[1,2]\fnmColleen \surMitchell
[1]\orgdivMathematics, \orgnameUniversity of Iowa, \orgaddress\street2 West Washington Street, \cityIowa City, \postcode52242, \stateIowa, \countryUSA
2]\orgdivApplied Mathematical & Computational Sciences, \orgnameUniversity of Iowa, \orgaddress\street2 West Washington Street, \cityIowa City, \postcode52242, \stateIowa, \countryUSA
3]\orgdivMolecular Physiology and Biophysics, \orgnameUniversity of Iowa, \orgaddress\street51 Newton Road, \cityIowa City, \postcode52242, \stateIowa, \countryUSA
4]\orgdivFraternal Order of Eagles Diabetes Research Center (FOEDRC), \orgnameUniversity of Iowa, \orgaddress\street169 Newton Road, \cityIowa City, \postcode52246, \stateIowa, \countryUSA
5]\orgdivPappajohn Biomedical Institute, \orgnameUniversity of Iowa, \orgaddress\street169 Newton Road, \cityIowa City, \postcode52246, \stateIowa, \countryUSA
6]\orgdivUniversity of Iowa Carver College of Medicine, \orgnameUniversity of Iowa, \orgaddress\street451 Newton Road, \cityIowa City, \postcode52246, \stateIowa, \countryUSA
Parameter Estimation and Identifiability in Kinetic Flux Profiling Models of Metabolism
Abstract
Metabolic fluxes are the rates of life-sustaining chemical reactions within a cell and metabolites are the components. Determining the changes in these fluxes is crucial to understanding diseases with metabolic causes and consequences. Kinetic flux profiling (KFP) is a method for estimating flux that utilizes data from isotope tracing experiments. In these experiments, the isotope-labeled nutrient is metabolized through a pathway and integrated into the downstream metabolite pools. Measurements of proportion labeled for each metabolite in the pathway are taken at multiple time points and used to fit an ordinary differential equations model with fluxes as parameters. We begin by generalizing the process of converting diagrams of metabolic pathways into mathematical models composed of differential equations and algebraic constraints. The scaled differential equations for proportions of unlabeled metabolite contain parameters related to the metabolic fluxes in the pathway. We investigate flux parameter identifiability given data collected only at the steady state of the differential equation. Next, we give criteria for valid parameter estimations in the case of a large separation of timescales with fast-slow analysis. Bayesian parameter estimation on simulated data from KFP experiments containing both irreversible and reversible reactions illustrates the accuracy and reliability of flux estimations. These analyses provide constraints that serve as guidelines for the design of KFP experiments to estimate metabolic fluxes.
keywords:
Bayesian Parameter Estimation, Parameter Identifiability, Kinetic Flux Profiling, Mathematical Biology1 Introduction
Metabolism refers to the interconnected set of chemical reactions that allow an organism to utilize nutrients, break down waste, grow, and function. The substrates and products of these reactions are called metabolites and the reaction rates are called metabolic fluxes. More abstractly, metabolic flux can be viewed as the rate at which metabolites flow between states in a network representation of a metabolic pathway. In response to changes in diet, cellular stress, or disease, distinct patterns emerge in metabolite concentrations indicating changes in the metabolic fluxes. Therefore, metabolite concentrations and fluxes are essential information for defining cell physiology and investigating changes in metabolic function [5, 17]. Since disruption in metabolic networks is connected to numerous disease states including cancer, heart disease, and diabetes, the ability to measure changes in metabolic fluxes can provide insight into the pathophysiology of these conditions [8]. Quantification of metabolic fluxes has the potential to improve diagnosis of diseases with metabolic features and aid in the development of novel treatments [1, 3, 6, 23].
Several methods for estimating metabolic fluxes have been proposed. Earlier methods, referred to as Flux Balance Analysis, were based on constrained optimization and required the assumption that the system was optimizing some element of cellular function or production [14]. Metabolic Flux Analysis is also based on constrained optimization and incorporates some measurable rates such as inputs, outputs, or oxygen consumption to further constrain the unknown metabolic fluxes [2]. Another similar approach, 13C Metabolic Flux Analysis, [2] incorporates measurement of levels of 13C, a stable isotope of Carbon. Metabolites in which the carbons have been replaced with this heavy isotope are called labeled and the small change in the mass can be detected using mass spectrometry (MS) or nuclear magnetic resonance (NMR). Following the incorporation of a labeled nutrient, proportions of each metabolite labeled are measured after the labeling patterns have equilibrated. This steady-state pattern of isotope incorporation is included as an additional constraint.
An advance from these methods is Kinetic Flux Profiling (KFP). This method takes advantage of the dynamics of the changing isotope labeling patterns to better determine the network fluxes. This combined experimental and computational approach is sometimes referred to as dynamic flux analysis [19]. The key principle behind KFP is that greater metabolic fluxes are linked to quicker transmission of isotopic label from a labeled nutrient input [20]. An ordinary differential equation (ODE) model for isotopic labeling is derived from the metabolic network architecture. By fitting the parameters in that model, we obtain estimates of the underlying fluxes. The method requires that the metabolites in the network maintain constant concentration levels, but the isotopically labeled proportion of each metabolite changes over time. We therefore say that the network is in a metabolic steady state but not in an isotopic steady state. Some examples of the successful application of KFP include the investigation of changes in metabolic fluxes in E. coli during starvation [21, 22] and in oleaginous green algae [18].
Kinetic Flux Profiling is an ideal forum for the exploration of parameter identifiability. The method is intended, from its inception, to provide data that can be used to estimate certain parameters in an ODE system. These parameters are the central goal of the profiling technique because of the insight they can provide into the function of a metabolic network. While the setup of the system of ODEs from a directed weighted graph is not unique to this system, KFP models have several idiomatic characteristics that give the equations additional structure. These include the fluxes of both labeled and unlabeled substrates into the pathway, the mixed fluxes out of the pathway, and the addition of algebraic constraints on the flux parameters. In the next section we will give a brief introduction to the KFP experimental procedure.
1.1 Kinetic Flux Profiling
The method of Kinetic Flux Profiling includes experimental data collection, conversion of a network diagram to a model consisting of a system of ordinary differential equations and algebraic constraints, and a computational step for the estimation of parameters from the data. The experiment begins by allowing the cells to reach a metabolic steady state in unlabeled media. At the metabolic steady state, all fluxes and all metabolite concentrations are constant. Next, the unlabeled media is switched out for its stable-isotope-labeled equivalent. In most cases, one specific metabolite in the media will be labeled with the carbon isotope 13C in place of all its carbons while the rest of the media remains unchanged. After the switch to isotope-labeled media, the 13C carbons will be incorporated into metabolites within the network. Samples from the cells are taken at multiple time points, and the proportions of labeled and unlabeled metabolites are quantified using MS or NMR. Ideally, these steps are performed without disrupting the metabolic steady state. That is, without perturbing the metabolic concentrations or fluxes.
Next, the architecture of the metabolic pathway under study is used to write a system of ordinary differential equations that describe the change in isotope labeling. The metabolic pathway is represented as a directed weighted graph where the nodes represent metabolites and the edges represent reactions. The pathway also includes additional inputs and outputs, edges that do not begin or do not terminate at a node. To ensure non-trivial solutions, the pathway will contain at least one labeled input and at least one output. For simplicity, the diagram should only include metabolites that may become labeled. That is, there must be a path from a labeled input to each metabolite in the diagram. In a metabolic steady state the concentrations of the metabolites are not changing. Therefore the total flux into and out of each metabolite must be equal. This flux balance condition gives an additional set of algebraic constraints on the fluxes.
The resulting system contains parameters for each flux in the network as well as for the total concentration of each metabolite. In a standard KFP protocol, it is presumed that these total concentrations are all known. The final step is to use a parameter fitting method to fit the parameters for the metabolic fluxes to the isotope labeling time courses. Since the ODE system is linear, if we had access to perfect, noise-free, continuous time data the parameters could, in theory, be computed. However, we address the accuracy and reliability of the parameter estimates when they are made with limited and noisy data. In the following sections, we seek to answer three crucial questions about the estimation of fluxes in KFP, motivated by realistic limitations on data availability. What can we learn without estimates of the total concentrations? What can we learn with only steady-state labeled proportions? What can we learn when there is a separation of time scales between metabolites?
We begin by introducing a general method for formulating the ODE system and flux parameter constraints. We next suggest a scaling of the system that does not include explicit dependence on the total concentrations of each metabolite. We finish section 2 with a condition on the graph that allows us to estimate relative fluxes (proportion of each flux to the total through a metabolite) and turnover rates of each metabolite without measuring metabolite concentrations. In section 3, we investigate the steady-state problem. Often metabolic changes occur on a time scale that make it technically challenging to collect sufficient data before isotopic steady state is reached. While it is not possible, in general, to compute turnover rates from steady-state data, we give a simple necessary condition for recovering the relative fluxes from steady-state only. This is illustrated with two examples using Bayesian parameter estimation on simulated data to show both the accuracy and reliability of the estimates. Finally, in section 4 we address what can happen if one of the turnover rates is substantially faster than the others. We show that the rapid turnover rate parameter is not identifiable unless the fast metabolite is the one that receives labeled input. Again, this is illustrated using Bayesian parameter estimation on simulated data from specific examples.
2 The KFP Model
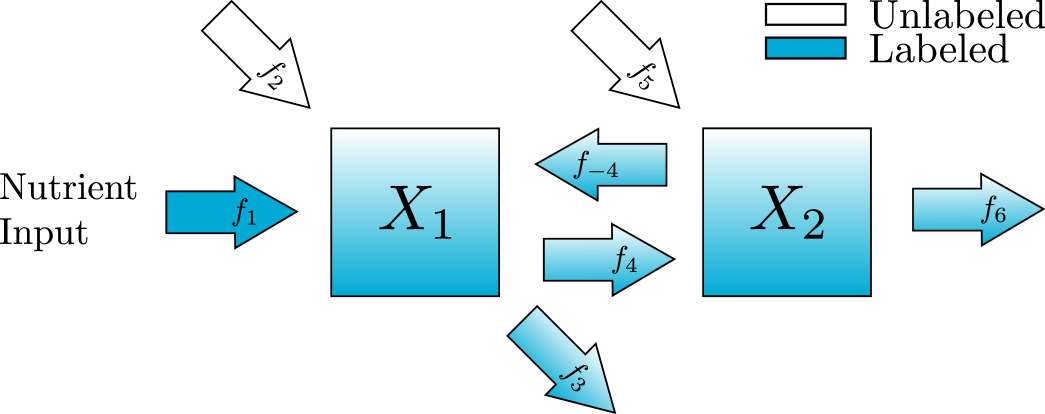
In this section, we introduce a new standard procedure for converting the diagram representation of a metabolic network into a matrix representation of the differential equation and algebraic constraints. For clarity, we begin with a simple example depicted in fig. 1 and written in the original notation typically used to describe KFP equations [20]. In this example there are three metabolites, named , , and and ten reactions with constant fluxes . We can write a system of differential equation in terms of the concentrations of either labeled metabolites or unlabeled metabolites , . Here we follow [20] and write all equations in terms of the unlabeled metabolites and use the notation for the total concentration of each metabolite. In this context, , and are all in units of concentration and the fluxes are in units of concentration over time.
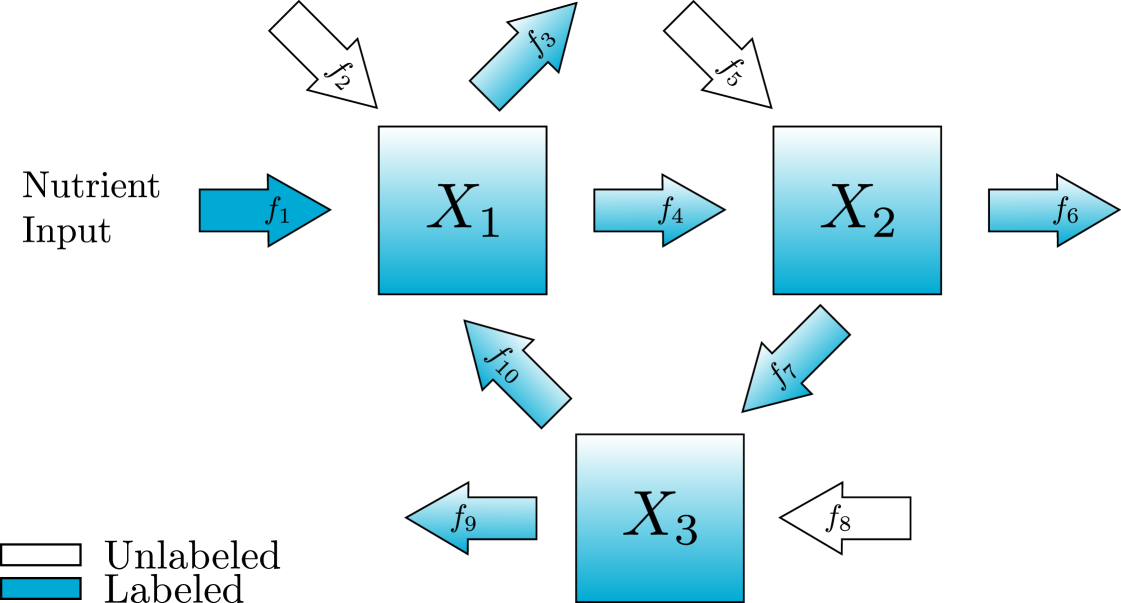
Next, we write a system of differential equations consisting of terms for each flux into or out of each metabolite. Terms that correspond to fluxes originating from metabolite will contain unlabeled metabolite proportional to the current proportion unlabeled for that metabolite . Terms corresponding to fluxes that do not originate at a metabolite are entirely unlabeled.
| (1) | ||||
The initial conditions are that all metabolites begin as unlabeled
| (2) |
Note that these equations do not contain any term for the labeled input because this influx contributes only to the labeled pool. Therefore, this flux would appear in the system for labeled concentrations. It is essential because without it, no label will be added and all metabolites will remain unlabeled. A similar formulation is possible for the labeled concentrations and combined for the total concentrations. For existing KFP methods, the additional assumption is made that the total concentrations of each metabolite are not changing. This assumption means that the fluxes into and out of each metabolite must balance leading to a set of constraints on the fluxes. In this example
| (3) | ||||
While classic KFP analysis requires that the total concentrations be constant and thus induces these algebraic constraints, the formulation of the equations eq. 1 can be generalized to a case where the fluxes are constant but total concentrations are allowed to change. In this case, each will be a linear function of time and the equations eq. 1, while still linear, will not be autonomous.
The purpose of the remainder of this section is to formalize this process of transforming the graph representation of the reaction diagram into a system of equations in the form of equations eq. 1, eq. 2, eq. 3. The formulation of the ODE system in existing literature is ad hoc for each individual application. In these applications, it is typically assumed that the network will be an arborescence with one labeled input and exactly one directed walk to each node. Here we make a more general formulation that can also be used when the graph contains cycles such as in our example or reversible reactions as in the examples in section 3 and section 4. Our goal is to write the ODE system for isotope-labeling change for a general diagram of a pathway containing metabolites and reactions in the form
| (4) |
In eq. 4 the vector represents the concentrations of unlabeled metabolites at time . The matrix describes the biochemical reactions in the pathway whose fluxes originate from a metabolite. This includes the three types of fluxes that will be addressed individually before combining into matrix . There are positive terms that are inputs from other metabolites, negative terms that are outputs to other metabolites, and negative terms that correspond to fluxes out of the system. The vector consists of the fluxes providing unlabeled metabolite into the pathway from a source outside the scope of the diagram.
We denote the time of the media switch from unlabeled to labeled as time zero. Therefore the initial conditions are that all metabolites begin as unlabeled.
Additionally, we derive the algebraic constraints for metabolic steady state. The algebraic constraints are defined by the matrix equation
| (5) |
The diagonal matrices consist of the total flux into and out of each metabolite. When we additionally assume that these fluxes are equal, we can introduce the diagonal matrix for the flux through each metabolite. Descriptions of , , , , and based on the structure of the metabolic pathway are given in the following section.
2.1 Graph representation of the pathway diagram
Suppose the diagram of the metabolic pathway is represented by the graph . Let be a special directed weighted graph where the set of nodes represent metabolites and the set of edges have weights that represent metabolic flux in the direction of the edge. The set contains edges that do not originate or terminate at a node (i.e. they enter and exit the scope of the graph). It is therefore convenient to partition into four disjoint subsets
where is the set of edges that provide labeled metabolite to the pathway, is the set of edges that provide unlabeled metabolite to the pathway, is the set of edges that exit the scope of the pathway, and are the edges that connect nodes within the pathway. We will consider only connected graphs in which there is a path from the labeled input(s) to every node. This is because any node that can not receive label will not provide any additional information. In some cases where a system has edges exiting or entering, another node is added to be the target or origin of those edges. We have chosen not to do that in this case both because it would require separate handling of inputs with labeled and unlabeled metabolites and because we feel the notion of entering and exiting the pathway is useful for the interpretation of the experiments.
We will use the following notation for the number of metabolites and reactions in the pathway, and . Because we only consider the case where there is at least one labeled influx . Each metabolite may have an unlabeled influx and there must be at least one outflux so and . Finally, since the graph is connected, . In Figure 1 we have metabolites and reactions. corresponds to the labeled inflow with rate . corresponds to the unlabeled inflows with rates and . corresponds to the outflows with rates and . corresponds to the flows between nodes with rates and .
By considering only the directed weighted graph with edges in we can define the weighted adjacency matrix. The weighted adjacency matrix, , is the matrix composed of the weights of the directed edges between nodes, . The matrix entry is the weight of the edge from node to node . If no connection between node and node exists [13]. We further define the total concentration matrix as the diagonal matrix containing the total concentration of each metabolite . Then the terms in eq. 4 corresponding to the influx into each node from the other nodes is . In our example,
Another commonly used matrix in graph theory is the degree matrix. The degree matrix, , is a diagonal matrix of the degree of each node [12]. Since we have a directed weighted graph, we will define two variations of the degree matrix: the weighted out-degree matrix and the weighted in-degree matrix.
Definition 1.
The weighted out-degree matrix, , is a diagonal matrix composed of the sum of weights on the edges leaving a node and entering another node. The matrix entries are computed by . Similarly, the weighted in-degree matrix, , is a diagonal matrix composed of the sum of weights on the edges entering a node from another node. The matrix entries are computed by .
The terms in eq. 4 that correspond to outfluxes to other metabolites can be written. . In our example,
| (6) |
Our graph also includes edges in sets , , and that enter and exit the scope of the graph so we define matrices corresponding to these sets of fluxes.
Definition 2.
The labeled entry matrix, , is the diagonal matrix consisting of the weights of the edges in , is the weight of the edge that enters nodes . The unlabeled entry matrix, , is the diagonal matrix consisting of the weights of the edges in for unlabeled metabolites that enter nodes . The exit matrix, , is the diagonal matrix consisting of the weights in for the edges that leave node .
The terms in eq. 4 which correspond to outfluxes exiting the graph can be written . In our example,
The last set of terms in eq. 4 are the constant terms for the unlabeled inputs and are the entries on the diagonal of . Therefore, we can define the vector in eq. 4 as having entries .
Finally, we can define in eq. 4 and in eq. 5. The matrix is defined by the equation
| (7) |
where the diagonal matrix is defined by the equation and gives the total rate of flux out of each metabolite. Similarly, we define the matrix to be the diagonal matrix of all fluxes entering each metabolite, . As stated above, the algebraic constraints for constant total metabolite concentrations is that . When these constraints are satisfied, we call this diagonal matrix for simplicity. The diagonal entries of will be denoted for the flux through the metabolite.
2.2 Scaling for Isotope Enrichment
Measurements of labeled and unlabeled metabolite concentrations are typically reported as a “percent enrichment”, the percentage of the total pool of a metabolite that is labeled with at least one 13C. This is because the mass spectrometer measures a signal intensity at specific masses. The intensity of the signal at the mass of the labeled metabolite is divided by the total signal intensity for the metabolite to compute a labeled relative signal intensity. Conversion of signal intensity to concentration requires extensive additional experiments to develop calibration curves for each metabolite in the experiment. However, the relative signal intensity for metabolite is a reasonable approximation of the relative concentration for metabolite whether labeled () or unlabeled (). Therefore, we scale the model so that the new variables are the proportions of each metabolite that are unlabeled, or in matrix form
| (8) |
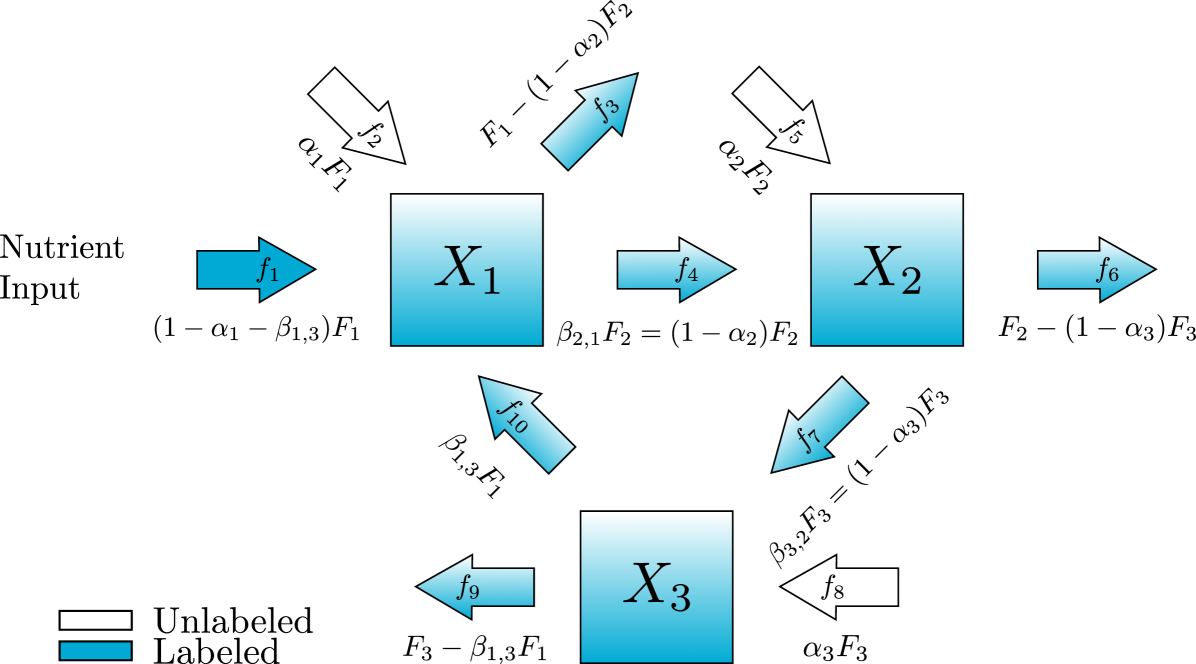
In this scaled format, it is useful to also write these equations in terms of new parameters. Let us define the vector and the matrices , , and . The entries of are , the proportion of the total flux into metabolite that comes from an unlabeled input originating outside of the diagram. Similarly, for the fluxes originating from other metabolites, the entries of are , the proportion of the total flux into metabolite that comes from metabolite . This new notation for the fluxes has been incorporated into a diagram of the network for our example and is shown in fig. 2. The entries of and are all the dimensionless proportions of fluxes into each metabolite. Finally, and are diagonal matrices with entries that can be viewed as turnover rates of the metabolites in units time. The scaled system can be written
As before, if the metabolite concentrations are unchanging then we have the algebraic constraints which gives . This simplifies the system further to
| (9) | ||||
where is the vector with all entries equal to one.
This formulation of the problem is powerful because it allows us to write the model variables entirely in terms of proportions unlabeled. This proportion can be measured directly as one minus the isotopic enrichment. Additionally, the parameters in and are also ratiometric. They are proportions of each flux to total flux through the metabolites so we will refer to them as flux ratio parameters. The other parameters in are the turnover rates for each metabolite. There is no explicit dependence on the total concentrations. This means we can construct the model and fit the parameters in this format without measuring metabolite concentrations. To convert the resulting values for the parameters back to fluxes in units of concentration per unit of time would still require the costly measurement of total concentrations. However, in many instances functional changes in metabolic networks could be gleaned from changes in the turnover rates and relative flux values which are the parameters in equation eq. 9.
2.3 Number of Independent Parameters
Since the computational time for parameter estimation can quickly become impractical, it is essential to reduce the number of parameters as much as possible. In this section, we use the algebraic constraints to find the number of independent parameters which must be fit. We begin with a general statement of the number of parameters needed. Next, we investigate the special case where each metabolite has a non-zero flux exiting the graph. Finally, we discuss the more difficult case, where some exiting fluxes are missing from the reaction diagram.
Theorem 1.
Proof.
In the original formulation before scaling, the model contains parameters for the fluxes . These fluxes can be organized into an incidence matrix, . In the context of chemical reactions, this is equivalent to the stoichiometry matrix for this set of reactions. The rows are the metabolites and the columns correspond to the fluxes. The entries of , will be if flux is an input for metabolite , and if it is an output from metabolite . All other entries will be zero. Our algebraic constraints that the total input flux must equal the total output flux for each metabolite can therefore be written
The matrix will be full rank. This is easiest to observe in the row reduction of . We can assume that there is at least one input since we must have labeled input. The row of for this input will include a in the column for the metabolite entered, and a zero for all other columns. We can therefore eliminate all other entries in this column. Any flux that connected this metabolite to another metabolite will now have a row with only one non-zero entry. These can be used to eliminate other entries in those columns, and so on. Because the graph is connected this will eventually reach all columns leaving a pivot in each column. Since the matrix has rank , we can solve for of the fluxes in terms of the other . In general, the system will have independent parameters. ∎
Before we turn to the special case, let us begin by counting the parameters in our scaled system eq. 9. This model has parameters corresponding to the non-zero entries of , for the turnover rate of each metabolite, parameters for the non-zero entries of for the unlabeled inputs, and parameters corresponding to the non-zero entries of for the fluxes between metabolites. Since and are all of the dimensionless proportions of fluxes into metabolite , for any metabolite which has no labeled inputs, we know that
| (10) |
We can therefore, without loss of generality, replace the first non-zero entry in these rows
| (11) |
There are therefore remaining independent values. In our example, this means we can replace with and with so we have written both forms in fig. 2. Now we can write our system in terms of the seven remaining parameters.
A graph which is an arborescence will have and . Therefore, such a graph will have no remaining independent parameters. On the other hand, a graph that is not an arborescence will have either or or both. Therefore, any graph which is not an arborescence will have non-zero parameters in this scaling.
So far we have counted the turnover rate parameters, , and the proportional flux parameters, and . This brings us to a total number of parameters in eq. 9 of . In developing this parameter set, we have labeled the edges in with s and those in with s. Let us now turn our attention to and . Because of our choice to scale all inputs to the total input for each metabolite, a labeled input edge in can also scale to the influx into its node as . In our example, this means that the labeled input will be . In practice, it is typical to have only one labeled input so each of our examples has one edge in which is an input into the first metabolite.
The labeling of the edges in may pose a new complication because of our algebraic constraints. Notice first that in the special case , the number of parameters already defined after the substitution in eq. 11 will be exactly the minimum number, . This is because in this case, every node has an output vector that can be used to satisfy the algebraic constraint that the total output from each node must equal the flux through that node. Since the total of all fluxes out of node must be , the flux from metabolite exiting the diagram will be . In our example, this means that , , and . Since every node in the example has an output, we have completed our parameterization in a way that gives the minimum number of parameters and does not depend on any concentrations which would require additional measurements.
We will finish this section with a discussion about the case where . In this case, there is at least one metabolite that does not have an outflux leaving the pathway. This means that we still have too many parameters in our formulation. However, our algebraic constraints now imply that the equation for the missing outflux must be zero. That is, for any node which does not have a flux out of the pathway, . This constraint is challenging because it is a relationship among the total fluxes through multiple metabolites. It can be solved for one of the parameters or one of the parameters, however, the resulting equation will depend on the total concentrations of node and any immediately downstream nodes. In our example, suppose there is no outflux from metabolite . Then implies To write this in our preferred parameters we have or . In general, any metabolite that does not have an outflow will create a constraint on the parameters which requires reintroduction of the total concentrations of the metabolites. In designing KFP experiments, this leads to a decision that must be made. In some cases, the experimenter may already plan to conduct additional experiments to measure the concentrations of the relevant metabolites, either as part of their larger study to understand mechanistic changes or because they wish to convert the relative fluxes and turnover rates in equation eq. 9 back to the original fluxes in eq. 4. In this case, the constraint induced by the missing outflux can be used to further reduce the number of parameters. If the total concentrations will not be measured, we will need to include a flux out of the pathway for every metabolite. The additional parameter not only increases computation time, but it may also increase the number of time points needed to accurately and confidently estimate relative fluxes and turnover rates.
In this section, we have used the structure of the directed weighted graph representation of a metabolic pathway to formulate differential equations for the unlabeled metabolite concentrations. Scaling this model in terms of isotope enrichment allows us to write the model entirely in terms of relative fluxes and turnover rates. Using the algebraic constraints that the flux in and out of each metabolite must be equal, we can further reduce the number of parameters. In the case where every metabolite has a flux out of the pathway () the model can be written in terms of the minimal number of parameters using only relative fluxes and turnover rates. In the case where not all metabolites have a flux out of the pathway, the resulting minimal set of parameters will include dependence on the total concentrations.
3 Steady State Problem
In this section, we turn our attention to the second question. What can be learned from the steady-state fractional isotopic enrichments? Other methods such as 13C metabolic flux analysis use data collected only after the isotopic steady state is reached. In practice, one must design the experimental protocol without preexisting knowledge of the rates of the reaction. At the same time, collecting data from time points very soon after the isotope switch without perturbing cellular metabolism can be technically challenging. Therefore, the metabolites may have attained their isotopic steady state by the time the first data points are collected. We show below that only the proportional flux parameters can be estimated from the steady-state information and only under specific conditions on the graph structure.
3.1 Proportional Flux Parameters and the Isotopic Steady State
Theorem 2.
The steady state of eq. 9 is unique. This steady state depends on the proportional flux parameters and does not depend on the turnover rates.
Proof.
The steady state of eq. 9, , is found by solving the matrix equation
| (12) |
The matrix in equation eq. 9 does not appear in eq. 12 because is invertible. By definition, the diagonal entries of , are non-zero because the metabolite must be present () and there must be flux through it ().
Next we will show that is weakly chained diagonally dominant. Because the entries of the matrix in row are the proportions of the fluxes into metabolite , the row sums of are between zero and one. Subtracting, this implies that has nonnegative row sums and is therefore weakly diagonally dominant. Now, we must use two properties of the underlying graph structure, first that there is at least one labeled input, and second that there is a path to every node from a labeled input. The row of corresponding to a node that receives a labeled input will be strictly diagonally dominant. Since there is a path to all other nodes in the pathway, a directed graph constructed from will have a path back to the labeled input node. Since is weakly chained diagonally dominant, it is invertible [16]. Therefore, the steady-state values only depends on the proportional flux parameters, and . ∎
Note that in the special case where each metabolite receives at least one input from or we can show that has strictly positive row sums. This is equivalent to the condition that for all metabolites with no labeled input. Consider a metabolite with no labeled input. Recall from eq. 10 that the entries of row of matrix must add to . This implies that the row sum for the row of is . In the case of a row corresponding to a metabolite which does have labeled input, the row sum of must be strictly less than one since we require a non-zero labeled influx. Therefore, is a Z-Matrix with positive row sums and is invertible [4].
We have chosen the scaled parameters so that the equilibrium equation eq. 12 will have no dependence on the turnover rates in , therefore these turnover rates can not be estimated without some data collected during the transient time. While we have defined the function from and parameters to the steady state values, this function is not, in general, invertible. Recall from section 2.3 that the number of nonzero parameters in is and that the number of non-zero parameters in is . After substitution using eq. 11, there will be proportional flux parameters in eq. 12. The simple condition that there must be at least as many steady state values as parameters leads to the following necessary condition for recovery of the and parameters
| (13) |
Note that the number of arrows leaving the pathway, is not included in this condition. As we saw in section 2.3, if all nodes have an output vector in then these output vectors are determined by the algebraic constraints. If one of the nodes does not have such an output vector, the algebraic constraint gives a new condition on parameters. However, this can not reduce the number of parameters in or so can be ignored for this discussion.
A few simple examples illustrate why this condition eq. 13 is not sufficient. If then the only steady state is all zeros. Intuitively, this case has no unlabeled input so at steady state, all metabolites are fully labeled. Clearly no information about the values of the parameters can be deduced from this steady state. Another example is if metabolite only receives input from metabolite , that is , for . In this case, the metabolites and will approach the same steady state and the steady states will provide fewer than equations for specifying underlying flux ratios.
In the case where the graph is an arborescence, the condition is met and the proportional flux parameters can always be recovered from steady state values. In this case the steady state of the root node will be its proportion of unlabeled input. Every other node , can be written in terms of only its unique upstream metabolite . ). Therefore .
Next we will look in detail at two simple examples which illustrate this necessary condition. In the first, there are two metabolites and the reaction between them is not reversible. In this case, the condition eq. 13 is met and the parameters can be written as functions of the steady state values. Using Bayesian parameter estimation of simulated noisy data, we see that the parameters are recovered accurately and confidently. Next, we consider the similar case with a reversible reaction. In this case the eq. 13 condition is not met and the estimation of parameters is problematic.
3.2 Examples: Irreversible and Reversible Reactions
Given data collected only at the steady state of the system, proportional flux parameters can only be uniquely recovered from steady-state estimates if the map from proportional flux parameter values to steady-state values is one-to-one. In this section we explore two examples, one irreversible and one reversible which demonstrate this condition.
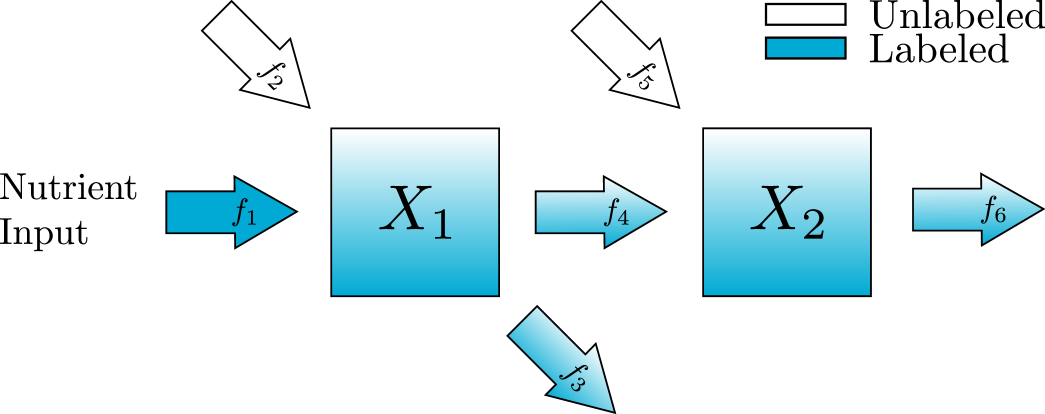
Suppose we can get estimates for the steady-state values of the metabolites, . The proportional parameters and can be recovered with the map
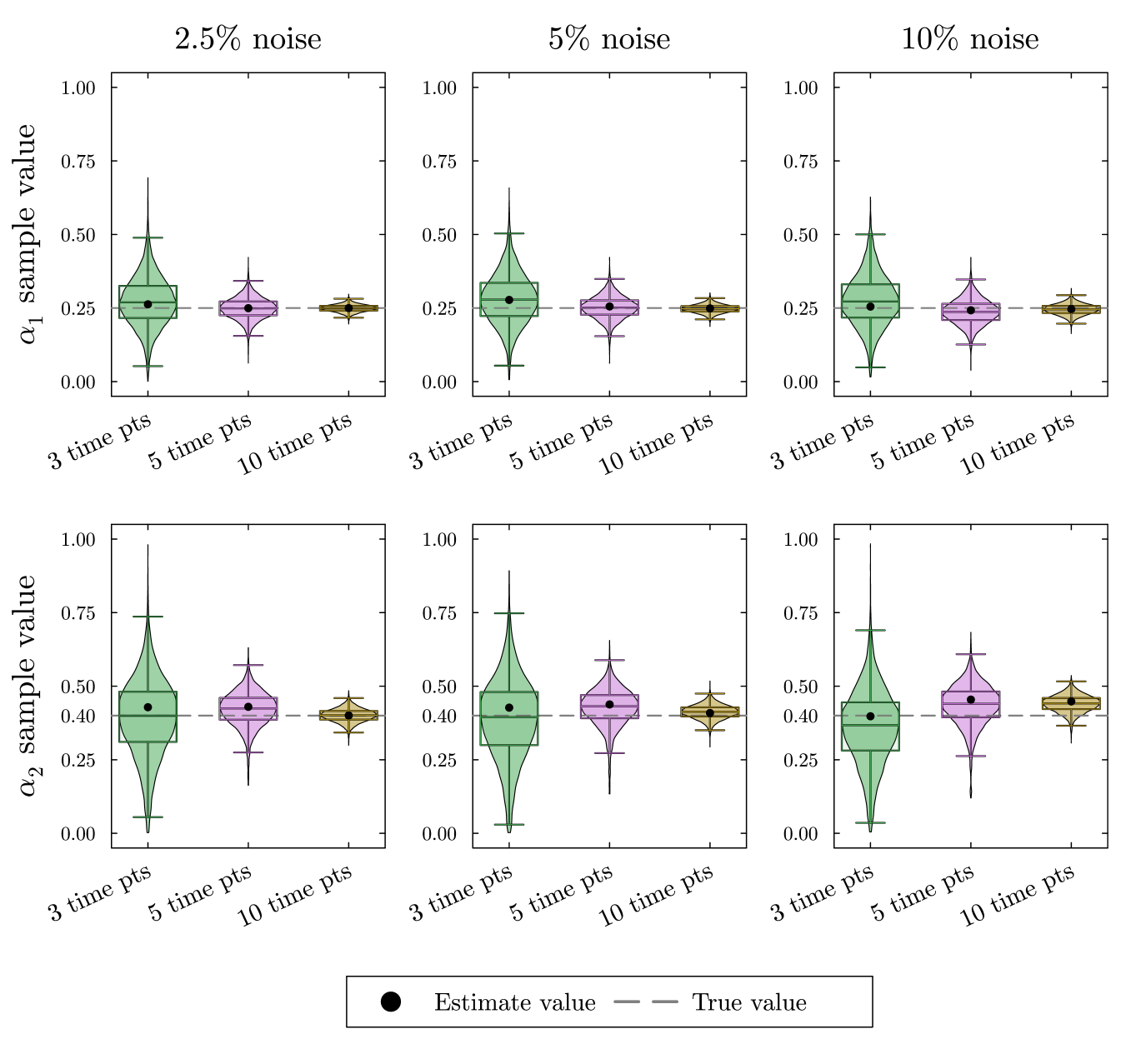
To illustrate the ability to recover and in this example, we have used Bayesian parameter estimation with noisy simulated data as described in Appendix appendix A. In all of our Bayesian parameter estimation examples we have used the following general procedure. We generate solutions to the ODE system using known parameter values. Then at each time point, we produce three noisy data points to simulate technical replicates of the experiment. To explore the role of the noise, we have added normally distributed noise to the true solution with a standard deviation that is 2.5, 5, or 10% of the true value. To explore the dependence on the number of time points we have included 3, 5, or 10 equally spaced time points in each parameter estimation. All parameters, including proportional flux parameters and turnover rates are given naive priors. In this section we show only the posterior distributions for the proportional flux parameters, since we anticipate poor estimates of turnover rates. The simulated data, the estimates for the turnover rates, and the credible intervals for each parameter estimation can all be found in the supplement.
In the violin plots in fig. 4, we see that the method consistently provides accurate recovery of both and as the mode of the posterior distributions. The spread of the violin plots or box plots, is a visual indicator of the uncertainty in our estimate. The comparison across number of time points shows, not surprisingly, that more time points generally provides a more accurate and less variable estimate. The results are relatively insensitive to the level of noise in the data. Increasing the noise level only slightly increases the error and the uncertainty in the estimate.
Next, we turn to the second example shown in fig. 5. In this reversible reaction, the number of proportional flux parameters is 3, and therefore it does not satisfy the condition eq. 13. The scaled system for this example is
| (16) |
which has a steady state
| (17) |
Suppose we can get estimates for the steady-state values of the metabolites, . Since these values depend on all three parameters, there is no way to recover unique values for the parameter with only two pieces of information.
Providing Bayesian parameter estimation with simulated data of this system as described in Appendix A shows the inability to recover all parameter values accurately. In the violin plots in fig. 6, we see that we only get moderately accurate estimates for . As before, as we increase the number of time points, the uncertainty for estimates decreases and the results are relatively insensitive to the magnitude of the noise. The estimates for and on the other hand are completely unsatisfactory. The estimates of are much lower than the true value, while the estimates for are much higher than the true value. The sample distributions for both and show that there is a high uncertainty in the estimates. Since the two steady-state values depend on the values of , , and , several combinations of parameter values give the same steady-state value. While the method may be able to correctly determine combinations of these parameters that give the correct steady-state values for both and , it cannot discern the correct parameter values.
We further hypothesize that and are more difficult to estimate because of the structure of our steady state solutions. The true values for , , and are all fairly small, so if we ignore the quadratic terms in eq. 17 we obtain approximate steady states . In this expression, and always occur in the same combination and therefore cannot be distinguished.
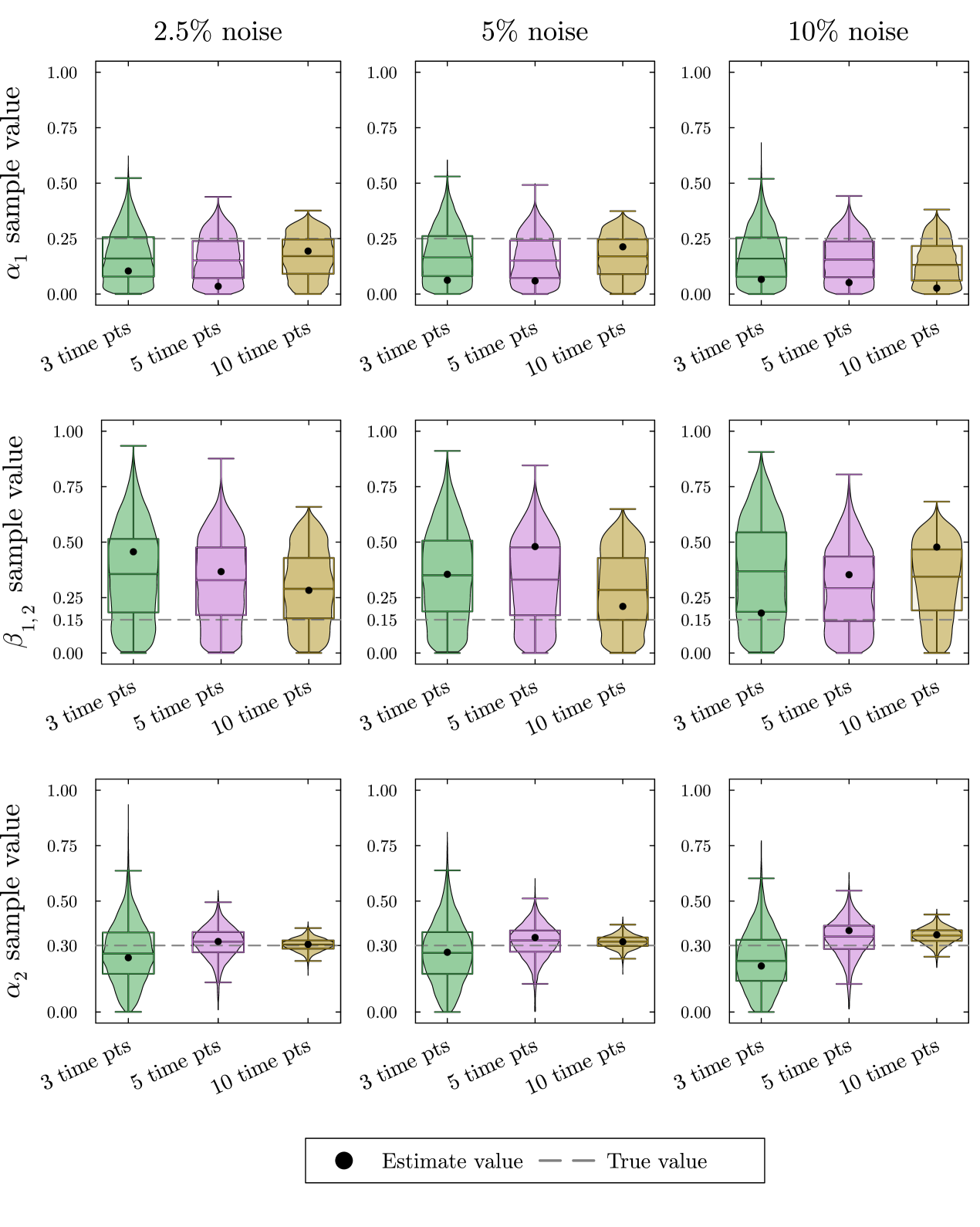
In this section we have shown that the estimation of parameters may be severely limited if only steady state data is obtained. In this case, the values for the turnover rates can not be estimated as they do not appear in the steady state equation. It may, however, be possible to estimate the proportional flux parameters if the number of measured steady state exceeds the number of parameters. The specific example with irreversible and reversible reactions illustrates this necessary condition. The examples also makes clear the utility of using a Bayesian parameter estimation. A classic least squares parameter estimate will be able to replicate the limited data but will not necessarily give accurate estimates of the underlying fluxes. The Bayesian approach, however, allows the researcher to simultaneously quantify the best estimate and the certainty in that estimate. This allows for iterative improvement of the experimental protocol for a particular pathway and lowers the chances of misinterpretation.
4 Fast-Slow Analysis
In this section, we address separation in time scales for different metabolites. Here, we will be comparing turnover rates which are the ratio of the total flux through a metabolite to the total concentration of that metabolite. A metabolite may be considered fast if the fluxes into and out of that metabolite are large, or if the total concentration of that metabolite is small. Here we will begin with the general proof that data collected from a reaction network with a disparity of time scales does not contain fast dynamics if the metabolite with the fast turnover rate is not receiving pure isotopically labeled nutrient. Next we will investigate a chain reaction network with the fast metabolite either first or later in the chain. Finally, we will return to the reversible two metabolite model and use Bayesian parameter estimation to illustrate the accuracy and reliability of estimates of the turnover rates.
4.1 Fast-Slow Dynamics Limit Turnover Rate Identifiability
Here we show that if the metabolite with the fast turnover rate is not the metabolite receiving the labeled nutrient input, the solution is entirely on the slow manifold and the parameter for the fast turnover rate cannot be estimated.
Theorem 3.
In the scaled reaction network model in eq. 9, suppose . If is not the target of any edge in , then the initial condition is on the slow manifold.
Proof.
Let . Then, the slow manifold is obtained by setting
| (18) |
Since is not the target of any edge in , the sum of the proportional flux parameters coming into this metabolite will be one. By eq. 10 we have
Plugging the initial condition, into the equation for the slow manifold, we have
Hence, the initial condition is on the slow manifold in eq. 18. ∎
As a result of theorem 3, fast dynamics will not be present in the system and the experimenter will not be able to estimate the faster turnover rate . In this situation, the experimenter may still be able to estimate all the slower turnover rates and the proportional flux paramters.
In the special case where the metabolite with the quickest turnover rate is a target of an edge in , the fast subsystem is defined by
Fast dynamics are present in this system but estimating relies on the ability of the experimenter to collect time points on the scale of .
In the following example, we show that data collected from a chain reaction network with a disparity of time scales does not contain fast dynamics if the slow turnover rate is upstream of a more rapid turnover rate. We will begin by formulating the general reversible chain reaction network model and its fast and slow subsystems.
4.2 Chain Reaction Model
Consider the reversible chain reaction network in fig. 7. The scaled ODE model can be written in form eq. 9 with the following variables and parameters. For ,
and for ,
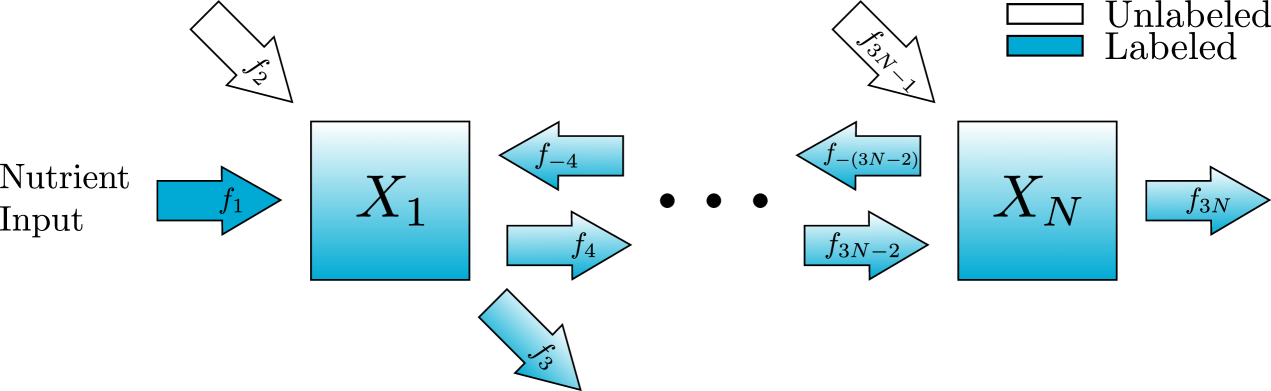
4.2.1 Nondimensionalized Reversible Chain Reaction Model
To investigate the effectiveness of experimental data from a chain reaction network containing a disparity between time scales, we include the full nondimensionalization of the reversible chain reaction model to fast and slow subsystems. To simplify the analysis we will only consider the case where the turnover rate of one metabolite is much faster than the turnover rate of all other metabolites.
Since each metabolite receives inputs only from neighboring metabolites, The matrix is tri-diagonal. We will therefore construct the fast and slow systems using the system of equations in eq. 19 instead of the matrix representation.
| (19) | ||||
Assume we know the turnover rate of one metabolite in the reversible chain reaction network is much greater than the turnover rate of all other metabolites. Thus, we will have one fast variable and slow variables. The effectiveness of the experimental data is directly related to the location of the metabolite with a quick turnover rate. We will derive the dimensionless model for two cases. In the first case, the metabolite with the fastest turnover rate is the first metabolite in the chain reaction network. In the second case, the metabolite with the fastest turnover rate is not the first in the chain reaction network.
Case 1:
Suppose the metabolite with the greatest turnover rate is the metabolite generated directly from nutrient, , making the fast variable. So, for . Let the dimensionless variable be the fast time scale and let . By taking , we obtain the fast subsystem.
| (20) | ||||
On the fast time scale, approaches the equilibrium of eq. 20 at .
Let the dimensionless variable be the slow time scale. The slow system is derived by taking to obtain
| (21) | ||||
In this case, the solution will start at the initial condition , then quickly approach the slow manifold, , which is the nullcline of . The quick jump from the initial condition to the slow manifold shows the fast dynamics of the system. Data collected quickly after the isotope switch will be on the fast time scale and may be used to estimate the fast turnover rate. Data collected later in the experiment is on the slow time scale eq. 21 and may be used to approximate the other turnover rate parameters. The proportional flux parameters and will be particularly easy to estimate because the solutions will remain on the slow manifold for most of the experiment. For this scenario, the fluxes approximated from data collected both early and later in the experiment will be accurate since both fast and slow dynamics can be observed.
Case 2:
On the other hand, if the metabolite with the greatest turnover rate is a downstream product of the metabolite generated directly from the nutrient, then fast dynamics will not be observed in the data. The issue arises because the initial condition is located on the slow manifold. Let for be the metabolite with the greatest turnover rate, making the fast variable. So, for with . Let the dimensionless variable be the fast time scale and let . By taking we obtain the fast subsystem
| (22) | ||||
Given that the initial condition is , the fast subsystem begins at its equilibrium . This implies that the trajectory does not leave the initial condition on the fast scale. Let the dimensionless variable be the slow time scale. We derive the slow subsystem for this scenario by taking
| (23) | ||||
From eq. 23 we obtain the slow manifold defined by which is the nullcline. We know the slow manifold contains the initial condition by investigating the fast subsystem in eq. 22. Therefore solutions will display only slow dynamics and all variables will approach the equilibrium point at the intersection of all nullclines along the slow manifold. The turnover rate for the fast metabolite cannot be estimated. However, the proportional flux parameters for fluxes into the fast metabolite, and will be evident throughout the experiment as the solutions track along the slow manifold. While the slow dynamics of the upstream metabolites limit our ability to estimate the fast dynamics accurately, the slow dynamics are still able to be estimated.
The conclusions of case 1 and case 2 also apply to the irreversible chain reaction. In the irreversible chain reaction . The initial condition is still on the slow manifold if a slow turnover rate is upstream of the faster turnover rate. The irreversible two-metabolite example illustrating this conclusion is included in the supplementary material.
4.3 Two-Metabolite Example
Using the reversible two-metabolite example, we will illustrate both cases in section 4.2.1. Consider the reversible two-metabolite reaction network in fig. 5 and its scaled ODE model eq. 16.
Case 1: Fast-Slow System
Suppose we know the turnover rate of is much greater than the turnover rate of , i.e. . Let the dimensionless variable be the fast time scale and let . Following the same process as in section 4.2.1 for the general reversible chain reaction model, we obtain the fast subsystem.
Now, let be the slow time scale to obtain the slow subsystem.
In this example, the slow manifold is defined by .
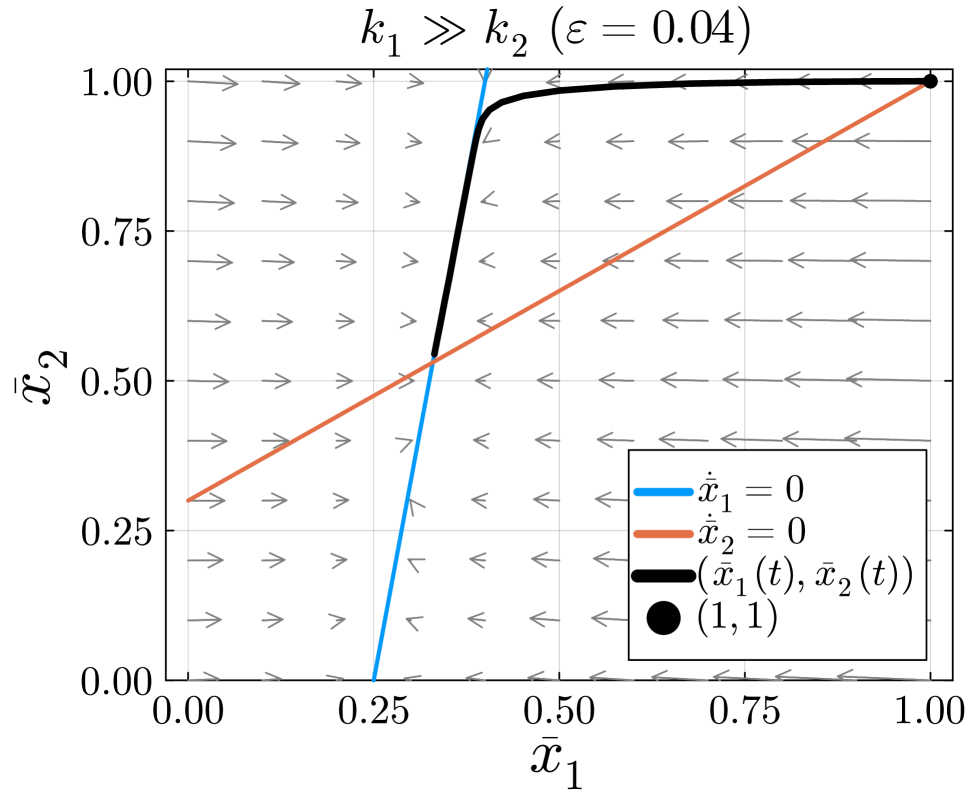
The solution in fig. 8 begins at the initial condition . Next, it quickly moves from the initial condition to the slow manifold. This portion of the solution shows the fast dynamics of the system. After approaching the slow manifold, the solution slowly approaches the equilibrium point eq. 15. The movement along the slow manifold represents the slow dynamics of the system. In this case, data collected quickly after the isotope switch will be on the fast time scale and data collected later in the experiment will be on the slow time scale. With both early and later measurements from this reaction network, KFP will provide more accurate flux estimations given that both fast and slow dynamics are represented.
We simulate data for this system as described in Appendix appendix A. The resulting posterior sample distributions for and are included in fig. 9. As with previous Bayesian estimates, all parameters including proportional flux parameters and turnover rates are given naive priors. In this section, we show only the posterior distributions for the turnover rates since the estimation of the proportional flux parameters follows the pattern seen in section 3. The simulated data, the estimates for the proportional flux parameters, and the credible intervals for each parameter estimation can all be found in the supplement.
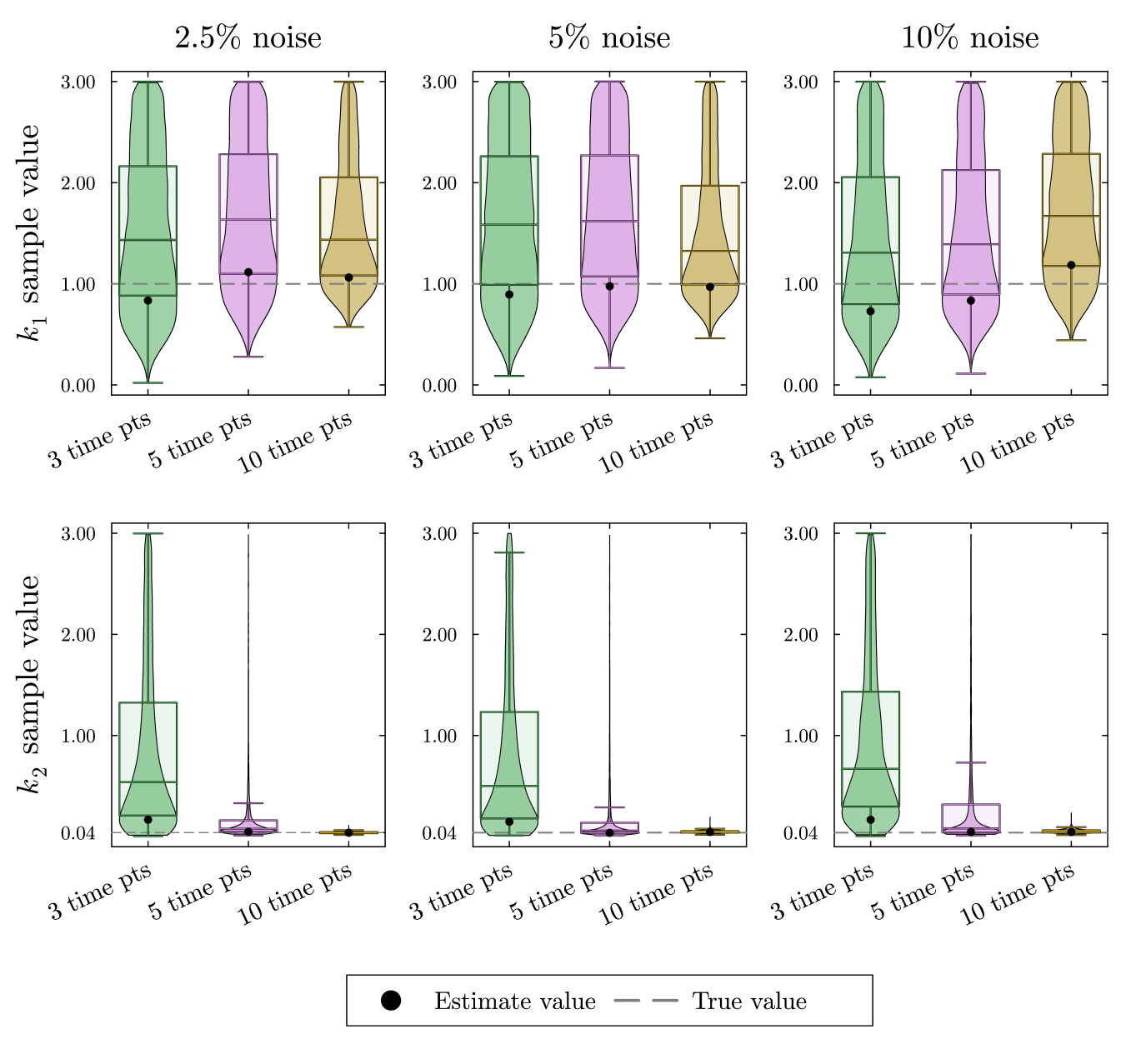
In the top row of fig. 9, we see the estimates for are accurate but highly uncertain. Because there was only a single time point taken during the rapid decay of , we cannot get a good estimate for . In the bottom row of fig. 9, we see the estimate for increases in accuracy and decreases in uncertainty with the addition of time points despite the noise level.
Case 2: Slow-Fast System
Now, we assume the opposite situation. Suppose we know the turnover rate of is much greater than the turnover rate of , i.e. . Let the dimensionless variable be the fast time scale and let . Following the same process as in section 4.2.1 we obtain the fast subsystem.
Now, let be the slow time scale to obtain the slow subsystem.
In this example, the slow manifold is defined by the line .
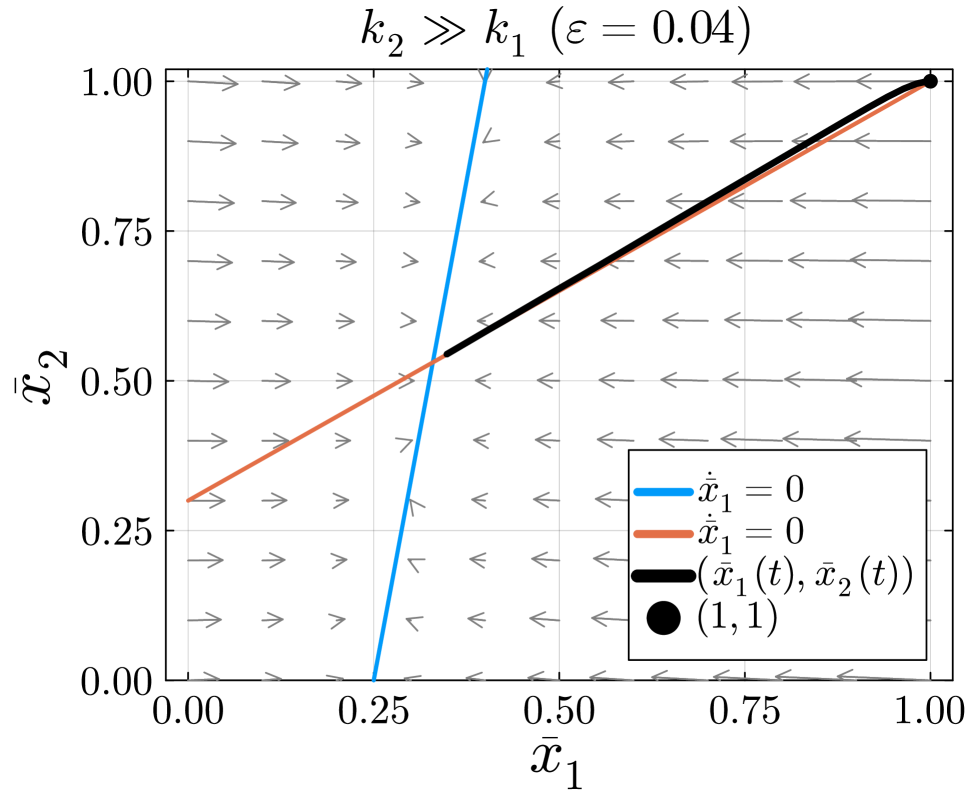
The solution in fig. 10 begins at the initial condition . The initial condition is located on the slow manifold . The solution will slowly move along the slow manifold until it approaches the equilibrium located at the intersection of and . Therefore, only the slow dynamics will be visible in the experimental data. Metabolite ’s slow turnover rate will restrict the amount of label entering metabolite , preventing an accurate approximation of the much faster rate through . To measure the faster turnover rate through , we would need to change the initial condition of the system. Changing the initial condition would require a different experimental setup.
We simulate data for this system as described in Appendix A. The resulting posterior sample distributions for and are included in fig. 11.
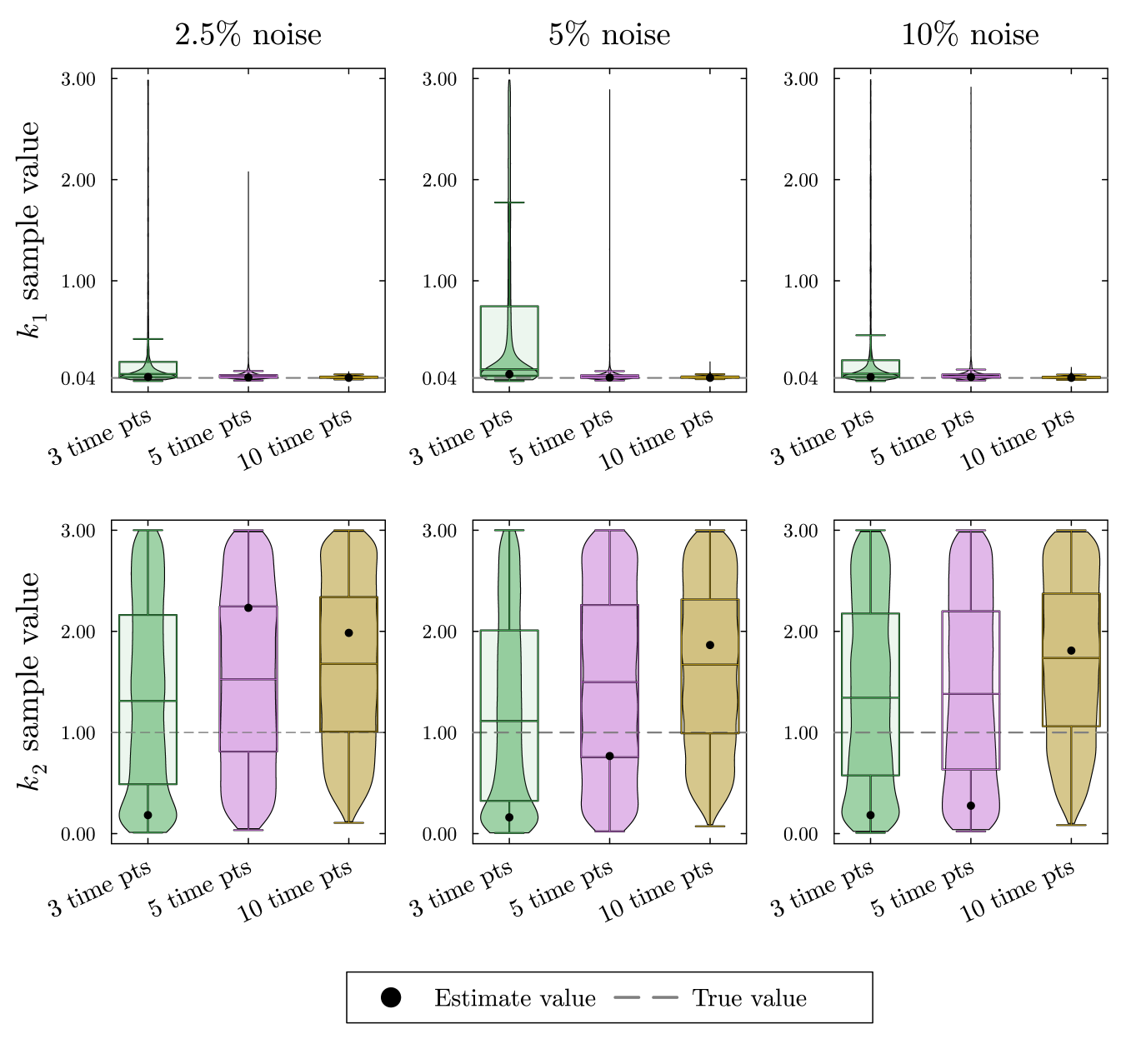
At the top of fig. 11, the estimates for are very accurate and have extremely low uncertainty. With many experimental measurements throughout the decay of , we expected to get good estimates for . Contrarily, we receive very poor estimates for with incredibly high uncertainty as shown at the bottom of fig. 11. The solution for is not sensitive to changes in the large value. With enough data points, Bayesian parameter estimation can rule out small values in but cannot define a good range for the true value of the parameter.
5 Discussion
In this paper, we have provided a general formulation of KFP models along with a useful scaling that eliminates dependence on total metabolite concentrations. This general formulation allows for more complex graph structures and facilitates the understanding of the relationship between graph structure and parameter identifiability. We have shown that steady-state data alone can only provide estimates of relative fluxes, not turnover rates, and only when the steady-state system is not underdetermined. Finally, by investigating a separation of time scales, we show that the fast turnover rate can only be estimated if it is the node that receives the labeled input. In these latter sections, we have demonstrated the utility of Bayesian parameter estimation in conjunction with KFP. In contrast to other fitting methods, Bayesian methods allow the experimenter to judge not only the best fitting parameter but also to quantify the credibility of that estimate. In addition, by identifying larger turnover rates with large credible intervals, fast turnover metabolites can be identified and targeted for future experiments. We answered three crucial questions for the experimenter, but many open questions have yet to be investigated. For the remainder of this section, we will address a few of the many open questions related to the theme of how to incorporate multiple experiments or multiple types of data. In some cases, it may be reasonable to use several types of data in one parameter estimation. In others, the Bayesian approach allows for an iterative method where new experiments are used to update the distribution for each parameter value.
Often it is not feasible to accurately measure all metabolites in the pathway of interest with the mass spectrometer. Many unknown and uncontrollable features factor into the ability to detect a metabolite. For example, some metabolites are very low in abundance, others ionize poorly and still others are unstable, all of which can prevent identification in the sample. Therefore, it is important to consider how missing measurements affect the identifiability of the model’s parameters. If the unmeasurable metabolite is included in the network and therefore in the KFP model, the steady-state problem becomes underdetermined. By excluding the unmeasurable metabolite from the KFP model we reduce the number of parameters. With a reduced model, the experimenter must be aware that the reduced parameter set is a combination of some of the unreduced parameters. Therefore, an important open question is how the estimates in the reduced model relate to the parameters in the unreduced model.
All of the examples presented here have only one source of labeled input (i.e. ). In practice, the generation of secondary tracers can lead to more than one source for the label to enter the system simultaneously. For a more biologically accurate representation, multiple sources of labeled input should be included in the model. In the general model formulation we can incorporate multiple labeled inputs. However, we suspect this will further complicate the parameter estimation problem. For example, if the type of label from one source does not differ from the other we will not be certain which source provided the label.
Currently, the KFP models only recognize one type of label. The metabolites are either labeled or unlabeled. In an isotope tracing experiment, the total pool of a metabolite can be composed of multiple types of label. If a metabolite contains multiple carbon atoms, those carbons may be a mix of 13C and unlabeled 12C atoms. For example, citrate contains 6 carbon atoms so there are 7 different types of label called isotopologues for that metabolite (i.e. 0, 1, 2, 3, 4, 5, or 6 13C molecules). If the labeled substrate is pyruvate, one sequence of reactions including pyruvate dehydrogenase can produce citrate with 2 13C atoms while a different route through pyruvate carboxylase produces citrate with 3 13C atoms. To more accurately represent the biological system, multiple types of labels, should be incorporated into the KFP model. Specific labeling types can be incorporated by including a variable for each label type for each metabolite. This greatly increases the dimension of the KFP model, but using the stoichiometry of each reaction, may lead to better flux estimates.
Another example where multiple labels may be useful is to include experiments with different stable isotopes. The same metabolite could have labeled nitrogen, oxygen or hydrogen atoms. By repeating the tracing experiment with the same pathway but with multiple isotopes we can better deduce the sequence of reactions for each molecule. Alternatively, one may want to use data from multiple experiments studying the same pathway but differing in the source node of the labeled input. This would create an ensemble of KFP models working together to estimate the same set of unknown fluxes. The ensemble may produce more accurate estimates because the fluxes estimated by one model can be used as to inform the choice of prior distributions for the following model. Iterating through the models may help the parameter estimation method reduce uncertainty and pinpoint the true parameter values.
Previously, KFP has been used to estimate relative flux changes (rKFP) [10] between an experimental and control condition. rKPF requires multiple parameter fits on the same KFP model. It would be useful to consider how the conditions and constraints described here will impact the comparison of multiple experimental conditions with the same pathway.
Kinetic Flux Profiling is an intriguing application for parameter identifiability because the accurate measurement of the flux parameters is the central motivation for the method. The algebraic constraints on the parameters provide additional structure to the problem that makes the parameter estimation not only more tractable but also more nuanced. From a biological standpoint, the information obtained from the estimates of flux can provide essential insight into the mechanistic changes in metabolism during disease. At the same time, the limited and noisy data challenge our ability to make accurate estimates.
Supplementary information Supplementary file 1 includes additional figures and examples resulting from Bayesian parameter estimation. Supplementary File 1
Acknowledgements We would like to thank Mitchell Riley for helping review and improve the manuscript.
Declarations
The authors have no relevant financial or non-financial interests to disclose.
The authors declare that the data supporting the findings of this study are available within the paper or its supplementary information files.
This work was supported by grants NIH RO1 DK104998 (EBT), NIH RO1 DK138664 (EBT), University of Iowa Distinguished Scholar Award (EBT)
Appendix A Simulated Data and Bayesian Parameter Estimation
Using Bayesian parameter estimation, we illustrate the accuracy and reliability of parameter estimation for various scenarios. To achieve this, we vary the number of time points and level of noise in the simulated experimental data for each model.
First, we select parameter values to compute the true solution and simulate experimental measurements by adding noise to the true solution at specified time points. We vary the number of measurements using 3, 5, and 10 time points evenly spaced throughout the time frame of the experiment. Next, we add 2.5%, 5%, or 10% random normally distributed noise to the true solution at these time points. Since an experiment is usually run three times, we have 3 noisy measurements for each time point for each metabolite measured. We run Bayesian estimation using measurements from all three experiments instead of the average value of the measurements from experiments first.
We apply Bayesian parameter estimation to our models using the Julia package Turing.jl [7].
In the process of parameter estimation, we will need to solve the differential equation many times.
We will be using the Julia package DifferentialEquations.jl [15] for defining and solving the DE.
Bayesian parameter estimation requires prior distributions for each parameter. Since we expect the experimenter to have little prior knowledge of the true parameter values, we provide the method with naive prior distributions. For and , we set the prior distributions to be
Since , , and are proportions we naturally set their prior distributions to be
This method returns samples from the posterior distributions for each parameter. We use the No-U-Turn sampler (NUTS) to sample the posterior distribution. NUTS is a Markov Chain Monte Carlo (MCMC) algorithm that builds a set of points that covers a wide range of the desired distribution by automatically adaption the step size and number of steps [9]. After receiving sample distributions for our parameter values, we must choose a metric from the distribution to be the parameter estimate. We use the mode of distribution to the estimated value. The mode is computed by finding the maximum of the kernel density estimation of the sample distribution. Uncertainty in the estimated value is measured by the spread of the distribution. If the difference in the 97.5% and 2.5% quartiles is large, we will say the estimate has high uncertainty. Conversely, if the difference between the 97.5% and 2.5% quartiles is small the estimate has low uncertainty. The difference between the 97.5% and 2.5% quartile is called the Bayesian 95% credible interval. The 95% credible interval is the interval with a 95% probability of containing the true parameter value given the data [11].
References
- \bibcommenthead
- Agus et al. [2020] Agus, A., Clément, K., Sokol, H.: Gut microbiota-derived metabolites as central regulators in metabolic disorders. Gut 70, 1174–1182 (2020)
- Antoniewicz [2015] Antoniewicz, M.R.: Methods and advances in metabolic flux analysis: a mini-review. Journal of Industrial Microbiology and Biotechnology 42(3), 317–325 (2015) https://doi.org/10.1007/s10295-015-1585-x
- Aron‐Wisnewsky et al. [2020] Aron‐Wisnewsky, J., Warmbrunn, M.V., Nieuwdorp, M., Clément, K.: Metabolism and metabolic disorders and the microbiome: The intestinal microbiota associated with obesity, lipid metabolism and metabolic health: pathophysiology and therapeutic strategies. Gastroenterology (2020)
- Berman and Plemmons [1994] Berman, A., Plemmons, R.J.: Nonnegative Matrices in the Mathematical Sciences. SIAM, Philadelphia (1994)
- Emwas et al. [2022] Emwas, A.-H., Szczepski, K., Al-Younis, I., Lachowicz, J.I., Jaremko, M.: Fluxomics - new metabolomics approaches to monitor metabolic pathways. Frontiers in Pharmacology 13, 805782 (2022)
- Gowda and Djukovic [2014] Gowda, G.N., Djukovic, D.: Overview of mass spectrometry based metabolomics: opportunities and challenges. Mass Spectrometry in Metabolomics: Methods and Protocols, 3–12 (2014)
- Ge et al. [2018] Ge, H., Xu, K., Ghahramani, Z.: Turing: a language for flexible probabilistic inference. In: International Conference on Artificial Intelligence and Statistics, AISTATS 2018, 9-11 April 2018, Playa Blanca, Lanzarote, Canary Islands, Spain, pp. 1682–1690 (2018). http://proceedings.mlr.press/v84/ge18b.html
- Hollywood et al. [2006] Hollywood, K., Brison, D.R., Goodacre, R.: Metabolomics: current technologies and future trends. Proteomics 6(17), 4716–4723 (2006)
- Hoffman et al. [2014] Hoffman, M.D., Gelman, A., et al.: The no-u-turn sampler: adaptively setting path lengths in hamiltonian monte carlo. J. Mach. Learn. Res. 15(1), 1593–1623 (2014)
- Huang et al. [2014] Huang, L., Kim, D., Liu, X., Myers, C.R., Locasale, J.W.: Estimating relative changes of metabolic fluxes. PLoS Computational Biology 10(11), 1003958 (2014)
- Hespanhol et al. [2019] Hespanhol, L., Vallio, C.S., Costa, L.M., Saragiotto, B.T.: Understanding and interpreting confidence and credible intervals around effect estimates. Brazilian journal of physical therapy 23(4), 290–301 (2019)
- [12] Li, H.: Properties and applications of graph laplacians
- Musulin [2014] Musulin, E.: Process disturbances detection via spectral graph analysis. In: Computer Aided Chemical Engineering vol. 33, pp. 1885–1890. Elsevier, USA (2014)
- Orth et al. [2010] Orth, J.D., Thiele, I., Palsson, B.Ø.: What is flux balance analysis? Nature biotechnology 28(3), 245–248 (2010)
- Rackauckas and Nie [2017] Rackauckas, C., Nie, Q.: Differentialequations.jl – a performant and feature-rich ecosystem for solving differential equations in julia. The Journal of Open Research Software 5(1) (2017) https://doi.org/10.5334/jors.151 . Exported from https://app.dimensions.ai on 2019/05/05
- Shivakumar and Chew [1974] Shivakumar, P., Chew, K.H.: A sufficient condition for nonvanishing of determinants. Proceedings of the American mathematical society, 63–66 (1974)
- Stephanopoulos [1999] Stephanopoulos, G.: Metabolic fluxes and metabolic engineering. Metabolic engineering 1(1), 1–11 (1999)
- Wu et al. [2016] Wu, C., Xiong, W., Dai, J., Wu, Q.: Kinetic flux profiling dissects nitrogen utilization pathways in the oleaginous green alga chlorella protothecoides. Journal of phycology 52(1), 116–124 (2016)
- Xiong et al. [2020] Xiong, W., Jiang, H., Maness, P.: Dynamic flux analysis: An experimental approach of fluxomics. Metabolic Pathway Engineering, 179–196 (2020)
- Yuan et al. [2008] Yuan, J., Bennett, B.D., Rabinowitz, J.D.: Kinetic flux profiling for quantitation of cellular metabolic fluxes. Nature protocols 3(8), 1328–1340 (2008)
- Yuan et al. [2006] Yuan, J., Fowler, W.U., Kimball, E., Lu, W., Rabinowitz, J.D.: Kinetic flux profiling of nitrogen assimilation in escherichia coli. Nature chemical biology 2(10), 529–530 (2006)
- Yuan and Rabinowitz [2007] Yuan, J., Rabinowitz, J.D.: Differentiating metabolites formed from de novo synthesis versus macromolecule decomposition. Journal of the American Chemical Society 129(30), 9294–9295 (2007)
- Zheng et al. [2021] Zheng, X., Chen, T., Zhao, A.-h., Ning, Z., Kuang, J., Wang, S., You, Y., Bao, Y., Ma, X., Yu, H., Zhou, J., Jiang, M., Li, M., Wang, J., Ma, X., Zhou, S.-p., Li, Y., Ge, K., Rajani, C., Xie, G., Hu, C., Guo, Y., Lu, A., Jia, W., Jia, W.: Hyocholic acid species as novel biomarkers for metabolic disorders. Nature Communications 12 (2021)