Pair-Relationship Modeling for Latent Fingerprint Recognition
Abstract
Latent fingerprints are important for identifying criminal suspects. However, recognizing a latent fingerprint in a collection of reference fingerprints remains a challenge. Most, if not all, of existing methods would extract representation features of each fingerprint independently and then compare the similarity of these representation features for recognition in a different process. Without the supervision of similarity for the feature extraction process, the extracted representation features are hard to optimally reflect the similarity of the two compared fingerprints which is the base for matching decision making. In this paper, we propose a new scheme that can model the pair-relationship of two fingerprints directly as the similarity feature for recognition. The pair-relationship is modeled by a hybrid deep network which can handle the difficulties of random sizes and corrupted areas of latent fingerprints. Experimental results on two databases show that the proposed method outperforms the state of the art.
Index Terms:
Latent fingerprint recognition, pair-relationship modeling, hybrid deep learning, convolutional neural network, restricted Boltzmann machine.1 Introduction
Biometric authentication has been used prominently in human verification and identification. Of the many biometrics, fingerprint has proven to be a very reliable index, and has been widely used as evidence by law enforcement and forensic agencies [1]. The three types of fingerprints in law enforcement applications are rolled, plain, and latent. The first two are obtained intentionally by rolling or placing a finger on a piece of paper or scanner platen while the last are lifted from finger impressions unintentionally left by a person at a crime scene. Compared with plain and rolled fingerprints, a latent one is usually smudgy and blurred, showing only a small finger area and usually a large non-linear distortion. As shown in Fig. 1, these fingerprints are of low quality, with unclear ridge structures, complex background noise, and various overlapping patterns. Therefore, the performance of a fingerprint identification system for latent fingerprints is much poorer than that for rolled or plain ones [2, 3].
In the past decades, many efforts have been made towards recognizing latent fingerprints. The developed methods can be basically classified into two categories: 1) traditional methods and 2) learning-based methods. Using more manual features has been widely reported improving recognition accuracy in early traditional methods [4, 5, 6, 7]. However, manually marking features is very time-consuming/labor-intensive and possibly infeasible for low-quality fingerprints. Using a reduced number of manual features but constructing more complex strategies or more efficient algorithms is another choice in traditional methods [8, 9, 10].

However, these techniques face significant challenges because only a small proportion of latent fingerprints are available for their feature extraction. With the great success of machine learning for various recognition tasks, learning-based methods have been proposed for latent fingerprint recognition [11, 12, 13, 14], which aim to extract more robust features to represent fingerprints to improve the recognition accuracy. Generally, these methods still follow the traditional way of extracting representation features for each fingerprint independently and then compare the similarity of these representation features for recognition in a different process. Thus, useful correlations of the two compared fingerprints are lost during the representation feature extraction process. Once they are lost, they cannot be recovered in the recognition process. Also, as the representation feature extraction process and the recognition process are separate and independent, they cannot be jointly optimized. Without the supervision of similarity, the extracted representation features are hard to optimally reflect the similarity of the two compared fingerprints which is the base for matching decision making.
Therefore, in this paper, we propose a new scheme for latent fingerprint recognition. Instead of extracting representation features of each fingerprint independently and then comparing the similarity of these representation features for recognition in a different process, we propose to directly model the pair-relationship111The pair-relationship represents the similarity of two fingerprints (/fingerprint patches). of two fingerprints as the similarity feature for recognition. Hence, correlations of two fingerprints can be exploited for better characterization of the similarity which is the base for matching decision making. Specifically, the pair-relationship is modeled by a hybrid deep network using tensors of two fingerprints which are concatenations of two fingerprint images and concatenations of their orientation fields. The hybrid deep network consists of a set of convolutional neural networks (CNNs) and a restricted Boltzmann machine (RBM). The CNNs are designed to have different sizes and architectures to handle the difficulties of random sizes and corrupted areas of latent fingerprints. The RBM is designed to make a decision based on the complementary outputs of the CNNs. Experimental results on two databases show that the proposed method outperforms the state of the art.
The main contributions of this paper are as follows.
-
1)
A new idea is proposed for latent fingerprint recognition. Unlike the current methods that extract representation features of each fingerprint independently and then compare the similarity of these representation features for the recognition in a different process, we directly model the pair-relationship of the two fingerprints as the similarity feature for the recognition.
-
2)
A hybrid deep network is proposed to model the pair-relationship, which is composed of a set of CNNs and an RBM. The set of CNNs is delicately designed to have different sizes and architectures and thus can model the pair-relationship from multiple information levels and handle the difficulties of random sizes and corrupted areas of latent fingerprints. The matching decision is made by the RBM based on the complementary outputs of these CNNs, which is more effective.
-
3)
Most of the existing learning-based methods extract representation features directly from fingerprint images. The proposed hybrid deep network extracts complementary pair-relationship from fingerprint images and their orientation fields regularized by the FOMFE model [15, 16] which provides a function of denoising and estimating orientation fields for moderately corrupted areas.
-
4)
A new concept of macro-patch is introduced. Together with the innovative latent-rolled fingerprint tensor, the pair-relationship can be effectively encoded in the presence of distortion and corrupted areas in the latent fingerprints.
-
5)
A new M-DLO alignment is proposed based on the DLO alignment [17], which provides more accurate alignment in the challenging latent fingerprint environment.
2 Related Works
Over the last few decades, many methods for dealing with the inherent complexity of latent fingerprints and improving recognition accuracy have been proposed, as surveyed in [18]. Early methods used many manually marked features to improve recognition accuracy. For example, Jain et al. [6] used minutiae, orientations, and quality maps for the recognition. Feng et al. [19] used minutiae, pattern types, orientation fields, reference points, and singular points for the recognition. Jain et al. [4] used seven types of features to improve recognition accuracy. Although these methods achieve good recognition performance, they are laborious and time-consuming due to their manual feature marking. Also, the repeatability of this form of feature markup is low and thus limits the practical application of these methods.
Later, methods of using a reduced number of manual features have been proposed. For example, Yoon et al. [8] proposed a method which requires only manually marked ROI and singular points for the recognition. Paulino et al. [9] proposed a method based on a descriptor-based Hough transform for the recognition, where only minutiae are manually marked. Medina-Perez et al. [10] proposed a method based on clustering, which aims to improve its comparison algorithm while not adding extended features, achieves impressive results in the presence of large non-linear deformations in latent fingerprints. In general, these methods attempt to construct more complex structures of features or seek more efficient comparison strategies for latent fingerprint recognition. Their performance heavily depend on the accuracy of the few features they used, and extracting these features is difficult and even infeasible for many latent fingerprints.
Recently, with the superiority of deep learning for various recognition tasks, learning-based methods have been proposed for latent fingerprint recognition. For example, Cao et al. [12] proposed using CNNs to estimate ridge flows and extract minutiae descriptors, and then extracting minutiae and texture templates to represent fingerprints for the recognition. Cao et al. [13] further improved the template extraction in [12] to better represent fingerprints for the recognition. Cao et al. [14] proposed using autoencoders to enhance a latent fingerprint and extract its minutiae, and then using CNNs to extract minutia descriptor and texture template to represent fingerprints for the recognition. In general, these methods follow the traditional way of extracting representation features for each fingerprint independently and then comparing the similarity of these representation features in a different process. The representation features used to represent the fingerprint are learned without the supervision of similarity. These methods achieve impressive results, yet the performance can be further improved.
Therefore, in this paper, we propose a new scheme that can directly model the pair-relationship of two fingerprints as the similarity feature for recognition. Consequently, correlations of two fingerprints are exploited for better characterization of the similarity which is the base for matching decision making. The similarity feature is learned with the supervision of recognition which improves its robustness. Experimental results on two databases show that the proposed method outperforms the state of the art.
3 Proposed Method
3.1 Overview of Framework
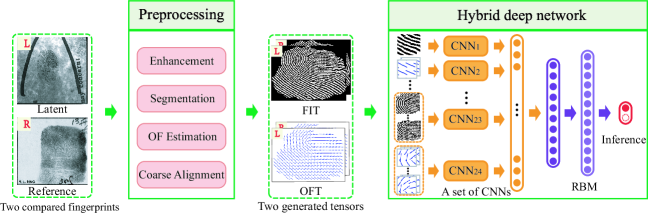
Fig. 2 illustrates the framework of the proposed method which consists of two main steps: 1) preprocessing two compared fingerprints to generate the required tensors and 2) pair-relationship modeling by a hybrid deep network. Specifically, for two compared fingerprints (a latent one and a reference one), their preprocessing includes enhancement, segmentation, orientation field (OF) estimation, and coarse alignment, which follows the usual preprocessing procedures in current common practice. The preprocessing generates two tensors: fingerprint image tensor (FIT) and orientation field tensor (OFT) which are concatenations of two preprocessed fingerprint images and their corresponding orientation fields, respectively (Section 3.2). The hybrid deep network, which is composed of a set of CNNs and an RBM, models the pair-relationship from multi-scale and multi-type patches of the FIT and OFT, and makes a prediction whether the input two fingerprints is a match (Section 3.3). The entire network is jointly trained and optimized (Section 3.4).
3.2 Preprocessing

Fig. 3 illustrates the workflow of the preprocessing. For both a latent and a reference fingerprint, their enhanced fingerprint images and FOMFE-based orientation fields are firstly produced. Then, the M-DLO alignment is performed on the enhanced fingerprint images and the FOMFE-based orientation fields to generate the tensors FIT and OFT. Details are presented as follows.
3.2.1 Enhanced Fingerprint Image and Corresponding Orientation Field Generation
Due to the different qualities of the latent and the reference fingerprints, we use different techniques to generate their enhanced fingerprint images and corresponding orientation fields. For the latent fingerprint, the method in Ref. [20] is used to firstly produce an enhanced fingerprint image, an estimated orientation field, and a quality map. Then, the produced quality map is used to segment the region of interest (ROI) of the produced fingerprint image and orientation field. Finally, the segmented orientation field is further regularized by a fingerprint orientation model FOMFE [15, 16] for denoising and estimating orientations for moderately corrupted areas. For the reference fingerprint, because it is usually of good quality, the STFT method [21] is used to produce its enhanced fingerprint image, estimated orientation field, and ROI segmentation. By the same token, its segmented orientation field is further regularized by the FOMFE model. Therefore, for both the latent and the reference fingerprints, their enhanced fingerprint images and FOMFE-based orientation fields are produced.
3.2.2 FIT and OFT Generation
To generate the tensors FIT and OFT, the two enhanced fingerprint images and the two FOMFE-based orientation fields need to be aligned first. Due to the poor quality of latent fingerprints, we propose to use orientation field for the alignment because it can provide a robust coarse alignment. We have observed that the random hexagon partition in the DLO alignment [17] could generate significant discrepant hexagons over the ROI, leading to poor alignment results. To address this issue, we propose an improved minutia-based DLO alignment named as M-DLO alignment where the hexagons are formed around the most reliable minutia. One or two reliable minutiae will be sufficient to help produce a sound alignment with our proposed M-DLO alignment. Algorithm 1 summarizes the M-DLO alignment.
After aligning the two enhanced fingerprints and the two FOMFE-based orientation fields, they are respectively concatenated to generate the tensors FIT and OFT. There are two ways of the concatenation: 1) the fingerprint image (or orientation field) of the latent fingerprint at front and the one of reference fingerprint at back; and 2) in reverse. We name the tensors generated by these two ways as FIT1 (or OFT1) and FIT2 (or OFT2), respectively.
3.3 Proposed Hybrid Deep Network
In this section, an overview of the hybrid deep network is firstly presented in Section 3.3.1. Then, the details of the set of CNNs are described in Section 3.3.2 and Section 3.3.3, followed by the description of the RBM in Section 3.3.4.
3.3.1 Overview
For convenience, we define the architecture of a network only by the types of its layers and their connections, such that a network refers to an architecture with specific hyper-parameters, and a model refers to a network with specific inputs.
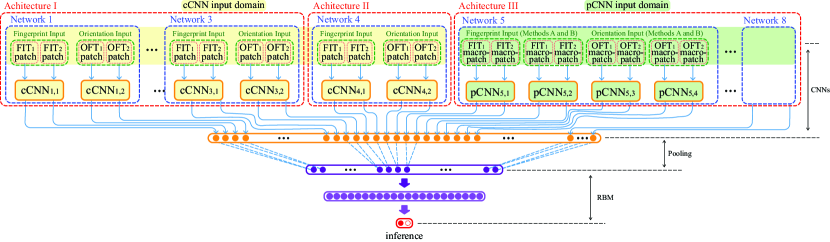
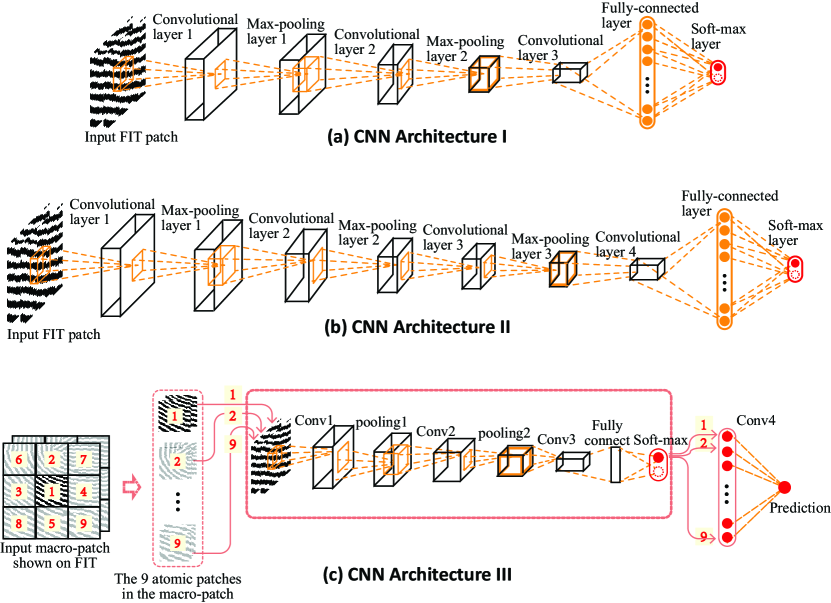
Fig. 4 illustrates the proposed hybrid deep network. Its inputs are patches (or macro-patches as detailed in Section 3.3.3) taken from the FIT and OFT tensors, thus they are also tensors. In the remaining paper, we refer these patch-level tensors as patches (or macro-patches) unless stated otherwise. It have eight different CNN networks, which are constructed from three architectures I, II, and III, as illustrated in Fig. 5. Architectures I and II are designed to extract features from multi-scale patches and architecture III is designed to learn the neighborhood relationship of a set of atomic patches in a macro-patch. They provide complementary information. Compared to architecture I, architecture II has one more convolution layer and one more pooling layer due to its larger input size. Compared with architectures I and II, architecture III has an additional convolution layer after the softmax for combining the softmax outputs of multiple input atomic patches. We name the CNN networks based on the architectures I and II as cCNNs, and the CNN networks based on the architecture III as pCNNs.
cCNNs: There are four cCNN networks corresponding to four input sizes 6464, 8080, 9696, and 192192 (detailed in Appendix A). Under each network, two models are trained to extract complementary information from two types of inputs: FIT type input and OFT type input. Hence, there are a total of eight cCNN models. Each model will generate two outputs corresponding to two sets of input patches cropped from FIT1 and FIT2 (or OFT1 and OFT2), respectively999The input patches to the cCNN models are obtained using a sliding window and thus there are many cropped patches corresponding to a cCNN model. They are all input to the corresponding cCNN model and their outputs are averaged for one output. Thus, for each model, there are two outputs corresponding to two sets of input patches cropped from FIT1 and FIT2 (or OFT1 and OFT2). . Therefore, there are 16 outputs from cCNNs.
pCNNs: There are also four pCNN networks corresponding to four input sizes 3232, 4848, 6464, and 9696 (detailed in Appendix B). However, four models are trained under each network to extract complementary information from four types of inputs: FIT type input and OFT type input each generated through two methods and (detailed in Section 3.3.3). Hence, there are a total of 16 pCNN models. Similar to cCNNs’ output generation, there are 32 outputs from pCNNs.
A total of 48 outputs are generated by these 24 CNN models, and they pass through a pooling layer which can reduce the prediction variance by averaging the two outputs of each CNN model. Finally, the RBM makes a decision based on the outputs of this pooling layer.
Motivation: Latent fingerprints have major challenges of distorted/corrupted areas and small ROIs. Our hybrid deep network is delicately designed to handle these challenges through the utilization of noise resistant orientation field, multi-scale patches, and neighborhood relationship of macro-patches. The patch partition can help generate some quality inputs to the network and reduce the impact of poor-quality parts due to the distorted/corrupted areas. As the average fingerprint ridge frequency (distance between ridges) is about eight pixels for images with 500dpi resolution [23], the smallest atomic patch is set as 3232. This would make sure the atomic patch contains at least three ridges/valleys. A smaller size patch will likely contain one or two ridges/valleys, which is less reliable or discriminative. By the same token, the stride of different patch sizes is set to be 16 pixels, which can normally add two new ridges/valleys incrementally. Also, we have surveyed the sizes of the ROI area of all latent fingerprints in SD27 database which is a practical database provided by the FBI and found that the smallest ROI area is larger than the size of 3232 which fits well with the smallest atomic patch size we set. Accordingly, we have the patch size list 3232, 4848, 6464, 8080, 9696, , 192192. The largest patch size is set to be 192192 because 95% of the latent fingerprints have a ROI area larger than the size of 192192. A size larger than 192192 would increase the number of latent fingerprints whose ROI sizes are smaller than 192192, resulting patches with many void areas. The setting of the numbers and sizes of cCNNs and pCNNs in our deep network can systematically cover almost all the sizes in the above patch list.
3.3.2 Details of the cCNNs
The cCNNs are designed to model the pair-relationship from patches. They have different input sizes and thus can encode multi-level local relationships into the pair-relationship. To enhance the network’s discriminative power and reduce the number of parameters, we set the kernel size to be 33 for all convolution layers except the last one. The kernel size of the last convolution layer is adaptively decided to ensure that the final output is always of size 11. Therefore, the cCNN network corresponding to the input size of 192192 uses architecture II instead of architecture I (Details of the parameters of the four cCNN networks can be found in Appendix A). A cCNN network takes its corresponding sized patch as input and outputs a two-way softmax which represents the probability distribution over two classes. For all convolution layers except the last one, ReLU active function is adopted. Also, the dropout is employed as a regularizer on the fully-connected layer to prevent over-fitting.
Training Input Generation: The input patches are cropped from the FIT and OFT tensors using a sliding window. In addition, the entire FIT and OFT tensors are resized to 192192 for use as patches, which ensures that the entire overlap of the two fingerprints is considered. To exclude unreliable patches from these patches, a quality evaluation needs to be conducted. As the FOMFE-based orientation is comparatively reliable, the quality evaluation is not conducted on the patches cropped from the OFT tensor. This also enables the OFT patches to provide complementary information and guidance in the case of missing quality FIT patches. The quality evaluation on the FIT patches is conducted as follows. Firstly, good-quality masks are respectively obtained for the latent and rolled fingerprints in the FIT. Then, only the patch with more than 75% of its area being the overlap of two good-quality masks is treated as quality patch and kept. The good-quality mask for the latent fingerprint in the FIT is its quality map generated in Section 3.2.1. The good-quality mask for the reference fingerprint in the FIT is generated as follows. Firstly, its quality map is obtained by evaluating its orientation coherence [1] which is formulated as:
| (1) |
with
| (2) |
where represents a 1717 window center. The local gradient is calculated as in a 33 window with being its center. is a 1717 window centered at the pixel . Then, the good-quality mask is generated by applying a threshold 0.9 on .
3.3.3 Details of the pCNNs
The pCNNs are designed to model the pair-relationship from macro-patches which can be generated by two methods and , and formulated as:
| (3) |
where and are macro-patches generated by the methods and , respectively. is one of the nine atomic patches, represents the atomic patch size, and is the center coordinate of . and are the Euclidean distances along the and directions. This way, the macro-patch pair-relationship can be modeled by summarizing its nine atomic patches’ pair-relationships through convolution. Such summarization can increase the robustness of the pair-relationship modeling against the unreliable pair-relationship occurred at some atomic patches.
All four pCNN networks use the same architecture III, which consists of a sub-architecture (marked by the pink dotted rectangle in the middle) identical to the architecture I and a following convolutional layer used to summarize the softmax outputs of nine input atomic patches, as shown in Fig. 5(c). Detailed parameters of these four pCNN networks can be found in Appendix B. The inputs of the pCNNs are nine atomic patches in a macro-patch and the output is a prediction representing the pair-relationship of the macro-patch area. Hence, a pCNN can capture the neighborhood relationship of the central atomic patch and provide complementary information to the cCNNs.
Training Input Generation: The input macro-patches are cropped from the FIT and OFT tensors using a sliding window. Similar to the cCNN training input generation, the quality evaluation is also conducted only on the macro-patches cropped from the FIT to exclude unreliable ones. Also, the same good-quality masks used in the cCNN training input generation are used here. A FIT macro-patch will be kept if it has more than four atomic patches where each one has more than 75% of its area inside the overlap of the two good-quality masks.
3.3.4 RBM
RBM is a generative stochastic artificial neural network which learns a probability distribution over its set of inputs. It has been successfully applied to a classification task by Hinton et al. [24], where the joint distribution of an input and output is modeled using a hidden layer of binary stochastic units . This is achieved by firstly defining an energy function as:
| (4) |
where W and U are weight matrices. r, s, and t represent the bias weights (offsets) for input x, hidden units h and the representation , respectively. is the ‘one out of ’ representation of . Then, the probabilities of the values of and x can be assigned as [24]:
| (5) | ||||
where .
The RBM is adopted in the proposed hybrid deep network to combine the outputs of the set of CNNs and make a decision on whether an input fingerprint pair is a genuine pair or not. Since it is conducted in a supervised learning setting and only needs to obtain a good prediction of the target according to the given input, discriminative training is adopted to minimize the objective function formulated as:
| (6) |
where represents the training set, and is the RBM loss function.
3.4 Joint Optimization
The hybrid deep network is jointly optimized as follows. Firstly, the set of CNNs are trained separately using the binary cross entropy loss, where the binary classes are the binary fingerprint verification targets. The loss is minimized by stochastic gradient descent, where the gradient is calculated by back-propagation. Then, the RBM is trained by fixing the CNNs and its loss is also optimized by stochastic gradient descent as the CNNs. Its gradient can be computed explicitly due to the closed form expression of the likelihood, where are parameters to be learned. Finally, the entire network is tuned by the back-propagating errors from the RBM layer to all the CNNs’ layers with the gradient of the loss with regard to , which is calculated by:
| (7) |
where and are the weight value and prediction of the -th CNN, respectively. is calculated by the closed form expression of Eq. (5) and can be calculated using the back-propagation algorithm in the CNNs.
4 Experimental Results and Evaluation
In this section, experiment settings are firstly detailed in Section 4.1. Then, the performance evaluation and comparison are presented in Section 4.2, followed by the analysis and robustness validation of the proposed method in Section 4.3.
4.1 Experiment Settings
4.1.1 Training Database
A challenging problem of applying deep learning to latent fingerprint application is the training database preparation. As the current public databases are either short of the correspondence between latent fingerprints and their true mates or lack of quantity, they are more suitable to be used as the evaluation databases to evaluate the performance of the proposed method. Therefore, for training the hybrid deep network, we propose to generate the training database using the NIST SD14 database [25] as follows.
The NIST SD14 database consists of 54,000 rolled fingerprints, and thus we synthesize 54,000 corresponding latent fingerprints for them. To generate latent fingerprints that better mimic real cases, we propose to add complex and realistic noise to the rolled fingerprints to synthesize their latent ones. This also enables the proposed deep network to learn more effective pair-relationship modeling from tough latent fingerprint situations.
To this end, firstly, a realistic noise image database is created, which consists of noise images with diverse types of noises. Those noise images are cropped from natural images and resized to the same size as the rolled fingerprint images in NIST SD14 database. Then, given a rolled fingerprint , a plastic distortion [26] is added by
| (8) |
where is a point in and is its distorted point. is the skin plasticity coefficient. is the torsion and traction amount computed on the basis of a rotation angle and a displacement vector , which is given by
| (9) |
| (10) |
where is the center of rotation. is the gradual transition defined as:
| (11) |
Function returns a measure proportional to the distance between the point and the border of an ellipse centered at with semi-axes and , and is formulated as:
| (12) |
| (13) |
These plastic distortion parameters , , , , and are set in the ranges of , , , , and , respectively, where is half the width of the image. Fig. 6 illustrates samples of multiple generated distortions and their related distorted fingerprints for one rolled fingerprint.

Finally, a synthesized latent fingerprint is generated by integrating the distorted fingerprint and a noise image randomly picked up from the created noise image database, with the intensity degree of the noise image ranging from to . Fig. 7 shows some examples of the synthesized latent fingerprints. Overall, the training database consists of the rolled fingerprints in the NIST SD14 database and their generated corresponding latent fingerprints.
4.1.2 Training Settings
In the NIST SD14 database, the two fingerprint impressions of each finger are stored with labels ‘f’ and ‘s’. A positive pair of fingerprints is formed by the latent fingerprint derived from ‘f’ and the rolled fingerprint ‘s’, or the latent fingerprint derived from ‘s’ and the rolled fingerprint ‘f’. Thus, there is a total of 54,000 positive pairs of fingerprints for the training. The negative pairs of fingerprints are formed by randomly selecting a non-mated rolled fingerprint for each of the synthesized latent ones, and thus the total number of the negative pairs is also 54,000. We randomly choose 80% of these pairs of fingerprints to train the set of CNNs and use the remaining 20% pairs to train the RBM and tune the entire network.
4.1.3 Evaluation Databases
Latent fingerprint databases: In line with current methods, the latent fingerprint databases NIST SD27 [27] and IIIT-Delhi MOLF [28] are used to evaluate the proposed method.
Reference fingerprint databases: In the literature, many methods use different reference databases. For a comprehensive evaluation, four reference databases are used in this paper and summarized as follows.
Reference database DB-A: It consists of the rolled fingerprints provided in NIST SD27 database.
Reference database DB-B: It consists of the rolled fingerprints provided in NIST SD27 database and the 2,000 fingerprints in NIST SD04 database.
Reference database DB-C: It consists of the rolled fingerprints provided in NIST SD27 database and the 27,000 fingerprints in NIST SD14 database.
Reference database DB-L: In general, the larger the reference database, the closer it will be to the realistic application of latent fingerprint recognition. The latest methods [12] [14] use a large-scale reference database consisting of 100,000 fingerprints. However, it is not publicly available. Therefore, the large-scale reference database DB-L is created using public rolled fingerprint databases: NIST SD04 [29], NIST SD14 [25], FVC2002 DB1A-DB4A [30], FVC2004 DB1A-DB4A [31], FVC2006 DB1A and DB3A [32], Sokoto [33], the database in [34], the database in [35], and the database in [36], and the associated full fingerprints in databases: NIST SD27 [27], IIIT-Delhi MOLF [28], and IIIT-D Latent [37], which has a total of 97,998 fingerprints. All the fingerprint images are resized to 500ppi for the recognition. Note that the NIST SD14 database has been only used for synthesizing latent training data and has not been used in any way for the recognition task, and thus it can be used here to enlarge the reference database.
4.1.4 Evaluation Settings
For the evaluation, all patches and macro-patches cropped from the FIT and OFT are correspondingly input to the trained hybrid deep network. The quality evaluation used in the training input generation is not used here. For the case of the size of the FIT and OFT being smaller than the size of the required patch (or macro-patch), the required patch (or macro-patch) is generated by filling the remaining area with . The performance of the latest method [14] reported in the following is obtained by running its public code.
4.2 Performance Evaluation and Comparison
4.2.1 Evaluation on NIST SD27 Database
The NIST SD27 database is provided by the NIST in collaboration with the FBI. It consists of 258 crime-scene latent fingerprints, which are classified based on three different image qualities, namely ‘good’, ‘bad’, and ‘ugly’, with numbers of images 88, 85, and 85, respectively. The resolutions of these fingerprint images are 500ppi. Many methods [4, 6, 7, 8, 9, 10, 12, 13, 14] have been evaluated on this database but their reference databases vary. We evaluated the proposed method (using DLO and M-DLO alignments respectively) over the four reference databases (DB-A, DB-B, DB-C, DB-L). Table I compares the rank-1 accuracies of the proposed method, the recent method [10] which uses manually marked minutiae, and the latest method [14]. It has been reported that using manually marked minutiae could improve the accuracy performance by up to 38% [38]. This is not surprising because it gets the benefit of the assistance from latent fingerprint experts. Compared with these results achieved using manually marked minutiae, our results without using any manual inputs are competitive, with two results being very close and one result being better. Also, our results evaluated using four reference databases are all superior to those of the latest method [14].
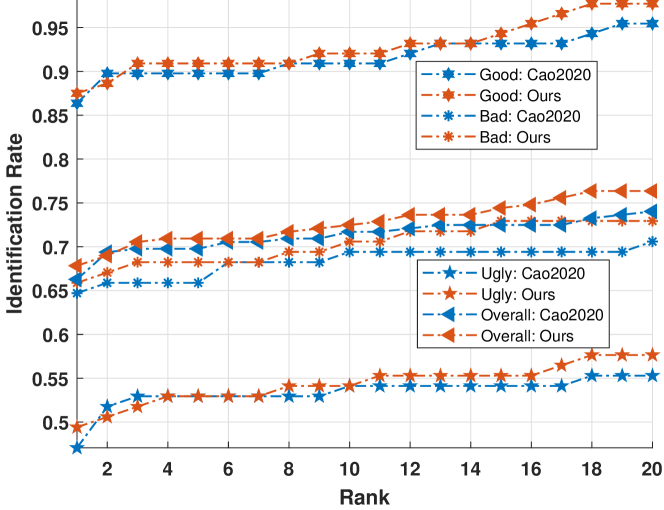
Fig. 8 compares the CMC curves of the proposed method and the latest method [14] (labeled as Cao2020 in the figure) evaluated using the reference database DB-L with respect to both the overall and the three quality types of latent fingerprints in the NIST SD27 database. As can be seen, the performance of all algorithms for good latent fingerprints are significantly better than those for bad and ugly latent fingerprints. This is expected because the quality of fingerprints has an important impact on the recognition performance. The low-quality latent fingerprints usually mean seriously corrupted ridges and small regions of fingers, which increase the difficulty of recognition. The proposed method achieves better results than the latest method on all these three quality types of fingerprints.
4.2.2 Evaluation on IIIT-Delhi MOLF Database
The IIIT-Delhi MOLF database is publicly provided by [28]. It contains 4,400 latent fingerprints sampled from 10 fingers of 100 individuals. The associated reference fingerprints are captured using three different sensors and partitioned into three sub-databases labeled as ‘L’, ‘S’, and ‘C’, respectively. The resolution of these fingerprint images is 500ppi. These latent fingerprints are very challenging for recognition due to their bad quality, as shown in Fig. 9. The latent fingerprint recognition experiments are conducted according to the testing protocol established in Experiment III in [28]. The recognition performance reported in [28] is used as a baseline.

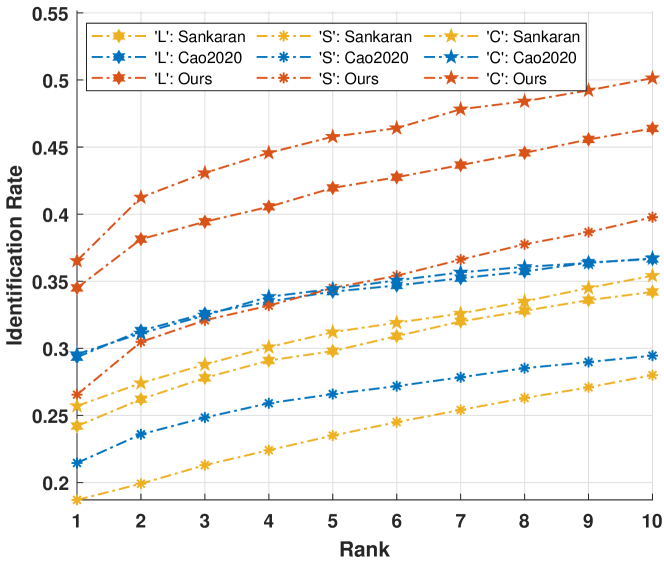
Fig. 10 compares the CMC curves of the proposed method, the latest method [14] (labeled as Cao2020 in the figure), and the baseline with respect to the three reference sub-databases. As can be seen, the proposed method achieves much better rank-1 accuracy and a continuously rising identification rate with the increase of for all three reference sub-databases. This is attributed to: 1) the proposed pair-relationship modeling is robust for recognition because it does not rely on extracting reliable representation features from a latent fingerprint image; and 2) the preprocessing provides relatively reliable OFT as a supplement to FIT for the pair-relationship modeling.
4.3 Ablation Experiments and Discussions
4.3.1 Architecture Variants Analysis
To analyze the soundness of the proposed hybrid deep network, latent fingerprint recognition experiments using different architecture variants are conducted as follows.
Experiment I: half of the proposed 24 CNNs are used for the latent fingerprint recognition. This is achieved by removing a total of CNNs: the cCNN1 (including cCNN1,1 and cCNN1,2 ), cCNN3 (as cCNN1), pCNN5 (including pCNN5,1, pCNN5,2, pCNN5,3 and pCNN5,4), and pCNN7 (as pCNN5), and using the remaining 12 CNNs to form a new architecture which is named as M-Half.
Experiment II: only cCNN-typed CNNs are used for the latent fingerprint recognition. Specifically, cCNN1 (including cCNN1,1 and cCNN1,2), cCNN2 (as cCNN1), cCNN3 (as cCNN1), and cCNN4 (as cCNN1) are used to form a new architecture named as M-C.
Experiment III: only CNNs taking FIT patches or marco-patches as input are used for the latent fingerprint recognition. Specifically, cCNN1,1, cCNN2,1, cCNN3,1, cCNN4,1, pCNN5,1, pCNN5,2, pCNN6,1, pCNN6,2, pCNN7,1, pCNN7,2, pCNN8,1, and pCNN8,2 are used to form a new architecture named as M-F.
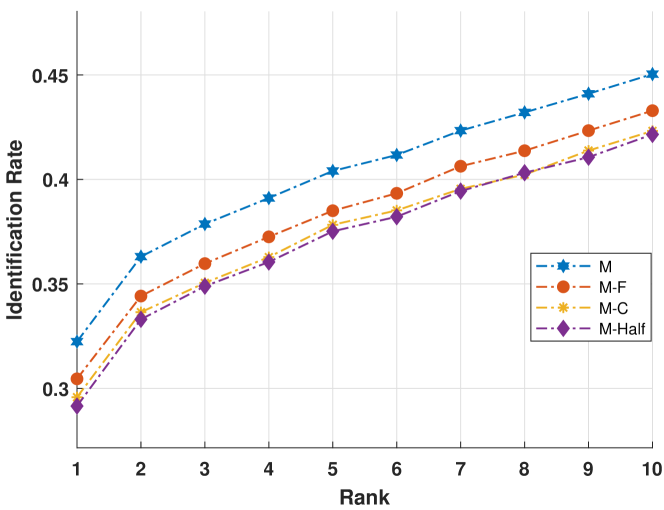
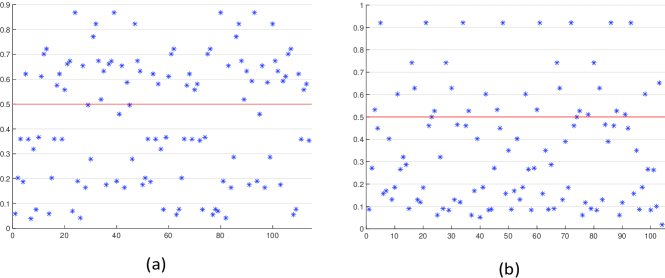
These experiments are conducted using the experiment settings described in Section 4.1.2 and 4.1.4. The performance of these three models is evaluated using IIIT-Delhi MOLF database with testing protocol described in Section 4.2.2. Fig. 11 compares the CMC curves of these three models (M-Half, M-C, M-F) and the proposed full model (with CNNs and named as M). As can be seen, the performance of these three models is worse than that of the proposed full model. Specifically, first, the results of M-Half and M-C support our claim that different sizes and types of CNNs can model multi-level pair-relationship and provide complementary information to contribute to the final decision. This can be further explained by observing the outputs of the CNNs, which are removed in forming the models M-half, M-C, and M-F, in the model M. Fig. 12 shows the outputs (before average, see Footnote 9) of one of these CNNs (cCNN1,1) for a true pair of fingerprints (a latent fingerprint and its true match) and a false pair of fingerprints. As can be seen, nearly half of the outputs (49%) of the true pair are greater than 0.5, and most outputs (72%) of false pair are less than 0.5. This proves the contribution of cCNN1,1 (removed and not included in M-Half) to the final decision and explains why the result of M-half is worse than that of M. Second, the result of M-F demonstrates the necessity and effectiveness of incorporating the orientation field for the pair-relationship modeling.
4.3.2 Analysis of Alignment Accuracy and Its Impacts on Recognition Performance
Alignment Accuracy Analysis: Two experiments IV and V are conducted to evaluate the alignment accuracy in terms of two metrics.
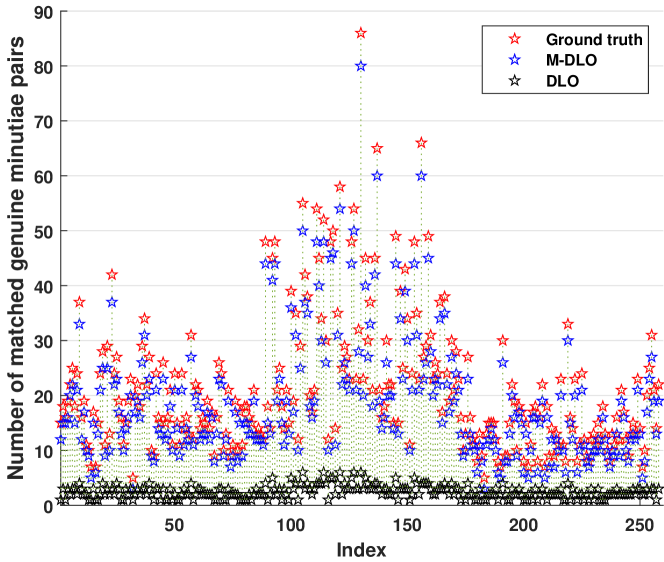
Experiment IV: The number of matched genuine minutia pairs after the proposed M-DLO alignment is compared with that of the DLO alignment and the manually marked minutiae. Fig.13 shows the statistical results on the NIST SD27 database. As can be seen, the M-DLO alignment is significantly better than the DLO alignment with larger numbers of matched genuine minutia pairs and comparable with the ground-truth alignment with similar numbers of matched genuine minutia pairs. The MSE values 480.7519 and 7.3178 obtained by the D-LO and M-DLO alignments mean that the average numbers of unmatched genuine minutia pairs are 18.72 and 2.47, respectively.
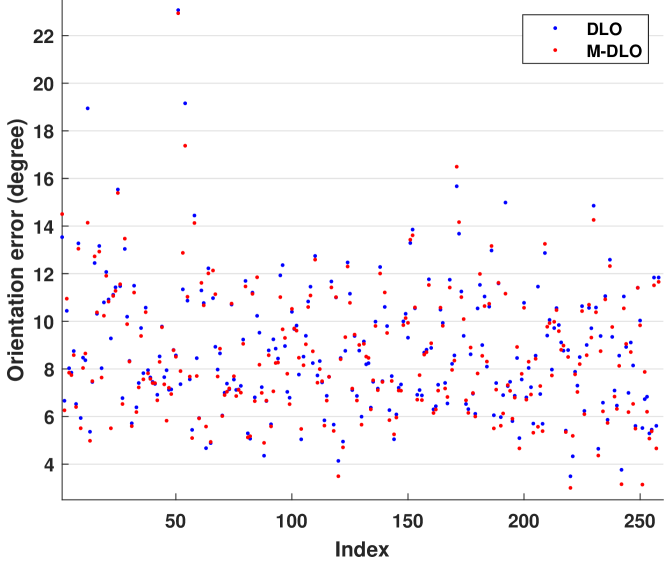
Experiment V: The orientation errors produced by the DLO and the proposed M-DLO alignments are compared. The orientation error measures the difference between two aligned orientation fields of the latent and its corresponding rolled fingerprints and is calculated using the Eq. (3) in method [17]. Fig. 14 shows the statistical results on the NIST SD27 database. As can be seen, the M-DLO alignment achieves a moderately smaller alignment error than the DLO alignment. The MSE values 84.38 and 80.99 mean that the average differences between two aligned orientations by the DLO and M-DLO alignments are 8.78 and 8.59, respectively.
Alignment Impacts on Recognition Performance: Based on the experiments IV and V, we can conclude that: 1) the M-DLO alignment is more accurate than the DLO alignment. This alignment improvement also leads to the corresponding recognition performance improvement (see Table I). 2) The hexagon partition of the DLO algorithm is constructed around a random point which could produce inconsistent hexagon partitions. Our proposed M-DLO constructs the hexagon partitions based on the most reliable minutia, which leads to better consistent partitions evidenced by more matched genuine minutia pairs. 3) A larger number of unmatched pairs of minutiae will generally lead to a poor recognition performance in many minutia-based algorithms. However, our recognition network depends on the orientation field instead of direct minutia features. Both DLO and M-DLO alignments are orientation-based coarse alignments, but they also provide the advantage of noise resistance due to their averaging characteristics. Also, both the DLO and M-DLO alignments select the alignment point based on the minimum average orientation difference cost among all candidate points. Therefore, the minimum alignment error, in terms of orientation difference cost, is guaranteed even though there exists a certain number of unmatched minutiae. Therefore, our proposed recognition network is less sensitive to the number of matched genuine minutia pairs. This is evidenced by the graceful performance degradation (see Table I) even though there exists a significant variation of the number of matched genuine minutia pairs.
4.3.3 Preprocessing Impacts on Recognition Performance
Two ablation experiments VI and VII that using the same preprocessing module but different recognition methods are conducted to evaluate the preprocessing impact on the recognition performance. Results are summarized in Table II, and shown in Fig. 16.
|
|
|
|||||||
| Experiment VI |
|
Ours |
|
||||||
|
Cao’s [14] |
|
|||||||
| Experiment VII | Ours | Ours |
|
||||||
|
|||||||||
|
|||||||||
| Ours | Yager’s [17] |
|
|||||||
|
|||||||||
|
|||||||||
-
The experiment VI is conducted on the NIST SD27 database. The experiment VII is conducted on the IIIT-Delhi MOLF database. The labels ‘L’, ‘S’, and ‘C’ represent the three sub-datasets in the IIIT-Delhi MOLF database.
Experiment VI: The same preprocessing module (Cao’s [14]) with different recognition methods (Cao’s and ours) are respectively used for the latent fingerprint recognition on the NIST SD27 database against the reference database DB-L.
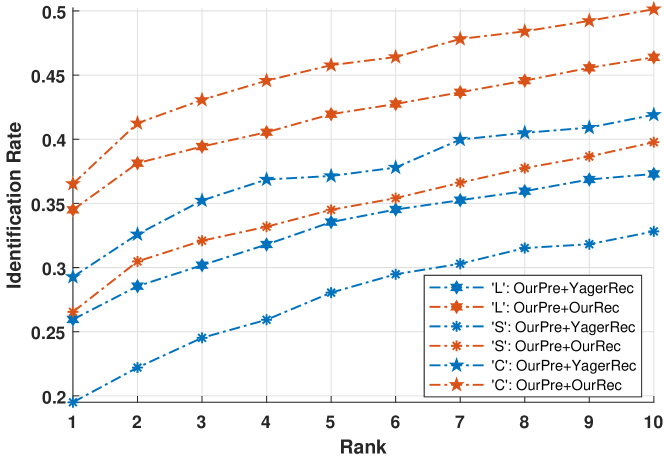
Experiment VII: The same preprocessing module (ours) with different recognition methods (Yager’s [17] and ours) are respectively used for the latent fingerprint recognition on the IIIT-Delhi MOLF database with respect to the three reference sub-databases ‘L’, ‘S’, and ‘C’.
In experiment VI, Cao’s preprocessing module plus M-DLO alignment and Cao’s preprocessing module are regarded as the same preprocessing module because: 1) Cao’s system is independent of alignment. Hence, it implies that its system performance is independent of alignment, i.e., Cao’s preprocessing module plus M-DLO is virtually the same as using Cao’s preprocessing module in Cao’s framework. 2) It is impossible to directly connect Cao’s preprocessing module to our recognition network if alignment is not added because our recognition network requires inputs of tensors of latent-rolled fingerprints where a coarse registration is required. Therefore, the best we can do is to use Cao’s preprocessing module plus the alignment component. Also, the enhanced fingerprint image generated by Cao’s preprocessing method is a gray image, and we translate it into the binary image by a threshold . The generated orientation field is also regularized by the FOMFE model for the alignment.
Table II summarizes the results of these two ablation experiments. As can be seen, in the case of using Cao’s preprocessing method with different recognition methods, our proposed recognition method has enhanced the rank-1 accuracy by 2.94%. In the case of using ours preprocessing method with different recognition methods, our recognition method has enhanced the rank-1 accuracy by 41.32%, 40.64%, and 40.86% over sub-databases ‘L’, ‘S’, and ‘C’, respectively. These experimental results strongly support the capability of our recognition network.
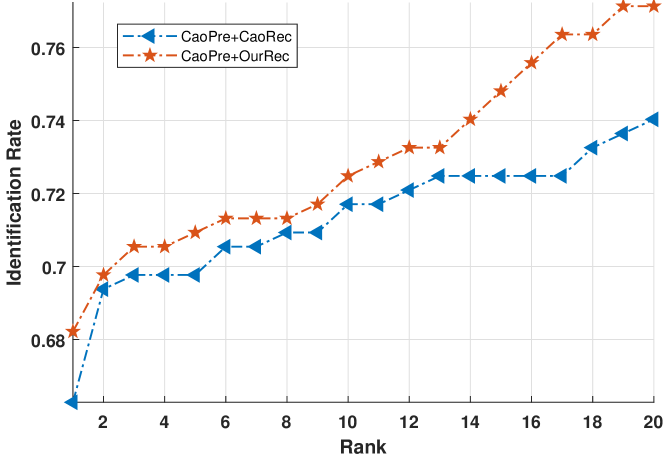
Fig. 15 and Fig. 16 compares respectively the CMC curves of the two methods in experiment VI (labeled as ‘CaoPre+CaoRec’ and ‘CaoPre+OurRec’ in the figure) and the two method in experiment VII (labeled as ‘OurPre+YagerRec’ and ‘OurPre+OurRec’ in the figure). As can be seen, the performance achieved by using our recognition network is much better than using the other recognition methods, which demonstrates the soundness and robustness of the proposed hybrid deep network.
An illustration example (see Appendix D) is also provided as follows. For a pair of fingerprints recognized by the proposed recognition method at rank-1, an alignment noise is added to its M-DLO alignment to generate new FIT and OFT tensors input to the hybrid deep network for the recognition. Experimental result shows that it can still be recognized by the proposed recognition method at rank-1, which demonstrate the robustness of the proposed method against inaccurate alignment.
4.3.4 Joint Optimization Impacts on Recognition Performance
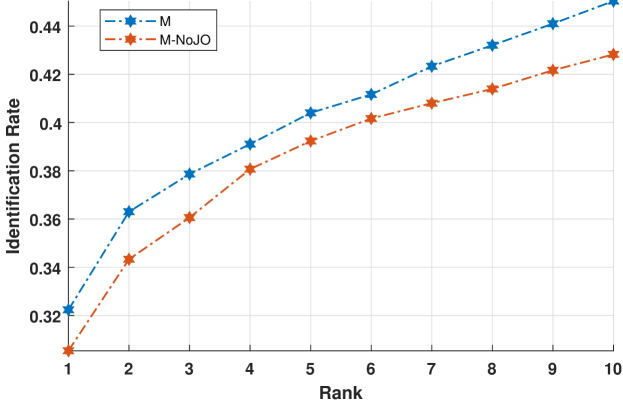
To verify the effectiveness of the joint optimization, we compare the recognition performance of the hybrid deep network trained with and without the joint optimization evaluated on the IIIT-Delhi MOLF database. Fig. 17 shows the CMC curves of these two networks trained with and without the joint optimization, which are labeled as M and M-NoJO in the figure, respectively. As can be seen, the performance achieved by the network without the joint optimization is obviously worse than that of the network with the joint optimization, which supports our choice of the joint optimization.
4.3.5 Visualization of Learned Features
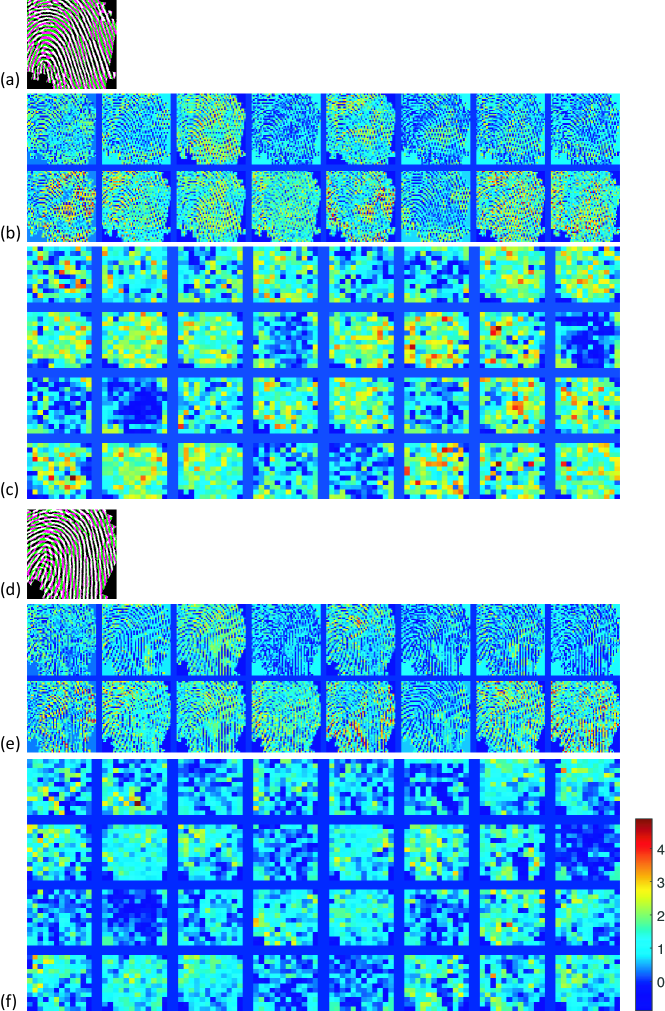
A visualization of the features learned by the first and second layers of the cCNN4,1 is shown in Fig. 18. As can be seen, the proposed deep network tends to learn the similarity of two fingerprint images. The higher the similarity, the higher the response in the feature maps. For a genuine pair of fingerprints, most of its feature maps have a high response, and for a false pair of fingerprints, most of its feature maps have a low response. This shows the interpretability and the soundness of the proposed deep network and the learned features.
4.3.6 Running Times
The hybrid deep network is trained off-line on the Australia National Computational Infrastructure (NCI). The training time for each component and the overall hybrid deep network is provided in Appendix E. The recognition is run on Intel(R) Xeon(R) E5-2670 CPUs (2.6 GHz) powered by a Linux system. On the recognition stage, using the pre-trained network to perform prediction for each fingerprint pair about 0.2s. This time cost is mainly due to the processing of the large number of patches and macro-patches by the set of CNNs. To reduce the computational burden caused by this, we use 24 threads to process the patches and marco-patches for different CNNs in parallel, which can reduce the running time to less than 0.02s.
5 Conclusion
This paper proposed a new scheme for latent fingerprint recognition. Instead of extracting representation features of each fingerprint independently and then compare the similarity of these representation features for recognition in a different process, we proposed to directly model the pair-relationship of two fingerprints as the similarity feature for recognition. This way, correlations of two fingerprints are exploited for better characterization of the similarity which is the base of matching decision making. The pair-relationship is modeled by a hybrid deep network using FIT and OFT tensors of two fingerprints which can provide complementary information. The hybrid deep network is delicately designed to have a set of CNNs with different sizes and architectures to handle the difficulties of random sizes and corrupted areas of latent fingerprints. Experimental results evaluated on two databases demonstrate that the proposed method outperforms the state of the art.
Acknowledgments
This project is supported by ARC Discovery Grant with project ID DP190103660 and ARC Linkage Grant with project ID LP180100663.
References
- [1] D. Maltoni, D. Maio, A. K. Jain, and S. Prabjakar, Handbook of fingerprint recognition Second Ed. Springer-Verlag, 2009.
- [2] C. Watson, G. Fiumara, E. Tabassi, S. L. Cheng, P. Flanagan, and W. Salamon, Fingerprint vendor technology evaluation: evaluation of fingerprint matching algorithms. NISTIR 8034, 2012.
- [3] M. D. Indovina, V. Dvornychenko, R. A. Hicklin, and G. I. Kiebuzinski, Evaluation of latent fingerprint technologies: extended feature sets (Evaluation 2). NISTIR 7859, 2012.
- [4] A. K. Jain and J. Feng, “Latent fingerprint matching,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, no. 1, pp. 88–100, 2011.
- [5] J. Feng, S. Yoon, and A. K. Jain, “Latent fingerprint matching: fusion of rolled and plain fingerprints,” in International Conference on Biometrics. Springer, 2009, pp. 695–704.
- [6] A. K. Jain, J. Feng, A. Nagar, and K. Nandakumar, “On matching latent fingerprints,” in IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2008, pp. 1–8.
- [7] S. S. Arora, E. Liu, K. Cao, and A. K. Jain, “Latent fingerprint matching: performance gain via feedback from exemplar prints,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 12, pp. 2452–2465, 2014.
- [8] S. Yoon, J. Feng, and A. K. Jain, “Latent fingerprint enhancement via robust orientation field estimation,” in International Joint Conference on Biometrics, 2011, pp. 1–8.
- [9] A. A. Paulino, J. Feng, A. K. Jain et al., “Latent fingerprint matching using descriptor-based hough transform,” IEEE Trans. on Information Forensics and Security, vol. 8, no. 1, pp. 31–45, 2013.
- [10] M. A. Medina-Pérez, A. M. Moreno, M. Á. F. Ballester et al., “Latent fingerprint identification using deformable minutiae clustering,” Neurocomputing, vol. 175, pp. 851–865, 2016.
- [11] D.-L. Nguyen, K. Cao, and A. K. Jain, “Robust minutiae extractor: Integrating deep networks and fingerprint domain knowledge,” in International Conference on Biometrics, 2018, pp. 9–16.
- [12] K. Cao and A. K. Jain, “Automated latent fingerprint recognition,” IEEE Trans. Pattern Anal. Mach. Intell., 2018.
- [13] K. Cao and A. K. Jain, “Latent fingerprint recognition: role of texture template,” in IEEE International Conference on Biometrics Theory, Applications and Systems, 2018, pp. 1–9.
- [14] K. Cao, D.-L. Nguyen, C. Tymoszek, and A. K. Jain, “End-to-end latent fingerprint search,” IEEE Trans. on Information Forensics and Security, 2020.
- [15] Y. Wang, J. Hu, and D. Phillips, “A fingerprint orientation model based on 2D fourier expansion (FOMFE) and its application to singular-point detection and fingerprint indexing,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 29, no. 4, pp. 573–585, 2007.
- [16] Y. Wang and J. Hu, “Global ridge orientation modeling for partial fingerprint identification,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, pp. 72–87, 2011.
- [17] N. Yager and A. Amin, “Coarse fingerprint registration using orientation fields,” EURASIP Journal on Advances in Signal Processing, vol. 2005, no. 13, p. 935080, 2005.
- [18] A. Sankaran, M. Vatsa, and R. Singh, “Latent fingerprint matching: A survey.” IEEE Access, vol. 2, no. 982-1004, p. 1, 2014.
- [19] J. Feng and A. K. Jain, “Filtering large fingerprint database for latent matching,” in International Conference on Pattern Recognition, 2008.
- [20] A. Dabouei, H. Kazemi, S. M. Iranmanesh, J. Dawson et al., “ID preserving generative adversarial network for partial latent fingerprint reconstruction,” in IEEE International Conference on Biometrics Theory, Applications and Systems, 2018, pp. 1–10.
- [21] S. Chikkerur, A. N. Cartwright, and V. Govindaraju, “Fingerprint enhancement using STFT analysis,” Pattern Recognition, vol. 40, no. 1, pp. 198–211, 2007.
- [22] A. Jain, L. Hong, and R. Bolle, “On-Line fingerprint verification,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 19, pp. 302–314, 1997.
- [23] T. Orczyk and L. Wieclaw, “Fingerprint ridges frequency,” in Third World Congress on Nature and Biologically Inspired Computing, 2011, pp. 558–561.
- [24] G. E. Hinton, S. Osindero, and Y.-W. Teh, “A fast learning algorithm for deep belief nets,” Neural Computation, vol. 18, no. 7, pp. 1527–1554, 2006.
- [25] C. I. Watson, “NIST special database 14: Mated fingerprint cards pairs 2 version 2,” tech. rep., Citeseer, 2001.
- [26] R. Cappelli, D. Maio, and D. Maltoni, “Modelling plastic distortion in fingerprint images,” in International Conference on Advances in Pattern Recognition, 2001, pp. 371–378.
- [27] NIST and FBI. (2007) NIST special database SD27. [Online]. Available: http://www.nist.gov/itl/iad/ig/sd27a.cfm
- [28] A. Sankaran, M. Vatsa, and R. Singh, “Multisensor optical and latent fingerprint database,” IEEE Access, vol. 3, pp. 653–665, 2015.
- [29] C. I. Watson and C. Wilson, “NIST special database 4,” Fingerprint Database, National Institute of Standards and Technology, vol. 17, p. 77, 1992.
- [30] D. Maio, D. Maltoni, R. Cappelli, J. L. Wayman, and A. K. Jain, “FVC2000: Fingerprint verification competition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 24, pp. 402–412, 2002.
- [31] D. Maio, D. Maltoni, R. Cappelli, J. L. Wayman, and A. K. Jain, “FVC2004: Third fingerprint verification competition,” in International Conference on Biometric Authentication, 2004, pp. 1–7.
- [32] R. Cappelli, M. Ferrara, A. Franco, and D. Maltoni, “Fingerprint verification competition 2006,” Biometric Technology Today, vol. 15, pp. 7–9, 2007.
- [33] Y. I. Shehu, A. Ruiz-Garcia, V. Palade, and A. James, “Detection of fingerprint alterations using deep convolutional neural networks,” in International Conference on Artificial Neural Networks, 2018, pp. 51–60.
- [34] W. Zhou, J. Hu, I. Petersen, S. Wang, and M. Bennamoun, “A benchmark 3d fingerprint database,” in International Conference on Fuzzy Systems and Knowledge Discovery, 2014, pp. 935–940.
- [35] C. Puri, K. Narang, A. Tiwari, M. Vatsa, and R. Singh, “On analysis of rural and urban indian fingerprint images,” in International Conference on Ethics and Policy of Biometrics, 2010, pp. 55–61.
- [36] C. Lin and A. Kumar, “Matching contactless and contact-based conventional fingerprint images for biometrics identification,” IEEE Trans. on Image Processing, vol. 27, no. 4, pp. 2008–2021, 2018.
- [37] A. Sankaran, T. I. Dhamecha, M. Vatsa, and R. Singh, “On matching latent to latent fingerprints,” in International Joint Conference on Biometrics, 2011, pp. 1–6.
- [38] S. Yoon, J. Feng, and A. K. Jain, “On latent fingerprint enhancement,” in Biometric Technology for Human Identification VII, vol. 7667, 2010, p. 766707.