Pan-STARRS1: Galaxy Clustering in the Small Area Survey 2
Abstract
The Pan-STARRS1 survey is currently obtaining imaging in 5 bands (, , , and ) for the steradian survey, one of the largest optical surveys ever conducted. The finished survey will have spatially varying depth, due to the survey strategy. This paper presents a method to correct galaxy number counts and galaxy clustering for this potential systematic based on a simplified signal to noise measurement. A star and galaxy separation method calibrated using realistic synthetic images is also presented, along with an approach to mask bright stars. By using our techniques on a sq. degree region of science verification data this paper shows PS1 measurements of the two point angular correlation function as a function of apparent magnitude agree with measurements from deeper, smaller surveys. Clustering measurements appear reliable down to a magnitude limit of . Additionally, stellar contamination and false detection issues are discussed and quantified. This work is the second of two papers which pave the way for the exploitation of the full survey for studies of large scale structure.
keywords:
Surveys, methods:observational, large-scale structure of Universe1 Introduction
Pan-STARRS1 (PS1) is a 1.8m telescope on Haleakala, Maui (Hodapp et al., 2004). Its unique selling point is its high etendue, the product of its collecting area and field of view, which allows it to survey large areas of sky quickly (Kaiser et al., 2002). To fully utilise this it has a huge camera (GPC1), with 1.4 Gpixels and a 3.3 degree field of view (Tonry et al., 2008). It was designed as a prototype of PS4, an array of four identical telescopes scanning the whole sky in relatively short intervals for potentially threatening Near Earth Objects (NEOs) (Kaiser et al., 2002). The multiepoch nature of PS1 observations is not only good for the detection of moving and transient objects but also provides the redundancy necessary for highly accurate zero point calibration (Schlafly et al., 2012; Magnier et al., 2013), which is important for large scale structure analysis.
As well as the main goal of detecting NEOs, PS1 has always been envisaged to meet a wide variety of science goals, including comets, extra-solar planets, supernovae, AGNs and large scale structure. PS1 does not have a spectrograph but photometric redshifts will be available from a dedicated pipeline (Saglia et al., 2012). As of July 2013, PS1 has been successful in detecting many new solar system objects222http://www.minorplanetcenter.org/iau/mpc.html, as well as supernovae (e.g. Valenti et al., 2010), variable AGN (e.g. Ward et al., 2011) and satellite galaxies around Andromeda (Martin et al., 2013). It has also been successfully used as a source of optical data for other surveys to measure the clustering of Extremely Red Galaxies (Kim et al. in preparation). We now extend this success to large scale structure using PS1 data alone with static objects, where individual exposures are co-added to gain greater depth.
The finished PS1 survey will have two major co-added data products. The 3 survey with 31,500 square degrees of imaging and ten deeper 8.5 square degree fields known as the “Medium Deeps”, both in the PS1 bands of , , , and . The 3 survey will be deeper and have a larger area than its predecessors, and it will also benefit from, , a near infrared band. For more details on the 3 survey please refer to Chambers et al. (in preparation).
In this work we lay the foundations of exploiting the 3 survey for large scale structure by demonstrating how galaxy number counts and the angular two point galaxy correlation function, , can be reliably measured. Namely we tackle, from a large scale structure stand-point, issues of star/galaxy separation, false positives, depth, angular masks and how completeness varies with sky position. We will refer to the fraction of objects detected as a function of magnitude as the “detection efficiency” throughout. As this paper is mainly a proof of concept, we concentrate mostly on the -band. This is the second of two papers assessing PS1 viability for large scale structure studies, we will refer to our first paper, Metcalfe et al. (2013), as Paper I hereafter.
This paper is organised as follows. In Section 2 we introduce the data sets we are using from PS1 along with the SDSS comparison samples. In Section 3 we present the angular masks and in Section 4 we create synthetic images and use them to define star and galaxy separators. Section 5 introduces our method of dealing with spatially varying depth. In Section 6 we present our measurements of clustering and number counts along with careful tests of how systematic errors and our corrections affect them. In Section 7 we discuss implications of our work to the scientific exploitation of the finished 3 survey.
2 The Data
2.1 The PS1 small area survey 2
The Small Area Survey 2 (SAS2) is a subset of the survey roughly covering the region of and . It is designed to be representative of the finished survey. A large number of individual exposures were taken, co-added and mosaiced to form around 69 square degrees of imaging. It has a median PSF FWHM of , which has an rms scatter of less than 0.05″across the field (Paper I). PS1 has a raw pixel scale of before “warping” (see later in this section) and after. A careful study of the depth of this data set can be found in Paper I, which reports that 50% of stars are recovered at magnitudes in ,,,and of 23.4, 23.4, 23.2, 22.4 and 21.3 respectively. All magnitudes in this paper are measured in the AB system.
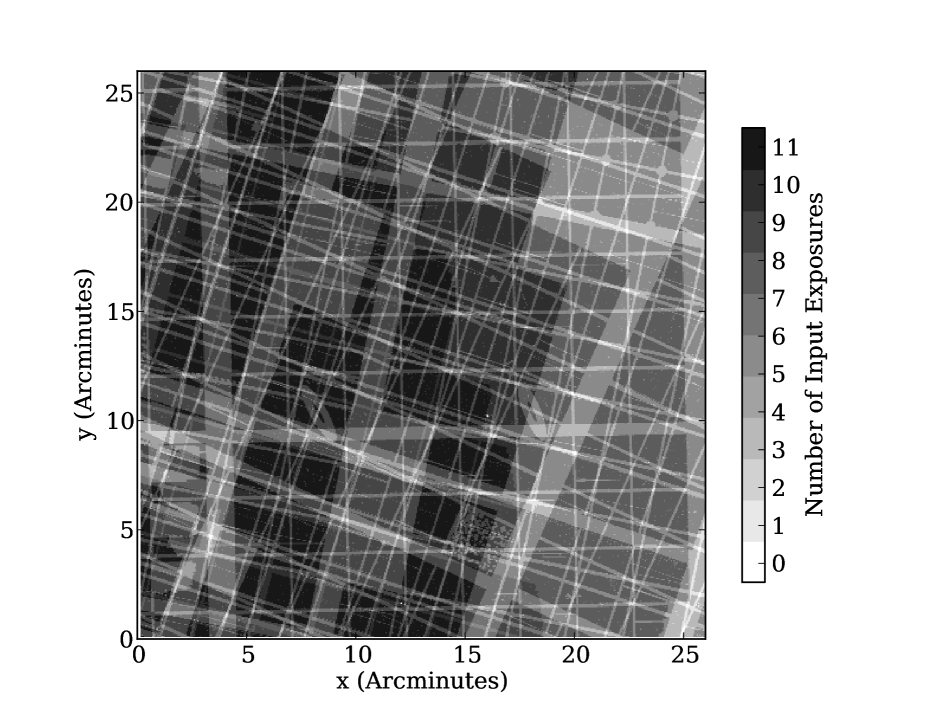
Different sub-areas of the finished SAS2 stacked data have different numbers of input exposures. This is down to the observing strategy, which means exposures in a stack are not always coincident with each other. Additionally around 25% of individual exposures are masked (Paper I), which is mainly due to gaps between CCD chips as well as defective CCD cells and other regions. The decision to build up stacks using multiple, rotated and non-coincident individual exposures was chosen in order to meet the needs of scientists interested in transient and moving objects, who require large area imaging over multiple epochs.
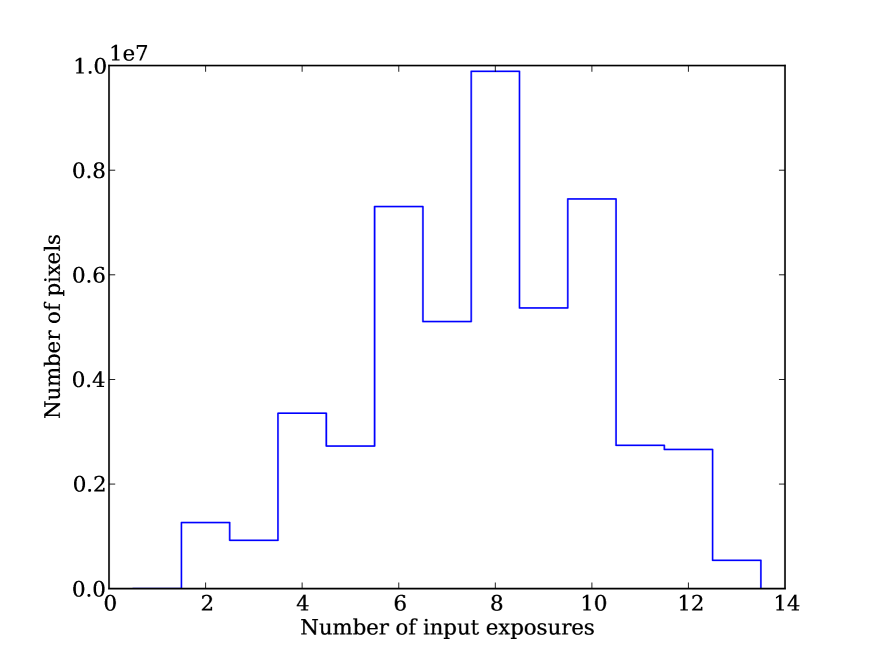
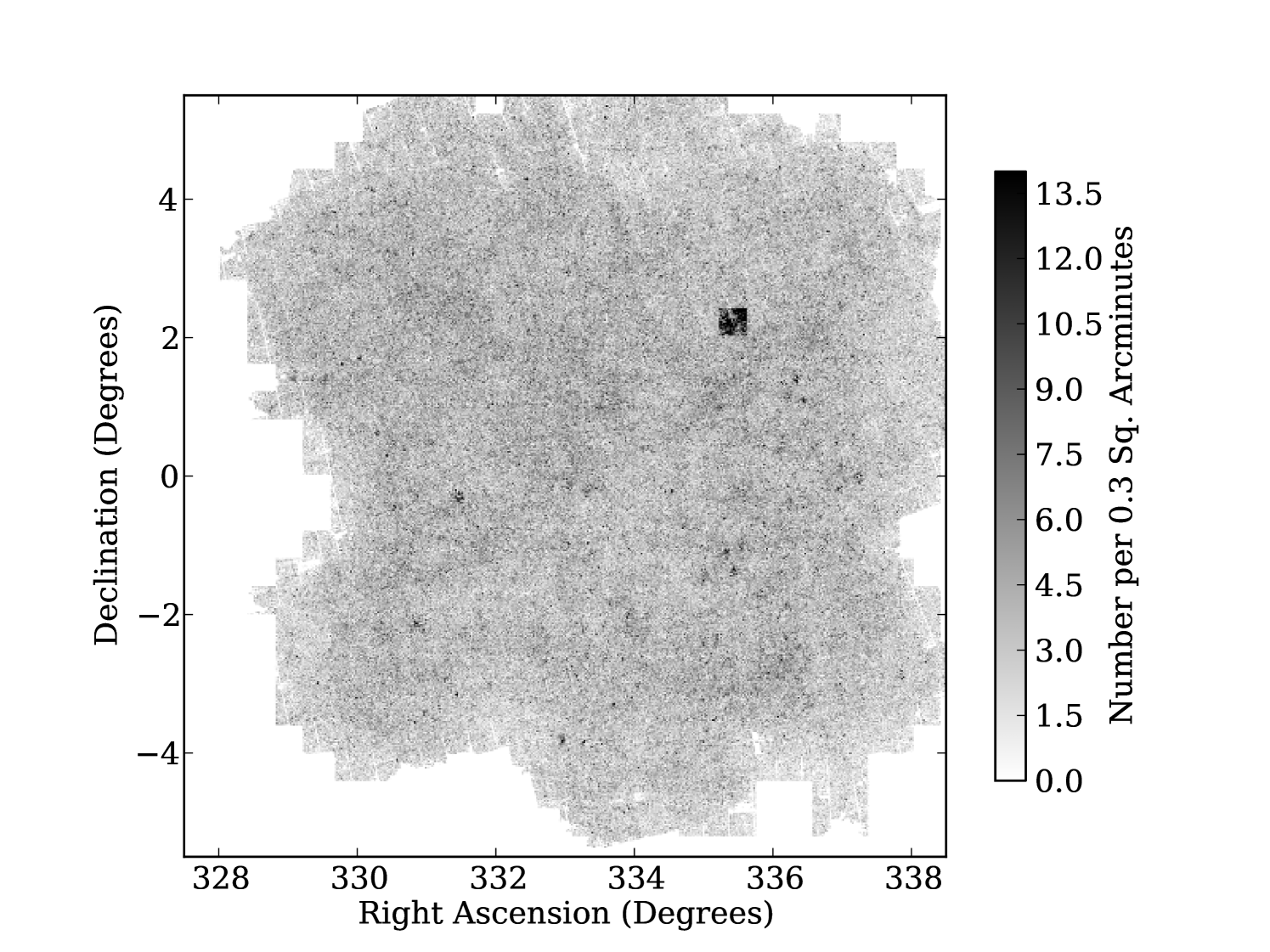
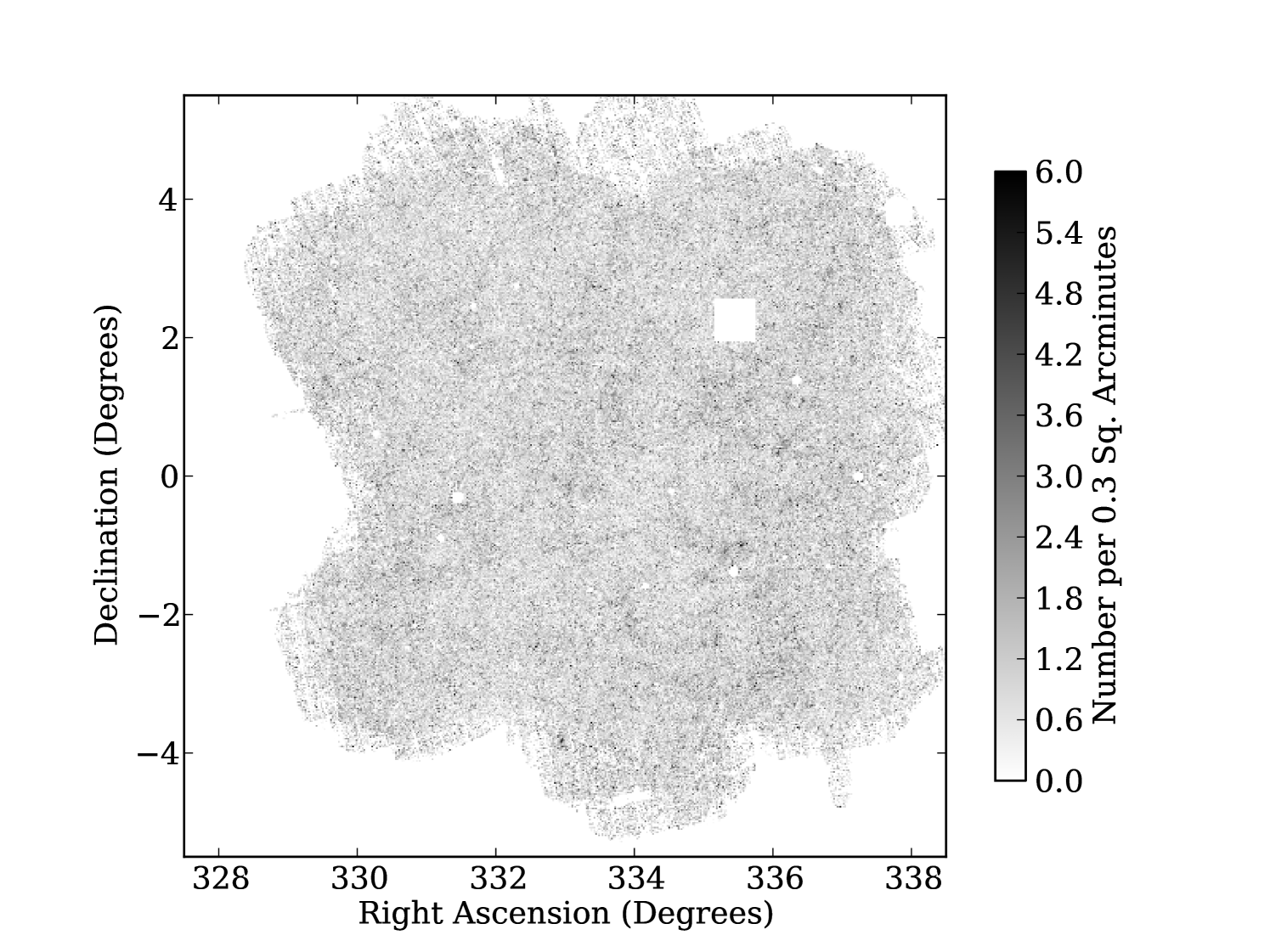
We will refer to the number of input exposures to a pixel as the “coverage” throughout this paper. To illustrate this Fig. 1 gives the “coverage map”, i.e. an image recording the number of exposures stacked for each pixel, in a by region. A typical SAS2 stacked image has an average coverage of around 8.9 exposures per pixel (Paper I), and this coverage has a standard deviation of around 3 exposures per pixel. In the stacks this gives rise to a spatially varying noise level. To track this PS1 produces “variance maps” which record the variance of the noise in each image pixel. This variance includes contributions from sources of astronomical noise including sky background, read noise and Poisson noise, and how they scale with the weighting of exposures in a stack. Naturally the spatially varying image noise leads to different depths in different positions on the sky (see Section 5).
In addition to coverage maps and variance maps the PS1 Image Processing Pipeline (IPP) (Magnier, 2006) also produces image masks. These image masks track pixel quality and highlight pixels which have been flagged as suspicious (e.g. likely to be cosmic rays or image artifacts) by the pipeline. Image masks, variance maps, coverage maps and images are all supplied in approximately by units called “skycells”. These skycells do not represent unique areas on the sky but overlap, and in these overlap regions pixels from different skycells are not necessarily the same, since decisions on which exposures to reject from a stack are made on a skycell by skycell basis.
It is also important to note that transforming the exposures from the CCD coordinates to the stack pixel coordinate system, a process known as “warping”, introduces correlations between the image pixels on scales of less than around (see Paper I). The image, , the variance and the warped image, , and variance, , are related by a warping kernel, , thus
| (1) |
| (2) |
where and are image pixel indices and and are kernel pixel indices. Here the kernel has been normalised so it sums to unity. This warping process converts some variance into covariance, such that no longer represents all of the noise associated with a pixel. To measure a warped pixel’s total noise one needs to use a covariance matrix which accounts for the correlations between the pixels in the image. Storing the full covariance matrix would require a prohibitive amount of space so a much smaller matrix, known as the “covariance pseudo-matrix” is stored per stack image.
The covariance pseudo-matrix, , describes the covariance of a single pixel with each of the pixels in its neighbourhood, with relative pixel coordinate . For initially uncorrelated data this matrix is simply a function of the warping kernel,
| (3) |
where , such that and . The latter property follows from the normalisation of kernel, . When making measurements which combine many pixels the effect of covariance on the overall variance of the measurement can be approximated by simply boosting individual variances by the factor and otherwise ignoring covariance. This approximation is asymptotically exact for apertures much larger than the kernel size. The value of changes from place to place on the sky but has an approximately Gaussian distribution with a mean of 1.379 with an rms of 0.006 for SAS2 -band. In Paper I we show how the warping process has no effect on the depth of images, but we will revisit the covariance pseudo-matrix in Section 3.1.
2.2 PS1 magnitudes, flags and nomenclature
In this work we use Kron magnitudes (Kron, 1980) as measured by the IPP code psphot (Magnier, 2006) with zeropoints accurate to 10 mmag from the calibration described in Schlafly et al. (2012) and Tonry et al. (2012). Kron magnitudes measure flux in an aperture with a radius called the “Kron radius”, which is some multiple (2.5 for PS1) of the first moment radius of the flux (Kron, 1980). Kron magnitudes are designed to contain the majority of flux for a given source profile regardless of size, but a small, profile dependent correction term is required to account for flux outside the Kron radius. For defining clustering samples we base our selection on uncorrected Kron magnitudes, as they are well defined for all of our objects. This correction needs to be considered when comparing total magnitudes from synthetic objects to observed quantities and when comparing to literature galaxy number counts. From Table 2 of Paper I we see this correction has a weak magnitude dependence, and changes by a few hundredths of a magnitude. It is also expected this correction will slightly depend on galaxy profile. For this work we adopt an average correction of to convert from Kron magnitude to total magnitudes; we will state explicitly wherever we apply this correction throughout this paper.
For the purposes of star/galaxy separation we also use point spread function (PSF) magnitudes, which are magnitudes based on extrapolating the magnitude from a small aperture, chosen to maximise the signal-to-noise ratio (SNR), using the IPP PSF model (see Section 4.1). We shall label these magnitudes with the suffix “PSF” to contrast with the Kron magnitudes which are labelled using the name of the filter, i.e. , , , and .
All number count, colour-colour, colour-magnitude and clustering plots are corrected for galactic extinction using the dust maps and associated IDL code of Schlegel et al. (1998), using the coefficients from Schlafly & Finkbeiner (2011). Star and galaxy separation and detection efficiency plots are all uncorrected for extinction, as the measured magnitude is more relevant for these plots. These extincted, measured magnitudes will be labelled with the suffix “raw”.
To remove known spurious detections we use IPP flags. All objects with the psphot flags fitfail, satstar, badpsf, defect, saturated, cr_limit, moments_failure, sky_failure, skyvar_failure or size_skipped set are removed. Further discussion of these flags can be found in Paper I.
2.3 SDSS magnitudes and flags for the comparison sample
The SAS2 field overlaps with SDSS DR8 and is partially covered by the SDSS Stripe 82 co-added data (Annis et al., 2011), the size of the Stripe 82 overlap region is around 16 square degrees (see figure 1 of Paper I). We compare PS1 to both of these. Stripe 82 comparisons are particularly useful as Stripe 82 is deeper than PS1.
SDSS measures magnitudes in an magnitude system (Lupton et al., 1999). We adjust this to the standard Pogson system using the formula available on the SDSS website111http://www.sdss3.org/dr8; accessed 27/07/2012. This adjustment is very small, at its maximum value, at , it is only 0.04 magnitudes in size. The SDSS bands are slightly different to those of PS1, transformations are given in Tonry et al. (2012). These transformations in our comparison band, , are very small, less than 0.01 magnitudes for a wide range of colours in figure 6 of Tonry et al. (2012), and hence are neglected.
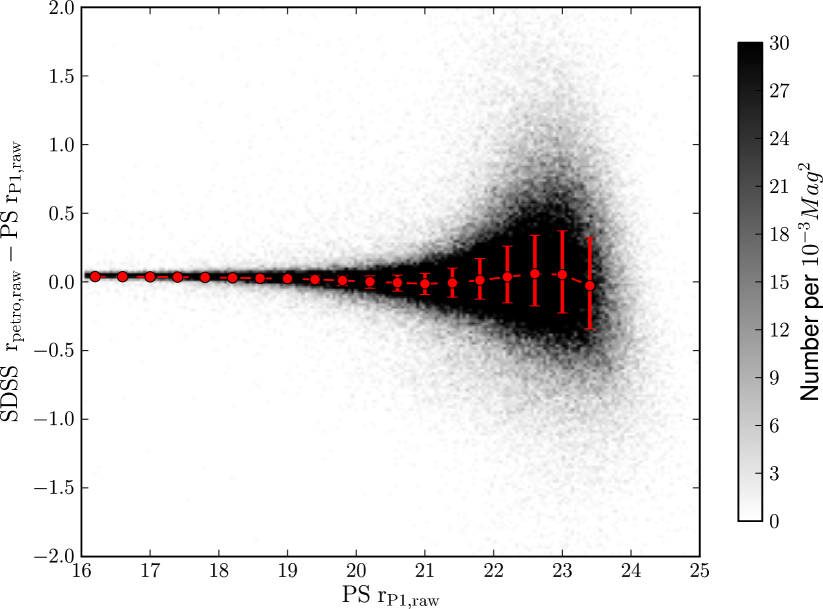
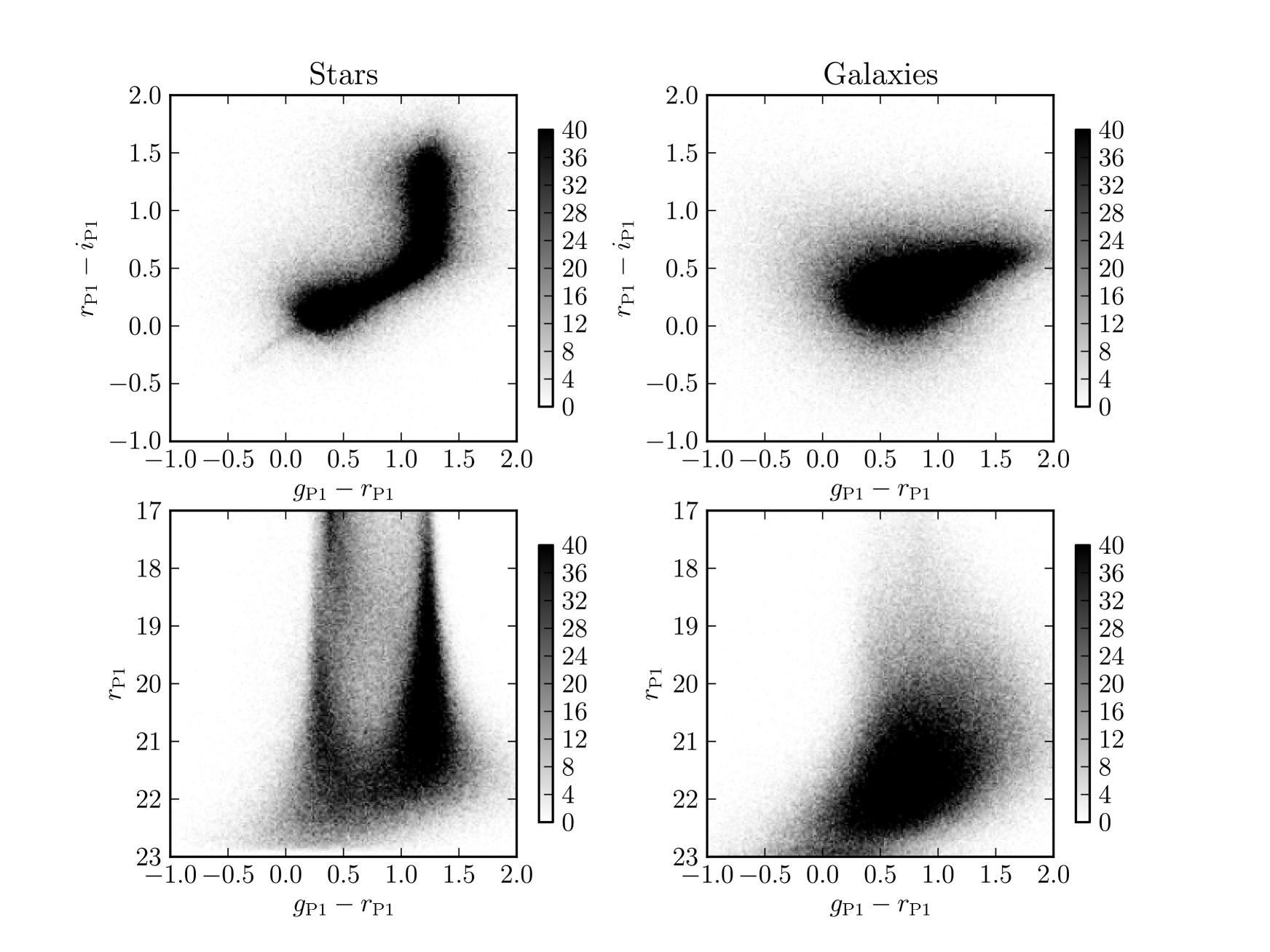
SDSS DR8 and SDSS Stripe 82 do not provide Kron magnitudes. Whilst the SDSS magnitudes measured using model fits, so called “modelMags”, give an estimate of the total magnitude of a galaxy, we want to select a magnitude estimator most similar to our Kron magnitudes (see Paper I for PS1 Kron and SDSS modelMag comparisons). Petrosian magnitudes (Petrosian, 1976), a modified form of which are provided by SDSS (see Blanton et al., 2001; Yasuda et al., 2001) measure flux within an aperture of a size determined by the ratio of a surface brightness in an annulus around a source to the average surface brightness of the region interior to that annulus. In theory the fraction of flux enclosed by a Kron magnitude and a Petrosian magnitude could differ. A comparison of PS1 measured Kron magnitudes and SDSS DR8 Petrosian magnitudes (Fig. 2) shows that these two magnitude measures are fairly well matched in the -band and band for objects in SDSS.
To define SDSS galaxies we use the Strauss et al. (2002) star-galaxy separator,
| (4) |
where is the SDSS PSF magnitude and is the SDSS model magnitude. We use SDSS flags to remove false positives in SDSS DR8. Following the spectroscopic target selection of Strauss et al. (2002) we reject SDSS objects with saturated or bright flags, and require the binned1 flag to be set (i.e. a detection). Again following Strauss et al. (2002) we apply, to the DR8 data, a Petrosian half light surface brightness cut of
| (5) |
where is the Petrosian magnitude and is the radius enclosing 50% of the Petrosian flux. Strauss et al. (2002) adopted a similar cut to remove low surface brightness false positives; though they used a slightly more complicated cut than ours, which was dependent on sky values and fibre magnitudes. We adopt this simplified, less conservative cut (the Strauss et al. (2002) could be as bright as ) to DR8 as we find it is sufficient to remove SDSS false (unmatched to PS1) detections from the magnitude ranges we consider. Applying this surface brightness cut limits SDSS DR8 depth faintward of , so we do not compare to SDSS DR8 faintward of this value. With more work it is likely possible to measure SDSS DR8 clustering over SAS2 for galaxies fainter than this, but we choose instead to use literature and Medium Deep data for faint clustering comparisons.
We do not apply any surface brightness cut to Stripe 82 data as our main use of Stripe 82 is to estimate PS1 depth and these cuts could limit Stripe 82 depth. How Stripe 82 false detections affect this work will be discussed in Section 5. Stripe 82 does not have a publicly available mask for the co-added data, so we created our own by visual inspection of the area. This masks defines areas with no Stripe 82 imaging and removes a satellite trail in Stripe 82.
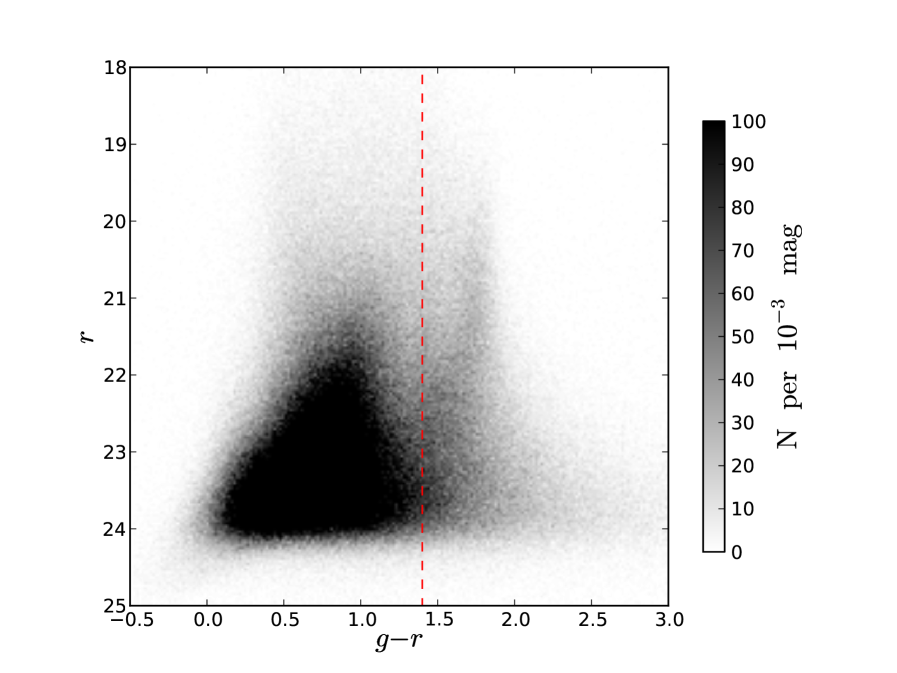
A further use for Stripe 82 is to test how strongly detection efficiency depends on apparent colour. A galaxy’s colour is correlated with its morphology, red galaxies tend to be ellipticals and blue galaxies tend to be spirals. Galaxies with different morphologies have different surface brightness distributions and as such may have a different chance of being detected. Since galaxy clustering is a function of colour and morphology, with red ellipticals being more clustered, this effect could modify our clustering for cuts and depth corrections based on apparent magnitude. Fig. 3 shows a colour magnitude diagram using Stripe 82 model magnitudes for objects classed as galaxies by Stripe 82’s own morphological star and galaxy separator, type = 3. We separate galaxies on the red sequence from those in the blue cloud using the cut indicated on Fig. 3, . We will use this sample of red and blue galaxies when testing the dependence of detection efficiency on apparent colour and hence morphology.
2.4 PS1 Medium Deep Data
When comparing our faint galaxy clustering to other measurements we both compare to literature data and to results from the much deeper and more spatially homogeneous PS1 Medium Deep survey. Foucaud et al. (in preparation) has produced their own stacks of Medium Deep field 7 (MD07) using PS1 data and reduced them using SExtractor (Bertin & Arnouts, 1996). They measure the Kron magnitudes of galaxies, using SExtractor MAG_AUTO, and star/galaxy separate using a combined morphological and SED fitting approach. They also adopt a mask to remove bright stars and poorer quality data. After masking, MD07 has an area of 7 square degrees, much smaller than the SAS2 field. For more details on these stacks see Jian et al. (2013) and Foucaud et al. (in preparation).
3 Angular Masks and False Positives
3.1 Creating the mask
To create a set of random points suitable for measuring clustering and to remove regions of low data quality we define a new set of angular masks. These masks differ from IPP image masks in that a single, unique mask covers the whole region of interest. In IPP two overlapping skycells will have two different masks, one for each skycell. As well as masks we produce variance maps and coverage maps binned-up to the same resolution as our mask pixels. We take variance maps, coverage maps and image masks at the native pixel scale and compute their mean on a grid of , equal area pixels, which covers the whole SAS2 area. As binned-up pixel boundaries do not align with the IPP pixel boundaries, we assign pixels to their nearest binned-up pixels. Our binned up pixel grid has the same rotation as the IPP pixels. For our coverage maps we take the lowest value of any IPP pixel in our binned-up pixels, to be conservative in our estimates of low coverage areas. Our binned-up pixel size was chosen to preserve the fine structure in the variance whilst still yielding a mask of manageable size. Experimenting with different mask and map pixels sizes and different mask and map tessellations is left for later work.
Only taking into account the variance recorded in the variance maps would result in underestimating the noise, as we would be ignoring the covariance. We therefore multiply variance values from IPP variance maps by the sum of the elements of their associated covariance pseudo-matrix (see Section 2.1). This is almost the same as multiplying all of variance map values by a constant, as the rms of this scaling factor, given in Section 2.1, is only around across the SAS2 field. We carry this scaling out to allow easier comparison to the work of Paper I, which works with uncorrelated noise measurements. We also apply this scaling now as it could become more important if the warping kernel were to change.
Where data from two skycells overlap we take data from the skycell whose centre is closest to the overlapping data. We do this for both the pixels and the object detections to ensure the catalogues, masks and maps are consistent.
As well as defining the basic geometry of the survey, we also use angular masks to avoid two other types of potential problem: deblending and image artifacts.
3.2 Masks for bright stars
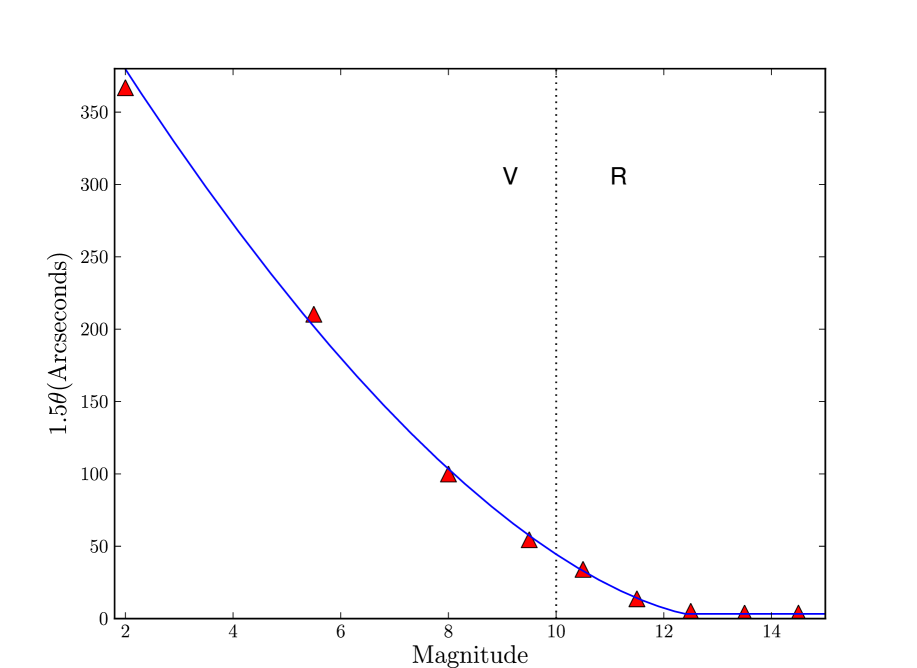
In common with a large amount of image reduction software (see e.g Bertin & Arnouts, 1996), psphot can split bright objects and diffraction spikes into multiple detections. To avoid this we mask out regions around bright stars. To decide mask sizes we use photometry from the UCAC4 catalogue (Zacharias et al., 2013) rather than PS1, since PS1 saturates at around . We use -band photometry from the UCAC astrograph up to a bright limit of , where the astrograph becomes saturated. To mask even brighter objects we use -band data from Hipparcos, FK6 and Tycho-2. This data is already included in the UCAC4 catalogue. Zacharias et al. (2013) states that the UCAC4 catalogue is a complete catalogue of stars down to .
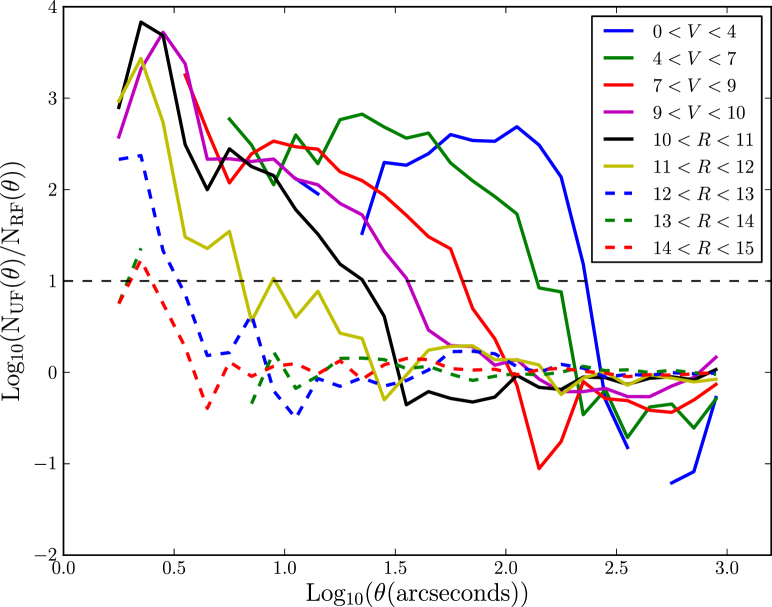
We identify likely candidates for false positives by identifying objects in the -band that are not in the -band catalogue, with a matching radius. To eliminate objects that are not detected in both bands due to image depth, we remove objects with . We assume these candidate false positives trace the spatial distribution of all false positives caused by bright stars. Selecting the central, deeper region we count “false positive” and UCAC4 pairs as a function of angular separation, , as well as pairs of “false-positive” and random points uniformly distributed across the area, . We calculate the ratio of these pairs
| (6) |
where is the number of UCAC4 objects and is the number of random points. This technique is very similar to a cross-correlation function. We adopt this technique to map out the scale out to which one finds false positives around bright stars. In Fig. 4(top) we plot the results as a function of UCAC4 magnitude and magnitude. The brightest bin contains only one magnitude star. From Fig. 4(top) we can see brighter objects cause false positives out to a larger spatial extent than fainter ones. We also see a relative deficit of false positives at smaller separations. This is due to masked, saturated regions closer into the bright object. Also note that false positives are preferentially found near brighter objects all the way down to the magnitude limit of . Whilst Fig. 4(top) shows one is ten times more likely to find false positives at a separation of from objects with , it does not imply that all of these objects cause false positives and in real terms the number of bright false positives is very small. To decide on the size of mask to put on bright objects, as a function of and magnitude, we use the last crossing of the line as a reference separation and increase this distance by 50%. The curve describing mask size is smooth across the -band to -band boundary, see Fig. 4(bottom). We fit these sizes with a simple power law, truncated such that mask size cannot be less than one mask pixel (i.e. ),
| (7) |
where is the mask radius in arcseconds, and is the stellar magnitude. We use this to mask down to and .
3.3 Masks for regions of low quality data
The second potential issue we combat with masks is that certain regions of PS1 images have instrumental signatures (i.e. image artifacts) caused by scattered light and electronic noise. This is particularly noticeable in regions of low coverage where we do not have sufficient numbers of exposures to remove these image defects statistically, i.e. by median filtering or outlier rejection in the stacking procedure. We therefore mask regions with a coverage of three exposures or fewer. In the finished survey the area with coverage this low should be very small. To estimate this value we took the central area, and , of our binned up version of the coverage map and produced Fig. 5. The central area of SAS2 should be representative of the finished data and as such we can see from Fig. 5 only of the full survey area should be lost by this cut.
Masked regions are expanded by a one binned-up mask pixel border in order to exclude from the catalogue objects with unreliable measurements caused by being on the edge of the mask. This is similar to using cuts in the IPP value psf_qf_perfect, which quantifies the fraction of masked or suspicious pixels in a source (for more details on these cuts see Paper I).
3.4 The effects of masking
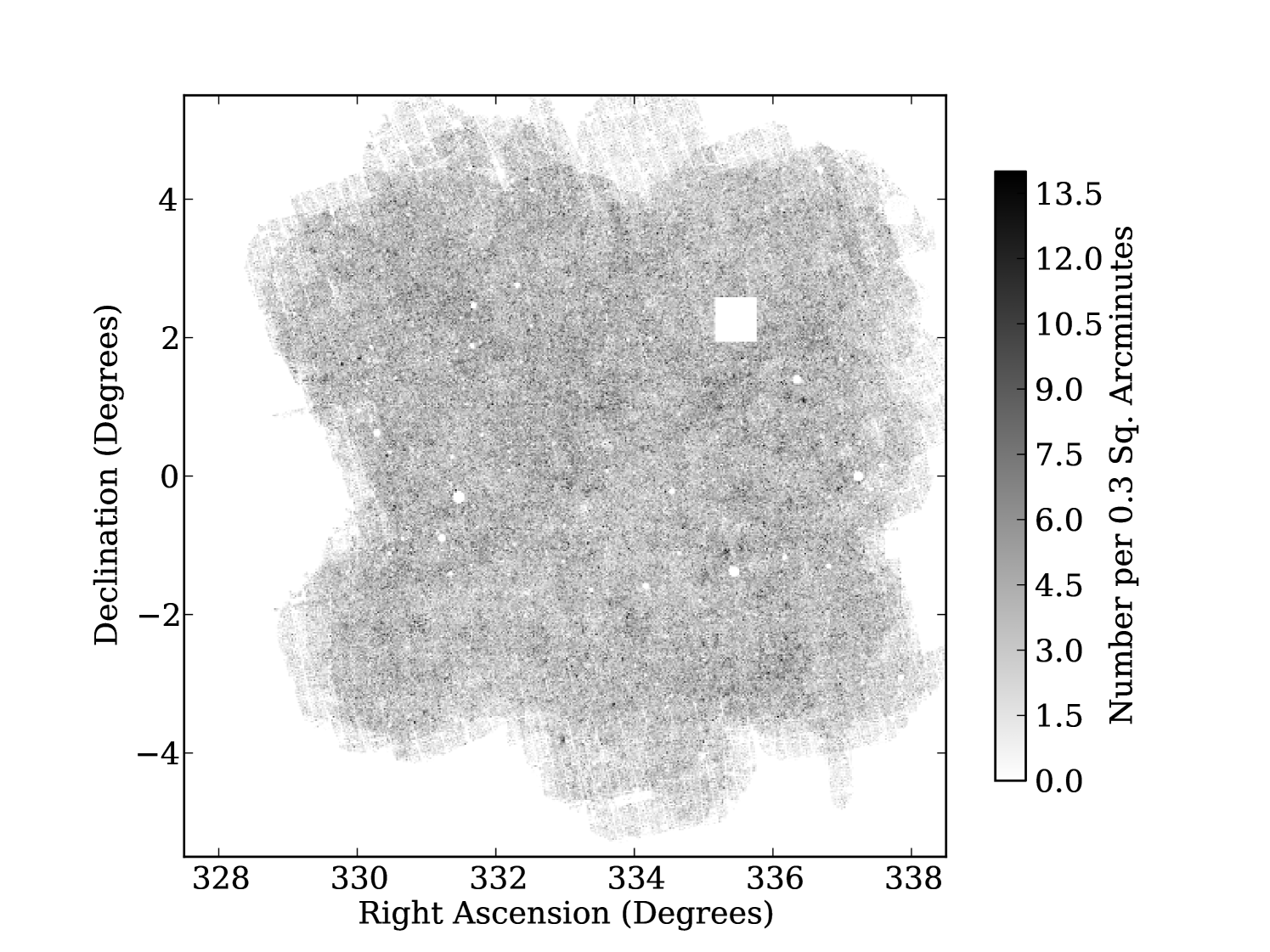
The source detections before and after applying the final mask are shown in Fig. 6; the regions of fewer objects on the outskirts of the masked field are not caused by depth variations but simply the larger number of masked pixels caused by a lower coverage in these areas. The grid like patterns are also caused by our masking of low coverage regions; the grid pattern in coverage is caused by gaps between individual chips on the detector. One can see from Fig. 6 how our angular mask removes peaks of false positives caused by bright objects: peaks of false detections in the unmasked field are removed in the masked field. Finally we mask, by hand, a square region in SAS2 where the data reduction process failed, an issue that will be rectified for the final survey.
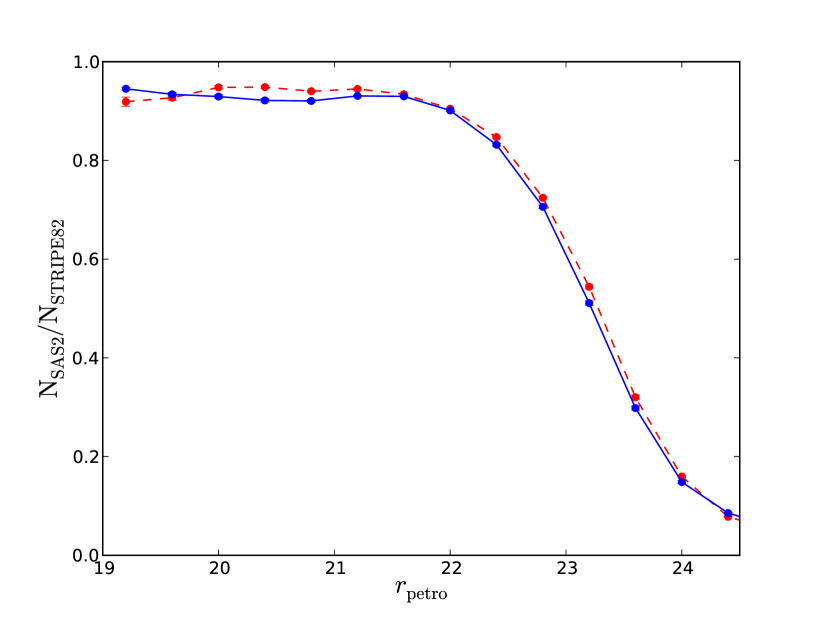
A quantitative measure of how our mask removes false detections was made by cross matching the Stripe 82 and PS1 catalogues after applying our SDSS Stripe 82 mask (see Section 2.3) to PS1 data and the PS1 mask to Stripe 82 data. Fig. 7 shows the fraction of unmatched objects to Stripe 82, for an square degrees overlap region and a matching radius of , before and after applying the masking and flags.
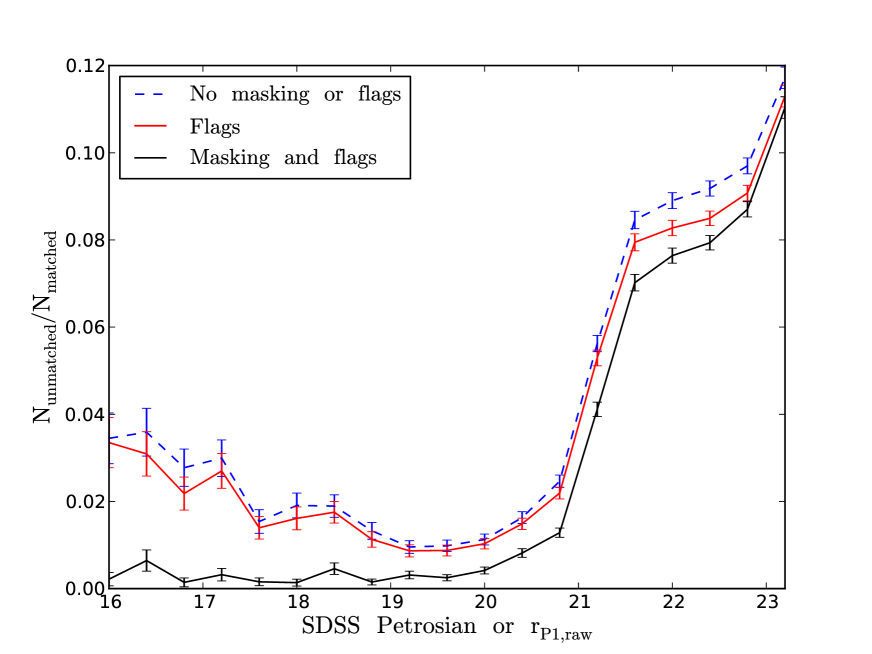
Fig. 7 shows a decrease in the fraction of false positives once flags have been applied and masking conducted. In particular brighter false positives associated with bright stars are almost entirely removed. Some unmatched objects do remain, but at magnitudes brighter than these are mostly real objects missed by Stripe 82 or objects with proper motions. Fainter than this false positives can be caused by the previously mentioned instrumental signatures. Note that Paper I achieves similarly low numbers of false positives by applying the psf_qf_perfect flag; however the use of this flag, which depends on the number of masked or suspect pixels near a source, can change the angular selection function. The approach using masks presented here deals with these false positives in a way that keeps track of this, which is more appropriate for clustering studies.
4 Star/Galaxy Separation
4.1 Galaxy and stellar profiles
To describe our morphological approach to star galaxy separation, we first review the basic properties of galaxies. Galaxies have light profiles well fitted by the famous Sérsic functions (Sérsic, 1963). For a review see Graham & Driver (2005). In flux this can be expressed as
| (8) |
where is the distance to the centre, is the flux at and is a scaling constant that depends on the index, , defined such that is the half light radius. A value of and gives an exponential profile, typical of the discs of spiral galaxies while a value of and gives the de Vaucouleurs profile typical of elliptical galaxies (see Graham & Driver, 2005; de Vaucouleurs, 1948). Due to the atmosphere and telescope optics galaxy light profiles appear convolved by the point spread function (PSF) of the instrument and the atmosphere. In the PS1 IPP stars are fitted with a PSF model of the form
| (9) | |||
| (10) |
where is the central intensity, and are the -axis and -axis distances from the centre, is a free parameter and , , are free parameters that represent the -axis width, the -axis width and a cross term respectively. During image reduction IPP fits the PSF model parameters on a grid across each skycell. Between these grid points parameters are interpolated to give a smoothly varying model of the PSF. Typically PS1 PSFs, and indeed real PSFs in general, have more extended wings than Gaussian PSFs of the same full width half max (FWHM): figure 5 of Paper I gives a typical curve of growth for a PS1 PSF.
4.2 Synthetic objects
To develop and test morphological star/galaxy separation we generate synthetic sources with the profiles as described in Section 4.1. To generate a synthetic star one needs to simply choose a magnitude and a position and then evaluate the model. Generating a galaxy is harder as several parameters must be chosen, namely: the position, the bulge to disc ratio, the Sérsic index, the size, the ellipticity and the orientation on the sky. The last of these is chosen at random. As the clustering of the synthetic sources is not important here a position is randomly assigned.
When choosing the Sérsic index we approximate the Universe as being made up entirely of de Vaucouleurs profiles for elliptical type galaxies and bulges, or exponential profiles for discs. This follows the classic bi-modality in Sérsic index between elliptical galaxies and discs. In reality galaxies follow a distribution of Sérsic indices, with elliptical galaxies displaying a positive correlation between luminosity and Sérsic index (see e.g. Ferrarese et al., 2006). For this work the galaxies that will be difficult to star/galaxy separate will have small angular sizes, faint apparent magnitudes and are convolved with a PSF so we feel this approximation makes negligible difference to our results. We also treat bulges in disc galaxies in the same way as elliptical galaxies, which is a common approximation adopted in the literature (Bertin & Arnouts, 1996; Shen et al., 2003).
For the axis ratios of discs we choose a random inclination angle, , distributed uniformly in and assuming circular flat discs with a thickness which is some fraction, , of the radius we calculate the apparent axis ratio, , using simple geometry as
| (11) |
We take for our disc height to radial scale length ratio. The resulting distribution is flat and a reasonable fit to the observations in Padilla & Strauss (2008). For bulges we select a major to minor axis ratio, , between 0.3 and 1.0, corresponding to the classical elliptical types of E0 to E7 (see e.g. Mo et al., 2010). Within this range we select from a truncated Gaussian distribution of mean and variance of , which we chose to give a reasonable fit to the data in figure 4 of Padilla & Strauss (2008).
For physical galaxy sizes we use the empirically measured relation and its scatter given in equations 14, 15 and 16 of Shen et al. (2003). We adopt parameters measured in Shen et al. (2003) for galaxies separated into late and early types by Sérsic index (figure 6 of that paper). It was reported in Dutton et al. (2011) that using the Shen et al. (2003) measurements would result in discs too small by a factor of around 1.4, due to not factoring in the effects of inclination which decreases the size by the square root of the apparent axis ratio. We therefore increase the size of our disc galaxies by this factor. We also correct the empirical bulge size relation for this effect, adopting a correction of 1.2, calculated from the typical bulge ellipticity . For bulges and elliptical galaxies we choose not to extrapolate the relation from Shen et al. (2003) to fainter magnitude bins than measured in that paper. Instead, we keep the sizes of bulges and elliptical galaxies fixed fainter than ; this is motivated by observations that dwarf elliptical galaxies have a nearly constant size regardless of magnitude (see e.g. Shen et al., 2003; Mo et al., 2010).
We now have a relation between physical size and absolute magnitude, therefore we need a redshift and an absolute magnitude to predict angular sizes. One could generate these using observed luminosity functions and redshift distributions, but here we use data from the mock catalogues produced for Merson et al. (2013) using the galaxy formation model presented in Bower et al. (2006). Using these catalogues gives us the potential to extend this work to generate synthetic images with realistic galaxy clustering. For the purposes of this work, however, we use random angular positions. The model adopts a concordance cosmology of ; we use this cosmology for the whole of this work. The galaxy formation model gives magnitudes and redshift distributions in good agreement with observations at low redshift (Bower et al., 2006). We split the total flux of the model galaxy into a bulge component and a disc component by randomly sampling bulge to total ratios from table 3 of Simard et al. (2011), which gives an observational estimate of bulge to total ratios for around a million SDSS galaxies. The measured magnitudes of the synthetic galaxies are faded by the mean extinction of SAS2, 0.2 magnitudes (Paper I).
Once we have the galaxy morphological properties, we evaluate Equation 8 on a pixel grid of a linear scale three times smaller than PS1 warped pixel scale of before binning up. This is to minimise the effect of gradients in the profile across pixels. Pixels on the finer grid whose centres are closer than to the profile centre are further subdivided 3 by 3 to take into account the steeper profile near the centre. If any of these subdivided fine pixels are on the centre of a de Vaucouleurs profile, an analytic integral is used to approximate the flux required, as de Vaucouleurs profiles asymptote to infinity at zero. Stars, conversely, are evaluated directly on to the native pixel scale as this is the scale at which the model is measured. Galaxy profiles are convolved with the PSF using the C-library fftw (Frigo & Johnson, 2005). The grid dimensions are chosen to ensure that the finished, convolved galaxy image contains more than 99.8% of the flux. Stars are evaluated on a grid of by which contains more than 99.9% of the flux for PS1 SAS2 PSFs.
Paper I shows results from our synthetic stars agree with a set of synthetic stars produced by IPP. It also uses our synthetic objects to test PS1 depth and photometry. Interested readers can refer to Paper I for basic results from the synthetic objects, such as recovered versus input magnitude.
4.3 Morphological Separator
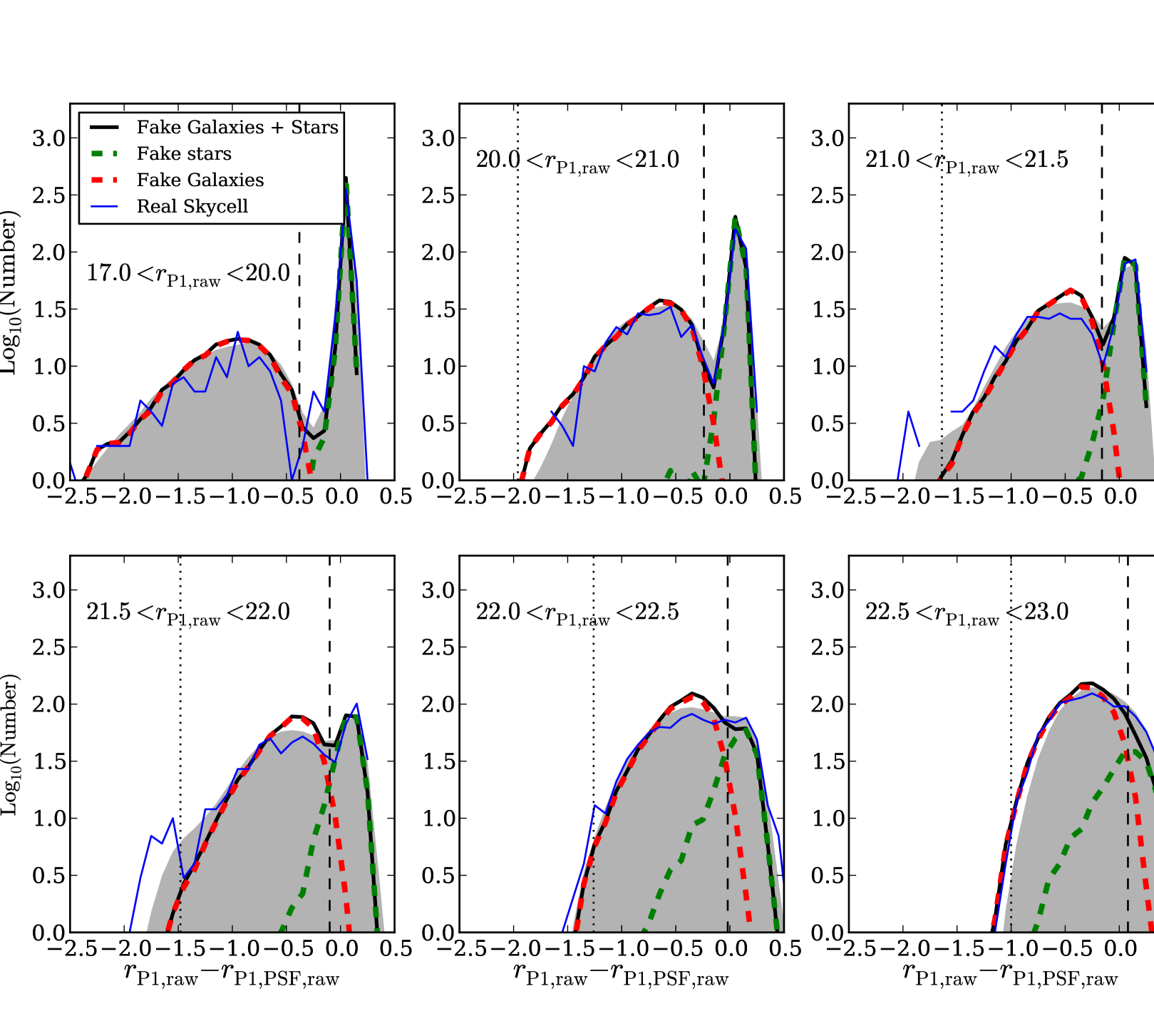
The PS1 SAS2 -band skycell 1315.028 was taken as an example and 286 synthetic galaxies and 300 synthetic stars down to a limit of were inserted into it, created as described by Section 4.2. This skycell was chosen as it has a PSF FWHM typical of SAS2. The PS1 photometry code psphot was run on this skycell and this process was repeated 40 times yielding data from 11,440 synthetic galaxies and 12,000 synthetic stars. Motivated by the often used star and galaxy separator of a PSF magnitude minus an aperture-like magnitude (e.g. Strauss et al., 2002), we show in Fig. 8 a histogram of the psphot measured Kron minus PSF magnitude for the synthetic galaxies, the real sources in this skycell and for sources over the whole of SAS2. The number of synthetic galaxies and stars are scaled to the observed number of objects in each magnitude bin. We can see from Fig. 8 that the synthetic stars and galaxies follow the distribution of the real sources. This indicates we are justified in using Kron minus PSF magnitude as a star and galaxy separator. We see the synthetic stars follow a peaked, stellar locus whereas the synthetic galaxies follow a more negative locus of extended sources.
We use our synthetic objects to define cuts in Kron minus PSF magnitude ( hereafter) that define samples of stars or galaxies. We can also define a smallest allowed value of for galaxy samples, this removes objects with extremely negative which are likely false positives. We place this extreme cut at a value where only of synthetic galaxies are to the left of this cut. Fig. 9 shows cuts in that define galaxy samples of a given completeness, these cuts were measured from the histograms in Fig 8. The cut defines a minimum for stars or a maximum value for galaxies. The dashed lines are fits to the cuts using a second order polynomial of the form
| (12) |
We use the 98% cut to define galaxies throughout this work. Table 1 gives the values of the coefficients of this equation for different samples. For our adopted cut we again use our synthetic objects, along with fits to the observed SAS2 bright star and galaxy number counts (shown in Fig. 17), to predict completeness and stellar contamination rates. In Fig. 10 the predicted galaxy completeness line follows the 98% line (solid, black), by construction, down to a faint magnitude limit. Near the end of this magnitude range the completeness does drop very slightly and this suggests our fits with Eq. 12 cannot be used beyond a faint magnitude limit of . The dotted line in Fig. 10 shows the completeness of the sample after applying the extreme . This cut, again by construction, has very little effect on the completeness of real galaxies.
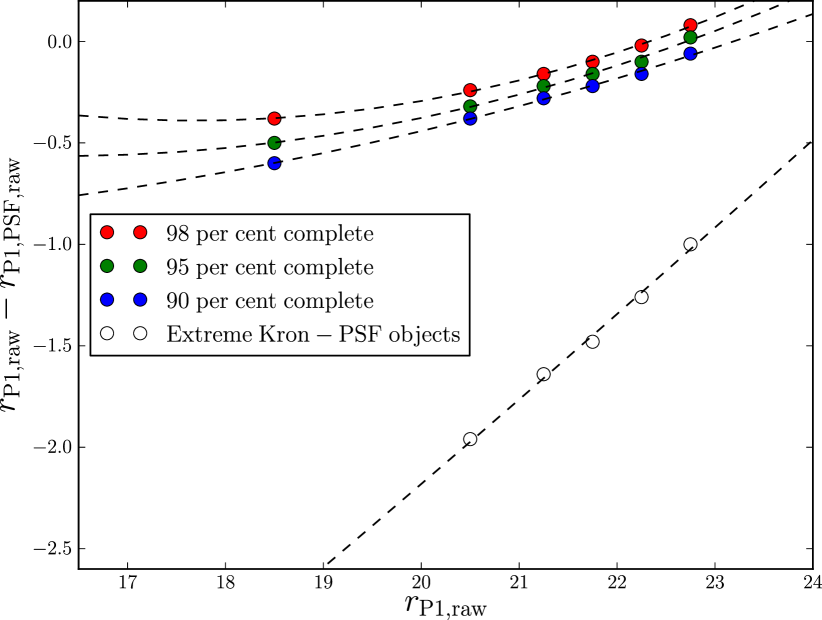
Fig. 10 also gives the probability of misclassifying a star as a galaxy (solid red) and the predicted stellar contamination as a fraction of the galaxy sample (dashed red). The latter were calculated from our power law fits to the observed SAS2 bright star and galaxy number counts (Fig. 17). We see stellar contamination stays below 10% for all magnitude ranges.
| Sample | Upper or Lower Limit | |||
|---|---|---|---|---|
| 98% Galaxies | Upper | |||
| 95% Galaxies | Upper | |||
| 90% Galaxies | Upper | |||
| Extreme | Lower |
In order to further test our star/galaxy separator, we match our -band data to the and -bands and plot the colour-colour and colour-magnitude diagrams for stars and galaxies classified via our 98% cut in the -band. The diagrams in Fig. 11 follow those for SDSS objects seen in Finlator et al. (2000). In Finlator et al. (2000) the shape of the distribution of stars in these plots is explained as being driven by different spectral types, with M dwarfs causing the upturn in the colour-colour diagram and F and G disc stars along with fainter, bluer halo stars causing the locus at . We see no evidence of these features in objects classified as galaxies, which gives further support to the effectiveness of our star and galaxy separator.
4.4 Comparison to VVDS Spectroscopic Star and Galaxy Classification
As a further test of our star/galaxy separator, we compare to the spectral classifications from the F22 field VIMOS VLT Deep Survey (VVDS) (Le Fèvre et al., 2005), which we downloaded from the CeSAM website333http://www.lam.fr/cesam/?lang=en. The VVDS survey is an selected sample of objects. Objects targeted for redshifts are purely selected on apparent magnitude to be , though the full photometric catalogue is deeper than PS1 (McCracken et al., 2003; Le Fèvre et al., 2005). F22 and SAS2 overlap by square degrees. We match the two catalogues using a matching radius. From the matched catalogue we select objects which have been targeted for spectroscopy based on the value of the column zflags, taking zflags=99 to mean the object was not targeted. Following Ilbert et al. (2005) we also use zflags to select objects with secure redshifts, by requiring the last digit of zflags to be greater than or equal to 2. Objects with these zflags are expected to have the correct redshift 80-99% of the time, depending on their value of zflags (Le Fèvre et al., 2005).
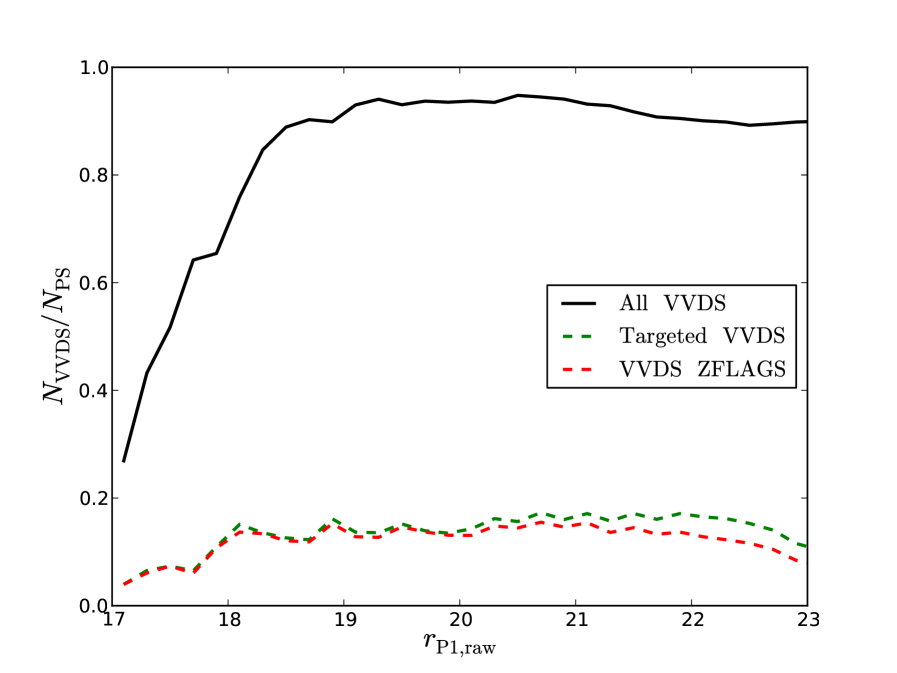
In Fig. 12 we show the fraction of objects in PS1 matched to VVDS as a function of PS1 raw Kron magnitude. We do not correct for the VVDS mask, which explains why the curve does not reach unity. An -band selected sample may have a different morphological mix than an -band selected sample in the same magnitude range. From Fig. 12 we see the fraction of objects targeted for spectroscopy drops brighter than around and fainter than : this is the region where the effects of the VVDS -band selection may become important and as such results from these magnitude ranges may be unreliable. Also note from Fig. 12 the fraction of objects with secure redshifts decreases with magnitude, as one might expect.
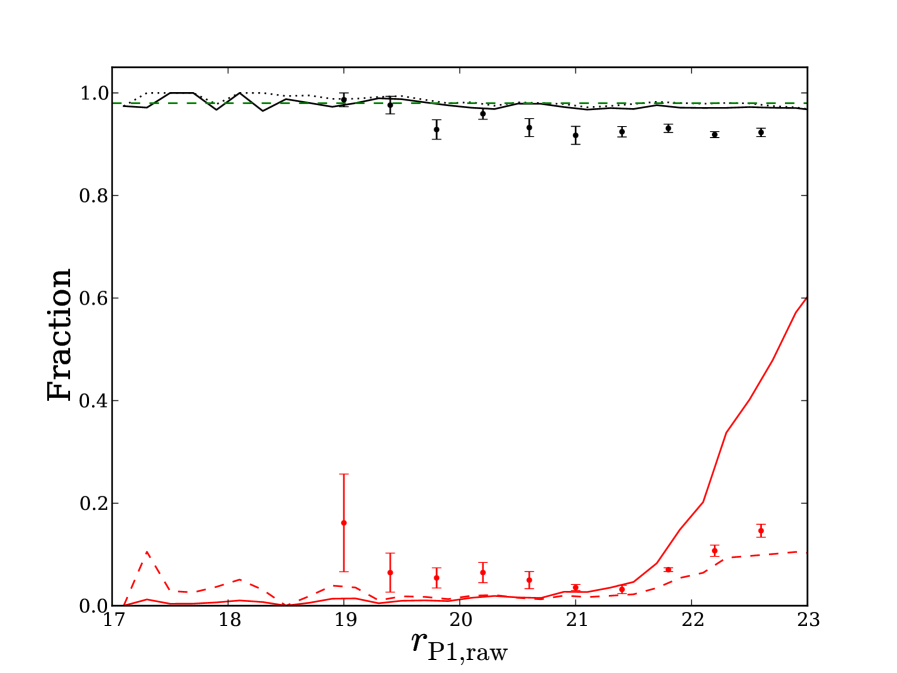
A well reported issue in VVDS is its bias against extended sources. Whilst the targeting criteria is purely based on apparent magnitude the program which allocates VIMOS slits to targets, the Slit Positioning Optimization Code (SPOC) (Bottini et al., 2005), is biased against extended sources as they take up more space on the -axis of the spectrograph and so decrease the efficiency with which spectra are taken (Bottini et al., 2005). When computing luminosity functions Ilbert et al. (2005) corrected for this incompleteness by weighting galaxies in a way proportional to their -axis size on VIMOS. We choose to weight galaxies depending on their . In magnitude and bins we measure the completeness as the ratio of objects with good zflags to all objects matched between PS1 and VVDS in the overlap region. The weight of each object is then the inverse of the completeness of its magnitude and bin.
When comparing to VVDS there are three different cases to consider. The first case is where the object is classed as a galaxy in VVDS and PS1, we label weights for these objects as . The second case is for an object classed as a galaxy in PS1 but has a VVDS stellar spectral classification, we label weights for these objects as . The final case is an object classed as a star in PS1 but with a galaxy spectra in VVDS, these objects are assigned weights labelled . The completeness, , and contamination, , are estimated using the following weighted sums
| (13) |
We plot these estimates, along with jack-knife errors from 9 re-samplings of the data, in Fig. 10. Estimates of stellar contamination are slightly higher than the estimates based on synthetic images, but this is only a small discrepancy given the size of the errors. Estimates of completeness agree until around when it looks like our synthetic source estimates are too optimistic. The spectroscopic estimates suggest a completeness of around 91%, as opposed to the predicted 98%.
There are several possible reasons for this difference. A major cause of disagreement is likely to be misclassifications in the VVDS sample. To calculate the fraction of objects in our sample which could be misclassified by VVDS we use zflags. The value of zflags has been related to the probability of having been assigned the correct redshift, , by Le Fèvre et al. (2005). We assume this is also the probability of being correctly classified as a star or galaxy. Table 2 gives the different fractions of the full sample, , and sample with discrepant star/galaxy classification, , that have certain values of zflags. Table 2 also gives our estimate of the fraction of objects in the full sample with incorrect VVDS classification, . Given that 9% of the full sample have discrepant classfications, is the number of objects in the discrepant sample with a certain zflags value as a fraction of the total matched sample. Taking the minimum of or for each zflags value in Table 2 and summing suggests that 6% of our disagreement could be down to misclassified VVDS objects. This would lead to a VVDS misclassification-corrected estimate of completeness of 97%, consistent within random errors with our estimate from synthetic sources.
| zflags | ||||
|---|---|---|---|---|
| 2 | 0.80 | 0.25 | 0.42 | 0.05 |
| 3 | 0.91 | 0.22 | 0.23 | 0.02 |
Another potential explanation is that the synthetic galaxies may be slightly too extended in their values. Simplification of modelling galaxies with de Vaucouleurs and exponential profiles, adopting a mean extinction value for the galaxies, using redshifts and magnitudes from galform and only generating synthetic images on one skycell could all contribute to this effect.
From Fig. 10 it appears that our classification is around 91%-98% accurate down to faint magnitudes depending on how you estimate classification completeness. Brighter than stellar contamination is below 6%, increasing to around 10% at magnitudes fainter than this. The action of stellar contamination, on smaller scales where the stars are uniformly distributed, is to dilute the clustering by , where is the fraction of stars in the galaxy sample (e.g. Hudon & Lilly, 1996; Roche & Eales, 1999). We will revisit the effect of stellar contamination in Section 6.3.
Classification contamination and completeness can influence galaxy clustering measurements and as such work on star and galaxy separation is ongoing. Classifications based on SED fits along with star/galaxy separators calibrated on other data sets and other morphological measurements will be available to help meet the future PS1 science goals.
5 Dealing with Variable Depth
The finished PS1 3 survey will have spatially variable image depth for several reasons. These include spatially varying stack coverage due to masking and greater or fewer visits to any piece of sky (see Fig. 1), varying PSFs and varying sky brightness. To measure reliable clustering it is vital to measure the angular incompleteness, otherwise fluctuations in galaxy density caused by changes in depth would contaminate the clustering measurements. Once this angular incompleteness is modelled we can deal with it by introducing the same depth variations into the random distribution of points we use to measure clustering, which we shall refer to from now on as our “random catalogue”.
We assume that the probability of detecting an object is only dependent on the signal-to-noise ratio. In order to make a simplified estimate of the signal to noise ratio we assume all sources have a Gaussian light distribution. For the stacked data most galaxies near the magnitude limit have small angular sizes so this is a reasonable approximation (we further test this later in this section). Using a PS1 PSF rather than a Gaussian would simply scale our FWHM measurements to different values, an effect that would be removed by the empirical calibration we present later in this section. We define the “fiducial” SNR as
| (14) |
where is the FWHM of the PSF in units of pixels, is the apparent flux of the source (without extinction correction) and is the variance according to the variance map. Whilst is measured for all PS1 detections, for this work we use the typical FWHM of SAS2 of . As SAS2 has fairly uniform seeing this simplifies our work whilst not affecting our results. We use our masks to extract which results in the loss of some spatial accuracy. This is unavoidable due to the otherwise prohibitively slow process of retrieving the individual variance maps at the native pixel scale.
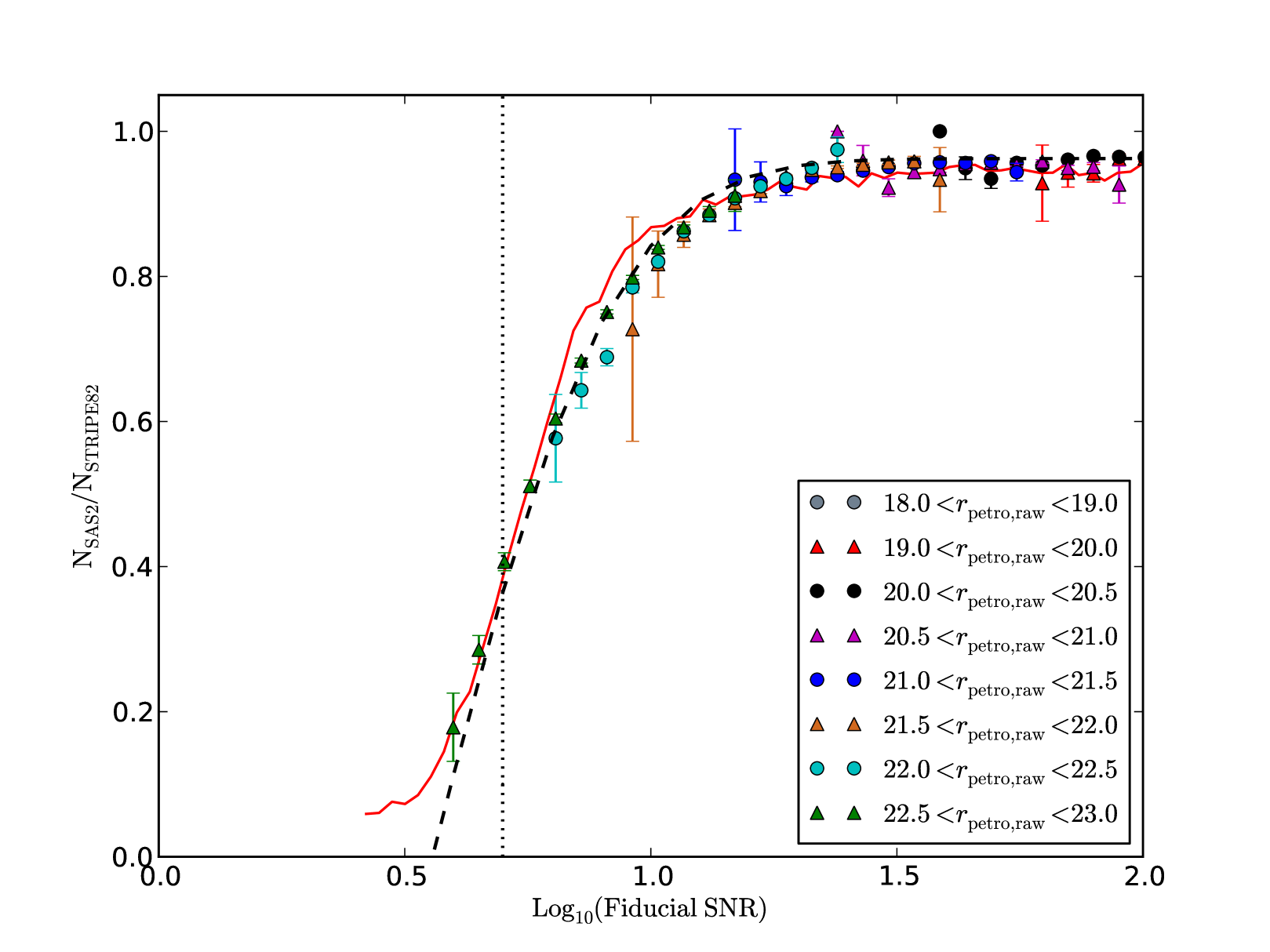
To calibrate the relationship between our fiducial SNR measurements and source recovery fraction we again make use of the overlap region with Stripe 82. We use the Stripe 82 Petrosian magnitude to calculate the fiducial SNR for all Stripe 82 galaxies and then match to PS1 SAS2 and see what fraction are recovered. We plot these fractions in Fig. 13 in different magnitude bins. The fact that over different magnitude bins the fiducial SNR values have the same detected fraction shows that this measurement can be used to assess the probability of detection. We parameterize this curve with the fitting formula
| (15) |
where , and are constants with best-fitting values , and . The fact that is not unity implies there is always some fraction of Stripe 82 objects undetected by PS1. We believe this fraction is caused by false positives in SDSS Stripe 82 and visually inspecting a subset of these objects suggests they are mainly caused by spurious detections in the wings of extended objects. So long as the number of false positives in Stripe 82 remains a constant fraction of the real objects this effect should not bias our results, this seems to be the case as the curve is flat for large values of fiducial SNR. As a sanity check we also add a curve to Fig. 13 showing the detection efficiency estimated from our synthetic galaxies, using the input synthetic object magnitude corrected to Kron magnitude using a correction of 0.2 magnitudes (explained in Section 2.1). Our estimate of detection efficiency from synthetic objects shows a reasonable agreement with the real data on the plot, though the synthetic galaxies seem to suggest the Stripe 82 comparisons slightly underestimate the depth at fiducial SNR values of around 6 to 9. The differences could be due to multiple causes. For example, it could be Stripe 82 false positives or slightly above average seeing in the skycell used in Section 4.3. As these differences are only of the order of a few percent we choose to defer further careful studies to the analysis of the full dataset, where a larger amount of deeper comparison data will be available.
We can see in Fig. 13 that a SNR implies a 20-30% detected fraction which is lower than the measurements in Paper I of 50-60% recovery of fake stars at that SNR, this is to be expected as extended objects at these magnitudes are lower surface brightness and therefore harder to detect. None the less this highlights the fact that where the curve of Fig. 13 is steep small changes in the SNR can lead to large changes in detection fraction. To avoid any problems caused by this we impose a default lower limit on the fiducial SNR by excluding spatial regions where . We experiment with different values of this parameter in Section 6.2.
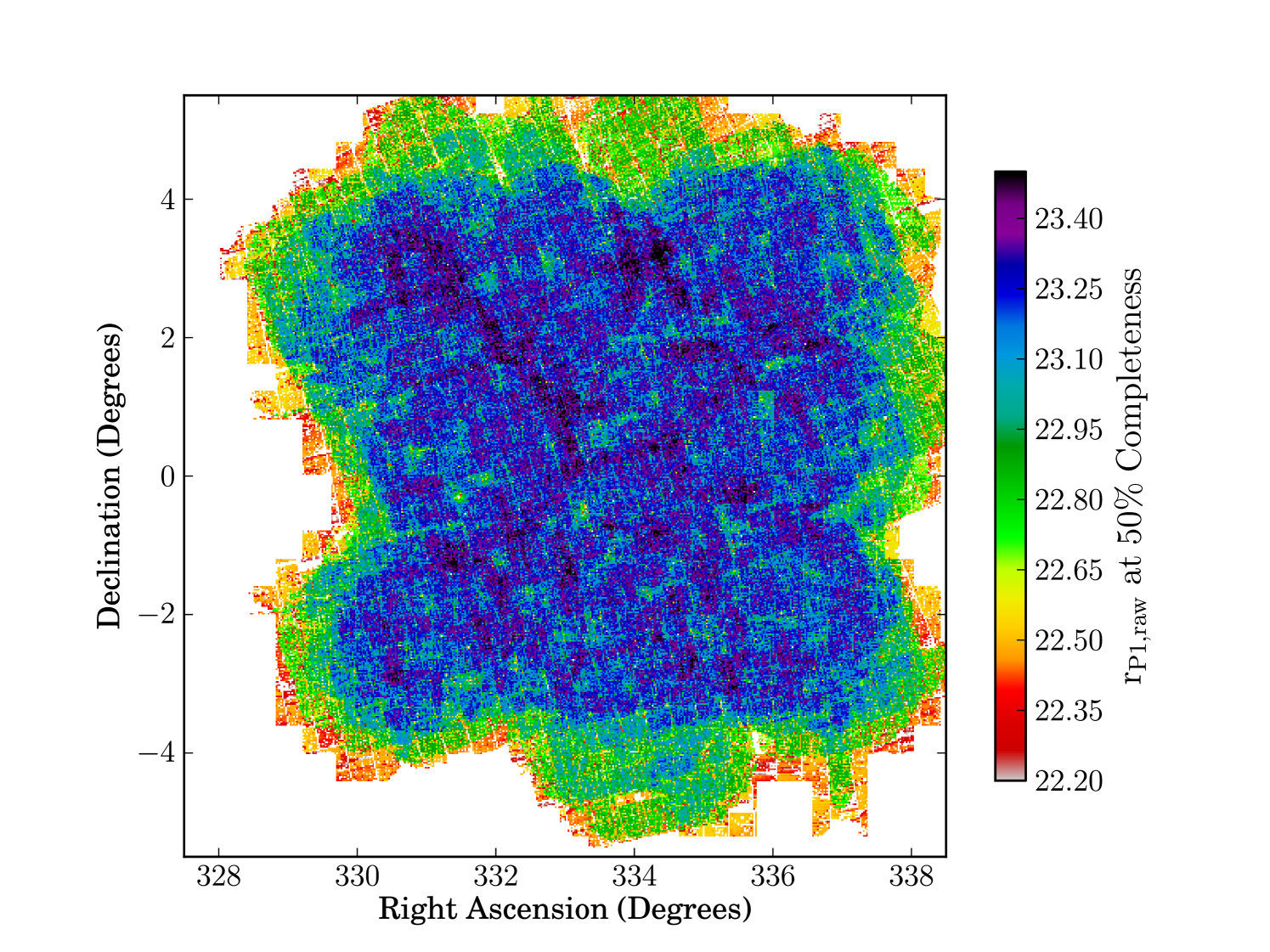
Using our binned up variance maps and Eq. 15 we can produce a map of the magnitude at 50% galaxy recovery, shown in Fig. 14. Note we can produce these maps even in SAS2 regions without Stripe 82 overlap, as we only need Stripe 82 to calibrate Eq. 15. One can clearly see the shallower regions near the edges of the SAS2 field, along with patterns of deeper regions in the central area caused by the overlapping pattern of input exposures. Fig. 14 demonstrates our technique produces maps of depth to very high resolution, contrast this with the much lower resolution depth maps produced using synthetic stars presented in figure 15 of Paper I. Reassuringly we see common features, including the shallower edge region and the deeper diagonal feature.
We use the curve measured in Fig. 13 to correct our random catalogue by making the chance of placing a random point of a certain magnitude in any region equal to the detected fraction expected for that region given the random point’s fiducial SNR. Magnitudes are assigned to the random points from the observed galaxy counts, uncorrected for extinction. As a first pass we estimate these number counts by fitting the bright end of the galaxy counts with a power law (in Section 6.1 we show we can use our method to yield depth corrected number counts, which we use to assign magnitudes to the random points). After assigning magnitudes and deciding if a random is detected, we extinction-correct the random catalogue. This technique results in a random catalogue with the same spatial depth variation as the data.
We plot the depth-corrected density of galaxies in Fig. 15. To produce this figure we binned the galaxies and detection efficiency randoms onto the same grid and then divided the galaxy grid by the random grid, normalising by the ratio of the relative numbers of galaxies and randoms. To eliminate noise from regions with very few randoms, generally near the edge of the field, we white-out pixels with fewer than 5 randoms. Comparing Fig. 6(bottom) to Fig. 15 we see the over-densities caused by varying image depth are removed. There are fewer objects in Fig. 15 than Fig. 6(bottom) as star/galaxy separation has removed the stars.
One key assumption of our depth correction method is that all galaxies in our sample have the same detection efficiency properties for the same fiducial SNR, i.e. that secondary parameters such as morphology or colour are unimportant in determining how likely objects are to be detected (consider Eq. 14). We argue that for faint magnitudes galaxies predominantly have small angular sizes and as such look similar to one another after being convolved with the PSF. To further test this we plot, in Fig. 16, the detection efficiency curves of our Stripe 82 red and blue samples of galaxies. In Fig. 16 we see, for the same reasons as in Fig. 13, that the curve does not reach unity. We also see that at brighter magnitudes blue galaxies have a lower detection efficiency. As this effect is at magnitudes far brighter than our detection limit we attribute this to false positives in Stripe 82 falling on the blue side of our colour cut. The agreement between the red and blue detection efficiency curve at faint magnitudes in Fig. 16 suggests that an undetected low surface brightness population of galaxies must either be split equally between our two colour bins or represent a very small fraction of our sample. This supports our assumption that at the limiting magnitude of 3 data detection efficiency depends on a single parameter, SNR. However in small regions of the 3 survey where the limiting magnitude may be much brighter, and galaxies near this magnitude have larger angular sizes, the situation may be more complicated.
Another important thing to note is that our method gives a measurement of the clustering of only the detected galaxies. As our faintest samples become incomplete towards faint magnitudes they will, to some extent, be biased towards bright galaxies. To test how much of an effect this is we utilize our random catalogues, measuring the median magnitude of random samples before and after degrading them for detection efficiency effects. In this paper we mainly use 0.5 magnitude bins, here the difference in median magnitudes is less than 0.04 magnitudes for the faintest sample of , and zero for samples brighter than around . Our measurements of clustering in these bins will not be significantly affected by this small difference. In general, however, it is important to note that this method assumes the detected galaxies have the clustering properties of the full population, i.e. the method only corrects for the spatial dependence of image depth. Care will have to be taken to not apply this method where there is a large variation in completeness across the apparent magnitude range of a sample.
6 Results and Tests for Systematics
6.1 Number Counts
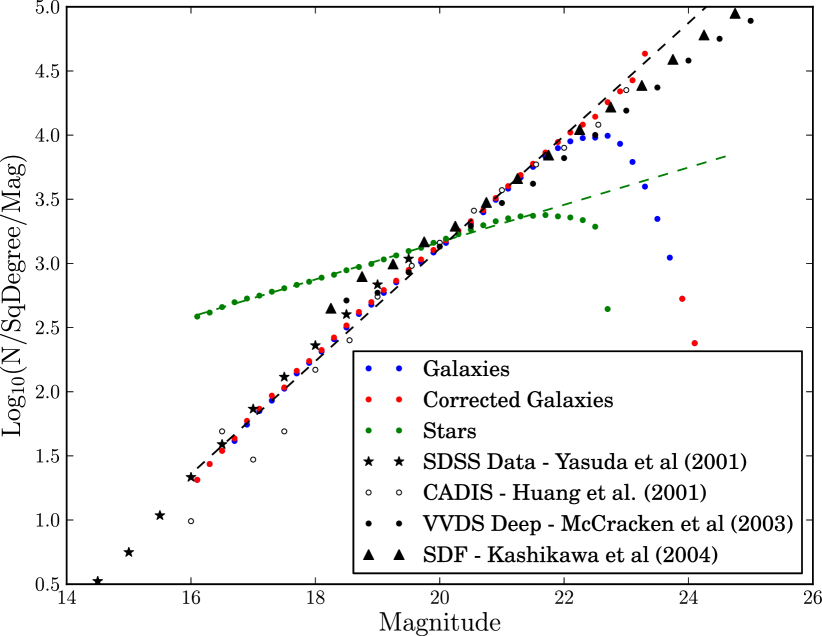
We plot, in Fig. 17, the -band differential number magnitude counts of galaxies before and after our correction. A Kron to total correction of 0.2 magnitudes is applied to the galaxy counts, as explained in Section 2.1. To generate the detection efficiency corrected number counts in Fig. 17 we use our extinction corrected random catalogue, from before and after the detection efficiency corrections, to predict the fraction of galaxies detected as a function of extinction corrected magnitude. We then correct the observed number counts by these fractions. We see after the counts have been corrected the turnover no longer occurs, and the counts continue to grow to very faint magnitudes until we stop using our depth correction at , where the correction is very large (a factor of 70 at this magnitude). We see that our number counts show reasonable agreement with the published data of Huang et al. (2001), Yasuda et al. (2001), McCracken et al. (2003) and Kashikawa et al. (2004). At the faintest magnitude our number counts are slightly above the literature measurements, both where our correction is and is not important. This could be partially due to the 10% false positives at these magnitudes (see Fig. 7 and also Paper I). It could also be partially explained by cosmic variance, as the literature measurements also disagree to a similar extent at these magnitudes.
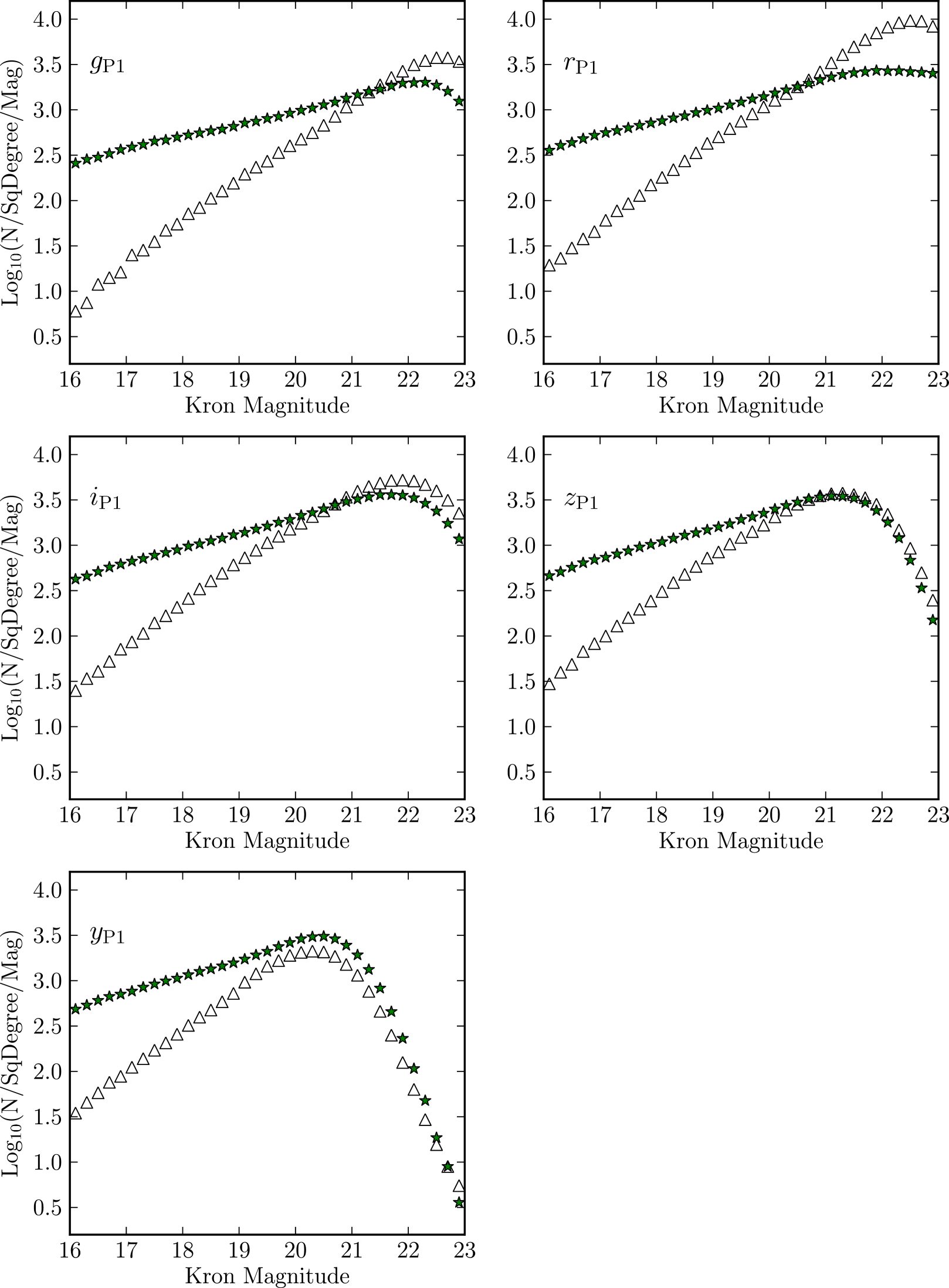
In Fig. 18 we show our measured, uncorrected number counts for different bands. Each band was matched to the -band, where the star/galaxy classification was made. The galaxies show a power law trend in good agreement with previous measurements. The stars show a shallower power law trend. The turnover in the samples is caused by the incompleteness and this turnover happens at brighter magnitudes as we move toward redder bands. In redder bands the ratio of stars to galaxies increases, until the -band where we see more stars than galaxies at all magnitudes. As these are the same objects as seen in Fig. 17 the main purpose of this plot is to check if our -band star/galaxy classification gives sensible results for different bands. We leave detailed science analyses using the number counts to later work.
6.2 Angular Clustering
In this section we present measurements of angular clustering. To measure this clustering we make use of the GPU code of Bard et al. (2012). We use the Hamilton (1993) estimator, though our results are unchanged if we use the Landy & Szalay (1993) estimator. Error bars for all clustering measurements are from 9 jack-knife re-samplings of the data. We use eight times as many random points as data points throughout. On each clustering plot we draw the same dashed-black reference line, for easier comparisons between plots.
When measuring clustering an effect known as the integral constraint can artificially weaken clustering on scales comparable to the area of the survey (e.g. Roche & Eales, 1999). For SAS2 data, over the scales we measure clustering, this has no effect on our results, except in one case we will discuss later. For the MD07 measurements however the smaller area results in the integral constraint being important on the scales we consider. We therefore estimate the true clustering of the MD07 data on large scales by fitting a power law between scales of 0.002 to 0.165 degrees and then use this fit to estimate the size of the integral constraint using the standard formula (e.g. equation 9 of Roche & Eales, 1999). As an example, for our threshold sample the integral constraint is 80% of the signal at the largest separations plotted, dropping to 14% by deg.
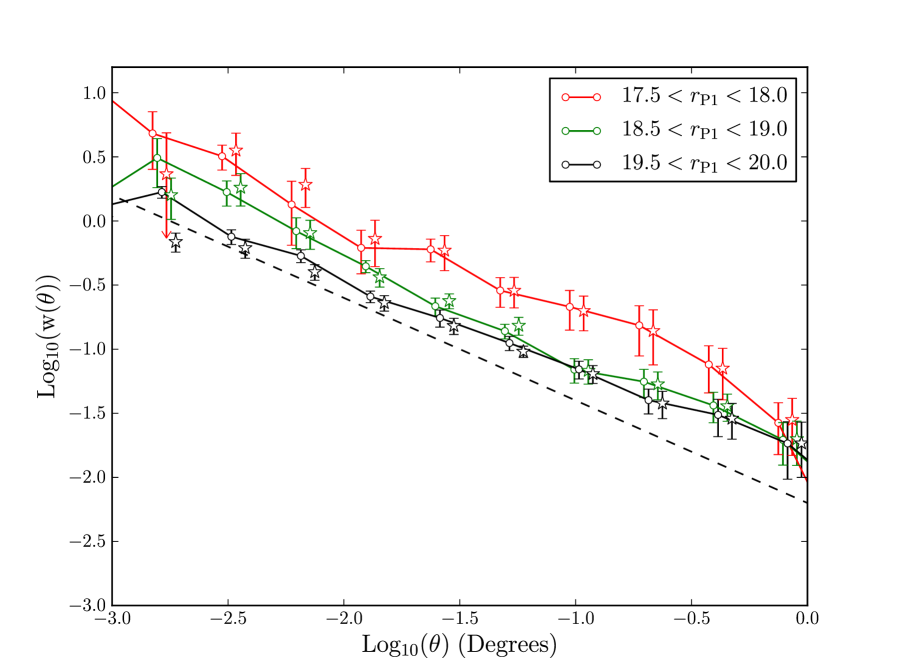
We begin by studying the regime where the spatially varying depth correction has no effect. Fig. 19 shows the clustering of PS1 data compared the the clustering of DR8 data over the same region, which we measured from our galaxy sample (Section 2.3). We see the well-reported effect of clustering being stronger in brighter apparent magnitude bins. This result is caused by two effects. The first is that fainter magnitude bins are projected over larger radial distance ranges so incoherent clustering signals are summed together decreasing the clustering strength. The second cause is that intrinsically fainter galaxies are less clustered, usually interpreted as evidence they lie in less massive dark matter haloes. This latter effect is much smaller than the former as apparent magnitude ranges relate to similar absolute magnitude ranges. We see good agreement between the SDSS and PS1 measurements for these ranges, an agreement much closer than the jack-knife error bars as the two data samples are from the same area of sky. We do see some differences, but photometric errors scatter galaxies in and out of the different magnitude bins and so the two samples can contain a significant fraction of galaxies that are not in common. Overall, Fig. 19 acts as a detailed test to determine if PS1 is capable of measuring the clustering of galaxies down to . Fainter than this it becomes more difficult to measure reliable clustering with SDSS DR8 and as such we compare to measurements in the literature.
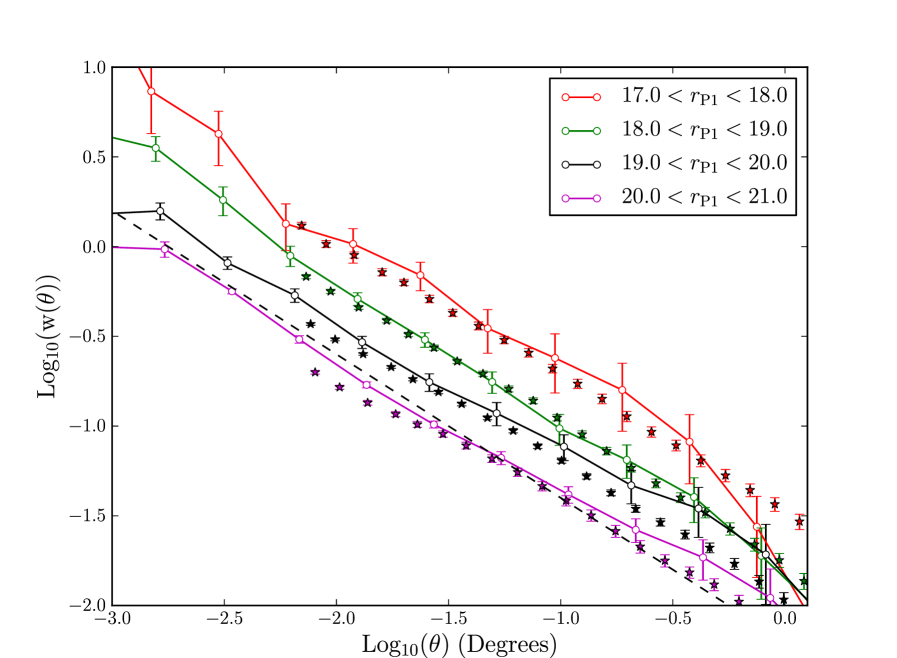
In Fig. 20 we compare our angular clustering measurements from PS1 SAS2 to recent angular clustering measurements from Wang et al. (2013) from 8000 square degrees of SDSS DR7 data. In Wang et al. (2013) careful studies are carried out which suggest SDSS DR7 can measure clustering down to , Fig. 20 demonstrates PS1 data shows reasonable agreement with the SDSS data. Naturally, differences arise due to sample variance in the relatively small SAS2 field, but Fig. 20 is a promising indicator that PS1 clustering measurements are capable of matching SDSS depth. Fainter than the spatially varying depth will start to become important.
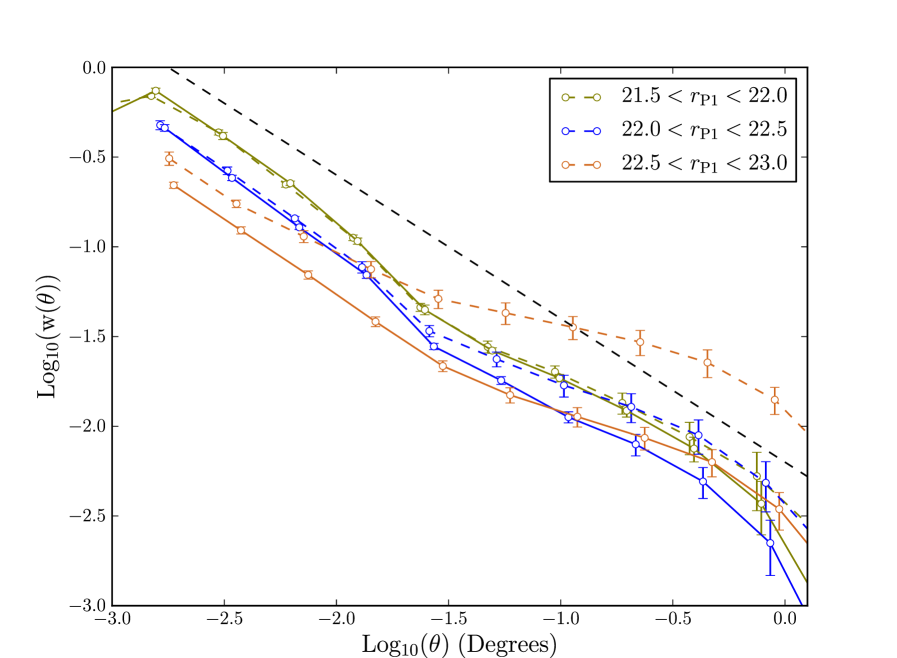
To see the effects of our depth correction we plot, in Fig. 21, the 2-point angular correlation function of galaxies before and after correcting the random catalogue for spatially varying depth. At and , the edges of the brightest and faintest bins in Fig. 21, the average completeness is only and respectively. We see that without corrections clustering in these faint bins is enhanced by under-densities and over-densities caused by the spatially varying incompleteness. After correction the clustering strength is decreased, with the effect being more marked for the fainter bins where one would expect the depth to be most spatially inhomogeneous. The strength of clustering in the fainter bins has its largest correction at large scales. Magnitude ranges brighter than seem to need very little correction, whereas the correction becomes larger for fainter bins. The SAS2 region is more uniform than the full data so the magnitudes at which the spatial depth variation correction becomes important may differ for the full 3 survey.
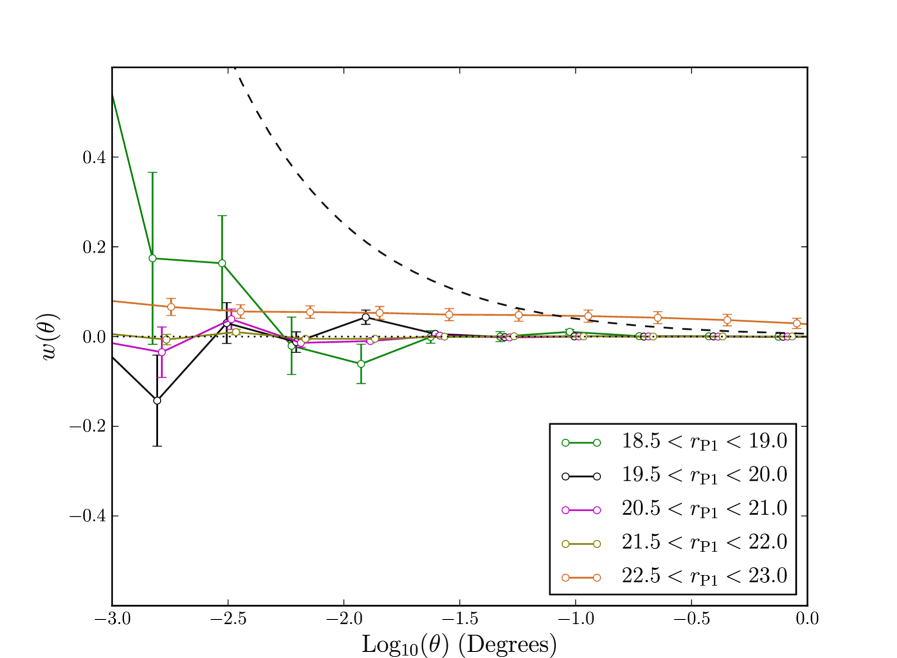
As an alternate way of understanding our correction we measure the angular correlation function of our spatial depth corrected random catalogue, relative to an uncorrected, spatially uniform random catalogue. This gives us an estimate of the signal we remove from the faint magnitude bins. We see in Fig. 22 the clustering of the bright randoms is consistent with no clustering signal. Bright randoms have larger errors as there are fewer bright randoms. For the faintest bin, where we see the strongest correction, the randoms are clustered. This type of clustering signal is the effect of variable depth on our measurements. We can infer that without correction clustering is enhanced on all scales. This effect will be particularly noticeable on larger scales where the intrinsic galaxy clustering is weak, this is seen in Fig. 21.
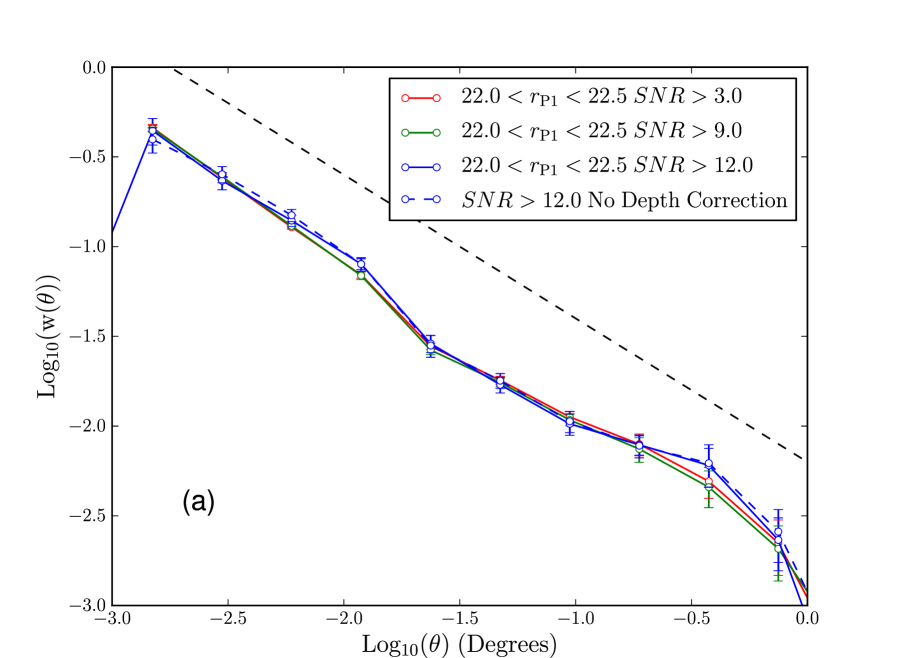
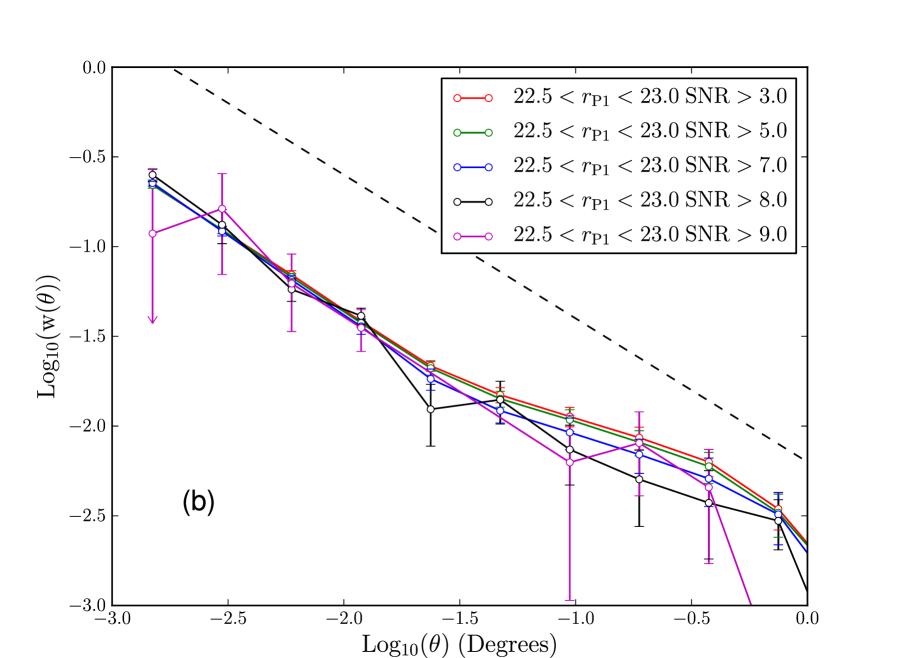
Qualitatively the correction appears to be doing a good job. To carry out a quantitative test we find the variance value which corresponds to some fiducial SNR at the faint edge of a magnitude bin, and mask spatial regions in the randoms and data that have a variance value higher than this. This limits our depth correction by removing data and randoms with fiducial SNR lower than some limit. The corrected clustering measurements for the range in Fig. 23(a) are robust to changes in the choice of the SNR limit, with more conservative cuts in SNR being in agreement with the more lenient cuts. To further emphasise this we plot the clustering of galaxies with and without spatial depth corrections, in regions with where the depth is fairly uniform. We see from these curves that using the full SAS2 region combined with a correction gives results in agreement with using a smaller region of uniform depth.
We plot in Fig. 23(b) the same tests for the faintest magnitude bin, . The conservative SNR cuts in the faintest magnitude bin restrict the area of the survey, and as such the integral constraint becomes important. We therefore correct clustering measurements in this plot for the integral constraint, using the power law fit plotted in grey. We do not show cuts more conservative than as there are very little data beyond that cut in this magnitude range. Unfortunately the results of this test are less convincing, the different cuts agree within error but there does appear to be a systematic trend for more conservative cuts to measure a slightly weaker clustering signal on larger scales. This could suggest our correction is too small, though it could also be caused by other problems at very faint magnitudes such as false positives. Remember that in this faintest magnitude bin our correction is extremely large and the data is very incomplete. Completeness is only around 50% at (Paper I), so it is perhaps not surprising that the method is less successful in this regime. For science applications we do not intend to apply corrections as large as this. Instead we would place a limit on the minimum SNR of the data analysed and so would exclude the shallower areas of the survey when constructing the faintest datasets. However, the fact that our method is reasonably successful in this regime is a positive indication that our method will work for more uniform data.
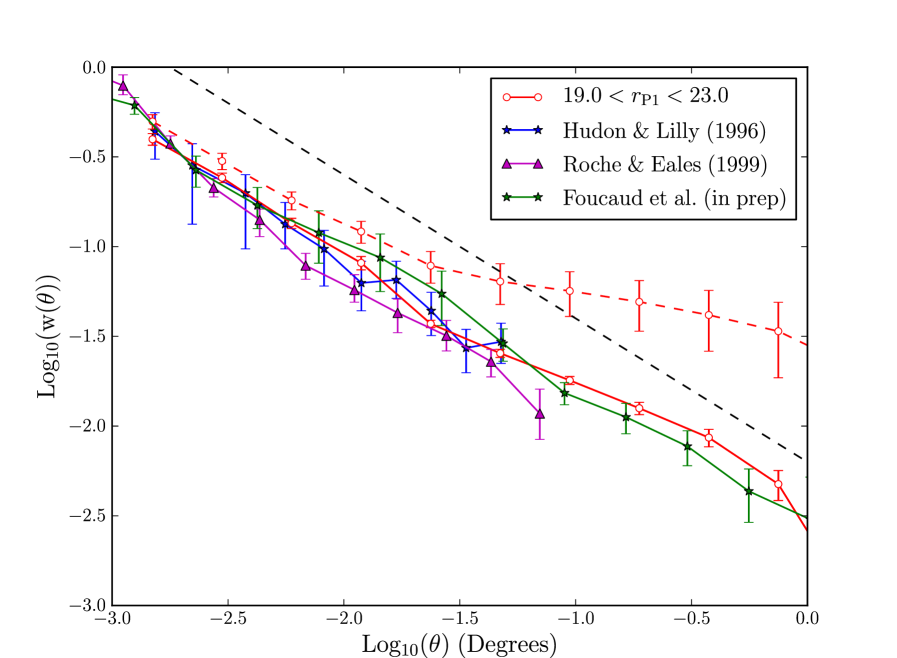
In Fig. 24 we compare our measurements of clustering to those of Hudon & Lilly (1996), field “e” of Roche & Eales (1999) and Foucaud et al. (in preparation) for the magnitude range . Note that the Roche & Eales (1999) sample is for measured in the Vega system, but despite these small differences it is still a useful comparison. The amplitudes of Hudon & Lilly (1996) and Roche & Eales (1999) have been corrected for stellar contamination using their estimate of the contamination fraction of and respectively. As introduced in Section 4.4 this correction is boosting the amplitude by and is the same correction Hudon & Lilly (1996) and Roche & Eales (1999) apply to their own results. We estimate our contamination fraction, from the dashed red line in Fig. 10, to be for this sample and we correct our amplitude accordingly. Foucaud et al. (in preparation) estimate their stellar contamination to be , so we also correct their clustering measurements.
In Fig. 24 we see our depth correction brings us closer to the other measurements of clustering. On smaller scales we show reasonable agreement with the literature measurements of Hudon & Lilly (1996) and Roche & Eales (1999). Within the errors we show agreement with the MD07 clustering measurements of Foucaud et al (in preparation). Our correlation function is slightly higher than the MD07 measurements on scales greater than degrees, and slightly lower on scales less than this. However, these differences are within the reasonably large error bars of the MD07 sample. The scatter in the literature measurements is also large due to the small size of the samples. As such current available comparison data in the -band is limited by sample variance, limiting our ability to assess any remaining systematic errors. Another limitation of this comparison is that, for this magnitude range, the median magnitude of our incomplete sample of galaxies will be 0.16 magnitudes brighter than that of a complete sample. As explained, this occurs where the completeness of the galaxy sample shows significant variation across the sample’s apparent magnitude range. This would lead to our measurements having a slightly stronger clustering amplitude than a complete sample, which could explain some of our disagreement with the MD07 clustering measurements on larger scales. Despite the limitations of this comparison plot, it is still impressive that in the regime where the corrections are very large our method does a qualitatively good job at recovering the clustering signal. We do not intend our method to be applied to such incomplete data for science applications.
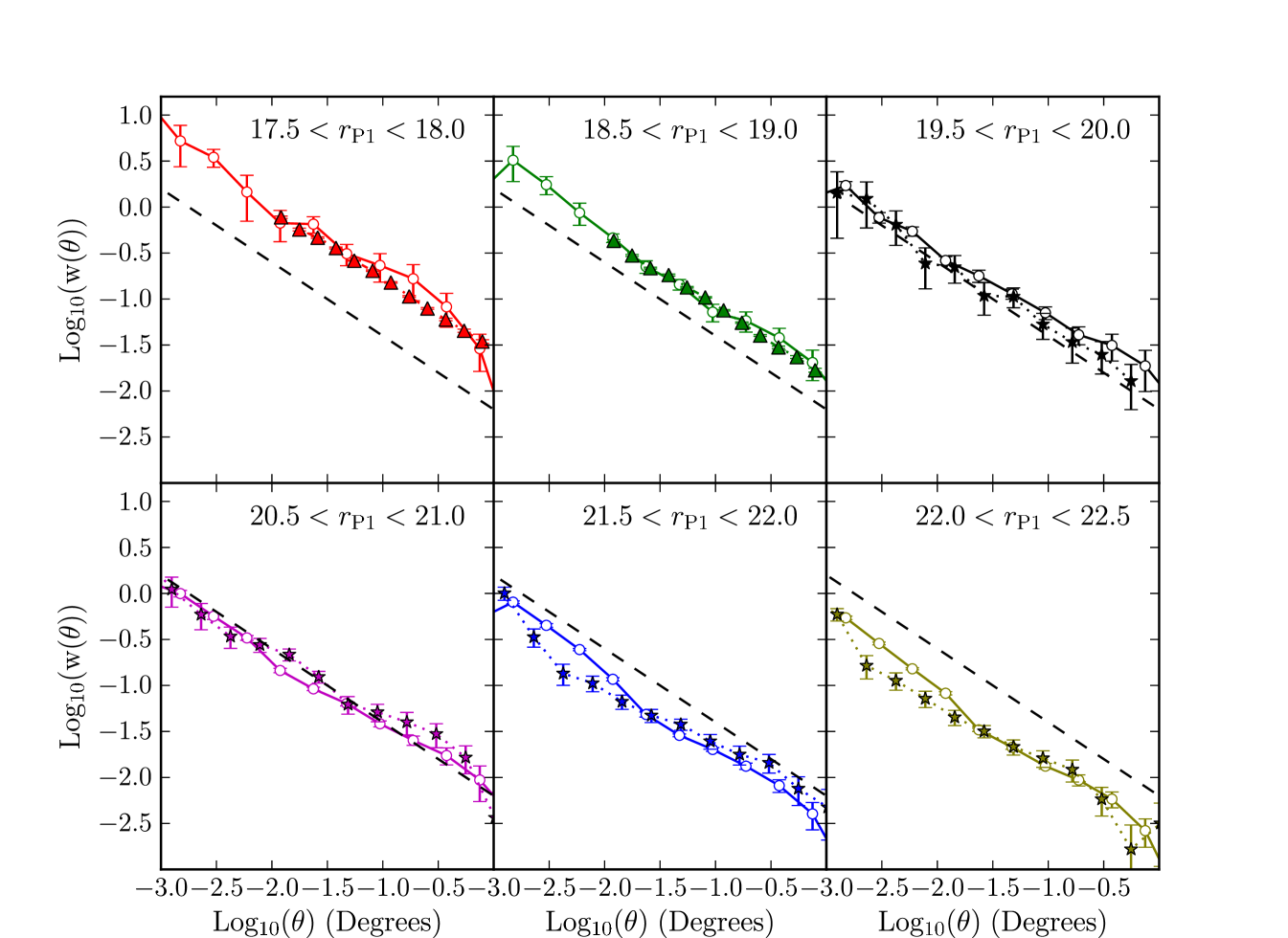
In Fig. 25 we show the angular correlation function measurements, using all the depth corrections described, down to in mag steps where we expect the clustering to still be reliable from Fig. 23(a). The angular clustering results from the whole of SDSS DR7 measured for Christodoulou et al. (2012), and measurements of the clustering of fainter galaxies from PS1 MD07 from Foucaud et al. (in preparation) are also shown. Again, our clustering measurements and those of Foucaud et al. (in preparation) have been corrected for stellar contamination.
The bright measurements are consistent within errors with the measurements made for Christodoulou et al. (2012). The fainter bins have power law shapes and lower amplitudes than the brighter bins, and agree with the MD07 measurements. Fig. 25 is a positive indication that PS1, combined with these depth corrections, can measure clustering to fainter magnitudes than existing wide field optical surveys.
6.3 Clustering of Stars and False Positives
As it is expected that some contamination of our galaxy sample will occur due to stars and false positives, we estimate their effect on clustering by measuring their correlation functions. We begin by looking at stars; Fig. 26 gives the clustering of objects classified as stars by our separator. We do not correct these objects for extinction in this plot, as it is unclear that this would be appropriate. We have so far assumed that stars are distributed fairly uniformly across SAS2, and so simply affect the amplitude of the galaxy clustering. The brighter stellar bins do indeed show a less scale dependent signal than the galaxy samples, which is much weaker than the galaxy clustering except on the largest scales.
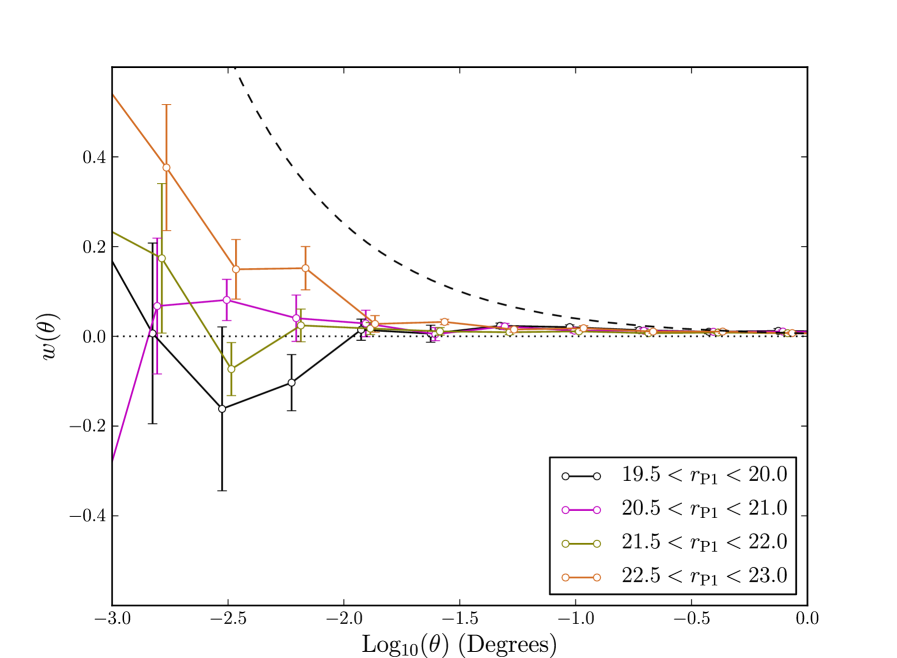
Whilst we expect the clustering of stars to be weaker than that of the galaxies, we do not necessarily expect the stars to be unclustered. Stars appear in star clusters and gradients in stellar density exist due to the structure of the Milky Way. Measurements of the angular correlation function of stars have shown it to be flat and non-zero on larger scales (e.g. Ross et al., 2011; Myers et al., 2006). In Fig 27(a) we compare the clustering of faint galaxies to that of stars. We detect clustering in the stars which is weaker than the galaxies on small scales but stronger than the galaxies on larger scales. As such one could argue that the small scale clustering of stars is caused by contamination of the stellar sample by galaxies, whilst the large scale clustering of stars cannot be attributed to the galaxies. The clustering of stars in Fig 27(a) is fairly insensitive to detection efficiency corrections. In contrast, extinction correcting the sample of stars enhances their clustering. This latter observation is concordant with the picture of stars having spatial density variations caused by the structure of the Milky Way. This is because one would expect dust to be correlated with the Milky Way’s structure, and as such extinction correcting the stars would act to enhance spatial structure in the stellar sample. The enhancement of clustering signal after extinction correction is the opposite of what one would expect for galaxies. The flat angular correlation function we measure on larger scales for stars is in accord with the shape reported in the literature for brighter stellar samples (e.g. Ross et al., 2011; Myers et al., 2006).
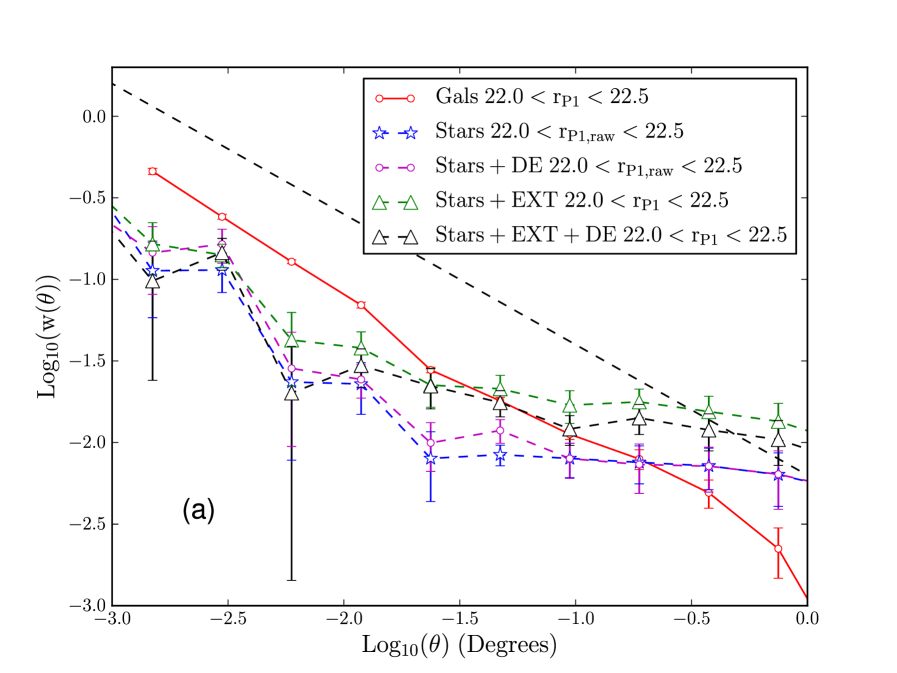
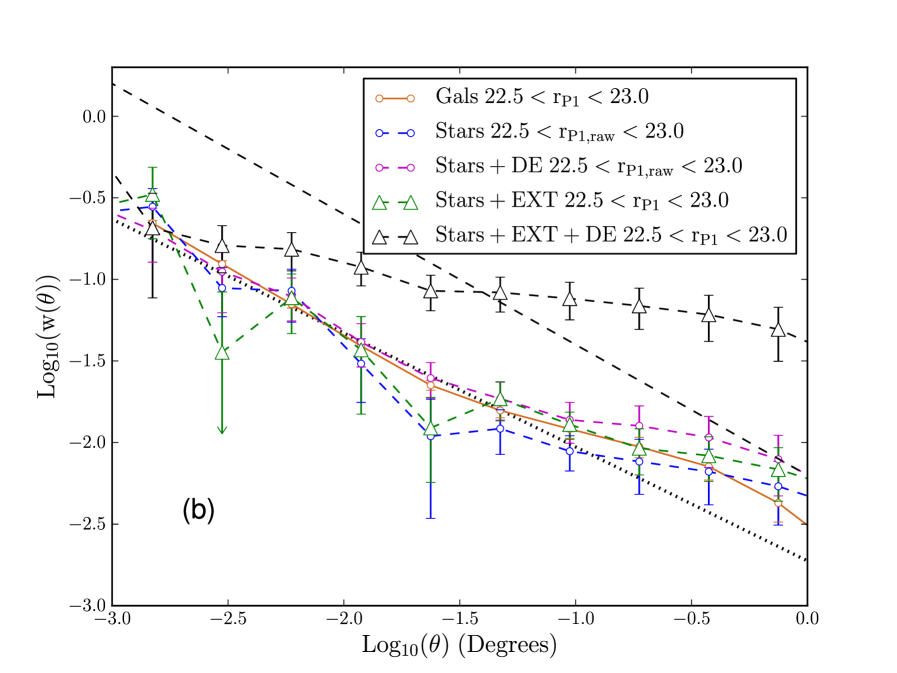
In Fig 27(b) we compare the clustering of a fainter sample of galaxies to that of stars. The clustering of stars in Fig 27(b) has a similar amplitude to that of the the brighter stars; the galaxy clustering is weaker however, such that the stars and galaxies have a similar amplitude of clustering on all scales. Again we do not believe the clustering in the star sample can be caused by galaxy contamination alone. This is because the clustering of galaxies in the stellar sample should be diluted by the stars in the sample and the resultant correlation function should have a lower amplitude than the galaxy sample. As in Fig 27(a), extinction correcting the stellar sample boosts its clustering, though the effect is smaller than for the brighter magnitude bin. Detection efficiency corrections also boost the clustering of the stellar sample in Fig 27(b). The likely cause of this is that the corrections are calibrated on galaxies which are harder to detect at these magnitudes, because they are extended. The combined effect of applying extinction corrections and detection efficiency corrections greatly boosts the clustering. This can be understood since their effect on the clustering will be compounded by the fact that extinction corrections bring objects with fainter observed magnitudes into the sample. These objects at fainter magnitudes have a larger detection efficiency correction and, since the detection efficiency corrections are based on galaxies, may artificially boost the stellar clustering further.
Clearly the clustering of stars and the effect of stellar contamination on galaxy clustering measurements will have to be further studied. For the full 3 survey measurements of the distribution of stars in the Milky Way could be used to attempt to model these effects. Cross correlating galaxy samples with stellar samples is also an important test we will carry out with the full 3 data, which will allow us to further study the effects of misclassification and stellar contamination. For this work, the clustering of stars and contamination of the galaxy sample could be boosting the estimates of the galaxy correlation function on large scales. This will be a larger effect for the fainter galaxy samples where the large scale clustering of stars has a higher amplitude than that of the galaxies and the stellar contamination fractions are larger. An expression relating the true angular correlation function of galaxies, , to the measured correlation function, , given the angular correlation function of stars, , can be found in Myers et al. (2006),
| (16) |
where is a very small cross term which is expected to be too small to influence our results. Eq. 16 was derived by Myers et al. (2006) for the Landy & Szalay (1993) estimator, but the Landy & Szalay (1993) gives very similar (much smaller than the error bars) results to the Hamilton (1993) estimator for our samples so we can still use Eq. 16 to estimate the effect of stellar contamination. On small scales where , Eq. 16 reduces to the amplitude scaling we have used thus far. On larger scales and for fainter galaxy samples the star clustering can be stronger than the galaxy clustering. Using the measured clustering of the extinction and detection efficiency corrected star samples we can estimate the effect of stars on the galaxy clustering. We do this by correcting the measured galaxy clustering using Eq. 16 and comparing the result to using the simple correction we adopted. The faintest bin, , has a contamination fraction of (from Fig. 10) which leads to an enhancement of the galaxy clustering signal by clustered, stellar contaminants of and at 0.7 and 0.3 degrees respectively. For the brighter magnitude bin of , with , this drops to and for 0.7 and 0.3 degrees respectively. All of these differences are smaller than the errorbars, and as such adopting the for this data, instead of a more thorough modelling of stellar contamination, does not effect our conclusions. For the full 3 survey where clustering on larger spatial scales will be measured this issue will have to be revisited.
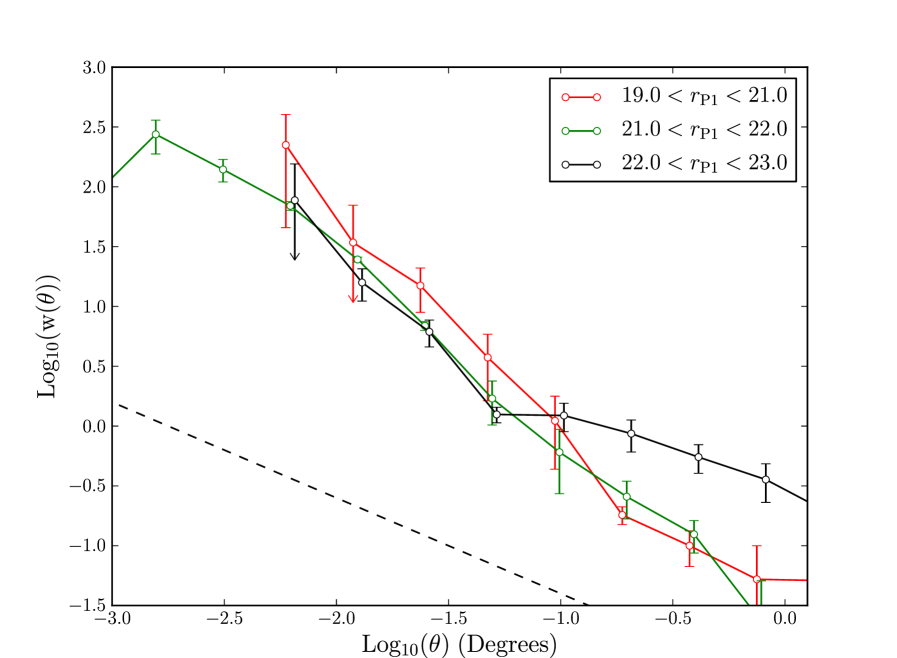
Fig. 28 gives the clustering of objects with extreme , removed by our cut in Fig. 8, split into three magnitude bins. These objects are thought to be false positives. We see that, unfortunately, these objects have a strong clustering signal. This signal is well described by a power law that is steeper than the galaxy correlation functions. This is as false positives tend to appear in clumps around image artifacts and around real objects (see Paper I). Fortunately for magnitude bins brighter than false positives make up less than of the data (Fig. 7) and are likely to have a negligable effect on clustering. For the fainter bins shown here, , clustering could be affected by the false positives which can be as prevalent as of the sources. Remember that Fig. 28 is measured from objects removed by our cut, false positives that evade this cut and so contaminate the galaxy sample could have different clustering. As we do not know if the false positives which evade our extreme have the same clustering as the objects in Fig. 28, Eq. 16 cannot be used to estimate their effect on clustering.
Improvements in the modelling of image artifacts will help ameliorate the problem of clustered false positives. Additionally requiring detections in multiple bands can also be effective in eliminating false positives.
7 Discussion and Conclusions
We have presented methods of star and galaxy separation, angular masking and completeness corrections for PS1. Our star and galaxy separation approach uses fake images to identify cuts in that yield galaxy samples. Our separator is 92%-98% complete with less than around stellar contamination down to a magnitude of . However, SAS2 has uniform properties so before applying this to the full 3 data we need to test and calibrate the star/galaxy separator for different seeing and background noise. It is likely that the galaxy distribution in will depend on seeing. Changing the PSF of an image has a different effect on the surface brightness of stars and galaxies and this will drive a change in a galaxy’s measured PSF magnitude. Ultimately a more sophisticated star and galaxy separator with better completeness and less contamination will need to be developed. Using the colours of galaxies (e.g Saglia et al., 2012) and other morphological measurements, such as galaxy size, are promising avenues to achieve this with PS1 data.
We present a method of generating angular masks for PS1 3 data, using a statistical approach to define the size of masked regions around bright stars. The relation between mask size and magnitude may vary across the much larger 3 field and as such the relation may need to be re-calibrated on the full data. We also presented our binned-up variance maps, which we have used to develop a method of correcting PS1 measurements for spatially varying depth. A question left to address is what binning scale to choose for masks and maps of the whole survey. One has to balance accuracy with the computational costs of using large amounts of data. Ultimately the mask size will also depend on the science goals; BAO measurements for example will be less sensitive to small scale systematics than galaxy formation studies using small scale clustering.
Some further questions related to our depth corrections will have to be addressed in future work. Firstly, we need to test how well our technique applies across a larger field with more variable PSFs and depths. One way to calibrate and test our method for the full survey is to utilise the 10 Medium Deep fields, which are scattered across the sky. Using surveys in addition to Stripe 82, such as the Medium Deep surveys, can also help remove the effects of false positives from our measurements of the probability of detection versus fiducial SNR. Additionally our assumption that all galaxies have the same detection efficiency properties will have to be further explored, perhaps by studying clustering as a function of colour. Our comparisons of detection efficiency for red and blue Stripe 82 galaxies are a positive indication that this is a valid assumption. We can also gain more insight into our depth correction method by utilising our synthetic images to simulate more greatly varying PSFs and backgrounds.
One important test of our method is excluding regions which fail to meet some SNR requirement and testing if clustering measurements from them agree with data with a less conservative cut. This test was demonstrated in Fig. 23 for SAS2 data but will have to be applied to the full 3 data. The application of this test to the the full 3 data may be more fruitful as the much larger area will decrease the random errors on the measurement and make any systematics more apparent. Ultimately this SNR cut can be used as a free parameter in our method, which can be varied to ensure science results are not sensitive to its value. It is also important when using this method to choose magnitude limits which ensure the detected galaxies have clustering representive of the full galaxy sample. This can be achieved by using narrow magnitude bins or by only applying this correction to fairly complete samples.
By applying our methods to a set of science verification data we show that in the PS1 3 measurements of clustering show reasonable agreement with literature data down to a magnitude of . Though tests using regions with different fiducial SNR limits, and the large size of correction needed at these faint magnitudes, suggest perhaps a limit of is a more reliable estimate of how faint we can use this method. These limits may change as the PS1 survey matures. At bright magnitudes we show agreement with the published angular correlation function estimates of Christodoulou et al. (2012) and Wang et al. (2013), fainter than this our measurements show the decrease in amplitude expected. Our fainter measurements agree, within error, with the measurements of Hudon & Lilly (1996), Roche & Eales (1999) and with Foucaud et al. (in preparation) for the threshold sample . Our magnitude bin samples also agree within error with Foucaud et al. (in preparation) down to a limit of . We also demonstrate our method yields sensible measurements of the number counts of galaxies, with -band counts, showing agreement with published data.
One difficulty with the literature comparisons is the relative deficit of faint -band comparison data, especially from fields large enough to test the scales where our correction is strongest. In places large sample variance could be masking residual systematics caused by the spatially varying depth. Future work will be able to further test our depth correction technique in several ways. Firstly, the extension of this work to different bands will allow a larger number of literature comparisons to be made. Additionally, combining the data across multiple bands will allow us to test the depth correction technique with more complex selection criteria, such as colour. Finally, using the full 3 data will greatly decrease the random errors in the SAS2 measurements, making systematics more apparent.
Clustered false positives are a potential limitation to measuring clustering, but these only affect the fainter magnitude bins and this problem should be improved by future efforts in understanding the instrumental signature of the PS1 camera. Additionally, matching between bands, which will be necessary for photometric redshifts, will go a long way in removing these false positives as image defects are very unlikely to be located in the same place in multiple bands.
Further issues not covered in this work, but which will still have to be considered when utilising the full survey also include how extinction corrections and stellar contamination affect the measured clustering signal. Issues such as these are common to many large galaxy surveys and there are approaches in the literature to deal with them (e.g. Ross et al., 2012; Wang et al., 2013).
Once the 3 survey is complete we will apply these methods to the full survey, which is due to be completed by around January 2014, with data reduction complete by mid 2014 (Magnier et al. in preparation). If the techniques developed here are successfully applied, the PS1 survey will be able to push forward our understanding of cosmology and galaxy formation. One particularly exciting application will be to measure the Integrated Sachs-Wolfe effect by cross correlating PS1 galaxies with CMB data. The large area of will be ideal for minimizing sample variance and false positives will become less of an issue as they are not correlated with the CMB.
Acknowledgements
DJF acknowledges the support of an STFC studentship (ST/F007299/1). The authors acknowledge a grant with the RCUK reference ST/F001166/1. PN acknowledges the support of the Royal Society through the award of a University Research Fellowship and the European Research Council, through receipt of a Starting Grant (DEGAS-259586). PD acknowledges support from an ERC Starting Grant (DEGAS-259586). We also thank the referee for their comments on this paper.
The Pan-STARRS1 Surveys (PS1) have been made possible through contributions of the Institute for Astronomy, the University of Hawaii, the Pan-STARRS Project Office, the Max-Planck Society and its participating institutes, the Max Planck Institute for Astronomy, Heidelberg and the Max Planck Institute for Extraterrestrial Physics, Garching, The Johns Hopkins University, Durham University, the University of Edinburgh, Queen’s University Belfast, the Harvard-Smithsonian Center for Astrophysics, the Las Cumbres Observatory Global Telescope Network Incorporated, the National Central University of Taiwan, the Space Telescope Science Institute, the National Aeronautics and Space Administration under Grant No. NNX08AR22G issued through the Planetary Science Division of the NASA Science Mission Directorate, the National Science Foundation under Grant No. AST-1238877, and the University of Maryland.
The clustering measurements for this paper where carried out on the GPUs of the Cosmology Machine supercomputer at the Institute for Computational Cosmology, Durham. The Cosmology Machine is part of the DiRAC Facility jointly funded by the STFC, the Large Facilities and Capital Fund of BIS, and Durham University.
Durham University’s membership of PS1 was made possible through the generous support of the Ogden Trust.
The PS1 catalogue data is currently restricted to the private PS1 consortium but will be made available through the Space Telescope Science Institute when the proprietary period is complete. Access to the measurements published here can be obtained from the lead author.
References
- Annis et al. (2011) Annis J. et al., 2011, ArXiv e-prints
- Bard et al. (2012) Bard D., Bellis M., Allen M. T., Yepremyan H., Kratochvil J. M., 2012
- Bertin & Arnouts (1996) Bertin E., Arnouts S., 1996, A&AS, 117, 393
- Blanton et al. (2001) Blanton M. R. et al., 2001, AJ, 121, 2358
- Bottini et al. (2005) Bottini D. et al., 2005, PASP, 117, 996
- Bower et al. (2006) Bower R. G., Benson A. J., Malbon R., Helly J. C., Frenk C. S., Baugh C. M., Cole S., Lacey C. G., 2006, MNRAS, 370, 645
- Christodoulou et al. (2012) Christodoulou L., Eminian C., Loveday J., 2012, MNRAS, 425, 1527
- de Vaucouleurs (1948) de Vaucouleurs G., 1948, Annales d’Astrophysique, 11, 247
- Dutton et al. (2011) Dutton A. A. et al., 2011, MNRAS, 410, 1660
- Ferrarese et al. (2006) Ferrarese L. et al., 2006, ApJS, 164, 334
- Finlator et al. (2000) Finlator K. et al., 2000, AJ, 120, 2615
- Frigo & Johnson (2005) Frigo M., Johnson S. G., 2005, Proceedings of the IEEE, 93, 216, special issue on “Program Generation, Optimization, and Platform Adaptation”
- Graham & Driver (2005) Graham A. W., Driver S. P., 2005, Publications of the Astronomical Society of Australia, 22, 118
- Hamilton (1993) Hamilton A. J. S., 1993, ApJ, 417, 19
- Hodapp et al. (2004) Hodapp K. W. et al., 2004, Astronomische Nachrichten, 325, 636
- Huang et al. (2001) Huang J.-S. et al., 2001, A&A, 368, 787
- Hudon & Lilly (1996) Hudon J. D., Lilly S. J., 1996, ApJ, 469, 519
- Ilbert et al. (2005) Ilbert O. et al., 2005, A&A, 439, 863
- Jian et al. (2013) Jian H.-Y. et al., 2013, ArXiv e-prints
- Kaiser et al. (2002) Kaiser N. et al., 2002, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Vol. 4836, Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Tyson J. A., Wolff S., eds., pp. 154–164
- Kashikawa et al. (2004) Kashikawa N. et al., 2004, PASJ, 56, 1011
- Kron (1980) Kron R. G., 1980, ApJS, 43, 305
- Landy & Szalay (1993) Landy S. D., Szalay A. S., 1993, ApJ, 412, 64
- Le Fèvre et al. (2005) Le Fèvre O. et al., 2005, A&A, 439, 845
- Lupton et al. (1999) Lupton R. H., Gunn J. E., Szalay A. S., 1999, AJ, 118, 1406
- Magnier (2006) Magnier E., 2006, in The Advanced Maui Optical and Space Surveillance Technologies Conference
- Magnier et al. (2013) Magnier E. A. et al., 2013, ApJS, 205, 20
- Martin et al. (2013) Martin N. F. et al., 2013, ApJ, 772, 15
- McCracken et al. (2003) McCracken H. J. et al., 2003, A&A, 410, 17
- Merson et al. (2013) Merson A. I. et al., 2013, MNRAS, 429, 556
- Metcalfe et al. (2013) Metcalfe N. et al., 2013, MNRAS, 435, 1825
- Mo et al. (2010) Mo H., van den Bosch F. C., White S., 2010, Galaxy Formation and Evolution
- Myers et al. (2006) Myers A. D. et al., 2006, ApJ, 638, 622
- Padilla & Strauss (2008) Padilla N. D., Strauss M. A., 2008, MNRAS, 388, 1321
- Petrosian (1976) Petrosian V., 1976, ApJ, 209, L1
- Roche & Eales (1999) Roche N., Eales S. A., 1999, MNRAS, 307, 703
- Ross et al. (2011) Ross A. J. et al., 2011, MNRAS, 417, 1350
- Ross et al. (2012) Ross A. J. et al., 2012, MNRAS, 424, 564
- Saglia et al. (2012) Saglia R. P. et al., 2012, ApJ, 746, 128
- Schlafly & Finkbeiner (2011) Schlafly E. F., Finkbeiner D. P., 2011, ApJ, 737, 103
- Schlafly et al. (2012) Schlafly E. F. et al., 2012, ApJ, 756, 158
- Schlegel et al. (1998) Schlegel D. J., Finkbeiner D. P., Davis M., 1998, ApJ, 500, 525
- Sérsic (1963) Sérsic J. L., 1963, Boletin de la Asociacion Argentina de Astronomia La Plata Argentina, 6, 41
- Shen et al. (2003) Shen S., Mo H. J., White S. D. M., Blanton M. R., Kauffmann G., Voges W., Brinkmann J., Csabai I., 2003, MNRAS, 343, 978
- Simard et al. (2011) Simard L., Mendel J. T., Patton D. R., Ellison S. L., McConnachie A. W., 2011, ApJS, 196, 11
- Strauss et al. (2002) Strauss M. A. et al., 2002, AJ, 124, 1810
- Tonry et al. (2008) Tonry J. L., Burke B. E., Isani S., Onaka P. M., Cooper M. J., 2008, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Vol. 7021, Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series
- Tonry et al. (2012) Tonry J. L. et al., 2012, ApJ, 750, 99
- Valenti et al. (2010) Valenti S. et al., 2010, The Astronomer’s Telegram, 2773, 1
- Wang et al. (2013) Wang Y., Brunner R. J., Dolence J. C., 2013, MNRAS, 432, 1961
- Ward et al. (2011) Ward M. J., Hutton S., Mattila S., Kotak R., 2011, in American Astronomical Society Meeting Abstracts #218
- Yasuda et al. (2001) Yasuda N. et al., 2001, AJ, 122, 1104
- Zacharias et al. (2013) Zacharias N., Finch C. T., Girard T. M., Henden A., Bartlett J. L., Monet D. G., Zacharias M. I., 2013, AJ, 145, 44