Parallel WaveNet conditioned on VAE latent vectors
Abstract
Recently the state-of-the-art text-to-speech synthesis systems have shifted to a two-model approach: a sequence-to-sequence model to predict a representation of speech (typically mel-spectrograms), followed by a ’neural vocoder’ model which produces the time-domain speech waveform from this intermediate speech representation. This approach is capable of synthesizing speech that is confusable with natural speech recordings. However, the inference speed of neural vocoder approaches represents a major obstacle for deploying this technology for commercial applications. Parallel WaveNet is one approach which has been developed to address this issue, trading off some synthesis quality for significantly faster inference speed. In this paper we investigate the use of a sentence-level conditioning vector to improve the signal quality of a Parallel WaveNet neural vocoder. We condition the neural vocoder with the latent vector from a pre-trained VAE component of a Tacotron 2-style sequence-to-sequence model. With this, we are able to significantly improve the quality of vocoded speech.
Index Terms— Text To Speech, Neural TTS, Vocoding
1 Introduction
Statistical parametric speech synthesis (SPSS) systems were developed to enable a consistent level of naturalness which is flexible across the wide range of linguistic contexts which may be encountered at synthesis-time [1, 2]. In this paradigm statistical models predict parameters of speech from linguistic context features. A time-domain speech waveform is constructed from these parameters using a signal processing-based vocoder [3, 4]. Whilst SPSS systems are flexible and produce a consistent level of naturalness, the vocoders used at the time place a ceiling effect on the naturalness that is possible within this synthesis paradigm [5]. Hybrid synthesis aimed to leverage the stability of statistical models in order to drive the selection of units in a unit selection system [6, 7, 8], thus removing the effect of signal processing-based vocoders. However, hybrid synthesis still relies on the selection units observed in the training data. This makes joins inevitable; due to the large number of possible linguistic contexts it is impossible for these to all be present in the speech database.
Neural approaches have been proposed to overcome the aforementioned ceiling effect of vocoding. Originally WaveNet-like approaches [9, 10] predicted the time-domain waveform signal from linguistic context and f0, using a large model of stacked dilated convolutions and autoregression. This model is effectively being asked to estimate the vocal tract configuration in addition to constructing the time domain waveform. More recently, researchers in literature have found that breaking the problem down into 2 stages allows the models to produce very high quality audio [11]: 1) estimate a speech representation (e.g., mel-spectrograms), 2) use a neural vocoder to produce the time domain waveform from the speech representation. In addition, this makes the task of the speech waveform prediction component simpler, enabling for more compact models to produce high quality speech [12, 13]. Although it has been possible to make neural vocoding models more compact whilst preserving high quality, one issue which remains is the time required for inference. This is largely due to the presence of autoregression in the model topologies and is a limitation when putting neural vocoders into production for commercial systems.
Approaches aiming to solve this limitation can be grouped into three main categories: knowledge distillation-based (e.g. Parallel WaveNet [14] and ClariNet [15]), directly training the data likelihood maximization (e.g. WaveGlow [16]), and adversarial training (e.g. WaveGAN [17]). In this investigation we focus on the Parallel WaveNet neural vocoding approach due to its success in commercial deployments.
Parallel WaveNet was proposed to improve the inference speed at synthesis-time. It uses a large WaveNet neural vocoder model as a teacher. A student model is then trained to replicate the predictions of the teacher network. The student network learns to shape noise input into a speech waveform based on the conditioning passed to the vocoder. Crucially, the student network uses Inverse Autoregressive Flows (IAFs) [18] for which the sampling procedure is easy to parallelize because all noise samples are available at the same time and thus vastly improves the inference speed.
Even though Parallel WaveNet improves the performance speed compared to neural vocoders, whilst maintaining a high signal quality, these approaches are still behind the quality of natural recordings. We train our vocoders on natural recordings to solve the spectrogram to waveform problem. During inference we use it to synthesize from predicted spectrograms, introducing a mismatch due to the imperfect predicted spectrograms. To help bridge this gap, we train the network with additional conditioning in the form of a pre-trained Variational Auto Encoder (VAE) [19] latent vector. This utterance level vector is extracted from the VAE reference encoder of a Tacotron 2-like sequence-to-sequence acoustic model [20]. We show on two different speakers that this additional conditioning improves synthesis quality for predicted spectrograms, especially for very expressive voices. During inference, the conditioning vector can be replaced by a constant vector from within the training distribution without loss of quality, resulting in efficient inference without the need for additional calculations.
2 Architecture
As described in the introduction, we are working in the paradigm of having two separate models for synthesis: an acoustic model that predicts mel-spectrograms from text and a neural vocoder that predicts audio from the predicted mel-spectrograms.
2.1 Neural Vocoder
For the neural vocoder, we use a model inspired by Parallel WaveNet. This means we train two models using the Student-Teacher paradigm. The teacher is a WaveNet-like model which provides sequential sampling but parallel likelihood computation via teacher forcing which makes it fast to train but slow for inference. The student uses IAFs where the affine transform parameters are predicted by autoregressive conditioners built from WaveNet-like blocks of dilated convolutions. IAFs allow parallel sampling which makes them efficient during inference. But they require sequential calculations to estimate likelihood and are therefore slow to train. Training first the teacher and then the student to match the teacher’s outputs, results in a model that can be trained and sampled from efficiently.
The WaveNet-like models used for both student and teacher are convolutional networks which are conditioned on textual information via extra bias parameters in the convolutional layers. The original paper proposed the use of linguistic features, f0 and durations. Instead, we condition on mel-spectrograms. As observed in the original paper, Student-Teacher training alone leads to whispering artefacts. Hence, the authors proposed training on a combination of other losses: Power Loss, Phoneme Recognition Style Loss, and Contrastive Loss. We additionally propose conditioning both teacher and student models on the utterance-level latent vector extracted as described in section 2.2. The latent vector is concatenated with the output of the conditioning sub-network (see Figure 1).
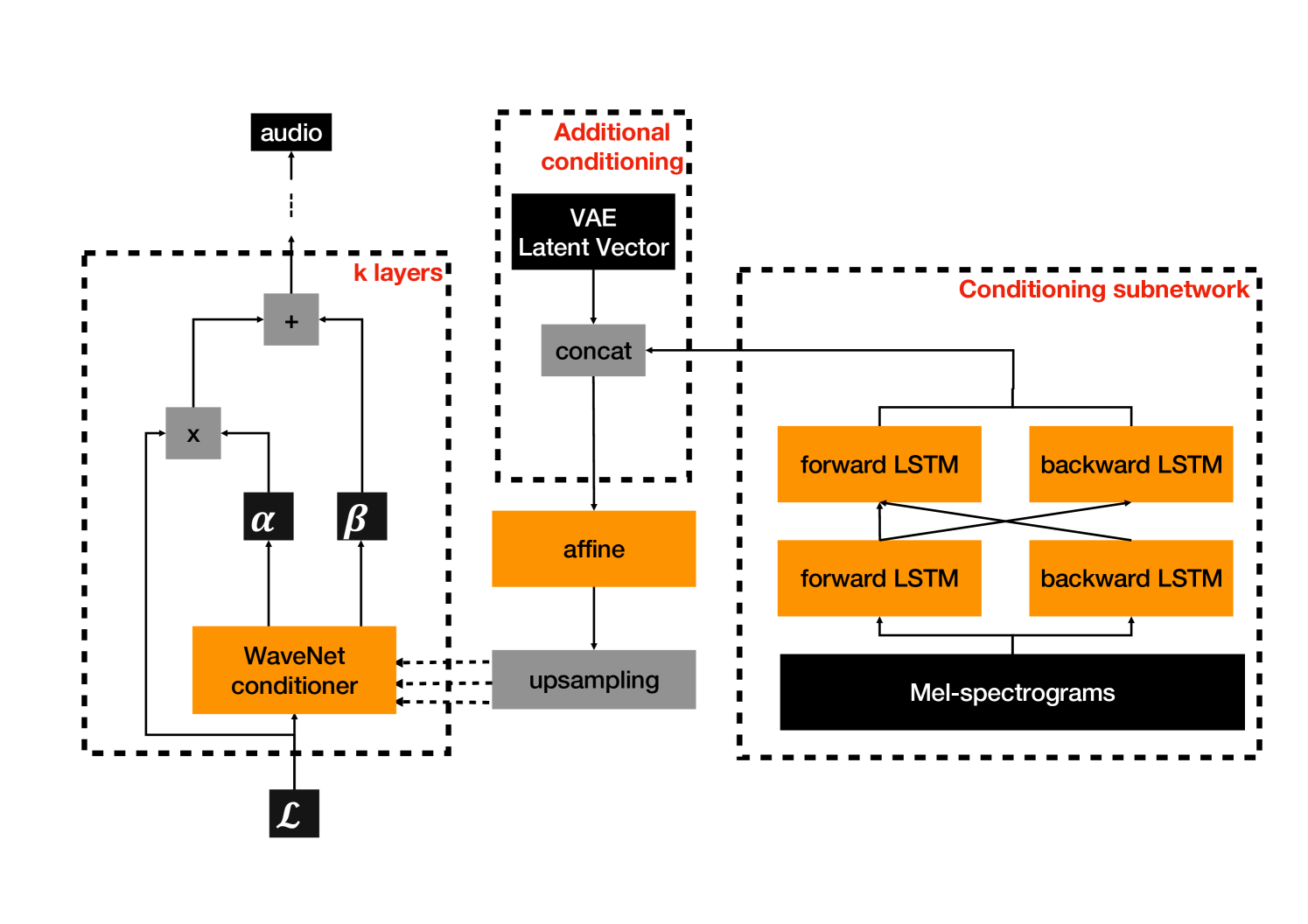
2.2 Latent Vector Extractor
To extract the utterance-level latent vector we use to condition the Parallel WaveNet models, we train an acoustic model with a Tacotron 2-like architecture [20] (see Figure 2). It uses a VAE reference encoder [21] to extract a latent representation from the target mel-spectrograms. This VAE reference encoder consists of a stack of convolutional layers followed by a bi-LSTM and two projections for the mean and standard deviation of an n-dimensional Gaussian distribution from which an n-dimensional latent vector is sampled.
Mel-spectrograms (extracted from recordings or predicted by an acoustic model) are input to the VAE reference encoder block to extract an utterance-level bottlenecked representation. We are effectively repurposing the VAE reference encoder trained alongside the acoustic model as a latent vector extractor that is used to condition the neural vocoder.
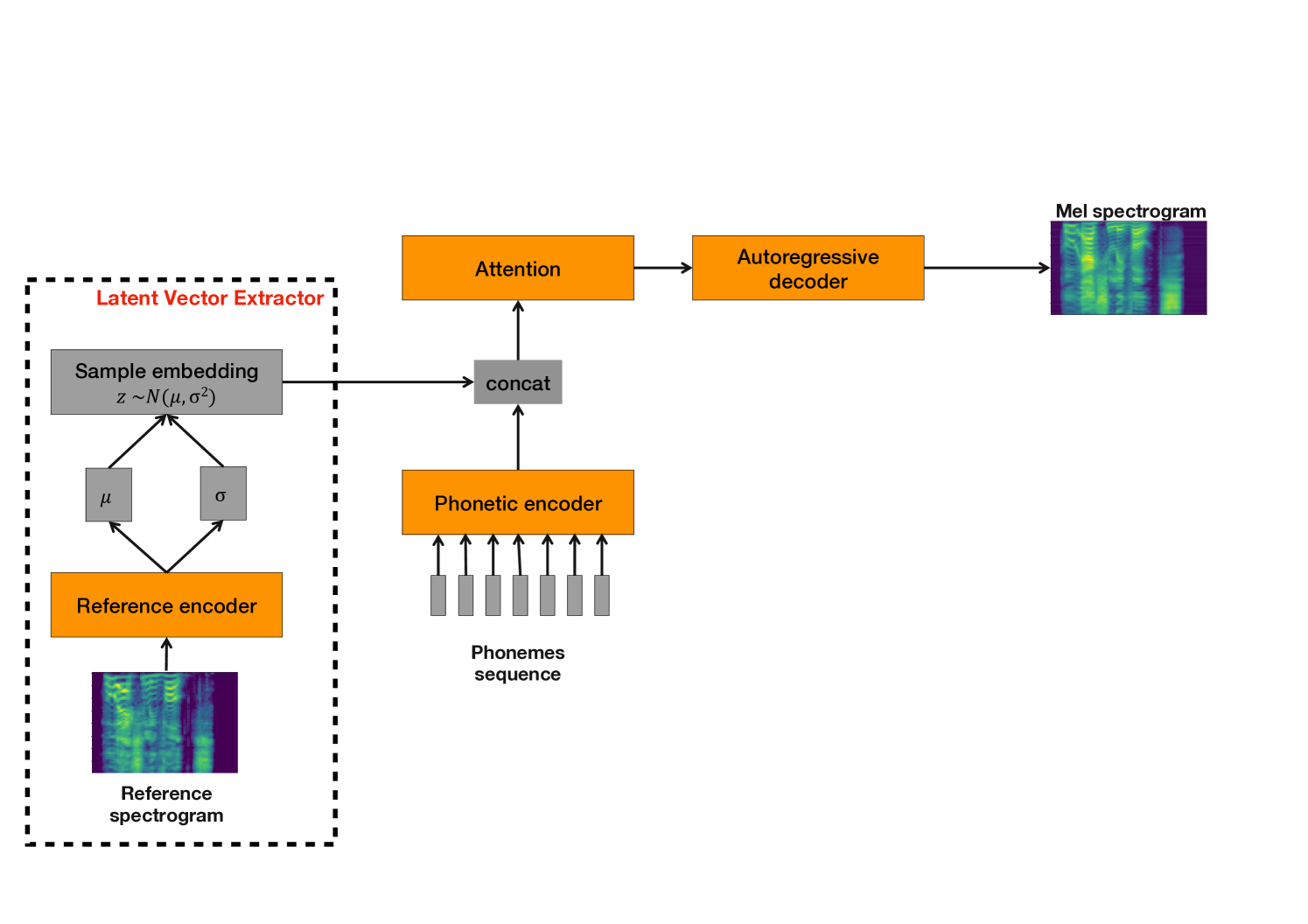
3 Experiments
3.1 Data and model details
We train the acoustic model, the Parallel WaveNet teacher and student models on a diverse set of hours of data from a single female US speaker. It contains hours of audio in the traditional neutral style and additional hours of expressive data covering the following domains: news [22], long-form book reading111https://developer.amazon.com/en-US/blogs/alexa/alexa-skills-kit/2020/04/new-alexa-long-form-speaking-style-and-polly-voices, as well as excited and disappointed emotions222https://developer.amazon.com/en-US/blogs/alexa/alexa-skills-kit/2019/11/new-alexa-emotions-and-speaking-styles.
The acoustic model architecture is similar to [22] with the exception of replacing the two-dimensional style ID with a VAE reference encoder that outputs a -dimensional latent vector. This places less constraints on the categories of speech samples since the representation is extracted from the signal rather than a manual label which is potentially inconsistent. The VAE latent space is learned in an unsupervised manner without providing explicit information about the different expressive domains. We follow [20] and increase the Kullback-Leibler divergence (KLD) loss factor from to between iterations k and k and additionally only take it into account every training steps to avoid the well-documented KL loss collapse. Once this model is converged, we use the VAE reference encoder to extract latent vectors for all the training data. These are used as additional conditioning for the training of the Parallel WaveNet teacher and student models.
The Parallel WaveNet teacher model uses a hidden size of for the two-layer bi-LSTM in the conditioning subnetwork. The output of this is concatenated with the -dimensional VAE latent vector extracted from the acoustic model, before being upsampled to match the audio. The main block of the teacher model is a WaveNet architecture with layers of dilated convolutions where the dilation value is doubling every layer and reset to every layers. The Residual Gated CNN blocks use -dimensional skip and gated channels, the filter activation is tanh and the gate activation is sigmoidal. The output is a mixture of logistics. The Parallel WaveNet student model shares the conditioning subnetwork with frozen weights with the teacher. The student is using affine transform flow layers conditioned using a WaveNet like architecture predicting scale and shift. The flow conditioners contain dilated convolutions with , , and layers. The last block uses same dilation value growth and reset as the teacher network. The dilated convolutions use -dimensional gated channels with tanh filter activation and sigmoidal gate activation. We are training the vocoder using a batch size of , the Adam optimizer with default parameters and learning rate decay of for the teacher and no decay for the student. We use Polyak averaging with decay of .
3.2 In-domain evaluation
To evaluate the quality of our proposed model, we conduct a preference test comparing it to a baseline. We use mel-spectrograms predicted by the acoustic model described in section 2.2 which also functions as the latent vector extractor. The baseline model is a Parallel WaveNet student as described in section 2.1, i.e. without additional conditioning, trained on the data described in section 3.1. Our proposed model differs from the baseline only in having the additional conditioning on the latent vector during training and inference. We evaluate utterances covering all expressive domains described in section 3.1 by asking native US speakers to ’Please choose the better sounding version.’. The in-domain results in Table 1 show a statistically significant preference for our proposed model ( in a binomial test). The preference is found across all expressive domains and informal listening shows that more expressive utterances receive a stronger preference and are characterized by a ’cleaner’ sound (i.e. less distortion and buzzing).
| In-domain | Out-of-domain | ||||
|---|---|---|---|---|---|
| Option | Votes | % | Votes | % | |
| prefer baseline | |||||
| no preference | |||||
| prefer proposed | |||||
3.3 Out-of-domain evaluation
We also evaluate our model on another set of data from the same speaker but from an expressive domain unseen during training. The mel-spectrograms are predicted using a separate acoustic model based on the same architecture described in 2.2. We evaluate utterances by asking native US speakers to ’Please choose the better sounding version.’. The out-of-domain results in Table 1 again show a statistically significant preference for our proposed model ( in a binomial test).
3.4 Different speaker evaluation
To understand if the proposed approach scales to other voices, we train the same acoustic and Parallel WaveNet models on hours of expressive data of a male US voice. We apply our proposed technique and run a MUSHRA evaluation using 200 utterances comparing Parallel WaveNet with and without the additional conditioning. We ask 6 native US speakers to rate the systems in terms of their naturalness. The recordings are rated 97.48, while the model without extra conditioning received 47.70 and the model with extra conditioning 58.97. The p-values of pairwise two sided t-tests between all systems are 0. The additional conditioning on latent vectors improves the MUSHRA score by 11 points, showing that the approach can be scaled to other expressive voices. The gap between both synthesis systems and recordings is large since it is a very expressive voice with fairly limited amount of data resulting in less accurate predictions from the acoustic model. The results indicate that the additional conditioning can bring a larger uplift on overall lower quality voices.
4 Discussion & interpretation
We have shown that conditioning the Parallel WaveNet models on the latent vector helps with synthesis quality in different scenarios. Since the baseline Parallel WaveNet models are already conditioned on the spectrograms, we need to understand why conditioning them on a latent vector derived from the same spectrograms brings an improvement. Our hypothesis is that the latent vectors represent a compressed version of the spectrograms in a bottlenecked space in which there is less difference between natural and predicted spectrograms. The vocoder is conditioned on natural spectrograms during training and on predicted ones during inference. The extra conditioning provides some additional information about corresponding spectrograms, reducing the mismatch between training and inference.
4.1 Natural speech
To test our hypothesis, we perform an evaluation on spectrograms from natural speech rather than predicted ones. We focus on the long-form domain only and evaluate utterances from a book unseen during training, asking native US listeners to rate the systems on a scale from to . We perform two tests, one asking the listeners to ’Please rate the systems in terms of their naturalness.’ and one asking them to ’Please listen to the reference sample on each testing screen and then rate how similar the systems sound to the reference audio.’ providing the recordings as reference audio. The results are shown in the top half of columns 1) and 2) in Table 2. For both questions, a pairwise two sided t-test shows no statistical difference between baseline and proposed system (p-value ). The p-values between recordings and both systems are . The evaluation on corresponding predicted spectrograms shows a statistically significant preference for the proposed system (see top half of column 3) in Table 2 and section 4.2 for more details).
System MUSHRA test 1) Natural 2) Natural 3) Predicted Similarity Recordings N/A N/A Baseline Proposed 65.42 VAE long-form 65.41 VAE neutral 65.66 VAE random 65.06
These results indicate that the additional conditioning helps the model to produce better quality only when vocoding predicted spectrograms. To get a better understanding of the relation between natural and predicted speech in the latent space, we calculate the KLD between clusters as a measure of distances. We assume Gaussian distributions for the different clusters of expressive data (neutral, news, long-form book reading, emotions) and calculate the two-sided averaged KLD between all domain clusters. Table 3 shows that for long-form the natural and predicted clusters are closer to one another than the natural long-form cluster is to any other natural cluster and the predicted long-form cluster is to any other predicted cluster. The results for the other clusters are not shown but follow the same trend. This further supports our hypothesis that the latent vectors of predicted spectrograms carry additional information about corresponding natural spectrograms.
natural predicted long-form long-form natural long-form 0 1 natural emotions natural news natural neutral predicted long-form 1 0 predicted emotions predicted news predicted neutral
4.2 Inference conditioning
To better understand the importance of the latent vector conditioning during inference, we provide latent vectors other than the one extracted from the predicted spectrogram. We work with the same test set as in section 4.2 but with predicted spectrograms instead of ones extracted from natural speech. The predicted spectrograms are created using an acoustic model different from the one repurposed as the latent vector extractor but also based on the same architecture including a VAE reference encoder, trained on neutral and long-form data. We are comparing the following latent vectors:
-
•
Baseline: without additional conditioning.
-
•
Proposed: latent vector extracted from the spectrogram.
-
•
VAE long-form: latent vector mean of the distribution of training utterances in the long-form domain.
-
•
VAE neutral: latent vector within the distribution of the neutral domain of the training data.
-
•
VAE random: a random latent vector close to but outside of the training distribution.
-
•
VAE outside: a latent vector several magnitudes outside of the training distribution.
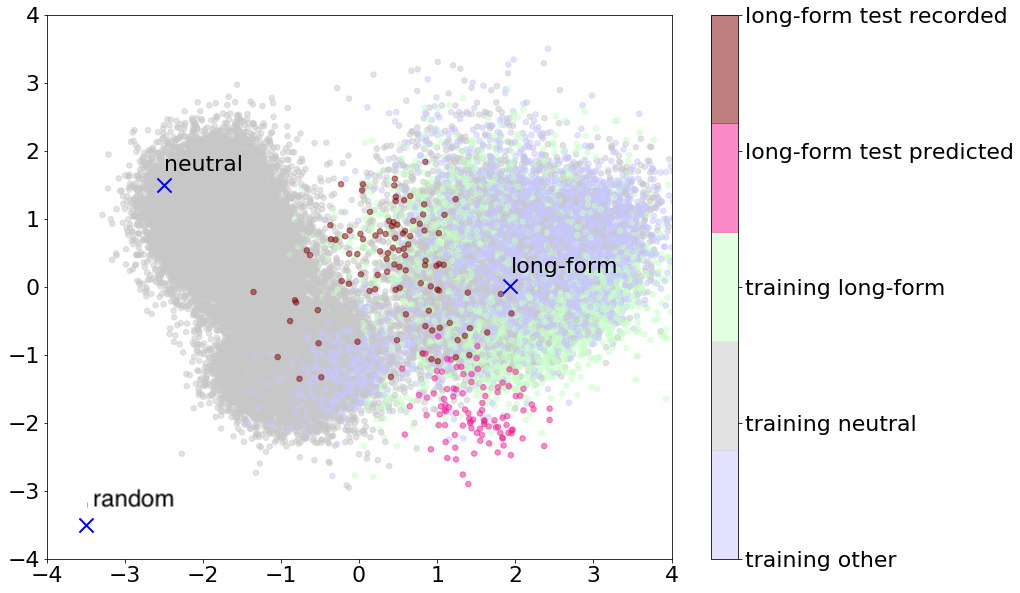
Figure 3 shows a two-dimensional PCA projection of the VAE latent space created by the latent space extractor. Blue Xs indicate the latent vectors used for conditioning. Grey points represent the latent vectors of neutral training data, light green training points in the long-form domain and light blue training points from other expressive domains. The brown and pink points indicate the extracted latent vectors for the utterances used in the evaluations; the recordings and their predicted counterparts respectively.
We evaluate the synthesis quality using a MUSHRA tests, asking native US listeners to’Please rate the systems in terms of their naturalness.’ on a scale from to . Using the VAE outside vector, the synthesized audio only contained noise and therefore we did not include this in the evaluation. The results of the MUSHRA tests can be seen in column 3) of Table 2. The vocoders conditioned on latent vectors are rated higher than the baseline, by between and points. The p-values of a pairwise two sided t-test between the baseline and all VAE systems are , showing statistical significance of the results. The p-values between all VAE systems are , indicating that there is no difference in naturalness when conditioning on different latent vectors.
These results show that providing the additional conditioning during training helps to create a model that produces better quality when vocoding predicted spectrograms. Once the model is trained, the actual vector used for conditioning during inference does not seem to affect the quality. However, unreasonable points far outside of the training distribution completely destabilize the model and result in pure noise inference. This finding allows us to train an improved vocoder by providing additional conditioning during training while not having to introduce additional latency during inference for the computation of latent vectors. We are able to provide the mean of the training distribution and still get improved synthesis quality compared to the baseline.
5 Conclusions and future work
We have investigated the use of a global conditioning vector to boost the signal quality of a Parallel WaveNet neural vocoder. This is achieved by conditioning the neural vocoder with the latent vector from a pre-trained VAE component from a Tacotron 2-style sequence-to-sequence model, which summarises the spectrogram sequence at an utterance-level. We find that by conditioning the Parallel WaveNet model with the latent vector we are able to significantly improve the signal quality when synthesizing predicted spectrograms, a conclusion which was confirmed on a second very expressive speaker. Our investigations indicate that the latent vector informs the model during training to the region of speech, helping to bridge the gap between predicted spectrograms and those extracted from natural speech. The selection of the latent vector to use at synthesis-time appears not to be important, providing it comes from a point which is close to that which was observed in the training data. This indicates that we are able to make use of the improvements of this model without needing to introduce latency during inference for the computation of latent vector. We are able to provide the fixed mean of the training distribution to condition the model.
In this paper we investigated the use of a pre-trained VAE component for conditioning the Parallel WaveNet model; however, there are a number of questions which remain to be investigated in future work. Firstly, does the component need to be pre-trained? Is this conditioning acting as an expert which informs the Parallel WaveNet model of the behaviours of the speech space, or is it providing the model with an utterance-level approximation and prior knowledge is not necessarily required, i.e. this utterance-level representation can be jointly trained with the network? Secondly, is this conditioning best handled in the form of a variational representation or can other global summarizations of the spectrogram sequence be equally effective? Finally, in this investigation we focused on a speaker dependent neural vocoder. Previously we found that we are able to train ‘universal’ WaveRNN-style neural vocoders to generate high quality speech which is invariant to a number of unseen scenarios [13]. Future work is required to understand whether we are able to develop a universal Parallel WaveNet neural vocoder and whether the global conditioning vector also brings a performance gain in such a scenario.
References
- [1] Heiga Zen, Keiichi Tokuda, and Alan W Black, “Statistical parametric speech synthesis,” speech communication, vol. 51, no. 11, pp. 1039–1064, 2009.
- [2] Heiga Zen, “Acoustic modeling in statistical parametric speech synthesis-from HMM to LSTM-RNN,” in MLSLP, 2015.
- [3] Hideki Kawahara, Jo Estill, and Osamu Fujimura, “Aperiodicity extraction and control using mixed mode excitation and group delay manipulation for a high quality speech analysis, modification and synthesis system STRAIGHT,” in Second International Workshop on Models and Analysis of Vocal Emissions for Biomedical Applications, 2001.
- [4] Masanori Morise, Fumiya Yokomori, and Kenji Ozawa, “WORLD: a vocoder-based high-quality speech synthesis system for real-time applications,” IEICE TRANSACTIONS on Information and Systems, vol. 99, no. 7, pp. 1877–1884, 2016.
- [5] Thomas Merritt, Overcoming the limitations of statistical parametric speech synthesis, Ph.D. thesis, University of Edinburgh, 2017.
- [6] Yao Qian, Frank K Soong, and Zhi-Jie Yan, “A unified trajectory tiling approach to high quality speech rendering,” IEEE transactions on audio, speech, and language processing, vol. 21, no. 2, pp. 280–290, 2012.
- [7] Thomas Merritt, Robert AJ Clark, Zhizheng Wu, Junichi Yamagishi, and Simon King, “Deep neural network-guided unit selection synthesis,” in ICASSP, 2016.
- [8] Vincent Wan, Yannis Agiomyrgiannakis, Hanna Silen, and Jakub Vit, “Google’s Next-Generation Real-Time Unit-Selection Synthesizer Using Sequence-to-Sequence LSTM-Based Autoencoders,” in INTERSPEECH, 2017, pp. 1143–1147.
- [9] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu, “Wavenet: A generative model for raw audio,” arXiv preprint arXiv:1609.03499, 2016.
- [10] Sercan O Arik, Mike Chrzanowski, Adam Coates, Gregory Diamos, Andrew Gibiansky, Yongguo Kang, Xian Li, John Miller, Andrew Ng, Jonathan Raiman, Shubho Sengupta, and Mohammad Shoeybi, “Deep voice: Real-time neural text-to-speech,” in arXiv:1702.07825v2, 2017.
- [11] Jonathan Shen, Ruoming Pang, Ron J Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, et al., “Natural tts synthesis by conditioning wavenet on mel spectrogram predictions,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 4779–4783.
- [12] Nal Kalchbrenner, Erich Elsen, Karen Simonyan, Seb Noury, Norman Casagrande, Edward Lockhart, Florian Stimber, Aäron Van Den Oord, Sander Dieleman, and Koray Kavukcuoglu, “Efficient neural audio synthesis,” in 35th International Conference on Machine Learning, ICML 2018. feb 2018, vol. 6, pp. 3775–3784, International Machine Learning Society (IMLS).
- [13] Jaime Lorenzo-Trueba, Thomas Drugman, Javier Latorre, Thomas Merritt, Bartosz Putrycz, Roberto Barra-Chicote, Alexis Moinet, and Vatsal Aggarwal, “Towards achieving robust universal neural vocoding,” in Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, nov 2019, vol. 2019-Septe, pp. 181–185.
- [14] Aaron Van Den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George Van Den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman, Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, and Demis Hassabis, “Parallel WaveNet: Fast high-fidelity speech synthesis,” in 35th International Conference on Machine Learning, ICML 2018. nov 2018, vol. 9, pp. 6270–6278, International Machine Learning Society (IMLS).
- [15] Wei Ping, Kainan Peng, and Jitong Chen, “Clarinet: Parallel wave generation in end-to-end text-to-speech,” in 7th International Conference on Learning Representations, ICLR 2019, 2019.
- [16] Ryan Prenger, Rafael Valle, and Bryan Catanzaro, “Waveglow: A Flow-based Generative Network for Speech Synthesis,” in ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings. may 2019, vol. 2019-May, pp. 3617–3621, Institute of Electrical and Electronics Engineers Inc.
- [17] Chris Donahue, Julian McAuley, and Miller Puckette, “Adversarial audio synthesis,” in 7th International Conference on Learning Representations, ICLR 2019. feb 2019, International Conference on Learning Representations, ICLR.
- [18] Diederik P. Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, and Max Welling, “Improved variational inference with inverse autoregressive flow,” in Advances in Neural Information Processing Systems. jun 2016, pp. 4743–4751, Neural information processing systems foundation.
- [19] Diederik P. Kingma and Max Welling, “Auto-encoding variational bayes,” in 2nd International Conference on Learning Representations, ICLR 2014 - Conference Track Proceedings. dec 2014, International Conference on Learning Representations, ICLR.
- [20] Ya-Jie Zhang, Shifeng Pan, Lei He, and Zhen-Hua Ling, “Learning latent representations for style control and transfer in end-to-end speech synthesis,” ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6945–6949, 2019.
- [21] Zack Hodari, Oliver Watts, and Simon King, “Using generative modelling to produce varied intonation for speech synthesis,” in Proc. 10th ISCA Speech Synthesis Workshop, 2019.
- [22] Nishant Prateek, Mateusz Lajszczak, Roberto Barra-Chicote, Thomas Drugman, Jaime Lorenzo-Trueba, Thomas Merritt, Srikanth Ronanki, and Trevor Wood, “In Other News: a Bi-style Text-to-speech Model for Synthesizing Newscaster Voice with Limited Data,” apr 2019, pp. 205–213.