Optimizing distortion riskmetrics with distributional uncertainty
Abstract
Optimization of distortion riskmetrics with distributional uncertainty has wide applications in finance and operations research. Distortion riskmetrics include many commonly applied risk measures and deviation measures, which are not necessarily monotone or convex. One of our central findings is a unifying result that allows us to convert an optimization of a non-convex distortion riskmetric with distributional uncertainty to a convex one, leading to great tractability. A sufficient condition to the unifying equivalence result is the novel notion of closedness under concentration, a variation of which is also shown to be necessary for the equivalence. Our results include many special cases that are well studied in the optimization literature, including but not limited to optimizing probabilities, Value-at-Risk, Expected Shortfall, Yaari’s dual utility, and differences between distortion risk measures, under various forms of distributional uncertainty. We illustrate our theoretical results via applications to portfolio optimization, optimization under moment constraints, and preference robust optimization.
Keywords: risk measures; deviation measures; distributionally robust optimization; convexification; conditional expectation
1 Introduction
Riskmetrics, such as measures of risk and variability, are common tools to represent preferences, model decisions under risks, and quantify different types of risks. To fix terms, we refer to riskmetrics as any mapping from a set of random variables to the real line, and risk measures as riskmetrics that are monotone in the sense of Artzner et al. (1999).
In this paper, we focus on distortion riskmetrics which is a large class of commonly used measures of risk and variability; see Wang et al. (2020a) for the terminology “distortion riskmetrics”. Distortion riskmetrics include L-functionals (Huber and Ronchetti, 2009) in statistics, Yaari’s dual utilities (Yaari, 1987) in decision theory, distorted premium principles (Wang et al., 1997) in insurance, and spectral risk measures (Acerbi, 2002) in finance; see Wang et al. (2020a) for further examples. After a normalization, increasing distortion riskmetrics are distortion risk measures, which include, in particular, the two most important risk measures used in current banking and insurance regulation, the Value-at-Risk (VaR) and the Expected Shortfall (ES). Moreover, convex distortion riskmetrics are the building blocks (via taking a supremum) for all convex risk functionals (Liu et al., 2020), including classic risk measures (Artzner et al., 1999; Föllmer and Schied, 2002) and deviation measures (Rockafellar et al., 2006).
When riskmetrics are evaluated on distributions that are subject to uncertainty, decisions should be taken with respect to the worst (or best) possible values a riskmetric attains over a set of alternative distributions; giving rise to the active subfield of distributionally robust optimization. The set of alternative distributions, the uncertainty set, may be characterized by moment constraints (e.g., Popescu (2007)), parameter uncertainty (e.g., Delage and Ye (2010)), probability constraints (e.g., Wiesemann et al. (2014)), and distributional distances (e.g., Blanchet and Murthy (2019)), amongst others. Popular distortion risk measures such as VaR and ES are studied extensively in this context; see e.g., Natarajan et al. (2008) and Zhu and Fukushima (2009).
Optimization of convex distortion risk measures, i.e., distortion riskmetrics with an increasing and concave distortion function, is relatively well understood under distributional uncertainty; see Cornilly et al. (2018), Li (2018), and Liu et al. (2020) for some recent work. Nevertheless, many distortion riskmetrics are not convex or monotone. For example, in the Cumulative Prospect Theory of Tversky and Kahneman (1992), the distortion function is typically assumed to be inverse-S-shaped; in financial risk management, the popular risk measure has a non-concave distortion function, and the inter-quantile difference (Wang et al., 2020b) has a distortion function that is neither concave nor monotone. Another example is the difference between two distortion risk measures, which is clearly not increasing or convex in general. Optimizing non-convex distortion riskmetrics under distributional uncertainty is difficult and results are available only for special cases; see Li et al. (2018), Cai et al. (2018), Zhu and Shao (2018), Wang et al. (2019), and Bernard et al. (2020), all with an increasing distortion function.
There is, however, a notable common feature in the above mentioned literature when a non-convex distortion risk metric is involved. For numerous special cases, one often obtains an equivalence between the optimization problem with non-convex distortion riskmetric and that with a convex one. Inspired by this observation, the aim of this paper is to address:
What conditions provide equivalence between a non-convex riskmetric and a convex one in the setting of distributional uncertainty?
An answer to this question is still missing in the literature. In this sense, we offer a novel perspective on distributionally robust optimization problems by converting non-convex optimization problems to their convex counterpart. Transforming a non-convex to a convex optimization problem through approximation and via a direct equivalence has been studied by Zymler et al. (2013) and Cai et al. (2020). Both contributions, however, consider uncertainty sets described by some special forms of constraints. A unifying framework applicable to numerous uncertainty sets and the entire class of distortion riskmetrics is however missing and at the core of this paper.
The main novelty of our results is three-fold: first, we obtain a unifying result (Theorem 1) that allows, under distributional uncertainty, to convert an optimization problem of a non-convex distortion riskmetric to an optimization problem with a convex one. The result covers, to the authors’ best knowledge, all known equivalences between optimization problems of non-convex and convex riskmetrics with distributional uncertainty. The proof requires techniques beyond the ones used in the existing literature, as we do not make assumptions such as monotonicity, positiveness, and continuity. Our framework can also be easily applied to settings with atomic probability space or with uncertainty sets of multi-dimensional distributions. Second, we introduce the concept of closedness under concentration as a sufficient condition to establish the equivalence, and it is also a necessary condition on the set of optimizers given that the equivalence holds (Theorem 2). We show how the properties of closedness under concentration within a collection of intervals and closedness under concentration for all intervals can easily be verified and provide numerous examples. Third, the classes of distortion riskmetrics and uncertainty formulations considered in this paper include all special cases studied in the literature; examples are presented in Sections 3-4. In particular, our class of riskmetrics include all practically used risk measures and variability measures (some via taking a sup), dual utilities with inverse-S-shaped distortion functions of Tversky and Kahneman (1992), and differences between two dual utilities or distortion risk measures. Our uncertainty formulations include both supremum and infimum problems,111Thus we provide a universal treatment of worst-case and best-case risk values. Calculating best-case risk values allows us to solve economic decision making problems where optimal distributions are chosen to minimize the risk. moment constraints, convex order/risk measure constraints, marginal constraints in risk aggregation with dependence uncertainty (e.g., Embrechts et al. (2015)), preference robust optimization (e.g., Armbruster and Delage (2015) and Guo and Xu (2021)), and some one-dimensional and multi-dimensional uncertainty sets induced by Wasserstein metrics.
The great generality distinguishes our work from the large literature on distributional robust optimization cited above. Our work is of analytical and probabilistic nature, and we focus on theoretical equivalence results which will be also illustrated via numerical implementations. The target problems are formulated in Section 2. Sections 3 is devoted to our main contribution of the equivalence of non-convex and convex optimization problems with distributional uncertainty. We illustrate by many examples the concepts of closedness under conditional expectation and closedness under concentration, and distinguish them in several practical settings. Section 4 demonstrates the equivalence results in multi-dimensional settings. In addition to a general multi-dimensional model with a concave loss function, we solve a robust risk aggregation problem with ambiguity on both the marginal distributions and the dependence structure. In Section 5, our results are used to solve optimization problems with uncertainty sets defined via moment constraints. In particular, we generalize a few well-known results in the literature on optimization and worst-case values of risk measures. Sections 6 and 7 contain numerical illustrations of optimizing differences between two distortion riskmetrics, portfolio optimization, and preference robust optimization. Some concluding remarks are put in Section 8. Proofs of all results are relegated to Appendix B.
2 Distortion riskmetrics with distributional uncertainty
2.1 Problem formulation
Throughout, we work with an atomless probability space . For , represents a set of actions, is an objective functional, is a loss function, and is an -dimensional random vector with distributional uncertainty. Many problems in distributionally robust optimization have the form
| (1) |
where denotes the distribution of and is a set of plausible distributions for . We will first focus on the inner problem
| (2) |
which we may rewrite as
| (3) |
where denotes the distribution of and is a set of distributions on . We suppress the reliance on as it remains constant in the inner problem (2). The supremum in (3) is typically referred to as the worst-case risk measure in the literature if is monotone.222A risk measure is monotone if for all with . The problem (3) can also represent an optimal decision problem, where is an objective to maximize, and a decision maker chooses an optimal distribution from the set which is interpreted as an action set instead of an uncertainty set (i.e., no uncertainty in this problem). Since the two problems share the same mathematical formulation (3), we will navigate through our results mainly with the first interpretation of worst-case risk under uncertainty.
We denote by , , the space of random variables with finite -th moment. Let represent the set of bounded random variables and let represent the space of all random variables. Denote by the set of functions with bounded variation satisfying . For and , a distortion riskmetric is defined as
| (4) |
whenever the above integrals are finite; see Proposition 5 below for a sufficient condition. The function is called a distortion function. Note that we allow to be non-monotone; if is increasing and , then is a distortion risk measure. The distortion riskmetric is convex if and only if is concave; see Wang et al. (2020b) for this and other properties of .
In this paper we consider the objective functional in (1) to be a distortion riskmetric for some , as the class of distortion riskmetrics includes a large class of objective functionals of interest. Note that a general analysis of (3) also covers the infimum problem , since is again a distortion riskmetric. This illustrates an advantage of studying distortion riskmetrics over monotone ones, as our analysis unifies best- and worst-case risk evaluations. Best-case risk measures are also of practical importance. In particular, they may represent risk minimization problems through the second interpretation of (3), where represents a set of possible actions (see Section 3.4 for some examples).
If is not convex, or equivalently, is not concave, optimization problems of the type (3) are often highly nontrivial. However, the optimization problem of maximizing over , where is the smallest concave distortion function dominating , is convex and can often be solved relatively easily either analytically or through numerical methods. Clearly, since , we have
and one naturally wonders when the above inequality holds as equality, that is, under what conditions, it holds
| (5) |
The main contribution of this paper is a sufficient condition on the uncertainty set that guarantees equivalence of these optimization problems, that is (5) holds. We will also obtain a necessary condition. If (5) holds, then the non-convex problem (the left-hand side of (5)) is converted into the convex problem (the right-hand side of (5)), providing huge convenience, which in turn helps to solve the minimax problem (1).
2.2 Notation and preliminaries
For and , we denote by the set of all distributions on with finite -th moment. Let be the set of -dimensional distributions of bounded random variables. For , write for simplicity. The set inclusion and terms like “increasing” and “decreasing” are in the non-strict sense. For , we write to represent that and have the same distribution. For a distribution , let its left- and right-quantile functions be given respectively by
with the convention . For , we write and . Since is of bounded variation, its discontinuity points are at most countable and the left- and right-limits exist at each of these points. We write
and the upper semicontinuous modification of is denoted by
Note that at all continuous points of , and we do not make any modification at the points and even if has a jump at these points. For and , define its concave and convex envelopes and respectively by
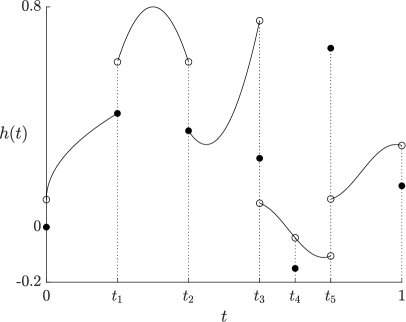
Both and are continuous functions on for all , and if is continuous at and , then so are and (see Figure 4 below for an illustration of and ). Denote by (resp. ) the set of concave (resp. convex) functions in . Note that for all , we have and . As a well-known property of the convex and concave envelopes of a continuous (e.g., Brighi and Chipot (1994)), (resp. ) differs from on a union of disjoint open intervals, and (resp. ) is linear on these intervals. The functions , , and are illustrated in Figure 1.
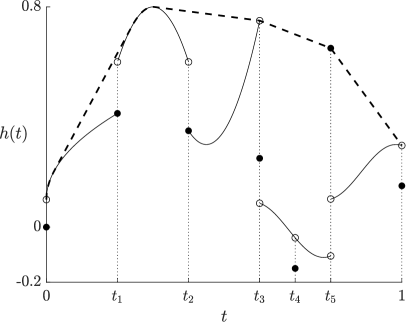
While in general and are different functionals, one has for any random variable with continuous quantile function; see Lemma 1 of Wang et al. (2020a). Moreover, and the four functions are all equal if is concave. Below, we provide a new result on convex envelopes of distortion functions that are not necessarily monotone or continuous, which may be of independent interest.
Proposition 1.
For any , we have and the set is the union of some disjoint open intervals. Moreover, is linear on each of the above intervals.
In the sequel, we mainly focus on , which will be useful when optimizing in (3). A similar result to Proposition 1 holds for , useful in the corresponding infimum problem, where the upper semicontinuous modification of is replaced by the lower semicontinuous one. This follows directly from Proposition 1 by setting which gives and .
For all distortion functions , from Proposition 1, there exist (countably many) disjoint open intervals on which . Using a similar notation to Wang et al. (2019), we define the set
The set is easy to identify in practice; see Section 3.2 for examples of commonly used distortion riskmetrics and their corresponding sets .
3 Equivalence between non-convex and convex riskmetrics
3.1 Concentration and the main equivalence result
In this section, we introduce the concept of concentration, and use this concept to explain our main equivalence results, Theorems 1 and 2. For a distribution and an interval (when speaking of an interval in , we exclude singletons or empty sets), we define the -concentration of , denote by , as the distribution of the random variable
| (6) |
where is a standard uniform random variable. In other words, is obtained by concentrating the probability mass of on at its conditional expectation, whereas the rest of the distribution remains unchanged. For and , it is clear that the left-quantile function of is given by
| (7) |
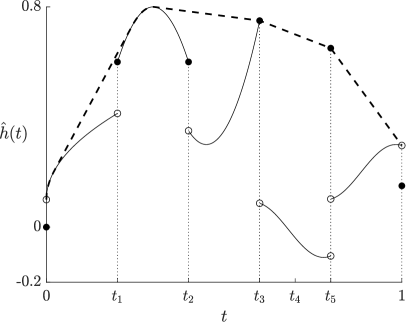
For a collection of (possibly infinitely many) non-overlapping intervals in , let be the distribution corresponding to the left-quantile function given by the left-continuous version of
| (8) |
where is the Lebesgue measure; see Figure 2 for an illustration.
Definition 1.
Let be a set of distributions in and be a collection of intervals in . We say that (a) is closed under concentration within if for all ; (b) is closed under concentration for all intervals if for all , we have for all intervals ; (c) is closed under conditional expectation if for all , the distribution of any conditional expectation of is in .
The relationship between the three properties of closedness in Definition 1 is discussed in Propositions 2 and 3 below. Generally, (c)(b)(a) if is finite. Our main equivalence result is summarized in the following theorem.
Theorem 1.
For and , the following hold.
Both suprema in (9) may be infinite, and this is discussed in Remark 5 in Appendix A.2. The proof of Theorem 1 is more technical than similar results in the literature because of the challenges arising from non-monotonicity, non-positivity, and discontinuity of ; see Figure 1 for a sample of possible complications. In (ii), does not need to be upper semicontinuous on for (9) to hold because closedness under concentration for all intervals in (ii) is stronger than the condition in (i).
Remark 1.
For and , if and for all and , then the equivalence relation (9) also holds. If is finite, then this condition is generally stronger than closedness under concentration within in (i).
A natural question from Theorem 1 is whether our key condition of closedness under concentration is necessary in some sense for the equivalence (9) to hold.333We thank an anonymous referee for raising this question. It is immediate to notice that adding any distributions satisfying to the set does not affect the equivalence, and therefore we turn our attention to the set of maximizers instead of the whole set . In the next result, we show that closedness under concentration within of the set of maximizers of (3) is necessary for the equivalence (9) to hold.
Theorem 2.
For and such that , suppose that the set of all maximizers of is non-empty. If the equivalence (9) holds, i.e., , then is closed under concentration within .
If the equivalence (9) holds, then each also maximizes the problem . Conversely, if , then this condition and closedness of under concentration within together are necessary (by Theorem 2) and sufficient (by Theorem 1) for the equivalence (9) to hold. If the maximizer of the original problem (3) is unique, then by Theorem 2, must be equal to . The equivalence (9) does not imply closedness under concentration within of the uncertainty set itself; an example showing this is discussed in Remark 2.
3.2 Some examples of distortion riskmetrics
We provide a few examples of distortion riskmetrics commonly used in decision theory and finance, and obtain their corresponding set . The Value-at-Risk (VaR) and the Expected Shortfall (ES) are the most popular risk measures in practice. We introduce them first, followed by an inverse-S-shaped distortion function of Tversky and Kahneman (1992).
Example 1 (VaR and ES).
For , using the sign convention of McNeil et al. (2015), VaR is defined as the left-quantile, and upper VaR () is defined as the right-quantile; that is,
ES at level is defined as
Both and belong to the class of distortion riskmetrics. Take . Let , . It follows that and , . In this case, . Moreover, , and . Since and differ on we have .
Example 2 (TK distortion riskmetrics).
The following function is an inverse-S-shaped distortion function (see also Figure 4):
| (10) |
Distortion riskmetrics with distortion function (10) are commonly used in behavioural economics and finance; see e.g., Tversky and Kahneman (1992). For simplicity, we call such distortion riskmetrics TK distortion riskmetrics. Typical values of are in ; see Wu and Gonzalez (1996). For in (10), it is clear that on by continuity of . We have on , for some , and is linear on . Thus, . An example of in (10) and its concave envelope are plotted in Figure 3 (left).
For , we write and consider the difference between two distortion riskmetrics, that is
| (11) |
Such type of distortion riskmetrics measure the difference or disagreement between two utilities, risk attitudes, or capital requirements. Determining the upper and lower bounds, or the largest absolute values of such measures of disagreement, is of interest in practice but rarely studied in the literature. Note that is in general not monotone or concave even when and themselves have the specified properties. Below we show some examples of distortion riskmetrics taking the form of (11).
Example 3 (Inter-quantile range and inter-ES range).
For , we take and , . It follows that , , , and
Correspondingly, we have , , and
This distortion riskmetric is called an inter-quantile range and is called an inter-ES range. As the distortion functions and differ on the open intervals and , we have . The distortion functions and are displayed in Figure 3 (right).

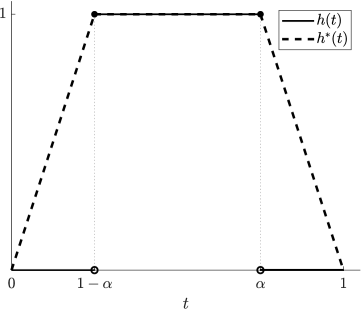
Example 4 (Difference of two inverse-S-shaped distortion functions).
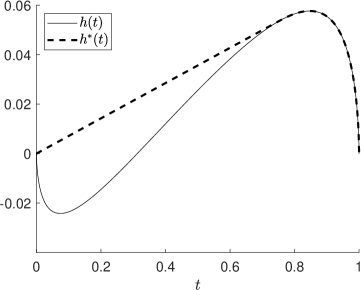
We take and to be the inverse-S-shaped distortion functions in (10), with parameters and , respectively. By calculation, the function is convex on , concave on , and as seen in Figure 4 not monotone. The concave envelope is linear on and on . Thus, we have . The graphs of the distortion functions , , , and are displayed in Figure 4.

The functions in are a.e. differentiable, and for an absolutely continuous function , let be a (representative) function on that is a.e. equal to the derivative of . If is left-continuous or is continuous with respect to , the risk measure in (4) has representation
| (12) |
see Lemma 1 of Wang et al. (2020a). If is absolutely continuous it holds
| (13) |
Another example of a recently introduced distortion riskmetric with concave distortion function may be of independent interest in risk management.
Example 5 (Second-order superquantile).
As introduced by Rockafellar and Royset (2018), a second-order superquantile is defined as
By Theorem 2.4 of Rockafellar and Royset (2018), is a distortion riskmetric with a concave distortion function given by
Clearly, . The difference between second-order superquantile and ES, which has a similar interpretation as , is a distortion riskmetric with a non-concave and non-monotone distortion function , and the set contains a single interval of the form for some .
3.3 Closedness under concentration for all intervals
In this section, we present some technical results and specific examples about closedness under concentration for all intervals and under conditional expectation. The proposition below clarifies the relationship between closedness under concentration for all intervals and closedness under conditional expectation.
Proposition 2.
Closedness under conditional expectation implies closedness under concentration for all intervals, but the converse is not true.
Example 6.
We present 6 classes of sets that are closed under conditional expectation, and hence also under concentration for all intervals.
-
1.
(Moment conditions) For , , and , the set
is closed under conditional expectation by Jensen’s inequality. The set corresponds to distributional uncertainty with moment information, and the setting (mean and variance constraints) is the most commonly studied.
-
2.
(Mean-covariance conditions) For , , , and positive semidefinite, let
where , , is the covariance matrix of , and means that the matrix is positive semidefinite for two positive semidefinite symmetric matrices and . With a simple verification in Appendix A.1, .
-
3.
(Convex function conditions) For , , , a collection of convex functions on , and a vector , let
The set corresponds to distributional uncertainty with constraints on expected losses or test functions. The set includes as a special case.
-
4.
(Distortion conditions) For , a collection and a vector , let
The set corresponds to distributional uncertainty with constraints on preferences modeled by convex dual utilities.
-
5.
(Convex order conditions) For and a collection of random variables , let
where is the inequality in convex order.444Precisely, we write if for all (increasing) convex functions such that the above two integrals are well defined. Similar to the above two examples, is closed under conditional expectation (cf. Remark 6 in Appendix A.2).
-
6.
(Marginal conditions) For given univariate distributions , let
In other words, is the set of all possible aggregate risks with given marginal distributions of ; see Embrechts et al. (2015) for some results on . Generally, is not closed under concentration for all intervals or conditional expectation, since closedness under concentration for all intervals is stronger than joint mixability (Wang and Wang, 2016). In the special case where , Proposition 1 and Theorem 5 of Mao et al. (2019) imply that is closed under conditional expectation if and only if .
Remark 2.
The uncertainty set of the moment condition in Example 6 can be restricted to the set
which is the “boundary” of . For , the suprema on both sides of (9) are obtained by some distributions in ; see Theorem 5. As a direct consequence, we get
Hence, equivalence holds even though is not closed under concentration for any interval. By Theorem 2, the set of optimizers is closed under concentration within for each .
For a distribution and a collection of disjoint intervals in , we have the following result regarding to the distribution .
Proposition 3.
Let be a collection of disjoint intervals in and be a set of distributions. If is closed under concentration for all intervals and is finite, or is closed under conditional expectation, then is closed under concentration within .
3.4 Examples of closedness under concentration within but not for all intervals
In practice, it is much easier to check closedness under concentration within a specific collection of intervals than closedness under concentration for all intervals or under conditional expectation. In this section, we show several examples for closedness under concentration within some .
For distortion functions such that (resp. ) for some , the result in Theorem 1 (i) only requires to be closed under concentration within (resp. ). Such distortion functions include the inverse-S-shaped distortion functions in (10), those of , and , and that of the difference between the second-order superquantile and ES in Example 5. Below we present some more concrete examples.
Example 7 ( has two elements).
Let and where is the point-mass at . We can check that is closed under concentration within but is not closed under concentration for all intervals. Indeed, any set closed under concentration for all intervals and containing has infinitely many elements. In general, a finite set which contains any non-degenerate distribution is not closed under conditional expectation in an atomless probability space, since there are infinitely many possible distributions for the conditional expectation of a given non-constant random variable. Another similar example that is closed under concentration within is the set of all possible distributions of the sum of several Pareto risks; see Example 5.1 of Wang et al. (2019).
Example 8 (VaR and ES).
Example 9 (TK distortion riskmetric).
If we take to be an inverse-S-shaped distortion function in (10), then for some , and is the TK distortion riskmetric. As a direct consequence of Theorem 1 (i), if is closed under concentration within , then
This result implies Theorem 4.11 of Wang et al. (2019) on the robust risk aggregation problem based on dual utilities with inverse-S-shaped distortion functions.
Example 10 (Wasserstein ball, -dimensional).
Optimization problems under the uncertainty set of a Wasserstein ball are common in literature when quantifying the discrepancy between a benchmark distribution and alternative scenarios; see e.g., Blanchet and Murthy (2019). We discuss the application of the concept of concentration to optimization with Wasserstein distances. For and , the -Wasserstein distance between and is defined as
For , the uncertainty set of an -Wasserstein ball around a benchmark distribution is given by
Suppose that the benchmark distribution has a quantile function that is constant on each element in some collection of disjoint intervals . As shown in Appendix A.1, is closed under concentration within for all . Using this closedness property and Theorem 1 (i), the equivalence
| (14) |
holds for all such that .
Remark 3.
In general, if the quantile function in Example 10 is not constant on some interval in , then is not necessarily closed under concentration within , and the equivalence (14) may not hold. For instance, the worst-case over is generally different from the worst-case over as obtained in Proposition 4 of Liu et al. (2022). We also refer to Bernard et al. (2020) who consider a Wasserstein ball together with moment constraints.
Example 11 (Wasserstein ball, -dimensional).
For , , and , the -Wasserstein distance on between and is defined as
where is the -norm on . Similarly to the -dimensional case, for , an -Wasserstein ball on around a benchmark distribution is defined as
In a portfolio selection problem, we consider the worst-case riskmetric of a linear combination of random losses. For , , , and , as shown in Appendix A.1, the uncertainty set
is closed under concentration within for all . For a practical example, assume that an investor holds a portfolio of bonds (for simplicity, assume that they have the same maturity). The loss vector from this portfolio at maturity has an estimated benchmark loss distribution , and the probability of no default from these bonds (i.e., ) is estimated as (usually quite large). Suppose that the investor uses a distortion riskmetric with an inverse-S-shaped distortion function given in (10) of Example 2, and considers a Wasserstein ball around with radius . Note that for some from Example 9. By Theorem 1 (i), we obtain an equivalence result on the worst-case riskmetrics for the portfolio with weight vector ,
whenever .
Example 12 (Optimal hedging strategy).
Suppose that an investor is willing to hedge her random loss only when it exceeds some certain level . Mathematically, for a fixed continuously distributed on such that for some and , define the set of measurable functions
representing possible hedging strategies. Let be an increasing and convex function. The final payoff obtained by a hedging strategy is given by , where is a fixed cost of the hedging strategy that depends on the expected value of calculated by a risk-neutral seller in the market using the same probability measure . As shown in Appendix A.1, the action set in this optimization problem,
is closed under concentration within for all . On the other hand, it is obvious that is not closed under concentration for all intervals or closed under conditional expectation since the quantiles of the distributions in are fixed beyond the interval . The above closedness under concentration property allows us to use Theorem 1 to convert the optimal hedging problem for with an inverse-S-shaped distortion function as in (10) to a convex version .
Example 13 (Risk choice).
Suppose that an investor is faced with a random loss . The distortion function of her riskmetric is inverse-S-shaped with for some . Suppose that is known to the seller. Since the investor is averse to risk for large losses, the seller may provide her with the option to stick to the initial investment or to convert the upper part of the random loss into a fixed payment to avoid large loss. Specifically, we consider the set containing two elements, where for some . It is clear that is closed under concentration within but not closed under conditional expectation. We assume that the costs of the two investment strategies are calculated by expectation and thus are the same. By (i) of Theorem 1, it follows that the risk minimization problem satisfies
where the last equality follows from Theorem 3 of Wang et al. (2020a). By (iii) of Theorem 1, we further have the minimum of the original problem is obtained by ; intuitively, the investor will choose to convert the upper part of her loss into a fixed payment.
3.5 Atomic probability space
The definition of closedness under concentration in Definition 1 requires the assumption of an atomless probability space since a uniform random variable is used in the setup. It may be of practical interest in some economic and optimization settings to assume a finite probability space. In this section, we let the sample space be for and the probability measure be such that for all (such a space is called adequate in economics). The possible distributions in such a probability space are supported by at most points each with probability a multiple of , and we denote by the set of these distributions.
Define the collection of intervals . We say a set of distributions is closed under grid concentration within if for all , the distribution of the random variable
is also in , where is a random variable such that for all . For a distribution with finite mean and , it is straightforward that the left-quantile function of is given by (7). The following equivalence result holds with additional assumption . The proof can be obtained directly from that of Theorem 1.
Proposition 4.
Let and . If , and is closed under grid concentration within , then
We note that the condition in Proposition 4 is satisfied by all distortion functions which are linear (or constant) on each of , . It is common to assume such a distortion function in an adequate probability space of states, since any distribution function can only take values in .
4 Multi-dimensional setting
Our main equivalence results in Theorems 1 and 2 are stated under the context of one-dimensional random variables. In this section, we discuss their generalization to multi-dimensional framework with a few additional steps.
In the multi-dimensional setting, closedness under concentration is not easy to define, as quantile functions are not naturally defined for multivariate distributions. Nevertheless, closedness under conditional expectation can be analogously formulated. For , we say that is closed under conditional expectation, if for all , the distribution of any conditional expectation of is in . The following theorem states the multi-dimensional version of our main equivalence result using closedness under conditional expectation.
Theorem 3.
For , increasing function and concave in the second argument, if is closed under conditional expectation, then for all ,
| (15) |
If and the second supremum in (15) is attained by some , then attains both suprema. Moreover, if is linear in the second component, then (15) holds for all (not necessarily monotone).
Remark 4.
If we assume that is convex (instead of concave) in the second argument in Theorem 3 and keep the other assumptions, then for an increasing ,
This statement follows by noting . The case of a decreasing is similar.
Theorem 3 is similar to Theorem 3.4 of Cai et al. (2020) which states the equivalence (15) for increasing and a specific set which is a special case in Example 14 below. In contrast, our result applies to non-monotone (with an extra condition on ), more general set , and also the infimum problem. The setting of a function linear in the second argument often appears in portfolio selection problems where ; see Example 11 and Section 6.
Example 14.
Similarly to Example 6, we give examples of sets of multi-dimensional distributions closed under conditional expectation.
-
1.
(Convex function conditions) For , a convex set , set of convex functions on , and a mapping , let
It is clear that is closed under conditional expectation due to Jensen’s inequality. The uncertainty set proposed by Delage et al. (2014) and used in Theorem 3.4 of Cai et al. (2020) can be obtained as a special case of this setting by taking , where , for all , and is a set of convex functions. The specification for is that , , for all , .
-
2.
(Distortion conditions) For , , , and , the set
is closed under conditional expectation. In portfolio optimization problems, this setting incorporates distributional uncertainty with constraints on convex distortion risk measures of the total loss. In particular, optimization with the riskmetrics chosen as ES is common in the literature; see e.g., Rockafellar and Uryasev (2002), where ES is called CVaR.
-
3.
(Convex order conditions) For and random vectors , , we naturally extend from part 5 of Example 6 and obtain that the set
is closed under conditional expectation.
Next, we discuss a multi-dimensional problem setting involving concentrations of marginal distributions. For , we assume that marginal distributions of an -dimensional distribution in are uncertain and are in some sets . For , define the set
which is the set of all possible joint distributions with specified marginals; see Embrechts et al. (2015). For , and , the worst-case distortion riskmetric can be represented as
| (16) |
The outer problem of (16) is a robust risk aggregation problem (see Embrechts et al. (2013, 2015) and item 6 of Example 6), which is typically nontrivial in general when is not concave. With additional uncertainty of the marginal distributions, (16) can be converted to a convex problem given that are closed under concentration.
Theorem 4.
For , increasing with , and increasing, supermodular and positively homogeneous in the second argument, if are closed under concentration within , then the following hold.555For a function , we say is supermodular if for all ; is positively homogeneous if for all and .
-
(i)
For all ,
(17) -
(ii)
If the supremum of the right-hand side of (17) is attained by some and , then for all , and a comonotonic random vector with , attain the suprema on both sides of (17).666A random vector is called comonotonic if there exists a random variable and increasing functions on such that almost surely for all .
Some examples of functions on that are supermodular and positively homogeneous are given below. These functions are concave due to Theorem 3 of Marinacci and Montrucchio (2008).
Example 15 (Supermodular and positively homogeneous functions).
For , the following functions are supermodular and positively homogeneous. Write .
-
(i)
(Linear function) for . The function is increasing for .
-
(ii)
(Geometric mean) on for odd . The function is also increasing on .
-
(iii)
(Negated -norm) for . The function is increasing on .
-
(iv)
(Sum of functions) for positively homogeneous functions . The function is increasing if are increasing.
5 One-dimensional uncertainty set with moment constraints
A popular example of an uncertainty set closed under concentration for all intervals is that of distributions with specified moment constraints as in Example 6. We investigate this uncertainty set in detail and offer in this section some general results, which generalize several existing results in the literature; none of the results in the literature include non-monotone and non-convex distortion functions. Non-monotone distortion functions create difficulties because of possible complications at their discontinuity points.
For , and , we recall the set of interest in Example 6:
Let be the Hölder conjugate of , namely , or equivalently, . For all or , we denote by
| (18) |
We introduce the following quantities:
We set if is not continuous. It is easy to verify that is unique for . The quantity may be interpreted as a -central norm of the function and as its -center. Note that for and continuous, and . We also note that the optimization problem is trivial if , which corresponds to the case that and is a linear functional, thus a multiple of the expectation. In this case, the supremum and infimum are attained by all random variables whose distributions are in , and they are equal to . Furthermore, for or , and , we define a function on by
In case , for , if and otherwise. We summarize our findings in the following theorem.
Theorem 5.
For any , , and , we have
| (19) |
Moreover, if , and , then the supremum and infimum in (19) are attained by a random variable such that with its quantile function uniquely specified as a.e. equal to and , respectively.
The proof of Theorem 5 follows from a combination of Lemmas A.1 and A.2 in Appendix B.4 and Theorem 1. Note that for (resp. ) and , is increasing (resp. decreasing) on . Hence, (resp. ) in Theorem 5 indeed determines a quantile function.
The following proposition concerns the finiteness of on .
Proposition 5.
For any and , is finite on if and .
As a special case of Proposition 5, is always finite on if is convex or concave with bounded because and .
As a common example of the general result in Theorem 5, below we collect our findings for the case of VaR.
Corollary 1.
For , , and , we have
and
where
We see from Theorem 5 that if , then the supremum and the infimum of over are always attainable. However, in case , the supremum or infimum may no longer be attainable as a maximum or minimum. We illustrate this in Example 16 below.
Example 16 (VaR and ES, ).
Take , and , which implies . Corollary 1 gives . This is the well-known Cantalli-type formula for ES. By Lemma A.1, the unique left-quantile function of the random variable that attains the supremum of is given by , a.e. We thus have , and hence does not attain . It follows by the uniqueness of that the supremum of over cannot be attained. However, the supremum of is attained by since .
Example 17 (Difference of two TK distortion riskmetrics).
Take and to be the difference between two inverse-S-shaped functions in (10) with parameters the same as those in Example 4 (, ). By Theorem 5, the worst-case distortion riskmetrics under the uncertainty set are given by , and the unique left-quantile function of the random variable attaining both suprema above is given by , a.e. The worst-case distortion riskmetrics obtained above are independent of the mean as , which is sensible since and only incorporate the disagreement between two distortion riskmetrics. Similarly, we can calculate the infimum of over , and thus obtain the largest absolute difference between the two preferences numerically represented by and .
6 Related optimization problems
In this section, we discuss the applications of our main results to some related optimization problems commonly investigated in the literature by including the outer problem of (1).
6.1 Portfolio optimization
Our equivalence results can be applied to robust portfolio optimization problems. For an uncertainty set with , let the random vector , representing the random losses from risky assets. For , denote by a vector the amounts invested in each of the risky assets. For a distortion function and distortion riskmetric , we aim to solve the robust portfolio optimization problem given by
| (20) |
where is a penalty function of risk concentration. Note that is irrelevant for the inner problem of (20). For a general non-concave , there is no known algorithm to solve the inner problem of (20). The outer optimization problem is also nontrivial in general. Therefore, we usually cannot obtain closed-form solutions of (20) using classical results of optimization problems for non-convex risk measures. However, as a direct consequence of Theorems 1 and 3, the following proposition converts (20) to an equivalent convex optimization problem that becomes much easier to solve. The proof of Proposition 6 follows directly from Theorems 1 and 3.
6.2 Preference robust optimization
We are also able to solve the preference robust optimization problem with distributional uncertainty. For , an -dimensional action set , a set of plausible distributions , and a set of possible probability perceptions , the problem is formulated as follows:
| (22) |
Preference robust optimization refers to the situation when the objective is not completely known, e.g., is in the set but not identified. Therefore, optimization is performed under the worst-case preference in the set . Also note that the form includes (but is not limited to) all coherent risk measures via the representation of Kusuoka (2001). For the problem of (22) without distributional uncertainty (thus, only the minimum and the second supremum), see Delage and Li (2018). We have the following result whose proof follows from Theorems 1 and 3.
Proposition 7.
Let and with .
-
(i)
If and the set is closed under concentration within for all , then for all ,
(23) -
(ii)
If the set is closed under concentration for all intervals for all , then (23) holds for all .
-
(iii)
If is a set of increasing functions in , is concave in the second component, and is closed under conditional expectation, then (23) holds.
The preference robust optimization problem without distributional uncertainty (i.e., problem (22) with only the minimum and the second supremum) is generally difficult to solve when the distortion function is not concave. However, when the distribution of the random variable is not completely known, we can transfer the original non-convex problem to its convex counterpart using (23), provided that the set of plausible distributions is well structured.
7 Applications and numerical illustrations
Following the discussion in Section 6, we provide several applications of our theoretical results to portfolio management for specific sets of plausible distributions. None of the considered optimization problems in this section are convex, and we provide numerical calculations or approximation for the solutions to these optimization problems.777The processors we use are Intel(R) Xeon(R) CPU E5-2690 v3 @ 2.60GHz 2.59GHz (2 processors). The numerical results are calculated by MATLAB.
7.1 Difference of risk measures under moment constraints
We demonstrate a price competition problem as an application of optimizing the difference between two risk measures shown in Example 17. Similar to the portfolio management problem discussed in Section 6.1, we consider risky assets with random losses that are only known to have a fixed mean and a constrained covariance. That is, we choose the set
for and positive semidefinite. For an -dimensional , the set of all possible distributions of aggregate portfolio losses
| (24) |
is closed under concentration for all intervals as is shown in Example 6. Let be an investor’s own price of the portfolio, while is her opponent’s price of the same portfolio. We choose and to be the inverse-S-shaped distortion functions in (10), with parameters the same as those in Example 17 ( and ). Write . For an action set , the investor chooses the optimal , such that the worst-case overpricing from her opponent is minimized.
From the calculation in Example 17, we get
| (25) | ||||
We note that optimizing is generally nontrivial since the difference between two distortion functions is not necessarily monotone, concave, or continuous, even though and themselves may have these properties. The generality of our equivalence result allows us to convert the original problem to the much simpler form (25), which can be solved efficiently.888The convex problem (25) is solved numerically by the constrained nonlinear multivariable function “fmincon” with the interior-point method. Table 1 demonstrates the optimal values of and for different choices of .
7.2 Preference robust portfolio optimization with moment constraints
Next, we discuss an example of preference robust optimization with distributional uncertainty using the results in Sections 5. Similarly to Section 7.1, we consider the set of plausible aggregate portfolio loss distributions
and the action set representing the weights the investor assigns to each random loss. The investor considers TK distortion riskmetrics, however, she is not certain about the parameter of the distortion function . Thus, the investor consider the set of TK distortion riskmetrics with distortion functions in
which is approximately the two-sigma confidence interval of in Wu and Gonzalez (1996).999The aggregate least-square estimate of in Section 5 of Wu and Gonzalez (1996) is with standard deviation . Therefore, the investor aims to find a optimal portfolio given the uncertainty in the riskmetrics. To penalize deviations from the benchmark parameter (Wu and Gonzalez, 1996), the investor use the term for some . Since the set is closed under concentration for all intervals for all , Proposition 7, (24), and Theorem 5 lead to
| (26) | ||||
We calculate the optimal values for different choices of parameters (, , and ) and report them in Table 2, where and represent the optimal weights and the parameters of the inverse-S-shaped distortion function, respectively. Note that the last optimization problem in (26) can be calculated numerically.101010The problem (26) is solved numerically by the constrained nonlinear multivariable function “fmincon” with the interior-point method.
7.3 Portfolio optimization with marginal constraints
A special case of the portfolio optimization problem introduced in Section 6.1, which is of interest in robust risk aggregation (see e.g., Blanchet et al. (2020)), is to take to be the Fréchet class defined as
| (27) |
for some known marginal distributions . In this case, although the left-hand side of (21) is generally difficult to solve, for , the right-hand side of (21) can be rewritten using convexity and comonotonicity as
| (28) |
where , . We see that (28) is a linear optimization problem with a penalty , which often admits closed-form solutions when is properly chosen. For any given , we define
| (29) |
The set is the weighted version of in Example 6. Note that is generally neither closed under concentration for all intervals nor closed under conditional expectation. However, is asymptotically (for large ) similar to a set of distributions closed under concentration for all intervals; see Theorem 3.5 of Mao and Wang (2015) for a precise statement in the case of equal weights and identical marginal distributions. Therefore, even though is not closed under concentration for all intervals for some , our result of the problem (28) is a good approximation of the original problem for large . Such asymptotic equivalence between worst-case riskmetrics of aggregate risks with equal weights has already been well studied in the literature; see e.g., Theorem 3.3 of Embrechts et al. (2015) for the / pair and Theorem 3.5 of Cai et al. (2018) for distortion risk measures.
We conduct numerical calculations to illustrate the equivalence between both sides in (21). We choose the action set , for and the penalty function to be the -norm multiplied by a scaler , namely , where the scaler is a tuning parameter of the penalty. We first solve the optimization problems separately for the well-known VaR/ES pair at the level of . Specifically, the two problems are given by
| (30) | ||||
| (31) |
where the true value of the original inner VaR problem is approximated by the rearrangement algorithm (RA) of Puccetti and Rüschendorf (2012) and Embrechts et al. (2013), whereas the optimal value of the inner ES problem is obtained by simultaneously minimizing the sum of a linear combination of ES and the -norm of the vector , which can be done efficiently.111111The outer problems of (30) and (31) are solved numerically by the constrained nonlinear multivariable function “fmincon” with the sequential quadratic programming (SQP) algorithm. The same method is also applied when solving outer problems of (32) and (33). In particular, if the marginals of the random losses are identical (i.e., ), the optimal solution is and . We consider the following marginal distributions
-
(i)
follows a Pareto distribution with scale parameter and shape parameter for ;
-
(ii)
is normally distributed with parameters , for ;
-
(iii)
follows an exponential distribution with parameter , for .
We choose to be , , and . For comparison, we calculate the value , where is the difference between the optimal weights of the non-convex problem and the convex problem. In addition, we calculate the absolute differences between the optimal values obtained by the two problems, , and the percentage differences . Tables 3 and 4 show the numerical results that compare both optimization problems with two choices of the action sets . The computation time is reported (in seconds). We observe that the optimal values obtained in the two problems get closer and become approximately the same as gets larger. As explained before, this is because the set of plausible distributions is asymptotically equal to a set closed under concentration for all intervals.
Next, we consider a TK distortion riskmetric with parameter . Due to the non-concavity of , there are no known ways of directly solving the non-convex optimization problem
| (32) |
We may get an approximation of (32) using a lower bound of in (32) produced with the dependence structure created by the rearrangement algorithm (RA);121212Such a dependence structure obviously provides a lower bound for the worst-case value in (32). In theory, the result from RA is thus not an optimal dependence structure for (32). In our numerical results, this lower bound is very close to an upper bound only for the case of VaR and ES but not for the case of TK distortion riskmetrics. for simplicity, we denote by this lower bound. On the other hand, by (21), the convex counterpart of (32) can be written (using Theorem 1) as
| (33) | ||||
where for . We calculate the absolute differences between the optimal values of the convex and non-convex problems , and the percentage differences . Tables 5 and 6 compare the numerical results of the two optimization problems with different choices of . We observe that the percentage differences between the RA lower bound for the non-convex problem (32) and the minimum value of the convex problem (33) are roughly between to . Note that the RA lower bound is not expected to be very close to the true minimum of (32), and hence the differences between the solution of (32) and the optimal value in (33) are smaller than the observed numbers.
Note that, by transforming a non-convex optimization problem to a convex one, we significantly reduce the computational time of calculating bounds with negligible errors, as shown in Tables 3-6.
| time | time | (%) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| (i) Pareto | |||||||||
| (ii) Normal | |||||||||
| (iii) Exp | |||||||||
| time | time | (%) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| (i) Pareto | |||||||||
| (ii) Normal | |||||||||
| (iii) Exp | |||||||||
8 Concluding remarks
We introduced the new concept of closedness under concentration, which is, in the context of distributional uncertainty, a sufficient condition to transform an optimization problem with a non-convex distortion riskmetric to its convex counterpart. This concept is genuinely weaker than closedness under conditional expectation, and our main result unifies and improves many existing results in the literature. Many sets of plausible distributions commonly used in the literature of finance, optimization, and risk management are closed under concentration within some . Moreover, by focusing on distortion riskmetrics whose distortion functions are not necessarily monotone, concave, or continuous, we are able to solve optimization problems for the class of functionals larger than classical risk measures or deviation measures. In particular, we are able to obtain bounds on differences between two distortion riskmetrics, which represent measures of disagreement between two utilities/risk attitudes. Our result can also be applied to solve the popular problem of optimizing risk measures under moment constraints. In particular, we obtain the worst- and best-case distortion riskmetrics when the underlying random variable has a fixed mean and bounded -th moment.
We demonstrate the applicability of our result by numerically calculating the solution to optimizing the difference between risk measures, preference robust optimization and portfolio optimization under marginal constraints. In all numerical examples, the original non-convex problem is converted or well approximated by a convex one which can be solved efficiently.
Our condition of closedness under concentration within in Theorem 1 is sufficient but not necessary for the equivalence of a non-convex and a convex optimization problem under distributional uncertainty. A necessary condition of the equivalence is closedness under concentration of the set of maximizers in Theorem 2. An open question is to find a necessary and sufficient condition on the uncertainty set itself such that the desired equivalence holds. Pinning down such a condition may facilitate many more applications in decision theory, finance, game theory, and operations research.
Acknowledgments
The authors would like to thank anonymous referees for their constructive comments enhancing the paper. SMP would like to acknowledge the support of the Natural Sciences and Engineering Research Council of Canada with funding reference numbers DGECR-2020-00333 and RGPIN-2020-04289. RW acknowledges financial support from the Natural Sciences and Engineering Research Council of Canada (RGPIN-2018-03823, RGPAS-2018-522590).
References
- Acerbi (2002) Acerbi, C. (2002). Spectral measures of risk: A coherent representation of subjective risk aversion. Journal of Banking and Finance, 26(7), 1505–1518.
- Armbruster and Delage (2015) Armbruster, B. and Delage, E. (2015). Decision making under uncertainty when preference information is incomplete. Management Science, 61(1), 111–128.
- Artzner et al. (1999) Artzner, P., Delbaen, F., Eber, J.-M. and Heath, D. (1999). Coherent measures of risk. Mathematical Finance, 9(3), 203–228.
- Bernard et al. (2020) Bernard, C., Pesenti, S. M. and Vanduffel, S. (2020). Robust distortion risk measures. SSRN: 3677078.
- Blanchet et al. (2020) Blanchet, J., Lam, H., Liu, Y. and Wang, R. (2020). Convolution bounds on quantile aggregation. arXiv: 2007.09320.
- Blanchet and Murthy (2019) Blanchet, J. and Murthy, K. (2019). Quantifying distributional model risk via optimal transport. Mathematics of Operations Research, 44(2), 565–600.
- Brighi and Chipot (1994) Brighi, B. and Chipot, M. (1994). Approximated convex envelope of a function. SIAM Journal on Numerical Analysis, 31, 128–148.
- Cai et al. (2020) Cai, J., Li, J. and Mao, T. (2020). Distributionally robust optimization under distorted expectations. SSRN: 3566708.
- Cai et al. (2018) Cai, J., Liu, H. and Wang, R. (2018). Asymptotic equivalence of risk measures under dependence uncertainty. Mathematical Finance, 28(1), 29–49.
- Cornilly et al. (2018) Cornilly, D., Rüschendorf, L. and Vanduffel, S. (2018). Upper bounds for strictly concave distortion risk measures on moment spaces. Insurance: Mathematics and Economics, 82, 141–151.
- Delage et al. (2014) Delage, E., Arroyo, S. and Ye, Y. (2014). The value of stochastic modeling in two-stage stochastic programs with cost uncertainty. Operations Research, 62(6), 1377–1393.
- Delage and Li (2018) Delage, E. and Li, Y. (2018). Minimizing risk exposure when the choice of a risk measure is ambiguous. Management Science, 64(1), 327–344.
- Delage and Ye (2010) Delage, E. and Ye, Y. (2010). Distributionally robust optimization under moment uncertainty with application to data-driven problems. Operations Research, 58(3), 595–612.
- Denneberg (1994) Denneberg, D. (1994). Non-additive Measure and Integral. Springer Science & Business Media.
- Embrechts et al. (2013) Embrechts, P., Puccetti, G. and Rüschendorf, L. (2013). Model uncertainty and VaR aggregation. Journal of Banking and Finance, 37(8), 2750–2764.
- Embrechts et al. (2015) Embrechts, P., Wang, B. and Wang, R. (2015). Aggregation-robustness and model uncertainty of regulatory risk measures. Finance and Stochastics, 19(4), 763–790.
- Föllmer and Schied (2002) Föllmer, H. and Schied, A. (2002). Convex measures of risk and trading constraints. Finance and Stochastics, 6(4), 429–447.
- Guo and Xu (2021) Guo, S. and Xu, H. (2021). Statistical robustness in utility preference robust optimization models. Mathematical Programming Series A, 190, 679–720.
- Huber and Ronchetti (2009) Huber, P. J. and Ronchetti E. M. (2009). Robust Statistics. Second Edition, Wiley Series in Probability and Statistics. Wiley, New Jersey.
- Kusuoka (2001) Kusuoka, S. (2001). On law invariant coherent risk measures. Advances in Mathematical Economics, 3, 83–95.
- Li et al. (2018) Li, L., Shao, H., Wang, R. and Yang, J. (2018). Worst-case Range Value-at-Risk with partial information. SIAM Journal on Financial Mathematics, 9(1), 190–218.
- Li (2018) Li, Y. (2018). Closed-form solutions for worst-case law invariant risk measures with application to robust portfolio optimization. Operations Research, 66(6), 1457–1759.
- Liu et al. (2020) Liu, F., Cai, J., Lemieux, C. and Wang, R. (2020). Convex risk functionals: Representation and applications. Insurance: Mathematics and Economics, 90, 66–79.
- Liu et al. (2022) Liu, F., Mao, T., Wang, R. and Wei, L. (2022). Inf-convolution, optimal allocations, and model uncertainty for tail risk measures. Mathematics of Operations Research, published online.
- Mao et al. (2019) Mao, T., Wang, B. and Wang, R. (2019). Sums of uniform random variables. Journal of Applied Probability, 56(3), 918–936.
- Mao and Wang (2015) Mao, T. and Wang, R. (2015). On aggregation sets and lower-convex sets. Journal of Multivariate Analysis, 138, 170–181.
- Mao et al. (2022) Mao, T., Wang, R. and Wu, Q. (2022). Model aggregation for risk evaluation and robust optimization. arXiv: 2201.06370.
- Marinacci and Montrucchio (2008) Marinacci, M. and Montrucchio, L. (2008). On concavity and supermodularity. Journal of Mathematical Analysis and Applications, 344(2), 642–654.
- McNeil et al. (2015) McNeil, A. J., Frey, R. and Embrechts, P. (2015). Quantitative Risk Management: Concepts, Techniques and Tools. Revised Edition. Princeton, NJ: Princeton University Press.
- Natarajan et al. (2008) Natarajan, K., Pachamanova, D. and Sim, M. (2008). Incorporating asymmetric distributional information in robust value-at-risk optimization. Management Science, 54(3), 573–585.
- Popescu (2007) Popescu, I. (2007). Robust mean-covariance solutions for stochastic optimization. Operations Research, 55(1), 98–112.
- Puccetti and Rüschendorf (2012) Puccetti, G. and Rüschendorf, L. (2012). Computation of sharp bounds on the distribution of a function of dependent risks. Journal of Computational and Applied Mathematics, 236(7), 1833–1840.
- Rockafellar and Royset (2018) Rockafellar, R. T. and Royset, J. O. (2018). Superquantile/CVaR risk measures: second-order theory. Annals of Operations Research, 262(1), 3–28.
- Rockafellar and Uryasev (2002) Rockafellar, R. T. and Uryasev, S. (2002). Conditional value-at-risk for general loss distributions. Journal of Banking and Finance, 26(7), 1443–1471.
- Rockafellar et al. (2006) Rockafellar, R. T., Uryasev, S. and Zabarankin, M. (2006). Generalized deviation in risk analysis. Finance and Stochastics, 10, 51–74.
- Shaked and Shanthikumar (2007) Shaked, M. and Shanthikumar, J. G. (2007). Stochastic Orders. Springer Series in Statistics.
- Simchi-Levi et al. (2005) Simchi-Levi, D., Chen, X. and Bramel, J. (2005). The Logic of Logistics. Theory, Algorithms, and Applications for Logistics and Supply Chain Management. Third edition. New York, NY: Springer.
- Tchen (1980) Tchen, A. H. (1980). Inequalities for distributions with given marginals. Annals of Probability, 8(4), 814–827.
- Tversky and Kahneman (1992) Tversky, A. and Kahneman, D. (1992). Advances in prospect theory: Cumulative representation of Uncertainty. Journal of Risk and Uncertainty, 5(4), 297–323.
- Wang and Wang (2016) Wang, B. and Wang, R. (2016). Joint mixability. Mathematics of Operations Research, 41(3), 808–826.
- Wang et al. (2020a) Wang, Q., Wang, R. and Wei, Y. (2020a). Distortion riskmetrics on general spaces. ASTIN Bulletin, 50(4), 827–851.
- Wang et al. (2015) Wang, R., Bignozzi, V. and Tsakanas, A. (2015). How superadditive can a risk measure be? SIAM Jounral on Financial Mathematics, 6, 776–803.
- Wang et al. (2019) Wang, R., Xu, Z. Q. and Zhou, X. Y. (2019). Dual utilities on risk aggregation under dependence uncertainty. Finance and Stochastics, 23(4), 1025–1048.
- Wang et al. (2020b) Wang, R., Wei, Y. and Willmot, G. E. (2020b). Characterization, robustness and aggregation of signed Choquet integrals. Mathematics of Operations Research, 45(3), 993–1015.
- Wang et al. (1997) Wang, S., Young, V. R. and Panjer, H. H. (1997). Axiomatic characterization of insurance prices. Insurance: Mathematics and Economics, 21(2), 173–183.
- Wiesemann et al. (2014) Wiesemann, W., Kuhn, D. and Sim, M. (2014). Distributionally robust convex optimization. Operations Research, 62(6), 1203–1466.
- Wu and Gonzalez (1996) Wu, G. and Gonzalez, R. (1996). Curvature of the probability weighting function. Management Science, 42(12), 1676–1690.
- Yaari (1987) Yaari, M. E. (1987). The dual theory of choice under risk. Econometrica, 55(1), 95–115.
- Zhu and Shao (2018) Zhu, W. and Shao, H. (2018). Closed-form solutions for extreme-case distortion risk measures and applications to robust portfolio management. SSRN: 3103458.
- Zhu and Fukushima (2009) Zhu, S. and Fukushima, M. (2009). Worst-case conditional value-at-risk with application to robust portfolio management. Operations Research, 57(5), 1155–1168.
- Zymler et al. (2013) Zymler, S., Kuhn, D. and Rustem, B. (2013). Distributionally robust joint chance constraints with second-order moment information. Mathematical Programming, 137(1–2), 167–198.
Technical appendices
Appendix A Omitted technical details from the paper
In this appendix, we present technical details for some examples and as well as some technical remarks omitted from the paper.
A.1 Proofs of claims in some Examples
Proof of the claim in Example 6.
We show that is equivalent to
For a proof of the equivalence between the sets with fixed mean and covariance matrix, see Popescu (2007). Indeed, it is clear that . On the other hand, for all , we write , , and take such that , for . It follows that . Therefore, we have . ∎
Proof of the claim in Example 10.
We will show that is closed under concentration within for all . Write for some . For all and , we have for for some . For all , by Jensen’s inequality,
It follows that
and thus . Moreover, (8) and the above argument lead to
Hence, . ∎
Proof of the claim in Example 11.
For , , , and , by Theorem 7 of Mao et al. (2022), the uncertainty set
where is the conjugate of (i.e., ). Suppose that for a benchmark distribution , there exists a random vector such that and for some . Note that and the quantile function of is equal to on . It follows from Example 10 that the set is closed under concentration within for all . ∎
Proof of the claim in Example 12.
We will show that the set of distributions,
is closed under concentration within for all . For each and a standard uniform random variable , we write . Since , we can take
It follows that . Noting that , we have
which follows the same distribution as . It follows that is closed under concentration within for all . ∎
A.2 A few additional technical remarks mentioned in the paper
Remark 5 (on Theorem 1).
Using Theorem 1, if for some , the set is closed under concentration for all intervals and , then . Thus, both objectives in the inner optimization of (1) are infinite for this , which can be excluded from the outer optimization over . Verifying is easier than verifying since generally is smaller than .
Remark 6 (on Example 6).
Using Strassen’s Theorem (e.g., Theorem 3.A.4 of Shaked and Shanthikumar (2007)), closedness under conditional expectation can equivalently be expressed using convex order. A set is closed under conditional expectation if and only if it holds that for and , we have .
Remark 7 (on Proposition 3).
In Proposition 3, if is closed under conditional expectation, can be taken as an infinite set. However, may not be closed under concentration within an infinite if we only assume that is closed under concentration for all intervals. Indeed, if we take as the set of distributions obtained by some with finitely many concentrations, then clearly is closed under concentration for all intervals. However, when is an infinite collection of disjoint intervals. This also serves as a counter-example of the converse statement of Proposition 2 since is closed under concentration for all intervals but not closed under conditional expectation.
Appendix B Proofs of all technical results
We present all proofs of technical results in this appendix. Throughout, we denote the set of discontinuity points of (excluding and ) by
| (A.1) |
Note that can be written as
| (A.2) |
B.1 Proof of results in Section 2
Proof of Proposition 1.
Note that on and . For all , since , we have . On the other hand, we have for . Indeed, if for some , then we have for some , which leads to a contradiction. Similarly, we have for . Together with on , we have on , which implies that on . Therefore, on .
Next, we assert that the set is a union of disjoint sets that are not singletons. To show this assertion, assume that the converse is true. There exists , such that and on for some . It is clear that . Since is continuous on , we have
This contradicts (A.2). Therefore, the set is the union of some disjoint intervals, denoted by for some . For all , we denote the left and right endpoints of by and , respectively, with . Define a function via linear interpolation
It is clear that and is continuous on . We will prove that on . Suppose for the purpose of contradiction that on . Since for some point in , there exists for some such that . Thus we can take a point with , which has the largest perpendicular distance to the straight line , namely,
The existence of the maximizer is due to the upper semicontinuity of . There exists a function with on and , such that is concave and on . Since on , we have . Thus cannot be the concave envelope of , which leads to a contradiction. Thus, on . Since on , we have . Therefore, is a union of disjoint open intervals, and is linear on each of the intervals. ∎
B.2 Proofs of results in Section 3
Proof of Theorem 1.
We will first show that, assuming that is closed under concentration within , we have
| (A.3) |
After proving (A.3), we show the three statements in Theorem 1 in the order (i), (ii), and (iii).
For , suppose that is closed under concentration within . Take an arbitrary random variable with . Let . For , write functions and for . By definition of , on each set in and on other sets. For any , we have for all and for all . Using the fact that is linear on and for , we have
| (A.4) | ||||
Define the sets
To better understand these sets, we recall Figure 1 (without concave envelopes) as Figure A.1 to demonstrate an example of a distortion function , the corrresponding , the sets , , , and , and the sets , , , , and (defined in the proof of (i) below).
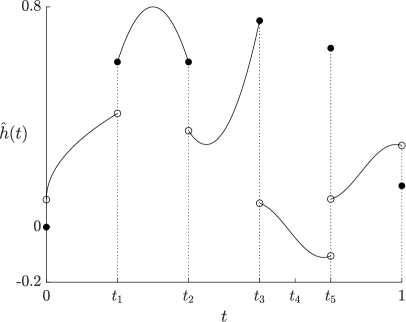
Note that for a random variable , we have
Hence using (A.4) and (8), we get
| (A.5) | ||||
Since is closed under concentration within , we have by definition. Thus we have
which gives our desired equality (A.3) since .
Proof of (i): Using and (A.3), we have .
Proof of (ii): We will prove (ii) in two main steps. First, we show that (ii) holds if is finite and has finitely many discontinuity points. Next, we discuss general .
Finite case: Here we prove (9) under the case where is finite and has finitely many discontinuity points (i.e. in (A.1) is a finite set). Suppose that is closed under concentration for all intervals, it directly implies that is closed under concentration within by Proposition 3. Therefore, (A.3) holds for all . Next, we need to show that Define
For , write intervals
Let . Note that has finitely many discontinuity points. Thus the intervals in are disjoint when is large enough. For all and , we define
It follows that and the right-quantile function of , denoted by , is given by the right-continuous adjusted version of
Thus we get
Similarly, if we denote the left-quantile function of by , then is given by the left-continuous version of
It follows that
Define, further, the sets
For , write
Note that when and . We have . Therefore, by the dominated convergence theorem,
Similarly, we get . On the other hand, it is clear that . Therefore, we have
Thus we have
| (A.6) |
General case: We prove Theorem 1 for all general where or the number of discontinuity points of is countable.
1. If is countable, it suffices to prove (A.3). We write as the collection of for and define for all . Define the function
It is clear that for all , the set is a finite union of disjoint open intervals and is linear on each of the intervals. For all random variables with , let random variable . Similar to (A.3), we have
Note that as for all . By the monotone convergence theorem, we get as . It follows that
2. If has countably many discontinuity points, it suffices to prove (A.6). There exist series of finite sets , such that as . For all , write
and define
For , let with
Following the same argument as (A.6), for all random variable with , we have
where . Moreover, we have for all as . By the monotone convergence theorem, we have as . Therefore, we have
Proof of (iii): For all , if is closed under concentration within and , we have by definition. Since , (A.5) gives
Note that generally. Therefore, if is attained by , then so is by . Obviously, these two quantities share a common maximizer because
The proof is complete. ∎
Proof of Theorem 2.
Suppose for contradiction that is not closed under concentration within . There exists , such that . Define the set . Since , there exists an interval , such that is not constant on . Thus the Lebesgue measure . Since on ,
| (A.7) | ||||
On the other hand, we have
which leads to a contradiction to (A.7). Therefore, is closed under concentration within . ∎
Proof of Proposition 2.
We first prove that closedness under conditional expectation implies closedness under concentration for all intervals. For all random variables and intervals , define
where . The distribution of is the concentration . For all -measurable random variables , we have that is constant. Hence,
It follows that , -almost surely. If a set of distributions, , is closed under conditional expectation and , then , which implies that . Thus is also closed under concentration for all intervals. ∎
B.3 Proofs of results in Section 4
Proof of Theorem 3.
Proof of Theorem 4.
(i) For all , take a comonotonic such that for all . It follows that for all supermodular functions due to Theorem 5 of Tchen (1980). By Proposition 2.2.5 of Simchi-Levi et al. (2005), we have . Moreover, there exists a standard uniform random variable such that for all and almost surely (Denneberg, 1994). Take
It follows that , where . Similarly, for all , where
Since is supermodular and positively homogeneous, we have by Theorem 3 of Marinacci and Montrucchio (2008) that is concave in . By Jensen’s inequality, we have
Thus we have
where the first inequality follows from Theorem 4.A.3 of Shaked and Shanthikumar (2007) and Theorem 5 of Wang et al. (2020a) and the second equality is by the proof of Theorem 1. Combined with the fact that
we have (17) holds.
(ii) Suppose that the supremum of the right-hand side of (17) is attained by some and . For comonotonic such that for all , using the argument in (i),
where is comonotonic and for all . Similarly to the proof of Theorem 1 (iii), since , we have the supremum of the left-hand side of (17) is attained by and , which also obtain the supremum of the right-hand side of (17) since
B.4 Proofs of results in Section 5 and related lemmas
In the following, we write as the Hölder conjugate of . The following lemma closely resembles Theorem 3.4 of Liu et al. (2020) with only an additional statement on the uniqueness of the quantile function of the maximizer.
Lemma A.1.
For , , and , we have
If , the above supremum is attained by a random variable such that with its quantile function uniquely determined by
| (A.8) |
If , the above maximum value is attained by any random variable such that .
Proof.
The only statement that is more than Theorem 3.4 of Liu et al. (2020) is the uniqueness of the quantile function (A.8). Without loss of generality, assume and . Using the Hölder inequality
The maximum is attained by only if the above inequality is an equality, which is equivalent to that the function is a multiple of . Therefore,
Hence, the quantile function of is uniquely determined by (A.8). ∎
Lemma A.2.
For all with , , and , if , we have
and the above suprema are simultaneously attained by a random variable such that with
| (A.9) |
Proof of Theorem 5.
Proof of Proposition 5.
Proof of Corollary 1.
We prove the first half (the suprema). The second half is symmetric to the first half. Theorem 5 and Lemma A.2 give
By Lemma A.1, the corresponding random variable which attains has left-quantile function
Note that only takes two values for and , respectively. Thus is a bi-atomic random variable, and using , we have, for some ,
We note that the number can be determined from , that is,
leading to
and thus the desired equalities in the statement on suprema hold. ∎