Outer Channel of DNA-Based Data Storage: Capacity and Efficient Coding Schemes
Abstract
In this paper, we consider the outer channel for DNA-based data storage, where each DNA string is either correctly transmitted, or being erased, or being corrupted by uniformly distributed random substitution errors, and all strings are randomly shuffled with each other. We first derive the capacity of the outer channel, which surprisingly implies that the uniformly distributed random substitution errors are only as harmful as the erasure errors. Next, we propose efficient coding schemes which encode the bits at the same position of different strings into a codeword. We compute the soft/hard information of each bit, which allows us to independently decode the bits within a codeword, leading to an independent decoding scheme. To improve the decoding performance, we measure the reliability of each string based on the independent decoding result, and perform a further step of decoding over the most reliable strings, leading to a joint decoding scheme. Simulations with low-density parity-check codes confirm that the joint decoding scheme can reduce the frame error rate by more than 3 orders of magnitude compared to the independent decoding scheme, and it can outperform the state-of-the-art decoding scheme in the literature in a wide parameter regions.
Index Terms:
Capacity, DNA-based data storage, joint decoding scheme, low-density parity-check (LDPC) code, outer channel.I Introduction
Due to the increasing demand for data storage, DNA-based data storage systems have attracted significant attention, since they can achieve extremely high data storage capacity, with very long life duration and low maintenance cost [2, 3, 4]. A typical model for these systems is shown by Fig. 1 [5]. Due to biochemical constraints, the source data is stored in many short DNA strings in an unordered manner. A DNA string/strand/oligo can be missing or corrupted by insertion, deletion, and/or substitution errors during the synthesis, storage, and/or sequencing processes. Therefore, in typical DNA-based data storage systems, an inner code is used to detect/correct the errors within a string, whereas an outer code is used to recover the missing strings and correct the undetectable substitution errors from inner decoding.
In this paper, we focus on the outer code in Fig. 1. Thus, we adopt a simplified system model shown in Fig. 2, where the channel of interest, referred to as the outer channel, is the concatenation of channel-1 and channel-2. The input of channel-1 is an binary matrix , each row of which corresponds to a DNA string. Each row (NOT each bit) of is correctly transmitted over channel-1 with probability , or erased with probability , or corrupted by length- uniformly distributed random substitution errors with probability , where . After that, the rows at the output of channel-1 are randomly shuffled with each other by channel-2. In this case, we indeed view the inner code as a part of channel-1 such that only the valid (but possibly incorrect) inner codewords from the inner decoding form the output of channel-1. It explains why channel-1 adds erasure and substitution errors to a whole row of instead of its bits independently.
We say that the rate (number of information bits stored in per transmitting coded bit) is achievable if there exists a code with rate such that the decoding error probability tends to as , and the channel capacity refers to the maximum achievable code rate. In this paper, we are interested in both computing the capacity and developing practical and efficient coding schemes for the outer channel.

I-A Related Work
| Work | Channel model | Difference |
|---|---|---|
| this work | outer channel | |
| [1] | outer channel | no capacity result |
| [5] | concatenation channel | no erasure errors; no capacity result |
| [6] | noisy permutation channel | no erasure errors; modified capacity for and fixed (i.e., ) |
| [7] | noise-free shuffling-sampling channel | no sustitution errors |
| [7, 8, 9] | noisy shuffling-sampling channels | bits within a string independently suffer from substitution errors |
This is an extended work of its conference version [1]. In [1], we proposed an efficient coding scheme for the outer channel. In this work, we further prove the capacity of the outer channel.
The outer channel is almost the same as the concatenation channel in [5, Fig. 2(a)], except that we additionally consider erasure errors in this paper. In [5], fountain codes [10, 11] were used as the outer codes, and an efficient decoding scheme, called basis-finding algorithm (BFA), was proposed for fountain codes. BFA can also work for the outer channel in this paper when fountain codes are being used, and it serves as a benchmark for the simulation results later in Section V. However, the capacity of the concatenation channel has not been discussed in [5].
In [6, Fig. 2], Makur considered a noisy permutation channel which essentially is the same as the concatenation channel in [5, Fig. 2(a)]. Define
| (1) |
in which and are the number of rows and number of columns in , respectively. Makur modified the conventional definition of channel capacity and computed the modified capacity for and fixed (i.e., in this case). However, we will soon see that the (conventional) capacity of the outer channel equals zero for , and we thus aim to compute the capacity of the the outer channel for in this paper.
In [7], Shomorony and Heckel considered a noise-free shuffling-sampling channel, which can also be described as the concatenation of two sub-channels. The second sub-channel is the same as our channel-2. The first sub-channel outputs some noise-free copies of rows of the input , where the number of copies follows a certain probability distribution, e.g, the Bernoulli distribution. Let denote the probability that the first sub-channel does not output any copy for a row of . According to [7, Theorem 1], the noise-free shuffling-sampling channel has capacity
| (2) |
as long as , and for . In (2), can be understood as the loss due to the random permutation of the second sub-channel, which implies that index-based coding scheme that uses bits for uniquely labelling each row of is optimal [7].
Shomorony and Heckel [7] additionally studied a noisy shuffling-sampling channel. In [8] and [9], more noisy shuffling-sampling channels (also called noisy drawing channels) were considered. However, these channels include discrete memoryless channels (e.g., binary symmetric channel (BSC)), which independently add substitution errors to each bit within a row of . This is the key difference from our channel-1 which does not independently add substitution errors to each bit within a row.
I-B Main Contributions
This paper provides two main contributions. Our first contribution is to derive the capacity of the outer channel, given by the following theorem.
Theorem 1.
The capacity of the outer channel is
| (3) |
as long as , and for .
From [7], it is known that for . Therefore, we focus on by default from now on except where otherwise stated. Intuitively, the received rows in that are corrupted by uniformly distributed random substitution errors can provide no (at most negligible) information about . Suppose there is a genie-aided outer channel which has a genie to identify and remove these incorrect rows, then the channel becomes a type of noise-free shuffling-sampling channel in [7] with . According to (2), its capacity is given by . In contrast to (3), it implies that the uniformly distributed random substitution errors are as harmful as erasure errors when and (recall that we compute capacity for ). This motivates us to develop efficient decoding schemes by treating incorrect rows as erased ones in Section IV, i.e., identify and remove the incorrect rows.
Our second contribution is to develop an efficient coding scheme for the outer channel. More specifically, our encoding scheme is first to choose a block error-correction code (ECC) to encode each column of as a codeword so as to tackle erasure and substitution errors from channel-1, and then to add a unique address to each row of so as to combat disordering of channel-2. Our decoding scheme is first to derive the soft/hard information for each data bit in . It allows us to decode each column of independently, leading to an independent decoding scheme. However, this scheme may not be very efficient since it requires the successful decoding of all columns to fully recover . Therefore, we further measure the reliability of the received rows of based on the independent decoding result. Then, we take the most reliable received rows to recover like under the erasure channel, leading to an efficient joint decoding scheme. Simulations with low-density parity-check (LDPC) codes [12] show that the joint decoding scheme can reduce the frame error rate (FER) by more than 3 orders of magnitude compared to the independent decoding scheme. Moreover, it demonstrates that the joint decoding scheme and the BFA can outperform each other under different parameter region.
I-C Organization
The remainder of this paper is organized as follows. Section II illustrates the outer channel and the encoding scheme. Section III proves Theorem 1. Section IV develops both the independent and joint decoding schemes. Section V presents the simulation results. Finally, Section VI concludes this paper.
I-D Notations
In this paper, we generally use non-bold lowercase letters for scalars (e.g., ), bold lowercase letters for (row) vectors (e.g., ), bold uppercase letters for matrices (e.g., ), non-bold uppercase letters for random variables and events (e.g., ), and calligraphic letters for sets (e.g., ). For any matrix , we refer to its -th row and -th entry by and , respectively, i.e., , where is the transpose of a vector or matrix. For any two matrices and , denote as the set intersection of their rows (only one copy of the same rows is kept). For any two events and , denote as their union, and denote as the probability that happens. Denote as the binary field and for any positive integer .
II System Model and Encoding Scheme

Recall that we focus on the outer code in Fig. 1. Therefore, motivated by [5], we consider the simplified system model in Fig. 2, where the encoder and decoder are related to the outer code, the inner code is viewed as a part of channel-1, and channel-2 is to randomly shuffle DNA strings with each other. The outer channel considered in this paper is the concatenation of channel-1 and channel-2.
More specifically, first, the data matrix is encoded as , where each row of corresponds to a DNA string in DNA-based data storage systems. Then, the rows of are transmitted over channel-1 and received one-by-one in order. For each , the -th received row indeed corresponds to the inner decoding result of the -th transmitted row . Thus, we regard (instead of each its bit) as a whole to be transmitted over channel-1. Particularly, can be classified into three cases:
-
•
: The inner decoding of succeeds.
-
•
: The inner decoding of fails to give a valid inner codeword such that is regarded as an erasure error. This case can be caused by either that is corrupted by too many errors or that is missing during the synthesizing, storage, or sequencing process.
-
•
: The inner decoding of gives a valid but incorrect inner codeword, i.e., an undetectable error happens.
Accordingly, we model the transition probability of channel-1 by
| (4) |
where . Note that in practice, should be large enough to ensure the success of the outer decoding. Thus, we further require
| (5) |
Next, is transmitted over channel-2 where its rows are shuffled uniformly at random to form . For convenience, we regard both and having rows in which any erased rows are represented by ‘?’. Finally, the decoder gives an estimation of based on .
To protect against the above channel errors, we adopt the encoder illustrated by Fig. 3 to convert the data matrix into the encoded matrix with the following two steps:
-
•
A (binary) ECC of block length- is chosen to encode each column of as a column (codeword) of , so as to tackle the erasure errors and substitution errors from channel-1. Random ECCs will be used for proving the capacity and any excellent linear ECCs (e.g., LDPC codes) can be used in practical scenarios.
-
•
A unique address of bit-width is added to the tail of each row of , leading to , so as to combat the disordering of channel-2. Without loss of generality (WLOG), we set the address of as for any . Note that given , increasing can reduce the probability that an address is changed to a valid address when substitution errors occur. Since for DNA-based data storage, we can simply discard the received rows without valid addresses, increasing is equivalent to reducing and increasing in our system model. Thus, we use the minimum by default, i.e., . By convenience, we refer to the first columns and the last columns of by data and address, respectively.
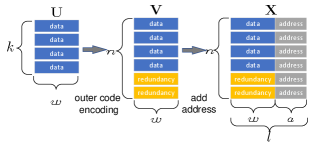
Example 1.
This example shows the encoding process of Fig. 3. Consider the following source data matrix:
| (6) |
We systematically encode each column of by an linear block ECC with a minimum distance of and with the following parity-check matrix:
| (7) |
We then get
| (8) |
where denotes the parity-check part. For each , adding address (of bits) into the -th row of leads to
| (9) |
where denotes the address part.
III Proof of Theorem 1
The code rate of the system in Fig. 2 is
Recall that . According to [7], the outer channel has capacity for . Therefore, to prove Theorem 1, we only need to further show the following two lemmas.
Lemma 1 (achivability).
For and arbitrarily small fixed , the following code rate is achievable:
| (10) |
Lemma 2 (converse).
For and arbitrarily small fixed , as , any achievable code rate satisfies
| (11) |
III-A Proof of Lemma 1
To prove Lemma 1, we only need to show that for and arbitrarily small fixed , there is a code with rate such that the decoding error probability as . WLOG, assume , , and are integers. Let and such that the code rate is . Define for convenience.
Encoding scheme: We choose matrices from uniformly at random to form the codebook of ECC, and adopt the encoding scheme in Fig. 3. More specifically, for any , we first encode the -th data matrix to , and then add address to the -th row of for all to form the encoded matrix .
Decoding scheme: After receiving , if there exists a unique such that , where is the set intersection of ’s rows and ’s rows, then return as the decoding result; otherwise, return to indicate a decoding failure.
Decoding error probability: For any , define as the event of and as the event of . WLOG, assume the source data matrix and the transmitted encoded matrix . Then, the decoding error probability is given by
| (12) |
We first bound . Let denote the number of correctly transmitted rows of . We have . Then,
| (13) |
where the last inequality is based on Hoeffding’s inequality [13].
We now bound for any . Recall that any erased one of rows in is represented by ‘?’. Thus, there are many ways to select rows from to form submatrices which are denoted by . Define as the event of . happens if and only if (iff) for all , ’s -th row has a unique address and equals ’s -th row. Given that has a unique address , equals ’s -th row with probability . Thus, , leading to
| (14) |
III-B Proof of Lemma 2
Note that
| (16) |
where is the mutual information function and is the entropy function. As forms a Markov chain, by the data processing inequality [14]. Meanwhile, according to Fano’s inequality [14], we have , where is the set that takes values from and in this paper. Therefore, (16) becomes
| (17) |
Since we consider as in (III-B), to prove Lemma 2, it suffices to show
| (18) |
To this end, we partition into two submatrices and which consist of the rows in corrupted by uniformly distributed random substitution errors and the remaining rows, respectively. Note that the order of the rows in and does not matter. We have
| (19) |
We first bound in (19). Since only contains correctly received rows and erased rows, can be regarded as the output of the noise-free shuffling-sampling channel [7], where each row of is either sampled once with probability or never sampled with probability . Therefore, using a similar proof as [7, Section III-B] yields
| (20) |
We now bound in (19) based on
| (21) |
Denote as the number of rows in . We have
| (22) |
where follows the fact that is specified by , and holds since given , consists of bits. Moreover, for any , suppose the -th row of came from . Let . We have
| (23) |
where holds because given , for any , the -th row of only relates to , and has equiprobable choices according to (4). By applying (III-B) and (III-B) to (21), we have
| (24) |
IV Decoding Scheme
In this section, we first derive the soft information and hard information of each bit in . This allows us to decode each column of independently, leading to the independent decoding scheme. Next, in view that it requires the successful decoding of all columns to fully recover (as well as and ), we propose an enhanced joint decoding scheme, which measures the reliability of rows of based on the independent decoding result and takes the most reliable rows for a further step of decoding.
Given any and , we begin with the computation of the soft information of . Conventionally, we should define . In fact, is only related to . But the problem is that we do not know corresponds to which row in due to the random permutation of channel-2, making it hard to compute exactly. Note from (4) that, if is erased or corrupted by random substitution errors such that its address is not any more, no (or at most negligible) information about can be inferred from even if we can figure out which row in corresponds to . Therefore, it is reasonable to reduce the computation of from to the rows with address . Accordingly, we define
| (25) |
where denotes the number of rows in with address , among which there are rows with the -th bit being . Based on (25), can be computed by the following proposition.
Proposition 1.
| (26) |
where
| (27) |
and
| (28) |
Proof:
See Appendix A. ∎
Based on Proposition 1, it is natural to define the hard information of by:
| (29) |
The following corollary simplifies (29).
Corollary 1.
| (30) |
Proof.
Eqn. (30) is quite intuitive since it coincides with the majority decoding result. Hence, it somehow verifies the correctness of (1). Given the soft information in (1) or hard information in (30), it is able to perform decoding independently for each column of . However, this decoding scheme can fully recover only if the decoding for each column succeeds. This condition is generally too strong to achieve a desired decoding performance, as illustrated by the following example.
Example 2.
Continued with Example 1. Suppose the in (9) is transmitted over channel-1 and the output is
| (32) |
where the underlined bits are flipped by channel-1. That is, is corrupted by substitution errors and its address changes to ’s address; is also corrupted by substitution errors but its address does not change. Assume for convenience (but the decoder does not know the correspondence between the rows of and ).
We compute the hard information of by (30), leading to
| (33) |
where the bold red bits are different from the corresponding bits of in (8). For examples, since does not have a row with address 1; since has rows with address 2 and their second bits differ from each other, i.e., . It is natural to decode each column of as the nearest codeword (in terms of Hamming distance), leading to
| (34) |
where the second column corresponds to a decoding failure since both and are the nearest codewords of the second column of . Thus, the independent decoding scheme fails to fully recover .
We find that in Example 2, all the known bits in are correct. In a general situation, the known bits in should also be correct with a high probability. We thus assume
| (35) |
Consequently, for a non-erased correct (resp. incorrect) row in with address , it generally has a relatively small (resp. large) distance from . This provides a way to measure the reliability of rows of . We can then perform a further step of decoding over the most reliable rows of like under the erasure channel, as shown by Algorithm 1. In the following, we give more explanations (including Example 3) for Algorithm 1.
-
•
Lines 1 and 2 are to decode as based on the independent decoding scheme.
-
•
Line 3 is to count the number of different positions (Hamming distance) between and , where is the address of . According to (35), larger implies a higher reliability of .
-
•
Lines 4 and 5 are to take the most reliable rows for a further step of decoding, where these rows are viewed as correct and the other rows of are viewed as erasure errors. Thus, the decoding actually works like under the erasure channel, which essentially is to solve linear systems when decoding linear ECCs. As our simulations are based on LDPC codes, the structured gaussian elimination (SGE) [15, 16, 17], also called inactivation decoding, is recommended since it works quite efficiently for solving large sparse linear systems. The SGE leads to if each row in is correct and is sufficiently large to uniquely determine (see Example 3).
-
•
Algorithm 1 definitely has a better chance to successfully recover than the independent decoding scheme, since it succeeds if the independent decoding scheme succeeds and it may still succeed otherwise.
Example 3.
Continued with Example 2. Recall that given by (32) before executing Line 4 of Algorithm 1. As a result, Line 2 of Algorithm 1 obtains in (34). Then, Line 3 gives . Next, Line 4 rearranges the rows of , say , where is the -th row of the in (32).
In Line 5, for a given , consists of the first rows in . Recall that given by (7) is the parity-check matrix. Our task is to find the smallest such that there exists a unique (then is uniquely determined) satisfying and is a part of . Here we say is a part of if for any such that has a valid address , equals the data of .
More specifically, we first try , yielding , where has address 2. Thus, we needs to solve with being known and being unknowns. Since the 1st, 3rd, 4th, 5th, and 6th columns of are linearly dependent, these unknowns cannot be uniquely determined. We need to increase .
We next try , yielding , where has address 4. We needs to solve with being known and being unknowns. Since the 1st, 3rd, 5th, and 6th columns of are linearly independent, these unknowns can be uniquely determined. Moreover, since and are correct, the decoding succeeds, i.e., as well as are fully recovered.
To end this section, we discuss the (computational) complexities of both the independent and joint decoding schemes. For the independent decoding scheme, it decodes each column independently. Thus, its complexity is , where is the number of data columns and denotes the complexity for decoding one column. The value of depends on the underlying ECC as well as the decoding algorithm. The joint decoding scheme needs to further perform Lines 3–5 of Algorithm 1. The complexity of Line 3 and 4 is and , respectively. The complexity of Line 5 also depends on the underlying ECC and decoding algorithm. However, since Line 5 is to correct erasures, its complexity is less than or equal to the complexity of the independent decoding scheme. As a result, the total complexity of the joint decoding scheme is , which generally equals since must hold and is required in practice to have a good code rate. That is, the joint decoding scheme has the same order of complexity as the independent decoding scheme.
For example, suppose the underlying ECC is an LDPC code which has a sparse parity-check matrix of a total number of non-zero entries. Then, the independent decoding scheme has complexity under message-passing algorithms with a max number of iterations. Line 5 generally has complexity [15] such that the complexity of the joint decoding scheme is in practical situations. Our simulations confirm that the joint decoding scheme is only slightly slower than the independent decoding scheme.
V Simulation Results
In this section, we consider using LDPC code as the outer code since it works very well with soft information. We evaluate the FERs of both the independent and joint decoding schemes. A frame error occurs when a test case does not fully recover the data matrix . We collect at least frame errors at each simulated point. The independent decoding scheme first computes the soft information by (1), and then adopts the belief propagation (BP) algorithm [18] with a maximum of iterations to recover each column of . Given the independent decoding result, the joint decoding scheme further executes Lines 3–5 of Algorithm 1 to recover . Since LDPC codes are characterized by their sparse parity-check matrices, the SGE[15, 16, 17] is adopted for the decoding in Line 5, and the decoding process is similar to that in Example 3.


We first consider the LDPC code [19]. For fixed , the simulation results are shown in Fig. 4. We can see that:
-
•
For the same , the joint decoding scheme always achieves lower FER than the independent decoding scheme. The difference can exceed orders of magnitude.
-
•
For the same , a decoding scheme has decreasing FER as increases (or equivalently as decreases). It implies that erasure errors are less harmful than substitution errors for finite . However, it should not be considered as a counter-example to Theorem 1 which indicates that erasure errors are as harmful as uniformly distributed random substitution errors, since Theorem 1 requires . In fact, we later can see from Fig. 5 that, increasing and/or can reduce the FER of the joint decoding scheme.


Next, we fix and vary . In Fig. 5(a), the independent and joint decoding schemes are used for decoding the LDPC code [19]. Meanwhile, in Fig. 5(b), they are used for decoding the LDPC code, which is constructed by enlarging the lifting size of the LDPC code from to . The FER of the BFA [5] for decoding the Luby Transform (LT) codes [11] is presented as a baseline, where the BFA takes the sorted-weight implementation. For a fair comparison, the LT codes have code length and information length in Fig. 5(a) and have in Fig. 5(b), and each LT symbol consists of address (seed) bits and data bits. The robust soliton distribution (RSD) with [5] is chosen to generate LT symbols. From Fig. 5, we can see that:
-
•
For the same , as changes from to , FER of the independent decoding scheme slightly increases since it needs to correctly recover more columns to fully recover ; FER of the joint decoding scheme obviously decreases since the independent decoding result can provide more information to better measure the reliability of rows of ; FER of the BFA significantly decreases except for the error floor region.
-
•
For the same , as changes from to , FERs of both the independent and joint decoding schemes obviously decrease, since longer LDPC codes lead to stronger error-correction capability; FER of the BFA significantly increases except for the error floor region.
In summary, we should always choose the joint decoding scheme compared to the independent decoding scheme. In addition, the joint decoding scheme and the BFA can outperform each other in different parameter regions. Specifically, increasing and/or can obviously reduce the FER of the joint decoding scheme, since larger leads to stronger error-correction capability and larger can get more information from the independent decoding result. However, the BFA is very sensitive to . According to [5] as well as Fig. 5, the BFA requires to have low FER. Therefore, the joint decoding scheme can generally outperform the BFA for relatively large and small , e.g., see Fig. 5.
VI Conclusions
In this paper, we considered the outer channel in Fig. 2 for DNA-based data storage. We first derived the capacity of the outer channel, as stated by Theorem 1. It implies that simple index-based coding scheme is optimal and uniformly distributed random substitution errors are only as harmful as erasure errors (for ). Next, we derived the soft and hard information of data bits given by (1) and (30), respectively. These information was used to decode each column of independently, leading to the independent decoding scheme. Based on the independent decoding result, the reliability of each row of can be measured. Selecting the most reliable rows to recover , similar to the case under the erasure channel, leads to the joint decoding scheme. Simulations showed that the joint decoding scheme can reduce the frame error rate (FER) by more than 3 orders of magnitude compared to the independent decoding scheme, and the joint decoding scheme and basis-finding algorithm (BFA) [5] can outperform each other in different parameter regions.
Appendix A Proof of Proposition 1
Consider the transmission of over channel-1. is the channel output. We define the following five events:
-
•
: is correctly transmitted, i.e., .
-
•
: is erased, i.e., .
-
•
: changes to with a different address.
-
•
: changes to with the same address and the same -th bit.
-
•
: changes to with the same address and a different -th bit.
It is easy to figure out that , where and is given by (28). As a result, we have
| (36) |
To compute each in (A), it needs the probability of that the address of is for a specific (i.e., the address of changes into after transmission over channel-1). According to (4), this probability is given by (27). If we further require the -th bit of being , the probability reduces to . For any , we define the following event:
-
•
: the addresses of exact rows in are , and for exact out of the rows, the -th bit equals to .
According to (4) and (27), we have
| (37) |
| (38) |
| (39) |
References
- [1] Y. Ding, X. He, K. Cai, G. Song, B. Dai, and X. Tang, “An efficient joint decoding scheme for outer codes in DNA-based data storage,” in Proc. IEEE/CIC Int. Conf. Commun. China Workshops, Aug. 2023, pp. 1–6.
- [2] Y. Erlich and D. Zielinski, “DNA fountain enables a robust and efficient storage architecture,” Science, vol. 355, no. 6328, pp. 950–954, Mar. 2017.
- [3] L. Organick, S. D. Ang, Y.-J. Chen, R. Lopez, S. Yekhanin, K. Makarychev, M. Z. Racz, G. Kamath, P. Gopalan, B. Nguyen et al., “Random access in large-scale DNA data storage,” Nature biotechnology, vol. 36, no. 3, p. 242, Mar. 2018.
- [4] R. Heckel, G. Mikutis, and R. N. Grass, “A characterization of the DNA data storage channel,” Scientific Reports, vol. 9, pp. 1–12, 2019.
- [5] X. He and K. Cai, “Basis-finding algorithm for decoding fountain codes for DNA-based data storage,” IEEE Trans. Inf. Theory, vol. 69, no. 6, pp. 3691–3707, Jun. 2023.
- [6] A. Makur, “Coding theorems for noisy permutation channels,” IEEE Trans. Inf. Theory, vol. 66, no. 11, pp. 6725–6748, Nov. 2020.
- [7] I. Shomorony and R. Heckel, “DNA-based storage: Models and fundamental limits,” IEEE Trans. Inf. Theory, vol. 67, no. 6, pp. 3675–3689, Jun. 2021.
- [8] N. Weinberger and N. Merhav, “The DNA storage channel: Capacity and error probability bounds,” IEEE Trans. Inf. Theory, vol. 68, no. 9, pp. 5657–5700, Sep. 2022.
- [9] A. Lenz, P. H. Siegel, A. Wachter-Zeh, and E. Yaakobi, “The noisy drawing channel: Reliable data storage in DNA sequences,” IEEE Trans. Inf. Theory, vol. 69, no. 5, pp. 2757–2778, May 2023.
- [10] J. W. Byers, M. Luby, M. Mitzenmacher, and A. Rege, “A digital fountain approach to reliable distribution of bulk data,” ACM SIGCOMM Computer Communication Review, vol. 28, no. 4, pp. 56–67, 1998.
- [11] M. Luby, “LT codes,” in Proc. IEEE Symposium on Foundations of Computer Science, 2002, pp. 271–280.
- [12] R. G. Gallager, “Low-density parity-check codes,” IRE Trans. Inf. Theory, vol. IT-8, no. 1, pp. 21–28, Jan. 1962.
- [13] W. Hoeffding, “Probability inequalities for sums of bounded random variables,” Journal of the American Statistical Association, vol. 58, no. 301, pp. 13–30, 1963.
- [14] T. M. Cover, Elements of Information Theory. John Wiley & Sons, 1999.
- [15] X. He and K. Cai, “Disjoint-set data structure-aided structured Gaussian elimination for solving sparse linear systems,” IEEE Commun. Lett., vol. 24, no. 11, pp. 2445–2449, Nov. 2020.
- [16] M. A. Shokrollahi, S. Lassen, and R. Karp, “Systems and processes for decoding chain reaction codes through inactivation,” Feb. 2005, US Patent 6,856,263.
- [17] A. M. Odlyzko, “Discrete logarithms in finite fields and their cryptographic significance,” in Workshop on the Theory and Application of Cryptographic Techniques, 1984, pp. 224–314.
- [18] S. Lin and D. J. Costello, Error Control Coding: 2nd Edition. NJ, Englewood Cliffs: Prentice-Hall, 2004.
- [19] IEEE standard for information technology—telecommunications and information exchange between systems—local and metropolitan area networks-specific requirements Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications, IEEE Std. 802.11n, Oct. 2009.