11email: {dinukamanohara.15,ashkar.15,isurumaldeniya.15, indika}@cse.mrt.ac.lk 22institutetext: Lawrence Berkeley National Lab, California, USA
22email: {esaliya}@gmail.com 33institutetext: University of Virginia, USA
33email: {asv9v}@virginia.edu
Parallel Algorithms for Densest Subgraph Discovery Using Shared Memory Model
Abstract
The problem of finding dense components of a graph is a widely explored area in data analysis, with diverse applications in fields and branches of study including community mining, spam detection, computer security and bioinformatics. This research project explores previously available algorithms in order to study them and identify potential modifications that could result in an improved version with considerable performance and efficiency leap. Furthermore, efforts were also steered towards devising a novel algorithm for the problem of densest subgraph discovery. This paper presents an improved implementation of a widely used densest subgraph discovery algorithm and a novel parallel algorithm which produces better results than a 2-approximation.
Keywords:
Densest subgraph K-core Task parallelism OpenMP Graph algorithms Data mining Shared memory algorithms.1 Introduction
1.1 Background
Discovering the dense components of a graph has become an important primitive in data analysis over the past few decades. Numerous algorithms and techniques had been developed and they have evolved throughout the period in order to ascertain the adequacy of methods to determine the dense components of different types of graphs namely, undirected, directed and weighted graphs with minimal requirement of resources. One such approach to discover dense components of a graph is to find the densest subgraph of a given graph.
By observing the applications that exploit the methods of finding densest subgraphs, one can easily acknowledge the substantial impact these methods have over modern technology due to their supplementary nature with well-known fields of research such as bioinformatics, data science and network analysis. Even though researchers have developed a variety of methods to perform the task of finding the densest subgraph of a graph, we could discern that there are areas yet to be explored and implementations that could be improved such that resource and time consumption can be mitigated further. This research focuses on improved methods for undirected graphs which can be modified for other types of graphs.
1.2 Preliminaries
Definition 1
Edge density of a graph G(V,E) is defined as . V is the set of vertices and E is the set of edges induced by V.
Definition 2
The k-core of a graph is the largest subgraph in which every vertex has degree at least k.
Definition 3
For , an algorithm is said to obtain an to the undirected densest subgraph if it outputs a set such that [9]. is the density of the densest subgraph of graph G(V,E).
1.3 Contributions
Our main contributions are,
-
1.
Highly scalable shared memory implementation of densest subgraph approximation algorithm, Algorithm 1 in Bahmani et. al [9]. (In this paper we call this algorithm as Bahmani’s algorithm.)
-
2.
A new highly scalable parallel algorithm which calculates more accurate density values than 2-approximation algorithms.
2 Related Work
Dense subgraph discovery in graphs has extensively been studied[25, 40, 13, 50]. The algorithms for finding the dense components in a graph can be categorized as exact enumeration, fast heuristics, and bounded approximation algorithms [3].
The simplest and the most common way to define the density of an undirected graph is the edge density. The densest subgraph of a given graph based on the edge density is the subgraph that has the highest edge density than all the other possible subgraphs. Goldberg et al. presented a maximum-flow based exact algorithm to calculate that densest subgraph [26]. Finding densest subgraphs with size restrictions (i.e., densest subgraphs which consist of a specified number of vertices) is a variant of this edge density densest subgraph problem and identified as NP-hard [8, 7]. Another variant is the optimal quasi-clique problem [50]. This is also NP-hard [11]. Solutions for finding the top-k locally densest subgraphs were presented by Qin et al. [39]. Densest subgraph problem induced by evolving graphs is studied in [18]. Graph decomposition based on the edge density is explored in [48, 17]. The density for directed graphs is expatiated in [34] and the densest subgraph problem on directed graphs is studied in [12].
Approximation algorithms and algorithms based on heuristics to discover the densest subgraphs come into the picture when the exact algorithms fail to perform efficiently on large graphs. A greedy 2-approximation algorithm is presented in [12]. Bahmani et al. [9] presented ()-approximation algorithm () and this is the algorithm that is being parallelized in this project. There exists an approximation algorithm to discover the densest subgraph in directed graphs [35]. The h-clique densest subgraph problem is defined and studied by Tsourakakis et al. [49, 37]. Top-k local triangle-densest subgraph discovery is based on the 3-clique and has been studied in [41]. Fang et al. [56] proposed exact and approximation algorithms for h-clique () densest subgraph problem based on core decomposition. Two prime issues of previous algorithms namely, resulting in isolated graphs and neglecting of important features of natural graphs are addressed by Bo Wu and Haiying Shen [4]. They present a heuristic algorithm for massive undirected graphs and an exact algorithm for big data in order to handle the aforementioned issues.
Rozenshtein et al. [5] study the problem of dynamic dense subgraph whose edge occur in a short time interval or equivalently, are temporary compact. This problem is NP-hard [5]. McGregor et al. [6] discuss the problem of approximating the densest subgraph in the dynamic graph stream model. They also present the first algorithm for approximating the density of the densest subgraph up to () factor in the dynamic graph stream model.
K-core [10, 36, 38, 21, 20, 19, 23, 24, 51, 14], k-truss [15, 30, 53, 32, 31], k-(r, s) nucleus [44, 42, 45, 43], k-clique [16, 27], k-edge connected components [28, 29] and k-plexes [46] can also be identified as the other formations of dense graph component models. Tatti et al. [47] proved that the largest core of a graph is a 2-approximation to the densest subgraph.
3 Methodology
3.1 Parallelization of Bahmani’s Algorithm
3.1.1 Introduction
Bahmani et al. presents a greedy approximation algorithm for finding densest subgraph of an undirected graph. For any , their algorithm makes passes over the input data and finds a subgraph of which the density is guaranteed to be within a factor of () of the optimum. As the authors claim, the algorithm is inherently parallelizable with minimal data dependencies between parallelized components.
As provided in their description, the algorithm takes an undirected graph G(V,E) as input. It proceeds in passes while removing a constant fraction of the remaining nodes in each pass. They have also proved that one of such intermediate subgraphs forms a ()-approximation to the densest subgraph. Furthermore, they note that, via flows or linear programming densest subgraph problem in undirected graph can be solved in polynomial time. Conversely, they have observed that flow and linear programming techniques scale poorly to internet sized graphs. However, despite the worst-case examples, they have established the evidences for their claim of their algorithms having the capability of yielding near-optimal solutions and being simpler and highly efficient than flow or linear programming-based techniques.
3.1.2 Approach
The approach can be broken down mainly into two parts as described below:
Exploitation of task parallelism:
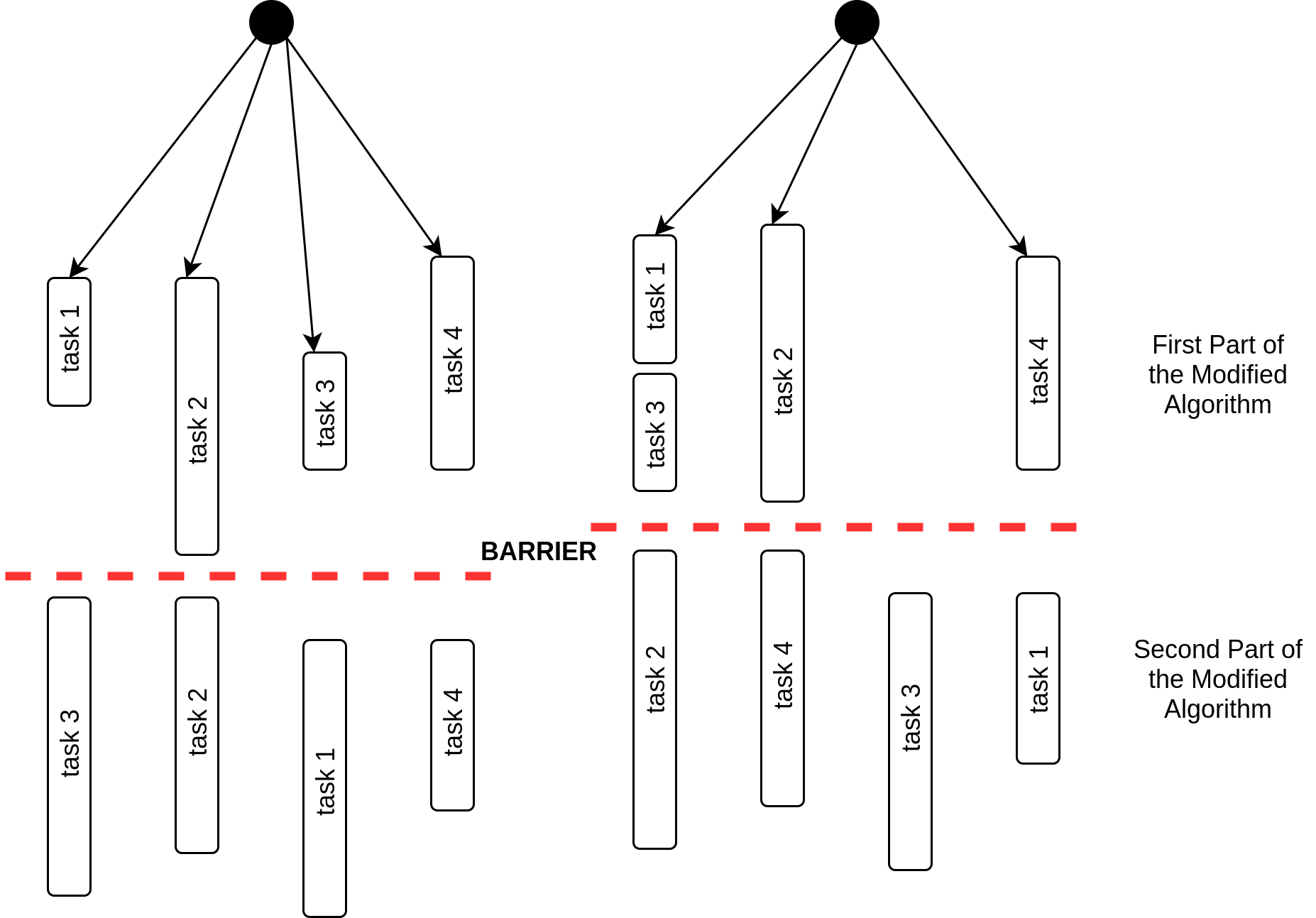
Tasks were introduced in version 3.0 of OpenMP. Before the availability of tasks, it was possible to execute loops of which the length was known at run time. In addition, there was also an imposed limit in the number of parallel sections. Most of the times this did not work well with even some well- known problems. i.e., even though it was possible to come with a feasible workaround, the solution was often unattractive. Until the introduction of tasks, it was not possible to efficiently and easily implement several types of parallelism. With tasks the programmer has to specify where the tasks are; then the OpenMP runtime system will generate a new task when a thread encounters a task construct. It is up to the OpenMP runtime system to ‘decide’ the moment of execution of the task whereas it can be delayed or immediate. task synchronization is used to enforce the completion of a task. Real world graphs are often highly unbalanced. Due to the nature of task creation, execution and its properties, it is plain that OpenMP tasks are highly applicable to the problem at hand. This is because if we use other patterns such as loop parallelism or work sharing constructs, the parallelized components that have comparatively lower amount of work to do have to be idle for most of the execution time. On the contrary, if the pattern used is task parallelism then the aforementioned occurrence would not be the case as tasks are not always unique to threads; consequently, a task can take over another component in the queue as soon as its work is done as opposed to being idle. In a considerable number of cases this could reduce the overhead of thread creation while helping execute the program quicker than other cases. The component above the dashed line representing barrier synchronization in figure 3 diagrammatically depicts this setting for a program with four tasks.
Partitioning the algorithm into two major parts:
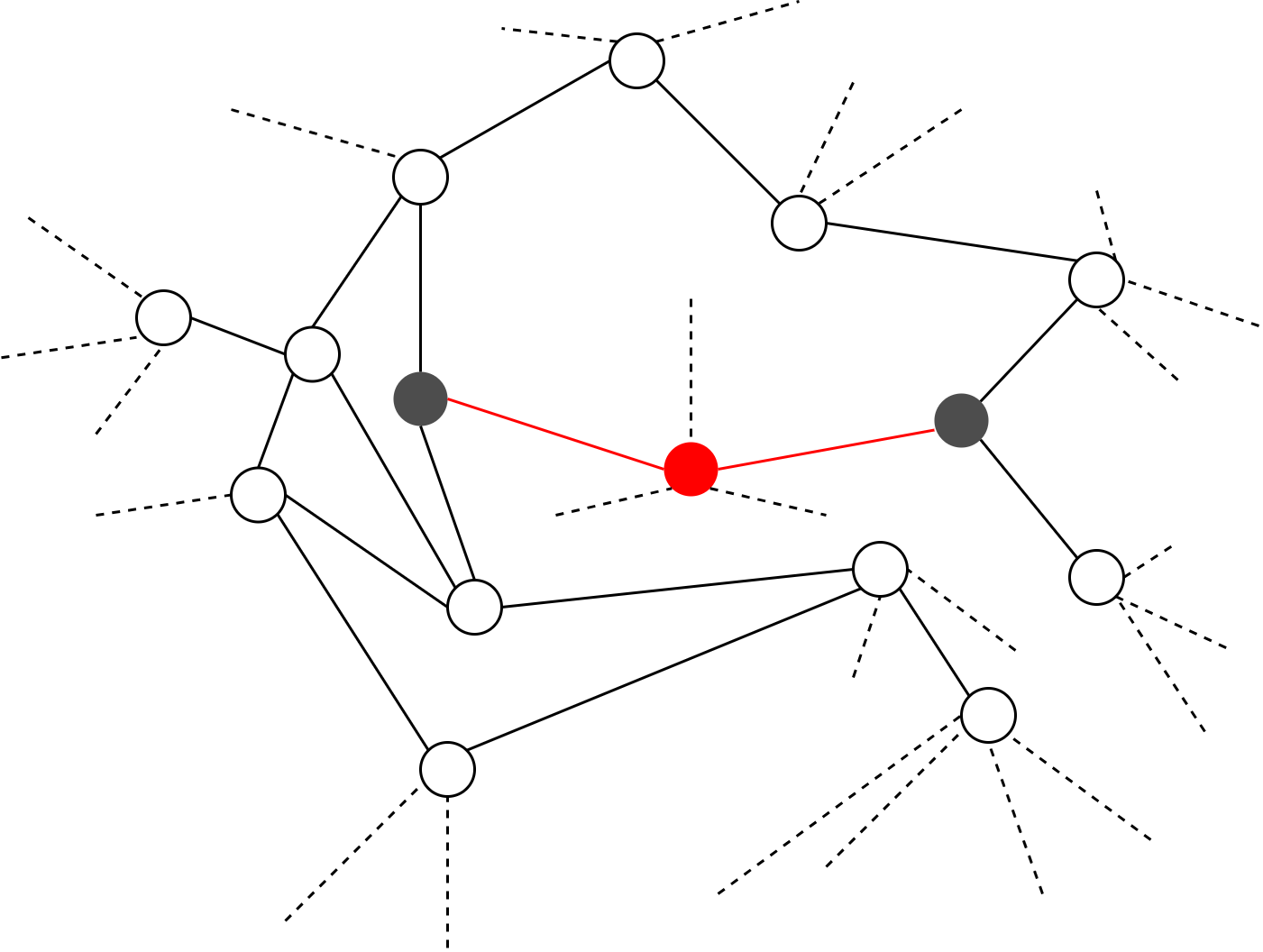
First major part of the modified algorithm can execute without any synchronizations between the parallelized components. When it comes to the second major part, a synchronization is required due to the updating of degrees of vertices. Assuming that the threshold for removing vertices is between 3 and 4 in a given iteration, we can see in figure 3 that the grey shaded vertices should fail as their degree is lower than the threshold. If those vertices belong to two different tasks, then the neighboring red coloured critical vertex is vulnerable to race condition. This establishes the requirement for a synchronization.
3.1.3 Implementation
Data structures:
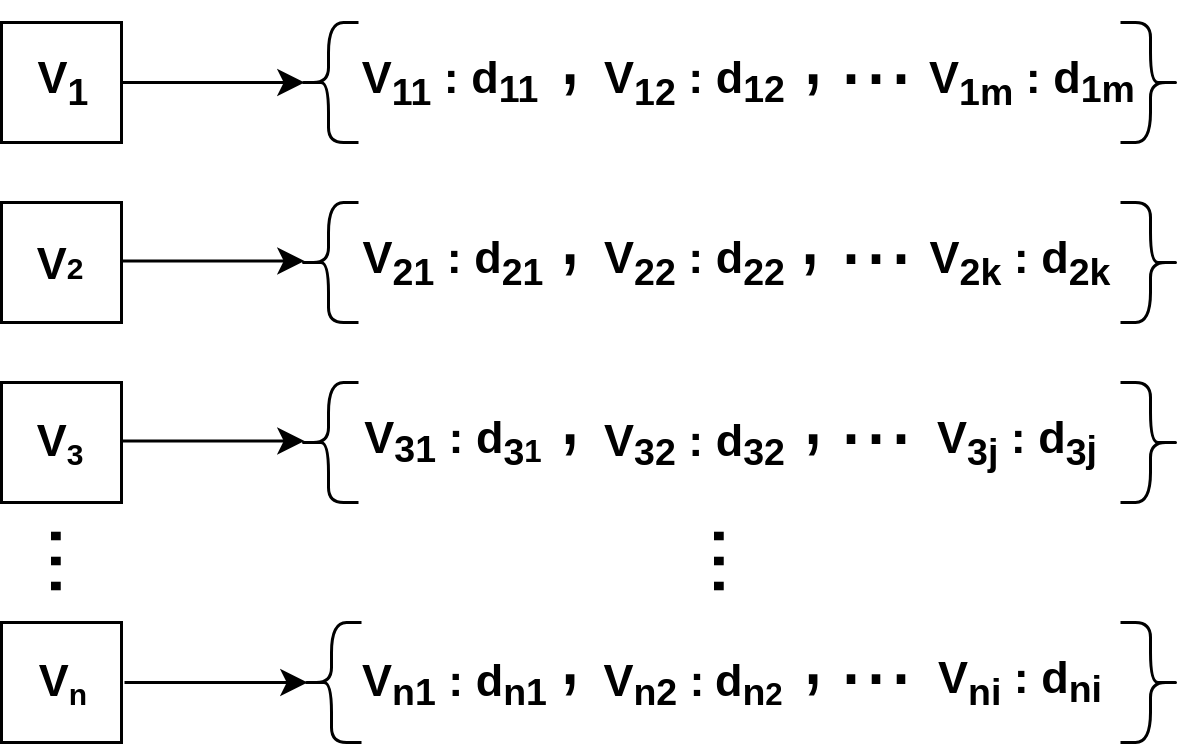
Despite relatively high memory usage we have used hash tables for storing the graph as our main focus was to be able to test the run-times for graphs of all types of vertex distribution. i.e., by doing this, we were able to support the graphs regardless of whether a graph of n vertices contains vertices from to or not. For this purpose, we have used the unordered map which is the C++ implementation of hash tables. We define a structure named super map which concretely represents the whole graph. Each key of the hash table represents a vertex of the graph. The value for each key is another hash table unordered map which has the neighboring vertices and their degrees as keys and values respectively.
Parallelization:
-
•
Task ID creation: As mentioned previously, tasks and threads does not always have one to one relationship. Therefore, as our program requires an ID unique to each task, the ID creation process is done by defining and initializing a shared variable ID and then atomically assigning the variable to the thread private ID immediately after each individual task commences. This is followed by increment of the shared variable which can then be assigned to the next task. The id creation process is identical in both the major parts of P-Bahmani.
-
•
Parallelism in the first part of P-Bahmani: This part does not contain any inter-task data dependencies. Moreover, for the purposes of time reduction in execution of the program, we have exercised a strategy where the algorithm avoids the testing of already visited vertices by removing those vertices. Here, each parallelized component iterates over the set of locally assigned vertices and removes the failed vertices from the locally assigned active set of vertices. With this strategy, the algorithm does not need to go over the failed vertices in the upcoming iteration. This cannot be done with work sharing constructs or basic type of loop parallelism where the Internal Control Variables are bound to a thread because an increment clause of OpenMP for loop must only perform simple addition/subtraction on the loop variable. However, the kind of increment our program consists in order to perform the removal of elements and the iteration over the same set is case dependent. The for loop is defined only with the pointer initiation and the condition. But the method of the pointer assignment must be defined on the fly depending on whether the current vertex failed or not. This can only be realized with tasks.
-
•
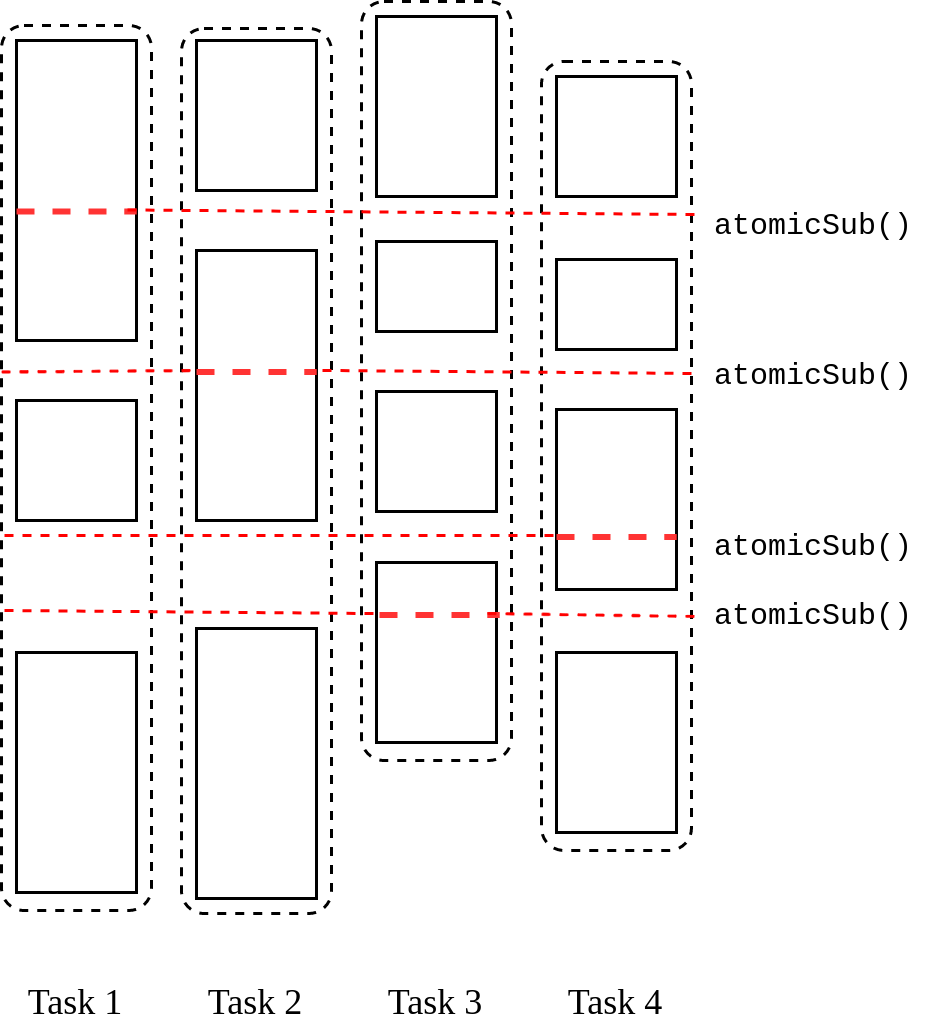
Parallelism in the second part of P-Bahmani: Each of the parallelized unit of executions contains a unique set of failed vertices resulted from the first part of the algorithm. When removing edges, we have to decrease the degrees of sources as well as the destinations. Therefore, while iterating over the unique set of task-local failed vertices, it is necessary to iterate over the set of neighbors of the current vertex since we have to decrease the degree of source vertex via the direction sourcedestination and the degree of destination vertex via the direction destinationsource. Since the source vertex is unique to each task and both the aforementioned directions consists the source, we can vouch that the assignment of variables at the addresses of sources won’t encounter any race conditions. Hence, the task local edge reduction variable can safely be used for decreasing the number of edges. Conversely, it is obvious that the destination vertex is vulnerable to race conditions which dictates us to use a critical section when updating its degree. We have tackled this through the C++’s built-in function for atomic reductions. The second part of the algorithm has the form shown in figure 6.
3.2 Core-based Dense Subgraphs
3.2.1 Approach
We previously described how the densest subgraph is correlated to the densest k-core (). Identification of the densest k-core provides us with a 2-approximation to the densest subgraph. This connotes that if we attempt to improve the density of the densest k-core, we will end up with a better approximation to the densest subgraph.
The notion of improving the density of can be realized by adding new vertices from the set of vertices that does not belong to . We show that the density of a subgraph can be increased by adding appropriately chosen vertices where is the subgraph which accommodates the newly added vertices, starting from . Therefore, we introduce a method of selecting outside vertices which would increase the density of when appended. This method is based on the density of , and the number of edges , induced by the set of vertices inside and the vertex in consideration of. As depicted by figure 6 and figure 6, the number edges marked in thick lines should be counted as . It is obvious that if we add a new vertex that introduces number of suitable edges such that , then is increased by an amount of , where n is the number of vertices and e is the number of edges inside before the addition of the new vertex.
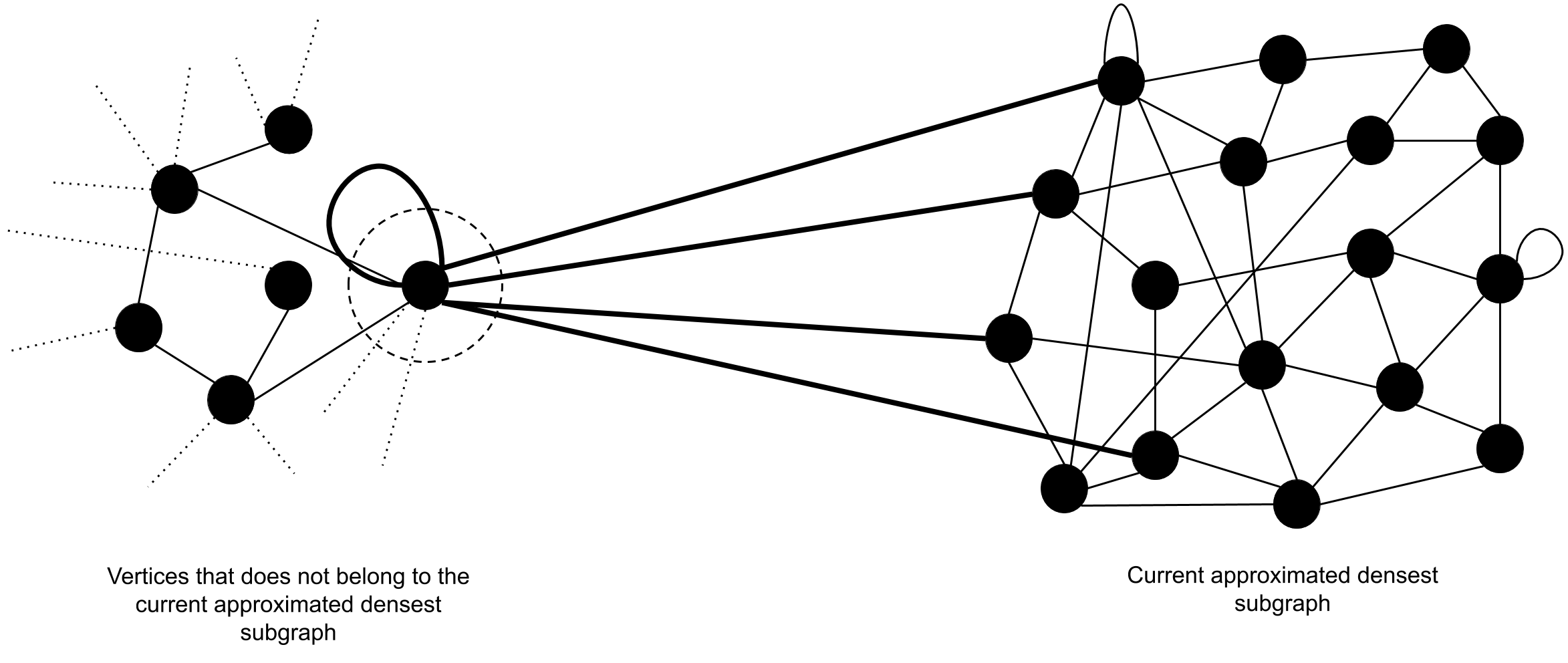
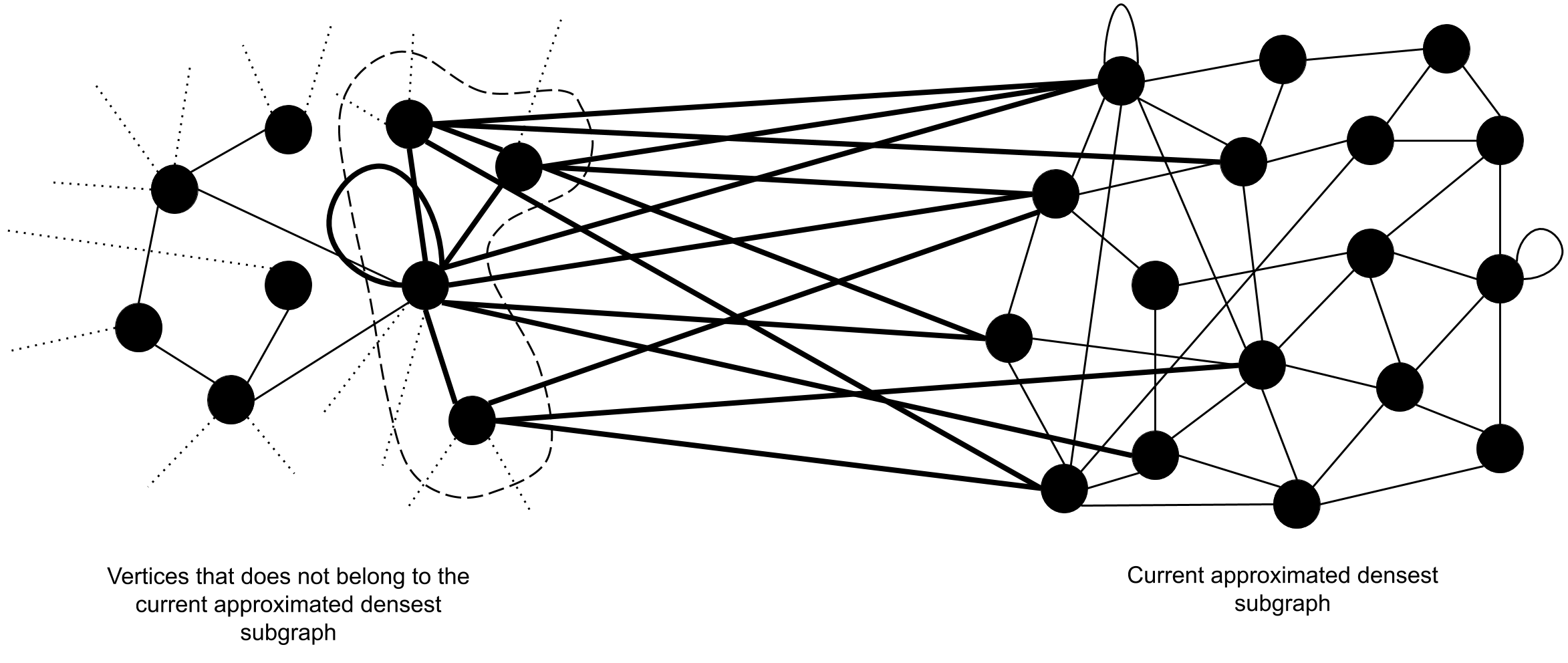
Our approach towards designing the algorithm consists of two distinct procedures. They are,
-
1.
Finding the densest k-core using an appropriate k-core decomposition algorithm. Here we have to use two different decomposition algorithms for serial and parallel versions.
-
2.
Selecting suitable vertices which can be added to and appending them to .
3.2.2 CBDS-P Algorithm
When designing the algorithm, we utilize the parallel k-core decomposition algorithm, PKC, proposed by Kabir et al. [55].
CBDS-P takes a graph and outputs an approximate densest subgraph. The first phase of the algorithm which is based on PKC algorithm, determines the core-ness values of the vertices. Apart from calculating the core-ness values, the first phase is modified to cater the self-edges of vertices and to calculate the densities of detected cores.
The second phase of CBDS-P detects suitable vertices outside the densest core. Threads find vertices which has a higher degree than the density of the densest core and a lesser degree than the core-ness value of the densest core. Then these selected vertices are processed in order to find vertices which possess legitimate edge counts that satisfy the conditions presented in the beginning of this subsection. We call these vertices, legitimate vertices. Ultimately the legitimate vertices’ degrees are set to max_density_core and the maximum density is calculated. Algorithm 2 returns the maximum density (max_density), maximum density core value (max_density_core) and the input graph. All the vertices that belong to the approximate densest subgraph can be identified by checking their degree values, degree values are greater than or equals to max_density_core. Note that some vertices may have a degree value equal to the max_density_core even though they do not belong to the densest core (i.e., here max_density_core value also serves as a labelling value).
First phase of CBDS-P has the time complexity equivalent to the time complexity of PKC. It is . Here, is the largest core value. In second phase, we go through the complete graph in order to detect the suitable vertices, adding a complexity. It takes another to go through number of neighbours introduced by the detected eligible vertices. Finally, to calculate the number of edges between the legitimate vertices, it takes . is the number of legitimate vertices. Therefore, the time complexity of CBDS-P is . Based on our experimental results, it is evident that and .
To implement CBDS-P, we followed the same design concepts and technologies we used to implement P-Bahmani.
4 Experimental Results and Evaluation
4.1 Datasets
All the datasets that we have used to evaluate the performance of our algorithms are real-world datasets (natural graphs). They were obtained from the Stanford Network Analysis Project (SNAP) and are publicly available for anyone to use[]. Table 1 provides the details of the datasets. In order to ensure the accuracy of our results obtained from our implementations, we used datasets and results given in [9] as the reference. The table 2 provides the table from the paper. Each of the algorithms are evaluated based on accuracy and runtime.
| Dataset | Label | ||
|---|---|---|---|
| ca-GrQc | GrQc | 5,242 | 28,980 |
| ca-HepTh | HepTh | 9,877 | 51,971 |
| facebook-combined | 4,039 | 88,234 | |
| ca-HepPh | HepPh | 12,008 | 237,010 |
| musae-squirrel-edges | Squirrel | 5,201 | 216,933 |
| as-skitter | Skitter | 1,696,415 | 11,095,298 |
| soc-LiveJournal1 | LJ | 4,847,571 | 68,993,773 |
| com-Orkut | Orkut | 3,072,441 | 117,185,083 |
| G(V, E) | |||||||
|---|---|---|---|---|---|---|---|
| as2000102 | 6,474 | 13,233 | 9.29 | 1.229 | 1.268 | 1.194 | |
| ca-AstroPh | 18,772 | 396,160 | 32.12 | 1.147 | 1.156 | 1.273 | |
| ca-CondMat | 23,133 | 186,936 | 13.47 | 1.072 | 1.072 | 1.429 | |
| ca-GrQc | 5,242 | 28,980 | 22.39 | 1.000 | 1.000 | 1.395 | |
| ca-HepPh | 12,008 | 237,010 | 119.004 | 1.000 | 1.017 | 1.151 | |
| ca-HepTh | 9,877 | 51,971 | 15.50 | 1.000 | 1.000 | 1.356 | |
| email-Enron | 36,692 | 367,662 | 37.34 | 1.058 | 1.072 | 1.063 |
4.2 Testing Environment
We used a m5.16xlarge Amazon EC2 which possess a 64 core Intel(R) Xeon(R) Platinum 8175M CPU @ 2.50GHz and a 246GB RAM.
4.3 Density and Runtime Comparisons
Table 3 contains the approximate maximum density values calculated by both P-Bahmani with and CBDS-P. Note that when , P-Bahmani algorithm produces the highest accuracy and it is equivalent to 2-approximation algorithm by Charikar et. al[]. Therefore, in the table 3, we can clearly observe that CBDS-P calculates more accurate maximum density values than a 2-approximation.
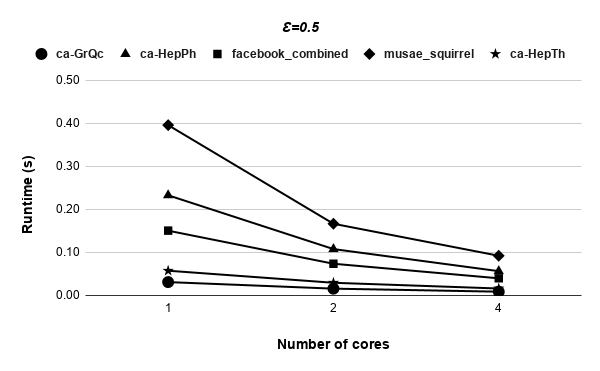
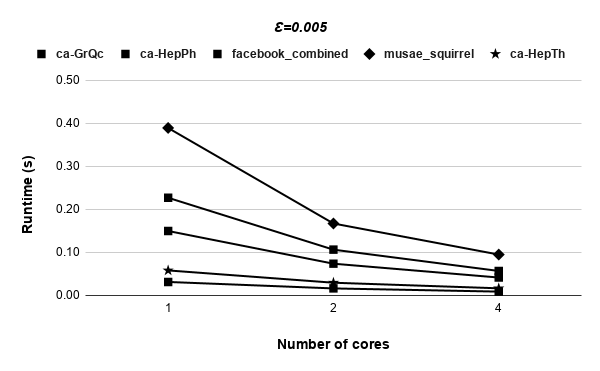
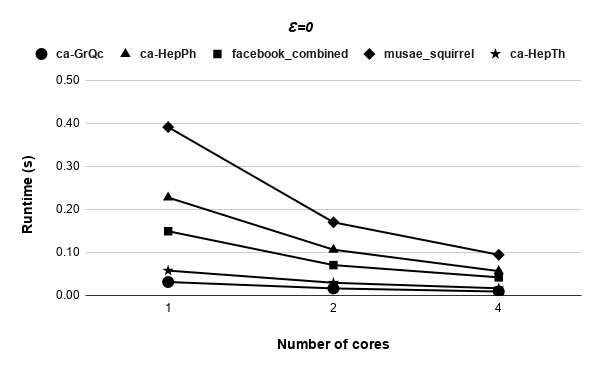
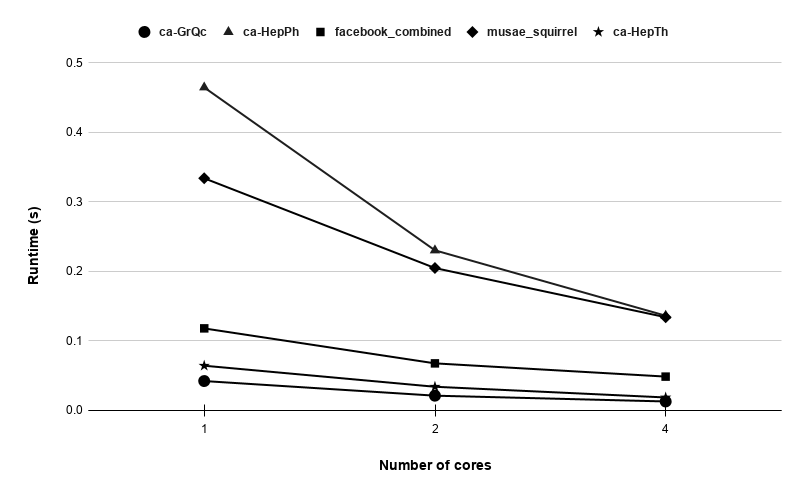
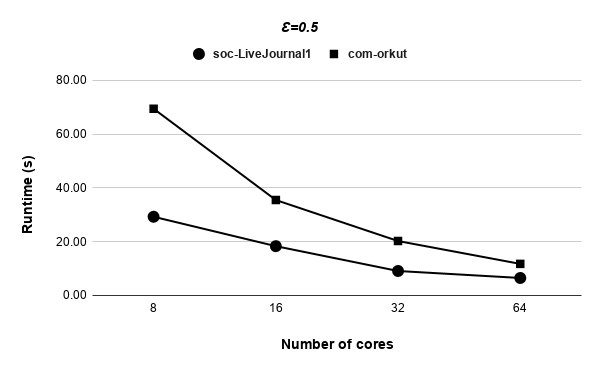
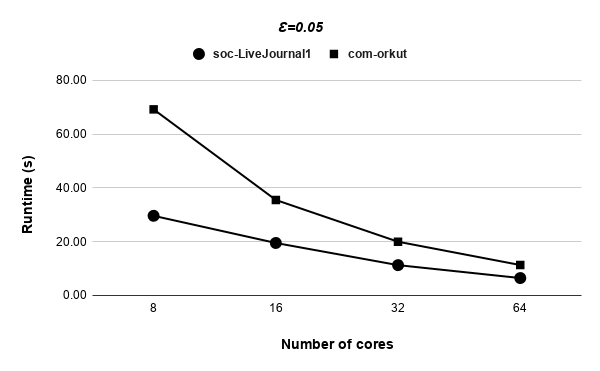
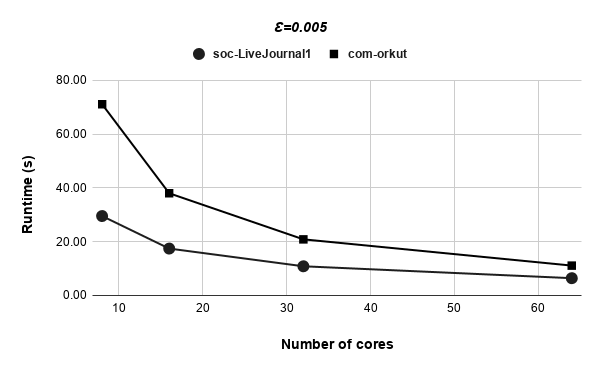
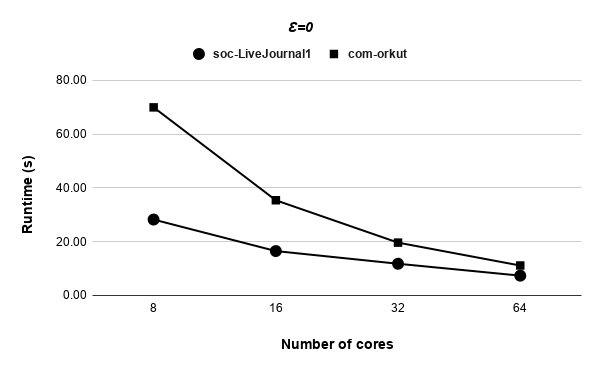
Figures 9, 9, 9, 12 for first 5 graphs and figures 15, 15, 15, 17 for last 2 graphs are the runtime variation of P-Bahmani against number of cores for values of 0.5, 0.05, 0.005 and 0 respectively.
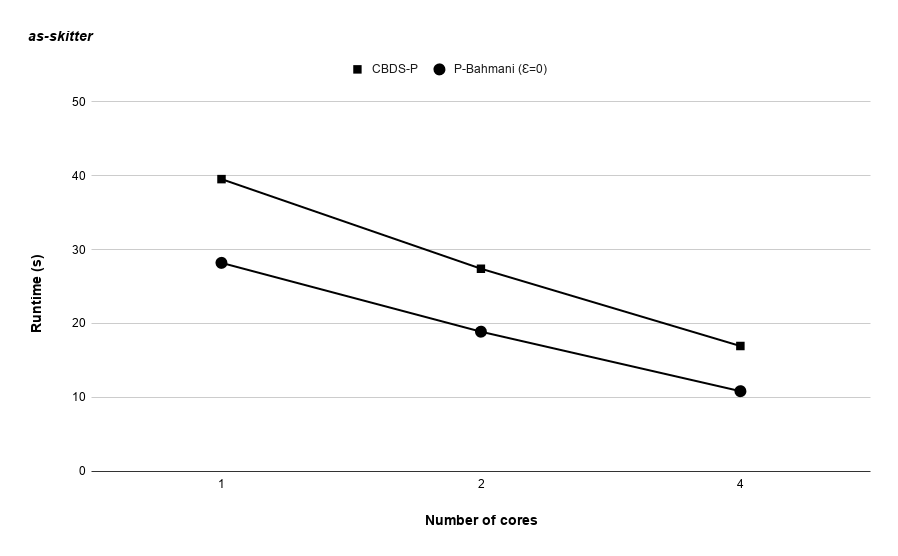
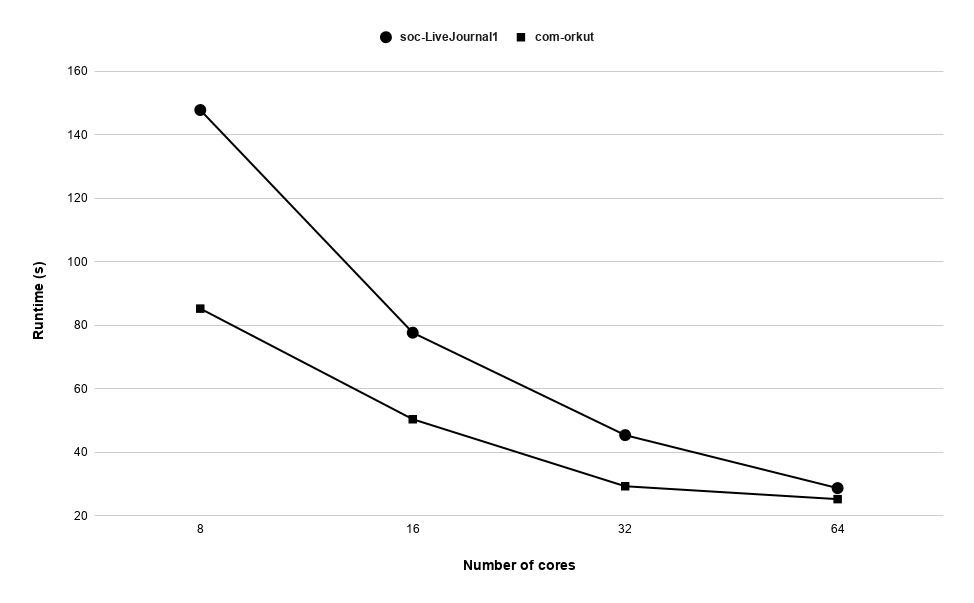
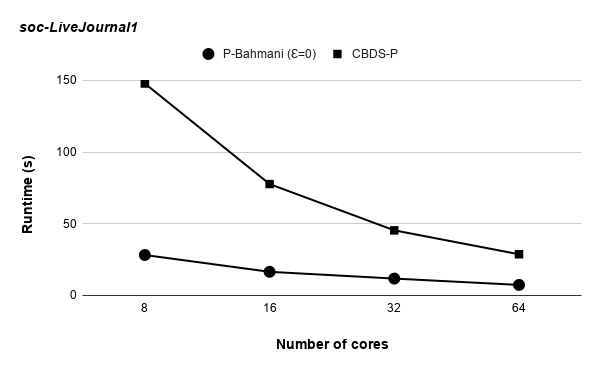
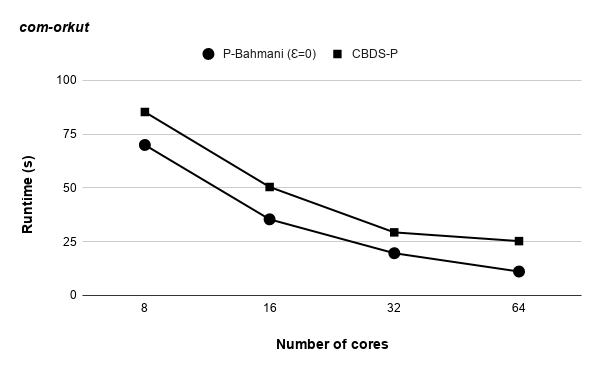
Runtime variation of graphs as-skitter, soc-LiveJournal1 and com-orkut against the number of cores with respect to both P-Bahmani() and CBDS-P are shown in figures 12, 19 and 19. Further, figure 17 depicts the runtime of CBDS-P against the number of cores with respect to both soc-LiveJournal1 and com-orkut graphs.
| Dataset | Exact Density | P-Bahmani | CBDS-P |
|---|---|---|---|
| ca-GrQc | 22.391 | 22.391 | 22.391 |
| ca-HepTh | 15.5 | 15.5 | 15.5 |
| facebook-combined | 77.347 | 69.9679 | 77.347 |
| ca-HepPh | 119.004 | 119.004 | 119.004 |
| musae-squirrel-edges | 152.543 | 131.779 | 152.542 |
| as-skitter | 89.4696 | 71.7748 | 89.4696 |
| soc-LiveJournal1 | — | 308.551 | 320.114 |
| com-Orkut | — | 220.063 | 227.866 |
5 Conclusion and Future Work
Even though the time complexity is higher than other 2-approximation algorithms, our CBDS-P algorithm is capable of producing approximate densest subgraphs that are more accurate than those 2-approximation algorithm within a considerable time complexity. CBDS-P proposes a new approach towards calculating approximate densest subgraphs based on k-cores.
P-Bahmani, the shared memory implementation of Bahmani et. al[] algorithm, is the first of its kind for that algorithm. Both P-Bahmani and CBDS-P are highly scalable in a shared memory, multi-core setting and it is evident by the experimental results. Further, this paper clearly expatiates the design considerations of our shared memory implementations.
Attempting to improve CBDS-P algorithm and working on shared memory implementations for other densest subgraph discovery algorithms can be identified as our future work.
References
- [1] Martinovic G., Krpic Z., and Rimac-Drlje S. “Parallelization Programming Techniques: Benefits and Drawbacks”. In: CLOUD COMPUTING 2010 (2010), pp. 7–13.
- [2] Prema S., and Jehadeesan R. Analysis of parallelization techniques and tools. International Journal of Information and Computation Technology, 3(4):471–478, 2013.
- [3] V. Lee, N. Ruan, R. Jin and C. Aggarwal. A survey of algorithms for dense subgraph discovery. Managing and Mining Graph Data, pages 303–336, 2010.
- [4] Wu B., and Shen H. Exploiting efficient densest subgraph discovering methods for big data. IEEE Transactions on Big Data, 3(3):334–348, 2017.
- [5] Rozenshtein P., Tatti N., and Gionis A. Finding dynamic dense subgraphs. ACM Transactions on Knowledge Discovery from Data (TKDD), 11(27), 2017.
- [6] McGregor A., Tench D., Vorotnikova S., and Vu H.T. Densest subgraph in dynamic graph streams. MFCS 2015: Mathematical Foundations of Computer Science 2015, 9235:472–482, 2015.
- [7] Y. Asahiro, R. Hassin, and K. Iwama. Complexity of finding dense subgraphs. Discrete Applied Mathematics, 121(1):15–26, 2002.
- [8] Y. Asahiro, K. Iwama, H. Tamaki, and T. Tokuyama. Greedily finding a dense subgraph. Journal of Algorithms, 34(2):203–221, 2000.
- [9] B. Bahmani, R. Kumar and S. Vassilvitskii, ”Densest subgraph in streaming and MapReduce”, Proceedings of the VLDB Endowment, vol. 5, no. 5, pp. 454-465, 2012. \doi10.14778/2140436.2140442
- [10] V. Batagelj and M. Zaversnik. An o(m) algorithm for cores decomposition of networks. arXiv preprint cs/0310049, 2003.
- [11] E. T. Charalampos. Mathematical and Algorithmic Analysis of Network and Biological Data. PhD thesis, Carnegie Mellon University, 2013. 2.1.
- [12] M. Charikar. Greedy approximation algorithms for finding dense components in a graph. In APPROX, pages 84–95. Springer, 2000.
- [13] J. Chen and Y. Saad. Dense subgraph extraction with application to community detection. TKDE, 24(7):1216–1230, 2012.
- [14] Y. Chen, Y. Fang, R. Cheng, Y. Li, X. Chen, and J. Zhang. Exploring communities in large profiled graphs. IEEE Transactions on Knowledge and Data Engineering, 31(8):1624–1629, 2019.
- [15] J. Cohen. Trusses: Cohesive subgraphs for social network analysis. National Security Agency Technical Report, 16, 2008.
- [16] W. Cui, Y. Xiao, H. Wang, Y. Lu, and W. Wang. Online search of overlapping communities. In SIGMOD, pages 277–288. ACM, 2013.
- [17] M. Danisch, T.-H. H. Chan, and M. Sozio. Large scale density-friendly graph decomposition via convex programming. In Proceedings of the 26th International Conference on World Wide Web, pages 233–242, 2017.
- [18] A. Epasto, S. Lattanzi, and M. Sozio. Efficient densest subgraph computation in evolving graphs. In WWW, pages 300–310, 2015.
- [19] Y. Fang, R. Cheng, Y. Chen, S. Luo, and J. Hu. Effective and efficient attributed community search. The VLDB Journal, 26(6):803–828, 2017.
- [20] Y. Fang, R. Cheng, X. Li, S. Luo, and J. Hu. Effective community search over large spatial graphs. PVLDB, 10(6):709–720, 2017.
- [21] Y. Fang, R. Cheng, S. Luo, and J. Hu. Effective community search for large attributed graphs. PVLDB, 9(12):1233–1244, 2016.
- [22] Y. Fang, X. Huang, L. Qin, Y. Zhang, W. Zhang, R. Cheng, and X. Lin. A survey of community search over big graphs. The VLDB Journal, 2019.
- [23] Y. Fang, Z. Wang, R. Cheng, X. Li, S. Luo, J. Hu, and X. Chen. On spatial-aware community search. IEEE Transactions on Knowledge and Data Engineering, 31(4):783–798, 2018.
- [24] Y. Fang, Z. Wang, R. Cheng, H. Wang, and J. Hu. Effective and efficient community search over large directed graphs. IEEE Transactions on Knowledge and Data Engineering (TKDE), 2018.
- [25] A. Gionis and C. E. Tsourakakis. Dense subgraph discovery: Kdd 2015 tutorial. In SIGKDD, pages 2313–2314, NY, USA, 2015. ACM.
- [26] A. V. Goldberg. Finding a maximum density subgraph. UC Berkeley, 1984.
- [27] J. Hu, R. Cheng, K. C.-C. Chang, A. Sankar, Y. Fang, and B. Y. Lam. Discovering maximal motif cliques in large heterogeneous information networks. In IEEE International Conference on Data Engineering (ICDE), pages 746–757. IEEE, 2019.
- [28] J. Hu, X. Wu, R. Cheng, S. Luo, and Y. Fang. Querying minimal steiner maximum-connected subgraphs in large graphs. In International on Conference on Information and Knowledge Management (CIKM), pages 1241–1250. ACM, 2016.
- [29] J. Hu, X. Wu, R. Cheng, S. Luo, and Y. Fang. On minimal steiner maximum-connected subgraph queries. IEEE Transactions on Knowledge and Data Engineering, 29(11):2455–2469, 2017.
- [30] X. Huang, H. Cheng, L. Qin, W. Tian, and J. X. Yu. Querying k-truss community in large and dynamic graphs. In SIGMOD, pages 1311–1322. ACM, 2014.
- [31] X. Huang and L. V. Lakshmanan. Attribute-driven community search. PVLDB, 10(9):949–960, 2017.
- [32] X. Huang, W. Lu, and L. V. Lakshmanan. Truss decomposition of probabilistic graphs: Semantics and algorithms. In Proceedings of the 2016 International Conference on Management of Data, pages 77–90. ACM, 2016.
- [33] M. Jha, C. Seshadhri, and A. Pinar. Path sampling: A fast and provable method for estimating 4-vertex subgraph counts. In WWW, pages 495–505, 2015.
- [34] R. Kannan and V. Vinay. Analyzing the structure of large graphs. Rheinische Friedrich-Wilhelms-Universität Bonn, 1999.
- [35] S. Khuller and B. Saha. On finding dense subgraphs. Automata, Languages and Programming, pages 597–608, 2009.
- [36] L. Lü, T. Zhou, Q.-M. Zhang, and H. E. Stanley. The h-index of a network node and its relation to degree and coreness. Nature communications, 7:10168, 2016.
- [37] M. Mitzenmacher, J. Pachocki, R. Peng, C. Tsourakakis, and S. C. Xu. Scalable large near-clique detection in large-scale networks via sampling. In International Conference on Knowledge Discovery and Data Mining (SIGKDD), pages 815–824. ACM, 2015.
- [38] Y. Peng, Y. Zhang, W. Zhang, X. Lin, and L. Qin. Efficient probabilistic k-core computation on uncertain graphs. In International Conference on Data Engineering (ICDE), pages 1192–1203. IEEE, 2018.
- [39] L. Qin, R.-H. Li, L. Chang, and C. Zhang. Locally densest subgraph discovery. In KDD, pages 965–974. ACM, 2015.
- [40] S.Sahu,A.Mhedhbi,S.Salihoglu,J.Lin,and M.T.Özsu. The ubiquity of large graphs and surprising challenges of graph processing. PVLDB, 11(4):420–431, 2017.
- [41] R. Samusevich, M. Danisch, and M. Sozio. Local triangle-densest subgraphs. In International Conference on Advances in Social Networks Analysis and Mining (ASONAM), pages 33–40. IEEE, 2016.
- [42] A. E. Sariyüce and A. Pinar. Fast hierarchy construction for dense subgraphs. PVLDB, 10(3):97–108, 2016.
- [43] A. E. Sariyüce, C. Seshadhri, and A. Pinar. Local algorithms for hierarchical dense subgraph discovery. PVLDB, 12(1):43–56, 2018.
- [44] A. E. Sariyüce, C. Seshadhri, A. Pinar, and U.V.Çatalyürek. Finding the hierarchy of dense subgraphs using nucleus decompositions. In WWW, pages 927–937, 2015.
- [45] A.E.Sariyüce, C.Seshadhri, A.Pinar,and U.V.Çatalyürek. Nucleus decompositions for identifying hierarchy of dense subgraphs. ACM Transactions on the Web (TWEB), 11(3):16, 2017.
- [46] S. B. Seidman and B. L. Foster. A graph-theoretic generalization of the clique concept. Journal of Mathematical sociology, 6(1):139–154, 1978.
- [47] N. Tatti. Density-Friendly Graph Decomposition. In: ACM Transactions on Knowledge Discovery from Data 13.5 (2019), pp. 1–29. \doi10.1145/3344210.
- [48] N. Tatti and A. Gionis. Density-friendly graph decomposition. In Proceedings of the 24th International Conference on World Wide Web, pages 1089–1099, 2015.
- [49] C. Tsourakakis. The k-clique densest subgraph problem. In WWW, pages 1122–1132, 2015.
- [50] C. Tsourakakis, F. Bonchi, A. Gionis, F. Gullo, and M. Tsiarli. Denser than the densest subgraph: extracting optimal quasi-cliques with quality guarantees. In KDD, pages 104–112. ACM, 2013.
- [51] K. Wang, X. Cao, X. Lin, W. Zhang, and L. Qin. Efficient computing of radius-bounded k-cores. In IEEE International Conference on Data Engineering (ICDE), pages 233–244. IEEE, 2018.
- [52] K. Wang, X. Lin, L. Qin, W. Zhang, and Y. Zhang. Vertex priority based butterfly counting for large-scale bipartite networks. PVLDB, 12(10):1139–1152, 2019.
- [53] Y. Wu, R. Jin, J. Li, and X. Zhang. Robust local community detection: on free rider effect and its elimination. PVLDB, 8(7):798–809, 2015.
- [54] J. Liu, S. Salehian, and Y. Yan. Comparison of Threading Programming Models. In: 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE, 2017. \doi10.1109/ipdpsw.2017.141.
- [55] H. Kabir, and K. Madduri “Parallel k-Core Decomposition on Multicore Platforms”. In: 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE, 2017. \doi10.1109/ipdpsw.2017.151.
- [56] Y. Fang, K. Yu, R. Cheng, L. V. S. Lakshmanan, and X. Lin. 2019. Efficient algorithms for densest subgraph discovery. Proc. VLDB Endow. 12, 11 (July 2019), 1719–1732. \doi10.14778/3342263.3342645