Parametric Object Coding in IVAS: Efficient Coding of Multiple Audio Objects at Low Bit Rates
Abstract
The recently standardized 3GPP codec for Immersive Voice and Audio Services (IVAS) includes a parametric mode for efficiently coding multiple audio objects at low bit rates. In this mode, parametric side information is obtained from both the object metadata and the input audio objects. The side information comprises directional information, indices of two dominant objects, and the power ratio between these two dominant objects. It is transmitted to the decoder along with a stereo downmix. In IVAS, parametric object coding allows for transmitting three or four arbitrarily placed objects at bit rates of 24.4 or 32 kbit/s and faithfully reconstructing the spatial image of the original audio scene. Subjective listening tests confirm that IVAS provides a comparable immersive experience at lower bit rate and complexity compared to coding the audio objects independently using Enhanced Voice Services (EVS).
Index Terms:
Audio coding, communication codec, Immersive Voice and Audio Services (IVAS), object-based audio, parametric coding.I Introduction
The Third Generation Partnership Project (3GPP) recently standardized Immersive Voice and Audio Services (IVAS) [1, 2, 3] with the aim of providing an immersive experience for several communication scenarios. It extends the 3GPP Enhanced Voice Services (EVS) mono codec [4, 5] towards a multitude of audio formats such as stereo, multi-channel audio, scene-based audio (Ambisonics), and object-based audio.
One of the use cases of the IVAS object-based audio mode, referred to as Independent Streams with Metadata (ISM) mode, is multi-party conferencing [6] where multiple participants are combined into an audio scene. The participants might be located at the same or different locations, and the scene might be combined with corresponding video streams or avatars. In order to create an immersive experience, each audio object is associated with metadata corresponding to the real or virtual scene. This metadata consists of direction information, distance, gain, and, optionally, additional parameters.
In mobile communication, codecs have to operate at low bit rates and be efficient in terms of computational complexity. Parametric coding approaches are especially suited for such bandwidth-constrained environments. Several parametric methods have been proposed over the years to facilitate the transmission of spatial audio at low bit rates. Binaural Cue Coding [7, 8, 9] was proposed to transmit multi-channel audio at lower bit rates by computing a single-channel downmix along with side information. While the side information mainly consists of interchannel cues, the mono downmix is computed by adding all the objects. Spatial Audio Object Coding (SAOC) [10, 11] enables the transmission of multiple objects at lower bit rates by transmitting either a mono or stereo downmix along with side information such as object level differences, inter-object cross coherence, downmix channel level differences, downmix gains, and object energies. At the decoder, the spatial audio scene is either rendered to stereo, binaural, or 5.1 loudspeaker format. Spatial Audio Object Coding 3D [12] extends SAOC by relaxing the constraint on the number of downmix channels. In addition, it also enables rendering to beyond the 5.1 loudspeaker layout. Joint Object Coding and Advanced Joint Object Coding [13, 14] transmit a downmix and metadata related to the downmix. In addition, another set of side information corresponding to the input audio objects and downmix is generated and transmitted. At the decoder, this side information is used to obtain the audio objects from the downmix signals. Finally, the decoded audio objects are rendered to a specific output layout using the metadata corresponding to the input objects.
The IVAS codec is designed for mobile communication and thus follows strong requirements for delay, bit rate and complexity. For any immersive mode, a delay not exceeding \unitms was mandated. Current mobile networks typically operate at bit rates not exceeding \unitkbit/s for voice communication. For efficiently coding multiple audio objects at such low total bit rates, strict requirements had to be set on the object side information: The side information bit rate of the previously mentioned methods is highly dependent on the number of objects and scales with an increase of the number of objects [10, 11, 12, 13, 14, 15]. While this was acceptable for the broadcasting application they were designed for, using these methods for mobile communication at target bit rates of and \unitkbit/s would have been unfeasible. In addition, the strong requirements on complexity not only include run-time complexity such as Weighted Million Operations Per Second (WMOPS) [16] and RAM demand, but also overall code size and ROM memory. To satisfy these requirements, an essential goal when designing the object-based audio mode within IVAS was the harmonization of components such as filter banks and rendering schemes across different coding modes.
In this paper, we present Parametric ISM (ParamISM), the parametric object coding mode within IVAS, which enables efficient coding of multiple audio objects at low bit rates. In particular, ParamISM is used in IVAS for efficiently coding three or four objects at or \unitkbit/s. It integrates seamlessly into IVAS by sharing filter banks, core coding, and rendering schemes with other modes. We show through subjective listening tests that, compared to independent coding of objects using EVS, ParamISM provides a better immersive experience at lower bit rates and complexity.
Sections II and III give detailed descriptions of the encoder and decoder processing of ParamISM. In Section IV, a subjective and objective evaluation of ParamISM against EVS is provided and Section V concludes the paper.
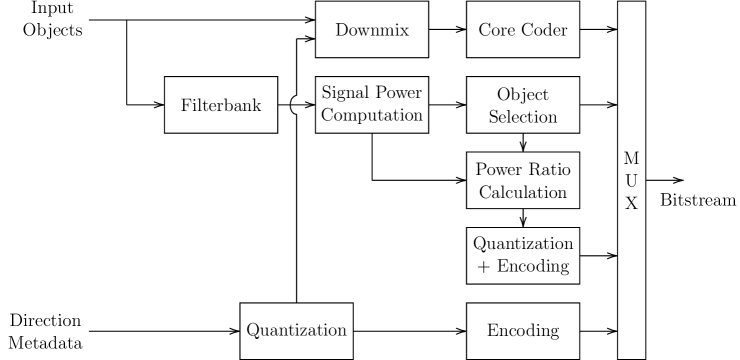
II Parametric ISM Encoder
The presented parametric object coding scheme works in the time-frequency domain, where it is assumed that per each time-frequency tile, two most dominant objects can be identified based on which a power ratio between these two dominant objects is calculated and transmitted to the decoder along with the direction information of all objects. This idea is derived from Directional Audio Coding (DirAC) [17], where the side information is based on one directional component per time-frequency tile. Our experiments showed, however, that for our purposes, two such directional components, or dominant objects, yield much better results. Since the dominant objects typically vary across the time-frequency tiles due to different frequency content, enough spatial information is retained in the side information to ensure a faithful reconstruction of three or four objects. The input audio objects themselves are transmitted by means of a two-channel time-domain downmix signal. Fig. 1(a) shows the encoder block diagram with the main functional blocks. In the following, we describe these functional blocks and give details on how the side information and downmix signal are obtained.
II-A Parametric Side Information
The mono input objects are transformed into a time-frequency representation by means of a filterbank, where and denote frequency bin and time slot indices, respectively. In IVAS, we use a Modified Discrete Fourier Transform analysis filterbank as defined in [2] which converts \unitms frames into time slots and frequency bins at a sampling rate of \unitkHz. For each time-frequency tile , the signal power of the -th object is then determined as . To reduce the data load, the time slots are grouped into one slot and the bins are grouped into psychoacoustically designed bands. The parameter band borders are given by and are specific to the input sampling rate. The signal power values per parameter band are then summed according to:
| (1) |
For each parameter band, the two objects with the greatest power values are identified and a power ratio between them is determined:
| (2) |
Note that denotes the power of the most dominant object within the parameter band and . As both ratios sum to one, is obtained by and does not need to be transmitted. is quantized with three bits using:
| (3) |
With parameter bands, the side information bit expenditure for each frame of \unitms amounts to bits for the dominant object identifications–each value is expressed with bits–and bits for the power ratio indices. Once per frame, the quantized azimuth ( bits) and elevation ( bits) information of each object is also transmitted.
II-B Stereo Downmix
The input audio objects are downmixed into two downmix channels using downmix gains that are derived from two cardioids and depend on the object positions–more specifically, the azimuth information of each object. The two cardioids are fixed and oriented towards 90° (left) and -90° (right), respectively. The downmix gains and for the left and right channel are given by:
| (4) | ||||
| (5) |
The downmix channels are then obtained by:
| (6) |
By taking into account the positions of the objects, all objects located in the left hemisphere are assigned a stronger weight for the left channel, while objects located in the right hemisphere are assigned a stronger weight for the right channel. This facilitates the rendering process. Our experiments further showed that one downmix channel is not enough to produce satisfactory results.
To prevent discontinuities, smoothing is applied between frames, and an energy compensation is conducted to account for differences between the power of the two dominant objects and the total power of all objects. The left and right downmix channels are encoded independently and transmitted to the decoder. Details on the core coding aspects are outside the scope of this paper and can be found in [2].
| Audio Scene | Type | Azimuth (deg) | Elevation (deg) | Motion |
|---|---|---|---|---|
| i1 | speech | 0, -180, 90, -90 | -5, -5, -5, -5 | static |
| i2 | speech, female | 60, 30, -30, -60 | 0, 0, 0, 0 | static |
| i3 | speech | 0, 60, -30 to -150, -45 | 0, 0, 15, 0 | object 3 |
| i4 | speech, male | 75, 25, -25, -75 | 30, 30, 30, 30 | static |
| i5 | speech | 45, -135, -45, 135 | 0, 0, 0, 0 | static |
| i6 | music | 100, 10, -80, -170 | 50, 50, 50, 50 | static |
| i7 | music | 90, 30, -30, -90 | 0, 0, 0, 0 | static |
| i8 | music, vocals | 0, -70, 50, -20 | 20, 22, 18, 0 | static |
| i9 | music | 20, 40, -30, -45 | -5, 20, 5, -5 | static |
| i10 | mixed | 60 to -10, -60, 90, -90 | 19, 25, -15, 0 | object 1 |
| i11 | vocals | 10, -10, 10, -10 | 15, 20, 30, 30 | static |
| i12 | speech | 20, 20, -20, -20 | 0, 40, 0, 40 | static |
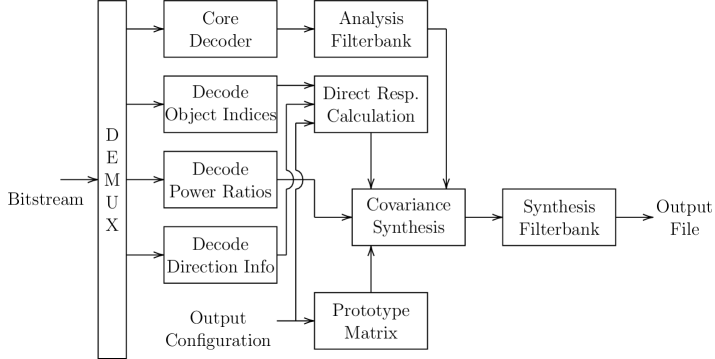
III Parametric ISM Decoder
The IVAS decoder receives a bitstream from which it extracts and decodes the transmitted downmix channels as well as the parametric side information. This information is then used for rendering the downmix signals to the desired output format. Fig.1(b) shows the decoder block diagram which we describe in the following.
III-A Parametric Side Information and Downmix
The power ratios are obtained from the transmitted power ratio index:
| (7) |
Together with the decoded direction information and the object indices of the two most dominant objects per parameter band, the output signals can be created from the two decoded downmix channels. For this, the downmix is first transformed into a time-frequency representation by means of a complex low-delay filterbank [18] which converts frames of \unitms into time slots and frequency bins. The analysis filterbank at the decoder differs from the analysis filterbank at the encoder to allow for a consistent rendering across different IVAS modes.
III-B Rendering
IVAS supports, among other output formats, the four loudspeaker layouts 5.1, 5.1.4, 7.1, and 7.1.4 according to the CICP setups as specified in [19]. To render the downmix to a specific loudspeaker layout, covariance synthesis [20] is employed where a mixing matrix is computed per time-frequency tile which transforms the transmitted downmix signals into the loudspeaker output signals
| (8) |
where denotes the decoded downmix signals, denotes the loudspeaker signals, and is the number of loudspeakers.
In order to compute the mixing mixing matrix , the covariance synthesis requires an input covariance matrix , a target covariance matrix , and a prototype matrix . The prototype matrix is dependent on the configured loudspeaker layout and is computed by mapping to all left-hemisphere loudspeakers and to the right-hemisphere loudspeakers. The center speaker is assigned both channels with a weight of .
Since the input objects are uncorrelated, the input covariance matrix is computed by considering only the main diagonal elements. It simplifies to:
| (9) |
In order to compute the target covariance matrix , we need panning gains (also referred to as direct responses ), a reference power , and the decoded power ratios which were calculated per parameter band and are now valid for all frequency bins contained in . The target covariance matrix is given by
| (10) |
where denotes the panning gains corresponding to the two dominant objects and is a diagonal matrix with element containing the power corresponding to the -th dominant object. It is given by
| (11) |
where . The panning gains are computed for the two dominant objects using Edge Fading Amplitude Panning (EFAP) [21], an improved panning method compared to Vector-Base Amplitude Panning (VBAP) [22], based on their corresponding direction information and the target loudspeaker layout. A synthesis filterbank is applied on the output signals to obtain the time-domain loudspeaker signals for playback.
IV Evaluation
To evaluate the presented parametric object coding scheme, we conducted subjective listening tests as well as objective complexity measurements. For this, IVAS is used in ParamISM mode with three and four input objects plus associated metadata and compared against its predecessor EVS. As EVS is a mono codec that is only able to process one monaural signal at a time, one instance of EVS is executed per each input object. We refer to this as multi-mono EVS.
IV-A Test Set
A set of twelve audio scenes containing different kinds of audio objects is used for the subjective evaluation of the proposed method. Since multi-party conferencing is probably the most relevant use case, most of the audio scenes feature speech uttered by different participants. The amount of overlapped speech varies from scene to scene, but mostly, it is kept small to create realistic scenarios of polite discussions. IVAS also supports music and mixed audio, which is why some audio scenes contain general audio content in the form of music (different instruments and vocals) and ambient sound.
Table I summarizes the details of each audio scene of the test set. Azimuth and elevation values are given for each of the objects of the scene; in case of a present moving object, the start and end position is given and the motion itself is uniform across all frames of the audio file. The duration of the test files varies between and seconds at \unitkHz.
IV-B Subjective Test
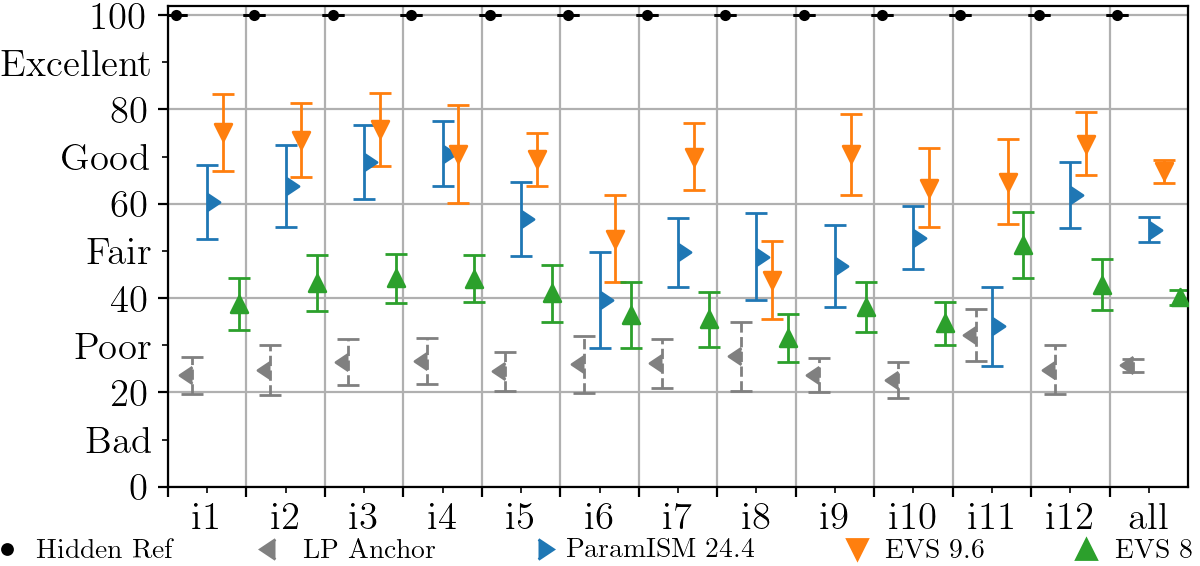
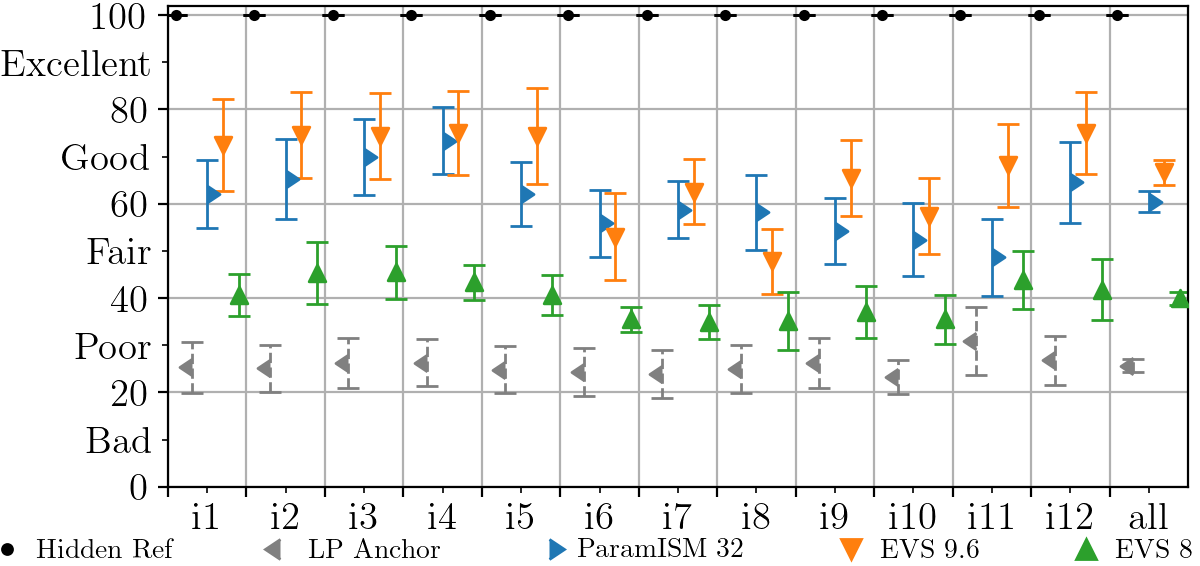
With the test set, two subjective listening tests following the Multiple Stimuli with Hidden Reference and Anchor (MUSHRA) methodology [23] were conducted on a 7.1.4 loudspeaker layout. The first test focuses on audio scenes containing three objects, while the second test focuses on scenes with four objects. In the three-object test, the fourth objects of the scenes are not used. The test comprises the following conditions: Hidden reference, 3.5 \unitkHz low-pass anchor, ParamISM at 24.4 \unitkbit/s, multi-mono EVS at 9.6 \unitkbit/s per object, and multi-mono EVS at 8 \unitkbit/s per object. For the four-object test, ParamISM at 32 \unitkbit/s is used instead of 24 \unitkbit/s. The rest of the conditions remain the same.
For multi-mono EVS, the coded objects were rendered to the loudspeaker layout using the unquantized object metadata in a post-processing step. The gains for the rendering were computed using EFAP [21]. In this context, it is important to note that the metadata bit rate is part of the total bit rate in IVAS. In contrast, EVS uses the full bit rate for coding the objects without taking into account any metadata bit rate. This puts multi-mono EVS at an advantage over IVAS when the exact same bit rates are compared. On average, the metadata consumes \unitkbit/s per object in IVAS.
Figure 2 shows the results of the listening tests. A total of expert listeners participated in both tests. The results show that ParamISM in IVAS achieves an audio quality in the good range for speech and in the fair range for music and other audio content. On average, it outperforms EVS at the same bit rate by to MUSHRA points. Notably, IVAS ParamISM supports super-wideband coding at the investigated bit rates, whereas multi-mono EVS at \unitkbit/s per object only supports wideband coding. At \unitkbit/s per object, EVS also supports super-wideband coding. Especially in the four-object test, it is seen that ParamISM approaches the audio quality of EVS at the higher bit rate, while also including the coded metadata in the total rate. Subtracting the metadata bit rate, ParamISM indeed uses only % of the rate of x EVS at \unitkbit/s for coding the audio objects. In the three-object case, ParamISM uses % of the rate of x EVS at \unitkbit/s.
The quality of ParamISM drops somewhat in audio scenes that contain strong object overlaps, e.g., audio scenes i1 and i5 where there is a 50-100% overlap of the talkers. One can argue, though, that such an overlap would not occur in a realistic conferencing or conversation scenario. Scene i11 contains a recording of a choir, where, in addition to a 100% temporal overlap, there is also the challenge of a large overlap in the frequency components. Scene i6 proves somewhat challenging due to simultaneously occurring transients in all objects. For pure music content, a higher bit rate is required to achieve good to excellent quality and for this, IVAS provides multiple other modes in the form of multi-channel and Ambisonics coding or non-parametric object coding at bit rates of up to \unitkbit/s. However, ParamISM is still able to produce acceptable quality at low bit rates, retaining immersion for any spatial audio scene, while at the same time fulfilling the low-delay and complexity requirements of a communication codec.
IV-C Complexity
To also evaluate ParamISM in an objective manner, Table II summarizes the complexity measured [16] in WMOPS for both IVAS ParamISM and multi-mono EVS. Measurements are conducted for ParamISM with three and four input objects. Accordingly, three and four instances of EVS are run and measured for comparison. The numbers show that the parametric object coding mode in IVAS generally requires fewer WMOPS to encode and decode audio scenes with three or four objects than multi-mono EVS.
| Condition, 3 objects | Encoder | Decoder | Total |
|---|---|---|---|
| ParamISM at 24.4 \unitkbit/s | 151.39 | 89.75 | 241.14 |
| ParamISM at 32 \unitkbit/s | 122.09 | 75.53 | 197.62 |
| 3x EVS at 8 \unitkbit/s | 144.10 | 93.47 | 237.57 |
| 3x EVS at 9.6 \unitkbit/s | 208.84 | 104.87 | 313.71 |
| Condition, 4 objects | Encoder | Decoder | Total |
| ParamISM at 24.4 \unitkbit/s | 153.99 | 94.18 | 248.18 |
| ParamISM at 32 \unitkbit/s | 124.95 | 80.35 | 205.30 |
| 4x EVS at 8 \unitkbit/s | 192.17 | 124.53 | 316.70 |
| 4x EVS at 9.6 \unitkbit/s | 278.45 | 139.41 | 417.86 |
V Conclusion
In this paper, the parametric object coding mode ParamISM as implemented within IVAS was presented. It was shown that employing a stereo downmix along with parametric side information based on two dominant objects allows for efficiently coding and transmitting multiple audio objects at low bit rates and rendering an immersive audio experience. Compared against multi-mono EVS, which requires external rendering of the objects, ParamISM provides an all-in-one solution for coding and rendering and is even able to retain a higher audio bandwidth. Within the IVAS standard, ParamISM is an efficient means for handling multi-party conferencing scenarios in low-delay and low-bit-rate environments.
Acknowledgment
The authors would like to thank Stefan Bayer, Jan Frederik Kiene, Jürgen Herre, Archit Tamarapu, and Oliver Thiergart for their contributions to this work.
References
- [1] “Codec for Immersive Voice and Audio Services (IVAS); General overview,” 3GPP, TS 26.250, July 2024. [Online]. Available: https://www.3gpp.org/DynaReport/26250.htm
- [2] “Codec for Immersive Voice and Audio Services (IVAS); Detailed Algorithmic Description including RTP payload format and SDP parameter definitions,” 3GPP, TS 26.253, July 2024. [Online]. Available: https://www.3gpp.org/DynaReport/26253.htm
- [3] M. Multrus et al., “Immersive Voice and Audio Services (IVAS) Codec – The New 3GPP Standard for Immersive Communication,” in AES Convention 157, no. 10188, New York, NY, USA, October 2024.
- [4] “Codec for Enhanced Voice Services (EVS); Detailed algorithmic description,” 3GPP, TS 26.445, May 2024. [Online]. Available: https://www.3gpp.org/DynaReport/26445.htm
- [5] M. Dietz et al., “Overview of the EVS codec architecture,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, April 2015, pp. 5698–5702.
- [6] E. Fotopoulou et al., “Use-Cases of the new 3GPP Immersive Voice and Audio Services (IVAS) Codec and a Web Demo Implementation,” in IEEE 5th International Symposium on the Internet of Sounds (IS2), Erlangen, Germany, September 2024.
- [7] C. Faller and F. Baumgarte, “Binaural Cue Coding: A Novel and Efficient Representation of Spatial Audio,” in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Orlando, FL, USA, May 2002, pp. II–1841–II–1844.
- [8] ——, “Binaural Cue Coding - Part II: Schemes and Applications,” IEEE Transactions on Speech and Audio Processing, vol. 11, no. 6, pp. 520–531, January 2004.
- [9] F. Baumgarte and C. Faller, “Binaural Cue Coding - Part I: Psychoacoustic Fundamentals and Design Principles,” IEEE Transactions on Speech and Audio Processing, vol. 11, no. 6, pp. 509–519, January 2004.
- [10] J. Breebaart et al., “Spatial Audio Object Coding (SAOC) - The Upcoming MPEG Standard on Parametric Object Based Audio Coding,” in AES Convention 124, no. 7377, Amsterdam, The Netherlands, May 2008.
- [11] J. Herre et al., “MPEG Spatial Audio Object Coding — The ISO/MPEG Standard for Efficient Coding of Interactive Audio Scenes,” Journal of the Audio Engineering Society, vol. 60, pp. 655–673, October 2012.
- [12] A. Murtaza et al., “ISO/MPEG-H 3D Audio: SAOC-3D Decoding and Rendering,” in AES Convention 139, no. 9434, New York, NY, USA, October 2015.
- [13] H. Purnhagen et al., “Immersive Audio Delivery Using Joint Object Coding,” in AES Convention 140, no. 9587, Paris, France, May 2016.
- [14] K. Kjörling et al., “AC-4 — The Next Generation Audio Codec,” in AES Convention 140, no. 9491, Paris, France, May 2016.
- [15] L. Terentiev et al., “Efficient Parametric Audio Coding for Interactive Rendering: The Upcoming ISO/MPEG Standard on Spatial Audio Object Coding (SAOC),” in International Conference on Acoustics. Rotterdam, The Netherlands: DAGA, March 2009.
- [16] “Software tools for speech and audio coding standardization,” ITU-T, Tech. Rep. G.191, May 2024. [Online]. Available: https://handle.itu.int/11.1002/1000/15940
- [17] V. Pulkki et al., “Directional audio coding – perception-based reproduction of spatial sound,” in International Workshop on the Principles and Applications of Spatial Hearing, Zao, Miyagi, Japan, November 2009.
- [18] M. Schnell et al., “Low Delay Filterbanks for Enhanced Low Delay Audio Coding,” in IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, October 2007, pp. 235–238.
- [19] “Information technology — Dynamic adaptive streaming over HTTP (DASH) — Part 3: Media presentation description and segment format,” ISO/IEC, Tech. Rep. 23091-3, 2018.
- [20] J. Vilkamo, T. Bäckström, and A. Kuntz, “Optimized Covariance Domain Framework for Time-Frequency Processing of Spatial Audio,” Journal of the Audio Engineering Society, vol. 61, no. 6, pp. 403–411, July 2013.
- [21] C. Borß, “A Polygon-Based Panning Method for 3D Loudspeaker Setups,” in AES Convention 137, no. 9106, Los Angeles, CA, USA, October 2014.
- [22] V. Pulkki, “Virtual Sound Source Positioning Using Vector Base Amplitude Panning,” Journal of the Audio Engineering Society, vol. 45, no. 6, pp. 456–466, June 1997.
- [23] “Method for the subjective assessment of intermediate quality level of audio systems,” Recommendation BS.1534-3, 2015.