári. Improved algorithms for linear stochastic bandits. In Advances in Neural Information Processing Systems, pages 2312–2320, 2011.
- Agrawal et al. (1989) Rajeev Agrawal, Demosthenis Teneketzis, and Venkatachalam Anantharam. Asymptotically efficient adaptive allocation schemes for controlled iid processes: Finite parameter space. IEEE Transactions on Automatic Control, 34(3), 1989.
- Burnetas and Katehakis (1997) Apostolos N. Burnetas and Michael N. Katehakis. Optimal adaptive policies for Markov decision processes. Mathematics of Operations Research, 22(1):222–255, 1997.
- Cappé et al. (2013) Olivier Cappé, Aurélien Garivier, Odalric-Ambrym Maillard, Rémi Munos, and Gilles Stoltz. Kullback–Leibler upper confidence bounds for optimal sequential allocation. Annals of Statistics, 41(3):1516–1541, 2013.
- Combes and Proutiere (2014) Richard Combes and Alexandre Proutiere. Unimodal bandits: Regret lower bounds and optimal algorithms. In International Conference on Machine Learning, 2014.
- Combes et al. (2017) Richard Combes, Stefan Magureanu, and Alexandre Proutiere. Minimal exploration in structured stochastic bandits. In Advances in Neural Information Processing Systems, pages 1763–1771, 2017.
- Durand et al. (2017) Audrey Durand, Odalric-Ambrym Maillard, and Joelle Pineau. Streaming kernel regression with provably adaptive mean, variance, and regularization. arXiv preprint arXiv:1708.00768, 2017.
- Gentile et al. (2014) Claudio Gentile, Shuai Li, and Giovanni Zappella. Online clustering of bandits. In International Conference on Machine Learning, pages 757–765, 2014.
- Graves and Lai (1997) Todd L Graves and Tze Leung Lai. Asymptotically efficient adaptive choice of control laws incontrolled markov chains. SIAM journal on control and optimization, 35(3):715–743, 1997.
- Honda and Takemura (2011) Junya Honda and Akimichi Takemura. An asymptotically optimal policy for finite support models in the multiarmed bandit problem. Machine Learning, 85(3):361–391, 2011.
- Honda and Takemura (2015) Junya Honda and Akimichi Takemura. Non-asymptotic analysis of a new bandit algorithm for semi-bounded rewards. Machine Learning, 16:3721–3756, 2015.
- Lai (1987) Tze Leung Lai. Adaptive treatment allocation and the multi-armed bandit problem. The Annals of Statistics, pages 1091–1114, 1987.
- Lai and Robbins (1985) Tze Leung Lai and Herbert Robbins. Asymptotically efficient adaptive allocation rules. Advances in applied mathematics, 6(1):4–22, 1985.
- Lattimore and Szepesvari (2017) Tor Lattimore and Csaba Szepesvari. The end of optimism? an asymptotic analysis of finite-armed linear bandits. In Artificial Intelligence and Statistics, pages 728–737, 2017.
- Magureanu (2018) Stefan Magureanu. Efficient Online Learning under Bandit Feedback. PhD thesis, KTH Royal Institute of Technology, 2018.
- Magureanu et al. (2014) Stefan Magureanu, Richard Combes, and Alexandre Proutiere. Lipschitz bandits: Regret lower bounds and optimal algorithms. Machine Learning, 35:1–25, 2014.
- Maillard (2018) O-A Maillard. Boundary crossing probabilities for general exponential families. Mathematical Methods of Statistics, 27(1):1–31, 2018.
- Maillard and Mannor (2014) Odalric-Ambrym Maillard and Shie Mannor. Latent bandits. In International Conference on Machine Learning, pages 136–144, 2014.
- Robbins (1952) H. Robbins. Some aspects of the sequential design of experiments. Bulletin of the American Mathematics Society, 58:527–535, 1952.
- Srinivas et al. (2010) Niranjan Srinivas, Andreas Krause, Sham Kakade, and Matthias Seeger. Gaussian process optimization in the bandit setting: no regret and experimental design. In Proceedings of the 27th International Conference on International Conference on Machine Learning, pages 1015–1022. Omnipress, 2010.
- Thompson (1933) William R Thompson. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika, 25(3/4):285–294, 1933.
- Thompson (1935) William R Thompson. On a criterion for the rejection of observations and the distribution of the ratio of deviation to sample standard deviation. The Annals of Mathematical Statistics, 6(4):214–219, 1935.
- Valko et al. (2014) Michal Valko, Rémi Munos, Branislav Kveton, and Tomáš Kocák. Spectral bandits for smooth graph functions. In International Conference on Machine Learning, 2014.
A Notations and reminders
For , we define
Then, there exists such that and such that for all , for all , for all ,
We also introduce the following constant of interest
Lastly, for all couple , for all , we consider the stopping times
and define
B Proof related to the regret lower bound (Section 2)
In this section we regroup the proofs related to the lower bounds.
B.1 Almost sure asymptotic lower bounds under consistent strategies
In this section we prove Proposition 5.
Let us consider a consistent strategy on . Let and let us consider . We show that almost surely implies
where .
Proof Let us consider , a maximal confusing distribution for the sub-optimal couple such that is the unique optimal arm of user for , defined as follows:
-
-
-
-
-
-
where . Our assumption on ensures that . Note that is chosen in such a way that for all , . Indeed we have:
- for
- for
- for and , we have . Since in this case it implies and since . Therefore on one hand we get
and on the other hand
Actually, we can choose so that :
We refer to Appendix A for the definitions of and . Note that is such that .
Let .We will show that almost surely implies
We start with the following inequality
Let us consider an horizon and let us introduce the event
We want to provide an upper bound on to ensure . We start by taking advantage of the following lemma.
Lemma 13 (Change of measure)
For every event and random variable both measurable with respect to and ,
where and is the sequence of pulled couples and rewards.
Let and let us introduce the event
Then we can decompose the probability as follows
Now, we control successively and and show that they both tend to as tends to .
B.1.1 tends to when tends to infinity
We first provide an upper bound on as follows, denoting ,
Thus, we have
Considering , we have . Then, the dominated convergence theorem ensures
Furthermore, since the considered strategy is assumed consistent we know that for , since is a sub-optimal arm for user and configuration ,
therefore we get
B.1.2 tends to when tends to infinity
For each time , the reward is sampled independently from the past and according to . Hence the likelihood ratio rewrites
where, for all and for all , we have : .
Thus, since for all , the log-likelihood ratio is
Let us introduce, for , where . Note that the random variables are predictable stopping times, since is measurable with respect to the filtration generated by . Hence we can rewrite the event
and, since , we have
For and , let us consider . Then is positive and bounded by , with mean . Furthermore, the random variables , for and , are independent. Thus, it holds
where
In the following, we apply Doob’s maximal inequality. For and , let us introduce the super-martingale
Then noting that
we obtain
where and . In order to have , we impose:
- (this implies )
- .
Thus for , we have
Furthermore, we have
Thus we have shown
that is .
B.2 Asymptotic lower bounds on the regret
Here, we explain how we obtain the lower bounds on the regret given in Corollary 8.
Proof [Proof of Corollary 8.] Let us consider a consistent strategy on and let . Let be a sub-sequence such that
We assume that this limit is finite otherwise the result is straightforward. This implies in particular that for all
By Cantor’s diagonal argument there exists an extraction of denoted by such that for all , there exist such that
Hence we get
But thanks to Proposition 5 we have for all , since user has a log-frequency ,
Therefore we obtain the lower bound
C Algorithms for the uncontrolled scenario
We regroup in this section the algorithms IMED-GS2 and IMED-GS for the uncontrolled scenario.
Algorithm 3 IMED-GS2 0: Weight matrix . for do Pull end for Algorithm 4 IMED-GS 0: Weight matrix . for For do Choose if then Choose else Choose if then if then Choose else Choose end if end if Priority rule in exploration phases: if then Choose (delayed forced-exploration) else if then Choose (delayed exploration) else Choose (current exploration) end if end if Pull end for
D IMED-GS⋆: Finite-time analysis
IMED-GS⋆ strategy implies empirical lower and empirical upper bounds on the numbers of pulls (Lemma 14, Lemma 15). Based on concentration lemmas (see Appendix D.7), the strategy-based empirical lower bounds ensure the reliability of the estimators of interest (Lemma 19). Then, combining the reliability of these estimators with the obtained strategy-base empirical upper bounds, we get upper bounds on the average numbers of pulls (Proposition 20). We first show that IMED-GS⋆ strategy is Pareto-optimal (for minimization problem 8) and that it is a consistent strategy which induces sequences of users with log-frequencies all equal to (independently from the considered bandit configuration). From an asymptotic analysis, we then prove that IMED-GS⋆ strategy is asymptotically optimal.
D.1 Strategy-based empirical bounds
IMED-GS⋆ strategy implies inequalities between the indexes that can be rewritten as inequalities on the numbers of pulls. While asymptotic analysis suggests lower bounds involving might be expected, we show in this non-asymptotic context lower bounds on the numbers of pulls involving instead the logarithm of the number of pulls of the current chosen arm, . In contrast, we provide upper bounds involving on .
We believe that establishing these empirical lower and upper bounds is a key element of our proof technique, that is of independent interest and not a priori restricted to the graph structure.
Lemma 14 (Empirical lower bounds)
Under IMED-GS⋆, at each step time , for all couple ,
Furthermore, for all couple ,
Proof According to IMED-GS⋆ strategy (see Algorithm 2), and for all couple
There is three possible cases.
Case 1: and .
Case 2: and
. Note that except if . Thus .
Case 3: and .
This implies for all couple ,
Thus, according to the definition of the indexes (Eq. 4) for all couple we obtain
and for all couple ,
Taking the exponential in the last inequality allows us to conclude.
Lemma 15 (Empirical upper bounds)
Under IMED-GS⋆, at each step time such that
we have
and
Proof For all current optimal couple , we have .
This implies
Furthermore, since , we have and the previous inequality implies
| (8) |
In the following we study separately the two cases either or .
Case 1:
Then and from Eq. 8 we get
Lemma 16 ( dominates )
Under IMED-GS⋆, at each time step such that
we have
Proof If , then and . In the following we assume that .
D.2 Reliable current best arm and means
In this subsection, we consider the subset of times where everything behaves well, that is: The current best couples correspond to the true ones, and, the empirical means of the best couples and the couples at least pulled proportionally (with a coefficient ) to the number of pulls of the current chosen couple are -accurate for , i.e.
We will show that its complementary is finite on average. In order to prove this we decompose the set in the following way. Let be the set of times where the means are well estimated,
and the set of times where the mean of a couple that is not the current optimal neither pulled is underestimated
Then we prove below the following inclusion.
Lemma 17 (Relations between the subsets of times)
Proof For all user it is assumed that there exists a unique optimal arm such that . We have . In particular, for all time step , if then there exists and such that (and ).
Let . Then and there exists such that . Thus we know that . In particular, we have . Since and , this implies
| (13) |
and . From Lemma 14 we have the following empirical lower bound
| (14) |
In particular, for all we have and Eq. 13 implies
| (15) |
and the monotonic properties of implies
| (16) |
Therefore, by combining Eq. 14, 15 and 16, we have for such
and
which concludes the proof.
Using classical concentration arguments we prove in Appendix D.8 the following upper bounds.
Lemma 18 (Bounded subsets of times)
Lemma 19 (Reliable estimators)
D.3 Pareto-optimality and upper bounds on the numbers of pulls of sub-optimal arms
In this section, we combine the different results of the previous sections to prove the following proposition.
Proposition 20 (Upper bounds)
Let . Let and . Let us consider
Then under IMED-GS⋆ strategy,
and for all horizon time ,
where and are defined as follows:
Furthermore, we have
Refer to Appendix A for the definitions of , and .
Proof From Lemma 19, we have:
Let . Let us consider such that , and . Then, according to IMED-GS⋆ strategy (see Algorithm 2), we have
From Lemma 15 this implies
| (17) |
Since and , we have
| (18) |
Combining inequality (17) with inclusion (18), it comes
| (19) |
Since , we have
| (20) |
By construction of (see Section A), since , inequalities (19) and (20) give us
| (21) |
This implies
Furthermore, using inequality (21), we get
| (22) |
Thus, we have shown that for all arm , for all time step such that , and :
and
This implies for all arm and for all time step ,
and
It can be easily proved that under IMED-GS⋆ for all (see Lemma 27). From previous Proposition 20, we deduce the following corollary by doing , then .
Corollary 21 (Pareto optimality)
Let . Let such that . Then, we have
D.4 IMED-GS⋆ is consistent and induces sequences of users with log-frequencies
In this section we show that IMED-GS⋆ is a consistent strategy that induces sequences of users with log-frequencies all equal to , independently from the considered bandit configuration in .
Lemma 22 (Consistency, log-frequencies )
IMED-GS⋆ is a consistent strategy and induces sequences of users with log-frequencies all equal to .
Proof We first show that IMED-GS⋆ induces sequences of users with log-frequencies all equal to .
Let and let us consider an horizon . Let and . Let us consider again the set of times
Then, according to Proposition 20, under IMED-GS⋆ strategy,
| (23) |
and for all horizon time , for all ,
| (24) |
where , and , , defined in Appendix A.
Note that, under IMED-GS⋆, for all such that we have
.
This implies by definition of that
| (25) |
Indeed the difference of pulls between two optimal couples is non-decreasing only at times such that the difference is greater than and . Combining Eq. 24 and 25 we get
Since (see Eq. 23), this implies that IMED-GS⋆ induces sequences of users with log-frequencies all equal to .
D.5 The counters and coincide at most times
In this section, we want to bound .
Lemma 23
Proof From Lemma 24, we get:
Then applying Lemma 25, it comes:
We end the proof by combining the previous inequality with Proposition 20 that ensures
Lemma 24
Proof Let . By construction of and , we have
| (26) |
Furthermore, the following inequalities are satisfied
| (27) |
Lemma 25
Proof Let . At each time step we increment only if and . Then, if , we have and we increment only if we increment one of the for such that .
D.6 All couples are asymptotically pulled an infinite number of times
Let (defined in Appendix A) and . Let us consider
Then, according to Proposition 20, under IMED-GS⋆ strategy, . In particular, almost surely .
Lemma 26 (The indexes tend to infinity)
For all strategy we have and, under IMED-GS⋆,
Proof
For all couple such that , we have . Then
This implies
Thus, since
we have
Furthermore, under IMED-GS⋆ strategy we have
which ends the proof.
Lemma 27 (The numbers of pulls tend to infinity)
Under IMED-GS⋆ the numbers of pulls almost surely satisfy
In particular, almost surely for all , .
Proof Lemma 26 ensures , for all .
Let . Since and , we have for all
Then, for all , and .
D.7 Concentration lemmas
We state two concentration lemmas that do not depend on the followed strategy. Lemma 28 comes from Lemma B.1 in Combes and Proutiere (2014) and Lemma 29 comes from Lemma 14 in Honda and Takemura (2015). Proofs are provided in Appendix F.
Lemma 28 (Concentration inequalities)
Let . For all and for all couples ,
Lemma 29 (Large deviation probabilities)
D.8 Proof of Lemma 18
Using Lemma 14, for all time step , we have
Then, based on the concentration inequalities from Lemma 28, we obtain
Furthermore, for , and , we have
where for all couple . Thus, considering estimators of means based on the numbers of pulls (see Appendix A), we have
and
| (30) |
Then, by applying Lemma 29 based on large deviation inequalities, we have
| (31) |
where .
By combining Eq. 30 and 31, we conclude that
E IMED-GS⋆: Proof of Theorem 11 (main result)
In this section we prove the asymptotic optimality of IMED-GS⋆ strategy. The proof is based on the finite time analysis detailed in Appendix D.
E.1 Almost surely tends to
For such that , let us define the linear programming
Then is the unique optimal solution of the previous minimization problem. Furthermore, we can state the following lemma.
Lemma 30
.
Lemma 31
Proof Let . There exists such that . Since , we have . In particular for all , . Furthermore, we have
Lastly since , we have
and
E.2 Almost surely and on expectation, for all sub-optimal couple tends to
Combining the upper bounds from the finite analysis and the asymptotic behaviour of , we prove the asymptotic optimality of IMED-GS⋆.
Lemma 32 (Asymptotic upper bounds)
For all sub-optimal couple ,
Proof Let (see Appendix A) and . Let and let us consider an horizon . Let us introduce the random variable
where and are respectively introduced in Appendix D.2 and D.5 . Then, by definition of and since , from Lemma 23 we have
| (32) |
Furthermore, since we have . In addition, since and , Lemma 15 implies the following empirical upper bound
| (33) |
In particular, since , Eq. 32 and 33 imply
and, since , from Lemma 30 we get
Lemma 33 (Asymptotic optimality)
For all sub-optimal couple , we have
Proof Since IMED-GS⋆ is a consistent strategy that induces sequences of users with log-frequencies equal to , we have
Then, Pareto-optimality of IMED-GS⋆ combined with asymptotic upper bounds given in Lemma 32 ensures that for all , . Since, the are dominated by an integrable variable (see Proposition 20 in Appendix D), we also have these convergences on average.
F Concentration lemmas: Proofs
Lemma Let . For all and for all couples ,
Proof Considering the stopping times we will rewrite the sum
and use an Hoeffding’s type argument.
Taking the expectation , it comes:
Proof The proof is based on a Chernoff type inequality and a calculation by measurement change. The proof comes from Honda and Takemura (2015). We explicit here the particular case of Bernoulli distributions for completeness.
Let us rephrase Proposition 11 from Honda and Takemura (2015). Since we consider Bernoulli distributions, we get a more explicit formulation.
Proposition 34
Let . Let and . Then, for all and , we have
We know rewrite equality (27) from Honda and Takemura (2015) with our notations.
Let . We have from Proposition 34 that :
To ends the proof, we use the following inequalities for :
G IMED-GS, IMED-GS2, IMED-GS: Finite-time analysis
In this subsection we rewrite and adapt the results established in Sections D, E for IMED-GS⋆ strategy to the other considered strategies. Mainly, we rewrite the empirical lower bounds and upper bounds detailed in Lemmas 14, and 15. These inequalities form the basis of the analysis of IMED-GS⋆ strategy. For the sake of brevity and clarity, proofs are not given.
G.1 IMED-GS finite-time analysis
Under IMED-GS strategy we do not solve empirical versions of optimisation problem 8 and pull the couples with minimum (pseudo) indexes. This leads to the following empirical bounds.
Lemma 35 (IMED-GS: Empirical lower bounds)
Under IMED-GS, at each step time , for all couple ,
Furthermore, for all couple ,
Lemma 36 (IMED-GS: Empirical upper bounds)
Under IMED-GS, at each step time such that we have
In particular
Based on this lemmas, one can prove IMED-GS Pareto-optimality in a similar way as for IMED-GS⋆ strategy.
Proposition 37 (IMED-GS: Upper bounds )
Let . Let and . Let us introduce
Then under IMED-GS strategy,
and for all horizon time , for all arm ,
where and are defined as follows:
Furthermore, we have
Refer to Appendix A for the definitions of , and .
From the previous proposition, we deduce the following corollary by doing , then .
Corollary 38 (IMED-GS: Pareto optimality)
Let . Under IMED-GS strategy we have
G.2 Uncontrolled scenario: Finite-time analysis
When uncontrolled scenario is considered, the learner does not choose the users to deal with and the exploration phases may be performed with some delay. This can be formalized within the empirical bounds induced by IMED-GS2 and IMED-GS strategies.
G.2.1 Empirical bounds on the numbers of pulls
For time step , let us introduce the last return time of couple as
By definition of we have
Now, empirical bounds on the numbers of pull can be formulated for the uncontrolled scenario. These inequalities are the same as those for the controlled scenario up to (random) time-delays.
Lemma 39 (Uncontrolled scenario: Empirical lower bounds)
Under IMED-GS2 and IMED-GS, at each step time there exists a random time delay such that and for all couple
Furthermore, for all couple ,
Lemma 40 (Empirical upper bounds)
Under IMED-GS2 and IMED-GS, at each step time such that , we have
where is a random time delay such that . Furthermore, we have under IMED-GS2
and under IMED-GS
Thus, we prove respectively the Pareto-optimality and optimality of IMED-GS2 and IMED-GS since we show that the empirical means of couples involved in the previous inequalities concentrate as in the case of the controlled scenario. This is the case as it is stated in Lemmas 41 of the next subsection.
G.2.2 Concentration inequality with bounded time delays
We prove a concentration lemma that does not depend on the followed strategy. It is a rewritting for the case of controlled scenario of Lemma 28.
Lemma 41 (Concentration inequalities)
Let , , and . Then for all sequence of stopping times such that for all , we have
Remark 42
There is no need to adapt Lemma 29 for the case of controlled scenario since this concentration lemma does not involve the current time steps explicitly.
Proof It is pointed out that for all time step , , then we proceed as in Appendix F.
H Continuity of solutions to parametric linear programs
In this section we recall Lemma 13 established in Magureanu et al. (2014) on the continuity of solutions to parametric linear programs.
Lemma 43
Consider , , and . Define . Consider the function and the set-valued map
Assume that:
(i) For all , all rows and columns of are non-identically 0
(ii)
Then:
(a) is continuous on
(b) is upper hemicontinuous on .
I Details on numerical experiments
For the fixed configuration experiments we used the weight matrix of Table 1 and the configuration described in Table 2. and have been chosen at random in such a way that the regret under IMED exceeds the structured lower bound on the regret. This means the structure is informative for the bandit configuration and not taking it into account hinders optimality.
| user\user | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.07 | 0.07 | 0.12 | 0.20 | 0.05 | 0.16 | 0.14 | 0.28 | 0.03 | |
| 0.07 | 0 | 0.14 | 0.13 | 0.21 | 0.12 | 0.09 | 0.07 | 0.21 | 0.04 | |
| 0.07 | 0.14 | 0 | 0.19 | 0.27 | 0.12 | 0.11 | 0.13 | 0.25 | 0.10 | |
| 0.12 | 0.13 | 0.19 | 0 | 0.26 | 0.17 | 0.22 | 0.20 | 0.34 | 0.09 | |
| 0.20 | 0.21 | 0.27 | 0.26 | 0 | 0.25 | 0.18 | 0.20 | 0.32 | 0.17 | |
| 0.05 | 0.12 | 0.12 | 0.17 | 0.25 | 0 | 0.21 | 0.19 | 0.33 | 0.08 | |
| 0.16 | 0.09 | 0.11 | 0.22 | 0.18 | 0.21 | 0 | 0.02 | 0.14 | 0.13 | |
| 0.14 | 0.07 | 0.13 | 0.20 | 0.20 | 0.19 | 0.02 | 0 | 0.16 | 0.11 | |
| 0.28 | 0.21 | 0.25 | 0.34 | 0.32 | 0.33 | 0.14 | 0.16 | 0 | 0.25 | |
| 0.03 | 0.04 | 0.10 | 0.09 | 0.17 | 0.08 | 0.13 | 0.11 | 0.25 | 0 |
| arm \user | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.15 | 0.11 | 0.19 | 0.19 | 0.08 | 0.15 | 0.09 | 0.08 | 0.13 | 0.13 | |
| 0.70 | 0.73 | 0.71 | 0.71 | 0.70 | 0.71 | 0.78 | 0.79 | 0.64 | 0.70 | |
| 0.13 | 0.14 | 0.13 | 0.15 | 0.02 | 0.08 | 0.17 | 0.17 | 0.04 | 0.14 | |
| 0.02 | 0.04 | 0.09 | 0.05 | 0.16 | 0.02 | 0.11 | 0.11 | 0.06 | 0.01 | |
| 0.95 | 0.98 | 1.00 | 0.97 | 0.98 | 0.98 | 0.90 | 0.91 | 0.84 | 0.97 |