Parameter Identification with Finite-Convergence Time Alertness Preservation*
Abstract
In this brief note we present two new parameter identifiers whose estimates converge in finite time under weak interval excitation assumptions. The main novelty is that, in contrast with other finite-convergence time (FCT) estimators, our schemes preserve the FCT property when the parameters change. The previous versions of our FCT estimators can track the parameter variations only asymptotically. Continuous-time and discrete-time versions of the new estimators are presented.
I PARAMETER ESTIMATORS WITH ALERTNESS-PRESERVING FINITE-CONVERGENCE TIME
The objective of this work is to propose continuous-time (CT) and discrete-time (DT) on-line estimators of the parameters of a linear regression equation (LRE) of the form
| (1) |
from the measurable quantities and . The estimators should satisfy three specifications
-
S1
Convergence of the estimates should be achieved in finite-time.
-
S2
Convergence is ensured under weak interval excitation (IE) conditions [4].
-
S3
The estimator should preserve its alertness to be able to estimate—still with FCT—future variations of the unknown parameters.
Instrumental to solve this problem is the use of the dynamic regressor extension and mixing (DREM) procedure proposed in [1]. In particular, we adapt the FCT-DREM estimator proposed in [6] to incorporate the new feature of FCT alertness preservation (AP). A CT version of such an scheme was reported in [7, Section V], in this note we give a DT version of it.
An early variation of the least-squares method, that converges in finite time, was proposed 32 years ago. Similarly to more recent FCT estimators [2, 3, 9] in its initial stage the algorithm is akin to an off-line estimator, which involves a numerically sensitive matrix inversion and, as it converges to a standard least-squares, loses its alertness. For the sake of completeness we present comparative simulations of the proposed estimator with the FCT estimator reported in [12], which relies on the injection of high-gain via the use of fractional powers and/or relays in the estimator dynamics. See also [8, 11] where a similar high-gain approach is adopted.
Notation. , , and denote the positive and non-negative real and integer numbers, respectively. Continuous-time (CT) signals are denoted , while for discrete-time (DT) sequences we use , with the sampling time. When a formula is applicable to CT signals and DT sequences the time argument is omitted.
II FCT ESTIMATORS: FORMULATION FROM SCALAR LRES VIA DREM
As it has been widely documented the powerful DREM estimator design procedure [1] allows us to generate, from the -dimensional LRE (1), -scalar LREs of the form
| (2) |
where is the determinant of an extended regressor matrix. In the remaining of the note, we will use this simple scalar LREs to design the AP-FCT parameter estimator.
II-A CT FCT-DREM
The following CT FCT-DREM estimator was reported in [6] and, as it constitutes the basis of our new AP-FCT, we repeat it for ease of reference. Also, to make the note self-contained we give a brief summary of the proof, referring the interested reader to [6] for further details.
Proposition 1
Consider the scalar CT LREs (2) and the gradient-descent estimators111In the sequel, the quantifier is omitted for brevity.
| (3) |
with . Define the FCT estimate
| (4) |
where is defined via the clipping functions
| (5) |
are designer chosen parameters, and is given by
| (6) |
Assume there exists a time such that the IE condition [4]
| (7) |
is satisfied. Then,
| (8) |
that is, the estimator has the feature of FCT.
Proof:
Define the parameter errors The scalar error equations are given by
whose explicit solution is
| (9) |
Now, notice that the solution of (6) is
The key observation is that, using the equation above in (9), and rearranging terms we get that
| (10) |
Now, observe that is a non-increasing function and, under the interval excitation assumption (7), we have that
| (11) |
Clearly, (10) and (11) imply that
completing the proof.
II-B DT FCT-DREM
In [6, Proposition 2] a DT DREM estimator was reported. We give below an FCT-version of this scheme and give a brief summary of the proof.
Proposition 2
Consider the scalar DT LREs defined by (2) with the DT gradient-descent estimator
| (12) |
with positive constants . Define the dynamic extension
| (13) |
and the clipping function
| (14) |
where are designer chosen constants. Assume there exists a such that the IE condition
| (15) |
is satisfied. Then,
| (16) |
ensures
Proof:
From, (2) and (12) we get the parameter error equation
| (17) |
whose explicit solution satisfies
| (18) |
where, for ease of future reference, we defined the scalar sequence
| (19) |
The solution of (13) is given by
| (20) |
whose replacement in (18) yields
Using the definition of the parameter error and rearranging terms we get that
| (21) |
According to (14) we have that, under the assumption (15), for all , Consequently, for we can write
The proof is completed, from (16), noting that for all .
III NEW ESTIMATOR WITH FCT ALERTNESS PRESERVATION
There are two practical problems with the approach described above. First, the estimates at the current time are reconstructed from the knowledge of the initial estimate , complicating the task of tracking variations of the true parameters after convergence of the estimates. Second, independently of the behaviour of , the functions are monotonically non-increasing and converge to zero if is not square summable (or integrable). In this case, , and the FCT estimator converges to a standard gradient, losing its FCT feature. Therefore, to keep the FCT alertness of the estimator, i.e., to track parameter variations in finite-time upon the arrival of new excitation, it is necessary to reset the estimators—a modification that is always problematic to implement. A typical procedure is the so-called covariance resetting for least-squares algorithms, see [10, Section 2.4.2].
These drawbacks can be overcome with the new FCT-DREM estimators proposed below.
III-A CT FCT-DREM with alertness preservation
For the sake of brevity, we present only the derivation of a relation similar to (10), from which we can easily construct the FTC estimator and prove that the new FTC estimator does not converge to the gradient one.
Proposition 3
Fix and define
| (22) |
Then,
| (23) |
Moreover, is bounded away from zero.
Proof:
Without loss of generality we assume that for . Then, the solution of (22) is
| (24) |
From (24), and the fact that
where , we conclude that
Now, from the solution of the parameter error equation (9) in the interval we get
Hence, The proof of the claim is established rearranging the terms of the equation above.
Remark 1
It is important to note that when decreases—that is, when we loose excitation— grows towards one, and the alertness in not lost. On the other hand, when new excitation arrives and grows, then decays and the FCT condition is satisfied. In this way, the new FTC estimator preserves its FTC property if the parameters change. This fact is illustrated in the simulations of Section IV. Notice also that, in contrast with the FCT estimator of Proposition 1, where the calculation of the in (4) is done using the initial parameter estimate , the FCT reconstruction of the estimated parameter is done in (23) using the estimate at time , that is, .
III-B DT FCT-DREM with alertness preservation
Similarly to the CT case, for the sake of brevity, we present only the derivation of a relation similar to (21), from which we can easily construct the FTC estimator and prove that the new FTC estimator does not converge to the gradient one.
Proposition 4
Fix a positive integer . Consider the DT, scalar LRE (2) and the gradient parameter update (12) with the dynamic extension (13) and the sequence
Then,
Proof:
First, we make the observation that, for all finite , the sequence is bounded away from zero. Replacing the solution of —given by (19) and (20)—in (LABEL:wdk) it is clear that
Hence, replacing the equation above in (18) we have that
The proof is completed rearranging the terms of the identity above.
Remark 3
It is clear that the same behavior that is indicated in Remark 1 regarding the CT version is observed in this DT one—explaining the important FCT-AP property.
IV SIMULATIONS
In this section we present simulations illustrating the results of Propositions 1-4 for a single parameter. Moreover, for the sake of comparison, we show some simulation results of the high-gain FCT estimator proposed in [12].
IV-A CT FCT-DREM with alertness preservation
In this subsection we compare the FCT DREM of Proposition 1 and the new FCT DREM of Proposition 3. The objective of the simulation is to prove that the new FTC DREM is able to react when new excitation arrives. This is in contrast with the old FCT DREM estimator that, since , converges to the gradient estimator and loses its FTC alertness property.
We consider two scenarios: with and without excitation in . For the first case we consider the PE signal , and for the second one . Note that in the second case , hence it is not PE. However, , hence it satisfies the conditions for convergence of the DREM estimator [1, 7].
To illustrate the FTC tracking capabilities of the estimators the unknown parameter is time-varying and given by
i.e., it starts at , jumps to at , and then linearly returns to .
For the simulations we set , , and . These parameters have been chosen such that the transients of both FCT estimators coincide in the ideal case when is constant and the system is excited.
The transient of the estimators for are given in Fig. 1, where we plot the time-varying parameter , the gradient estimate , as well as the old and the new FCT estimates, denoted in the plots as and , respectively. We observe that, as expected, in the time interval both FCT estimators are overlapped and converge in finite time, while the gradient converges only asymptotically. The difference between the old FCT estimator and the new one is clearly appreciated in the time interval , where we see that the new FCT estimator tracks the parameter variation in finite time, while the old one—now glued to the gradient—only does it asymptotically.
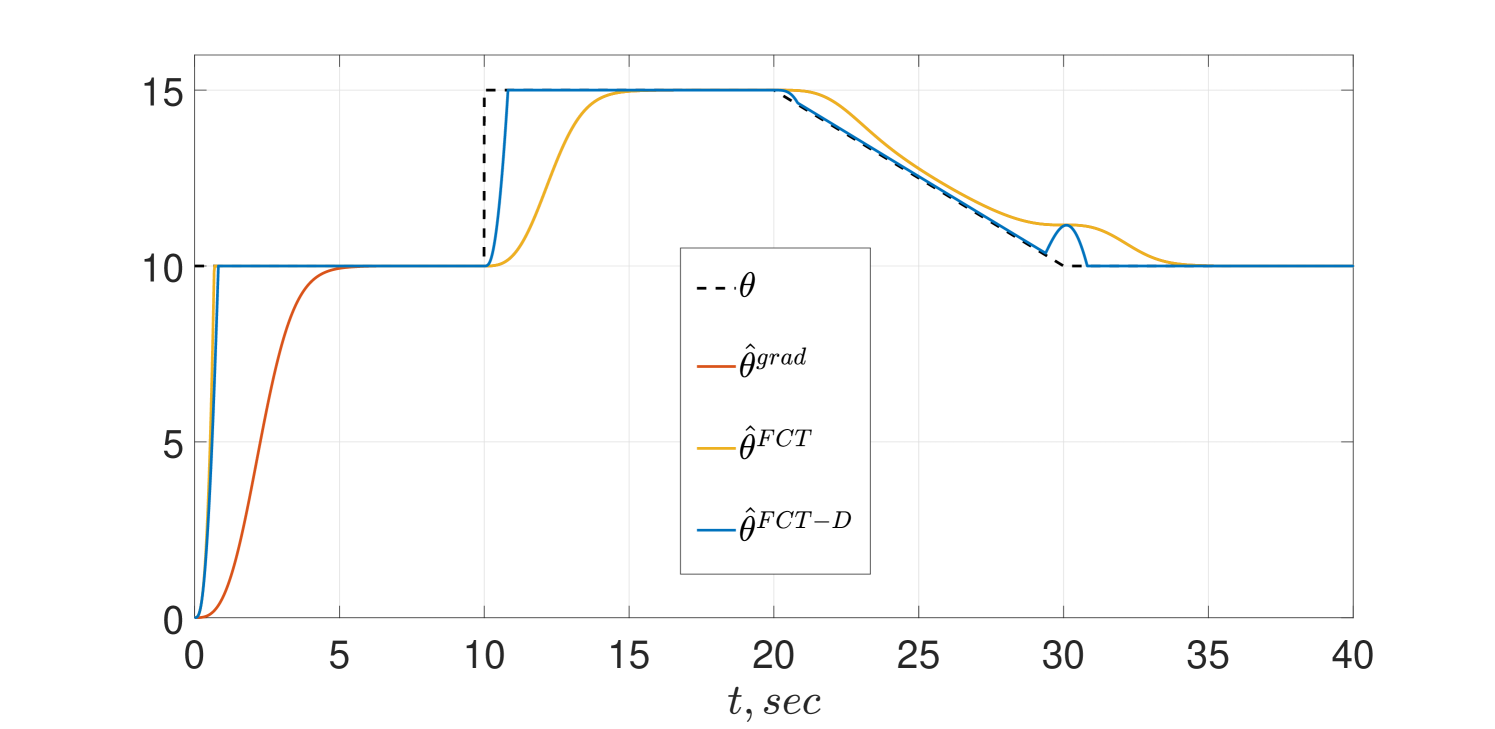
The behavior of the CT estimators for shows that, as predicted by the theory, the old FCT behaves as the gradient estimator and their trajectories coincide. On the other hand, the new estimator preserves FCT alertness after the first parameter jump and achieves fast tracking of the linearly time-varying . We also observe in the figure a blip in the estimates at that coincides with the time of freezing of the true parameter.
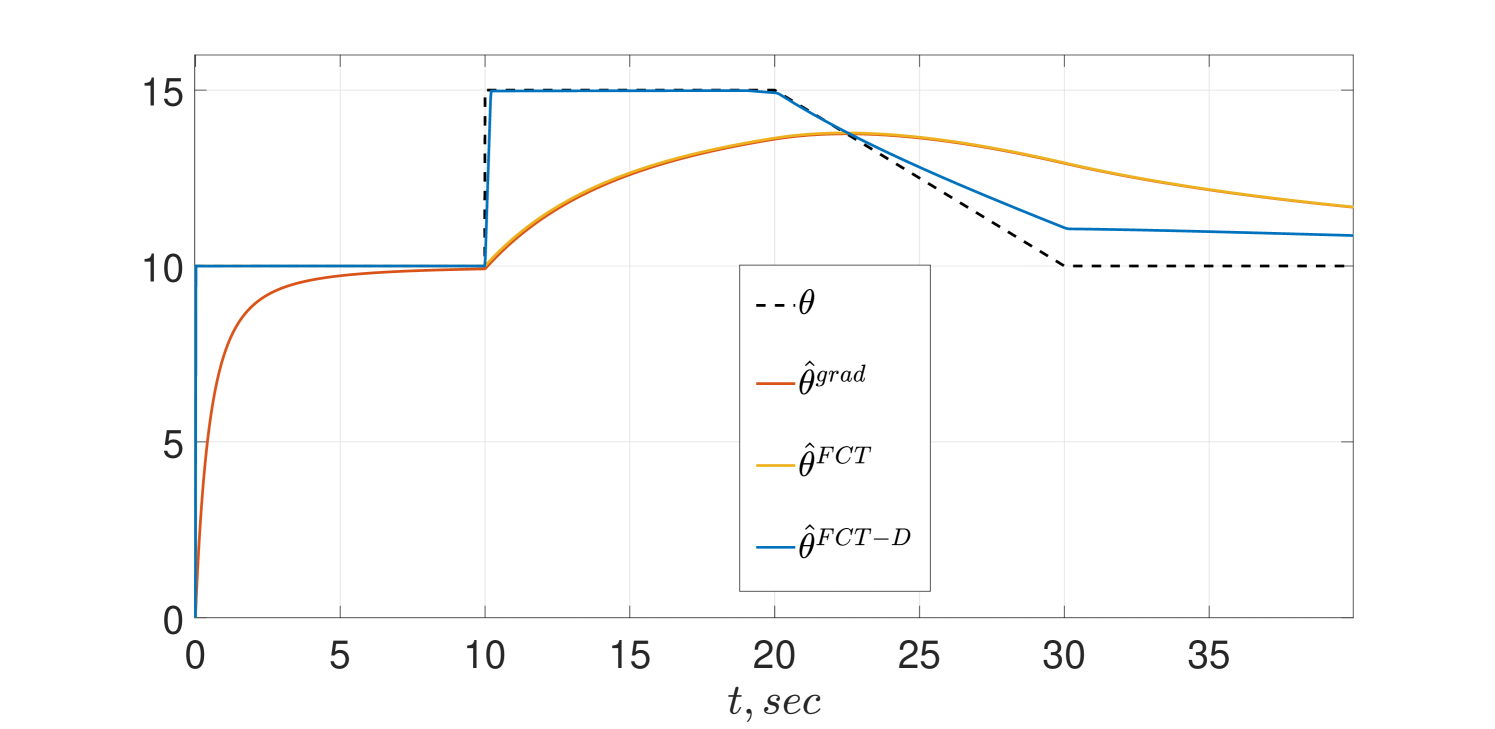
For the non-PE case of , the transients of the CT estimators are given in Fig. 2. We observe that both FCT estimators, again, essentially coincide in the first few seconds and converge in finite time, while the gradient does it only asymptotically. After the first parameter change at the old FTC and the gradient coincide, while the new FCT manages to track in finite time the parameter jump. However, during the ramp parameter change—because of the lack of excitation—neither one of the estimators can track the parameter variation but the new FCT estimator performs much better.
IV-B DT FCT-DREM with alertness preservation
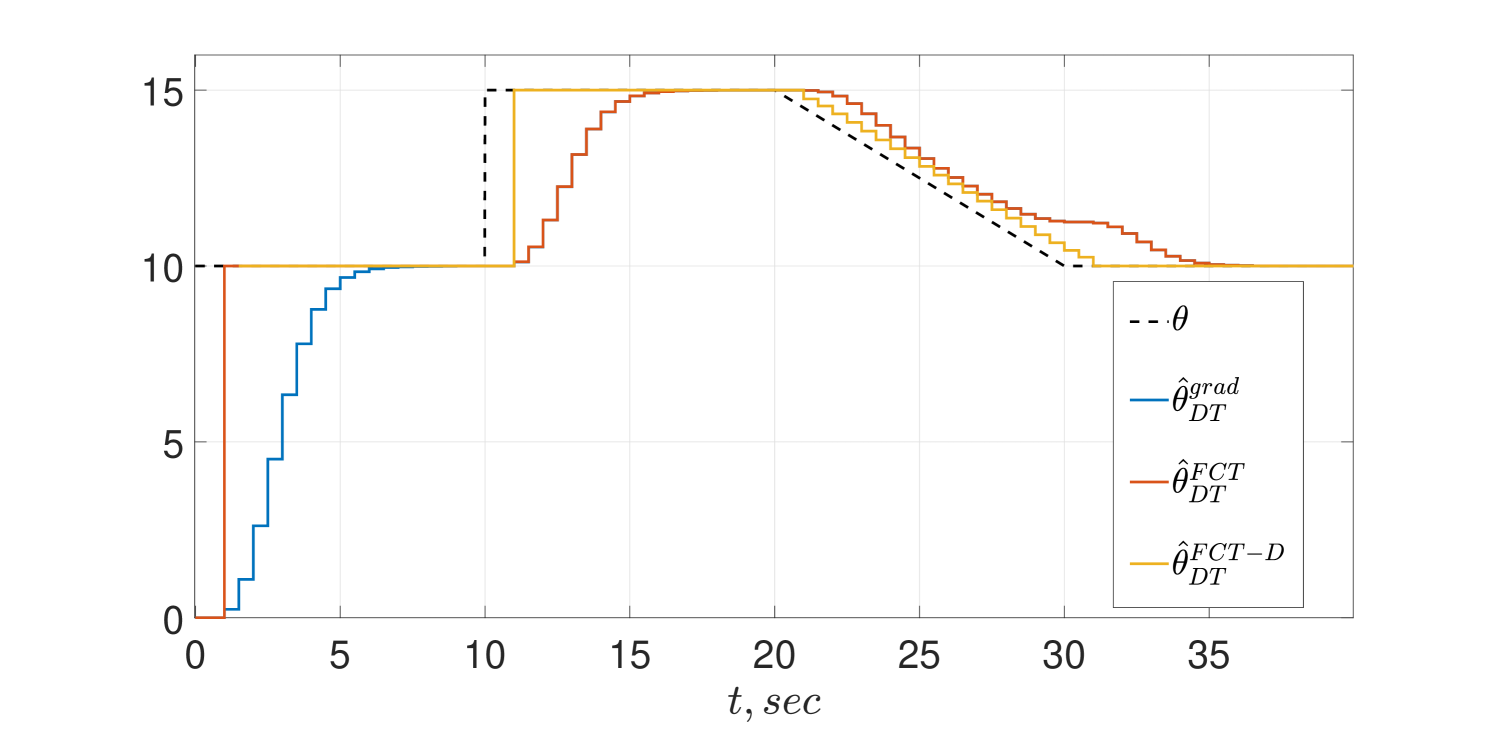
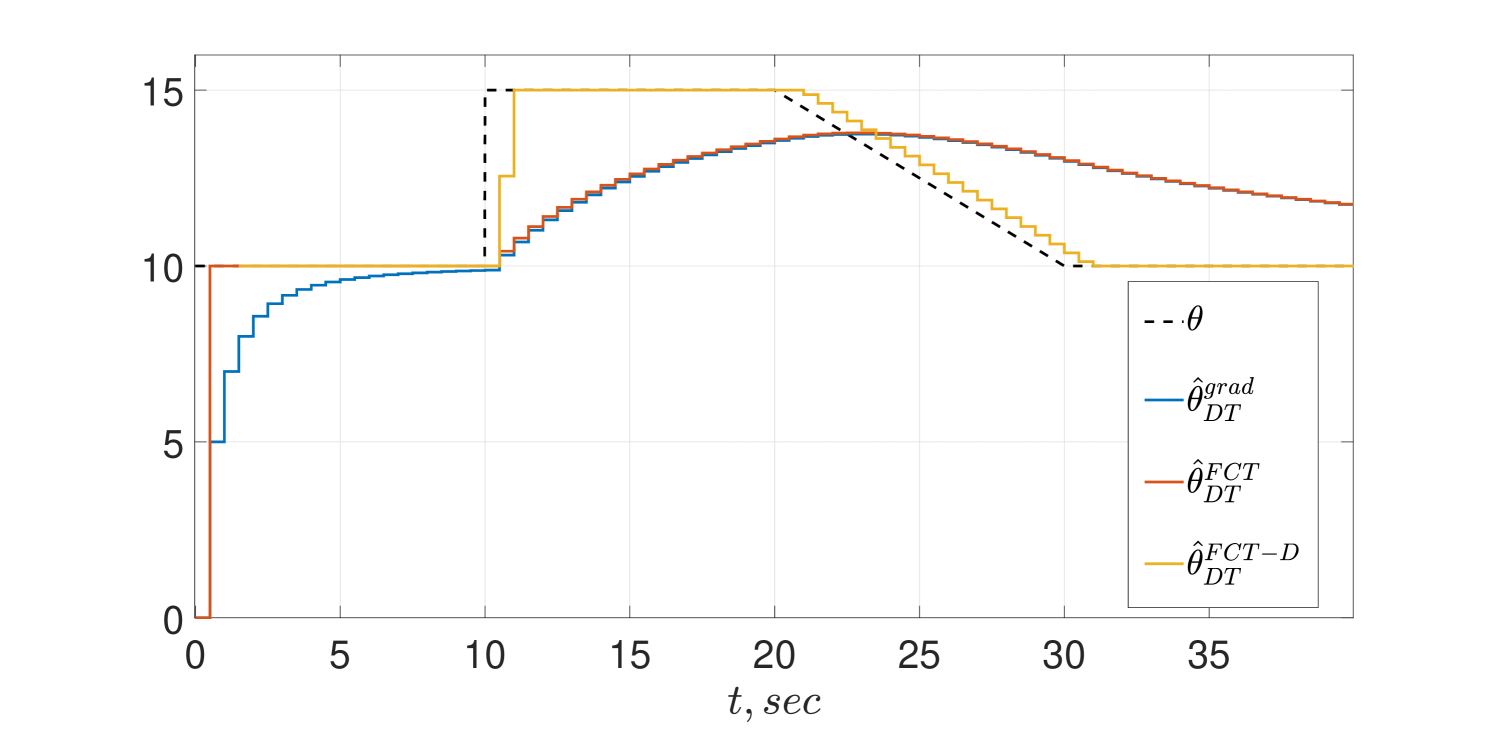
In this subsection we present the simulation results for the DT estimators of Propositions 2 and 4. The estimator gains were set to , , , and .
The same simulation scenario of the CT schemes given above is reproduced here and the transient behaviors are shown in Figs. 3 and 4. Essentially the same remarks made for the CT schemes of the previous subsection are applicable in the DT case.
IV-C Comparison of the CT FCT-DREM with two schemes of [12]
Now, we compare the FCT-D algorithm with two of the schemes proposed in [12]. Namely,
-
i)
Algorithm 1
(26) where and .
-
ii)
Algorithm 3
(27) where , , for given and .
It should be underscored in [12] a third estimator was also proposed but this scheme is not well-defined when and could not be simulated.
For the simulation of the CT FCT-D we set , , and , while for Algorithm 1 (26) we set and . and for Algorithm 3 (27) we set , .
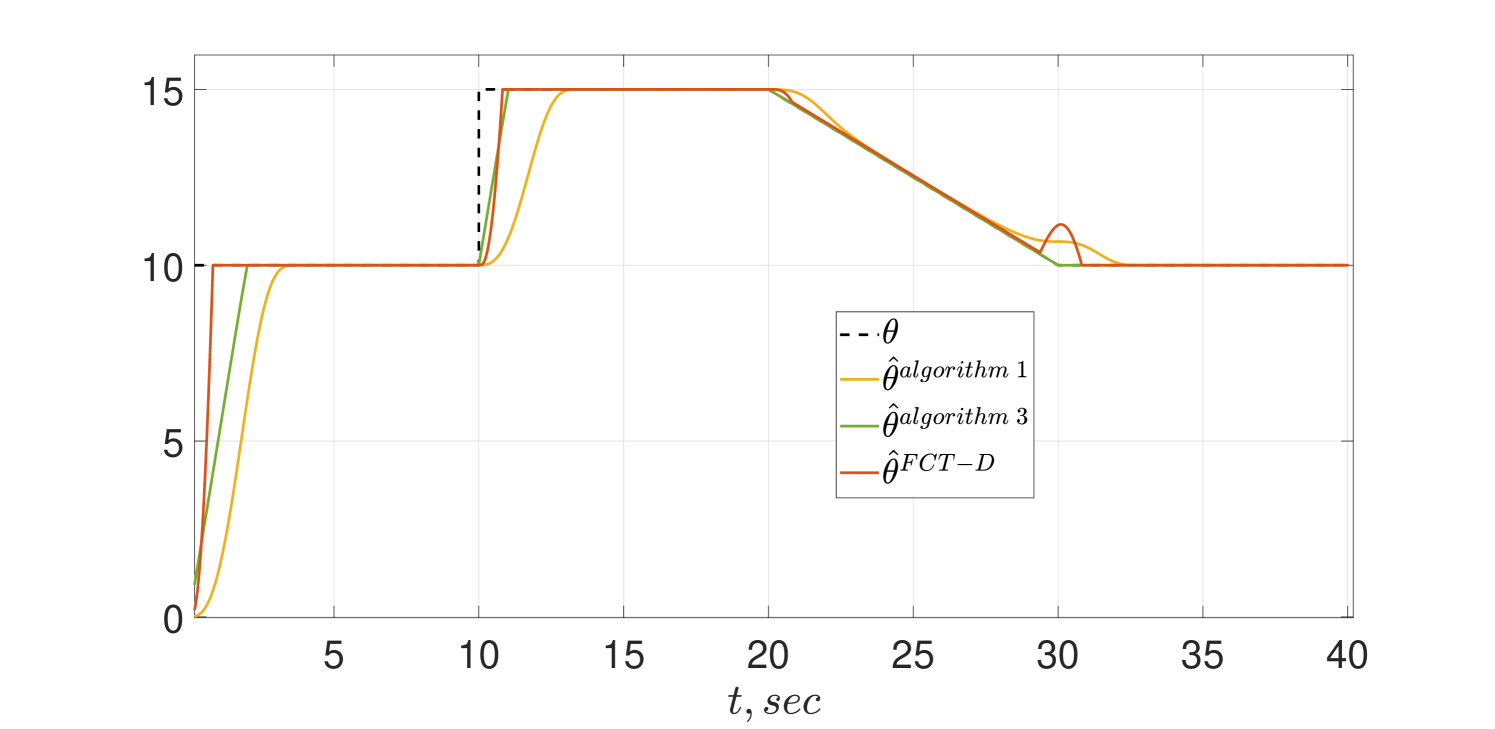
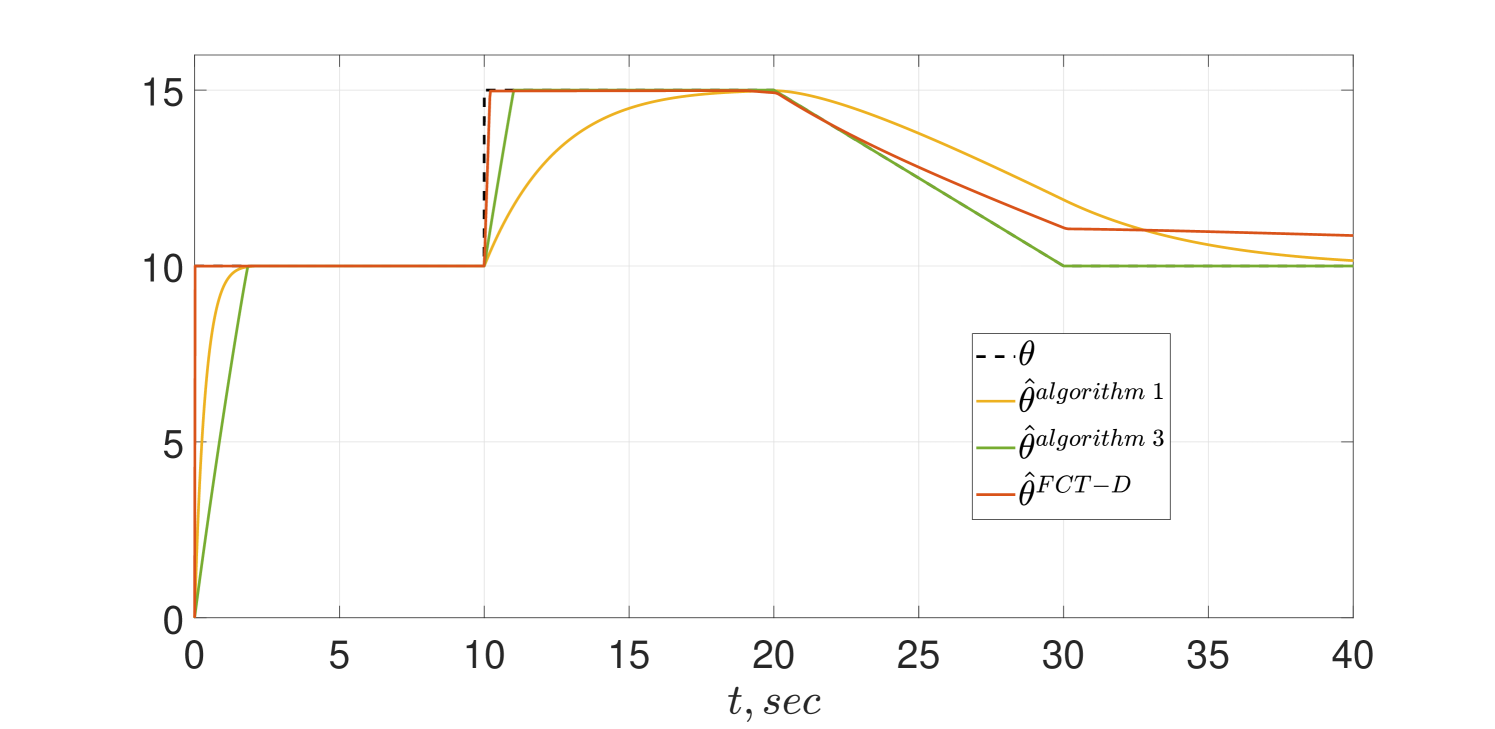
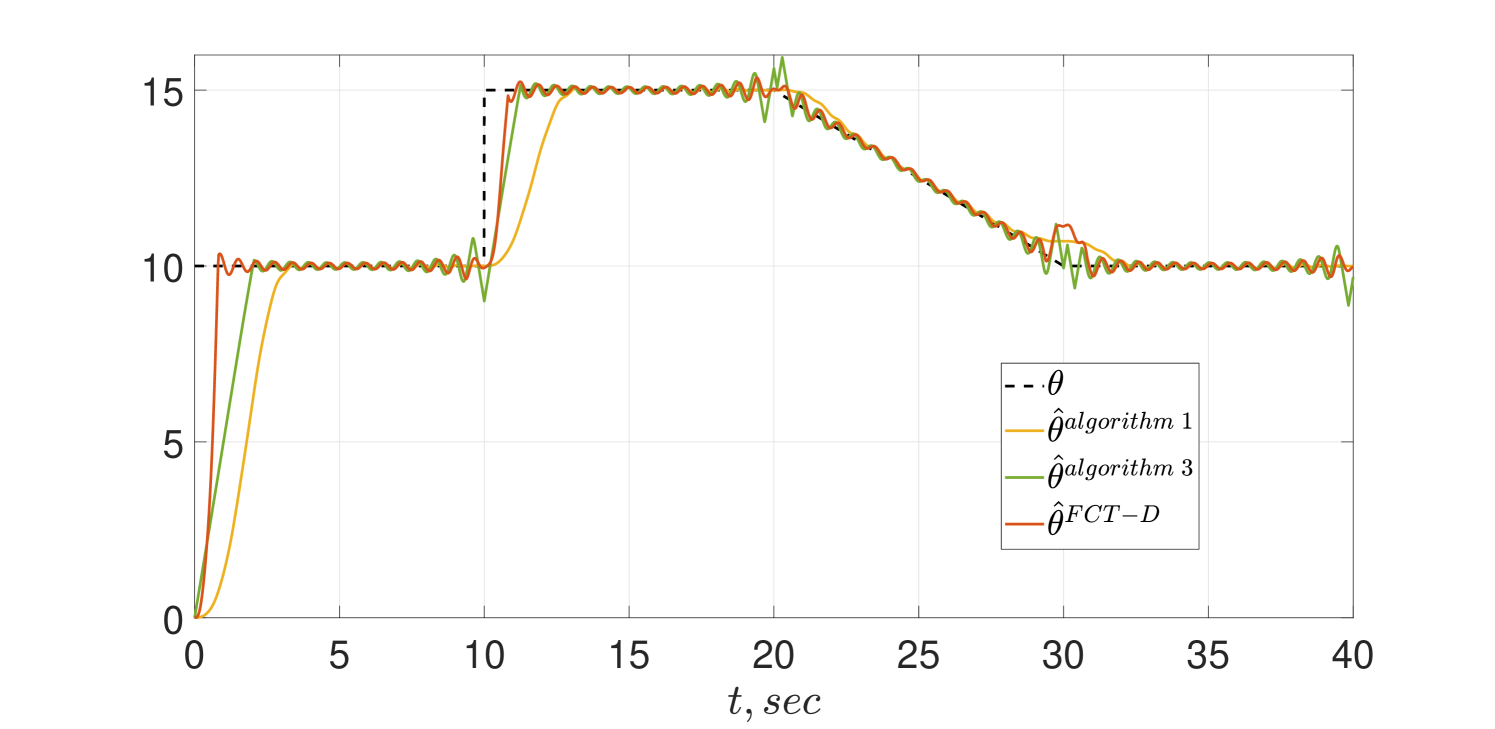
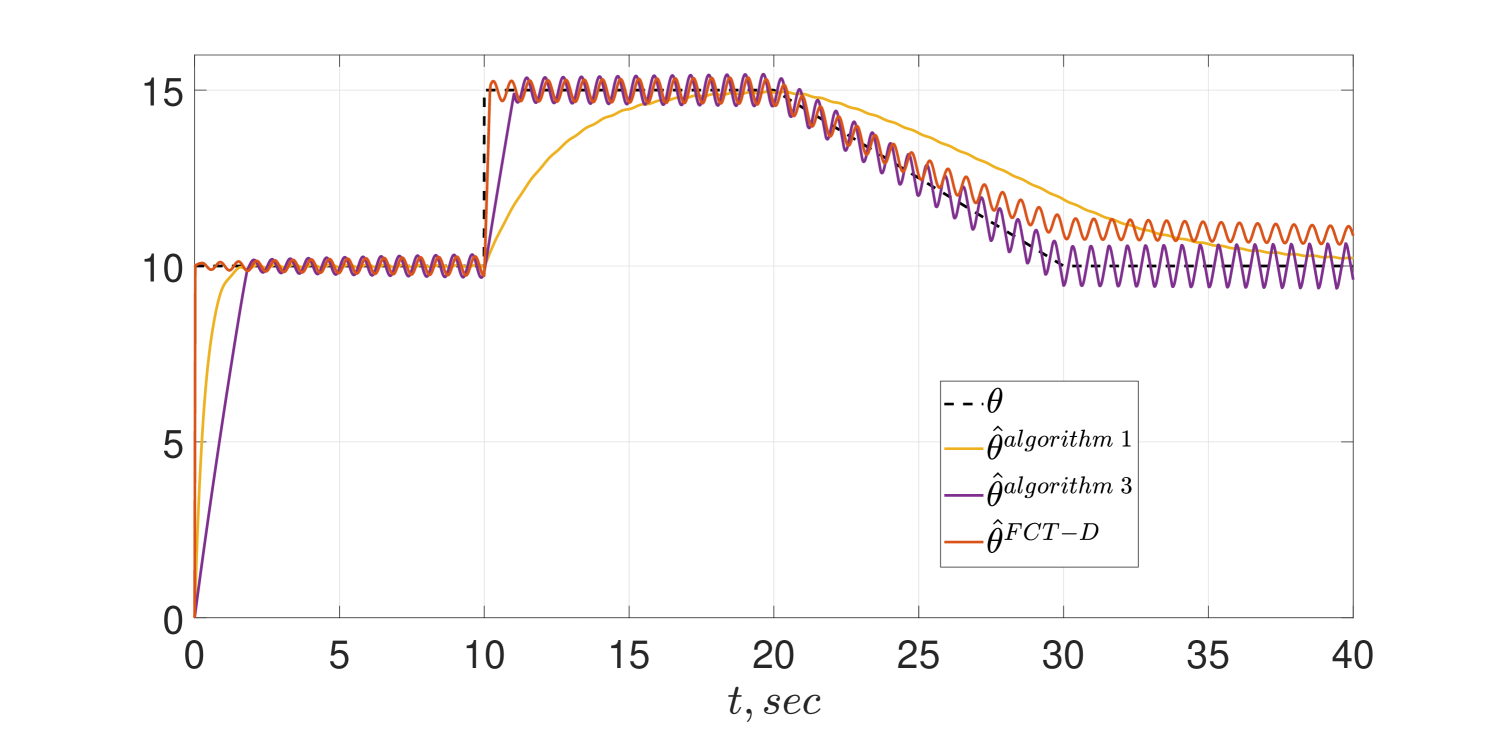
The same simulation scenario of the CT schemes given in Subsection IV-A is reproduced here and the transient behaviors are shown in Figs. 5 and 6. As shown in the figures Algorithm 3 indeed achieves FCT and preserves its alertness. However, in spite of the theoretical analysis reported in [12] the estimator of Algorithm 1 tracks only asymptotically.
To test the sensitivity of the algorithms to the presence of noise, we repeated the simulations adding a signal to the measurement . The results of the simulations are shown in Figs. 7 and 8. Interestingly, the behavior of Algorithm 1 does no seem to be affected by the noise—but, as before, the tracking is only asymptotic. For the PE case of Fig 7 we see only a minor performance degradation due to the noise in all schemes that is further degraded for the non-PE case of Fig 8.
V CONCLUSIONS
We have presented two new FCT-DREM parameter estimators with enhanced performance—in particular, with respect to their ability to track parameter variations in finite-time. CT and DT versions of the new estimators are given. The performance improvement of the proposed schemes was illustrated with representative simulations.
References
- [1] S. Aranovskiy, A. Bobtsov, R. Ortega and A. Pyrkin, Performance enhancement of parameter estimators via dynamic regressor extension and mixing, IEEE Transactions on Automatic Control, vol. 62, no. 7, pp. 3546-3550, 2017.
- [2] N. Cho, H. Shin, Y. Kim and A. Tsourdos, Composite MRAC with parameter convergence under finite excitation, IEEE Trans. Automatic Control, vol. 63, no. 3, pp. 811-818, 2018.
- [3] G. Chowdhary, T. Yucelen, M. Mhlegg and E. Johnson, Concurrent learning adaptive control of linear systems with exponentially convergent bounds, Int. J. on Adaptive Control and Signal Processing, vol. 27, no. 4, pp. 280-301, 2013.
- [4] G. Kreisselmeier and G. Rietze-Augst, Richness and excitation on an interval—with application to continuous-time adaptive control, IEEE Trans. Automatic Control, Vol. 35, No. 2, pp. 165-171, 1990.
- [5] R. Ortega, An on-line least-squares parameter estimator with finite convergence time, Proc. of the IEEE, vol. 76, no. 7, 1988.
- [6] R. Ortega, D. Gerasimov, N. Barabanov and V. Nikiforov, Adaptive control of linear multivariable systems using dynamic regressor extension and mixing estimators: Removing the high-frequency gain assumption, Automatica, (doi.org/10.1016/j.automatica.2019.108589.).
- [7] R. Ortega, S. Aranovskiy, A. A. Pyrkin, A. Astolfi and A. A. Bobtsov, New results on parameter estimation via dynamic regressor extension and mixing: continuous and discrete-time cases, IEEE Transactions on Automatic Control, (10.1109/TAC.2020.3003651), 2020.
- [8] H. Rios, D. Efimov, J. Moreno and W. Perruquetti, Time-varying parameter identification algorithms: finite and fixed-time convergence, IEEE Transactions on Automatic Control, vol. 62, no. 7, pp. 3671-3678, 2017.
- [9] S.B. Roy and S. Bhasin and I.N. Kar, Combined MRAC for unknown MIMO LTI systems with parameter convergence, IEEE Transactions on Automatic Control, vol. 63, no. 1, pp. 283-290, 2018.
- [10] S. Sastry and M. Bodson, Adaptive Control: Stability, Convergence and Robustness, Prentice-Hall, New Jersey, 1989.
- [11] J. Wang, D. Efimov, S. Aranovskiy and A. Bobtsov, Fixed-time estimation of parameters for non-persistent excitation, European Journal of Control, vol. 55, pp. 24-32, 2020
- [12] Wang, Jian, Denis Efimov, and Alexey A. Bobtsov. On robust parameter estimation in finite-time without persistence of excitation. IEEE Transactions on Automatic Control vol. 65 N. 4 pp. 1731-1738, 2020.
| AP | Alertness preservation |
|---|---|
| CT | Continuous-time |
| DREM | Dynamic regressor extension and mixing |
| DT | Discrete-time |
| FCT | Finite-convergence time |
| IE | Interval excitation |
| LRE | Linear regressor equation |