Order Estimates for the Exact Lugannani–Rice Expansion
This version: June 15, 2014)
Abstract
The Lugannani–Rice formula is a saddlepoint approximation method for estimating the tail probability distribution function, which was originally studied for the sum of independent identically distributed random variables. Because of its tractability, the formula is now widely used in practical financial engineering as an approximation formula for the distribution of a (single) random variable. In this paper, the Lugannani–Rice approximation formula is derived for a general, parametrized sequence of random variables and the order estimates (as ) of the approximation are given.
000Mathematical Subject Classification (2010) 62E17, 91G60, 65D15000JEL Classification (2010) C63 , C65
Keywords: Saddlepoint approximation, The Lugannani–Rice formula, Order estimates, Asymptotic expansion, Stochastic volatility models
1 Introduction
Saddlepoint approximations (SPAs) provide effective methods for approximating probability density functions and tail probability distribution functions, using their cumulant generating functions (CGFs). In mathematical statistics, SPA methods originated with Daniels (1954), in which an approximation formula was given for the density function of the sample mean of independent identically distributed (i.i.d.) random variables , provided that the law of has the density function. Lugannani and Rice (1980) derives the following approximation formula for the right tail probability:
| (1.1) |
as . Here, and are the standard normal distribution function and its density function , respectively, and and are expressed by using the CGF of and the saddlepoint of . That is, satisfies . Related SPA formulae have been studied in Daniels (1987), Jensen (1995), Kolassa (1997), Butler (2007), the references therein, and others.
Strictly, the Lugannani–Rice (LR) formula (1.1) should be interpreted as an asymptotic result as . However, it is popular in many practical applications of financial engineering as an approximation formula for the right tail probability because of its tractability. This approximation is
| (1.2) |
In other words, LR formula (1.1) is applied even when is ! For financial applications of SPA formulae, we refer the readers to papers such as Rogers and Zane (1999), Xiong, Wong, and Salopek (2005), Aït-Sahalia and Yu (2006), Yang, Hurd, and Zhang (2006), Glasserman and Kim (2009), and Carr and Madan (2009). It is interesting that the approximation formula (1.2) still works surprisingly well in many financial examples, despite its lack of theoretical justification.
The aim of this paper is to provide a measure of the effectivity of the “generalized usage” of the LR formula (1.2) from an asymptotic theoretical viewpoint. We consider a general parametrized sequence of random variables and assume that the th cumulant of has order as for each . This implies that converges in law to a normally distributed random variable (a motivation is provided for this assumption in Remark 2 of Section 3). We next derive the expansion
| (1.3) |
which we call the exact LR expansion (see Theorem 1 of Section 2). Here, is given by (2.1) and (2.3), and the () are given by (2.8). We then show that
| and as for all | (1.4) |
under some conditions. This is the main result of the paper (see Theorem 2 in Section 3 for the details).
Remark 1.
We note that the expansion (1.3) with the order estimates (1.4) and the classical LR formula (1.1) treat different situations, although they may have some overlap. Let
where is an i.i.d. sequence of random variables. Then, we can check that the law of satisfies the conditions necessary to apply Theorem 2 in Section 3 (see Remark 2 (iv) in Section 3). So, (1.3) holds with (1.4). On the other hand, the classical LR formula (1.1) gives an approximation formula of the far-right tail probability:
In this paper, with motivation from financial applications (e.g., call option pricing in Section 4), we choose to analyse the right tail probability instead of the far-right tail probability . For a related remark, see (i) in Section 7.
The organisation of the rest of this paper is as follows. In Section 2, we introduce the “exact” LR expansion: we first derive it formally, and next provide a technical condition sufficient to ensure the validity of the expansion. Section 3 states our main results: we derive the order estimates of the higher order terms in the exact LR expansion (1.3). Section 4 discusses some examples: we introduce two stochastic volatility (SV) models and numerically check the accuracy of the higher order LR formula. Section 5 contains the necessary proofs: Subsection 5.1 gives the proof of Theorem 1 and Subsection 5.2 gives the proof of Theorem 2. Section 6 discusses some extensions of Theorem 2: under additional conditions we obtain the sharper estimate as for , and the related order estimate of the absolute error of the th order LR formula. In addition, we introduce error estimates for the Daniels-type formula, which is an approximation formula for the probability density function. The last Section 7 contains concluding remarks. In Appendix, we present some toolkits for deriving the explicit forms of and .
2 The Exact Lugannani–Rice Expansion
In this section we derive the exact LR expansion (1.3), which is given as a natural generalisation of the original LR formula. For readability, we introduce here the formal calculations to derive that formula and leave rigorous arguments to Section 5.1 (see also Appendix in Rogers and Zane (1999)).
Let be a family of probability distribution on and define a distribution function and a tail probability function by
We denote by the CGF of , that is,
We assume the following conditions.
-
[A1]
For each , the effective domain of contains an open interval that includes zero.
-
[A2]
For each , the support of is equal to the whole line . Moreover, the characteristic function of is integrable; that is,
where is the imaginary unit.
It is well known that is analytic and convex on the interior of . Moreover, [A2] implies that has a density function, and thus is a strictly convex function (see Durrett (2010), for instance). Since the range of coincides with under [A1]–[A2], we can always find the solution to
| (2.1) |
for any . We call the saddlepoint of given . Here, note that is analytically continued as the function defined on .
Now, we derive (1.3). Until the end of this section, we fix an and an . To derive (1.3), we further that require the condition be satisfied. Applying Levy’s inversion formula, we represent by the integral form
| (2.2) |
Next, we represent as
| (2.3) |
where . Note that is well defined because of the calculation
| (2.4) | |||||
by virtue of the convexity of and Taylor’s theorem. We consider the following change of variables between and :
| (2.5) |
Then, replacing the variable with in the right-hand side of (2.2) and applying Cauchy’s integral theorem, we see that
| (2.6) | |||||
where is a Jordan curve in -space corresponding to the line and is defined by (2.5) as an implicit function with respect to . Note that is well defined for each and is analytic on each contour under suitable conditions. Denoting
we can decompose (2.6) into
where
is just the tail probability of the standard normal distribution; that is, , where
Here, if , we see that is analytic on ; hence, we obtain
| (2.7) | |||||
where we define
| (2.8) |
This is the exact LR expansion (1.3). Note here that the th order approximation formula
corresponds to the original LR formula (1.1). Indeed, we see that
The st order approximation formula
is also often called the LR formula, where we have that
with
The explicit forms of the higher order terms and are shown in Appendix.
The above formal derivation of the exact LR expansion (1.3) can be made rigorous under suitable conditions, such as the following.
-
[B1]
For each , there exists such that on .
-
[B2]
The range of the holomorphic map defined by
includes a convex set that contains and ,
-
[B3]
.
Under these conditions, we obtain the following, whose proof is given in Subsection 5.1.
Theorem 1.
Assume – and –. Then holds.
3 Order Estimates of Approximation Terms
In practical applications, we need to truncate the formula (1.3) with
| (3.1) |
We call the right-hand side of (3.1) the th LR formula. The aim of this section is to derive order estimates for () as .
We fix , which is an arbitrary value such that
| (3.2) |
We then impose the following additional assumptions.
-
[A3]
There is a such that for each and .
-
[A4]
For each , there is an interval such that as ; that is, for each and .
-
[A5]
For each nonnegative integer , converges uniformly to with on any compact subset of . Moreover, for each integer , has order as in the following sense: For each compact set , it holds that
(3.3)
Remark 2.
-
From , we see that for each compact set there is an such that for . Therefore, the assertions in make sense for small . Note that one of the sufficient conditions for is that
-
[A4’]
, .
-
[A4’]
-
implies that holds for . Therefore,
with some and , where the positivity of follows from ([A2] or) [A3]. Hence, is the normal distribution with mean and variance . Note here that the effective domain of is equal to , which is consistent with [A4].
-
An example which satisfies is the following. Let for be i.i.d. random variables with mean zero, let , and let be its distribution. We see that satisfies [A5] by the central limit theorem (setting ). SV models with small “vol of vol” parameters are introduced as additional examples in Section 4.
Now, we introduce our main theorem.
Theorem 2.
Assume that conditions – hold. Then and , both as for each .
Recall here that the notation implies .
Remark 3.
It may be natural to expect that holds as for some . In other words, to expect that the relation may not hold for . Here, is the Bachmann–Landau “Big-Theta” notation, meaning that
Under conditions [A1]–[A5], we have not obtained sharper estimates for () than given in Theorem 2. In Section 6.1 we show that by assuming [A6]–[A7] additionally we obtain
| (3.4) |
for each , and
| (3.5) |
for each . In the next section, we also numerically demonstrate these results by use of examples.
4 Examples
In this section, we introduce some examples and apply our results.
4.1 The Heston SV model
As the first example, we treat Heston’s SV model (Heston (1993)). We consider the following stochastic differential equation (SDE):
where , , and . It is known that the above SDE has the unique solution when . The process is regarded as the log-price process of a risky asset with the stocastic volatility process under the risk-neutral probability measure (the risk-free rate is set as zero for simplicity). Our goal is to approximate the tail probability for a time .
Here is the “vol of vol” parameter, which describes dispersion of the volatility process. In this section, we consider the case of a small . Note that when , has the normal distribution.
To apply our main result, we verify that the conditions [A1]–[A5] for hold. First, [A1] is satisfied and the explicit form of the CGF of with is given as
| (4.1) |
on a neighbourhood of the origin, where
(see Rollin, Castilla, and Utzet (2010) or Yoshikawa (2013)). Note that when , we have
where . Moreover, Theorem 3.3 and Corollary 3.4 in Rollin, Castilla, and Utzet (2010) imply [A2]. The same source also tells us that when , it is also true that , where are given by
We can easily see that and as ; thus, [A4] is satisfied. [A5] is obtained by Theorem 3.1 in Yoshikawa (2013). Finally, we numerically compute the minimum value of for each to confirm [A3]. We set the parameters as , , , , , , and . Then we get Figure 1, which implies that [A3] holds.
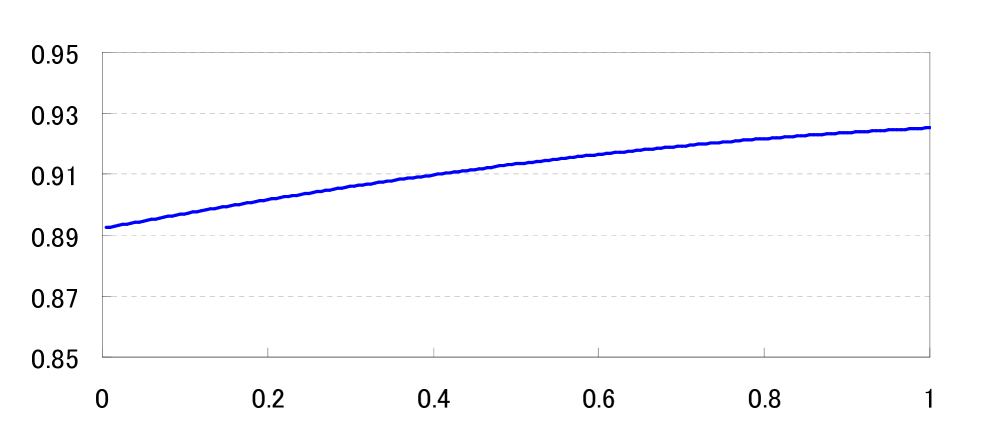
Remark 4.
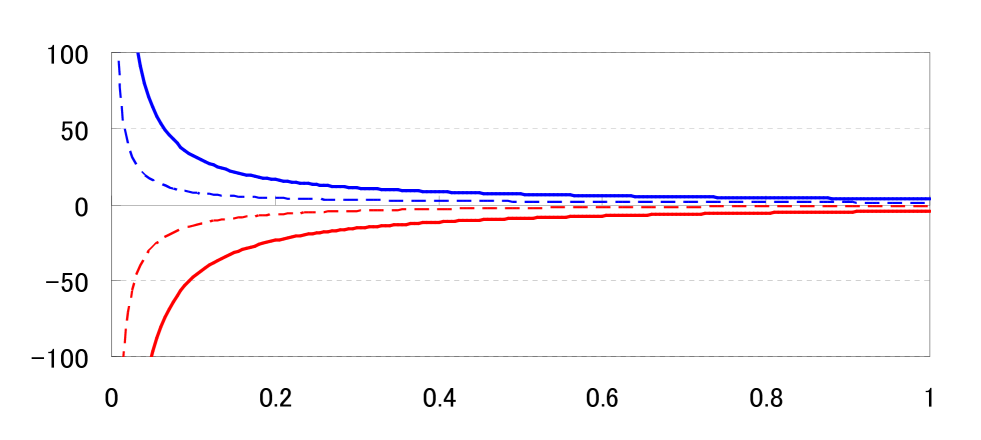
Theorem 3.1 in Rollin, Castilla, and Utzet (2010) presents a method to calculate the lower bound and the upper bound of the effective domain . When we set the parameters as above, the bounds are obtained by
where
and are the solutions to . Note that is given by (4.1) on and by
on . In Figure 2, we numerically calculate and for . This suggests the modified condition [A4’].
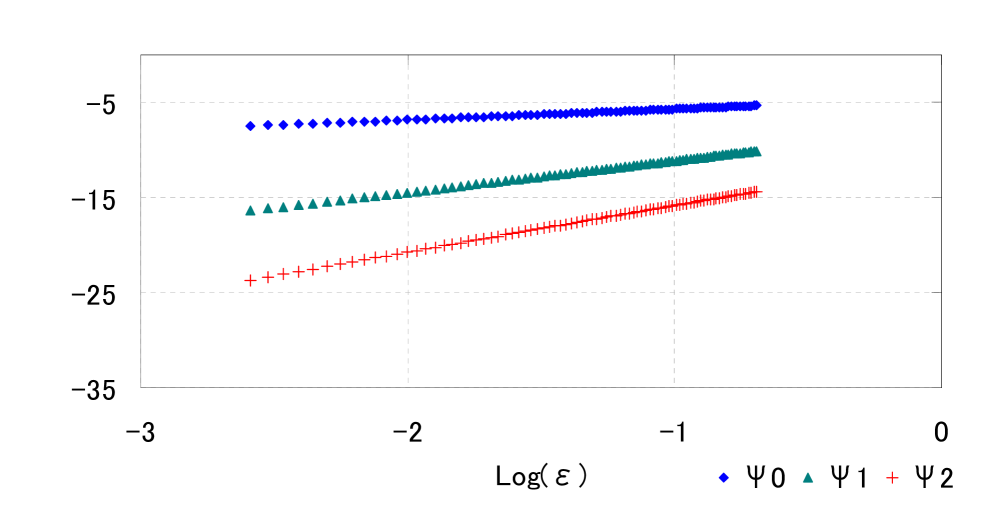
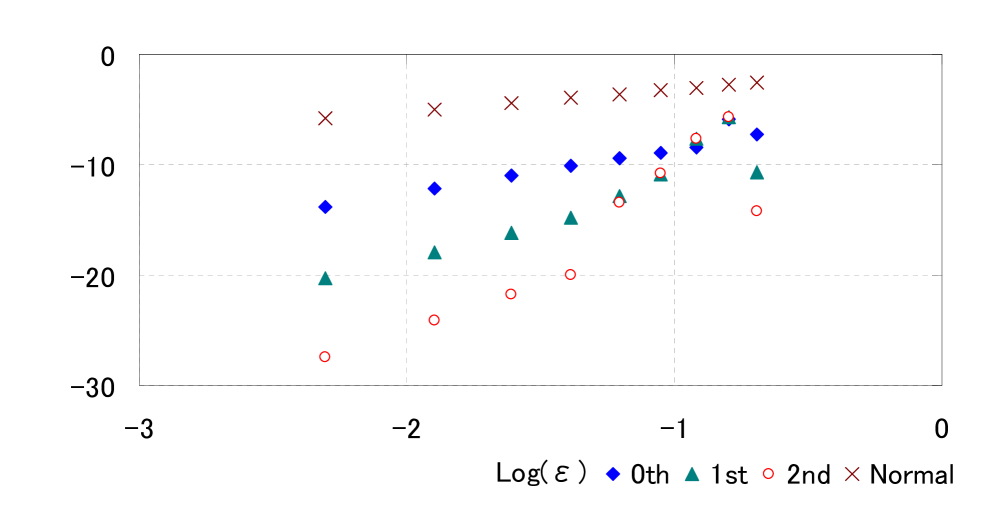
Now we verify the orders of approximate terms with . Figure 3 represents the log-log plot of the approximations for small . In this figure, we can find the linear relationships between and . We estimate their relationship by linear regression and get
Then we can numerically confirm that as for , which is consistent with Theorem 2 and (3.4) (see also Theorem 3 in Section 6.1).
Next, we calculate the relative errors of the LR formula. We let
| Normal formula | ||||
We define the relative error for approximated value of :
| (4.2) |
To find the true value of (‘True’ in Table 1), we directly calculate the integral (2.2) with .
| RE | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| True | Normal | 0th | 1st | 2nd | Normal | 0th | 1st | 2nd | |
| 0.2 | 0.06622 | 0.06788 | 0.06622 | 0.06622 | 0.06622 | 2.51E-02 | 2.84E-05 | 3.12E-07 | 3.18E-09 |
| 0.4 | 0.06521 | 0.06894 | 0.06523 | 0.06521 | 0.06521 | 5.71E-02 | 2.88E-04 | 9.57E-06 | 4.04E-07 |
| 0.6 | 0.06385 | 0.06996 | 0.06392 | 0.06385 | 0.06385 | 9.56E-02 | 1.11E-03 | 6.76E-05 | 6.28E-06 |
| 0.8 | 0.06219 | 0.07093 | 0.06237 | 0.06217 | 0.06219 | 1.41E-01 | 2.82E-03 | 2.60E-04 | 4.11E-05 |
| 1 | 0.06029 | 0.07184 | 0.06063 | 0.06025 | 0.06028 | 1.92E-01 | 5.69E-03 | 7.22E-04 | 1.40E-04 |
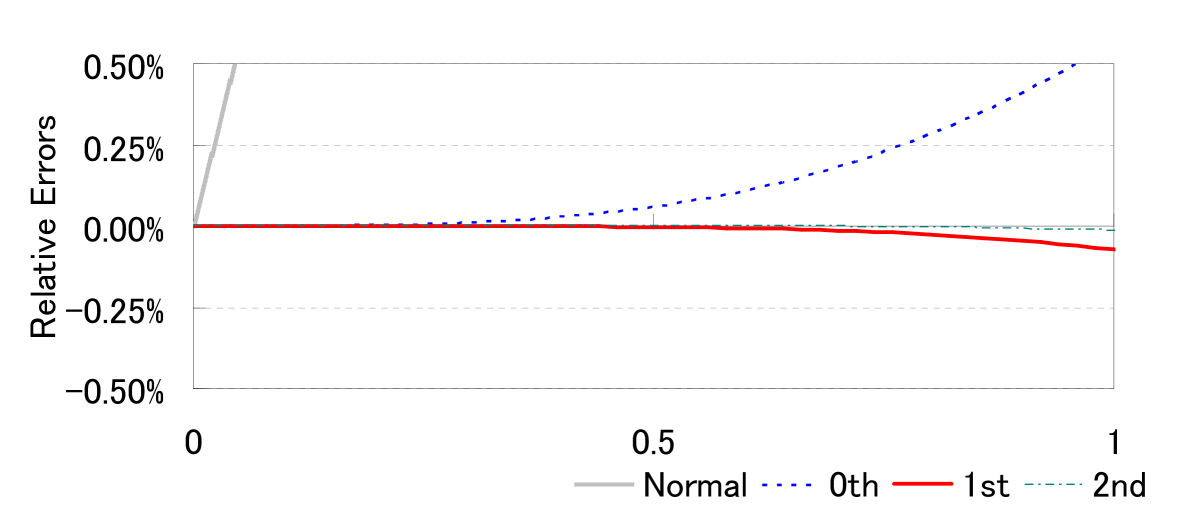
The results are shown in Table 1 and Figure 4. We see that the relative errors decrease when becomes small. Moreover, we can verify that the higher order LR formula gives a more accurate approximation. In particular, the accuracies of the ‘st’ and ‘nd’ formulae are quite high, even when is not small.
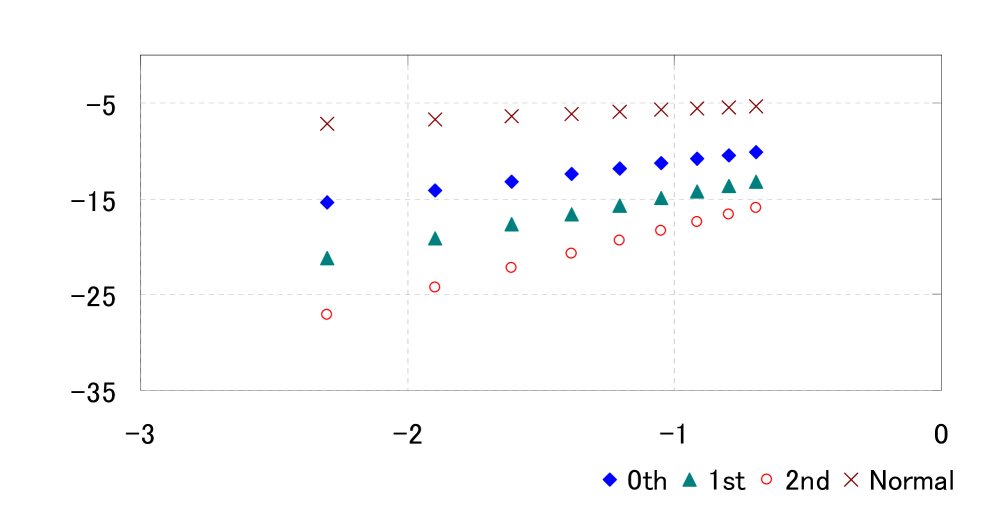
Figure 5 shows the log-log plot of the absolute errors, defined by
| (4.3) |
We see that there are linear relationships between and the functions: by linear regression, we have
These imply that the error of the th LR formula has order as , which is consistent with (3.5) and Theorem 4 in Section 6.1.
At the end of this section, we consider the application to option pricing. We calculate the European call option price
| (4.4) |
under the risk-neutral probability measure , where is the strike price.
The explicit form of was obtained by Heston (1993), so we can calculate the exact value, up to the truncation error associated with numerical integration. Applying the LR formula to (4.4) was proposed by Rogers and Zane (1999). Here, we briefly review the procedure to do so. First, we rewrite (4.4) as
where . For the second term in the right-hand side of the above equality, we can directly apply the LR formula. To evaluate the first term, we define a new probability measure (called the share measure) by the following Radon–Nikodym density
From this we obtain
Now, we can easily find the CGF of the distribution :
Obviously, satisfies our assumptions [A1]–[A5]. Therefore, we can apply the LR formula to .
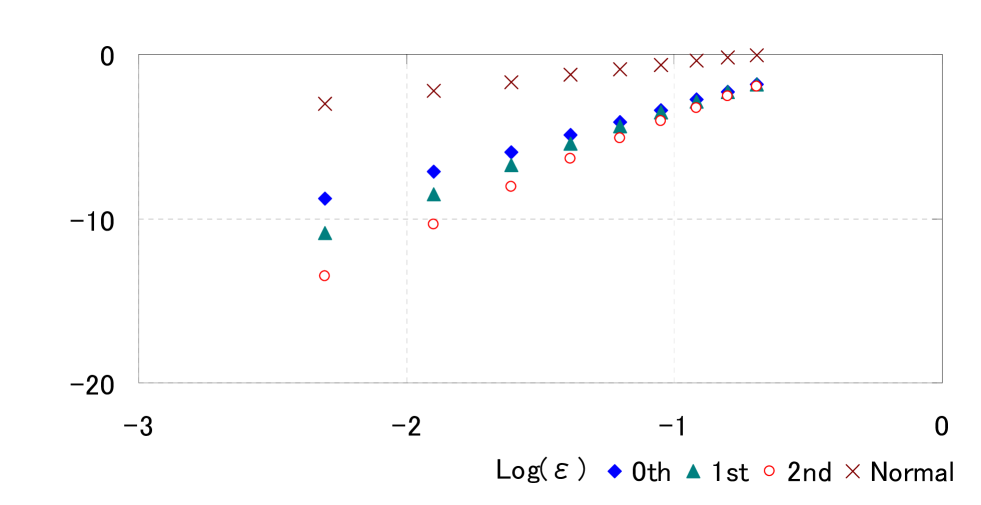
Now we set the initial price of the underlying asset as and the strike price as 105. For the model parameters, we set , , , and . We denote by , , and the approximations of using the LR formulae ‘Normal,’ ‘th,’ ‘st’ and ‘nd’, respectively. RE and AE are the same as in (4.2) and (4.3), respectively, with tail probabilities as option prices.
| Call Option Price | RE | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| True | Normal | 0th | 1st | 2nd | Normal | 0th | 1st | 2nd | |
| 0.2 | 9.352 | 9.367 | 9.352 | 9.352 | 9.352 | 1.62E-03 | 8.93E-06 | 5.95E-08 | 7.04E-10 |
| 0.4 | 9.358 | 9.419 | 9.357 | 9.358 | 9.358 | 6.46E-03 | 1.41E-04 | 3.78E-06 | 1.60E-07 |
| 0.6 | 9.337 | 9.471 | 9.330 | 9.337 | 9.337 | 1.43E-02 | 7.00E-04 | 4.29E-05 | 3.43E-06 |
| 0.8 | 9.291 | 9.523 | 9.271 | 9.293 | 9.291 | 2.50E-02 | 2.14E-03 | 2.38E-04 | 2.63E-05 |
| 1 | 9.223 | 9.576 | 9.177 | 9.231 | 9.224 | 3.82E-02 | 5.01E-03 | 8.79E-04 | 1.16E-04 |
4.2 The Wishart SV Model
Next, we introduce the Wishart SV model. The Wishart process was first studied by Bru (1991); it was first used to describe multivariate stochastic volatility by Gouriéroux (2006). Since then, modelling of multivariate stochastic volatility by using the Wishart process has been studied in several papers, such as Fonseca, Grasselli, and Tebaldi (2007, 2008), Grasselli and Tebaldi (2008), Gouriéroux, Jasiak, and Sufana (2009), and Benamid, Bensusan, and El Karoui (2010).
We consider the following SDE:
where is the -dimensional unit matrix, , and . Here, is the trace of and denotes the transpose matrix of . is assumed to satisfy
for some . and are -valued processes whose components are mutually independent standard Brownian motions. The process is regarded as the log-price of a security under a risk-neutral probability measure. is an -dimensional matrix-valued process which describes multivariate stochastic volatility. We verify the validity of the approximation terms of the exact LR expansion for .
The explicit form of the CGF of is studied in Bru (1991), Fonseca, Grasselli and Tebaldi (2008), and others. To simplify, we only treat the case of and restrict the forms of and as follows:
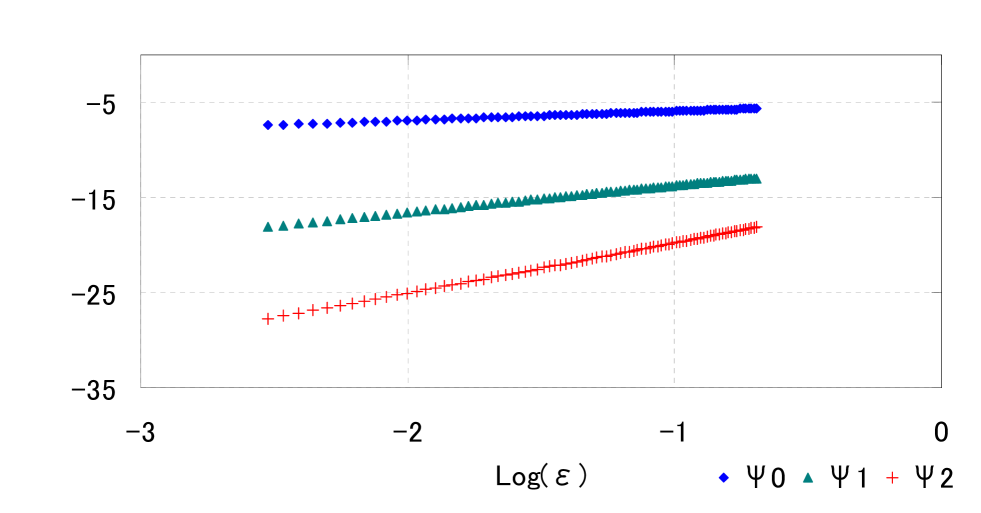
We set parameters as , , , , , , , and . Similar to the case in Section 4.1, we can find linear relationships between and in Figure 7 with . Linear regression gives
Thus, for this case also we can numerically confirm that , for .
Now we investigate the relative errors of the LR formula. We compare the approximations of by the formulae ‘Normal,’ ‘th,’ ‘st’, and ‘nd’, defined in the same way as in Section 4.1, with the true value, which is calculated by direct evaluation of the integral in (2.2).
| RE | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| True | Normal | 0th | 1st | 2nd | Normal | 0th | 1st | 2nd | |
| 0.2 | 0.06610 | 0.06462 | 0.06610 | 0.06610 | 0.06610 | 2.24E-02 | 2.97E-06 | 4.62E-09 | 1.73E-11 |
| 0.4 | 0.06624 | 0.06333 | 0.06623 | 0.06624 | 0.06624 | 4.38E-02 | 2.00E-05 | 1.88E-07 | 2.53E-09 |
| 0.6 | 0.06622 | 0.06198 | 0.06622 | 0.06622 | 0.06622 | 6.40E-02 | 5.25E-05 | 1.77E-06 | 4.76E-08 |
| 0.8 | 0.06604 | 0.06056 | 0.06603 | 0.06604 | 0.06604 | 8.30E-02 | 8.31E-05 | 7.92E-06 | -6.20E-07 |
| 1 | 0.06568 | 0.05908 | 0.06567 | 0.06568 | 0.06568 | 1.00E-01 | 9.12E-05 | 4.59E-06 | -2.52E-05 |
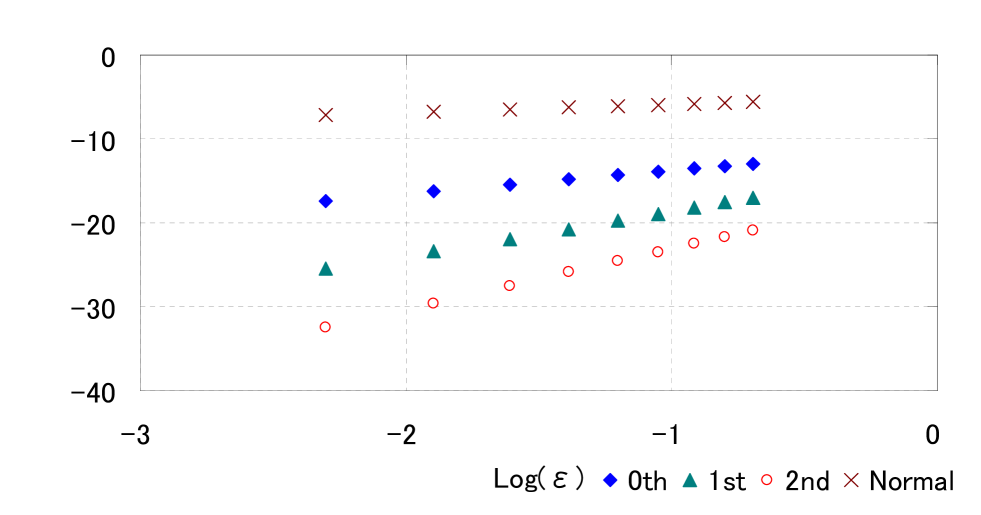
Similar to the case in Section 4.1, we show the relative errors and the log-log plot of absolute errors of the formulae in Table 3 and Figure 8. We can also confirm that the LR formulae are highly accurate. Using the data shown in Figure 8, we get the linear regression results
which suggest (3.5).
At the end of this section, we confirm the validity for application in option pricing. Similarly to (4.4), we consider the European call option
with the strike price . To find the true value of the option price, we apply a closed-form formula proposed in Benabid, Bensusan, and El Karoui (2010). We set the initial price of the underlying asset as and . For the initial volatility, we put . Other parameters are the same as in the previous case.
| Call Option Price | RE | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| True | Normal | 0th | 1st | 2nd | Normal | 0th | 1st | 2nd | |
| 0.2 | 10.90 | 10.91 | 10.90 | 10.90 | 10.90 | 1.13E-03 | 1.50E-06 | 8.61E-09 | 3.15E-11 |
| 0.4 | 10.76 | 10.80 | 10.76 | 10.76 | 10.76 | 4.58E-03 | 2.10E-05 | 4.56E-05 | 4.62E-05 |
| 0.6 | 10.60 | 10.70 | 10.59 | 10.59 | 10.59 | 9.88E-03 | 4.37E-04 | 3.08E-04 | 3.02E-04 |
| 0.8 | 10.46 | 10.60 | 10.40 | 10.41 | 10.41 | 1.27E-02 | 5.71E-03 | 5.29E-03 | 5.25E-03 |
| 1 | 10.15 | 10.49 | 10.20 | 10.21 | 10.21 | 3.37E-02 | 4.33E-03 | 5.41E-03 | 5.55E-03 |
5 Proofs
5.1 Proof of Theorem 1
In this subsection, we justify the formal calculations shown in Section 2. For ease of readability, we omit from the notation used in this section.
Proposition 1.
Assume – hold. Then
for .
Proof.
Without loss of generality, we may assume and . By [A2] and Theorem 3.3.5 in Durrett (2010), the density function of exists and is bounded and continuous. Moreover,
holds, where is the characteristic function of . Then we have for each that
by Fubini’s theorem, where
Now, consider the four lines , defined as
for a given . By Cauchy’s integral theorem, we have
| (5.1) |
Here, we observe that
to conclude
Since , the integral on the right-hand side is finite. Thus, the left-hand side must converge to zero as . Combining this result with (5.1), we obtain that
| (5.2) |
Since
we can take the limit on the right-hand side of (5.2); we conclude that
which is the assertion of Proposition 1. ∎
Now, we present the rigorous definition of the change of variables (2.5). For each , we can define by
| (5.3) |
Obviously, is analytic on . Moreover, by straightforward calculation we observe
| (5.4) |
Here we see that is also analytic at . Indeed, similar to (2.4), we have
where
By [A2], is positive, and thus is real analytic. As a consequence, the function is real analytic on . Now we can take the limit in (5.5) to obtain
by using l’Hôpital’s rule. This implies that . Therefore, we deduce that there exist a neighbourhood of and a holomorphic function on such that for .
Here we remark that
Lemma 1.
implies does not lie on .
Proof.
Let . By [A2], we have . Thus, we can find a neighbourhood of and an analytic inverse function function of defined on . On the other hand, [A2] implies that is an analytic -valued function, hence . ∎
Lemma 1 immediately implies
Corollary 1.
Let . If , then ; hence, .
Now, we consider an analytic continuation of . Until the end of this section, we will assume [A1]–[A2] and [B1]–[B3] hold. By [B2], (5.4) and Corollary 1, we can define the analytic function on an open set which contains a convex set that includes the line and the curve . Note that (5.4) immediately implies
| (5.5) |
for each .
By definition, the relation (2.5) holds everywhere on . Therefore, if we define the curves and as
then can be also defined and is analytic on . Then, we can apply the change of variables to obtain
In Section 2, we need the condition . In this section we only consider the case where ; the arguments are analogous for the case where . In any case, we have and thus does not pass . Here, we see that . Indeed, if , then the inequality in (2.4) must be changed to equality. However, the assumptions and [A2] imply that the left-hand side of (2.4) is positive. This is a contradiction. Moreover, by its definition, must be nonnegative. These arguments imply that does not exceed .
Proposition 2.
To prove this proposition, we prepare a lemma.
Lemma 2.
.
Proof.
By [B1] and Taylor’s theorem, we have
which implies the asserted statement. ∎
Proof of Proposition 2.
Proof of Theorem 1.
From Propositions 1 and 2, we get (2.6). Now we verify the holomorphicity of on . We define
| (5.8) |
when is defined and let , where is the principal value of the logarithm of . Since is analytic on the line , is also analytic. We can easily see that . This implies that is also analytic; this permits the following Taylor series expansion:
| (5.9) |
for .
5.2 Proof of Theorem 2
For simplicity, we only consider the case . First, we introduce the following lemma.
Lemma 3.
, as .
Proof.
First, we check that is bounded. By (2.1), we have
where . By [A5], we see that is bounded. Thus, from [A3], we get
Second, we observe that
to arrive at
for some compact set . Letting , we get the former assertion. The latter assertion follows immediately. ∎
The above lemma implies the following corollary.
Corollary 2.
There is a such that for .
Proof.
Since , we can find some such that holds for . The relation is obtained in the same way by using . ∎
By the above corollary, we may assume that and are strictly positive.
Proposition 3.
as .
Proof.
Since and are bounded and away from zero, it suffices to show that as . From the definition of , we have
Using and Taylor’s theorem, we get
Therefore,
from which our assertion follows. ∎
We write
Note that exists, because is analytic at . Similarly, we can define
for each . The next proposition is frequently used in the calculations shown later.
Proposition 4.
.
Proof.
Since both the numerator and the denominator in the right-hand side of (5.5) converge to zero with , we can apply l’Hôpital’s rule to obtain
Solving this equation for , we obtain the desired assertion. ∎
Recall that the function defined in (5.8) is analytic on . The following lemma is straightforward by using mathematical induction.
Lemma 4.
For each and ,
Note that . Therefore, we can define on a neighbourhood of . Obviously, we have . Hence,
| (5.11) |
Different but nevertheless straightforward calculations give
| (5.12) | |||||
We can show by induction the following.
Lemma 5.
For each and ,
for some and with .
By (5.11), Lemmas 3 and 5, it suffices to consider the estimation of the order of for . The next proposition gives the order estimate of .
Proposition 5.
as .
Proof.
Differentiating both sides of (5.5) with respect to , we get the following proposition.
Proposition 6.
For ,
| (5.16) |
Proposition 7.
For ,
with and for brevity.
Next, we consider the second derivative of at .
Proposition 8.
| (5.17) |
Proof.
Apply l’Hôpital’s rule for (5.16) and observe that
We then obtain our assertion by solving the above equation for . ∎
Proposition 9.
as .
Proof.
Applying l’Hôpital’s rule for the equality in Proposition 7 and using Proposition 8, we have
| (5.18) |
Similarly to Proposition 3, by applying Taylor’s theorem, we get
| (5.19) |
where
Note that as by [A5]. From (5.19), we get
Therefore, we can rewrite the numerator of the right-hand side of (5.18) as
Here, we use the relations for small , , and as . This completes the proof. ∎
In fact, we can refine the assertion of the above proposition. From Taylor’s theorem, we observe that
to arrive at
where
Then, by a calculation similar to that in the proof of the above proposition, we have
where we have applied the relation for small . This implies that
| (5.20) |
Here, we calculate the third derivative of at ().
Proposition 10.
| (5.21) |
Proof.
Proposition 11.
| (5.23) |
Now we are prepared to prove the next proposition.
Proposition 12.
as .
Proof.
Next we estimate and for . We let
Lemma 6.
for each .
Proof.
A straightforward calculation gives
which implies the desired assertion. ∎
Proposition 13.
For each , the following two assertions hold.
There are nonnegative integers such that
and also , for each .
.
Proof.
Proposition 14.
For each , we have as .
Proof.
When , the assertion is obvious by [A5] and Proposition 8. We suppose that the assertion is true for . By the definition of , we have
for . By Proposition 13(ii) and the definition of , we see that both the numerator and the denominator of the right-hand side of the above equality converge to zero by letting . Therefore, we can apply l’Hôpital’s rule to obtain
| (5.25) |
By Lemma 6 and Proposition 13, we see that has the form
| (5.26) |
for some with . By (5.25)–(5.26), we have
Here, by the supposition as for and that [A4] holds, we see that the term
has order as . Thus, as . Therefore, the assertion is also true for . Induction completes the proof. ∎
Lemma 7.
For each , as .
Proof.
6 Extentions
6.1 Error Estimates of the Higher Order LR Formulae
In the beginning of this subsection, we introduce the following proposition.
Proposition 15.
For each ,
| (6.1) |
Proof.
Here, by Proposition 14, there are positive constants (with ), such that
| (6.3) |
Therefore, if we assume the further condition [A6] below, then the series (6.1) converges absolutely when is small.
-
[A6]
There exists such that
Moreover, we obtain the following theorem.
Theorem 3.
Assume –. Then , holds for each . Moreover, , holds for each .
By the above theorem, we see that there are positive constants (where ) such that , and hence
Now we introduce the condition [A7].
-
[A7]
There exists such that
Then, obviously we have the theorem below.
Theorem 4.
Assume –and that holds. Then the expansion formula holds.
6.2 Application to the Daniels Formula for Density Functions
In this subsection, we study the order estimates for the saddlepoint approximation formula of Daniels (1954), which approximates the probability density function. Let and define as are done in Section 5.2. By an argument similar to that in Section 2, we can prove the following “exact” Daniels expansion:
| (6.4) |
under suitable conditions, where is the probability density function of and
In the case of the sample mean of i.i.d. random variables, this version of (6.4) was studied as (3.3) in Daniels (1954) and (2.5) in Daniels (1980). In the general case, we can obtain (6.4) under, for instance, [A1]–[A5], [B1]–[B2] and the following additional condition.
- [A8]
We can easily show the following by arguments similar to those in Section 5 and Subsection 6.1 (we omit the proof here).
Theorem 5.
Assume –. Moreover assume that holds. Then as for each . Moreover, if we further assume , it holds that
7 Concluding Remarks
For a general, parametrised sequence of random variables , assuming that the th cumultant of has order as for each , we derive the “exact” Lugannnani-Rice expansion formula for the right tail probability
where is fixed to a given value. In particular, we have obtained the order estimates of each term in the expansion. For the first two terms, we have that and as , respectively. Under some additional conditions, the th term satisfies as . Using these, we have established (3.5) for each . As numerical examples, we chose stochastic volatility models in financial mathematics; we checked the validity of our order estimates for the LR formula.
The following are interesting and important future research topics related to this work.
-
(i)
Analysing the far-right tail probability
using an LR type expansion, which is compatible with the classical LR formula (see Remark 1 in Introduction). In this case, the saddlepoint diverges as allowing us to avoid the difficulty in calculating (2.7) by using Watson’s lemma (see Watson (1918) or Kolassa (1997)). Hence, we can expect that condition [B3] may be omitted; this condition was imposed when we derived the exact LR expansion.
-
(ii)
Seeking more “natural” conditions than [A6]–[A7] for obtaining the error estimate (3.5).
-
(iii)
Studying order estimates for generalized LR expansions with non-Gaussian bases. Among studies of the expansions without order estimates are Wood, Booth and Butler (1993), Rogers and Zane (1999), Butler (2007), and Carr and Madan (2009).
Appendix A Explicit Forms of Higher Order Approximation Terms
In this section, we introduce the derivation of and . First, we can inductively calculate for by the same calculation as the proof of Proposition 14.
Proposition 16.
Acknowledgement
The authors thank communications with Masaaki Fukasawa of Osaka University, who directed their attentions to the Lugannani–Rice formula. Jun Sekine’s research was supported by a Grant-in-Aid for Scientific Research (C), No. 23540133, from the Ministry of Education, Culture, Sports, Science, and Technology, Japan.
References
- [1] Aït-Sahalia, Y. and Yu, H. (2006). Saddlepoint approximations for continuous-time Markov processes. J. Economet. 134, 507–551.
- [2] Benabid, A., Bensusan, H. and El Karoui, N. (2010). Wishart stochastic volatility: Asymptotic smile and numerical framework. Preprint.
- [3] Bru, M. F. (1991). Wishart processes. J. Theor. Prob. 4, 724–743.
- [4] Butler, R. W. (2007). Saddlepoint approximations with applications, Cambridge Series in Statistical and Probabilistic Mathematics, Cambridge University Press, Cambridge.
- [5] Carr, P. and Madan, A. (2009). Saddlepoints methods for option pricing. The J. Comput. Finance 13(1), 49–61.
- [6] Daniels, H. E. (1954). Saddlepoint approximations in statistics. Ann. Math. Statist. 25, 631–650.
- [7] Daniels, H. E. (1980). Exact saddlepoint approximations. Biometrika 67(1), 59–63.
- [8] Daniels, H. E. (1987). Tail probability approximations. Int. Statist. Rev. 55, 37–48.
- [9] Durrett, R. (2010). Probability: Theory and Examples, 4th edn. Cambridge University Press, Cambridge.
- [10] Fonseca, J. Grasselli, M. and Tebaldi, C. (2007). Option pricing when correlations are stochastic: an analytical framework. Rev. Derivatives Research 10(2), 151–180.
- [11] Fonseca, J. Grasselli, M. and Tebaldi, C. (2008). A multifactor volatility Heston model. Quant. Financ. 8(6), 591–604.
- [12] Glasserman, P. and Kim, K-K. (2009). Saddlepoint approximations for affine jump-diffusion models. J. Econ. Dyn. Control 33, 15–36.
- [13] Gouriéroux, C. (2006). Continuous time Wishart process for stochastic risk. Economet. Rev. 25(2), 177–217.
- [14] Gouriéroux, C., Jasiak, J. and Sufana, R. (2009). The Wishart autoregressive process of multivariate stochastic volatility. J. Economet. 150, 167–181.
- [15] Grasselli, M. and Tebaldi, C. (2008). Solvable affine term structure models. Math. Financ. 18(1), 135–153.
- [16] Heston, S. (1993). A closed form solution for options with stochastic volatility with applications to bond and currency options. Rev. Financ. Studies 6, 327–343.
- [17] Jensen, J. L. (1995). Saddlepoint Approximations. Oxford Statistical Science Series, 16, Oxford University Press, Oxford.
- [18] Kolassa, J. E. (2006). Series Approximation Methods in Statistics, 3rd edn. Lecture Notes in Statistics, 88, Springer-verlag.
- [19] Lugannani, R. and Rice, S. (1980). Saddlepoint approximations for the distribution of the sum of independent random variables. Adv. Appl. Prob. 12, 475–490.
- [20] Rogers, L.C.G. and Zane, O. (1999). Saddlepoint approximations to option prices. Ann. Appl. Prob. 9, 493–503.
- [21] Rollin, S.del Baño, Ferreiro-Castilla, A. and Utzet, F. (2010). On the density of log-spot in the Heston volatility model. Stoc. Proc. Appl. 120(10), 2037–2063.
- [22] Watson, G. N. (1918). The harmonic functions associated with the parabolic cylinder. Proc. London Math. Soc. 2(17), 116–148.
- [23] Wood, A. T. A., Booth, J. G. and Butler, R. W. (1993). Saddlepoint approximations with nonnormal limit disributions. J. Amer. Statist. Soc. 88, 680–686.
- [24] Xiong, J., Wong, A. and Salopek, D. (2005). Saddlepoint approximations to option price in a general equilibrium model. Statist. Prob. Lett. 71, 361–369.
- [25] Yang, J., Hurd, T. and Zhang, X. (2006). Saddlepoint approximation method for pricing CDOs. J. Comput. Financ. 10, 1–20.
- [26] Yoshikawa, K. (2013). On generalization of the Lugannani–Rice formula and its application to stochastic volatility models. Master Thesis, Graduate School of Engineering Science, Osaka University. (in Japanese)