Pattern Alternating Maximization Algorithm for Missing Data in “Large P, Small N” Problems
Abstract
We propose a new and computationally efficient algorithm for maximizing the observed log-likelihood for a multivariate normal data matrix with missing values. We show that our procedure based on iteratively regressing the missing on the observed variables, generalizes the standard EM algorithm by alternating between different complete data spaces and performing the E-Step incrementally. In this non-standard setup we prove numerical convergence to a stationary point of the observed log-likelihood.
For high-dimensional data, where the number of variables may greatly exceed
sample size, we add a Lasso penalty in the regression part of our algorithm
and perform coordinate descent approximations. This leads to a
computationally very attractive technique with sparse regression
coefficients for missing data imputation. Simulations and results on four
microarray datasets show that the new method often outperforms other imputation techniques as k-nearest neighbors imputation, nuclear norm
minimization or a penalized likelihood approach with an -penalty on
the inverse covariance matrix.
Keywords Missing data, observed likelihood, (partial) E- and M-Step, Lasso, penalized variational free energy
1 Introduction and Motivation
Missing data imputation for large datasets is an essential pre-processing step in complex data applications. A well-known example are microarray datasets which contain the expression values of thousands of genes from a series of experiments. Missing values are inherent to such datasets. They occur for diverse reasons, e.g. insufficient resolution, image corruption, dust or scratches on the slides. Apart from microarrays, much attention has been recently given to the so-called matrix completion problem. Most prominent in this context is the “Netflix” movie rating dataset with rows corresponding to customers and columns representing their movie rating and the customers have seen/rated only a small fraction of all possible movies. The goal is to estimate the ratings for unseen movies. Filling in missing values in gene expression data is a inherently different problem from dealing with missings in the context of matrix completion. For example the Netflix dataset involves a huge number of customers (480’000) and movies (17’000) with about 98% of the ratings missing. In big contrast, microarrays have the typical “large p, small n” form where the number of different genes is in the ten thousands and the number of experimental conditions is in the hundreds. Usually only a small fraction of the expression values are missing. In this paper, we propose a new and computationally efficient EM-type algorithm for missing value imputation in the high-dimensional multivariate normal model where the number of variables can greatly exceed the number of independent samples . Our motivating examples are microarray datasets with different genes (variables) and different experimental conditions (samples). The Gaussian assumption in our model is used for computation of the likelihood but empirical findings suggest that the method is useful for many continuous data matrices.
There is a growing literature of missing value imputation methods. For microarray data, examples are k-nearest neighbors imputation and singular value decomposition imputation (Troyanskaya et al., 2001), imputation based on Bayesian principal component analysis (Oba et al., 2003) or the local least squares imputation from Kim et al. (2006). For a review and a discussion on microarray data imputation see Aittokallio (2010). In the context of the so-called matrix completion problem, where the goal is to recover a low-rank matrix from an incomplete set of entries, it has been shown in a series of fascinating papers that one can recover the missing data entries by solving a convex optimization problem, namely, nuclear-norm minimization subject to data constraints (Candès and Recht, 2009; Candès and Tao, 2010; Keshavan et al., 2010). Efficient convex algorithms for the matrix completion problem were proposed by Cai et al. (2010) and Mazumder et al. (2010). If the missing data problem does not arise from a near low rank matrix scenario, there is substantial room to improve upon the convex matrix completion algorithms. We will empirically demonstrate this point for some microarray high-throughput biological data.
Here, we address the missing data problem through a likelihood approach (Little and Rubin, 1987; Schafer, 1997). We model the correlation between different variables in the data by using the Multivariate Normal Model (MVN) with a p-dimensional covariance matrix . Recently, in the high-dimensional setup with , Städler and Bühlmann (2012) proposed to maximize the penalized observed log-likelihood with an -penalty on the inverse covariance matrix. They called their method MissGLasso, as an extension of the GLasso (Friedman et al., 2008) for missing data. A similar approach, in the context of so-called transposable models, is given by Allen and Tibshirani (2010).
The MissGLasso uses an EM algorithm for optimization of the penalized observed log-likelihood. Roughly, the algorithm can be summarized as follows. In the E-Step, for each sample, the regression coefficients of the missing against the observed variables are computed from the current estimated covariance matrix . In the following M-Step, the missing values are imputed by linear regressions and is re-estimated by performing a GLasso on completed data. There are two main drawbacks of this algorithm in a high-dimensional context. First, the E-Step is rather complex as it involves (for each sample) inversion and multiplication of large matrices in order to compute the regression coefficients. Secondly, a sparse inverse covariance does not imply sparse regression coefficients while we believe that in high-dimensions, sparse regression coefficients would enhance imputations.
Our new algorithm, MissPALasso (Missingness Pattern Alternating Lasso algorithm) in this paper, generalizes the E-Step in order to resolve the disadvantages of MissGLasso. In particular, inversion of a matrix (in order to compute the regression coefficients) will be replaced by a simple soft-thresholding operator. In addition, the regression coefficients will be sparse, which leads to a new sparsity concept for missing data estimation.
In order to motivate MissPALasso, we develop first the Missingness Pattern Alternating maximization algorithm (MissPA) for optimizing the (unpenalized) observed log-likelihood. MissPA generalizes the E- and M-Step of the standard EM originally proposed by Dempster et al. (1977) by alternating between different complete data spaces and performing the E-Step incrementally. Such a generalization does not fit into any of the existing methodologies which extend the standard EM. However, by exploiting the special structure of our procedure and applying standard properties of the Kullback-Leibler divergence, we prove convergence to a stationary point of the observed log-likelihood.
The further organization of the paper is as follows: Section 2 introduces the setup and the useful notion of missingness patterns. In Section 3 we develop our algorithms: MissPA is presented in Section 3.2 and MissPALasso then follows in Section 3.3 as an adapted version for high-dimensional data with . Section 4 compares performance of MissPALasso with other imputation methods on simulated and real data and reports on computational efficiency. Finally, in Section 5, we present some mathematical theory which describes the numerical properties of the Missingness Pattern Alternating maximization algorithm.
2 Setup
We assume has a p-variate normal distribution with mean and covariance . In order to simplify the notation we set without loss of generality : for , some of the formulae involve the parameter and an intercept column of in the design matrices but conceptually, we can proceed as for the case with . We then write , where represents an i.i.d. random sample of size , denotes the set of observed values, and the missing data.
Missingness Patterns and Different Parametrizations
For our purpose it will be convenient to group rows of the matrix according to their missingness patterns (Schafer, 1997). We index the unique missingness patterns that actually appear in our data by . Furthermore, with and we denote the set of observed variables and the set of missing variables, respectively. is the index set of the samples (row numbers) which belong to pattern , whereas stands for the row numbers which do not belong to that pattern. By convention, samples with all variables observed do not belong to a missingness pattern.
Consider a partition of a single Gaussian random vector. It is well known that follows a linear regression on with regression coefficients and covariance given by
| (2.1) | |||||
Consequently, we can write the density of as
i.e., the density can be characterized by either the parameter or . With the transformation (2.1) we can switch between both parametrizations.
Observed Log-Likelihood and Maximum Likelihood Estimation (MLE)
A systematic approach to estimate the parameter of interest from maximizes the observed log-likelihood given by
| (2.2) |
Inference for can be based on the observed log-likelihood (2.2) if the underlying missing data mechanism is ignorable. The missing data mechanism is said to be ignorable if the probability that an observation is missing may depend on but not on (Missing at Random) and if the parameters of the data model and the parameters of the missingness mechanism are distinct. For a precise definition see Little and Rubin (1987).
Explicit maximization of is only possible for special missing data patterns. Most prominent are examples with a so-called monotone missing data pattern (Little and Rubin, 1987; Schafer, 1997), where is more observed than , which is more observed than , and so on. In this case, the observed log-likelihood factorizes and explicit maximization is achieved by performing several regressions. For a general pattern of missing data, the standard EM algorithm is often used for optimization of (2.2). See Schafer (1997) for a detailed description of the algorithm. In the next section we present an alternative method for maximizing the observed log-likelihood. We will argue that this new algorithm is computationally more efficient than the standard EM.
3 Pattern Alternating Missing Data Estimation and
-Regularization
For each missingness pattern, indexed by , we introduce some further notation:
Thus, is the submatrix of with rows belonging to the th pattern. Similarly, is the matrix with rows not belonging to the th pattern. In the same way we define and . For example, is defined as the matrix with
3.1 MLE for Data with a Single Missingness Pattern
Assume that the data matrix has only one single missingness pattern, denoted by . This is the most simple example of a monotone pattern. The observed log-likelihood factorizes according to:
| (3.3) |
The left and right part in Equation (3.1) can be maximized separately. The first part is maximized by the sample covariance of the observed variables based on all samples, whereas the second part is maximized by a regression of the missing against observed variables based on only the fully observed samples. In formulae:
| (3.4) |
and
| (3.5) |
Having these estimates at hand, it is easy to impute the missing data:
It is important to note, that, if interested in imputation, only the regression part of the MLE is needed and the estimate in (3.4) is superfluous.
3.2 MLE for General Missing Data Pattern
We turn now to the general case, where we have more than one missingness pattern, indexed by . The general idea of the new algorithm is as follows. Assume we have some initial imputations for all missing values. Our goal is to improve on these imputations. For this purpose, we iterate as follows:
-
•
Keep all imputations except those of the st missingness pattern fixed and compute the single pattern MLE (for the first pattern) as explained in Section 3.1. In particular, compute the regression coefficients of the missing st pattern against all other variables (treated as “observed”) based on all samples which do not belong to the st pattern.
-
•
Use the resulting estimates (regression coefficients) to impute the missing values from only the st pattern.
Next, turn to the nd pattern and repeat the above steps. In this way we continue cycling through the different patterns until convergence.
We now describe the Missingness Pattern Alternating maximization algorithm (MissPA) which makes the above idea precise. Let be the sufficient statistic in the multivariate normal model. Furthermore, denote by , . Let and be some initial guess of and , for example, using zero imputation. Our algorithm proceeds as follows.
| Algorithm 1: MissPA | |
|---|---|
| (1) | , : initial guess of and . |
| (2) | For do: |
| M-Step: Compute the MLE and , based on : | |
| Partial E-Step: | |
| Set for all (this takes no time), | |
| Set | |
| Update . | |
| (3) | Repeat step (2) until some convergence criterion is met. |
| (4) | Compute the final maximum likelihood estimator via: |
| , and . | |
Note, that we refer to the maximization step as M-Step and to the imputation step as partial E-Step. The word partial refers to the fact that the expectation is only performed with respect to samples belonging to the current pattern. The partial E-Step of our algorithm takes the following simple form:
where .
Our algorithm does not require an evaluation of in the M-Step, as it is not used in the following partial E-Step. But, if we are interested in the observed log-likelihood or the maximum likelihood estimator at convergence, we compute (at convergence), use it together with and to get via the transformations (2.1) as explained in step (4).
MissPA is computationally more efficient than the standard EM for missing data: one cycle through all patterns () takes about the same time as one iteration of the standard EM. But our algorithm makes more progress since the information from the partial E-Step is utilized immediately to perform the next M-Step. We will demonstrate empirically the gain of computational efficiency in Section 4.2. The new MissPA generalizes the standard EM in two ways. Firstly, MissPA alternates between different complete data spaces in the sense of Fessler and Hero (1994). Secondly, the E-Step is performed incrementally (Neal and Hinton, 1998). In Section 5 we will expand on these generalizations and we will provide an appropriate framework which allows analyzing the convergence properties of MissPA.
Finally, a small modification of MissPA, namely replacing in Algorithm 1 the M-Step by
M-Step2: Compute the MLE
and , based on :
3.3 High-Dimensionality and Lasso Penalty
The M-Step of Algorithm 1 is basically a multivariate regression of the missing () against the observed variables (). In a high-dimensional framework with the number of observed variables will be large and therefore some regularization is necessary. The main idea is, in order to regularize, to replace the regressions with a Lasso (Tibshirani, 1996). We give now the details.
Estimation of :
The estimation of the multivariate regression coefficients in the M-Step2 can be expressed as separate minimization problems of the form
where . Here, denotes the th row vector of the -matrix and represents the regression of variable against the variables from .
Consider now the objective function
| (3.6) |
with an additional Lasso penalty. Instead of minimizing (3.6) with respect to (for all ), it is computationally much more efficient to improve it coordinate-wise only from the old parameters (computed in the last cycle through all patterns). For that purpose, let be the regression coefficients for pattern in cycle and its th row vector. In cycle we compute by minimizing (3.6) with respect to each of the components of , holding the other components fixed at their current value. Closed-form updates have the form:
| (3.7) |
where
-
•
is the th component of equal to the element of matrix .
-
•
, the gradient of with respect to , which equals
(3.8) -
•
, is the standard soft-thresholding operator.
Estimation of :
We update the residual covariance matrix as:
| (3.9) |
Formula (3.9) can be viewed as a generalized version of Equation (3.5), when multiplying out the matrix product in (3.5) and taking expectations.
Our regularized algorithm, the MissPALasso, is summarized in Table 1. Note, that we update the sufficient statistic in the partial E-Step according to where . This update, motivated by Nowlan (1991), calculates as an exponentially decaying average of recently-visited data points. It prevents MissPALasso from storing for all which gets especially cumbersome for large ’s. As we are mainly interested in estimating the missing values, we will output the data matrix with missing values imputed by the regression coefficients () as indicated in step (4) of Table 1. MissPALasso provides not only the imputed data matrix but also , the completed version of the sufficient statistic . The latter can be very useful if MissPALasso is used as a pre-processing step followed by a learning method which is expressible in terms of the sufficient statistic. Examples include regularized regression (e.g., Lasso), discriminant analysis, or estimation of directed acyclic graphs with the PC-algorithm (Spirtes et al., 2000).
By construction, the regression estimates are sparse,
due to the employed -penalty, and therefore, imputation of missing
values is based
on sparse regressions. This is in sharp contrast to the MissGLasso approach
(see Section 4.1) which places sparsity on
. But this does not imply that regressions of variables in
on variables in are sparse since the inverse of sub-matrices of
a sparse are not sparse in general. MissPALasso employs
another type of sparsity and this seems to be the main reason for its
better statistical performance than MissGLasso.
Remark 3.1.
In practice, we propose to compute MissPALasso for a decreasing sequence of values for , using each solution as a warm start for the next problem with smaller . This pathwise strategy is computationally very attractive and our algorithm converges (for each ) after a few cycles.
| Algorithm 2: MissPALasso | |
|---|---|
| (1) | Set and start with initial guess for and (). |
| (2) | In cycle ; for do: |
| Penalized M-Step2: | |
| For all , compute by improving | |
| in a coordinate-wise manner from . | |
| Set | |
| Partial E-Step: | |
| Set | |
| Update where . | |
| Increase: | |
| (3) | Repeat step (2) until some convergence criterion is met. |
| (4) | Output the imputed data matrix , with missing values estimated by: |
| , . | |
4 Numerical Experiments
4.1 Performance of MissPALasso
In this section we will explore the performance of MissPALasso developed in Section 3.3. We compare our new method with alternative ways of imputing missing values in high-dimensional data. We consider the following methods:
-
•
KnnImpute: Impute the missing values by the K-nearest neighbors imputation method introduced by Troyanskaya et al. (2001).
-
•
SoftImpute: The soft imputation algorithm is proposed by Mazumder et al. (2010) in order to solve the matrix completion problem. They propose to approximate the incomplete data matrix by a complete (low-rank) matrix minimizing
Here, denotes the indices of observed entries and is the nuclear norm, or the sum of the singular values. The missing values of are imputed by the corresponding values of .
-
•
MissGLasso: Compute by minimizing where is the entrywise -norm. Then, use this estimate to impute the missing values by conditional mean imputation. MissGLasso is described in Städler and Bühlmann (2012).
-
•
MissPALasso: This is the method introduced in Section 3.3.
To assess the performances of the methods we use the normalized root mean squared error (Oba et al., 2003) which is defined by
| NRMSE |
Here, is the original data matrix (before deleting values) and is the imputed matrix. With mean and var we abbreviate the empirical mean and variance, calculated over only the missing entries.
All methods involve one tuning parameter. In KnnImpute we have to choose the number of nearest neighbors, while SoftImpute, MissGLasso and MissPALasso involve a regularization parameter which is always denoted by . In all of our experiments we choose the tuning parameters to obtain optimal performance in terms of NRMSE.
4.1.1 Simulation Study
We consider both high- and a low-dimensional MVN models with where
-
•
Model 1: and ;
: block diagonal with blocks of the form -
•
Model 2: and 1000;
: two blocks , each of size with and . -
•
Model 3: and 496;
: block diagonal with for and for (increasing) blocks of the size , with and . -
•
Model 4: and 500;
for
For all four settings we perform 50 independent simulation runs. In each run we generate i.i.d. samples from the model. We then delete randomly and of the values in the data matrix, apply an imputation method and compute the NRMSE. The results of the different imputation methods (tuning parameters such that NRMSE is minimal) are reported in Table 2 for the low-dimensional models and Table 3 for the high-dimensional models. MissPALasso is very competitive in all setups. SoftImpute works rather poorly, perhaps because the resulting data matrices are not well approximable by low-rank matrices. KnnImpute works very well in model 1 and model 4. Model 1, where each variable is highly correlated with its neighboring variable, represents an example which fits well into the KnnImpute framework. However, in model 2 and model 3, KnnImpute performs rather poorly. The reason is that with an inhomogeneous covariance matrix, as in model 2 and 3, the optimal number of nearest neighbors is varying among the different blocks, and a single parameter is too restrictive. For example in model 2, a variable from the first block is not correlated to any other variable, whereas a variable from the second block is correlated to other variables. Except for the low-dimensional model 3 MissGLasso is inferior to MissPALasso. Furthermore, MissPALasso strongly outperforms MissGLasso with respect to computation time (see Figure 4 in Section 4.2). Interestingly, all methods exhibit a quite large NRMSE in the high-dimensional model 3. They seem to have problems coping with the complex covariance structure in higher dimensions. If we look at the same model but with the NRMSE for 5% missing values is: 0.85 for KnnImpute, 0.86 for SoftImpute, 0.77 for MissGLasso and 0.77 for MissPALasso. This indicates an increase in NRMSE according to the size of . Arguably, we consider here only multivariate normal models which are ideal, from a distributional point of view, for MissGLasso and our MissPALasso. The more interesting case will be with real data (all from genomics) where model assumptions never hold exactly.
| KnnImpute | SoftImpute | MissGLasso | MissPALasso | ||
|---|---|---|---|---|---|
| Model 1 | 5% | 0.4874 (0.0068) | 0.7139 (0.0051) | 0.5391 (0.0079) | 0.5014 (0.0070) |
| p=50 | 10% | 0.5227 (0.0051) | 0.7447 (0.0038) | 0.5866 (0.0057) | 0.5392 (0.0055) |
| 15% | 0.5577 (0.0052) | 0.7813 (0.0037) | 0.6316 (0.0048) | 0.5761 (0.0047) | |
| Model 2 | 5% | 0.8395 (0.0101) | 0.8301 (0.0076) | 0.7960 (0.0082) | 0.7786 (0.0075) |
| p=100 | 10% | 0.8572 (0.0070) | 0.8424 (0.0063) | 0.8022 (0.0071) | 0.7828 (0.0066) |
| 15% | 0.8708 (0.0062) | 0.8514 (0.0053) | 0.8082 (0.0058) | 0.7900 (0.0054) | |
| Model 3 | 5% | 0.4391 (0.0061) | 0.4724 (0.0050) | 0.3976 (0.0056) | 0.4112 (0.0058) |
| p=55 | 10% | 0.4543 (0.0057) | 0.4856 (0.0042) | 0.4069 (0.0047) | 0.4155 (0.0047) |
| 15% | 0.4624 (0.0054) | 0.4986 (0.0036) | 0.4131 (0.0043) | 0.4182 (0.0044) | |
| Model 4 | 5% | 0.3505 (0.0037) | 0.5515 (0.0039) | 0.3829 (0.0035) | 0.3666 (0.0031) |
| p=100 | 10% | 0.3717 (0.0033) | 0.5623 (0.0033) | 0.3936 (0.0027) | 0.3724 (0.0026) |
| 15% | 0.3935 (0.0032) | 0.5800 (0.0031) | 0.4075 (0.0026) | 0.3827 (0.0026) |
| KnnImpute | SoftImpute | MissGLasso | MissPALasso | ||
|---|---|---|---|---|---|
| Model 1 | 5% | 0.4913 (0.0027) | 0.9838 (0.0006) | 0.6705 (0.0036) | 0.5301 (0.0024) |
| p=500 | 10% | 0.5335 (0.0020) | 0.9851 (0.0005) | 0.7613 (0.0031) | 0.5779 (0.0019) |
| 15% | 0.5681 (0.0016) | 0.9870 (0.0004) | 0.7781 (0.0013) | 0.6200 (0.0015) | |
| Model 2 | 5% | 0.8356 (0.0020) | 0.9518 (0.0009) | 0.8018 (0.0012) | 0.7958 (0.0017) |
| p=1000 | 10% | 0.8376 (0.0016) | 0.9537 (0.0007) | 0.8061 (0.0002) | 0.7990 (0.0013) |
| 15% | 0.8405 (0.0014) | 0.9562 (0.0006) | 0.8494 (0.0080) | 0.8035 (0.0011) | |
| Model 3 | 5% | 1.0018 (0.0009) | 0.9943 (0.0005) | 0.9722 (0.0013) | 0.9663 (0.0010) |
| p=496 | 10% | 1.0028 (0.0007) | 0.9948 (0.0004) | 0.9776 (0.0010) | 0.9680 (0.0007) |
| 15% | 1.0036 (0.0006) | 0.9948 (0.0003) | 0.9834 (0.0010) | 0.9691 (0.0007) | |
| Model 4 | 5% | 0.3487 (0.0016) | 0.7839 (0.0020) | 0.4075 (0.0016) | 0.4011 (0.0016) |
| p=500 | 10% | 0.3721 (0.0014) | 0.7929 (0.0015) | 0.4211 (0.0012) | 0.4139 (0.0013) |
| 15% | 0.3960 (0.0011) | 0.8045 (0.0014) | 0.4369 (0.0012) | 0.4292 (0.0014) |
4.1.2 Real Data Examples
We consider the following four publicly available datasets:
-
•
Isoprenoid gene network in Arabidopsis thaliana: The number of genes in the network is . The number of observations (gene expression profiles), corresponding to different experimental conditions, is . More details about the data can be found in Wille et al. (2004).
-
•
Colon cancer: In this dataset, expression levels of 40 tumor and 22 normal colon tissues () for human genes are measured. For more information see Alon et al. (1999).
-
•
Lymphoma: This dataset, presented in Alizadeh et al. (2000), contains gene expression levels of 42 samples of diffuse large B-cell lymphoma, 9 observations of follicular lymphoma, and 11 cases of chronic lymphocytic leukemia. The total sample size is and complete measured expression profiles are documented.
-
•
Yeast cell-cycle: The dataset, described in Spellman et al. (1998), monitors expressions of 6178 genes. The data consists of four parts, which are relevant to alpha factor ( samples), elutriation ( samples), cdc15 ( samples), and cdc28 ( samples). The total sample size is . We use the complete profiles in our study.
For all datasets we standardize the columns (genes) to zero mean and variance one. In order to compare the performance of the different imputation methods we randomly delete values to obtain an overall missing rate of , and . Table 4 shows the results for 50 simulation runs, where in each run another random set of values is deleted.
| KnnImpute | SoftImpute | MissGLasso | MissPALasso | ||
|---|---|---|---|---|---|
| Arabidopsis | 5% | 0.7732 (0.0086) | 0.7076 (0.0065) | 0.7107 (0.0076) | 0.7029 (0.0077) |
| n=118 | 10% | 0.7723 (0.0073) | 0.7222 (0.0052) | 0.7237 (0.0064) | 0.7158 (0.0060) |
| p=39 | 15% | 0.7918 (0.0050) | 0.7369 (0.0041) | 0.7415 (0.0053) | 0.7337 (0.0050) |
| Colon cancer | 5% | 0.4884 (0.0011) | 0.4921 (0.0011) | - | 0.4490 (0.0011) |
| n=62 | 10% | 0.4948 (0.0008) | 0.4973 (0.0006) | - | 0.4510 (0.0006) |
| p=2000 | 15% | 0.5015 (0.0007) | 0.5067 (0.0006) | - | 0.4562 (0.0007) |
| Lymphoma | 5% | 0.7357 (0.0014) | 0.6969 (0.0008) | - | 0.6247 (0.0012) |
| n=62 | 10% | 0.7418 (0.0009) | 0.7100 (0.0006) | - | 0.6384 (0.0009) |
| p=1332 | 15% | 0.7480 (0.0007) | 0.7192 (0.0005) | - | 0.6525 (0.0008) |
| Yeast cell-cycle | 5% | 0.8083 (0.0018) | 0.6969 (0.0012) | - | 0.6582 (0.0016) |
| n=73 | 10% | 0.8156 (0.0011) | 0.7265 (0.0010) | - | 0.7057 (0.0013) |
| p=573 | 15% | 0.8240 (0.0009) | 0.7488 (0.0007) | - | 0.7499 (0.0011) |
MissPALasso exhibits in all setups the lowest averaged NRMSE. MissGLasso performs nearly as well as MissPALasso on the Arabidopsis data. However, its R implementation cannot cope with large values of . If we would restrict our analysis to the 100 variables exhibiting the most variance we would see that MissGLasso performs slightly less than MissPALasso (results not included). Compared to KnnImpute, SoftImpute works well for all datasets. Interestingly, KnnImpute performs for all datasets much inferior to MissPALasso. In light of the simulation results of Section 4.1.1, a reason for the poor performance could be that KnnImpute has difficulties with the inhomogeneous correlation structure between different genes which is plausible to be present in real datasets.
To investigate the effect of already missing values on the imputation performance of the compared methods we use the original lymphoma and yeast cell-cycle datasets which already have “real” missing values. We only consider the 100 most variable genes in these datasets to be able to compare all four methods with each other. From the left panel of Figures 1 and 2 we can read off how many values are missing for each of the 100 variables. In the right panel of Figures 1 and 2 we show how well the different methods are able to estimate of additionally deleted entries.
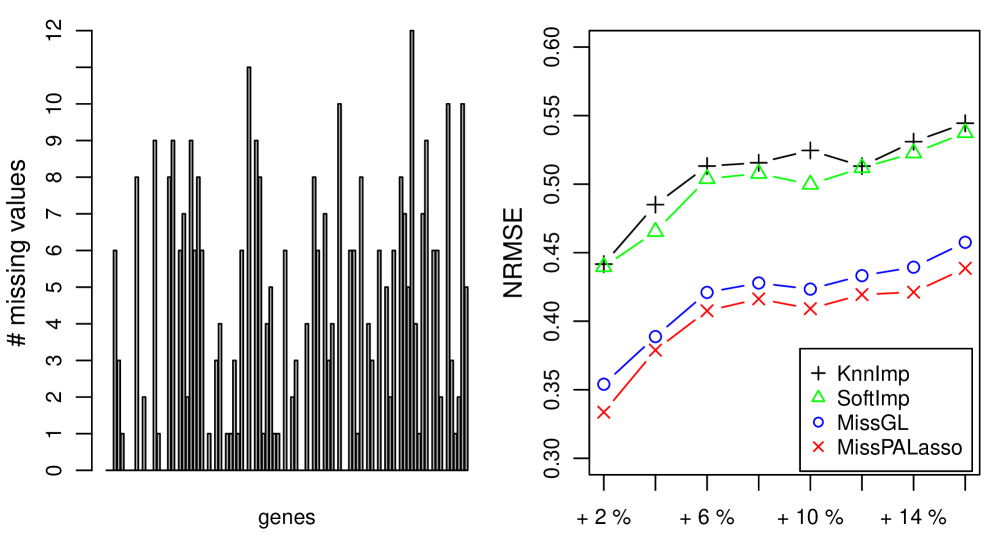
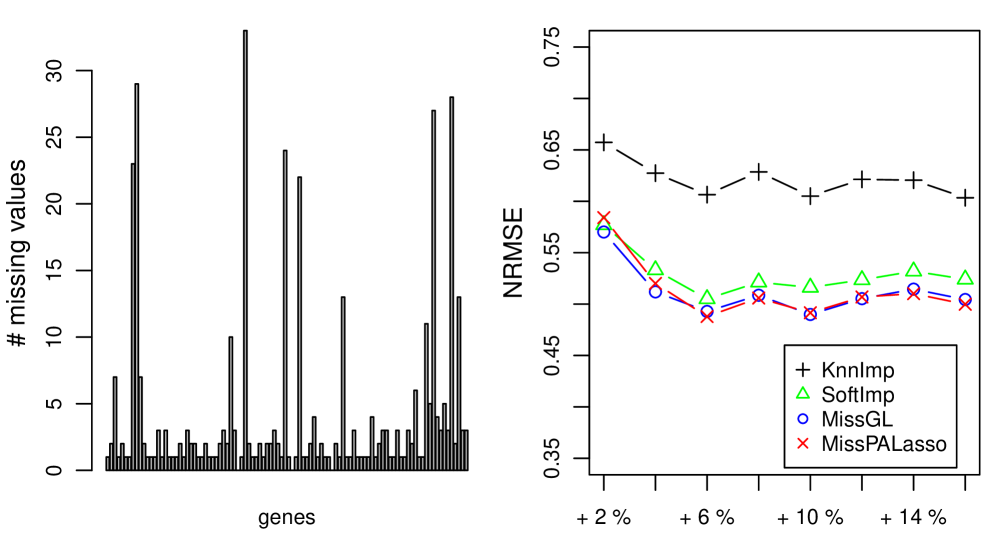
4.2 Computational Efficiency
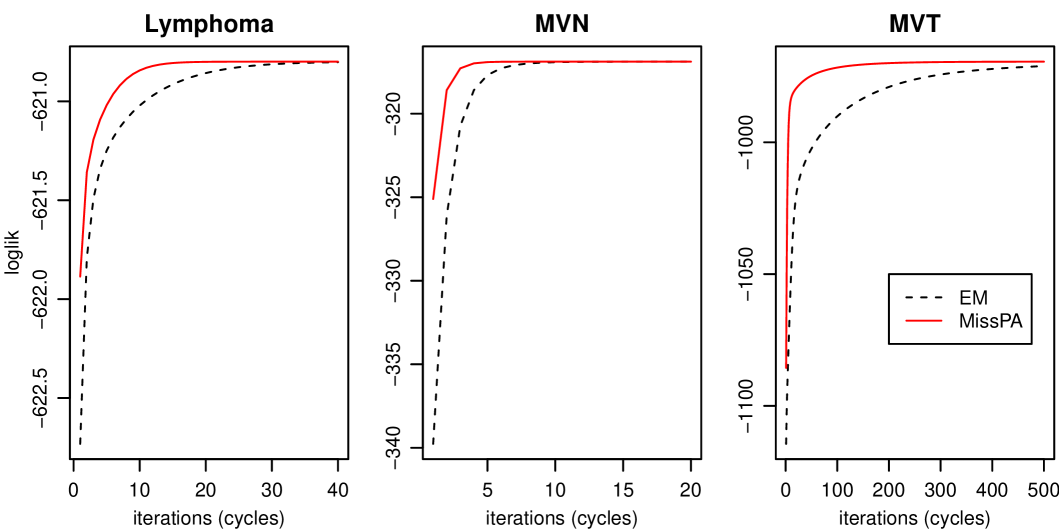
We first compare the computational efficiency of MissPA with the standard EM described for example in Schafer (1997). The reason why our algorithm takes less time to converge is because of the more frequent updating of the latent distribution in the M-Steps. A key attribute of MissPA is that the computational cost of one cycle through all patterns is the same as the cost of a single E-Step of the standard EM which requires computation of the regression parameters from obtained in the previous M-Step. This is a big contrast to the incremental EM, mostly applied to finite mixtures (Thiesson et al., 2001; Ng and McLachlan, 2003), where there is a trade-off between the additional computation time per cycle, or “scan” in the language of Ng and McLachlan (2003), and the fewer number of “scans” required because of the more frequent updating after each partial E-Step. The speed of convergence of the standard EM and MissPA for three datasets are shown in Figure 3, in which the log-likelihood is plotted as a function of the number of iterations (cycles). The left panel corresponds to the subset of the lymphoma dataset when only the ten genes with highest missing rate are used. This results in a data matrix with missing values. For the middle panel we draw a random sample of size from , , and delete the same entries which are missing in the reduced lymphoma data. For the right panel we draw from the multivariate t-model with degrees of freedom equal to one and again with the same values deleted. As can be seen, MissPA converges after fewer cycles. A very extreme example is obtained with the multivariate t-model where the standard EM reaches the log-likelihood level of MissPA about 400 iterations later. We note here, that the result in the right panel highly depends on the realized random sample. With other realizations, we get less and more extreme results than the one shown in Figure 3.
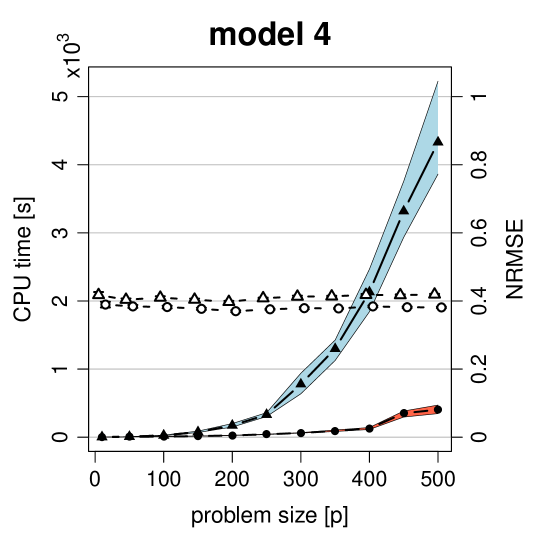
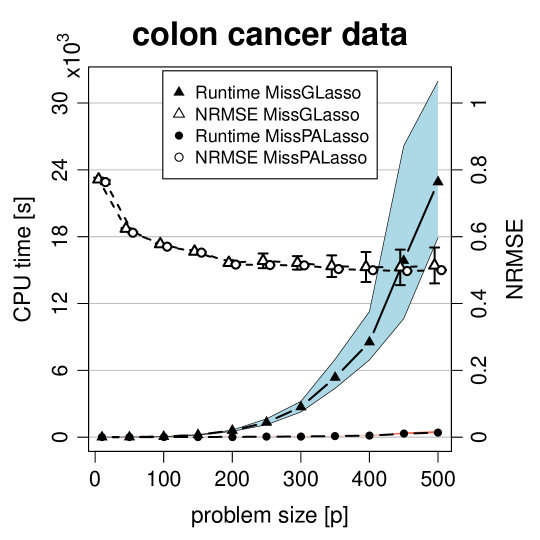
We end this section by illustrating the computational timings of MissPALasso and MissGLasso implemented with the statistical computing language R. We consider two settings. Firstly, model 4 of Section 4.1.1 with and a growing number of variables ranging from 10 to 500. Secondly, the colon cancer dataset from Section 4.1.2 with and also a growing number of variables where we sorted the variables according to the empirical variance. For each we delete of the data, run MissPALasso and MissGLasso ten times on a decreasing grid (on the log-scale) of values with thirty grid points. For a fixed we stop the algorithm if the relative change in imputation satisfies,
In Figure 4 the CPU times in seconds are plotted for various values of in the two settings. As shown, with MissPALasso we are typically able to solve a problem of size in about 9 seconds and a problem of size in about 400 seconds. For MissGLasso these times are highly increased to 27 and 4300 seconds respectively. Furthermore, we can see that MissPALasso has much smaller variability in runtimes. The graphical Lasso algorithm (Friedman et al., 2008) and therefore MissGLasso have computational complexity , whereas the complexity of MissPALasso is considerably smaller. We note that the matrix inversion in the M-Step of MissPA is replaced by soft-thresholding in MissPALasso. In sparse settings soft-thresholding as well as matrix multiplications can be evaluated very quickly as the regression coefficients contain many zeros. The exact complexity of MissPALasso depends on the fraction of missing values and also on the sparsity of the problem.
5 Theory
A key characteristic of our MissPA (Algorithm 1 in Section 3.2) is that the E-Step is only performed on those samples belonging to a single pattern. We already mentioned the close connection to the incremental EM introduced by Neal and Hinton (1998). In fact, if the density of , , is denoted by then the negative variational free energy (Neal and Hinton, 1998; Jordan et al., 1999) equals
| (5.10) |
Here, denotes the regression parameter of the latent distribution
and is the entropy. An iterative procedure alternating between maximization of with respect to
and maximizing with respect to
is equivalent to our Algorithm 1 with replaced by (see M-Step2 in Section 3.2). Alternating maximization of (5.10) is a GAM procedure in the sense of Gunawardana and Byrne (2005). Within their framework convergence to a stationary point of the observed log-likelihood can be shown.
Unfortunately, the MissPA algorithm does not quite fit into the GAM formulation. As already mentioned MissPA extends the standard EM also in another way namely by using for each pattern a different complete data space (for each pattern only those samples are augmented which do not belong to pattern ). MissPA is related to the SAGE algorithm (Fessler and Hero, 1994) as follows: Consider the parameter of interest in the parameterization introduced in Section 2, equation (2.1). From
and from observing that we conclude that is an admissible hidden-data space with respect to in the sense of Fessler and Hero (1994). The M-Step of MissPA then maximizes a conditional expectation of the log-likelihood with respect to . Different from a SAGE algorithm is the conditional distribution involved in the expectation. Our algorithm updates after each M-Step only the conditional distribution for a single pattern. As a consequence, we do not need to compute estimates for .
In summary, the MissPA algorithm has similarities with a GAM and a SAGE procedure. However, neither the SAGE nor the GAM framework fit our proposed MissPA. In the next section we provide theory which justifies alternating between complete data spaces and incrementally performing the E-Step. In particular, we prove convergence to a stationary point of the observed log-likelihood.
5.1 Convergence Theory for the MissPA Algorithm
Pattern-Depending Lower Bounds
Denote the density of , , by and define for
Set and consider for
Here denotes the entropy. Note that is defined for fixed observed data . The subscript highlights the dependence on the pattern . Furthermore, for fixed and fixed , is a function in the parameters . As a further tool we write the Kullback-Leibler divergence in the following form:
| (5.11) |
An important property of the Kullback-Leibler divergence is its non-negativity:
A simple calculation shows that
| (5.12) |
and can be written as
| (5.13) |
In particular, for fixed values of , lower bounds the observed log-likelihood due to the non-negativity of the Kullback-Leibler divergence.
Optimization Transfer to Pattern-Depending Lower Bounds
We give now an alternative description of the MissPA algorithm. In cycle through all patterns, generate given according to
| (5.14) |
with
We have
The entropy terms do not depend on the optimization parameter , therefore,
Using the factorization (for all ), and separate maximization with respect to and we end up with the expressions from the M-Step of MissPA. Summarizing the above, we have recovered the M-Step as a maximization of which is a lower bound of the observed log-likelihood. Or in the language of Lange et al. (2000), optimization of is transferred to the surrogate objective .
There is still an important piece missing: In M-Step of cycle we
are maximizing whereas in the following
M-Step () we optimize . In order
for the algorithm to make progress, it is essential that
attains higher values than its
predecessor . In this sense the following
proposition is crucial.
Proposition 5.1.
For we have that
Note that equality holds if and only if .
Convergence to Stationary Points
Ideally we would like to show that a limit point of the sequence generated by the MissPA
algorithm is a global maximum of . Unfortunately, this is too ambitious because for general missing data patterns the observed log-likelihood is a non-concave
function with several local maxima. Thus, the most we can expect
is that our algorithm converges to a stationary point. This is ensured by
the following theorem which is proved in the Appendix.
Theorem 5.1.
Assume that is compact. Then every limit point of is a stationary point of .
6 Discussion and Extensions
We have presented the novel Missingness Pattern Alternating maximization algorithm (MissPA) for maximizing the observed log-likelihood for a multivariate normal data matrix with missing values. Simplified, our algorithm iteratively cycles through the different missingness patterns, performs multivariate regressions of the missing on the observed variables and uses these regression coefficients for partial imputation of the missing values. We argued theoretically and gave numerical examples showing that our procedure is computationally more efficient than the standard EM algorithm. Furthermore, we analyze the numerical properties using non-standard arguments and prove that solutions of our algorithm converge to stationary points of the observed log-likelihood.
In a high-dimensional setup with the regression interpretation opens up the door to do regularization by replacing least squares regressions with Lasso analogues. Our proposed algorithm, the MissPALasso, performs a coordinate descent approximation of the corresponding Lasso problem in order to gain speed. On simulated and four real datasets (all from genomics) we demonstrate that MissPALasso outperforms other imputation techniques such as k-nearest neighbors imputation, nuclear norm minimization or a penalized likelihood approach with an -penalty on the inverse covariance matrix.
Even though MissPALasso performs well on simulated and real data it is a “heuristic” motivated by the previously developed MissPA and by the wish to have sparse regression coefficients for imputation. It is unclear which objective function is optimized by MissPALasso. The comments of two referees on this point made us thinking of another way of imposing sparsity in the regression coefficients: Consider a penalized variational free energy
| (6.15) |
with defined in equation (5.10) and . A small calculation shows that alternating minimization of (6.15) with respect to and leads to an algorithm which is similar but different from MissPALasso. In fact, minimizing (6.15) with respect to and gives and satisfies the subgradient equation
where is the subgradient of , applied componentwise to the elements of a matrix and . The formulation (6.15) looks very compelling and can motivate new algorithms for missing data imputation. For example in the context of the Netflix problem where the fraction of the missing values and the number of customers is huge one might impose constraints on the parameters and employ a stochastic gradient descent optimization strategy to solve (6.15).
Appendix A Proof of Theorem 5.1
Proof. First, note that the sequence lies in the compact set . Now, let be a subsequence converging to as . By invoking compactness, we can assume w.l.o.g (by restricting to a subsequence) that .
As a direct consequence of the monotonicity of the sequence we obtain
From (5.14) and Proposition 5.1, for and the following “sandwich”-formulae hold:
As a consequence we have for
| (A.16) | |||
| (A.17) |
Now consider the sequence . By compactness of this sequence converges w.l.o.g to some . We now show by induction that
From the st M-Step of cycle we have
Taking the limit we get:
In particular, is the (unique) maximizer of . Assuming would imply
But this contradicts , which holds by (A.16). Therefore we obtain .
Assume that we have proven . We will show that . From the k+1st M-Step in cycle :
Taking the limit for , we conclude that is the (unique) maximizer of
From (A.17),
and therefore must be equal to . By induction we have and so we proved that holds.
Finally, we show stationarity of . Invoking (5.13) we can write
Note that
Furthermore, as maximizes , we get in the limit as
Therefore, we conclude that .
References
- Aittokallio (2010) Aittokallio, T. (2010) Dealing with missing values in large-scale studies: microarray data imputation and beyond. Briefings in Bioinformatics, 11, 253–264.
- Alizadeh et al. (2000) Alizadeh, A., Eisen, M., Davis, R., Ma, C., Lossos, I., Rosenwald, A., Boldrick, J., Sabet, H., Tran, T., Yu, X., Powell, J., Yang, L., Marti, G., Moore, T., Hudson, J., Lu, L., Lewis, D., Tibshirani, R., Sherlock, G., Chan, W., Greiner, T., Weisenburger, D., Armitage, J., Warnke, R., Levy, R., Wilson, W., Grever, M. R., Byrd, J., Botstein, D., Brown, P. and Staudt, L. (2000) Distinct types of diffuse large b-cell lymphoma identified by gene expression profiling. Nature, 403, 503–511.
- Allen and Tibshirani (2010) Allen, G. and Tibshirani, R. (2010) Transposable regularized covariance models with an application to missing data imputation. Annals of Applied Statistics, 4, 764–790.
- Alon et al. (1999) Alon, U., Barkai, N., Notterman, D., Gishdagger, K., Ybarradagger, S., Mackdagger, D. and Levine, A. (1999) Broad patterns of gene expression revealed by clustering analysis of tumor and normal colon tissues probed by oligonucleotide arrays. Proceedings of the National Academy of Sciences of the United States of America, 96, 6745–6750.
- Cai et al. (2010) Cai, J.-F., Candès, E. and Shen, Z. (2010) A singular value thresholding algorithm for matrix completion. SIAM Journal on Optimization, 20, 1956–1982.
- Candès and Recht (2009) Candès, E. and Recht, B. (2009) Exact matrix completion via convex optimization. Foundations of Computational Mathematics, 9, 717–772.
- Candès and Tao (2010) Candès, E. and Tao, T. (2010) The power of convex relaxation: Near-optimal matrix completion. IEEE Transactions on Information Theory, 56.
- Dempster et al. (1977) Dempster, A., Laird, N. and Rubin, D. (1977) Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society, Series B, 39, 1–38.
- Fessler and Hero (1994) Fessler, J. and Hero, A. (1994) Space-alternating generalized Expectation-Maximization algorithm. IEEE Transactions on Signal Processing, 42, 2664–2677.
- Friedman et al. (2008) Friedman, J., Hastie, T. and Tibshirani, R. (2008) Sparse inverse covariance estimation with the graphical Lasso. Biostatistics, 9, 432–441.
- Friedman et al. (2010) Friedman, J., Hastie, T. and Tibshirani, R. (2010) Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software, 33, 1–22.
- Gunawardana and Byrne (2005) Gunawardana, A. and Byrne, W. (2005) Convergence theorems for generalized alternating minimization procedures. Journal of Machine Learning Research, 6, 2049–2073.
- Jordan et al. (1999) Jordan, M., Ghahramani, Z., Jaakkola, T. and Saul, L. (1999) An introduction to variational methods for graphical models. Machine Learning, 37, 183–233.
- Keshavan et al. (2010) Keshavan, R., Oh, S. and Montanari, A. (2010) Matrix completion from a few entries. IEEE Transactions on Information Theory, 56.
- Kim et al. (2006) Kim, H., Golub, G. and Park, H. (2006) Missing value estimation for DNA microarray gene expression data: local least squares imputation. Bioinformatics, 22, 1410–1411.
- Lange et al. (2000) Lange, K., Hunter, D. and Yang, I. (2000) Optimization transfer using surrogate objective functions. Journal of Computational and Graphical Statistics, 9, 1–20.
- Little and Rubin (1987) Little, R. and Rubin, D. (1987) Statistical Analysis with Missing Data. Series in Probability and Mathematical Statistics, Wiley.
- Mazumder et al. (2010) Mazumder, R., Hastie, T. and Tibshirani, R. (2010) Spectral regularization algorithms for learning large incomplete matrices. Journal of Machine Learning Research, 99, 2287–2322.
- Neal and Hinton (1998) Neal, R. and Hinton, G. (1998) A view of the EM algorithm that justifies incremental, sparse, and other variants. In Learning in Graphical Models, 355–368. Kluwer Academic Publishers.
- Ng and McLachlan (2003) Ng, S. and McLachlan, G. (2003) On the choice of the number of blocks with the incremental EM algorithm for the fitting of normal mixtures. Statistics and Computing, 13, 45–55.
- Nowlan (1991) Nowlan, S. (1991) Soft Competitive Adaptation: Neural Network Learning Algorithms based on Fitting Statistical Mixtures. Ph.D. thesis, School of Computer Science, Carnegie Mellon University, Pittsburgh.
- Oba et al. (2003) Oba, S., Sato, M.-A., Takemasa, I., Monden, M., Matsubara, K.-I. and Ishii, S. (2003) A Bayesian missing value estimation method for gene expression profile data. Bioinformatics, 19, 2088–2096.
- Schafer (1997) Schafer, J. (1997) Analysis of Incomplete Multivariate Data. Monographs on Statistics and Applied Probability 72, Chapman and Hall.
- Spellman et al. (1998) Spellman, P., Sherlock, G., Zhang, M., Iyer, V., Anders, K., Eisen, M., Brown, P., Botstein, D. and Futcher, B. (1998) Comprehensive identification of cell cycle-regulated genes of the yeast Saccharomyces cerevisiae by microarray hybridization. Molecular Biology of the Cell, 9, 3273–97.
- Spirtes et al. (2000) Spirtes, P., Glymour, C. and Scheines, R. (2000) Causation, Prediction, and Search. The MIT Press, 2nd edition.
- Städler and Bühlmann (2012) Städler, N. and Bühlmann, P. (2012) Missing values: sparse inverse covariance estimation and an extension to sparse regression. Statistics and Computing, 22, 219–235.
- Thiesson et al. (2001) Thiesson, B., Meek, C. and Heckerman, D. (2001) Accelerating EM for large databases. Machine Learning, 45, 279–299.
- Tibshirani (1996) Tibshirani, R. (1996) Regression shrinkage and selection via the Lasso. Journal of the Royal Statistical Society, Series B, 58, 267–288.
- Troyanskaya et al. (2001) Troyanskaya, O., Cantor, M., Sherlock, G., Brown, P., Hastie, T., Tibshirani, R., Botstein, D. and Altman, R. (2001) Missing value estimation methods for DNA microarrays. Bioinformatics, 17, 520–525.
- Wille et al. (2004) Wille, A., Zimmermann, P., Vranova, E., Fürholz, A., Laule, O., Bleuler, S., Hennig, L., Prelic, A., von Rohr, P., Thiele, L., Zitzler, E., Gruissem, W. and Bühlmann, P. (2004) Sparse graphical Gaussian modeling of the isoprenoid gene network in arabidopsis thaliana. Genome Biology, 5.