Parameter Estimation for Multivariate Diffusion Systems
Abstract
Diffusion processes are widely used for modelling real-world phenomena. Except for select cases however, analytical expressions do not exist for a diffusion process’ transitional probabilities. It is proposed that the cumulant truncation procedure can be applied to predict the evolution of the cumulants of the system. These predictions may be subsequently used within the saddlepoint procedure to approximate the transitional probabilities. An approximation to the likelihood of the diffusion system is then easily derived. The method is applicable for a wide-range of diffusion systems - including multivariate, irreducible diffusion systems that existing estimation schemes struggle with. Not only is the accuracy of the saddlepoint comparable with the Hermite expansion - a popular approximation to a diffusion system’s transitional density - it also appears to be less susceptible to increasing lags between successive samplings of the diffusion process. Furthermore, the saddlepoint is more stable in regions of the parameter space that are far from the maximum likelihood estimates. Hence, the saddlepoint method can be naturally incorporated within a Markov Chain Monte Carlo (MCMC) routine in order to provide reliable estimates and credibility intervals of the diffusion model’s parameters. The method is applied to fit the Heston model to daily observations of the S&P 500 and VIX indices from December 2009 to November 2010.
keywords:
Diffusion process , Fokker-Planck equation , Cumulant truncation procedure , Saddlepoint approximation , Markov Chain Monte Carlo1 Introduction
Diffusion processes are continuous-time, continuous-space stochastic processes that have proven to be natural modelling frameworks for many real world phenomena. Over an infinitesimal interval , the evolution of a multivariate diffusion process is represented by the following, possibly time inhomogeneous, stochastic differential equation (SDE):
| (1) |
where ; is the parameter vector; ; with and is an -dimensional vector of independent Brownian motions. The -dimensional vector represents a set of state variables which characterizes the diffusion system through time. The assumption that the Brownian motions are independent does not lead to any loss of generality since allowance is made for off-diagonal terms within the diffusion matrix . Within this framework, the primary focus is on estimating the parameter vector from discretely-sampled data.
The drift vector and the diffusion matrix characterize the evolution of . Their individual elements are defined as:
Over an infinitesimally small interval, the diffusion system is distributed as follows:
| (2) |
That is, the diffusion system has a multivariate-normal distribution characterized by the drift vector and diffusion matrix over any infinitesimal interval. Since diffusion processes are Markovian, equation (2) may be used to derive the likelihood for continuously sampled diffusion paths. However with discretely sampled diffusion paths, statistical inference is considerably more challenging. This is because the distribution of the diffusion increments over discretely sampled time points is often unknown.
Instead of representing a multivariate diffusion system as a stochastic differential equation, one may instead focus on the Kolmogorov forward equation, which dictates the evolution of its probability density function . This is given by:
| (3) | |||||
This is also known as the Fokker-Planck equation. Except where required, the dependence of the drift vector and diffusion tensor on the parameter vector shall be suppressed within the notation. Since a diffusion process is Markovian, the likelihood of a diffusion system sampled at discrete time points is given by:
| (4) |
Asymptotically, for large , the term may be ignored whilst the transitional probability distribution is the solution to equation (3) at time with the boundary condition that is given by the Dirac delta function centered around at time . The likelihood function is central to many inference procedures: it enables us to derive parameter estimates, confidence intervals and to conduct hypothesis tests. Unfortunately, except for a few special cases, equation (3) (and hence also the likelihood) is analytically intractable.
The inability to solve equation (3) is an impediment to statistical inference. This may be circumvented by attempting to match, by choice of parameters, characteristics of the sampled path with characteristics of the diffusion model. For example, one may choose to estimate the instantaneous means and variances using the corresponding sample moments of the differenced data (Gallant and Long, 1997; Ragwitz and Kantz, 2001). Alternatively one may employ Bayesian imputation to augment the observed data so that the diffusion increments are approximately normally distributed (Roberts and Stramer, 2001).
Since likelihood based methods tend to give more precise parameter estimates than method of moments estimators (Hurn et al., 2007), we instead seek an approximation to the transitional probability distribution of the diffusion process. Monte Carlo methods may be used to approximate the likelihood (Kleinhans and Friedrich, 2007; Durham and Gallant, 2002). Alternatively, equation (3) could be solved numerically. Wojtkiewicz and Bergman (2000) discretized the spatial domain and solved the partial differential equation numerically at each point on the lattice. The finite-difference method discretizes the time domain, taking advantage of the fact that over an infinitesimally small time period, the diffusion process is normally distributed (Wehner and Wolfer, 1987). Huang (2012) developed a quasi-maximum likelihood estimator that approximates the first two conditional moments using a Wagner-Platen approximation. The resulting normal distribution can be used to approximate the transitional probability.
Another possibility is to approximate the transitional probability distribution by a closed form analytic function; for example, a Hermite polynomial expansion (Ait-Sahalia, 2002). This method was shown by Ait-Sahalia to be superior to many of the competing methods - both in terms of the accuracy of the transitional distribution approximation as well as the speed of the algorithm. Stramer et al. (2010) created an MCMC procedure based on the Hermite approximation which could allow for measurement errors in the diffusion process.
It must be stressed that the Hermite approximation is only applicable for reducible diffusion processes. A diffusion process is reducible if there exists a one-to-one transformation such that the covariance function of is the identity matrix. Though all univariate diffusion processes are reducible, only some multivariate diffusions share this property. Ait-Sahalia (2008) extended the method to irreducible, multivariate diffusions, but not only is the procedure more difficult to implement, there is also a reduction in the accuracy of the closed-form approximation to the transitional density. Furthermore, the Hermite approximation does not in general integrate to one. Indeed, for parameter values far from the maximum likelihood estimates, the normalizer can be very far from one. This often prevents convergence when applying the Hermite approximation within an MCMC setting (Stramer et al., 2010). Consequently, without modification, the resulting MCMC credibility intervals often suffer from considerable undercoverage.
It is proposed that the transitional probability may rather be estimated by a saddlepoint approximation (Daniels, 1954). The saddlepoint approximation is an algebraic expression based on a random variable’s cumulant generation function (CGF). In cases where the first few moments of a random variable is known but the corresponding probability density is difficult to obtain, the saddlepoint approximation to the density can be calculated. The tails of a saddlepoint approximation are more accurate than those of a Edgeworth-expansion (Barndorff-Nielsen and Klüppelberg, 1999). Saddlepoint methods have already been used to approximate the transition densities of diffusions (Ait-Sahalia and Yu, 2006; Preston and Wood, 2012). Preston and Wood apply the saddlepoint approximation to the CGF of a truncated small-time sample-path expansion whilst Ait-Sahalia and Yu (2006) apply the saddlepoint to a truncated expansion, in small-time, of the characteristic function of the transition density.
The saddlepoint approximation will be applied to a truncated expansion of the CGF of with respect to the CGF parameters. In contrast to the aforementioned small-time methods, the focus is instead on predicting the evolution of the diffusion system’s cumulants through time, which may be achieved with the cumulant truncation procedure (Whittle, 1957; Gillespie and Renshaw, 2007). The cumulant truncation procedure may also be applied to multivariate diffusion processes (Varughese and Fatti, 2008; Varughese, 2011). These predicted cumulants can be subsequently substituted within a saddlepoint to approximate the transitional densities. After fitting a diffusion model, one may subsequently test for model misspecification of the SDE (Zhang et al., 2012).
In Section 2, the saddlepoint approximation to the transitional probability distribution of the diffusion process is introduced. In Section 3, an MCMC algorithm which uses this approximation for parameter estimation is introduced. Since Ait-Sahalia (2002) demonstrated that the Hermite approximation is superior to a number of alternative approximations, we compare the saddlepoint and the Hermite approximation in Section 4. The two methods are tested on univariate diffusion processes. The Heston model (an irreducible, multivariate diffusion process) is fitted in Section 5 to the S&P 500 and VIX indices. This is followed by a discussion of the various results and some conclusions being drawn.
2 Approximating the transitional probability distribution
2.1 The saddlepoint approximation
In cases where the distribution of a random vector is unknown, the saddlepoint method provides an algebraic approximation based on ’s cumulant generating function. Let be the parameters for ’s moment generating function (MGF) . Also, let denote the cumulant generating function (CGF). Assuming the MGF exists in an open neighbourhood around the origin (Daniels, 1954), the leading order -dimensional saddlepoint approximation is given by:
| (5) |
where is an -dimensional vector and represents the Hessian matrix for and
Except for some select cases such as the Normal and the Gamma distribution, substituting the true CGF within equation (5) does not simplify to the true distribution, but rather to an approximation thereof.
In many cases, the CGF is unknown, but it may be approximated. Given the first cumulants for a univariate random variable , may be approximated by:
| (6) |
In the univariate case, the saddlepoint is consequently given by:
| (7) |
The approximation within (7) is two-fold as not only is the saddlepoint an approximation to the true density, but the saddlepoint is now based on a truncated approximation to the true CGF. For a diffusion process, the approximate evolution of the cumulants (and hence also the approximation evolution of equation (6)) can be calculated through the cumulant truncation procedure.
2.2 Applying the cumulant truncation procedure to a diffusion process
Consider a diffusion process with MGF and CGF . In order to calculate the likelihood given in (4), we approximate the transitional density by a saddlepoint . This necessitates the calculation of an approximation to at time given that the diffusion process is equal to at time .
Let . Like the partial differential equation for the probability density (given in (3)), there is a corresponding partial differential equation for the MGF , the solution of which enables us to predict the evolution of the system’s cumulants. The MGF obeys the following relation (see Appendix):
| (8) |
Though the terms and denote functions of and , the terms and represent differential operators that act on the MGF . So, for example, if we have a 2-dimensional diffusion system with drift term , then is a differential operator and represents the action of the operator on the MGF . The MGF may be used to characterize the evolution of the diffusion system through time. Unfortunately, as with equation (3), equation (8) is generally analytically intractable.
The cumulant truncation procedure enables us to convert the partial differential equation for the MGF into a system of ordinary differential equations that also depends on the system parameters . The resulting set of equations proves to be far easier to solve numerically than the original partial differential equation. Though, in principle, one can derive a system of ordinary differential equations directly from equation (8), the cumulant truncation procedure is instead based on the corresponding partial differential equation for the CGF . This is because can be expressed as a series expansion of the diffusion system’s cumulants.
| (9) |
where:
In order to be able to predict the evolution of the diffusion system’s cumulants, we need to derive a partial differential equation governing the evolution of . Since , we have:
| (10) |
where and depend on some variable . By repeatedly applying the above relation, it is possible to derive the corresponding partial differential equation for the CGF from the partial differential equation for the MGF given by equation (8). The general form of this equation cannot be shown, but rather must be independently derived for each system of interest. The CGF partial differential equation is derived for selected examples within Sections 4 and 5.
By substituting the series expansion in (9), truncated to order , within the partial differential equation for and subsequently matching the cumulant coefficients , it is possible to derive a system of ordinary differential equations for the centered moments or cumulants. Consequently, by solving this system of differential equations, it is possible to predict the approximate evolution of the cumulants for each proposed parameter vector . Throughout the paper this analysis was performed using MATHEMATICA v6.0. These predictions are accurate across a wide range of parameter values (Varughese, 2009). This is key, as we can subsequently use the predicted cumulants within the saddlepoint to approximate and hence derive the approximate likelihood at . The parameter estimates are taken to be the values that maximize this approximate likelihood, which may be estimated by a Markov Chain Monte Carlo (MCMC) procedure.
3 A modified MCMC parameter estimation algorithm
In this section, a parameter estimation algorithm for a diffusion system is proposed. The algorithm uses the saddlepoint approximation introduced in Section 2 to recreate the transitional probability distribution. This is subsequently used to approximate the likelihood function of the diffusion system. The approximate likelihoods enable us to explore the parameter space of the diffusion system with a modified MCMC procedure. The algorithm is described below.
-
1.
Apply the cumulant truncation procedure to the diffusion system thus deriving a system of ordinary differential equations that describe the cumulants’ evolution. (Note these differential equations will depend on the model parameters .)
-
2.
Choose an arbitrary, starting set of parameter values . Set .
-
3.
Propose a jump from the old set of parameter values to a new set of parameter values, using a suitably chosen proposal distribution .
-
4.
Calculate the likelihoods and . is calculated as follows:
-
i.
Set the likelihood, .
-
ii.
Set to 1.
-
iii.
Use the system of ordinary differential equations from Step 1 together with the data values observed at time , to predict the values of the cumulants at time .
-
iv.
Given the data at time , the transitional probability distribution at time can be approximated by a saddlepoint approximation after substituting for the cumulants derived from step iii.
-
v.
Set the likelihood . This is an implementation of equation (4).
-
vi.
Set and if (where is the number of data points) go to step iii.
-
i.
-
5.
Calculate the acceptance ratio . This is given by:
where is the prior density. We then accept the proposed parameter values with probability . That is, set with probability . Otherwise leave unchanged.
-
6.
Go back to step 3.
After a suitably chosen burn-in period, the MCMC chains sample from the posterior distribution of the diffusion parameters. Hence, in addition to using the medians of the chains as estimates of the diffusion parameters, the -th and -th percentile may be used to construct % credibility intervals.
4 A comparative study of the Saddlepoint and Hermite methods
Since the Hermite approximation (Ait-Sahalia, 2002) is a popular method for estimating the parameters of a diffusion system, we compare its performance against the saddlepoint. In order to judge the relative accuracies of the saddlepoint and Hermite procedures, the true transitional probability distribution is required as a baseline. Unfortunately, the diffusion models for which the transitional distribution is known are few. Amongst, diffusion processes with analytical, non-normal transitional distributions, the Cox-Ingersoll-Ross (CIR) process and Geometric Brownian motion are arguably the most well known. Neither the saddlepoint nor the Hermite approximation in general integrate to one and the approximations are not normalized when performing the comparisons in this section.
Within this section, the CIR process is analyzed didactically: the analysis is meant to illustrate the general derivation of the saddlepoint approximation to a transitional distribution. This is followed by a study of the relative accuracy, for the CIR process, of the Hermite and saddlepoint approximations to the transitional distribution. The section concludes by comparing MCMC implementations for the Hermite and saddlepoint procedures for both the CIR process as well as Geometric Brownian motion.
4.1 Example: Deriving the saddlepoint approximation for the CIR process
The CIR process is commonly used to model financial data such as short-term interest rates. The model may be represented as follows:
| (11) |
The CIR process is mean-reverting. Furthermore, provided , the CIR process is always positive. This is advantageous as many real-world phenomena are positive and display mean reversion. The probability distribution of the process obeys the following partial differential equation:
| (12) |
An analytical solution to equation (12) exists (Cox et al., 1985). Hence it is possible to derive an analytical expression for the transitional distribution which may be subsequently compared with the Hermite and the saddlepoint approximations. This enables us to compare the relative accuracies of the two approximation schemes.
The first step of the cumulant truncation procedure is to derive the evolution of the moment generating function through time. This requires the drift and diffusion terms of the process. These are given by:
By substituting the drift and diffusion terms within equation (8), we derive the partial differential equation for the MGF :
| (13) |
By dividing both sides of equation (13) by and applying equation (10), it is possible to derive the differential equation for the CGF:
| (14) |
In most cases the partial differential equation for the CGF will be analytically intractable. Under such scenarios, one may instead substitute a truncated expansion of the CGF in place of the full CGF. As the order of the expansion increases, the accuracy of the approximation tends to increase (Varughese, 2009). Suppose we approximate by a fourth-order expansion of the CGF:
| (15) |
By substituting the above expansion within equation (14) and subsequently equating the various coefficients of , it is possible to derive a system of ordinary differential equations that describe the evolution of the cumulants:
Note that there is a trade-off as the order of the approximation to the CGF increases. Not only does the approximation’s accuracy increase, but the complexity of the system of equations also increases, which will lead to a rise in computing time. A fourth order approximation is chosen as it seems to be a good balance between accuracy and speed.
Boundary conditions must be specified in order to make the solution of the above system of equations unique. When predicting the cumulants at time , the boundary conditions are taken to be: , , , . That is, in predicting the cumulants at any future time , we condition on the observed value of the process at time . This enables the system of ordinary differential equations to be solved numerically. The resulting predictions may be inserted into equation (7) to give us the saddlepoint approximation to the transitional probability distribution .
Since the CGF is truncated after the fourth cumulant, we shall approximate the transitional probability distribution by . From equation (7) it follows that:
| (16) |
where:
Note that is a function of . A cursory glance at the above equation might suggest that does not depend on the first cumulant. This however is incorrect since depends on .
4.2 The relative accuracies of the transitional distribution approximations
The transitional distribution of the CIR process may be approximated using both the saddlepoint and Hermite approximations. Suppose the current value of the process is assumed to be 50 and we are interested in the probability distribution one month from now. That is, . Figure 1 compares the relative accuracies of the two methods, implemented in MATHEMATICA v6.0, at the parameter values: ; ; . On the whole, the saddlepoint approximation appears to be more accurate.
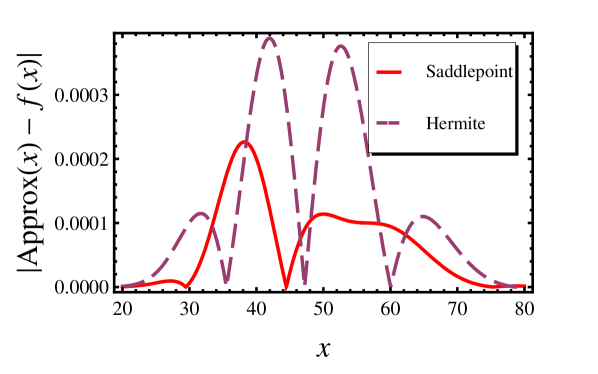
Let the Integrated Error of an approximation be defined as:
To get a better idea of how the relative accuracy of the two approximations behaves throughout the parameter space, we plot the Integrated Error of the two models for varying values of the parameters and .
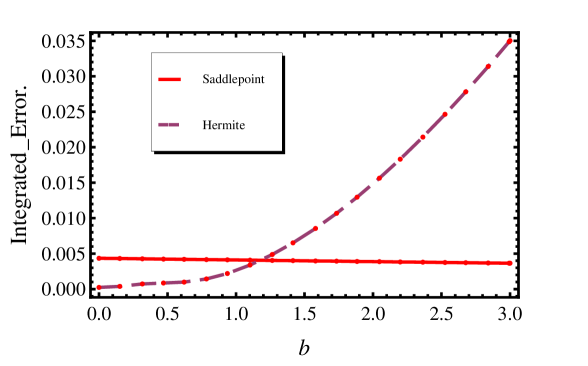
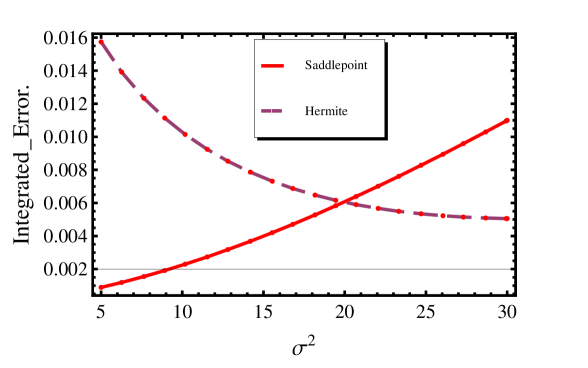
One can see from Figure 2 that there are regions in the parameter space where the Hermite approximation is more accurate and regions where the saddlepoint approximation is more accurate.
As a final point, note that unlike the saddlepoint approximation, the Hermite approximation is a small-time expansion. Consequently, the larger becomes, the less accurate the Hermite approximation will be. Figure 3 shows how the Integrated Error for both the saddlepoint and the Hermite approximations changes with . The Hermite approximation loses accuracy more quickly for larger time scales.
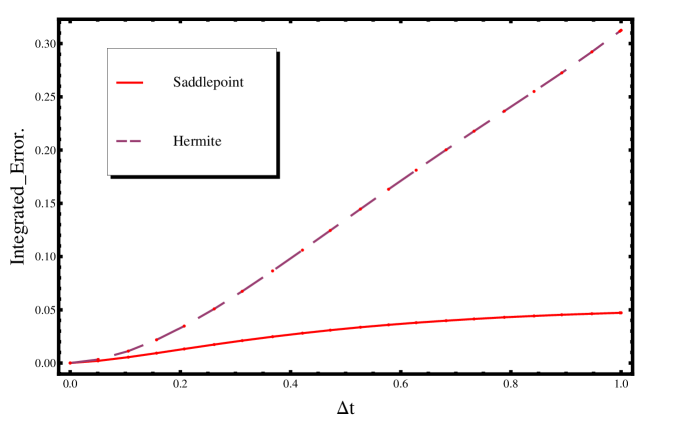
This investigation has been restricted to a subset of the parameter space for the CIR model. In some sense however, the accuracy of the transitional distribution is only important in as far as it enables us to obtain precise parameter estimates for the diffusion model. With multiple parameters, the computational efficiency of the MCMC procedure makes it suitable for parameter estimation. This motivates a comparison of the modified saddlepoint MCMC algorithm described in Section 3 with modified MCMC algorithms that uses the Hermite approximation.
4.3 A comparison of MCMC implementations of the two approximations
Both the saddlepoint MCMC and the Hermite MCMC are judged by comparing the coverage of their resulting credibility intervals with the corresponding coverage obtained from the true MCMC. The traditional Hermite MCMC is known to fail since the Hermite approximation can explode to infinity for parameter values that are far from the maximum likelihood estimate (Stramer et al., 2010). We thus run two versions of the Hermite MCMC: the traditional version that is known to fail and a modified algorithm developed by Stramer et al. (2010) that avoids computation of the posterior’s normalizing constant. To make the analysis more robust, the MCMC implementations are compared for both the CIR process as well as for Geometric Brownian motion.
The empirical coverage of the credibility intervals is calculated from 100 simulated time series; each of length 40. For each of the time series, the four variants of the MCMC procedure (the saddlepoint MCMC, the two Hermite MCMCs and the true MCMC) are run and a credibility interval is calculated. We use improper, uniform priors and a normal proposal density for the parameter values when running the MCMC chains. If a parameter must be positive, any negative value sampled from the proposal distribution is thrown out and another sample is taken. The coverage of each variant of the MCMC procedure is estimated as the proportion of the 100 credibility intervals that contain the true parameter values i.e. the parameter values used to simulate the time series. In calculating the credibility intervals, an MCMC chain of length 20,000 was run and the first 10,000 steps were trimmed as part of the burn-in period. 90% credibility intervals will correspond to the 5-th and 95-th percentiles of the resulting chains. It is desirable that the credibility intervals of a proposed MCMC implementation match as closely as possible the observed coverages of the true MCMC.
Despite the computational efficiency of both the saddlepoint and the two versions of the Hermite procedures, a study of the coverage of their corresponding implementations is computationally intensive. 100 MCMC chains, each of length 20,000, must be run for the three MCMC implementations. This restricts us to comparing the coverage of their credibility intervals for a single set of parameter values.
In order to make our analysis as robust as possible, we chose to compare the coverage of the credibility intervals at points in the parameter space where the saddlepoint approximation performs particularly badly in comparison to the Hermite approximation. We compare the relative accuracies of the two approximations using the following statistic:
| (17) |
where represents the true distribution and and represent the Hermite approximation and saddlepoint approximation respectively. If the saddlepoint approximation is more accurate than the Hermite approximation, one would expect to be less than 1.
First, for the CIR process, we choose to simulate 100 time series with the parameter values:
For the above parameter values, the relative efficiency statistic, . Second, for Geometric Brownian motion, we choose to simulate 100 time series with the parameter values:
For the above parameter values, . For both diffusion processes, the saddlepoint approximation to the transitional distribution is considerably less accurate than the Hermite approximation.
Table 1 shows the respective coverages of the saddlepoint MCMC, the two Hermite MCMCs (in the table, the traditional algorithm is referred to as Hermite whilst the modified algorithm developed by Stramer et al. (2010) is referred to as Hermite*) and the true MCMC for both the CIR process as well as Geometric Brownian Motion. A Euler-Maruyama scheme was used to determine the proposal density for the external variates of the Hermite* procedure. Despite running the comparison for both models at points where the saddlepoint is less accurate than the Hermite approximation, the credibility intervals of the saddlepoint MCMC is closer to the true credibility intervals. The results indicate that the saddlepoint MCMC may be reliably used both to estimate the parameters of a diffusion model as well as to derive their corresponding credibility intervals. This suggests that the stability of the approximations throughout the parameter space is more important than their accuracy at the true parameter values. The credibility intervals produced by the traditional Hermite MCMC have severe undercoverage. This is particularly true for the Geometric Brownian motion since the MCMC chains were started far from the true parameter values (, ) and the chains often became stuck. For the CIR process, all the chains were started at the true parameter values (, , ). This serves to highlight the convergence problems that the Hermite MCMC chains suffer from. Though, the modified Hermite* MCMC improves the coverage of the credibility intervals, there is still evidence of undercoverage for the Geometric Brownian motion. This seems to be due to the modified MCMC sometimes taking longer than the burn-in period to converge rather than the chains getting stuck. This is a topic for future research.
| CIR process | Geometric Brownian | |||||||||
| Par. | True | Saddle | Hermite | Hermite* | Par. | True | Saddle | Hermite | Hermite* | |
| 0.81 | 0.79 | 0.61 | 0.70 | 0.90 | 0.90 | 0.14 | 0.44 | |||
| 0.82 | 0.79 | 0.60 | 0.81 | 0.90 | 0.93 | 0.14 | 0.48 | |||
| 0.88 | 0.86 | 0.66 | 0.84 | |||||||
Table 2 shows the time taken to study the coverage properties of the credibility intervals as well as the average acceptance ratios for the proposed MCMC steps. There are indications that the acceptance ratios for the Hermite procedures are lower. Both the saddlepoint and the Hermite approximations schemes take considerably longer to run than the case where the true distribution is known. The Saddle MCMC takes 70% longer to run than the traditional Hermite for the CIR process and 217% longer for the Geometric Brownian motion. However, the modifications to the traditional algorithm, Hermite* MCMC take considerably longer to run. Hermite* MCMC takes 81% longer than the Saddle MCMC for the CIR process and 6% longer for the Geometric Brownian motion.
| CIR process | Geometric Brownian | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| True | Saddle | Hermite | Hermite* | True | Saddle | Hermite | Hermite* | ||
| time | 9.80 | 102.30 | 60.35 | 184.76 | 1.60 | 98.29 | 31.04 | 104.22 | |
| ratio | 0.63 | 0.69 | 0.49 | 0.54 | 0.73 | 0.55 | 0.23 | 0.37 | |
4.4 Coverage for non-standard diffusion processes
We extend our study of the coverage of the saddlepoint procedure to a nonlinear, multivariate diffusion process with unknown transitional distribution. Consider a bivariate-system that behaves as follows:
| (18) |
where the Brownian motions are independent. Both processes are mean-reverting: is an Ornstein-Uhlenbeck process and for a fixed value of , the process will have long-term mean . As increases, the instantaneous mean and variance of also increases. From equations (8) and (10), the corresponding partial differential for is given by:
| (19) | |||||
A third order cumulant truncation of yields:
| (20) | |||||
(20) may be substituted within (19) to give a system of ordinary differential equations for the cumlulants that can subsequently be solved and used within the saddlepoint approximation.
The diffusion system has six parameters: , , , , and . Suppose from (18) we simulate time series, each of length 100, for and . As in the previous subsection, an investigation into the coverage of the credibility intervals is computationally expensive and hence is only feasible for a single set of parameter values. We simulate 100 time series using the parameter values:
For each time series, the saddlepoint procedure is used to construct 90% credibility intervals for the six parameters. The observed coverages for the parameters are:
These coverages are close to the advertised values, suggesting that the procedure works well in this nonlinear, multivariate example.
5 Application to Financial Data
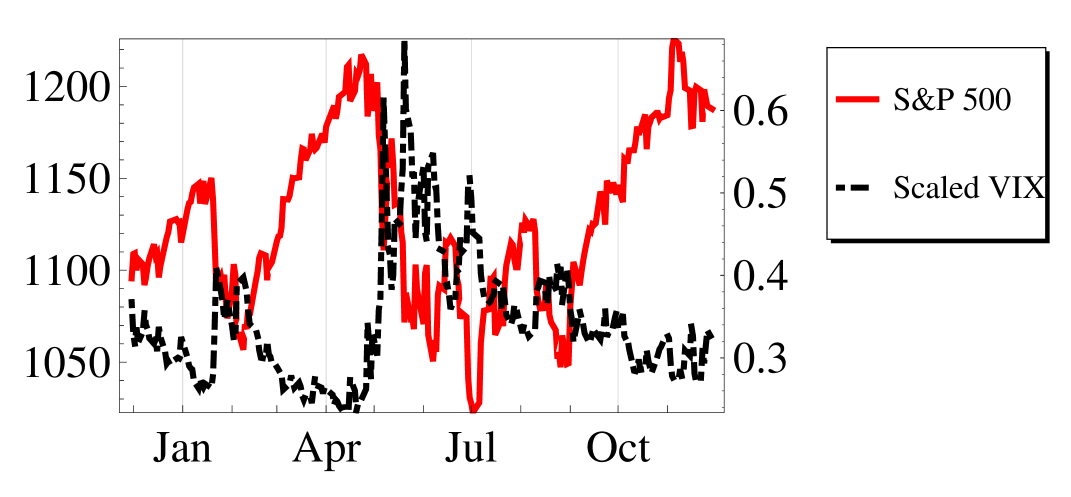
We study the S&P 500 and it’s relation to the VIX index (a popular measure of implied volatility) over the period December 2009 to November 2010. Figure 4 shows the two indices over this period. The Heston model is fitted to the dataset. It uses proxies for market volatility - such as the VIX index - to account for market movements. The key feature of this model is that the volatility of the asset price movements are assumed to be stochastic.
| (21) |
where represents the asset price, is the underlying volatility that drives the asset movements and , , , and are parameters. The Heston model is a multivariate, irreducible diffusion processes for which many of the competing methods would not be applicable.
We wish to run the saddle MCMC in order to obtain both estimates and credibility intervals for the parameters for the Heston model. To run the saddle MCMC, the diffusion tensor is needed. This is given by:
By applying equations (8) and (10) to the above diffusion process, we obtain the following partial differential equation for :
| (22) |
A third order cumulant truncation is performed to yield a system of ordinary differential equations for the cumulants. These may be subsequently used to approximate the likelihood of the Heston model. The modified MCMC (described in section 3) may then be run on the S&P and scaled VIX dataset.
The resulting parameter estimates and 95% credibility intervals are shown in Table 3. One may see that there is strong negative correlation between the two Brownian motions driving and . The parameters and have wide credibility intervals, suggesting that they are not strongly constrained by the data.
| Par. | Estimate | 95% C.I. |
|---|---|---|
| 0.118 | (0.008; 0.430) | |
| 9.863 | (1.410; 13.464) | |
| 0.034 | (0.020; 0.058) | |
| -0.855 | (-0.880; -0.824) | |
| 0.250 | (0.234; 0.266) |
6 Conclusion
A general statistical framework for estimating the parameters of a diffusion system is proposed. It is assumed that the elements of both the mean vector and the diffusion matrix may be represented by finite order polynomials. Apart from this, the method may be readily applied to multivariate diffusion systems. Many existing parameter estimation methods are only applicable for univariate diffusion processes or, if applicable to multivariate systems, require the diffusion system to be reducible (Ait-Sahalia, 2008; Beskos et al., 2006).
The transitional distribution of a diffusion system is approximated with a saddlepoint. We show how the cumulants of the system may be predicted and subsequently used to approximate the true transitional distribution of the system. The proposed method is compared with the Hermite approximation proposed by Ait-Sahalia (2002). For both the Cox-Ingersoll Ross model and Geometric Brownian motion, the accuracy of the saddlepoint is comparable to the Hermite approximation at the true parameter values. Furthermore, since the Hermite approximation is a small-time expansion, the Hermite approximation rapidly becomes inaccurate as the time interval between successive observations increases.
The saddlepoint approximations may be easily incorporated within an MCMC algorithm. Since, in regions far from the maximum likelihood estimates, the saddlepoint approximation to the transitional density is better behaved than the Hermite approximation, the saddlepoint MCMC chains have better convergence properties. Consequently, the coverage of the credibility intervals for the saddlepoint MCMC is close to those obtained from the true MCMC. In contrast, the credibility intervals for the unmodified Hermite MCMC suffer from undercoverage. This undercoverage is especially severe when the chains are not started at the true parameter values since the chains often become stuck. This is mitigated by the modified algorithm developed by Stramer et al. (2010) which does not require the computation of the posterior’s normalizing constant. However, the modified chains are not only slower than the saddlepoint MCMC, but they take longer to converge, which caused undercoverage for the Geometric Brownian motion example studied in Section 4 since the chains had not converged by the end of the burn-in period.
The comparison between the saddlepoint and Hermite approximations was only performed for univariate diffusion processes and hence caution must be exercised in making claims for multivariate diffusion processes. However, the good coverage observed for the credibility intervals of the saddlepoint MCMC for the non-linear, multivariate example suggests that the procedure still works well for multivariate diffusion processes. Also, for irreducible multivariate processes, the Hermite procedure requires a two-fold approximation, which leads to a further drop in its accuracy (Ait-Sahalia, 2008).
The saddlepoint MCMC is used to fit the Heston model to the S&P 500 and the VIX indices over the period December 2009 to November 2010. Since the Heston model is a multivariate, irreducible diffusion process, the estimation of the model parameters presents a formidable challenge, but the saddlepoint method provides reliable estimates and credibility intervals for the model parameters. As expected, there was significant negative correlation between the two Brownian motions driving the asset prices and the volatility process.
The proposed estimation algorithm has several virtues: it is fast; applicable for a wide range of diffusion systems and gives parameter estimates close to the true values. Furthermore, the corresponding credibility intervals for these estimates have coverage close to their advertised values. This makes the algorithm suitable for estimating the parameters of many diffusion systems.
Acknowledgments
This material is based upon work supported financially by the National Research Foundation of South Africa. The author is grateful to two referees for their constructive comments which have greatly improved the manuscript. Thanks are also due to Drs Trevor Hastie, Leonard Stefanski and Eric Renshaw for helpful discussions. Part of this work was performed whilst hosted by the Department of Mathematics and Statistics at the University of Melbourne.
Appendix: Derivation of equation (8)
The MGF of a diffusion system behaves according to the following partial differential equation:
| (A.1) |
Proof: Consider the multivariate diffusion system with instantaneous mean vector and diffusion matrix . We denote the transition probability by:
Let be the parameters of the MGF and let . The MGF, obeys the following differential equation (Barbour, 1972):
| (A.2) |
For small , we have:
| (A.3) |
For diffusion processes the higher order terms are negligible. We thus only require the joint and marginal transitional rates of the diffusion system to characterize the evolution of the MGF. We denote the joint transition probabilities for and by:
The marginal transition rate is denoted by:
Note that the instantaneous mean and covariances can be represented in terms of the joint and marginal transitional rates:
| (A.4) |
| (23) |
By substituting (A.3) within (A.2), we obtain:
| (24) |
The expressions for the instantaneous mean and variance may be substituted within (24). This gives us:
| (A.7) |
References
- Ait-Sahalia (2002) Ait-Sahalia, Y., 2002. Maximum likelihood estimation of discretely sampled diffusions: a closed-form approximation approach. Econometrica 70, 223–262.
- Ait-Sahalia (2008) Ait-Sahalia, Y., 2008. Closed-form likelihood expansions for multivariate diffusions. Ann. Stat. 36, 906–937.
- Ait-Sahalia and Yu (2006) Ait-Sahalia, Y., Yu, J., 2006. Saddlepoint approximations for continuous-time markov processes. J. Econometrics 134, 507–551.
- Barbour (1972) Barbour, A., 1972. The principle of the diffusion of arbitrary constants. J. Appl. Prob. 9, 519–541.
- Barndorff-Nielsen and Klüppelberg (1999) Barndorff-Nielsen, O., Klüppelberg, C., 1999. Tail exactness of multivariate saddlepoint approximations. Scand. J. Stat. 26, 253–264.
- Beskos et al. (2006) Beskos, A., Papaspiliopoulos, O., Roberts, G., Fearnhead, P., 2006. Exact and computationally efficient likelihood-based estimation for discretely observed diffusion processes. J. R. Statist. Soc. B 68, 333–382.
- Cox et al. (1985) Cox, J., Ingersoll, J., Ross, S., 1985. A theory of the term structure of interest rates. Econometrica 53, 385–407.
- Daniels (1954) Daniels, H., 1954. Saddlepoint approximations in statistics. Ann. Math. Stat. 25, 631–650.
- Durham and Gallant (2002) Durham, G., Gallant, A., 2002. Numerical techniques for maximum likelihood estimation of continuous-time diffusion processes (with discussion). J. Bus. Econ. Statist. 20, 297–338.
- Gallant and Long (1997) Gallant, A., Long, J., 1997. Estimating stochastic differential equations efficiently by minimum chi-squared. Biometrika 84, 125–141.
- Gillespie and Renshaw (2007) Gillespie, C., Renshaw, E., 2007. An improved saddlepoint approximation. Math. Biosci. 208, 359–374.
- Huang (2012) Huang, X., 2012. Quasi-maximum likelihood estimation of multivariate diffusions. Studies in Nonlinear Dynamics & Econometrics. 5, 390–455.
- Hurn et al. (2007) Hurn, A., Jeisman, J., Lindsay, K., 2007. Seeing the wood for the trees: a critical evaluation of methods to estimate the parameters of stochastic differential equations. J. Financ. Econometrics 5, 390–455.
- Kleinhans and Friedrich (2007) Kleinhans, D., Friedrich, R., 2007. Maximum likelihood estimation of drift and diffusion functions. Phys. Lett. A 368, 194–198.
- Preston and Wood (2012) Preston, S., Wood, A., 2012. Approximation of transition densities of stochastic differential equations by saddlepoint methods applied to small-time ito-taylor sample-path expansions. Stat. Comput. 22, 205–217.
- Ragwitz and Kantz (2001) Ragwitz, M., Kantz, H., 2001. Indispensable finite time corrections for fokker-planck equations from time series data. Phys. Rev. D 87, 25–29.
- Roberts and Stramer (2001) Roberts, G., Stramer, O., 2001. On inference for partially observed nonlinear diffusion models using the metropolis-hastings algorithm. Biometrika 88, 603–621.
- Stramer et al. (2010) Stramer, O., Bognar, M., Schneider, P., 2010. Bayesian inference for discretely sampled markov processes with closed-form likelihood expansions. Journal of Financial Econometrics 8, 450–480.
- Varughese (2009) Varughese, M., 2009. On the accuracy of a diffusion approximation to a discrete state-space markovian model of a population. Theor. Popul. Biol. 76, 241–247.
- Varughese (2011) Varughese, M., 2011. A framework for modelling ecological communities and their interactions with the environment. Ecol. Complex. 8, 105–112.
- Varughese and Fatti (2008) Varughese, M., Fatti, L., 2008. Incorporating environmental stochasticity within a biological population model. Theor. Popul. Biol.
- Wehner and Wolfer (1987) Wehner, M., Wolfer, W., 1987. Numerical evaluation of path-integral solutions to fokker-planck equations. Phys. Rev. A 35, 1795–1801.
- Whittle (1957) Whittle, P., 1957. On the use of the normal approximation in the treatment of stochastic processes. J. Royal Stat. Soc. 19, 268–281.
- Wojtkiewicz and Bergman (2000) Wojtkiewicz, S., Bergman, L., 2000. Numerical solution of high dimensional fokker planck equations. In: Proceedings of the 8th Specialty Conference on Probabilistic Mechanics and Structural Reliability,. Paper PMC2000-167.
- Zhang et al. (2012) Zhang, S., Song, P., Shi, D., Zhou, Q., 2012. Information ratio test for model misspecification on parametric structures in stochastic diffusion models. Comput. Stat. Data. An. 56, 3975–3987.