Optimality of Thompson Sampling with Noninformative Priors
for Pareto Bandits
Abstract
In the stochastic multi-armed bandit problem, a randomized probability matching policy called Thompson sampling (TS) has shown excellent performance in various reward models. In addition to the empirical performance, TS has been shown to achieve asymptotic problem-dependent lower bounds in several models. However, its optimality has been mainly addressed under light-tailed or one-parameter models that belong to exponential families. In this paper, we consider the optimality of TS for the Pareto model that has a heavy tail and is parameterized by two unknown parameters. Specifically, we discuss the optimality of TS with probability matching priors that include the Jeffreys prior and the reference priors. We first prove that TS with certain probability matching priors can achieve the optimal regret bound. Then, we show the suboptimality of TS with other priors, including the Jeffreys and the reference priors. Nevertheless, we find that TS with the Jeffreys and reference priors can achieve the asymptotic lower bound if one uses a truncation procedure. These results suggest carefully choosing noninformative priors to avoid suboptimality and show the effectiveness of truncation procedures in TS-based policies.
1 Introduction
In the multi-armed bandit (MAB) problem, an agent plays an arm and observes a reward only from the played arm, which is partial feedback (Thompson, 1933; Robbins, 1952). The rewards are further assumed to be generated from the distribution of the corresponding arm in the stochastic MAB problem (Bubeck et al., 2012). Since only partial observations are available, the agent has to estimate unknown distributions to guess which arm is optimal while avoiding playing suboptimal arms that induce loss of resources. Thus, the agent has to cope with the dilemma of exploration and exploitation.
In this problem, Thompson sampling (TS), a randomized Bayesian policy that plays an arm according to the posterior probability of being optimal, has been widely adopted because of its outstanding empirical performance (Chapelle and Li, 2011; Russo et al., 2018). Following its empirical success, theoretical analysis of TS has been conducted for several reward models such as Bernoulli models (Agrawal and Goyal, 2012; Kaufmann et al., 2012), one-dimensional exponential families (Korda et al., 2013), Gaussian models (Honda and Takemura, 2014), and bounded support models (Riou and Honda, 2020; Baudry et al., 2021) where asymptotic optimality of TS was established. Here, an algorithm is said to be asymptotically optimal if it can achieve the theoretical problem-dependent lower bound derived by Lai et al. (1985) for one-parameter models and Burnetas and Katehakis (1996) for multiparameter or nonparametric models. Note that the performance of any reasonable algorithms cannot be better than these lower bounds.
Apart from the problem-dependent regret analysis, several works studied the problem-independent or prior-independent bounds of TS (Bubeck and Liu, 2013; Russo and Van Roy, 2016; Agrawal and Goyal, 2017). In this paper, we study how the choice of noninformative priors affects the performance of TS for any given problem instance. In other words, we focus on the asymptotic optimality of TS depending on the choice of noninformative priors.
The asymptotic optimality of TS has been mainly considered in the one-parameter model, while its optimality under the multiparameter model has not been well studied. To the best of our knowledge, the asymptotic optimality of TS in the noncompact multiparameter model is only known for the Gaussian bandits (Honda and Takemura, 2014) where both the mean and variance are unknown. They showed that TS with the uniform prior is optimal while TS with the Jeffreys prior and reference prior cannot achieve the lower bound. The success of the uniform prior is due to its frequent playing of seemingly suboptimal arms. Its conservativeness comes from a moderate overestimation of the posterior probability that current suboptimal arms might be optimal.
In this paper, we consider the two-parameter Pareto models where the tail function is heavy-tailed. We first derive the closed form of the problem-dependent constant that appears in the theoretical lower bound in Pareto models, which is not trivial, unlike those for exponential families. Based on this result, we show that TS with some probability-matching priors achieves the optimal bound, which is the first result for two-parameter Pareto bandit models, to our knowledge.
We further show that TS with different choices of probability matching priors, called optimistic priors, suffers a polynomial regret in expectation. Therefore, being conservative would be better when one chooses noninformative priors to avoid suboptimality in view of expectation. Nevertheless, we show that TS with the Jeffreys prior or the reference prior can achieve the optimal regret bound if we add a truncation procedure on the shape parameter. Our contributions are summarized as follows:
-
•
We prove the asymptotic optimality/suboptimality of TS under different choices of priors, which shows the importance of the choice of noninformative priors in cases of two-parameter Pareto models.
-
•
We provide another option to achieve optimality: adding a truncation procedure to the parameter space of the posterior distribution instead of finding an optimal prior.
This paper is organized as follows. In Section 2, we formulate the stochastic MAB problems under the Pareto distribution and derive its regret lower bound. Based on the choice of noninformative priors and their corresponding posteriors, we formulate TS for the Pareto models and propose another TS-based algorithm to solve the suboptimality problem of the Jeffreys prior and the reference prior in Section 3. In Section 4, we provide the main results on the optimality of TS and TS with a truncation procedure, whose proof outline is given in Section 6. Numerical results that support our theoretical analysis are provided in Section 5.
2 Preliminaries
In this section, we formulate the stochastic MAB problem. We derive the exact form of the problem-dependent constant that appears in the lower bound of the expected regret in Pareto bandits.
2.1 Notations
We consider the stochastic -armed bandit problem where the rewards are generated from Pareto distributions with fixed parameters. An agent chooses an arm in at each round and observes an independent and identically distributed reward from , where denotes the Pareto distribution parameterized by scale and shape . This has the density function of form
| (1) |
where denotes the indicator function. We consider a bandit model where parameters are unknown to the agent. We denote the mean of a random variable following by . Note that is a necessary condition of an arm to have a finite mean, which is required to define the sub-optimality gap . We assume without loss of generality that arm has the maximum mean for simplicity, i.e., . Let be the arm played at round and denote the number of rounds the arm is played until round . Then, the regret at round is given as
Let be the -th reward generated from the arm . In the Pareto distribution, the maximum likelihood estimators (MLEs) of for arm given rewards and their distributions are given as follows (Malik, 1970):
| (2) |
where denotes the inverse-gamma distribution with shape and scale . Note that Malik (1970) further showed the stochastic independence of and .
2.2 Asymptotic lower bound
Burnetas and Katehakis (1996) provided a problem-dependent lower bound of the expected regret such that any uniformly fast convergent policy, which is a policy satisfying for all , must satisfy
| (3) |
where denotes the Kullback-Leibler (KL) divergence. Notice that the bandit model is considered as a fixed constant in the problem-dependent analysis.
The KL divergence between Pareto distributions is given as
Here the divergence sometimes becomes infinity since the scale parameter determines the support of the Pareto distribution. We denote the numerator in (3) for by
where
| (4) |
Notice that allows parameters whose expected rewards are infinite (), although we consider a bandit model with for all so that the sub-optimality gap becomes finite. This implies that does not depend on whether the agent considers the possibility that an arm has the infinite expected reward or not. Then, we can simply rewrite the lower bound in (3) as
The following lemma shows the closed form of this infimum, whose proof is given in Appendix B.
Lemma 1.
For any arm , it holds that
2.3 Relation with bounded moment models
In MAB literature, several algorithms based on the upper confidence bound (UCB) were proposed to tackle heavy-tailed models with infinite variance under additional assumptions on moments (Bubeck et al., 2013). One major assumption is that the moment of any arm satisfies for some fixed and known (Bubeck et al., 2013). Note that the -th raw moment of the density function of following is given as
which implies that the Pareto models and the bounded moment models are not a subset of each other.
Recently, Agrawal et al. (2021) proposed an asymptotically optimal KL-UCB based algorithm that requires solving the optimization problem at every round. Since the bounded moment model only covers certain Pareto distributions in general, the known optimality result of KL-UCB does not necessarily imply the optimality in the sense of (3).
3 Thompson sampling and probability matching priors
TS is a policy from the Bayesian viewpoint, where the choices of priors are important. Although one can utilize prior knowledge on parameters when choosing the prior, such information would not always be available in practice. To deal with such scenarios, we consider noninformative priors based on the Fisher information (FI) matrix, which does not assume any information on unknown parameters.
For a random variable with density , FI is defined as the variance of the score, a partial derivative of with respect to , which is given as follows (Cover and Thomas, 2006):
| (5) |
It is known that the FI matrix in (5) coincides with the negative expected value of the Hessian matrix of if the model satisfies the FI regular condition (Schervish, 2012). However, does not satisfy this condition since it is a parametric-support family. Therefore, for with density function in (1), one can obtain the FI matrix of based on (5) as follows (Li et al., 2022):
| (6) |
where , , and . Note that differs from .
Based on (6), the Jeffreys prior and the reference prior are given as and , respectively. Here, the reverse reference prior is the same as the reference prior from the orthogonality of parameters (Datta and Ghosh, 1995; Datta, 1996).
From the orthogonality of parameters, the probability matching prior when is of interest and is the nuisance parameter is given as
for arbitrary (Tibshirani, 1989). In this paper, we consider the prior for since the cases correspond to the Jeffreys prior and the (reverse) reference prior, respectively.
Remark 1.
The Pareto distribution discussed in this paper is sometimes called the Pareto type distribution (Arnold, 2008). On the other hand, Kim et al. (2009) derived several noninformative priors for a special case of the Pareto type distribution called the Lomax distribution (Lomax, 1954), where the FI matrix can be written using the negative Hessian.
In the multiparameter cases, the Jeffreys prior is known to suffer from many problems (Datta and Ghosh, 1996; Ghosh, 2011). For example, it is known that the Jeffreys prior leads to inconsistent estimators for the error variance in the Neyman-Scott problem (see Berger and Bernardo, 1992, Example 3). This might be a possible reason why TS with Jeffreys prior suffers a polynomial expected regret in a multiparameter distribution setting. More details on the probability matching prior and the Jeffreys prior can be found in Appendix E.
3.1 Sampling procedure
Let be the history until round . Under the prior with , the marginalized posterior distribution of the shape parameter of arm is given as
| (7) |
where denotes the Erlang distribution with shape and rate . Note that we require initial plays to avoid improper posteriors and MLE of . When the shape parameter is given as , the cumulative distribution function (CDF) of the conditional posterior of is given as
| (8) |
if . Since one can derive the posteriors following the same steps as Sun et al. (2020), the detailed derivation is postponed to Appendix E.3. At round , we denote the sampled scale and shape parameters of arm by and , respectively, and the corresponding mean reward by . We first sample the shape parameter from the marginalized posterior in (7). Then, we sample the scale parameter given the sampled shape parameter from the CDF of the conditional posterior in (8) by using inverse transform sampling. TS based on this sequential procedure, which we call Sequential Thompson Sampling (), can be formulated as Algorithm 1.
In Theorem 3 given in the next section, with the Jeffreys prior and the reference prior turns out to be suboptimal in view of the lower bound in (3). Their suboptimality is mainly due to the behavior of the posterior in (7) when is overestimated for small . To overcome such issues, we propose the policy, a variant of with truncation, where we replace with in (7). Note that such a truncation procedure is especially considered in the posterior sampling by (7) and (8). We show that with the Jeffreys prior and the reference prior can achieve the optimal regret bound in Theorem 4.
3.2 Interpretation of the prior parameter
The Erlang distribution is a special case of the Gamma distribution, where the shape parameter is a positive integer. If a random variable follows , then it has the density of form
| (9) |
where and denote the shape and rate parameter, respectively. Then, the CDF evaluated at is given as
| (10) |
where denotes the lower incomplete gamma function. Since holds, one can observe that for any
| (11) |
From the sampling procedure of and , depends on only when holds since results in . Therefore, for any in (8), will concentrate on for sufficiently large . Thus, will be mainly determined by and , where the choice of affects the sampling of by (7). From (11), one could see that the probability of sampling small increases as shape decreases. Therefore, of suboptimal arms would increase as increases for the same . In other words, the probability of sampling large becomes large as increases. Therefore, TS with large becomes a conservative policy that could frequently play currently suboptimal arms. In contrast, priors with small yield an optimistic policy that focuses on playing the current best arm.
4 Main results
In this section, we provide regret bounds of and with different choices of . At first, we show the asymptotic optimality of for priors with .
Theorem 2.
Assume that arm is the unique optimal arm with a finite mean. For every , let where for and . Given arbitrary , the expected regret of with is bounded as
where is a function such that for any fixed .
By letting in Theorem 2, we see that with satisfies
which shows the asymptotic optimality of in terms of the lower bound in (3).
Next, we show that with cannot achieve the asymptotic bound in the theorem below. Following the proofs for Gaussian bandits (Honda and Takemura, 2014), we consider two-armed bandit problems where the full information on the suboptimal arm is given to simplify the analysis. We further assume that two arms have the same scale parameter .
Theorem 3.
From Theorems 2 and 3, we find that the prior should be conservative to some extent when one considers maximizing rewards in expectation.
Although with the Jeffreys prior () and reference prior () were shown to be suboptimal, we show that a modified algorithm, , can achieve the optimal regret bound with .
Theorem 4.
From Theorems 2 and 4, we have two choices to achieve the lower bound in (3): use either the conservative priors with MLEs or moderately optimistic priors with truncated samples. Since initialization steps require playing every arm times, if the number of arms is large, the Jeffreys priors or the reference prior with the truncated estimator would be a better choice. On the other hand, if the model can contain arms with large , where the truncation might be problematic for small , it would be better to use with conservative priors.
5 Experiments
In this section, we present numerical results to demonstrate the performance of and , which supports our theoretical analysis. We consider the -armed bandit model with parameters given in Table 1 as an example where suboptimal arms have smaller, equal, and larger compared with the optimal arm. has and infinite variance. Further experimental results can be found in Appendix H.
| arm | arm | arm | arm | |
|---|---|---|---|---|
| 1.3 | 1.2 | 1.3 | 1.5 | |
| 1.4 | 1.6 | 1.9 | 2.0 |
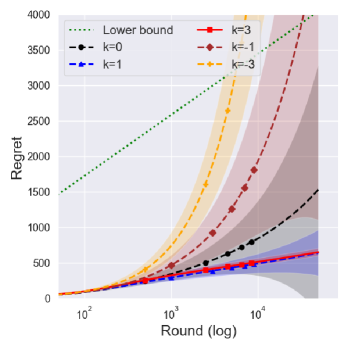
Figure 1 shows the cumulative regret for the proposed policies with various choices of parameters on the prior. The solid lines denote the averaged cumulative regret over 100,000 independent runs of priors that can achieve the optimal lower bound in (3), whereas the dashed lines denote that of priors that cannot. The green dotted line denotes the problem-dependent lower bound and shaded regions denote a quarter standard deviation.
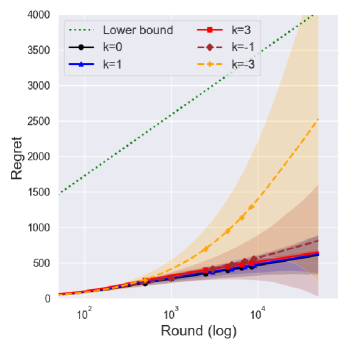
In Figures 2 and 3, we investigate the difference between and with the same . The solid lines denote the averaged cumulative regret over 100,000 independent runs. The shaded regions and dashed lines show the central interval and the upper of regret.
The Jeffreys prior ()
In Figure 1(a), the Jeffreys prior seems to have a larger order of the regret compared with priors , which performed the best in this setting. As Theorem 4 states, its performance improves under , which shows a similar performance to that of .
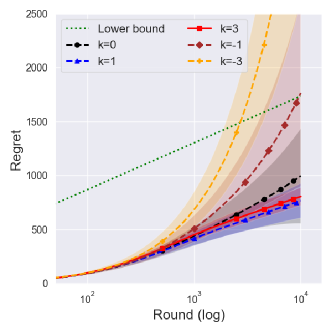
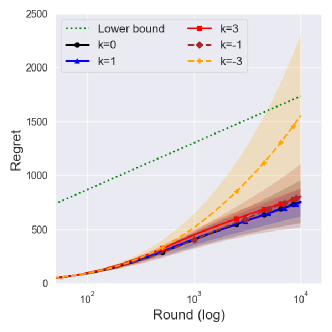
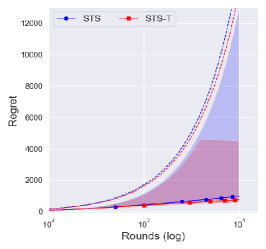
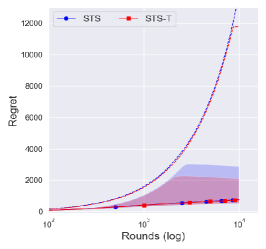
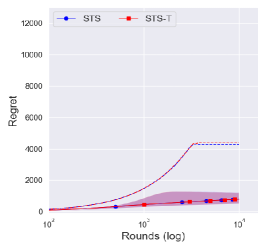
Figure 2(a) illustrates the possible reason for the improvements, where the central interval of the regret noticeably shrank under . Since the suboptimality of with the Jeffreys prior () is due to an extreme case that induces a polynomial regret with small probability, this kind of shrink contributes to decreasing the expected regret of with the Jeffreys prior.
The reference prior ()
The reference prior showed a similar performance to the asymptotically optimal prior , although it was shown to be suboptimal for some instances under in Theorem 3. Similarly to the Jeffreys prior , the reference prior () under has a smaller central interval of the regret than that under as shown in Figure 2(b), although its decrement is comparably smaller than that of the Jeffreys prior. This would imply that the reference prior is more conservative than the Jeffreys prior.
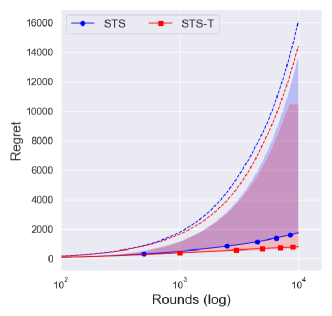
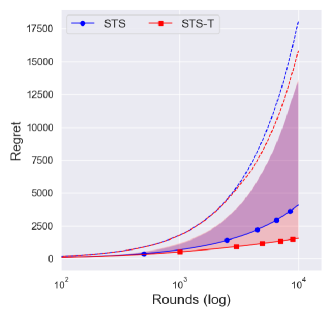
The conservative prior ()
Interestingly, Figure 2(c) showed that a truncated procedure does not affect the central interval of the regret and even degrade the performance in upper . Notice that the upper of the regret of is much lower than that of , which shows the stability of the conservative prior in Figure 2.
Since a truncation procedure was adopted to prevent an extreme case that was a problem for , it is natural to see that there is no difference between and with . This would imply that is sufficiently conservative, and so the truncated procedure does not affect the overall performance.
Optimistic priors ()
In Figure 1(a), one can see that the averaged regret of and increases much faster than that of under the policy, which illustrates the suboptimality of with priors .
As the optimistic priors () showed better performance under in Figure 1, we can check the effectiveness of a truncation procedure in the posterior sampling with optimistic priors. However, as Figures 3(a) and 3(b) illustrate, there is no big difference in the central interval of the regret between and with , which might imply that a prior with is too optimistic. Therefore, we might need to use a more conservative truncation procedure such as the one using or , which would induce a larger regret in the finite time horizon.
6 Proof outline of optimal results
In this section, we provide the proof outline of Theorem 2 and Theorem 4, whose detailed proof is given in Appendix C. Note that the proof of Theorem 3 is postponed to Appendix D.
Let us first consider good events on MLEs defined by
where and
| (12) |
Note that holds on for any . Here, we set to satisfy on for any . Define an event on the sample of the optimal arm
Then, the expected regret at round can be decomposed as follows:
where denotes the complementary set of . Lemmas 5–8 complete the proof of Theorems 2 and 4, whose proofs are given in Appendix C.
Lemma 5.
Under with ,
and under with ,
where .
Although Lemma 6 contributes to the main term of the regret, the proof of Lemma 5 is the main difficulty in the regret analysis. We found that our analysis does not result in a finite upper bound for with and designed to solve such problems.
Lemma 6.
Under and with , it holds that for any
where is a finite problem-deterministic constant satisfying .
Since large yields a more conservative policy and it requires additional initial plays of every arm, large might induce larger regret for a finite time horizon , which corresponds to the component of the regret discussed in Lemma 6. Thus, this lemma would imply that the policy has to be conservative to some extent and being overly conservative would induce larger regrets in a finite time.
Lemma 7.
Under and with ,
The key to Lemma 7 is to convert the term on , , to a term on . Since holds for , becomes infinity regardless of the value of if holds, which implies . Therefore, it is enough to consider the case where holds to prove Lemma 7. Although density functions of under and are different, conditional CDFs of given are the same, which is given in (8) as
Therefore, for sufficiently large and , will concentrate on with high probability, which is close to its true value under the event . Thus, holds with high probability, which implies that can be roughly bounded by for some problem-dependent constants . Since is deterministic given , we have
which implies is mainly determined by the value of under the event for both policies. In such cases, and behave like TS in the Pareto distribution with a known scale parameter, where for . Here, the Pareto distribution with the known scale parameter belongs to the one-dimensional exponential family, where Korda et al. (2013) showed the optimality of TS with the Jeffreys prior. Since the posterior of under the Jeffreys prior is given as the Erlang distribution with shape in the one-parameter Pareto model, we can apply the results by Korda et al. (2013) to prove Lemma 7 by using some properties of the Erlang distribution such as (11).
Lemma 8.
Under and with , it holds that for any
Lemma 8 controls the regret induced when estimators of the played arm are not close to their true parameters, which is not difficult to analyze as in the usual analysis of TS. In fact, the proof of this lemma is straightforward since the upper bounds of and can be easily derived based on the distributions of and in (2).
7 Conclusion
We considered the MAB problems under the Pareto distribution that has a heavy tail and follows the power-law. While most previous research on TS has focused on one-dimensional or light-tailed distributions, we focused on the Pareto distribution characterized by unknown scale and shape parameters. By sequentially sampling parameters via their marginalized and conditional posterior distributions, we can realize an efficient sampling procedure. We showed that TS with the appropriate choice of priors achieves a problem-dependent optimal regret bound in such a setting for the first time. Although the Jeffreys prior and the reference prior are shown to be suboptimal under the direct implementation of TS, we showed that they can achieve the optimal regret bound if we add a truncation procedure. Experimental results support our theoretical results, which show the optimality of conservative priors and the effectiveness of the truncation procedure for the Jeffreys prior and the reference prior.
Acknowledgement
JL was supported by JST SPRING, Grant Number JPMJSP2108. CC and MS were supported by the Institute for AI and Beyond, UTokyo.
References
- Agrawal and Goyal (2012) Shipra Agrawal and Navin Goyal. Analysis of Thompson sampling for the multi-armed bandit problem. In Conference on Learning Theory, pages 39–1. PMLR, 2012.
- Agrawal and Goyal (2017) Shipra Agrawal and Navin Goyal. Near-optimal regret bounds for Thompson sampling. Journal of the Association for Computing Machinery, 64(5):1–24, 2017.
- Agrawal et al. (2021) Shubhada Agrawal, Sandeep K Juneja, and Wouter M Koolen. Regret minimization in heavy-tailed bandits. In Conference on Learning Theory, pages 26–62. PMLR, 2021.
- Arnold (2008) Barry C Arnold. Pareto and generalized Pareto distributions. In Modeling income distributions and Lorenz curves, pages 119–145. Springer, 2008.
- Baudry et al. (2021) Dorian Baudry, Romain Gautron, Emilie Kaufmann, and Odalric Maillard. Optimal Thompson sampling strategies for support-aware CVaR bandits. In International Conference on Machine Learning, pages 716–726. PMLR, 2021.
- Berger and Bernardo (1992) James O Berger and José M Bernardo. On the development of the reference prior method. Bayesian Statistics, 4(4):35–60, 1992.
- Bernardo (1979) Jose M Bernardo. Reference posterior distributions for bayesian inference. Journal of the Royal Statistical Society: Series B (Methodological), 41(2):113–128, 1979.
- Bubeck and Liu (2013) Sébastien Bubeck and Che-Yu Liu. Prior-free and prior-dependent regret bounds for Thompson sampling. In Advances in Neural Information Processing Systems, volume 26, pages 638–646, 2013.
- Bubeck et al. (2012) Sébastien Bubeck, Nicolo Cesa-Bianchi, et al. Regret analysis of stochastic and nonstochastic multi-armed bandit problems. Foundations and Trends® in Machine Learning, 5(1):1–122, 2012.
- Bubeck et al. (2013) Sébastien Bubeck, Nicolo Cesa-Bianchi, and Gábor Lugosi. Bandits with heavy tail. IEEE Transactions on Information Theory, 59(11):7711–7717, 2013.
- Burnetas and Katehakis (1996) Apostolos N Burnetas and Michael N Katehakis. Optimal adaptive policies for sequential allocation problems. Advances in Applied Mathematics, 17(2):122–142, 1996.
- Chapelle and Li (2011) Olivier Chapelle and Lihong Li. An empirical evaluation of Thompson sampling. In Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc., 2011.
- Cover and Thomas (2006) Thomas M Cover and Joy A Thomas. Elements of information theory. Wiley-Interscience, 2nd edition, 2006.
- Datta (1996) Gauri Sankar Datta. On priors providing frequentist validity of Bayesian inference for multiple parametric functions. Biometrika, 83(2):287–298, 1996.
- Datta and Ghosh (1995) Gauri Sankar Datta and Malay Ghosh. Some remarks on noninformative priors. Journal of the American Statistical Association, 90(432):1357–1363, 1995.
- Datta and Ghosh (1996) Gauri Sankar Datta and Malay Ghosh. On the invariance of noninformative priors. The Annals of Statistics, 24(1):141–159, 1996.
- Datta and Sweeting (2005) Gauri Sankar Datta and Trevor J Sweeting. Probability matching priors. Handbook of Statistics, 25:91–114, 2005.
- DiCiccio et al. (2017) Thomas J DiCiccio, Todd A Kuffner, and G Alastair Young. A simple analysis of the exact probability matching prior in the location-scale model. The American Statistician, 71(4):302–304, 2017.
- Ghosh (2011) Malay Ghosh. Objective priors: An introduction for frequentists. Statistical Science, 26(2):187–202, 2011.
- Honda and Takemura (2014) Junya Honda and Akimichi Takemura. Optimality of Thompson sampling for Gaussian bandits depends on priors. In International Conference on Artificial Intelligence and Statistics, volume 33, pages 375–383. PMLR, 2014.
- Jeffreys (1998) Harold Jeffreys. The theory of probability. OUP Oxford, 1998.
- Kaufmann et al. (2012) Emilie Kaufmann, Nathaniel Korda, and Rémi Munos. Thompson sampling: An asymptotically optimal finite time analysis. In International Conference on Algorithmic Learning Theory, volume 7568, pages 199–213. Springer, 2012.
- Kim et al. (2009) Dal-Ho Kim, Sang-Gil Kang, and Woo-Dong Lee. Noninformative priors for Pareto distribution. Journal of the Korean Data and Information Science Society, 20(6):1213–1223, 2009.
- Korda et al. (2013) Nathaniel Korda, Emilie Kaufmann, and Remi Munos. Thompson sampling for 1-dimensional exponential family bandits. In International Conference on Neural Information Processing Systems, volume 26, pages 1448–1456. Curran Associates, Inc., 2013.
- Lai et al. (1985) Tze Leung Lai, Herbert Robbins, et al. Asymptotically efficient adaptive allocation rules. Advances in Applied Mathematics, 6(1):4–22, 1985.
- Li et al. (2022) Mingming Li, Huafei Sun, and Linyu Peng. Fisher–Rao geometry and Jeffreys prior for Pareto distribution. Communications in Statistics-Theory and Methods, 51(6):1895–1910, 2022.
- Lomax (1954) Kenneth S Lomax. Business failures: Another example of the analysis of failure data. Journal of the American Statistical Association, 49(268):847–852, 1954.
- Malik (1970) Henrick John Malik. Estimation of the parameters of the Pareto distribution. Metrika, 15(1):126–132, 1970.
- Mukerjee and Ghosh (1997) Rahul Mukerjee and Malay Ghosh. Second-order probability matching priors. Biometrika, 84(4):970–975, 1997.
- Riou and Honda (2020) Charles Riou and Junya Honda. Bandit algorithms based on Thompson sampling for bounded reward distributions. In International Conference on Algorithmic Learning Theory, pages 777–826. PMLR, 2020.
- Robbins (1952) Herbert Robbins. Some aspects of the sequential design of experiments. Bulletin of the American Mathematical Society, 58(5):527–535, 1952.
- Robert et al. (2007) Christian P Robert et al. The Bayesian choice: from decision-theoretic foundations to computational implementation. Springer, 2nd edition, 2007.
- Russo and Van Roy (2016) Daniel Russo and Benjamin Van Roy. An information-theoretic analysis of Thompson sampling. The Journal of Machine Learning Research, 17(1):2442–2471, 2016.
- Russo et al. (2018) Daniel J Russo, Benjamin Van Roy, Abbas Kazerouni, Ian Osband, Zheng Wen, et al. A tutorial on Thompson sampling. Foundations and Trends® in Machine Learning, 11(1):1–96, 2018.
- Schervish (2012) Mark J Schervish. Theory of statistics. Springer Science & Business Media, 2012.
- Simon and Divsalar (1998) Marvin K Simon and Dariush Divsalar. Some new twists to problems involving the Gaussian probability integral. IEEE Transactions on Communications, 46(2):200–210, 1998.
- Stein (1959) Charles Stein. An example of wide discrepancy between fiducial and confidence intervals. The Annals of Mathematical Statistics, 30(4):877–880, 1959.
- Sun et al. (2020) Fupeng Sun, Yueqi Cao, Shiqiang Zhang, and Huafei Sun. The Bayesian inference of Pareto models based on information geometry. Entropy, 23(1):45, 2020.
- Thompson (1933) William R Thompson. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika, 25(3/4):285–294, 1933.
- Tibshirani (1989) Robert Tibshirani. Noninformative priors for one parameter of many. Biometrika, 76(3):604–608, 1989.
- Vershynin (2018) Roman Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018.
- Wallace (1959) David L. Wallace. Bounds on normal approximations to student’s and the chi-square distributions. The Annals of Mathematical Statistics, 30(4):1121–1130, 1959.
- Welch and Peers (1963) BL Welch and HW Peers. On formulae for confidence points based on integrals of weighted likelihoods. Journal of the Royal Statistical Society: Series B (Methodological), 25(2):318–329, 1963.
Appendix A Notations
| Symbol | Meaning |
|---|---|
| the number of arms. | |
| time horizon. | |
| the index of the played arm at round . | |
| prior parameter, see Section 3 for details. | |
| initial plays to avoid improper posteriors. | |
| the number of playing arm until round . | |
| -th reward generated from the arm . | |
| the expected value of the random variable following . | |
| the expected rewards of arm . | |
| sub-optimality gap of arm . | |
| for | a half of sub-optimality gap of arm . |
| defined as the minimum of sub-optimality gap. | |
| the history until round . | |
| conditional probability given . | |
| KL-divergence from to for . | |
| the upper bound of satisfying for . |
| Symbol | Meaning |
|---|---|
| Pareto distribution with the scale and shape . | |
| density function of . | |
| Erlang distribution with the shape and rate . | |
| density function of . | |
| CDF of evaluated at . | |
| Inverse Gamma distribution with shape and scale . | |
| CDF of the chi-squared distribution with degree of freedom. | |
| Gamma function. | |
| the lower incomplete gamma function. | |
| the upper incomplete gamma function. | |
| MLEs of the scale and shape parameter of arm after observations, defined in (2). | |
| sampled parameters at round from posterior distribution in (8) and (7). | |
| truncated estimator of the shape parameter. | |
| a temporary notation that can be replaced by both () and (). | |
| computed mean rewards by the MLEs after observation. | |
| computed mean rewards by sampled parameters and at round . | |
| tuple of true parameters of arm . | |
| tuple of MLEs of arm after observations. | |
| tuple of estimators with a truncation procedure of arm after observations. | |
| a temporary notation that can be replaced by both () and (). |
| Symbol | Meaning |
|---|---|
| a function contributes to the main term of regret analysis defined in (42). | |
| an event where MLE of is close to its true value at round after observations. | |
| an event where MLE of is close to its true value at round after observations. | |
| intersection of and . | |
| an event where sampled mean of the optimal arm is close to its true mean reward at round . | |
| probability of after observation of arm given . | |
| another expression of the CDF of the Erlang distribution in (20). |
| Symbol | Meaning |
|---|---|
| problem-dependent constants to satisfy on for any . | |
| , | constants to control a deviation of under the event . |
| a difference from its true shape parameter to satisfy . | |
| a constant smaller than in (20). | |
| an uniform bound of under . | |
| a small constant with . |
Appendix B Proof of Lemma 1
See 1
Proof.
Here, we consider the partition of ,
| (13) |
where . Therefore, it holds that
For , holds regardless of . Therefore, we obtain
where the last equality holds since is an increasing function for .
Let to make KL divergence from to be well-defined. From its definition of in (13), any satisfies , i.e.,
Note that it holds that
since is decreasing with respect to . Then, we can rewrite the infimum of KL divergence as
where satisfying
| (14) |
Then, the inner infimum can be obtained when holds if , where .
Let be a deterministic constant such that
| (15) |
so that holds for any . Since the solution of is given as for principal branch of Lambert W function , one can obtain by solving the equality in (15), which is
| (16) |
Notice that holds so that is a real value. Here, we consider the principal branch to ensure since the solution on other branches, , is less than , which is out of our interest.
Let , which is positive as and . Then, we can rewrite as
Since the principal branch of Lambert W function, , is increasing for , we have
which implies that . Therefore, the infimum of can be written as
where we follow the convention that the infimum over the empty set is defined as infinity.
By substituting in (16), we obtain
Let us consider the following inequalities:
| (17) |
where the first inequality holds since the principal branch of Lambert W function is increasing and negative with respect to .
It remains to find the closed form of . From the definition of , we have and
| (18) |
Since the first term in (18) is positive for and , let us consider the last two terms for ,
Here,
and is increasing with respect to so that for . Therefore, is positive for , i.e., is an increasing function with respect to .
Thus, we have for ,
Denote where happens only when . Then, we have for
where the last inequality comes from the result in (17). Therefore, we have
which concludes the proof. ∎
Appendix C Proofs of lemmas for Theorems 2 and 4
In this section, we provide the proof of lemmas for the main results.
To avoid redundancy, we use a temporary notation when the same result holds for both and . When notation is used, one can replace it with either or depending on which policy we are considering. For example, it holds that
Similarly, we use the notation when it can be replaced by both and for any arm and . Based on notation, we provide an inequality on the posterior probability that the sampled mean is smaller than a given value with proofs in Appendix C.5.
Lemma 9.
For any arm and fixed , let . For any positive and , it holds that
where denotes the probability density function of the Erlang distribution with shape and rate .
Based on notation, we denote the probability of sample from the posterior distribution after times playing is smaller than by
| (19) |
Let be an open interval on . The Lemma 10 below shows the upper bound of conditioned on .
Lemma 10.
Given , define a positive problem-dependent constant . If , then for
where
| (20) |
for defined in (10). Here, and are deterministic constants of and .
Notice that holds and there exists a problem-dependent constant such that for any and
| (21) |
C.1 Proof of Lemma 5
Let us start by stating a well-known fact that is utilized in the proof.
Fact 11.
When with rate parameter , then follows the inverse gamma distribution with shape and scale , i.e., .
See 5
Proof.
Let us consider the following decomposition that holds under both and :
Notice that
implies that occurred times in a row on . Thus, we have
| (22) |
for defined in (19). From now on, we fix and drop the argument of , and for simplicity.
Under with :
By applying Lemma 10 and (21) under with , we can decompose the expectation in (22) as
| (23) |
where we denoted . For simplicity, let us define where holds from Fact (11) since in (2). From the independence of and and distributions of and in (9) and (2), respectively, we have
By substituting the CDF in (10), we obtain
| (24) |
Therefore,
| (25) |
By letting , we can bound the integral in (25) as
| (26) | ||||
| (27) |
where (27) holds only for since the integral in (26) diverges for .
Under with :
Under , we have the following inequality instead of (23):
| (29) |
From , it holds that
Since holds and and are independent, we have for
| (30) |
where the same techniques on can be applied to derive an upper bound of . By following the same steps as (25) and (26), we obtain
as a counterpart of the integral in (26). By following the same steps as (27) and (28), we have
| (31) |
Note that the probability term in is the same as the CDF of the with rate evaluated at since from (2). Thus, we have
| (32) | ||||
| (33) |
where (32) holds from for any and . Therefore, by combining (31) and (33) with (30) and , we have
| (34) |
By combining (34) with (29) and (22), we obtain for
where
Note that the analysis on term also holds for with . However, differently from the case of , priors with have additional problems in Lemma 10 under the event , where the upper bound becomes a constant . ∎
C.2 Proof of Lemma 6
Firstly, we state a well-known fact that is utilized in the proof.
Fact 12.
When with rate parameter , then follows the chi-squared distribution with degree of freedom, i.e., .
See 6
Proof.
From the sampling rule, it holds that
Fix a time index and denote and . To simplify notations, we drop the argument of and and the argument of .
Since holds from its posterior distribution, if holds, then holds for any . Recall that denotes a density function of with rate parameter , which is the marginalized posterior distribution of under and . From the CDF of in (8), if , then
Since is increasing with respect to and holds on , we have for
Let
| (35) |
be a deterministic constant that depends only on the model and and satisfies
Since , it holds that for any
Note that holds and the change of to with fixed that is , implies how the value of the shape parameter should be to satisfy . For example, satisfies . Thus, if , then should be smaller than . Hence, we have
| (36) | ||||
| (37) |
Therefore, by taking expectation and using Fact 12, we have
| (38) |
where is a random variable following the chi-squared distribution with degrees of freedom, i.e., .
C.2.1 Under
Here, we first consider the case of where we replace with .
Priors with .
Priors with
C.2.2 Under
Here, we consider the case of where we replace with . From the definition of , it holds that for
Therefore, for , the analysis on can be applied to directly.
C.2.3 Asymptotic behavior of
C.3 Proof of Lemma 7
Firstly, we state two well-known facts that are utilized in the proof.
Fact 13.
When with the scale parameter and rate parameter , then follows the exponential distribution with rate , i.e., .
Fact 14.
Let be identically independently distributed with the exponential distribution with the rate parameter , i.e., for any . Then, their sum follows the Erlang distribution with the shape parameter and rate parameter , i.e., .
See 7
Proof.
When one considers the Pareto distribution with known scale parameter that belongings to the one-dimensional exponential family, the posterior on the shape parameter after observing rewards is given for
| (45) |
where . Note that from Facts 13 and 14. Let be a sample from the posterior distribution in (45). Then, for one-dimensional Pareto bandits, it holds from (10) that
where we denoted satisfying . Therefore, Lemma 21 can be written as
where we injected the density function of the Erlang distribution into the last equality.
On the other hand, for two-parameter Pareto bandits where the scale parameter is unknown, it holds by the law of total expectation that
where the last equality holds since is determined by the history .
From Lemma 9 with , it holds for any that
| (46) |
which is a convex combination of and . Therefore, RHS of (46) increases as increases. From the definition of , it holds that for any positive and . Since holds for any , it holds for that
Let us denote , which follows the Erlang distribution with shape and rate [Malik, 1970]. By taking expectation with respect to , we have for any that
where we used in (2) for the last equality.
Therefore, under the two-parameter Pareto distribution, the following holds for any under both and with that
Therefore, Lemma 21 concludes the proof for any , by carefully selecting satisfying
Note that when we consider with , we have to find such that
From for any positive and , we have for any that
Therefore, for , we might not be able to apply the results by Korda et al. [2013]. ∎
C.4 Proof of Lemma 8
We first state two lemmas on the event and .
Lemma 15.
For any algorithm and , it holds that for all , , and
Lemma 16.
For any algorithm and for any , it holds that for all and , and
See 8
Proof.
C.4.1 Proof of Lemma 15
See 15
Proof.
C.4.2 Proof of Lemma 16
See 16
Proof.
Fix a time index and denote and . To simplify notations, we drop the argument of and .
Let be the -th order statistics of for arm such that . From the definition of MLE of ,
where the first equality holds from the definition of MLEs in (2), the second inequality holds since any sample generated from the Pareto distribution cannot be smaller than its scale parameter , and the last inequality holds from the definition of in (12).
Similarly, one can derive that
where the second inequality holds since holds on , the third inequality from for , and the last inequality comes from the definition of . From Fact 13, and the last probability can be considered as a deviation of the sum of exponentially distributed random variables.
For the exponential distribution , we say that Bernstein’s condition with parameter holds if
where implies the -th central moment. For , it holds that
where is the subfactorial of such that for . Hence, the exponential distribution with parameter satisfies Bernstein’s condition with parameter , so that it is subexponential with parameters . Therefore, by applying Lemma 18, we have
Note that it holds for that
for and , which satisfy . Hence, by recovering the original notations, we obtain
for with . ∎
C.5 Proof of Lemma 9
See 9
Proof.
Fix a time index with and denote . To simplify notations, we drop the argument of and and the argument of , , and .
When holds, can hold regardless of the value of if holds since holds from its posterior distribution in (8). Hence, if , then
| (47) |
When ,
| (48) |
C.6 Proof of Lemma 10
See 10
Proof.
Similarly to other proofs, fix and let . To simplify notations, we drop the argument of and and the argument of .
Case 1. On
Under the condition , the event is eventually determined by the value of since is a sufficient condition to . Therefore, if , then
Then,
where the second inequality holds from .
Case 2. On
By applying Lemma 9 with , we have for any that
| (52) |
Let us define . Then, it satisfies and
where the inequality holds from the decreasing property of the function with respect to . By replacing with in (52), we have
| (53) |
Let be a random variable that follows the chi-squared distribution with degree of freedom and denote the CDF of . Then, it holds that
| (54) |
where . By applying Lemma 19, we have if ,
where denotes the Gamma function. For , it holds from Stirling’s formula that
which results in
| (55) |
Notice that always holds from the assumption of where priors with satisfies regardless of . Thus, if , then the argument in the complementary error function in (55) becomes negative. This makes the upper bound in (55) greater than or equal to . Therefore, for the priors with , the right term in (55) is bounded by a constant since .
Since the complementary error function is a decreasing function, for priors with , it holds from (55) that
where we substitute . By the change of variables, the complementary error function is bounded for any as follows [Simon and Divsalar, 1998]:
which implies
| (56) |
where is a deterministic constants on and . By combining (56) with (53), we have
From the power-series expansion of , we have for and
Case 3. On
By applying Lemma 9 with and , we have
| (57) |
where . Since follows , it holds that
where denotes the lower incomplete gamma function. Therefore, letting
concludes the proof. ∎
Appendix D Proof of Theorem 3
As shown in proofs of Theorem 2, the integral term in (26) diverges for without the restriction on . In this section, we provide the partial proof of Theorem 3 for , which shows the necessity of such requirement to achieve asymptotic optimality.
Proof of Theorem 3.
We consider a two-armed bandit problem with and . Let and , so that . Assume and for all . Recall that starts from playing every arms twice for priors , i.e., holds for all . We have for
From the definition of , implies for . Therefore, for any ,
Let , then we have
| (58) |
Notice that and hold for all since only holds for all . Here, we first provide the lower bound on . Since holds, we can consider the case where occurs.
D.1 Priors
Note that is an increasing function with respect to for fixed . Therefore, (60) implies that if the lower bound of regret for the reference prior is larger than the lower bound, then every prior with are suboptimal. Therefore, let us consider the case , where we can rewrite (60) as
| (61) |
Since in (2), follows an exponential distribution with rate parameter , i.e., . By combining (61) with (58), we have
| (62) |
where we used the stochastic independence of and . Here,
| (63) |
where the last inequality holds from its power series expansion
and . By combining (63) with (62) and (58) and elementary calculation with , we have
Therefore, under with , there exists a constant such that
D.2 Priors
Similarly to the last section, it is sufficient to consider the case , where we can rewrite (60) as
| (64) |
From the definition of the upper incomplete Gamma function, we have
as a counterpart of in (62) with the same notations .
Therefore, by replacing in (62) with , we have
where we used the fact , in the second inequality. Since , holds, we have .
By applying this fact, we have for ,
| (65) | ||||
Notice that holds for , which gives
| (66) |
Appendix E Priors and posteriors
In this section, we provide details on the problem of Jeffreys prior and the probability matching prior under the multiparameter models. One can find more details from references in this section.
E.1 Problems of the Jeffreys prior in the presence of nuisance parameters
The Jeffreys prior was defined to be proportional to the square root of the determinant of the FI matrix so that it remains invariant under all one-to-one reparameterizations of parameters [Jeffreys, 1998]. However, the Jeffreys prior is known to suffer from many problems when the model contains nuisance parameters [Datta and Ghosh, 1995, Ghosh, 2011]. Therefore, Jeffreys himself recommended using other priors in the case of multiparameter models [Berger and Bernardo, 1992]. For example, for the location-scale family, Jeffreys recommended using alternate priors, which coincide with the exact matching prior [DiCiccio et al., 2017].
As mentioned in the main text, it is known that the Jeffreys prior leads to inconsistent estimators for the variance in the Neyman-Scott problem [see Berger and Bernardo, 1992, Example 3.]. Another example is Stein’s example [Stein, 1959], where the model of the Gaussian distribution with a common variance is considered. In this example, the Jeffreys prior lead to an unsatisfactory posterior distribution since the generalized Bayesian estimator under the Jeffreys prior is dominated by other estimators for the quadratic loss [see Robert et al., 2007, Example 3.5.9.]. Note that Bernardo [1979] showed that the reference prior does not suffer from such problems, which would explain why the reference prior shows better performance than the Jeffreys prior in the multiparameter bandit problems.
E.2 Probability matching prior
The probability matching prior is a type of noninformative prior that is designed to achieve the synthesis between the coverage probability of the Bayesian interval estimates and that of the frequentist interval estimates [Welch and Peers, 1963, Tibshirani, 1989]. Therefore, the posterior probability of certain intervals matches exactly or asymptotically the frequentist’s coverage probability under the probability matching prior. If the posterior probability of certain intervals exactly matches the confidence interval, such a prior is called an exact matching prior. In cases where the Bayesian interval estimate does not exactly match the frequentist’s coverage probability, but the difference is small, it is called a -th order matching prior. The difference between the two probabilities is measured by a remainder term, usually denoted as , where is the sample size and is the order of the matching111Some papers call a prior -th order matching prior when a remainder is [DiCiccio et al., 2017]. In this paper, we follow notations used in Mukerjee and Ghosh [1997] and Datta and Sweeting [2005]..
For example, let be a parameter of interest. For some priors , let be a posterior distribution after observing samples . Then, for any , let us define such that
When is the second order probability matching prior, it holds that
When is the exact probability matching prior, we have
For more details, we refer readers to Datta and Sweeting [2005] and Ghosh [2011] and the references therein.
E.3 Details on the derivation of posteriors
In this section, we provide the detailed derivation of posteriors.
Let the observation of an arm and let . Then, Bayes’ theorem gives the posterior probability density as
where
By direct computation with given prior with , we have
Therefore, the joint posterior probability density is given as follows:
which gives the marginal posterior of as
| (67) |
Thus, sample generated from the marginal posterior actually follows the Gamma distribution with shape and rate , i.e., as and if . When is given, the conditional posterior of is given as
| (68) |
Hence, the cumulative distribution function (CDF) of given is given as
| (69) |
Note that MLEs of are equivalent to the maximum a posteriori (MAP) estimators when one uses the Jeffreys prior [Sun et al., 2020, Li et al., 2022].
In sum, under aforementioned priors, we consider the marginalized posterior distribution on
and the cumulative distribution function (CDF) of the conditional posterior of
Note that we require initial plays to avoid improper posteriors and improper MLEs.
Appendix F Technical lemma
In this section, we present some technical lemmas used in the proof of main lemmas.
Lemma 17.
Let be a random variable following the chi-squared distribution with the degree of freedom . Then, for any
where .
Proof.
Let be random variables following the standard normal distribution, so that holds. From Lemma 20, one can derive
From the definition of the moment generating function, one can see that
which concludes the proof. ∎
Appendix G Known results
In this section, we present some proved lemmas that we use without proofs.
Lemma 18 (Bernstein’s inequality).
Let be a -subexponential random variable with and , which satisfies
Let be independent -subexponential. Then, it holds that
For more details, we refer the reader to Vershynin [2018].
Lemma 19 (Theorem 4.1. in Wallace [1959]).
Let be the distribution function of the chi-squared distribution on degrees of freedom. For all , all , and with ,
where and is the complementary error function.
Lemma 20 (Cramér’s theorem).
Let be i.i.d. random variables on . Then, for any convex set ,
where .
Lemma 21 (Result of term (A) in Korda et al. [2013]).
When one uses the Jeffreys prior as a prior distribution under the Pareto distribution with known scale parameter, TS satisfies that for sufficiently small ,
Appendix H Additional experimental results
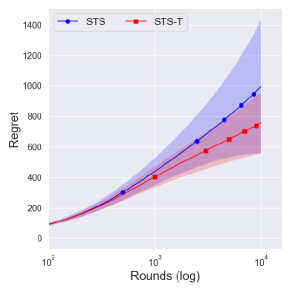
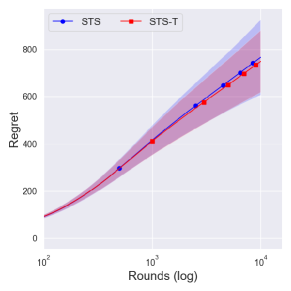
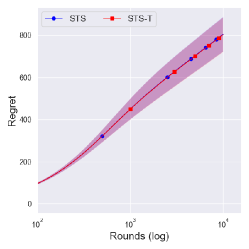
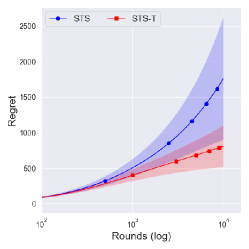
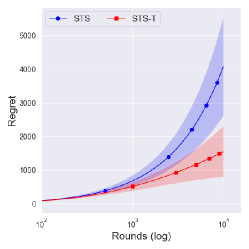
From Figure 4, one can observe that the performance difference between and is large as decreases. Since a truncation procedure aims to prevent an extreme case that can occur under with priors , it is quite natural to see that there is no difference between and with prior . We can further see the improvement of is dramatic as decreases, where an extreme case can easily occur.
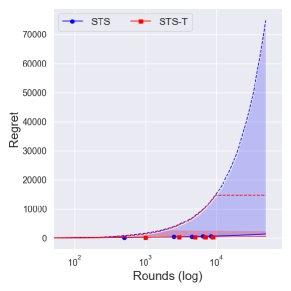
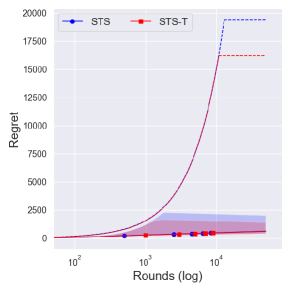
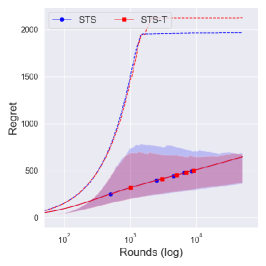
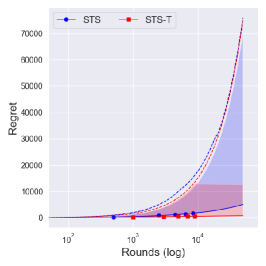
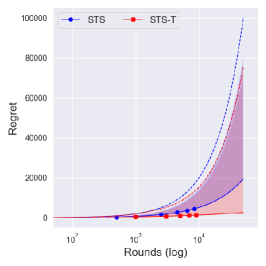
We further consider another -armed bandit problem where and where . would be a more challenging problem than in the sense that the determines the left boundary of the support, where larger implies larger minimum value of the arm. Therefore, if of the suboptimal arm is larger than that of the optimal arm, it would make a problem difficult in the first few trials. Figures 5 and 6 show the numerical results with time horizon 50,000 and independent 10,000 runs. Although with the reference prior shows similar performance to the conservative prior , its performance varies a lot.