Pareto Front-Diverse Batch Multi-Objective Bayesian Optimization
Abstract
We consider the problem of multi-objective optimization (MOO) of expensive black-box functions with the goal of discovering high-quality and diverse Pareto fronts where we are allowed to evaluate a batch of inputs. This problem arises in many real-world applications including penicillin production where diversity of solutions is critical. We solve this problem in the framework of Bayesian optimization (BO) and propose a novel approach referred to as Pareto front-Diverse Batch Multi-Objective BO (PDBO). PDBO tackles two important challenges: 1) How to automatically select the best acquisition function in each BO iteration, and 2) How to select a diverse batch of inputs by considering multiple objectives. We propose principled solutions to address these two challenges. First, PDBO employs a multi-armed bandit approach to select one acquisition function from a given library. We solve a cheap MOO problem by assigning the selected acquisition function for each expensive objective function to obtain a candidate set of inputs for evaluation. Second, it utilizes Determinantal Point Processes (DPPs) to choose a Pareto-front-diverse batch of inputs for evaluation from the candidate set obtained from the first step. The key parameters for the methods behind these two steps are updated after each round of function evaluations. Experiments on multiple MOO benchmarks demonstrate that PDBO outperforms prior methods in terms of both the quality and diversity of Pareto solutions.
1 Introduction
A wide range of science and engineering applications, including materials design (Ashby 2000), biological sequence design (Taneda 2015), and drug/vaccine design (Nicolaou and Brown 2013) involves optimizing multiple expensive-to-evaluate objective functions. For example, in nanoporous materials design (Deshwal et al. 2021), the goal is to optimize the adsorption property and cost of synthesis guided by physical lab experiments. Since the experiments are expensive in terms of the consumed resources, our goal is to approximate the optimal Pareto set of solutions. In many of the aforementioned applications, there are two important considerations. First, we can perform multiple parallel experiments which should be leveraged to accelerate the discovery of high-quality solutions. Second, practitioners care about diversity in solutions and their outcomes. For example, in penicillin production application, diverse solutions for objectives including penicillin production, the time to ferment, and the byproduct (Birol et al. 2002).
We consider the problem of multi-objective optimization (MOO) over expensive-to-evaluate functions to find high-quality and diverse Pareto fronts when we are allowed to perform a batch of experiments. We solve this problem using Bayesian optimization (BO) (Shahriari et al. 2015) which has been shown to be highly effective for such problems. The key idea behind BO is to learn a surrogate model (e.g., Gaussian process)from past experiments and use it to intelligently select the sequence of experiments guided by an acquisition function (e.g., expected improvement). There is prior BO work on selecting a batch of experiments to find diverse high-performing solutions for single-objective optimization. However, there is very limited work on batch BO for MOO problems and to produce diverse MOO solutions. A key drawback of the existing BO methods for MOO is that they evaluate diversity in terms of input space, which is not appropriate for MOO (diversity in input space diversity in output space). To overcome this drawback and to measure the diversity of MOO solution in the output space, we define a new metric referred to as Diversity of the Pareto Front (DPF).
We propose a novel approach referred to as Pareto front-Diverse Batch Multi-Objective BO (PDBO). PDBO selects a batch of inputs for evaluations in each iteration using two main steps. First, it employs a principled multi-arm bandit strategy to dynamically select one acquisition function (AF) from a given library of AFs within the single-objective BO literature. A cheap MOO problem is solved by assigning the selected AF for each expensive objective function to obtain a Pareto set. Second, a principled configuration of determinantal point processes (DPPs) (Borodin 2009; Kulesza et al. 2012) for multiple objectives is used to select inputs for evaluation from the Pareto set of the first step to improve the diversity of the uncovered Pareto front. PDBO updates the key parameters of the algorithms for these two steps (dynamic selection of AF and selecting Pareto-front diverse inputs from a candidate Pareto set) after obtaining the objective function evaluations. Our experiments on multiple benchmarks with varying input dimensions and number of objective functions demonstrate that PDBO outperforms prior methods in finding high-quality and diverse Pareto fronts.
Contributions. The key contribution of this paper is developing and evaluating the PDBO approach for solving MOO problems to find high-quality and diverse Pareto fronts.
Specific contributions are as follows:
-
•
A multi-arm bandit strategy with a novel reward function to dynamically select one acquisition function from a given library for MOO problems.
-
•
A novel DPP method for selecting a batch of inputs from a given Pareto set to maximize Pareto front diversity using a new mechanism to generate the DPP kernel for MOO.
-
•
To demonstrate the effectiveness of PDBO and study the Pareto front diversity, we propose a new metric to measure the diversity of Pareto fronts. To the best of our knowledge, this is the first attempt at extensive experimental evaluation of Pareto front diversity within BO.
-
•
Theoretical analysis of our PDBO algorithm in terms of asymptotic regret bounds.
-
•
Experimental evaluation of PDBO and baselines on multiple benchmark MOO problems. The code for PDBO is publicly available at https://github.com/Alaleh/PDBO.
2 Problem Setup and Background
We first formally define the batch MOO problem along with the metrics to evaluate the quality and diversity of solutions. Next, we provide an overview of the BO framework.
Batch Multi-Objective Optimization. We consider a MOO problem where the goal is to optimize multiple conflicting functions. Let be the input space of design variables, where each candidate input is a -dimensional input vector. And let with be the objective functions defined over the input space where . We denote the functions evaluation at an input as , where for all . Without loss of generality, we assume minimization for all objective functions. The optimal solution of the MOO problem is a set of inputs such that no input Pareto-dominates another input . An input Pareto-dominates another point if and only if and . The set of input solutions is called the optimal Pareto set and the corresponding set of function values is called the optimal Pareto front. We can select inputs for parallel evaluation in each iteration, and our goal is to uncover a high-quality and diverse Pareto front while minimizing the total number of expensive function evaluations.
Metrics for Quality and Diversity of Pareto Front. Our goal is to find high-quality and diverse Pareto fronts. The diversity of the Pareto front has not been formally evaluated in any previous work. We introduce an appropriate evaluation metric to measure the diversity of the Pareto front and discuss an existing measure of Pareto front quality below.
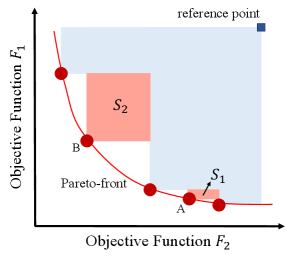
Diversity of Pareto Front. Diversity is an important criterion for many optimization problems. Prior work on batch BO, both in the single-objective and MO settings focused on evaluating diversity with respect to the input space (Jain et al. 2022). However, in most real-world MOO problems, diversity in the input space does not necessarily reflect diversity in the output space. In MOO, practitioners might care more about the diversity of the Pareto front rather than the Pareto set. Yet, little work has gone into understanding, formalizing, and measuring Pareto front diversity in MOO. In most cases, finding a more diverse set of points in the output space leads to a higher hypervolume (Zitzler and Thiele 1999). However, a higher hypervolume does not necessarily correspond to a more diverse Pareto front. (Konakovic Lukovic et al. 2020) is the only prior work that proposed a diversity-guided approach for batch MOO. However, the diversity of the produced Pareto front was not evaluated. To fill this gap, we propose an evaluation metric to fill this gap to assess the Diversity of the Pareto Front (DPF). Given a Pareto front , is the average pairwise distance between points (i.e., output vectors) in Pareto front . It is important to clarify that the pairwise distances are computed in the output space between different vector pairs , unlike previously used metrics to assess input space diversity in the single-objective setting (Angermueller et al. 2020).
We provide a more detailed discussion of existing metrics and some illustrative results on previous metrics and their utility in evaluating diversity in the Appendix.
Hypervolume Indicator. The hypervolume indicator (Zitzler and Thiele 1999) is the most commonly employed measure to evaluate the quality of a given Pareto front. Given a set of functions evaluations , the Pareto hypervolume (PHV) indicator is the volume between a predefined reference point and the given Pareto front.
2.1 Bayesian Optimization Framework
BO (Shahriari et al. 2015) is a general framework for solving expensive black-box optimization problems in a sample-efficient manner. BO algorithms iterate through three steps.
1) Build a probabilistic surrogate model of the true expensive objective function. Gaussian process (GPs) (Williams and Rasmussen 2006)) are widely employed in BO.
2) Define an acquisition function (AF) to score the utility of unevaluated inputs. It uses the surrogate model’s predictions as a cheap substitute for expensive function evaluations and strategically trades off exploitation and exploration.
Some examples of widely used acquisition functions in single-objective optimization include expected improvement (EI) (Mockus et al. 1978), upper confidence bound (UCB) (Auer 2002), Thompson sampling (TS) (Thompson 1933) and Identity (ID).
| (1) | |||
| (2) | |||
| (3) | |||
| (4) |
Here, is a parameter to balance exploration and exploitation in the UCB acquisition function (Srinivas et al. 2009), is the best-uncovered function value; and and are the CDF and PDF of a standard normal distribution respectively.
3) Select the input with the highest utility score for function evaluation by optimizing the acquisition function.
3 Related Work
Multi-Objective BO. There is relatively less work on MOO in comparison with single-objective BO. Prior work builds on the insights from single-objective methods (Shahriari et al. 2015; Hernández-Lobato et al. 2014; Wang and Jegelka 2017; Hvarfner et al. 2022) for MOO. Recent work on MOBO includes Predictive Entropy Search (Hernández-Lobato et al. 2016), Max-value Entropy Search (Belakaria et al. 2019), Multi-Objective Regionalized BO (Daulton et al. 2022), Uncertainty-aware Search (Belakaria et al. 2020a), Pareto-Frontier Entropy Search (Suzuki et al. 2020), and Expected Hypervolume Improvement (Daulton et al. 2020; Emmerich and Klinkenberg 2008). These methods are shown to perform well on a variety of MOO problems.
Batch Multi-objective BO. The Batch BO problem in the multi-objective setting is even much less studied. Diversity-Guided Efficient Multi-Objective Optimization (DGEMO) (Konakovic Lukovic et al. 2020) approximates and analyzes a piecewise-continuous Pareto set representation which allows the algorithm to introduce a batch selection strategy that optimizes for both hypervolume improvement and diversity of selected samples. However, DGEMO work did not study or evaluate the Pareto-front diversity of the produced solutions. qEHVI (Daulton et al. 2020) is an exact computation of the joint EHVI of new candidate points (up to Monte-Carlo integration error).
qPAREGO is a novel extension of ParEGO (Knowles 2006; Daulton et al. 2020) that supports parallel evaluation and constraints. More recent work (Lin et al. 2022) proposed an approach to address MOO problems with continuous/infinite Pareto fronts by approximating the whole Pareto set via a continuous manifold. This approach enables a better preference-based exploration strategy for practitioners compared to prior work (Abdolshah et al. 2019; Paria et al. 2020; Astudillo and Frazier 2020). However, it is typically unknown to the user if the Pareto front is dense/continuous, especially in expensive function settings where the data is limited. It is not known whether any of these batch methods produce diverse Pareto fronts or not, as they were not evaluated on diversity metrics. We perform an experimental evaluation to answer this question.
DPPs for Batch Single-Objective BO. DPPs are elegant probabilistic models (Borodin and Olshanski 2005; Borodin 2009) that characterize the property of repulsion in a set of vectors and are well-suited for the selection of a diverse subset of inputs from a predefined set. Prior work used DPPs for selecting batches for evaluation in the single-objective BO literature (Kathuria et al. 2016; Nava et al. 2022; Wang et al. 2017). In the context of MOO for cheap objective functions using evolutionary algorithms, DPP was deployed using non-learning-based kernels such as cosine function applied to points in the Pareto front while disregarding the input space (Wang et al. 2022; Zhang et al. 2020; Okoth et al. 2022). However, to the best of our knowledge, there is no work on using DPPs for multi-objective BO to uncover diverse Pareto fronts using a learned kernel that captures the trade-off between multiple objectives, similarity in the input space, and diversity of the Pareto front.
Adaptive Acquisition Function Selection. There has been a plethora of research on finding efficient and reliable acquisition functions (AFs). However, prior work has shown that no single acquisition function is universally efficient and consistently outperforms all others. GP-Hedge (Hoffman et al. 2011) proposed to use a portfolio of acquisition functions. The optimization of each AF will nominate an input, and the algorithm will select one of them for evaluation using the selection probabilities. The GP-Hedge method uses the Hedge strategy (Freund and Schapire 1997), a multi-arm bandit method designed to choose one action amongst a set of different possibilities using selection probabilities calculated based on the reward (performance given by function values) collected from previous evaluations. Vasconcelos et al. extended Hoffman et al. by proposing to use discounted cumulative reward and Vasconcelos et al. suggested using Thompson sampling to automatically set the hedge hyperparameter .
4 Proposed PDBO Algorithm
We start by providing an overview of the proposed PDBO algorithm illustrated in Figure 1. Next, we explain our algorithms for two key components of PDBO, namely, adaptive acquisition function selection via a multi-arm bandit strategy and diverse batch selection via determinantal point processes for multi-objective output space diversity.
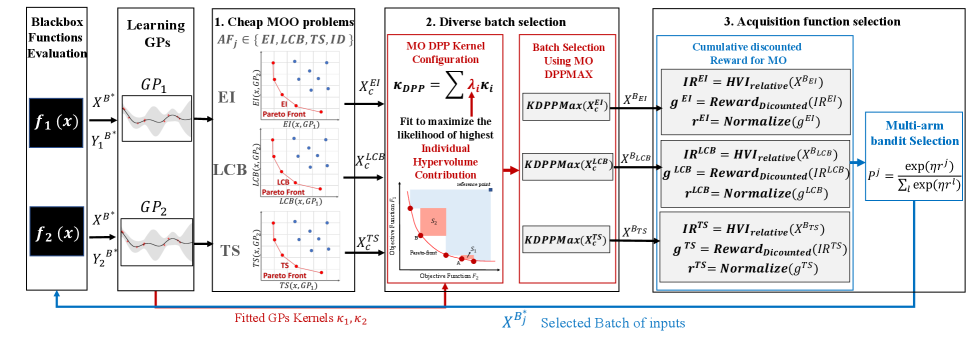
Overview of PDBO. PDBO is an iterative algorithm. It introduces novel methods for selecting varying acquisition functions and for bringing the diversity of inputs into the multi-objective BO setting. The method builds independent Gaussian processes as surrogates for each of the objective functions. Its three key steps at each iteration to select inputs for evaluation are:
1. Solving multiple cheap MOO problems: PDBO takes as input a portfolio of acquisition functions, for single-objective BO. It constructs cheap MOO problems, each corresponding to one AF. The multiple objectives defining the cheap MOO problems are acquisition functions respectively corresponding to the objective functions. Solving cheap MOO problems will generate cheap Pareto-sets of solutions .
2. Diverse batch selection: From each cheap Pareto set , a batch of inputs is selected using a diversity-aware approach based on DPPs. Importantly, the adapted DPP is configured to favor the diversity in the output space and to handle multiple objective settings by using a principally fitted convex combination of the kernels of the Gaussian processes. The convex combination scalars are strategically set to maximize the likelihood of selecting a diverse subset of inputs with respect to the Pareto front.
3. Acquisition function selection: From , only one nominated subset would be selected using a multi-arm bandit strategy. The keys to this selection are probabilities , one for each acquisition function to capture their performance based on past iterations. is the probability of selecting the batch generated by the acquisition function , defined in equation 9. These probabilities are updated based on the discounted cumulative reward of each of the respective acquisition functions. The reward values are updated based on the quality of the batches nominated by the respective acquisition functions.
Algorithm 1 provides a pseudocode with high-level steps of the PDBO approach. The DPP-Select and Adaptive-Af-Select represent the second and third key steps. The details of these methods and their corresponding pseudocodes are provided in Sections 4.1 and 4.2, respectively.
4.1 Multi-arm Bandit Strategy for Adaptive Acquisition Function Selection
In this section, we propose a multi-arm bandit (MAB) approach to adaptively select one acquisition function (AF) from a given library of AFs in each iteration of PDBO.
Input: input space; {}, black-box objective functions; = {} portfolio of acquisition functions; batch size; and number of iterations
Multi-arm Bandit Formulation. We are given a portfolio of acquisition functions = and our goal is to adaptively select one AF in each iteration of PDBO. Each acquisition function in corresponds to one arm, and we need to select an arm based on the performance of past selections for solving the MOO problem. Inspired by the previous work on AF selection and algorithm selection in the single objective setting (Hoffman et al. 2011; Vasconcelos et al. 2019, 2022), we propose an adaptive acquisition function selection approach for the MOO setting (see Algorithm 2). We explain the two main steps of this approach below.
Nominating Promising Candidates via Cheap MOO. In each PDBO iteration, we employ the updated statistical models and the portfolio to generate sets of candidate points. For each , the algorithm constructs a cheap MOO problem with the objectives defined as . Assuming minimization, the cheap MOO generate Pareto-sets of solutions (one for each acquisition function) defined as:
| (5) |
We employ the algorithm proposed by Deb et al. to solve cheap MOO problems defined in 5. From each , a batch of points is selected in iteration using a diversity-aware approach described in Section 4.2. We denote the function evaluations of inputs in by .
Multi-Objective Reward Update. We employ the relative hypervolume improvement as the quality metric to define our reward. The Pareto hypervolume captures the quality of nominated batches from a Pareto-dominance perspective and carries information about the represented trade-off between the multiple objectives. Defining the immediate reward as the raw Pareto hypervolume of the nominated batch can lead to an undesirable assessment of the suitable acquisition function since a batch of points can have a large hypervolume value at iteration but does not provide a significant improvement over the previous Pareto front while another batch nominated in iteration may have a smaller hypervolume yet provides a higher improvement over . Additionally, initial iterations might provide drastic hypervolume improvements even if the selected points are not optimal. To mitigate these issues, we use the relative hypervolume improvement as the immediate reward instead of the hypervolume. In each BO iteration , the immediate reward for each acquisition function is defined as follows.
| (6) |
where is the Pareto front at iteration and is the evaluation of the batch of points nominated by computed using the predictive mean of the updated GP based statistical models. As optimization progresses, statistical models provide a better representation of the objective functions, and the batches nominated by each AF become more informative about the quality of its selections. Hence, the impact of the early iterations may become irrelevant later. Consequently, we employ a discounted cumulative reward for each acquisition function at iteration (denoted ).
| (7) |
Where is a decay rate that trades off past and recent improvements. The use of the decay rate can lead to equal or comparable rewards in advanced iterations, causing the algorithm to select the acquisition function randomly. To address this problem, the discounted cumulative reward should be normalized (Vasconcelos et al. 2019). The rewards at the first iteration are all initialized to zero and then updated at each iteration using the following expression:
| (8) |
where = and = . Finally, the probability of selection of each AF at each iteration is calculated using equation 9.
| (9) |
The proposed MAB approach is an extension of the Hedge algorithm but is fundamentally distinct in its methodology and applicability. While it does generalize certain aspects of Hedge, it introduces critical variations that make it unique within the context of this study. Our approach diverges from the original Hedge algorithm by incorporating two key modifications: 1) The use of discounted rewards and the application of normalization. Unlike the conventional Hedge, where rewards are typically used without any discounting or normalization, our strategy accounts for these factors, enhancing its adaptability to the specific problem domain. 2) Another significant departure lies in the problem setting itself. Hedge was initially designed for single-objective optimization while our proposed approach solves the more challenging problem of multi-objective optimization. This shift in focus has substantial implications, as it requires an entirely different set of considerations and techniques to address the complexities introduced by multiple conflicting objectives.
Input: training data ; Batches nominated by different AFs
Remark. It is important to note that we are using a full information multi-arm bandit strategy that requires the reward to be updated for all possible actions (i.e., for all acquisition functions) at each iteration. Since we evaluate only the batch nominated by the selected AF, we achieve this by computing the reward using the predictive mean functions of the updated surrogate models. For this reason, we solve a cheap MOO problem for each even though the acquisition function is selected based on the data from the previous iterations. Algorithm 2 provides the pseudocode of the adaptive AF selection based on the estimated rewards and probabilities.
4.2 DPPs for Batch Selection
We explain our approach to select a batch of diverse inputs by configuring DPPs to promote output space diversity.
Determinantal Point Processes. (DPPs) (Kulesza et al. 2012) are well-suited to model samples of a diverse subset of points from a predefined set of of points. Given a similarity function over a pair of points, DPPs assign a high probability of selection to the most diverse subsets according to the similarity function. The similarity function is typically defined as a kernel. Formally, given a DPP kernel defined over a set of elements, the -DPP distribution is defined as selecting a subset of size with with probability proportional to the determinant of the kernel:
| (10) |
(Kathuria et al. 2016) introduced the use of DPP for batch BO in the single-objective setting. Given the surrogate GP of the objective function, the covariance of the GP is used as the similarity function for the DPP. The approach selects the first point in the batch by maximizing the UCB acquisition function. Next, it creates a set of points referred to as relevance region by bounding the search space with the maximizer of the LCB acquisition function and manually discretizing the bounded space into a grid of points. DPP selects the remaining points out of the points in the relevance region. (Wang et al. 2017; Oh et al. 2021; Nava et al. 2022) used similar techniques to apply DPPs to high-dimensional and discrete spaces.
There exist two approaches to selecting a diverse subset with a fixed size via DPP: 1) Choosing the subset that maximizes the determinant referred to as DPP-max; and 2) Sampling with the determinantal probability measure referred to as DPP-sample. In this paper, we will focus on DPP-max. Although selecting the subset that maximizes the determinant is an NP-Hard problem, several approximations were proposed (Nikolov 2015). A greedy strategy (Kathuria et al. 2016) provides an approximate solution and was adopted in several BO papers (Wang et al. 2017)
Limitations of Prior Work and Challenges for MOO. We list the key limitations of prior methods for DPP-based batch selection in the single-objective setting as they are applicable to the multi-objective setting too. L1) How can we overcome the limitation of selecting the first point separately regardless of the DPP diversity? L2) How can we prevent the potential limitation of under-explored search space caused by the discretization of the space to create the relevance region set?
The key challenges to employing DPPs for batch selection in the MOO setting include C1) How to define a kernel that captures the diversity for multiple objectives given that we have separate surrogate models and their corresponding kernel? C2) How can the DPP kernel capture the Pareto front diversity and the trade-off between the objectives without compromising the Pareto quality of selected points?
DPPs for Multi-objective BO. We propose principled methods to address the limitations of prior work on DPPs for batch BO (L1 and L2) and the challenges C1 and C2 for MOO.
Multi-objective Relevance Region. Our proposed algorithm naturally mitigates the two limitations of the single-objective DPP approach. Recall that the first step of PDBO algorithm (Section 4.1) proposes to generate cheap approximate Pareto-sets which capture the trade-offs between the objectives in the utility space and might include, with high probability, optimal points (Belakaria et al. 2020a; Konakovic Lukovic et al. 2020). We consider the cheap Pareto sets as the multi-objective relevance region. Our approach allows for generating the relevance region without manually discretizing the search space. Also, the full batch is selected from the multi-objective relevance region leading to a better diversity among all the points in the batch.
Input: cheap Pareto set ; surrogate models ; data .
Multi-objective DPP Kernel Fitting. To overcome the challenges of using DPPs in the MOO setting, we build a new kernel that is defined as a convex combination of the kernels of the statistical models (GPs) representing each of the black-box objective functions. Let be a vector of size where each corresponds to the convex combination scalar associated with kernel of the objective function . The DPP kernel is defined as:
| (11) |
The hyperparameters of the kernels are fixed during the fitting of the GPs. To set the convex combination scalars in a principled manner that promotes diverse batch selection, we propose to set the by maximizing the log marginal likelihood of selecting points with the highest individual hypervolume contribution.
The individual hypervolume contribution (HVC) of each point in the evaluated Pareto front (via evaluated training data ) is the reduction in hypervolume if the point is removed from the Pareto front. HVC is considered a Pareto front (PF) diversity indicator (Daulton et al. 2022). Points in crowded regions of the Pareto front have smaller HVC values. Therefore, more Pareto front points with high HVC indicate more output space coverage and consequently, higher PF diversity.
| (12) |
Given equation 12, we can construct the training set for the fitting of . Let = be a vector of the individual HV contributions of evaluated points .
| (13) |
Algorithm 3 provides the pseudo-code for selecting the diverse batch from a given candidate/cheap Pareto set .
5 Theoretical Analysis
Prior work developed regret bound for different single objective acquisition functions including UCB (Srinivas et al. 2009; Belakaria et al. 2020a). However, the theoretical analysis of our proposed MAB algorithm is more challenging as it involves input selection based on different acquisition functions at each iteration . The choices made at any given iteration influence the state and subsequent rewards of all future iterations (Hoffman et al. 2011) and therefore there is a need to adapt prior theoretical analysis. Additionally, regret bounds for Hedge MAB strategies have been developed independently outside the context of acquisition function selection (Cesa-Bianchi and Lugosi 2006). We follow similar steps suggested by Hoffman et al. (2011) to derive a suitable regret bound for our MOO setting.
We assume maximization of objectives and further assume that the UCB acquisition function is in the portfolio of acquisition functions used by PDBO. We make this choice for the sake of clarity and ease of readability as we build our theoretical analysis on prior seminal work (Srinivas et al. 2009; Hoffman et al. 2011). Notably, this is not a restrictive assumption, and with minimal mathematical manipulations, the same derived regret bound holds for the case of minimization with the LCB acquisition function being in the portfolio instead.
To simplify the proof and solely for the sake of theoretical regret bound, we consider the instant reward at iteration to be the sum of predictive means of the Gaussian processes
| (14) |
where is the posterior mean of function . The cumulative reward over iterations that would have been obtained using acquisition function is defined as:
| (15) |
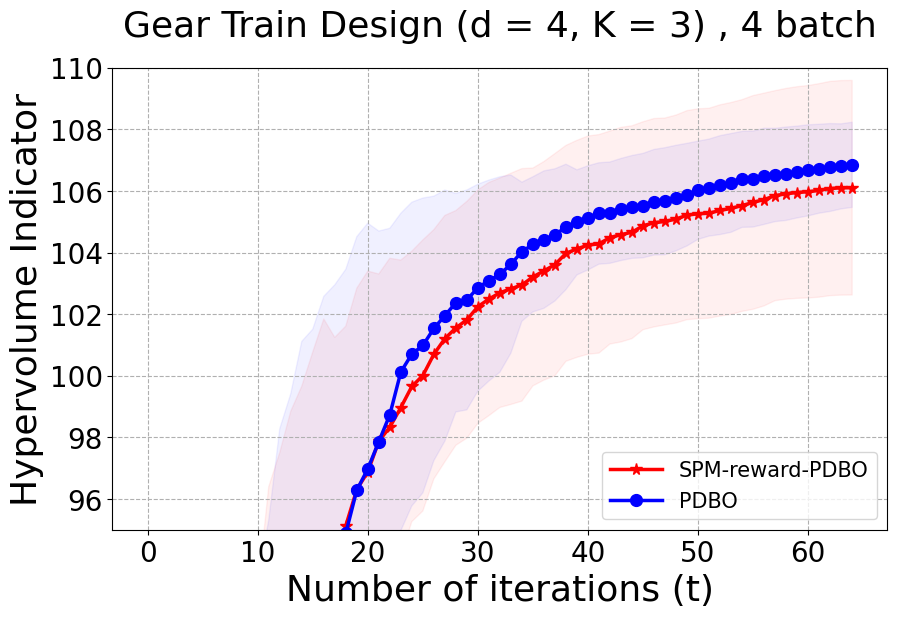
It is important to note that in our proposed PDBO algorithm, we use a different and better instant reward and cumulative reward . The rewards in equation 14 is a design choice to achieve the following regret bound. In Section 5.1, we provide a discussion accompanied by an experimental ablation study comparing the reward function used in theory to the reward function used in PDBO.
Theorem 5.1.
Let be a point in the optimal Pareto set . Let be a point in the Pareto set estimated by PDBO via solving cheap MOO problem at the iteration. Let the cumulative regret for the multiple objectives be defined as
Assuming maximization of objectives and that UCB is in the portfolio of acquisition functions, let be the UCB parameter and be the bound on the information gained for function at points selected by PDBO after iterations, then with probability at least the cumulative regret is bounded by
We provide complete proof in the Appendix. The theorem suggests that our regret is bounded by two sublinear terms and another term that might include points suggested by UCB but not necessarily selected by the Hedge strategy. Additionally, the theoretical proof accounts only for sequential input selection. Extension to batch selection using DPP is possible by carefully accounting for results introduced by Kathuria et al. (2016).

5.1 Analysis and Ablation Study
To simplify the proof for regret bound, we defined a new instant reward and cumulative reward in equations 14 and 15 that are different from the rewards we use for PDBO in equations 6, 7, and 8. The goal of this section was to define a reward that allows tractable theoretical analysis. However, this reward is not intuitive and has several practical issues: 1) It is defined as a summation over predictive means of the functions and does not provide any insight on the quality of the selected points; 2) It does not account for improvement with respect to previous iterations which is uninformative in terms of the quality of points selected by different acquisition functions at different iterations; 3) It is non-discounted and does not account for the importance of the iterative progress of the input selection; and 4) It is not normalized and therefore can lead to random selection in the advanced iterations. All stated issues have been addressed by our proposed reward function which we carefully designed to be intuitive and informative about the different acquisition strategies and to mitigate potential numerical issues. We performed an ablation study to compare the performance of PDBO when using our proposed reward function and the reward function in the theoretical proof. Our results in the Appendix show superior performance for our proposed reward strategy.
6 Experiments and Results
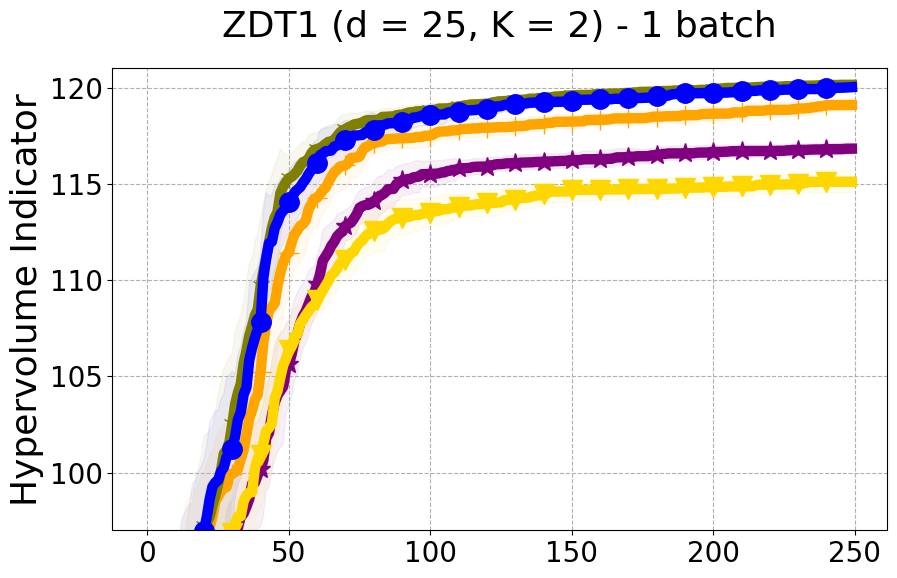
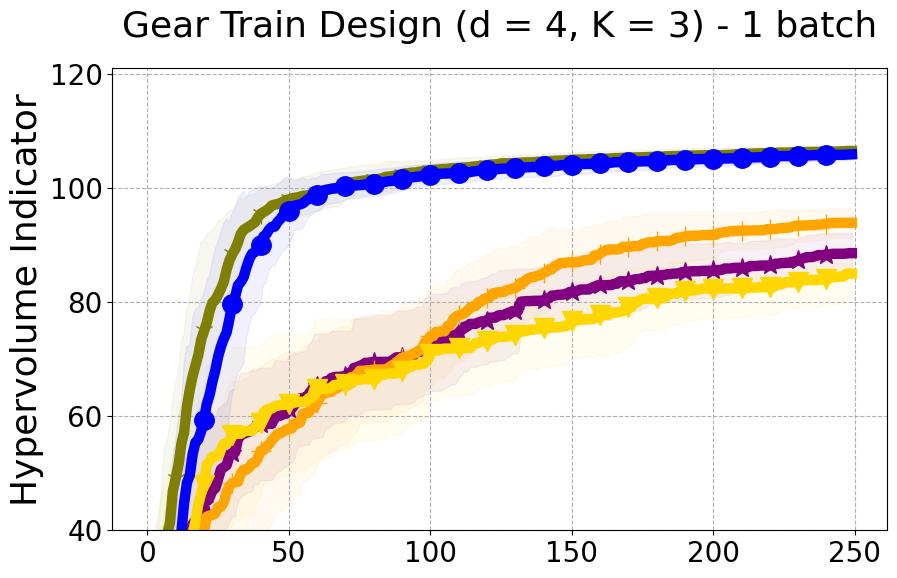
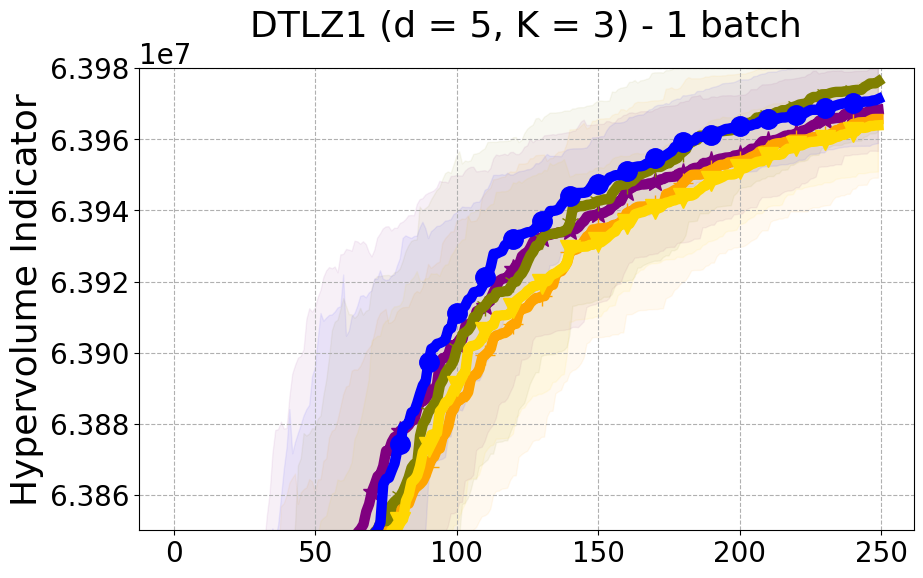
We provide experimental details and compare PDBO to baseline methods on multiple MOO benchmarks and varying batch sizes. We evaluate all methods using the hypervolume indicator and diversity of Pareto front (DPF) measure.
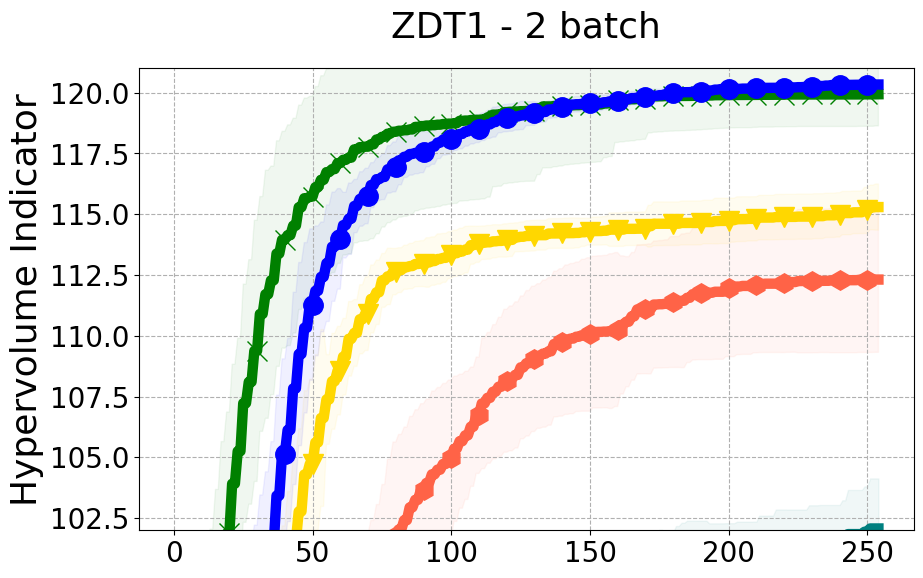
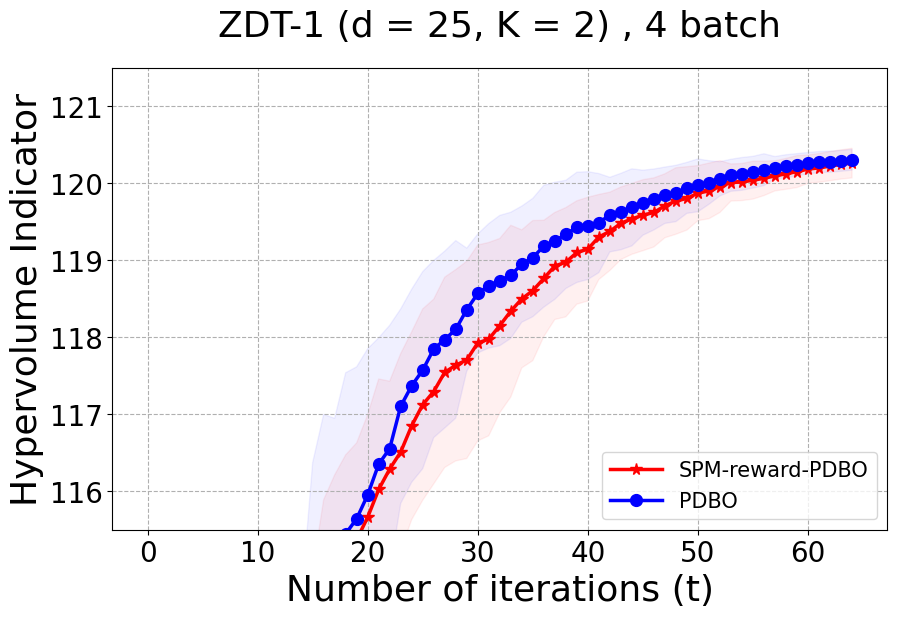
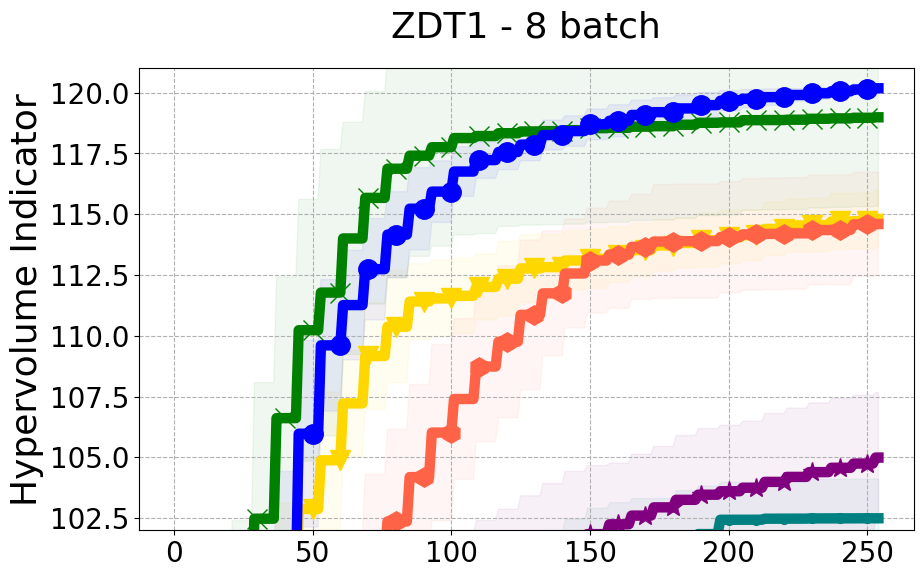
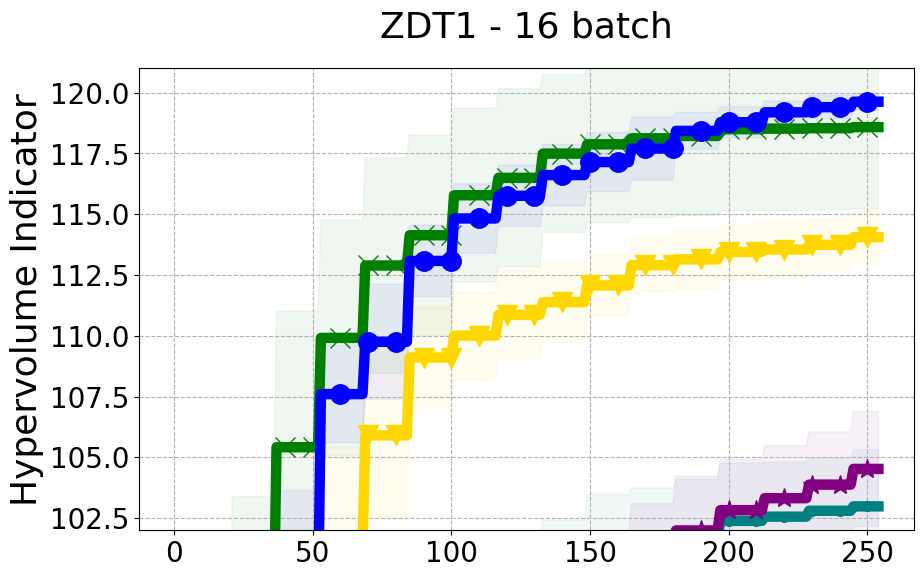
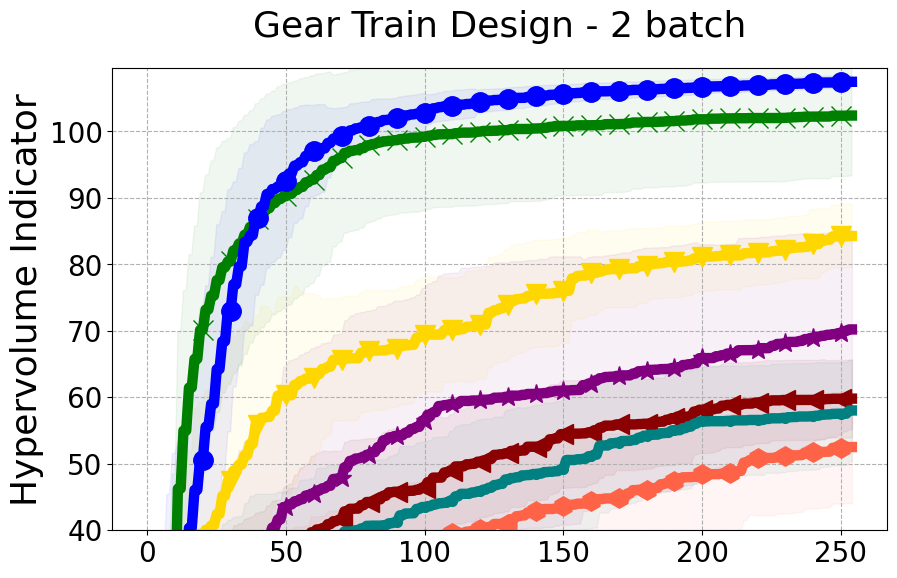
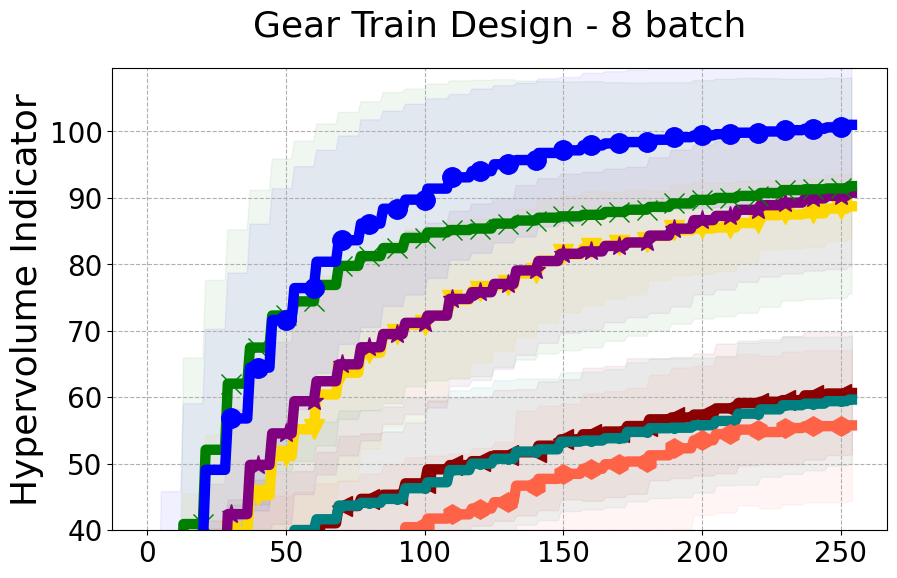
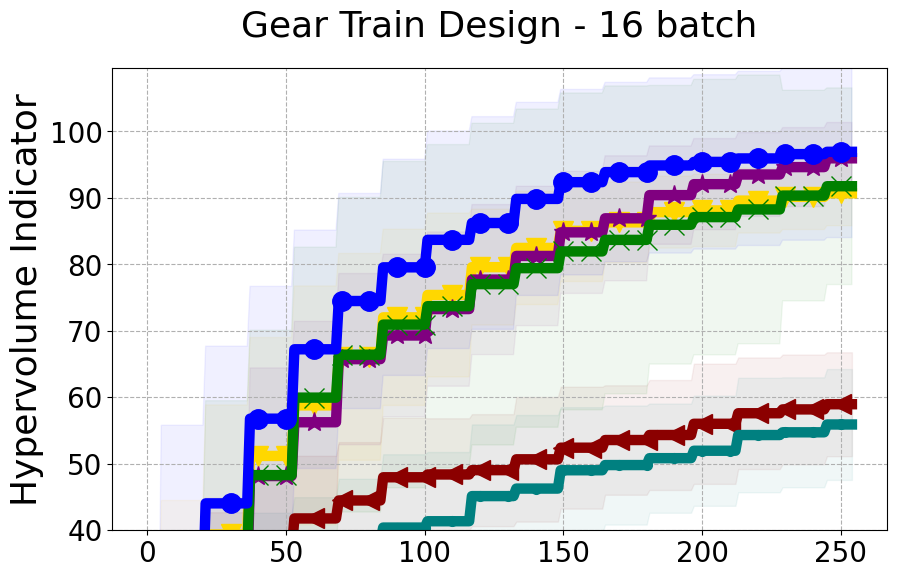
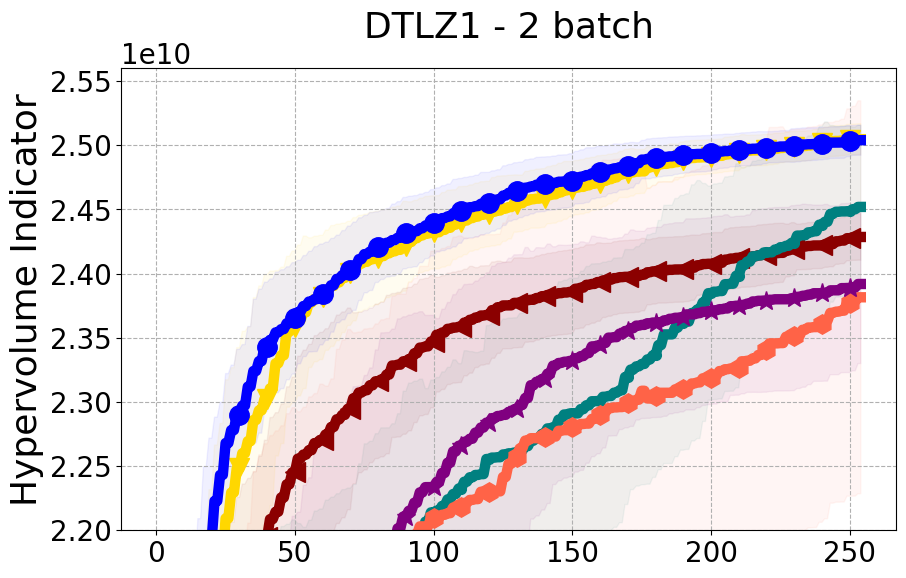
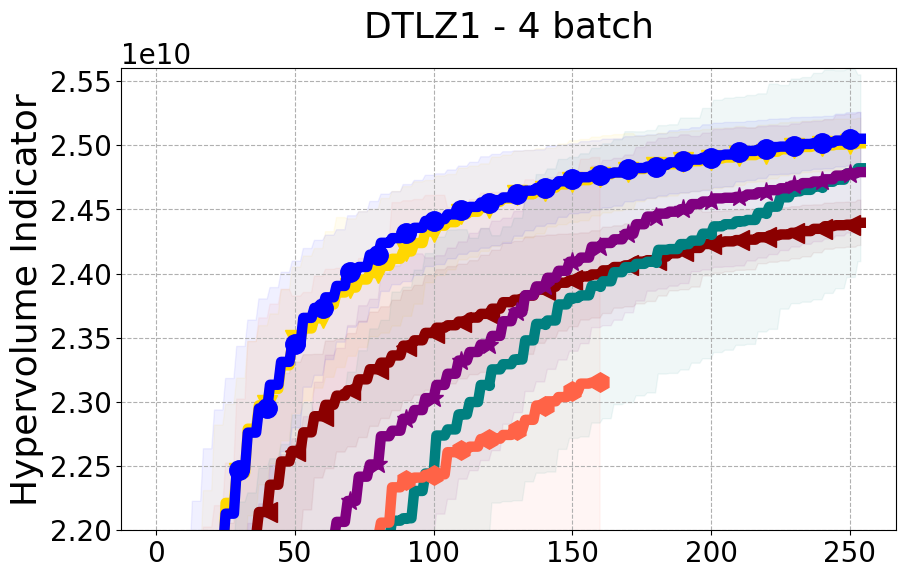
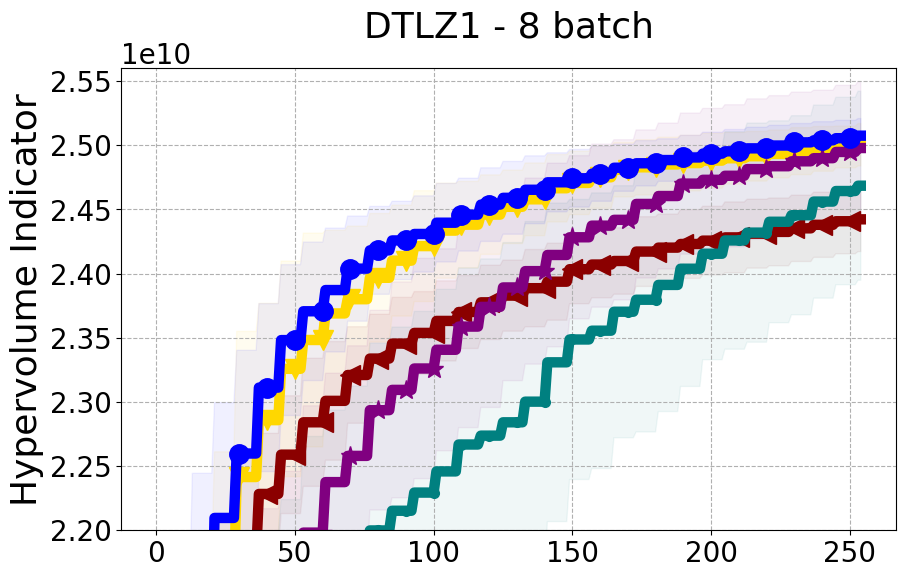
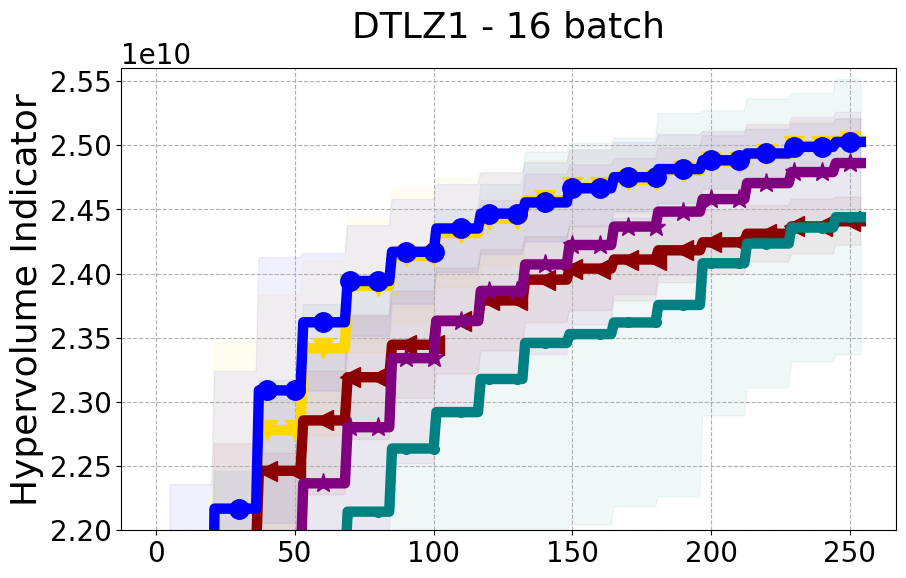
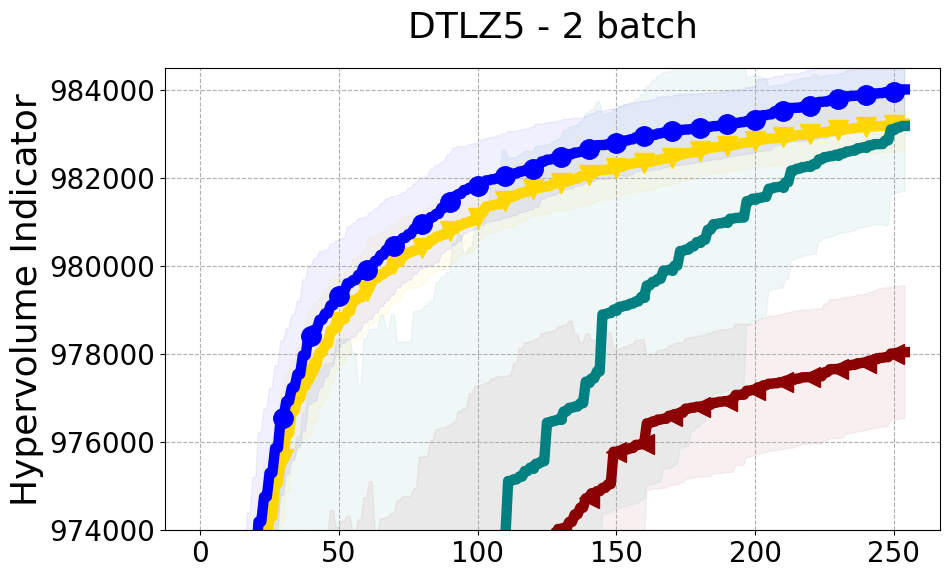
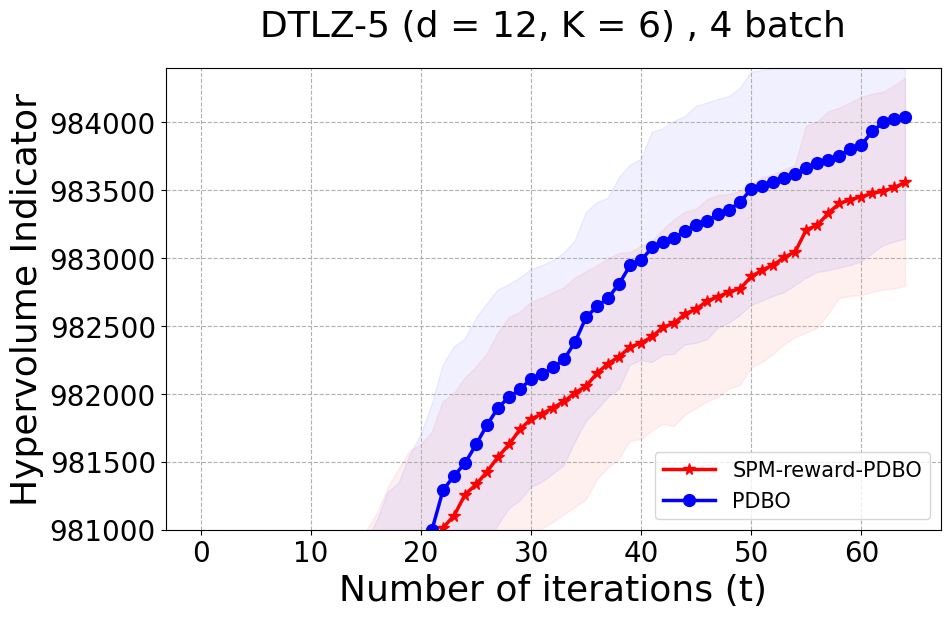
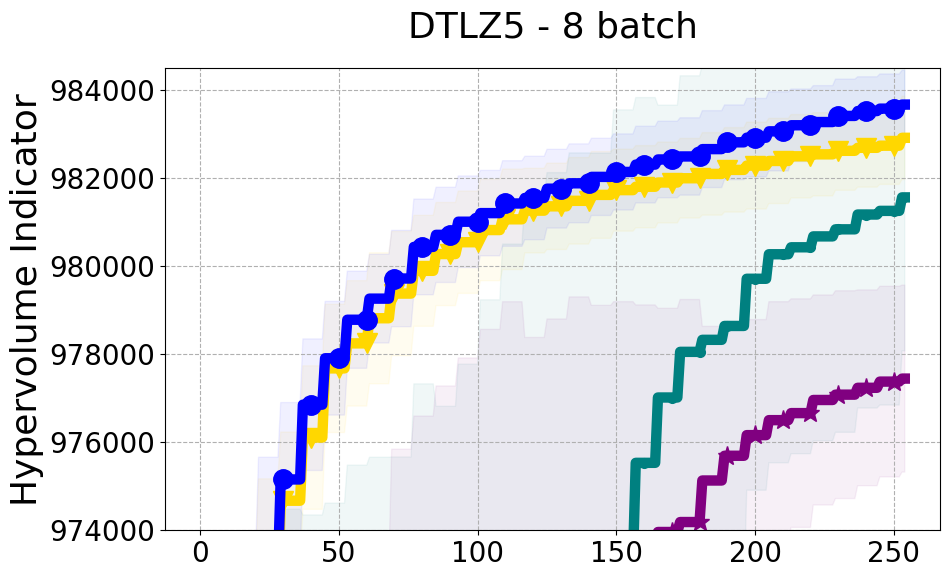

Benchmarks. We conduct experiments on benchmarks with varying numbers of input and output dimensions to show the versatility and flexibility of our method. We use several synthetic problems: ZDT-1, ZDT-2, ZDT-3 (Zitzler et al. 2000), DTLZ-1, DTLZ-3, DTLZ-5 (Deb et al. 2005) and three real wold problems: the gear train design problem (Deb and Srinivasan 2006; Konakovic Lukovic et al. 2020), SWLLVM (Siegmund et al. 2012) and Unmanned aerial vehicle power system design (Belakaria et al. 2020b). More details and descriptions of problem settings are included in the Appendix. In the ablation studies, we provide additional experiments with synthetic benchmarks where we vary the input and output dimensions.
Baselines. We compare our PDBO method to state-of-the-art batch MOO methods: DGEMO, qEHVI, qPAREGO, and USEMO-EI. We also include NSGA-II as the evolutionary algorithm baseline and random input selection. We set the hyperparameters of PDBO to = 0.7 and = 4 as recommended by (Hoffman et al. 2011; Vasconcelos et al. 2019). We define the AF portfolio as .
Experimental Setup. All experiments are initialized with five random inputs/evaluations and run for at least 250 function evaluations. We conduct experiments with four different batch sizes and adjust the number of iterations accordingly. For instance, when using a batch size of two, we run the algorithm for 125 iterations. Each experiment is repeated 25 times, and we report the average and standard deviation of the hypervolume indicator and the DPF metric. To solve the constrained optimization problem in the DPP algorithm, we utilize an implementation of the SQP method (Lalee et al. 1998; Nocedal and Wright 2006) from the Python SciPy library (Virtanen et al. 2020). For baselines, we use the codes and hyperparameters provided in the open source repositories of DGEMO 111https://github.com/yunshengtian/DGEMO and Botorch 222https://github.com/pytorch/botorch. We provide the details for the NSGA-II baseline and cheap MO solver, and more details about the setup for fitting the hyperparameters of GP models in the Appendix.
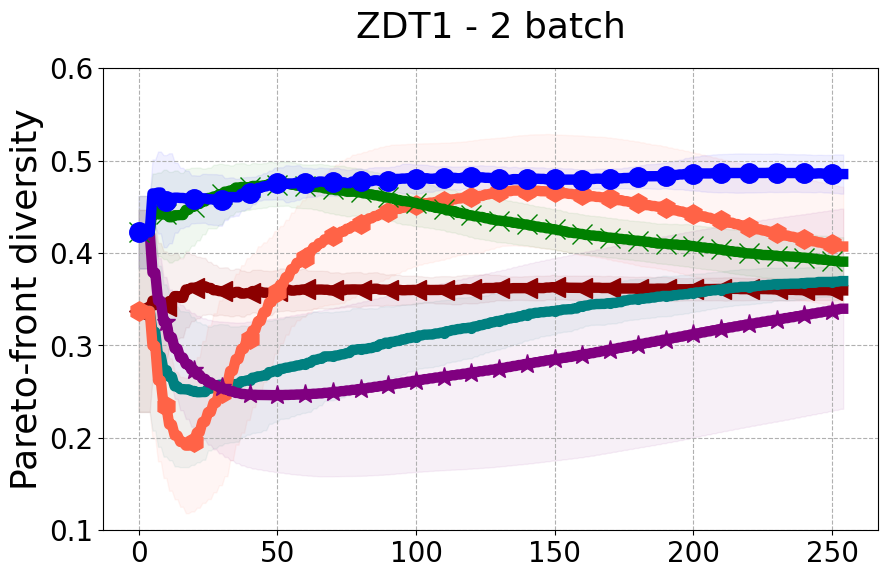
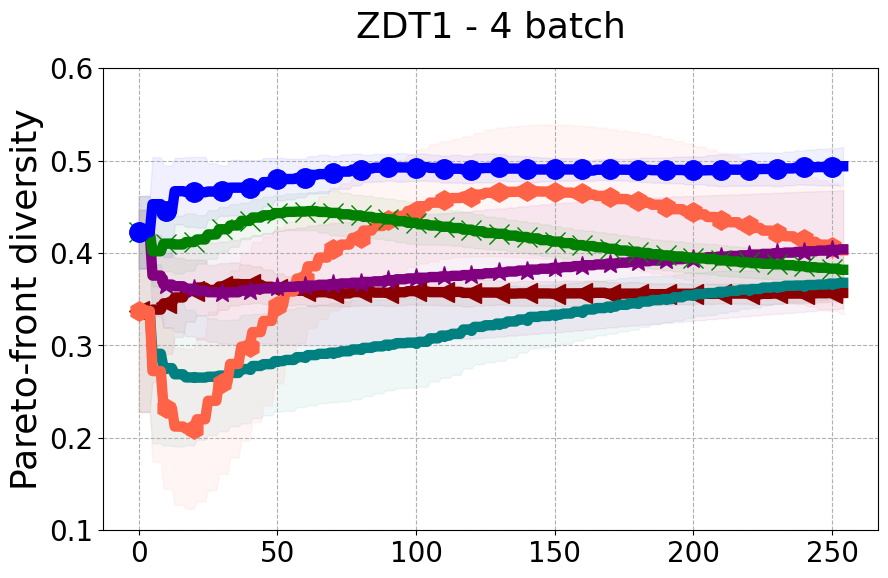
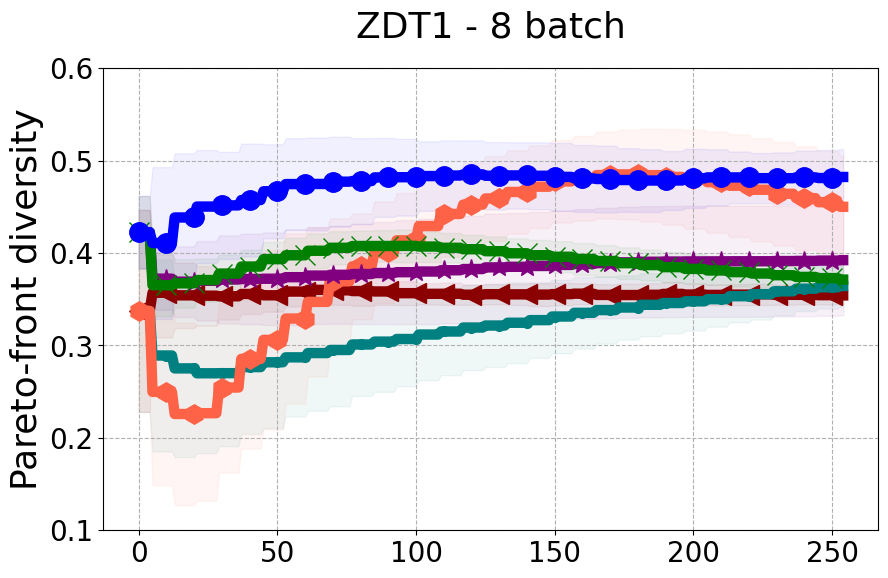
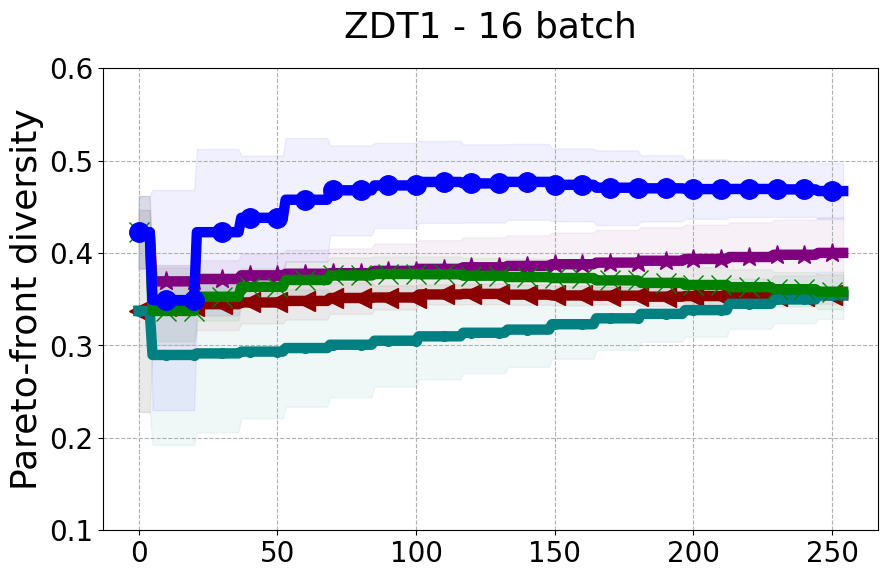
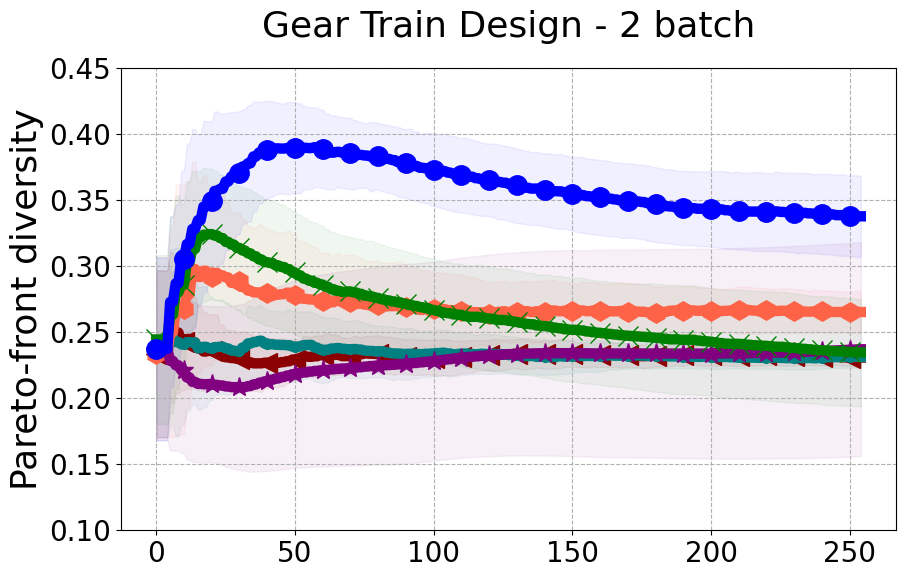
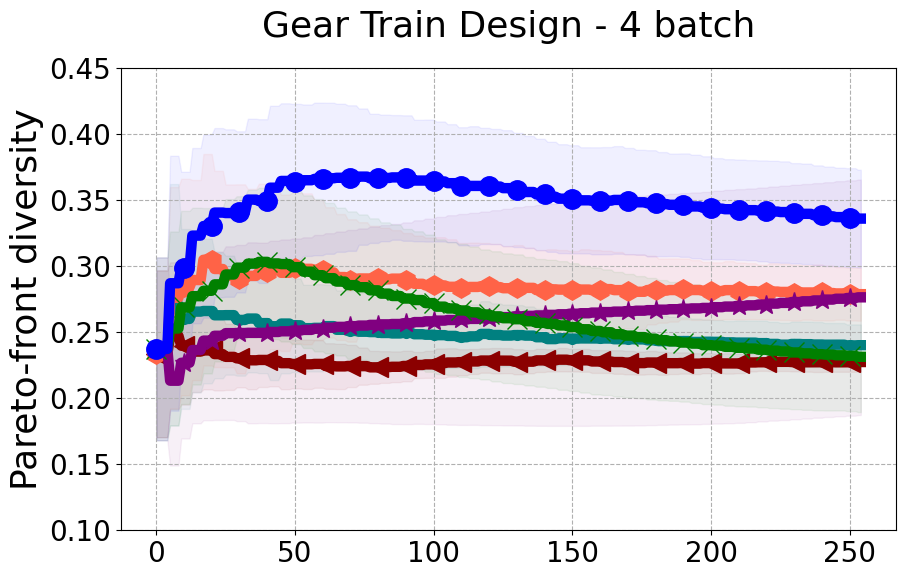
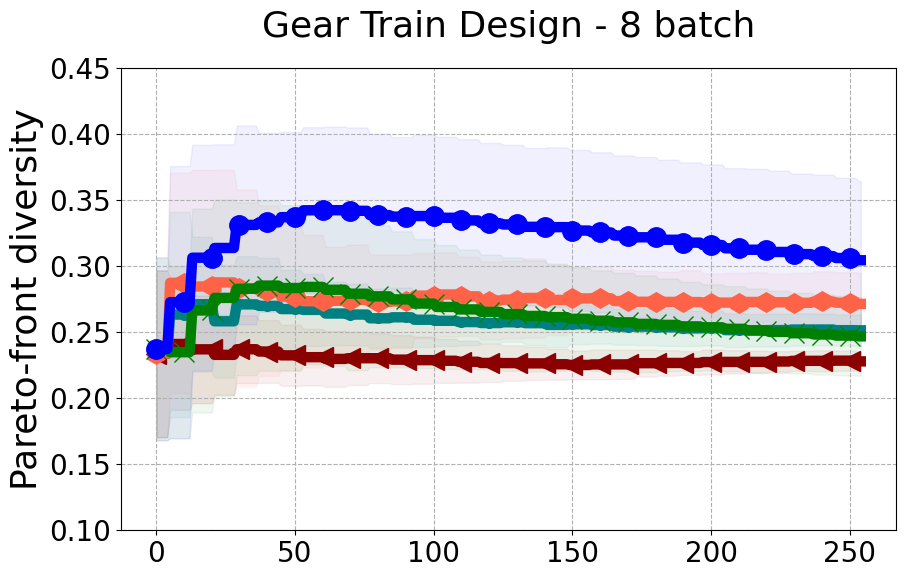
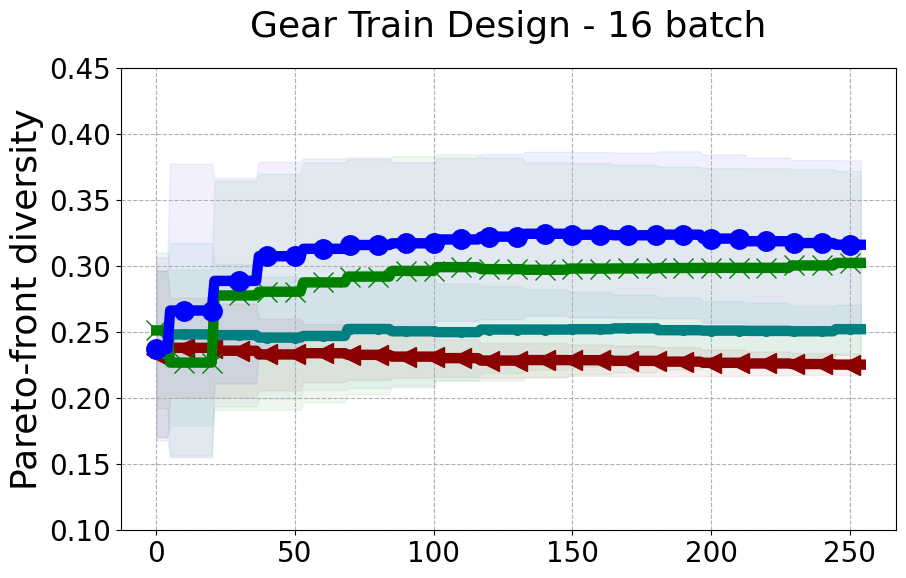
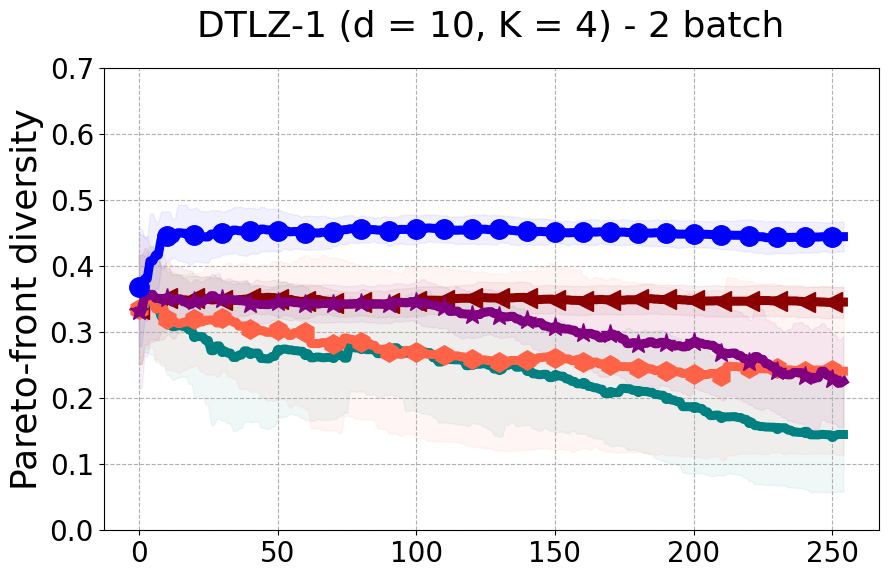
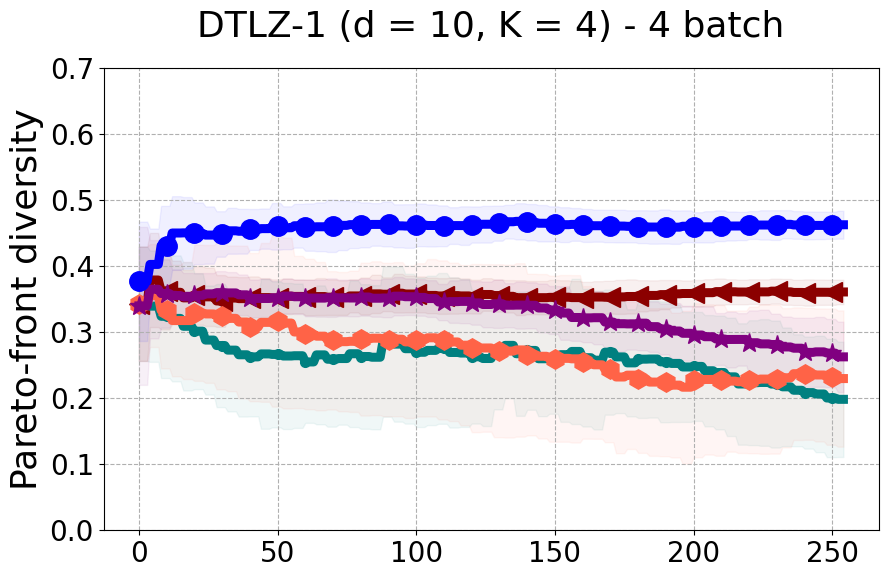
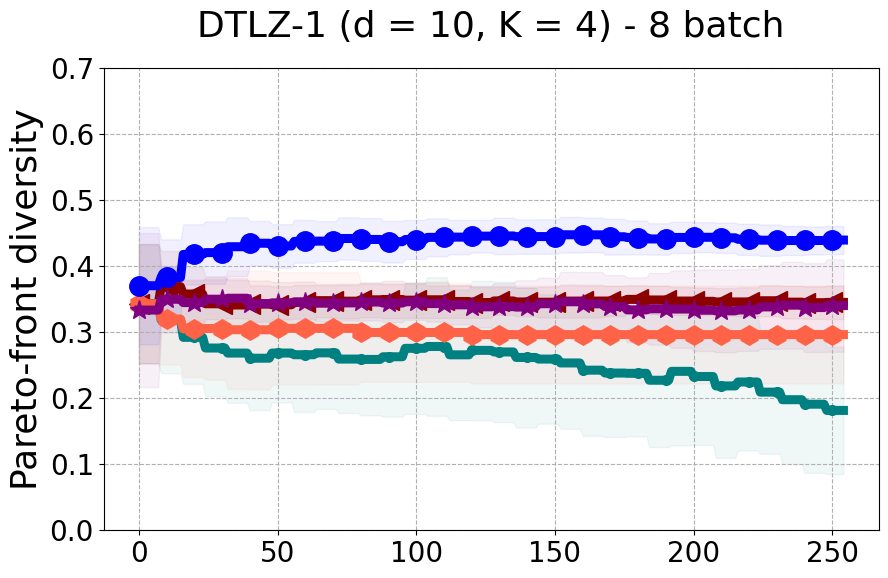
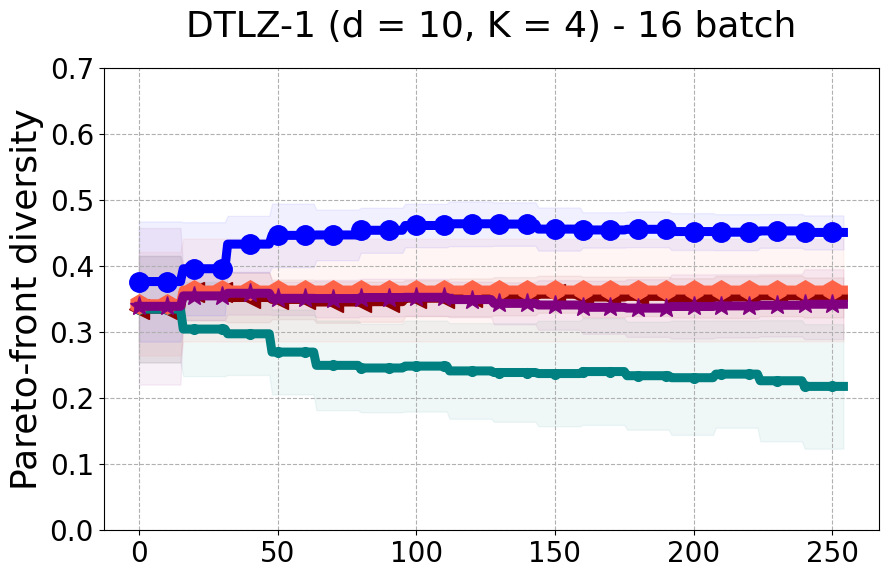
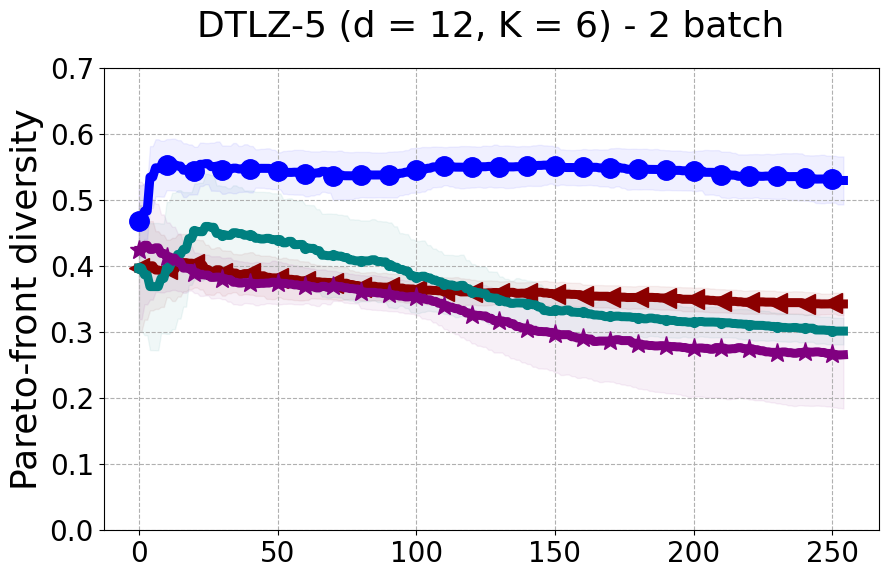
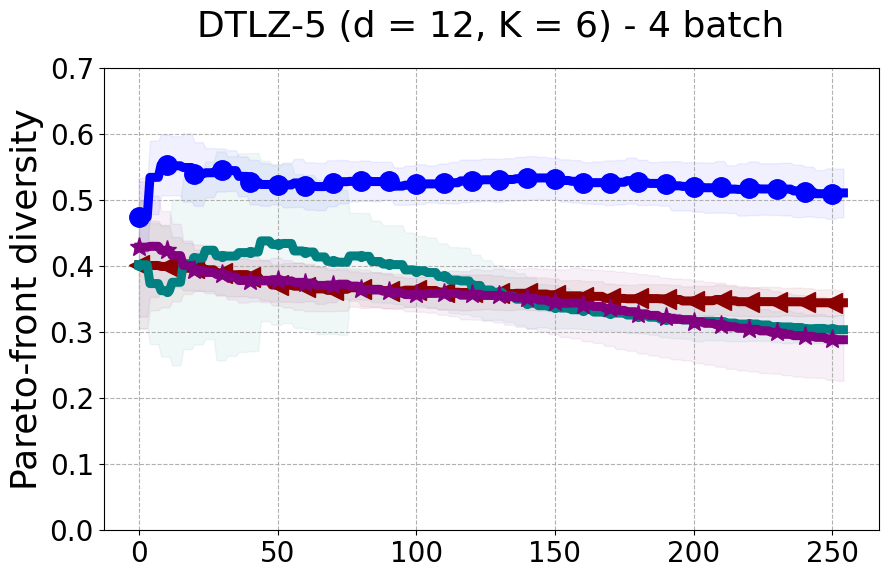
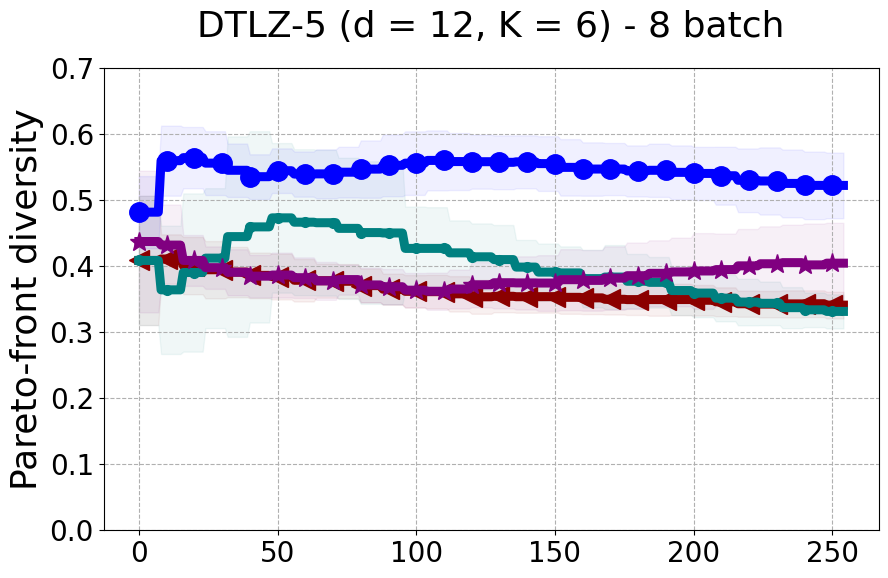
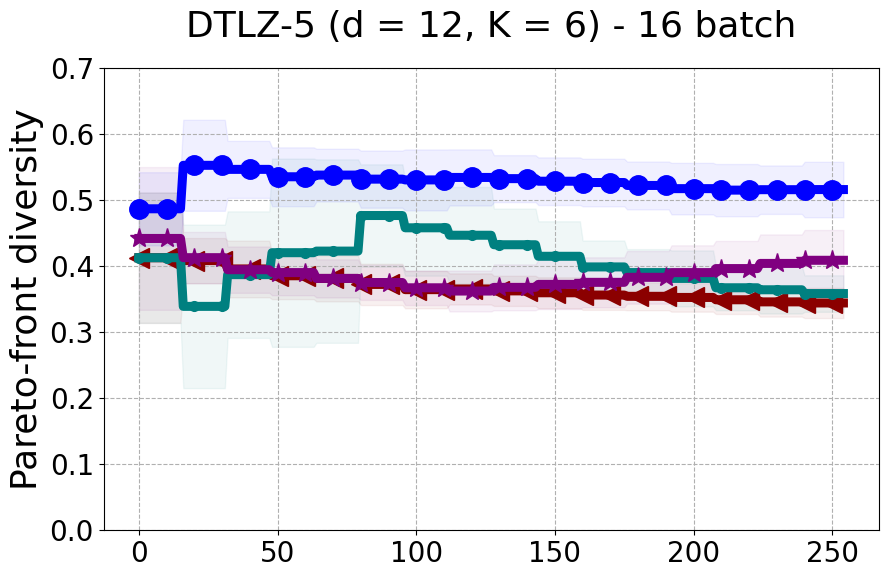
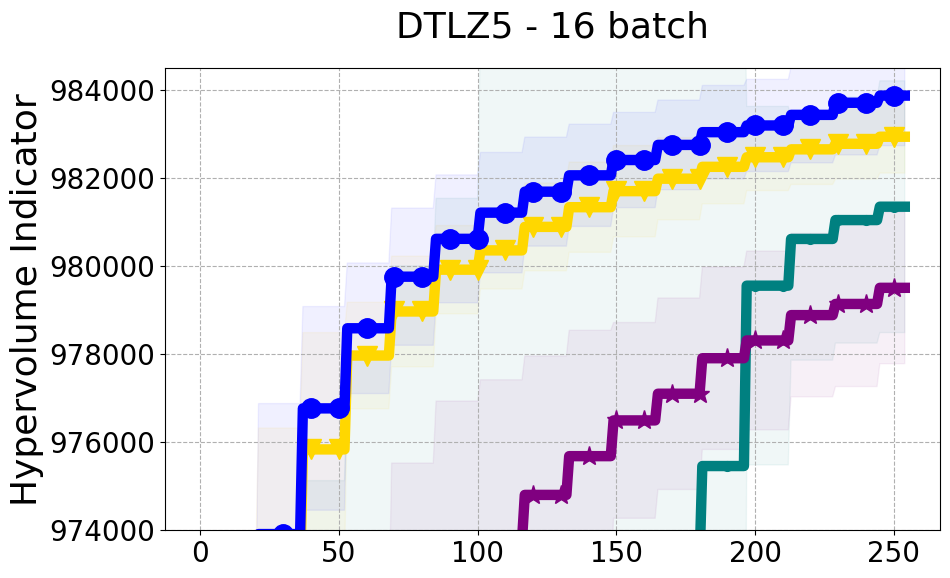
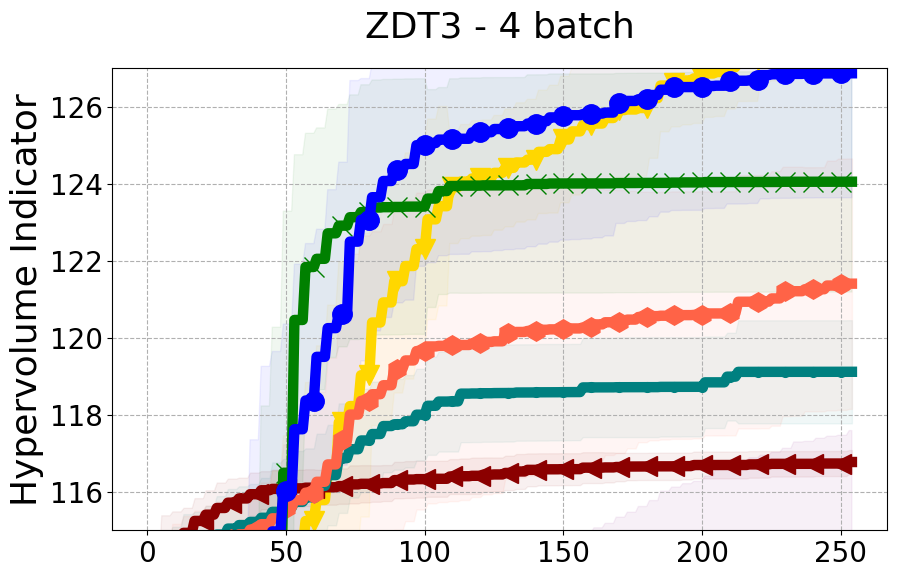
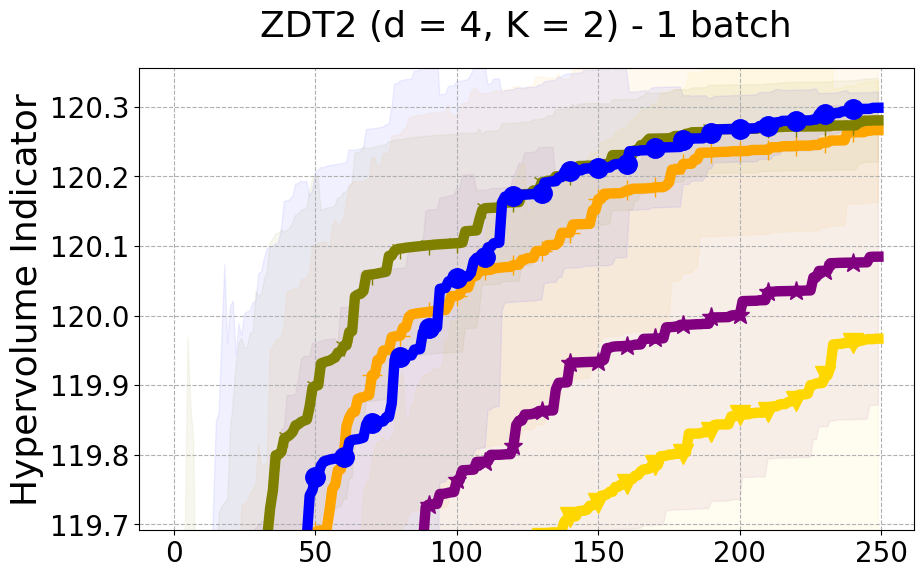
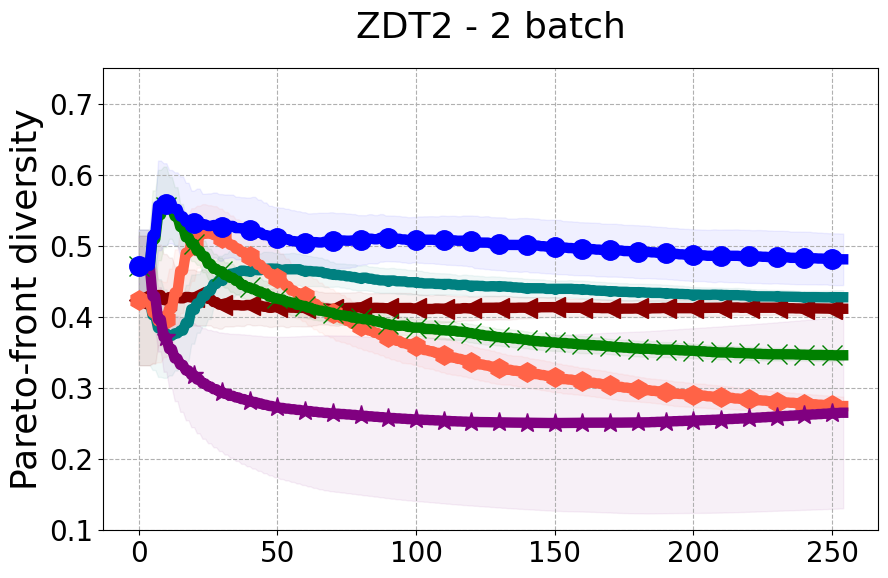
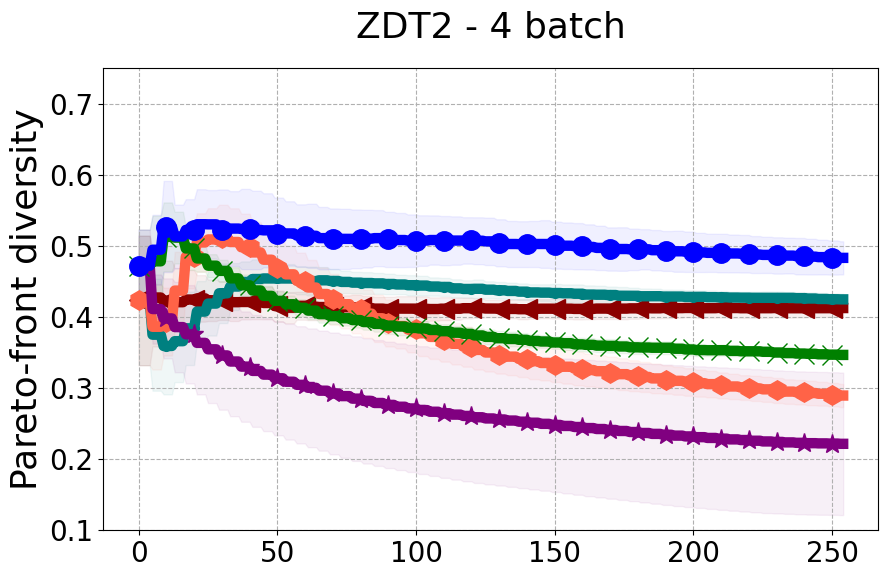
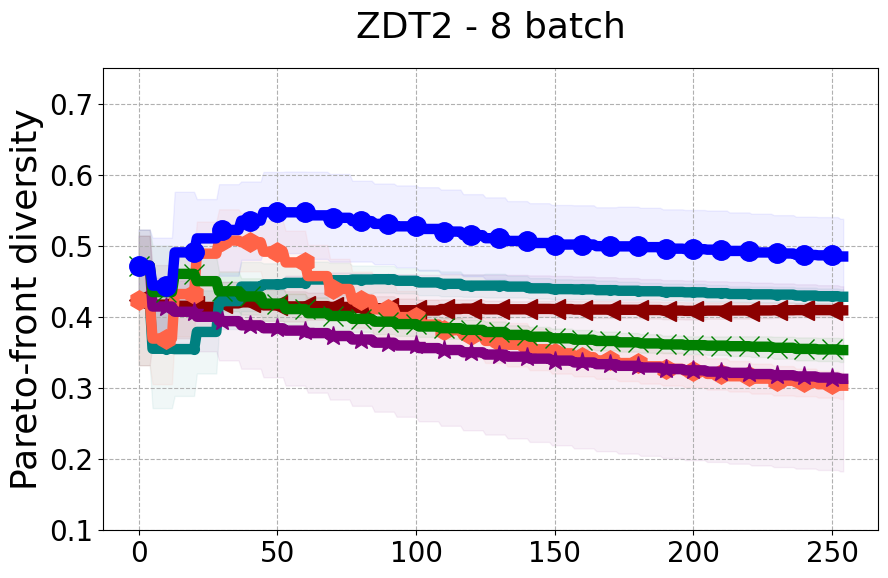
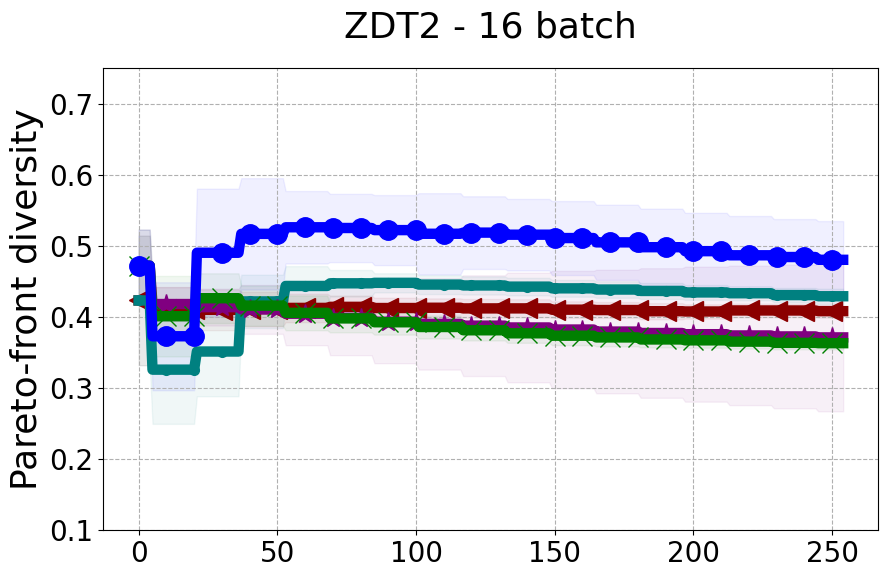
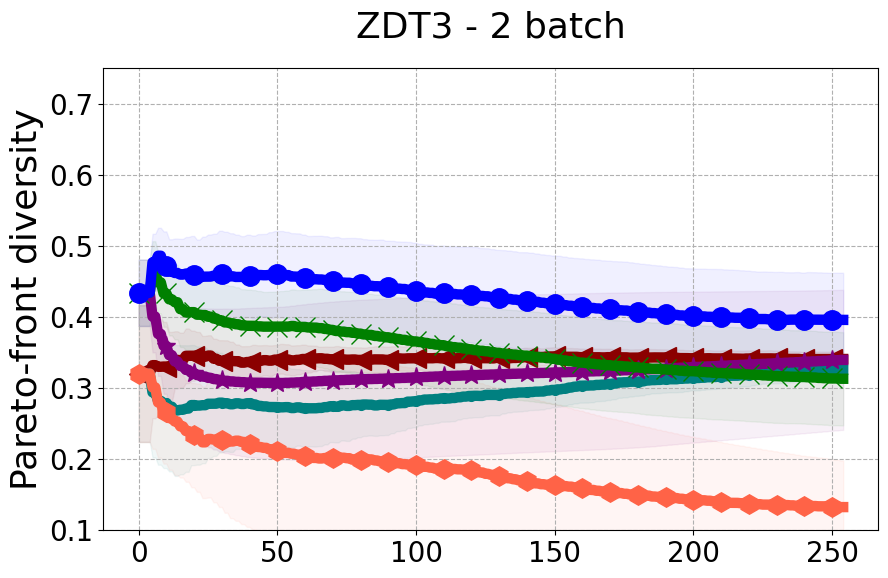
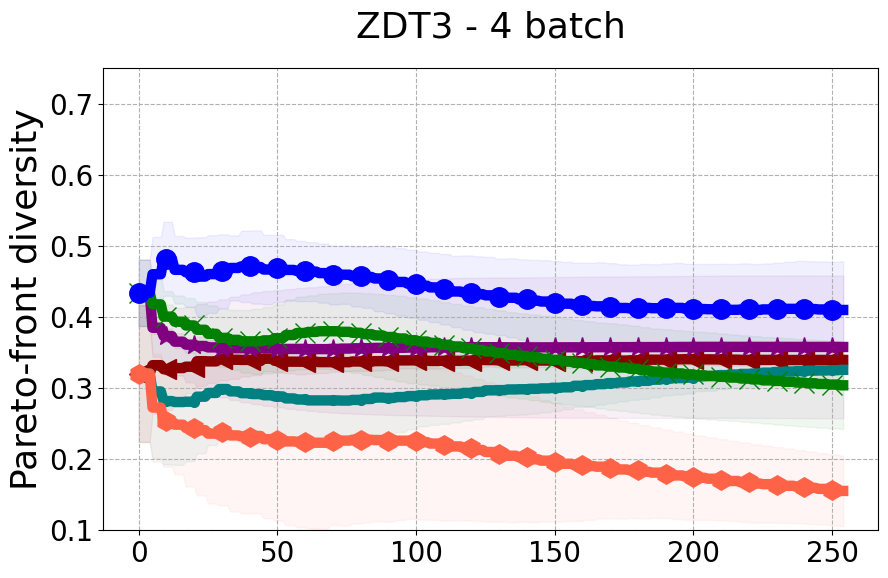
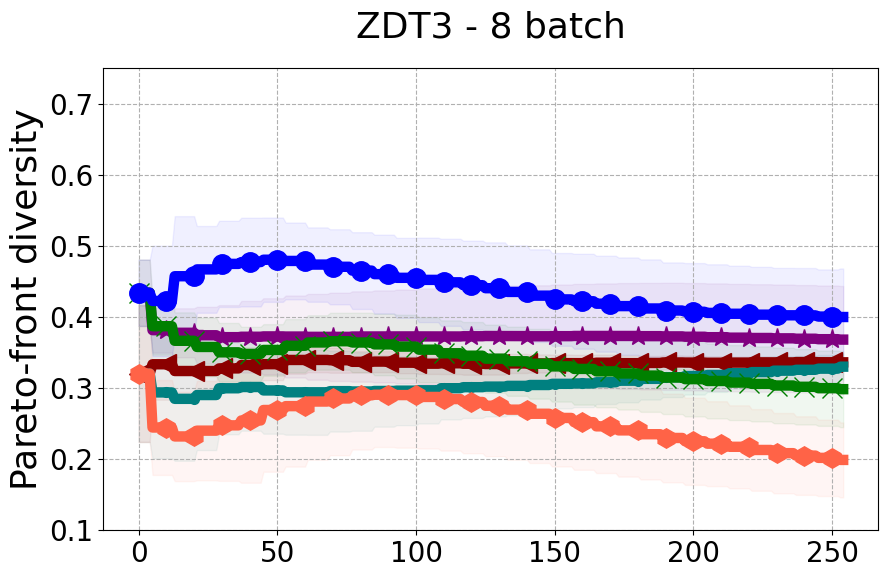
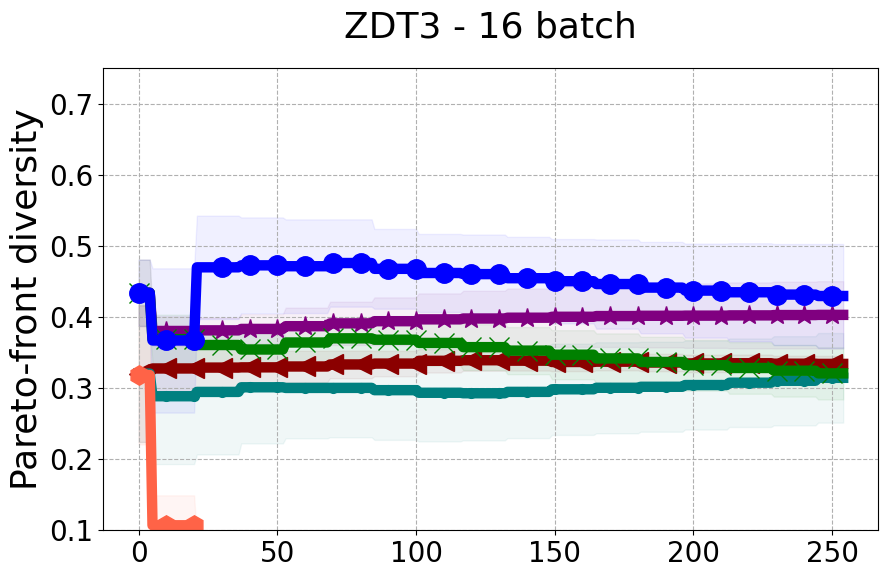
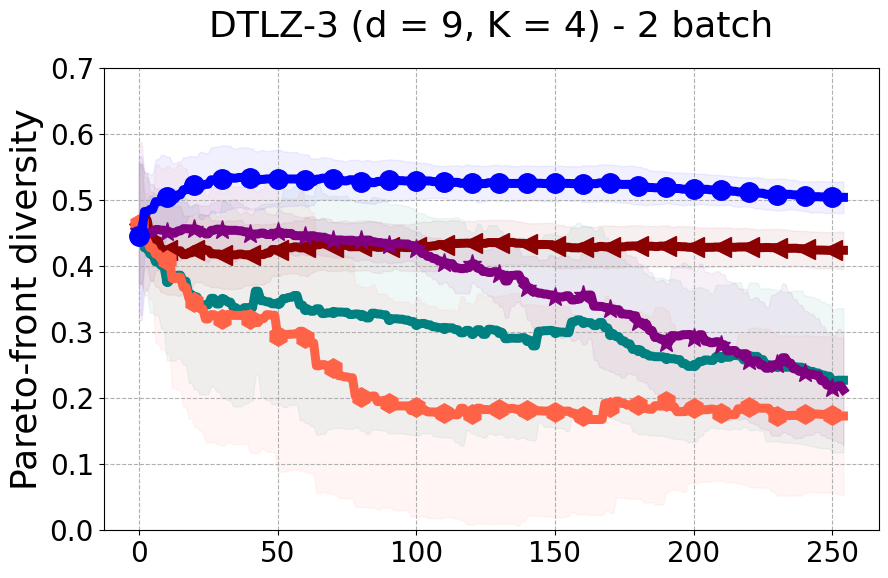
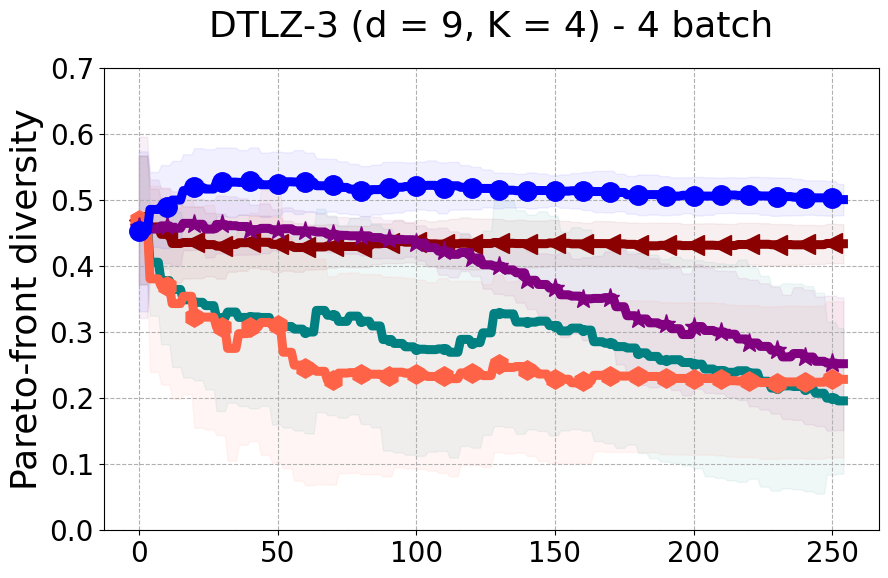
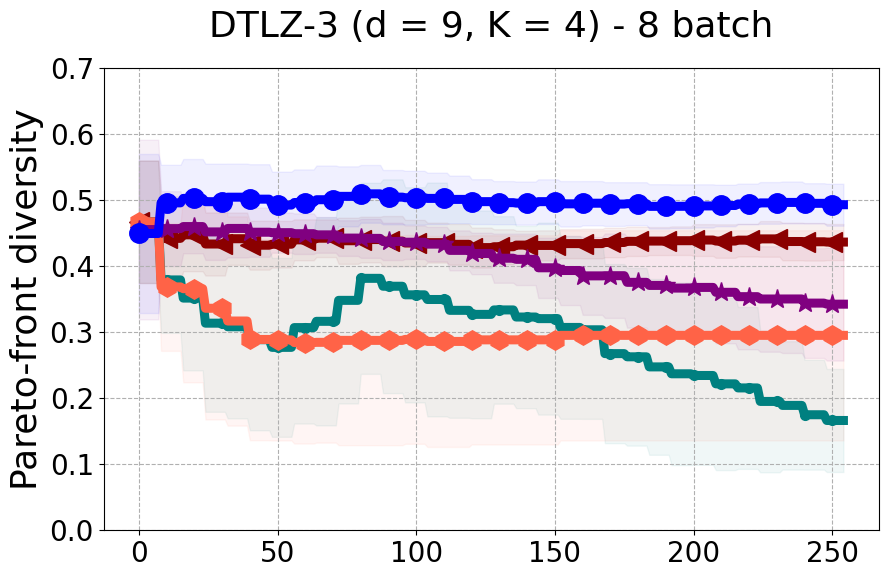
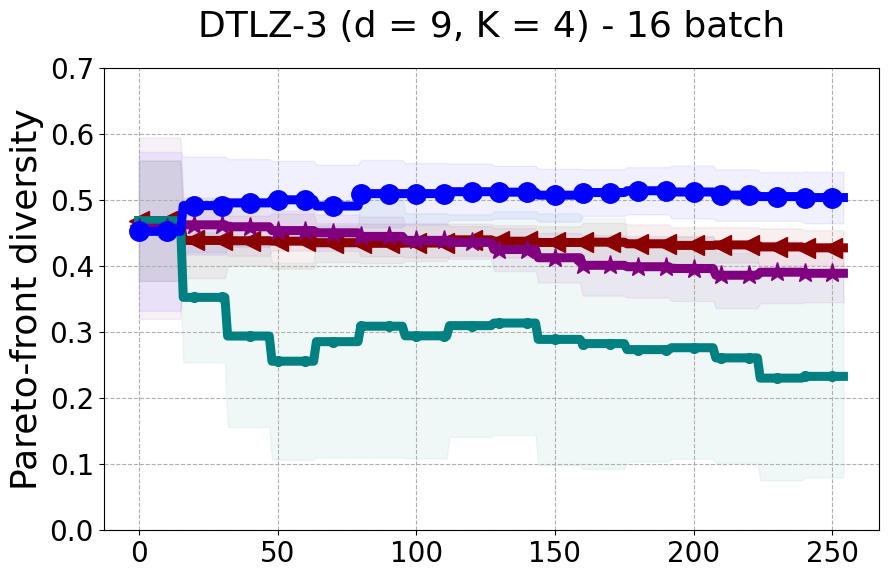
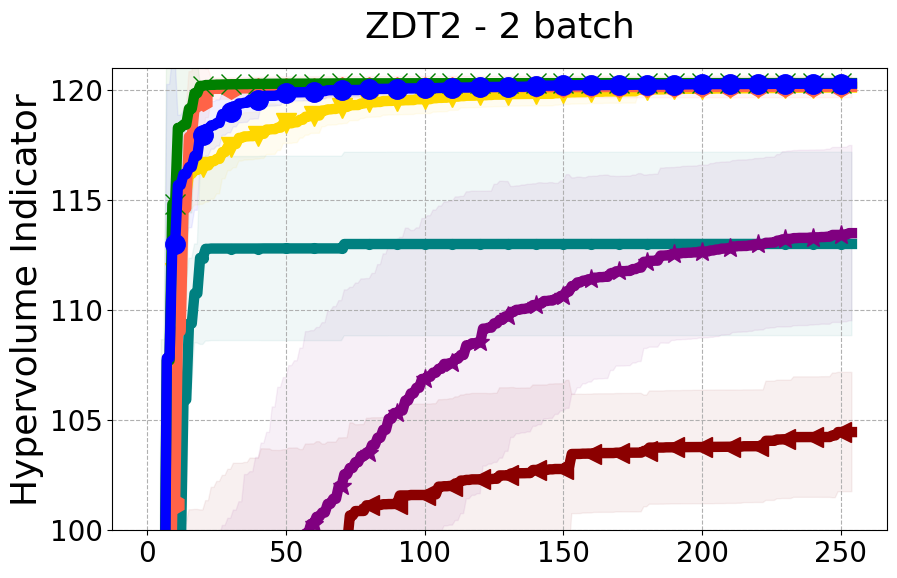
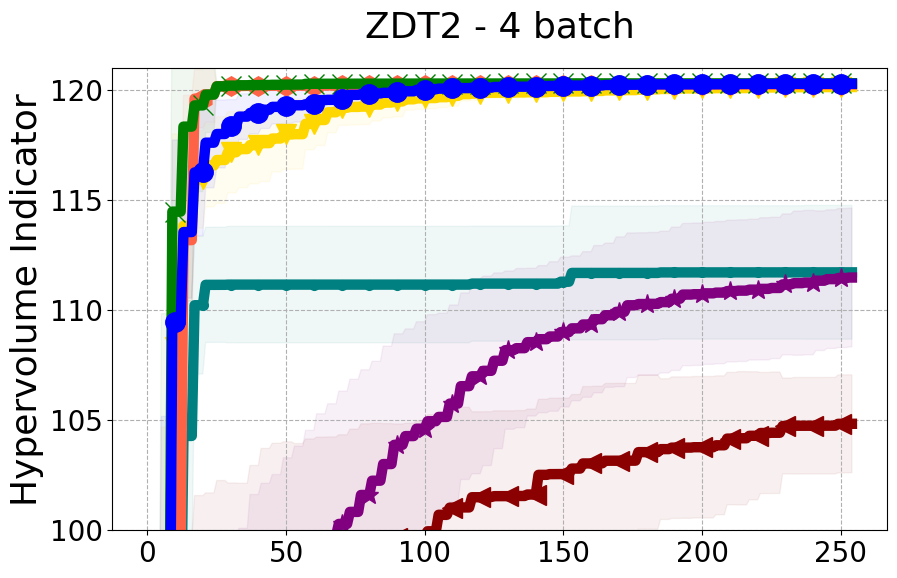
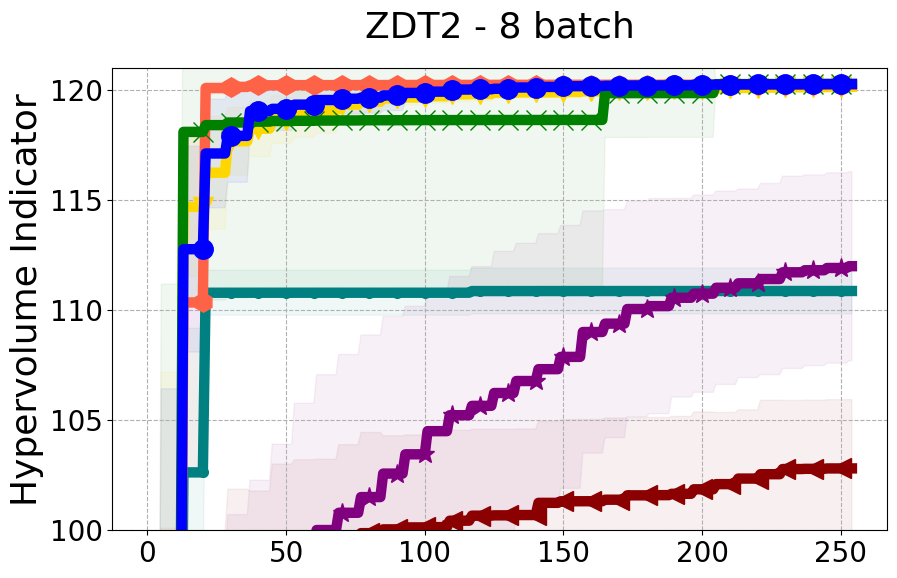
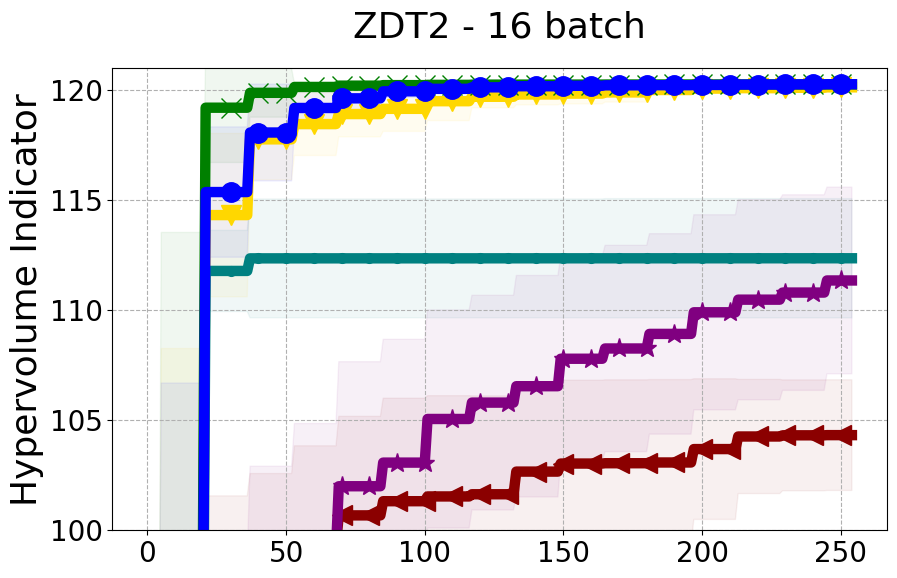
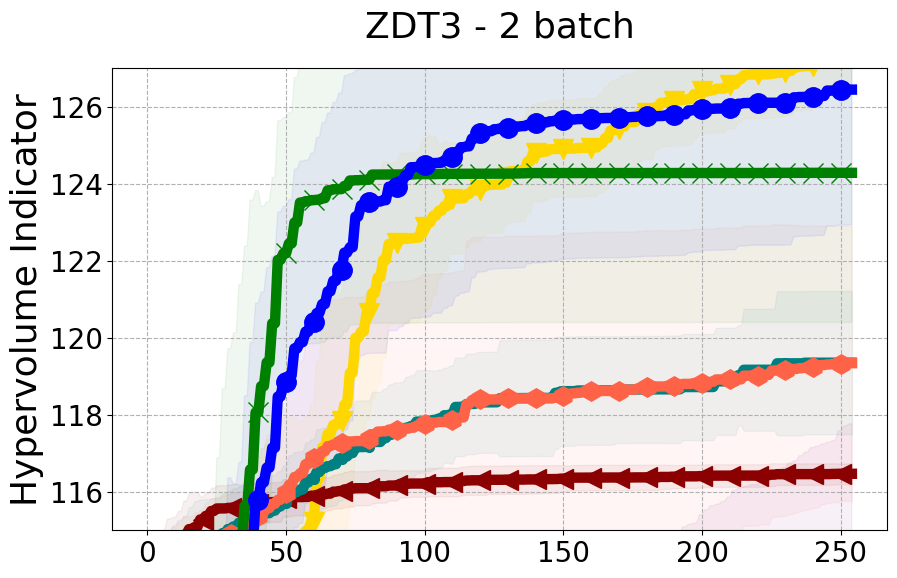
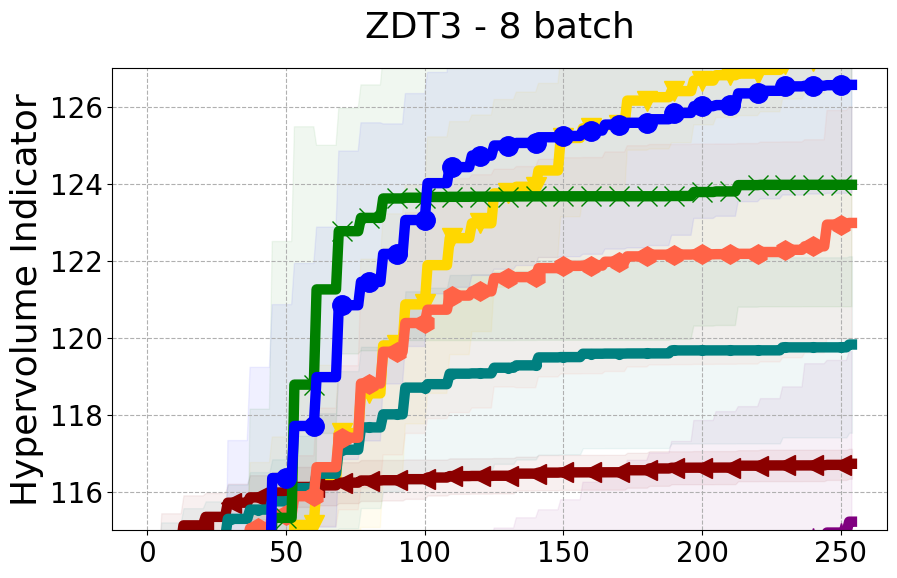
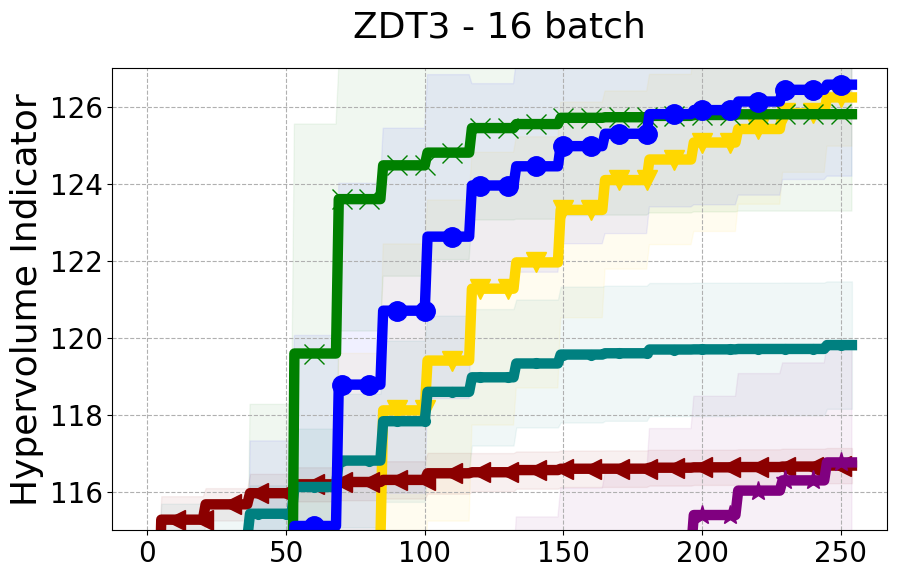
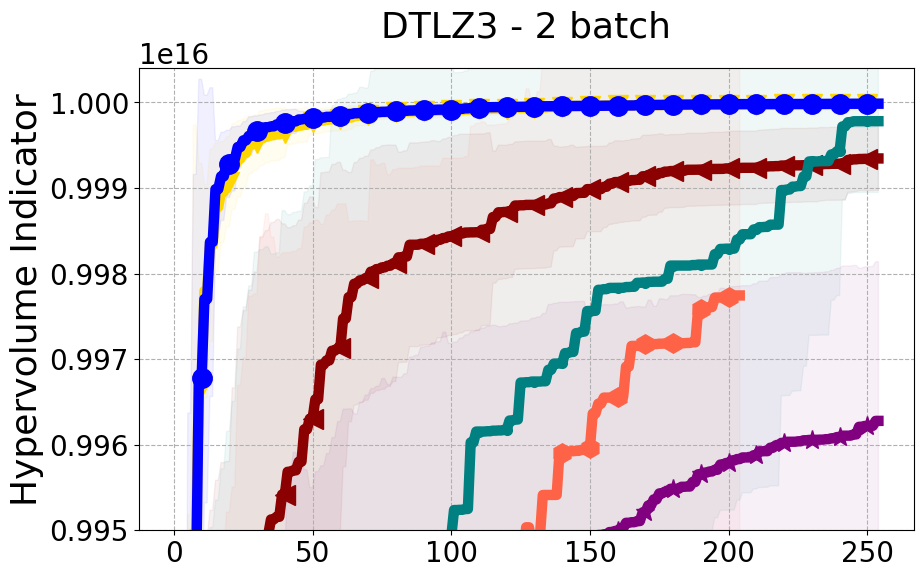
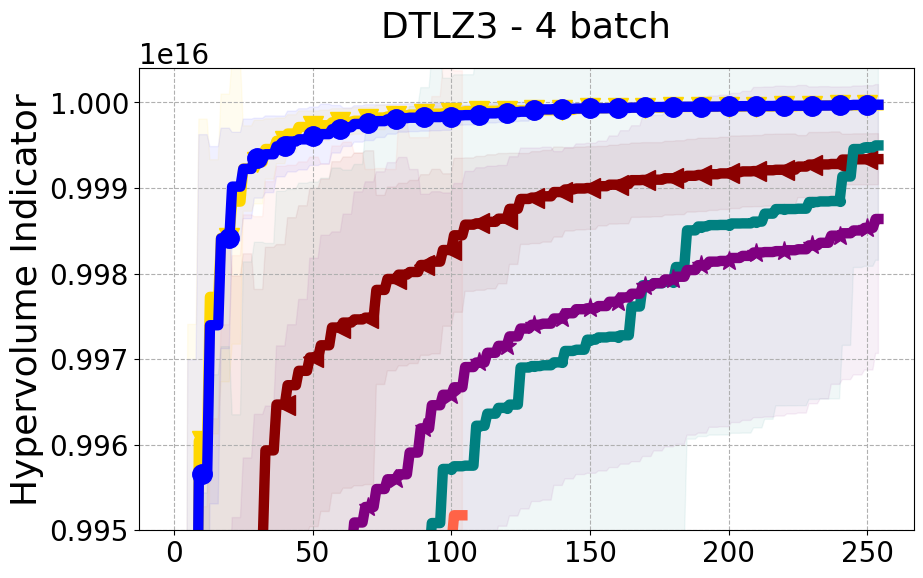
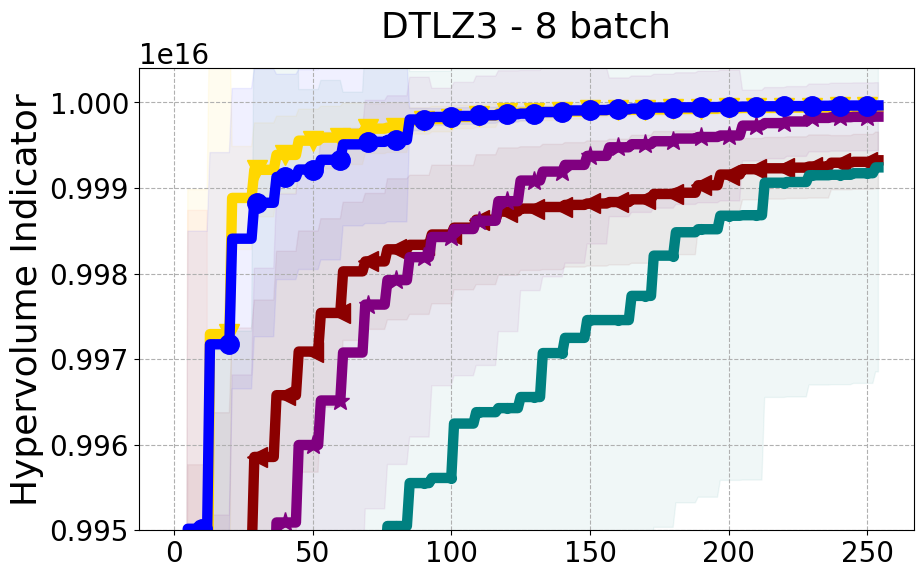
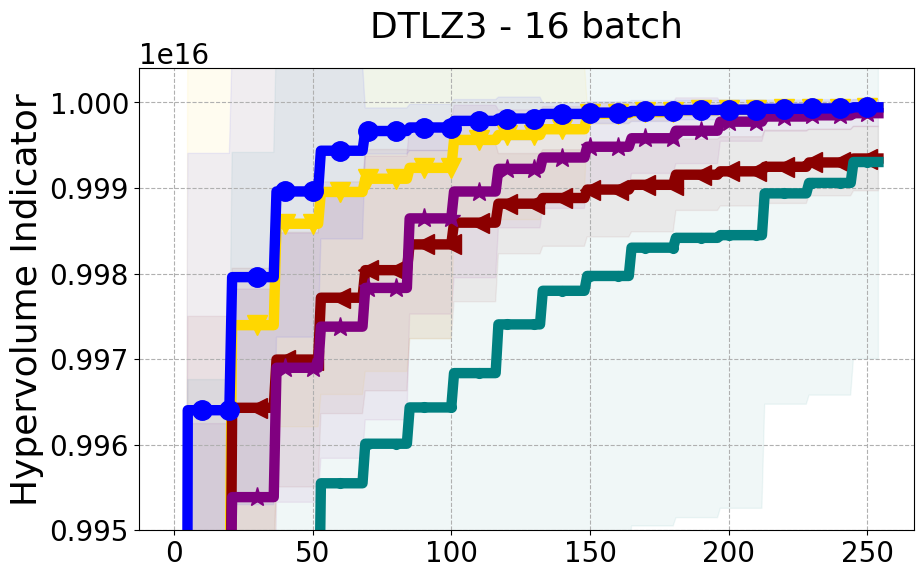
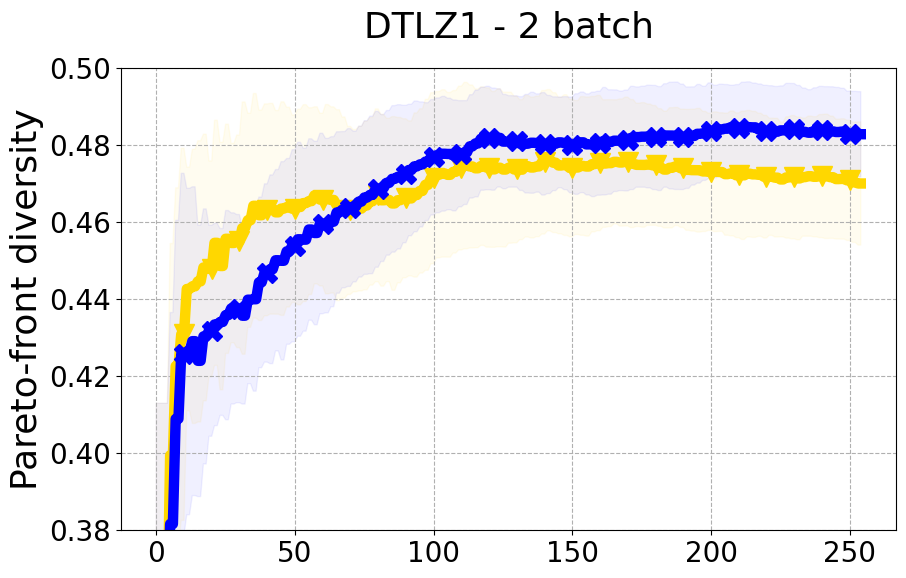
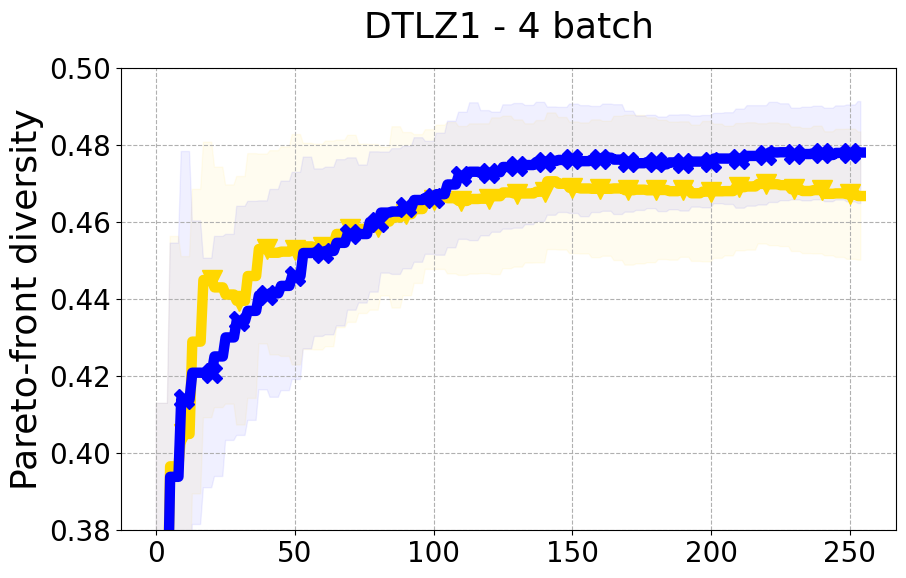
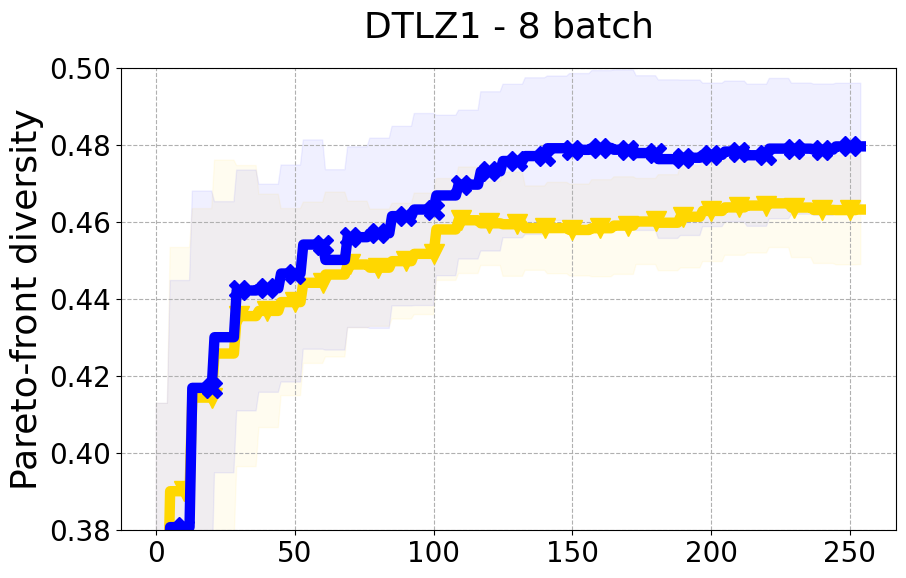
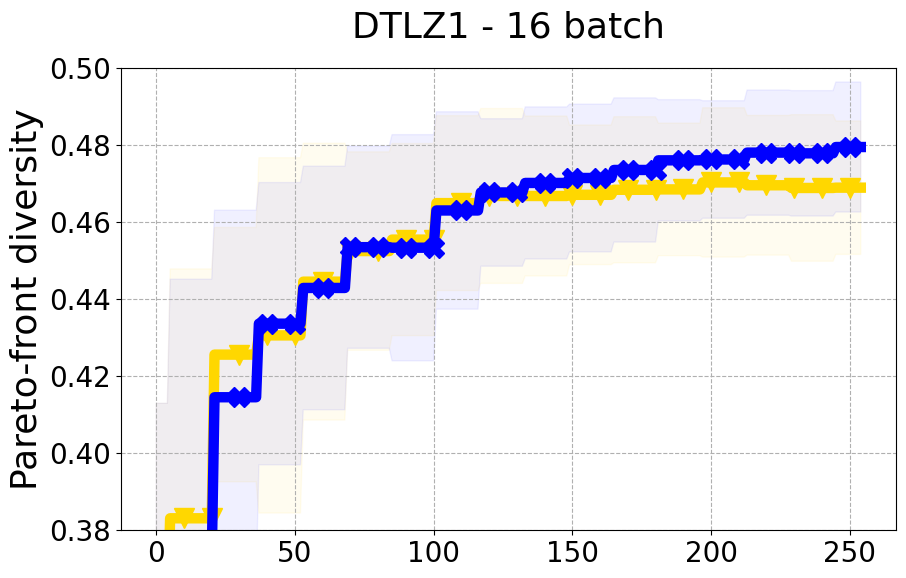
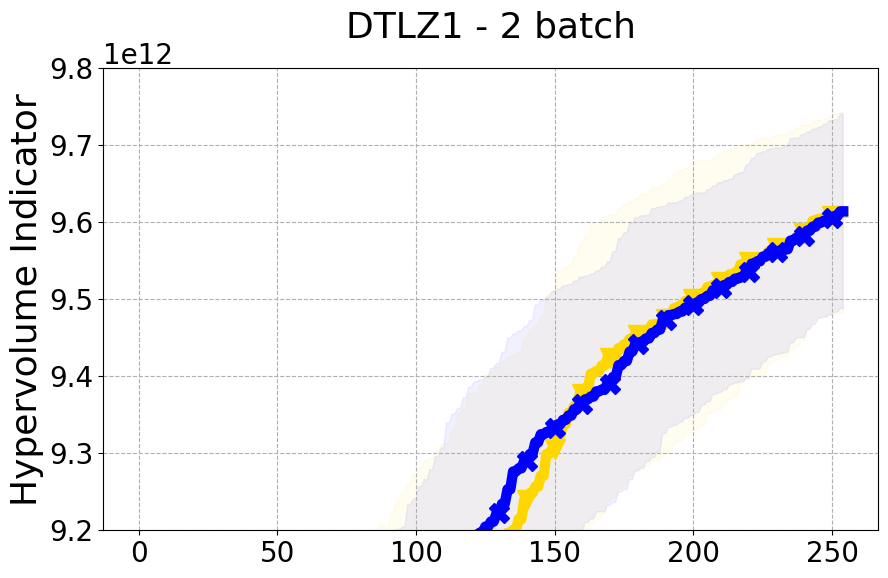
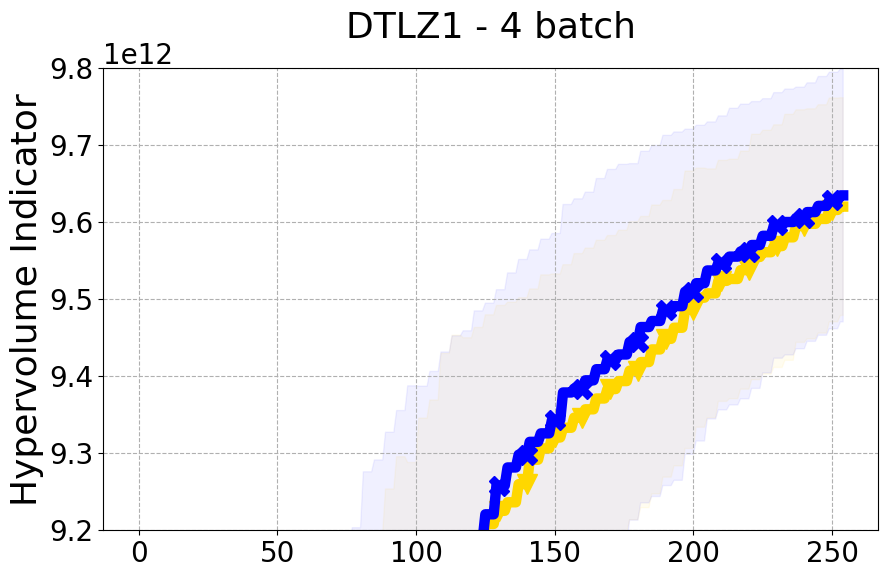
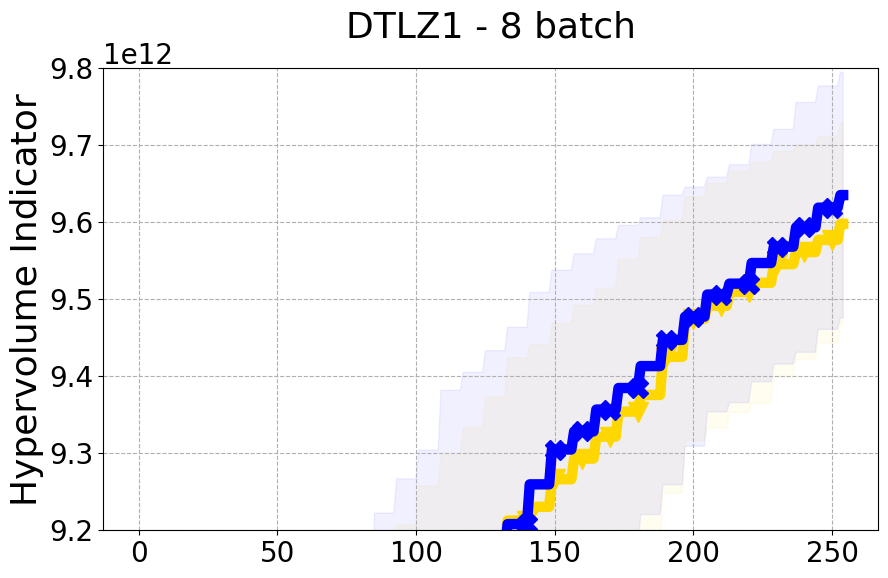
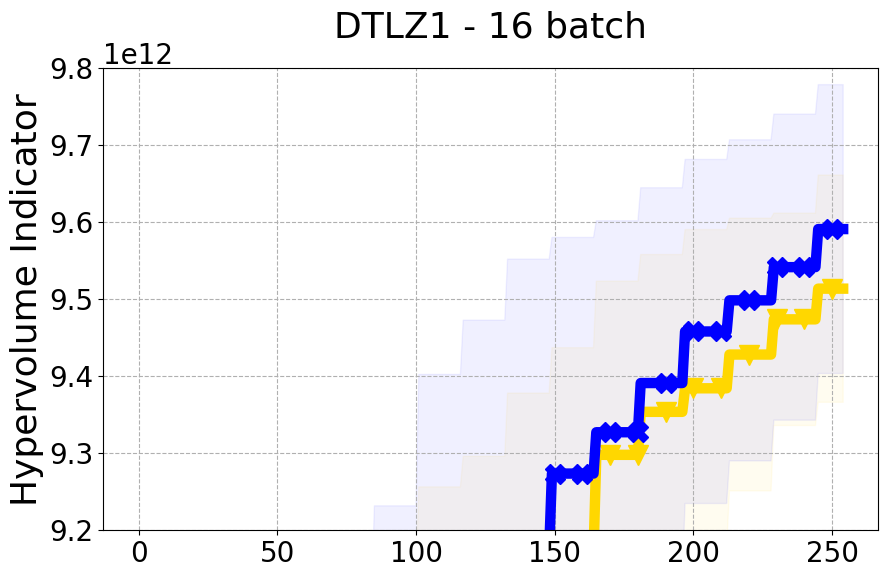
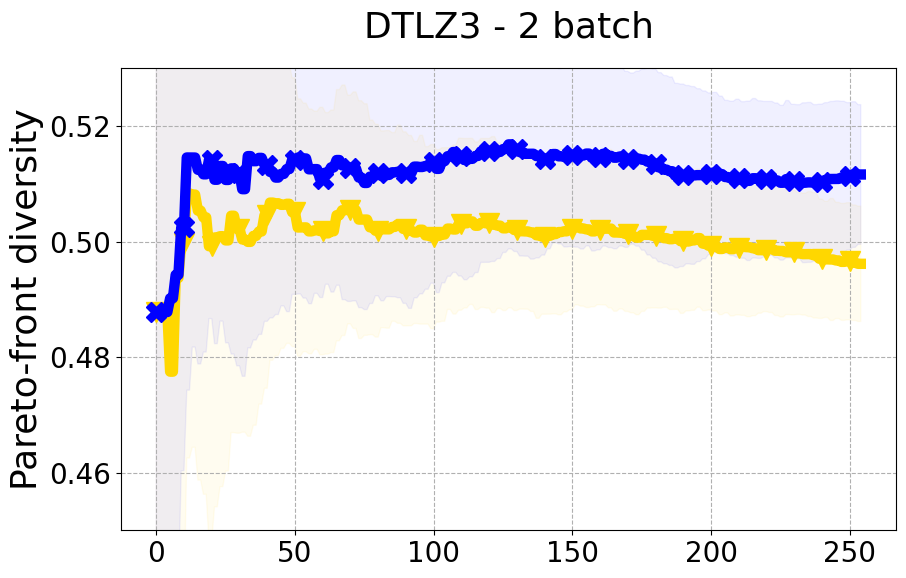
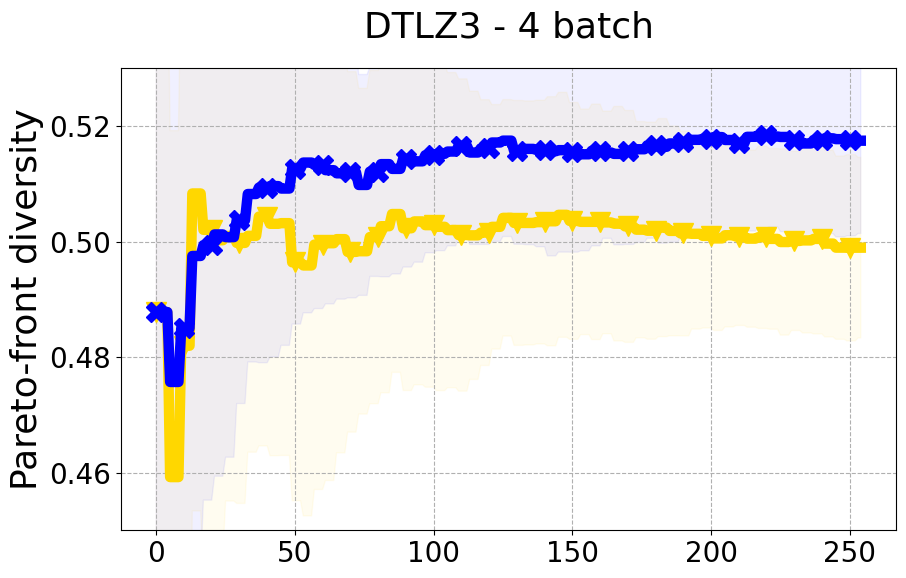
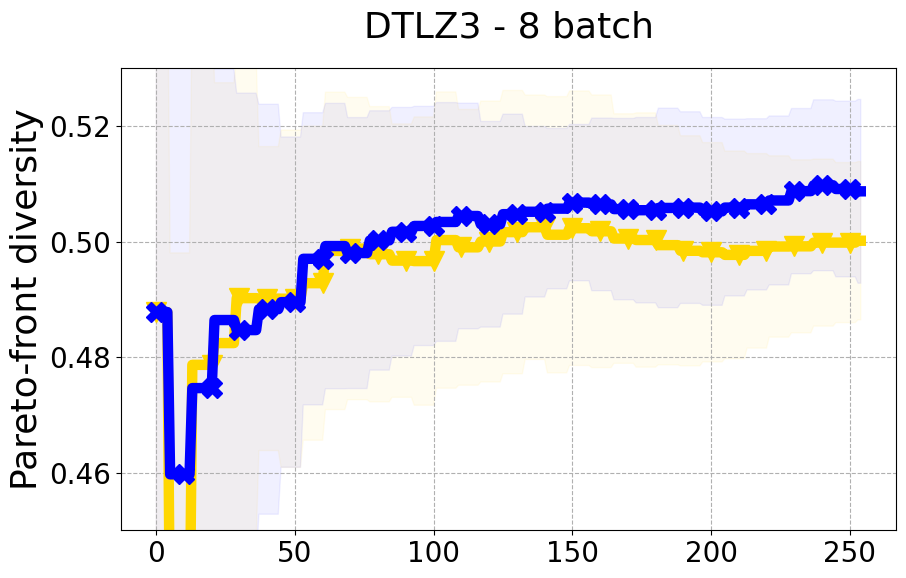
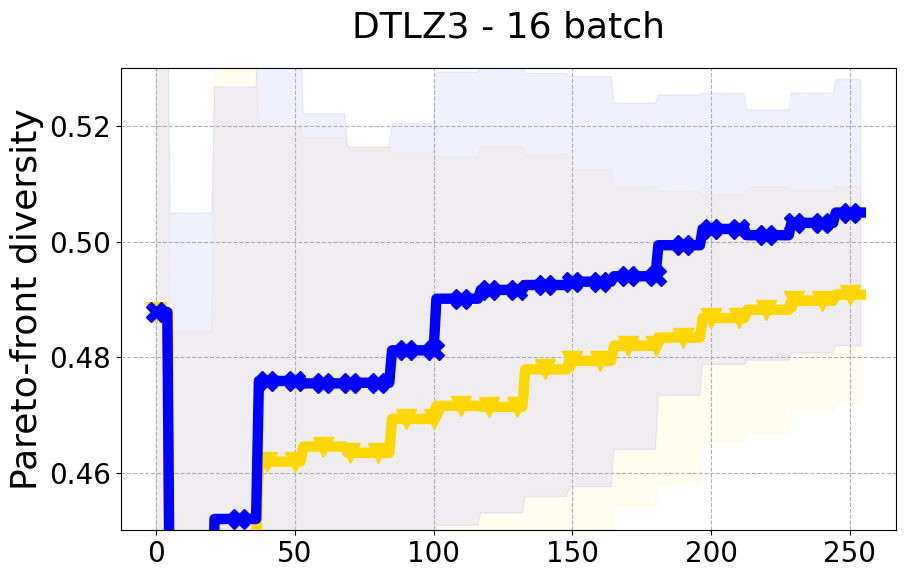
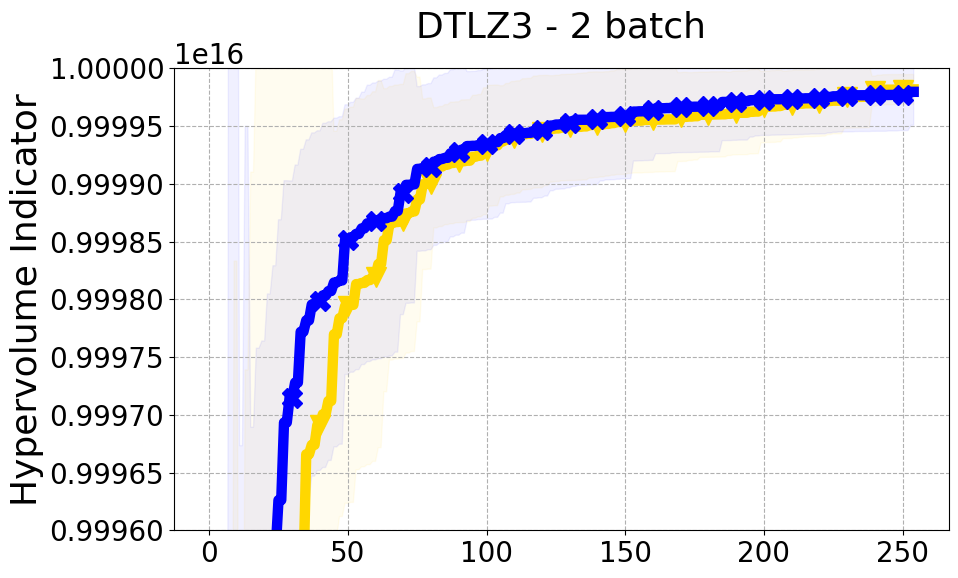
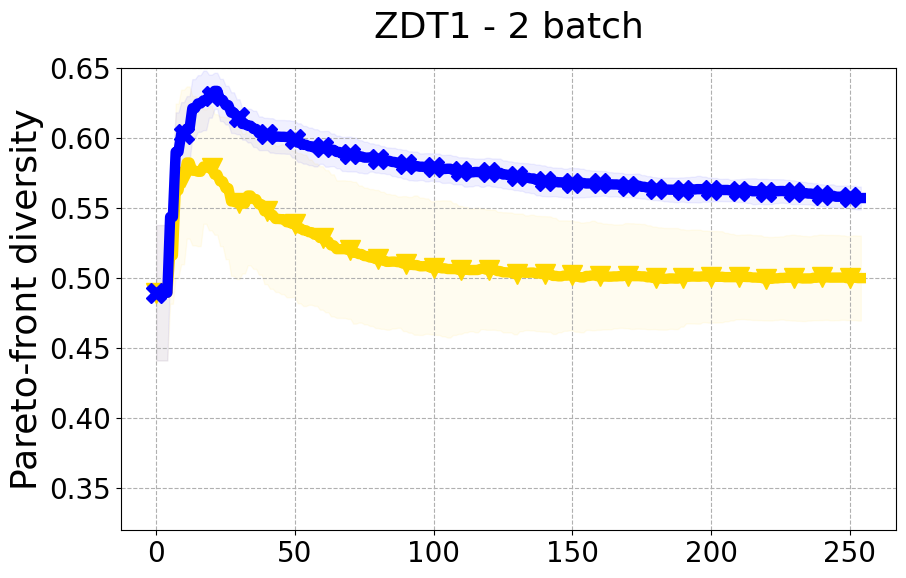
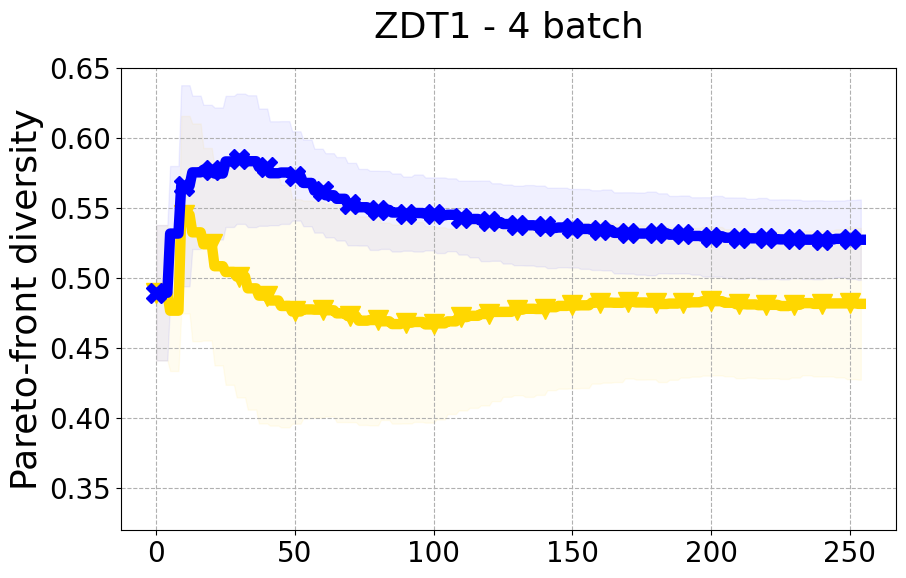
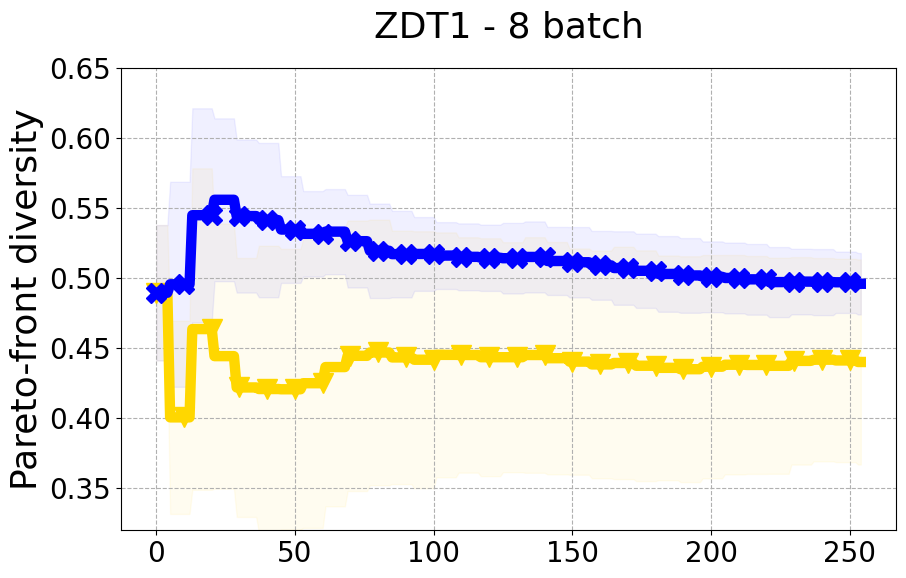
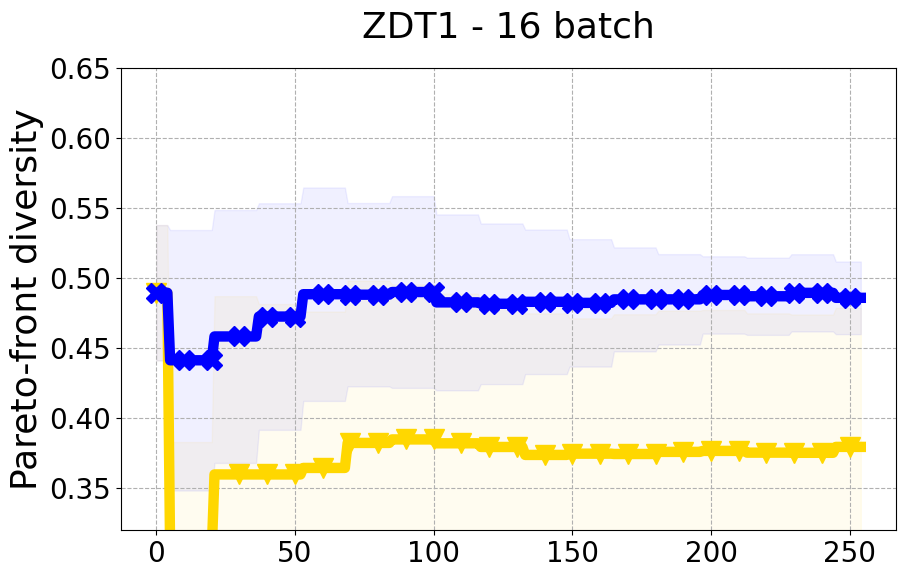
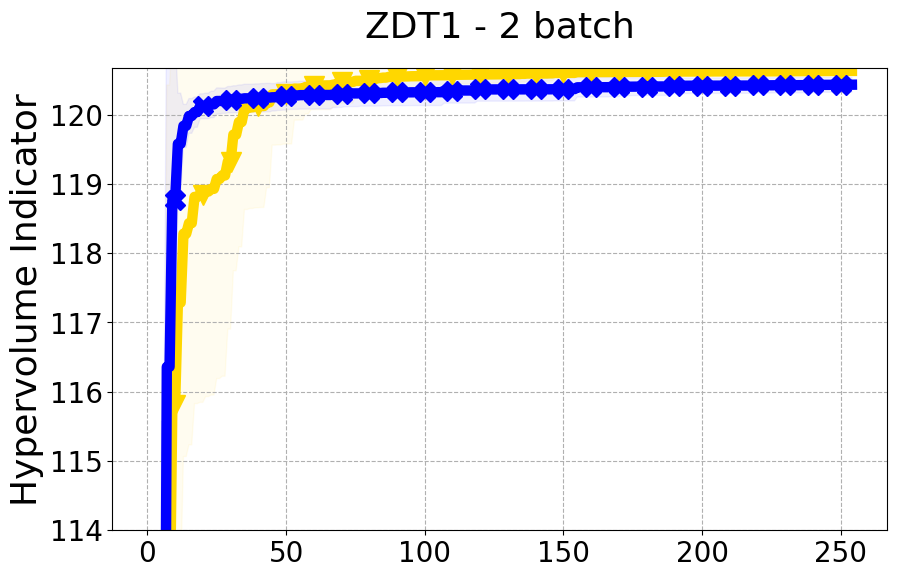
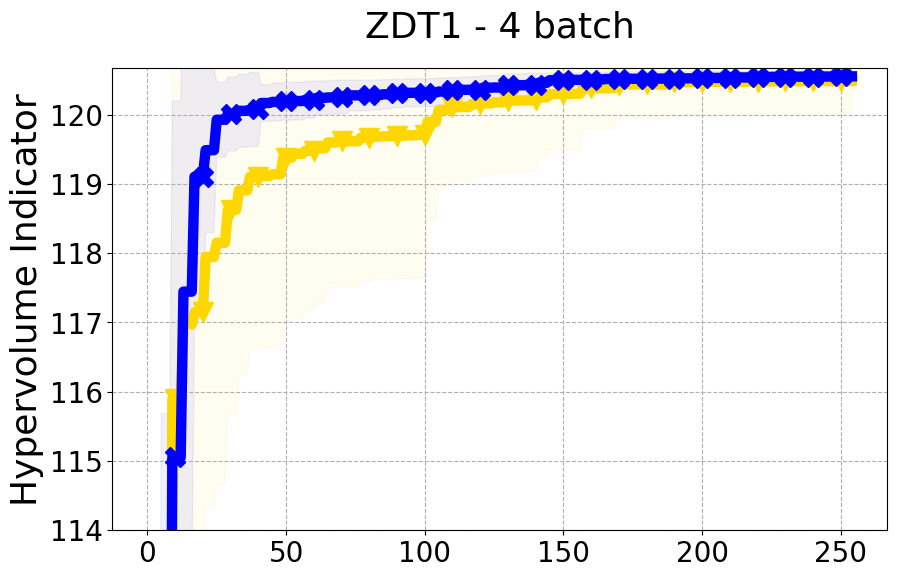
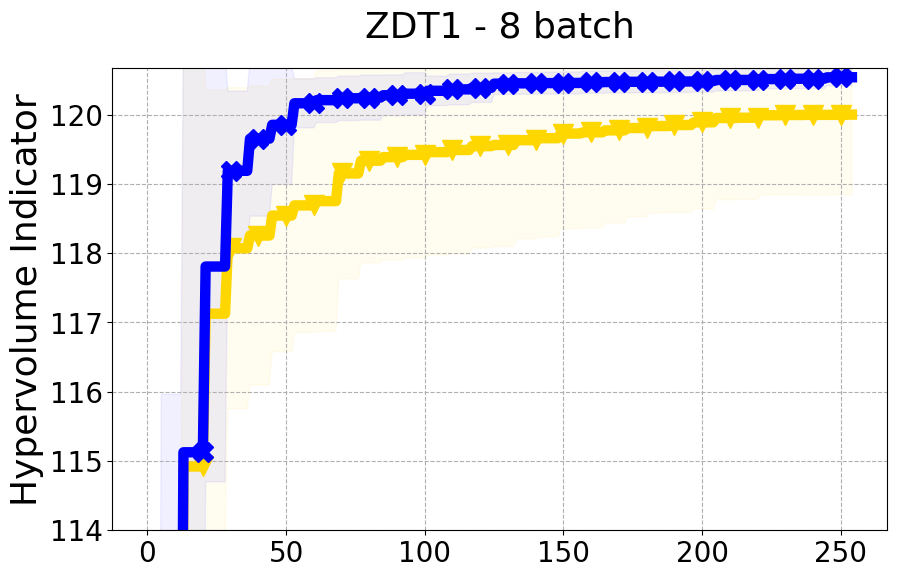
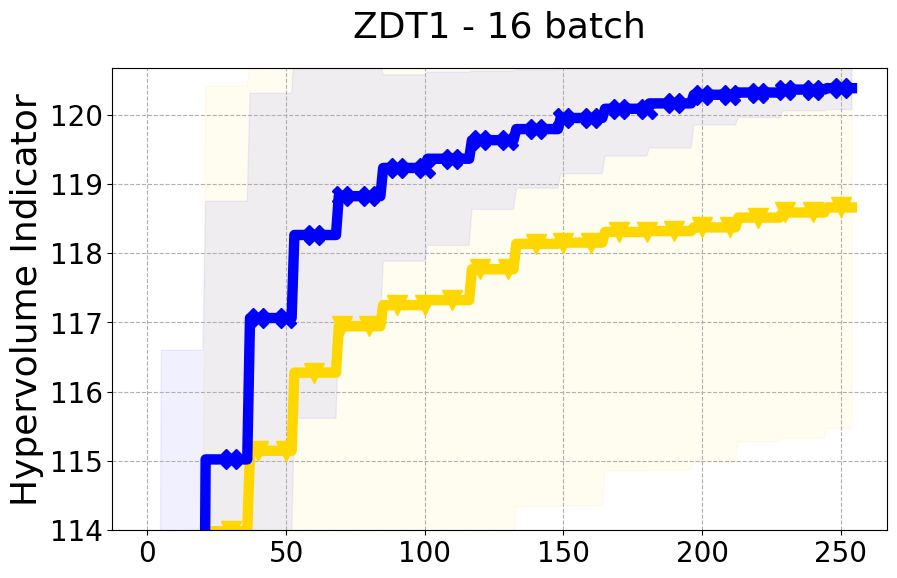
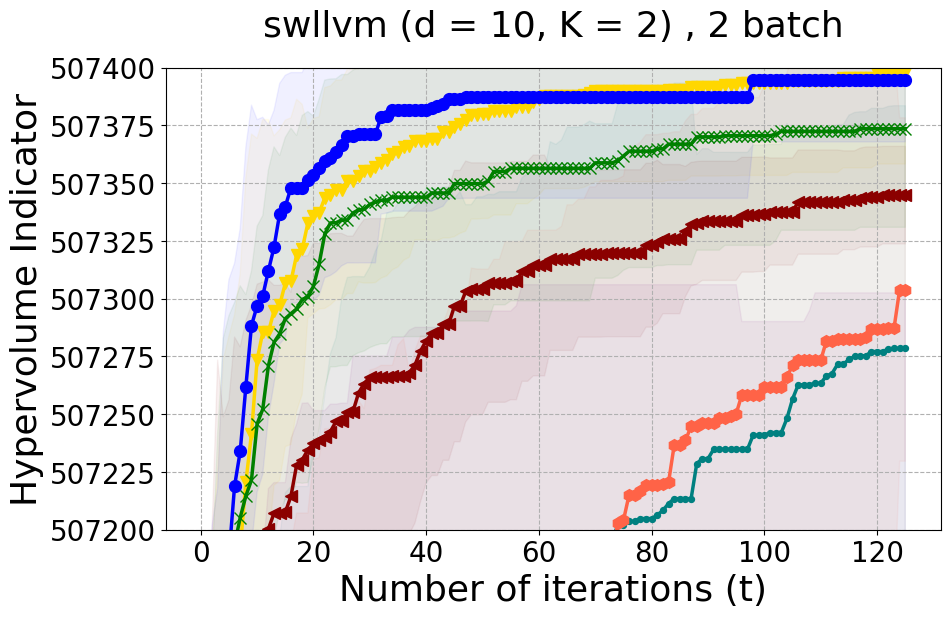
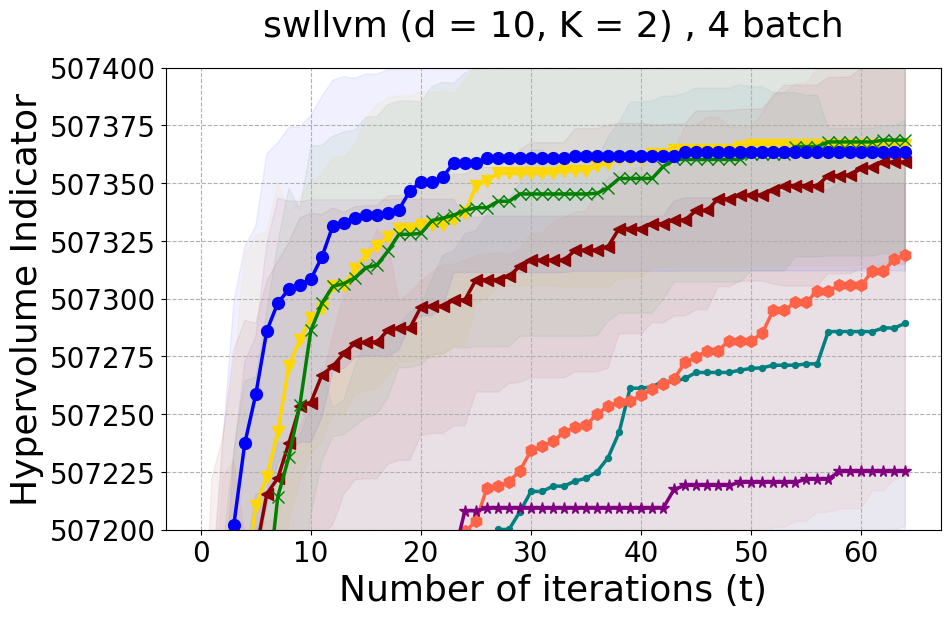
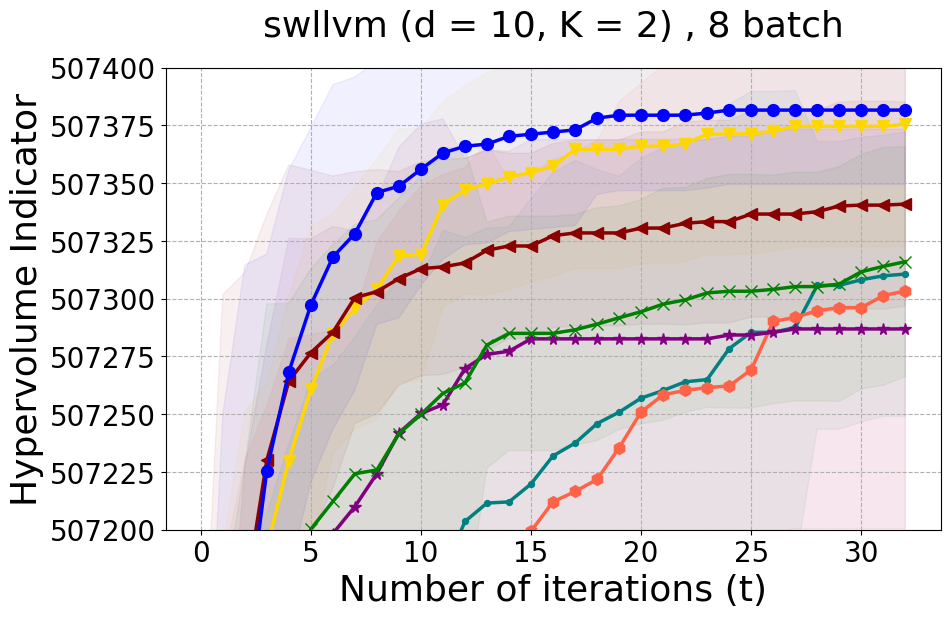
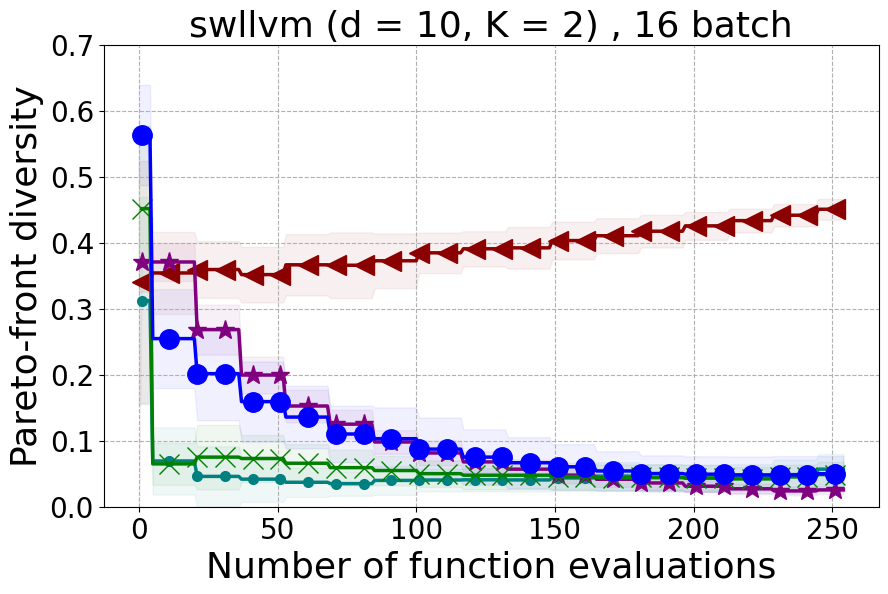
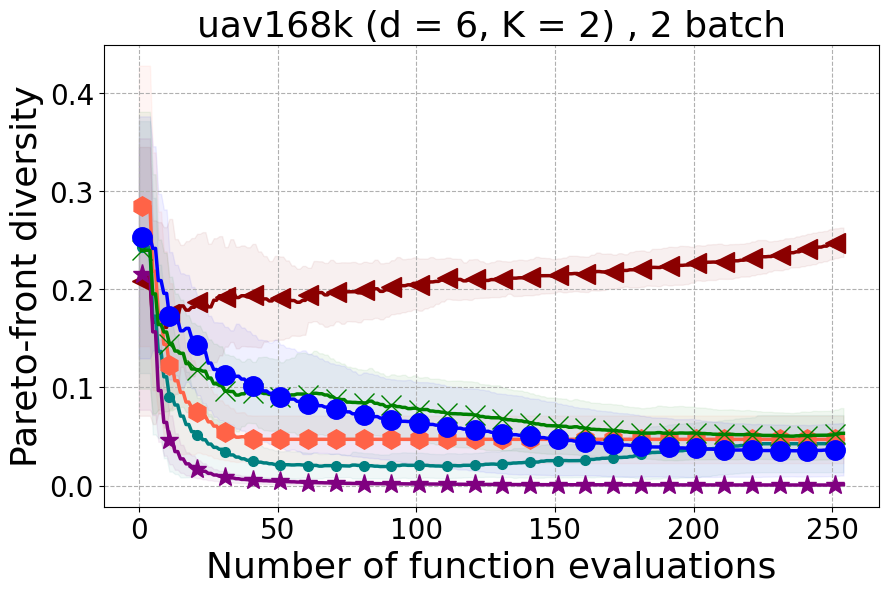
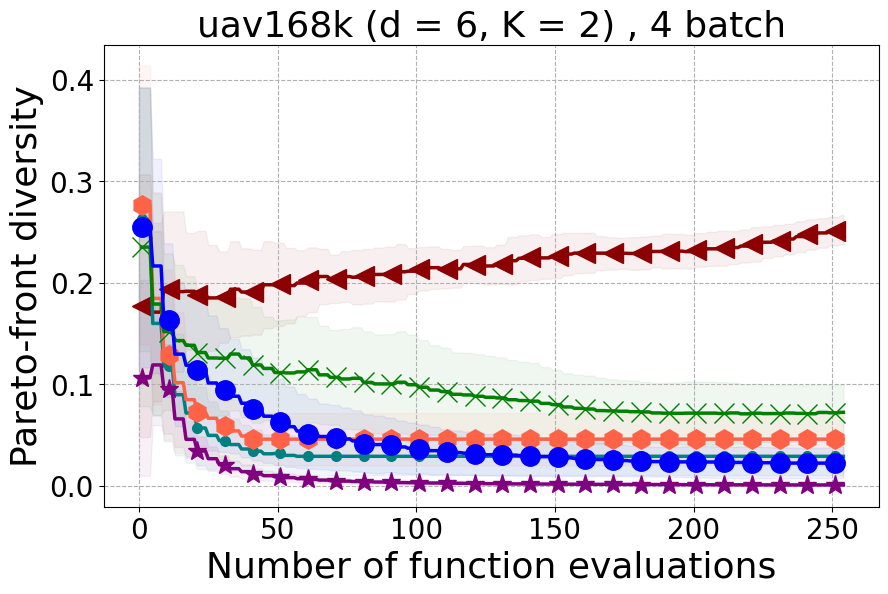
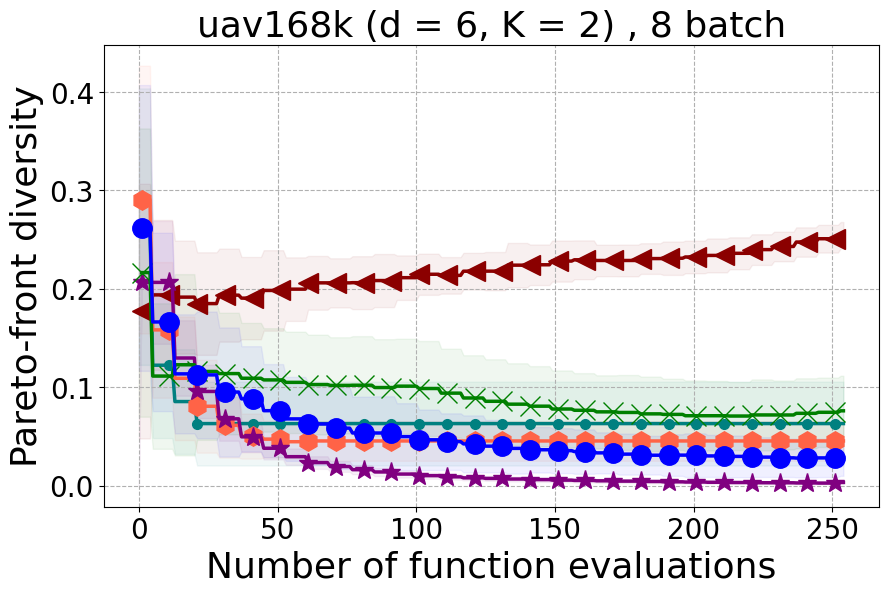
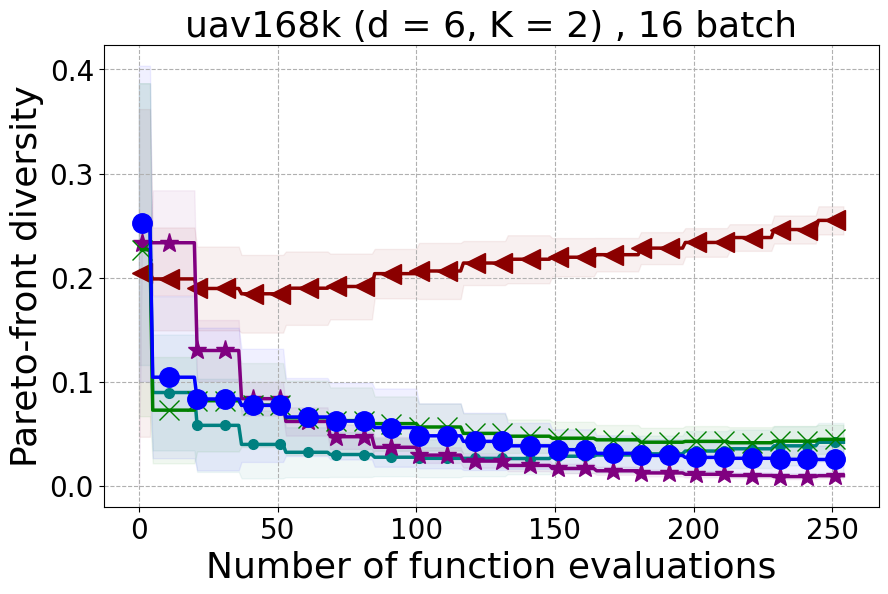
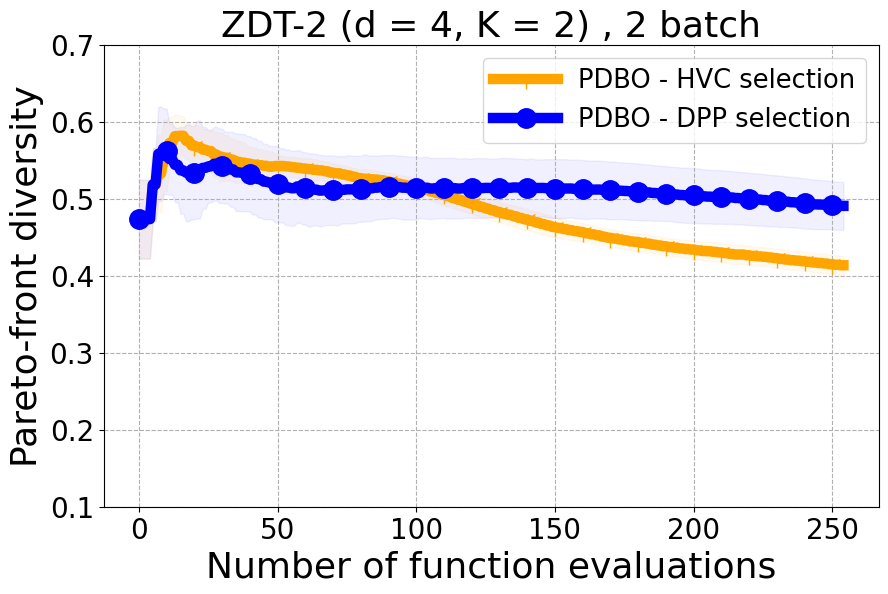
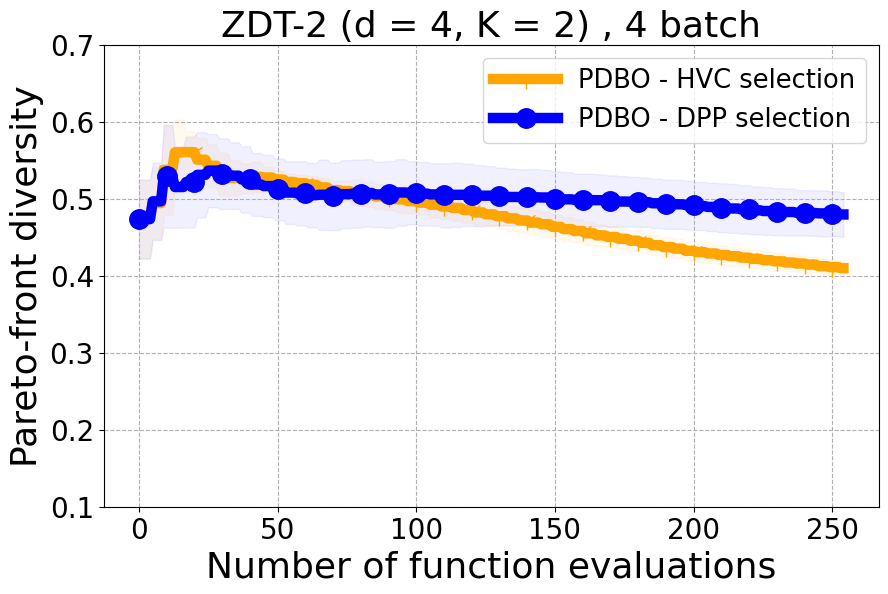
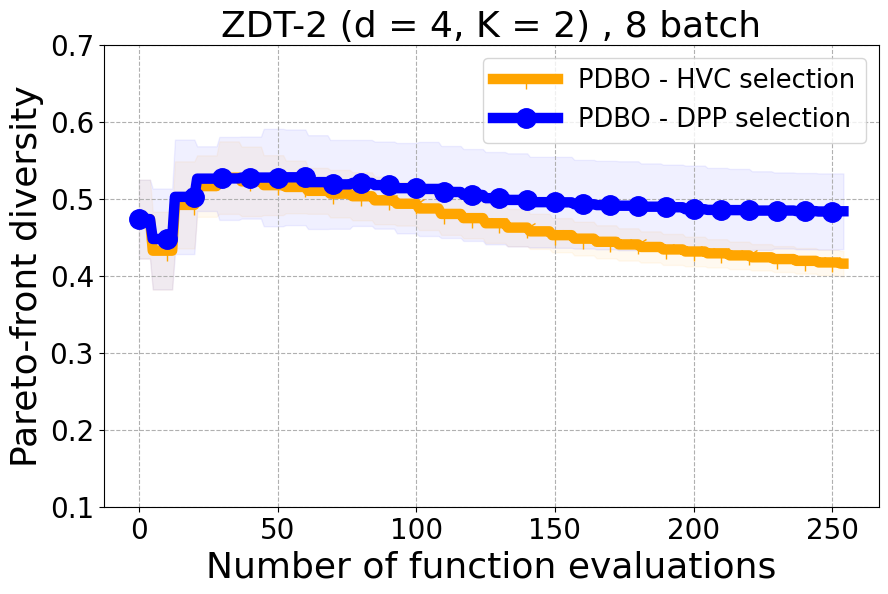
Results and Discussion. Figure 2 demonstrates that PDBO outperforms other baselines with respect to the Pareto-front diversity metric. Additionally, Figure 3 demonstrates that PDBO outperforms all baseline methods in most experiments with respect to the Hypervolume indicator and provides a competitive performance on the others.
In the Appendix, we present a comprehensive set of additional results and analyses. This includes the evaluation of hypervolume and DPF on various benchmarks. We also introduce results using other metrics, notably the Inverted Generational Distance (IGD) and a modified version of DPF, accompanied by a relevant discussion. Additionally, we compare the run-time of all baseline methods. For visual insight into the diversity of solutions, we include scatter plots representing the Pareto front for problems with two objectives. Lastly, we provide statistics on the selection of AF.
PDBO Advantages. PDBO is fast and effective in producing high-quality and diverse Pareto fronts. While outperforming the baseline methods, it can also be used with any number of input and output dimensions as well as being flexible to run with any batch size. The two state-of-the-art methods are DGEMO and qEHVI. The DGEMO method fails to run for experiments with more than three objective functions as the graph cut algorithm consistently crashes (same observation was made by (Daulton et al. 2021)). qEHVI fails to run with batch sizes higher than eight as the method becomes extremely memory-consuming even with GPUs. We provide a more detailed discussion about these limitations in the Appendix. Therefore, PDBO’s ability to easily run with any input and output dimensions as well as any batch size is an advantage for practitioners. PDBO is capable of proactively creating a diverse Pareto front while improving or maintaining the quality of the Pareto front.
Given that PDBO incorporates two key contributions, namely adaptive acquisition function selection and multi-objective batch selection using DPPs, we examine the individual contributions of each component to the overall performance by conducting ablation experiments.
Merits of Adaptive AF Selection. We demonstrate the superiority of the adaptive AF selection method, as outlined in Section 4.1, compared to using a static AF from the portfolio. To isolate the impact of this component from the batch selection process, we conduct an ablation study using the USEMO baseline. With a batch size of one, we consider USEMO with UCB, TS, ID, and EI as baselines. We then evaluate the efficacy of our MAB method by incorporating the adaptive AF selection approach into USEMO. Results shown in the Appendix consistently demonstrate the superior performance of the MAB strategy over using a static AF.
Merits of DPP-Based Batch Selection for MOO. Following a similar ablation approach, we employ the USEMO-EI baseline to examine the impact of the DPP-based batch selection. USEMO-EI selects the next input for evaluation from the cheap Pareto set based on an uncertainty metric. To perform this ablation, we replace the input selection mechanism utilized in USEMO with our proposed DPP selection strategy and compare their performance. The ablation is conducted across different batch sizes . The results presented in the Appendix reveal that the proposed DPP selection strategy, referred to as DPP-EI, surpasses the USEMO selection strategy in terms of diversity while simultaneously improving the quality of hypervolume.
7 Summary
We studied the Pareto front-Diverse Batch Multi-Objective BO (PDBO) method based on the BO framework. It employs a full information multi-arm bandit algorithm with discounted reward to adaptively select the most suitable acquisition function in each iteration. We also proposed an appropriate reward based on the relative hypervolume contribution of each acquisition function and a multi-objective DPP approach configured to select a batch of Pareto-diverse inputs for evaluation. Experiments on multiple benchmarks demonstrate that PDBO outperforms prior methods in terms of both diversity and quality of Pareto-front solutions.
Acknowledgements The authors gratefully acknowledge the in part support from National Science Foundation (NSF) grants IIS-1845922, SII-2030159, and CNS-2308530. The views expressed are those of the authors and do not reflect the official policy or position of the NSF.
References
- Abdolshah et al. [2019] Majid Abdolshah, Alistair Shilton, Santu Rana, Sunil Gupta, and Svetha Venkatesh. Multi-objective bayesian optimisation with preferences over objectives. Advances in neural information processing systems, 32, 2019.
- Angermueller et al. [2020] Christof Angermueller, David Belanger, Andreea Gane, Zelda Mariet, David Dohan, Kevin Murphy, Lucy Colwell, and D Sculley. Population-based black-box optimization for biological sequence design. In International Conference on Machine Learning, pages 324–334. PMLR, 2020.
- Ashby [2000] MF Ashby. Multi-objective optimization in material design and selection. Acta materialia, 2000.
- Astudillo and Frazier [2020] Raul Astudillo and Peter Frazier. Multi-attribute bayesian optimization with interactive preference learning. In International Conference on Artificial Intelligence and Statistics, pages 4496–4507. PMLR, 2020.
- Auer [2002] Peter Auer. Using confidence bounds for exploitation-exploration trade-offs. JMLR, 2002.
- Belakaria et al. [2019] Syrine Belakaria, Aryan Deshwal, and Janardhan Rao Doppa. Max-value entropy search for multi-objective Bayesian optimization. In Conference on Neural Information Processing Systems, 2019.
- Belakaria et al. [2020a] Syrine Belakaria, Aryan Deshwal, Nitthilan Kannappan Jayakodi, and Janardhan Rao Doppa. Uncertainty-aware search framework for multi-objective bayesian optimization. In AAAI, 2020a.
- Belakaria et al. [2020b] Syrine Belakaria, Derek Jackson, Yue Cao, Janardhan Rao Doppa, and Xiaonan Lu. Machine learning enabled fast multi-objective optimization for electrified aviation power system design. In IEEE Energy Conversion Congress and Exposition (ECCE), 2020b.
- Birol et al. [2002] Gulnur Birol, Cenk Undey, and Ali Cinar. A modular simulation package for fed-batch fermentation: penicillin production. Computers and chemical engineering, 2002.
- Borodin [2009] Alexei Borodin. Determinantal point processes. arXiv preprint arXiv:0911.1153, 2009.
- Borodin and Olshanski [2005] Alexei Borodin and Grigori Olshanski. Harmonic analysis on the infinite-dimensional unitary group and determinantal point processes. Annals of mathematics, pages 1319–1422, 2005.
- Cesa-Bianchi and Lugosi [2006] Nicolo Cesa-Bianchi and Gábor Lugosi. Prediction, learning, and games. Cambridge university press, 2006.
- Coello Coello and Reyes Sierra [2004] Carlos A Coello Coello and Margarita Reyes Sierra. A study of the parallelization of a coevolutionary multi-objective evolutionary algorithm. In MICAI 2004: Third Mexican International Conference on Artificial Intelligence, Mexico City, Mexico, April 26-30, 2004. Proceedings 3. Springer, 2004.
- Daulton et al. [2020] Samuel Daulton, Maximilian Balandat, and Eytan Bakshy. Differentiable expected hypervolume improvement for parallel multi-objective bayesian optimization. Advances in Neural Information Processing Systems, 33:9851–9864, 2020.
- Daulton et al. [2021] Samuel Daulton, Maximilian Balandat, and Eytan Bakshy. Parallel bayesian optimization of multiple noisy objectives with expected hypervolume improvement. NeurIPS, 34, 2021.
- Daulton et al. [2022] Samuel Daulton, David Eriksson, Maximilian Balandat, and Eytan Bakshy. Multi-objective bayesian optimization over high-dimensional search spaces. In The 38th Conference on Uncertainty in Artificial Intelligence, 2022. URL https://openreview.net/forum?id=r5IEvvIs9xq.
- Deb and Srinivasan [2006] Kalyanmoy Deb and Aravind Srinivasan. Innovization: Innovating design principles through optimization. In Proceedings of the 8th annual conference on Genetic and evolutionary computation, pages 1629–1636, 2006.
- Deb et al. [1995] Kalyanmoy Deb, Ram Bhushan Agrawal, et al. Simulated binary crossover for continuous search space. Complex systems, 1995.
- Deb et al. [1996] Kalyanmoy Deb, Mayank Goyal, et al. A combined genetic adaptive search (geneas) for engineering design. Computer Science and informatics, 26:30–45, 1996.
- Deb et al. [2002a] Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, T Meyarivan, and A Fast. Nsga-ii. IEEE Transactions on Evolutionary Computation, 6(2):182–197, 2002a.
- Deb et al. [2002b] Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and TAMT Meyarivan. A fast and elitist multiobjective genetic algorithm: Nsga-ii. IEEE transactions on evolutionary computation, 6, 2002b.
- Deb et al. [2005] Kalyanmoy Deb, Lothar Thiele, Marco Laumanns, and Eckart Zitzler. Scalable test problems for evolutionary multiobjective optimization. In Evolutionary multiobjective optimization. Springer, 2005.
- Deshwal et al. [2021] Aryan Deshwal, Cory M Simon, and Janardhan Rao Doppa. Bayesian optimization of nanoporous materials. Molecular Systems Design and Engineering, 2021.
- Emmerich and Klinkenberg [2008] Michael Emmerich and Jan-willem Klinkenberg. The computation of the expected improvement in dominated hypervolume of pareto front approximations. Leiden University, 2008.
- Eriksson et al. [2019] David Eriksson, Michael Pearce, Jacob Gardner, Ryan D Turner, and Matthias Poloczek. Scalable global optimization via local bayesian optimization. NeurIPS, 2019.
- Freund and Schapire [1997] Yoav Freund and Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting. Journal of computer and system sciences, 55(1), 1997.
- Hernández-Lobato et al. [2016] Daniel Hernández-Lobato, Jose Hernandez-Lobato, Amar Shah, and Ryan Adams. Predictive entropy search for multi-objective Bayesian optimization. In Proceedings of International Conference on Machine Learning (ICML), pages 1492–1501, 2016.
- Hernández-Lobato et al. [2014] José Miguel Hernández-Lobato, Matthew W Hoffman, and Zoubin Ghahramani. Predictive entropy search for efficient global optimization of black-box functions. In NeurIPS, 2014.
- Hoffman et al. [2011] Matthew Hoffman, Eric Brochu, Nando De Freitas, et al. Portfolio allocation for bayesian optimization. In UAI, pages 327–336, 2011.
- Hvarfner et al. [2022] Carl Hvarfner, Frank Hutter, and Luigi Nardi. Joint entropy search for maximally-informed bayesian optimization. arXiv preprint arXiv:2206.04771, 2022.
- Jain et al. [2022] Moksh Jain, Sharath Chandra Raparthy, Alex Hernandez-Garcia, Jarrid Rector-Brooks, Yoshua Bengio, Santiago Miret, and Emmanuel Bengio. Multi-objective gflownets. arXiv preprint arXiv:2210.12765, 2022.
- Kathuria et al. [2016] Tarun Kathuria, Amit Deshpande, and Pushmeet Kohli. Batched gaussian process bandit optimization via determinantal point processes. NeurIPS, 29, 2016.
- Knowles [2006] Joshua Knowles. Parego: A hybrid algorithm with on-line landscape approximation for expensive multiobjective optimization problems. IEEE Transactions on Evolutionary Computation, 10(1):50–66, 2006.
- Konakovic Lukovic et al. [2020] Mina Konakovic Lukovic, Yunsheng Tian, and Wojciech Matusik. Diversity-guided multi-objective bayesian optimization with batch evaluations. Advances in Neural Information Processing Systems, 2020.
- Kulesza et al. [2012] Alex Kulesza, Ben Taskar, et al. Determinantal point processes for machine learning. Foundations and Trends in Machine Learning, 2012.
- Lalee et al. [1998] Marucha Lalee, Jorge Nocedal, and Todd Plantenga. On the implementation of an algorithm for large-scale equality constrained optimization. SIAM Journal on Optimization, 8(3):682–706, 1998.
- Lin et al. [2022] Xi Lin, Zhiyuan Yang, Xiaoyuan Zhang, and Qingfu Zhang. Pareto set learning for expensive multi-objective optimization. arXiv preprint arXiv:2210.08495, 2022.
- Mockus et al. [1978] Jonas Mockus, Vytautas Tiesis, and Antanas Zilinskas. The application of bayesian methods for seeking the extremum. Towards global optimization, 1978.
- Nava et al. [2022] Elvis Nava, Mojmir Mutny, and Andreas Krause. Diversified sampling for batched bayesian optimization with determinantal point processes. In International Conference on Artificial Intelligence and Statistics, pages 7031–7054. PMLR, 2022.
- Nicolaou and Brown [2013] Christos A Nicolaou and Nathan Brown. Multi-objective optimization methods in drug design. Drug Discovery Today: Technologies, 2013.
- Nikolov [2015] Aleksandar Nikolov. Randomized rounding for the largest simplex problem. In Proceedings of the forty-seventh annual ACM symposium on Theory of computing, pages 861–870, 2015.
- Nocedal and Wright [2006] J Nocedal and SJ Wright. Numerical optimization (springer, new york, 1999)., 2006.
- Oh et al. [2021] Changyong Oh, Roberto Bondesan, Efstratios Gavves, and Max Welling. Batch bayesian optimization on permutations using acquisition weighted kernels. arXiv preprint arXiv:2102.13382, 2021.
- Okoth et al. [2022] Michael Aggrey Okoth, Ronghua Shang, Licheng Jiao, Jehangir Arshad, Ateeq Ur Rehman, and Habib Hamam. A large scale evolutionary algorithm based on determinantal point processes for large scale multi-objective optimization problems. Electronics, 11(20):3317, 2022.
- Paria et al. [2020] Biswajit Paria, Kirthevasan Kandasamy, and Barnabás Póczos. A flexible framework for multi-objective bayesian optimization using random scalarizations. In Uncertainty in Artificial Intelligence, pages 766–776. PMLR, 2020.
- Pierrot et al. [2022] Thomas Pierrot, Guillaume Richard, Karim Beguir, and Antoine Cully. Multi-objective quality diversity optimization. In Proceedings of the Genetic and Evolutionary Computation Conference, 2022.
- Shahriari et al. [2015] Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P Adams, and Nando De Freitas. Taking the human out of the loop: A review of bayesian optimization. Proceedings of the IEEE, 2015.
- Siegmund et al. [2012] Norbert Siegmund, Sergiy S Kolesnikov, Christian Kästner, Sven Apel, Don Batory, Marko Rosenmüller, and Gunter Saake. Predicting performance via automated feature-interaction detection. In Proceedings of the 34th International Conference on Software Engineering (ICSE), pages 167–177, 2012.
- Srinivas et al. [2009] Niranjan Srinivas, Andreas Krause, Sham M Kakade, and Matthias Seeger. Gaussian process optimization in the bandit setting: No regret and experimental design. arXiv preprint arXiv:0912.3995, 2009.
- Suzuki et al. [2020] Shinya Suzuki, Shion Takeno, Tomoyuki Tamura, Kazuki Shitara, and Masayuki Karasuyama. Multi-objective bayesian optimization using pareto-frontier entropy. In International Conference on Machine Learning, pages 9279–9288. PMLR, 2020.
- Taneda [2015] Akito Taneda. Multi-objective optimization for rna design with multiple target secondary structures. BMC bioinformatics, 2015.
- Thompson [1933] William R Thompson. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika, 25:285–294, 1933.
- Vasconcelos et al. [2019] Thiago de P Vasconcelos, Daniel ARMA de Souza, César LC Mattos, and João PP Gomes. No-past-bo: Normalized portfolio allocation strategy for bayesian optimization. In International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 2019.
- Vasconcelos et al. [2022] Thiago de P Vasconcelos, Daniel Augusto RMA de Souza, Gustavo C de M Virgolino, César LC Mattos, and João PP Gomes. Self-tuning portfolio-based bayesian optimization. Expert Systems with Applications, 188:115847, 2022.
- Virtanen et al. [2020] Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, İlhan Polat, Yu Feng, Eric W. Moore, Jake VanderPlas, Denis Laxalde, Josef Perktold, Robert Cimrman, Ian Henriksen, E. A. Quintero, Charles R. Harris, Anne M. Archibald, Antônio H. Ribeiro, Fabian Pedregosa, Paul van Mulbregt, and SciPy 1.0 Contributors. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17:261–272, 2020. doi: 10.1038/s41592-019-0686-2.
- Wang et al. [2022] Mengzhen Wang, Fangzhen Ge, Debao Chen, and Huaiyu Liu. A many-objective evolutionary algorithm using determinantal point process in potential region. In Proceedings of the 6th International Conference on Control Engineering and Artificial Intelligence, pages 83–91, 2022.
- Wang and Jegelka [2017] Zi Wang and Stefanie Jegelka. Max-value entropy search for efficient Bayesian optimization. In ICML, 2017.
- Wang et al. [2017] Zi Wang, Chengtao Li, Stefanie Jegelka, and Pushmeet Kohli. Batched high-dimensional bayesian optimization via structural kernel learning. In International Conference on Machine Learning, pages 3656–3664. PMLR, 2017.
- Williams and Rasmussen [2006] Christopher KI Williams and Carl Edward Rasmussen. Gaussian processes for machine learning. MIT press Cambridge, MA, 2006.
- Zhang et al. [2020] Peng Zhang, Jinlong Li, Tengfei Li, and Huanhuan Chen. A new many-objective evolutionary algorithm based on determinantal point processes. IEEE Transactions on Evolutionary Computation, 2020.
- Zitzler and Thiele [1999] Eckart Zitzler and Lothar Thiele. Multiobjective evolutionary algorithms: a comparative case study and the strength pareto approach. IEEE transactions on Evolutionary Computation, 1999.
- Zitzler et al. [2000] Eckart Zitzler, Kalyanmoy Deb, and Lothar Thiele. Comparison of multiobjective evolutionary algorithms: Empirical results. Evolutionary computation, 8(2):173–195, 2000.
8 Appendix
8.1 Theoretical Analysis
In this section, we assume maximization and assume that the UCB acquisition function is in the portfolio of acquisition functions used during the multi-objective Bayesian optimization process. We make this choice for the sake of clarity and ease of readability as we build our theoretical analysis on prior seminal work [Srinivas et al., 2009, Hoffman et al., 2011]. It is important to clarify that this is not a restrictive assumption and that with minimal mathematical transformations, the same derived regret bound holds for the case of minimization with the LCB acquisition function being in the portfolio instead.
In order to simplify the proof and solely for the sake of theoretical regret bound, we consider the instant reward of iteration to be the sum of predictive means of the Gaussian processes.
| (16) |
with is the posterior mean of function .
The cumulative reward over iterations that would have been obtained using acquisition function is defined as:
| (17) |
It is important to note that in our proposed algorithm, we use different and better-designed instant reward and cumulative reward functions. The rewards in equation 16 is a design choice to achieve the following regret bound. In section 5.1, we provide a discussion accompanied with an ablation study comparing the reward function used in theory to the reward function used in our proposed approach.
To bound the regret of Hedge with respect to the gain, we define the maximum strategy as:
Lemma 8.1.
With probability at least and , the regret is bounded by
| (18) |
This result follows directly from [Cesa-Bianchi and Lugosi, 2006, Section 4.2] for rewards in the range . This result is also used in the proof of regret bound in [Hoffman et al., 2011]. [Hoffman et al., 2011] discussed possible generalizations that come at the cost of worsening the bound with a multiplicative or additive constant. These relaxations include a non-restrictive reward bound and a time variant term. These generalizations also hold in the context of our proof. We refer the reader to [Hoffman et al., 2011] for more details. It is important to note that this lemma holds for any choice of where the reward is a result of the action taken by the Hedge algorithm.
The next lemmas are defined in [Srinivas et al., 2009] and [Hoffman et al., 2011]. We will refer the reader to [Srinivas et al., 2009, Lemma 5.1 and 5.3] and [Hoffman et al., 2011, Lemma 4 and 5] for proofs. We provide them here for the sake of completeness. It is important to clarify that these lemmas only depend on the surrogate Gaussian process models and can be used regardless of the UCB acquisition function.
Lemma 8.2.
Assume , a finite sample space , and where and . Then with probability at least , the absolute deviation of the mean is bounded by
Lemma 8.3.
Given points selected by the algorithm, the following bound holds for the sum of variances:
where .
The next lemma is defined in [Hoffman et al., 2011] and follows directly from [Srinivas et al., 2009, Lemma 5.2]. This lemma depends only on the definition of the UCB acquisition function, and does not require that points at any previous iteration were selected via UCB acquisition function.
Lemma 8.4.
The cheap multi-objective optimization (MOO) problem when the UCB acquisition function is selected is defined as follows:
| (19) |
Assuming that the cheap MOO solver achieves optimality, leading to the optimal Pareto set for the above defined problem, with the Pareto set defined as , either there exists a such that
| (20) |
or is in the optimal Pareto set generated by cheap MOO solver (i.e., ).
Now, if the bound from Lemma 8.2 holds, then for a point proposed by UCB with parameters , the following bound holds for any function ,
| (21) |
Leading to the following bound
| (22) |
We can now combine these results to construct the proof of Theorem 5.1.
Proof of Theorem 5.1.
With probability at least , the result of Lemma 8.1 holds. If we assume that UCB acquisition function is included in the portfolio of acquisition functions, we have
and by adding to both sides of the inequality, we have:
With probability at least the bound from Lemma 8.2 can be applied to the left-hand-side and the result of Lemma 8.4 can be applied to the right side of the inequality leading to the following inequality
which means that the regret is bounded by
We should note that we cannot use Lemma 8.3 to further simplify the terms involving . This is because the lemma only holds for points that are sampled by the algorithm, which may not include those proposed by UCB acquisition function.
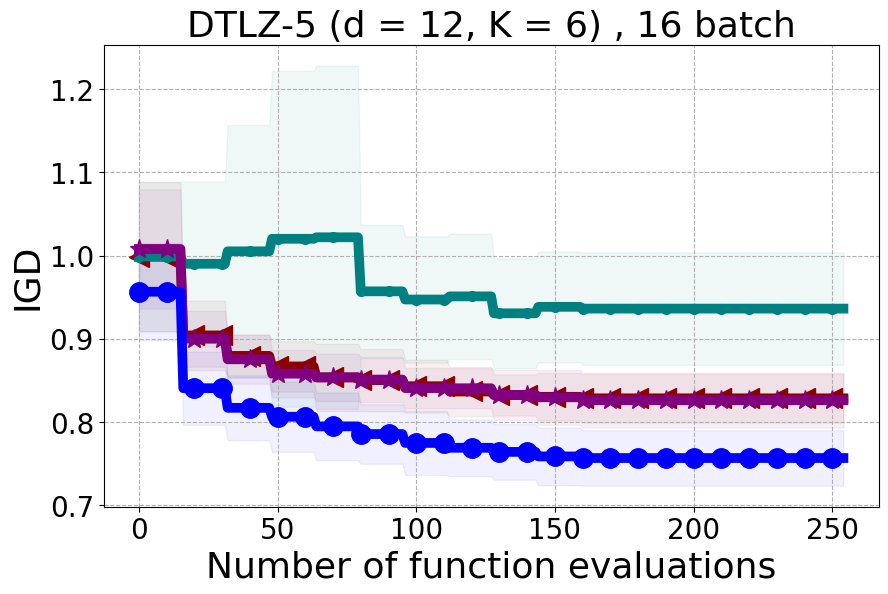
8.2 PDBO Hypervolume Experiments
In this section, we present supplementary experiments that focus on the comparison of hypervolume between our proposed method, PDBO, and other existing baselines. We refer the interested reader to Figure 11 for the additional results.
8.3 PDBO Diversity Experiments
In terms of Pareto front diversity, we conduct a comprehensive comparison between PDBO and state-of-the-art methods introduced in Section 6. It is worth noting that, apart from DGEMO, none of the other baseline methods explicitly address Pareto front diversity. The results depicted in Figure 8 demonstrate the superior performance of PDBO, outperforming all existing methods in terms of Pareto front diversity measure.
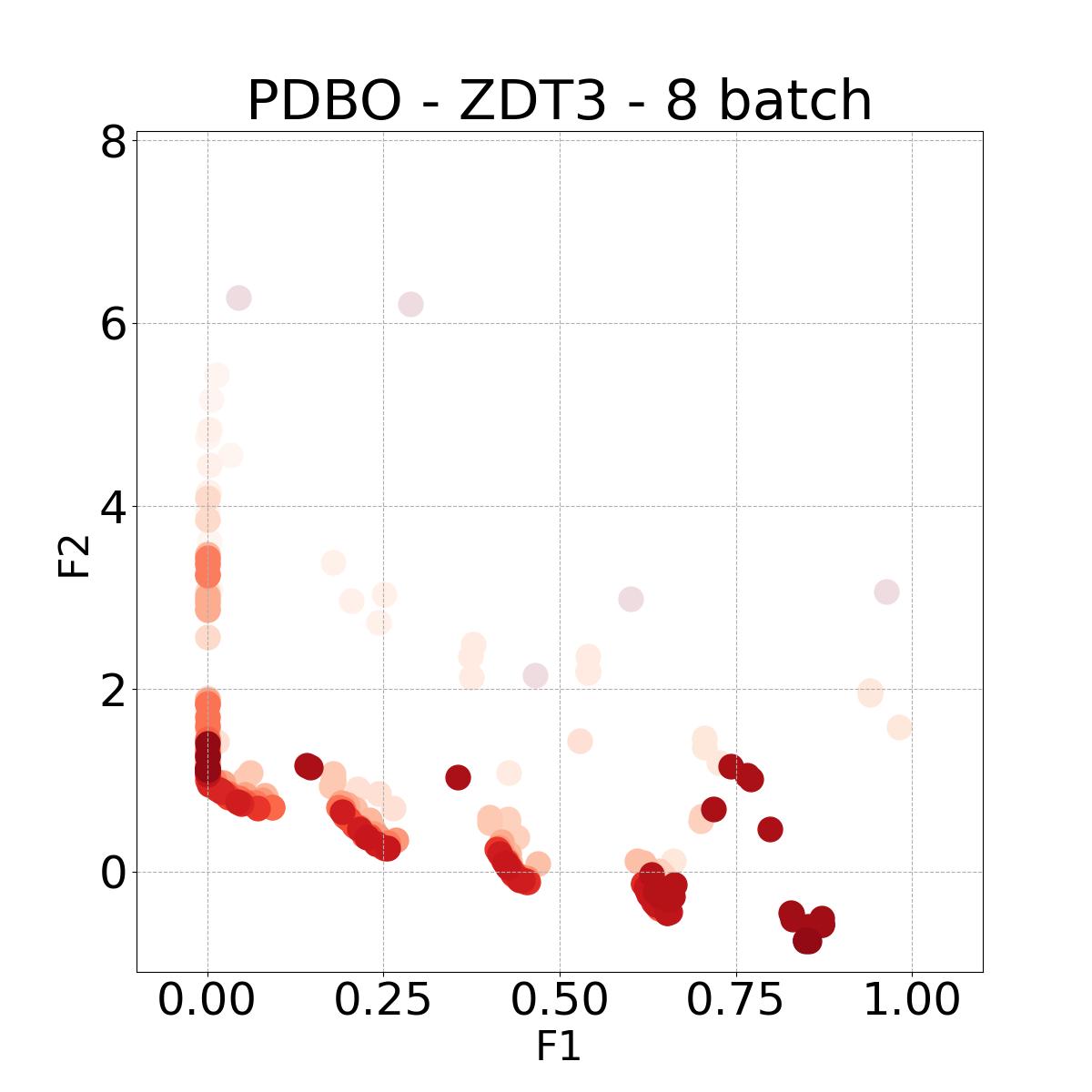
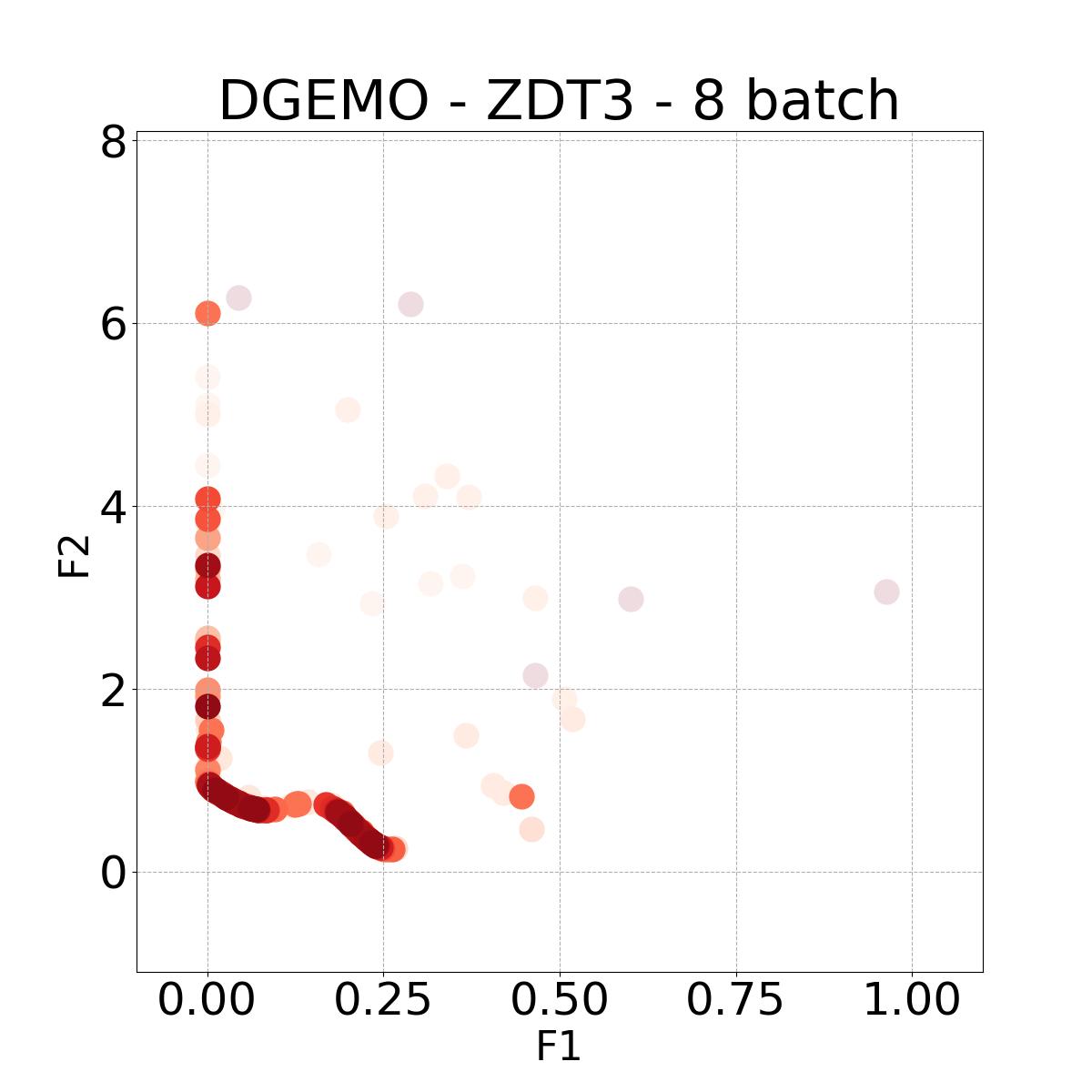
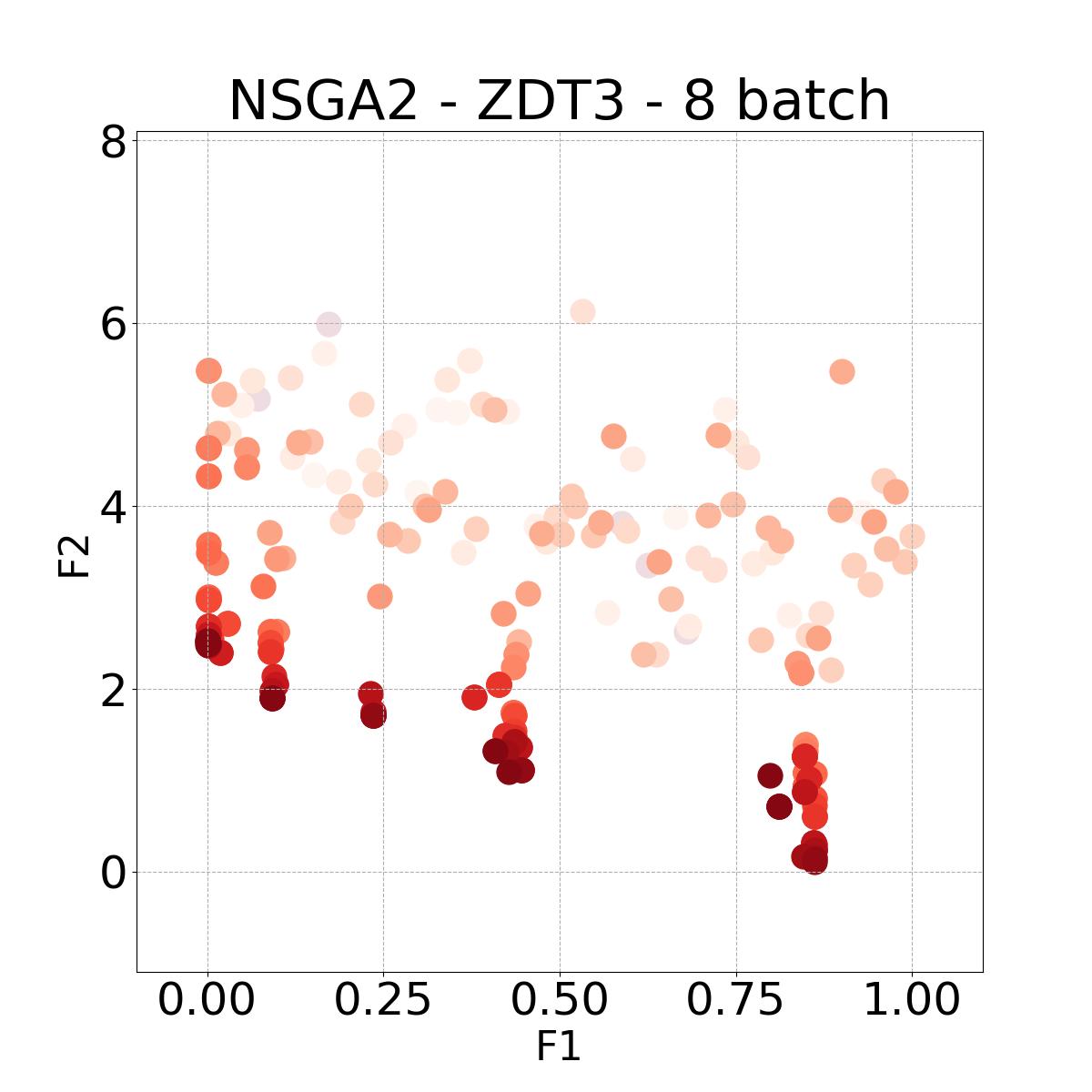
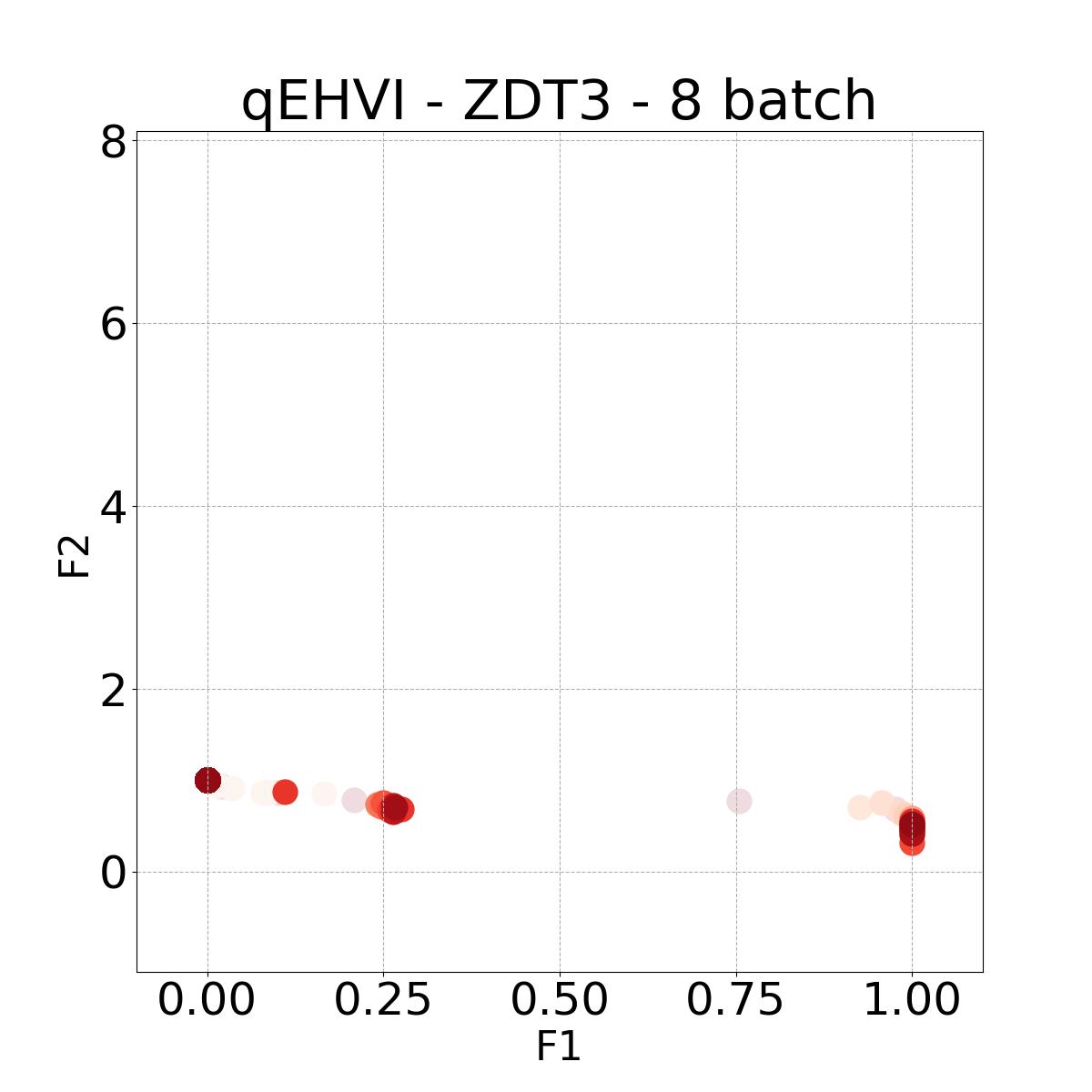
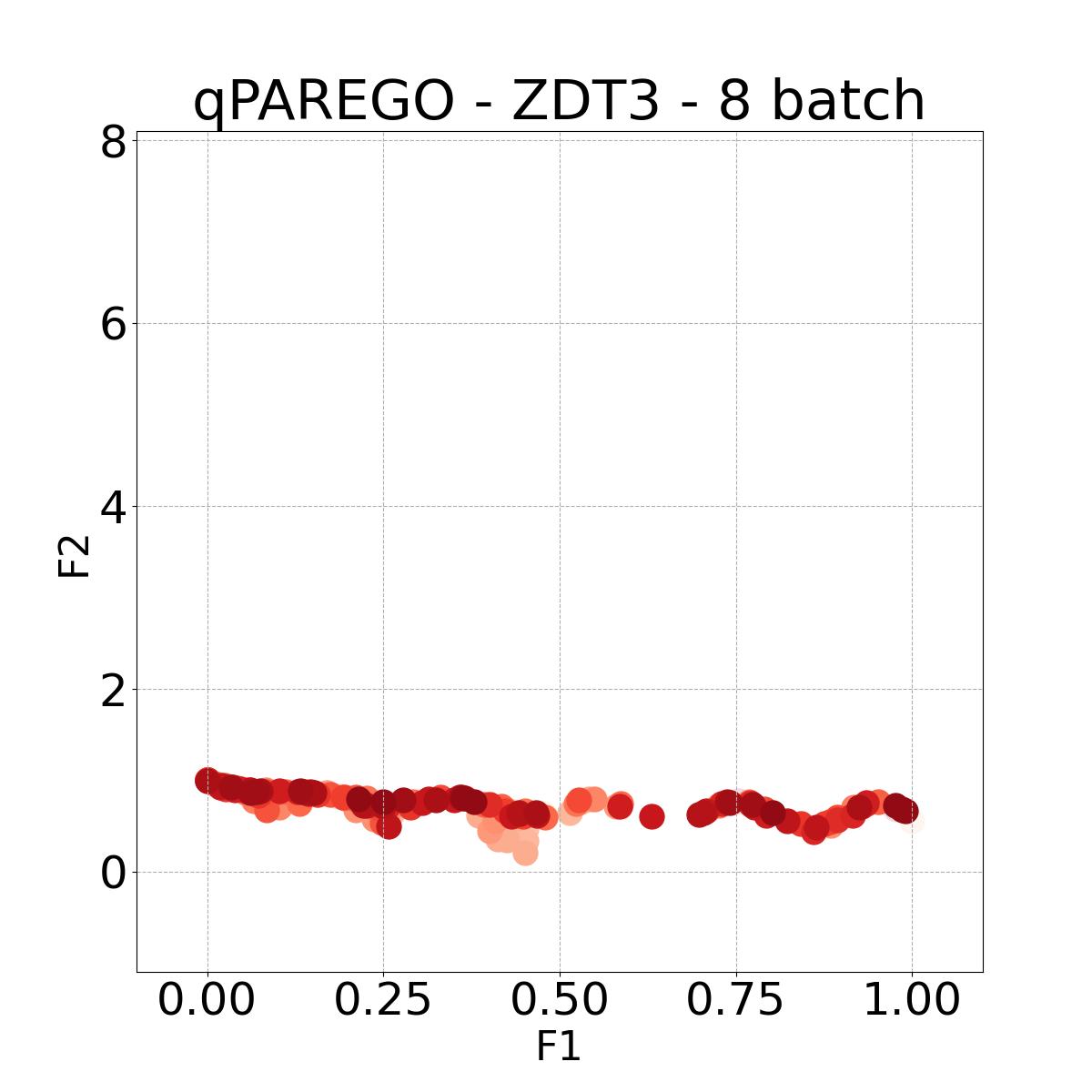
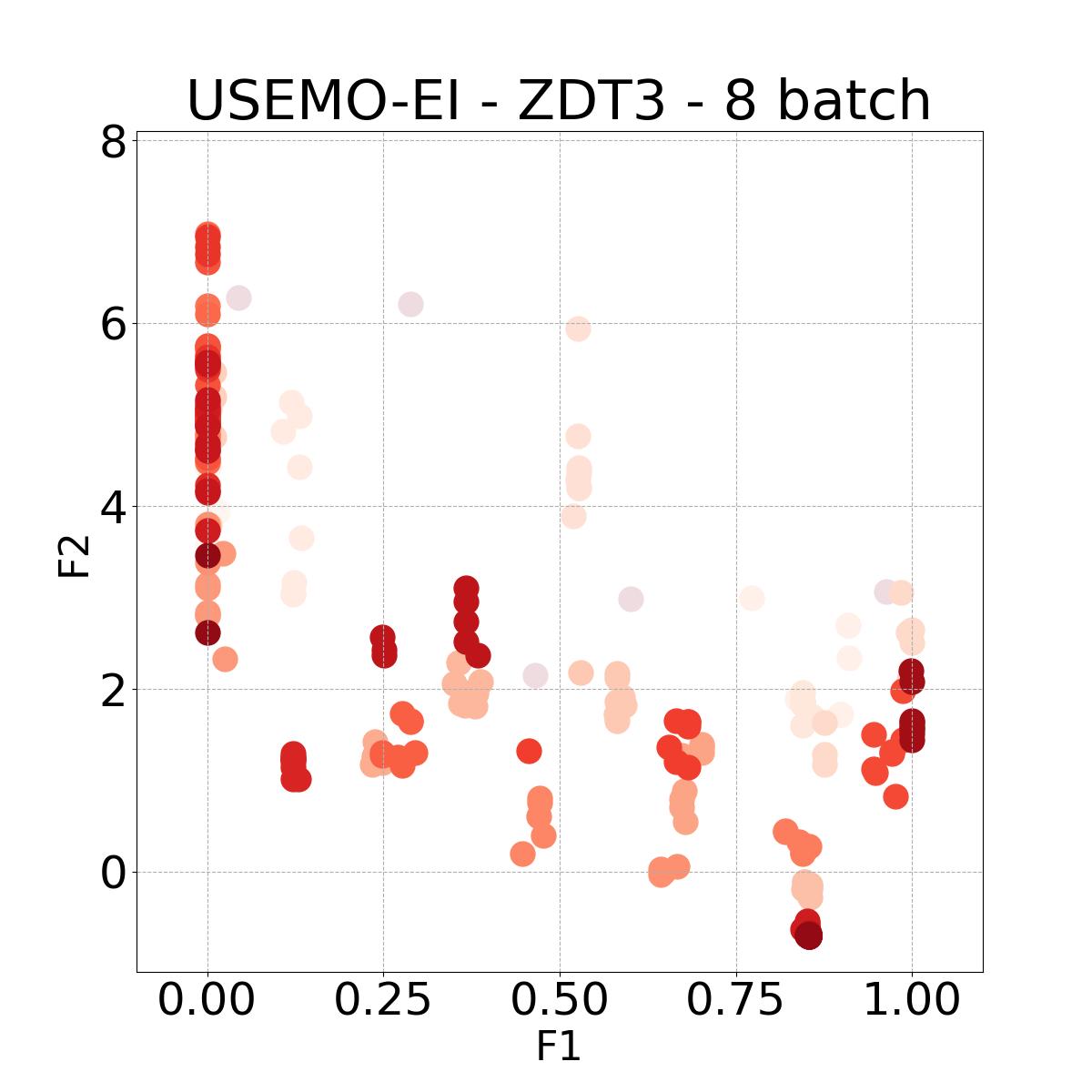
8.4 Visualization of Diversity of Pareto front
In Figure 4, we present illustrative examples of Pareto front figures achieved by each baseline. In each experiment, we deliberately vary the batch size to showcase the consistent diversity of results, irrespective of the batch size chosen. It’s worth noting that several of benchmarks featured in this paper involve more than two objective functions, rendering it impractical to effectively visualize the Pareto front points in a coherent and legible manner.
8.5 Acquisition Function Selection Statistics
Table 1 contains statistics regarding the selection of each acquisition function by the MAB algorithm. It is important to clarify that the goal of the acquisition function selection multi-armed bandit algorithm is not solely to converge to a single acquisition function. Instead, its purpose is to dynamically choose the most appropriate acquisition function at each iteration to maximize overall performance improvement. Therefore, we believe that these statistics are interesting but do not necessarily lead to the conclusion that the most selected acquisition function is necessarily the best for the experiment.
8.6 Additional Real-World Experiments
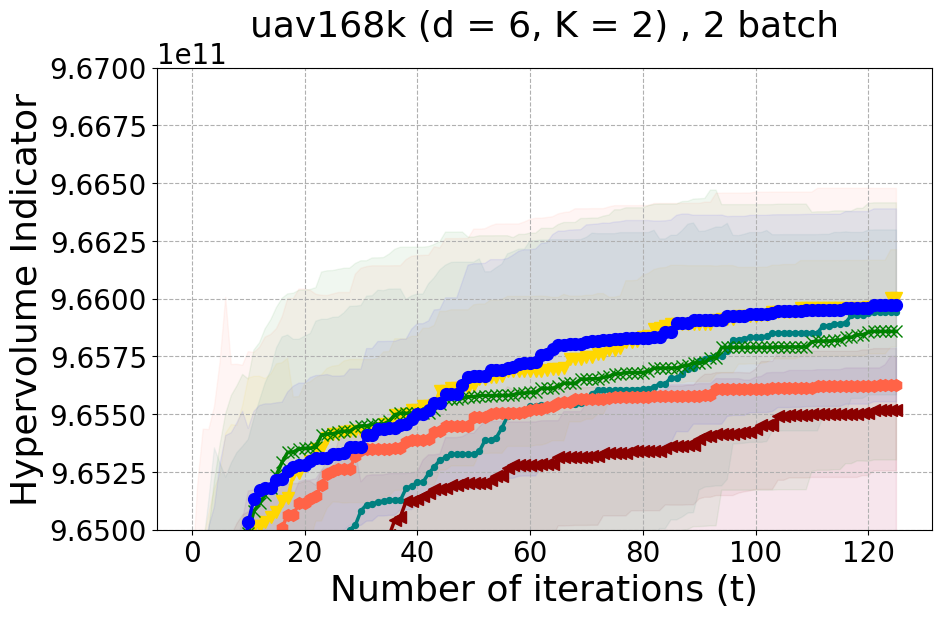
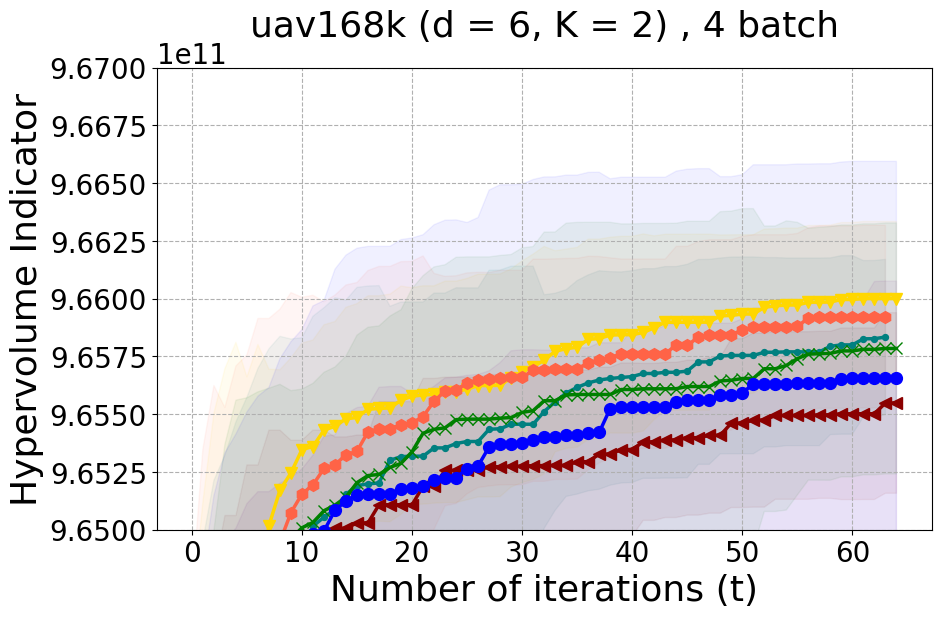
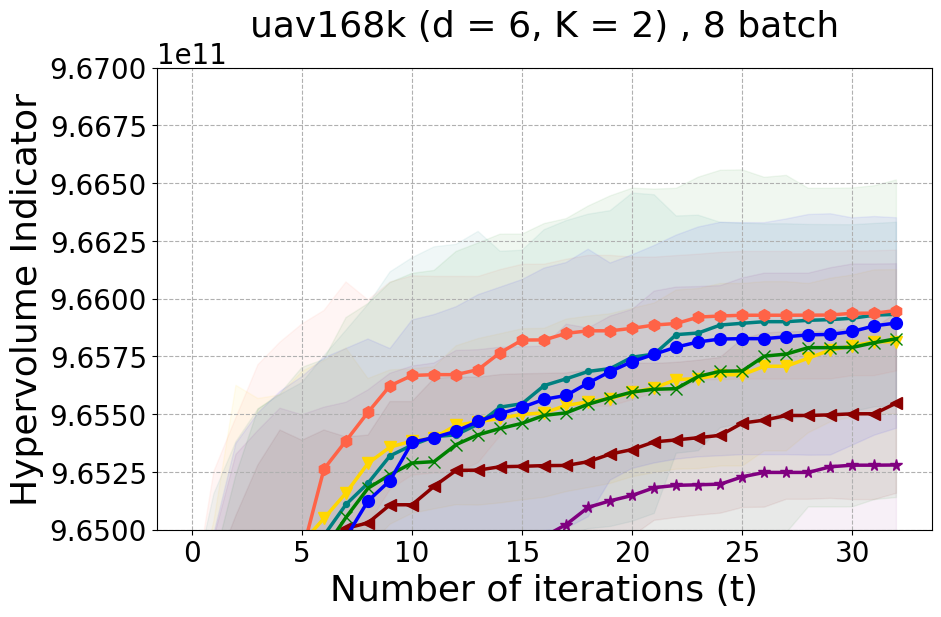
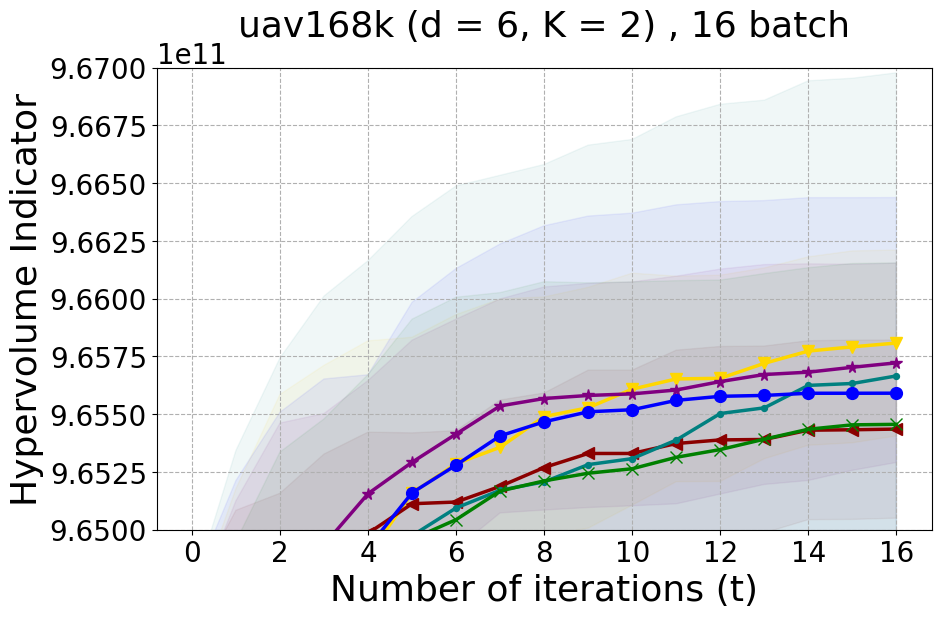
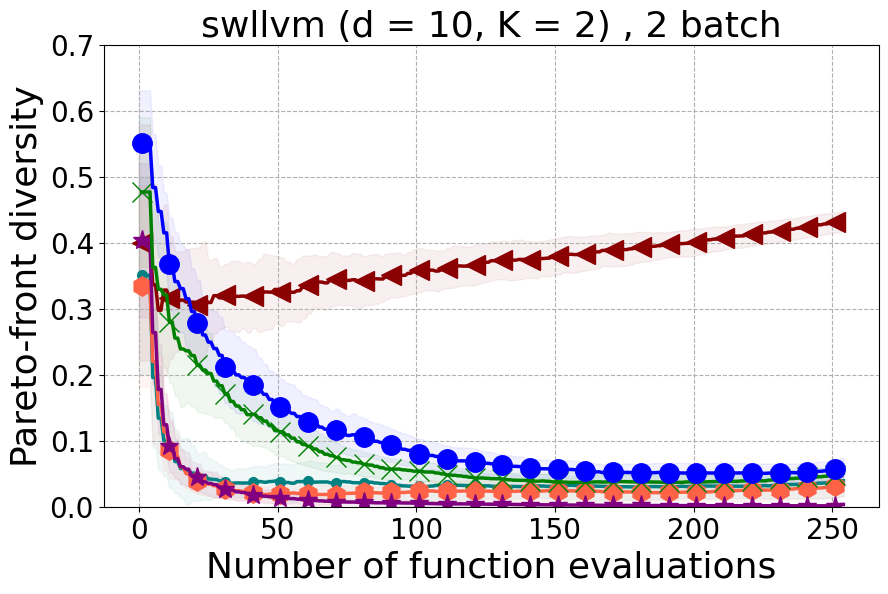
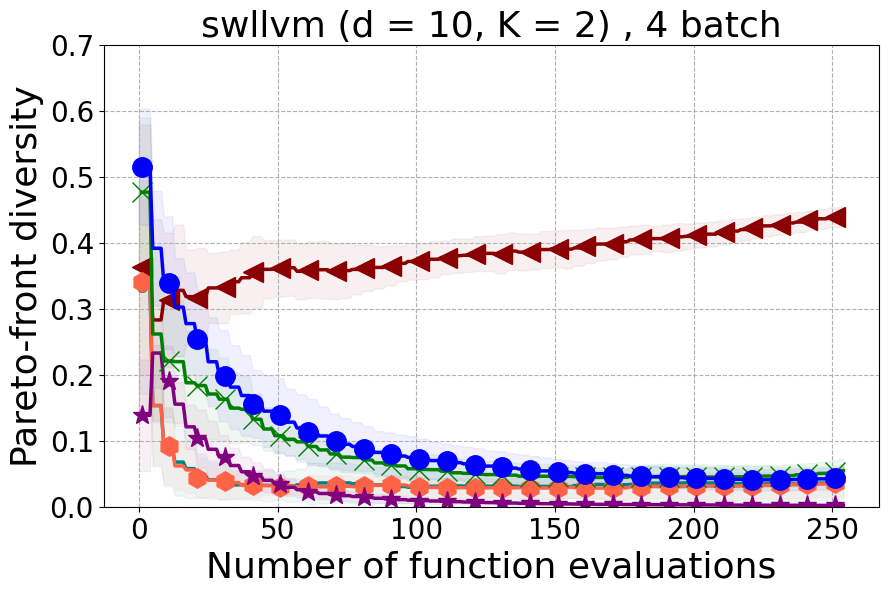
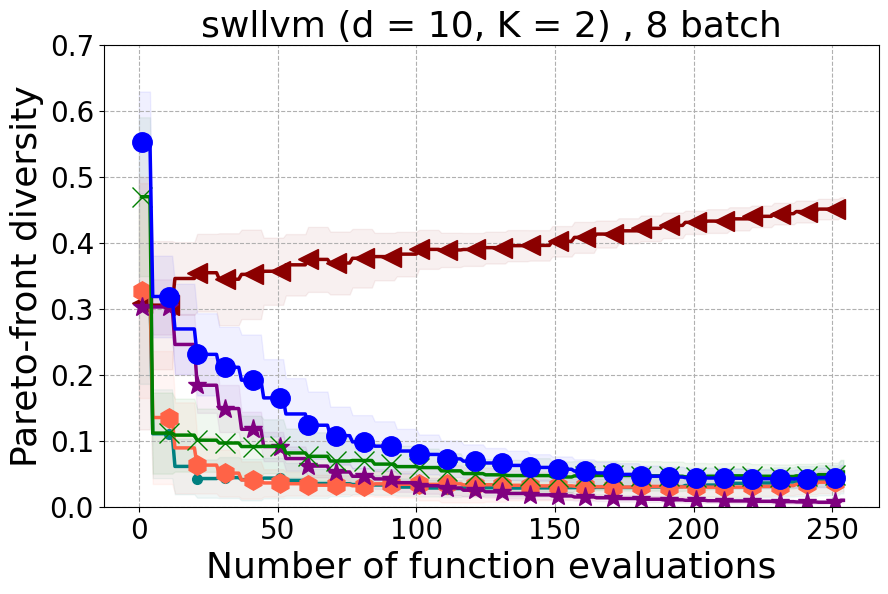
This section offers insights into two supplementary real-world experiments carried out to further demonstrate the effectiveness of PDBO when compared to existing baselines in terms of the hypervolume metric and diversity of the Pareto front.
Unmanned Aerial Vehicle (UAV) power system design: This real-world benchmark [Belakaria et al., 2020b] has two objective functions: minimizing the energy consumption and minimizing the UAV’s total mass. The search space has five input variables defined as the battery cells in series (ranging between 10 and 18), the battery cells in parallel (ranging between 16 and 70), the motor quantity (ranging between 6 and 10), the height of the stator structure (ranging between 80 and 260), and the motor stator winding turns (ranging between 100 and 550). We use a high-fidelity simulator to evaluate the two objective functions for any candidate input configuration.
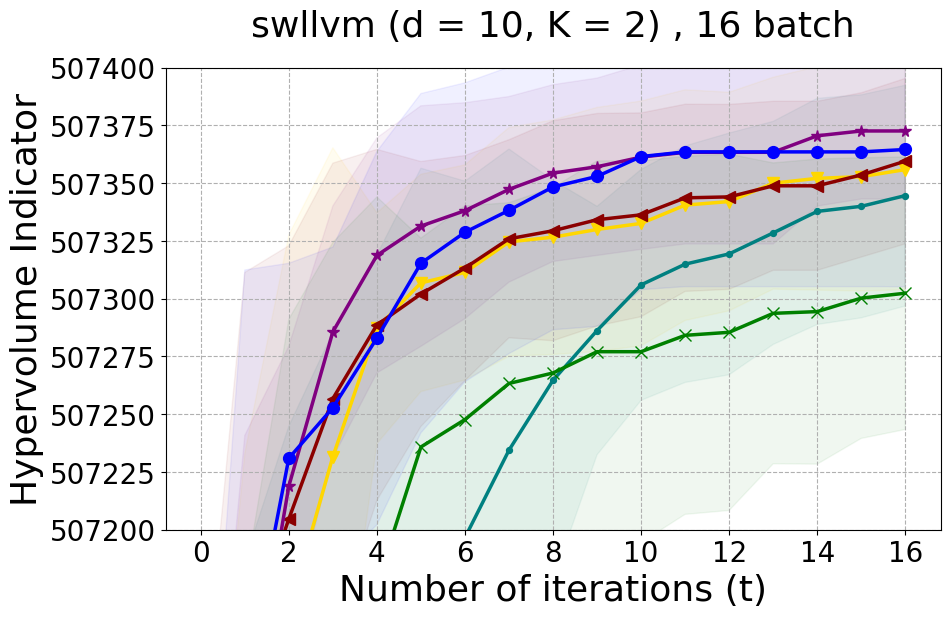
SW-LLVM compiler settings optimization: SW-LLVM [Siegmund et al., 2012] is a compiler settings problem determined by d=10 compiler configurations. The goal of this experiment is to find a setting of the LLVM compiler that optimizes the memory footprint and performance on a given set of software programs.
In Figure 15 and Figure 16, we provide hypervolume and diverse Pareto front (DPF) results for these two additional real-world problems.
| Problem Name | 2-Batch | 4-Batch | 8-Batch | 16-Batch | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TS | EI | UCB | ID | TS | EI | UCB | ID | TS | EI | UCB | ID | TS | EI | UCB | ID | |
| ZDT1 | 1212 | 97 | 11 | 7515 | 1318 | 1412 | 43 | 6717 | 1628 | 1012 | 55 | 6730 | 1021 | 57 | 1110 | 7221 |
| ZDT2 | 2317 | 2211 | 1910 | 3318 | 1718 | 2518 | 1617 | 4030 | 919 | 3127 | 2124 | 3927 | 719 | 4038 | 2429 | 2834 |
| ZDT3 | 15 | 86 | 45 | 8510 | 12 | 1211 | 23 | 8312 | 12 | 1614 | 78 | 7417 | 12 | 2833 | 73 | 6235 |
| DTLZ1 | 1310 | 139 | 75 | 6516 | 1112 | 1311 | 76 | 6717 | 1013 | 1217 | 1010 | 6627 | 1424 | 2026 | 1614 | 4835 |
| DTLZ3 | 76 | 911 | 34 | 7915 | 1619 | 910 | 56 | 6923 | 1320 | 1724 | 910 | 6032 | 2636 | 1532 | 2124 | 3738 |
| DTLZ5 | 43 | 858 | 33 | 54 | 56 | 828 | 32 | 86 | 68 | 6820 | 1010 | 1419 | 717 | 6129 | 149 | 1722 |
| Gear Train Design | 14 | 23 | 11 | 945 | 14 | 23 | 22 | 936 | 27 | 56 | 31 | 888 | 26 | 1015 | 88 | 7918 |
8.7 Ablation Studies
Merits of DPP-Based Batch Selection compared to Greedy HVC selection.
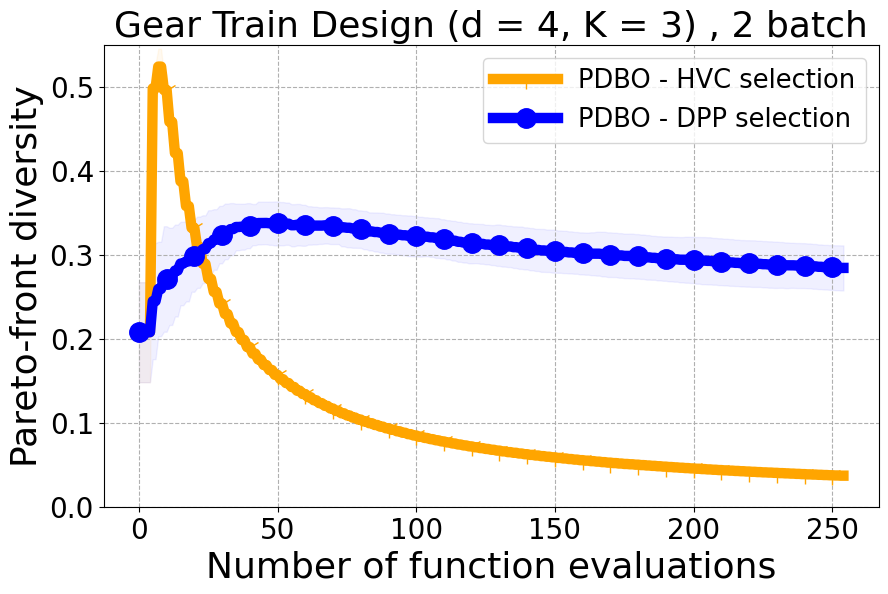
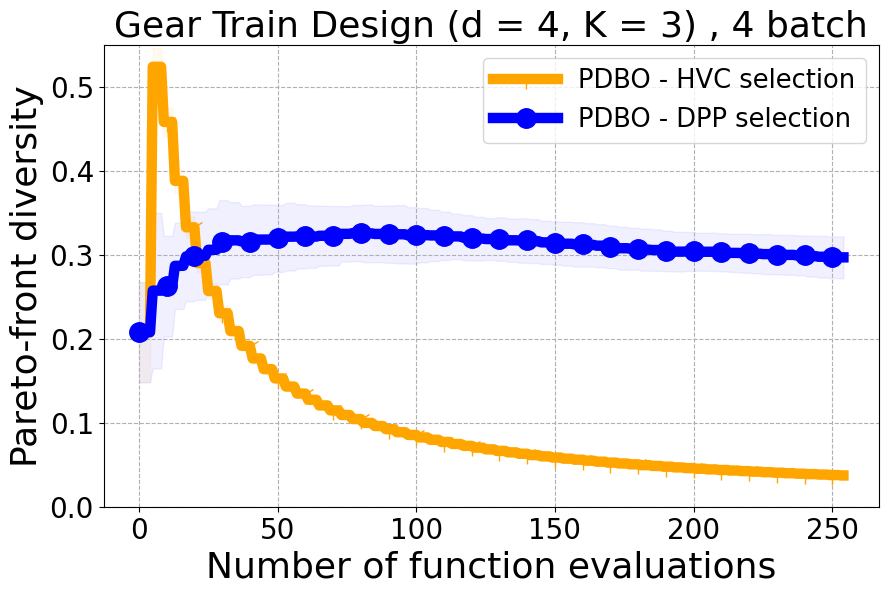
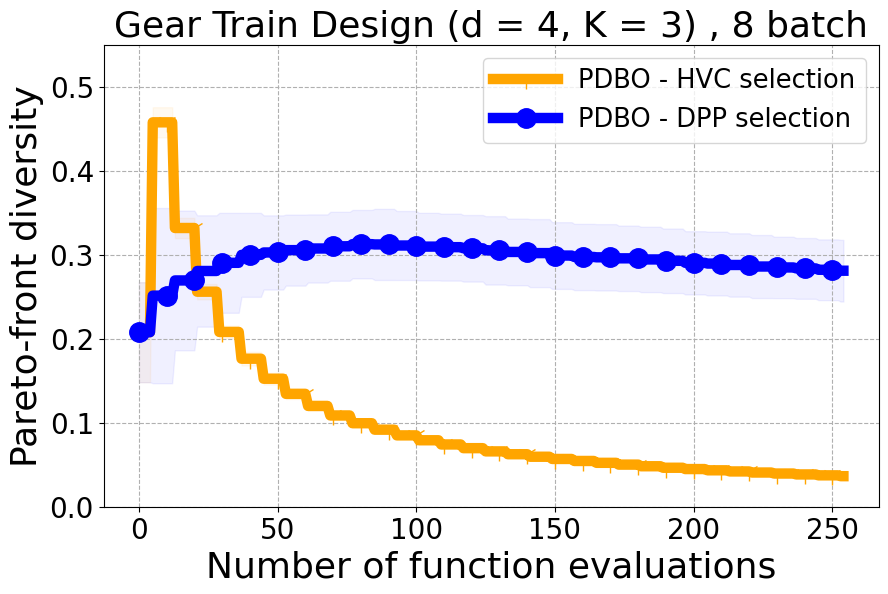
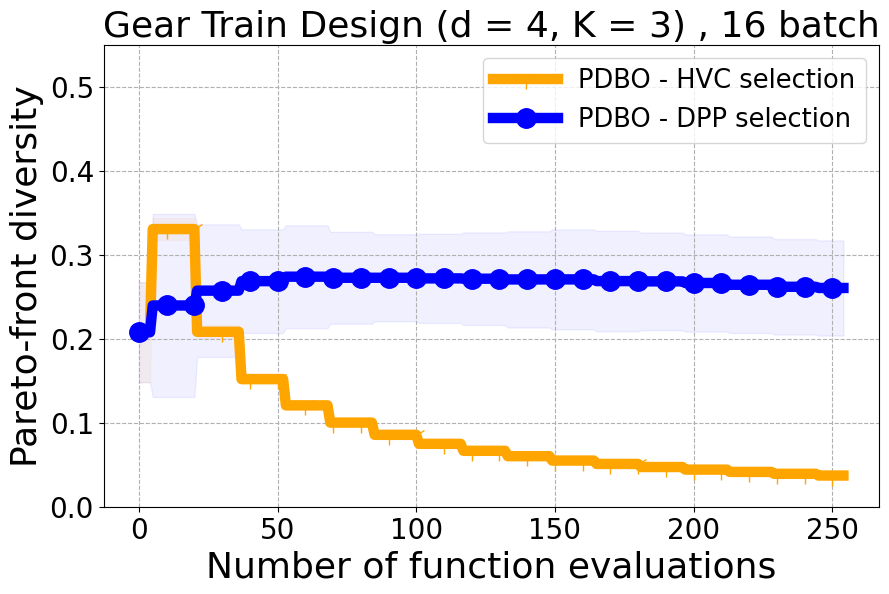
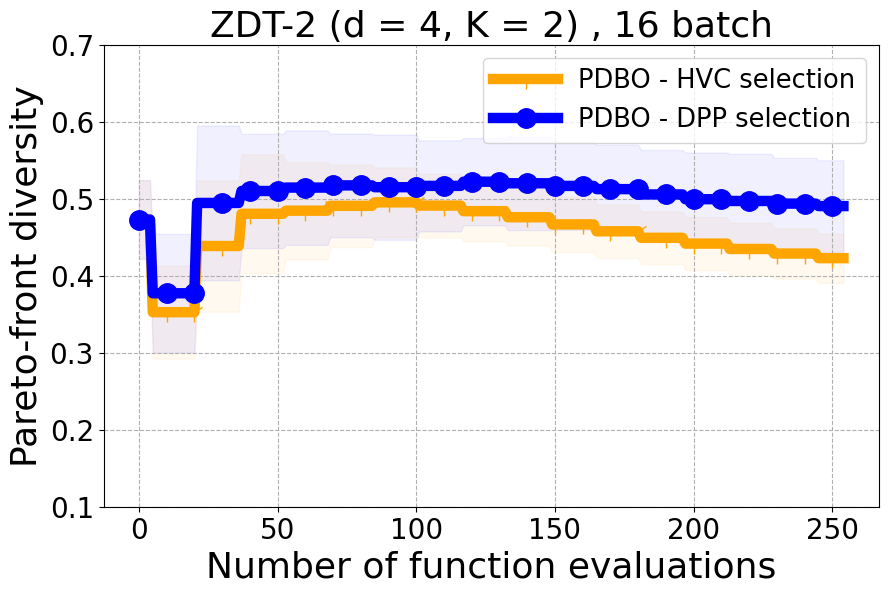
As detailed in Section 4.2 of our paper, we have established that Hypervolume alone may not effectively capture the diversity of individual data points. For a more nuanced assessment of each new point in relation to previously evaluated designs, we turn to Individual Hypervolume Contributions (HVCs). However, selecting points solely based on the highest HVC values presents several potential issues: 1. It may lead to exploitative behavior, as it relies solely on predictive mean information; 2. It may undermine diversity considerations, especially when multiple points exhibit closely ranked HVC values; 3. It may overlook diversity in the input domain, as DPP’s utilization of a kernel allows for a more comprehensive representation of diversity across the input space. Figure 17 presents the results of our ablation study on both a real-world problem and a synthetic problem offering a comparative evaluation of batch selection methods: one based on the highest hypervolume contribution (HVC) and the other based on our proposed multi-objective DPP-based batch selection approach.
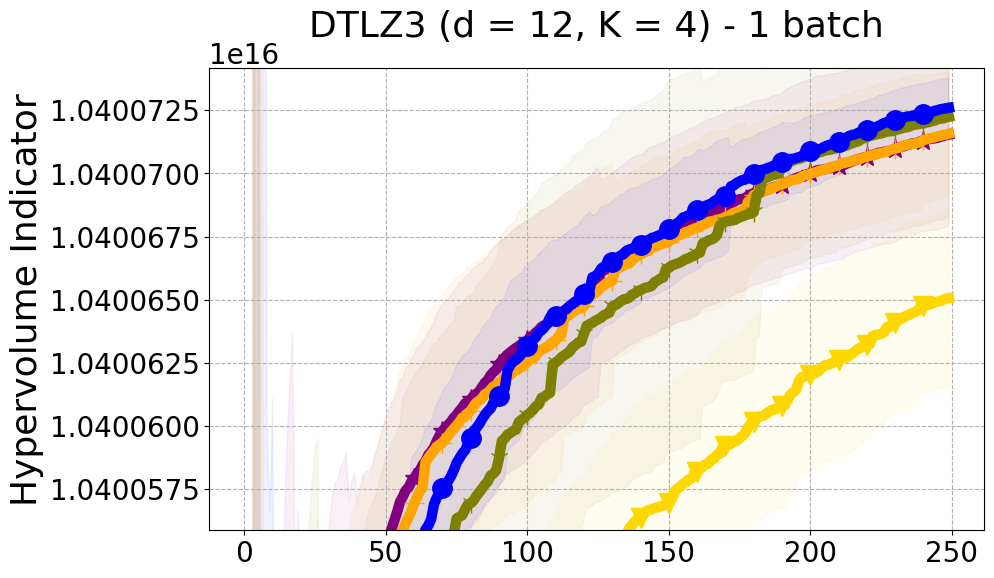
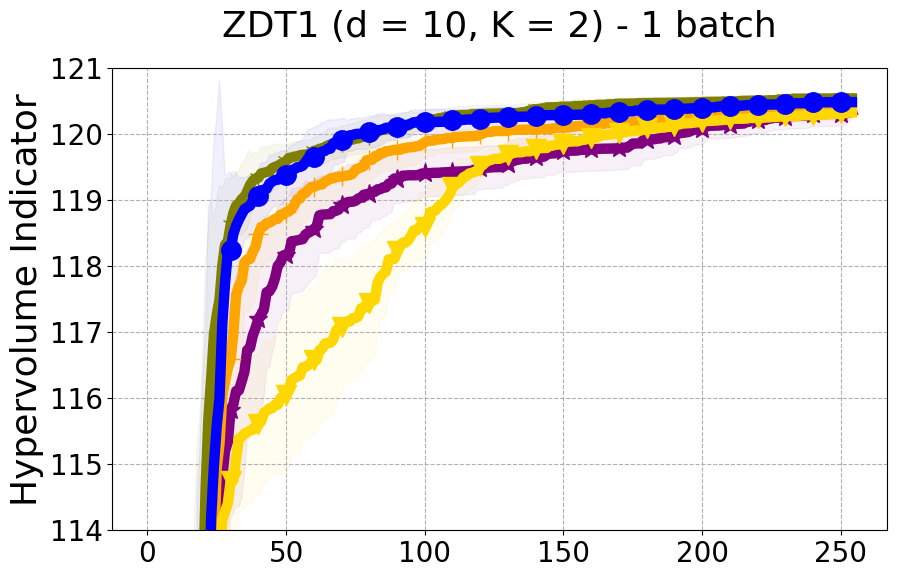
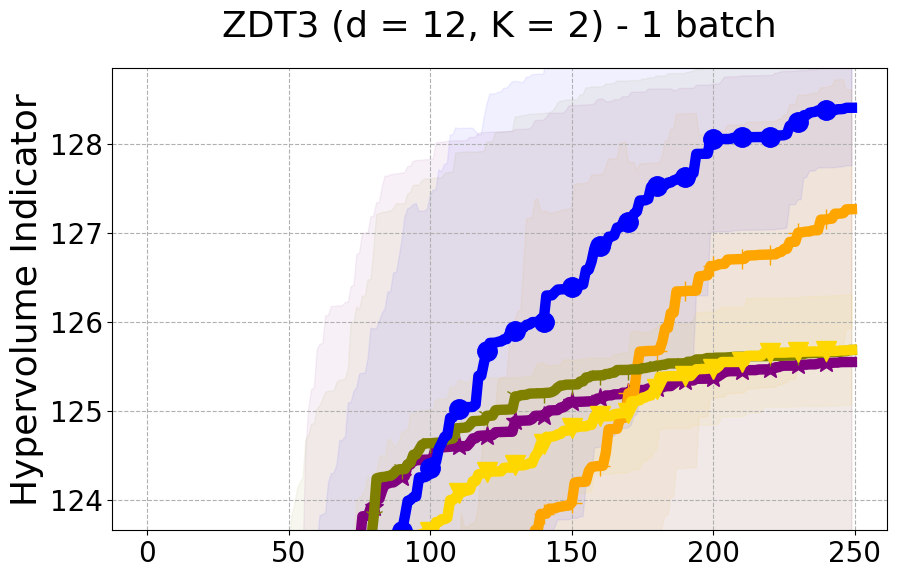
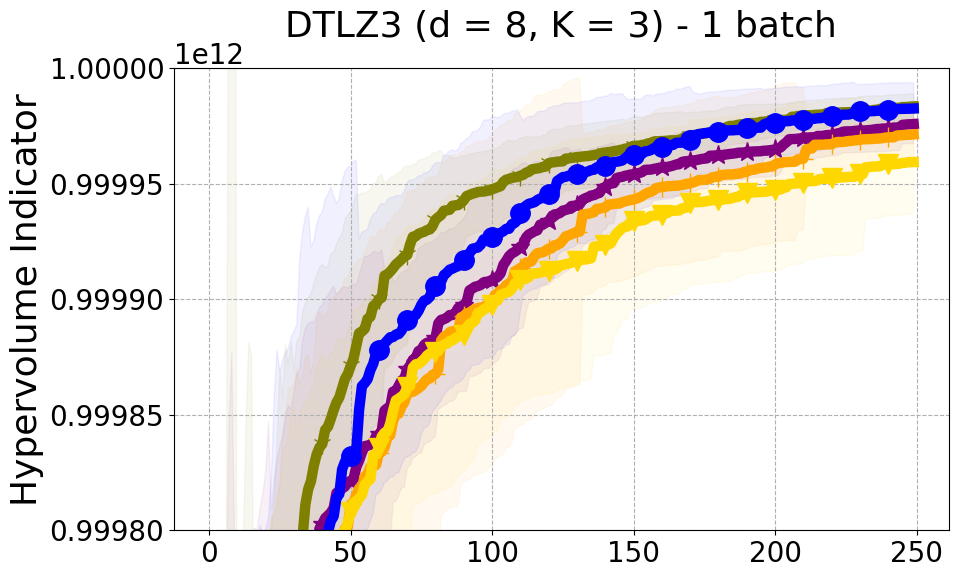

8.8 Additional Diversity Metrics
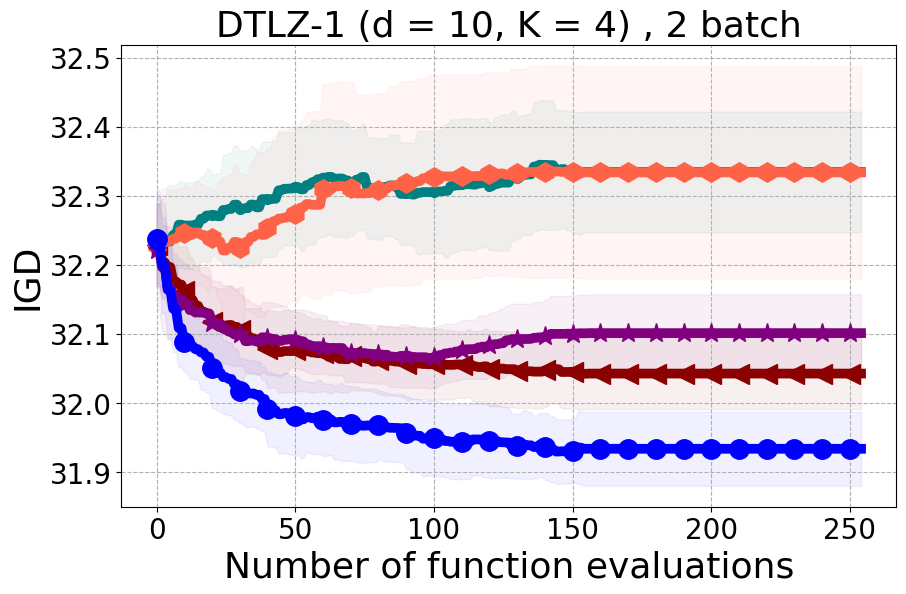
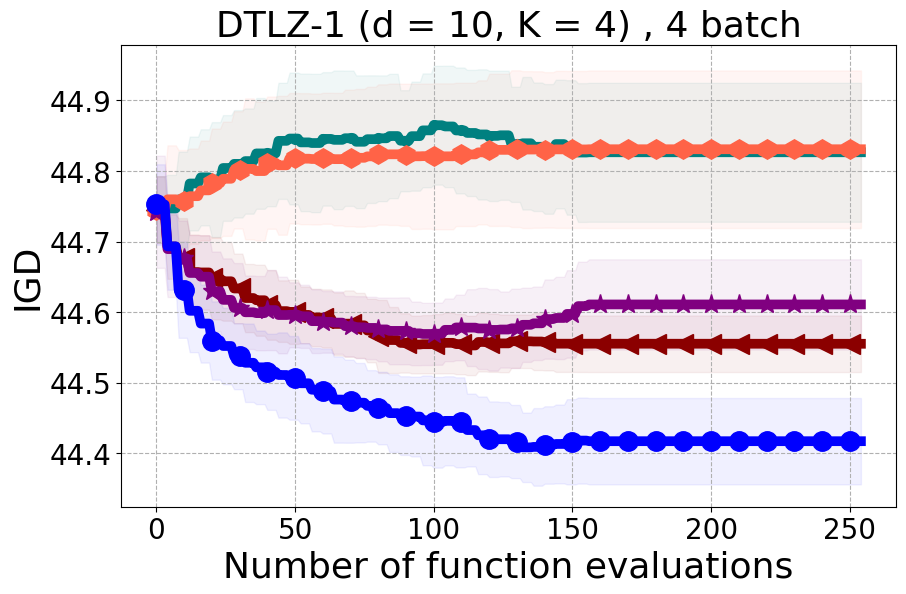
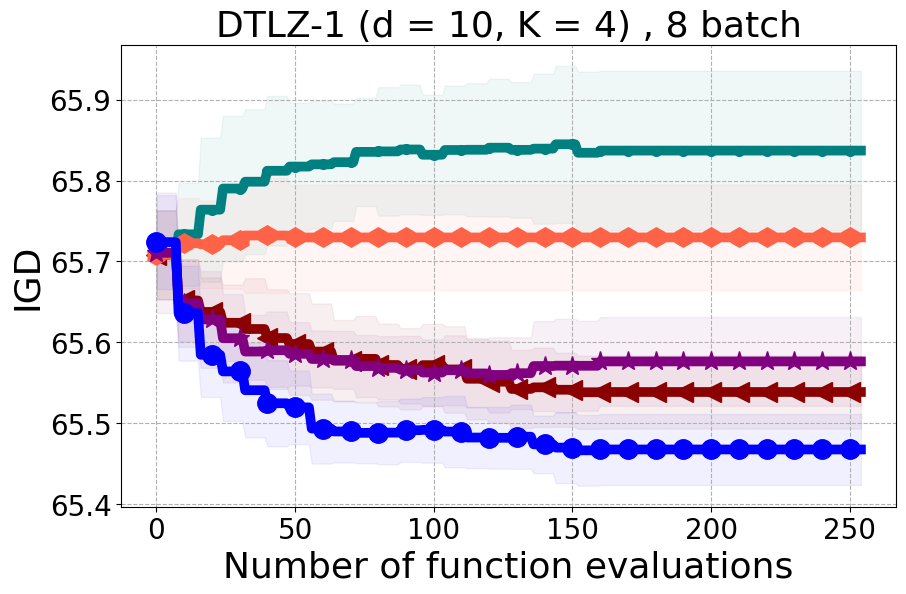
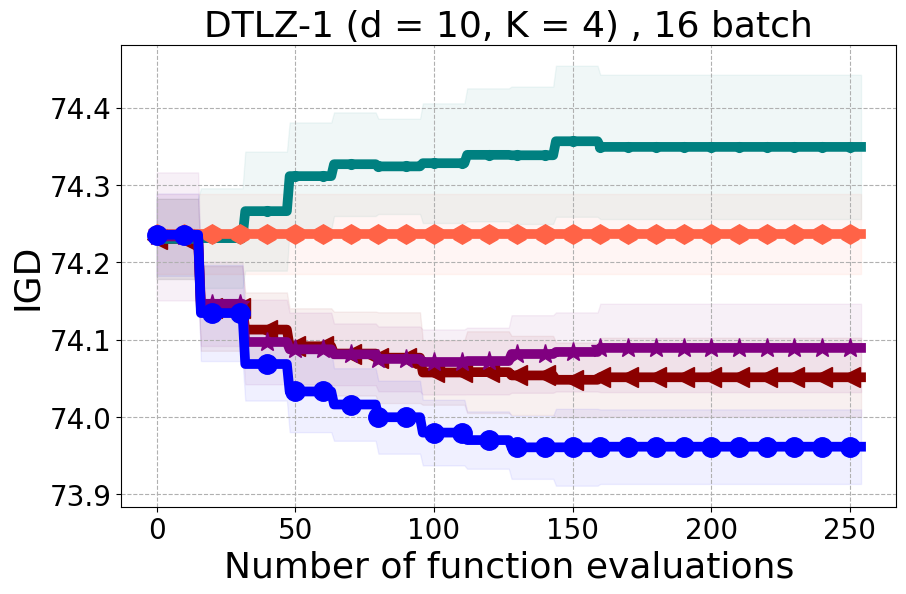
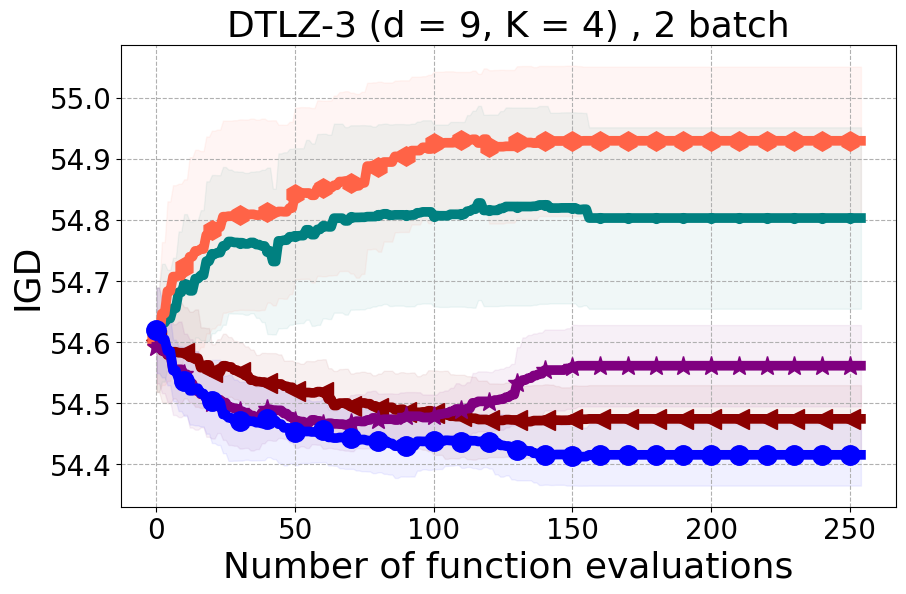
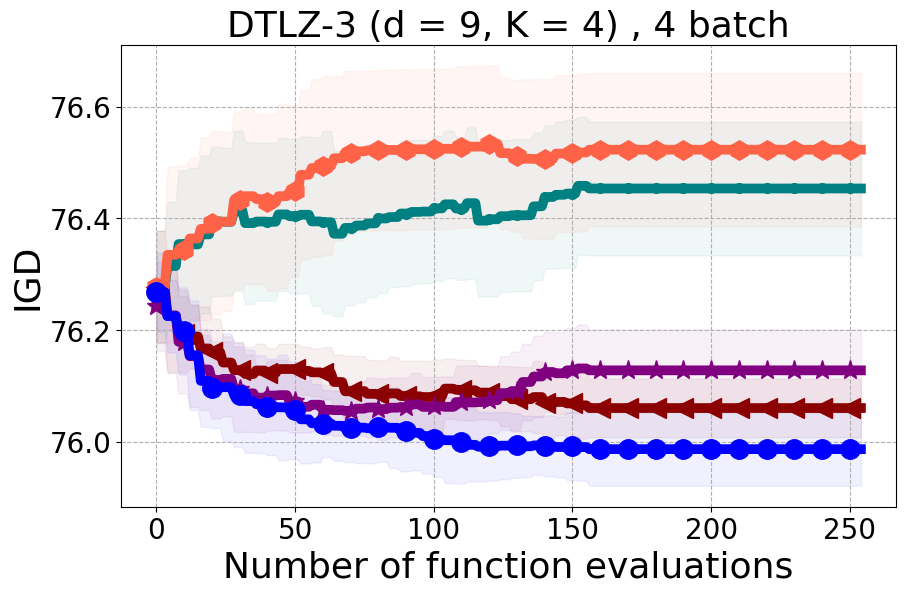
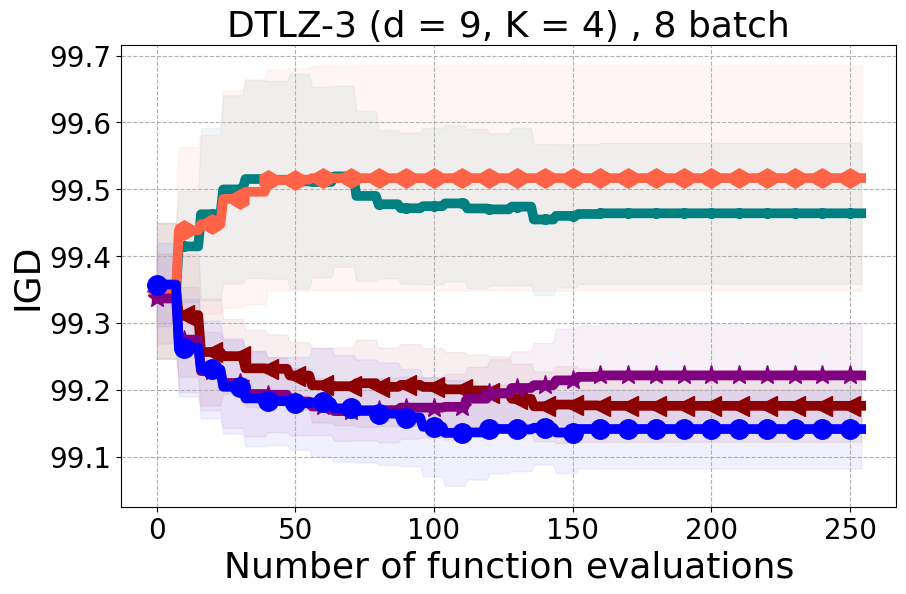
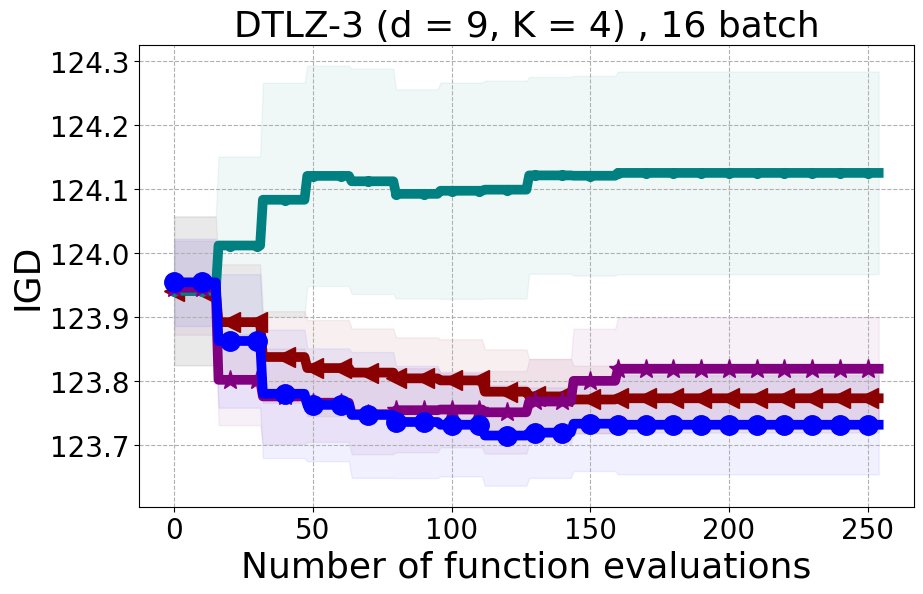
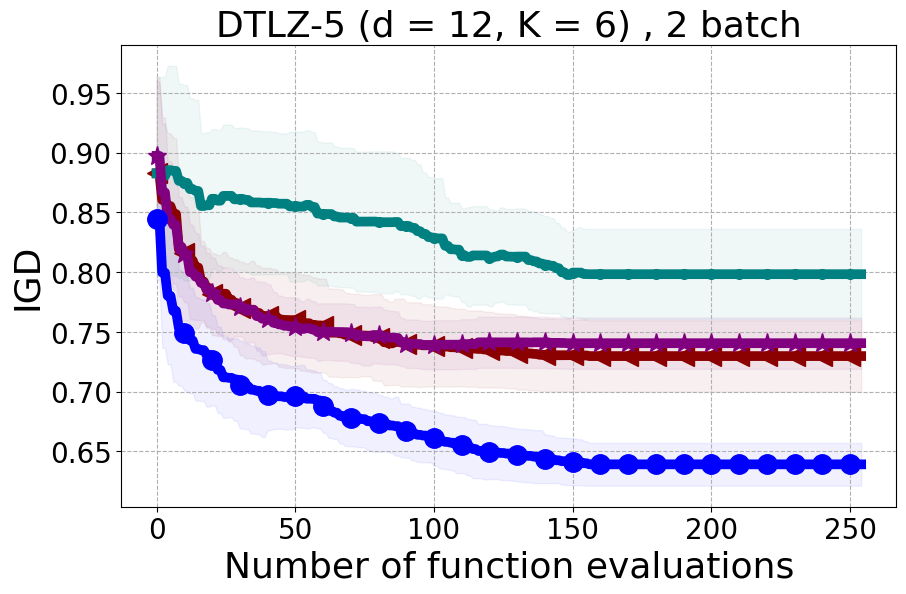
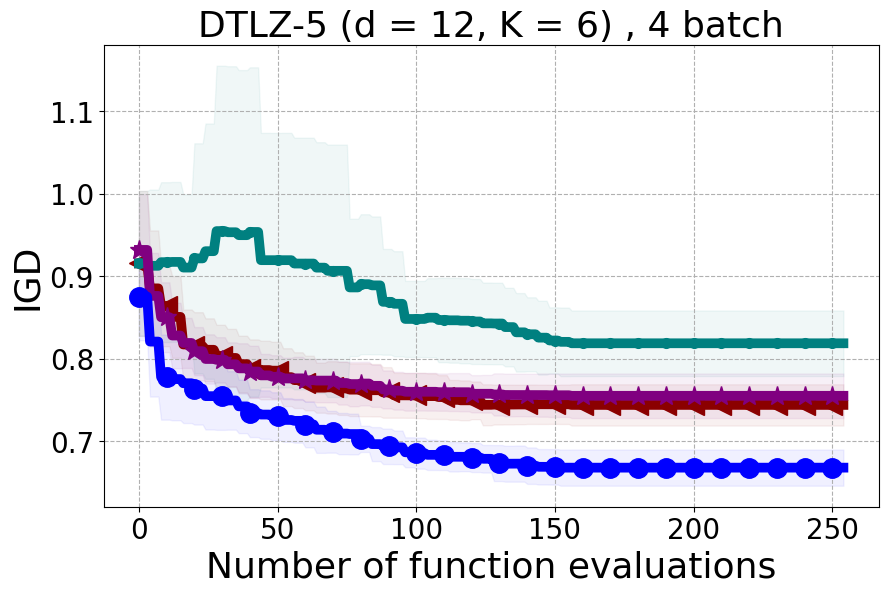
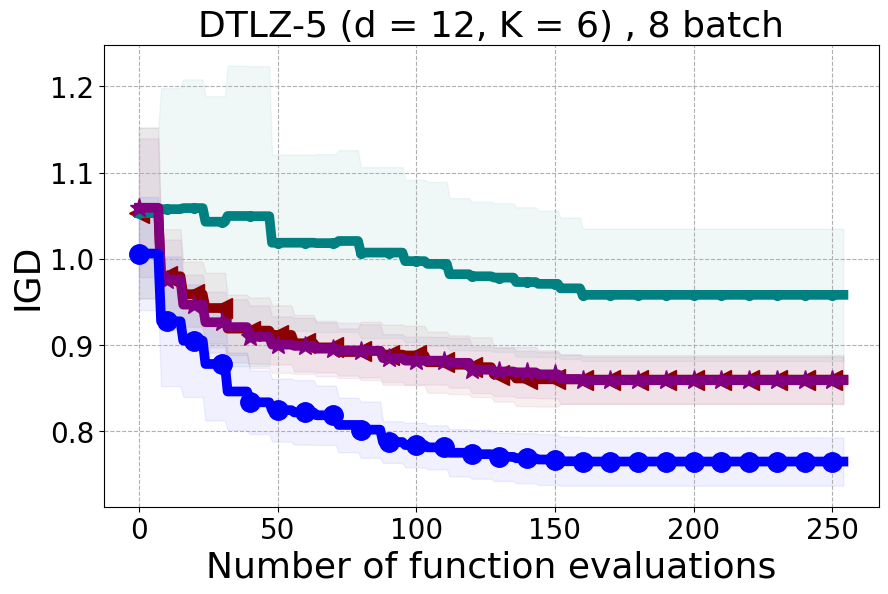
We present examples of our results evaluated using the Inverted Generational Distance (IGD) metric [Coello Coello and Reyes Sierra, 2004]. However, we contend that IGD may not be a suitable metric for assessing diversity. This is because IGD is heavily influenced by the number of points discovered, which can lead to misleading results. As an example, if one baseline uncovers only two points very close to the ideal Pareto front, it may achieve a heavily more favorable IGD value than a method finding 50 diverse points slightly further away. Clearly, the set of two points is not inherently more diverse. Furthermore, the IGD metric relies on a predefined ground truth Pareto front, which is often unavailable in black-box settings, rendering its use less meaningful. Moreover, the choice of the ideal Pareto front shape can impact whether IGD primarily reflects diversity or performance. Recent work [Pierrot et al., 2022] proposed an approach to evaluate diversity for cheap multi-objective problems. However, the proposed approach requires the user to manually define space descriptors. Depending on the descriptors’ definition, the results provided by the metric will change leading to potentially inconsistent results, especially in the black-box expensive setting where it is harder to define the descriptors. To our understanding, there is no clear/known strategy to define the descriptors.
As additional metrics, we employ the Pareto Hypervolume (PHV) to evaluate the quality of the uncovered optimal Pareto front and use the Diversity of Pareto Front (DPF) metric to assess the algorithm’s ability to select diverse designs. We believe that incorporating DPF alongside PHV provides a more comprehensive evaluation of the algorithm since these metrics offer complementary insights into different aspects of performance.
8.9 Experimental Details
This section includes supplementary implementation elements and experimental details.
Table 2 provides information regarding the dimensions, objectives, and reference points utilized for each benchmark problem in the primary hypervolume and DPF results. Additionally, Table 3 presents the hyperparameters of the GP surrogate model. In all experiments, a consistent definition of the GP surrogate model is employed, featuring a zero mean function and an anisotropic Matern 5/2 kernel.
| Problem Name | d | K | reference point |
|---|---|---|---|
| ZDT-1 | 25 | 2 | [11.0, 11.0] |
| ZDT-2 | 4 | 2 | [11.0, 11.0] |
| ZDT-3 | 12 | 2 | [11.0, 11.0] |
| SW-LLVM | 10 | 2 | [1000.0, 500.0] |
| UAV | 6 | 2 | [1e9, 1000.0] |
| Gear Train Design | 4 | 3 | [6.6764, 59.0, 0.4633] |
| DTLZ-1 | 10 | 4 | [400.0, …, 400.0] |
| DTLZ-3 | 9 | 4 | [10000.0, …, 10000.0] |
| DTLZ-5 | 12 | 6 | [10.0, …, 10.0] |
| Hyperparameter name | Hayperparameter value |
|---|---|
| initial l | |
| l range | |
| initial | 1 |
| range | |
| initial | |
| range |
The NSGA-II multi-objective optimization (MOO) solver adopts simulated binary crossover [Deb et al., 1995] with a parameter of , and polynomial mutation [Deb et al., 1996] with a parameter of . It utilizes a population size of 100 and runs for a total of 200 generations to explore the Pareto front of acquisition function values. The initial population is derived from the best current samples identified using non-dominated sorting [Deb et al., 2002b]. As for the baseline NSGA-II algorithm, it employs the same crossover and mutation parameters ( and ), but the population size is adjusted to match the batch size, and the number of generations aligns with the number of algorithm iterations. These hyperparameters are as mentioned in [Konakovic Lukovic et al., 2020]
Table 4 presents a comprehensive comparison of the runtime performance for all the methods discussed. The qEHVI and qPAREGO techniques have the capability to leverage GPUs for their execution. However, considering the limited accessibility of GPUs for many BO problems, we also provide an analysis of these methods when executed on CPUs. It should be noted that the runtime of qEHVI-CPU and qPAREGO-CPU is notably longer when compared to their counterparts. Therefore, for these two methods, we report the average runtime based on 4 runs, whereas for all other experiments, we report the runtime based on 25 runs. The experiments utilizing GPUs were conducted using four NVIDIA Quadro RTX 6000 GPUs, while the CPU experiments were performed on an AMD EPYC 7451 24-Core Processor.
Practical Issues and Limitations of Existing Baselines
The two state-of-the-art methods are DGEMO and qEHVI. The both have practical issues and limitations leading to their inapplicability in some experiments. Below we provide a detailed explanation of these limitations:
-
•
DGEMO: One algorithmic step of the DGEMO algorithm is to divide the points in the Pareto front into different regions (line 9, Algorithm 1 in [Konakovic Lukovic et al., 2020]). Depending on the number of objective functions, the algorithm used to divide the Pareto front into regions would be different. In the implementation of DGEMO, only the cases of 2 and 3 functions were implemented, any case beyond 3 objectives is not handled. So this limitation of the DGEMO approach prevents it from being applicable to any problem. The inability to handle more than 3 objectives was not explicitly discussed in the paper. Therefore, no solution was suggested for it and no implementation was provided for this case. Finding the appropriate algorithm for the splitting approach when the number of objectives exceeds 3 and implementing it is not straightforward, and a research investigation in itself.
-
•
qEHVI: qEHVI algorithm has the capability to use auto differentiation and batch selection parallelization. However, this leads to high memory consumption when the batch sizes increase or when the input dimension or the number of objective functions increases, leading to an out-of-memory issue even on (GPU) machines with 40 GB of memory. Unfortunately, we do not have access to higher memory machines. We believe that this is a limitation of the approach since most scientists and practitioners using BO algorithms might not necessarily have access to very high-memory GPU machines.
8.10 Limitations
Our approach overcomes the adaptive acquisition function selection problem via a MAB approach. However, our algorithm requires the proper selection of the MAB algorithm hyperparameters, namely, the decay factor and the probability of selection hyperparameter . We set these hyperparameters manually based on a previous study of their suitable value [Hoffman et al., 2011]. We leave the study of the adaptive selection of hyperparameters to future work. Another limitation of our work is its inability to handle high-dimensional search space. However, it is important to note that this work is not proposed in the context of high-dimensional BO, and it can be synergistically combined with effective high-dimensional BO approaches such as [Eriksson et al., 2019] to handle high-dimensional search spaces.

| Problem Name | Batch Size | PDBO | DGEMO | qEHVI CPU GPU | NSGA-II | qPAREGO CPU GPU | USEMO-EI | ||
|---|---|---|---|---|---|---|---|---|---|
| ZDT-1 | 2 | 52.66 | 58.22 | 192.64 | 7.31 | 0.01 | 66.57 | 3.64 | 1.34 |
| 4 | 57.73 | 57.93 | 510.11 | 16.17 | 0.01 | 113.00 | 5.94 | 1.47 | |
| 8 | 62.57 | 60.24 | 1781.94 | 53.67 | 0.01 | 226.20 | 11.93 | 1.55 | |
| 16 | 70.40 | 65.28 | NA | NA | 0.01 | 667.65 | 44.92 | 1.50 | |
| ZDT-2 | 2 | 52.37 | 51.47 | 48.22 | 2.95 | 0.01 | 16.58 | 1.37 | 0.89 |
| 4 | 56.70 | 51.96 | 127.10 | 5.25 | 0.01 | 26.40 | 2.04 | 0.97 | |
| 8 | 60.25 | 52.14 | 626.71 | 15.67 | 0.01 | 56.98 | 3.43 | 0.95 | |
| 16 | 64.91 | 51.94 | NA | NA | 0.01 | 163.08 | 9.05 | 0.91 | |
| ZDT-3 | 2 | 49.52 | 61.81 | 201.73 | 8.95 | 0.01 | 69.55 | 4.23 | 1.18 |
| 4 | 54.46 | 61.42 | 530.65 | 22.54 | 0.01 | 114.35 | 9.48 | 1.33 | |
| 8 | 57.74 | 60.34 | 1871.59 | 68.70 | 0.01 | 247.07 | 18.39 | 1.33 | |
| 16 | 65.46 | 60.20 | NA | NA | 0.01 | 745.80 | 43.90 | 1.24 | |
| Gear Train Design | 2 | 30.42 | 77.65 | 60.01 | 1.54 | 0.01 | 17.82 | 0.92 | 1.09 |
| 4 | 34.51 | 77.15 | 316.89 | 5.62 | 0.01 | 43.32 | 2.19 | 1.08 | |
| 8 | 40.50 | 76.83 | 1534.78 | 37.66 | 0.01 | 200.46 | 7.05 | 1.08 | |
| 16 | 51.12 | 74.88 | NA | NA | 0.01 | 780.58 | 17.70 | 0.96 | |
| DTLZ-1 | 2 | 55.50 | NA | 267.98 | 25.99 | 0.02 | 112.70 | 7.43 | 2.28 |
| 4 | 60.86 | NA | NA | NA | 0.02 | 240.43 | 13.41 | 2.25 | |
| 8 | 64.68 | NA | NA | NA | 0.03 | 545.08 | 21.82 | 2.23 | |
| 16 | 75.46 | NA | NA | NA | 0.05 | 1492.85 | 45.54 | 2.16 | |
| DTLZ-3 | 2 | 54.29 | NA | NA | NA | 0.02 | 111.90 | 9.20 | 2.07 |
| 4 | 58.44 | NA | NA | NA | 0.02 | 265.97 | 16.58 | 2.10 | |
| 8 | 63.90 | NA | NA | NA | 0.03 | 603.90 | 25.97 | 2.05 | |
| 16 | 74.11 | NA | NA | NA | 0.04 | 1676.98 | 50.30 | 2.02 | |
| DTLZ-5 | 2 | 242.78 | NA | NA | NA | 1.15 | 146.71 | 6.89 | 4.86 |
| 4 | 244.08 | NA | NA | NA | 4.64 | 201.05 | 9.08 | 4.81 | |
| 8 | 268.75 | NA | NA | NA | 1.59 | 368.43 | 12.69 | 4.41 | |
| 16 | 303.58 | NA | NA | NA | 2.06 | 935.33 | 29.46 | 4.20 | |