Overlapping and nonoverlapping models
Abstract
Consider a directed network with row communities and column communities. Previous works found that modeling directed networks in which all nodes have overlapping property requires for identifiability. In this paper, we propose an overlapping and nonoverlapping model to study directed networks in which row nodes have overlapping property while column nodes do not. The proposed model is identifiable when . Meanwhile, we provide one identifiable model as extension of ONM to model directed networks with variation in node degree. Two spectral algorithms with theoretical guarantee on consistent estimations are designed to fit the models. A small scale of numerical studies are used to illustrate the algorithms.
Keywords: Community detection, directed networks, spectral clustering, asymptotic analysis, SVD.
1 Introduction
In the study of social networks, various models have been proposed to learn the latent structure of networks. Due to the extremely intensive studies on community detection, we only focus on identifiable models that are closely relevant to our study in this paper. For undirected network, the Stochastic Blockmodel (SBM) (Holland et al., 1983) is a classical and widely used model to generate undirected networks. The degree-corrected stochastic blockmodel (DCSBM) Karrer and Newman (2011) extends SBM by introducing degree heterogeneities. Under SBM and DCSBM, all nodes are pure such that each node only belong to one community. While, in real cases some nodes may belong to multiple communities, and such nodes have overlapping (also known as mixed membership) property. To model undirected networks in which nodes have overlapping property, Airoldi et al. (2008) designs the Mixed Membership Stochastic Blockmodel (MMSB). Jin et al. (2017) introduces the degree-corrected mixed membership model (DCMM) which extends MMSB by considering degree heterogeneities. Zhang et al. (2020) designs the OCCAM model which equals DCMM actually. Spectral methods with consistent estimations under the above models are provided in Rohe et al. (2011); Qin and Rohe (2013); Lei and Rinaldo (2015); Joseph and Yu (2016); Jin (2015); Jin et al. (2017); Mao et al. (2020, 2018). For directed networks in which all nodes have nonoverlapping property, Rohe et al. (2016) proposes a model called Stochastic co-Blockmodel (ScBM) and its extension DCScBM by considering degree heterogeneity, where ScBM (DCScBM) is extension of SBM (DCSBM). ScBM and DCScBM can model nonoverlapping directed networks in which row nodes belong to row communities and column nodes belong to column communities, where can differ from . Zhou and A.Amini (2019); Qing and Wang (2021b) study the consistency of some adjacency-based spectral algorithms under ScBM. Wang et al. (2020) studies the consistency of the spectral method D-SCORE under DCScBM when . Qing and Wang (2021a) designs directed mixed membership stochastic blockmodel (DiMMSB) as an extension of ScBM and MMSB to model directed networks in which all nodes have overlapping property. Meanwhile, DiMMSB can also be seen as an extension of the two-way blockmodels with Bernoulli distribution of Airoldi et al. (2013). All the above models are identifiable under certain conditions. The identifiability of ScBM and DCScBM holds even for the case when . DiMMSB is identifiable only when . Sure, SBM, DCSBM, MMSB, DCMM and OCCAM are identifiable when since they model undirected networks. For all the above models, row nodes and column nodes have symmetric structural information such that they always have nonoverlapping property or overlapping property simultaneously. As shown by the identifiability of DiMMSB, to model a directed network in which all nodes have overlapping property, the identifiability of the model requires . Naturally, there is a bridge model from ScBM to DiMMSB such that the bride model can model a directed network in which row nodes and column nodes have asymmetric structural information such that they have different overlapping property. In this paper, we introduce this model and name it as overlapping and nonoverlapping model.
Our contributions in this paper are as follows. We propose an identifiable model for directed networks, the overlapping and nonoverlapping model (ONM for short). ONM allows that nodes in a directed network can have different overlapping property. Without loss of generality, in a directed network, we let row nodes have overlapping property while column nodes do not. The proposed model is identifiable when . Recall that the identifiability of ScBM modeling nonoverlapping directed networks holds even for the case , and DiMMSB modeling overlapping directed networks is identifiable only when , this is the reason we call ONM modeling directed networks in which row nodes have different overlapping property as column nodes as a bridge model from ScBM to DiMMSB. Similar as DCScBM is an extension of ScBM, we propose an identifiable model overlapping and degree-corrected nonoverlapping model (ODCNM) as extension of ONM by considering degree heterogeneity. We construct two spectral algorithms to fit ONM and ODCNM. We show that our method enjoy consistent estimations under mild conditions by delicate spectral analysis. Especially, our theoretical results under ODCNM match those under ONM when ODCNM degenerates to ONM.
Notations. We take the following general notations in this paper. For any positive integer , let . For a vector and fixed , denotes its -norm. For a matrix , denotes the transpose of the matrix , denotes the spectral norm, denotes the Frobenius norm, and denotes the maximum -norm of all the rows of . Let be the -th largest singular value of matrix , and denote the -th largest eigenvalue of the matrix ordered by the magnitude. and denote the -th row and the -th column of matrix , respectively. and denote the rows and columns in the index sets and of matrix , respectively. For any matrix , we simply use to represent for any . For any matrix , let be the diagonal matrix whose -th diagonal entry is . is a column vector with all entries being ones. is a column vector whose -th entry is 1 while other entries are zero.
2 The overlapping and nonoverlapping model
Consider a directed network , where is the set of row nodes, is the set of column nodes, and is the set of edges from row nodes to column nodes. Note that since row nodes can be different from column nodes, we may have , where denotes the null set. In this paper, we use subscript and to distinguish terms for row nodes and column nodes. Let be the bi-adjacency matrix of directed network such that if there is a directional edge from row node to column node , and otherwise.
We propose a new block model which we call overlapping and nonoverlapping model (ONM for short). ONM can model directed networks whose row nodes belong to overlapping row communities while column nodes belong to nonoverlapping column communities.
For row nodes, let be the membership matrix of row nodes such that
| (1) |
Call row node pure if degenerates (i.e., one entry is 1, all others entries are 0) and mixed otherwise. From such definition, row node has mixed membership and may belong to more than one row communities for .
For column nodes, let be the vector whose -th entry if column node belongs to the -th column community, and takes value from for . Let be the membership matrix of column nodes such that
| (2) |
From such definition, column node belongs to exactly one of the column communities for . Sure, all column nodes are pure nodes.
Let be the probability matrix (also known as connectivity matrix) such that
| (4) |
where controls the network sparsity and is called sparsity parameter in this paper. For convenience, set where for , and for model identifiability. For all pairs of with , our model assumes that are independent Bernoulli random variables satisfying
| (5) |
where , and we call it population adjacency matrix in this paper.
The following conditions are sufficient for the identifiability of ONM:
-
•
(I1) and .
-
•
(I2) There is at least one pure row node for each of the row communities.
Here, means that for all ; means that each column community has at least one column node. For , let . By condition (I2), is non empty for all . For , select one row node from to construct the index set , i.e., is the indices of row nodes corresponding to pure row nodes, one from each community. W.L.O.G., let (Lemma 2.1 Mao et al. (2020) also has similar setting to design their spectral algorithms under MMSB.). is defined similarly for column nodes such that . Next proposition guarantees that once conditions (I1) and (I2) hold, ONM is identifiable.
Proposition 2
If conditions (I1) and (I2) hold, ONM is identifiable: For eligible and , if , then , and .
Compared to some previous models for directed networks, ONM models different directed networks.
-
•
When all row nodes are pure, our ONM reduces to ScBM with row clusters and column clusters Rohe et al. (2016). However, ONM allows row nodes to have overlapping memberships while ScBM does not. Meanwhile, for model identifiability, ScBM does not require while ONM requires, and this can be seen as the cost of ONM when modeling overlapping row nodes.
-
•
Though DiMMSB Qing and Wang (2021a) can model directed networks whose row and column nodes have overlapping memberships, DiMMSB requires for model identifiability. For comparison, our ONM allows at the cost of losing overlapping property of column nodes.
2.1 A spectral algorithm for fitting ONM
The primary goal of the proposed algorithm is to estimate the row membership matrix and column membership matrix from the observed adjacency matrix with given and .
We now discuss our intuition for the design of our algorithm to fit ONM. Under conditions (I1) and (I2), by basic algebra, we have . Let be the compact singular value decomposition of , where , , and is a identity matrix. Let be the size of the -th column community for . Let and . Meanwhile, without causing confusion, let be the -th largest size among all column communities. The following lemma guarantees that enjoys ideal simplex structure and has distinct rows.
Lemma 3
Under , there exist an unique matrix and an unique matrix such that
-
•
where . Meanwhile, when for .
-
•
. Meanwhile, when for , i.e., has distinct rows. Furthermore, when , we have for all .
Lemma 3 says that the rows of form a -simplex in which we call the Ideal Simplex (IS), with the rows of being the vertices. Such IS is also found in Jin et al. (2017); Mao et al. (2020); Qing and Wang (2021a). Meanwhile, Lemma 3 says that has distinct rows, and if two column nodes and are from the same column community, then .
Under ONM, to recover from , since has distinct rows, applying k-means algorithm on all rows of returns true column communities by Lemma 3. Meanwhile, since has distinct rows, we can set to measure the minimum center separation of . By Lemma 3, when under . However, when , it is challenge to obtain a positive lower bound of , see the proof of Lemma 3 for detail.
Under ONM, to recover from , since is full rank, if and are known in advance ideally, we can exactly recover by setting by Lemma 3. Set , since and for , we have
With given , since it enjoys IS structure , as long as we can obtain the row corner matrix (i.e., ), we can recover exactly. As mentioned in Jin et al. (2017); Mao et al. (2020), for such ideal simplex, the successive projection (SP) algorithm Gillis and Vavasis (2015) (for detail of SP, see Algorithm 3) can be applied to with row communities to find .
Based on the above analysis, we are now ready to give the following algorithm which we call Ideal ONA. Input with . Output: and .
-
•
Let be the compact SVD of such that .
-
•
For row nodes,
-
–
Run SP algorithm on all rows of assuming there are row communities to obtain . Set .
-
–
Set . Recover by setting for .
For column nodes,
-
–
Run k-means on assuming there are column communities, i.e., find the solution to the following optimization problem
where denotes the set of matrices with only different rows.
-
–
use to obtain the labels vector of column nodes.
-
–
Follow similar proof of Theorem 1 of Qing and Wang (2021a), Ideal ONA exactly recoveries row nodes memberships and column nodes labels, and this also verifies the identifiability of ONM in turn. For convenience, call the two steps for column nodes as “run k-means on assuming there are column communities to obtain ”.
We now extend the ideal case to the real case. Set be the top--dimensional SVD of such that , and contains the top singular values of . For the real case, we use given in Algorithm 1 to estimate , respectively. Algorithm 1 called overlapping and nonoverlapping algorithm (ONA for short) is a natural extension of the Ideal ONA to the real case. In ONA, we set the negative entries of as 0 by setting for the reason that weights for any row node should be nonnegative while there may exist some negative entries of . Note that, in a directed network, if column nodes have overlapping property while row nodes do not, to do community detection for such directed network, set the transpose of the adjacency matrix as input when applying our algorithm.
-
•
Apply SP algorithm (i.e., Algorithm 3) on the rows of assuming there are row clusters to obtain the near-corners matrix , where is the index set returned by SP algorithm. Set .
-
•
Compute the matrix such that . Set and estimate by .
2.2 Main results for ONA
In this section, we show the consistency of our algorithm for fitting the ONM as the number of row nodes and the number of column nodes increase. Throughout this paper, are two known integers. First, we assume that
Assumption 4
.
Assumption (4) controls the sparsity of directed network considered for theoretical study. By Lemma 4 of Qing and Wang (2021a), we have below lemma.
Lemma 5
(Row-wise singular eigenvector error) Under , when Assumption (4) holds, suppose , with probability at least ,
where is the incoherence parameter defined as .
For convenience, set in this paper. To measure the performance of ONA for row nodes memberships, since row nodes have mixed memberships, naturally, we use the norm difference between and . Since column nodes are all pure nodes, we consider the performance criterion defined in Joseph and Yu (2016) to measure estimation error of ONA on column nodes. We introduce this measurement of estimation error as below.
Let be the true partition of column nodes obtained from such that for . Let be the estimated partition of column nodes obtained from of ONA such that for . The criterion is defined as
where is the set of all permutations of and the superscript denotes complementary set. As mentioned in Joseph and Yu (2016), measures the maximum proportion of column nodes in the symmetric difference of and .
Next theorem gives theoretical bounds on estimations of memberships for both row and column nodes, which is the main theoretical result for ONA.
Theorem 6
Under , suppose conditions in Lemma 5 hold, with probability at least ,
-
•
for row nodes, there exists a permutation matrix such that
-
•
for column nodes,
Especially, when ,
Add conditions similar as Corollary 3.1 in Mao et al. (2020), we have the following corollary.
Corollary 7
Under , suppose conditions in Lemma 5 hold, and further suppose that , with probability at least ,
-
•
for row nodes, when ,
-
•
for column nodes,
When ,
Especially, when and ,
-
•
for row nodes, when ,
-
•
for column nodes,
When ,
When , though it is challenge to obtain the lower bound of , we can roughly set as the lower bound of since when .
When ONM degenerates to SBM by setting and all nodes are pure, applying the separation condition and sharp threshold criterion developed in Qing (2021b) on the upper bounds of error rates in Corollary 7, sure we can obtain the classical separation condition of a balanced network and sharp threshold of the Erdös-Rényi random graph of Erdos and Rényi (2011), and this guarantees the optimality of our theoretical results.
3 The overlapping and degree-corrected nonoverlapping model
Similar as DCSBM Karrer and Newman (2011) is an extension of SBM by introducing node specific parameters to allow for varying degrees, in this section, we propose an extension of ONM by considering degree heterogeneity and build theoretical guarantees for algorithm fitting our model.
Let be an vector whose -th entry is the degree heterogeneity of column node , for . Let be an diagonal matrix whose -th diagonal element is . The extended model for generating is as follows:
| (6) |
Definition 8
Note that, under ODCNM, the maximum element of can be larger than 1 since also can control the sparsity of the directed network . The following proposition guarantees that ODCNM is identifiable in terms of and , and such identifiability is similar as that of DCSBM and DCScBM.
Proposition 9
If conditions (I1) and (I2) hold, ODCNM is identifiable for membership matrices: For eligible and , if , then and .
Remark 10
By setting for , ODCNM reduces to ONM, and this is the reason that ODCNM can be seen as an extension of ONM. Meanwhile, though DCScBM Rohe et al. (2016) can model directed networks with degree heterogeneities for both row and column nodes, DCScBM does not allow the overlapping property for nodes. For comparison, our ODCNM allows row nodes have overlapping property at the cost of losing the degree heterogeneities and requiring for model identifiability. Furthermore, another identifiable model extends ONM by considering degree heterogeneity for row nodes with overlapping property is provided in Appendix D, in which we also explain why we do not extend ONM by considering degree heterogeneities for both row and column nodes.
3.1 A spectral algorithm for fitting ODCNM
We now discuss our intuition for the design of our algorithm to fit ODCNM. Without causing confusion, we also use , and so on under ODCNM. Let be the row-normalized version of such that for . Then clustering the rows of by k-means algorithm can return perfect clustering for column nodes, and this is guaranteed by next lemma.
Lemma 11
Under , there exist an unique matrix and an unique matrix such that
-
•
where . Meanwhile, when for .
-
•
. Meanwhile, when for . Furthermore, when , we have for all .
Recall that we set , by Lemma 11, when under . However, when , it is challenge to obtain a positive lower bound of , see the proof of Lemma 11 for detail.
Under ODCNM, to recover from , since has distinct rows, applying k-means algorithm on all rows of returns true column communities by Lemma 11; to recover from , just follow same idea as that of under ONM.
Based on the above analysis, we are now ready to give the following algorithm which we call Ideal ODCNA. Input with . Output: and .
-
•
Let be the compact SVD of such that . Let be the row-normalization of .
-
•
For row nodes,
-
–
Run SP algorithm on all rows of assuming there are row communities to obtain . Set .
-
–
Set . Recover by setting for .
For column nodes: run k-means on assuming there are column communities to obtain .
-
–
Sure, Ideal ODCNA exactly recoveries row nodes memberships and column nodes labels, and this also supports the identifiability of ODCNM.
We now extend the ideal case to the real case. Let be the row-normalized version of such that for . Algorithm 2 called overlapping and degree-corrected nonoverlapping algorithm (ODCNA for short) is a natural extension of the Ideal ODCNA to the real case.
-
•
Apply SP algorithm (i.e., Algorithm 3) on the rows of assuming there are row clusters to obtain the near-corners matrix , where is the index set returned by SP algorithm. Set .
-
•
Compute the matrix such that . Set and estimate by .
3.2 Main results for ODCNA
Set , and . Assume that
Assumption 12
.
By the proof of Lemma 4.3 of Qing (2021a), we have below lemma.
Lemma 13
(Row-wise singular eigenvector error) Under , when Assumption (12) holds, suppose , with probability at least ,
Next theorem is the main theoretical result for ODCNA, where we also use same measurements as ONA to measure the performances of ODCNA.
Theorem 14
Under , suppose conditions in Lemma 13 hold, with probability at least ,
-
•
for row nodes,
-
•
for column nodes,
where is a parameter defined in the proof of this theorem, and it is when . Especially, when ,
Add some conditions on model parameters, we have the following corollary.
Corollary 15
Under , suppose conditions in Lemma 13 hold, and further suppose that , with probability at least ,
-
•
for row nodes, when ,
-
•
for column nodes,
When ,
Especially, when and ,
-
•
for row nodes, when ,
-
•
for column nodes,
When ,
When , though it is challenge to obtain the lower bounds of and , we can roughly set and as the lower bounds of and , respectively, since and when . Meanwhile, if we further set and , we have below corollary.
Corollary 16
Under , suppose conditions in Lemma 13 hold, and further suppose that and , with probability at least ,
-
•
for row nodes, when ,
-
•
for column nodes,
When ,
Especially, when and ,
-
•
for row nodes, when ,
-
•
for column nodes,
When ,
4 Simulations
In this section,we present some simulations to investigate the performance of the three proposed algorithms. We measure their performances by Mixed-Hamming error rate (MHamm for short) for row nodes and Hamming error rate (Hamm for short) for column nodes defined below
where is defined as if and 0 otherwise for .
For all simulations in this section, the parameters are set as follows. Unless specified, set . For column nodes, generate by setting each column node belonging to one of the column communities with equal probability. Let each row community have pure nodes, and let all the mixed row nodes have memberships . is set independently under ONM and ODCNM. Under ONM, is 0.5 in Experiment 1 and we study the influence of in Experiment 2; Under ODCNM, for , we generate the degree parameters for column nodes as below: let such that for , where denotes the uniform distribution on . We study the influences of and under ODCNM in Experiments 3 and 4, respectively. For all settings, we report the averaged MHamm and the averaged Hamm over 50 repetitions.
Experiment 1: Changing under ONM. Let range in . For this experiment, is set as
Let under for this experiment designed under ONM. The numerical results are shown in panels (a) and (b) of Figure 1. The results show that as increases, ONA and ODCNA perform better. Meanwhile, the total run-time for this experiment is roughly 70 seconds. For row nodes, since both ONA and ODCNA apply SP algorithm on to estimate , the estimated row membership matrices of ONA and ODCNA are same, and hence MHamm for ONA always equal to that of ODCNA.
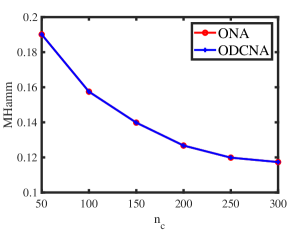
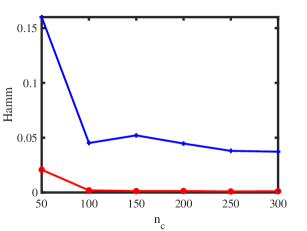
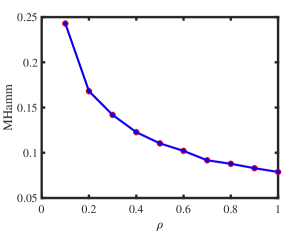
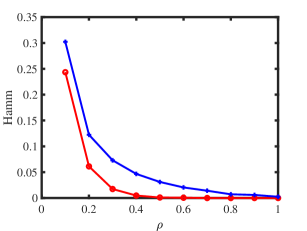
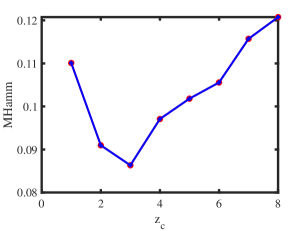
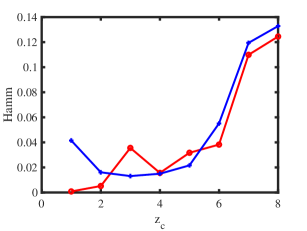
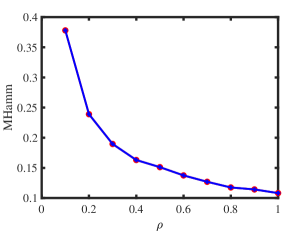
Experiment 2: Changing under ONM. is set same as Experiment 1, and we let range in to study the influence of on performances of ONA and ODCNA under ONM. The results are displayed in panels (c) and (d) of Figure 1. From the results, we see that both methods perform better as increases since a larger gives more edges generated in a directed network. Meanwhile, the total run-time for this experiment is roughly 136 seconds.
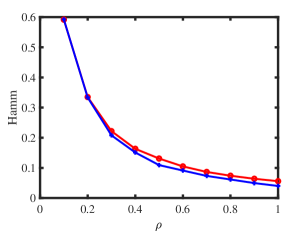
Experiment 3: Change under ODCNM. is set same as Experiment 1. Let range in . Increasing decreases edges generated under ODCNM. Panels (e) and (f) in Figure 1 display simulation results of this experiment. The results show that, generally, increasing the variability of node degrees makes it harder to detect node memberships for both ONA and ODCNA. Though ODCNA is designed under ODCNM, it holds similar performances as ONA for directed networks in which column nodes have various degrees in this experiment, and this is consistent with our theoretical findings in Corollaries 7 and 15. Meanwhile, the total run-time for this experiment is around 131 seconds.
Experiment 4: Change under ODCNM. Set , is set same as Experiment 1, and let range in under ODCNM. Panels (g) and (h) in Figure 1 displays simulation results of this experiment. The performances of the two proposed methods are similar as that of Experiment 2. Meanwhile, the total run-time for this experiment is around 221 seconds.
5 Discussions
In this paper, we introduced overlapping and nonoverlapping models and its extension by considering degree heterogeneity. The models can model directed network with row communities and column communities, in which row node can belong to multiple row communities while column node only belong to one of the column communities. The proposed models are identifiable when and some other popular constraints on the connectivity matrix and membership matrices. For comparison, modeling directed network in which row nodes have overlapping property while column nodes do not with is unidentifiable. Meanwhile, since previous works found that modeling directed networks in which both row and column nodes have overlapping property with is unidentifiable, our identifiable ONM and ODCNM as well as the DCONM in Appendix D supply a gap in modeling overlapping directed networks when . Theses models provide exploratory tools for studying community structure in directed networks with one side is overlapping while another side is nonoverlapping. Two spectral algorithms are designed to fit ONM and ODCNM. We also showed estimation consistency under mild conditions for our methods. Especially, when ODCNM reduces to ONM, our theoretical results under ODCNM are consistent with those under ONM. But perhaps the main limitation of the models is that the and in the directed network are assumed given, and such limitation also holds for the ScBM and DCScBM of Rohe et al. (2016). In most community problems, the number of row community and the number of column community are unknown, therefore a complete calculation and theoretical study require not only the algorithms and their theoretically consistent estimations described in this paper but also a method for estimating and . We leave studies of this problem to our future work.
A Successive Projection algorithm
Algorithm 3 is the Successive Projection algorithm.
B Proofs under ONM
B.1 Proof of Proposition 2
Proof
By Lemma 3, let be the compact SVD of such that , since , we have , which gives . By Lemma 3, since , we have where we have used the fact that the inverse of exists. Since , we have . By Lemma 7 of Qing and Wang (2021a), we have , i.e., where we set . Let be the vector of column nodes labels obtained from . For , from , we have , which means that we must have for all , i.e., and . Note that, for the special case , can be obtained easily: since and is assumed to be full rank, we have . Thus the proposition holds.
B.2 Proof of Lemma 3
Proof For , since and , we have . Recall that , we have , where we set . Since , we have . For , , so sure we have when .
For , follow similar analysis as for , we have , where . Note that . Sure, when for .
Now, we focus on the case when . For this case, since , is full rank when . Since , we have . Since , we have . When , we have for any and . Then ,we have and the lemma follows.
Note that when , since is not full rank now, we can not obtain from . Therefore, when , the equality does not hold for any . And we can only know that has distinct rows when , but have no knowledge about the minimum distance between any two distinct rows of .
B.3 Proof of Theorem 6
Proof For row nodes, when conditions in Lemma 5 hold, by Theorem 2 of Qing and Wang (2021a), with probability at least for any , there exists a permutation matrix such that, for , we have
Next, we focus on column nodes. By the proof of Lemma 2.3 of Qing and Wang (2021b), there exists an orthogonal matrix such that
| (7) |
Under , by Lemma 10 of Qing and Wang (2021a), we have
| (8) |
Since all column nodes are pure, . By Lemma 3 of Qing and Wang (2021a), when Assumption (4) holds, with probability at least , we have
| (9) |
Substitute the two bounds in Eqs (8) and (9) into Eq (7), we have
| (10) |
Let be a small quantity, by Lemma 2 in Joseph and Yu (2016), if
| (11) |
then the clustering error . Recall that we set to measure the minimum center separation of . Setting makes Eq (11) hold for all . Then we have . By Eq (10), we have
Especially, when , under by Lemma 3. When , we have
B.4 Proof of Corollary 7
Proof For row nodes, under conditions of Corollary 7, we have
Under conditions of Corollary 7, and for some by the proof of Corollary 1 Qing and Wang (2021a). Then, by Lemma 5, we have
which gives that
Note that, when , we can not draw a conclusion that . Because, when , the inverse of does not exist since . Therefore, Lemma 8 of Qing and Wang (2021a) does not hold, and we can not obtain the upper bound of , causing the impossibility of obtaining the upper bound of , and this is the reason that we only consider the case when for row nodes here.
For column nodes, under conditions of Corollary 7, we have
For the special case , since when , we have
When and , the corollary follows immediately by basic algebra.
C Proofs under ODCNM
C.1 Proof of Proposition 9
C.2 Proof of Lemma 11
Proof
-
•
For : since and , we have . Recall that under ODCNM, we have , where . Sure, holds when for .
-
•
For : let be a diagonal matrix such that for . Let be an matrix such that for . For such and , we have and , i.e., .
Since and , we have . Since , we have , where we set . Note that since , we have . Now, for , we have
which gives that
Then we have
(12) Sure, we have when for . Let such that for . Eq (12) gives , which guarantees the existence of .
Now we consider the case when . Since and , we have and . Since , we have when . Then we have
(13) Since , we have by Eq (12), and when for , i.e., for .
Note that, when , since and , the inverse of does not exist, which causes that the last equality in Eq (13) does not hold and for all .
C.3 Proof of Theorem 14
Proof For row nodes, when conditions in Lemma 13 hold, by Theorem 2 of Qing and Wang (2021a), we have
Next, we focus on column nodes. By the proof of Lemma 2.3 of Qing and Wang (2021b), there exists an orthogonal matrix such that
| (14) |
Under , by Lemma 4 of Qing (2021a), we have
| (15) |
By Lemma 4.2 of Qing (2021a), when Assumption (12) holds, with probability at least , we have
| (16) |
Substitute the two bounds in Eqs (15) and (16) into Eq (14), we have
| (17) |
For , by basic algebra, we have
Set , we have
Next, we provide lower bounds of . By the proof of Lemma 11, we have
where we set . Note that when , by the proof of Lemma 11, we know that , which gives that for , i.e., when . However, when , it is challenge to obtain a positive lower bound of . Hence, we have . Then, by Eq (17), we have
C.4 Proof of Corollary 15
Proof For row nodes, under conditions of Corollary 15, we have
Under conditions of Corollary 15, and for some by Lemma 2 of Qing (2021a). Then, by Lemma 13, we have
which gives that
The reason that we do not consider the case when for row nodes is similar as that of Corollary 7, and we omit it here.
For column nodes, under conditions of Corollary 15, we have
For the case , we have
When and , the corollary follows immediately by basic algebra.
D The degee-corrected overlapping and nonoverlapping model
Here, we extend ONM by introducing degree heterogeneities for row nodes with overlapping property in the directed network . Let be an vector whose -th entry is the degree heterogeneity of row node , for . Let be an diagonal matrix whose -th diagonal element is . The extended model for generating is as follows:
| (19) |
Definition 17
The following conditions are sufficient for the identifiability of DCONM:
-
•
(II1) , and for .
-
•
(II2) There is at least one pure row node for each of the row communities.
For degree-corrected overlapping models, it is popular to require that has unit-“diagonal” elements for model identifiability, see the model identifiability requirements on the DCMM model of Jin et al. (2017) and the OCCAM model of Zhang et al. (2020). Follow similar proof as that of Lemma 3, we have the following lemma.
Lemma 18
Under , there exist an unique matrix and an unique matrix such that
-
•
where .
-
•
. Meanwhile, when for , i.e., has distinct rows. Furthermore, when , we have for all .
The following proposition guarantees the identifiability of DCONM.
Proposition 19
If conditions (II1) and (II2) hold, DCONM is identifiable: For eligible and , if , then .
Proof By Lemma 18, since , we have . Since , we have by the condition that for . Therefore, we also have , which gives that . Since , we have . By Lemma 18, since and is an nonsingular matrix, we have . Since for , we have and .
Remark 20
(The reason that we do not introduce a model as an extension of ONM by considering degree heterogeneities for both row and column nodes) Suppose we propose an extension model (call it nontrivial-extension-of-ONM, and ne-ONM for short) of ONM such that . For model identifiability, we see that if ne-ONM is identifiable, the following should holds: when , we have and . Now we check the identifiability of ne-ONM. Follow proof of Lemma 19, since , we have . If we assume that for , we have . Similarly, we have , and it is impossible to guarantee the uniqueness of such that unless we further assume that is a fixed matrix. However, when we fix such that ne-ONM is identifiable, ne-ONM is nontrivial due to the fact is fixed. And ne-ONM is trivial only when we set , however, for such ne-ONM when , ne-ONM is DCONM actually. The above analysis proposes the reason that why we do not extend ONM by considering and simultaneously.
Follow similar idea as Qing (2021a), we can design spectral algorithm with consistent estimation to fit DCONM. Compared with ONM and ODCNM, the identifiability requirement of DCONM on is too strict such that DCONM only model directed network generated from with diagonal “unit” elements, and this is the reason we do not provide DCONM in the main text and propose further algorithmic study as well as theoretical study for it. .
References
- Airoldi et al. (2008) Edoardo M. Airoldi, David M. Blei, Stephen E. Fienberg, and Eric P. Xing. Mixed membership stochastic blockmodels. Journal of Machine Learning Research, 9:1981–2014, 2008.
- Airoldi et al. (2013) Edoardo M. Airoldi, Xiaopei Wang, and Xiaodong Lin. Multi-way blockmodels for analyzing coordinated high-dimensional responses. The Annals of Applied Statistics, 7(4):2431–2457, 2013.
- Erdos and Rényi (2011) P. Erdos and A. Rényi. On the evolution of random graphs. pages 38–82, 2011.
- Gillis and Vavasis (2015) Nicolas Gillis and Stephen A. Vavasis. Semidefinite programming based preconditioning for more robust near-separable nonnegative matrix factorization. SIAM Journal on Optimization, 25(1):677–698, 2015.
- Holland et al. (1983) Paul W. Holland, Kathryn Blackmond Laskey, and Samuel Leinhardt. Stochastic blockmodels: First steps. Social Networks, 5(2):109–137, 1983.
- Jin (2015) Jiashun Jin. Fast community detection by SCORE. Annals of Statistics, 43(1):57–89, 2015.
- Jin et al. (2017) Jiashun Jin, Zheng Tracy Ke, and Shengming Luo. Estimating network memberships by simplex vertex hunting. arXiv: Methodology, 2017.
- Joseph and Yu (2016) Antony Joseph and Bin Yu. Impact of regularization on spectral clustering. Annals of Statistics, 44(4):1765–1791, 2016.
- Karrer and Newman (2011) Brian Karrer and M. E. J. Newman. Stochastic blockmodels and community structure in networks. Physical Review E, 83(1):16107, 2011.
- Lei and Rinaldo (2015) Jing Lei and Alessandro Rinaldo. Consistency of spectral clustering in stochastic block models. Annals of Statistics, 43(1):215–237, 2015.
- Mao et al. (2018) Xueyu Mao, Purnamrita Sarkar, and Deepayan Chakrabarti. Overlapping clustering models, and one (class) svm to bind them all. In Advances in Neural Information Processing Systems, volume 31, pages 2126–2136, 2018.
- Mao et al. (2020) Xueyu Mao, Purnamrita Sarkar, and Deepayan Chakrabarti. Estimating mixed memberships with sharp eigenvector deviations. Journal of the American Statistical Association, pages 1–13, 2020.
- Qin and Rohe (2013) Tai Qin and Karl Rohe. Regularized spectral clustering under the degree-corrected stochastic blockmodel. Advances in Neural Information Processing Systems 26, pages 3120–3128, 2013.
- Qing (2021a) Huan Qing. Directed degree corrected mixed membership model and estimating community memberships in directed networks. arXiv preprint arXiv:2109.07826, 2021a.
- Qing (2021b) Huan Qing. A useful criterion on studying consistent estimation in community detection. arXiv preprint arXiv:2109.14950, 2021b.
- Qing and Wang (2021a) Huan Qing and Jingli Wang. Directed mixed membership stochastic blockmodel. arXiv preprint arXiv:2101.02307, 2021a.
- Qing and Wang (2021b) Huan Qing and Jingli Wang. Consistency of spectral clustering for directed network community detection. arXiv preprint arXiv:2109.10319, 2021b.
- Rohe et al. (2011) Karl Rohe, Sourav Chatterjee, and Bin Yu. Spectral clustering and the high-dimensional stochastic blockmodel. Annals of Statistics, 39(4):1878–1915, 2011.
- Rohe et al. (2016) Karl Rohe, Tai Qin, and Bin Yu. Co-clustering directed graphs to discover asymmetries and directional communities. Proceedings of the National Academy of Sciences of the United States of America, 113(45):12679–12684, 2016.
- Wang et al. (2020) Zhe. Wang, Yingbin. Liang, and Pengsheng. Ji. Spectral algorithms for community detection in directed networks. Journal of Machine Learning Research, 21:1–45, 2020.
- Zhang et al. (2020) Yuan Zhang, Elizaveta Levina, and Ji Zhu. Detecting overlapping communities in networks using spectral methods. SIAM Journal on Mathematics of Data Science, 2(2):265–283, 2020.
- Zhou and A.Amini (2019) Zhixin Zhou and Arash A.Amini. Analysis of spectral clustering algorithms for community detection: the general bipartite setting. Journal of Machine Learning Research, 20(47):1–47, 2019.